这个暑假加入了一个课题组, 方向是多模态大模型, 具体点就是流视频理解
方向还比较感兴趣, 正好暑假也比较闲, 加一个组也正是在我的计划范围之中
用这一篇博客记录一下我的第一段科研经历, 持续更新
最好的结局
其实这个是以大创的形式招募的, 说是预计产出: 一篇 ICLR + 一篇 Nature Communications
要是能中九月末的 ICLR 我就很满足了
此外希望借着这次机会详细体验一下科研的流程, 也体验一下 LLM 领域科研的多个环节
希望能参与一些重要的工作, 同时在论文发表中有一个比较高的排名
详细经历
6.27 进组
刚刚搬到新宿舍, 一大早接到项目负责老师的信息, 通知我待会开会
我进组了
不过其实方向并不是我第一顺位, 我其实第一顺位是大模型思维链 & AI security 相关的
不过老师说这个更适合我, 说这个学长更有经验. 看了一下也确实如此, 便同意了
加了学长微信, 在晚间简单聊了聊, 比如项目大概方向, 现有学习路线等等等等, 还是给我的一些固有思想带来一些改变的
我倒是觉得我有一定基础, 同时也很有兴趣和自驱力, 主动和学长申请想要更深入地参与其中, 也想了解更多环节.
不过并没给我什么具体任务
6.28 开始读论文
下午又一个学长Q加了微信, 丢给了我相关领域的几篇论文, 主要是 Benchmark 相关的.
后面主要跟这个Q学长沟通.
现在看来我觉得他应该是本次项目的一作, 至少是核心作者.
巧合的是, 丢给我的第一篇论文让我如此眼熟:
这是我亲学长的第一篇一作论文
正好我那天晚上还约了他吃饭, 真是太巧太巧了.
跟学长吃饭聊天的途中也有许多认知的改变和提升, 我觉得多和厉害的人交流还是蛮好的一件事, 别人不经意说出的一些经验就可能让你少走很多弯路
然后就开始读论文
我原先其实没有自己看过论文, 因为一直觉得自己水平不够. 看的都是李沐的"论文精读"系列视频, 不过也没看几个.(现在看来我觉得 emmm 讲的也不算那么好)
一开始是自己读, 配合着英文翻译硬读, 不过感觉缺一些背景知识, 同时也缺少一些对于文章宏观上的把握.
然后就开始用 GPT 辅助我读, 效果好了不少, 直到现在(7.5) 也是如此. 不过感觉一个缺点就是光看 GPT 消化后输出的内容了, 缺少了一些对于原文的关注
晚上, 学长开了个腾讯会议, 给我又详细讲解了一下当前的工作
给我推了俩 LLaVa 的视频, 不过说实话我现在还没看完呢.
6.29 继续读论文 整理了一些笔记
一共给了我四篇论文, 然后我继续读了, 但是给我的感觉是文章由于领域高度相同, 感觉内容大差不差, 因此想做一些比较, 同时记录一些自己觉得巧妙的部分
然后就写了一篇博客, 不过后面就没太更新(其实也是因为后面没太继续看相关论文, 这两天会看的…)
【读论文】论文对我的启发
6.30 第一次用服务器
学长给了我服务器账号密码, 我第一次用 VScode SSH 连进服务器, 还是蛮新奇的体验的.
组里, 至少这个服务器上, 卡不是很多, 也就几张 A40 吧.
学长让我部署一下 SVBench 中的 StreamingChat 模型, 这个文章也是我们主要对标的一个工作之一.
