多模态大模型LLaVA模型讲解——transformers源码解读_哔哩哔哩_bilibili
参考的这个视频
之前读过论文, 但是仅仅是读了论文, 代码并不是很了解, 现在回想起来原理都没有掌握得很好, 或许之前仅仅是停留在"看了"的层面, 现在深入了解一下
LLaMA
LLaVA 是在 LLaMA 的基础上增加了视觉能力, 成为了一个多模态的模型
要搞懂 LLaVA 的原理, 需要先搞懂 LLaMA 的原理
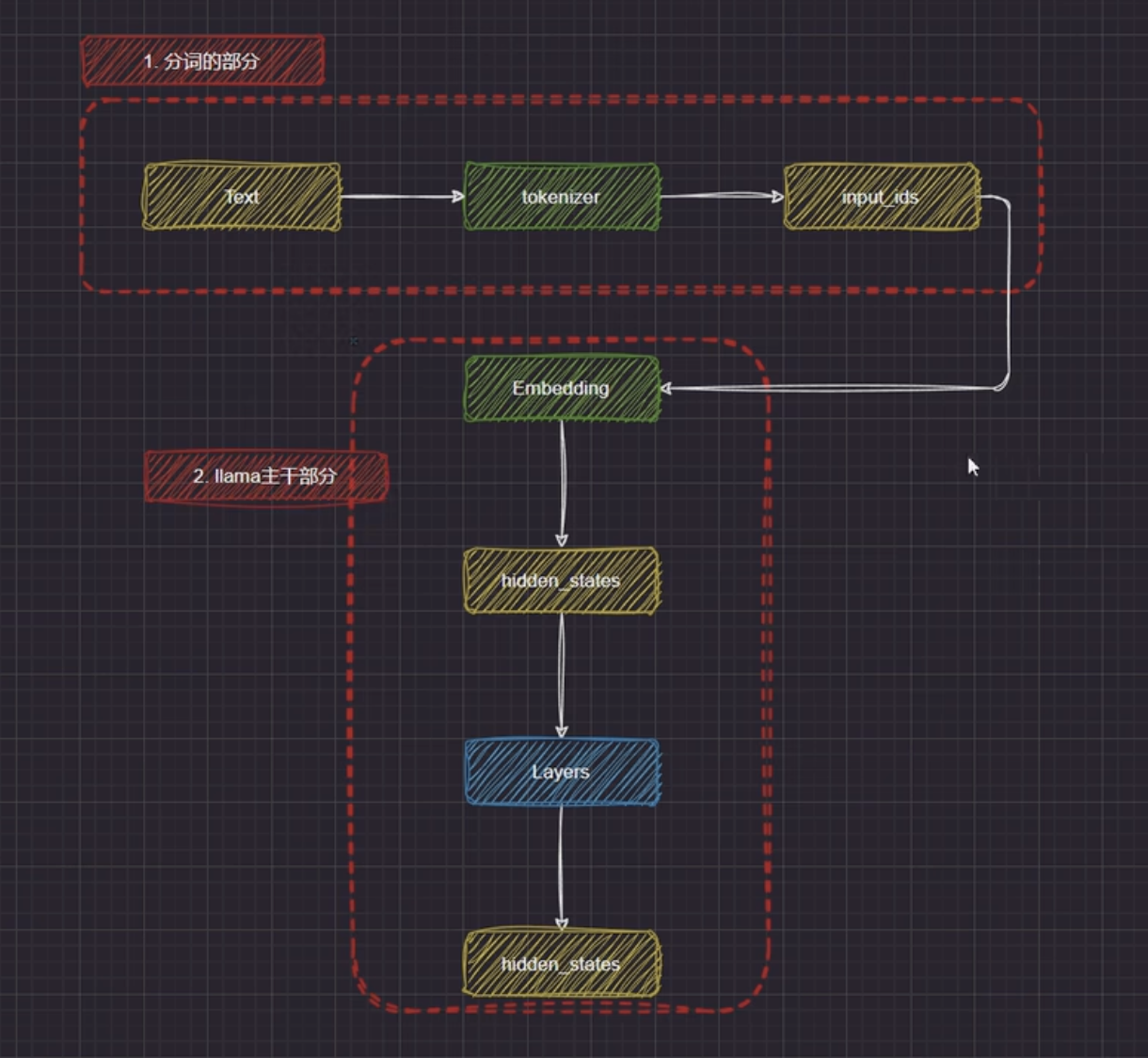
这里是 LLaMA 的大概构成, 以及处理流程
分词
LLaMA是一个纯文本大模型
- 接受文字输入
- 经过 tokenizer 分词器, 将文本分词成为 tokens
- 将 tokens 转换为对应的 input_ids
- 将 input_ids 向量化, 映射成为 embeddings
主干部分
这里主要是 Layers, 本质上其实就是 Transformer 块的堆叠
具体咋堆叠的可以看 Attention Is All You Need 这篇论文
初始的 Embeddings 经过 Layers 的处理后, 得到的隐藏状态已经包含了上下文信息和全局依赖
这里再把隐藏层映射回词表大小, 用 softmax 计算概率即可进行下一个 token 的预测
