StreamingBench


✅ 整体结构分两步:
STEP 1:Caption 生成(带时间戳)
→ 目的:先获得基础描述文本,为 QA 构造提供素材。
-
输入:每隔 1 秒截取一帧图像,并附带时间戳。
-
输出:
-
以时间段为单位的描述文本
-
格式:
[HH:MM:SS - HH:MM:SS]: 描述内容
[HH:MM:SS]: 描述内容(单时间戳)
-
-
具体要求:
-
描述尽量详细,包含:
-
物体特征(颜色、形状、位置等)
-
动作(如移动、举手)
-
人与物关系、背景
-
-
只描述视频里确实看到的,避免猜测。
-
一口气自然描述,避免一帧一描述。
-
不总结、无主观词汇。
-
语法正确,时态和人称要规范。
-
→ 这一步相当于:先做 dense captioning,只是格式偏工程化。
STEP 2:基于 Caption 生成 QA
→ 目的:把 Step 1 的描述加工成规范格式的问答。
- 核心格式:
|
|
-
关键规则:
-
只基于 Caption 内容出题,禁止凭空想象。
-
全部是多选题(multiple-choice),答案有 4 个选项。
-
选项要有迷惑性,不能太明显。
-
问题不能太细节/太短时,只看整体场景。
-
注意时态统一: 尽量用现在时或者最近发生。
-
句式要求自然流畅,不能出现:“在视频开头”这类表述。
-
✅ 核心目的解读:
-
为什么先 caption 再 QA?
-
保证 QA 来源有依据,避免无意义 QA。
-
方便后续检查与修正。
-
大模型两步走比一步直接问答生成更稳健。
-
-
为什么统一格式?
-
方便数据标注与模型训练。
-
流视频理解场景下,统一格式有利于 prompt 设计和后续微调。
-
-
为什么强调时间戳?
-
因为流式场景重点就是“何时回答”,
-
所以时间戳必须精确。
-
✅ 补充注意事项
-
prompt 本身并不直接包含视频图像,它是依赖外部预处理(step 1)后的字幕或描述。