在服务器上动手时间确实有很多收获, 详情请见"第一次在服务器上部署模型"的博客
【动手实践】第一次连服务器&部署模型
后来遇到一些大大小小的问题基本都解决了, 但是由于卡一直被占用, 也就没有再跑这个模型
然后又看了 LLaVA 的两篇论文, 对应 1.0 和 1.5 版本
7.2 在 Benchmark 上跑模型 (但失败)
回家呆着, 给同学过生日来着, 没太推进工作
学长让我在 OVOBench 上跑一跑其他模型, offline 和 online 各跑一个
不过在下载其他模型, 接入 bench 去评测的时候遇到了很大的问题, 就是接口问题
原 bench 的代码里的接口是人家 ailab 自己的, 我搜了一下没有很好的解决方案
搁置了….
晚上开会, 说了一下做数据相关的工作(至少 Q 学长主要负责这个方面)
把工作主要交给了几位之前就在组里干的实习生负责
出于好奇和积极, 我跟学长说, 我也想看看参与一下, 了解下到底是要干啥
他给我推了个本院学长的微信, 我就跟着那个 P学长干去了
7.3 下载数据集 QA 类型调研
真正跟着干上了才发现这个才是真正的脏活累活
至少P学长让我干的是从 huggingface 上 clone 数据集, 这个纯牛马
不过我倒是确实在实操遇到的问题中学会了不少应对方法, 不过主要还是靠 GPT
P 学长的话, 应该主要是搞这个数据集, 然后后面处理一下那些标注数据, 弄成本次需要的统一的格式
这个后面有点想摆了, 我其实主要想了解标注的事情的, 后来也了解到自动化处理标注这些确实是一门必修课, 至少对于做 Benchmark 来说
开了个组会, 不过实际上老师和主要带头的 D 学长 并没到, 还是 Q 学长简单布置了一下工作
其中提到了后面要思考一下我们做的 Bench 的 QA 类型的一些选取, 也就是要通过什么类型的 QA去考察模型的什么方向的能力
主动承接了调研相关的工作, 因为我其实想了解一下咋干, 并且我也看了几篇 Bench 相关的文章了
(后来发现设计 QA 类型算是很核心的一个工作, 我真是有眼无珠啊, 竟然有这个活不干去做数据)
不过这两天一直在跟 Transformer 作斗争, 认认真真读了一遍 Attention is All You Need 这篇论文, 并且跟着教程做了部分的代码复现(感觉还差很多, 或者应该换一个教程)
然后就懒得再去看那么多论文了, 问学长能不能用 LLM 搞, 他说行
然后我分别用 GPT 4o, GPT DeepResearch, Gemini DeepResearch, NotebookLM 去完成这项任务: 把精心设计的提示词丢给他们, 然后把相关工作合订版 pdf 喂给他们, 等待结果
最终我的感受是两个 Deep Research 效果更好, Gemini 甚至直接整出了一篇综述出来, 不过学长觉得汇总的太杂了, 还是让我分论文总结归纳, 让我自己看看论文内容
我觉得他觉得我有些太急了, 我也觉得是
7.4 再次调研
(其实我还是没看新的论文, 不过我这两天一定会看的……)
GPT 的调研结果出来了, 我觉得不错, 我对着他总结的内容, 看了一下相关的工作的那些提到的部分, 按照更有条理的归类方法, 做了一下 QA 类型设置的一些分析
QA调研
学长认可了这次的工作, 耶
不过我应该做的远不止这些, 学长说我还应该看一下构建 QA 的 pipeline, 然后自己跑一跑, 同时看一下真实的 json 文件

忠言逆耳利于行. 急于求成的我一开始觉得这其实是快速做出某些看得见的成果的"阻碍"
(我从小到大或许都有这种心态, 或许是有些依赖正反馈. 不过也导致在有正反馈的情况下我会效率++++ 后面单独写一篇来剖析一下)
不过我觉得 Q 学长是真心为我好, 这或许才是做科研真正需要掌握的一些内容和知识, 绝非简简单单拿个东西去学长那里邀功请赏.
