
词向量 Word Vectors
字词的含义
字词可以表示一定的含义, 但是仅仅通过"近义词"“反义词"等表示词语的性质并不精准
我们希望借助一种量化的手段, 可以将字词的含义量化, 一是可以更加精确地表示含义, 确定之间的关系; 二是量化后的数字可以很好的被计算机处理
One-hot Vector
在传统的 NLP 中, 我们把词语当做离散的符号
因而在向量中, 我们用独热向量进行表示
由于词语数量庞大, 再加上独热向量的特性, 词向量的维数巨大
劣势
向量没有自然, 固有的意义
只是表示不同的向量(词语), 无法建立词语间的关系/关联
Word Vectors
You should know a word by the company it keeps. — Firth 1957
分布语义 Distributional semantic
在分布语义中, 我们通过一个词语的上下文来定义它的含义
词向量
基于分布语义的思想 我们用更加密集, 短小的向量来表示词语, 解释词义
因此, 我们可以通过向量的相似程度来表示对应词语的含义是否接近, 在运算中, 我们通过点乘大小来衡量词向量间的相似程度
词向量又被称为词嵌入 embedding, 神经词表示 neural word representation
Word2vec
这是一种学习词向量的框架, 于 2013 年被谷歌提出
并非是最早的想法, 但是是表现最好的
步骤
- 准备文本语料库 corpus
- 每一个词语都用向量表示(其实是做一个初始化,后面会更新)
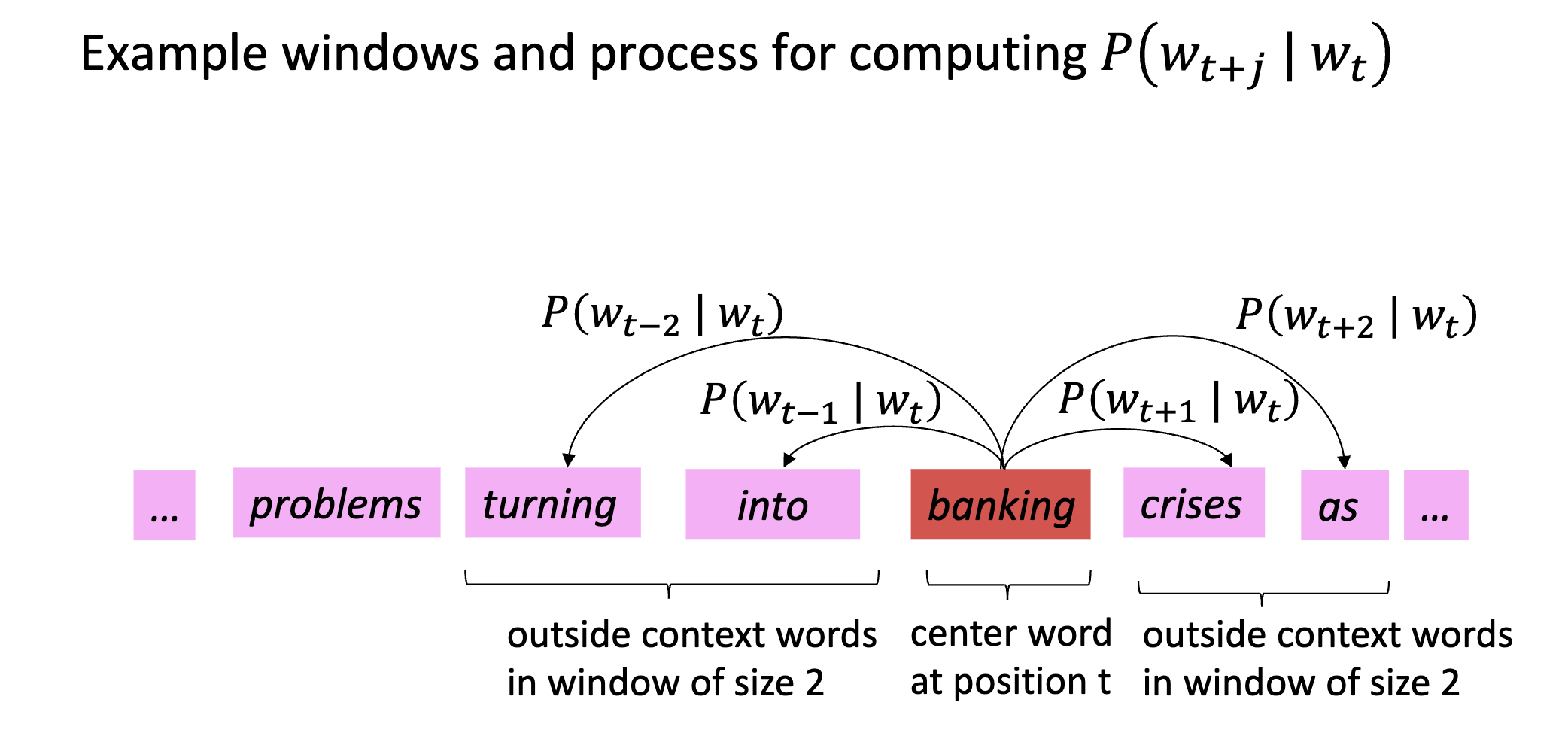
- 遍历文本中的每一个位置 t , 其中中心词语 c, 上下文词语 o
- 使用 c 和 o 的词向量的相似性, 计算给定 c 的条件下, o 的概率
- 调整词向量, 使得概率最大化
目标函数
什么是目标函数
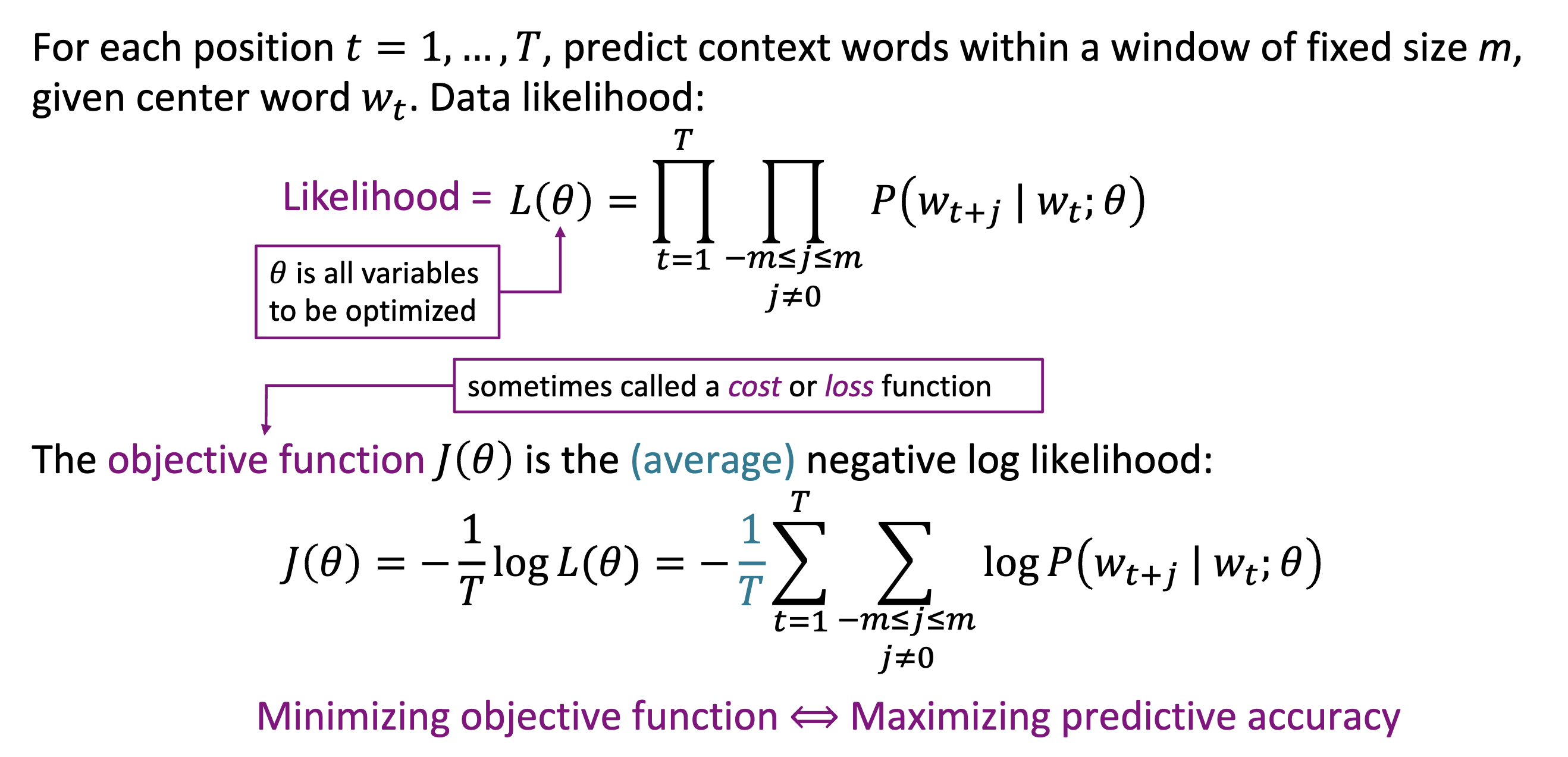
首先, 我们定义似然, 是所有条件概率的乘积
进一步, 我们写出目标函数, 通常被成为 loss, 是在似然的基础上取负,取平均,取对数得到
- 取负: 纯粹是因为一开始的目标是降低函数值, 因此取负以遵循惯例
- 取平均:让数值收敛一些?
