CS231N Lecture 6: CNN Architectures
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Zane Durante 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2025 |

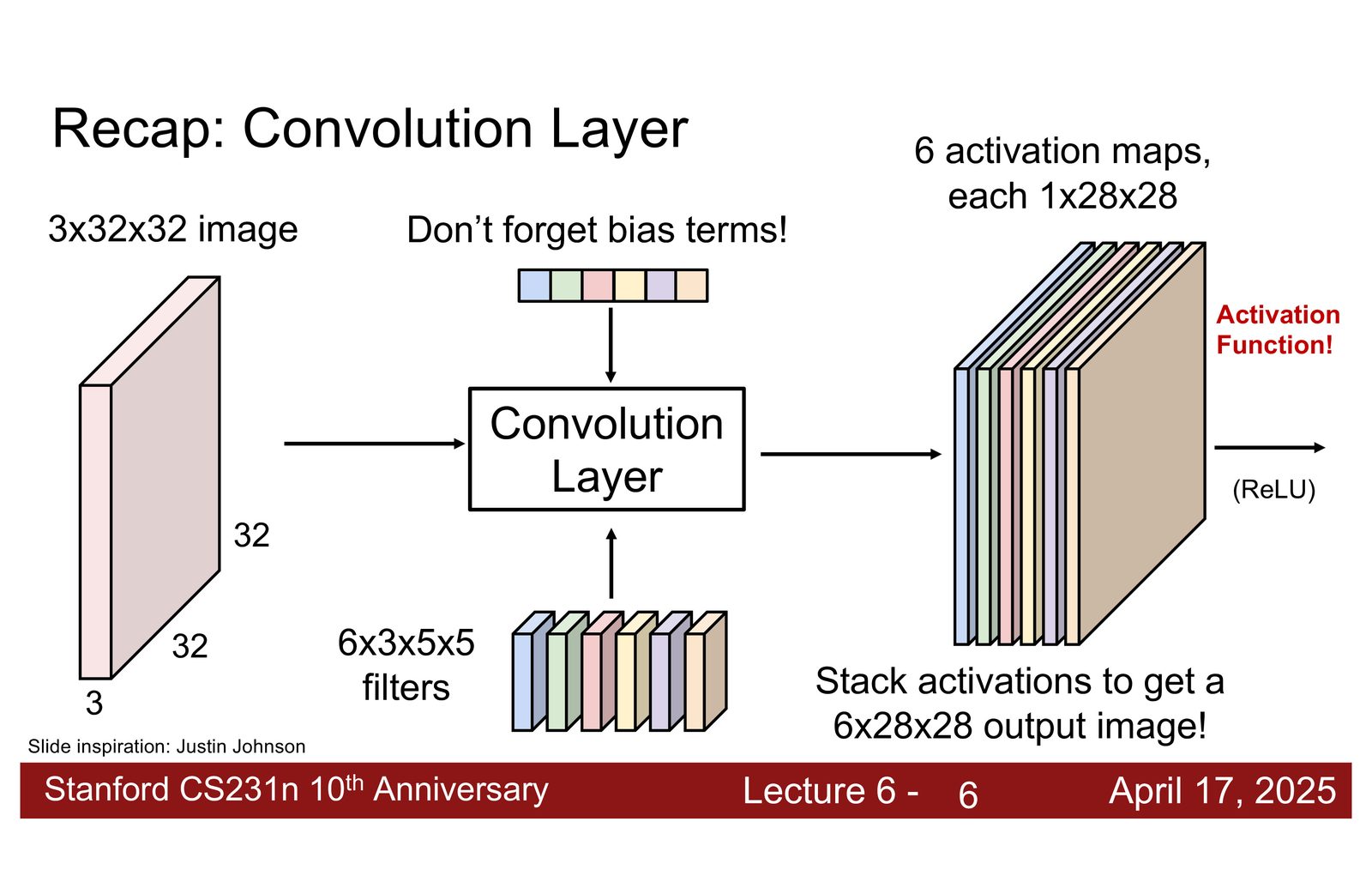
CNN 的构建模块
本节课由 Zane Durante 主讲,分为两个主要部分:(1)如何构建 CNN——包括各类层组件和经典架构设计;(2)如何训练 CNN——包括权重初始化、学习率调度、数据增强等实用技巧。
卷积层回顾

来源:Slides 第2页。
卷积层是上节课的核心内容,这里简要回顾:
- 每个滤波器的深度匹配输入通道数(如 RGB 图像的深度为 3)
- 滤波器在空间维度上滑动,在每个位置计算内积 + 偏置
- 每个滤波器产生一个二维激活图
