MIT 6.S191: Introduction to Deep Learning
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Alexander Amini 授课内容整理 |
| 来源 | Alexander Amini (MIT) |
| 日期 | 2025年春季 |

课程概览与深度学习的进步
MIT 6.S191 是 MIT 官方的深度学习入门课程,由 Alexander Amini 和 Ava Amini 主讲。这是一门为期一周的密集训练营(boot camp),涵盖深度学习的核心理论与实践。2025 年是该课程开设的第 8 年,已累计教授超过 1300 万名全球学生。
深度学习的十年进化
Amini 教授以一个生动的对比开场:仅仅十年前(2015 年),最先进的深度学习人脸生成系统只能产出模糊的像素块(Goodfellow et al.);到 2018 年(Karras, Laine, Aila),生成的人脸已具备照片级真实感;2020 年,MIT 6.S191 课程组更是制作了一段以"奥巴马"形象欢迎学员的 deepfake 视频,该视频在 YouTube 上获得了超过 110 万次观看。

来源:Slides 第 2 页。
2020 年 deepfake 的制作成本
2020 年制作那段 2 分钟的 deepfake 视频需要:2 小时的专业音频录制、50 小时的高清视频数据、预定义的静态脚本、以及超过 15000 美元的计算资源。而到 2025 年,Amini 现场演示了实时语音克隆:仅录制数分钟讲课音频,即可立刻生成他的声音克隆体,并与之进行无脚本的动态对话。这充分说明了生成式 AI 在短短几年内的巨大飞跃。

来源:Slides 第 6 页。
什么是深度学习?
在理解深度学习之前,需要先厘清三个层次的概念:
AI ML DL 的层级关系
- Artificial Intelligence (AI):使计算机模拟人类行为的任何技术
- Machine Learning (ML):不显式编程,而是让机器从数据中学习模式的方法
- Deep Learning (DL):使用深层神经网络从原始数据中提取模式的 ML 子集
核心理念:教会计算机直接从原始数据中学习如何完成任务(learn a task directly from raw data)。
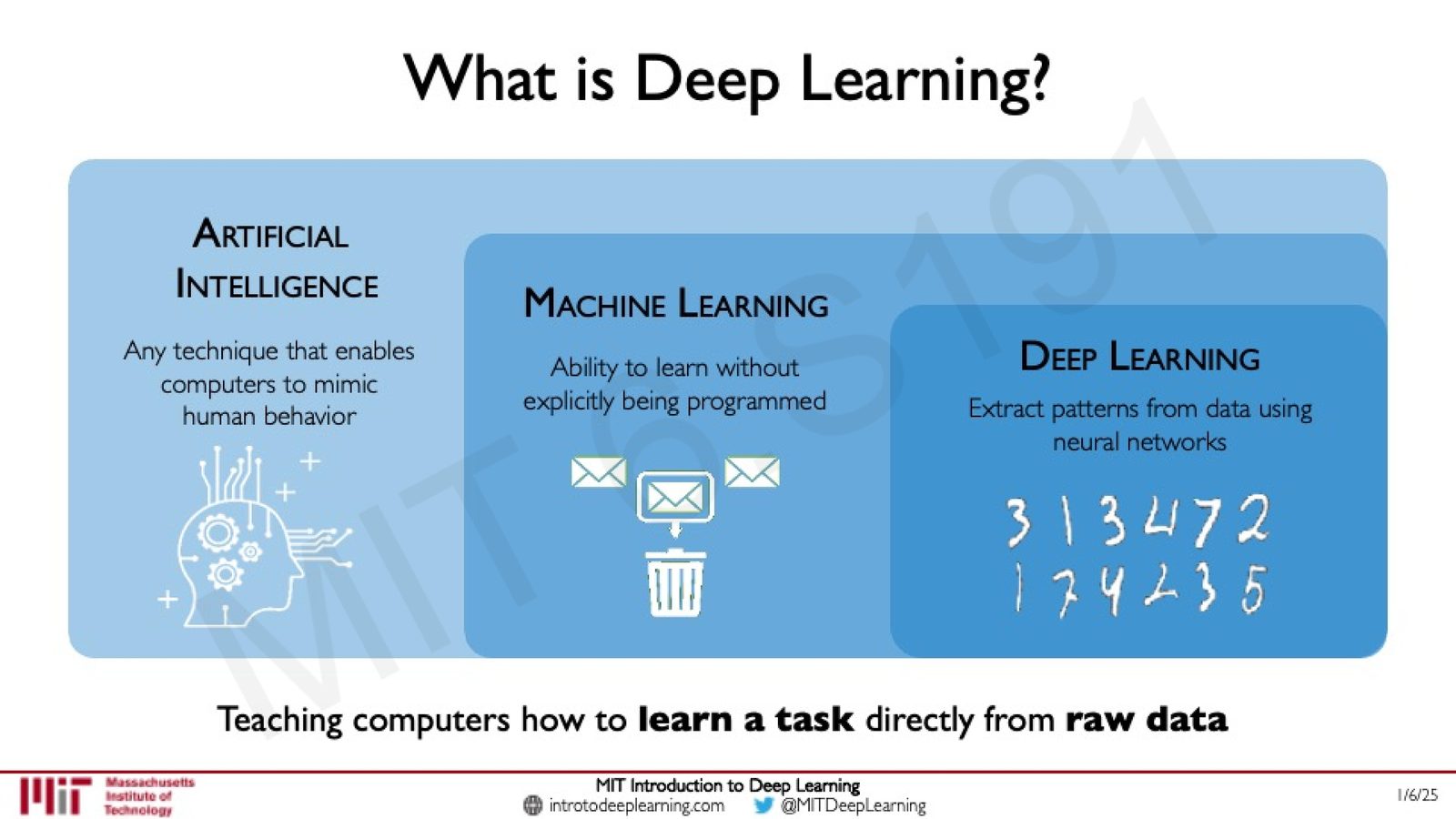
来源:Slides 第 7 页。
Intelligence(智能)的本质是处理信息以指导未来决策的能力。Artificial Intelligence 就是构建人工算法来完成同样的过程——利用数据来驱动决策。Machine Learning 不直接告诉计算机如何处理数据,而是让它从数据中自主发现模式。Deep Learning 则进一步使用深层神经网络来完成这一过程。
课程结构
MIT 6.S191 为期一周,包含以下模块:
| 日期 | 讲座主题 | 实验 |
|---|---|---|
| Day 1 | Introduction to Deep Learning | Lab 1: 音乐生成 |
| Day 2 | Deep Sequence Modeling | Lab 2: 计算机视觉 |
| Day 3 | Deep Computer Vision | Lab 3: 大语言模型 |
| Day 4 | Deep Generative Modeling | – |
| Day 5 | Deep Reinforcement Learning | Final Project |
今年的亮点包括:同时支持 TensorFlow 和 PyTorch 两个框架的实验,以及全新的 LLM 实验(微调 20 亿参数的 Gemma 模型并构建 AI 评判器)。
本章小结
深度学习在过去十年取得了惊人进步:从模糊的像素生成到实时语音克隆和动态对话。MIT 6.S191 课程旨在通过一周密集训练,让学生掌握驱动这些进步的基础技术。整个课程围绕一个核心理念:教会计算机直接从原始数据中学习任务。
为什么是深度学习?为什么是现在?
