先记住三件事
MolmoWeb 不是从零训练一个网页模型,也不是给浏览器套一个 HTML/DOM 工具。它是在 Molmo2 这个 VLM checkpoint 上,用 MolmoWebMix 这套网页操作数据继续 SFT,训出一个推理时只看截图、任务指令和动作历史的网页 agent。
可以把关系压成一句:MolmoWebMix 像教材,MolmoWeb 是读完这套教材的学生,AxTree teacher 写出了很多标准步骤;真正上场时,学生只看截图。
这篇的重点不在架构多新,而在数据怎么造、怎么筛、怎么把结构化 teacher 的能力压到一个 screenshot-only student 里。
Abstract 其实说了五件事
摘要的逻辑很紧:网页 agent 有用,但强系统大多闭源;作者要做开放数据和开放模型;模型每一步看截图和任务,预测下一步 browser action;4B/8B 在 open-weight web agent 里表现很强;多 rollout 加 best-of-N selection 能明显涨分。
这里最重要的短语是 instruction-conditioned visual-language action policy。不用把它想复杂,意思就是:用户给一个任务,模型看当前网页截图和动作历史,然后输出下一步要做什么。这个动作可以是点击、输入、滚动、返回、等待、给用户发消息等。
摘要里还有一个很容易读漏的点:MolmoWeb 推理时不需要 HTML、accessibility tree 或网站 API。这是部署时的 observation space,不等于训练数据生成阶段完全没有借助结构化信息。后面 AxTree teacher 那部分正好解释这个区别。
Introduction:这篇在反对什么
Intro 先把 web agent 的动机放大。人每天都在网页上做很多多步任务:订机票、查政府服务、管财务、比价购物、填表、找信息。网页 agent 如果可靠,不只是帮人省时间,也可能帮残障用户或数字能力较弱的人更容易使用网络。
然后它转到论文真正想解决的问题:现在最强的 web agent 大多是 hosted proprietary service。你能调用,但不知道训练数据、训练流程、评测细节,也很难审计行为。对一个会替用户在开放网页上操作的系统来说,这个不透明会比普通聊天模型更敏感,因为它可能真的点按钮、提交表单、影响用户账户和决策。
作者的主张就是那句:
agents for the open web should be built in the open
所以这篇不是单纯发一个模型榜单,而是想给 open web agent 做一个开放基座:数据、模型、训练 recipe、评测 harness 都尽量公开。
Figure 1 定义了 MolmoWeb 的基本循环。模型拿到任务、截图和动作历史,输出 thought 和 action。浏览器执行 action 后产生新页面,再截图给模型,继续下一步。

Intro 里另一个关键选择是 vision-only。作者给了三个理由:
- 人用网页也是看屏幕、读文字、点按钮,所以截图接口更接近人类操作。
- DOM/AxTree 在动态网页、前端框架和页面小改版下可能不稳定,也可能和用户实际看到的东西不一致。
- AxTree 这类结构化页面输入可能一页几万 tokens,截图反而是更紧凑的观察。
我读下来觉得,Intro 真正要你接受的是一个赌注:只看截图也许足够通用,只要训练数据把网页视觉理解和网页操作行为都教够。
MolmoWebMix 和 MolmoWeb 的关系
这两个名字一定要分清:
MolmoWebMix 是数据。 它回答的是:拿什么训练网页 agent?
MolmoWeb 是模型。 它回答的是:模型如何根据截图和任务预测下一步动作?
