LLM 的现状与历史
神经网络之前
- 香农提出用语言模型来测量熵 entropy
- 有许多工作关注 n-gram 语言模型
神经网络时期
- Bengio 提出第一个 NLM(神经网络语言模型)
- Ilya 提出Seq-Seq 序列模型
- Adam 优化器
- 注意力机制
- Transformer 架构
- MoE
- 模型并行化
早期基础模型
- ELMo: 用 LSTM 预训练, 然后微调
- BERT: 用 Transformer 预训练, 然后微调
- T5: 把任何信息用 text-text 方式映射
拥抱 Scaling
开源模型
开源的不用程度
- 闭源(GPT-4): 只能调用 API
- 开放模型权重(DeepSeek): 权重完全开放, 详细介绍模型架构, 但是没有提及数据集相关内容
- 开源模型(Qwen):开放权重和数据, 以及尽可能详尽的论文
课程构成

课程概览
基础知识 Basics
Tokenization
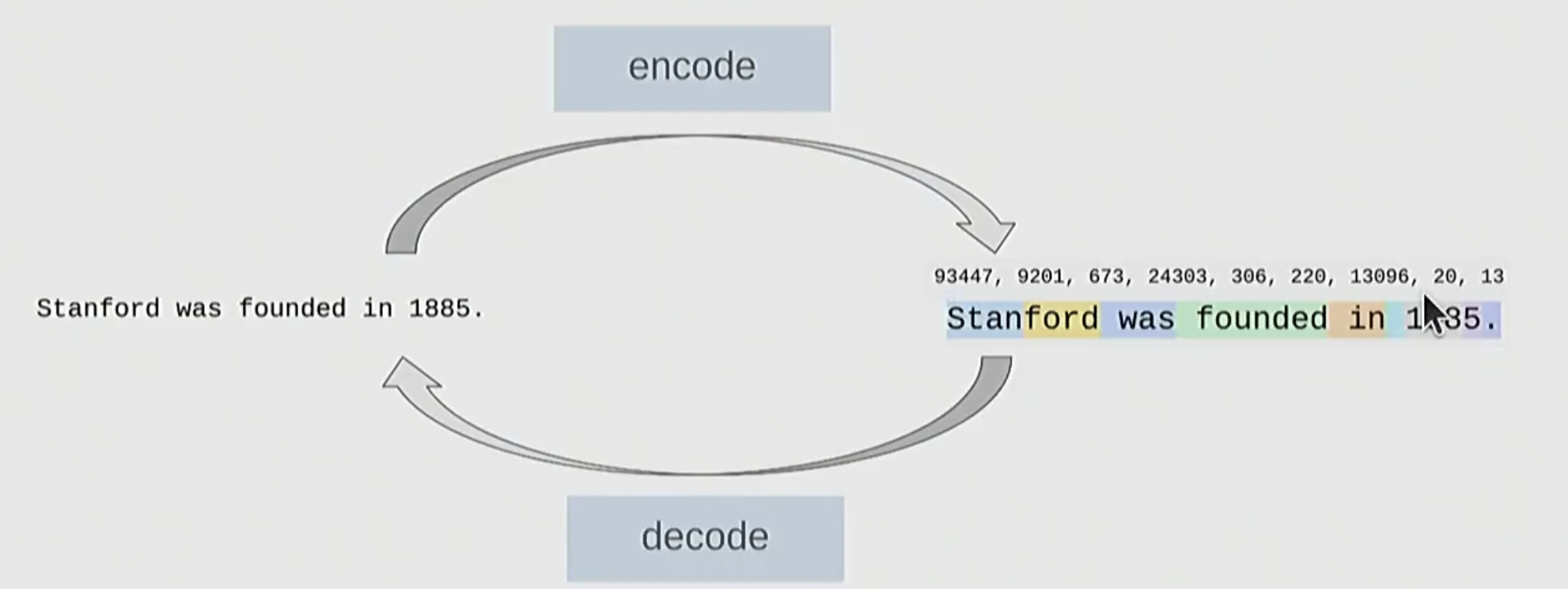
把一串自然语言分割成字符串序列, 并分别映射至向量空间之中
