CS224R Lecture 16: Autonomy — Chelsea Finn
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Stanford CS224R 公开资料整理 |
| 来源 | Stanford CS224R: Reinforcement Learning |
| 日期 | 2025年3月18日 |

自主机器人学习的逻辑脉络
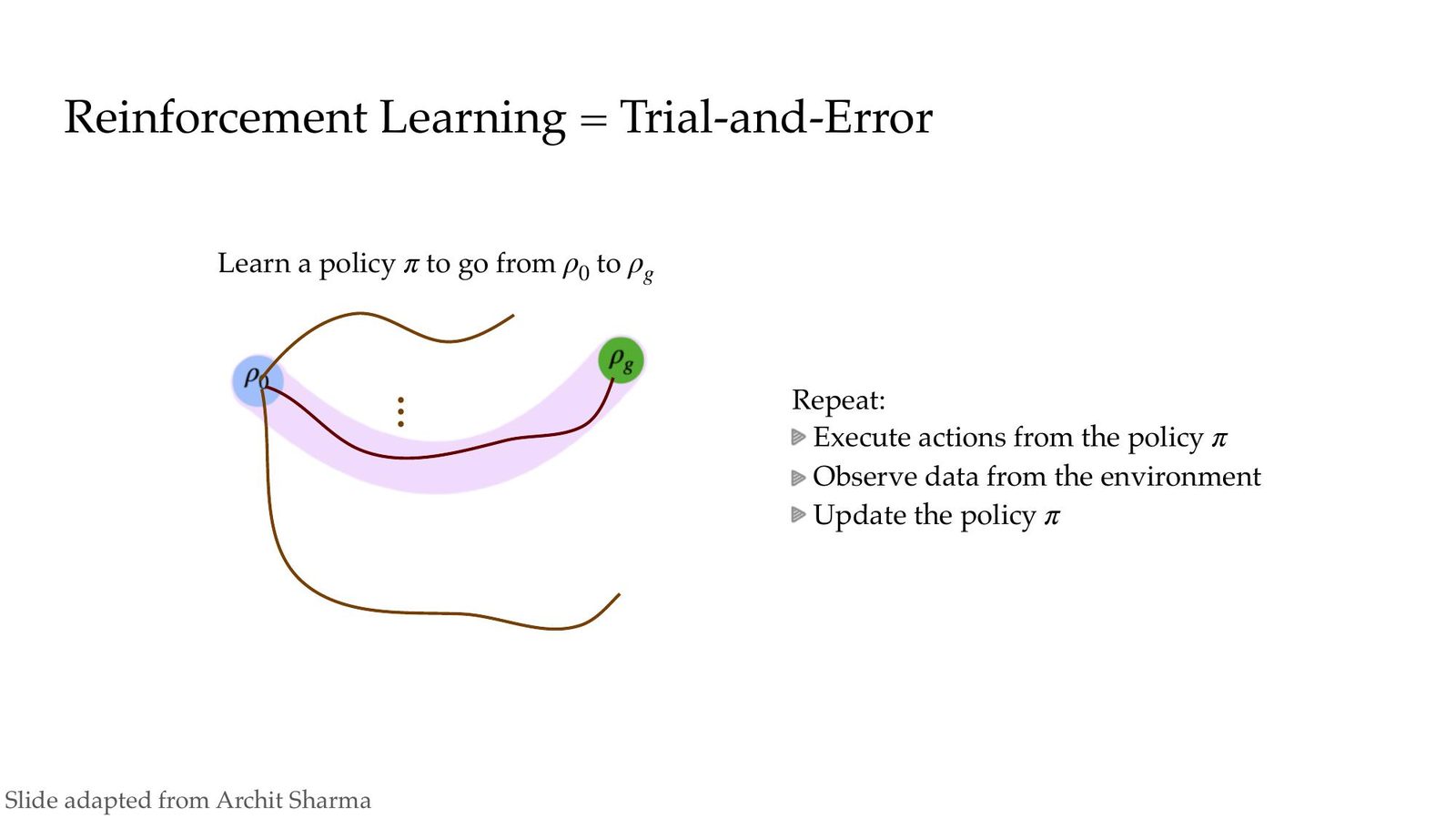
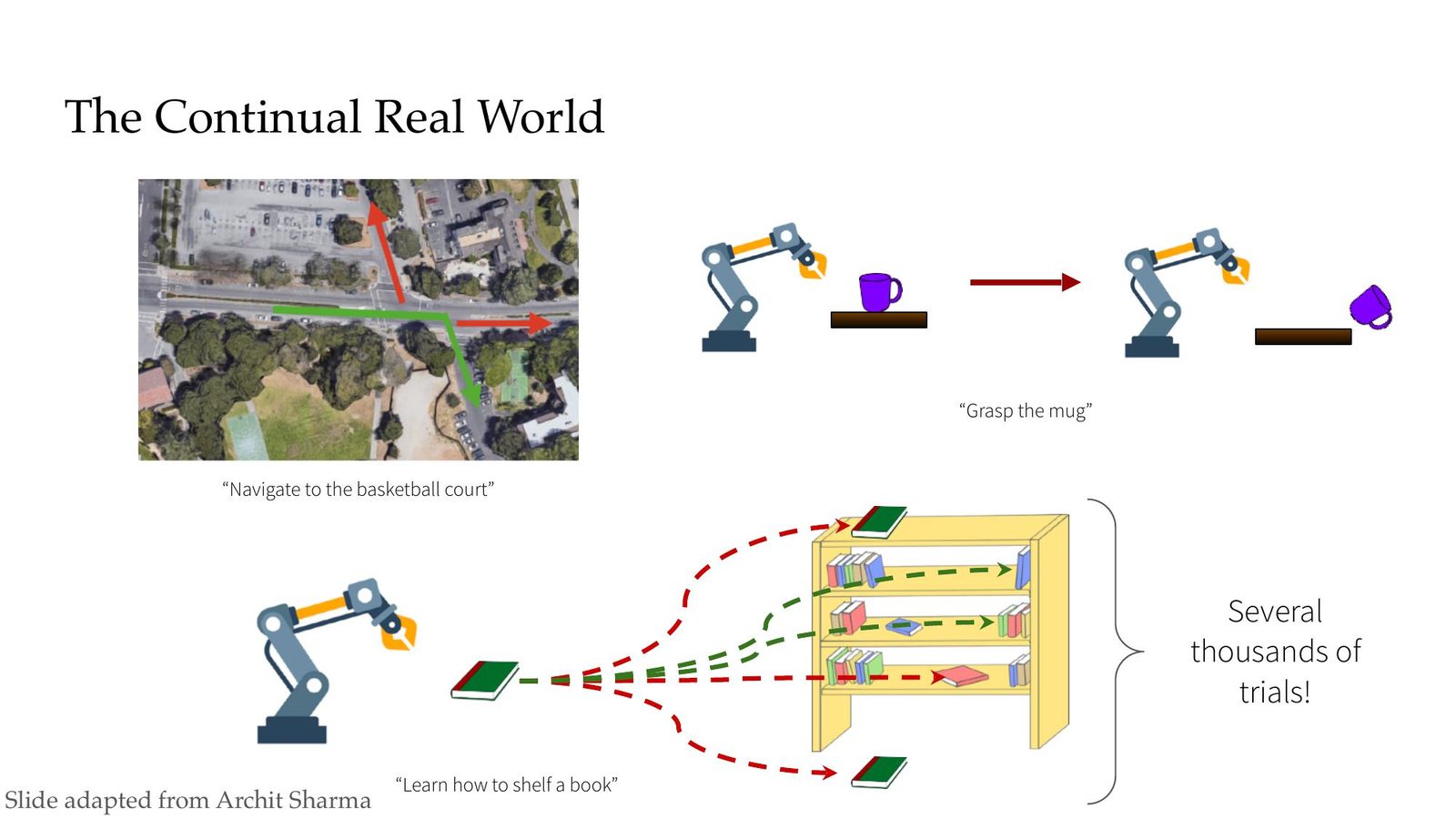
Human-in-the-loop 与 Autonomy 的落差
当前机器人学习体系依赖于人类的监督:奖励函数、环境重置、数据采集均靠工程师完成。《Autonomy》讲座提出挑战:让机器人在复杂物理世界中像婴儿一样主动探索,而不是等着人类定目标。

Autonomy 的三维目标
- 自动构造奖励或理解任务成果;\
- 在不重置的世界里持续操作;\
- 自主选择目标并安全探索。
面对现实的评估标准
讲者强调三个评价维度:可学习性(是否能获得足够 signal)、可扩张性(是否不依赖人工重置)、可持续性(是否能长期运行并在新的目标上迁移)。教学逻辑:先从 reward 说起,再从环境与目标的逻辑演化到安全与系统集成。
教学逻辑映射
Autonomy 研究线索依次是:自动奖励→Reset-free 控制→Goal Management→Safe Exploration→系统监控。每一段都以旧假设(reward, reset, goal)为起点,描述如何撤回它们。
本章小结
本章梳理了自主机器人学习的现状与教学逻辑,以“奖励-环境-目标-安全-系统”五阶段为后续章节的纲领框架。
自动奖励与理解信号
图像与语言的目标表示
自主奖励的核心要求是减少人工工程量。Chelsea 讲述了用目标图像或语言描述自动化奖励的管线:预训练模型提取视觉语义,比较当前状态与目标的 embedding 缩放,从而给出拖拽式奖励。

Embedding Distance Reward
- 使用 VAE/CLIP 等模型提取
f(I);\ - 奖励采用 \(r_t = -\|\phi(I_t) - \phi(I_g)\|_2\);\
- 可通过 scratch/finetune 弱化域差异,但核心是通过 representation 比较状态。
视觉-语言 reward 组合
Slide 03 展示了将自然语言描述与视觉 embedding 结合生成 reward 的流程:LLM 生成 task prompt,VLM 依据 prompt 评估 current frame,最后用 ensemble output 过滤。通过少量 human-in-the-loop 的特殊 cases,系统可以辨别不安全的 reward signal。

LLM + VLM Reward Pipeline
- LLM 接受 task prompt,生成 structured description;\