- 取对数: 许多条件概率相乘, 为了简化运算, 我们通过取对数把计算转化为相加, 能避免乘积的许多问题
预测函数
如何计算条件概率
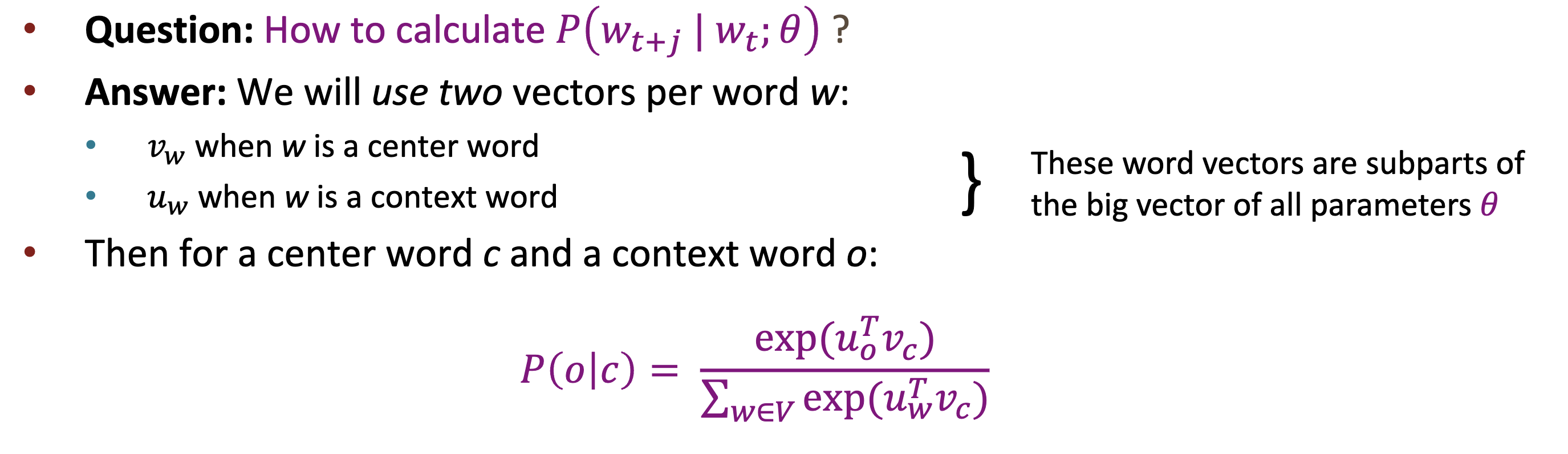
对于每个词语 w, 有两个对应的词向量, 分别用于表示其为中心词, 上下文词的词向量
这里的条件概率通过计算中心词语上下文的点乘, 然后经过 softmax 归一化得到
softmax
softmax 运算可以将数值归一化到(0,1)的区间, 并且各项相加为 1, 适用于把 logits 转化为概率
为什么 Word2Vec 每个词要有两个向量?
- 目的:分别用于“中心词”(预测上下文)和“上下文词”(被预测)。
- 原因:
- 表达更灵活:同一个词在“说话”和“听话”角色下语义可能不同,用两套向量能更好表达。
- 优化更高效:避免同一向量同时优化两个方向,收敛更快,训练更稳定。
- 结构决定:模型本质是输入和输出两层网络,自然需要两套参数。
- 结论:虽然一个向量也能用,但两个向量效果更好,是实践和理论都支持的设计。
优化
这里的优化使用梯度下降方法
然而, 这需要等到遍历完所有数据, 才能做出一次更新, 效率太慢了
为了解决这个问题, 我们采用随机梯度下降/小批量梯度下降
随机梯度下降
这里在所有数据中随机抽取一小批量的数据, 作为一个 batch, 基于 batch 的计算来更新参数
这里每一次的更新方向, 都只是对"真实方向"的近似, 因此可以看做带有噪声
即使是近似, 但是快速的近似方向的优化, 效果和效率远大于缓慢的精确方向的优化, 这里似乎 zero2hero中讲过
然而正式这种噪声, 可以再训练神经网络时, 让模型表现的更加稳定, 不让模型死记数据中的细节, 避免过拟合