CS224N Lecture 7: Attention and LLM Intro
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Chris Manning 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2024年春季 |

机器翻译评估
本讲的第一部分承接上一讲的序列到序列(Sequence-to-Sequence)机器翻译模型,讨论如何评估机器翻译系统的质量。

来源:Slides 第2页。
序列到序列模型回顾
在上一讲中,我们介绍了基于多层 LSTM 的编码器-解码器(Encoder-Decoder)架构用于机器翻译。编码器读入源语言句子,将信息压缩到最后一个隐藏状态中;解码器以此为初始状态,逐词生成目标语言翻译。
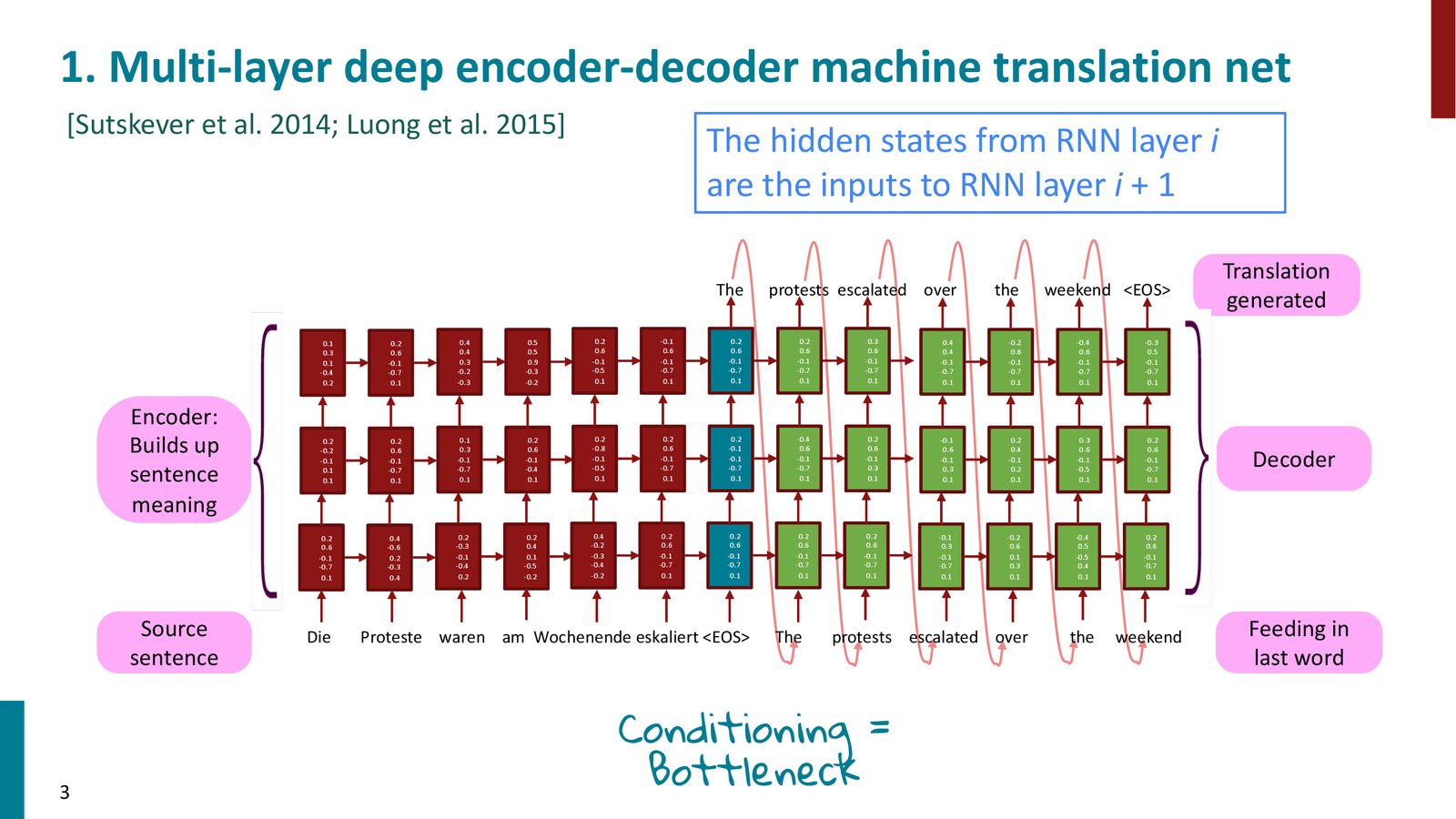
来源:Slides 第3页。参考 Sutskever et al. 2014; Luong et al. 2015。
信息瓶颈问题
在标准的 Seq2Seq 架构中,源句的所有信息必须被压缩到编码器最后一个隐藏状态向量中。对于短句子这或许可以接受,但当源句长达 40 个词时,将全部语义信息塞入一个固定大小的向量显然是不合理的。这个问题被称为信息瓶颈(Information Bottleneck),也是注意力机制被发明的直接动因。
BLEU 评估指标
为了自动评估机器翻译质量,Papineni 等人(2002)提出了 BLEU(Bilingual Evaluation Understudy)指标。在此之前,翻译质量只能通过人工评估来衡量,这虽然是金标准,但成本高昂且无法嵌入训练循环。

来源:Slides 第4页。来源:Papineni et al., 2002。
BLEU 指标的核心思想
BLEU 通过计算机器翻译与人工参考翻译之间的 n-gram 重叠度来衡量翻译质量:
- 计算 1-gram、2-gram、3-gram、4-gram 的精确率(precision)
- 取这些精确率的几何平均值
- 加入简短惩罚(brevity penalty),防止系统通过只翻译简单部分来获取高分
BLEU 分数理论上在 0--100 之间,但由于翻译的多样性,永远不会达到 100。

来源:Slides 第5页。
BLEU 分数的解读
- 20 分左右:可以大致理解源文档的主题
- 30--40 分:翻译质量开始变得不错
- 50--60 分:现代神经机器翻译系统在一些语言对上已能达到的水平
原始设计建议使用多个参考翻译来更好地覆盖翻译空间,但实践中使用单个参考翻译也很常见。
BLEU 的局限性
BLEU 是一个有用但不完美的指标:
- 一个好的翻译可能因为措辞与参考翻译不同而获得低分
- 一个差的翻译可能因为碰巧包含一些正确的词而获得一些分数
- 它无法捕捉语义等价性——同义词替换会被错误惩罚
因此,人工评估在高风险场景中仍然是必不可少的。
机器翻译的历史进展
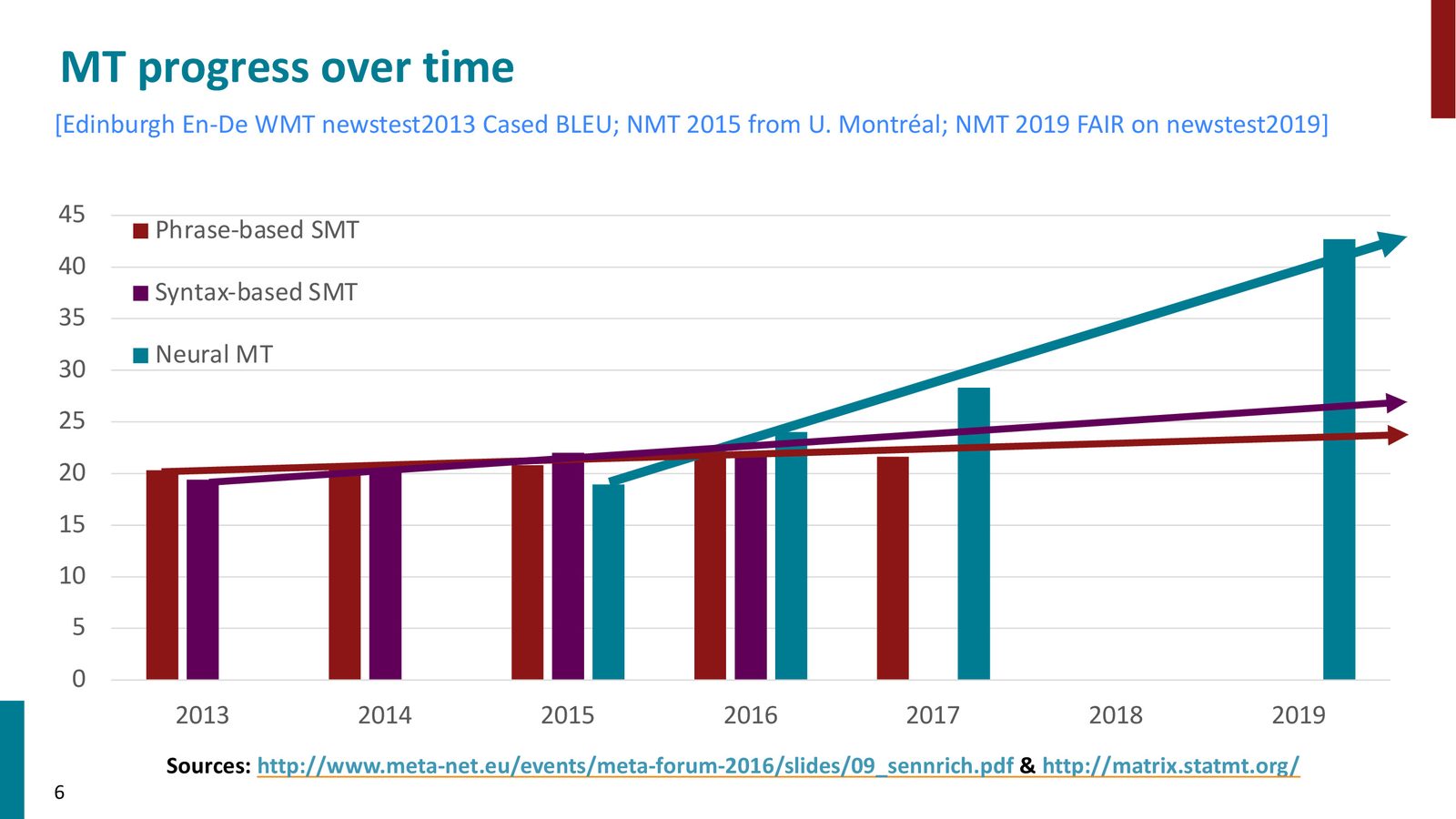
来源:Slides 第6页。
机器翻译技术经历了三个重要阶段:
- 统计短语翻译(Phrase-based SMT,1990s--2010s):IBM 开创,Google Translate 最初使用此方法。进展缓慢,BLEU 分数几乎停滞。
