摘要
目前的评测体系(benchmark)无法有效评估 MLLMs 在 动态、实时环境中持续处理信息的能力
本文提出一个 Bench, 针对实时视频分析, 有三个核心机制:
- 多时间戳问答
- 层级式问题结构
- 多维度评估
实验发现:
- 开源实时模型 > 开源离线模型
在线模型(实时处理)明显优于传统离线处理模型。 - 但实时模型仍落后于闭源商业模型(比如 GPT-4o)。
- 模型大小与采样帧率并不能有效提升表现,有时甚至会导致性能下降
未来 MLLM 的设计需要更关注视频流处理和长序列建模的架构改进,才能更好地支持实时视频分析任务
引言
现状
- 当前的评测标准 严重不足,无法有效检验模型在连续、动态、实时场景中的表现
- 现有基准更偏向离线视频总结,忽略了视频流中的实时响应能力和瞬时细节捕捉能力
已有尝试
当下的方法有以下问题:
- 对实时性响应要求不严格
- 没有重点评估模型是否能够在连续输入流中正确追踪信息变化
核心贡献
本文的重点创新有三个:
- 多时间戳问答
- 层级式问题结构
- 多维度评估
实验发现
- 目前的大部分 MLLM 在实时视频分析上的准确率 低于 50%,整体存在明显瓶颈
- 模型大小、输入帧率与性能几乎无明显关联,有时更大的模型反而表现下降
- 在线实时模型明显优于离线模型
RTV-Bench
视频分析的挑战
- 长视频基准缺少连续时间段内的跟踪要求
- 一些评估缺少了记忆遗失问题, 注意力漂移问题
基准概览
- 要求模型在 实时视频流 中:
- 理解当前场景
- 记忆历史信息
- 预测未来发展
模型需要具有回忆过去, 预测未来的能力
作者提出八个任务维度:
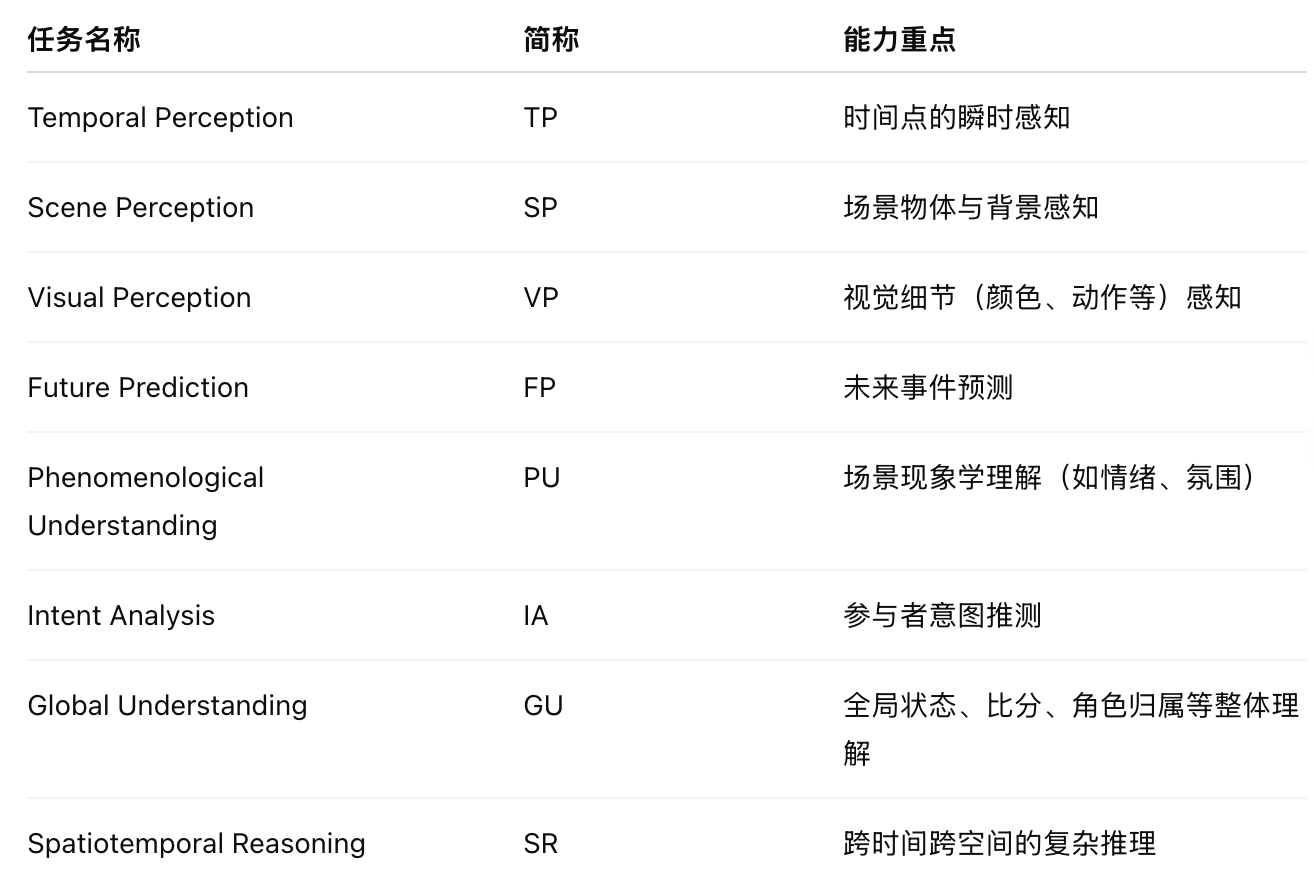
数据集构建
- 每个视频配备一组三连题(难度递增):
- 前两个是基础题
- 第三个是复杂题,要求整合更多上下文信息
多时间戳问答
同一问题, 在不同时间点的答案不同
要求模型持续跟踪变化
和 OVO-Bench 不同:
- OVO-Bench:不同时间点提问的是不同的问题。
- RTV-Bench:同一个问题,不同时刻答案不同,更考验模型的持续跟踪能力
多样性设计:
视频场景包含三大类:
- 智能驾驶
- 体育赛事
- 第一视角(egocentric)视频
这些场景特别强调:
- 实时性
- 状态变化快
- 需要持续关注视频流
实验
实验设置
模型选择
离线开源, 在线开源, 闭源商业模型
