被 Colab 折磨, 没有额度了, 只能放下马上昨晚的 lab, 继续学习课程
../动手学深度学习/6.1 从全连接层到卷积
计算机如何"看到"图片
图像是数字
图像只是一个由数字构成的多维数组
其中各个位置的数字分别代表颜色, 通道数等等
计算机视觉中的任务
- 回归(Regression):预测连续数值,例如年龄估计、边框坐标。
- 分类(Classification):预测图像所属的类别,例如猫/狗识别、多类场景识别等。
图像变化中的挑战
面对多种多样的图像, 识别特征是一个困难的问题:
- 角度变化会改变图像的外观特征
- 光照影响颜色、边缘、阴影等
- 距离、缩放导致物体大小变化
- 部分信息缺失使识别更难
因此, 人工设计一个特征用于提取变得十分困难, 采用"自动特征学习"是一个更好的方法
深度学习就很好的满足了这一特点
学习特征表示
深度学习通过端到端学习的方式,能自动从图像中提取适合任务的特征:
- 不再依赖人工定义的特征模板,而是从数据中学习特征;
- 不同层的神经元学习到的特征具有不同的抽象层次:
- 低层:边缘、纹理等局部信息;
- 中层:局部形状、纹理组合;
- 高层:语义层面的概念(如“耳朵”“狗脸”)。
因此,深度神经网络非常适合图像分类、检测、分割等任务。
学习视觉特征
将图像输入神经网络
从处理序列(如文本)转向处理图像时,我们面临一个关键问题:
如何将二维图像有效输入神经网络?
一个朴素的想法是将图像**展平(flatten)**成一个一维向量再输入神经网络,但这样会导致严重信息损失:
- 丢失了图像中的空间结构(spatial structure);
- 像素之间的相对位置和局部相关性无法保留;
- 类似于在 RNN 中忽略序列顺序或隐藏状态——丧失上下文信息。
因此,直接展平并不可取,尤其是在处理高维图像数据时。
使用空间结构:卷积(Convolution)
为了解决这个问题,我们引入一种能够保留局部空间关系的结构——卷积神经网络(CNN)。
核心思想如下:
- 局部感受野(Local receptive field):
- 将图像划分为多个小区域(如 3×3 的 patch);
- 每次只对其中一个小区域进行处理。
- 权重共享(Weight sharing):
- 使用同一个卷积核(filter)扫描整张图片;
- 对每一块区域执行相同的操作,得到一个输出神经元。
- 滑动窗口(Sliding window):
- 卷积核逐步滑动(通常有步长 stride);
- 每次滑动生成一个新的特征值。
- 输出保持空间结构:
- 得到的特征图(feature map)仍是一个二维矩阵;
- 代表输入图像在空间上的特征响应。
通过这种方式,神经网络能够感知空间分布信息和局部模式,这正是 CNN 在图像识别中如此强大的原因。
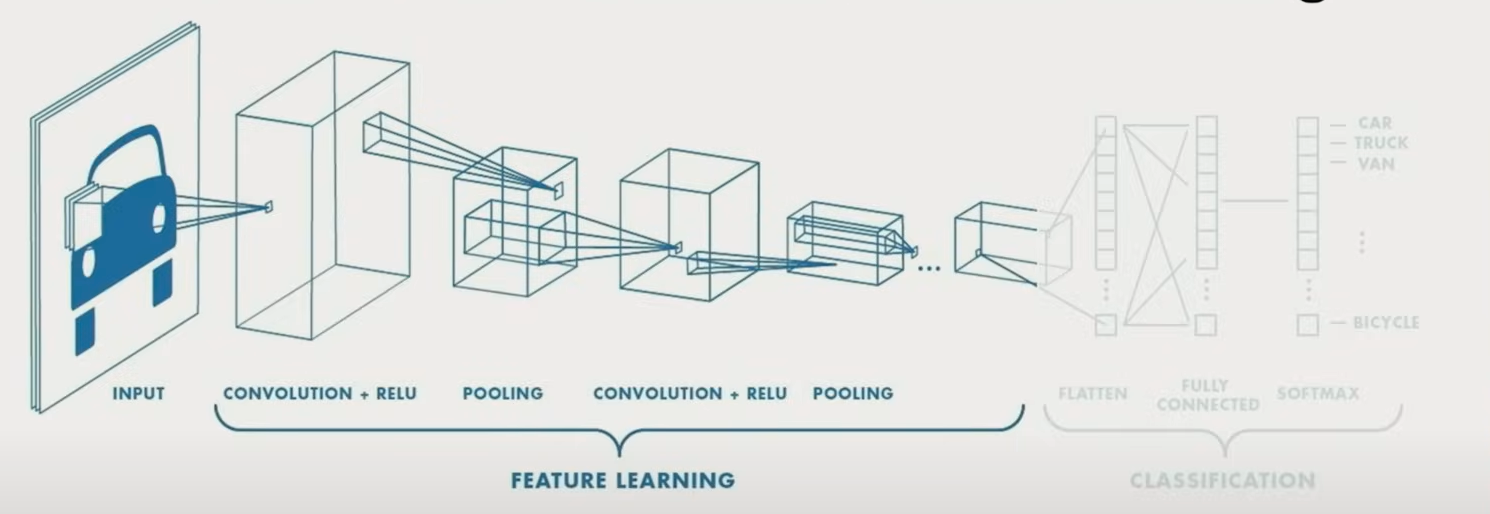
卷积神经网络 CNN
用于分类的CNN
卷积
- 从小片区域中获得输入
- 根据 filter 计算加权求和
- 加上 bias
输出特征图的空间结构
对于输出特征图, 它具有 h, w, d
