CS224N Lecture 14: Reasoning and Agents
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Shikhar Murty 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2024年 |

引言:语言模型能推理吗?
本节课分为两大主题:(1)语言模型的推理能力——能否用语言模型进行数学、逻辑、空间等领域的多步推理;(2)语言模型智能体(Agents)——能否让语言模型在真实环境中执行操作、完成任务。这两个主题紧密相关:智能体需要在环境中进行多步推理和规划才能完成复杂任务。

来源:Slides 第1页。
课程背景
本讲内容基于近3--4年的最新研究,许多问题尚无定论。讲者特别提醒:关于“语言模型是否真的在推理”这一核心问题,学术界仍存在大量争论,本讲将展示正反两方面的证据。在前几讲(Lecture 9--11)中,我们已经了解到 LLM 擅长生成符合人类偏好的文本延续,本讲的核心问题是:它们是否也能进行推理?
什么是推理
推理(Reasoning)的核心定义是:使用事实(facts)和逻辑(logic)来得出结论。

来源:Slides 第5页。Slide credit: Graham Neubig (11-711 ANLP)。
推理可以分为三种基本类型:
推理的三种类型
- 演绎推理(Deductive Reasoning):从逻辑规则和前提出发,推导出确定性结论。例如:所有哺乳动物有肾脏 \(+\) 所有鲸鱼是哺乳动物 \(\Rightarrow\) 所有鲸鱼有肾脏。
- 归纳推理(Inductive Reasoning):从观察到的实例中总结规律,得出可能性结论。例如:每次看到有翅膀的生物都是鸟 \(\Rightarrow\) 看到有翅膀的生物,推测它可能是鸟。
- 溯因推理(Abductive Reasoning):从观察到的现象出发,推测可能的解释。例如:车无法启动且引擎下有液体 \(\Rightarrow\) 可能是散热器漏液。
形式推理与非形式推理

来源:Slides 第8页。
- 形式推理(Formal Reasoning):遵循形式逻辑的公理和规则来推导真值条件。
- 非形式推理(Informal Reasoning):利用直觉、经验和常识来得出结论,这是我们日常生活中最常用的推理方式。
本讲中提到的“推理”主要指非形式的演绎推理,且通常涉及多个步骤。
本章小结
推理是利用事实和逻辑得出结论的过程,分为演绎、归纳和溯因三类。本讲聚焦于非形式多步推理,探讨语言模型能否通过提示或训练来展现推理能力,以及这种能力的本质和局限性。
基于提示的推理方法
Chain-of-Thought 提示
Chain-of-Thought(CoT)提示是激发语言模型推理能力的最基本方法。其核心思想是:让模型在给出最终答案之前,先产生中间推理步骤(rationale)。
CoT 提示有两种主要形式:
- Few-shot CoT:在提示中提供带有推理步骤的示例,模型在测试时模仿这些示例的推理模式。
- Zero-shot CoT:仅在提示末尾添加“Let's think step by step”,无需提供示例,模型即可产生推理过程。

来源:Slides 第11页。Source: Kojima et al. 2023。
CoT 的核心洞察
让模型“展示工作过程”(show its work)——即在输出答案前先生成推理步骤——可以显著提升模型在数学、逻辑等推理任务上的表现。这一发现表明,中间计算步骤对于复杂任务至关重要,即使这些步骤只是文本形式的。
Self-Consistency:多数投票
Self-Consistency(自一致性)是对 CoT 的直接改进。标准 CoT 使用贪婪解码生成一条推理路径和答案;Self-Consistency 则采样多条推理路径,选择出现频率最高的答案。
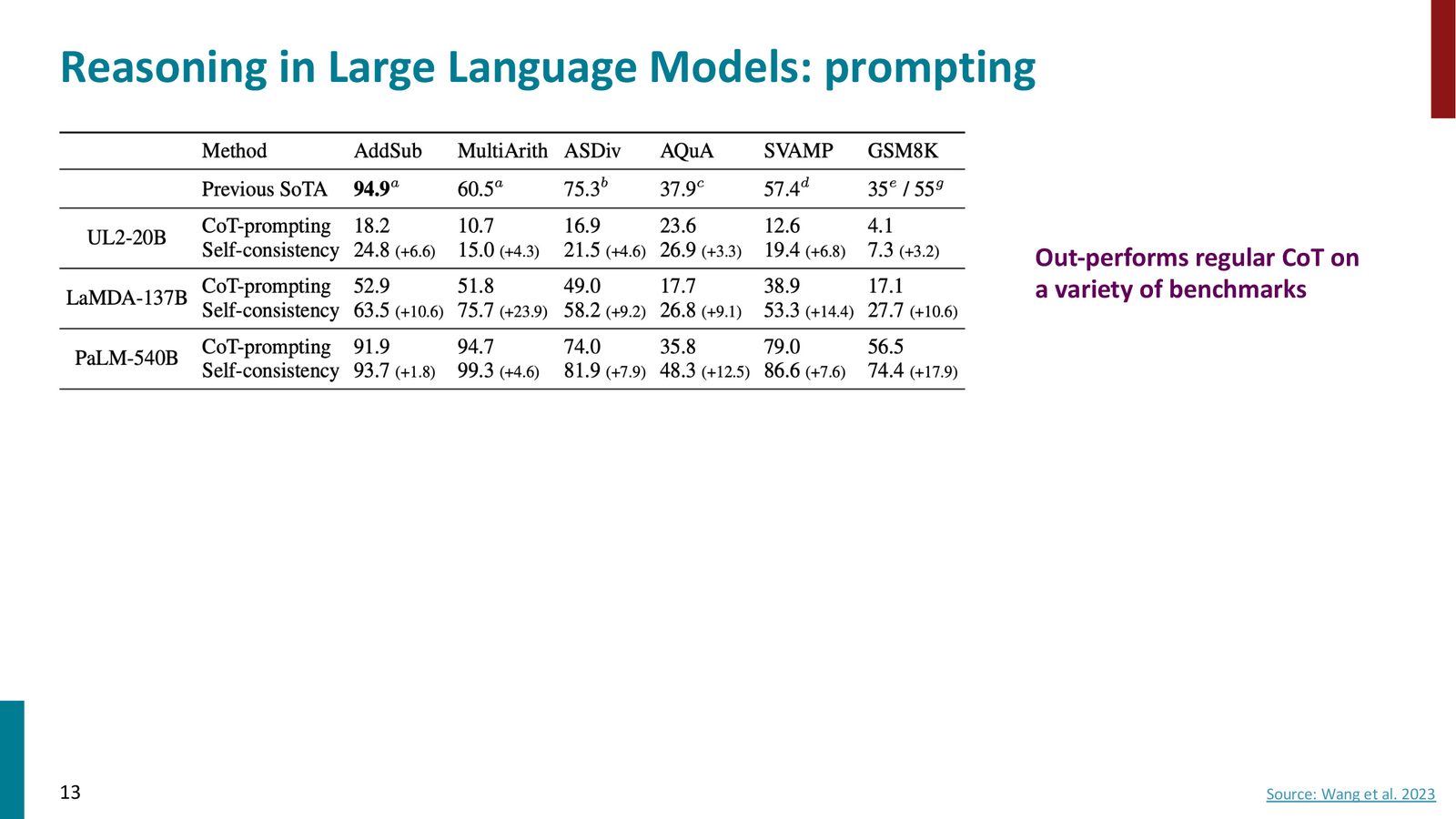
来源:Slides 第13页。Source: Wang et al. 2023。
Self-Consistency vs 集成学习
Self-Consistency 看似类似于传统的集成学习(Ensemble),但实验表明它的效果优于简单的 prompt 集成(同一模型用不同 prompt 后投票)。这可能是因为 Self-Consistency 通过采样不同的推理路径,探索了更多样化的解题思路,而非仅仅是对同一种推理的随机变体。
Least-to-Most Prompting:问题分解
Least-to-Most Prompting 引入了问题分解策略:将大问题拆分为子问题,依次求解,最后综合得出最终答案。
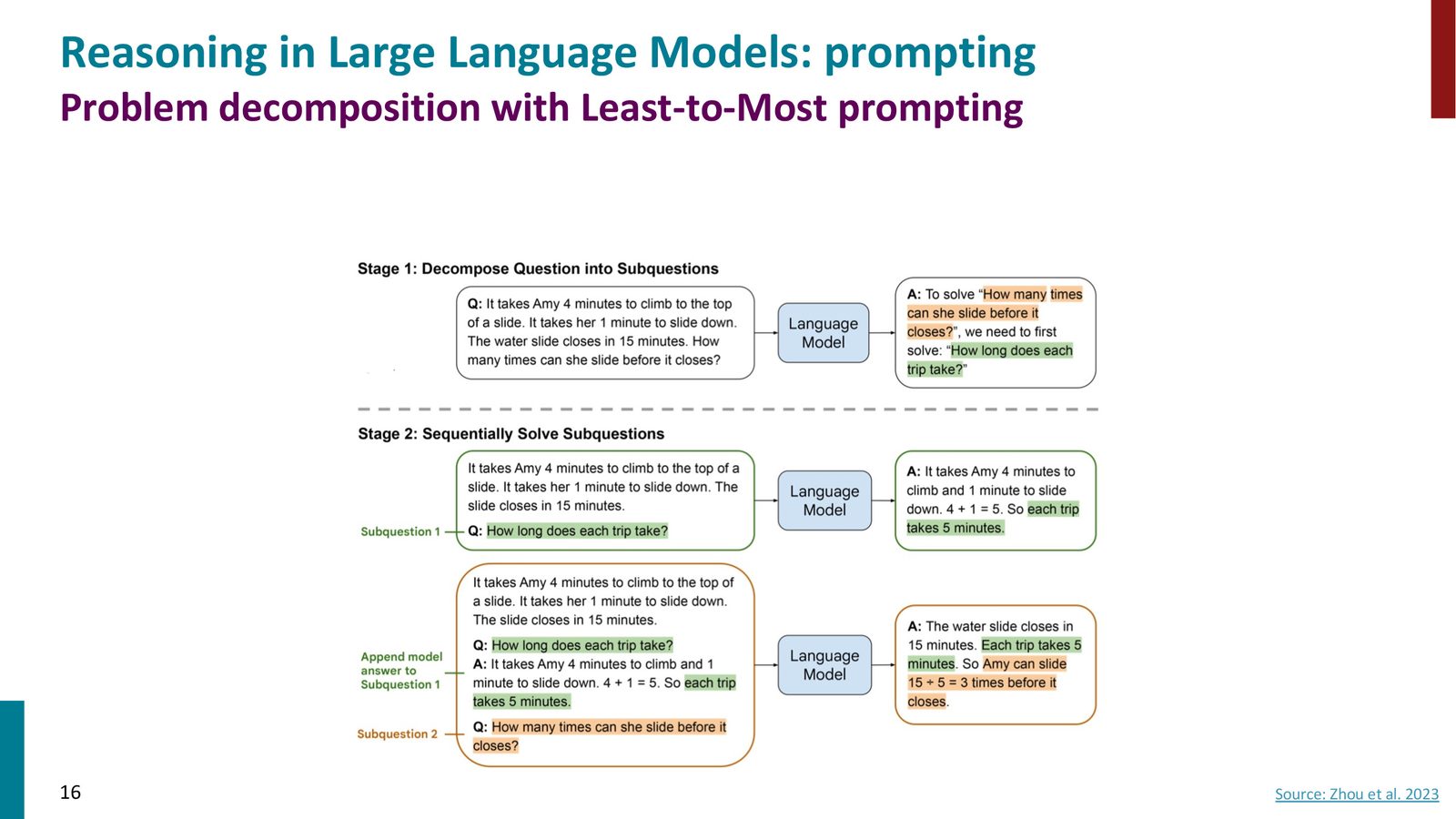
来源:Slides 第16页。Source: Zhou et al. 2023。
Least-to-Most Prompting 的一个有趣发现是:即使提示中仅包含需要2步推理的示例,模型也能泛化到需要5步以上推理的问题——这种泛化能力优于标准 CoT。但作者也指出,经过充分 prompt 工程的标准 CoT 可以达到类似的效果。
提示方法的局限性
所有基于提示的方法都依赖于大语言模型(通常是 GPT-4 级别),且效果高度依赖提示的设计。对于较小的模型,这些提示方法往往效果有限。这引出了下一个问题:能否通过训练让小模型也具备推理能力?
本章小结
基于提示的推理方法从简单到复杂包括:(1)Chain-of-Thought——让模型生成推理步骤;(2)Self-Consistency——采样多条路径后多数投票;(3)Least-to-Most Prompting——将问题分解为子问题逐步求解。这些方法都不修改模型参数,仅通过巧妙的提示设计来引导推理行为。
通过训练获取推理能力
知识蒸馏:Orca
提示方法只能用于大模型。如果我们想让小模型也具备推理能力,一个自然的思路是知识蒸馏(Distillation):用大模型生成的推理解释来微调小模型。
Orca 是这一思路的典型代表。其流程分为三步:
- 从 FLAN V2 数据集收集大量指令(instructions)和问题
- 用 GPT-4 / ChatGPT 对这些指令生成详细的解释性回答(通过系统消息引导模型“请逐步解释你的推理过程”)
- 使用这些解释来微调 LLaMA-13B