LLaVA
这张图展现了 LLaVA 模型如何分别处理多模态输入, 并最终拼接处理, 得到最终结果的
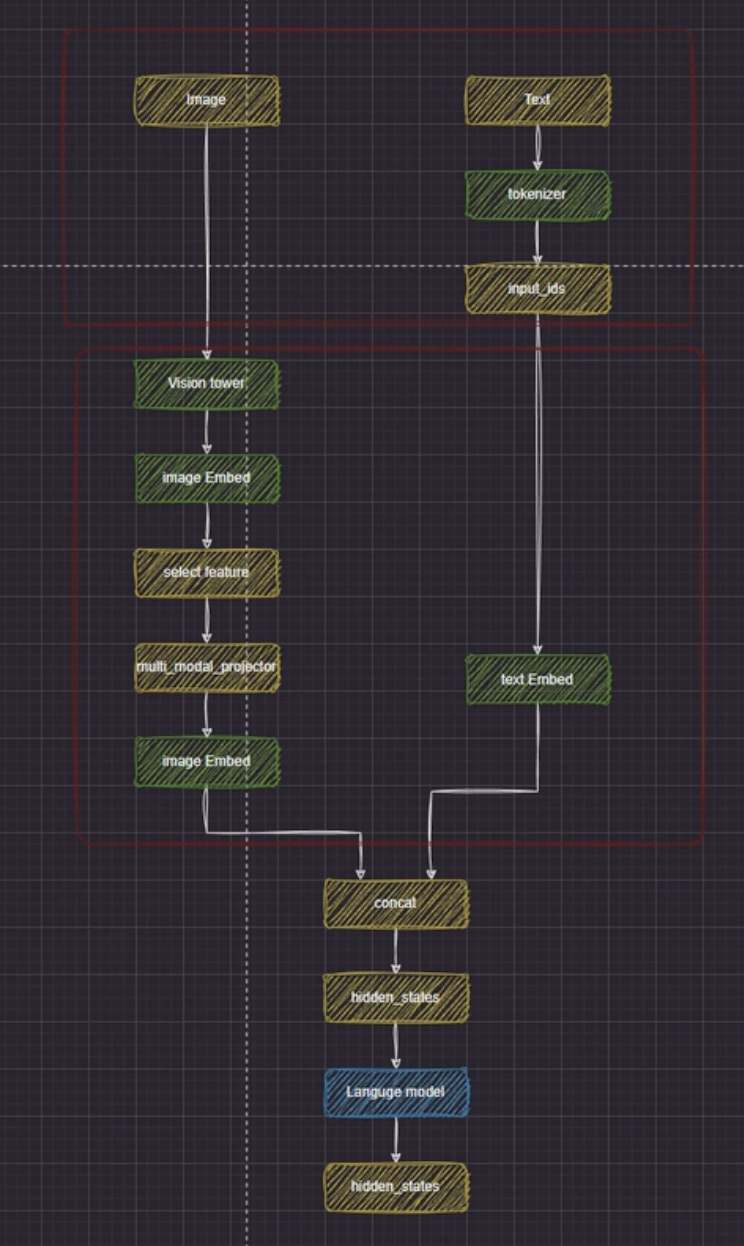
处理流程
图像
这里其实就是 LLaVA 与 LLaMA 的主要区别, 引入了图像这一多模态处理能力
- 输入图像, 这里用 PIL 等方式读取, 本身就是数值化的数据, 因此没有 tokens 到 input_ids 转换的这一步骤
- image 经过 Vision Tower, 转换成初始的 image Embeddings
- 这里的 Vision Tower 其实就是视觉编码器, 比如 CLIP
- Vision Tower 用于将图片与文字的含义对齐
- 挑选出 Vision Tower 对图片处理时, 关键的部分, 送进模型
- 避免序列长度暴增, 计算量爆炸
- 一些图像的 patch 中信息冗余
- 经过 multi-modal-projector, 使得图像 emb 和文字 emb 的维度对齐, 得到最终的图像 emb
- 这里的 projector 大概就是一个线性层, 用于进行维度之间的映射
- 线性层可学习, 一般就是一个简单的比较浅的神经网络
我的疑问: 为什么这里为什么不能直接让二者维度对齐?
