StreamingBench
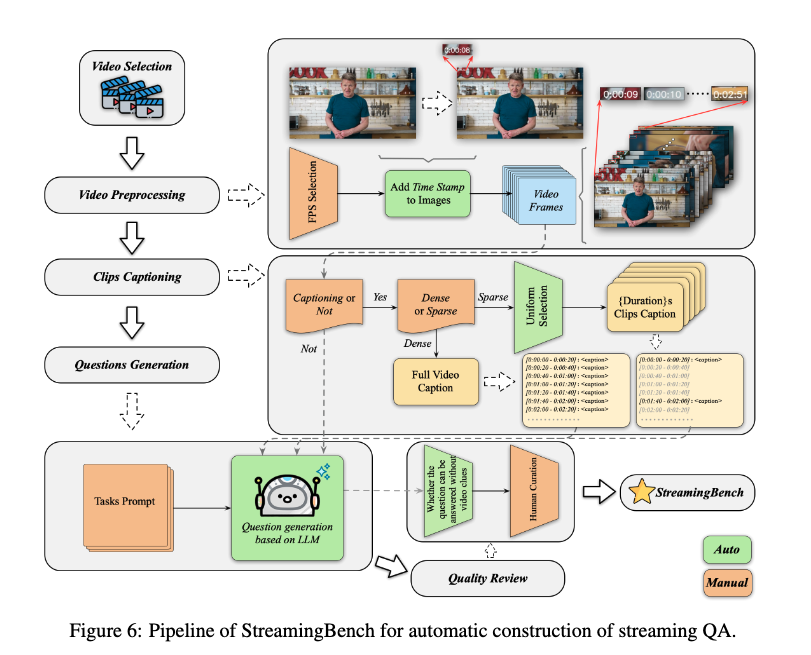
问答生成。我们使用混合注释流程为StreamingBench中的不同任务类别生成问答对。对于实时视觉理解任务和主动输出任务,我们首先以1fps的帧率从视频中采样帧,并使用GPT-4o为每20帧生成字幕。由于StreamingBench需要在视频的各个点进行查询,我们在每个帧的左上角添加时间戳,这使得GPT-4o能够创建具有更精细时间粒度的字幕(间隔小于20秒)。使用这些带时间戳的精细字幕,GPT-4o随后为不同任务生成问答对,并自动分配问题时间戳。对于全源理解任务和其他上下文理解任务,我们要求人工注释员手动标记问答对。
质量控制。为确保StreamingBench中数据的质量,我们对自动生成和人工注释的问答对实施严格的人工验证流程。每对问答都经过准确性、清晰度和相关性的审查。包含歧义或错误标签的低质量问答对被修改,而无需视频信息即可回答的问题被丢弃。此外,我们打乱选项以确保平衡分布。这一细致的质量控制流程确保StreamingBench有效地挑战模型,以展示其实时流媒体视频理解能力。
1. 初始时间戳的生成(大模型辅助)
- 带有时间标记的视觉输入: 在生成问答对的过程中,研究人员首先将视频以1fps的速率采样成一帧帧的图像。关键的一步是,他们在每一帧图像的左上角都添加了可视的时间戳(例如 “0:01:20”)
这里咱们也是 1fps, 只是没有加上可视化的时间戳
- GPT-4o生成带时间戳的问答: 随后,他们将这些带有明显时间标记的图像序列输入到GPT-4o模型中。模型被指示先生成精细化的视频描述,然后再基于这些描述创建问答对,并自动为每个问题分配一个查询时间戳 。这个过程确保了生成的问题从一开始就与视频的特定时间点相关联
用模型基于frames, 给出标注, 并给出查询时间戳, 以及事件时间
事件时间准确度的提升主要靠后续人工提升
2. “可回答时间窗”的定义
- 标注线索出现的时间范围: 在生成过程中,每个问题都会被标记上一个时间范围,这个范围指明了回答该问题所需的相关线索在视频中出现的时间段 。这一定义至关重要,因为它为后续的人工校验提供了明确的“答案可寻”的时间依据
这个主要是为了方便人工审核的, 可以略过
硬要说的话, 可以说是为了降低幻觉, 提升问答质量, 要求模型给出一个答案的出处
3. 严格的人工校验(核心校验环节)
所有由模型生成的问答对都必须经过一个
严格的人工验证流程
- 审核标准: 人类审核员会审查每一个问答对,其校验标准包括:
