图像分类的挑战
- 不同视角
- 不同种类
- 更加细分的分类
- 杂乱背景
- 光照变化
- 物体形变/不同动作
- 遮挡
机器学习
一般流程
- 收集数据集(包含图像, 标签)
- 用 ML 算法训练分类器
- 在新图像上评测分类器
常见数据集
- MNIST : 手写数字
- CIFAR10/100 : 10/100 种常见物体
- ImageNet : 1000 种物体
- Omniglot: 训练从较少样本中学习的算法
最临近分类器 Nearest Neighbor
方法
利用某个度量函数, 评估输入图像与训练过图像的相似程度, 把最相似的 label 作为预测值
度量函数
L1 距离
又称为曼哈顿距离
对图片所有像素求绝对值的差, 然后求和
L2 距离
又称为欧几里得距离
对图片所有像素求绝对值的平方, 再开平方根(也就是求两点间距离), 再求和
决策边界
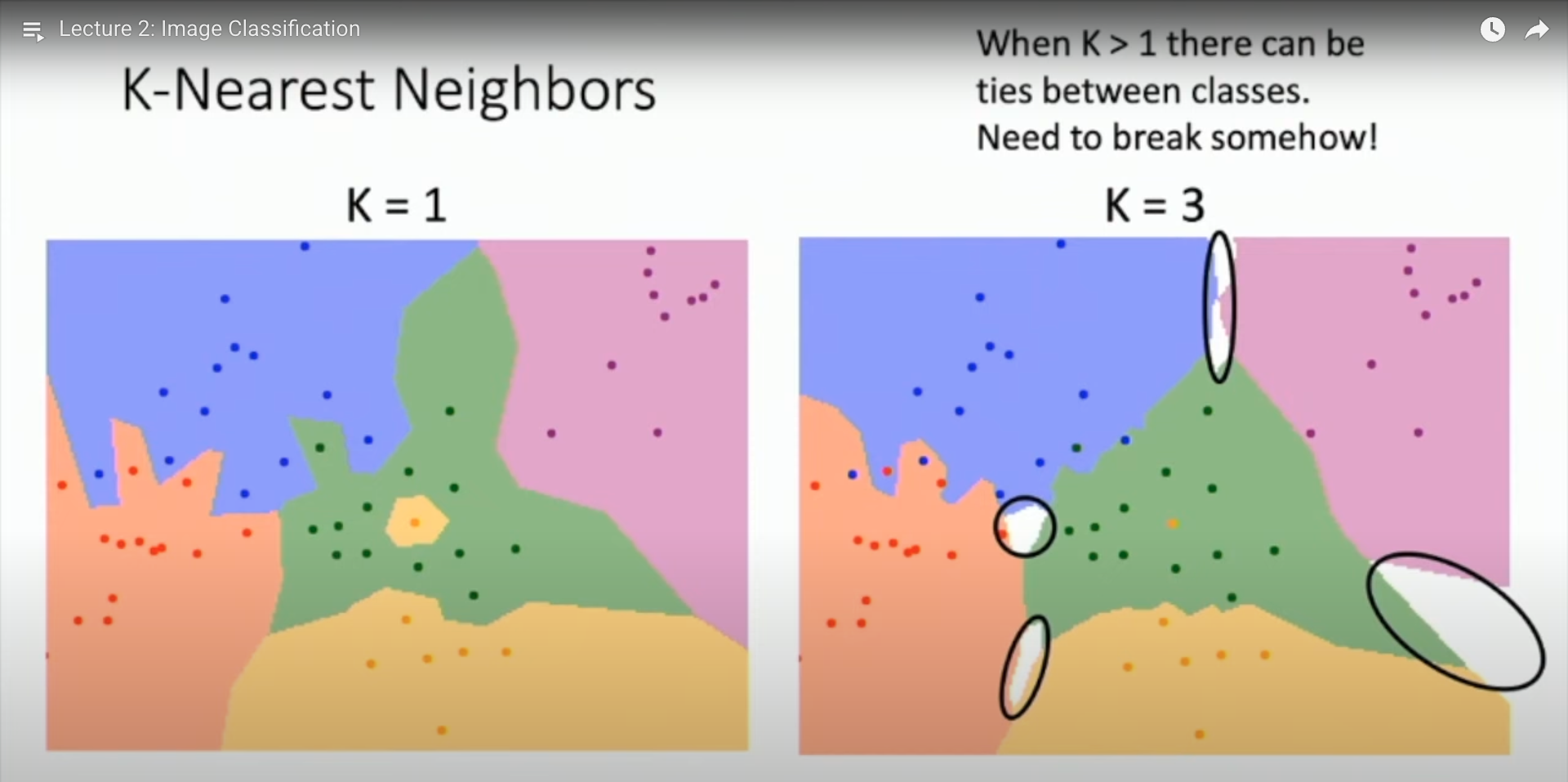
基于NN, 我们引入一个概念: 决策边界, 可以形象的表明分类的范围
这些范围的边界并不平滑, 意味着会有较大的误差和分歧
在 NN 的基础上, 我们引入 KNN, 发现随着 K 的增大, 边界逐渐平滑; 但也多了一些难以决策的空白区域(几个预测值等可能性), 需要引入一些方法来进行决策
K临近分类器 KNN
找到距离最近的 k 个邻居, 根据邻居类别决定预测值
当 k 无限大的时候, 会逼近真实的函数
超参数 Hyperparameters
机器无法学习, 由人类指定, 且影响模型训练评测的一些参数
在 KNN 中, 度量函数, K 值都是超参数
选择超参数
切分数据集
把数据分为三份: 训练, 验证, 测试
大概 8:1:1?