- \(C_{out}\) 个滤波器产生深度为 \(C_{out}\) 的输出张量
- 激活图后通常接 ReLU 等非线性激活函数
池化层回顾

来源:Slides 第3页。
池化层对每个通道独立地进行空间下采样。最常用的是 \(2 \times 2\) 最大池化(stride 2),也有平均池化。
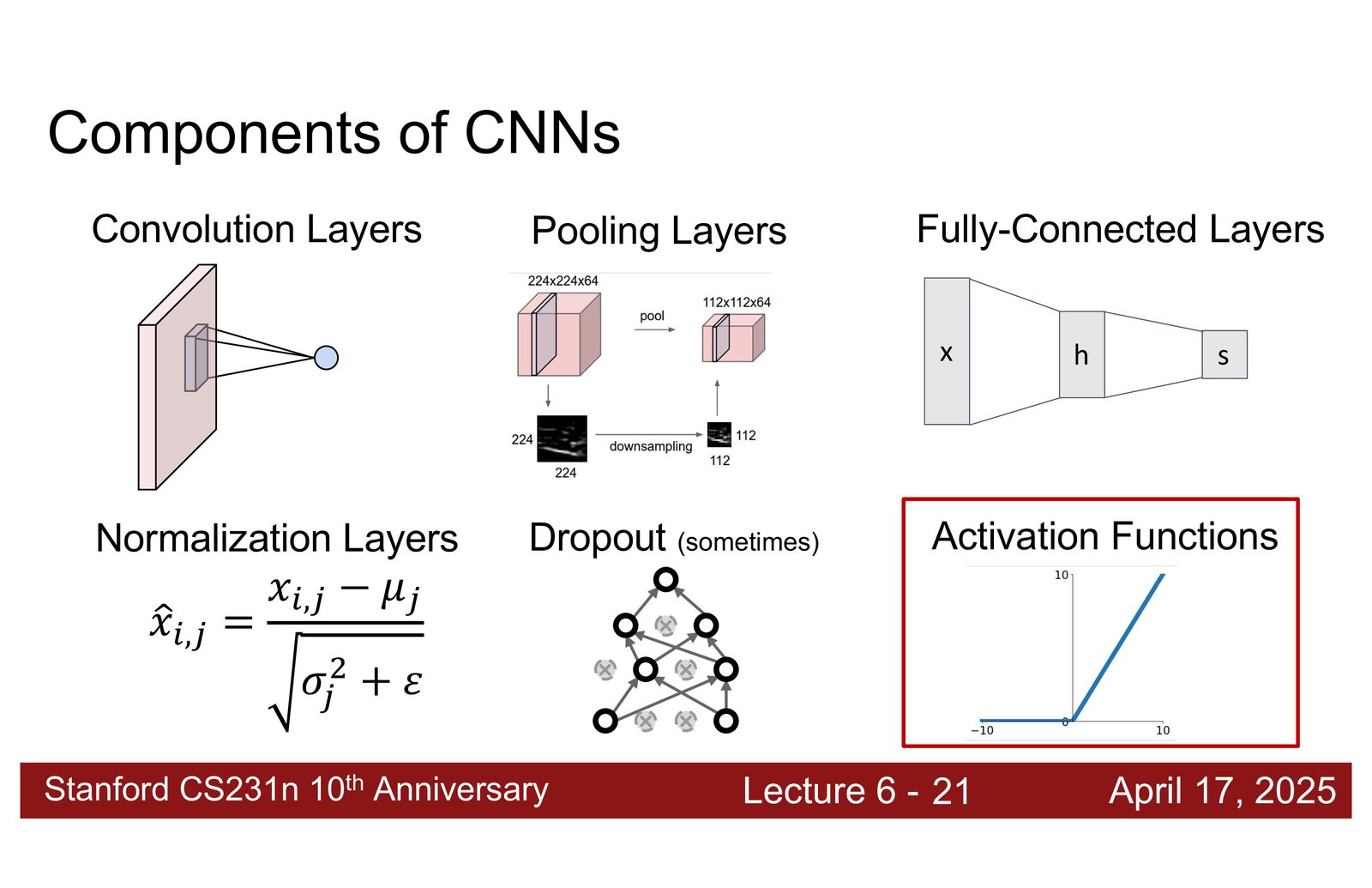
CNN 构成总览

来源:Slides 第4页。
到目前为止,课程已经介绍了三种基本层:
- 卷积层(Convolution)—— 提取空间特征
- 池化层(Pooling)—— 空间下采样
- 全连接层(Fully Connected)—— 矩阵乘法 + 偏置
本节课将补充三种重要组件:
- 归一化层(Normalization)—— 稳定训练
- Dropout —— 正则化
- 激活函数(Activation Functions)—— 非线性
本章小结