传统机器学习的局限
传统机器学习依赖于手工设计的特征(hand-engineered features)。以人脸检测为例,工程师需要手动定义如何从图像中提取边缘、曲线、五官等特征。这种方法存在三个根本问题:
- 耗时:特征工程需要大量领域专家的时间和经验
- 脆弱:手工特征对环境变化(光照、角度等)不具鲁棒性
- 不可扩展:每个新任务都需要重新设计特征集
深度学习的核心思想
深度学习的关键突破在于:让模型自动从数据中学习特征的层次化表示(hierarchical feature representations)。低层特征(如边缘和线条)自动组合成中层特征(如眼睛、鼻子),再进一步组合成高层特征(如面部结构)。无需人工干预。

来源:Slides 第 18 页。
三大驱动力
尽管神经网络的理论可以追溯到数十年前(1952 年的随机梯度下降、1958 年的感知机、1986 年的反向传播、1995 年的深度卷积网络),但其真正的爆发得益于三大驱动力的同时成熟:

来源:Slides 第 19 页。
| 驱动力 | 具体表现 |
|---|---|
| Big Data | 大规模数据集(如 ImageNet、Wikipedia)的出现,数据收集与存储成本大幅下降 |
| Hardware | GPU 的大规模并行计算能力使得训练深度网络成为可能 |
| Software | 开源框架(TensorFlow、PyTorch、Keras)使得构建和训练深度学习模型变得简便 |
历史视角:这些技术并不新
Amini 特别强调,本讲中介绍的几乎所有技术——感知机、反向传播、梯度下降——都是数十年前发明的。真正新的是它们在大数据、强算力和好工具三者交汇下所展现出的惊人能力。理解这些基础对于推动领域进一步发展至关重要。
本章小结
深度学习相比传统机器学习的核心优势在于自动学习特征表示,无需人工特征工程。尽管基础理论已有数十年历史,但大数据、GPU 硬件和开源软件的三重驱动力使得深度学习在近年来迎来爆发式发展。
感知机:深度学习的基本构建块
感知机的前向传播
感知机(Perceptron)是所有神经网络的基本结构单元,也被称为一个"神经元"(neuron)。其前向传播过程包含三个步骤:
- 加权求和:将每个输入 \(x_i\) 乘以对应权重 \(w_i\),然后求和
- 加偏置:加上偏置项 \(w_0\)(bias)
- 非线性激活:通过非线性激活函数 \(g(\cdot)\) 得到输出
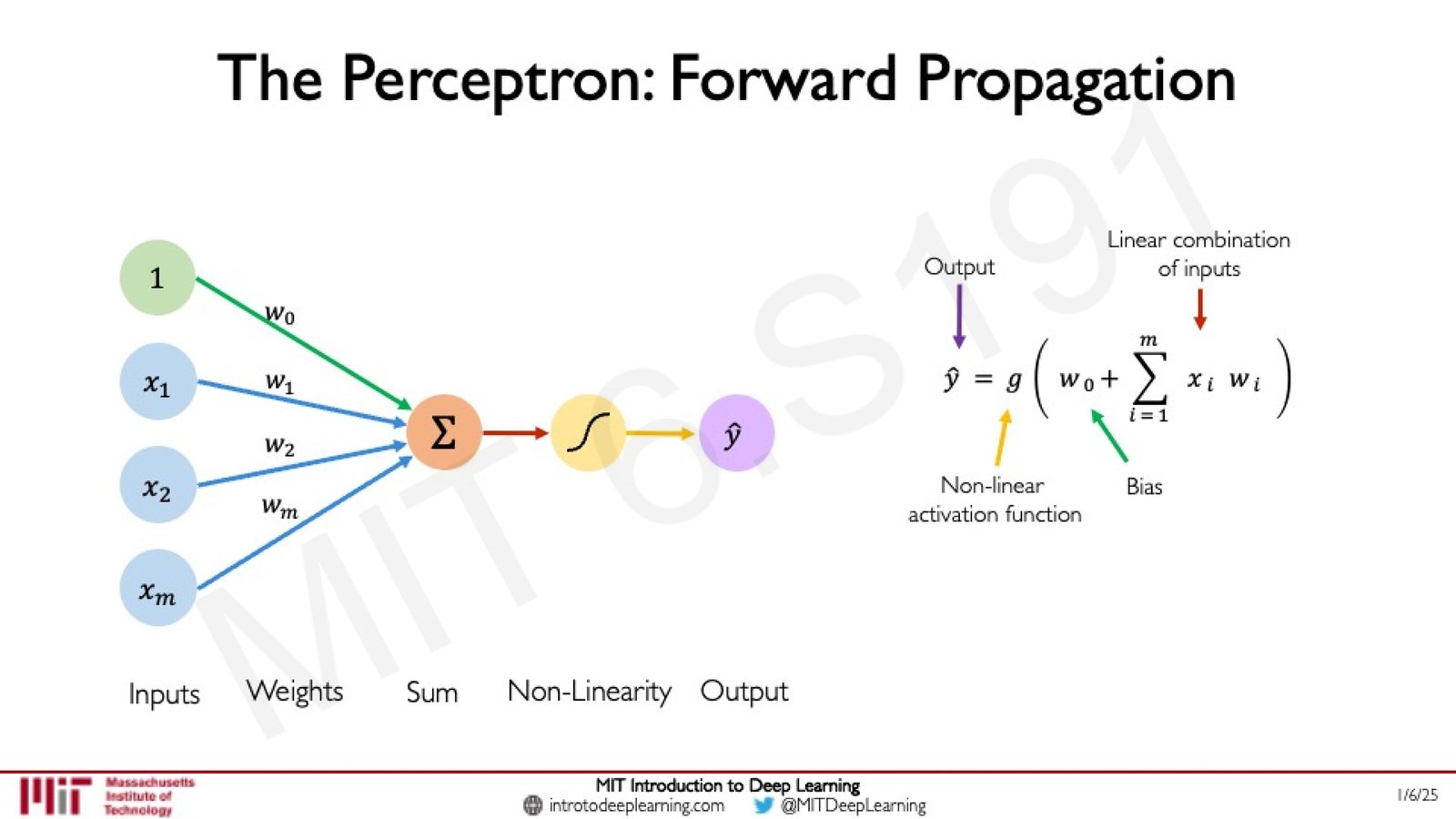
来源:Slides 第 22 页。
其数学表达式为:
其中:
- \(\mathbf{X} = [x_1, x_2, \ldots, x_m]^T\):输入向量
- \(\mathbf{W} = [w_1, w_2, \ldots, w_m]^T\):权重向量
- \(w_0\):偏置项(bias),允许激活函数沿 \(z\) 轴平移
- \(g(\cdot)\):非线性激活函数
- \(\hat{y}\):预测输出
偏置项的作用
偏置项 \(w_0\) 是感知机中不可或缺的参数。它允许激活函数独立于输入值进行平移,使得即使所有输入为零,神经元也能产生非零输出。没有偏置的感知机只能学习通过原点的决策边界。
激活函数
激活函数 \(g(\cdot)\) 的核心作用是为网络引入非线性。常见的激活函数包括:

来源:Slides 第 25 页。
| 激活函数 | 公式 | 输出范围 | 特点 |
|---|---|---|---|
| Sigmoid | \(σ(z) = 1/1+e^-z\) | \((0, 1)\) | 适合概率输出 |
| Tanh | \(g(z) = e^z - e^-z/e^z + e^-z\) | \((-1, 1)\) | 零中心化 |
| ReLU | \(g(z) = (0, z)\) | \([0, +∞)\) | 计算高效,最常用 |
为什么必须使用非线性激活函数?
