机器翻译
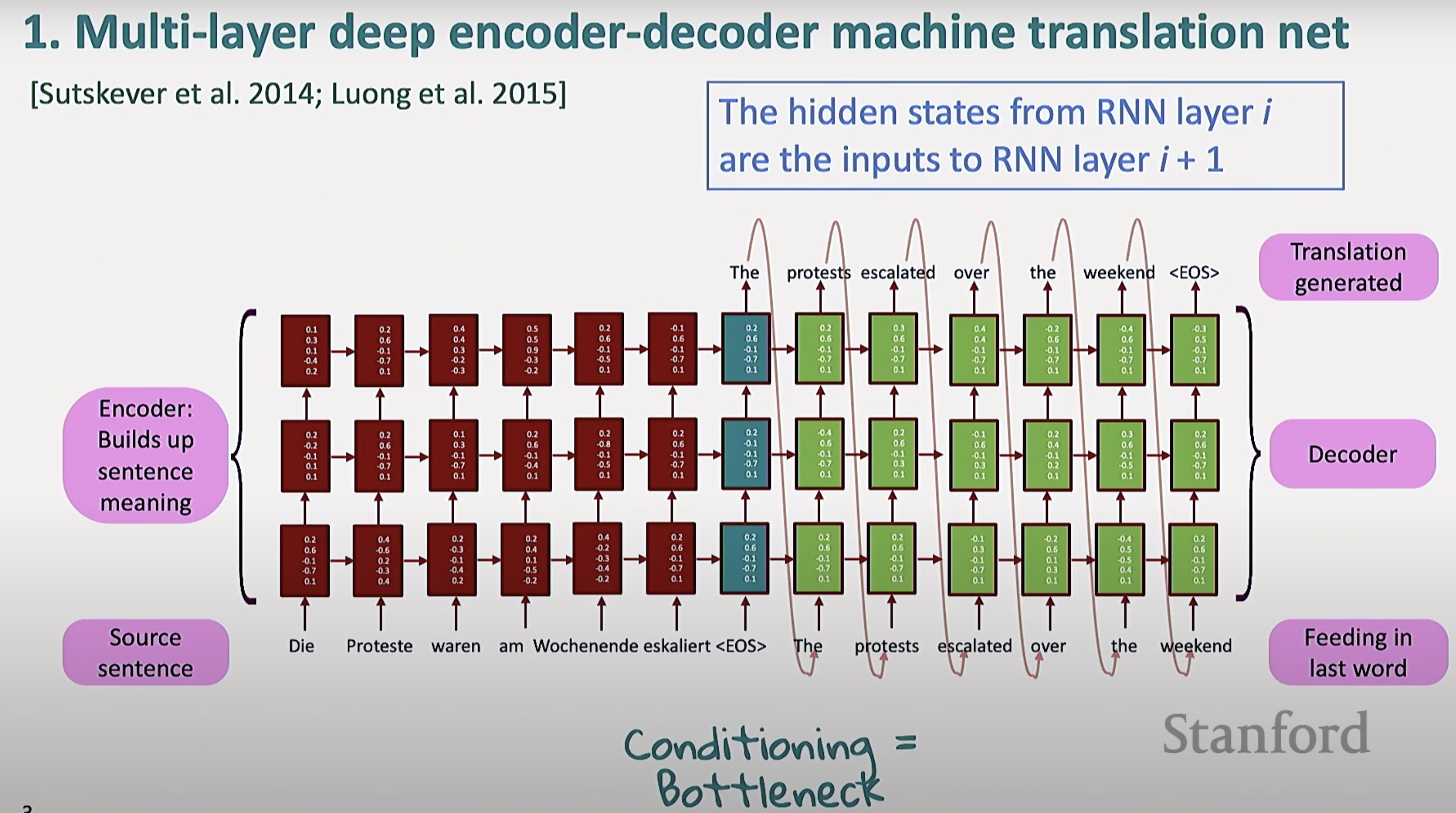
这是最早的神经网络机器翻译框架, 是多层(Multi-layer)深度编码器-解码器(Encoder-Decoder)神经网络机器翻译结构
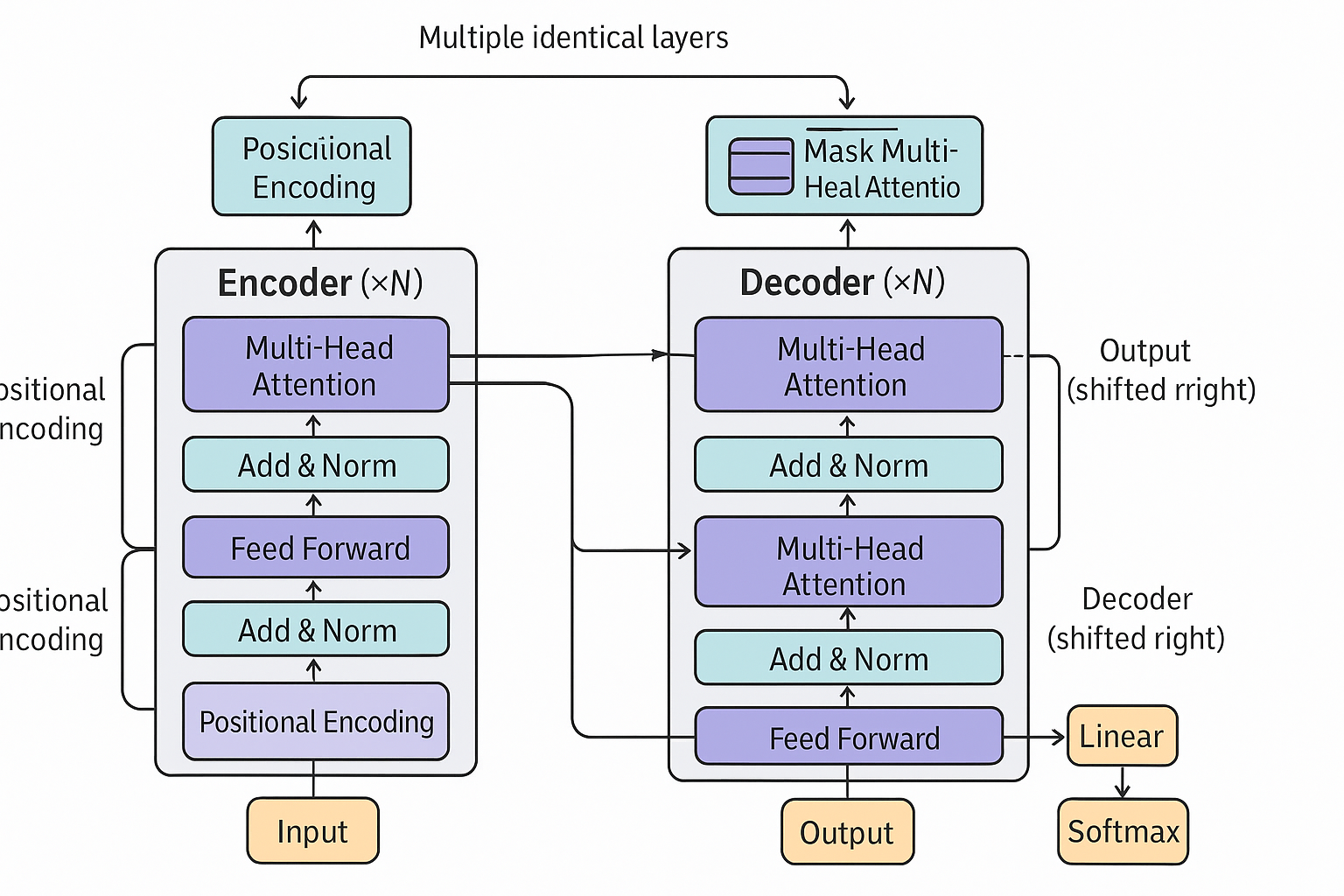
结构
编码器 Encoder
- 左侧的红方块为输入, 是源语言句子
- 句子中每个词被送进 RNN, 提取上下文含义
- 采用多层结构, 下层的输出会作为上一层的输入,类似堆叠 LSTM
解码器 Decoder
- 根据提取出的上下文含义, 逐步生成目标语言的翻译
- 解码器的输入是上一步生成的词, 并结合编码器的上下文
信息瓶颈 Conditioning = Bottleneck
- 从编码器到解码器, 需要传递上下文信息
