基本概念
Benchmark
在大模型领域(如 LLM 或多模态模型),benchmark 就是一个评估框架或数据集,用于系统地测试模型在特定任务上的表现。一个 benchmark 通常包括:
- 一组 标准化数据(inputs)(如视频、图片、文本等);
- 一组 任务定义(如问答、总结、定位、识别);
- 一套 评价指标(metrics);
- 以及一种 标准流程(pipeline) 来统一评估不同模型的表现
inference
推理的作用是:用模型对 benchmark 提供的测试数据进行响应生成,即模拟真实使用中的预测行为。例如:
- 输入一个视频片段 + 问题;
- 你的模型(如 GPT、InternVL、Qwen-VL 等)生成一个回答
在你的 inference.py 中,推理的主要部分是这段代码:
1
|
model.eval(anno, args.task, args.mode)
|
它的作用是:根据任务类型(backward/realtime/forward),将输入的 annotation 数据送入模型中运行 eval() 方法,生成推理结果(response)
这些推理的结果会被保存到 results/[model]/… 的 .json 文件中,每个样本包含类似这样的结构:
1
2
3
4
5
6
|
{
"video": "...",
"question": "When does the person pick up the bottle?",
"response": "The person picks up the bottle at 00:15.",
"task": "EPM"
}
|
evaluation
有了推理结果之后,还要 评估模型的表现好不好,这就是评测的任务:
- 检查完整性:
- 有没有 response?
- response 是不是空的?
- response 是否出现错误标记(如 “error”, “failed” 等)?
- 定量评估:
- 统计每种任务的准确率、召回率、F1 等;
- 比如在视觉问答中,是否与“标准答案”匹配?
inference.py
这是这个 Bench 的推理部分
数据参数与任务配置
1
2
3
4
5
6
7
8
9
10
11
12
|
parser = argparse.ArgumentParser(description='Run OVBench')
parser.add_argument("--anno_path", type=str, default="data/ovo_bench_new.json", help="Path to the annotations")
......
parser.add_argument("--task", type=str, required=False, nargs="+", \
choices=["EPM", "ASI", "HLD", "STU", "OJR", "ATR", "ACR", "OCR", "FPD", "REC", "SSR", "CRR"], \
default=["EPM", "ASI", "HLD", "STU", "OJR", "ATR", "ACR", "OCR", "FPD", "REC", "SSR", "CRR"], \
help="Tasks to evaluate")
parser.add_argument("--model", type=str, required=True, help="Model to evaluate")
parser.add_argument("--save_results", type=bool, default=True, help="Save results to a file")
|
这里定义了一些命令行参数, 也就是运行的时候必须指定的一些东西, 需要手动输入
包括: 文件路径, 视频文件, 推理模式, 运行的任务类型, 使用模型 等等
模型初始化
1
2
3
4
5
6
7
8
9
10
|
if args.model == "GPT":
from models.GPT import EvalGPT
assert not args.gpt_api == None
model = EvalGPT(args)
elif args.model == "Gemini":
from models.Gemini import EvalGemini
assert not args.gemini_project == None
......
|
这里根据命令行中, 选择不同模型, 进行不同的初始化方法
models 是一个文件夹, 其中存着作者提前写好的一些模型的初始化方法
数据处理与加载
1
2
3
4
5
6
7
|
# 加载标注文件
with open(args.anno_path, "r") as f:
annotations = json.load(f)
# 为每个标注项添加完整的视频路径
for i, item in enumerate(annotations):
annotations[i]["video"] = os.path.join(args.video_dir, item["video"])
|
首先, 加载标注文件
然后, 根据用户的输入, 为标注文件添加正确的路径
我的疑问: 为什么 benchmark 需要标注文件?