如果不使用非线性激活函数(即使用线性激活 \(g(z)=z\)),那么无论网络有多少层,整个网络的输出仍然只是输入的线性组合。这意味着多层网络退化为单层线性模型,无法学习任何非线性模式。只有引入非线性,网络才能逼近任意复杂的函数。

来源:Slides 第 28 页。左:线性激活只能产生线性决策边界;右:非线性激活可以逼近任意复杂的函数。
感知机的几何直觉
Amini 通过一个具体的二维示例来建立直觉。考虑一个具有两个输入 \((x_1, x_2)\) 的感知机,参数为 \(w_0=1\),\(\mathbf{W}=[3, -2]^T\):
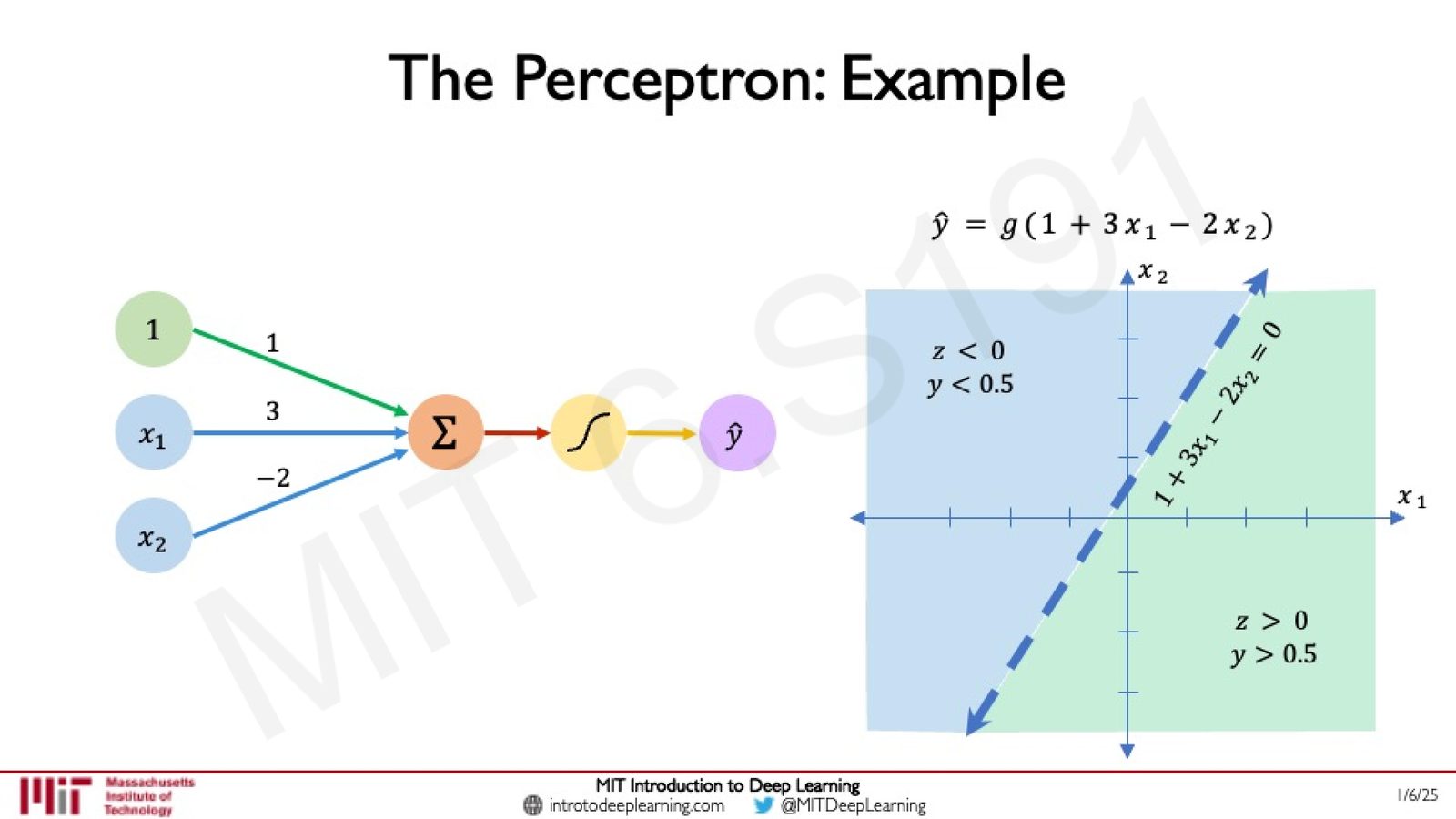
来源:Slides 第 32 页。
括号内的线性部分 \(z = 1 + 3x_1 - 2x_2\) 定义了二维空间中的一条直线。这条线就是决策边界:
- 当 \(z > 0\) 时,经过 Sigmoid 激活后 \(\hat{y} > 0.5\),预测为正类
- 当 \(z < 0\) 时,\(\hat{y} < 0.5\),预测为负类
- 当 \(z = 0\) 时,\(\hat{y} = 0.5\),恰好在决策边界上
以输入 \(\mathbf{X}=[-1, 2]^T\) 为例:\(\hat{y} = g(1 + 3\times(-1) - 2\times 2) = g(-6) \approx 0.002\),远小于 0.5,因此该点被分类为负类。
单个感知机的局限
单个感知机只能学习线性决策边界(在二维空间中是一条直线,在高维空间中是一个超平面)。这意味着它无法解决 XOR 等非线性可分问题。要处理更复杂的模式,需要将多个感知机组合成多层网络。
本章小结
感知机是神经网络的最小单元,其前向传播包括加权求和、加偏置、通过激活函数三步。偏置项允许决策边界不必通过原点,非线性激活函数使网络能学习复杂模式。单个感知机只能表示线性分类器。
用感知机构建神经网络
多输出感知机与 Dense 层
单个感知机只有一个输出。通过将多个感知机并列排放,让所有输入同时连接到每个感知机,就构成了Dense 层(全连接层)。
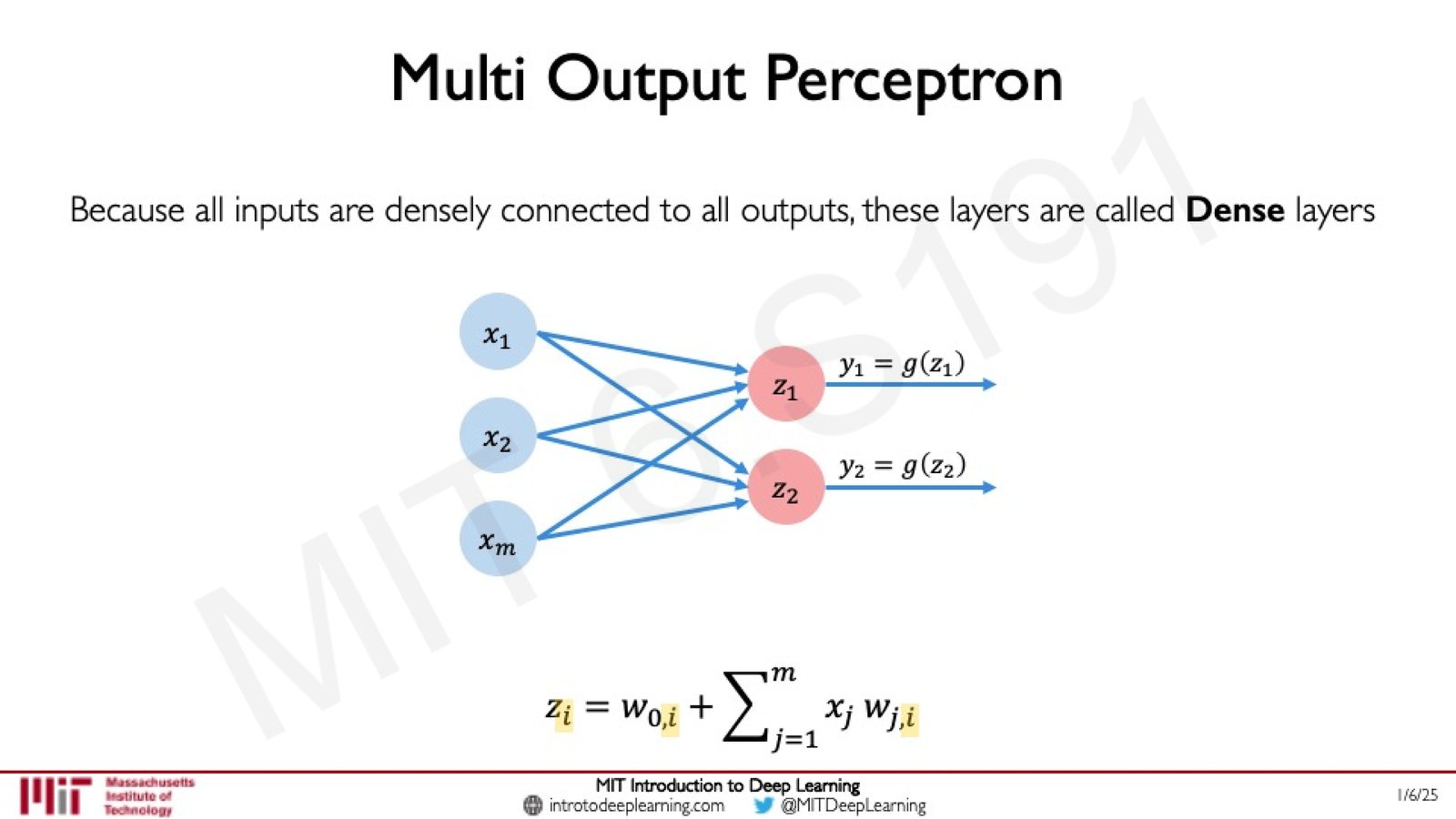
来源:Slides 第 36 页。
对于第 \(i\) 个输出神经元:
因为所有输入都与所有输出相连,这种层被称为 Dense(密集连接)层或全连接层(Fully Connected Layer)。
在代码中实现 Dense 层非常简洁:
# TensorFlow
import tensorflow as tf
layer = tf.keras.layers.Dense(units=2)
# PyTorch
import torch.nn as nn
layer = nn.Linear(in_features=m, out_features=2)

来源:Slides 第 37 页。
单隐藏层神经网络
在输入层和输出层之间加入一个 Dense 层作为隐藏层(Hidden Layer),就构成了一个单隐藏层神经网络:
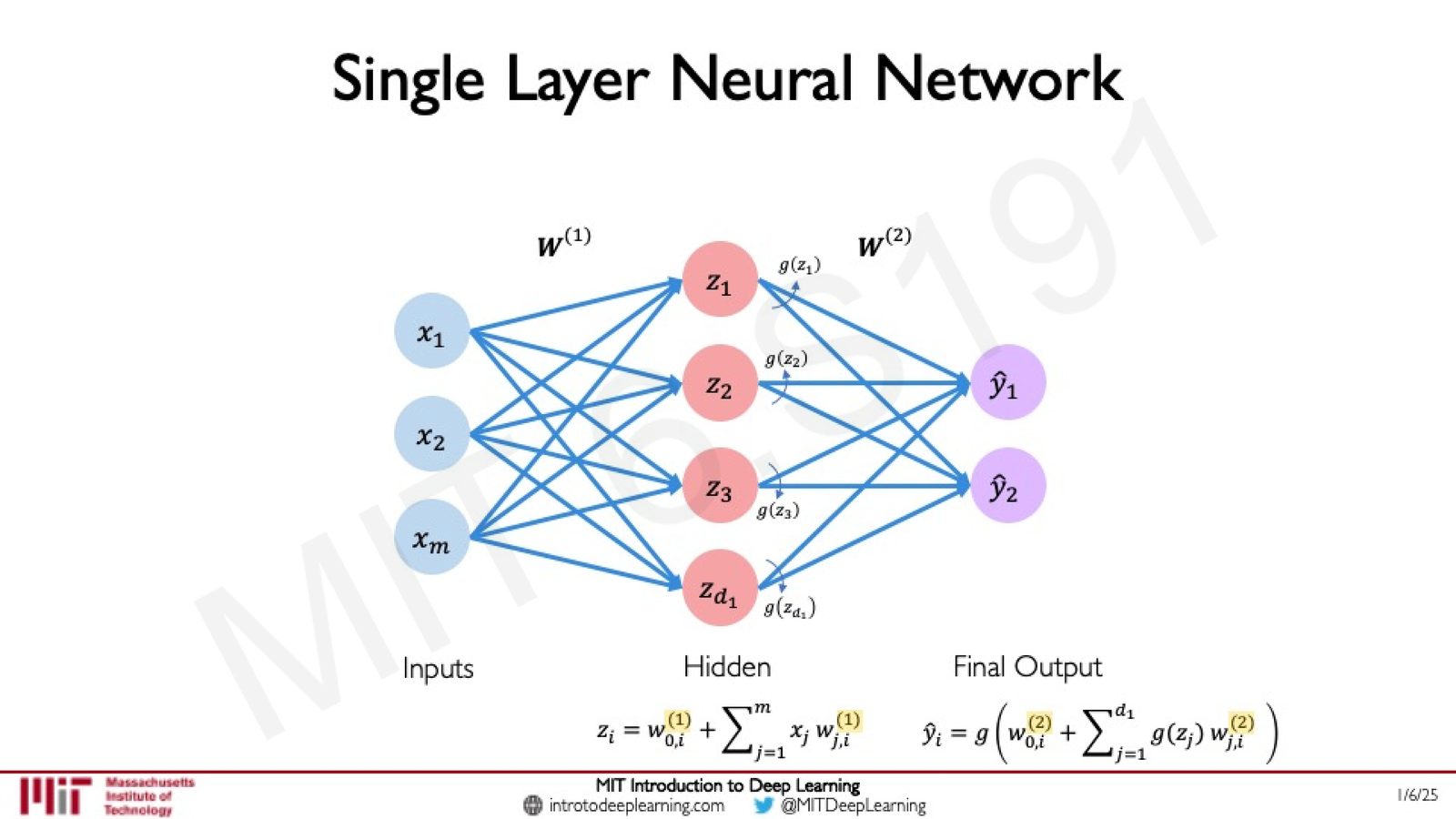