CNN 由六类核心组件构成:卷积层负责提取特征,池化层负责下采样,全连接层负责最终映射,归一化层稳定训练过程,Dropout 提供正则化,激活函数引入非线性。理解每个组件的作用和组合方式是设计高性能 CNN 的基础。
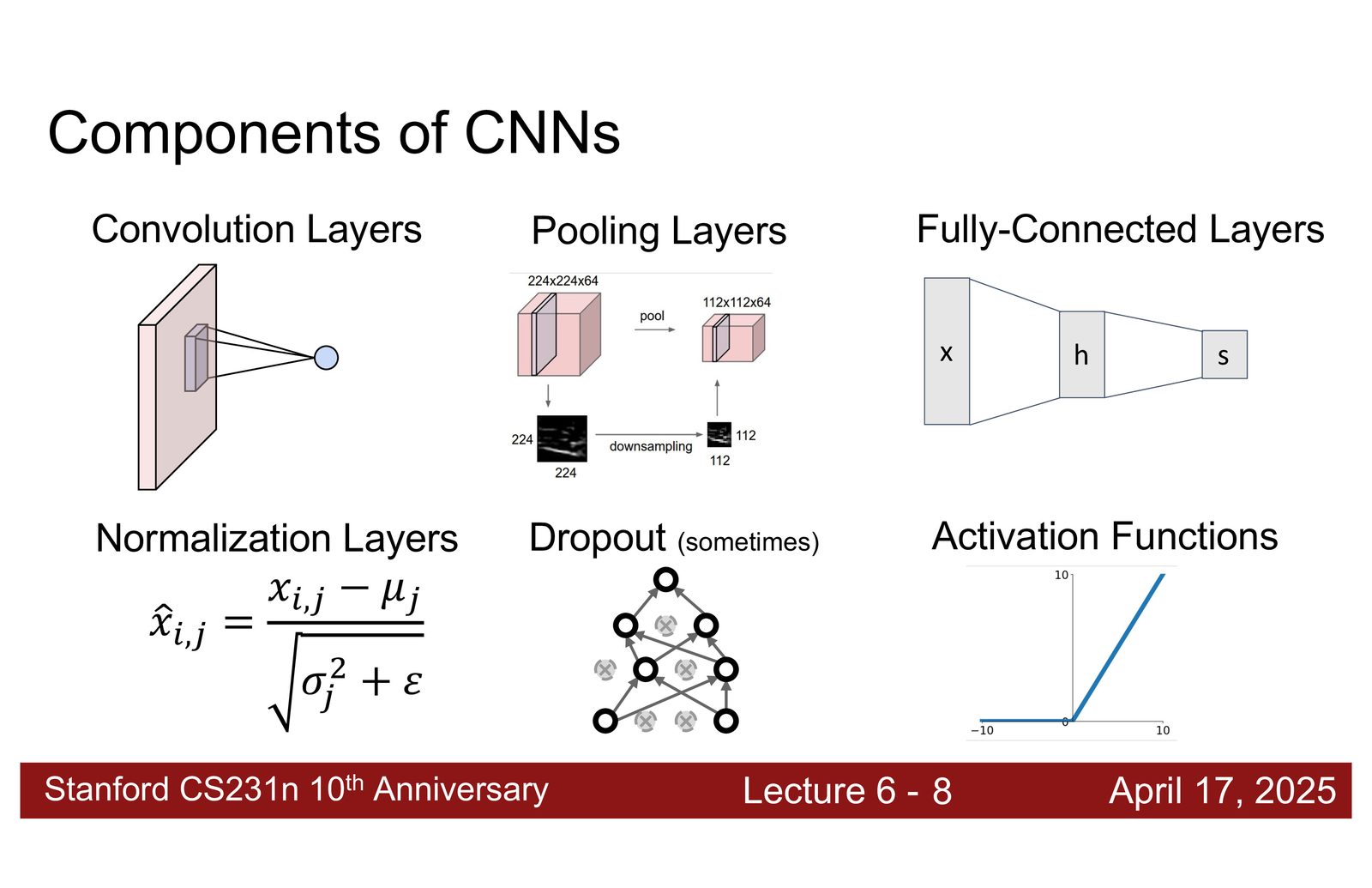
归一化层
归一化的基本原理
归一化层的核心思想分两步:
- 标准化:将输入数据变换为均值为 0、标准差为 1 的分布
- 可学习的缩放与平移:通过可训练参数 \(\gamma\)(缩放)和 \(\beta\)(平移),让网络自己决定每一层的最优分布
所有归一化层都遵循同一个公式:
- \(\mu\), \(\sigma\):计算得到的均值和标准差
- \(\gamma\), \(\beta\):可学习参数
- \(\epsilon\):防止除零的小常数
不同归一化方法的唯一区别在于:在哪些维度上计算 \(\mu\) 和 \(\sigma\)。
Layer Normalization
来源:Slides 第6页。
Layer Norm 是目前最常用的归一化方法(尤其在 Transformer 中):