- 句法翻译(Syntax-based SMT,2005--2015):试图利用句法结构改善翻译,尤其针对词序差异大的语言对(如德-英、中-英),但改进幅度有限。
- 神经机器翻译(Neural MT,2014至今):2014年首次出现,2015年在 bake-off 评测中亮相,2016年超越所有传统方法,此后一路高歌猛进。
NMT 的崛起
Manning 教授指出,在 2005--2014 年间,机器翻译社区的主流观点是“要想做好翻译,必须理解句法结构”。然而,神经机器翻译的成功表明,端到端学习可以隐式地捕获这些结构信息,这彻底颠覆了传统思维。注意力机制是推动 NMT 成功的关键技术之一。
本章小结
- BLEU 是最广泛使用的机器翻译自动评估指标,基于 n-gram 精确率的几何平均
- BLEU 有用但不完美,好翻译可能低分,差翻译可能得分
- 神经机器翻译从2014年起迅速超越传统方法,注意力机制是其成功的核心要素
- 编码器-解码器架构存在信息瓶颈,这直接催生了注意力机制的发明
注意力机制
注意力(Attention)是近年来神经网络领域最重要的创新之一。Manning 教授强调,前面课程中介绍的所有技术(前馈网络、RNN、LSTM、CNN)都是上世纪发明的,而注意力是2014年在神经机器翻译背景下全新发明的概念,它对提升神经网络的能力具有变革性意义。
动机:序列到序列的信息瓶颈
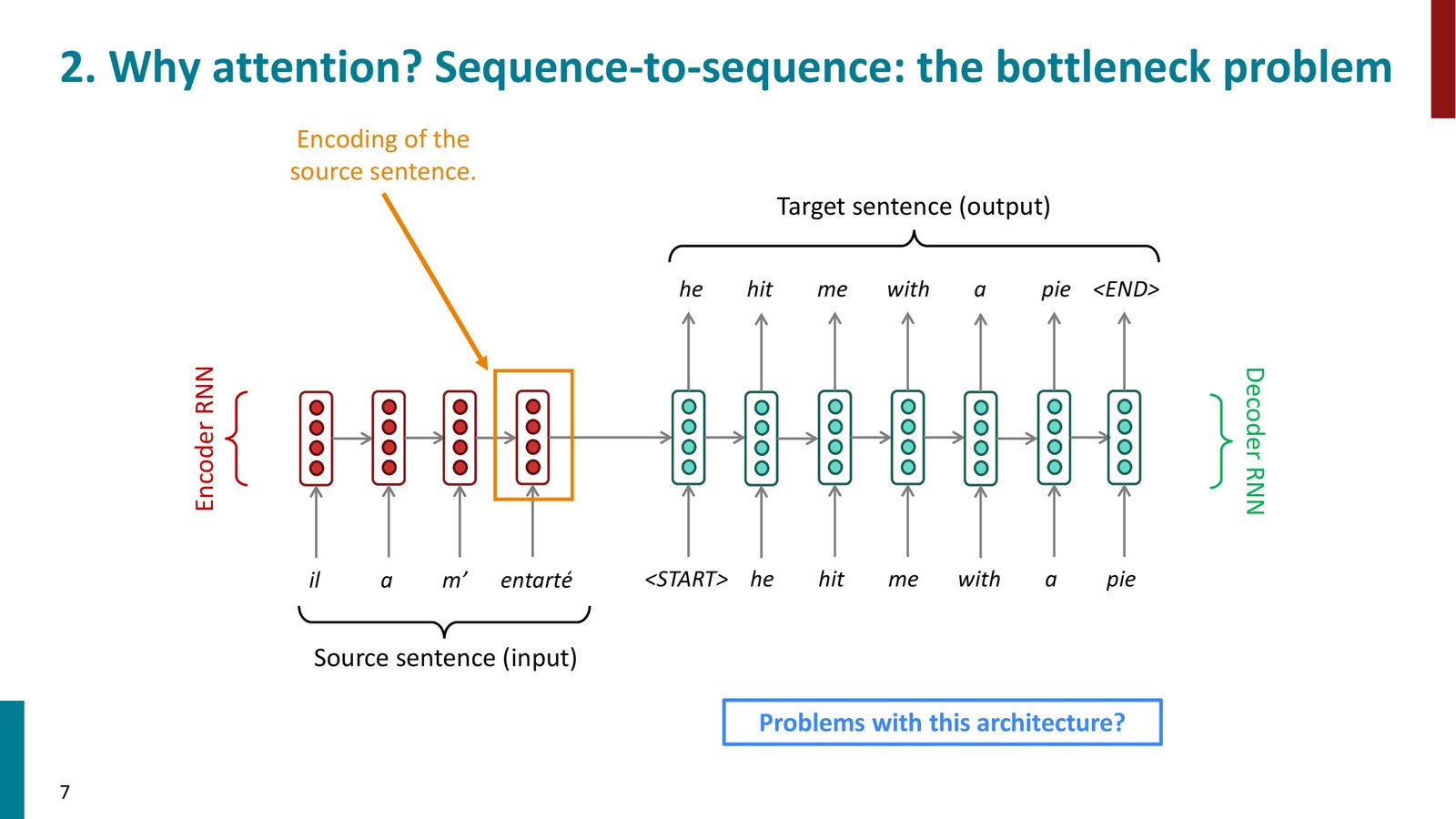
来源:Slides 第7页。
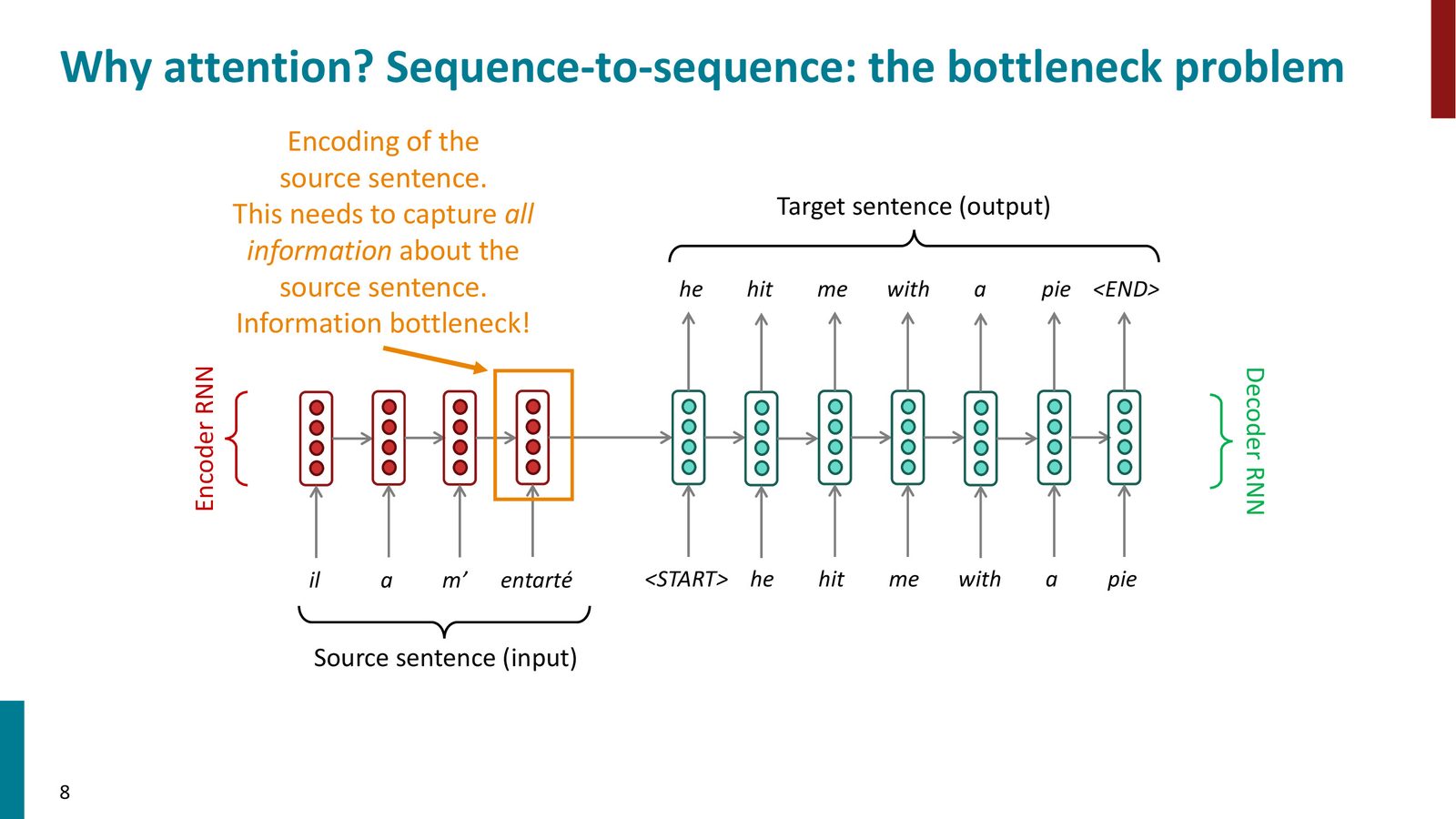
来源:Slides 第8页。
标准 Seq2Seq 模型的核心问题在于:
- 编码器将整个源句压缩为单一向量
- 对于长句子,这个向量无法承载所有必要信息
- 粗暴的解决方案(增大隐藏状态、增加层数)效果有限
- 人类翻译时会回头查看源句的不同部分,而不是一次性记住所有内容
注意力的核心思想
在解码器的每一步,建立与编码器的直接连接,让解码器能够聚焦于源序列的特定部分,从而按需获取信息。这就像人类翻译时回头查看原文的特定词语一样。

来源:Slides 第9页。
注意力机制的工作流程
注意力机制在 Seq2Seq 中的完整工作流程可以分解为以下步骤:
Step 1: 计算注意力分数
在解码器的每个时间步 \(t\),用解码器当前隐藏状态 \(\mathbf{s}_t\) 与编码器每个位置的隐藏状态 \(\mathbf{h}_i\) 计算注意力分数(最简单的方式是点积)。
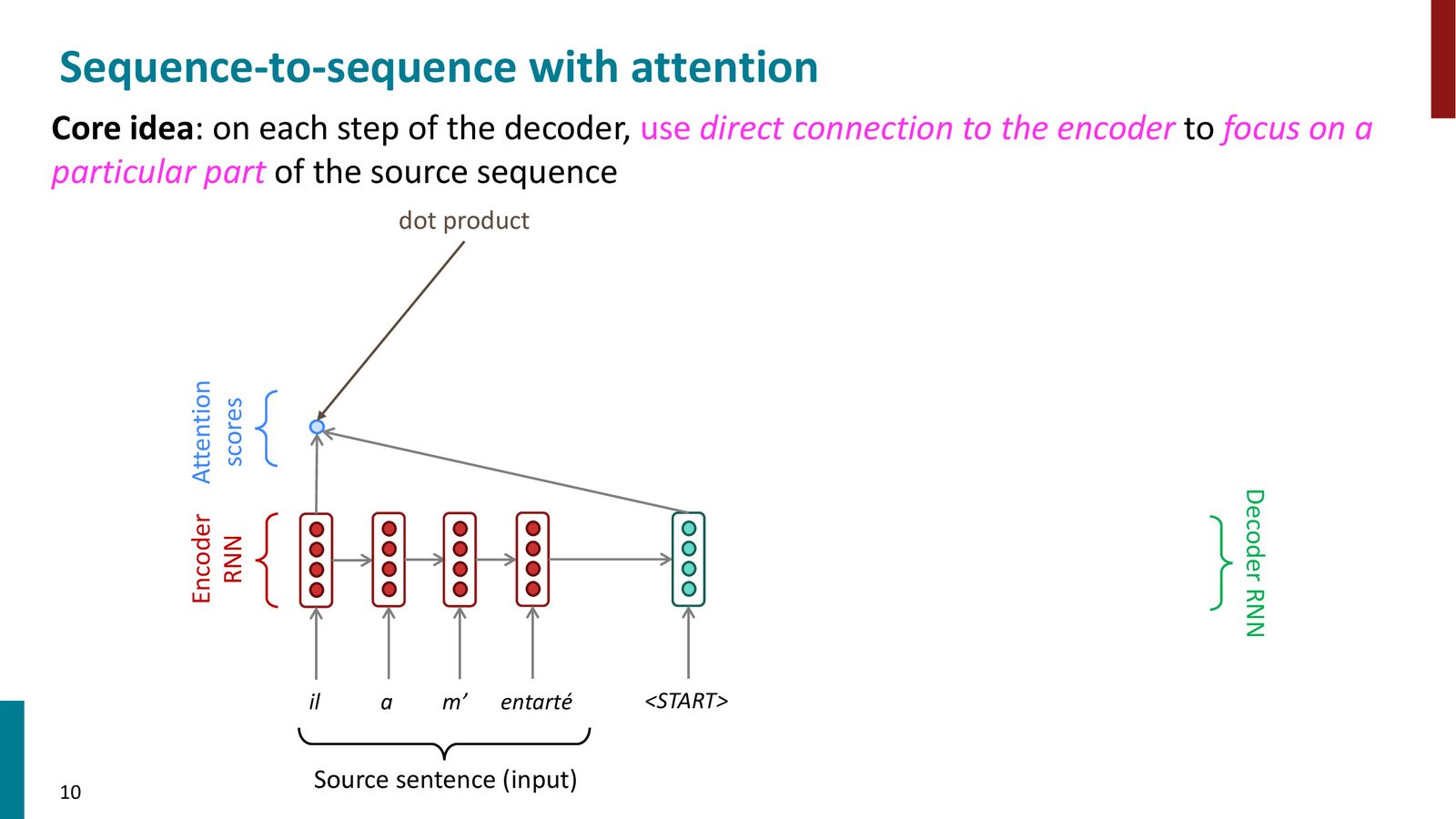
来源:Slides 第10页。
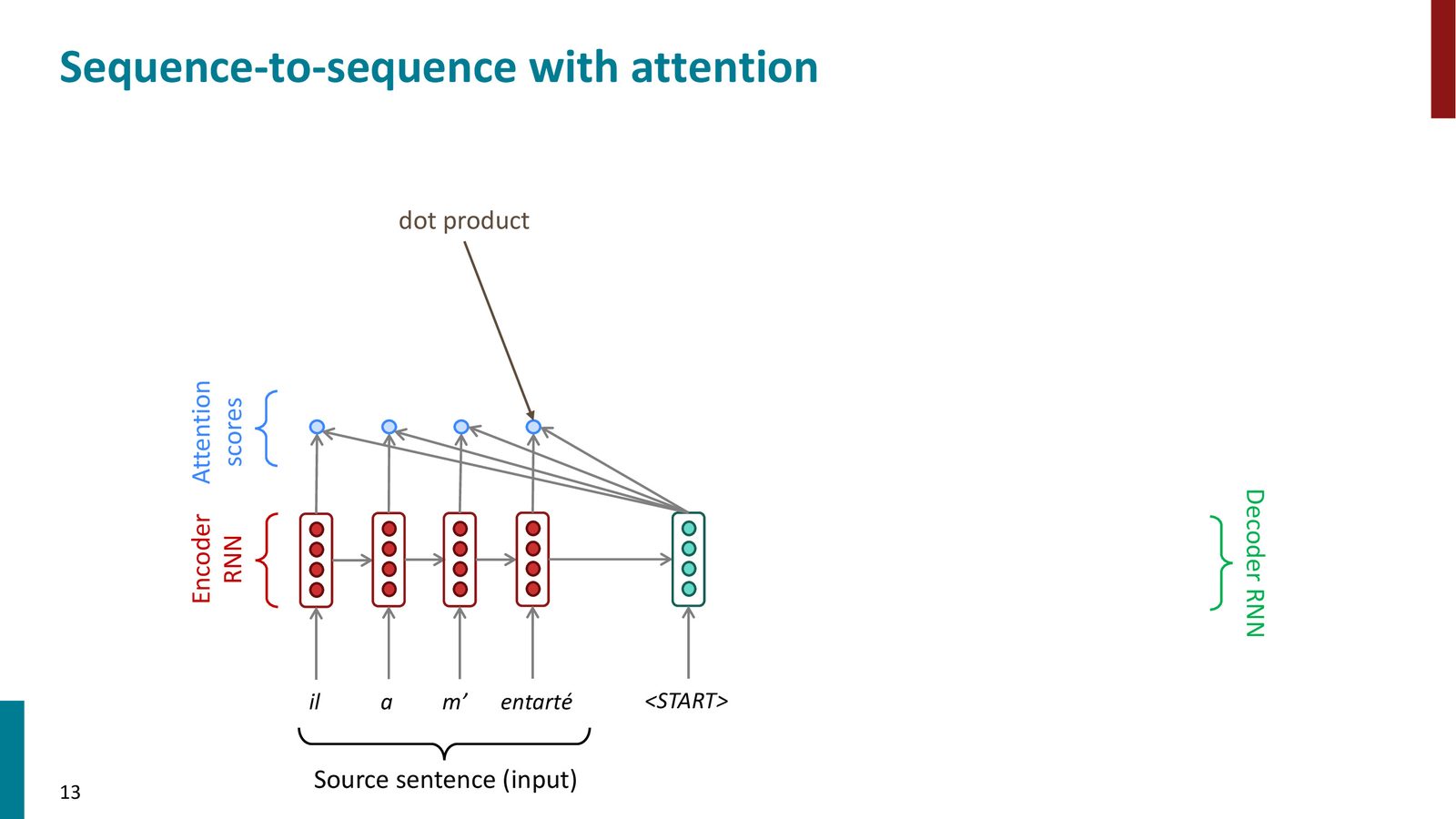
来源:Slides 第13页。
Step 2: 通过 Softmax 获得注意力分布
将注意力分数通过 softmax 转换为概率分布,表示解码器在当前时间步应该“关注”源句哪些位置。
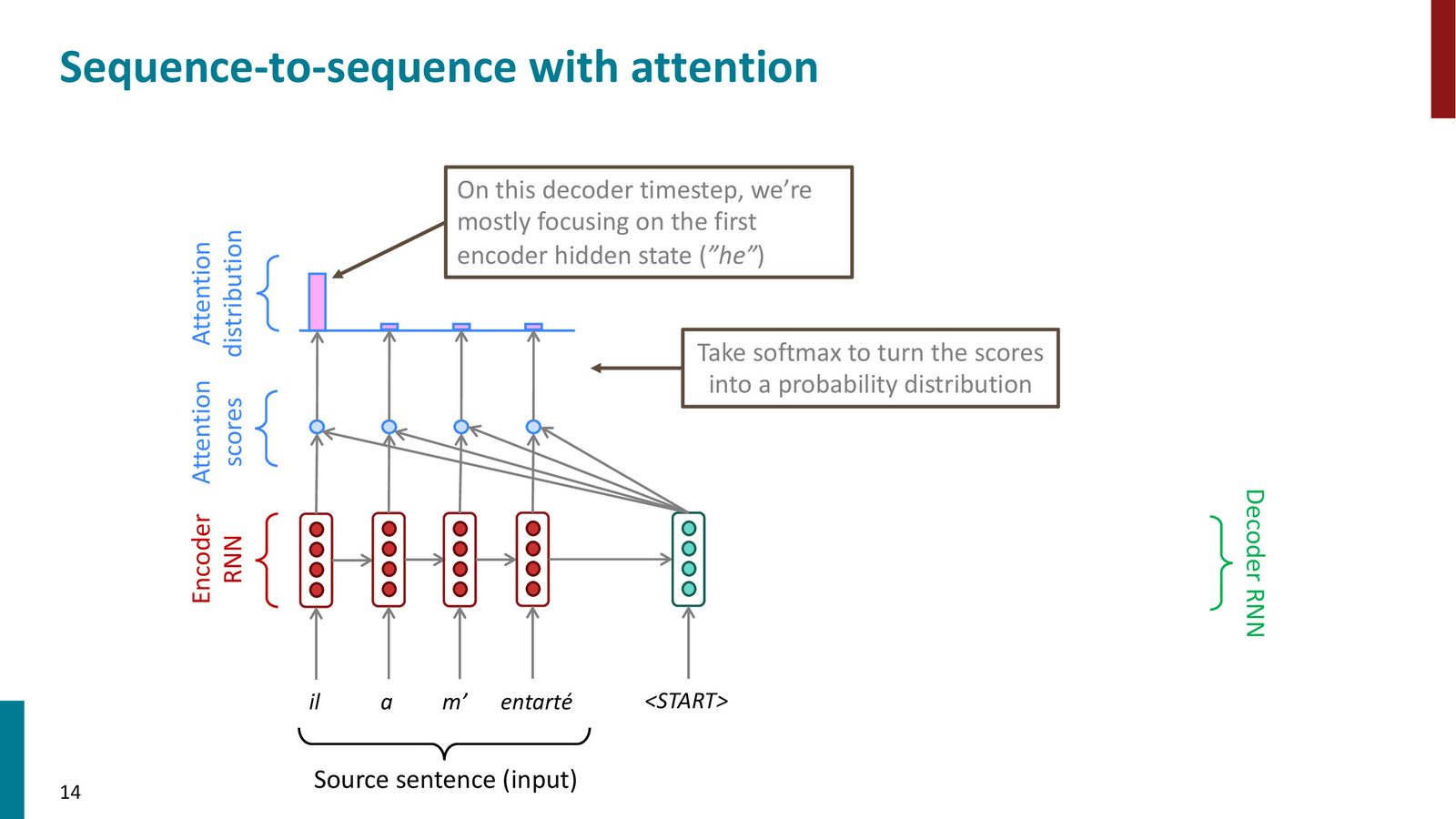
来源:Slides 第14页。
Step 3: 计算注意力输出
用注意力分布对编码器隐藏状态做加权求和,得到注意力输出(attention output),也称为上下文向量(context vector)。
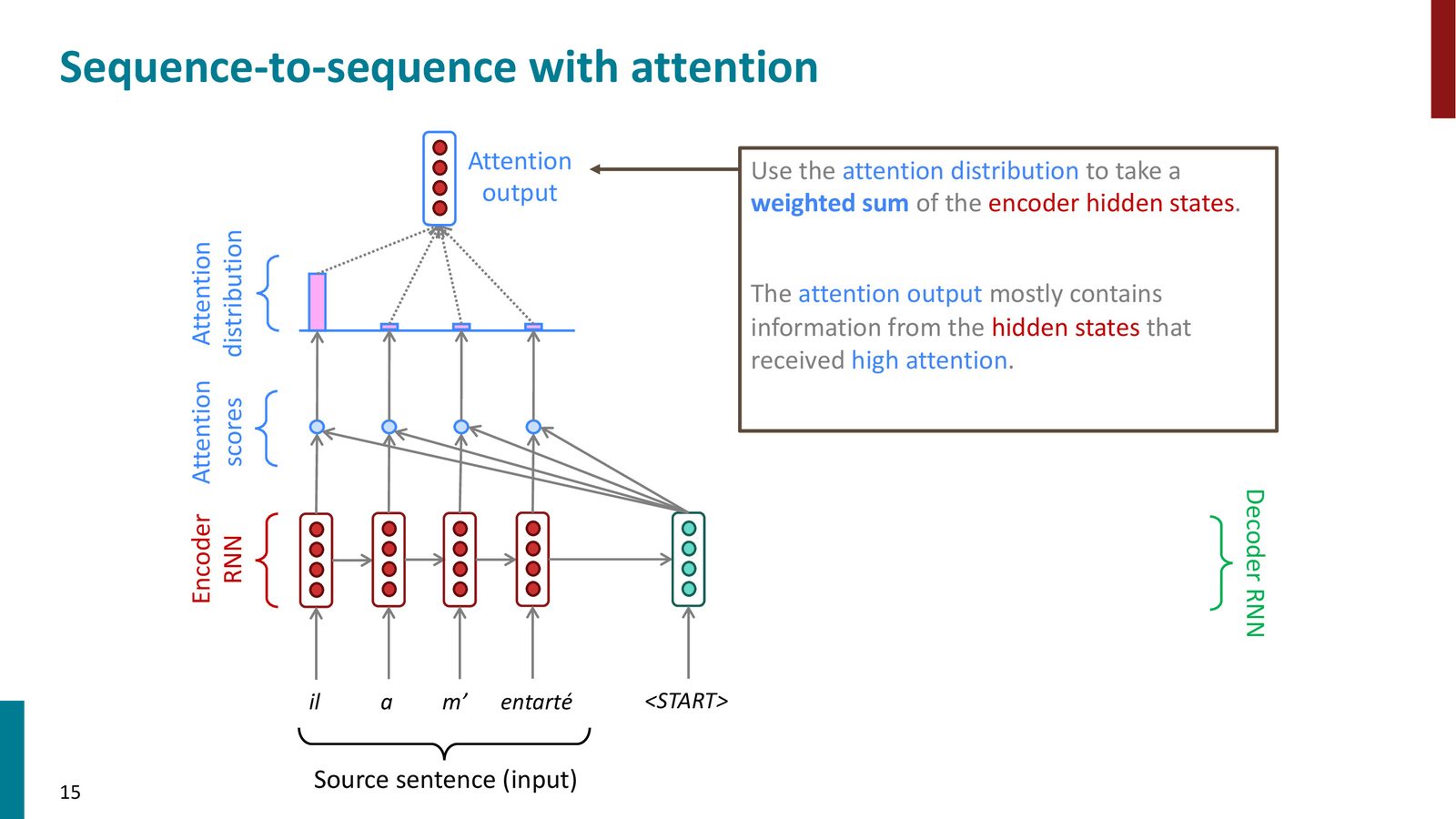
来源:Slides 第15页。
Step 4: 拼接并生成输出词