- VLM(如 CLIP/BLIP)对当前 frame 打分;\
- 通过 confidence filter(如 softmax temperature)控制 reward 强度。
Reward Pipeline 深度解析
在 slide 03 所示流程基础上,讲者细化了 reward pipeline 的三段:signal extraction(从 sensors 获取图像/语言)、affinity scoring(embedding similarity)、confidence gating(置信度过滤与 ensemble)。这三段必须在每次模型更新后同步改动,才能保证 reward not drift。
Pipeline 抽象框架
- Signal extraction:logging sensors + normalization;\
- Affinity scoring:embedding 距离或 classifier probability;\
- Confidence gating:用 threshold/ensemble/temporal smoothing filter 掉异常 reward。
基于成功分类器的自我监督
讲者借助 few-shot 标注让 robot 学会识别成功状态:收集少量 positive/negative 快照,训练二分类器 \(\sigma(s)\),然后该 classifier 输出是 reward 函数。该方式非常适合完成“目标数量未知”的任务。
Success Classifier Pipeline
- 收集 50-100 个自定义“成功”帧,生成负样本;\
- 训练轻量 CNN/RNN 输出概率;\
- 将概率直接用作 reward,或结合时间衰减防止过早收敛。
多模态 reward 过滤
Chelsea 进一步指出:CLIP/LLM 生成 reward 时,必须加入可信度过滤,避免模型对 irrelevant features(如背景)给予高分。常用做法是 ensemble 多个模态、加入 temporal consistency 正则化。
不要让 pretrained 模型 hallucination 结果传递给 policy
Clip-based reward 可能强化背景闪光点。建议:
- 使用 temporal smoothing 保证 reward 连续;\
- 对于多模态判断,采用 majority vote/variance penalty;\
- 保留 human-in-the-loop audit 通道,应急 override。
本章小结
自动奖励通过图像、语言、模型分类器等多种信号取代传统手工 reward,并强调需要对多模态输出进行置信度控制。
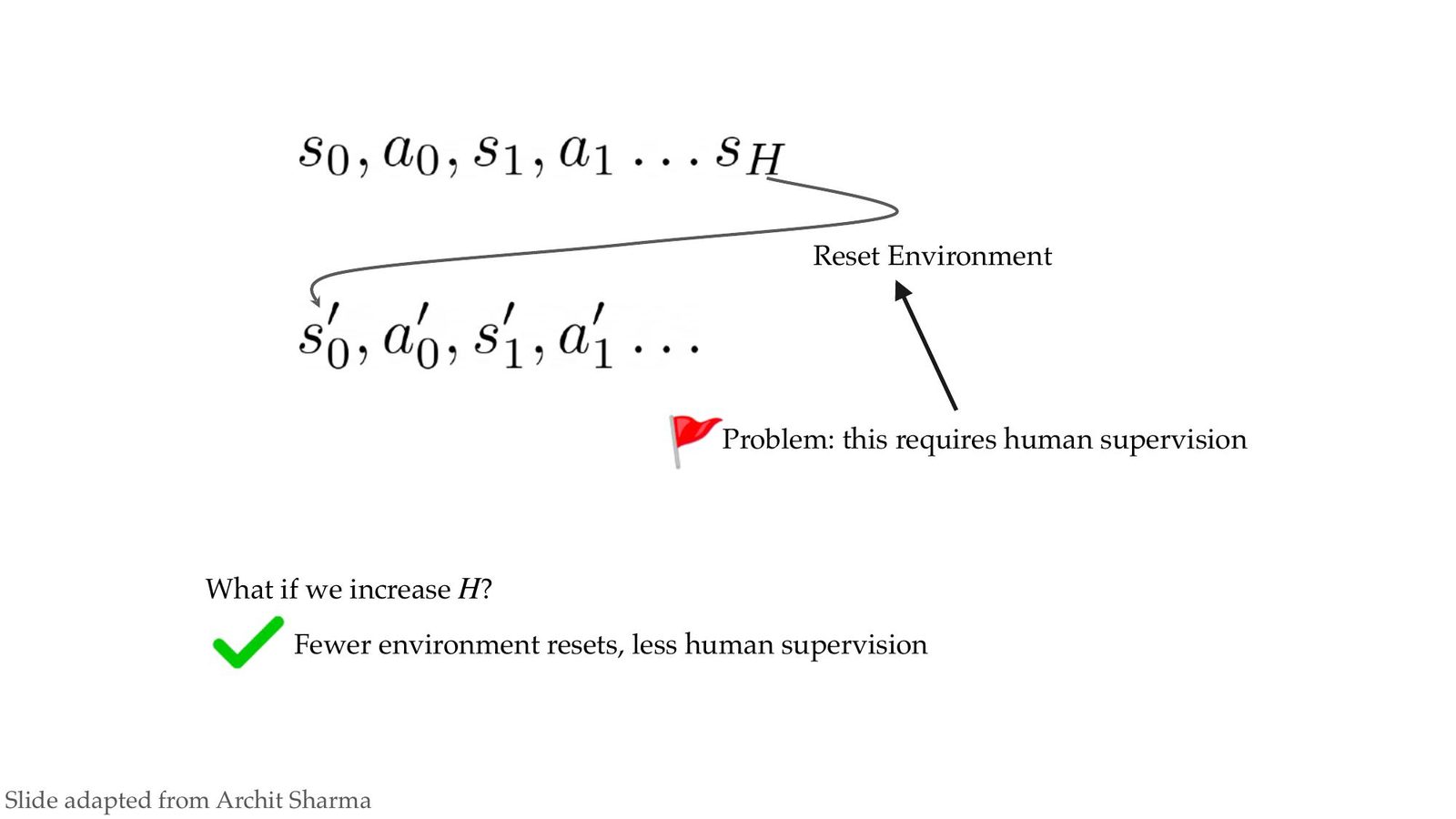
Reset-free 控制与记忆管理
重置假设的弱化
传统 RL 依赖人为或 simulator 重置。Chelsea 提出“让 policy 本身来 reset”——在每轮任务结束后启动另一个 policy,让环境回到新的初始集合,使 robot 能持续运行。