MolmoWebMix 不是一堆同质的网页轨迹,它有三个层次:
task trajectories: 完整网页任务轨迹
atomic skill trajectories: 单项网页技能
GUI perception: grounding 和 screenshot QA
Figure 2 很直观。上半部分教模型看懂网页截图,比如回答商品价格、识别按钮、根据描述点某个元素;下半部分教模型按任务一步步操作网页。
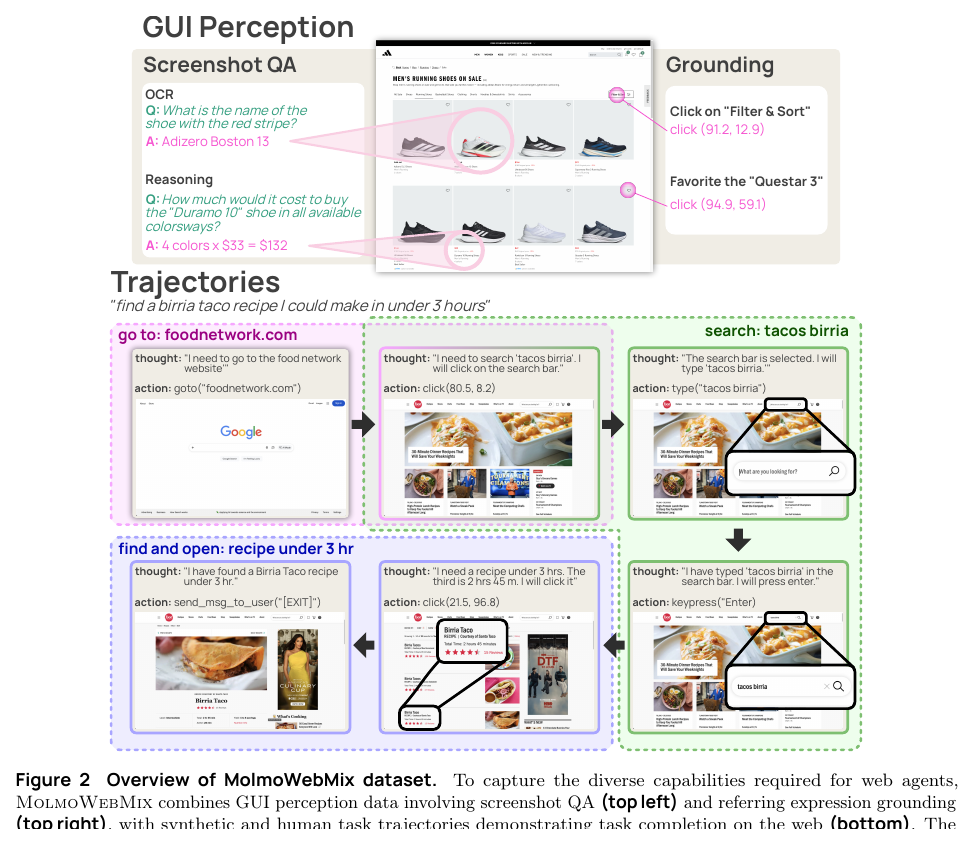
我会把这套数据理解成三种训练信号放在一起:
完整任务轨迹教多步行为。
atomic skills 教基本功。
grounding / screenshot QA 教看懂网页。
这也是为什么这篇不是简单地说“我们收了很多数据”。它更像在做一个网页 agent 的课程设计。只喂完整任务,模型可能学不到稳定基本功;只喂 grounding,模型会点但不会规划;只喂 screenshot QA,模型会读页面但不会操作。
AxTree teacher:这篇最容易误解的地方
我们之前聊最多的就是这个:MolmoWeb 推理时只看截图,但很多 synthetic trajectories 是 AxTree teacher 生成的。这不是矛盾,关键是把时间点分清。
数据生成阶段:teacher 可以看 AxTree。
模型训练阶段:student 看截图和 teacher 产生的动作。
推理部署阶段:student 只看截图。
所以 MolmoWeb 是 screenshot-only student,不是完全没有接触过结构化网页信息的系统。
AxTree 到底是什么
AxTree 是 Accessibility Tree,浏览器根据 DOM、HTML 语义、ARIA、文本内容和控件状态生成。它原本是给屏幕阅读器和辅助功能用的。它能把网页上的按钮、输入框、链接、选项、当前值、focused/checked/disabled 这些状态整理成一份结构化清单。
比如一个搜索页的 AxTree 可能长这样:
[1] RootWebArea 'Google Search'
[6] combobox 'Search' [focused]
[7] [value='weather in Paris']
[8] listbox 'Suggestions'
[9] option 'weather in Paris today'
[10] option 'weather in Paris France'
[11] button 'Google Search'
[14] link 'Privacy'
对 LLM teacher 来说,这比截图容易很多。截图里模型要自己 OCR、判断哪个区域是搜索框、哪个按钮可点;AxTree 里这些语义已经被浏览器整理出来了。
不过 AxTree 不是只有“规范网站”才有。现代浏览器通常都会生成某种 accessibility tree,但质量差别很大。网页如果用真实的 <button>、<input>、label、aria-label,AxTree 就比较有用;如果大量用没有语义的 div onclick、背景图按钮、canvas、自绘组件,AxTree 可能只剩 generic clickable、空名字,甚至漏掉关键区域。
所以更准确的说法是:大多数网页都有某种 AxTree,但不是每个网页都有高质量、可靠、语义清楚的 AxTree。
teacher 怎么把元素变成点击坐标
teacher 通常不直接输出坐标。它在 bid 空间里选元素,bid 可以理解成浏览器给可交互节点分配的编号。
流程大概是:
浏览器生成当前页面的 AxTree
-> 系统给可交互节点分配 bid
-> teacher 读 AxTree、任务和历史动作
-> teacher 输出 click bid=11 这类动作
-> 浏览器执行器找到 bid 对应的 DOM/AX node
-> 查询这个元素在 viewport 里的 bounding box
-> 取中心点或框内点,得到实际点击坐标
-> 保存成 MolmoWeb 要学的 mouse_click(x, y)