来源:Slides 第 39 页。
隐藏层的计算:
输出层的计算(以隐藏层的激活值为输入):
其中上标 \((1)\) 和 \((2)\) 分别表示第一层和第二层的参数,\(d_1\) 是隐藏层的神经元数量。
隐藏层的含义
隐藏层之所以称为"隐藏",是因为我们在训练数据中只能直接观察到输入和输出,而隐藏层的表示是由网络自动学习得到的,对于外部观察者来说是"不可见"的。隐藏层的每个神经元都学习了输入的某种非线性变换,这些变换共同为最终预测提供了丰富的特征表示。
深度神经网络
通过堆叠更多的隐藏层,就构成了深度神经网络(Deep Neural Network)。"深度学习"中的"深度"正来源于此。
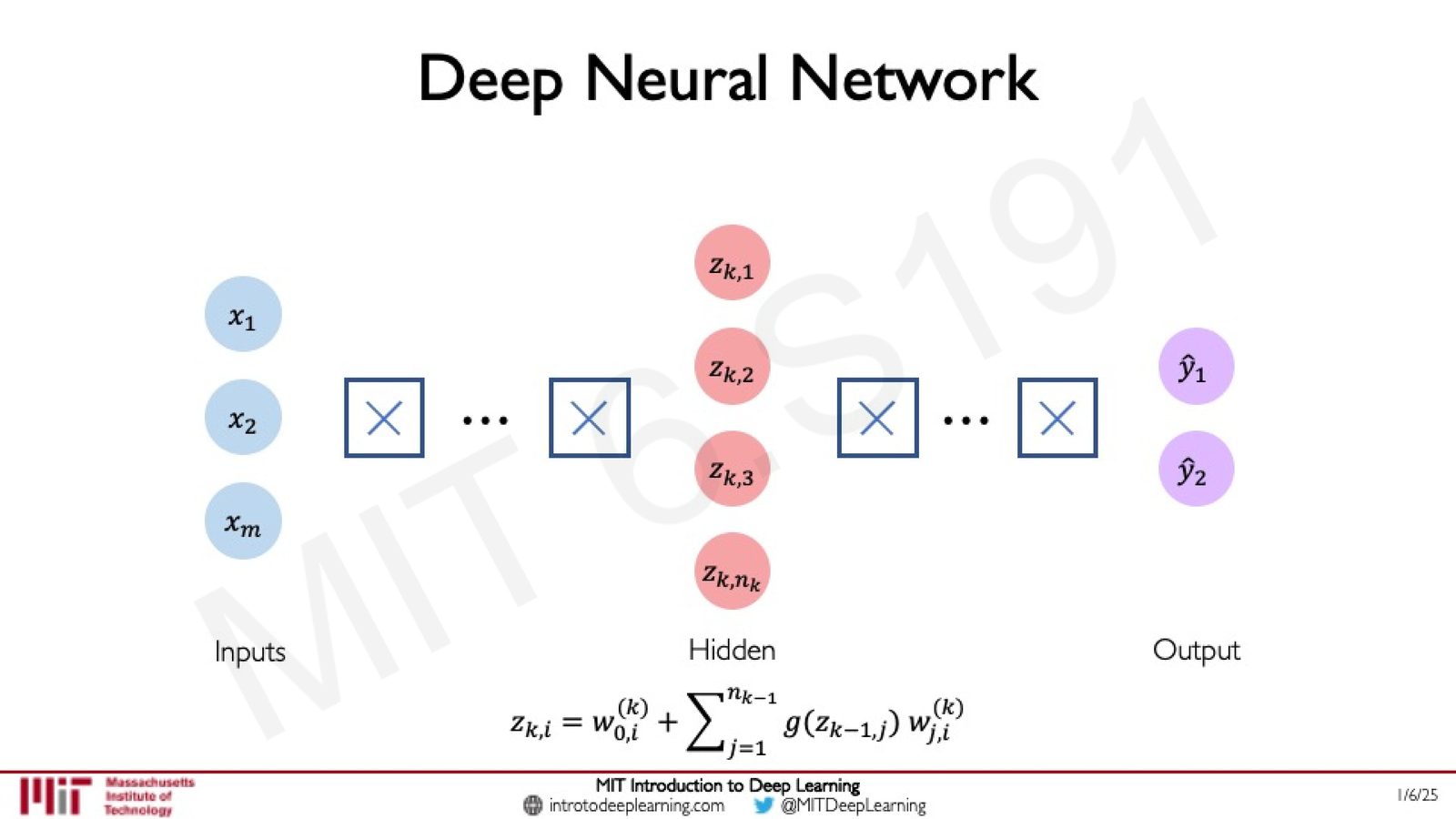
来源:Slides 第 42 页。
第 \(k\) 层第 \(i\) 个神经元的计算公式为:
其中 \(n_{k-1}\) 是第 \(k-1\) 层的神经元数量。
在代码中构建深度网络同样直观:
# TensorFlow
model = tf.keras.Sequential([
tf.keras.layers.Dense(n1),
tf.keras.layers.Dense(n2),
# ...
tf.keras.layers.Dense(2)
])
# PyTorch
model = nn.Sequential(
nn.Linear(m, n1), nn.ReLU(),
nn.Linear(n1, n2), nn.ReLU(),
# ...
nn.Linear(nK, 2)
)
本章小结
从单个感知机出发,通过并列多个感知机构成 Dense 层,再通过堆叠多个 Dense 层构成深度神经网络。每一层的输出作为下一层的输入,逐层提取越来越抽象的特征。深度神经网络的"深度"来源于其多层级结构。
应用神经网络:量化损失
示例问题:能否通过考试?
Amini 用一个直觉性的例子来说明神经网络的应用流程。问题是:根据学生的出勤次数 \(x_1\) 和在期末项目上花费的小时数 \(x_2\),预测学生是否能通过 6.S191 课程。
![示例问题:给定新数据点 \([4,5]\),预测是否通过?](slides-images/slide-047.jpg)
来源:Slides 第 47 页。
将数据点 \(x^{(1)} = [4, 5]\) 送入一个具有单隐藏层的网络,假设网络(使用随机初始化的权重)输出 \(\hat{y}_1 = 0.1\)。但该学生实际通过了课程(真实标签 \(y^{(1)} = 1\))。这说明当前的网络权重还不够好——我们需要一种方法来量化预测与真实值之间的差距。
损失函数
损失函数(Loss Function)衡量的是网络预测值与真实值之间的差距。
对于单个数据点的损失:
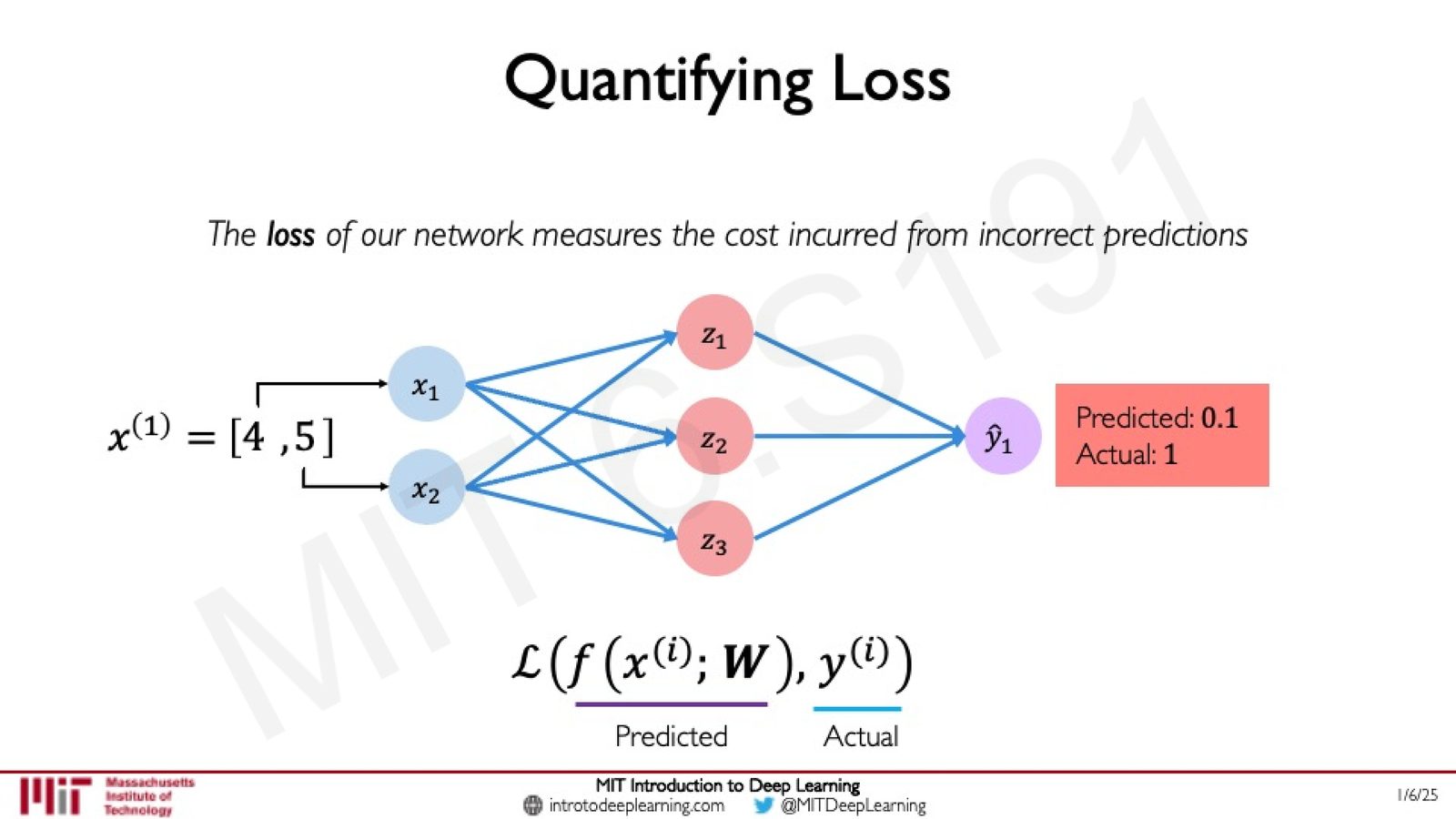
来源:Slides 第 50 页。
整个数据集上的经验损失(Empirical Loss)是所有样本损失的平均:
经验损失也被称为目标函数(Objective Function)、代价函数(Cost Function)或经验风险(Empirical Risk)。
两种核心损失函数
