Transformer
原版 Transformer
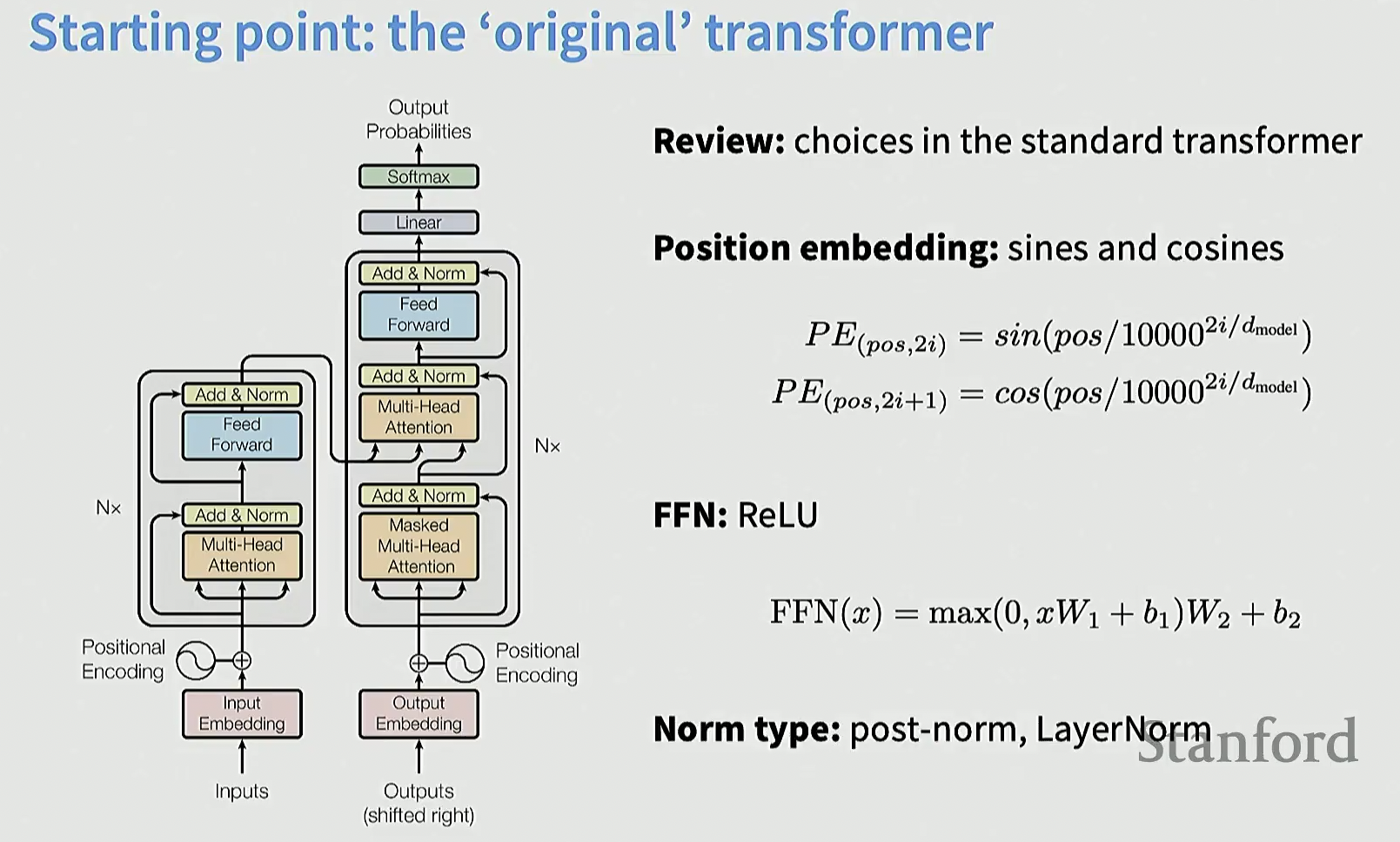
这是最初的 Transformer 架构, 在 Attention is All You Need 文章中提出
历经多年研究和改进, 已经有了多种变体, 能力也有所提升
通用改进版 Transformer
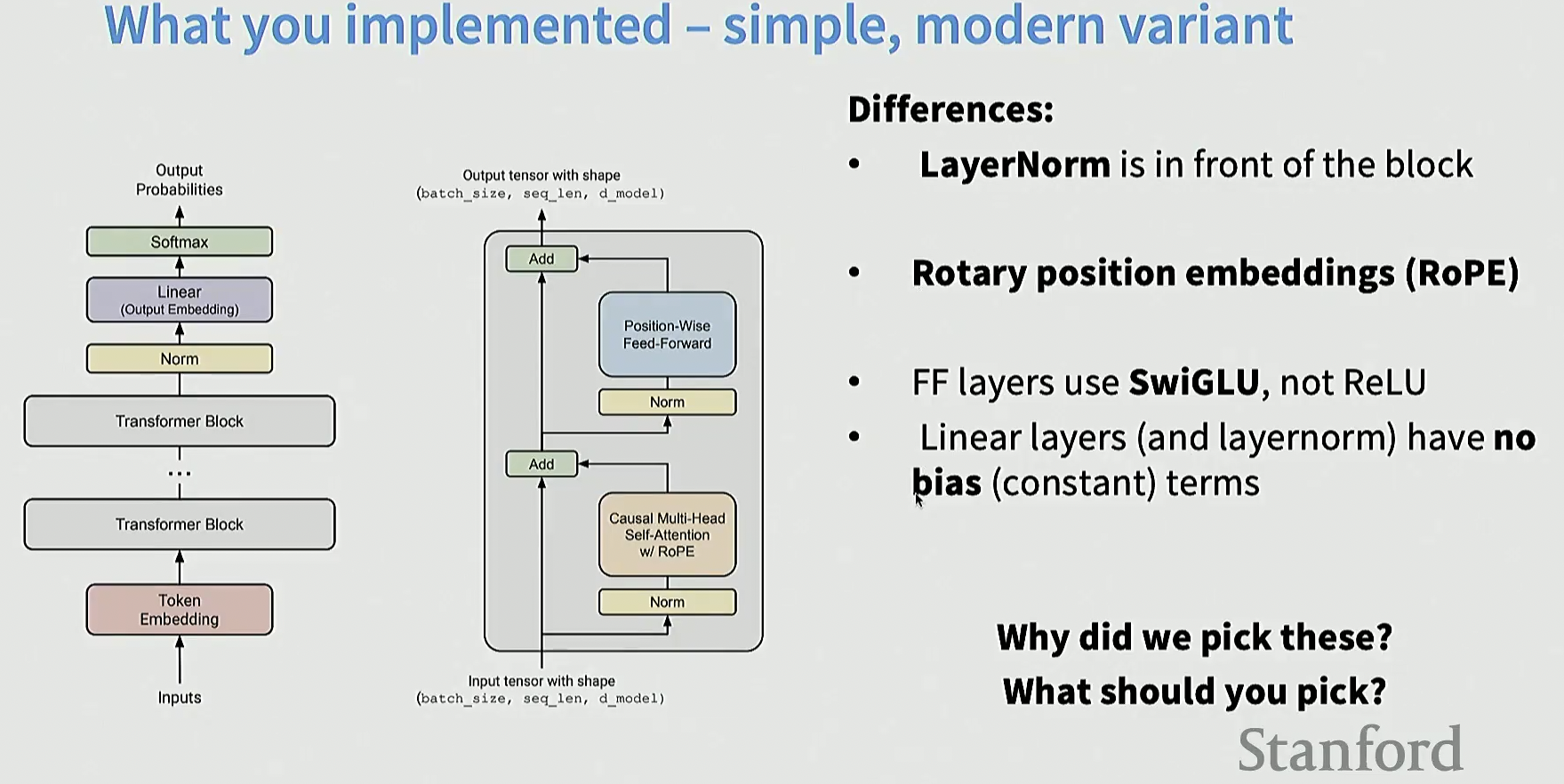
以下是和原版的一些区别:
- LayerNorm 放在了模块的前端
- 位置编码采用 RoPE
- 前馈层用 SwiGLU 取代 ReLU
- 线性层去掉了偏置项
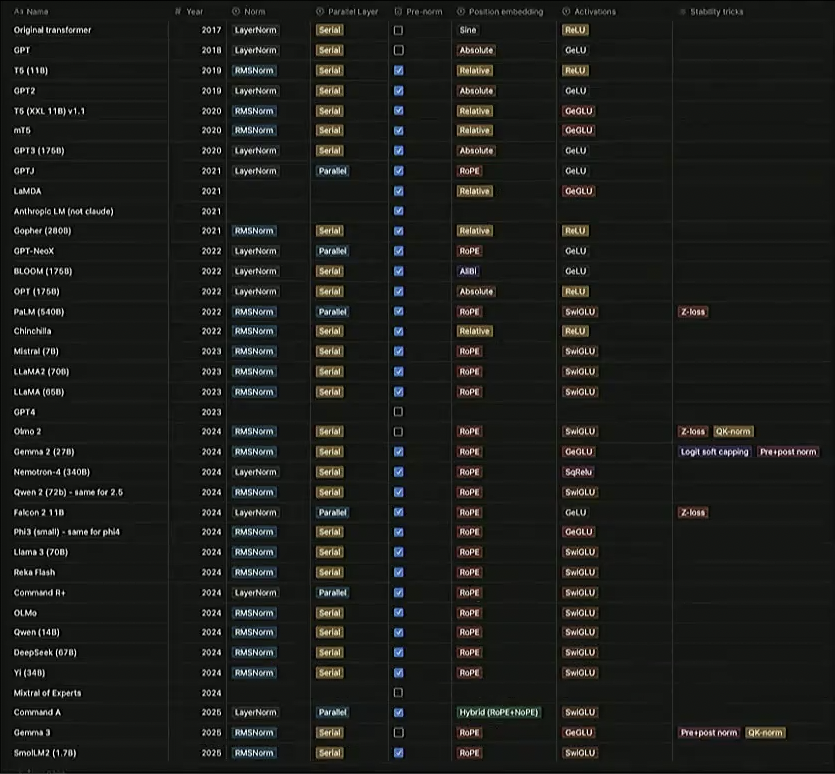