这点很重要:LLM teacher 不是凭空从树里想象坐标。teacher 负责选元素,browser harness 负责把元素 ID 映射成屏幕坐标。
举个具体例子:
AxTree:
[6] combobox 'Search'
[11] button 'Google Search'
任务:
Search for tacos birria.
teacher:
click bid=6
type "tacos birria"
click bid=11
训练样本:
screenshot + task + history -> mouse_click(48.2, 8.5)
学生训练时看不到 [6] combobox 'Search' 这份树,它只能从截图里学:这个位置像搜索框,下一步应该点这里。这样看,MolmoWeb 的核心就很清楚了:把结构化 teacher 的行为轨迹蒸到一个只看截图的 VLM 里。
MolmoWebMix 具体有哪些数据
Table 2 给了最终混合比例。这个比例不是原始样本量自然决定的,而是作者作为超参调出来的。
| Source | 规模 | Avg steps | Mixture ratio |
|---|---|---|---|
| MolmoWebMix-Traj | 278.5K trajectories, 2.2M steps | 13.2 | 0.80 |
| AxTree Single-Agent | 70K trajectories, 793K steps | 11.4 | 0.35 |
| AxTree Multi-Agent | 35K trajectories, 438K steps | 12.5 | 0.18 |
| AxTree Atomic Skills | 5.5K trajectories, 68.7K steps | 12.4 | 0.02 |
| Node-Traversal | 16K trajectories, 151K steps | 9.5 | 0.02 |
| Human | 36K trajectories, 623K steps | 20.8 | 0.18 |
| Human Skills | 116K trajectories, 781K steps | 6.8 | 0.05 |
| MolmoWebMix-Perception | 10.5M samples | N/A | 0.20 |
| PixMoPoints + SyntheticGround | 8.3M samples | N/A | 0.15 |
| ScreenshotQA | 2.2M samples | N/A | 0.05 |
轨迹数据占 80%,感知数据占 20%。这说明作者还是把网页任务完成作为主目标,但给了 GUI perception 很大权重,因为只看截图的 agent 必须先能读懂 UI。
完整任务轨迹
完整任务轨迹就是一条网页任务从开始到结束的过程。每一步都可以变成训练样本:
当前截图 + 任务 + URL/title + 最近动作历史
-> thought + 下一步 browser action
论文里有四种来源。
AxTree single-agent trajectories 是最主要的合成来源。Gemini-3-Flash-Preview 看 AxTree、任务和历史动作,输出基于 bid 的动作。系统保存每一步截图,再把 bid-space action 转成 pixel-space action,失败轨迹用 WebVoyager judge 过滤掉。
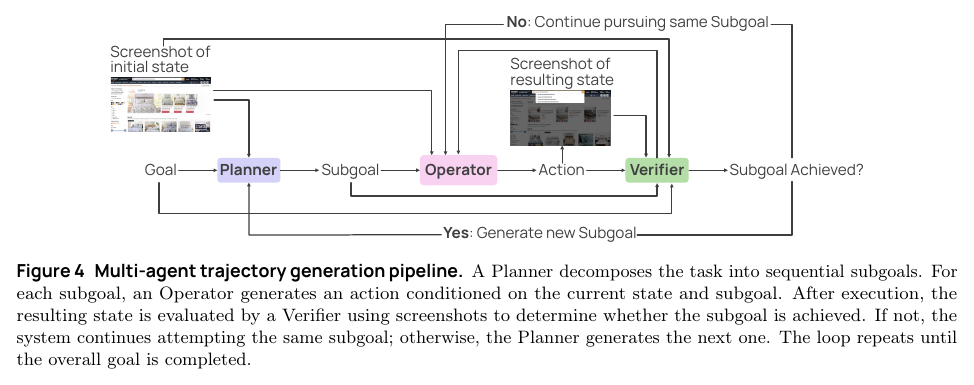
Multi-agent harness 是为了生成更高质量轨迹。Planner 负责把总任务拆成当前子目标,Operator 执行一个低层动作,Verifier 看最近几张截图判断子目标是否完成。这个设置比单个 AxTree agent 在 WebVoyager 上成功率高,78.5 vs 74.4。