对于 OVOBench :
这个 JSON 标注文件本质上就是一份结构化的 QA 数据集,但相比“单纯的问答对”,它包含更多用于推理和评测的字段,可以说是“扩展版的 QA 数据”
对于标注文件, 我们后面再详细讲解
任务分类与过滤
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
# 初始化三个类别的标注列表
backward_anno = [] # 回顾性任务
realtime_anno = [] # 实时性任务
forward_anno = [] # 前瞻性任务
# 定义任务分类
backward_tasks = ["EPM", "ASI", "HLD"] # Event Prediction Memory, Action Sequence Inference, High-Level Description
realtime_tasks = ["STU", "OJR", "ATR", "ACR", "OCR", "FPD"] # Spatial-Temporal Understanding等
forward_tasks = ["REC", "SSR", "CRR"] # Retrieval, Summary, Causality Reasoning
# 根据任务类型和用户选择的任务进行分类过滤
for anno in annotations:
if anno["task"] in args.task: # 只处理用户指定的任务
if anno["task"] in backward_tasks:
backward_anno.append(anno)
if anno["task"] in realtime_tasks:
realtime_anno.append(anno)
if anno["task"] in forward_tasks:
forward_anno.append(anno)
# 组织最终的标注数据结构
anno = {
"backward": backward_anno,
"realtime": realtime_anno,
"forward": forward_anno
}
|
这里把任务分为三个类别: 回顾性, 实时性, 前瞻性
同时, 每个任务下面有各自的子任务
然后, 我们读取标注文件, 遍历各个标注, 根据标注中的信息, 将不同的任务归类
同时, 根据用户对于需要评测的任务类型的输入, 进行筛选
最后, 把分类好的数据整理拼接
执行评测
1
|
model.eval(anno, args.task, args.mode)
|
这里调用 model 的 eval 方法, 实现评测
我的疑问: 这里是咋调用的 eval 呢?
这里其实是我看走眼了, 这里是 model(一个变量) , 并非 models(一个文件夹)
这里的 model 其实在前面选择模型并初始化的时候, 就已经被实例化了, 可见以下代码
1
2
3
|
if args.model == "GPT": # args.model 的值是 "GPT"
from models.GPT import EvalGPT # 导入 EvalGPT 类
model = EvalGPT(args) # 创建 EvalGPT 类的实例,赋值给变量 model
|
其中, eval 是每一个 model 实例的方法, 所以可以直接调用了
关于 eval 的具体讲解请见后文
data/ovo_bench_new.json
这是作者所谓的 annotation(标注), 但是其实发挥的是 QA 的功能, 我认为这个其实就是 QA
下面对着其中一份标注来详细分析:
哦我后来发现不同任务类型的 QA 是不一样的, 我们各选取一个进行分析
EMP 情节记忆
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
{
"id": 0,
"task": "EPM",
"video": "Ego4D/clips/ec4a3ba3-eb00-4aa8-9b41-36043ece98f7.mp4",
"realtime": 215,
"question": "Who did I communicate to when chopping egg plants?",
"answer": "a person with blue shirt",
"options": [
"a person with brown shirt",
"a person with green shirt",
"a person with blue shirt",
"a person with white shirt"
],
"gt": 2
}
|
id: 样本唯一标识符task: 任务类型(EPM = Episodic Memory)video: 视频文件路径realtime: 关键时间点(秒),表示问题发生的时刻
- 模型需要利用 real-time 之前的时间段的视频内容回答问题
question: 待回答的问题answer: 标准答案options: 干扰选项gt: Ground Truth 标签(0 为正确答案,1-n 为选项编号)
HLD 高级描述
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
{
"id": 308,
"task": "HLD",
"video": "Ego4D/clips/6e73e4ca-d147-40ea-8587-035e8f2850c7.mp4",
"question": "where did I place the trowel?",
"answer": "Unable to answer",
"options": [
"at the top of the table",
"inside the bucket",
"at the top of the cement frame",
"Unable to answer"
],
"gt": 3,
"realtime": 711
}
|
- 很多HLD任务的标准答案是 “Unable to answer”
- 这类任务测试模型对无法确定信息的处理能力
ASI 序列动作推理
1
2
3
4
5
6
7
8
9
10
11
12
|
{
"id": 483,
"task": "ASI",
"video": "COIN/Hf2AisK1wHY.mp4",
"realtime": 136,
