RNN 的问题
在 Transformer 被提出前, RNN 在 NLP 领域占有主导地位, 以下是它存在的一些问题
线性交互距离
在 RNN 中, 对于距离较远的两个词语, 需要花费很长的时间计算
无法并行计算
RNN 的前向/反向传播是按照顺序的, 不能跳步
因此无法并行运算
Attention
核心思想
- 把每个词的 embedding 作为一个 query
- 访问并整合 value 的信息
不同的注意力
- 先前: Decoder 关注 Encoder, 跨句子关注
- 现在: 句子内部之间相互关注
类比查找表
Attention 中, 相当于一个 query 会对所有 key 匹配相似度, 并将相似度作为权重, 对所有 value 值加权求和
自注意力块 Self-Attention Block
计算步骤
- 将词语转换成 embedding形式
- 将词向量用 QKV 矩阵转换为对应的 QKV
- 用点乘计算相似度, 用 softmax 进行归一化
- 把 softmax 后得到的相似度与对应 value 相乘, 求和
顺序编码
Self-Attention 仅仅解决了内容问题, 但是没有关注到词语间的顺序问题
需要采取一些手段, 表示出每个词的位置信息
- 用向量表示出词语的位置信息
- 把位置向量与语义向量相加
三角函数表示法
用三角函数(类似于傅里叶变换), 表示每个词语的位置编码
Transformer 中用的就是这种方法
- 然而不可学习, 且外推效果不好, 现在不太常用
深度学习表示法
用深度学习的方法, 学习出一个位置编码的表示
- 很灵活, 每一个位置都会通过学习与该位置的数据相匹配
- 但是只能学固定长度的位置表示
- 不过大部分主流模型用的也是这个
非线性元素
- 加入前馈神经网络提供非线性
$$
m_{i}=MLP(output_{i})=W_2⋅ReLU(W_1⋅output_i+b_1)+b_2
$$
避免"偷看"未来预测信息
使用掩码自注意力机制
- 在使用 decoder 时, 需要确保其不能偷看未来预测的信息, 使得训练无效
- 统一计算所有词的注意力, 人为屏蔽未来信息: 把不能看的注意力得分设置为负无穷
- 负无穷经过 softmax 后为 0, 等价于不考虑未来的词
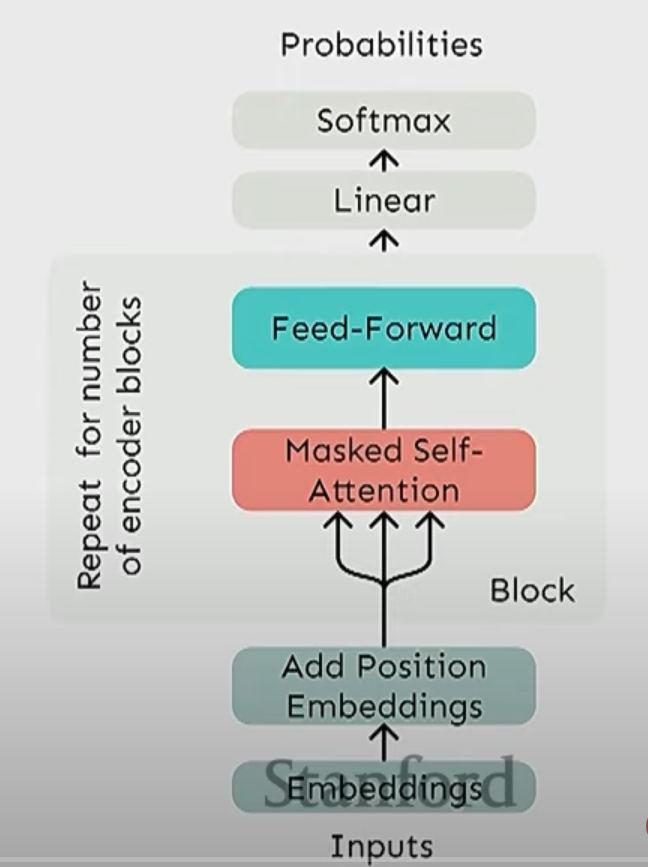
Transformer 块
和前面一步步构建的自注意力块对比一下
多头自注意力
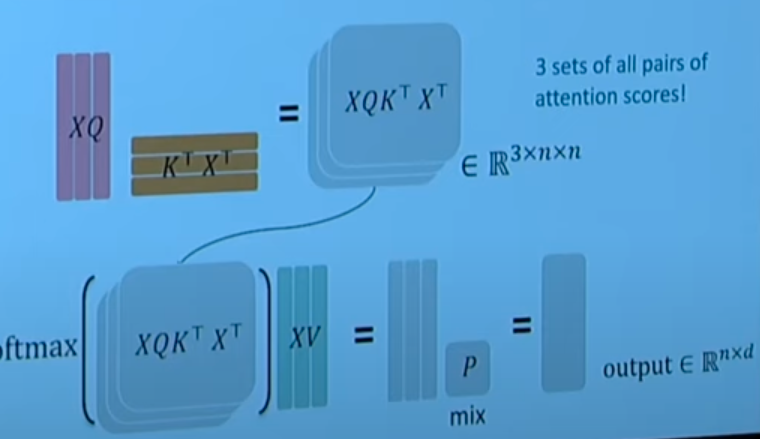
这里的不同点在于"多头"
- 这里把原有的 KQV 计算切分成多个低维的计算, 用于捕获不同的特征
- 然后把结果拼接起来, 经过线性层后恢复到正常维度
点乘注意力
点乘之外, 对结果除以根号 d
因为当维度 d 增大后, 点乘一般也会相应增大, 导致进入 softmax 后的梯度会很小, 不利于更新计算
残差连接
$$
X(i)=X^{(i−1)}+Layer(X^{(i−1)})
$$
当前层的输出 = 上一层输入 + 本层的运算结果
- 更容易训练
- 避免梯度消失
- 偏向于学习恒等映射
层归一化
- 减少不同隐藏向量维度之间的无关方差
- 把每个输入向量归一化成均值为 0,标准差为 1,帮助模型更快、更稳定地收敛
- LayerNorm 是对单个 token 的每一个维度做归一化,不依赖 batch。

- 加快收敛速度
- 避免激活值爆炸/消失
- 归一化梯度, 梯度更加问题
- 对于序列长度, batch size 不敏感