Human demonstrations 来自众包工人。他们用 Chrome extension 操作真实网页,系统记录点击、滚动、输入和截图。任务会拆成 ordered subtasks,工人完成一个 subtask 就 check 一下,最后还有人工审核。
Node traversal 更像一种便宜的导航数据生成法。作者先在 500 个热门网站上构造 URL 图,再用确定性流程沿着路径滚动、点击。因为目标 URL 已知,成功可以用 URL matching 验证。最后再让 LLM 给这条路径生成一个合理任务指令。
这里最值得注意的是,MolmoWebMix 不是只有“智能 teacher 做任务”这一条路。它混了 LLM teacher、人类演示、确定性 graph traversal 和 GUI perception,数据来源比较杂,但每类都有自己的作用。
Atomic skills:网页任务的基本功
Atomic skills 是单项网页技能,比如:
go_to
search
find
find_and_open
find_and_click
fill_form
fill_form_and_submit
apply_filters
apply_filters_and_search
add_to_cart
navigate
它们不是模型最终输出的动作,而是数据组织层的概念。模型真正输出的是 mouse_click、keyboard_type、scroll 这类 browser action。Atomic skill 负责把复杂任务拆成可训练的基本功。
关系可以这么看:
task = 多个 atomic skills
atomic skill = 多个 browser actions
browser action = 模型真正执行的一步
比如 search coffee 这个 skill,落到动作上可能是:
mouse_click(search box)
keyboard_type("coffee")
keyboard_press("Enter")
这类数据的意义是降低长任务难度。完整任务需要组合很多技能,但如果模型连搜索、筛选、填表、打开目标页面这些基本动作都不稳,长任务一定容易崩。
GUI perception:补上看懂网页这件事
GUI perception 包括 grounding 和 screenshot QA。
Grounding 是:
screenshot + element description -> click point
比如给一句 “Click on Filter & Sort”,模型要预测该点哪里。作者从 AxTree 轨迹里枚举 clickable elements,用 accessible name + role 或 GPT-5 生成自然语言描述,再从元素 bounding box 里采样点击点。不是永远点中心,而是用 centered clipped Gaussian,让模型知道目标是一个区域,不是唯一像素。
Screenshot QA 是:
screenshot + question -> answer
它教模型 OCR、读页面内容、理解 affordance 和总结页面区域。生成 QA 时可以借助 AxTree 出题,但会过滤掉 “Click on Bid 32” 这种依赖 AxTree 内部编号的问题。最后得到 395 个网站、2,237,252 个 QA,问题类型大概是 54% OCR、26% affordance、20% summarization。
这一块对 screenshot-only agent 很关键。只看截图的模型如果不会读页面文字、不会识别按钮和输入框,再好的规划也没用。
Synthetic task generation:这篇最值得学的数据工程
我们前面讨论过,人类数据在消融里效果一般,所以 Appendix C 的 synthetic task generation 反而更值得看。C 节主要讲 task sampling,也就是先生成什么任务;真正执行任务、保存轨迹、过滤失败是在正文 2.1。
完整 synthetic pipeline 可以这样理解:
先生成网页任务