1. 模块解耦 & 可复用性
- Vision Tower 往往是独立于训练的, 有自己的 hidden size
- 如果被绑死到一个 LLM 的配置中, 则失去了夸模型复用的能力
- 使用 projector, 模型可以
- 和不同大小语言模型配对
- 换模型只需要重新训练 projector, 不需要重新训练视觉backbone
2. 冻结策略零活
- 在多模态微调时,我们通常 冻结 Vision Tower,只训练 projector 和部分 LLM 参数:
- 原因:Vision Tower 已有很强的通用视觉特征,改动它代价大(容易灾难性遗忘,还耗显存/算力)
- 如果直接让 Vision Tower 输出 LLM 维度,那想冻结它也不方便,因为一旦 LLM 改变维度,你必须改 Vision Tower 最后一层权重并重新训
3. 训练稳定性
- Vision hidden_size 和 LLM hidden_size 差距可能很大(比如 1024 vs 4096),直接在 Vision Tower 内部输出大维度会导致:
- 参数量陡增(最后线性层巨大)
- 预训练阶段梯度波动更大,收敛难
- 用 projector 可以:
- 分离视觉特征学习(塔内保持原维度)
- 在最后一步做一次简单线性映射,梯度路径短、调节快
文本
这里其实就和 LLaMA 的没啥区别了, 经过同样的流程, 然后最后得到 text emb
拼接
此时两种模态的 emb 维度已经对齐
这里把 image emb 和 text emb 拼接, 把拼接后的多模态 emb 送进模型中, 进行处理, 得到结果
一个例子
多模态输入

这里作者举了一个例子, 是一个多模态的输入
这里 input_ids 里除了有文字之外, 还有< image > 这个占位符
在实际推理时 image 会被整段图像向量序列所替换
图像向量
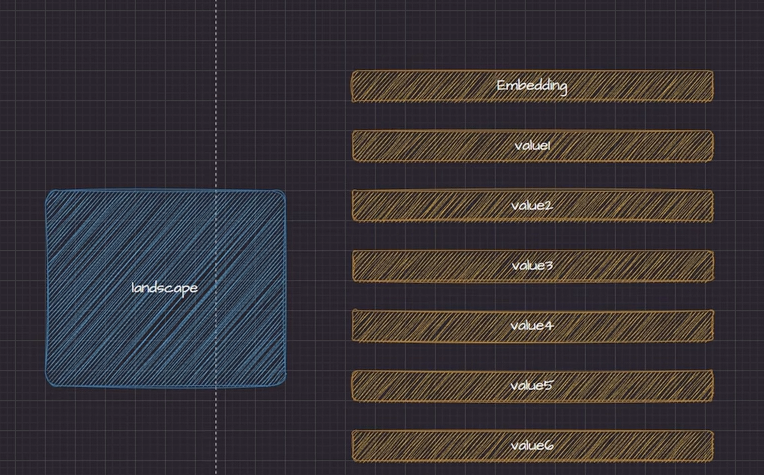
这里是图像经过 vision tower 后转变成的图像向量序列, 会在后续进行推理时替换占位符 image 所在的地方
拼接后的 emb
构建 LLaVA
自定义多模态大模型LLaVA——LLaVA系列_哔哩哔哩_bilibili
作者这里使用 Qwen1.5 文本模型, 以及 OpenAI 的 CLIP 共同构建一个多模态模型
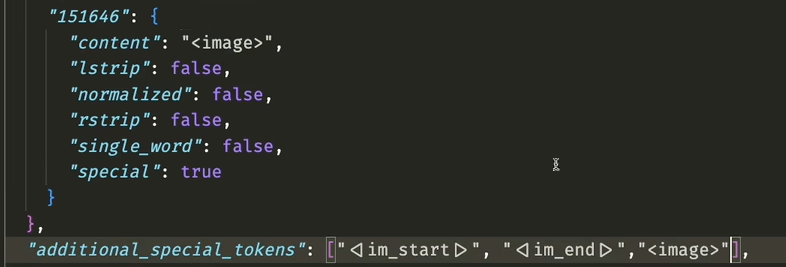
加入新 token
多模态模型中需要有< image >这样的占位符.