Tatsu 根据近些年最新的模型的一些论文, 统计出了一些表格, 里面有关于模型架构的一些信息, 可以直观的看出模型架构的演变, 以及各家的差异
架构差异
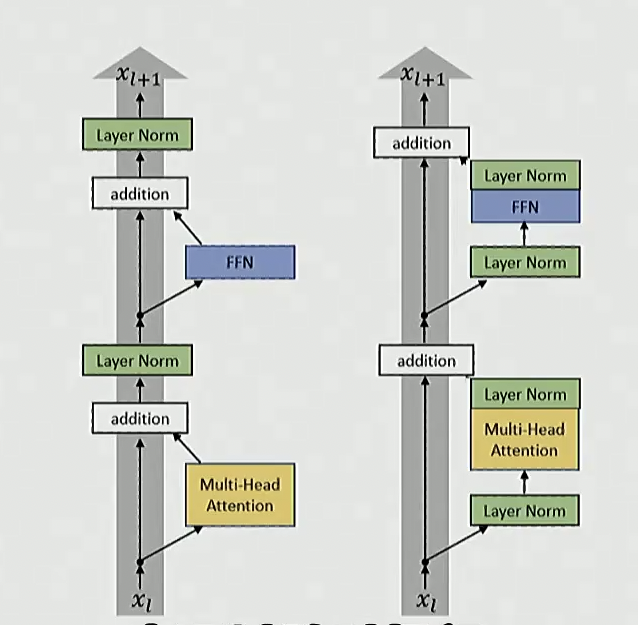
归一化的先后顺序
业界共识: 采用前归一化, 而非后归一化
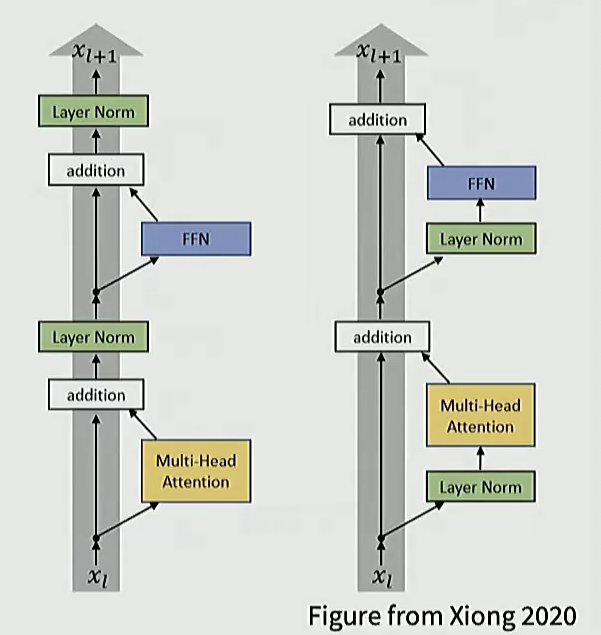
左侧是原始 Transformer, 右侧是改进后的版本, 使用前归一化
右侧的效果普遍更加, 当下的模型基本都采用这一方法
后归一化相对没有那么稳定, 因此需要谨慎设置 warmup 等策略, 以保证训练过程稳定
双重归一化
此外, 还有更创新的方法: 双重归一化
右侧在预归一化的基础上, 在 MHA 和 FFN 后都加了一个层归一化, 使得每个块都有两个归一化
有人认为这种方法更好
归一化的方式选择
原始的归一化方式是 LayerNorm, 现在的主流做法是 RMSNorm

LayerNorm
- 对输入向量 x 减去均值(中心化)
- 除以标准差(归一化方差)
- 再乘以可训练的缩放系数 $\gamma$ 并加上偏置 $\beta$
RMSNorm
- 做法
- 不减均值(不做中心化)
- 只用向量的 均方根 来缩放
- 没有加偏置 $\beta$,只有缩放系数 $\gamma$
- 特点
- 比 LayerNorm 计算更简单(少了减均值和加偏置的步骤)
- 在某些 LLM 中效果相近甚至更好
- 更节省计算量,适合大规模模型