来源:Slides 第21页。Source: Mukherjee et al. 2023。
评估:BigBench-Hard
Orca 在 BigBench-Hard 上进行了评估。BigBench-Hard 包含23个聚焦多步推理的子任务,涵盖布尔表达式求值、日期理解、几何形状识别(根据 SVG 路径判断形状)等。

来源:Slides 第26页。Source: Suzgun et al. 2022。

来源:Slides 第29页。
蒸馏的有效性
Orca 的成功说明:通过在大模型生成的详细推理解释上微调小模型,可以有效迁移推理能力。相比仅在(问题,答案)对上微调,加入中间推理步骤的训练数据能带来显著的性能提升。
自我训练:ReST\(^EM\)
一个自然的问题是:为什么要用大模型的推理来训练小模型,能否让模型在自己的推理输出上进行自我改进?
ReST\(^{EM}\)(Reinforced Self-Training)正是基于这一思路,交替执行两个阶段:
- E-Step(生成):给定推理问题,让模型采样多个推理方案,根据答案正确性进行过滤——仅保留得出正确答案的推理链
- M-Step(更新):在过滤后的正确推理链上微调模型
这两个步骤可以迭代进行:更新后的模型能生成更好的推理链,从而进一步改进模型。

来源:Slides 第31页(标注为29)。Source: Singh et al. 2024。
自我训练可以超越人类标注
ReST\(^{EM}\) 的一个重要发现:经过多轮迭代自我训练,模型在自己生成的推理链上微调的效果可以超越在人类编写的推理链上微调的效果。这意味着模型自己生成的推理方式可能比人类提供的更适合模型自身的“认知模式”。
自我训练的收敛问题
在 GSM8K 上,ReST\(^{EM}\) 的性能在2--3轮迭代后开始下降,表明自我训练并非总是单调改进的。可能的原因包括:(1)模型陷入自身偏见的“回声室”;(2)过滤器不够精确,部分错误推理链被保留;(3)数据多样性随迭代逐渐减少。
本章小结
通过训练来获取推理能力有两条路径:(1)蒸馏——用大模型的推理解释微调小模型(如 Orca);(2)自我训练——让模型在自己的正确推理上迭代微调(如 ReST\(^{EM}\))。两种方法都表明,推理链(而非仅仅是正确答案)是训练推理能力的关键信号。
语言模型真的在推理吗?
前面展示的各种方法在 benchmark 上取得了不错的成绩,但一个更深层的问题是:语言模型是真正在推理,还是在利用记忆和模式匹配来模拟推理的表象?
来源:Slides 第34页(标注为31)。
CoT 推理链的忠实性
第一个问题:模型生成的推理链是否忠实地反映了其决策过程?
实验设计如下:让模型正常生成完整的推理链(比如4句话),然后在不同位置强制截断,让模型直接给出答案。如果推理链是忠实的,截断后答案应该会改变。
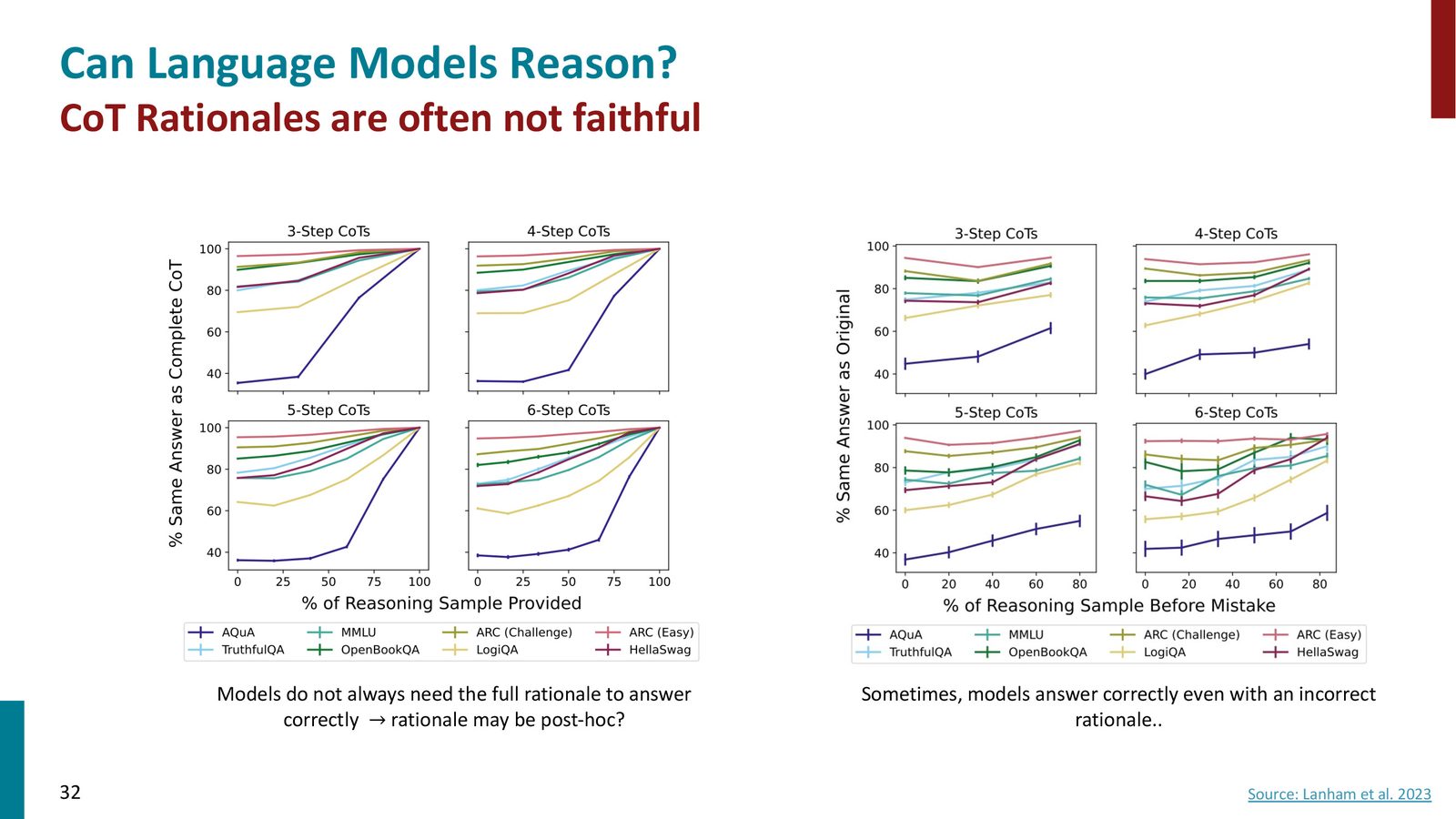
来源:Slides 第32页。
推理链可能是“事后解释”
实验发现:在多个数据集上,即使完全截断推理链(不让模型看到任何推理步骤),模型依然给出相同的答案。这意味着在这些情况下,推理链可能只是模型已确定答案后的事后合理化解释(post-hoc rationalization),而非真正驱动决策的推理过程。
另一个实验进一步验证了这一点:在推理链的中间故意插入错误,观察是否影响最终答案。如果模型忠实地依赖推理链,插入错误应该导致答案改变。但实验发现,在部分数据集上,即使在第一步就引入错误,最终答案依然不变。
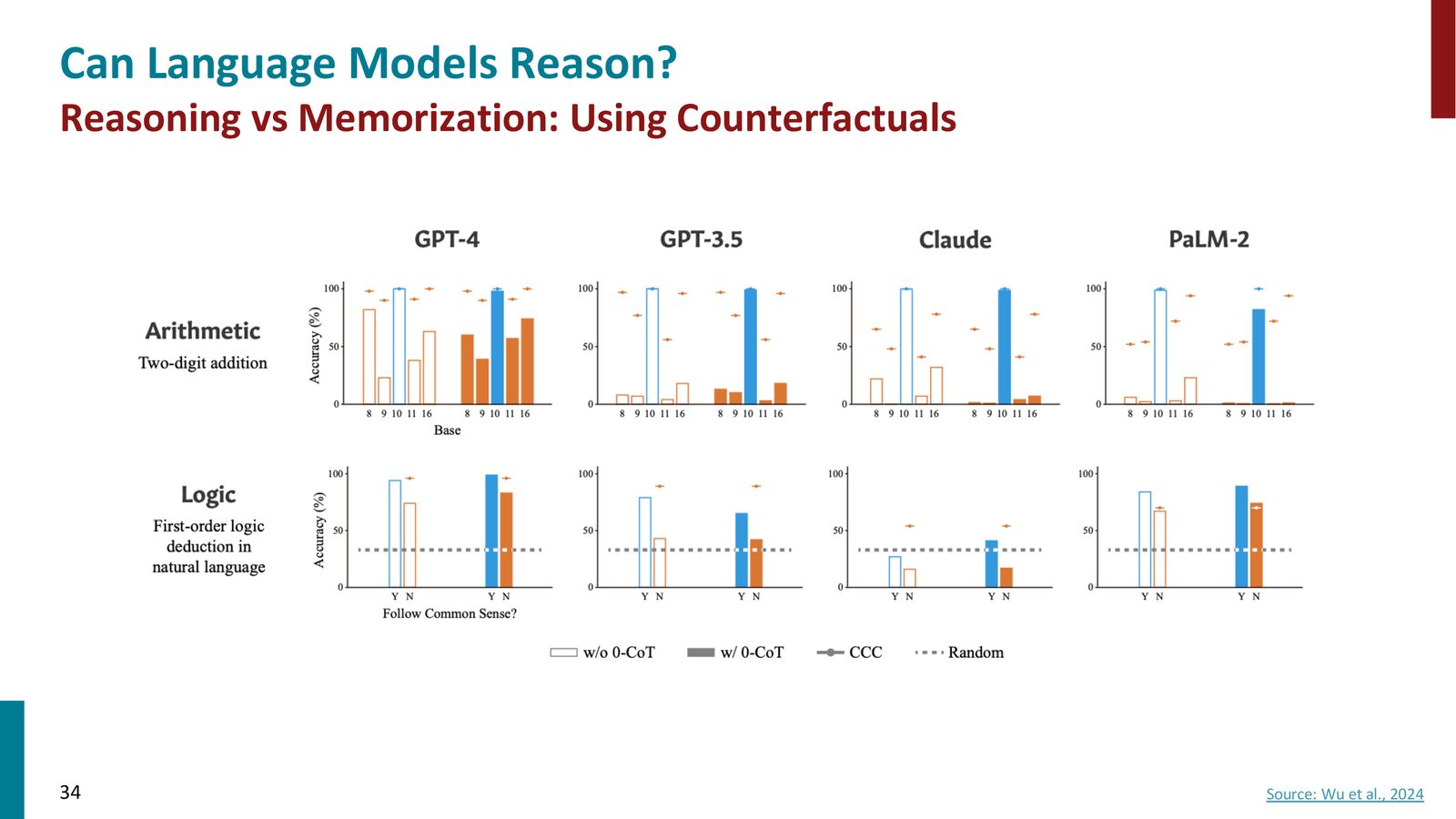
反事实评估:推理还是记忆?
第二个更尖锐的问题:模型在标准 benchmark 上的好表现,是真的因为掌握了推理能力,还是因为训练数据中包含了类似的例子?

来源:Slides 第38页(标注为34)。Source: Wu et al., 2024。
实验设计了两种反事实:
- 算术反事实:模型能做十进制加法(如 \(12 + 14\)),但十进制加法在训练数据中大量存在。如果改为九进制加法,模型的准确率大幅下降——说明它可能是在匹配模式而非真正理解进位规则。
- 逻辑反事实:模型能正确处理“所有狗是哺乳动物”这类符合常识的逻辑推理。但如果改为违反常识的前提(如“柯基是爬行动物”),模型的推理能力显著退化——说明它可能依赖常识记忆而非纯逻辑推导。
类比推理中的反事实
类比推理任务进一步揭示了这一问题。标准的类比推理(如扩展字母序列 abcd \(\rightarrow\) abcde)语言模型可以完成得很好。

