CS224R Lecture 14: 探索与元探索
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于公开课程资料整理 |
| 来源 | Stanford Online |
| 日期 | 2025 年春季 |
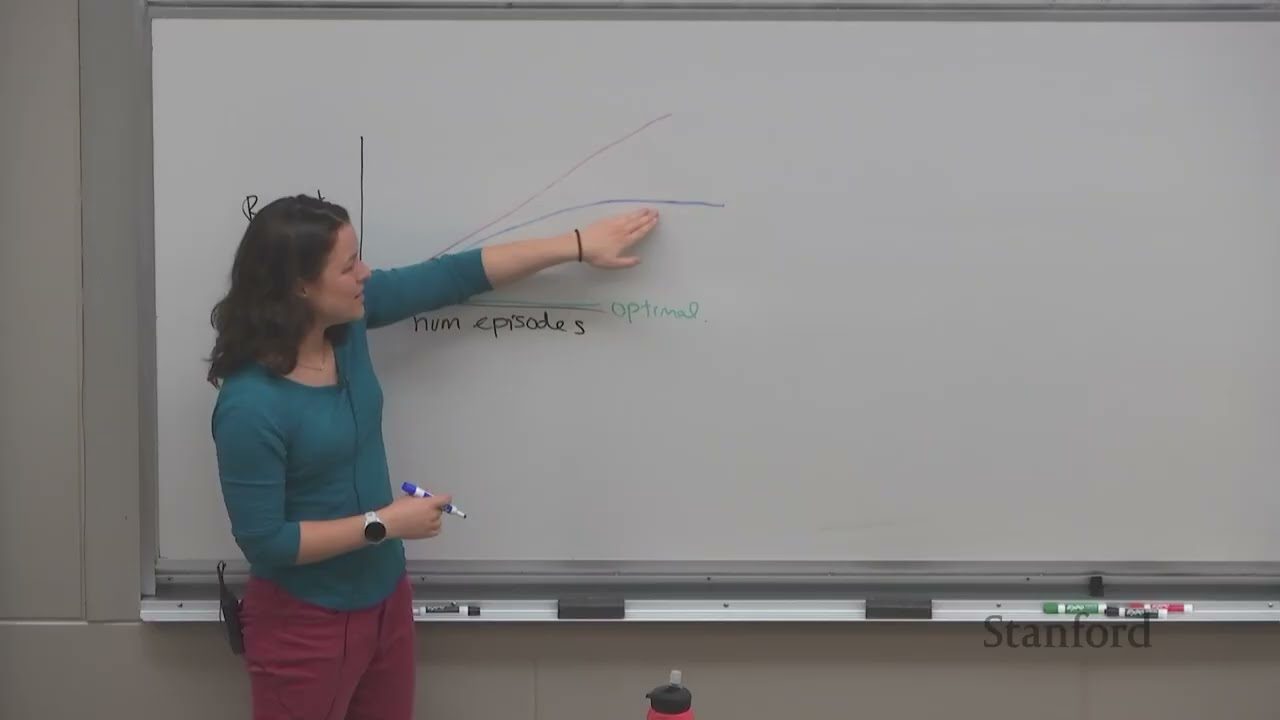
探索问题的本质
为什么探索很重要
在强化学习中,智能体必须在利用(exploitation,选择已知最好的动作)和探索(exploration,尝试可能更好的动作)之间取得平衡。
探索的核心困境
如果我们总是选择当前估值最高的动作(贪心策略),可能永远发现不了真正的最优策略。例如在多臂赌博机中,如果第一次拉臂恰好获得了正奖励,贪心策略会一直拉同一个臂,即使其他臂的期望奖励更高。
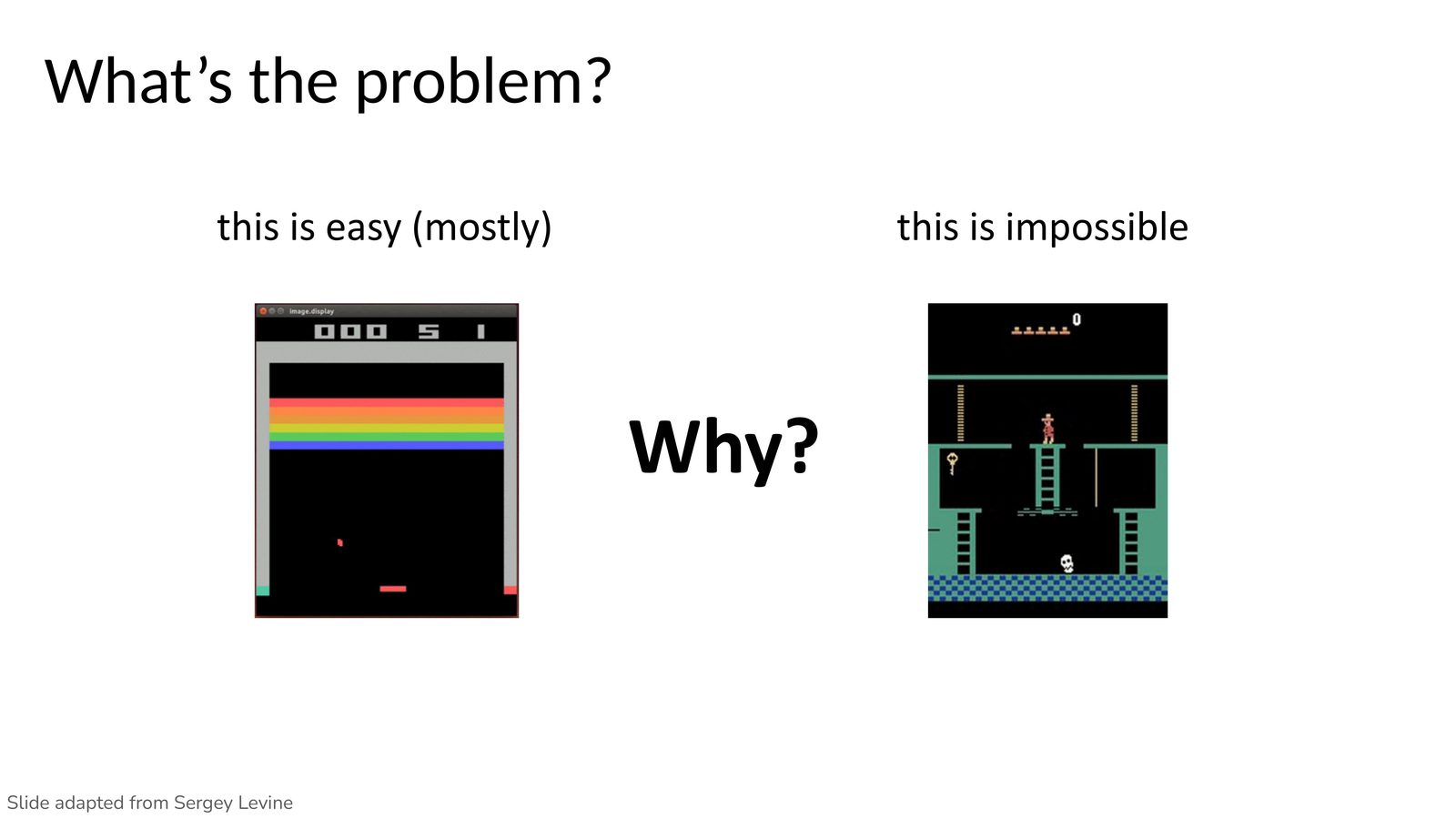
为什么 Montezuma's Revenge 成了经典探索基准
课程先用 Montezuma's Revenge 这种稀疏奖励游戏说明问题:拿到钥匙有奖励、开门有奖励、被 skull 杀死却未必立刻给出足够明确的负反馈,而完成任务的关键行为之间间隔又非常长。人类之所以知道要做什么,不是因为看到了 reward,而是因为理解了 sprite 的语义和任务结构。

把自己放到算法的位置上
讲者进一步用牌类游戏 Mao 做类比:你只知道 “违反规则会受罚”,但规则本身只能靠试错发现,而且规则未必直观。这恰好刻画了长时序稀疏奖励任务的本质困难。

探索和利用其实是同一个问题
课程强调,两种常见表述本质等价:
- “如何发现需要复杂长链行为才能到达的高奖励策略?”
- “何时该继续做当前已知最好的事,何时该尝试新行为?”
