ImageNet Classification with Deep Convolutional Neural Networks
这是深度学习的奠基之作, 发表于十多年前
第一遍阅读
标题
ImageNet Classification with Deep Convolutional Neural Networks
在那个年代, 深度卷积神经网络是很小众的方法, 因为当时主要都在用树, SVM 之类的
作者
Alex, Ilya, Hinton
Hinton 是神经网络的奠基人之一
李沐认为当时 Ilya 的报告仅仅展示了比较好的效果, 并没有解释背后的原理, 或许因此导致深度学习没有被更多的人了解
因此, 当时并没有在机器学习界走红, 主要是在计算机视觉界比较火, 因为用的是 ImageNet 数据集
摘要
- 模型在 ImageNet 中获得了冠军, 大幅超过原先的最佳水平
- 模型的大概结构
- 使用 GPU 进行训练 (当时已经比较常见, 在 Nvidia 推出 CUDA 之后)
- 为了减少过拟合, 使用 Dropout 的正则化方法
李沐评价
摘要写的并不算很好, 更像一个技术报告
结论
没有结论, 而是一个讨论, 比较奇怪
- 模型的深度 (层数) 很重要
- 本次实验主要采用监督学习的方式 (然而在此之间主要是无监督学习, 不需要 label)
- 如果网络够大, 数据够多, 就能训练得更好
- 与人类视觉仍有差距
- 希望把网络用于视频方向 (然而视频到了现在仍是一个进展比较缓慢的状态, 因为数据量, 版权等因素)
配图
深度学习神经网络中, 图片训练出来得到的最终向量在语义空间中的表现特别好, 主题体现是:
接近的向量基本表示的是同一物体
李沐认为这是这篇文章最大的意义
第二遍阅读
介绍
- 我们在做图片分类, 通过手机更多数据, 训练更强模型, 利用正则化避免过拟合
现在认为正则似乎没有那么重要, 更重要的是神经网络的结构设计
- 为了识别很大的数据集, 需要使用很大的模型, 这里使用的是神经网络, 用的是CNN
这里的写法有问题: 当时主流做法是其他的方法, 因此应该涉及一些其他的方法, 而非只阐述自己的方法
- GPU 为算力提供了保障, 数据集够大为训练 CNN 提供保障
- 用了一些不寻常的方法来提升模型性能
相较于比较好的成绩, 新技术对他人更有启发性, 更容易得到更高的引用.
因此"挖坑", 相比于"炫技"“组合旧方法”, 更值得推荐
- 用的 GPU 并没那么强, 这里把网络拆开放到 GPU 中
然而在后续被证明并没有太大必要, 即使作者花了很多时间去实现这个, 这些工程型的细节不是很重要
数据集
这里的一大创新点是, 没有使用 ImageNet 中的 SIFT (特征提取), 而是直接把原始的图片的像素放进网络里进行学习. 最后的结果证明: 对于神经网络, 不需要特征提取, 网络会自己把特征学出来, 效果比原始方法更好
这一点虽然在当时不算亮点, 但是这算是一种历史局限性, 在后人看来十分重要.
网络架构
ReLU 非线性激活函数
使用 ReLU 相较于 tanh 训练的更快
实际上区别并不算很大, 当时的一些关于更快的原因的猜想再后来也被证明是错的.
但是现在仍有很多人首选 ReLU, 主要原因是公式简单
使用多个 GPU 训练
由于当时使用的 GTX 580 的显存不大, 因此需要使用多个 GPU 才能跑这个训练
这部分其实是偏工程的实现细节, 如果只是关注机器学习相关的话, 可以等复现的时候需要再看
正则化
这里提出了一个正则化的方法, 避免激活函数过饱和
现在来看并不重要, 没啥人用. 现在有更好的正则化的方法.