来源:Slides 第36页。Source: Hodel et al. 2024。
但当引入两种反事实修改时:
- 修改任务定义:将“扩展序列”从输出下一个字符改为输出下下个字符
- 修改字母表:将标准字母表替换为合成字母表(如 xylkwbfztn...)
模型性能显著下降。而在人类受试者上进行同样的实验,人类的准确率几乎不受影响。
推理 vs 记忆:目前的结论
综合这些实验,目前的证据表明:
- 语言模型确实展现了某种程度的推理能力——它们能够在标准设置下解决多步推理问题
- 但这种推理能力并不系统——面对反事实或分布外的变体时,性能急剧下降
- 相当一部分“推理”可能是模式匹配和记忆的结果,而非真正的逻辑推导
这一领域仍在快速发展,未来的研究可能会改变这些结论。
本章小结
通过忠实性测试和反事实评估,我们发现语言模型的“推理”能力存在显著局限:推理链可能是事后合理化而非真正的推理过程,模型在偏离训练分布的问题上性能显著下降。这些发现提醒我们,在使用 LLM 进行推理时需要保持审慎态度。
语言模型智能体:基本概念
本讲的第二部分转向语言模型智能体(Language Model Agents)。智能体与推理密切相关:在环境中完成任务需要对后续状态、对象可操作性和不确定性进行多步推理和规划。
智能体的核心术语
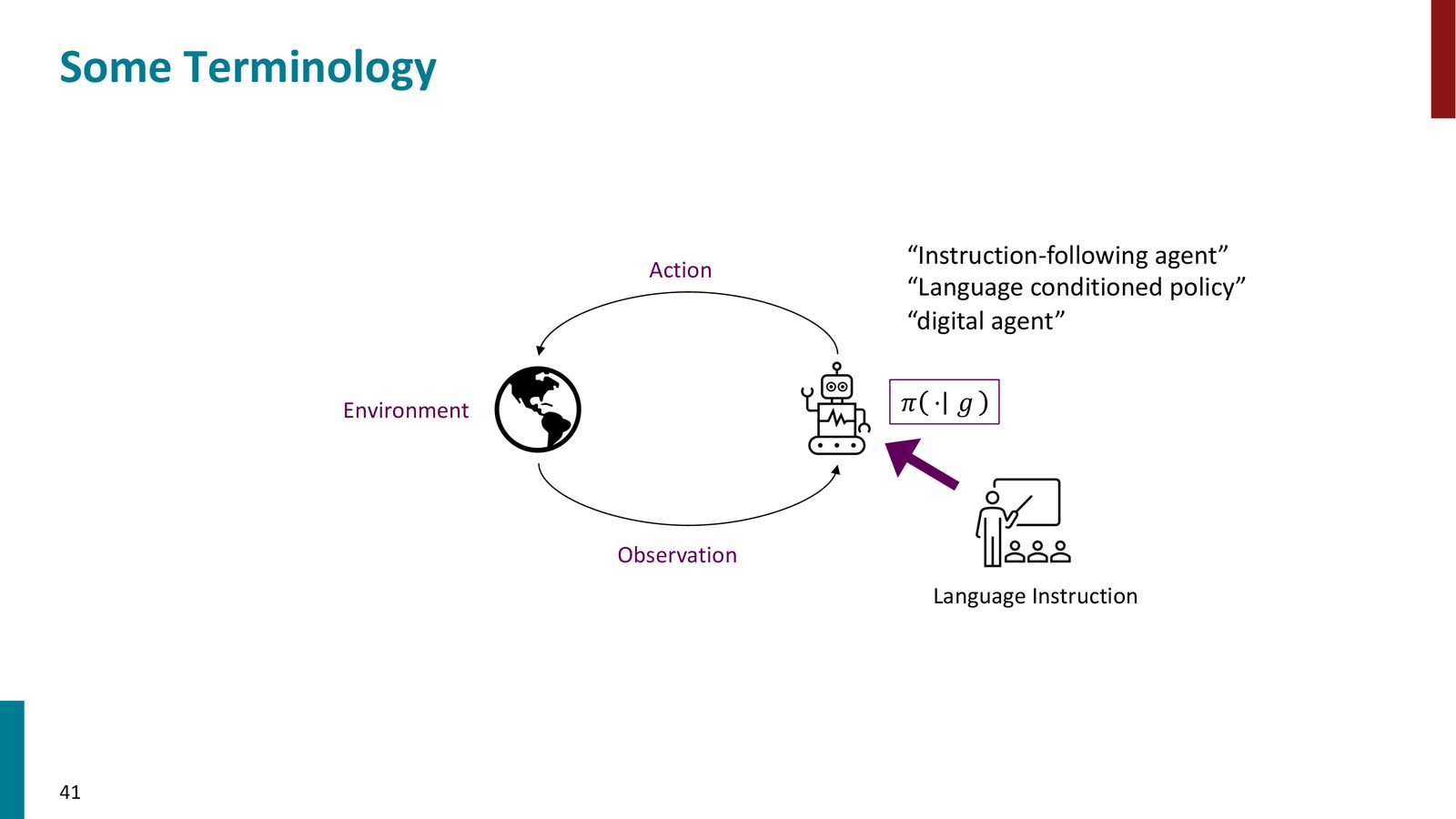
来源:Slides 第41页。
智能体的三要素
- Agent(智能体):执行任务的神经网络(或语言模型),其策略 \(\pi(\cdot | g)\) 以语言指令 \(g\) 为条件
- Environment(环境):智能体交互的对象,可以是网页浏览器、数据库、物理世界的模拟等
- 三个核心变量:Observation(环境观测,如 HTML DOM 或屏幕截图)、Action(动作,如点击、输入文字)、Language Instruction(自然语言指令,如“订一张从旧金山到纽约的机票”)
这种设置有多种名称:数字智能体(Digital Agent)、语言条件策略(Language Conditioned Policy)、指令跟随智能体(Instruction-Following Agent)。
应用场景
语言模型智能体的应用场景极为广泛:
- 数字助理:自然语言控制手机设置闹钟、设置提醒等
- 自然语言编程:根据自然语言描述生成 Python 代码
- UI 自动化测试:用语言模型替代人工测试 UI 元素
- 用户场景自动化:如在 Spotify 上播放歌曲、在电商网站购物
- 工具使用:为语言模型添加插件或工具,使其能控制各种应用