前者强调 temporally extended behavior,后者强调 exploration-exploitation trade-off,但它们都在问同一件事:今天愿不愿意承受一点损失,去换取明天可能更高的回报。

探索之所以难,不只是因为动作空间大
真正棘手的地方是:很多关键探索行为在局部上看不到收益,甚至会让短期回报下降。于是如果训练信号只盯着即时表现,agent 就很容易被推向保守但次优的局部策略。

探索在 RL 应用中的体现
- 机器人:探索不同的抓取策略、运动模式
- 大语言模型:在 RLHF/RL for reasoning 中,探索不同的推理路径
- 推荐系统:探索用户可能喜欢但尚未展示过的内容
本章小结
探索是所有 RL 问题的根本挑战之一。没有有效探索,智能体会陷入次优策略。
经典探索方法
Multi-Armed Bandit 设定
Multi-Armed Bandit
Bandit 问题是探索问题的最简化版本:\(K\) 个臂(动作),每个臂有未知的奖励分布 \(p(r | a)\)。没有状态转移,目标是在 \(T\) 轮交互中最大化累积奖励。遗憾(regret)定义为与最优臂的差距:
Bandit 里怎样定义 “好探索”
bandit 场景之所以重要,是因为这里还能较清楚地定义 “最优探索”。课程采用 regret 作为核心指标:比较你实际拿到的累计奖励,与始终拉最优臂时的期望回报之间的差距。

-Greedy
最简单的探索策略:以概率 \(1 - \epsilon\) 选择当前最优动作,以概率 \(\epsilon\) 随机选择。
-Greedy 的局限
\(\epsilon\)-Greedy 的探索是无方向的——它在所有动作上均匀随机探索,不考虑哪些动作更有信息价值。在动作空间大或环境复杂时,这种盲目探索效率极低。
Upper Confidence Bound (UCB)
UCB 算法
