作者与单位
作者主要来自 Google Brain 和 Google Research, 还有多伦多大学
这几位后面基本都成为了深度学习, 大模型领域的领军人物
摘要
- 本文针对序列转换, 现有模型大多依赖于: RNN, CNN, Encoder-Decoder 等结构, 一些更好的模型会用注意力机制链接 Encoder 和 Decoder
- 本文提出一种新的架构: Transformer, 其只保留了 Attention 机制
- 实验证明, Transformer 效果好, 且容易并行, 训练时间更短, 在翻译任务上取得了非常好的成绩
引言
主流模型与局限
- 一些 RNN 网络, 比如 LSTM 和 GRU, 被认为是序列建模最优解
- RNN 按时序逐步计算, 导致计算只能串行, 计算效率很低
Attention 机制的现状
- 注意力机制可以很好的建模长距离依赖, 不收序列位置的限制
- 当前 Attention 只是被作为 RNN 的辅助, 而不是替代
提出 Transformer
- 本文完全摒弃 RNN, 只采用 Attention 机制对于输入输出的全局依赖进行建模
- Transformer 架构支持高并行, 训练速度很快
背景
改进思路 : 用 RNN 替代 CNN
- 对于 RNN 的一些弊端, 有人通过 CNN 来改进和解决
- 这样一来, 可以并行计算
- 但是仍然在建模长距离依赖时存在结构限制
自注意力机制发展现状
- 自注意力: 序列内部不同位置相互关注, 构建序列的新表示
- 自注意力机制表现不错
Transformer 突破点
- 第一个完全基于自注意力的序列转换模型
模型架构
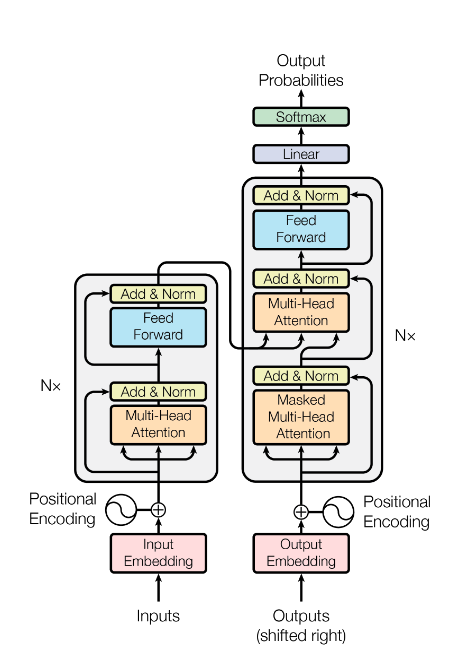
Encoder - Decoder 框架
- 现有最主流的序列模型都采用这种框架
- Encoder 把输入序列转换成连续表示
- Decoder 基于 z 和之前的输出(自回归), 逐步生成输出序列
- Transformer 整体结构:
- Encoder : 堆叠多层自注意力+前馈网络
- Decoder : 堆叠多层 Masked 自注意力 + Attention + 前馈网络
Encoder - Decoder 堆叠结构
Encoder
- 包含 6 个相同的层
- 每层包含:
- 多头自注意力
- 前馈神经网络
- 残差连接
- 层归一化
- 所有子层, Embedding 的输出维度一致 : d_model = 512
Decoder
- 包含 6 个相同的层
- 每层包含:
- 掩码自注意力 : Mask 是为了防止看到未来信息
- 输入序列的注意力
- 前馈神经网络
Attention 机制
给定一个 Query(查询),在一组 Key-Value(键-值)对 中,计算每个 Value 的加权平均
点乘注意力
$$
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
$$
- Q:查询矩阵(Query)
- K:键矩阵(Key)
- V:值矩阵(Value)
- d_k:Key 的维度
$\sqrt{d_K}$
- 防止维度太大时,点积结果过大,导致 softmax 梯度消失
多头注意力
- 单个注意力容易平均掉所有信息,多头可以并行关注不同的子空间信息
- 计算:
- 每个头把 QKV 线性映射到低维空间
- 各自计算 Attention
- 拼接所有头的结果
- 映射回原维度
- 其中,参数:
- 头数: head = 8
- 每个头的维度: d_k = d_v = 64
注意力应用场景:
- Encoder Self-Attention:输入序列内部互相关注
- Encoder-Decoder Attention:解码时关注整个输入序列
- Decoder Self-Attention:生成当前词时,关注已经生成的词,必须 Mask 未来
前馈网络
$$
FFN(x)=max(0,xW_{1}+b_1)W_2+b_2
$$
- 输入输出维度: 512
- 中间层维度: 128
- 每个位置单独应用(point-wise), 全序列并行
Embedding 和 Softmax
- 输入输出序列用 Embedding 转换成 512 维向量
- Decoder 输出经过 线性层 + Softmax 预测词概率
- 输入、输出 Embedding、Softmax 权重共享
位置编码
- Attention 机制无法包含位置信息, 需要额外引入
- 使用正弦-余弦位置编码
$$
PE(pos,2i)=cos(\frac{pos}{10000^{2i/d_{model}}})
$$
$$
PE(pos,2i+1)=cos(\frac{pos}{10000^{2i/d_{model}}})
$$