图中 timeline 表示一次任务执行后的回收过程:任务 policy(中间)完成 goal 后,将 current state 交给 reset policy。reset policy 运行后把 system 带回 base manifold,继续提供任务起点。
Forward-Backward Controller 机制
- \(\pi_f\): 从 initial state 探索 task-specific trajectory;\
- \(\pi_b\): 接受当前 state,尝试回到 initial manifold;\
- 轮流训练两者,\(\pi_b\) 的成功率定义新 episode 的起点。
持续 episodic buffer
Reset-free 要求 long-lived buffer 记住“最近 failed states”,以便策略不断学习重置。Chelsea 建议维护 prioritized replay buffer,同时引入time-aware sampling,优先回放发生在最近一次 reset 之后的数据。
Time-Aware Replay
- 将每个 transition 附加 timestamp;\
- 在训练中采用 \(w_t \propto \exp(-\lambda (t_{now}-t))\) 近似 latest priority;\
- 保证新数据被充分利用,同时保留少量 rare event。
经验撤销与环境多样性
讲者进一步指出:自主系统需具备撤销经验的能力,即模型在 fail 的轨迹上回退,并尝试新的策略组合。这涉及动态规划多个 reset-policy 以覆盖不同物理扰动。
Fail-fast but recover-fast
鼓励策略快速尝试多个动作组合,如果当前控制失败,马上启动 reset policy;同时记录失败模式供 future policy adaptation。
本章小结
Reset-free 框架用 forward-backward controllers、time-aware buffer 和 fast recovery 实现持续运行,避免依赖人工 reset。
自主目标设定与课程学习
目标库与分层 curriculum
Chelsea 使用“goal replay buffer”记录已达成或接近的目标,结合curriculum policy 选择难度适中的目标进行训练。每次 policy 达成目标后,把该目标与其能力指标一同写入“目标状态 tracker”。
| 阶段 | 核心措施 |
|---|---|
| 探索 | 采样训练目标时,偏向 novel/uncertain states; |
| 平衡 | 设定 success rate window(比如 50%-80%)保持学习区; |
| 进阶 | 每成功一个目标,使用 parameterized difficulty increment; |
Goal-Query 与代理思维