来源:Slides 第43页。
本章小结
语言模型智能体将 LLM 从纯文本生成扩展到环境交互,核心框架是:Agent 根据 Observation 和 Language Instruction 生成 Action,通过与 Environment 的循环交互来完成任务。这种框架统一了从网页操作到代码生成的各种应用场景。
历史回顾:LLM 之前的智能体方法
在大语言模型出现之前,研究者已经探索了三种构建指令跟随智能体的主要方法。
方法一:语义解析(类机器翻译)
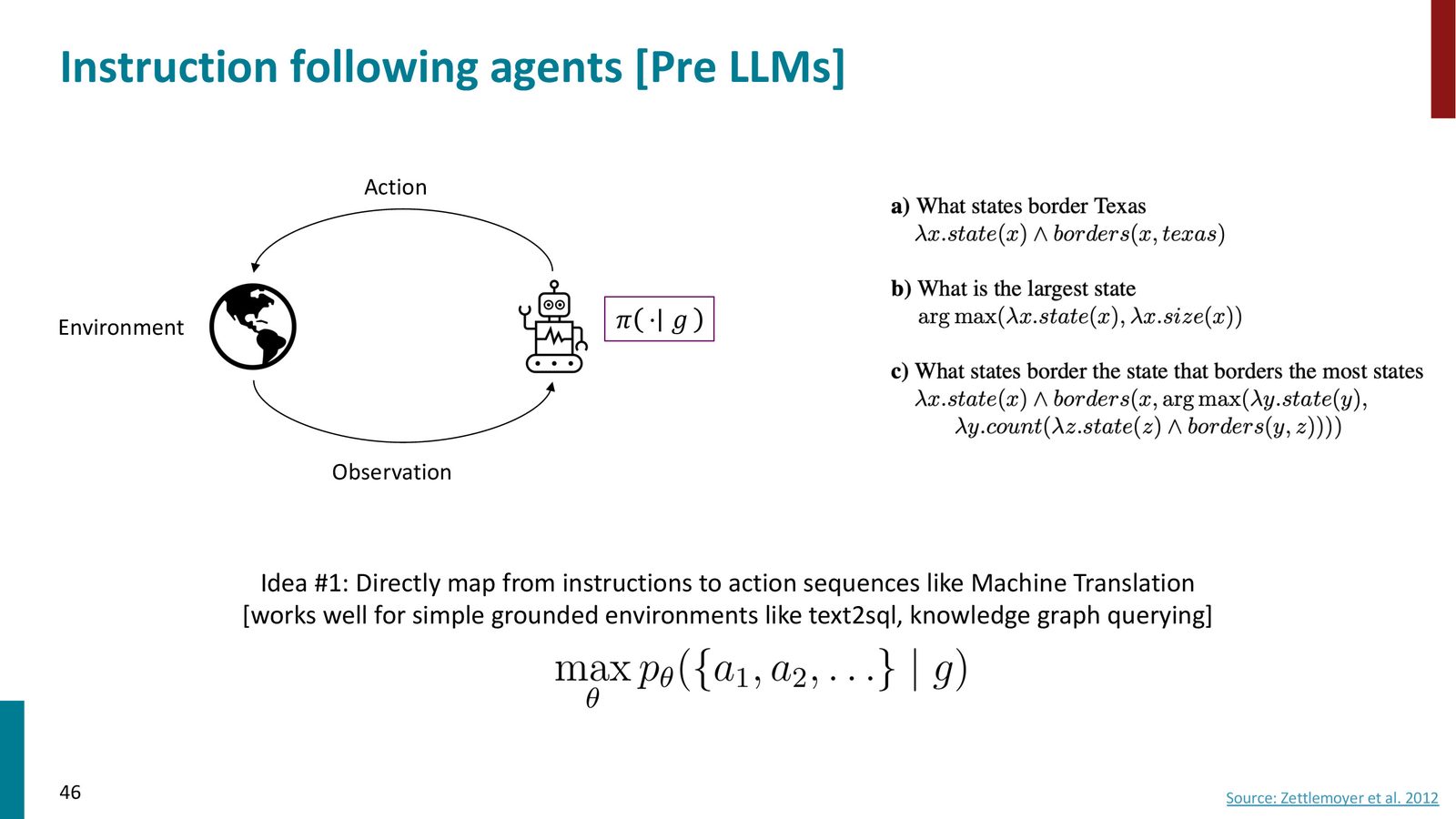
来源:Slides 第46页。Source: Zettlemoyer et al. 2012。
核心思路:将自然语言指令视为“源语言”,将可执行的逻辑表示视为“目标语言”,直接训练一个序列到序列模型来完成映射:
适用于简单的接地环境如 text-to-SQL 和知识图谱查询。
方法二:推断计划 + 执行模型
不直接映射指令到动作,而是:
- 从(指令,动作轨迹)对中推断出抽象计划
- 训练模型将指令映射到计划
- 定义执行模型来执行这些计划
优势在于计划可以编码更高层次的决策,而不仅仅是低层动作序列。
方法三:强化学习
直接使用 RL 学习以自然语言指令和环境观测为条件的策略:
奖励可以是稀疏的(完成整个任务后才获得反馈)或密集的(每一步都有反馈)。
三种方法的对比
- 语义解析:需要大量标注的(指令,逻辑形式)对,但对简单领域效果好
- 计划推断:可以处理更复杂的任务,但需要设计执行模型
- 强化学习:最通用,但需要环境反馈和大量交互
这些方法都需要针对特定环境从头训练模型,缺乏泛化能力。
本章小结
LLM 之前的智能体方法虽然在各自的适用场景内有效,但都需要为每个新环境重新训练模型。LLM 的出现带来了新的可能性:利用预训练中获得的广泛知识,以最少的适配来处理各种环境中的任务。
基于 LLM 的智能体
决策即语言建模
LLM 时代的核心观察:决策制定可以被重新表述为因果语言建模问题。
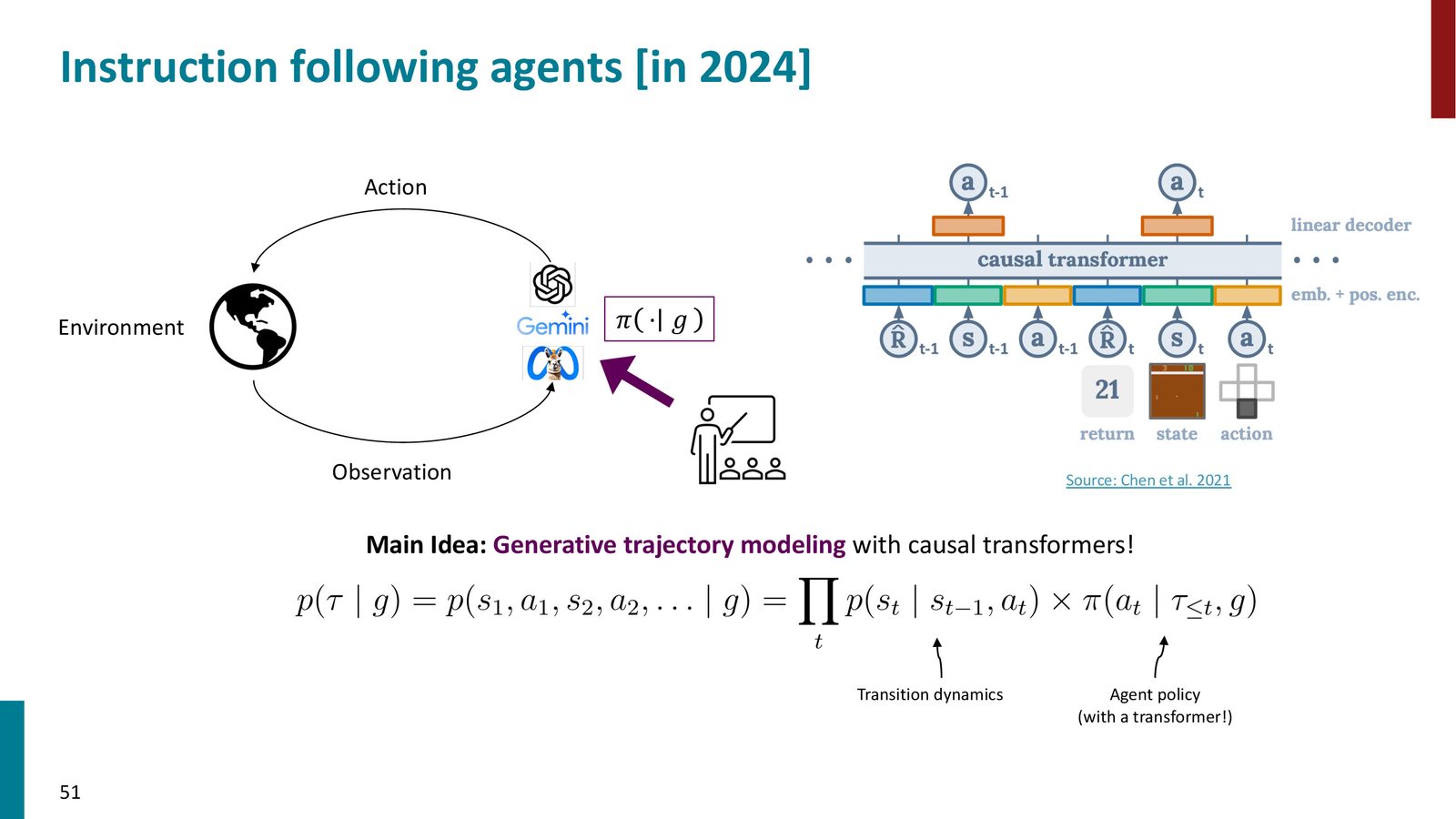
来源:Slides 第51页。Source: Chen et al. 2021。
轨迹概率的分解:
其中:
