第一遍阅读
标题
Attention is all you need, 意思是"你只需要注意力就够了"
由于标题的特殊性+论文的影响力, 这个格式在后续走红, xxx is all you need 常常被后人效仿
作者
单位: Google
作者主要都是在 google, 其中有两位是在实习期间完成的
同等贡献
这里一共八个作者, 每个作者都打了星号, 意思是"同等贡献"
这种情况很少见, 一般有三人共享一作就已经是极限了
在首页的末尾, 提到"排序是随机的", 并且详细地写出了每一名作者在这里的具体贡献内容. 这是值得提倡的
摘要
Seq2Seq
本文主要是针对机器翻译领域的 Seq2Seq 模型, 那时主流的模型一般有编码器-解码器结构, 同时使用注意力机制
Transformer
更简单的结构
本文提出了一种"比较简单"的结构, 能实现比较好的效果
这个结构仅仅使用注意力机制, 没有使用循环/卷积
起名
Transformer 其实是变压器/变形金刚的意思
论文起名需要注意, 不然如果没有论文并不出名, 且遇到重名的情况, 别人很难检索到
更好的实验结果
这个模型具有更好的并行训练效果, 训练时间也更短
在其他领域上的泛化性也更好
结论
- Transformer 是第一个只采用注意力机制的序列转录模型, 把所有循环都换成了多头注意力
- 在机器翻译领域上, 该模型取得了很好的效果
- 除了机器翻译以外, 作者也希望把该模型应用到图像, 视频, 音频等多模态领域; 使生成不那么 “时序化” 也是另外的一个研究方向
这一点在后续的其他工作中都得到了验证, 作者预测对了大方向
- 把代码开源了(不过主流做法是把代码放在摘要的最后)
第二遍阅读
导言
时序模型
那时最热门的时序模型是 RNN, 包括 LSTM, GRU
其中可以分为两类模型: 语言模型, 编码器-解码器模型(当输出结构化信息比较多时)
RNN的一些问题
RNN 在运行的时候需要按顺序根据先前信息计算当下的隐状态, 用于进一步计算
这也带来了一些相应问题:
- 训练无法并行, 无法高效利用计算卡: 因为此处的计算具有时序性
- 丢失信息: 由于信息按时序流动/传递, 因此在后续可能会遗忘/丢失先前的信息
注意力机制在 RNN 上的应用
新模型: Transformer
为了改进 RNN 的一些问题, Transformer 舍弃了循环结构, 改为自注意力机制, 避免了时序性带了的一些问题
相关工作
卷积代替循环