本节课主要讨论 BPE 分词器 (Byte-Pair Encoding)
模型架构
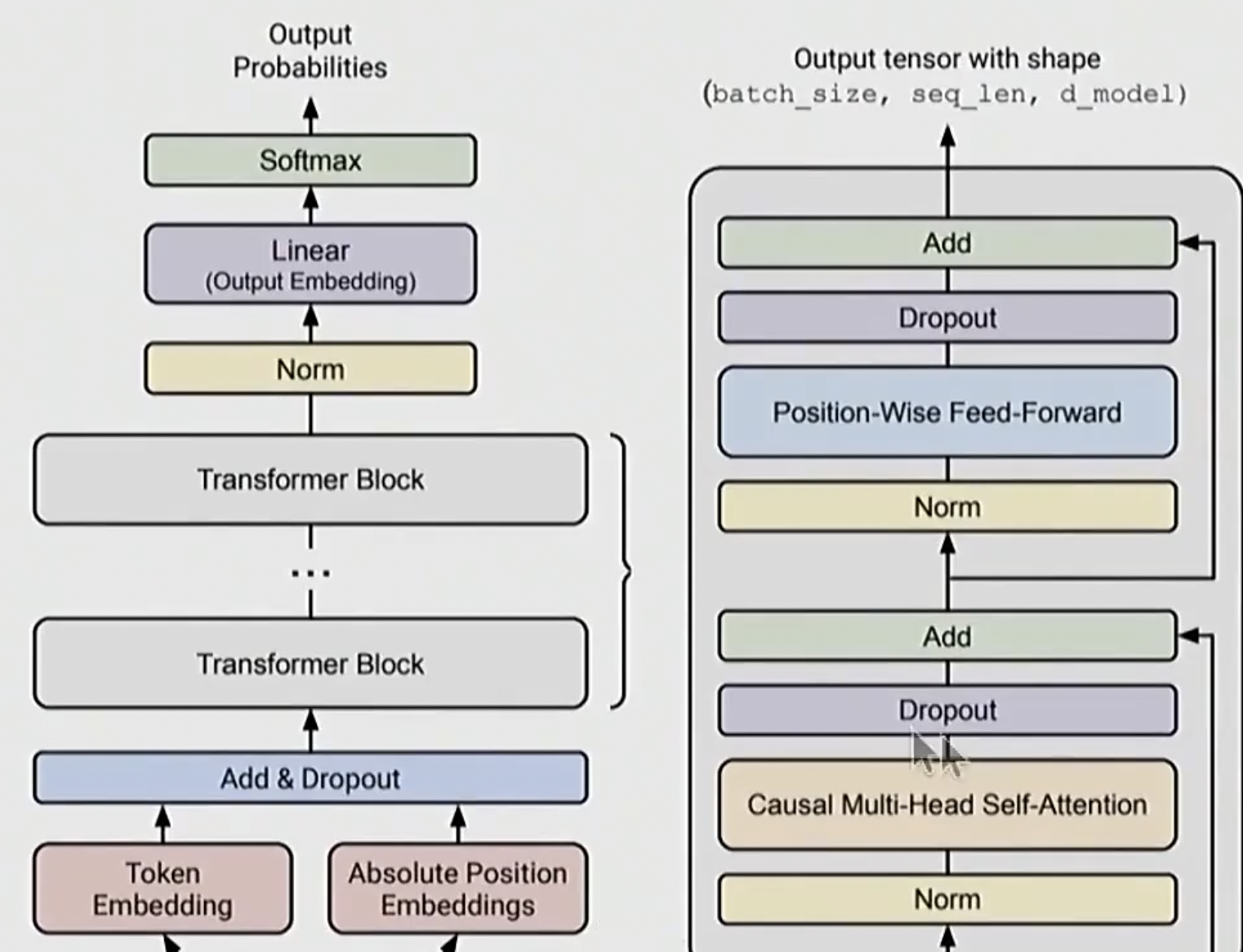
主要是 Transformer, 以及它的许多变体, 变化主要集中在以下方面:
- 改变激活函数
- 位置编码
- 归一化的方式和位置
- Attention 形式
- MLP
训练
在训练相关的决策中, 也有许多考虑因素:
- 优化器
- 学习率调整
- batch size
- 正则化方式
- 超参数
系统 Systems
主要聚焦于如何最大限度地利用现有计算资源
内核 kernels
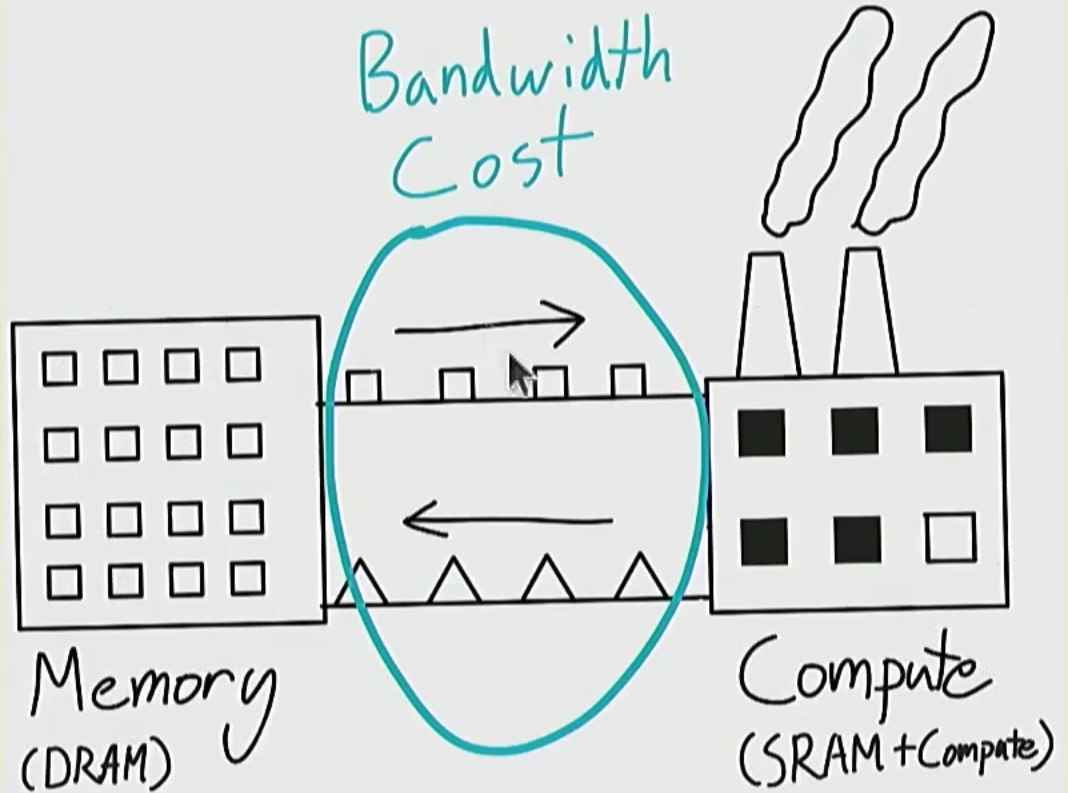
这是一个形象的类比, 数据通过一定带宽在内存和计算单元之间传输
因为我们需要尝试, 通过优化计算方式, 减少数据移动, 以此最大化利用 GPU
我们需要用一些工具来构建和编写 kernels
并行运算 Parallelism
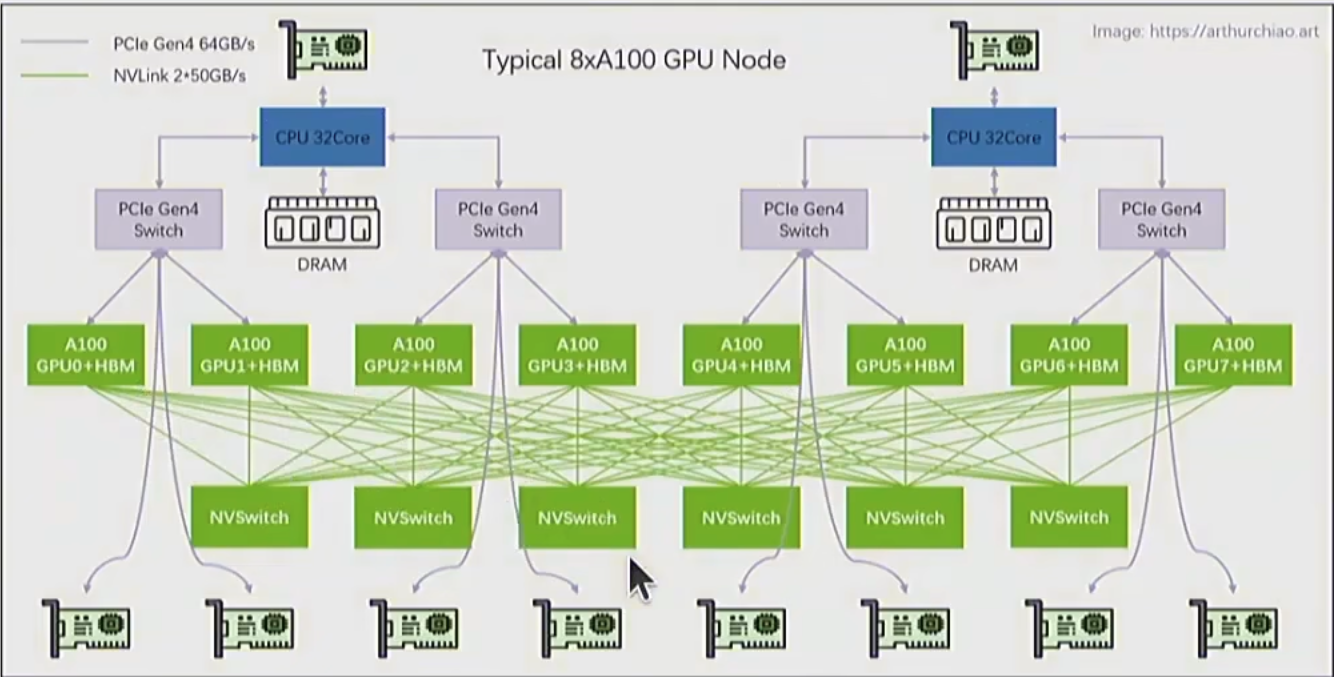
训练大模型避免不了使用多张 GPU
这需要我们解决数据传输, 尽量减少传输量, 尽可能提高传输速度
推理 Inference