也希望我能更深入的参入到 QA 构建的工作中
7.5 纠结与困惑
其实到这几天时间线已经有些混乱了
主要是苦于下载数据, 让我瞬间感觉变成了牛马(其实是我自找的)
同时, 自己过于积极的一些态度似乎不宜长期坚持, 让我开始思考我该以什么态度去对待这个项目
我列出了一些困惑, 去询问前文提到一起吃饭的 L 学长, 同时也询问了 GPT

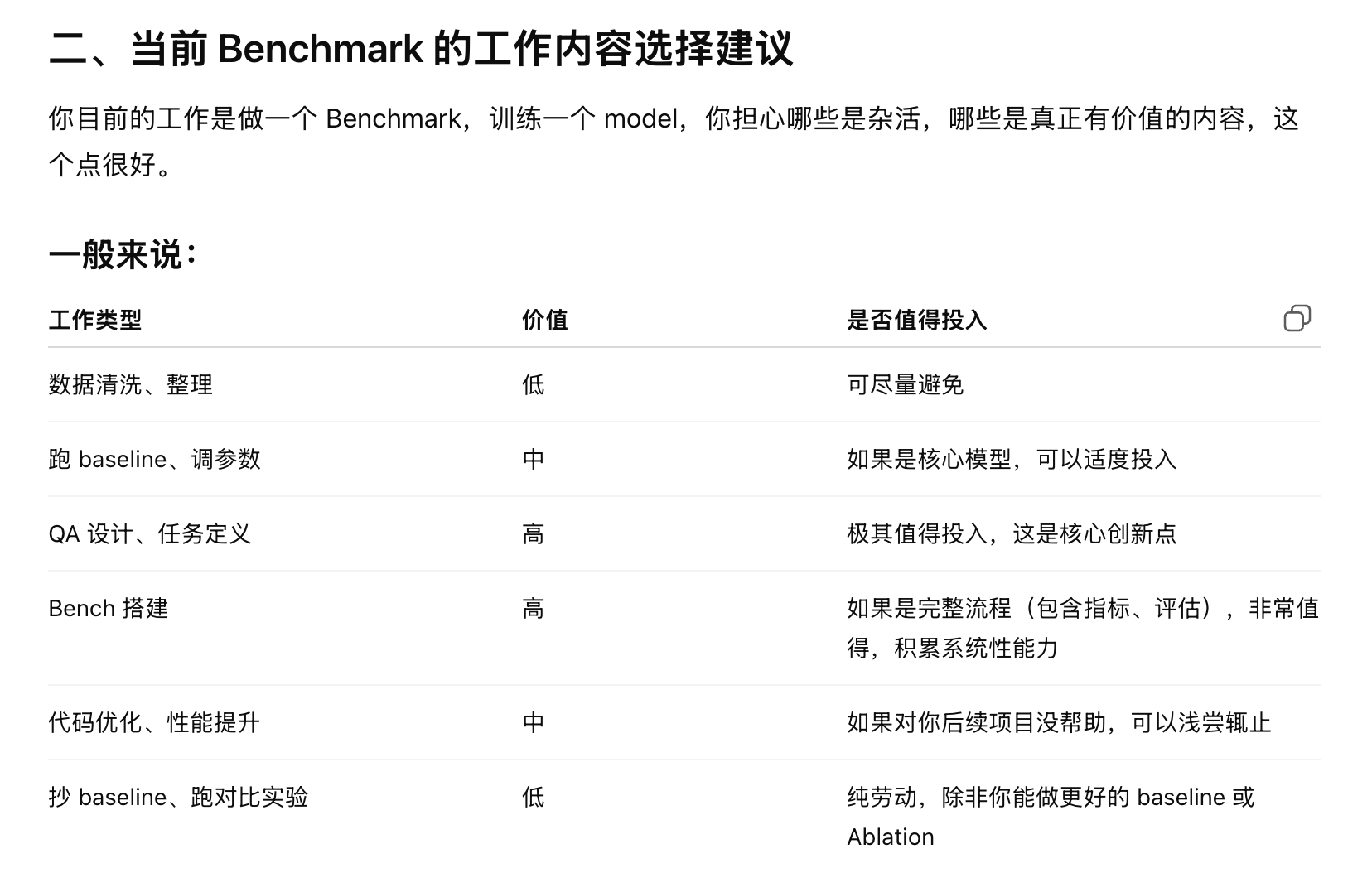
以下是 GPT 的一些回答, 他列举出了有价值的一些工作, 看到 QA 设计, 让我重燃了希望之火
晚些时候, L 学长解答了我的疑问, 让我坚定了想法

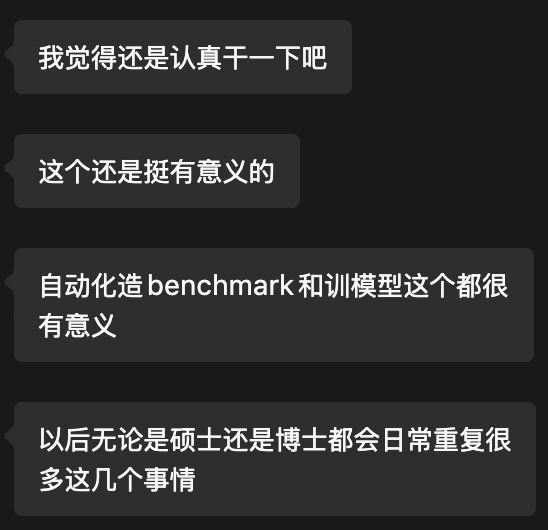
既然如此, 那就踏踏实实好好干下去吧, 希望自己能在这个项目中获得尽可能大的提升, 同时也希望能够深入的参与到 Benchmark 构建和模型训练这两个关键环节之中.
(以上为 7.5 更新内容, 后续持续更新)
7.7-7.10 HF-LLM 教程
学习 HF - LLM 教程
具体是学了一下怎么调用 HF 相关的库, 完成一些操作, 主要是 Transformer
有了这点基础之后后面做一些微调的小项目也会更容易一些
7.11 处理标注