其中 h 和 w 对应的是输出特征图的大小
这里的 d 对应的是特征图的深度
|
|
为什么会有深度
对于 filter 滤波器来说, 通常不只有一层, 而是有多层, 也就是多通道
其中每个通道负责扫描各自的特征, 给出不同的输出, 输出的数量为 d
非线性函数 (激活函数)
以 ReLU 为例, 激活函数在这里主要是为了让经过 filter 后的数值有着更明显的差距, 比如正数不变, 负数全设置为 0, 这样能够进一步的凸显特征
池化 Pooling
池化是一种对局部区域做下采样(downsampling的操作,常见方式有 最大池化(Max Pooling) 和 平均池化(Average Pooling)。
池化的优点
- 降低特征图尺寸:减少计算量、节省显存;
- 提高鲁棒性:增强模型对平移、旋转、缩放等微小变化的容忍;
- 抑制噪声:Max Pooling 会丢弃无关特征,保留最显著的激活;
- 引入非线性:虽然本质是一个固定规则,但由于和 ReLU 等非线性层组合使用,会增加模型表达力。
分类问题
在利用 CNN 完成特征提取后, 我们再用 MLP 进行分类, 在分类时, 我们使用 Softmax 函数处理数值
这个函数很好的满足了分类问题中需要得到一组概率分布的需求
代码实现
|
|
我的困惑:输入输出通道的关系
torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3)
我曾长期不理解“通道”在 CNN 中到底代表什么,以及卷积层是如何进行输入/输出通道的变换的。经过反复与 GPT 沟通,现在有了一些清晰的理解,记录如下:
通道是什么?
通道可以理解为:每一张“图像”的一个维度或一层。
- 在图像处理中,RGB 彩色图像是典型的三通道输入(R、G、B 三张图);
- 在卷积网络中,每一层的输出往往包含多个通道,每个通道就是一张由某种卷积滤波器提取出的特征图;
- 所以,一个
[C × H × W]的张量可以理解为有 C 张大小为 H×W 的图像。
卷积时的通道变换过程
以如下卷积层为例:
torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3)
- 输入为:
32 通道(即 32 张 H×W 的图像); - 输出为:
64 通道(即 64 张提取后的特征图); - 卷积核大小为
3×3。
对于每个输出通道的生成过程:
- 每个输出通道都对应一组专属的 32 个 3×3 卷积核,称为一套卷积核组合;
- 每个卷积核分别应用于输入的每个通道(每张图),进行卷积操作,得到 32 张中间特征图;
- 将这 32 张卷积结果加权求和,再加上一个偏置项(bias);
- 得到 1 张输出特征图。
所以:
- 每一个输出通道的背后,都是一套“32 个 3×3 核”的组合;
- 一共需要 64 套这样的组合,因为我们希望最终得到 64 个输出通道;
- 因此,卷积层的参数数量为:
64×32×3×3+64=1849664×32×3×3+64=18496
特征数量
每次卷积都是在做一次特征提取, 那如何知道每次卷积提取特征的数量呢?