-> 交给 AxTree agent / multi-agent harness / node traversal 执行
-> 每一步保存截图、thought、action
-> bid-space 动作转成 pixel-space action
-> judge / verifier / URL matching 过滤失败轨迹
C 节讲的是第一步:任务怎么来。
三种造题方法
第一类是手写模板,主要覆盖 WebVoyager 里的网站和任务风格。这有点现实主义,想在目标 benchmark 上表现好,就要覆盖那些网站和问题形式。
第二类是 LLM 生成 benchmark-like tasks。对 WebVoyager,它会生成匹配分布的任务;对 Online-Mind2Web,它还会以一定概率换成同类别网站,比如原来是购物站,就换到另一个购物站生成类似任务。这样既贴近 benchmark,又避免只记住原网站。
第三类是 taxonomy-based generation,也是最有启发的部分。作者定义四个轴:
intent:
info-seeking, transactional, tool-use, messaging, navigation
domain:
travel, ecommerce, productivity-apps, communication-apps, devtools,
social, finance, education, media, reference, local, gov, health
difficulty:
D0: 0-1 个约束
D1: 2-3 个约束
D2: 4-5 个约束
D3: 6+ 个约束
ambiguity:
A0: 单一正确答案
A1: 多个可行答案,需要优化
A2: 开放式比较或推荐
A3: 模糊、欠指定,需要澄清或自行判断
然后遍历 intent x domain x difficulty x ambiguity,让 GPT-4o 为每个格子生成真实网页任务。每个任务会带 target website、task type label、concrete browser action steps,以及 high/mid/low 三种自然语言指令。
比如一个电商任务可以被生成成:
domain: ecommerce
intent: transactional
difficulty: D2
ambiguity: A1
target website: bestbuy.com
steps:
go to bestbuy.com
search wireless earbuds
apply filters: price < $100, rating >= 4
find product with longest battery life
open product page
low-level instruction:
Go to BestBuy, search for wireless earbuds, filter under $100 and rating over 4 stars,
then open the product with the longest battery life.
mid-level instruction:
Find highly rated wireless earbuds under $100 on BestBuy with strong battery life.
high-level instruction:
Help me choose affordable wireless earbuds with good battery life.
这个设计比“让 LLM 随便生成一堆网页任务”强很多。它能控制覆盖面,也能给后续分析留下 metadata。之后如果模型在 transactional + travel + D3 上很差,就可以针对这个格子补数据。
taxonomy 不能保证任务真实可行
我们当时聊到一个关键问题:intent x domain x difficulty x ambiguity 的组合,怎么保证现实网页里一定能做?