将注意力输出与解码器隐藏状态拼接(concatenate),送入后续层生成下一个词。
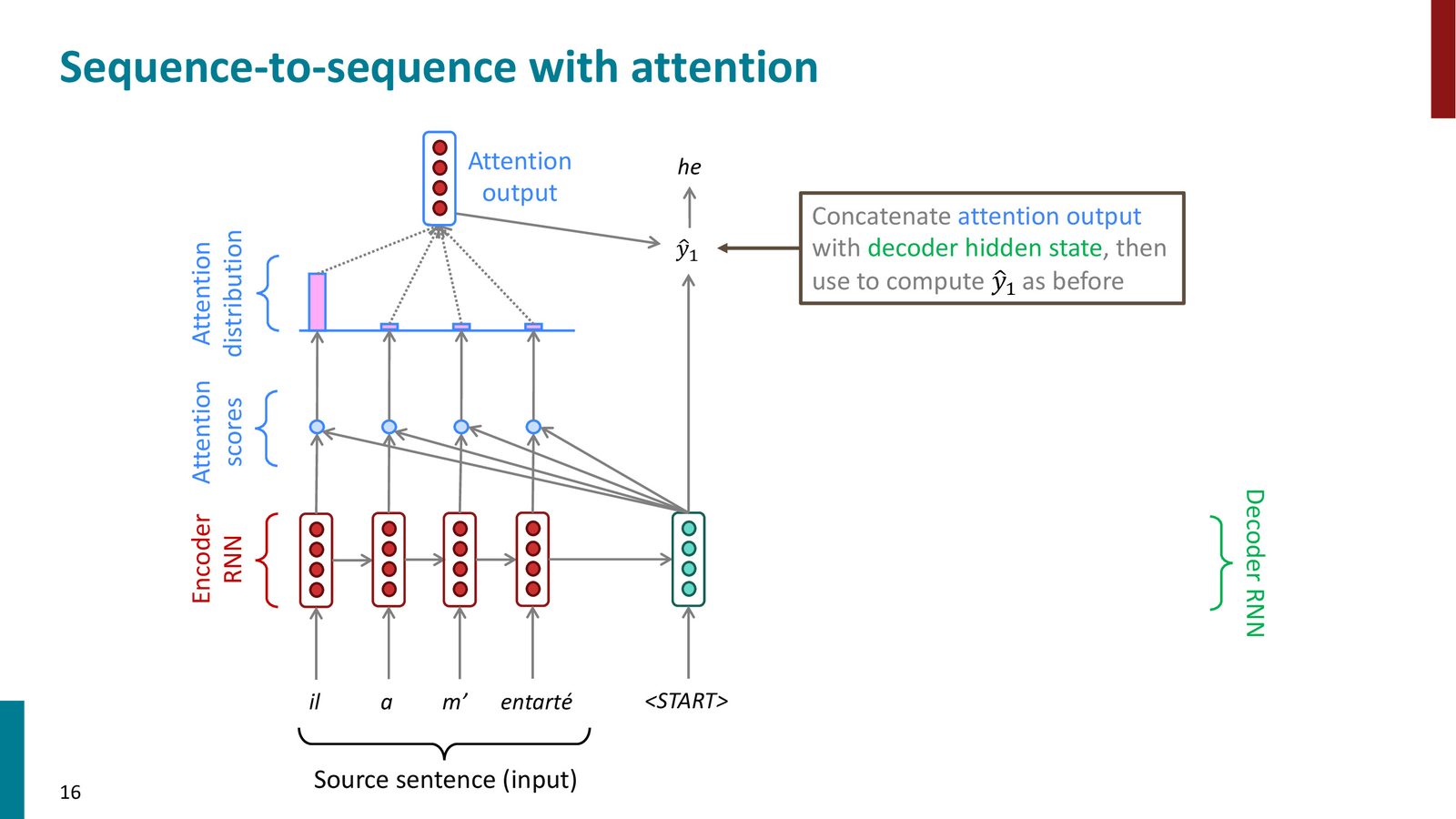
来源:Slides 第16页。
重复:逐步翻译
在后续的每个解码步骤中,重复上述过程。每一步解码器都会重新计算注意力,关注源句的不同部分。
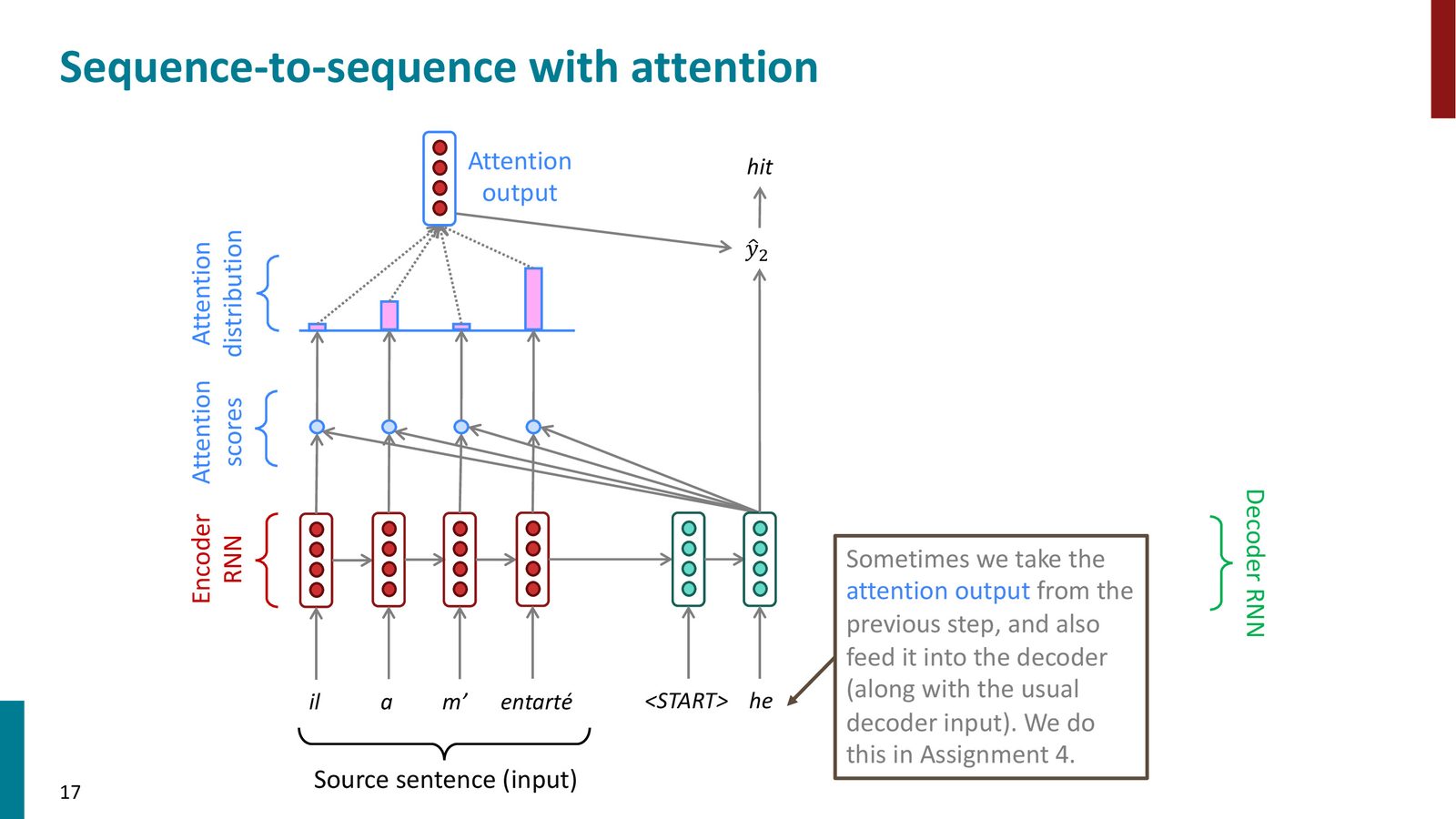
来源:Slides 第17页。
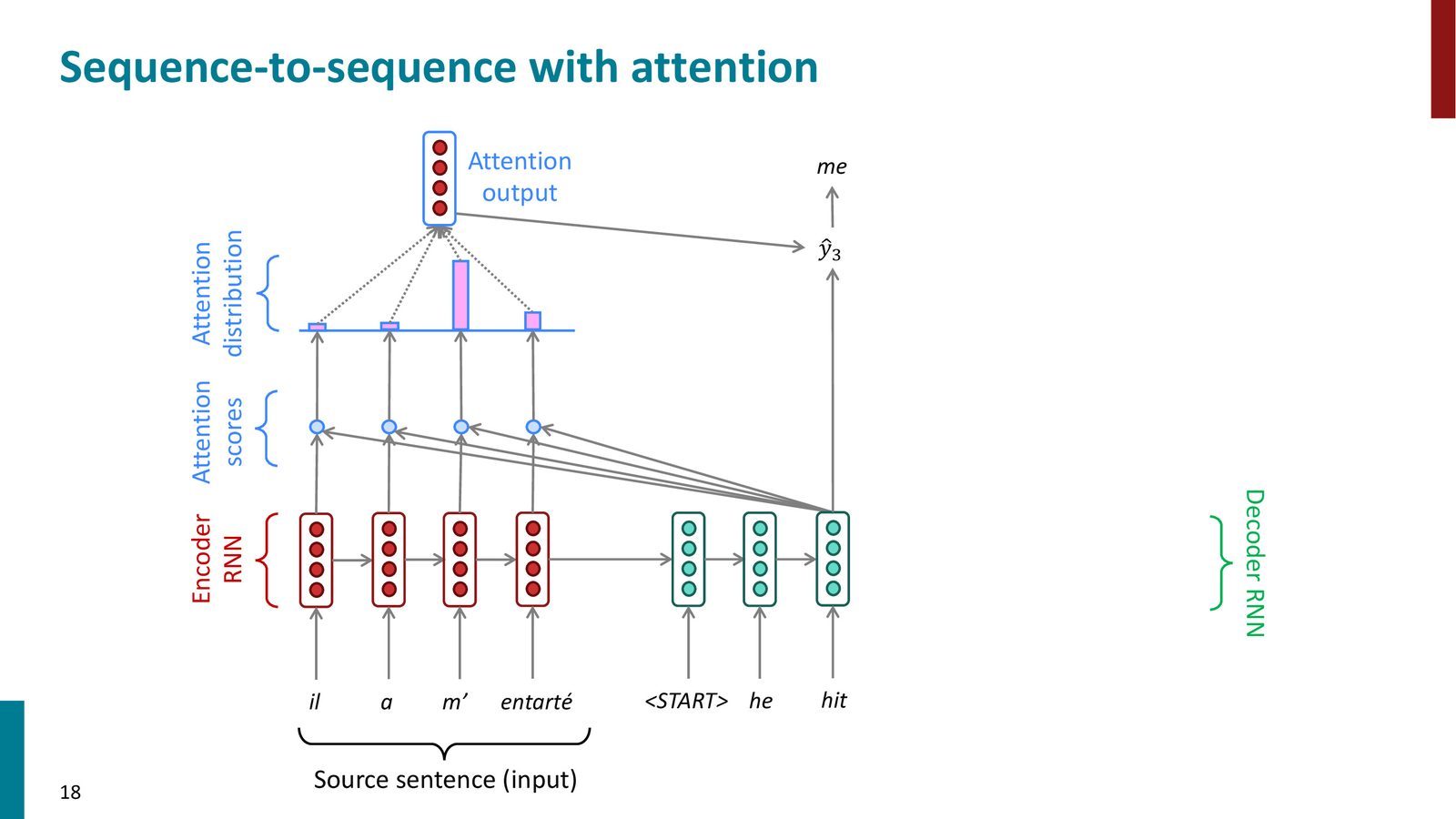
来源:Slides 第18页。
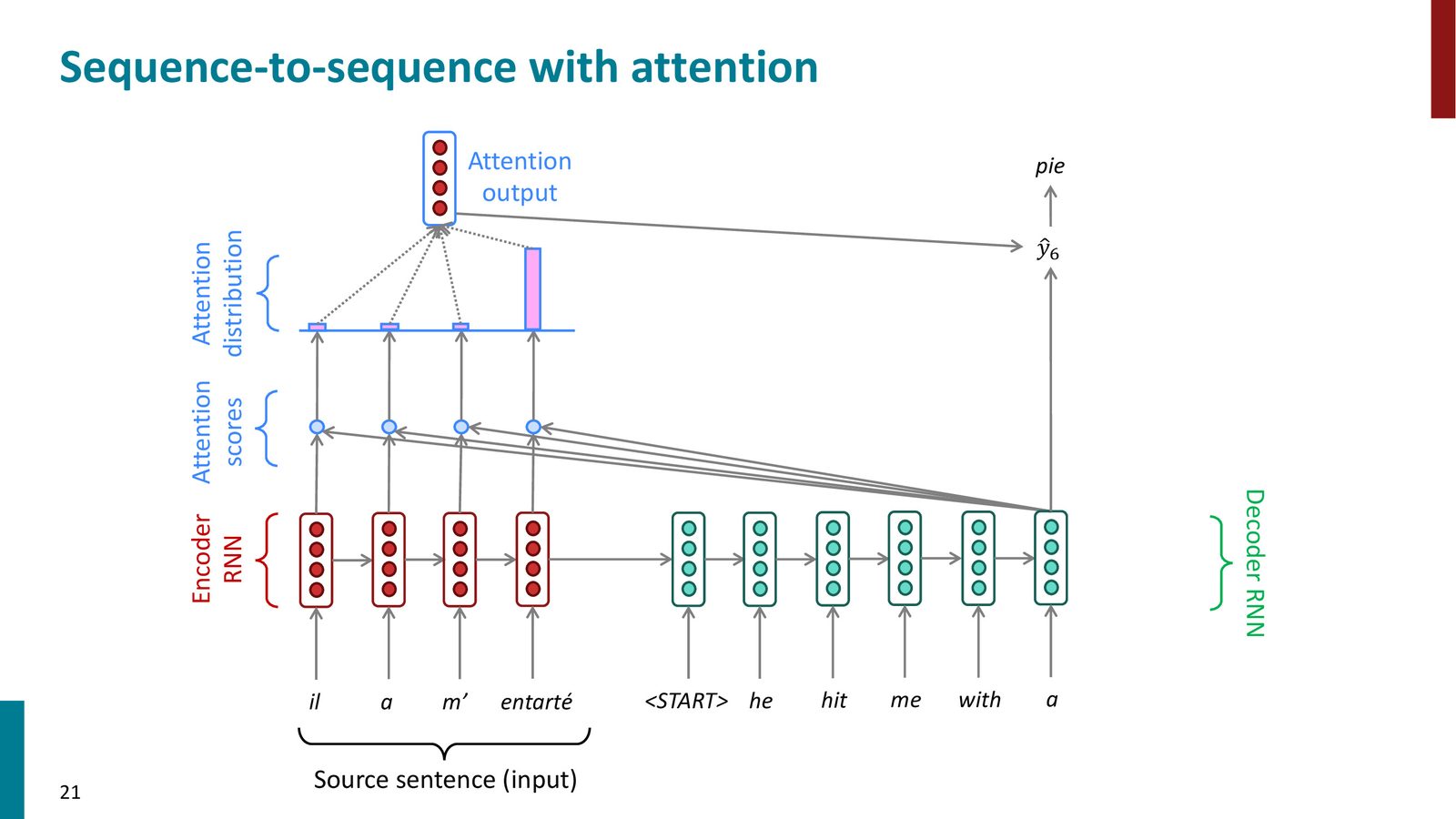
来源:Slides 第21页。
本章小结
注意力机制的工作流程可以总结为四步:
- 计算注意力分数:解码器隐藏状态与编码器各位置隐藏状态的相似度
- Softmax:将分数转换为概率分布
- 加权求和:用注意力分布对编码器隐藏状态求加权平均,得到上下文向量
- 拼接与生成:将上下文向量与解码器隐藏状态拼接,生成输出词
注意力的数学形式化
Dot-Product Attention 的数学表示

来源:Slides 第22页。
设编码器隐藏状态为 \(\mathbf{h}_1, \ldots, \mathbf{h}_N \in \mathbb{R}^h\),解码器在时间步 \(t\) 的隐藏状态为 \(\mathbf{s}_t \in \mathbb{R}^h\)。注意力计算的完整公式如下:
第一步:计算注意力分数
- \(\mathbf{e}^t\):时间步 \(t\) 的注意力分数向量
- \(\mathbf{s}_t^T \mathbf{h}_i\):解码器状态与编码器第 \(i\) 个位置状态的点积
第二步:通过 Softmax 得到注意力分布
- \(\boldsymbol{\alpha}^t\) 是一个概率分布,所有元素非负且和为1
第三步:计算注意力输出(上下文向量)
- \(\mathbf{a}_t\):编码器隐藏状态的加权平均,权重由注意力分布决定
第四步:拼接并生成
将注意力输出与解码器隐藏状态拼接,得到双倍长度的向量,通过线性变换和 softmax 生成输出词的概率分布。
注意力机制的本质
注意力机制本质上是一种软性信息检索:给定一个查询(query,即解码器状态),在一组值(values,即编码器状态)中寻找最相关的信息,并通过加权平均的方式提取出来。这种“查询-键值”的思想后来在 Transformer 中被进一步发展为 Query-Key-Value 框架。
注意力变体
注意力机制的通用框架包含一组值(values)\(\mathbf{h}_1, \ldots, \mathbf{h}_N \in \mathbb{R}^{d_1}\) 和一个查询(query)\(\mathbf{s} \in \mathbb{R}^{d_2}\)。不同的注意力变体在“如何计算注意力分数”这一步有所不同。

来源:Slides 第24页。
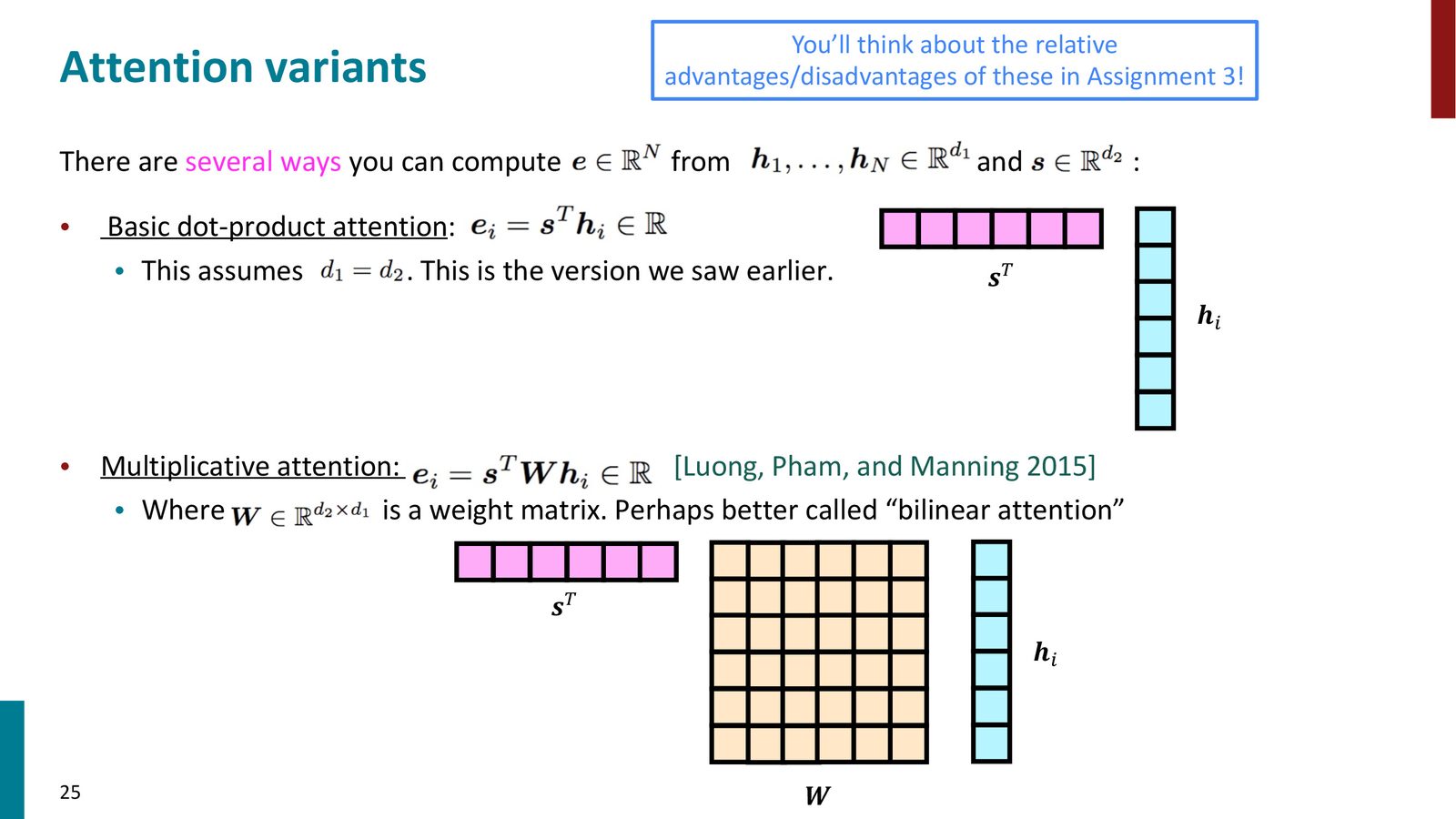
基本点积注意力(Basic Dot-Product Attention)
- 最简单的形式,直接计算查询和值的点积
- 要求 \(d_1 = d_2\)(查询和值的维度必须相同)
- 优点:计算高效,无需额外参数
- 缺点:隐藏状态必须同时存储多种信息(输出当前词、记录语法结构、规划未来),并非所有维度都与“回头查看”相关