- \(\tau\):完整轨迹(状态-动作序列)
- \(g\):自然语言目标
- \(s_t\):\(t\) 时刻的环境状态
- \(a_t\):\(t\) 时刻的动作
关键洞察:智能体策略 \(\pi(a_t \mid \tau_{\leq t}, g)\) 本质上就是一个条件语言模型——给定历史轨迹和目标,预测下一个动作。因此,可以直接用自回归 Transformer 来建模。
提示循环:最简单的 LLM 智能体
最简单的 LLM 智能体就是在循环中进行提示:
- 在提示中描述动作空间(如:可以点击、输入、移动鼠标)
- 提供指令
- 将历史动作和观测追加到提示中
- 让模型预测下一个动作
- 执行动作,获取新观测,回到步骤3
来源:Slides 第53页。
提示循环的本质
提示循环智能体本质上就是Chain-of-Thought prompting 在循环中运行。每一步的“思考”对应推理,“动作”对应与环境的交互。这建立了推理与智能体之间的直接联系——推理能力越强的模型,理论上也能成为越好的智能体。
本章小结
LLM 将智能体问题简化为条件语言建模:决策可以表述为根据目标和历史预测下一个动作。最简单的实现是提示循环,本质上是 CoT 在交互式环境中的应用。
智能体评估基准
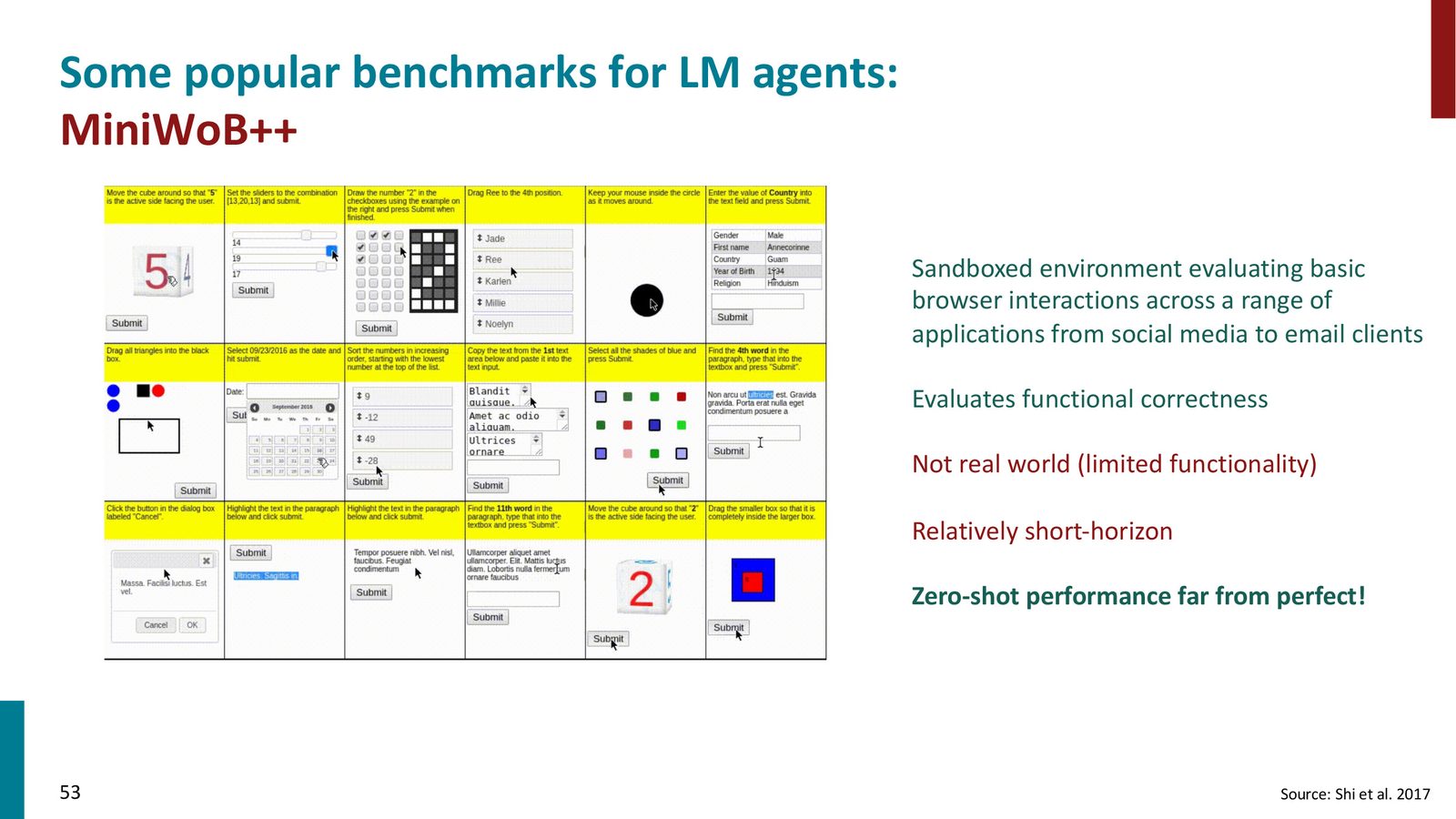
MiniWoB:简单沙盒环境
MiniWoB 是最简单的智能体评估环境,提供模拟的网页交互任务(如在模拟 Twitter 上转发、在模拟邮件客户端转发邮件等)。
特点:
- 非真实网站,仅为沙盒模拟
- 短周期任务——大多数任务只需 \(\leq 3\) 个动作
- 尽管如此简单,最好的语言模型在 zero-shot 设置下仍远未达到完美
WebArena:近真实环境
WebArena 更接近真实世界:
- 沙盒环境但高度模拟真实网站(电商、社交媒体、地图等)
- 支持多标签浏览——智能体需要在多个应用间切换
- 评估功能正确性——判断最终结果是否正确,而非动作序列是否与预设一致
WebLinx:真实网站交互
WebLinx 在真实网站上进行评估,增加了一个新的动作:与用户沟通——智能体可以请求缺失信息(如信用卡号)。但它不是一个交互环境,仅是一个交互记录集合,因此无法进行探索或在线学习。