讲者提到“Goal-Query”模块——agent 在训练中不断提问“我应该完成哪个 skill 以便后续推广?”并基于 novelty score 选择目标。这个过程照顾 exploration (novel targets) 与 exploitation (熟悉目标) 的平衡。
Goal-Query 流程
- 通过 uncertainty estimate 计算每个 stored goal 的 novelty;\
- 如果 novelty 超过 threshold,调度 exploration goal;\
- 结合 skill graph 推测 goal 间依赖,决定是否先学习基础 goal。
Goal space engineering
Chelsea 强调:goal space 应支持动态缩放,对不同目标设定中心/半径/priority。例如,把 complex goal 拆成 primitives,训练时多次 sample Primitive-level goal,再用 scheduler 提升到 composite goal。
| 策略 | 作用 |
|---|---|
| Primitive sampling | 从基础动作组合生成 reward-distinct goals; |
| Composite scheduler | 当 primitive success rate 达标时,按比例加权 composite goal 选择概率; |
| Priority annealing | 根据 novelty/entropy 动态调整 goal priority; |
本章小结
自主目标设定把课程学习、Goal-Query 与 difficulty scheduler 结合,使机器人能在没有人类指定任务的情况下逐步积累技能。
安全探索与长期运行
约束优化与软边界

安全探索策略
- 将 safety constraint 转化为 penalty term \(c(s_t,a_t)\);\
- 用 Lagrangian multiplier \(\lambda\) 控制 penalty 强度;\
- 在 uncertainty 高时(如 new goal),降低 exploration rate,避免 high-risk 动作。
长时间 horizon 的监控
Chelsea 强调:Autonomy 不仅是一次训练,而是多次 deployment 的 property,因此需要系统级监控:
- 记录每个 goal 的 success/failure 轨迹;
- track \(\Delta reward\) 与 \(\Delta constraint\) 以判断 drifting;
- 对于重复失败,动态回退 reward 模型或缩小 goal space。
部署时留有回退通道
部署 pipeline 需保留“回滚 checkpoint”与“重新训练 reward 估计”的机制,以便在出现 hallucination reward、reset policy 失效等问题时快速救火。
本章小结
安全探索通过 penalty/constraint 架构保障行为,长期运行则靠监控统计与回退计划,并最终形成可靠的 Autonomy 系统。