乘法注意力 / 双线性注意力(Multiplicative / Bilinear Attention)
其中 \(\mathbf{W} \in \mathbb{R}^{d_2 \times d_1}\) 是可学习的权重矩阵。
来源:Slides 第25页。参考 Luong, Pham, and Manning 2015。
为什么乘法注意力更好
Manning 教授解释道:LSTM 的隐藏状态是它的“完整记忆”,需要存储多种不同类型的信息。编码器和解码器可能将相同类型的信息存储在不同的维度上。乘法注意力通过可学习的矩阵 \(\mathbf{W}\),能够学习到“解码器的哪些维度应该与编码器的哪些维度匹配”,而不要求维度对维度的精确对应。这是 Luong, Pham 和 Manning 在2015年提出的方法。
降秩乘法注意力(Reduced-Rank Multiplicative Attention)
乘法注意力的一个问题是矩阵 \(\mathbf{W}\) 的参数量为 \(d_1 \times d_2\)(如果隐藏状态维度为1000,则有100万个参数)。解决办法是将 \(\mathbf{W}\) 分解为两个低秩矩阵:
其中 \(\mathbf{U} \in \mathbb{R}^{k \times d_2}\),\(\mathbf{V} \in \mathbb{R}^{k \times d_1}\),\(k \ll d_1, d_2\)。
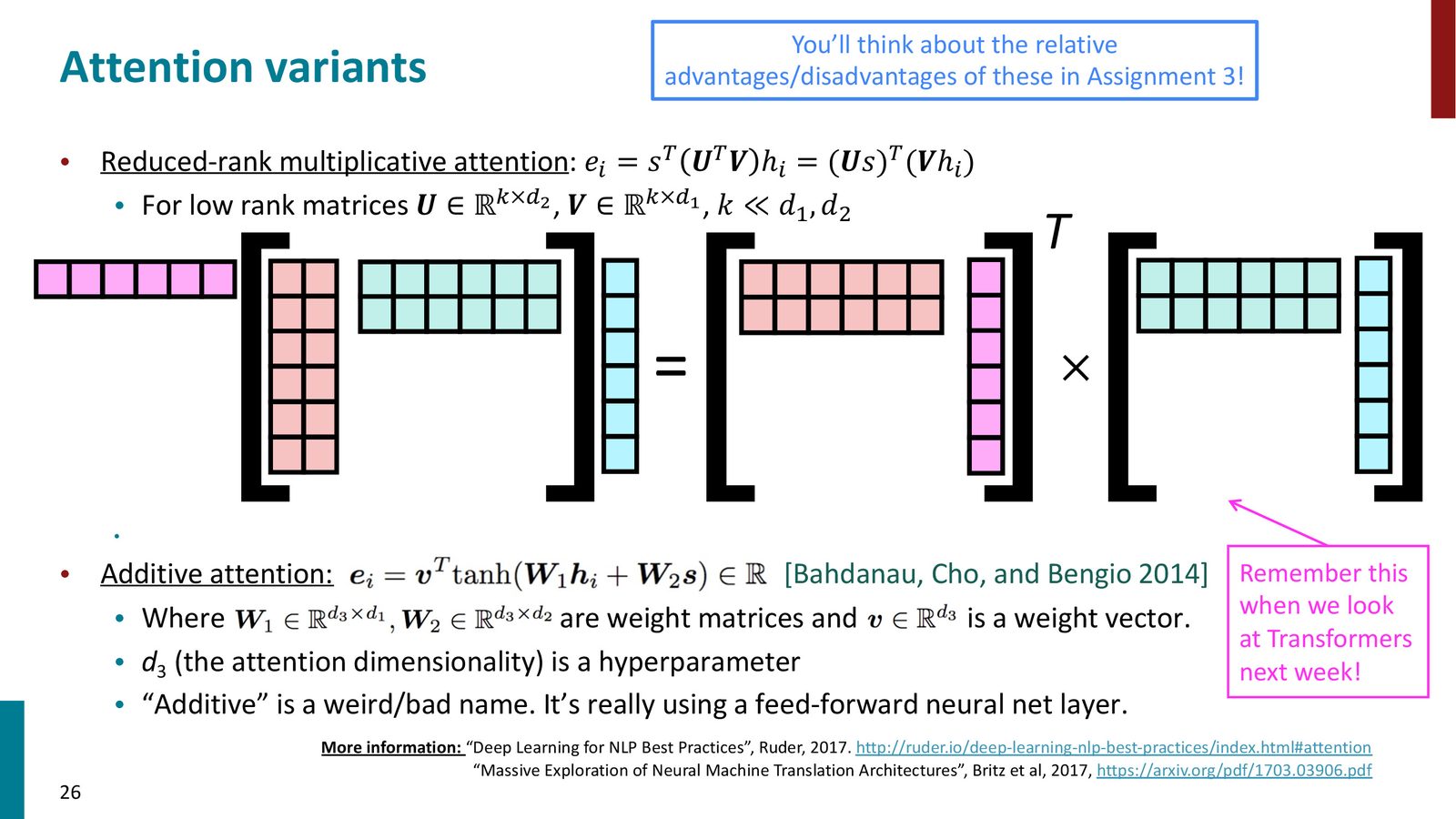
来源:Slides 第26页。
从降秩注意力到 Transformer
降秩乘法注意力的本质是:先将查询和值投影到低维空间,再在低维空间中做点积。这正是 Transformer 中多头注意力的做法!Transformer 取每个大向量,通过投影矩阵将其映射到低维空间,然后在低维空间中计算点积注意力。理解这一点是理解 Transformer 的关键。
加法注意力(Additive Attention)
其中 \(\mathbf{W}_1 \in \mathbb{R}^{d_3 \times d_1}\),\(\mathbf{W}_2 \in \mathbb{R}^{d_3 \times d_2}\),\(\mathbf{v} \in \mathbb{R}^{d_3}\),\(d_3\) 是注意力维度(超参数)。
加法注意力的历史地位
加法注意力是 Bahdanau, Cho, and Bengio(2014)提出的最早的注意力形式。它本质上是一个小型前馈神经网络,用于计算注意力分数。虽然后续研究表明,经过良好的超参数调优后加法注意力可能优于乘法注意力,但由于乘法注意力更简单、更高效,在实践中(特别是 Transformer 中)乘法注意力几乎完全胜出。
| 注意力类型 | 公式 | 额外参数 | 提出者 |
|---|---|---|---|
| 基本点积 | \(s^T h_i\) | 无 | — |
| 乘法/双线性 | \(s^T W h_i\) | \(W\) | Luong et al. 2015 |
| 降秩乘法 | \((Us)^T(Vh_i)\) | \(U, V\) | (Transformer 使用) |
| 加法 | \(v^T (W_1 h_i + W_2 s)\) | \(W_1, W_2, v\) | Bahdanau et al. 2014 |
本章小结