这里的输出通道其实就是本次卷积提取的特征数量, 在这个例子里也就是 64
相对应的就是得到的 64 张特征图
共享参数
卷积层中的“共享参数”指的是:同一个卷积核的参数在整张输入图像上滑动使用,不同空间位置使用同一组参数。
这使得卷积操作无需为每个位置都单独学习一套参数,极大地减少了模型的参数量,并增强了模型对图像平移的鲁棒性。
共享参数仅在空间维度上进行(H×W),不同输入通道和不同输出通道使用的卷积核参数是各自独立的。
更广泛的应用
物体识别
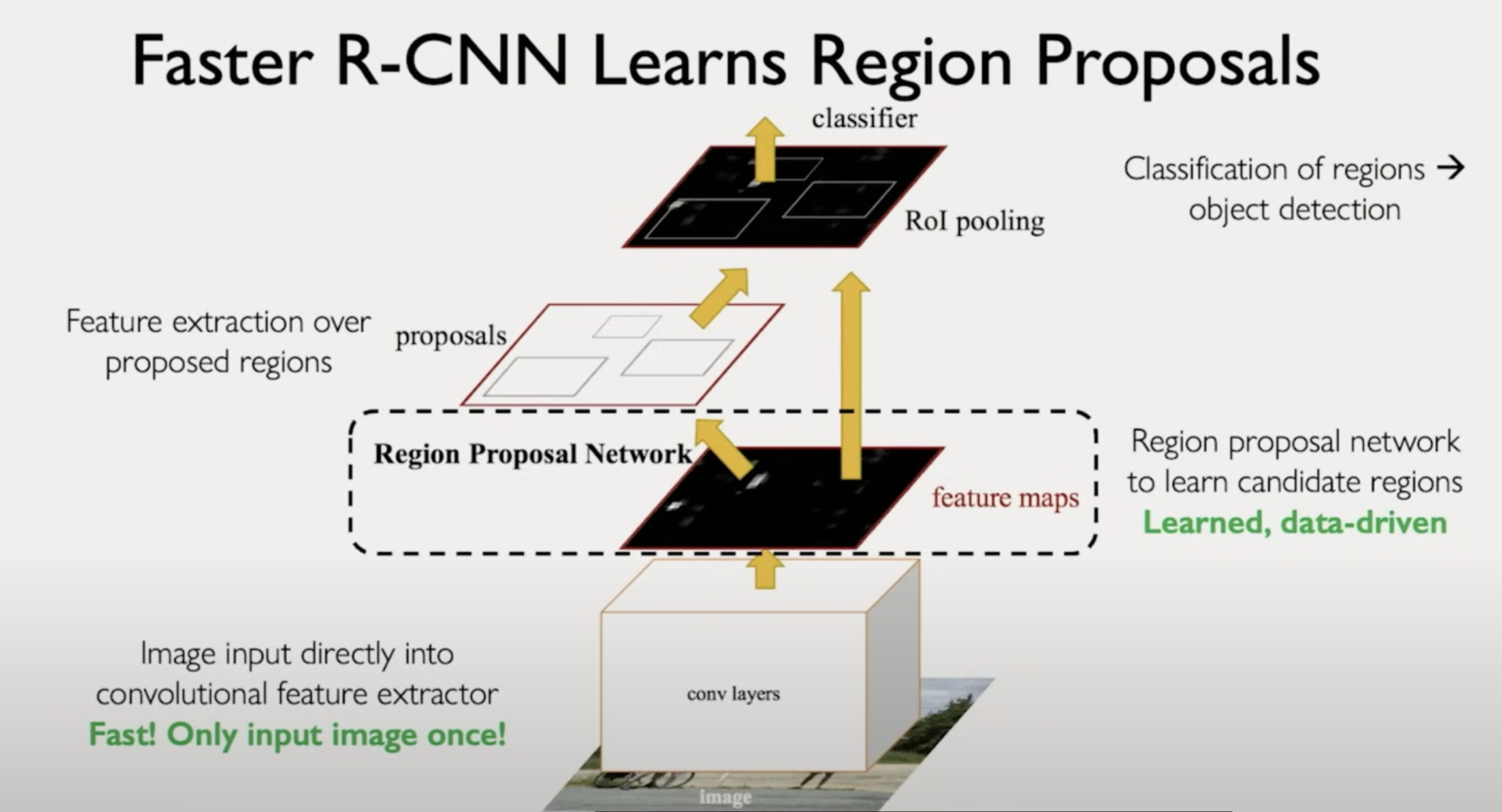
RCNN 区域卷积神经网络
相比于传统的 CNN, RCNN 在卷积之前加入了区域选取这一步
然后在选中的目标区域中使用 CNN 进行特征提取, 最后做分类, 得出该区域的图像对应的类别
RCNN 中, 区域选取用的是比较传统的搜索算法, 然而效率并不高
Faster RCNN
这里最大的提升是在选择搜索这一部分, 换成了 RPN Region Proposal Network
| 对比点 | Selective Search | RPN |