"question": "What does the person do after load the wheel",
"answer": "pump up the tire",
"options": [
"load the inner tube"
],
"gt": 0
}
|
- 关注动作序列和因果关系
- 通常问 “before/after” 的动作关系
好像也都差不多, 都是选择题, 每个类型的特点可以参考论文
models/QWen2VL.py
由于我们的模型也是基于 Qwen 家族微调得到, 因此选择先阅读一下 Qwen 的相关代码
如果还需要读的话, 可能考虑再读一个闭源, 调用 api 的模型作为补充
文件信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
"""
Qwen2VL Eval Code
Weight from:
- https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct
- https://huggingface.co/Qwen/Qwen2-VL-72B-Instruct
Inference Code from:
- https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct
Inference Platform:
- 7B: 4*A100 80GB
- 72B: 8*A100 80GB
"""
|
- 模型来源: 支持 7B 和 72B 两个版本的 Qwen2-VL
- 硬件需求: 7B 版本需要 4张 A100 80GB,72B 版本需要 8张 A100 80GB
- 推理代码: 基于 HuggingFace 官方实现
导入模块
1
2
3
4
|
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
from utils.OVOBench import OVOBenchOffline
from decord import VideoReader
|
这里把相关需要的库和模块导入
发现了新的需要研究的内容: utils 的相关组件, 下面细说
辅助函数: 获取最大帧数
1
2
3
|
def get_max_frames(video_file_name, max_frames):
video = VideoReader(video_file_name)
return min(max_frames, len(video) - 2)
|
函数功能:
- 输入: 视频文件路径和最大帧数限制
- 输出: 实际可用的最大帧数
- 逻辑: 防止视频帧数不足导致的错误,同时限制最大帧数以控制计算资源
为什么减去2?
- 避免读取到视频末尾可能存在的空帧或损坏帧
- 确保视频读取的稳定性
我的疑问: 获取最大帧数有啥用?
在视频推理(Video Reasoning)或视频问答(VideoQA)系统中,我们经常需要“从视频中读取固定长度的帧序列”,比如:
- 只处理前 64 帧 / 前 300 帧;
- 取出某个时间段的帧做输入;
- 构造滑动窗口 / 模型输入张量。
而 get_max_frames() 的作用就是为了在【读取帧之前】确认最多能读多少帧,以防越界或浪费资源
评测类
1
2
3
4
5
|
class EvalQWen2VL(OVOBenchOffline):
def __init__(self, args) -> None:
super().__init__(args)
self.args = args
self._model_init()
|
类继承关系:
- 继承自
OVOBenchOffline,这是离线模型评测的基类
- 基类提供了统一的评测框架和接口
- 子类只需实现具体的推理方法
模型初始化
1
2
3
4
5
6
7
8
9
|
def _model_init(self):
model_path = self.args.model_path
self.model = Qwen2VLForConditionalGeneration.from_pretrained(
model_path,
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2"
)
self.processor = AutoProcessor.from_pretrained(model_path)
|
关键参数解析:
- torch_dtype=“auto”: 自动选择数据类型,通常是 float16 或 bfloat16,节省显存
- device_map=“auto”: 自动分配模型到可用的 GPU 设备上,支持多卡推理
- attn_implementation=“flash_attention_2”: 使用 Flash Attention 2 优化,提高推理速度和显存效率
模型加载过程:
- 从指定路径加载预训练的 Qwen2-VL 模型
- 加载对应的处理器,用于预处理输入数据
- 自动配置多卡分布式推理
核心推理方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
def inference(self, video_file_name, prompt):
# 1. 获取视频帧数
frames_num = get_max_frames(video_file_name, max_frames=64)
# 2. 构建消息格式
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": video_file_name,
"max_pixels": 360 * 420, # 控制视频分辨率
"nframes": frames_num, # 视频帧数
},
{
"type": "text",
"text": prompt # 问题文本
}
]
}
]
|
消息格式设计:
- 多模态输入: 同时包含视频和文本
- 分辨率控制:
max_pixels=360*420 限制视频分辨率,平衡质量和性能
- 帧数限制: 最多使用 64 帧,避免过长视频导致的计算负担
这里 prompt 应该也非常重要, 我待会需要去找一下 prompt 到底在哪部传入的
数据预处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 3. 应用聊天模板