- 注意力机制可以用四个步骤的数学公式完整描述
- 核心差异在于如何计算注意力分数:点积、乘法、降秩乘法、加法
- 降秩乘法注意力通过低维投影 + 点积实现,这正是 Transformer 的做法
- 实践中,乘法/降秩注意力因高效而成为主流
注意力的优势与通用性
注意力带来的四大优势

来源:Slides 第23页。
显著提升 NMT 性能
注意力机制的引入对神经机器翻译性能有变革性提升。Manning 教授讲述了一个重要历史:
- 2014年,Google(Sutskever 等)使用纯 LSTM(8层深,非常大的隐藏状态)进行机器翻译,需要巨大的计算资源
- 同年,蒙特利尔大学的 Bahdanau, Cho, Bengio 引入注意力机制,以远小的计算预算获得了更好的结果
- 此后,所有新的机器翻译系统都使用了注意力机制
注意力是 NMT 的秘密武器
Bahdanau 等人在蒙特利尔大学以远低于 Google 的计算预算,通过引入注意力机制获得了更好的翻译结果。注意力不仅是一种优化,更是一种根本性的架构改进,它使得网络能够更有效地利用已编码的信息。
更接近人类的翻译过程
人类翻译时不会先把整个句子“记住”再翻译,而是会在翻译每个词或短语时回头查看源句的对应部分。注意力机制模拟了这种行为:解码器在每个时间步都可以“回看”编码器的不同位置。
解决信息瓶颈
有了注意力,解码器不再需要仅依赖编码器最后一个隐藏状态。它可以直接访问编码器在每个位置的隐藏状态,从而利用整个编码表示空间。
缓解梯度消失问题
注意力机制在编码器隐藏状态和解码器之间建立了直接的快捷连接(shortcut connections)。这与残差连接的思想相同:通过跳过中间的长链依赖,梯度可以更容易地反向传播到编码器的早期位置。
注意力提供可解释性
注意力机制的一个额外好处是提供了一定程度的可解释性。通过查看注意力分布,我们可以观察到模型在翻译每个词时“关注”的是源句的哪个位置,从而获得一种软对齐(soft alignment)。
免费获得的对齐信息
传统机器翻译中,词对齐(word alignment)是需要单独训练的组件。而注意力机制在翻译过程中自动学会了对齐,无需任何显式的对齐监督。Manning 教授称这是“cool”的——网络自己发现了源语言和目标语言词汇之间的对应关系。例如在法译英中,翻译 “he” 时关注 “il”,翻译 “me” 时关注 “m”',翻译 “pie” 时关注 “entart\'{e}”。
注意力可解释性的局限
虽然注意力权重提供了有价值的直觉,但将其直接解读为“模型在关注什么”需要谨慎。后续研究表明:
- 注意力权重并不总是与特征重要性一致
- 不同的注意力分布有时会产生相似的输出
- 多层 Transformer 中的注意力模式更加复杂,简单的可视化可能产生误导
因此,注意力权重只能作为一种近似的可解释性工具,而非确定性的因果解释。
注意力是通用技术
Manning 教授强调,注意力不仅仅适用于机器翻译。它是一种通用技术(general technique),可以应用于任何需要从一组值中选择性提取信息的场景:
- 给定一组值(values)和一个查询(query)
- 通过注意力计算值的加权平均
- 从中提取与查询最相关的信息
注意力的通用公式
给定值 \(\mathbf{h}_1, \ldots, \mathbf{h}_N \in \mathbb{R}^{d_1}\) 和查询 \(\mathbf{s} \in \mathbb{R}^{d_2}\):