来源:Slides 第55页。
本章小结
从 MiniWoB 到 WebArena 再到 WebLinx,评估基准越来越接近真实世界:任务更复杂、环境更真实、交互更多样。但在所有基准上,语言模型的表现仍远低于人类水平,尤其是在需要多步规划的任务上。
智能体的训练:合成数据与探索
当前实践:上下文学习
当前训练 LLM 智能体的标准做法是:为每个新环境提供人工编写的 few-shot 示范作为上下文。

来源:Slides 第56页。
人工示范不可扩展
现实中有成千上万种不同的网站和应用,每种环境的交互方式都不同。为每种环境都准备人工示范既昂贵又不现实。核心问题变为:智能体能否自主探索环境来生成高质量的合成训练数据?
BAGEL:探索 + 模型生成数据
BAGEL 方法巧妙地结合了前面在推理部分学到的迭代自我训练思想,将其应用到智能体的训练数据生成中。
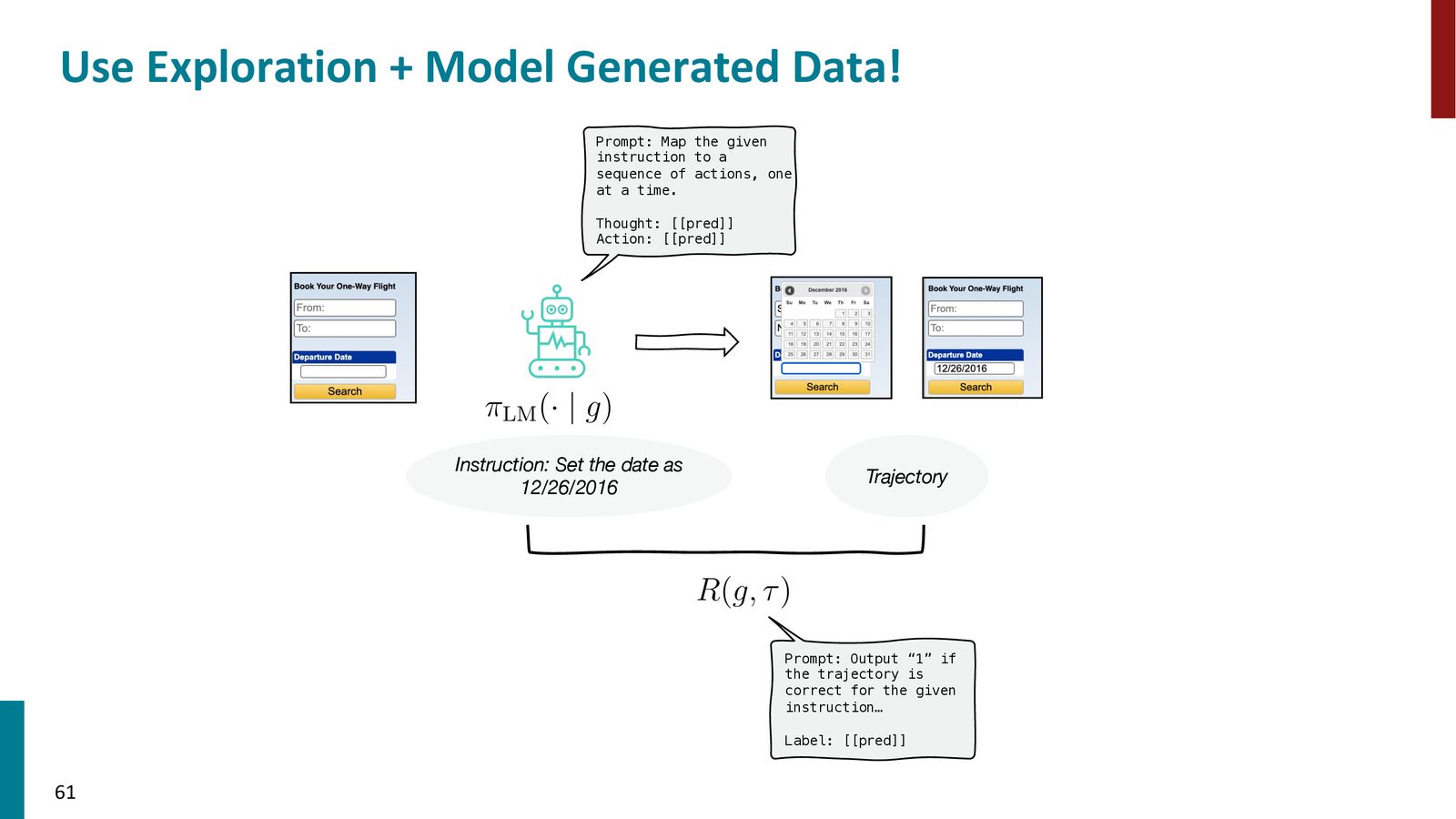
来源:Slides 第61页。
BAGEL 的完整流程:
- 探索:让语言模型无目标地随机探索环境,收集动作轨迹
- 标注:用第二个语言模型为轨迹生成自然语言描述——推断“这条轨迹完成了什么任务”
- 条件生成:用推断出的描述作为指令,让模型有目标地重新生成轨迹
- 过滤:用过滤器判断(指令,轨迹)对的质量
- 重标注:对于失败的轨迹,重新推断它实际完成了什么(而非原目标),赋予新标签
- 迭代:重复步骤3--5,直到获得足够多的高质量(指令,轨迹)对
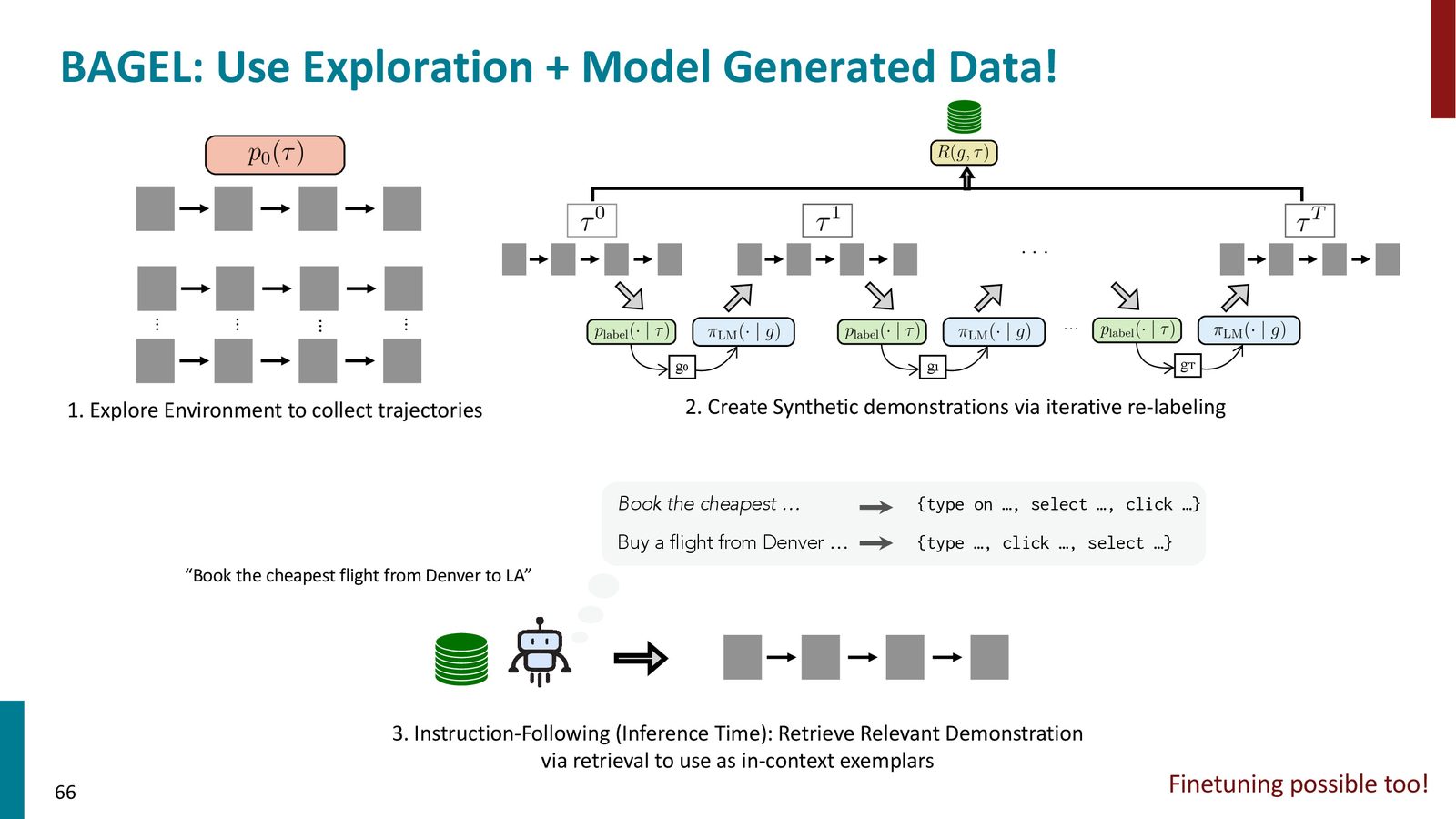
来源:Slides 第66页。
BAGEL 的核心创新:重标注
当智能体未能完成目标任务时,BAGEL 不会丢弃这条轨迹,而是重新标注它——推断智能体实际完成了什么子任务。例如,智能体试图“订一张从旧金山到纽约的机票”但只完成了“将出发地设为 SFO、目的地设为纽约”,重标注后这条轨迹仍然是有价值的训练数据。这与推理部分的迭代自我训练异曲同工。
获得合成训练数据后,有两种使用方式:
- 上下文学习:用合成示范替代人工示范作为 few-shot 示例
- 微调:直接在合成数据上微调模型
实验表明,在 MiniWoB 上使用 BAGEL 可以获得 13个百分点的提升。
本章小结
通过探索环境和迭代重标注,智能体可以自主生成高质量的合成训练数据,减少对人工示范的依赖。这种思路与推理部分的自我训练一脉相承——核心都是让模型从自己的经验中学习和改进。
多模态智能体与当前挑战