-
StreamingBench 也提到:
-
先做 open QA,后做选择题;
-
只是 prompt 示例里直接放了选择题模板。
-
✅ 如果你要模仿做的工作流程总结:
1️⃣ 先做 Caption:
-
人工/模型输出:
- [时间段]:场景描述。
2️⃣ 再做 QA:
-
人工/模型输出:
-
多项选择题格式,严格对应时间段。
-
选项要合理干扰。
-
3️⃣ 验证:
-
人工 + 模型辅助,
-
内容是否符合逻辑;
-
时间戳是否正确。
-
OVOBench
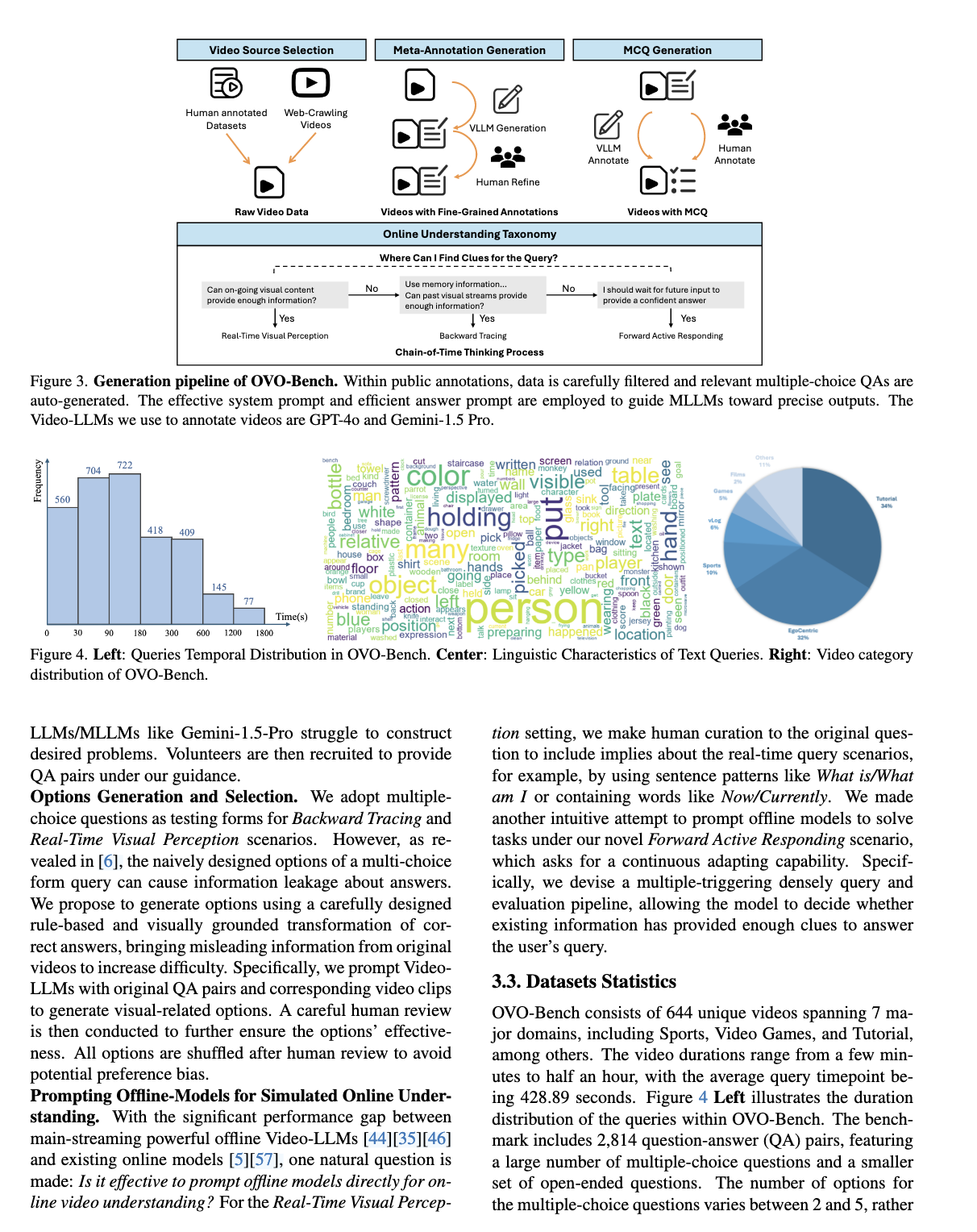
✅ 整体流程步骤(对应图3)
1️⃣ Video Source Selection
-
来源包括:
-
人工标注过的视频数据集(public datasets)
-
网络爬取的视频
-
2️⃣ Meta-Annotation Generation
-
大模型 + 人工协作完成:
-
第一步:用 VLLM(如 GPT-4o、Gemini 1.5 Pro)自动标注:
- 标注包括:时间段、动作描述、对象属性等
-
第二步:人工 refine:
- 人工检查、修正,保证质量。
-
3️⃣ MCQ Generation
-
在已经 refine 过的 annotation 基础上:
-
Prompt + 大模型:
- 生成多项选择题(MCQ)格式的 QA。
-
人工二次 review:
- 核对选项合理性,打乱顺序,避免偏好 bias。
-
✅ QA 生成背后的理念
场景类型:
-
Backward Tracing:
- 问过去:发生了什么?在哪里?
-
Real-Time Visual Perception:
- 基于当前画面回答:看到什么?
-
Forward Active Responding:
- 预测未来:接下来可能发生什么?
如何保证 QA 有效?