- 计算注意力分数:\(\mathbf{e} \in \mathbb{R}^N\)
- 计算注意力分布:\(\boldsymbol{\alpha} = \mathrm{softmax}(\mathbf{e}) \in \mathbb{R}^N\)
- 计算注意力输出:\(\mathbf{a} = \sum_{i=1}^N \alpha_i \mathbf{h}_i \in \mathbb{R}^{d_1}\)
这个框架在各种神经网络架构中都被证明能一致地提升性能。而这一通用框架最重要的应用就是 Transformer 中的自注意力(self-attention),将在下一讲详细介绍。
关于 RNN 注意力中的位置信息
在课堂问答中,有同学问到 RNN 注意力是否需要位置编码。Manning 教授解释:
为什么 RNN 注意力不需要位置编码
在基于 RNN 的注意力中,编码器的隐藏状态是通过递归计算得到的,每个位置的表示都依赖于前面所有位置。因此,位置信息已经隐式编码在隐藏状态中——第3个位置的隐藏状态“知道”它处于句子的第3个位置,因为它已经处理了前两个词。
而 Transformer 必须使用显式的位置编码,正是因为它没有递归结构,所有位置是并行处理的,没有天然的顺序信息。
本章小结
- 注意力带来四大优势:提升性能、更人类化、解决瓶颈、缓解梯度消失
- 注意力自动学会软对齐,提供可解释性(但需谨慎解读)
- 注意力是通用技术,适用于任何“从值集合中按需提取信息”的场景
- RNN 注意力不需要位置编码(信息已隐含在递归计算中),但 Transformer 需要
- 注意力的下一个重大飞跃是自注意力——Transformer 的核心
从注意力到 Transformer 与大语言模型
注意力的历史演进
注意力机制从2014年的发明到成为现代 AI 的基石,经历了快速而深远的发展:
| 年份 | 里程碑 | 关键人物 |
|---|---|---|
| 2014 | 加法注意力(NMT) | Bahdanau, Cho, Bengio |
| 2015 | 乘法/双线性注意力 | Luong, Pham, Manning |
| 2017 | Transformer(自注意力) | Vaswani et al. |
| 2018 | BERT(双向 Transformer) | Devlin et al. |
| 2018–今 | GPT 系列(大语言模型) | OpenAI |
注意力是深度学习新时代的开端
Manning 教授指出,此前神经网络的所有核心组件(前馈网络、RNN、LSTM、CNN)都是在2000年之前发明的,深度学习革命的前半段主要是“等待数据和算力赶上”。而注意力是2014年之后真正的新发明,它开启了 Transformer、BERT、GPT 等一系列变革性工作。
从编码器-解码器注意力到自注意力
在 Seq2Seq 中,注意力用于解码器“回头查看”编码器。而 Transformer 的核心创新是自注意力(Self-Attention)——让序列中的每个位置都可以关注同一序列中的所有其他位置。

Manning 教授预告,下一讲(Lecture 8)将详细介绍 Transformer 架构,包括自注意力、多头注意力、位置编码等核心概念。
大语言模型简介
课程后半段还涉及了大语言模型(LLM)时代对 NLP 研究和实践的影响:
- BERT:基于 Transformer 编码器的双向预训练模型,通过微调适应各种下游任务