从文本到视觉:多模态智能体
前面讨论的智能体主要以文本(HTML DOM)作为环境观测。但在实际应用中,HTML 可能包含数万个 DOM 元素,直接输入语言模型既不高效也不自然。更自然的方式是直接使用屏幕截图作为输入。
这催生了两类视觉-语言模型在智能体中的应用:
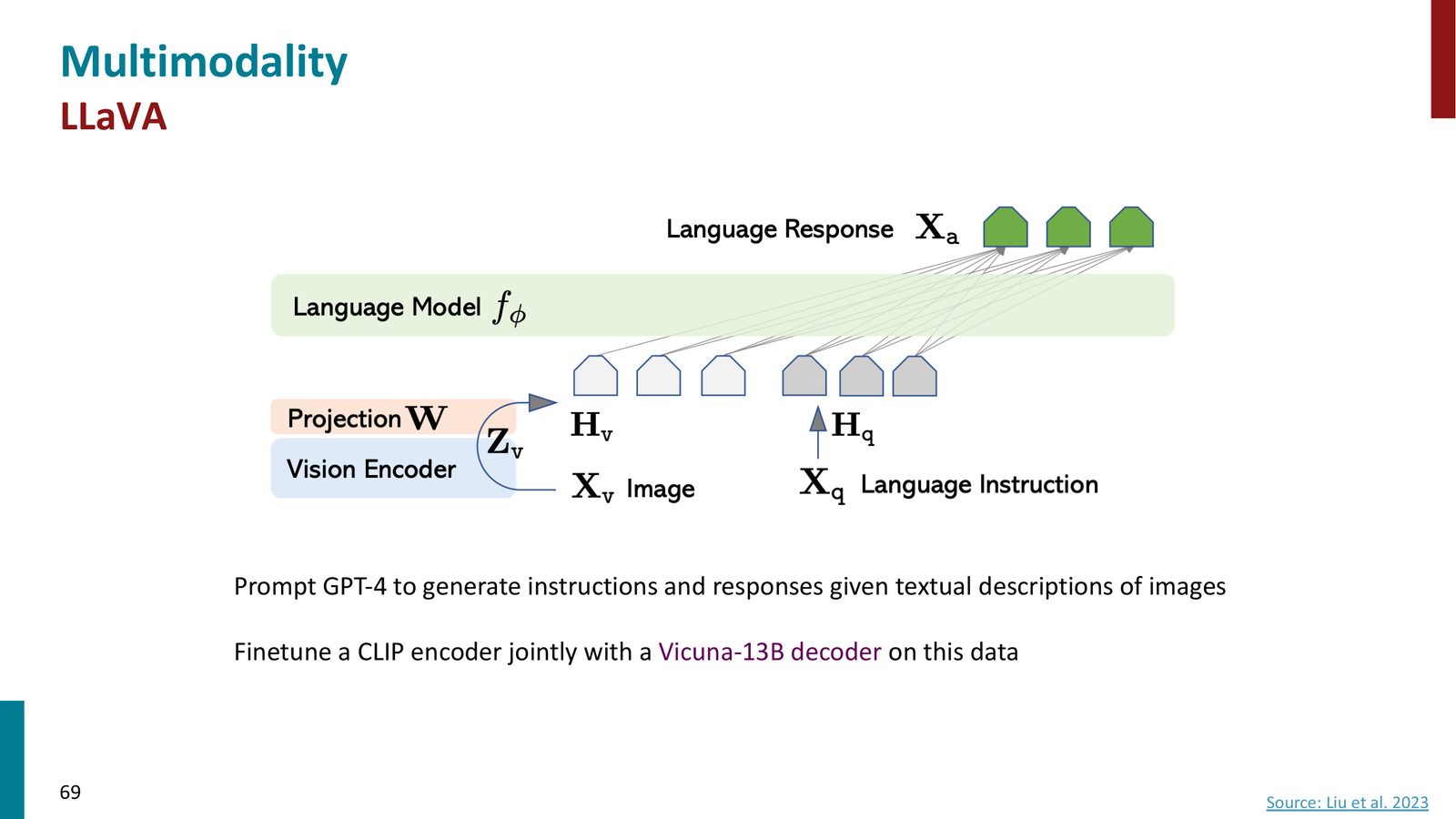
LLaVA:合成数据训练 VLM
LLaVA 的思路类似 Orca(蒸馏):
- 用图像的文本描述(而非图像本身)提示 GPT-4 生成问答对
- 联合微调图像编码器(CLIP)和文本解码器(instruction-tuned LLaMA)
- 最终得到能理解图像并生成文本回答的多模态模型
来源:Slides 第68页。
Pix2Struct:截图-to-HTML 预训练
Pix2Struct 引入了更自然的预训练任务:
- 将网页截图中的部分区域遮挡
- 让模型预测被遮挡区域对应的 HTML 代码
这种预训练方式建立了视觉表示与结构化文本之间的直接对应关系,非常适合后续用于构建多模态智能体。
来源:Slides 第69页。
当前挑战:巨大的性能鸿沟
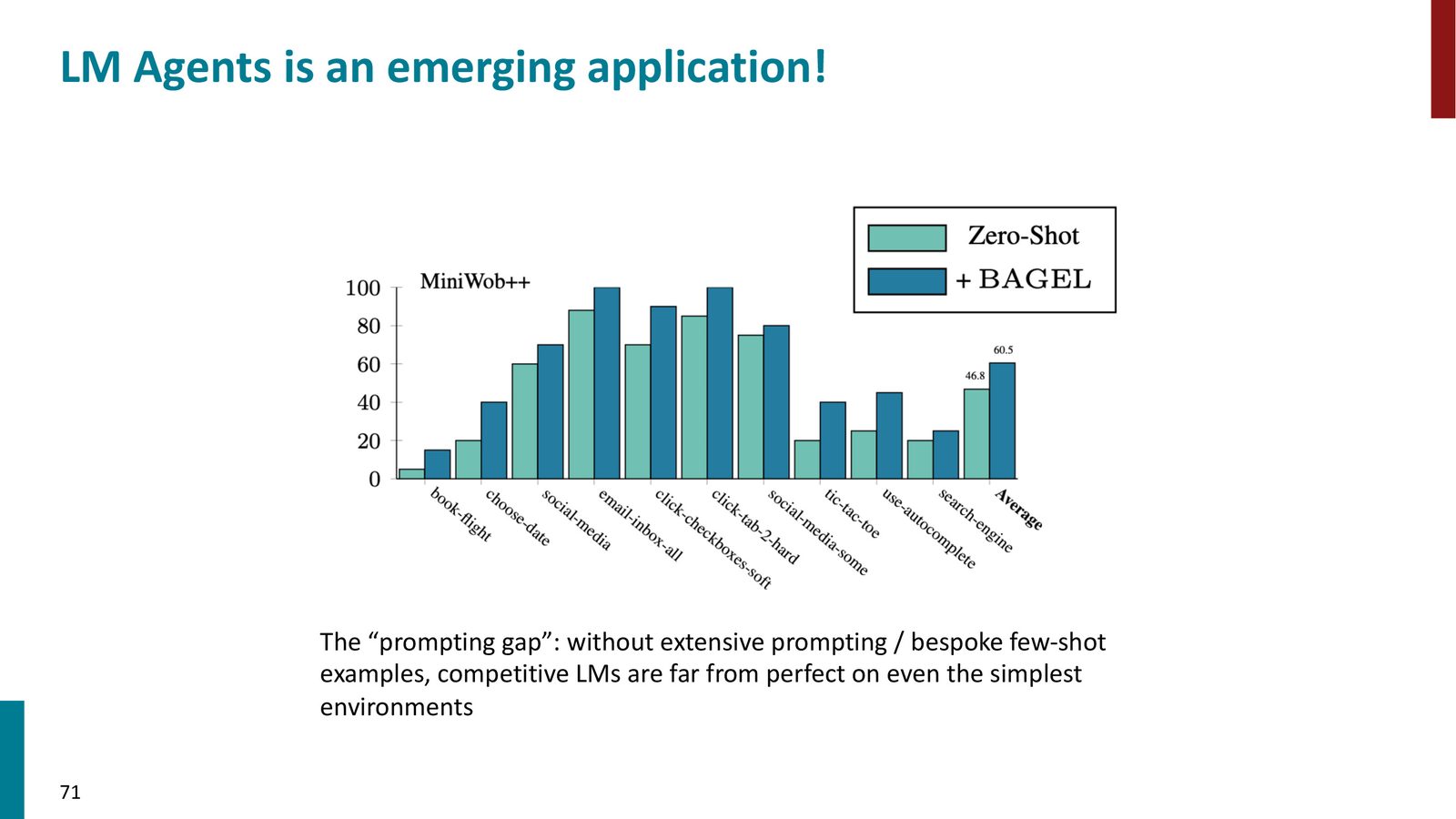
来源:Slides 第71页。
当前 LLM 智能体面临的核心挑战:
- 提示鸿沟(Prompting Gap):不进行大量 prompt 工程和定制 few-shot 示例,即使最好的 LLM 在最简单的环境上也表现很差
- 长周期规划困难:从单步动作到5--10步任务,性能急剧下降
- 低级错误频发:模型会犯人类不太会犯的低级错误(如在密码框里输入邮箱地址),且无法从错误中恢复
- 人机差距巨大:在 WebArena 等更复杂的环境中,人类成功率与模型成功率之间存在数十个百分点的差距
低级错误示例
在 WebLinx 的一个任务中,GPT-4V 需要打开 Google Translate 并用给定的凭据登录。结果模型把邮箱地址输入到了密码框中,之后始终无法恢复——反复尝试输入邮箱。另一个例子中,模型需要执行搜索,却将同一个搜索词重复了三遍才提交。这些看似“愚蠢”的错误揭示了当前模型在环境理解和错误恢复方面的根本缺陷。
本章小结
多模态智能体通过直接处理视觉输入来避免 HTML 解析的复杂性,但当前所有智能体方法都面临巨大的性能鸿沟。无论是简单的 MiniWoB 还是复杂的 WebArena,模型都远未达到人类水平,尤其在长周期规划和错误恢复方面。
总结与延伸
讲者的核心总结