重叠的池化
在传统的池化层的基础上做了一些改动
整体的架构
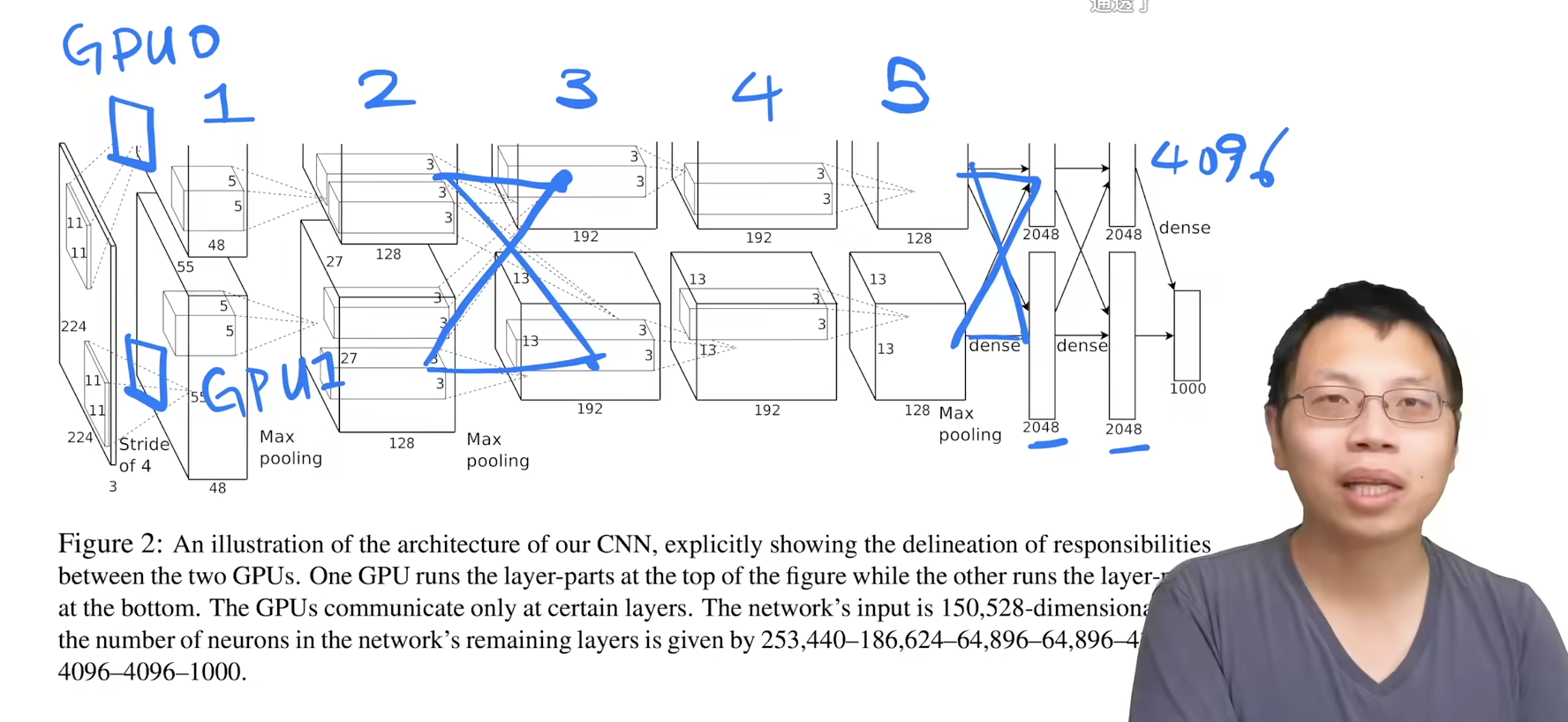
这里由于使用的两块 GPU, 因此对图片进行卷积时输出到不同的 GPU 上, 然后各自处理, 中间偶尔会互相看一下数据, 然后最后经过稠密层得到 4096 维的向量, 表示图片压缩后得到的信息
从现在的角度来看, 这是一个过于复杂的技术细节, 没有过多的通用性
到了最近模型变得巨大后, 又重新拾起了这种"模型并行训练"的方法
降低过拟合
数据增强
- 从原始图片上进行抠图
- 在原图的 RGB 通道上进行一些变换, 使得颜色有些变化
- 用 CPU 做数据增强
然而现在 GPU 的发展已经远远超过 CPU 了
丢弃 Dropout
随机地把一些隐藏层的输出变成 0, 相当于搞一个新的模型, 相当于是多个模型做融合
Dropout 会导致训练变慢, 但是可以降低过拟合
然而, 其实并不是做模型融合, 而是作为一个正则化的方法
训练细节
使用 SGD 训练
SGD 在现在是比较常用的优化算法, 但是当年由于不好调参等原因, 并不是很常用
这里提到了 weight decay, 其实在机器学习中是模型里的一个正则项, 不过深度学习把它放到了优化当中
权重初始化
这里使用均值为 0, 方差 0.01 的高斯随机变量对权重进行初始化
调整学习率
学习率从 0.01 开始, 如果验证误差不再下降, 则手动降低 lr 为 1/10
关于从多少开始, 现在比较常用的是用 warmup, 从 0 开始逐渐增大, 再下降