- GPT 系列:基于 Transformer 解码器的自回归语言模型,展现出强大的零样本和少样本学习能力
- 上下文学习(In-Context Learning):大模型可以通过提示(prompt)中的少量示例学习新任务,无需更新参数
LLM 时代的研究范式转变
Manning 教授提到,LLM 的出现改变了研究方式:许多项目不再需要从头训练模型,而是通过 API 调用大语言模型、进行上下文学习或微调来完成任务。这使得更多研究精力可以投入到理解模型行为、评估能力边界、探索新的交互范式等方面。同时,较小的开源模型(如7B参数级别)也为预算有限的研究者提供了可能。
本章小结
- 注意力机制从2014年的 NMT 应用发展到2017年的 Transformer,再到当今的大语言模型
- 自注意力是 Transformer 的核心,允许序列内部各位置相互交互
- 降秩乘法注意力直接对应 Transformer 的多头注意力设计
- 大语言模型建立在多层 Transformer 之上,通过预训练获得通用能力
NLP 实验实践建议
课程的后半部分,Manning 教授给出了关于 NLP 研究和实验的实用建议。
研究项目的基本要素
好的 NLP 研究项目的关键要素
- 明确的数据来源:在项目开始前就确定使用什么数据
- 清晰的评估方法:定义如何衡量系统性能
- 合适的基线(Baseline):必须有一个对比对象来证明你的方法有价值
- 实质性的价值贡献:不能只是下载一个好模型跑一下数据——需要有分析、理解、改进
基线的重要性
Manning 教授强调,任何研究都需要一个合适的基线:
- 如果之前有人做过相同任务,使用他们的结果作为基线
- 如果是全新任务,设计一个简单直觉的方法作为基线(例如:用词向量平均值的余弦相似度做文本相似度)
- 你的复杂模型必须显著优于这个简单基线,否则不具说服力
没有基线的研究是不完整的
仅仅展示“我的模型达到了某个数字”是不够的。没有对比,读者无法判断这个数字是好还是坏。Manning 教授举例:如果你构建了一个复杂的神经网络来计算文本相似度,但它的表现还不如简单地将词向量取平均后做点积,那么这个系统就不是一个好系统。
计算资源的策略
在 GPU 资源日益紧张的今天(Manning 教授戏称“这都怪 OpenAI”),合理利用计算资源至关重要:
- 云端 Notebook:Google Colab、Kaggle Notebooks、AWS SageMaker Studio Lab 提供免费 GPU
- 低成本 GPU 提供商:Modal、Vast.ai 等
- API 访问:对于 LLM 项目,API 调用(如 Together AI)可能比自己训练更高效
- 选择合适的模型大小:7B 参数模型的 API 成本远低于 70B 模型,在许多任务上已经够用
模型大小的权衡
Manning 教授建议:在做实验之前,先考虑你真正需要多大的模型。如果 7B 参数模型足以证明你的观点,就不必使用更大的模型。50美元的 API 额度在 7B 模型上可以处理海量 token,但在大模型上可能很快用完。研究的关键不在于使用最大的模型,而在于证明有趣的结论。
本章小结
- 好的研究需要明确的数据、评估方法和基线
- 基线是不可或缺的——没有对比就没有说服力
- 合理选择模型大小和计算策略,可以在有限预算下完成高质量研究
- 批判性思维是研究的核心能力:理解方法的优缺点,而非简单复述
总结与延伸
讲者的核心总结