1. 交叉熵损失(Binary Cross Entropy Loss)——用于分类问题(输出为概率):
2. 均方误差损失(Mean Squared Error Loss)——用于回归问题(输出为连续值):
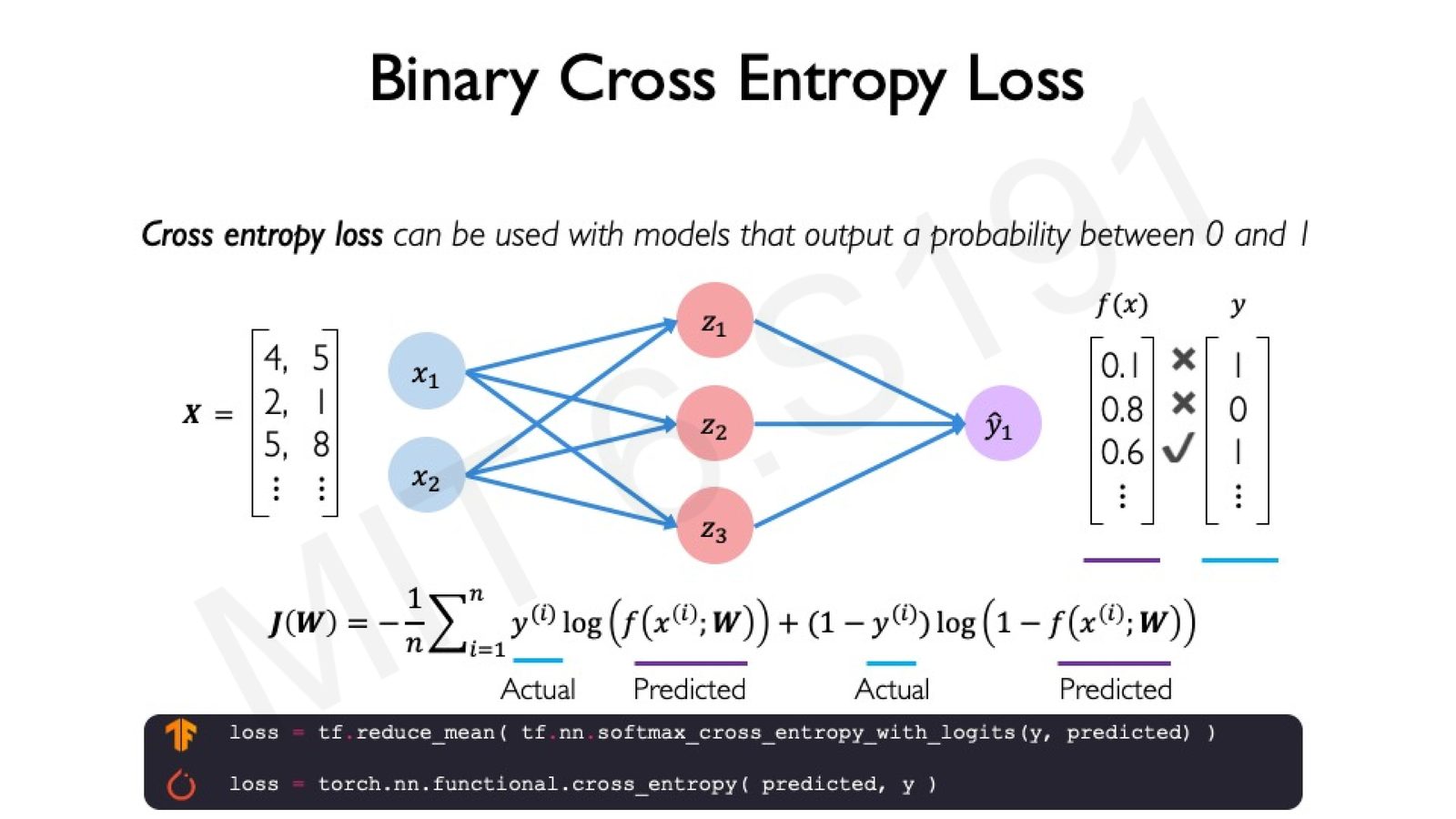
来源:Slides 第 52–53 页。
选择正确的损失函数
损失函数的选择必须与任务类型匹配:
- 分类任务(Pass/Fail、猫/狗)使用交叉熵损失
- 回归任务(预测成绩分数、预测房价)使用均方误差
错误的损失函数会导致模型无法正确学习。例如,将 MSE 用于分类任务会因为损失函数对概率边界不敏感而导致训练缓慢。
本章小结
损失函数是训练神经网络的核心组件,它量化了模型预测与真实标签之间的差距。经验损失是所有训练样本上损失的平均值。分类任务通常使用交叉熵损失,回归任务使用均方误差。训练的目标就是找到使经验损失最小的权重参数。
训练神经网络
损失优化的目标
训练神经网络的目标是找到使经验损失 \(J(\mathbf{W})\) 最小化的权重 \(\mathbf{W}^*\):
需要注意的是,\(\mathbf{W}\) 包含网络中所有层的所有权重和偏置:\(\mathbf{W} = \{\mathbf{W}^{(0)}, \mathbf{W}^{(1)}, \ldots\}\)。
来源:Slides 第 57 页。
梯度下降
梯度下降(Gradient Descent)是优化损失函数的核心算法。其基本思想简洁而优雅:
梯度下降算法
- 随机初始化权重 \(\mathbf{W}\)
- 计算梯度:\(\frac{\partial J(\mathbf{W})}{\partial \mathbf{W}}\),梯度指向损失增大最快的方向
- 更新权重:沿梯度的反方向迈出一小步
$$ \mathbf{W} \leftarrow \mathbf{W} - \eta \frac{\partial J(\mathbf{W})}{\partial \mathbf{W}} $$ 4. 重复步骤 2--3 直到收敛
其中 \(\eta\) 是学习率(learning rate),控制每步更新的幅度。
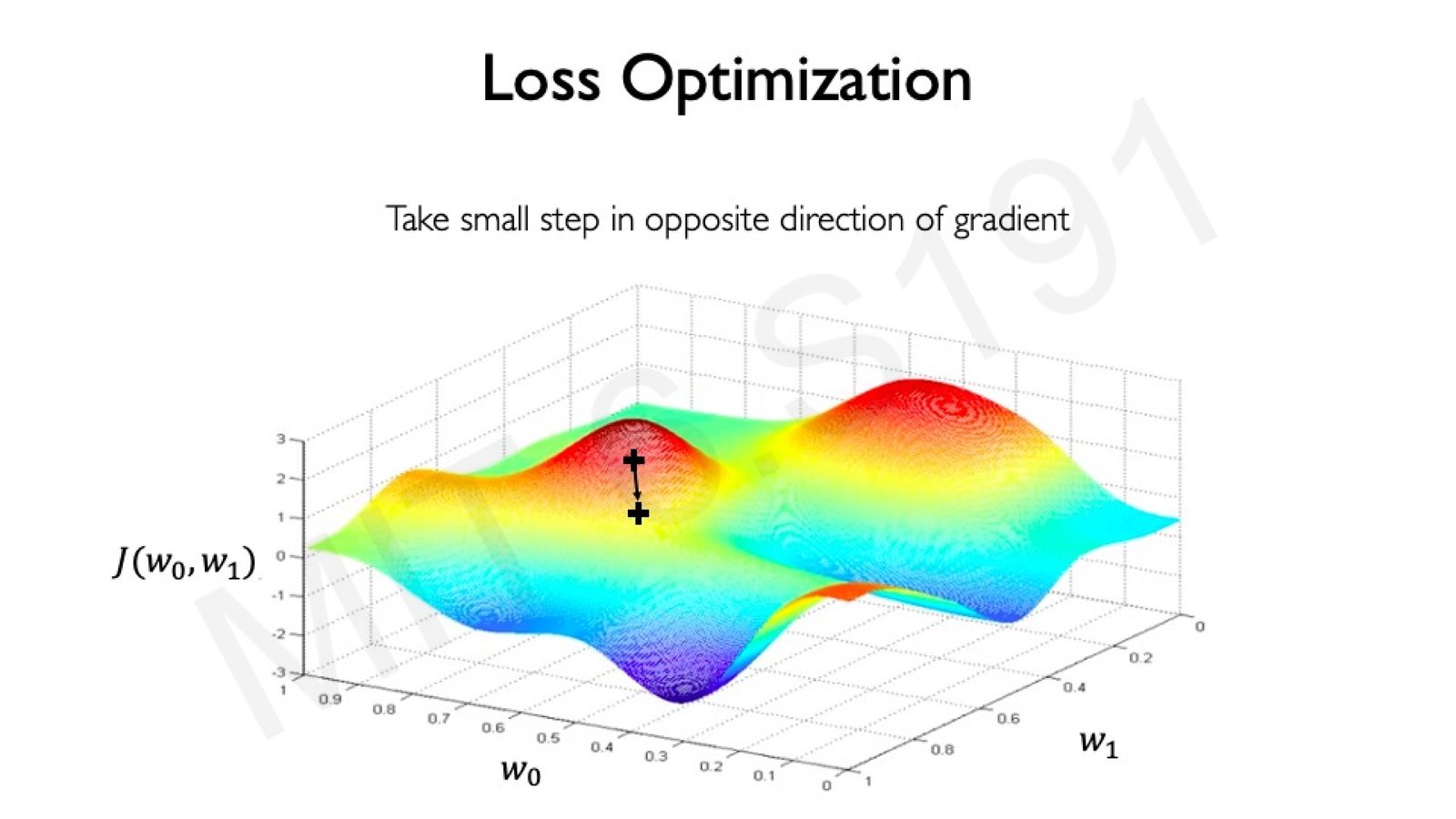
来源:Slides 第 60 页。
梯度的直觉解释:想象你站在一个丘陵地带,蒙着眼睛,想要走到最低点。你能做的就是感受脚下地面的坡度(梯度),然后向最陡下降的方向迈一步。重复这个过程,最终你会到达某个低洼处。
反向传播
那么,如何高效地计算梯度 \(\frac{\partial J}{\partial \mathbf{W}}\) 呢?答案是反向传播(Backpropagation)。
反向传播利用链式法则(Chain Rule),从输出层开始,逐层向回传播梯度。对于网络中的每个权重 \(w\),我们可以通过链式法则将最终损失对该权重的梯度分解为若干中间梯度的乘积。
以一个简单的两层网络为例,损失 \(J\) 对第一层权重 \(w_1\) 的梯度可以表示为:
反向传播的核心