答案是保证不了。
taxonomy 只是 coverage proposal,不是 feasibility guarantee。它负责提出“我想覆盖哪些任务类型”,真正判断任务能不能做,要靠后面的真实浏览器执行和成功过滤。
比如:
intent: transactional
domain: gov
difficulty: D3
ambiguity: A2
LLM 可能生成一个“在政府网站上比较多个许可证申请选项并选择最适合小企业的方案”的任务。但真实网页可能需要登录、没有这个功能、页面变了、信息不够、judge 也很难判断答案。这样的任务即使生成出来,也大概率会在执行或过滤阶段被丢掉。
所以可用训练轨迹的来源是:
task sampling 只是造题。
usable trajectory 必须经过真实执行和成功过滤。
这个 tradeoff 很实际。taxonomy 想覆盖全空间,但最后留下来的数据会被网页可行性、teacher 能力和 judge 标准共同塑形。
MolmoWeb 怎么训
MolmoWeb 不是从头训的。底座是 Molmo2,里面是 Qwen3 language model + SigLIP2 vision encoder。起点是 Molmo2 的 single-image checkpoint,这个 checkpoint 已经做过 image captioning 预训练和 single-image QA 微调。
MolmoWeb 做的是 end-to-end supervised fine-tuning。输入是网页截图、任务指令、URL/title 和最近 10 步动作历史;输出是一个 JSON,里面有 thought 和 browser action。训练时 language model、vision encoder、adapter 都一起继续调。
训练设置:
base: Molmo2 single-image checkpoint
data: MolmoWebMix
method: supervised fine-tuning
hardware: 64 H100
global batch size: 128
steps: up to 50K
epochs: about 3.2
这篇没有把 RL 当主训练路线。它先证明一件事:如果数据足够干净、覆盖足够好,SFT-first 的网页 agent 已经可以很强。RL 和 self-distillation 可以放在后面接。
Action space:模型的手脚
MolmoWeb 的 action space 接近人类 GUI 操作:
| Action | Meaning |
|---|---|
goto(url) | 打开 URL |
mouse_click(x, y, ...) | 点击视口坐标 |
mouse_drag_and_drop(...) | 从一个坐标拖到另一个坐标 |
scroll(delta_x, delta_y) | 滚动页面 |
scroll_at(x, y, dx, dy) | 在指定坐标处滚动,通常用于局部容器 |
hover_at(x, y) | hover 到某个坐标 |
keyboard_type(text) | 输入文本 |
keyboard_press(key) | 按键或组合键 |
go_back() | 返回上一页 |
new_tab() | 新建标签页 |
tab_focus(index) | 切换标签页 |
noop(wait_ms) | 等待页面加载或验证码等 |
send_msg_to_user(msg) | 给用户发消息 |
这个设计很干净:通用、接近人类、方便复现,也符合 screenshot-only 的研究设定。缺点也明显,轨迹容易变长,每一步都是一次出错机会。
比如搜索一个东西,没有 macro action 时要做:
goto("google.com")
mouse_click(search box)
keyboard_type(query)
keyboard_press("Enter")
中间任何一步错了,后面都可能偏掉。
作者在 limitation 里提到两个可能的改法。一个是 type_at(text, x, y, press_enter=True),把点击输入框、输入、按回车合成一步。另一个是 web_search(query),直接通过搜索引擎 URL 参数发起搜索。
我觉得 web_search(query) 很合理。产品级 agent 当然应该加,因为用户关心任务完成,不关心 agent 是否像人一样操作。但 MolmoWeb 没把它放进主 action space,也很合理。它这篇想回答的是:只看截图、用人类式 GUI 动作,VLM 能不能学会网页操作?如果加入 web_search,很多任务会从 GUI 操作问题变成检索工具问题,benchmark 的含义会变。
所以这里不是“web_search 不好”,而是研究设定和产品设定不一样:
研究设定:少加工具捷径,保持纯视觉 GUI 操作问题清楚。