- 每个维度对应一个不同频率的正弦波,支持模型自动学习相对位置
为何用自注意力机制
为何比较
本段比较三种模型: Self-Attention, RNN, CNN
比较这三种模型在序列建模时的表现差异
比较维度
- 计算复杂度: 每层的理论运算量
- 并行能力: 最少多少步完成运算
- 长距离依赖路径: 网络中两个远距离词之间的最短信息路径长度
其中, 这是序列任务中的难点
比较结果
| Layer Type | Complexity per Layer | Sequential Operations | Maximum Path Length |
|---|---|---|---|
| Self-Attention | O(n² · d) | O(1) | O(1) |
| Recurrent | O(n · d²) | O(n) | O(n) |
| Convolutional | O(k · n · d²) | O(1) | O(logₖn) |
| Restricted Self-Attention | O(r · n · d) | O(1) | O(n/r) |
字母解释:
- n:序列长度
- d:向量维度
- k:卷积核宽度
- r:Self-Attention 限制的窗口大小
结果解读:
- 自注意力机制的路径最短, 学习长依赖最简单
- 自注意力机制完全并行, 训练速度快
- 复杂度不算很低, 但是对于短句, 计算开销很低
- 此外, 自注意力机制具有可解释性:
- 注意力矩阵权重可以直观展现模型更关注哪些词, 有助于解释模型决策路径
训练
训练数据与批处理
- 使用WMT2014 英德数据集
- 使用 BPE 子词划分方法
- 按句子长度相近分批(减少 padding, 提升计算效率)
硬件配置与训练计划
- 使用 8 张 P100
- 总训练时长 12 小时(Base 模型)
- 训练速度比其他模型快了很多很多
优化器设计
- 使用 Adam 优化器: beta1=0.9, beta2=0.98, epsilon = 10^-9
- 学习率使用分段动态调整策略:
- 前期: 使用warmup : warmup_steps = 4000
- 后期: 按照 $1/\sqrt{step_{num}}$ 逐步衰减
正则化手段
- Dropout: 0.1
- 对每个子层和所有 embedding 都使用 dropout
- label smoothing:0.1
- 让模型对预测不那么自信, 分布更平滑
- 降低过拟合
结果
机器翻译
超越当时所有的集成模型
消融实验
| 变化项 | BLEU(基准 25.8) | 影响分析 |
|---|---|---|
| 单头 Attention | 24.9 | 明显变差 |
| 过多头数(32头) | 25.4 | 超过 8 头后效果不再提升 |
| 较小的 key size | 25.1 | 影响兼容性评分,效果下降 |
| 较大隐藏层(4096) | 26.2 | 增大模型提升效果 |
| 不使用 Dropout | 24.6 | 严重过拟合,效果下降 |
| 不使用 Label Smoothing | 25.3 | 小幅度变差 |
| 学习型位置编码 | 25.7 | 与正弦位置编码几乎等价 |
- 头数:8 个头最优,太少信息不足,太多会稀释注意力
- key size 不能太小,兼容性匹配复杂,key 必须高维
- Dropout 很重要,防止过拟合
- Label Smoothing 有正向帮助,但不是决定性因素
- 正弦位置编码和可学习位置编码效果差不多(后来 BERT 用的就是可学习型)
句法分析任务
表现非常接近 SOTA, 且参数几乎没有调整
说明泛化和迁移能力非常强
结论
Transformer 主要贡献
第一个完全基于 Attention 的序列建模模型
- Transformer 完全去除了 RNN 和 CNN
- 核心结构是 多头自注意力(Multi-Head Self-Attention)
- 去掉序列对齐
- 全面用 Attention 替代序列建模基础
- 并行性高,训练效率极高
- 单模型超越集成模型,训练成本更低
未来计划
- 拓展到 非文本任务,包括:
- 图像
- 音频
- 视频
- 研究 局部/限制性 Attention,以适配更大输入(例如长序列或高维图像)
- Vision Transformer(ViT)
- Longformer、BigBird、Sparse Attention
- Multimodal Transformer(如 CLIP、BLIP)
- 减少生成时的序列依赖(提高解码效率)
- Non-Autoregressive Translation(非自回归翻译)
- BERT-like Masked Language Models
- Parallel Decoding 的研究起点