UCB 的核心思想是乐观主义(optimism in the face of uncertainty):对不确定性高的动作赋予更高的估值,从而鼓励探索。
其中 \(\hat{\mu}_a\) 是动作 \(a\) 的经验均值,\(N_a\) 是动作 \(a\) 被选择的次数。第二项是不确定性奖励——被选择次数越少的动作,不确定性越高,越会被优先探索。
Thompson Sampling
Thompson Sampling
Thompson Sampling 采用贝叶斯方法:
- 对每个动作的奖励分布维护一个后验分布 \(p(\mu_a | \text{data})\)
- 每轮从后验中采样:\(\tilde{\mu}_a \sim p(\mu_a | \text{data})\)
- 选择采样值最高的动作:\(a_t = \arg\max_a \tilde{\mu}_a\)
- 收集奖励后更新后验
Thompson Sampling 在实践中通常表现优异,且具有理论最优的 regret bound。

为什么 Bandit 理论依然是探索研究的起点
Bandit 看似太简单,但它仍然是理解探索问题的关键入口,因为这是少数我们还能给出 regret 保证、还能讨论 “最优探索” 的设定。进入长时序、部分可观测、高维状态的 MDP 之后,很多结论都不再直接成立,因此 UCB 和 Thompson Sampling 更像是保留下来的设计原则,而不是可原样照搬的算法模板。
从 Bandit 学到的三个设计原则
- 不确定性必须进入决策,而不是只看经验均值。
- 探索优劣要看长期累计代价,而不是单步表现。
- 一旦任务从 1-step bandit 变成长时序决策,探索难度会急剧放大。
本章小结
经典探索方法从简单的 \(\epsilon\)-greedy 到有原则的 UCB 和 Thompson Sampling,核心区别在于如何利用不确定性来指导探索。
深度 RL 中的探索