产品设定:能完成任务就行,可以加 web_search、type_at、extract_visible_text 等 macro/tool actions。
低频动作也值得单独看。scroll_at 难在要判断滚哪个容器;mouse_drag_and_drop 不是一个点,而是起点、终点、路径和持续时间;hover 难在结果不稳定,有些网页 hover 才展开菜单,有些 hover 没效果。这些动作数据少、状态复杂,所以模型学得不稳。
实验结果怎么读
MolmoWeb-8B 在四个 benchmark 上:
WebVoyager 78.2
Online-Mind2Web 35.3
DeepShop 42.3
WebTailBench 49.5
MolmoWeb-4B:
WebVoyager 75.2
Online-Mind2Web 31.3
DeepShop 35.6
WebTailBench 43.8
它在 open-weight 视觉 web agent 里很强,超过 Fara-7B、UI-TARS-1.5-7B、GLM-4.1V-9B-Thinking、Holo1-7B 等。和闭源模型比的时候要谨慎,因为表里混了 AxTree agent、SoM agent、computer-use-preview,不同系统的 observation/action protocol 不完全一样。
最稳的结论是:MolmoWeb 在 open-weight web agents 里做得很强;对闭源系统的对比说明它有竞争力,但不是严格同条件胜出。
和 Gemini AxTree teacher 比,MolmoWeb-8B 仍然落后。原因也不难理解:Gemini 可能更大;AxTree teacher 选 bid,不需要预测像素坐标;teacher 直接读结构化文本,MolmoWeb 还要从截图里做 OCR 和阅读理解。
Test-time scaling:pass@4 很有信息量
这篇的 test-time scaling 很值得记。MolmoWeb-8B:
WebVoyager:
pass@1 = 78.2
pass@4 = 94.7
Online-Mind2Web:
pass@1 = 35.3
pass@4 = 60.5
这个差距说明,模型的采样分布里已经有不少成功路径,只是单次 rollout 不稳定。网页任务有 compounding error,一步点错、滚过头、漏掉条件,后面整条轨迹都可能被带偏。并行跑几条,再用 judge 选最好,就能绕过一部分坏轨迹。
这直接启发两个方向:
best-of-N self-distillation:
多跑几条,收集成功轨迹,过滤后继续 SFT,让 pass@1 接近原来的 pass@N。
RL:
用 reward/advantage 提高成功动作概率,压低失败行为。
我更倾向先做 self-distillation,因为它和这篇的数据路线更一致,也比在线 RL 稳。
Human data 为什么反而一般
Table 5 和 Table 6 很有意思。
数据规模消融:
1% data WebV 44.5 OM2W 11.7
10% data WebV 63.2 OM2W 20.4
100% data WebV 68.5 OM2W 21.9
10% 数据已经能达到 85-90% 的最终性能,说明 mix 信息密度很高。
Human vs synthetic:
human only 28K WebV 27.8 OM2W 13.2
synthetic only 106K WebV 67.8 OM2W 22.0
synthetic + human 134K WebV 68.5 OM2W 21.4
同样 2.7K 条任务下:
human DeepShop 19.8 WebV 35.4 OM2W 9.0
synthetic DeepShop 24.4 WebV 53.0 OM2W 16.8
这不是说人类不会用网页,而是 raw human demonstration 不一定适合 next-action SFT。人类会探索、犹豫、滚动幅度不稳定、走弯路,还可能有标注噪声。AxTree teacher 看到结构化语义,轨迹更短、更直接、更像 expert demonstration。
我会把这个结论记成:web agent SFT 最需要的不是“真实的人类探索过程”,而是“在当前状态下给出干净、直接、可泛化的下一步动作”。
这也改变了 human data 的价值定位。人类数据未必适合直接当 raw imitation data,但很适合做这些事:
- 对失败轨迹做 correction。
- 在多条 rollout 里选更自然、更稳的一条。
- 标注模型为什么失败。
- 收集用户偏好、澄清、多轮协作,而不是只收集完整操作轨迹。
Sampling:随机性不是为了创造性
采样策略也有一个小但有用的结论:
greedy, temperature=0.0 61.4
top-k, temperature=0.7, k=20 67.4
top-p, temperature=0.7, p=0.8 68.5