这里为了防止< image > 被切分成更小的 token, 需要进行特殊处理
需要再 Qwen1.5 模型代码中找到 tokenizer_config.json, 再最后一个 token 后加入我们新的 token, 并且添加到 additional_special_tokens 中, 做特殊处理
是否需要修改模型的emb模块?
不需要, qwen 模型中的 emb_tokens 已经留了足够的空间
|
|
因此修改后, 用现成的 embedding 表就可以存下, 不会越界
- 只是多出来的 embedding 行没用过,值是随机初始化的(模型没学过这些 token,需要微调才能学会它们的含义)
- lm_head 同理
- lm_head 是模型最后一层把隐藏状态转换成词表概率分布的部分
special token 是否需要被理解?
主要取决于 special token 的用途
只作为占位符
- < image >、< video >、< mask >
- 模型输入时,这些位置会在 forward 前被替换成其它 embedding(比如 Vision Tower 输出),embedding 表里的值几乎不会用
- 这种情况:不需要模型“理解”它们的 embedding,初始化后甚至可以忽略
- 在训练中,这个 token 的 embedding 通常不会参与更新,因为不会被直接送进 attention(已经被替换成视觉特征了)
需要出现在模型的输出中
- [SILENT]、[RESPONSE]、[END_OF_STREAMING]
- 模型在生成时会直接预测这些 token 的 ID → 对应的 embedding 会在训练中参与梯度更新
- 这种情况:必须在微调数据里让它出现在 label 里,这样它的 embedding 才能被学习
- 否则 embedding 永远是随机初始值,模型不会主动生成它
模型初始化
这里的初始化其实是把模型加载到内存中, 以便拼接成 LLaVA 结构
- 初始化 CLIP 和 Qwen
- 初始化 LLaVA
|
|
首先, 提取出文本, 视觉的模型配置;
然后, 用 LLaVA 联合配置, 将视觉语言的配置信息合并到一个对象之中
最后, 用这个配置初始化 LLaVA
不过, 此时初始化后的 LLaVA 模型的参数都是空的, 需要手动拷贝预训练权重
此外, 可能还需要复制 pad_token_id, image_token_index
保存模型
把训练好的多模态模型, 以及配套处理器保存到本地
保存模型权重
|
|
保存模型的分词器
|
|
保存视觉处理器
|
|
查看效果
这里从上面保存的配置中加载模型, 并测试效果
我们发现模型效果很差, 回答和提问驴唇不对马嘴
这是因为拼接后需要训练, 才能有效果
为什么需要训练?
LLaVA 类的多模态模型的关键是视觉-语言对齐(Vision-Language Alignment):
- 视觉编码器输出的特征向量(CLIP 的 image embedding)并不能直接被 LLM 理解,因为 LLM 习惯接收的输入是文本 token embedding
- 需要一个投影层(projector) 把视觉特征映射到 LLM embedding 空间,这个 projector 在你这里是随机初始化的
- 如果不训练这个 projector,它输出的东西在 LLM 看来就是“胡乱的 token embedding”,生成的回答也就驴唇不对马嘴
训练 LLaVA
创建数据集
拼接路径
这里需要注意拼接方法, 最好采用:
|
|
这种方式, 有助于避免格式等问题
继承 Dataset
为什么要继承?
官方的 torch.utils.data.Dataset 允许你:
- 自定义数据读取逻辑(比如图像路径读取 + tokenizer 编码)
- 灵活控制样本结构(多轮对话、特殊 token 位置、label mask)
- 高效处理多模态数据(图像 tensor + 文本 input_ids 一起返回)
具体代码
|
|
转换成 tensor
加载处理器
|
|
AutoProcessor是 Hugging Face 的一个自动加载工具,它会根据模型类型自动实例化对应的 processor- 在多模态模型(如 LLaVA)里,processor 可能同时包含:
- Tokenizer(处理文本)
- Image Processor(处理图片,例如 resize、normalize)
构造多模态输入 prompt
|
|
- 把一个问题文本(
q_text)用 chat 模板包装成模型能理解的 prompt; - 打开一张图片;
- 用
AutoProcessor同时处理这段文本和图片,转换成模型需要的张量(token id + 图像 tensor); - 返回这个张量字典,直接可以喂给模型
inputs 中的三个key

这里调用函数, 得到一个返回后的 inputs, 这是其中的三个 keys
1. input_ids
- 类型:
torch.LongTensor,形状[batch_size, seq_len] - 内容:文本 prompt(经过 tokenizer 编码后)的 token ID 序列。
- 在你的例子里,这个 token 序列是由:
- 系统提示 (
systemrole) - 用户问题(
q_text) - [IMAGE] 特殊 token(表示图片在这个位置被插入)
- 系统提示 (
- 这些 token 是模型理解文本的数字化表示。
2. attention_mask
- 类型:
torch.LongTensor,形状[batch_size, seq_len] - 内容:标记哪些位置是有效 token(值=1)或 padding token(值=0)。
- 模型在计算注意力时,会忽略 mask=0 的位置,防止对 padding 进行无意义计算。
- 如果有批量数据时,较短的句子会用 0 补齐到最长长度
attention mask是如何生成的? 哪些需要 mask?