- 准确性(Accuracy): 答案是否正确,以及问题在给定的时间戳下是否与视频内容相符
- 相关性(Relevance): 问题是否与流式视频的场景紧密相关
- 清晰度(Clarity): 问题和答案是否存在歧义
- 时序一致性校验: 审核员的核心任务之一是确认,在问题被提出的那个时间点,仅凭该时间点之前的视频内容,是否足以回答这个问题。
- 修正与筛选:
- 如果发现问答对存在任何
不准确、不清晰或与时间不匹配的情况,审核员会对其进行修正 - 对于那些在给定时间戳下无法回答,或者无需观看视频就能回答的问题,会被直接
丢弃
- 如果发现问答对存在任何
这里咱们的校验基本都涉及到了
OVOBench
元标注收集
我们采用三种方法来收集我们的元标注,其中包含事件级别的时间戳:
(1)现有标注重用。对于具有准确事件级别时间戳的人类标注数据集[1][43][15],我们明确利用这些标签并将它们重构到我们的最终提示中
(2)半自动生成。对于提供视频级别QA对但没有完整时间定位的数据集,包括[31][49][36][20][13],我们提示时间敏感的视频LLM如Gemini-1.5[44],以提供粗粒度时间戳,这些时间戳适合问题答案中提到的事件。对于实时视觉感知场景下的任务,时间戳在自动QA构建过程中给出,将在3.2.2中说明
(3)人工标注。对于[SSR]和[CRR]任务,问题、答案和真实时间戳由我们招募的志愿者收集。然后我们对所有收集到的源视频和相应的元标注进行细致检查,以确保精度
主要是人工搞的
没有提及半自动生成是咋搞的
SVBench
随后,我们使用PySceneDetect1来识别和列举过滤视频中的场景。这些结果对于确定视频内容是否表现出足够的变异和复杂性至关重要。进一步筛选仅保留包含5到15个场景的视频,从而排除过于单调或过于复杂的内容。此外,仅选择具有适当平均场景持续时间的视频,以确保流畅性和节奏。最后,选择了1,353个视频。最终,我们根据时间戳将每个视频分割成剪辑V = {si | 0 ≤ i < |V |},并将较短的剪辑合并
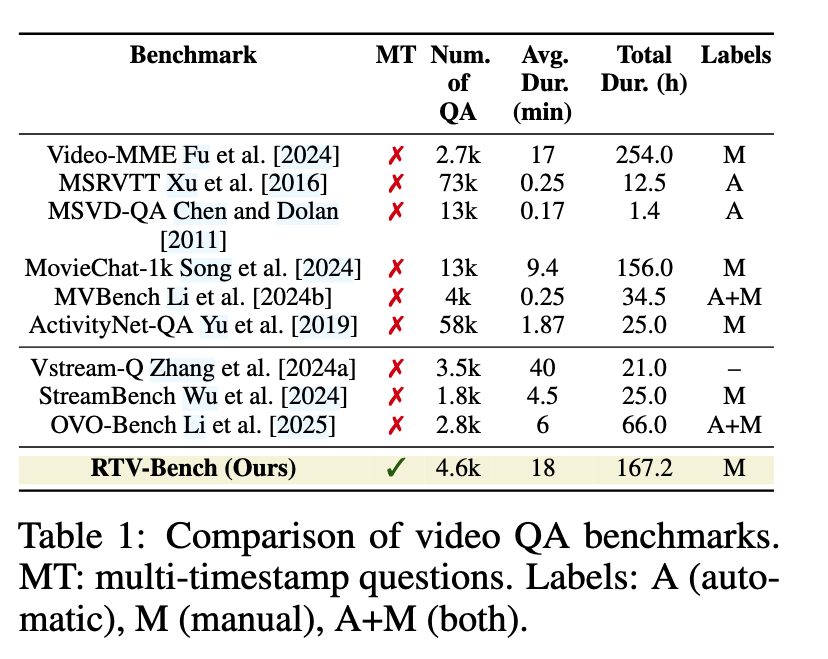
RTV-Bench
人工标注为了确保RTVBench在评估连续视频分析方面的可靠性,合格的专家进行了严格的人工标注。虽然一个LLM(Deepseek Liu等人[2024])提供了初始问题模板,但人工标注者显著改进了问题,以针对动态场景和时间推理。他们精心设计了答案随时间变化的提问,并在MTQA中确定了每个答案选项的第一个有效时间戳。这一以人为中心、多标注者的过程确保了稳健性,并创建了专注于视频时间动态性的特定评估