- 对每个样本独立计算统计量
- 计算维度:通道 \(\times\) 高度 \(\times\) 宽度(对于 CNN)或特征维度 \(D\)(对于 MLP)
- 每个样本只有一个 \(\mu\) 和一个 \(\sigma\)
对于向量输入 \(x \in \mathbb{R}^{N \times D}\):
Batch Normalization
来源:Slides 第8页。
Batch Norm 在每个通道内、跨 batch 中所有样本计算统计量:
- 对每个通道独立计算 \(\mu\) 和 \(\sigma\)
- 计算维度:batch \(\times\) 高度 \(\times\) 宽度
- 统计量依赖 mini-batch,因此训练和推理行为不同
Batch Norm 的训练/推理不一致
训练时,Batch Norm 使用当前 mini-batch 的统计量。推理时,使用训练过程中累积的全局均值和方差(running statistics)。这种不一致会带来问题:
- 小 batch size 时统计量不稳定
- 分布式训练时需要跨 GPU 同步统计量
- 推理行为依赖训练时的 batch 组成
这也是 Layer Norm 在现代架构中逐渐取代 Batch Norm 的原因之一。
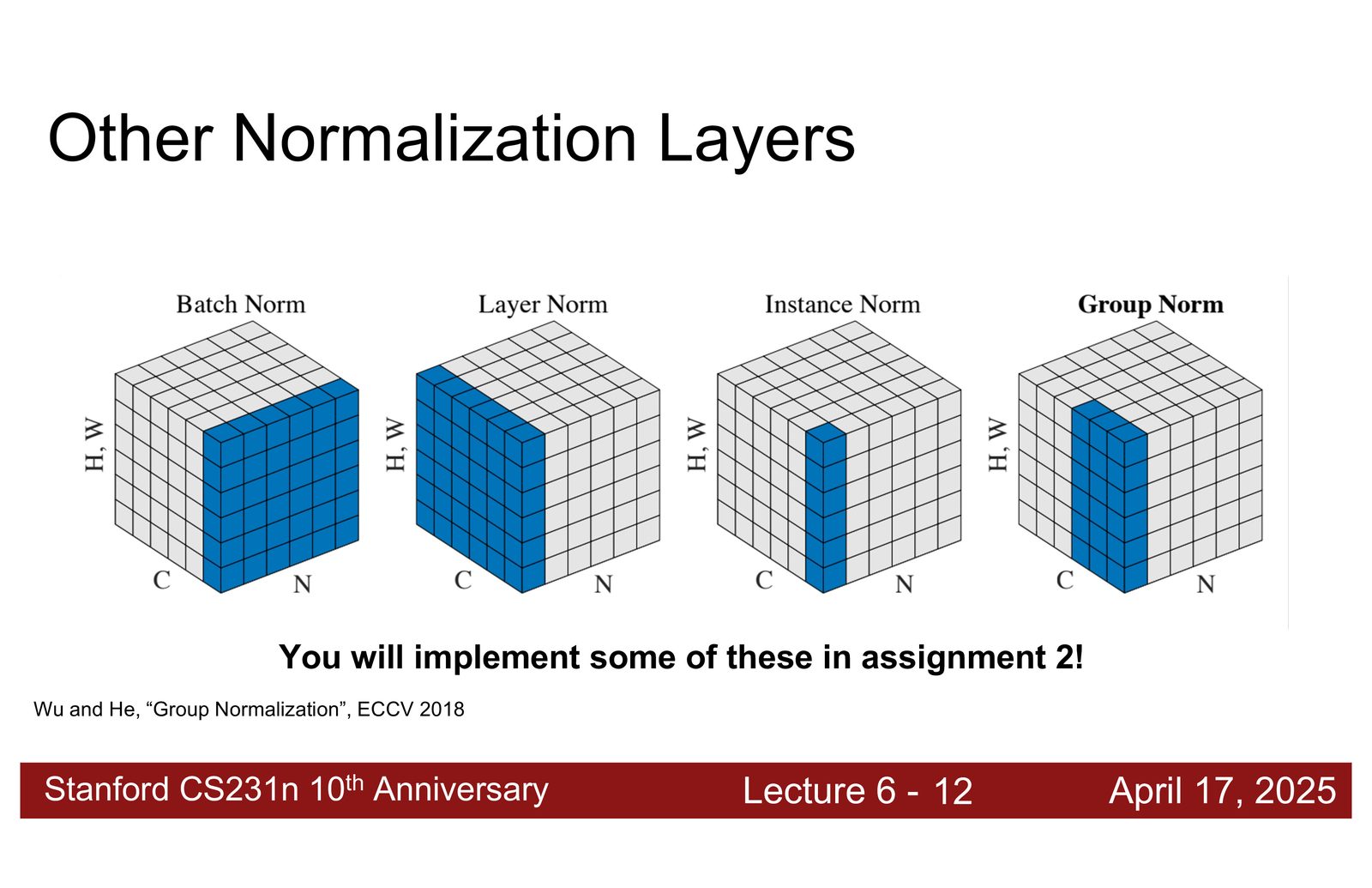
Instance Norm 与 Group Norm
- Instance Norm:对每个样本的每个通道独立计算统计量(只在空间维度上归一化)。常用于风格迁移。
- Group Norm:将通道分组,在每组内计算统计量。是 Layer Norm 和 Instance Norm 的折中。
归一化方法选择指南
- Transformer / 序列模型:Layer Norm(标准选择)
- 传统 CNN:Batch Norm(历史上最常用)
- 小 batch / 分布式训练:Group Norm 或 Layer Norm
- 风格迁移:Instance Norm
本章小结