- 目标: 在给定 prompt 的情况下生成 tokens
- 训练是一次性的, 而推理则是每次交互都需要进行的, 成本随使用次数增加, 要求我们让推理更加高效
推理中的阶段
- Prefill: 接受提示词, 运行模型, 得到一些激活值: 基于现有 tokens, 可以一节计算 (限制是计算资源)
- 进行自回归, 生成 tokens: 需要按顺序生成 tokens(限制是内存大小)
提高推理速度的方法
- 使用成本更低的模型
- 推测解码
- 系统优化
扩展法则 Scaling Laws
目标: 做一个小规模实验, 并基于此预测大规模实验的超参数和 loss
寻找平衡: 小模型+大数据? 大模型+小数据?
数据 Data
根据期望的模型功能, 筛选数据
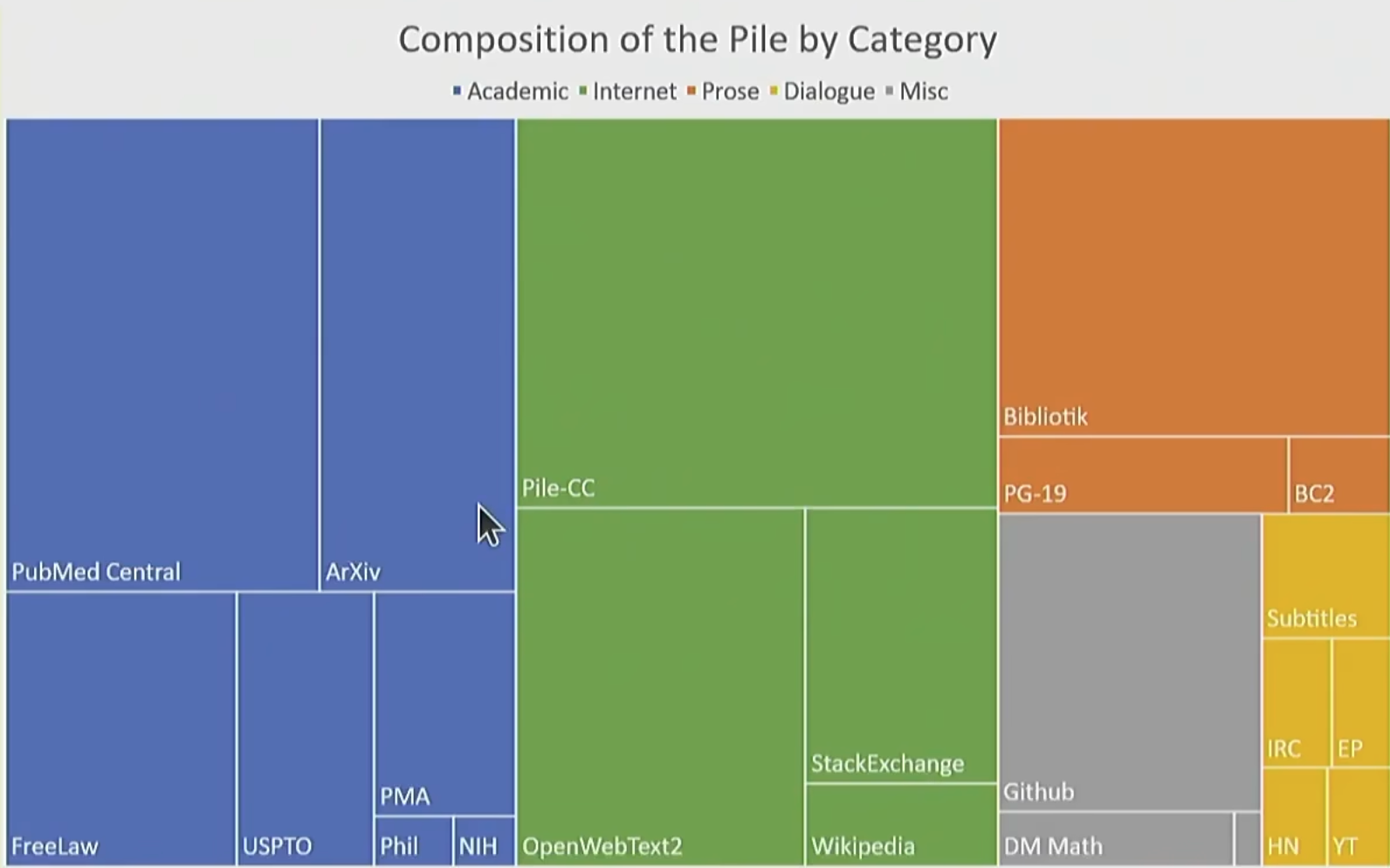
评估 Evaluation
- 困惑度
- 标准测试
- 指令遵循
- 扩展运行时计算
- 系统评估
数据筛选 Data curation
好的数据并非凭空产生, 随意获得
我们需要从数据源获取数据, 并且进行一些简单的处理
同时, 我们也需要处理各种各样类型的数据: HTML, PDF 等非文本数据