为确保基准的质量,每个视频及其对应的问答对都经历了多轮审查。我们根据长度分布和检查实时事件变化的子场景的存在手动筛选视频,从而得到专注于实时分析任务的高质量视频。我们进行了手动视频-问题对齐和精确时间戳检查,利用GPT-4和人工审查来验证注释格式、翻译和敏感信息
streambench
似乎不是多模态的
而仅仅是 stream 而已
VideoLLM Online
在线视频流对话标注。
一些视频数据集,如Ego4D叙述[28],本质上是按流式方式收集的,标注者在观看5分钟长的视频片段时提供实时叙述。然而,先前的研究[48, 96]主要关注从短、离散片段(例如只有32帧)中学习,而不是在连续流式环境中。对于这个数据集,我们遵循了提供给人类标注者的相同指示[28]作为我们的模型训练提示。这个提示指示模型模拟人类标注者,在5分钟的视频中流式生成叙述(大约600帧,2帧/秒)。出于演示目的(非实验),我们还利用Llama-2-13B-Chat[77]或Llama-3-8B-Instruct[1]重新措辞叙述文本,纠正语法错误和错别字,并将其转换为更易理解的版本(例如,将“C做…”改为“你做…”)离线注释到视频流对话。
尽管Ego4D叙述数据是以流式方式收集的,但大多数流行的视频数据集[15, 28, 57, 75]用于训练离线模型,并且只使用与基本语言描述(例如,活动、叙述)配对的时序段注释。为了弥合这一差距,我们提出了一种从这些来源合成对话数据的方法。如图3所示,我们的关键思想是使用LLM根据视频注释生成用户助手对话,包括以下步骤:• 首先,我们准备一个包含关于视频过去、现在和将来时态的各种查询的问题模板库,总共有N个查询。我们从库中随机抽取一个问题,记为Qi。• 然后,我们从离线数据集中获取视频注释时间线。这通常包括带时间戳的语言描述,我们将它们组织成语言提示,例如,“时间ta ∼ tb:烧水;时间tc ∼ td:切菜。”,记为A。我们认为所有状态变化的关键时间戳为理想的响应时间。对于这个例子,ta、tb、tc和td都被认为是响应时间。• 第三,我们提示大型语言模型在每个关键时间点生成响应,例如,ta、tb、tc、td,根据Qi和A。我们可以重复此过程,直到所有查询都得到处理。这些响应被保存以供训练时加载