大部分模型采用 7B 规模, 保证公平
评估指标
1. Accuracy(准确率)
- 衡量模型回答正确的比例。
- 这是传统的基础指标。
2. Score(分数)
- 设计用于衡量 模型的稳定推理能力,特别是:
- 是否真正掌握了基础问题(q0 和 q1)
- 是否在此基础上正确回答了复杂问题(q2)
实验结果
- 在线实时模型强于离线模型
- 闭源商业模型更强(gpt-4o)
准确率与得分
- 有些开源模型(尤其是离线模型):
- 准确率中等,但得分很低。
- GPT-4o:
- 准确率提升幅度不大,但得分远高于其他模型。
解释:
- 准确率提升幅度不大,但得分远高于其他模型。
- 得分 Score 更严格,要求模型必须掌握基础题,才能获得复杂题的有效得分
- 低得分说明:很多开源模型在高级推理阶段容易“蒙对”,但其实基础理解不牢
重要发现
- 在线模型持续感知能力更强
- GPT-4o 的优势在于稳健的推理链
- 模型大小的影响有限
(我的想法: 所以我们微调时不用选择很大的模型, 正好到时候结合无人机做端侧也方便) - 帧数增加对于实时任务无明显帮助
局限与未来工作
发现核心问题
- 模型规模提升对于性能提升有限: 说明模型设计没有有效利用更大参数量
- 增加帧数不一定有帮助: 当前模型不擅长处理视频流中长序列信息
根本原因
- 连续视频处理机制尚未成熟
- 当前主流多模态模型:
- 大多数在图片、短视频、离线任务上训练
- 没有针对实时视频流、长时间跟踪任务做充分优化
现有局限
- RTV-Bench 评测只有视觉模态
相关工作
多模态模型的实时视频理解
现有实时视频模型虽然有所突破,但缺乏严谨的连续理解能力评测体系,大多数工作仍停留在响应速度、基础感知、离散问题层面
现有视频基准
- 大多数集中于离线视频分析, 采用静态问答, 无法评估连续分析能力
- 近期流式视频基准缺少动态答案设计, 评估标准偏单一
RTVBench 独特贡献
- 动态问答设计:同一问题答案随时间变化
- 多时间戳追踪:要求模型持续跟踪视频状态变化
- 多维度评估体系:细致拆解感知、理解、推理等八个维度
结论
| 内容 | 结论 |
|---|---|
| 基准贡献 | RTV-Bench 支持多时间戳、层级推理、多维度评估 |
| 实验发现 | 在线模型 > 离线模型;模型规模与帧率效果有限 |
| 未来意义 | 促进 MLLM 向实时视频流处理能力发展 |