- 编码器需要把最后一层的隐状态传递给解码器作为初始状态 (在 LSTM 中, 同时传递隐状态和记忆单元)
- 这个地方称为信息瓶颈(Conditioning = Bottleneck),因为所有源句子的意义都必须被浓缩在这组向量里
评估
注意力机制
动机
原有架构的不足
在 Seq2Seq 网络中, 无论输入有多长, 包含多大的信息量, 都会被压成一个固定维度的向量
因此, 会面临一些问题:
- 长文本效果变差
- 细节信息丢失
因而, 在解码时, 解码器只能看到编码器最后一步的输出, 没法直接访问所有的中间信息
同时, 无法灵活地关注输入中的特定词
与人类的翻译不同
- 人类在翻译时,并不是“一口气记住所有内容再说”,而是一边看原文,一边生成译文。
- 当遇到不确定的词语或结构时,还会回头反复查看原文的某些部分,关注细节、上下文或者特定关键词
因此, 这同样引导我们, 需要改进模型, 让他能够更加灵活地关注句子中的不同细节
核心思想
解码器每一步都可以“直接访问”编码器的全部输出,专注于输入序列中的某一部分
注意力机制下的 Seq2Seq 模型
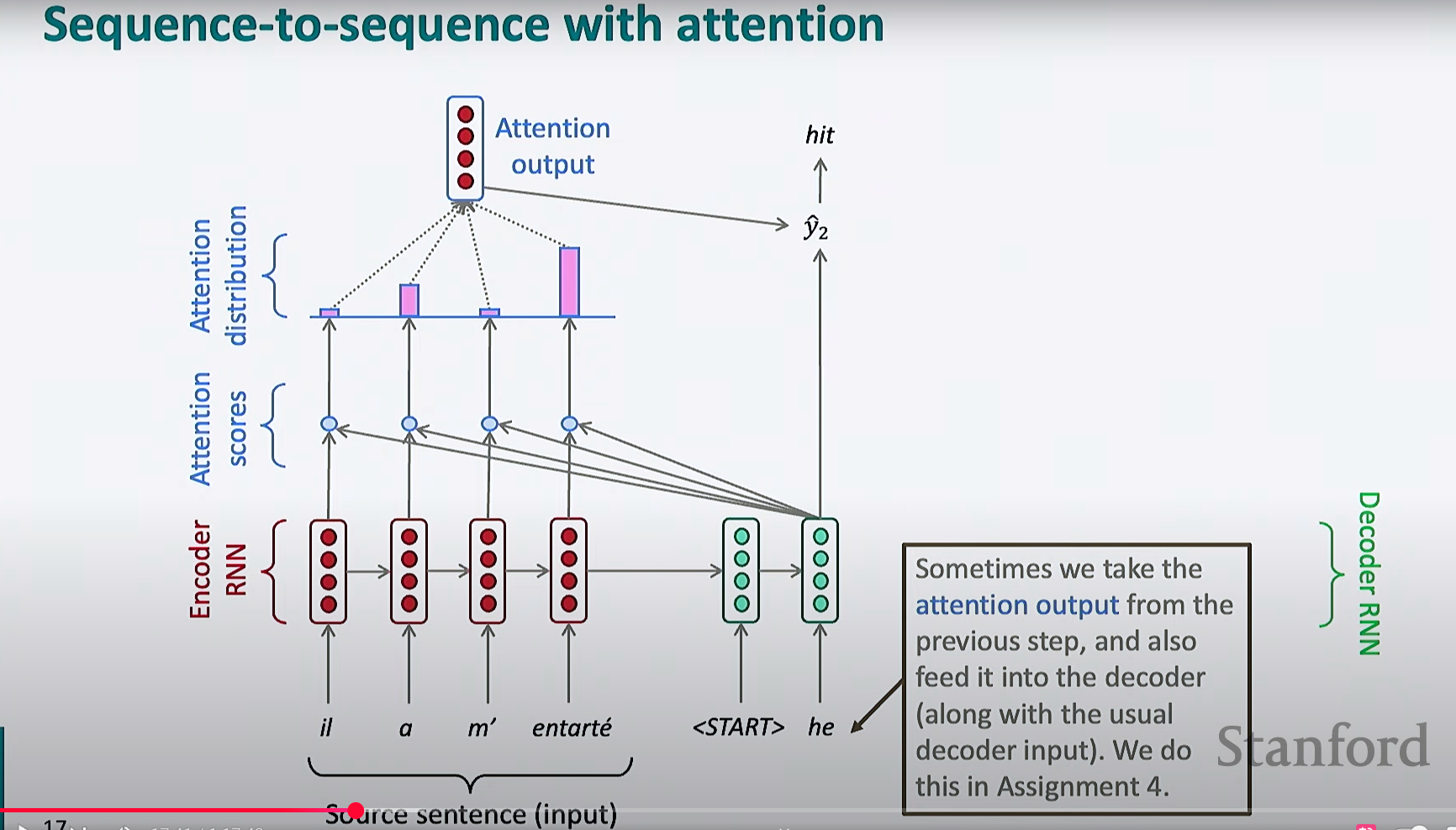
- 对于解码器的每一个时间步, 都会把编码器的每一步输出都拿来计算注意力分数
- 分数经过 softmax 归一化, 变为概率分布, 得到注意力分布
- 按照注意力分布的权重, 对每个隐状态加权求和, 得到新的向量, 这个向量是当前时间步下, 输入序列中最相关内容的提炼
- 解码器使用注意力输出作为辅助信息, 和解码器自己的隐状态相结合, 用于预测下一个词
我的疑问: 为什么解码器需要隐状态?