生成规则
调用
inputs = processor(prompt, raw_image, return_tensors="pt")
时,processor 会做两件事:
- 文本部分(tokenizer)
- 把
prompt转成 token id - 自动把 padding 的部分(补到同一 batch 的最长长度)标记为 0,其余为 1
- 例:
input_ids: [101, 42, 98, 0, 0] attention_mask: [1, 1, 1, 0, 0]
- 把
- 图像部分(image processor)
pixel_values本身不参与attention_mask[IMAGE]这个特殊 token 在文本中会作为一个普通 token 编码,所以它的 mask=1,不会被 mask 掉- 视觉特征的 mask 由模型内部视觉 backbone 自己处理,不在这里的
attention_mask里
哪些会被 mask 掉
- padding token → mask=0(不参与注意力计算)
- 有效 token(包括文字、特殊 token、[IMAGE]) → mask=1
3. pixel_values
- 类型:
torch.FloatTensor,形状[batch_size, 3, H, W] - 内容:图像的像素值张量,通常已经过:
- Resize 到模型要求的输入尺寸(如 224×224)
- Normalize(均值方差归一化)
- 是模型视觉编码部分(CLIP ViT 等)的输入
用 dataclass 结构包装
|
|
这样一来, 输出会整齐许多, 在后面调用的时候也非常方便
collator 类
为什么需要 collator?
- 在 多模态大模型训练 里,每条样本的长度(文本 token 数、图片 patch 数)都可能不同,而模型训练时必须输入 形状统一的张量
- Collator 就是用来把 DataLoader 一次批量(batch)里的样本对齐、打包成张量的
与上文"转换成张量"类比
上文中, 实际上还是再对单条数据操作
当 DataLoader 把多个样本打包成一个 batch 时:
- 每条数据的
input_ids长度不一样 - 图片的 shape 可能不一样(通常会 resize 过)
- 需要统一成同样形状的张量,才能一次性送进模型
collate_fn(collator)会:
- 收集这一批的所有
q_input_ids/pixel_values/a_input_ids - 对齐长度:
- 文本 → 用
pad_token_id进行 padding,让 batch 里每条文本长度相同 - 图片 → 用相同的尺寸(通常前面预处理阶段就固定了)
- 文本 → 用
- 生成 batch 张量:把这些列表堆叠成
(batch_size, seq_len)或(batch_size, C, H, W)的大张量 - (可选)构造
attention_mask、labels,屏蔽掉 padding 部分
构建 collator
|
|
inputs_ids 与 labels
q 与 a
|
|
这里分别是问题, 答案的文本经过 tokenizer 后的 token ID
inputs_ids
|
|
- 训练时通常会把 问题 + 答案 拼接在一起作为模型的输入(因为 decoder 要依赖上下文)
'eos_id'是句子结束的特殊 token(End Of Sequence)
labels
|
|
- labels 是训练时计算 loss 用的目标序列。
- 为什么前面是
-100?
因为我们只希望模型学习生成答案部分,不去预测问题部分- 在 PyTorch 的
CrossEntropyLoss里,ignore_index=-100表示这些位置的 loss 不参与计算 - 所以
labels中与问题部分对应的地方是-100,只有答案的 token 才保留真实的 ID
- 在 PyTorch 的
为什么要定义__call__
这个 __call__ 其实是为了让这个类的实例 可以像函数一样被 DataLoader 调用,是自定义 collator 的标准写法
这个 __call__ 就是批量组装数据的入口:
- 把一条条样本(Q/A文本 + 图片路径)处理成张量
- 拼成一个 batch
- 返回给模型能直接用的 dict
如果你不定义__call__,那就只能单独写一个函数去做 collate,然后丢给 DataLoader,但就没法把self.processor、self.convert_one_piece这些类的方法直接结合起来用了