P学长来让我搞标注的处理, 这时我才恍然大悟—这其实才是我一开始主动请缨想参与学习的东西, 而不是之前那些下载乱七八糟的数据
有些感觉被玩弄, 干了一堆本不属于自己的杂活
但是快速上手, 学习如何自动化处理原有数据集的标注, 统一格式
主要就是调用大模型就行, 反正 Gemini 就挺好用的
挺快就把 3 个数据集的标注都给统一格式了, 跟 Q 学长对接了工作
Q 学长人的真的很好很好, 给了我许多中肯的建议, 不仅是科研, 也有长远的学习建议, 我非常感谢他, 真的是我科研入门道路上很重要的导师
他向我推荐了 CS336, 这门课我也是之前就了解了, 后面看看试试
我也跟 Q 学长申请后面去做 QA 以及模型相关工作, 摆脱脏活累活, 他应该也是同意了
这两天学车结束, 和同学也都聚完了, 重回科研正轨.
7.12
跟 Q 学长沟通了一下, 现在主要任务回归到 QA 生成
Q 学长也给我推了Qwen 的微调脚本和文档让我学习
我目前主要负责这个大类的任务

主要就是调用大模型, 让大模型根据标注去生成一些相关的问题, 比较考察 prompt-engineering 的能力
或许是要设计一个更完备的工作流, 因为设计后后续关于QA 设计是否可靠的检验
我目前对这个工作还没有深入了解, 刚接触到后一个初步的想法是尝试构建 agent 工作流, 让每个 agent 分别完成每一小步工作, 这样或许效果更好?