从 Bandit 到 MDP
在 MDP 中,探索问题更加复杂:
- 动作不仅影响即时奖励,还影响未来的状态
- 需要探索状态--动作对而非仅是动作
- 有些状态本身就很难到达,需要长时间的定向探索
基于计数的探索
Count-Based Exploration
基本思想:对访问次数少的状态--动作对给予额外的探索奖励:
在深度 RL 中,由于状态空间连续且高维,无法直接计数。常用的近似方法包括:
- 哈希计数:将状态通过哈希函数映射到离散空间
- 密度模型:训练密度模型 \(\hat{p}(s)\),用 \(-\log \hat{p}(s)\) 作为新颖性度量
- RND(Random Network Distillation):用随机网络的预测误差度量新颖性
基于好奇心的探索
另一种思路:探索奖励 = 模型预测误差。如果对某个状态的预测误差大,说明这个状态是"新颖的",值得继续探索。
好奇心陷阱
基于预测误差的探索方法有一个著名的失败模式:噪声电视问题(noisy TV problem)。如果环境中存在本质上不可预测的随机性(如电视屏幕上的静态噪声),模型的预测误差永远不会降低,导致智能体被这种无意义的随机性"吸引",无法继续有意义的探索。
为什么机器人和 LLM 很少从零探索
课程在这部分给出的结论相当务实:对于机器人控制和 LLM 这类巨大 MDP,从零开始做有效探索通常在计算上不可承受。工业界和前沿研究更常见的策略是:
- 使用 demonstrations 或预训练 base model 缩小搜索空间;
- 尽可能提供 shaped rewards;
- 把真正困难的探索留给更小的、结构化得更好的子问题。

本章小结
深度 RL 中的探索需要在连续高维空间中处理新颖性度量,count-based 方法和好奇心方法各有优势和局限。
元探索:学习如何探索
什么是元探索
Meta-Exploration