其中, 训练集用来训练模型
验证集用来选择最佳的超参数
测试集用于测试模型效果
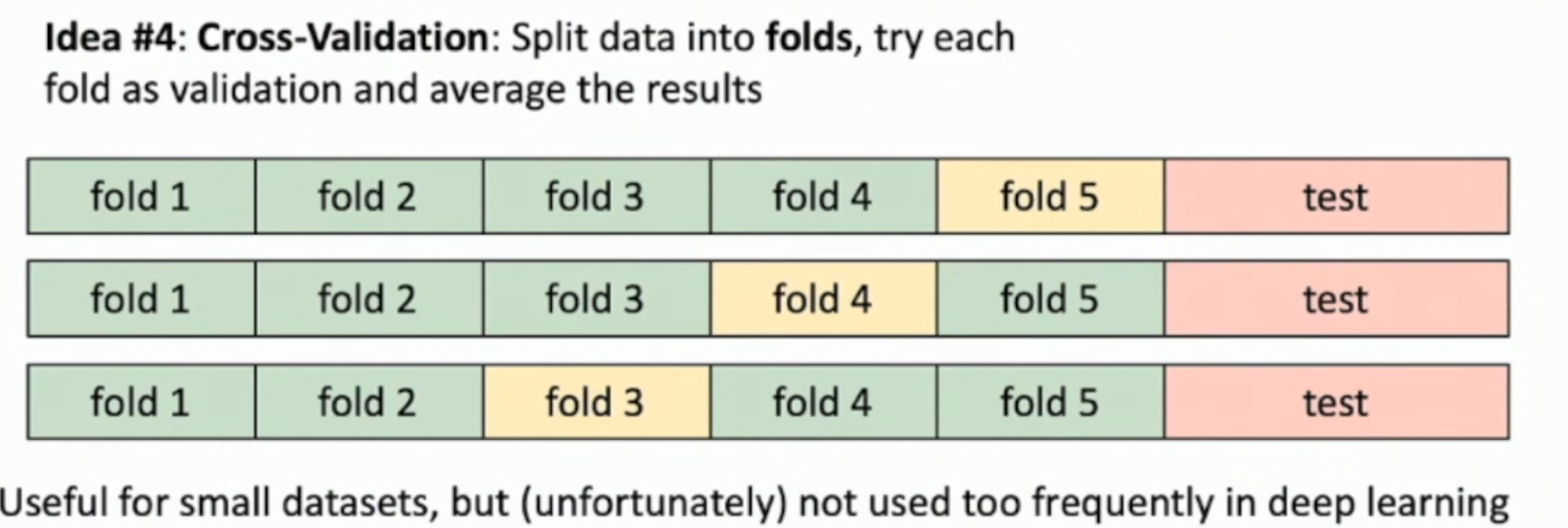
交叉验证
KNN 的一些问题
维度灾难
当数据的维度增加时,想要均匀覆盖这个空间所需要的样本数量会指数级增长
无法使用原始像素
若使用原始像素训练 KNN会有以下问题:
- 训练速度极慢
- 像素距离没有实际意义: 图像像素微小变化对人类无影响, 但可能引起度量函数巨变. 可以用 CNN 提取的特征再分类