text = self.processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
# 4. 处理视觉信息
image_inputs, video_inputs = process_vision_info(messages)
# 5. 统一处理所有输入
inputs = self.processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
|
- 聊天模板应用:
- 将消息转换为模型期望的对话格式
add_generation_prompt=True 添加生成提示符
- 视觉信息提取:
- 输入标准化:
- 将文本、图像、视频统一处理
padding=True 进行批次填充return_tensors="pt" 返回 PyTorch 张量
(需要仔细研究一下 OVOBenchOffline)
模型推理和编码
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 6. 模型生成
generated_ids = self.model.generate(**inputs, max_new_tokens=128)
# 7. 去除输入部分,只保留生成的 token
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
# 8. 解码为文本
output_text = self.processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
return output_text
|
- 文本生成:
max_new_tokens=128 限制生成长度- 避免过长回答影响评测效率
- Token 过滤:
- 移除输入部分的 token
- 只保留模型新生成的内容
- 文本解码:
- 将 token ID 转换回可读文本
skip_special_tokens=True 跳过特殊标记- 保持原始的空格格式
utils/OVOBench.py
这是 OVO-Bench 评测框架的基础类文件,定义了评测的标准流程和接口
导入模块
1
2
3
4
5
6
7
|
import abc
from tqdm import tqdm
import json
import os
import sys
sys.path.append("..")
from constant import BR_PROMPT_TEMPLATE, REC_PROMPT_TEMPLATE, SSR_PROMPT_TEMPLATE, CRR_PROMPT_TEMPLATE
|
abc: Python 抽象基类模块,用于定义接口tqdm: 进度条显示json: 结果保存constant: 包含各种提示词模板
这里的 constant 是根文件夹下的一个 py 文件, 待会需要好好研究一下, 里面包括一些提示词模板
Online 模型
1
2
3
4
5
6
|
class OVOBenchOnline():
def __init__(self) -> None:
pass
def inference():
pass
|
Offline 模型
1
2
3
|
class OVOBenchOffline():
def __init__(self, args):
self.args = args
|
- 本地部署模型的评测基类
- 所有本地模型(如 QWen2VL、InternVL2 等)都继承此类
评测流程
方法定义
1
|
def eval(self, anno, task_list, mode = "offline"):
|
anno 是标注数据类别task_list 是任务列表mode 是评测模式(online/offline)
Backward
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
if len(anno["backward"]) > 0:
backward_results = []
for _anno_ in tqdm(anno["backward"], desc="Backward Tasks"):
id = _anno_["id"]
video = _anno_["video"]
task = _anno_["task"]
question = _anno_["question"]
options = _anno_["options"]
realtime = _anno_["realtime"]
# 构建提示词
prompt = self.build_prompt(task=task, question=question, options=options, _anno_=None, index=None)
# 获取分块视频路径
chunk_video_path = os.path.join(self.args.chunked_dir, f"{id}.mp4")
# 模型推理
try:
response = self.inference(chunk_video_path, prompt)
except Exception as e:
print(f"Error during inference: {e}")
response = None
# 构建结果
result = {
"id": id,
"video": video,
"task": task,
"question": question,
"response": response,
"ground_truth": chr(65 + _anno_["gt"]) # 转换为 A/B/C/D
}
backward_results.append(result)
|
- 如果标注中有 backward 任务, 则执行以下程序
- 把标注中的数据进行赋值, 并集语数据构建提示词 (其中,
build_prompt 方法在下文)
- 获取分块模型的路径
- 基于路径,
prompt 进行推理, 得到response
- 整理
response, 构建标准格式的 result
realtime
跟 backward 差不多其实
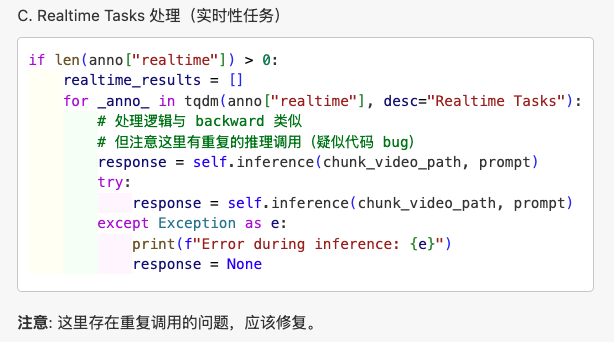
不过这里似乎确实有一些问题, 导致重复推理(会显著增加计算量和时间?)