反向传播的本质就是链式法则的递归应用。从输出端开始计算局部梯度,然后逐层向后传播,将所有局部梯度相乘得到最终梯度。这使得在含有数百万参数的深度网络中高效计算梯度成为可能。
现代深度学习框架(TensorFlow、PyTorch)通过自动微分(Automatic Differentiation)自动完成反向传播的梯度计算,开发者无需手动推导。
# TensorFlow: GradientTape
import tensorflow as tf
with tf.GradientTape() as tape:
loss = compute_loss(model, x, y)
grads = tape.gradient(loss, model.trainable_variables)
# PyTorch: autograd
import torch
loss = compute_loss(model, x, y)
loss.backward()
# Gradients stored in param.grad
学习率的重要性
学习率 \(\eta\) 是训练神经网络中最关键的超参数之一。它的设置直接影响训练的成败:
| 学习率 | 效果 |
|---|---|
| 太小 | 收敛极其缓慢,可能陷入局部最小值 |
| 太大 | 训练不稳定,损失值在最小值附近反复震荡甚至发散 |
| 适中 | 稳定收敛到良好的最小值 |
学习率调节常见陷阱
- 学习率过大不仅会导致震荡,还可能使损失值越来越大(发散),因为每步更新都跨越了最小值
- 学习率过小虽然安全,但可能需要极长的训练时间,且容易被困在浅层的局部最小值中
- 实践中常用自适应学习率方法(如 Adam、RMSProp),它们会根据梯度的历史信息自动调整每个参数的学习率
自适应学习率算法
实际训练中很少使用固定学习率。常用的自适应优化器包括:
- SGD with Momentum:利用梯度的指数移动平均来加速收敛
- Adam(Adaptive Moment Estimation):结合一阶矩和二阶矩估计,为每个参数独立调整学习率
- RMSProp:通过梯度平方的移动平均来归一化学习率
这些算法的核心思想是:不再对所有参数使用同一个固定学习率,而是根据每个参数梯度的历史动态调整。
Mini-batch 梯度下降
标准梯度下降需要在整个数据集上计算损失和梯度后才能进行一次权重更新,这在大规模数据集上计算量巨大。
随机梯度下降(Stochastic Gradient Descent, SGD)是另一个极端:每次只用一个样本来计算梯度和更新权重,虽然快但噪声很大。
实践中的折衷方案是 Mini-batch 梯度下降:每次从数据集中随机抽取一个小批量(batch)的样本来计算梯度:
其中 \(B\) 是 batch size。
| 方法 | 优点 | 缺点 |
|---|---|---|
| Full Batch GD | 梯度精确,收敛稳定 | 计算开销大,内存需求高 |
| SGD (\(B=1\)) | 极快的更新频率 | 梯度噪声大,收敛不稳定 |
| Mini-batch SGD | 兼顾速度与稳定性,可并行化 | 需要调节 batch size |
Mini-batch 的额外好处