-
不是完全自由生成,而是:
-
根据已有 annotation 生成 QA。
-
确保所有选项来自视频中真实时间段/内容。
-
Prompt 策略:
-
统一格式 + 明确指导:
-
不出现 What is/What am I 句式(防止太 open-ended)
-
避免 Now/Currently 等带实时含义的词(方便对齐 eval)
-
✅ 具体操作细节
-
先用 VLLM 生成粗标注,再人工 refine
-
然后再用 VLLM 生成 MCQ QA,依然人工 review
-
平衡:
-
MCQ(多选题)量大
-
开放式问答量小但有
-
-
所有选项 shuffle,避免模型因选项顺序倾向学到偏好
✅ 与你现在做的区别:
-
OVO-Bench 主要目标是多选题(MCQ),不是开放问答优先;
-
但 MCQ 也是基于 annotation 先生成 captions,再出问题;
-
和 StreamingBench 不同的是:
-
StreamingBench 强调训练阶段先开放问答,后评测用 MCQ。
-
OVO-Bench 一开始就直接围绕 MCQ 构建数据集。
-
✅ 你这边实际可以借鉴的点:
1️⃣ VLLM + annotation + 人工 refine 流程
2️⃣ 多轮人工 review:包括 shuffle 和有效性检查
3️⃣ 分类逻辑:
-
Real-Time → 只看当前
-
Backward → 看过去
-
Forward → 预测未来
4️⃣ Prompt 细节: -
明确句式
-
控制开放度
-
保证 answer 来源于 annotation
SVBench



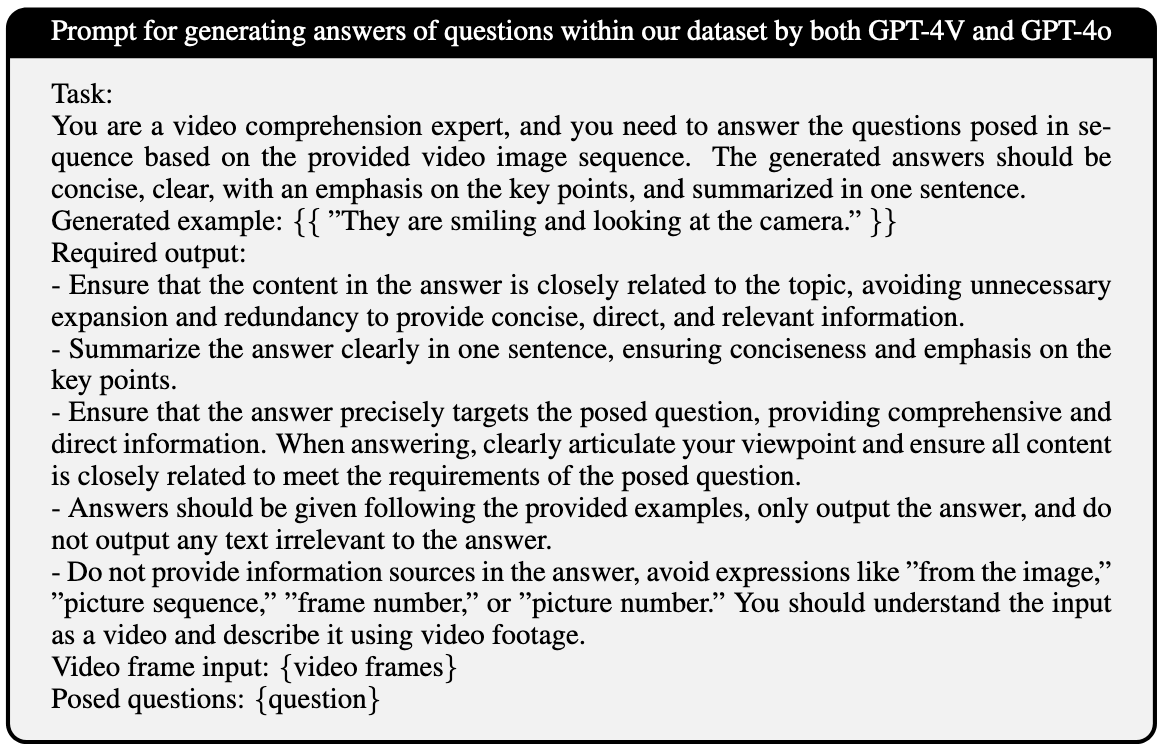


✅ SVBench QA系统工作逻辑和特色:
1️⃣ 核心框架:多轮对话链(QA Chain)
-
和StreamingBench、OVOBench不同:
-
SVBench更强调多轮QA Chain而不是单轮单独QA。
-
目的是:考察模型能否“带上下文”连续回答。
-
-
举例:
-
Q0: 第一个动作是什么?