有一些工作把 RNN 中的循环部分换成卷积神经网络, 用于避免时序性带来的一些问题
然而 CNN 并不擅长对长序列的建模, 因为需要多层逐层提取特征, 在最顶层聚合两端的信息
但 Transformer 可以同时看到每层中所有的像素
CNN 的优势是可以有多层输出通道, 代表识别的不同的特征
Transformer 采用多头注意力机制, 用来模拟 CNN 的多层通道
自注意力机制
这个想法其实先前就被提出过, 文章给了一些相关的文献
自注意力机制是 Transformer 中非常重要的一个点
记忆网络 Memory Network
在 17 年时, 这是一个研究的重点
(但李沐没有细讲)
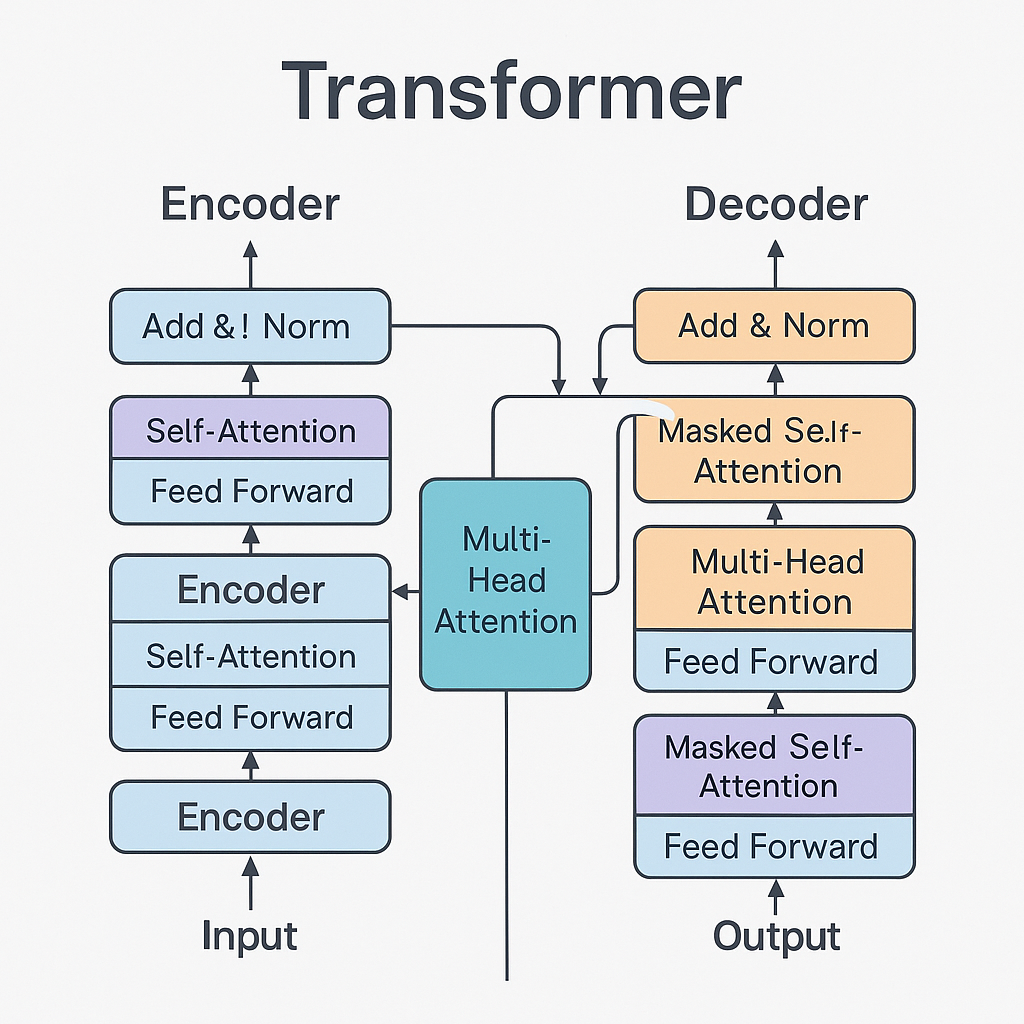
模型
编码器-解码器架构
编码器-解码器
那时最具有竞争力的序列模型大部分采用这个结构:
- 编码器把输入序列映射成连续向量序列(embedding)
- 解码器基于向量, 按顺序生成输出序列
自回归
解码器会使用先前生成的输出, 作为自己的输入
Transformer 块
多头注意力
先让 KQV 经过线性层投影到低维
再分别做点乘注意力
然后把每层的结果拼起来, 经过线性层投影, 得到最终的多头注意力
掩码 Mask
为了防止模型在训练的时候提前看到后面的东西
然而, 在计算注意力的时候会把所有 k 都考虑进去
因此只需要保证计算时不要考虑 t 时刻后的内容即可
mask 具体做法是把 t 时刻后的值换成很大的负数, 这样做完 softmax 就等于 0 了, 不会影响计算
残差链接
前馈层
就是一个 MLP
点乘注意力机制
QK 点乘计算相似度, 除以根号下 d_k 后, 计算 softmax 化成和为 1 的概率分布, 然后乘以 V, 得到注意力值
为什么除以根号d_k
d_k比较大的时候, 相对差距会更大
会导致做完 softmax 之后值分别向 1, 0 两端靠拢, 导致梯度比较小
Embedding 和 Softmax
embedding 用于将词转换为稠密的向量
其中, 编码器, 解码器, softmax 前的线性层也需要 embedding, 作者把这三个设置为同一个权重
此外, 把权重乘以了根号 d, 用于缩放大小, 使得后面与位置 embedding 相加时大小更加匹配
位置embedding
attention 并不包含时序信息, 因此需要用 positional embedding 来记录时序信息, 并加到 embedding 中, 作为输入