Mini-batch 梯度下降不仅是计算效率的折衷,其引入的梯度噪声实际上还有助于模型跳出尖锐的局部最小值,倾向于收敛到更平坦的最小值区域,而平坦的最小值通常具有更好的泛化性能。此外,GPU 硬件天然适合对 batch 数据进行并行计算,使得 mini-batch SGD 的实际训练速度远超逐样本更新。
梯度下降的挑战:局部最小值与鞍点
在高维参数空间中,损失函数的 landscape 非常复杂。梯度下降面临几个关键挑战:
- 局部最小值(Local Minima):损失函数可能有许多局部最小值,梯度下降可能收敛到一个不是全局最优的位置
- 鞍点(Saddle Points):在高维空间中,鞍点比局部最小值更为常见。在鞍点处,梯度在某些方向为零,导致优化停滞
- 平坦区域(Plateaus):损失函数的梯度接近零的区域,导致更新极其缓慢
高维空间中的优化直觉
在低维空间(如二维)中,局部最小值看起来很常见。但在神经网络常见的数百万维参数空间中,要形成一个真正的局部最小值需要所有维度同时向上弯曲,这在统计上极不可能。实际上,高维优化中更常见的问题是鞍点——某些维度向上、某些维度向下。这也解释了为什么深度学习在实践中能够成功:虽然损失 landscape 看起来复杂,但大多数"坑"都有逃逸路径。
本章小结
训练神经网络的核心是通过梯度下降最小化损失函数。反向传播利用链式法则高效计算梯度。学习率是最关键的超参数,过大过小都会导致问题,自适应学习率算法(如 Adam)可以自动调节。Mini-batch SGD 在计算效率和梯度质量之间取得了良好平衡。高维空间中的优化虽然面临局部最小值和鞍点等挑战,但现代优化算法在实践中表现出色。
正则化与泛化
过拟合问题
在训练神经网络时,一个核心挑战是过拟合(Overfitting):模型在训练数据上表现很好,但在从未见过的测试数据上表现很差。这意味着模型"记住"了训练数据中的噪声和特殊模式,而没有学到真正可泛化的规律。
欠拟合、适度拟合与过拟合
- 欠拟合(Underfitting):模型太简单,无法捕捉数据中的基本模式,在训练集和测试集上都表现差
- 适度拟合(Good Fit):模型恰当地学习了数据中的核心模式,在训练集和测试集上都表现好
- 过拟合(Overfitting):模型太复杂,拟合了训练数据中的噪声,训练集表现好但测试集表现差
正则化技术
为了缓解过拟合,需要使用正则化(Regularization)技术。Amini 介绍了两种主要方法:
1. Dropout
Dropout 的核心思想极其简单:在训练过程中,以概率 \(p\) 随机"关闭"(设为零)一部分神经元。
- 每个 mini-batch 的前向传播中,随机选取约 \(p\%\) 的神经元使其输出为零
- 这迫使网络不依赖于任何单个神经元,而是学习更加分布式和鲁棒的特征表示
- 测试时不使用 Dropout,但需要按比例缩放输出
# TensorFlow
tf.keras.layers.Dropout(rate=0.5)
# PyTorch
nn.Dropout(p=0.5)
2. Early Stopping
Early Stopping 监控模型在验证集上的表现:当验证损失不再下降(甚至开始上升)时,停止训练。这利用了一个关键洞察:过拟合通常发生在训练后期,此时模型开始"记忆"训练数据而非学习泛化规律。