元探索(meta-exploration)将元学习的思想应用于探索问题:不是手工设计探索策略,而是学习一个探索策略。
在 meta-RL 的框架下:
- 外层(meta)学习如何在新任务上有效探索
- 内层(task)利用探索收集的数据快速适应新任务
Meta-RL 中的探索挑战
在 meta-RL 中,智能体在每个新任务上的前几次交互至关重要——它们决定了智能体能否快速推断出任务的特性。因此,元探索关注的是:在有限的交互次数内,如何收集最有信息量的数据。
与经典探索的区别
经典探索关注单个任务中的 exploration-exploitation 权衡。元探索关注的是跨任务的探索策略学习——训练一个能在新任务上有效探索的策略。这是一个更高层次的优化问题。

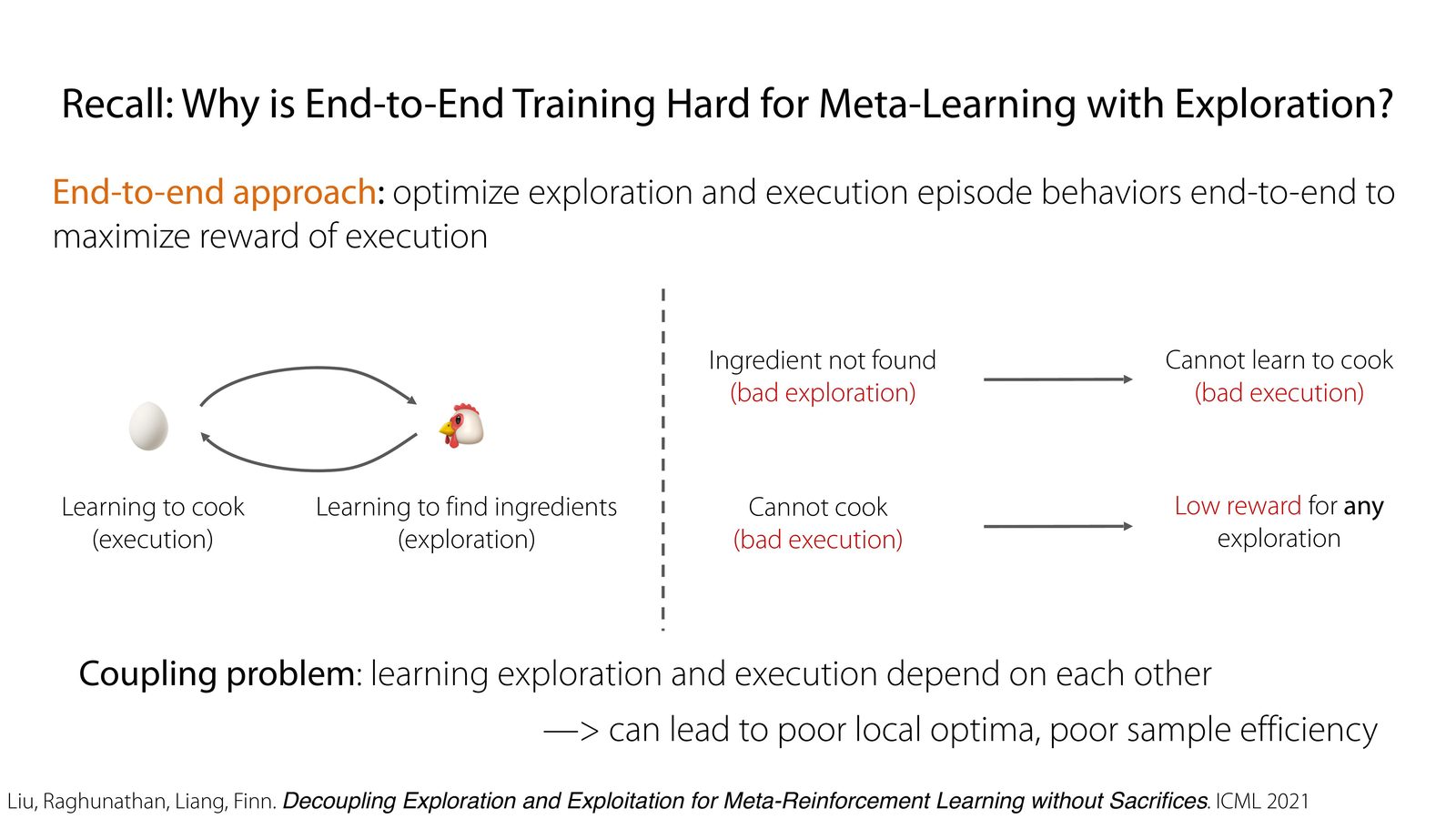
耦合问题:为什么端到端学探索经常失败
如果探索和执行都只通过最终任务奖励来训练,就会出现典型的 chicken-and-egg 困境:探索没做好,执行阶段拿不到好 reward;执行阶段一直失败,探索阶段也就收不到足够清晰的训练信号。
DREAM 和后验采样方法
讲者介绍了如何在 meta-RL 中实现有效探索:
- 维护对任务身份的信念(belief)
- 使用 Thompson Sampling 的思想指导探索
- 外层 RL 训练使内层探索策略最大化信息增益
替代策略一:后验采样、内在奖励与任务预测
课程先回顾了几类已有思路:PEARL 用 posterior sampling,MAME 用 intrinsic rewards,MetaCURE 用 task dynamics/reward prediction。它们的共同点是:不再把探索完全交给 end-to-end reward 信号,而是显式引入任务推断结构。

DREAM:把探索和执行显式解耦