实践建议与系统运维
Autonomy 监控仪表盘
讲者建议建立包含 reward accuracy、reset success、goal coverage 三个指标的仪表盘,用于日常 review。 | 维度 | 指标 | | --- | --- | | Reward fidelity | classifier precision/recall, clip similarity drift; | | Reset coverage | 近期 forward-backward > 80% 成功率; | | Goal expansion | 活跃 goal 数与每周新增 goal; |
跨阶段反馈循环
每运行一次 Autonomy experiment,记录:
- 当前 reward 模型与 safety penalty 版本;
- Reset policy 的 failure pattern;
- 新目标/技能的添加、旧目标的 retire 决策;
这些信息形成一个 cross-team log,便于 future replication。
Feedback Loop 模板
- Pre-scale:确认 reward/safety/checkpoint 状态;\
- Scale:运行 policy,同步 metrics;\
- Post-scale:复盘 metrics drift,如需 rollback 立即触发。
本章小结
实践层面,Autonomy 需要仪表盘、跨阶段反馈以及回退计划,确保研究结果可反复部署。
多尺度探索与跨任务泛化
多阶段探索策略
Slide 07 展示 multi-stage exploration framework:将 exploration policy 分成 coarse-grained 与 fine-grained 两层,分别控制不同尺度的目标与动作序列。这样的层次结构既能发现 macro-level goal cluster,又能自动收敛到 micro-level 执行步骤。
Multi-Stage Exploration
- Coarse policy 采样未见过的 goal cluster;\
- Fine policy 负责该 cluster 内的精细动作;\
- 定期更新 cluster centroids based on success rate 以维持 coverage。
跨任务泛化指标
Slide 08 提出 transfer matrix 检验 policy 在不同 goal 组合上的 capability,关键指标包括 success coverage、policy entropy 与 transfer ratio。讲者建议在实验报告中同时展示 base goals 与 transfer goals 的 performance,避免过拟合单一场景。
| 指标 | 说明 |
|---|---|
| Success coverage | 在 stored goals 中达到成功的比例,低于 70% 表明 coverage gap; |