正则化不是可选的
在实际应用中,不使用正则化的深度神经网络几乎一定会过拟合,特别是当模型参数数量远大于训练样本数量时(这在现代深度学习中很常见)。Dropout 和 Early Stopping 应作为标准实践,而非可选的附加项。
本章小结
过拟合是深度学习训练中的核心挑战。Dropout 通过随机关闭神经元迫使网络学习鲁棒特征,Early Stopping 通过监控验证集损失在恰当时机停止训练。二者结合可以显著提升模型的泛化能力。
总结与延伸
本讲核心要点回顾
MIT 6.S191 第一讲从宏观到微观,系统地介绍了深度学习的基础框架:
- 深度学习的定位:AI \(\supset\) ML \(\supset\) DL,核心是从原始数据中自动学习特征表示
- 感知机:神经网络的基本单元,包含加权求和、偏置和非线性激活三个步骤
- 激活函数:Sigmoid、Tanh、ReLU 等非线性函数使网络能够逼近任意复杂函数
- 深度网络:通过堆叠多个 Dense 层构成,每层学习越来越抽象的特征
- 损失函数:交叉熵(分类)和 MSE(回归)分别衡量预测与真实值的差距
- 训练过程:梯度下降 + 反向传播 + 适当的学习率
- 正则化:Dropout 和 Early Stopping 防止过拟合
| 概念 | 数学表达 | 直觉解释 |
|---|---|---|
| 感知机 | $ = g(w_0 + X^TW)$ | 加权投票 + 非线性决策 |
| Dense 层 | \(z_i = w_0,i + _j x_j w_j,i\) | 多个并行的感知机 |
| 损失函数 | \(J(W) = 1/n_i L\) | 预测质量的量化度量 |
| 梯度下降 | \(W ≤ftarrow W - η J\) | 沿最陡方向下山 |
| 反向传播 | 链式法则递归应用 | 从输出向输入逐层传递误差 |
| Dropout | 随机置零概率 \(p\) | 强制冗余,防止依赖单一特征 |
从基础到前沿
Amini 在讲座中多次强调,本讲的内容(感知机、梯度下降、反向传播)都是数十年前的发明,但它们是理解现代深度学习的必要基础。课程后续将涵盖:
- 序列建模:RNN、LSTM 等处理时序数据的架构
- 计算机视觉:CNN 和现代视觉架构
- 生成模型:VAE、GAN、Diffusion Models
- 强化学习:让模型通过与环境交互来学习策略
- 大语言模型:Transformer 架构与现代 LLM
拓展阅读
- 课程官网:https://introtodeeplearning.com
- 实验代码仓库:https://github.com/MITDeepLearning/introtodeeplearning
- Ian Goodfellow, Yoshua Bengio, Aaron Courville, Deep Learning, MIT Press, 2016
- Michael Nielsen, Neural Networks and Deep Learning, 在线免费教材
- 3Blue1Brown, Neural Networks 系列视频(直觉可视化)