Greedy 容易卡在重复动作里,比如一直点同一个位置,或者滚动失败后还继续滚。Top-p 给模型一点探索空间,确定时少采,不确定时多采。这里的随机性不是为了“更有创造力”,而是为了跳出坏循环。
Grounding 很强,但 scroll 还缺评测
MolmoWeb-Ground-8B 只用 grounding 数据训练,是 specialist;MolmoWeb-4B 是完整网页 agent。两者在 ScreenSpot / ScreenSpot v2 上:
MolmoWeb-4B 87.2 / 89.5
MolmoWeb-Ground-8B 88.7 / 91.8
这说明 GUI perception 数据确实有效,MolmoWeb 的长任务能力不是空中楼阁,它底层点击定位很强。
但 ScreenSpot 主要测当前截图内的目标点定位,不测滚动、不测多步规划、不测错误恢复。我们讨论时觉得,web agent 还缺一个类似 ScreenSpot 的 scroll diagnostic benchmark。很多失败并不是点不准,而是不知道该不该滚、往哪滚、滚哪个容器、滚多远、目标出现后什么时候停、滚过头后怎么恢复。
一个好的 ScrollSpot 至少应该测:
direction: 往上还是往下
amount: 滚多少
container selection: 主页面还是局部容器
stop condition: 看到目标后停不停
recovery: 滚过头后能不能回来
这块比普通 grounding 更接近网页操作里的真实难点。
Limitations 里最值得记的几条
作者在第 6 章讲了几个限制,我觉得最有用的是这些:
Instruction following:具体任务更稳,模糊任务和多约束任务更容易掉。给出网站名或 URL 往往更好。
OCR and reading comprehension:能读截图,但小字、长段落、复杂问答仍会失败。
Latency:轨迹本身追求少动作,但模型每步 forward 和浏览器执行动作都可能慢。Browserbase 方便并行,但本地浏览器通常更快。
Thoughts:thought 有时能当短期记忆,比如滚动新闻列表时记录标题;但 thought 和 action 不总一致,不能把 thought 当作忠实解释。
Action space:人类 GUI 动作很通用,但不一定高效。macro action 可以缩短轨迹,但会改变研究问题。
Error correction:模型偶尔会 go_back 或滚回顶部纠错,但也会卡在重复动作里。
外部资料怎么看
AlphaXiv 的结构化综述适合快速看研究格局。它把这篇论文放在 open web agent 的脉络里,强调的不只是模型,而是数据、训练、评测和模型一起开放。这个视角和论文 Intro 的主张一致。
AllenAI 官方 blog 更像项目发布页。它强调 MolmoWeb 是用 screenshots alone 操作浏览器的 open visual web agent,也强调 MolmoWebMix 是公开 web-agent 训练数据。这个口径适合理解项目定位,但具体技术判断还是要回到论文。
最后怎么记这篇
我会把 MolmoWeb 记成一个数据工程优先的 web agent 工作。
它的架构没有特别玄:
Molmo2 checkpoint
+ MolmoWebMix
+ 单阶段 SFT
+ screenshot-only closed-loop action policy
真正值得学的是数据组织:
用 taxonomy 和 benchmark-like generation 控制任务覆盖
用 AxTree teacher / multi-agent harness / node traversal 生成轨迹
用 GUI grounding 和 screenshot QA 补视觉理解
用 test-time scaling 看出模型采样分布里还有成功轨迹
这篇给我的启发是:做 web agent 不一定先上复杂 RL 或多代理执行框架。先把任务分布、teacher 轨迹、感知数据、动作空间和评测环境做扎实,SFT baseline 就能很强。
后续问题清单
- MolmoWebMix 的数据配比能不能迁移到其他 VLM,还是高度依赖 Molmo2?
- synthetic task generation 贴近 benchmark 分布,这会不会让结果里有一部分来自 distribution matching?
- teacher 用 Gemini-3-Flash-Preview,这对开放性 claim 的影响应该怎么评价?
- 如果网页 AxTree 质量差,teacher 生成的数据是否会系统性偏向 accessibility 做得好的网站?
- screenshot-only student 对 OCR、遮挡、响应式布局、移动端页面的鲁棒性如何?
- 多 rollout + judge 的提升,在真实部署中成本是否可接受?
- 如果加入
web_search(query)、type_at、scroll_until_visible这类 macro action,成功率和通用性会怎么权衡?