来源:Slides 第75页。
Shikhar Murty 在课程结尾将两大主题的要点归纳如下:
推理(Reasoning):
- 可以通过提示(CoT、Self-Consistency、Least-to-Most)激发推理行为
- 可以通过蒸馏(Orca)将大模型的推理能力迁移到小模型
- 可以通过自我训练(ReST\(^{EM}\))让模型在自己的输出上迭代改进
- 反事实评估表明推理可能并不系统——记忆和模式匹配起了很大作用
智能体(Agents):
- 主要使用提示和上下文学习
- BAGEL 通过探索和迭代重标注生成合成训练数据
- 多模态模型(LLaVA、Pix2Struct)使直接处理视觉输入成为可能
- 当前评估基准仍极具挑战性,模型表现与人类存在巨大差距
全课知识图谱

两大主题的深层联系
推理与智能体的统一视角
本讲的两个看似独立的主题实际上有深层联系:
- 技术共享:推理中的自我训练(ReST\(^{EM}\))和智能体中的合成数据生成(BAGEL)使用了相同的核心思路——生成、过滤、迭代改进
- 能力依赖:智能体需要推理能力来进行规划和决策;推理能力的缺陷直接限制了智能体的表现
- 共同挑战:两者都面临系统性的问题——推理的“记忆vs推理”困境对应着智能体的“提示鸿沟”
- 架构统一:两者都可以被建模为自回归序列生成——推理是生成推理链,智能体是生成动作轨迹
关键 Takeaways
五条核心原则
- 中间步骤至关重要:无论是推理链还是动作轨迹,让模型“展示工作过程”都能显著提升性能
- 自我改进是可能的:模型可以通过在自己的输出上训练来超越人类标注的上限
- 推理可能不系统:反事实评估揭示了 LLM “推理”中记忆和模式匹配的成分
- 决策即语言建模:智能体的动作预测本质上就是条件语言生成
- 差距仍然巨大:在推理和智能体两个领域,模型与人类之间的差距都还很大,还有大量改进空间
拓展阅读
- Wei et al., Chain-of-Thought Prompting: https://arxiv.org/abs/2201.11903
- Wang et al., Self-Consistency: https://arxiv.org/abs/2203.11171
- Zhou et al., Least-to-Most Prompting: https://arxiv.org/abs/2205.10625
- Kojima et al., Zero-shot CoT: https://arxiv.org/abs/2205.11916
- Mukherjee et al., Orca: https://arxiv.org/abs/2306.02707
- Singh et al., ReST\(^{EM}\): https://arxiv.org/abs/2312.06585
- Wu et al., Reasoning or Reciting: https://arxiv.org/abs/2307.13702
- Hodel et al., Analogical Reasoning Counterfactuals: https://arxiv.org/abs/2402.02442
- Chen et al., Decision Transformer: https://arxiv.org/abs/2106.01345
- Zhou et al., WebArena: https://arxiv.org/abs/2307.13854
- Liu et al., LLaVA: https://arxiv.org/abs/2304.08485
- Lee et al., Pix2Struct: https://arxiv.org/abs/2210.03347
- Murty et al., BAGEL: https://arxiv.org/abs/2401.15839