|---|---|---|
| 原理 | 基于启发式图像分割 | 基于 CNN 特征图预测 |
| 是否可训练 | ❌ 不可训练 | ✅ 可训练 |
| 是否 end-to-end | ❌ 否 | ✅ 是 |
| 速度 | 🐢 慢,秒级 | ⚡ 快,毫秒级 |
| 表现 | 好 | 更好(训练时 joint optimize) |
语义分割
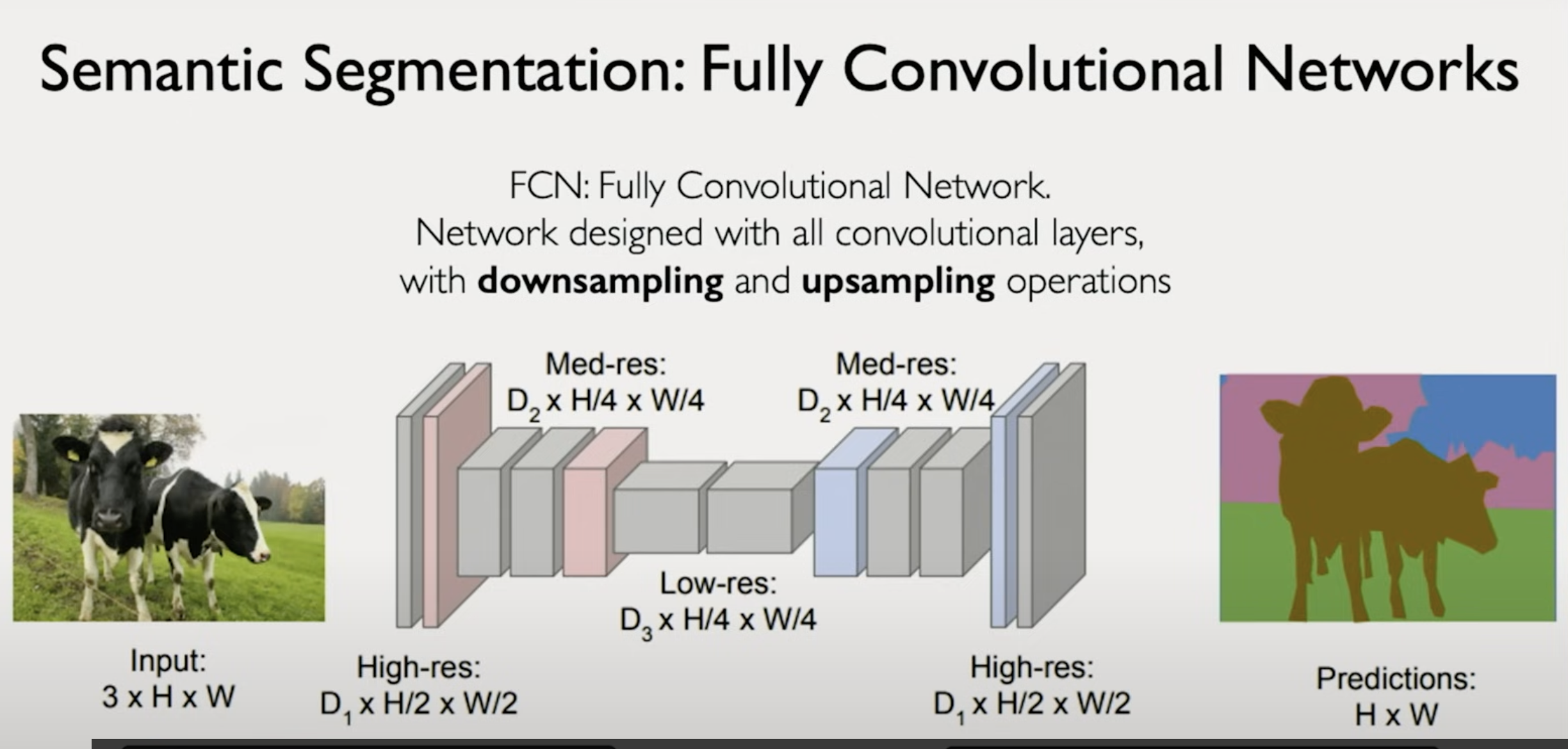
FCN 全卷积神经网络(Fully Convolutional Network)
- 相比图像分类(告诉你整张图“是什么”),语义分割是告诉你图中“每个像素是什么”
- FCN 的核心结构就是:
- 下采样(Downsampling):通过卷积和池化层逐步降低分辨率,提取语义特征(空间信息减少,语义增强)
- 上采样(Upsampling):将语义特征图逐步恢复到原图大小,对应到每个像素位置
- 逐像素分类:最终输出一张与输入图同大小的预测图
H × W,每个像素属于某个语义类别(如牛、草、天)