| Policy entropy | 监控 policy 在不同 goals 上的多样性,过低说明 degenerate; |
| Transfer ratio | 一个 goal 的 reward 在另一 goal 上带来的 improvement,衡量泛化; |
本章小结
多尺度探索与泛化指标帮助团队识别在哪些 goal 上要打破窄瓶颈,并提供衡量 transfer 成效的工具。
系统集成与部署流程
Slide 09-10 Pipeline
Slide 09-10 归纳 Autonomy 系统:Reward module、Reset policy、Goal manager、Safety guard 分层工作,结果推送至 dashboard 供 operator 审查。
部署流水线关键节点
- Reward model update 触发 shadow policy test,并在 simulation 中做 sanity check;\
- Reset controller 每天运行 recovery routine,确保 forward-backward policy 仍然可靠;\
- Goal manager 基于 live metric 更新 goal library,淘汰 stale 或 unsafe goal;\
跨团队反馈与知识共享
讲者提醒:Autonomy 需要跨团队反馈循环,例如 operator 将 reset failure case 上传 shared log,policy 团队据此调整 goal selection 或 reward normalization。文档记录与 weekly review meeting 有助于维护知识。
本章小结
系统集成关注 pipeline 的组织化与跨团队沟通,确保 Autonomy 不仅在研究中有效,也能在部署时快速响应异常。
案例研究:Vision-guided Autonomy
现实场景中的任务拆解
Slide 09 展示了一个 vision-guided manipulation case,包含 grasp、transport、place 三个模块,每个模块又嵌套自主 reward、reset 与 goal manager。讲者强调:真实场景常常有 long-tailed failure mode,需要在 pipeline 中引入 anomaly detection。

Vision-guided Autonomy 切分
- Grasp module:使用 visual affordance 预测 grasp point;\
- Transport module:通过 goal-conditioned policy 将物体移动;\
- Place module:利用 success classifier 判断目标放置是否完成。
可观察性与异常响应
讲者建议在每个阶段记录 anomaly metric:vision 模型 confidence drop、reset policy failure rate、goal coverage drop。把这些度量填入 dashboard,可以 trigger automated rollback 或 reward recalibration。