Chris Manning 在本讲中构建了从机器翻译评估到注意力机制的完整知识链:
- 评估是基础:BLEU 虽不完美,但为自动化评估机器翻译提供了可能,是推动 NMT 发展的重要工具
- 瓶颈催生创新:Seq2Seq 的信息瓶颈直接促使了注意力机制的发明
- 注意力是变革性创新:2014年发明的注意力机制是自 LSTM 以来神经网络最重要的新概念
- 理解变体为理解 Transformer 做准备:特别是降秩乘法注意力直接对应 Transformer 的设计
全课知识图谱

关键 Takeaways
五条核心原则
- 信息瓶颈催生注意力:将整个句子压缩为单一向量是有根本缺陷的,注意力通过直接连接解决了这一问题
- 注意力 = 软性信息检索:给定查询,在值集合中找到最相关的信息并通过加权平均提取
- 降秩投影是关键:将高维空间投影到低维再做点积,既减少参数又提高灵活性——这就是 Transformer 的做法
- 注意力是通用技术:不仅限于机器翻译,适用于任何需要选择性信息提取的场景
- 注意力开启了新时代:从2014年的发明到 Transformer 再到 GPT/BERT,注意力机制是过去十年 AI 领域最具影响力的技术创新
拓展阅读
- Bahdanau, Cho, Bengio, “Neural Machine Translation by Jointly Learning to Align and Translate”, 2014. https://arxiv.org/abs/1409.0473 —— 注意力机制的开山之作
- Luong, Pham, Manning, “Effective Approaches to Attention-based Neural Machine Translation”, 2015. https://arxiv.org/abs/1508.04025 —— 乘法注意力、多种注意力变体对比
- Vaswani et al., “Attention Is All You Need”, 2017. https://arxiv.org/abs/1706.03762 —— Transformer 原始论文
- Papineni et al., “BLEU: a Method for Automatic Evaluation of Machine Translation”, 2002. https://aclweb.org/anthology/P02-1040 —— BLEU 指标原始论文
- Ruder, “Deep Learning for NLP Best Practices”, 2017. http://ruder.io/deep-learning-nlp-best-practices/index.html#attention —— 深度学习 NLP 最佳实践
- Britz et al., “Massive Exploration of Neural Machine Translation Architectures”, 2017. https://arxiv.org/abs/1703.03906 —— NMT 架构大规模实验
- Sutskever, Vinyals, Le, “Sequence to Sequence Learning with Neural Networks”, 2014. https://arxiv.org/abs/1409.3215 —— Seq2Seq 原始论文