7.21 跑通 OVOBench, StreamingChat
前段时间去山西旅游, 强度比较大, AFK 了, 一直没推进进度
现在来匈牙利游学了, 上课比较简单, 也都学过, 便用上课时间和休息时间推进一下进度
QA构造我刚过了一遍, 问Q 学长一些问题, 然后他说基本的 pipeline 已经搭好了, 让我现在去试试跑一下 baseline
StreamingChat 之前是环境之类的都配好了, 但是一直没有空闲的卡, 没法跑, 现在跑成功了
OVOBench之前没跑通, 遇到了各种问题, 这回重新好好试了一下, 发现是之前从 tar 压缩包转换成视频切片没有弄完, 导致跑不通
以及 flash atten 有一堆问题
后来 OVOBench 跑通了
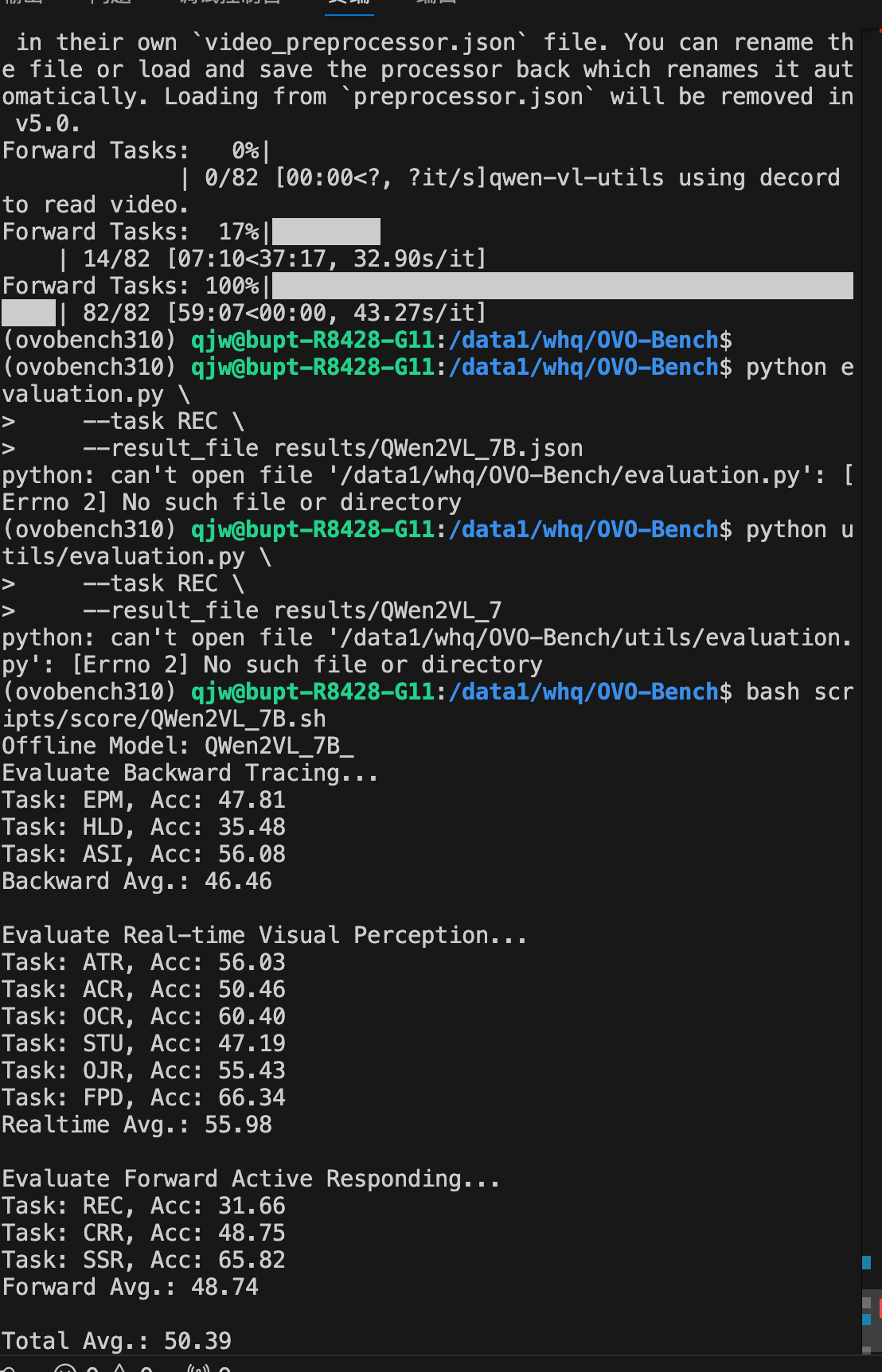
然后研究了一下 QA 构建的 pipeline, 学长说先不用管数据, 先试试能不能把我们的模型在 OVOBench 上面跑一下
7.22 把我们的模型在 OVOBench 上跑通
借助 copilot, 把我们微调过后的 QwenVL 2.5 3B 模型在 OVOBench 上部署了
不过经历非常曲折, 非常坎坷, 因为基本就是依靠 copilot
Q 学长及时提醒了我: 直接光靠 LLM 跑起来可以, 但是一定要理解 bench, 认为我有些着急了
确实如何, 我和他商量后, 准备详细读一读 ovobench 的代码部分, 了解一下完整的评测流程, 在后面给学长尝试讲一下, 检查我的理解程度
挂着跑 inference, 跑了很久, 得到了结果

或许是由于是 3B 的小模型, 跟一些主流模型还是有很大差距的, 不过我们毕竟刚开始微调