异常响应矩阵
| 异常类型 | 响应 |
|---|---|
| Vision confidence drop | 进入 safe mode,降低 exploration rate; |
| Reset failure | 立即触发 manual inspection ,并回滚到最近 stable checkpoint; |
| Goal coverage shrink | 扩展 goal replay buffer,重新 thaw failed goal cluster; |
本章小结
通过 vision-guided manipulation 案例,展示 Autonomy pipeline 在线下与线上部署中的可观察性与异常响应策略。
总结与延伸
核心总结表
| 维度 | 核心洞察 | 实践启示 |
|---|---|---|
| 奖励信号 | 图像、语言、success classifier 取代人工 reward | 设计 reward pipeline 时加入置信度/ensemble 机制; |
| 环境运维 | Forward-backward controllers 与 time-aware buffer 实现 reset-free | 每个 reset policy 都需要 recovery 记录并与 scheduler 绑定; |
| 目标管理 | Goal-Query 与 curriculum policy 实现难度自适应 | 维护 goal repository,并记录 novelty/skill dependency; |
| 安全与运维 | safety penalty + regular monitoring 防止 drift | 搭建 dashboard,保留 rollback 通道; |
进一步阅读
- Sharma et al., “Autonomous Reinforcement Learning: Formalism and Benchmarking,” ICLR 2022
- Eysenbach et al., “Leave No Trace: Learning to Reset for Safe and Autonomous RL,” ICLR 2018
- Pong et al., “Skew-Fit: State-Covering Self-Supervised RL,” ICML 2020
- Nair et al., “Visual Reinforcement Learning with Imagined Goals,” NeurIPS 2018
- Ma et al., “VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training,” ICLR 2023
本章小结
通过奖赏、reset、goal、安全与监控五个维度的系统讲解,本讲展示了自主机器人学习的完整路径,并为部署级 Autonomy 提供了可执行的反馈/回退机制。