forward
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
if len(anno["forward"]) > 0:
forward_results = []
for _anno_ in tqdm(anno["forward"], desc="Forward Tasks"):
id = _anno_["id"]
video = _anno_["video"]
task = _anno_["task"]
test_info = _anno_["test_info"]
# Forward 任务有多个测试点
for i in range(len(test_info)):
prompt = self.build_prompt(task=task, question=None, options=None, _anno_=_anno_, index=i)
realtime = test_info[i]["realtime"]
# 使用 {id}_{i}.mp4 格式的分块视频
chunk_video_path = os.path.join(self.args.chunked_dir, f"{id}_{i}.mp4")
try:
response = self.inference(chunk_video_path, prompt)
except Exception as e:
print(f"Error during inference: {e}")
response = None
# 直接修改原始数据结构
_anno_["test_info"][i]["response"] = response
forward_results.append(_anno_)
|
对于每一个 forward 类型的样本,其 test_info 中包含多个测试点(问题),我们需要对每个测试点生成一个 prompt,调用 inference() 得到模型的回答(response),并记录下来
forward 标注长什么样?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
{
"id": 1504,
"task": "CRR",
"video": "MovieNet/tt0080761.mp4",
"question": "The woman returned home. What does she find in her room that frighten her?",
"answer": "A snake.",
"ask_time": 1529,
"clue_time": 1549,
"test_info": [
{
"realtime": 1529,
"type": 0
},
{
"realtime": 1539,
"type": 0
},
{
"realtime": 1551,
"type": 1
},
{
"realtime": 1559,
"type": 1
},
{
"realtime": 1579,
"type": 1
}
]
},
|
这里是一个问题, 对应很多个提问的时间点, 以及对应的回答
type = 0: 问题提出阶段
- 含义: 在这个时间点,模型只能看到问题,但还看不到答案
- 测试目的: 测试模型在没有看到结果之前的预测能力
- 时间点:
ask_time 附近的时间
type = 1: 答案揭示阶段
- 含义: 在这个时间点,模型既能看到问题,也能看到答案/结果
- 测试目的: 测试模型在看到结果后的理解和推理能力
- 时间点:
clue_time 之后的时间
提示词构建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
def build_prompt(self, task, question, options, _anno_, index):
if task in ["EPM", "ASI", "HLD", "STU", "OJR", "ATR", "ACR", "OCR", "FPD"]:
# 标准选择题格式
formatted_options = '; '.join(f'{chr(65 + i)}. {option}' for i, option in enumerate(options)) + ';'
prompt = BR_PROMPT_TEMPLATE.format(question, formatted_options)
elif task == "REC":
# 检索任务:计数问题
activity = _anno_["activity"]
question = "How many times did they " + activity + "?"