7.23 跑一跑原始的3B 模型
为了做一个对比, 学长让我跑一下原始的3B 模型, 做一个小小的对比
我再服务器上用 copilot 一直连不上, 很奇怪, 于是尝试了一下新发布的 Qwen-code, 学长已经配好了
用了一下发现非常好用, agent 调用非常好, 上下文也很长
用 Qwen-code 成功跑起来了 3b 模型, 也跑出了结果
发现我们的模型竟然是负优化….
学长说这很正常, 因为他刚开始微调, 用的训练数据和 bench 也有比较大的出入
松了一口气, 我以为我跑错了
7.24 看 OVOBench 代码
【代码详解】 OVOBench 如何评测
这是最终的代码详解, 实际上我读了两三天才看完
我觉得还是看的比较细致的
读完后收获非常非常大, 感谢 Q 学长的建议, 真的让我收获了很多
此外, Q 学长还给我布置了一些大任务, 比如承担项目的某一部分:
非常非常感谢 Q 学长, 真的是我第一段科研经历的引路人, 是我的贵人😭
我觉得确实领到了许多有意义的任务, 但随之而来的也有一定的压力
问了问 Z 学长关于贡献和作者排名的看法, 他认为我现在做的事情完全够共一, 他说换成他就要共一了
不过我完全不了解这些东西该如何交流, 确定, 衡量, 回头找机会试试问问 Q 学长吧
接下来, 我准备开始读 QwenVL 的微调文档
8.4 造训练数据
已经回国了, 倒了半天时差后开始赶赶科研的进度
今天主要是处理 sharegpt 这个数据集的视频和图片, 把这里的原始标注转换成模型训练的格式
处理完了视频数据, 造出了 10k 的训练数据, 晚上熬了一会, 把图片的拼接策略也给弄好了, 明天继续!
后面该学习一下怎么训模型了, 等卡可以用了就可以用训练数据开训了 !
8.5-8.8?