最后,在训练过程中,我们 1)随机采样一个查询并在关键时间戳加载其响应,(2)随机将一个查询插入到视频时间戳tr中,(3)丢弃在tr之前发生的响应,并在tr处添加一个响应。这里可以将不同的查询插入到同一视频中,只需在新查询插入时间戳后丢弃前一个查询的响应即可。这样,我们可以在视频流中生成时间变化和自由形式的对话数据。我们为过去、现在和未来的事件各准备了50个问题,总计N = 150个查询。我们使用Llama-2-13B-Chat [77]或Llama-3-8B-Instruct [1]来生成响应,并在每个训练样本中插入最多3个查询。我们使用的离线数据集是COIN [75]和Ego4D GoalStep [73](用于演示用途),它们属于以自我为中心和教学视频数据集的类别,符合我们开发在线视频助手的宗旨。在这里,我们不考虑在线动作检测基准(例如,THUMOS14 [36],TVSeries [25]),因为它们是封闭集在线分类基准,它们的标签过于简短,可能会导致语言模型生成幻觉响应。请参阅补充材料以获取生成的对话示例。
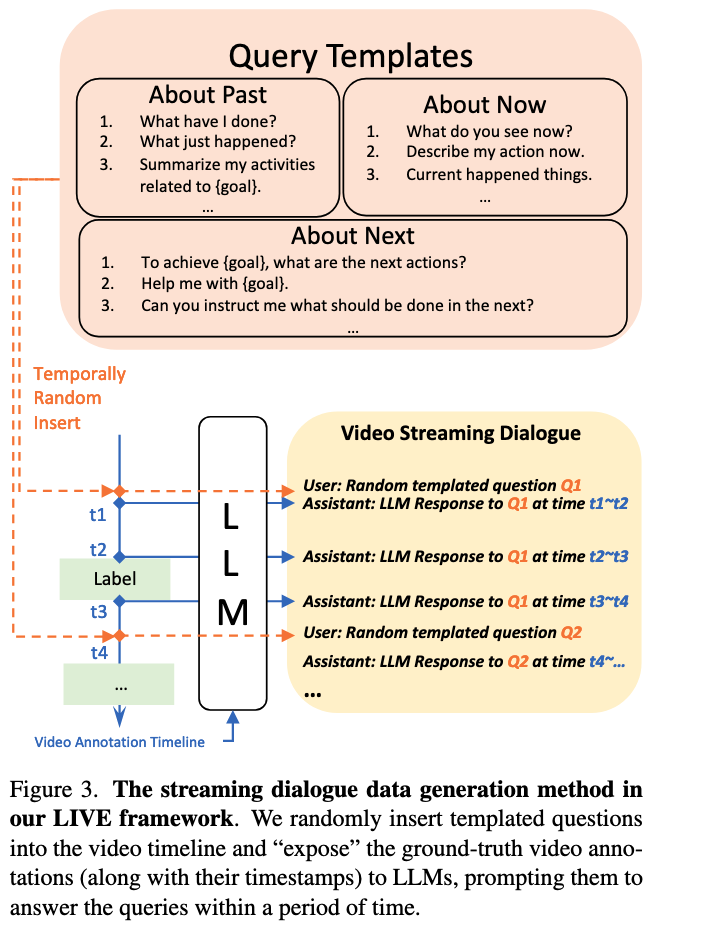
- 步骤一:识别关键响应时刻 从源数据集(如COIN)中提取所有已标注的事件及其起止时间戳。这些时间戳被视为模型需要做出响应的关键时刻
- 步骤二:生成模拟对话内容 研究人员创建了一个包含150个问题的模板库(覆盖过去、现在、未来等不同时态)。然后,他们使用一个大语言模型(如Llama 2/3),让它扮演“AI助手”的角色。在给定一个模板问题和视频的完整事件时间线(即所有标注)后,LLM会预先生成在每一个关键响应时刻,这位“AI助手”应该说什么
- 步骤三:构建最终训练序列 在为模型构建一条具体的训练样本时,系统会:
- 从模板库中随机挑选一个问题(例如,“请实时告诉我视频里在做什么”)
- 将这个问题随机插入到视频的一个时间点
tr - 然后,系统会加载在步骤二中为这个问题预先生成好的所有“标准答案”及其对应的时间戳
- 最终,模型接收到的训练序列就是:
[视频流... -> 随机提问时间点 tr -> 用户提问 -> 视频流继续... -> 关键响应时刻 t_response1 -> AI助手回答1 -> 视频流继续... -> 关键响应时刻 t_response2 -> AI助手回答2 ...]
顺便发现的一些数据集
- OVOBench 中提及的可以直接用的 qaego4d(还没搞), coin, ego4d
- OVObench 中提到需要 mllm 半自动标注的:Openeqa, Star, Perception test, Thumos challenge(这个咋有两版?)