-
A0: 抬起手。
-
Q1: 然后呢?
-
A1: 揉眼睛。
-
…
-
2️⃣ Contextual vs. Non-Contextual QA
-
两套版本:
-
没有上下文提示:直接问每个问题。
-
带上下文提示:提供之前问答结果,考察模型“顺接能力”。
-
-
从Figure 11看:
-
没有上下文时GPT-4v和GPT-4o容易答跑偏。
-
有上下文时表现明显更好。
-
-
这对你理解很关键:
-
你现在做的单轮触发类QA是Non-Contextual。
-
如果后面需要做多轮QA Chain,可能要参考SVBench这套。
-
✅ QA Chain Prompt部分拆解:
-
结构要求:
- 5-6轮连续问答,每轮问题和答案都必须和上一轮有关系。
-
核心要求:
-
不能出现具体时间戳(例如“第几秒”)。
-
不能出现“图片里”、“第几帧”等字样。
-
避免空洞泛问,强调“可以从视频直接观察到的信息”。
-
输出要求是JSON格式:
- questions: […], answers: […]
-
-
和你目前只做场景触发类最大区别:
-
SVBench是开放式+上下文连续问答。
-
你目前只要求“检测某事件出现”。
-
✅ Relationship Prompt(关系链生成)
-
任务:
- 给两个不同视频段的QA Chain,标注两段之间相关联的问题对。
-
关系类别:
-
Action
-
Quantity
-
Person
-
Object
-
Event
-
Environment
-
-
适用场景:
- 高级评测任务,用于检验模型在多视频段上的一致性和连贯性。
-
与你目前的关系:
-
暂时不涉及,纯触发类QA不需要标注关系。
-
但如果后面做多段连续事件分析,有参考价值。
-
✅ Answer Generation Prompt
-
关键点:
-
只回答关键信息。
-
一句话,简洁明了。
-
不允许出现“图片里”这种提示词。
-
-
和你场景触发类对齐点:
- 触发类QA的Answer部分,也建议保持这样简短自然语言描述。
✅ GPT4-Score Prompt(答案质量评测)
-
打分规则:
-
0–10分:
-
10分:完全正确。
-
7–9分:有细节错误但整体没问题。
-
5–6分:中等,有明显缺漏。
-
3–4分:差。
-
0–2分:完全错误或无关。
-
-
-
打分依据:
-
准确性
-
上下文连贯性
-
逻辑一致性
-
时间理解
-
信息完整性
-
-
对于你现在的工作:
- 如果要后续做自动评测或人工review,可以直接参考SVBench这套打分维度。
✅ Dialogue Evaluation Prompt
-
本质上是更细化版GPT4-Score:
- 维度拆得更细:5项评分标准。
-
你做纯触发类QA时是否需要?
-
如果只看单轮:不一定需要。
-
如果未来升级做Multi-turn QA:值得参考。
-
✅ 总结:
| 模块 | 和你当前任务的关系 |
|---|---|
| QA Chain 构建 | 暂时不用做,关注单轮即可 |
| Contextual/Non-Contextual | 只做Non-Contextual即可 |
| Relationship 标注 | 暂时不需要 |
| 简洁Answer 规范 | 强烈建议对齐SVBench的规范 |
| GPT4-Score与Dialogue Evaluation | 可以参考,后续做模型评测或人工审核时用 |