prompt = REC_PROMPT_TEMPLATE.format(question)
elif task == "SSR":
# 空间场景推理
step = _anno_["test_info"][index]["step"]
prompt = SSR_PROMPT_TEMPLATE.format(step)
elif task == "CRR":
# 因果关系推理
question = _anno_["question"]
prompt = CRR_PROMPT_TEMPLATE.format(question)
return prompt
|
- 对于几种选择题, 使用 BR prompt 模版
- 对于 REC, SSR, CRR 这三种特殊题型, 使用各自的模板
保存结果
1
2
3
4
5
6
7
8
9
|
# Save Results
if self.args.save_results:
os.makedirs(f"{self.args.result_dir}/{self.args.model}", exist_ok=True)
with open(f"{self.args.result_dir}/{self.args.model}/{self.args.model}_{'_'.join(task_list)}_{mode}_1.json", "w") as f:
json.dump({
"backward": backward_results,
"realtime": realtime_results,
"forward": forward_results
}, f, indent=4)
|
文件命名规则:
- 格式:
{model_name}_{task1_task2_...}_{mode}_1.json
- 示例:
QWen2VL_7B_EPM_ASI_HLD_offline_1.json
抽象方法定义
1
2
3
|
@abc.abstractmethod
def inference(self, video_file_name, prompt, start_time=0, end_time=0):
pass
|
接口约定:
- 所有继承的模型类必须实现此方法
- 输入:视频文件路径、提示词、可选的时间范围
- 输出:模型的文本响应
constant.py
这里包含了一些"常量", 比如任务类型, 提示词模板
这里主要讲解一下这些提示词
常规选择题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# 用于回顾性和实时性任务的选择题格式
BR_PROMPT_TEMPLATE = """
Question: {}
Options:
{}
Respond only with the letter corresponding to your chosen option (e.g., A, B, C).
Do not include any additional text or explanation in your response.
"""
# 中文翻译:
请只回答与您选择的选项对应的字母(例如:A、B、C)。
请不要在回答中包含任何额外的文字或解释。
"""
|
REC 检索计数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
REC_PROMPT_TEMPLATE = """
You're watching a video in which people may perform a certain type of action repetively.
The person performing this kind of action are referred to as 'they' in the following statement.
You're task is to count how many times have different people in the video perform this kind of action in total.
One complete motion counts as one.
Now, answer the following question: {}
Provide your answer as a single number (e.g., 0, 1, 2, 3…) indicating the total count.
Do not include any additional text or explanation in your response.
"""
# 中文翻译:
您正在观看一个视频,其中人们可能会重复执行某种类型的动作。
在以下陈述中,执行这种动作的人被称为"他们"。
您的任务是计算视频中不同的人总共执行了多少次这种动作。
一个完整的动作算作一次。
现在,回答以下问题:{}
请提供一个单独的数字(例如:0、1、2、3...)来表示总计数。
请不要在回答中包含任何额外的文字或解释。
|
SSR 空间场景推理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
SSR_PROMPT_TEMPLATE = """
You're watching a tutorial video which contain a sequential of steps.
The following is one step from the whole procedures:
{}
Your task is to determine if the man or woman in the video is currently performing this step.
Answer only with "Yes" or "No".
Do not include any additional text or explanation in your response.
"""
# 中文翻译:
您正在观看一个包含连续步骤的教程视频。
以下是整个过程中的一个步骤:
{}
您的任务是判断视频中的男性或女性是否正在执行这个步骤。
请只回答"是"或"否"。
请不要在回答中包含任何额外的文字或解释。
|
CRR 因果关系推理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
CRR_PROMPT_TEMPLATE = """
You're responsible of answering questions based on the video content.
The following question are relevant to the latest frames, i.e. the end of the video.
{}
Decide whether existing visual content, especially latest frames, i.e. frames that near the end of the video, provide enough information for answering the question.
Answer only with "Yes" or "No".
Do not include any additional text or explanation in your response.