数据处理 Data Processing
- 把 HTML/PDF 文件转换成文本
- 对数据进行筛选, 去除有害信息
- 对数据去重
对齐 Alignment
基础模型擅长预测下一个 token, 需要通过对齐/微调等方式激活潜在的能力
目的
- 让模型遵循指令
- 调整模型风格
- 保证安全
阶段
- 监督微调
- 基于指令的学习
- 偏好数据: 基于同一个 prompt, 让用户选择偏好, 并据此训练
- 验证器
- 算法: PPO, DPO, GRPO
词元化 tokenization
介绍
- 将原始字符串转化为 token 序列
- 将分词后的结果映射到语义空间之中, 实现文本-数字的映射和转换
- 输入时, 将文本编码为 token; 输出时, 将 token 解码回文本
基于字符的分词
- 一串字符串由一个 unicode 字符序列构成
- 每一个字符都能映射为对应的数字, 这个过程同样可逆
- 然而, 这样的问题是 : 这种做法相当于为词表中每一个字符分配对应的数字, 并不高效
基于字节的分词
- 字符串可以用字节序列表示
- 一些字符可以直接用 一个或多个 byte 表示
- 一定程度上解决了上面的稀疏性问题, 问题是: 压缩比为 1, 序列很长, 效率同样不高
基于词的分词
- 最朴素的 NLP 做法, 直接切分成多个词
- 问题 : 词表没有上限, 无法处理错词和新词的问题
字节对编码 BPE
发展历史
- 1994 年就被提出, 用于数据压缩
- 后被引入 NLP, 用于机器翻译
- 被 GPT-2 使用
基本概念
- 在原始文本上训练分词器, 而非预先设定分词方法
- 常见序列用单个 token 表示, 罕见序列用多个 token 表示
- 先进行基于字节的分词, 然后根据共现的频繁程度, 进行合并
算法
- 初始化:把每个 byte 当作一个 token
- 比如 “hello” → [“h”, “e”, “l”, “l”, “o”]
- 迭代合并:不断找到最常见的相邻 token 对,把它们合并成一个新 token
- 例:[“h”, “e”] → “he”
- 然后 [“he”, “l”, “l”, “o”] → [“he”, “l”, “l”, “o”]
- 再合并 [“l”, “l”] → “ll”,得到 [“he”, “ll”, “o”]
- 重复,直到达到预设的词表大小。