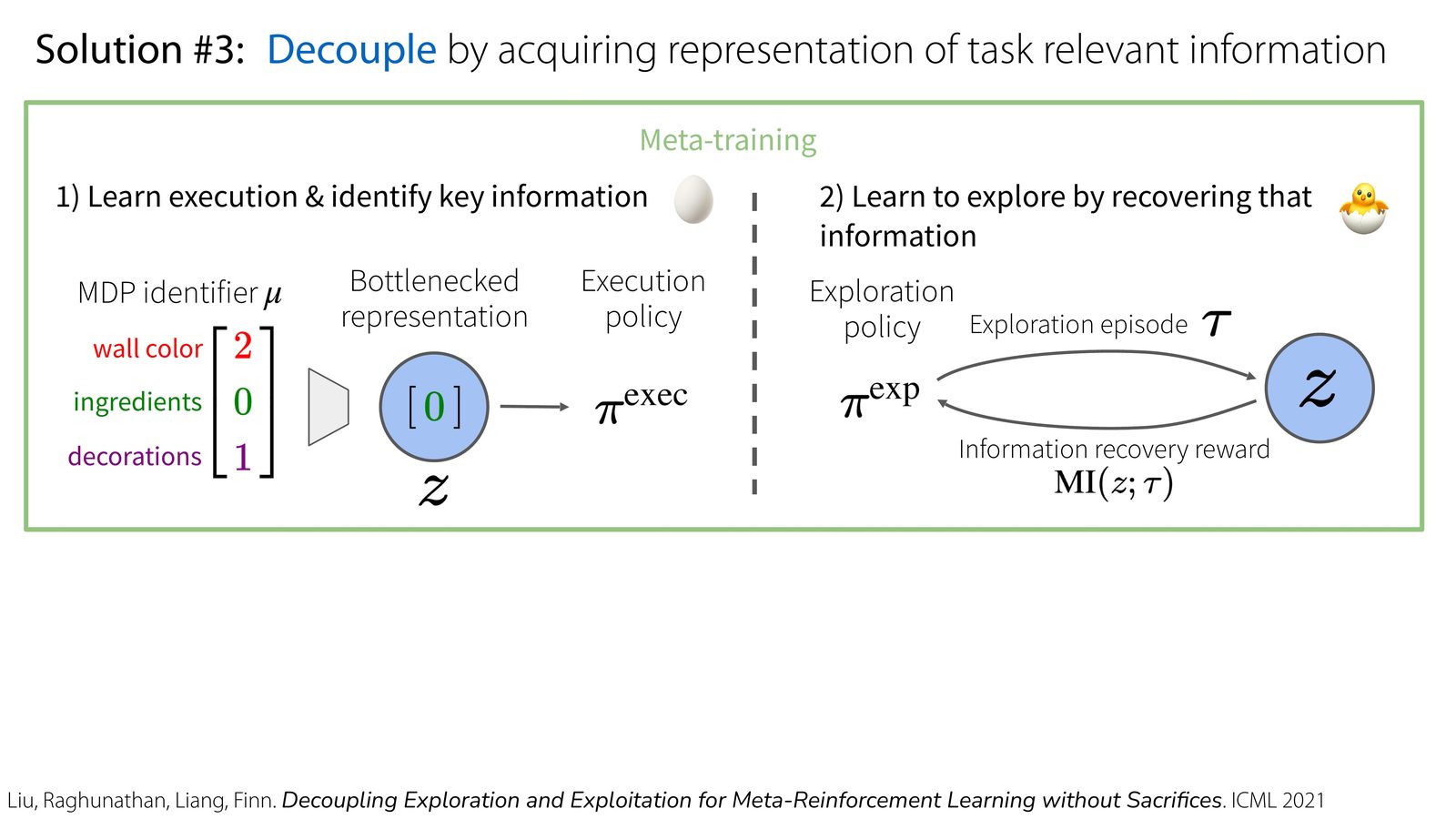
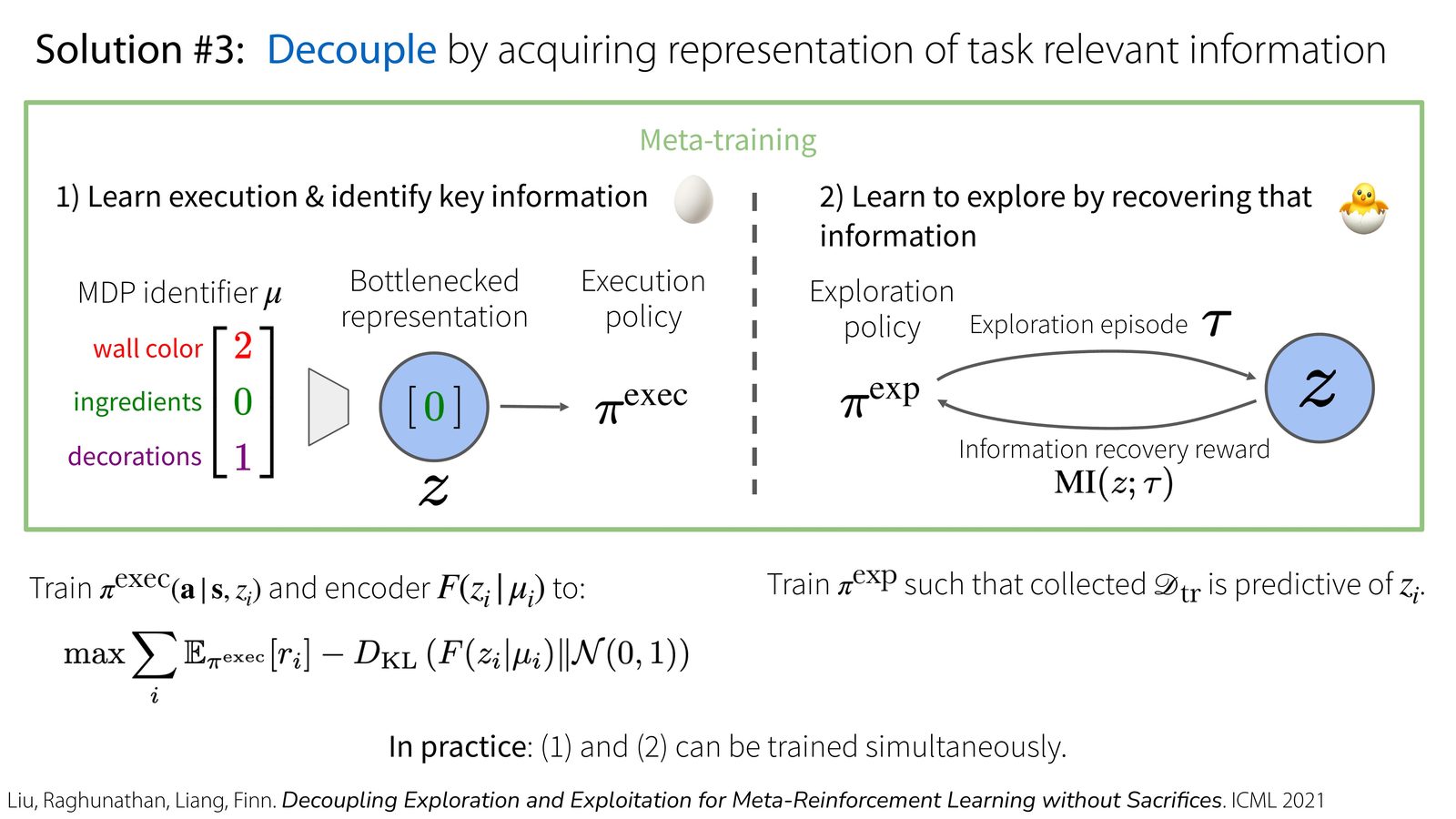
这节课真正的主角是 DREAM。它的关键想法不是直接学一个同时负责探索和执行的黑盒策略,而是分两步:
- 学会执行,同时找出真正决定任务差异的信息瓶颈表示。
- 再学一个探索策略,让它专门去恢复这些任务相关信息。
为什么信息瓶颈是必要的
如果不压缩任务表示,探索策略很容易被与任务无关的装饰性信息带偏。DREAM 借助 bottlenecked representation,只保留 wall color、食材位置等真正影响执行策略的变量,让探索策略的奖励更聚焦于 “找对信息”。
把信息恢复直接变成探索奖励
课程进一步把探索奖励写得很清楚:让探索策略收集的数据 \(D_{\text{train}}\) 尽可能有助于预测任务表示 \(z_i\)。这样 reward 不再依赖最终任务是否成功,而依赖 “本轮探索让我们对当前任务多了解了多少”。

信息瓶颈为什么值得单独建模
如果任务表示里塞进了太多与执行无关的细节,探索策略就会去恢复错误的信息,例如装饰、纹理或无关背景。课程专门回顾 variational information bottleneck 的原因就在这里:通过噪声和正则约束,把表示压到只剩执行真正需要的那部分任务差异。

理论与实验结果
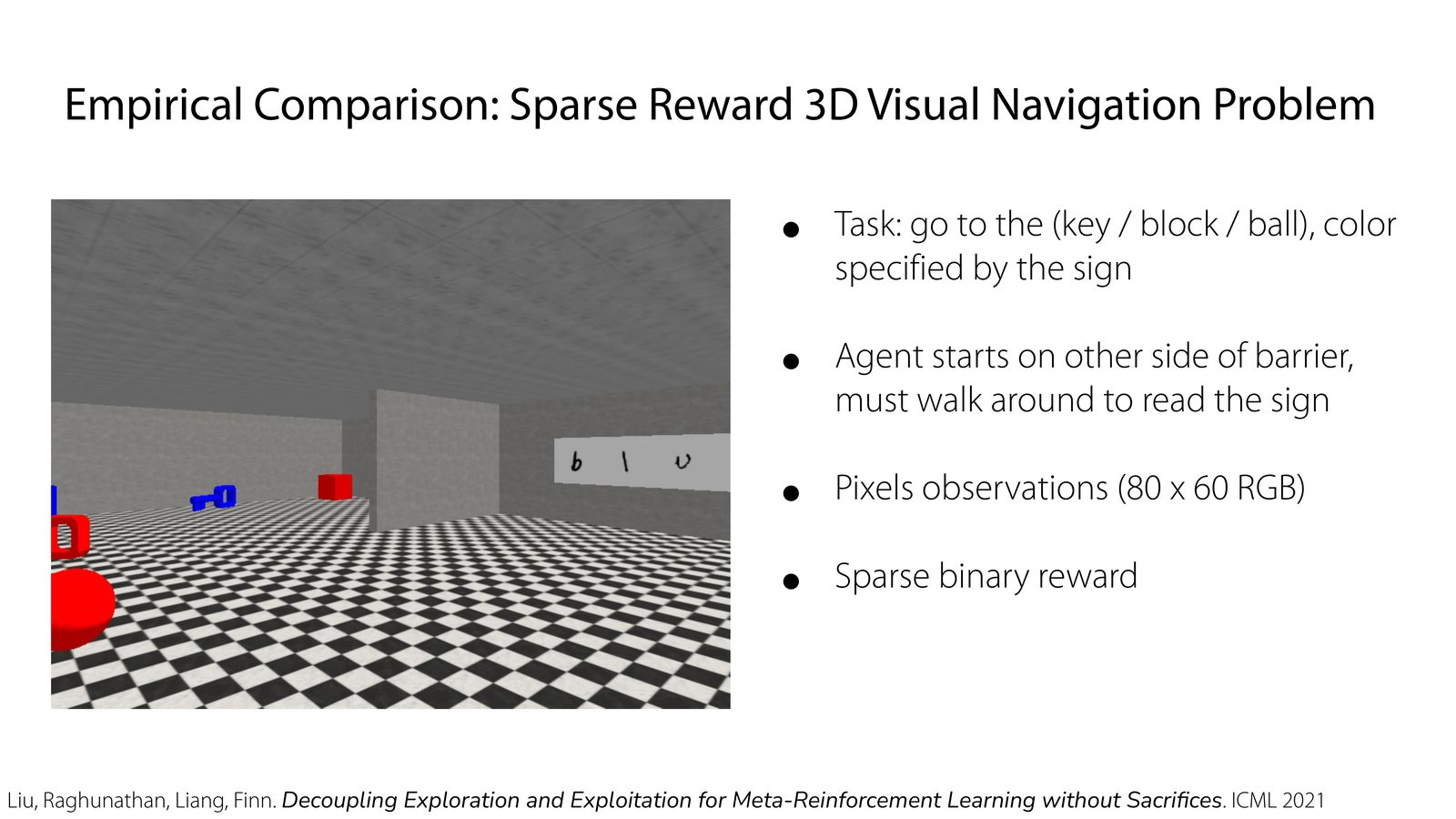
slides 给出的结论很有代表性:在 bandit-like setting 中,DREAM 的样本复杂度优于 RL\(^2\);在 3D visual navigation 这种稀疏奖励任务里,端到端方法会因为 coupling 问题显著掉队,而 DREAM 靠近似最优探索达到更高回报。

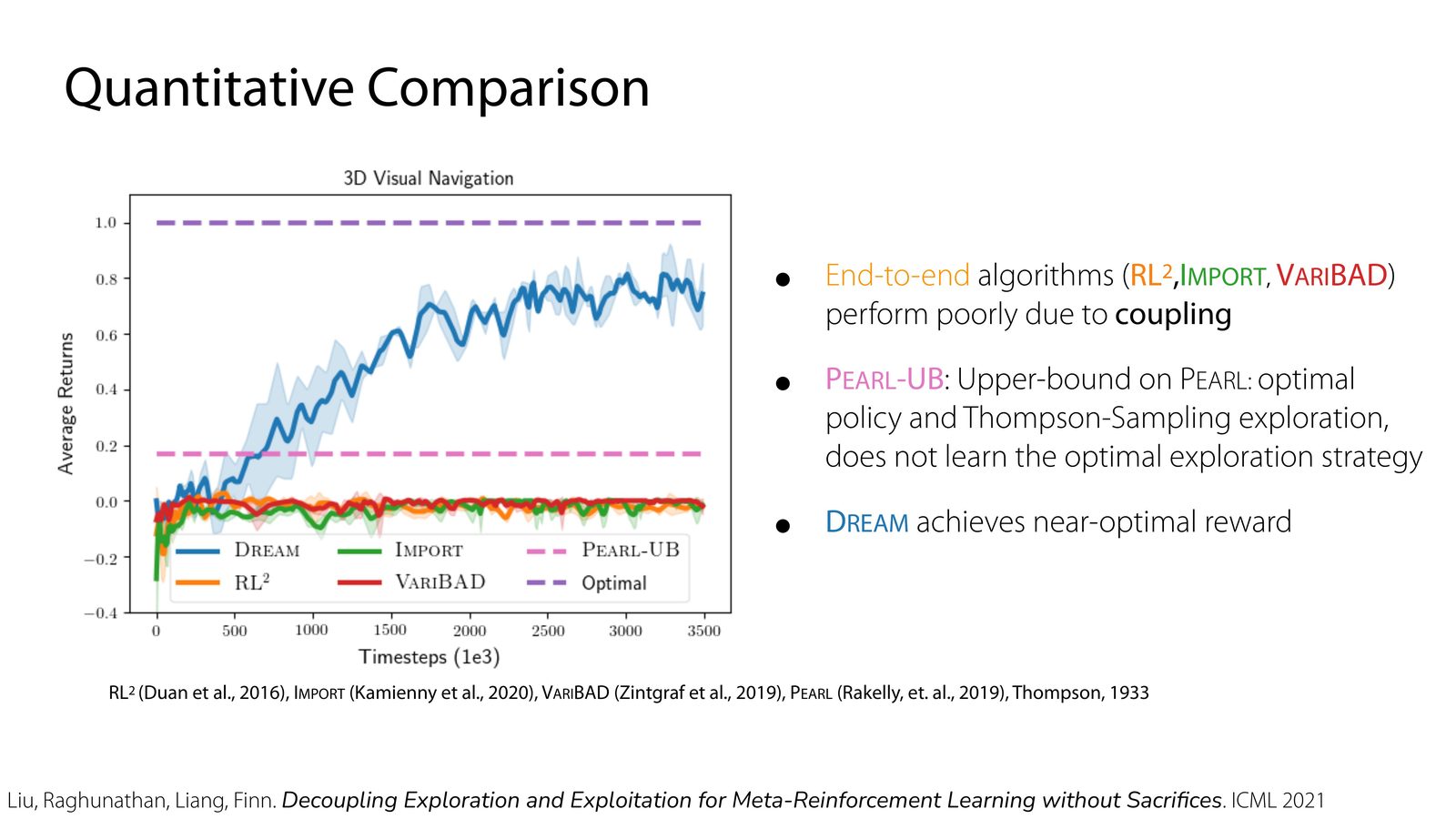