我也忘了搞了几天了, 反正最后搞出来了sharegpt 的标注
一共有三份, 我也懒得详细回忆细说了, 看这里吧

反正是差不多造好了, 但是没有等来训练
8.9-8.11 学习多模态大模型知识以及微调
中途回了趟老家, 进度又耽搁了一些
这段时间主要是在学习和熟悉微调, 为后面一阶段训练做准备
真准备训练了发现有些傻眼了—-看源代码根本看不懂
用 llm 辅助, 对着代码硬啃, 发现对于 llm, mllm 还是有不少细节或者说基础知识的缺失的
比如 ignore 掉哪些? 训练时哪些要冻结? 等等知识都不太清楚
于是去看了良睦路程序员的视频, 看的是 LLaVA 的, 其实和 qwen2.5vl 应该也差不太多, 回头再补一个技术报告或者看看模型细节之类的
感觉补知识补的差不多了, 但是还是没有能够过完 qwen2.5vl 微调的代码, 以及跑通流程, 现在卡不够用了, 大家都在占着用
8.12- 思考新的造数据方法
一阶段数据不能光靠合成, 毕竟太生硬了. 需要来一些自然的
重回本行, 目前再关注 HIVAU, 我觉得确实是个很对口的数据集
拉着学长开了个视频会议, 分享了一下对于数据集的解读, 以及自己新找到的数据集
真派上用场了, 不过是对二阶段训练, 一阶段训练还得我自己去搭一个 pipeline, 这样到时候 reviewer 提问的时候也有的回答
以下是近期的一些待办清单, 希望能趁着下一次旅游之前, 再赶一赶进度:
- shot2story 改写
- 想+造 pipeline
- 最好用到场景分割, caption
- 数据校验
- 看训练
- HIVAU(可能需要重下), sharegptVideo
-9.3
好久都没写了, 简单回顾一下干了啥吧
pipeline
这个 pipeline 在邮轮旅行之前搭好了, 反正可以正常跑了
就是 prompt 可能需要稍微改下
不过学长说后面用到的时候再说
verify 也没弄, 学长说他自己搞, 然后我就旅游去了
足球数据集
学长找到了个足球数据集, 但是那个 HF 上的下载需要权限, 我还真没碰到过这种
半天都没解决
事件触发类工作调研
学长让我调研一下 Benchmark 的文章, 看看他们对于回答的时间戳都是怎么验证和提高准确性的
看了一圈发现大部分都是人工标的, 还是太有钱了😅
在看文章的时候顺便发现了一些比较好的数据集
OVOBench 评测
原先光在 OVOBench 上跑 baseline 了
但是对于我们的模型, 由于强调"在线"这一特殊属性, 并在 sft 阶段引入了一些别样的对话方式, 因此需要对这些 bench 做一下适配
我对着学长给我的一段模拟推理的代码改
不过是调用大模型改的, 大模型改的一坨屎山, 我也改崩溃了
学长来帮忙, 看了一下代码说可以复用其他模型的代码然后稍微改一下推理部分就行
然后他就说自己改一下
当时已经挺晚的了, 凌晨一点多, 我其实是挺内疚的, 自己搞半天整出一堆屎山留给学长自己去 debug
突然想起来之前去奥匈没买的辅酶 Q10, 这几天老是熬夜, 学长也是, 后面时间比较紧估计更是, 于是便给我和学长各买了两盒
真的很感谢学长带我, 包容我, 我确实有点内疚, 一个是假期出游有点多, 或许耽误了进度. 还有就是代码能力差, 好多都用大模型写, 一堆 bug
不过跑起来后, 发现模型结果并不理想….