解码器的 hidden state 其实就像“解码器的大脑/记忆”,它记录了解码器到目前为止已经生成了哪些内容、当前处于什么语境
而 attention 提供的是“当前需要从输入句子里取哪些信息”
这两者信息来源不同,功能互补
我的疑问: 为什么用隐状态而不是记忆单元?
hidden state 更适合表达“语义内容”
- ht 是 LSTM 每步输出的“语义表示”,它被设计出来就是给下游网络直接用的。
- 在传统 RNN/LSTM-based seq2seq+attention 结构里,attention 实际上是在 encoder 输出的所有 hi 之间“分配关注度”,然后用这些 hi 拼加权和,传给 decoder。
cell state 是内部机制,不适合直接参与注意力
- ct 是 LSTM 的内部“长时记忆”容器,它往往没有经过额外的激活函数处理,可以存储信息,但不是直接用来表达当前输入语义的“输出”。
- 设计时,cell state 的意义主要是“记忆”,不适合作为显式信息暴露出去给其他层用,直接用作 value 反而没什么意义。
业界和论文都是用 hidden state 作为 value/key
- 包括最早的 Bahdanau attention、Luong attention,乃至后来的 transformer(虽然不再用 RNN,但思路一样),都是用 hidden state 做 value/key/query,因为它代表“这一步的所有已知信息、可用特征”。
Attention: 数学公式
- Encoder hidden states: $h_1, …, h_N \in \mathbb{R}^h$
- Decoder hidden state at $t$: $s_t \in \mathbb{R}^h$
- 注意力分数:
$e^t = [s_t^T h_1, …, s_t^T h_N] \in \mathbb{R}^N$ - 注意力分布 (softmax)
$\alpha^t = \mathrm{softmax}(e^t) \in \mathbb{R}^N$ - 注意力输出:
$a_t = \sum_{i=1}^N \alpha^t_i h_i \in \mathbb{R}^h$ - 拼接输出,用于生成下一个词:
$[a_t; s_t] \in \mathbb{R}^{2h}$
优势&提升
提升 NMT 性能
(NMT 神经机器翻译)
Attention 让解码器能够聚焦输入句子的关键部分,大大提升了翻译准确性和流畅度
提供更像人类的翻译模型
人类翻译时,也会不断回头查原文;attention 机制让模型可以“回看”输入,而不是靠短期记忆
解决瓶颈问题
让解码器在每一步都能直接访问全部编码器信息,“绕开”了 bottleneck,只关注相关部分
缓解梯度消失问题
注意力机制为“远距离依赖”提供了捷径,不需要通过多步 RNN 的传递,可以直接跨步获取需要的信息
增强模型可解释性
- 注意力分布可视化: 可以了解到每个时间步时的关注点
- 自动获得"软对齐": 无需人工标注, 可以得到输入词与输出词之间的对应关系
一般步骤
由于 Attention 有很多变体, 这里总结出最普遍的步骤
计算注意力分数
- 对于编码器的每一步的隐状态, 根据 query , 计算相关性, 得到注意力分数
- 这里计算相关性的方式有很多, 会在后面的"变体"中提到
转化为注意力分布
把注意力分数经过 softmax 计算, 得到概率分布, 也就是注意力分布
计算注意力输出
把注意力分布作为权重, 对每一个隐状态加权求和, 得到最终的注意力输出