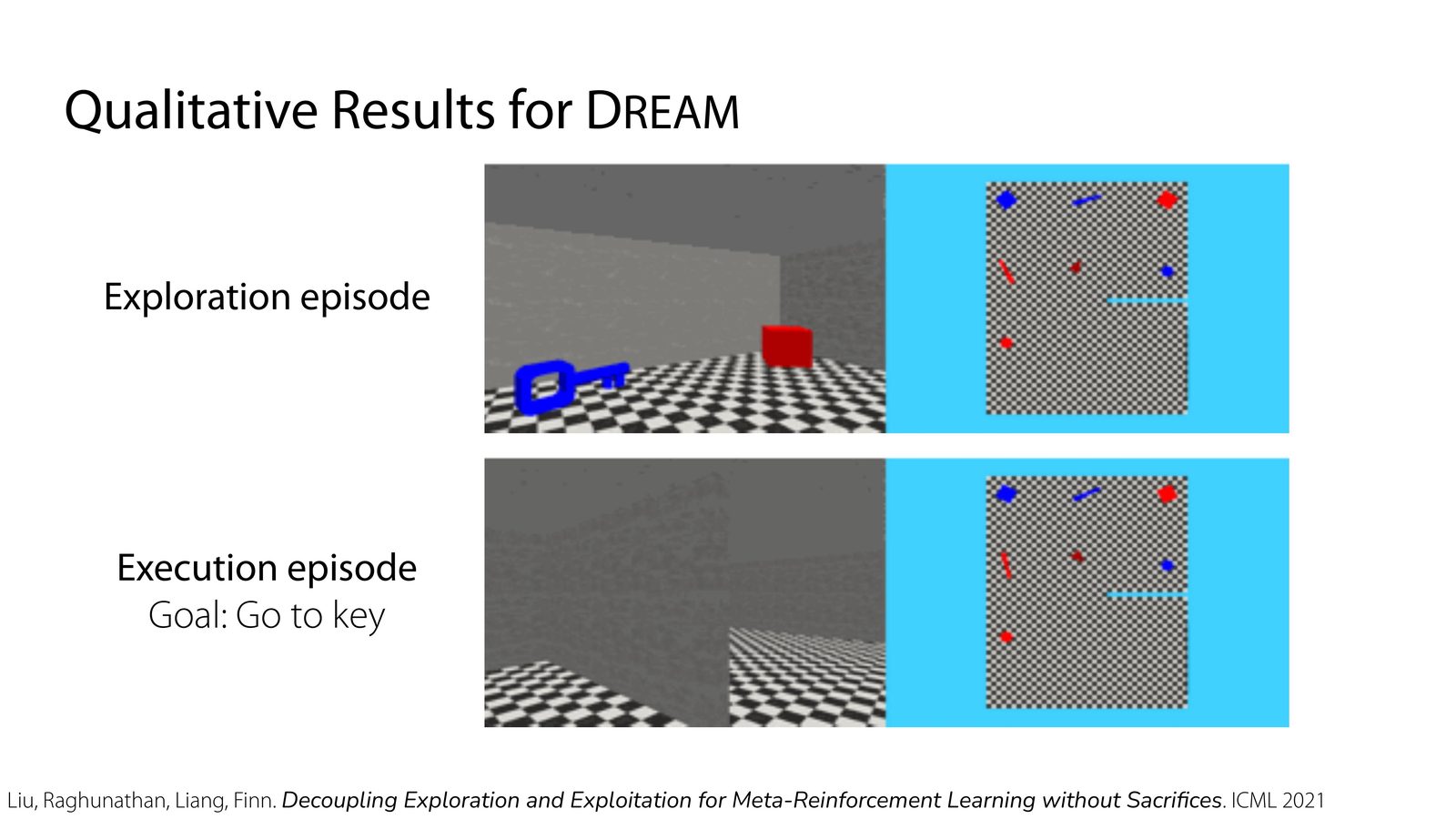
本章小结
元探索将探索策略本身作为学习对象,通过在多个任务上训练来学习高效的探索行为。
总结与延伸
- 探索是 RL 的核心挑战,\(\epsilon\)-greedy 到 UCB/Thompson Sampling 形成了一个日益精细的工具链
- 深度 RL 中需要用密度模型或网络预测误差来近似新颖性
- 基于好奇心的方法需警惕噪声电视问题
- 元探索将"如何探索"本身作为可学习的能力
- 在机器人和 LLM 等真实应用中,有效探索直接决定了学习效率
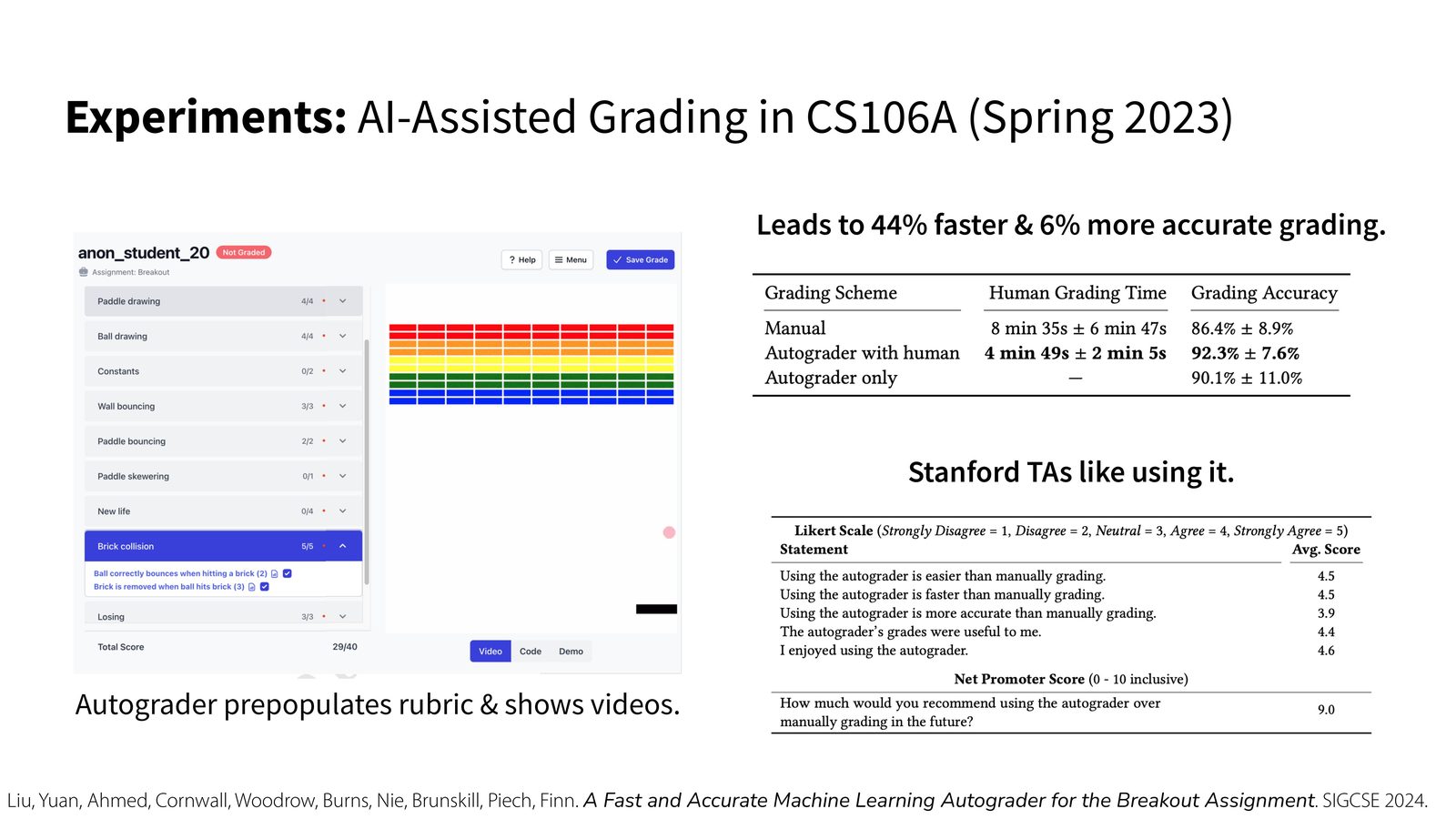
应用外延:把 meta-exploration 用到计算机教育
课程最后还展示了一个很少见但很有启发性的方向:把 meta-RL 的探索策略用于自动批改和学生程序反馈。系统先学习 “该运行哪些测试、该看哪些行为信号最有信息量”,再更快地找出 bug、生成评分建议。
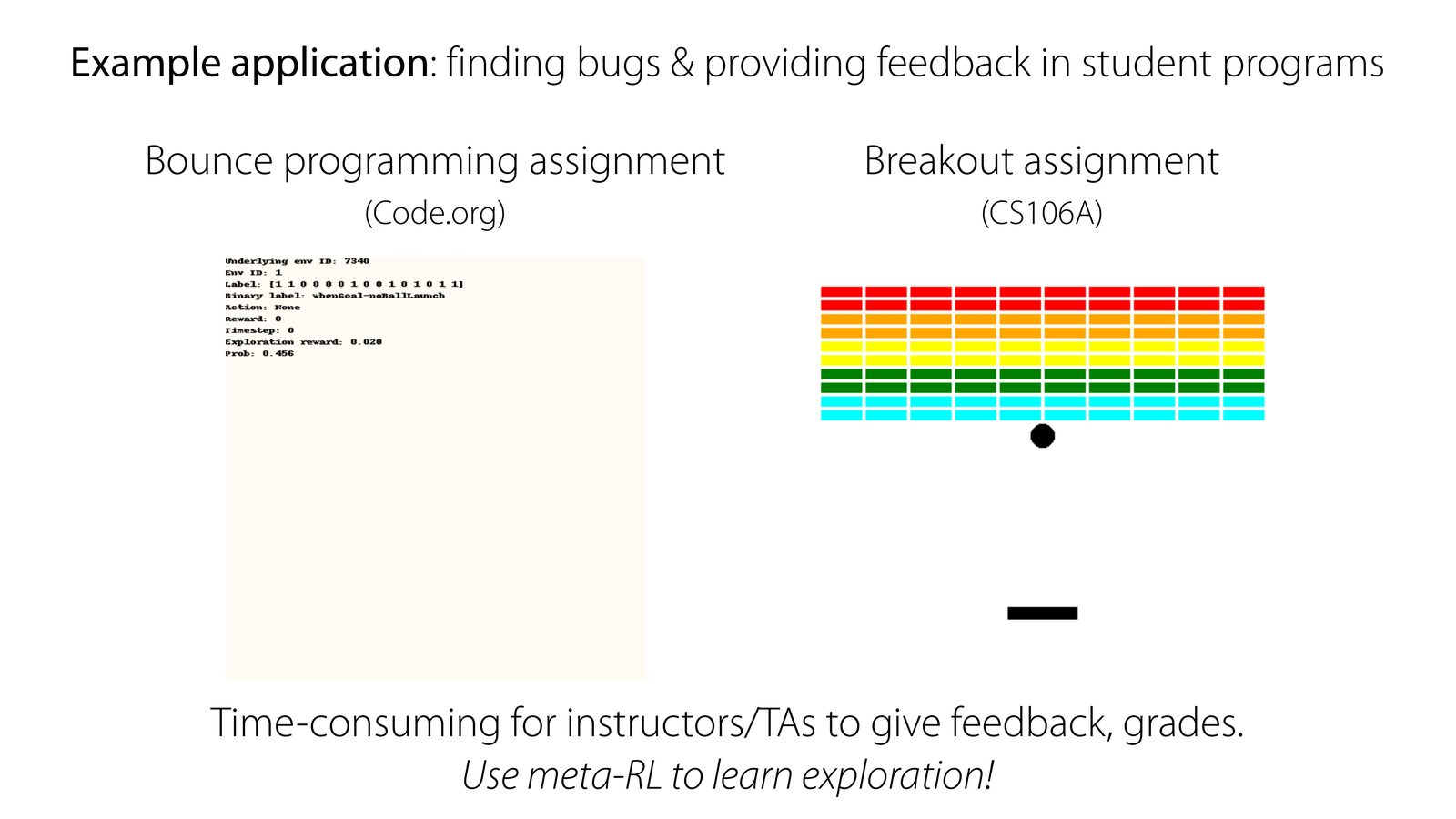
教育场景里的 “探索” 和传统 RL 有何不同
这里的探索不再是操控机器人或玩游戏,而是决定:为了判断学生程序哪里有问题,系统应该优先运行哪些交互、观察哪些信号、展示哪些视频片段。 这类探索的价值在于节省助教时间,同时让反馈更聚焦、更可操作。

| 教育任务 | 需要探索的信息 | 系统收益 |
|---|---|---|
| 交互式编程作业反馈 | 哪些测试情境最能触发 bug | 更快定位错误来源 |
| 助教评分辅助 | 哪些证据最足以支持 rubric 打分 | 减少人工查看和重复判断 |
| 错误模式分析 | 哪些学生行为属于同一类失误 | 形成更可复用的反馈模板 |
本讲总表
| 路线 | 核心思想 | 优势 | 主要问题 |
|---|---|---|---|
| -greedy / UCB / Thompson | 在 bandit 中用不确定性指导探索 | 可分析、可证明 regret | 难直接扩展到大规模 MDP |
| Deep RL intrinsic exploration | 用新颖性或预测误差鼓励探索 | 适配连续高维状态空间 | 易被噪声和伪新颖性误导 |
| End-to-end meta-exploration | 直接从任务 reward 学探索与执行 | 原理统一,理论上最优 | coupling 问题导致训练困难 |
| DREAM-style decoupling | 先学任务关键信息,再学恢复它的探索 | 更易优化,实践效果好 | 依赖任务表示与信息瓶颈设计 |
拓展阅读
- Auer et al., “Finite-time Analysis of the Multiarmed Bandit Problem,” Machine Learning 2002
- Bellemare et al., “Unifying Count-Based Exploration and Intrinsic Motivation,” NeurIPS 2016
- Burda et al., “Exploration by Random Network Distillation,” ICLR 2019
- Pathak et al., “Curiosity-driven Exploration by Self-Supervised Prediction,” ICML 2017
- Liu et al., “Explore then Execute: Adapting without Rewards via Factorized Meta-Reinforcement Learning,” 2022