其实主要是还没做针对理解能力的sft, 之前练的都是主动输出
RTVBench
弄完 OVO 后, 学长让我搞下剩下的两个 bench, 跑一下 baseline, 以及我们自己的模型
这个看了半天代码, 发现跟 OVOBench 很像, 尤其是推理部分
然后就上手改了, 还是像原先一样, 先抽帧保存, 然后输入帧进行推理, 自己补全 silent 的 token
跑 baseline 的时候, 注意到 qwen 模型的一个很奇怪的点: 特别爱选 A, 我也不知道是 prompt 的问题还是什么
吐槽一下, 这个 RTVBench 的代码真是不太行, 或许是因为是很新的文章吧, 开源工作都没做好呢, 我看两个月前才 release 的评测部分代码
跑通我们自己的模型了, 但是发现有些问题:
- 之前采样的时候有几个有问题, 报错, 导致有的时候会直接找不到目录
- 最重要的问题: 模型给回答, 只给回复空或者换行😅 不然就是 report 一系列东西, 是描述而不是选择题答案
后来从 model1 换成 model2, 发现模型有一些些进步, 就是可以在一些情况下输出选项 A 了, 但是只有 A, 没有其他选项, 有的时候还会回复调用工具的 token. 我怀疑跟 Qwen 爱选 A 有很大关系
我奔着刨根问底的精神, 去用 instruct 模型跑了一下我们模型的推理代码, 发现给回复, 但是全都是 A
绷不住了
我认为模型需要大大提升做选择题的能力, 之前光让他讲故事了
晚上遛弯的时候觉得应该在 sft 时多来点选择题
晚上开会, 学长也是这么想的, 并让我在原先开放式问答的 QA 的基础上, 来点选择题
QA 选择题
这个倒是简单一些, 下午搞了两个小时就搞好了吧
有一些细节跟学长碰了一下
其实我认为我在关于数据的一些想法还是有点道理的, 可惜大部分被学长否了
不过我感觉保持能有新 idea, 多思考, 多和学长交流就挺好的
问问 gpt 也行
9.4 -
适配SVBench
SVBench 弄的超级草率, 可能因为刚开源没多久
根本都没给具体的 demo 的 pipeline, 我让 qwen 根据提供的一些 eval 的函数去做的
最后捣鼓半天发现跑通了, 但是模型好像一直在 report 还是怎么的
而且发现这个是开放式问答, 还需要自己去调gpt4o去打分, 便没有再管了
学长说先搁置, 不一定用了
SoccerNet 数据集
这个算是我主导去做的一批 QA 吧
在和学长的讨论中根据原有 datasets 的特点和我们的 qa 的类型
我觉得这回算是我的一些好玩的有创造力的想法派上用场的时候了, 也确实想出了一些我觉得很不错的构造方式
而且这个构造起来也相对方便, 直接 python 做字符串拼接就 ok, 都不需要大模型
很快就搞完了, 蛮有成就感的
找论文的 case 图例
这个纯烂活, 感觉完全应该让美工的同学去搞得
学长让我从一些数据集里找不同问题类型的一些 demo, 然后把对应的视频/图片帧存下来, 放在文档里
顺便稍微过一眼数据
ovobench 上测试新模型
给 ovobench 加了一下断点续跑等功能, 但是似乎有些重复写入问题
后来学长又布置了其他任务, 这个就先搁置了
不过倒是跑了新模型, 对比 base 的 qwen2.5vl 3b 倒是负优化😭
但是在 online 的模型中倒是 sota 了
HIVAU 造数据
之前学长说过多次的HIVAU其实最后转来转去还是转到我这里来完成了hhh
一开始开了个会主要都是想了一些单轮的 QA, 缺少一些多轮链式 QA
我说了些想法被否了, 并且那天课有点多, 晚上开会的时候感觉脑子都不转了
骑车转了很大一圈, 从北邮到清华又绕到中关村, 骑行路上灵光一闪, 说了一两个好的思路, 得到了学长的认可
早上醒来看到这个消息还是蛮高兴的🤣
然后后面自己做了一些尝试后就开始不断跑 demo 发现问题, 然后准备造了
这个需要用大模型根据标注去生成合适的 QA, 用了阿里云的学生优惠券, 耗了 200 的额度, 可怕(算上后续 verify 的开销)
其实中间经历了很多很多很多的曲折, 一直到第十版 demo 才没啥问题
但是我也忘了具体有啥了, 很曲折就对了
也让我更深刻地感受到了 vibe coding 在 debug 时的痛苦
然后, 我的任务就基本告一段落了, 后面就在团队项目中缺哪补哪了