"""
# 中文翻译:
您负责根据视频内容回答问题。
以下问题与最新的帧相关,即视频的结尾部分。
{}
请判断现有的视觉内容,特别是最新的帧(即接近视频结尾的帧),是否提供了足够的信息来回答这个问题。
请只回答"是"或"否"。
请不要在回答中包含任何额外的文字或解释。
|
score.py
现在来到了评分部分
文件功能
这个脚本的作用是:
- 读取模型推理后保存的 JSON 结果文件
- 合并多个结果文件的数据
- 计算各种评测指标和准确率
命令行参数
1
2
3
4
5
6
7
8
9
10
|
import argparse
import os
import json
from utils.OVOBenchScore import OVOBenchOfflineScore, OVOBenchOnlineScore
parser = argparse.ArgumentParser(description='Eval OVBench')
parser.add_argument("--result_dir", type=str, default="results", help="Root directory of results")
parser.add_argument("--model", type=str, required=True, help="Model to evaluate")
parser.add_argument("--mode", type=str, required=True, choices=["online", "offline"], help="Online of Offline model for testing")
args = parser.parse_args()
|
参数说明:
--result_dir: 结果文件根目录,默认为 results--model: 要评分的模型名称(必需)--mode: 评测模式,“online” 或 “offline”(必需)
例如:
1
2
|
# 为 QWen2VL_7B 模型计算分数
python score.py --model QWen2VL_7B --mode offline
|
结果文件合并
1
2
3
4
5
6
7
8
9
10
11
12
13
|
results_paths = os.listdir(os.path.join(args.result_dir, args.model))
results = {
"backward": [],
"realtime": [],
"forward": []
}
for result_path in results_paths:
with open(os.path.join(args.result_dir, args.model, result_path), "r") as f:
result = json.load(f)
results["backward"] += result["backward"]
results["realtime"] += result["realtime"]
results["forward"] += result["forward"]
|
utils/OVOBenchScore.py
相较于 score.py 而言, 这是功能模块, 也就是 score 部分的具体实现
其中包含具体的评分算法, 分类评分逻辑, 统计和输出
两个 Class
1
2
|
class OVOBenchOnlineScore(): # 在线模型评分(空实现)
class OVOBenchOfflineScore(): # 离线模型评分(主要实现)
|
这里主要针对两种模型: online 和 offline 做了不同的设计
然而这里 online 模型类是空实现, 其实只有 offlinebench 发挥了作用
以下就主要讲解 offlinebench
初始化
1
2
3
|
def __init__(self, args, results):
self.args = args # 命令行参数(模型名称等)
self.results = results # 推理结果,格式:{"backward": [], "realtime": [], "forward": []}
|
初始化中, 接受 args 和 results
其实就是 score.py 中, 对 model_score 进行实例化之后, 传入的参数
Backward & Realtime 评分
这俩的 inference 和 score 都基本一样
评分函数
1
2
3
4
5
|
def calculate_score_backward_realtime(self, results):
def get_score(response, gt):
if response == None:
return 0
return int(gt in response) # 简单的字符串包含匹配
|
评分逻辑:
- 如果模型回答是
None(推理失败),得 0 分
- 如果标准答案(如 “A”)包含在模型回答中,得 1 分
- 否则得 0 分
这里"如果答案包含在模型回答中就得分", 我觉得设计的很好, 因为模型可能会回答不止一个选项
我的疑问 : 让LLM做选择题是否合理?
目前对于 LLM 学习尚浅, 但我觉得 LLM 被设计出来就不是用来去做选择题, 而是更适合去用自然语言回答一些问题的
即使用了一些严谨的 prompt, 我们真的能严格限制住 LLM 的输出格式吗?
示例
1
2
3
4
5
6
|
# 标准答案是 "A"
get_score("The answer is A", "A") # → 1 (正确)
get_score("A", "A") # → 1 (正确)
get_score("B", "A") # → 0 (错误)
get_score("BAD", "A") # → 1 (误判,包含A)
get_score(None, "A") # → 0 (推理失败)
|
分组统计
1
2
3
4
5
6
7
8
9
10
11
|
# 为每个结果计算分数
for i in range(len(results)):
results[i]["score"] = get_score(results[i]["response"], results[i]["ground_truth"])
# 按任务分组
scores = {}
for i in range(len(results)):
if not results[i]["task"] in scores.keys():
scores[results[i]["task"]] = [results[i]["score"]]
else:
scores[results[i]["task"]].append(results[i]["score"])
|
这里就是对 get_score 后的分数做一个统计
结果格式
1
2
3
4
5
|
scores = {
"EPM": [1, 0, 1, 1], # EPM任务:4题对3题
"ASI": [0, 1, 1], # ASI任务:3题对2题
"STU": [1, 1, 0, 1] # STU任务:4题对3题
}
|
Forward
Forward 任务包括 REC、SSR、CRR,每种都有特殊处理
REC 计数任务
1
2
3
4
5
6
7
|
def get_score_REC(response, gt):
if response == None:
return 0
import re
response = re.findall(r'\d+', response) # 提取所有数字
response = "".join(response) # 拼接所有数字
return response == str(gt) # 与标准答案比较
|
实例
1
2
3
4
|
get_score_REC("I count 3 times", 3) # → True (正确)
get_score_REC("The answer is 5", 5) # → True (正确)
get_score_REC("I see 2 or 3 times", 3) # → False (提取到"23",错误)
get_score_REC("No clear count", 0) # → False (没有数字)
|
我的疑问 : 万一用英文输出的数字怎么办
其实跟上面关于 LLM 的想法一样, 这里仅仅统计阿拉伯数字, 万一模型回复的是英文数字咋办?
SSR & CRR 任务
这俩是判断 yes/no 的
1
2
3
4
|
def get_score_SSR_CRR(response, gt):
if response == None:
return 0
return int(gt in response) # 检查 "Yes" 或 "No" 是否在回答中
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# SSR 任务评分
if result["task"] == "SSR":
for j, test_info_ in enumerate(result["test_info"]):
# 特殊情况:简化回答的处理
if (test_info_["response"] == "N" and test_info_["type"] == 0) or \
(test_info_["response"] == "Y" and test_info_["type"] == 1):
scores["SSR"].append(1)
continue
# 一般情况:根据 type 确定期望答案
gt = "No" if test_info_["type"] == 0 else "Yes"
scores["SSR"].append(get_score_SSR_CRR(test_info_["response"], gt))
|
核心逻辑:
- type = 0: 期望答案是 “No”(还没看到结果)
- type = 1: 期望答案是 “Yes”(已经看到结果)
- 简化回答: “N”/“Y” 等同于 “No”/“Yes”
主评分方法
就是这个 score()
接下来的代码就是按三个大类, 对回答的正确情况做一个统计, 然后输出即可
我的疑问 : 取平均合理吗?
我发现这里每一个任务的任务数量似乎不太相等, 但是最后的分数却是直接根据任务类型, 大类的数量取平均, 而不是加权平均
不过我想的似乎有些太多了, 但是对于提升在这个 bench 上的分数, 或许有一些对应的歪门邪道…?
视频分块
这其实是和 bench 关系不大, 但也离不开的一个部分
这一步其实是在 inference 之前, 是在下载好 benchmark 需要的相应的 datasets 之后, 对于 datasets 里的视频进行分块
我的疑问 : 为什么要对模型进行分块
- 确保公平性:不同时间点看到不同内容
- 防止作弊:避免从未来信息推断答案
- 精确测试:真正测试模型的时序推理能力
- 支持复杂场景:特别是 Forward 任务的多时间点测试
到此为止, OVOBench 的代码已经基本读完, 感觉收获非常非常大
对于 Benchmark 的基本结构有了大致的了解, 并且在阅读的过程中有了很多自己的想法和改进思路
同时, 也站在 bench 测试/使用者的角度, 思考了如何设计模型能让它更易使用
大概是目前写过最长的博客了