归一化层通过标准化中间激活值来稳定训练过程。所有归一化方法都遵循“标准化 + 可学习缩放平移”的两步范式,区别仅在于统计量的计算维度。Layer Norm 因其与 batch 无关的特性,成为现代深度学习中最受欢迎的选择。
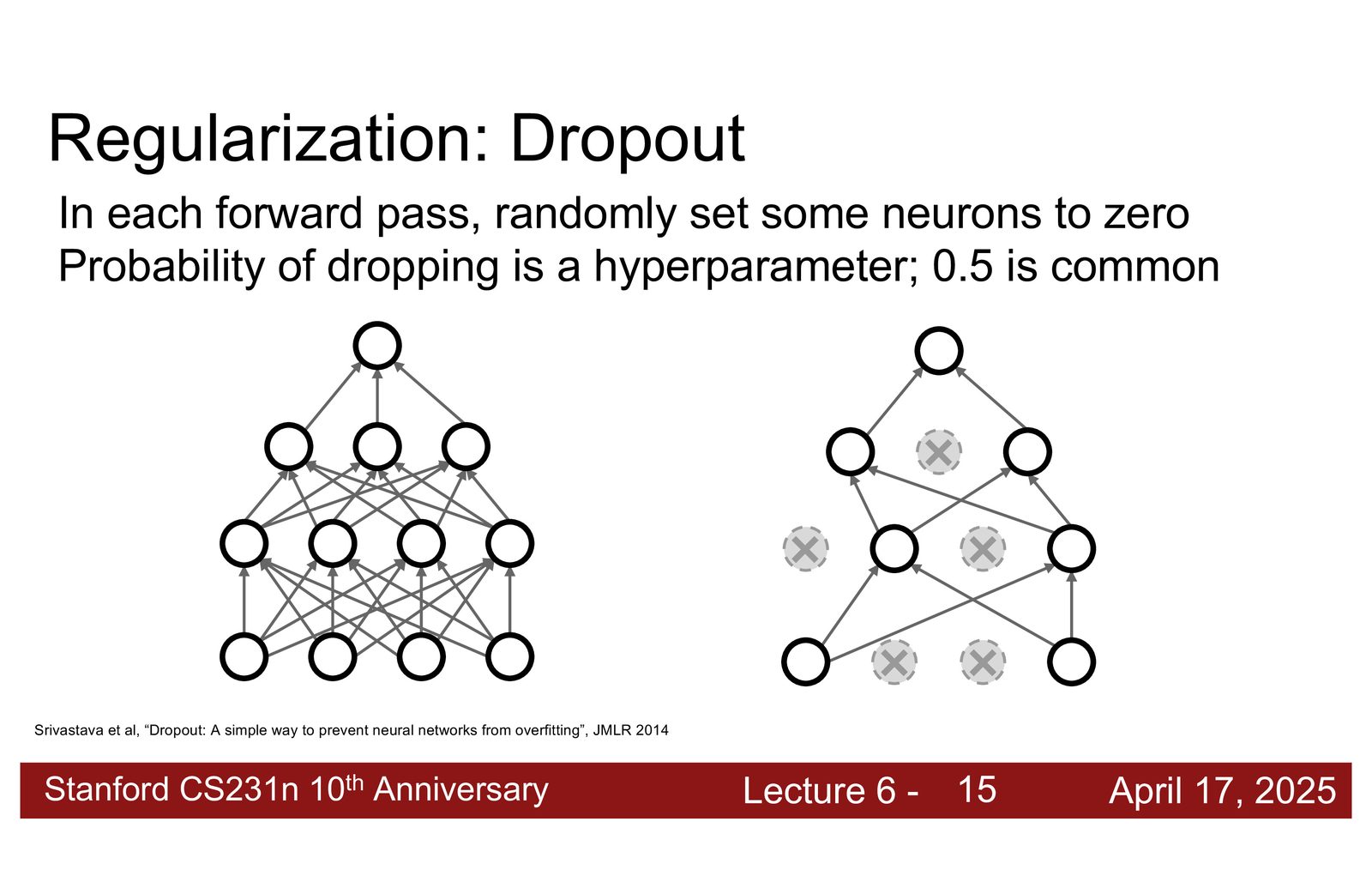
Dropout 正则化
Dropout 的基本原理

来源:Slides 第11页。
Dropout 是一种正则化技术,核心思想是:在训练时随机“关闭”一部分神经元,在测试时使用全部神经元。
具体操作:
- 训练时:以概率 \(p\)(通常 \(p = 0.5\))将每个激活值随机设为 0
- 测试时:使用所有激活值,但乘以 \(p\) 以保持期望值一致
# Training
mask = (np.random.rand(*H.shape) > p) # dropout mask
H_train = H * mask # zero out
# Testing
H_test = H * p # scale by p
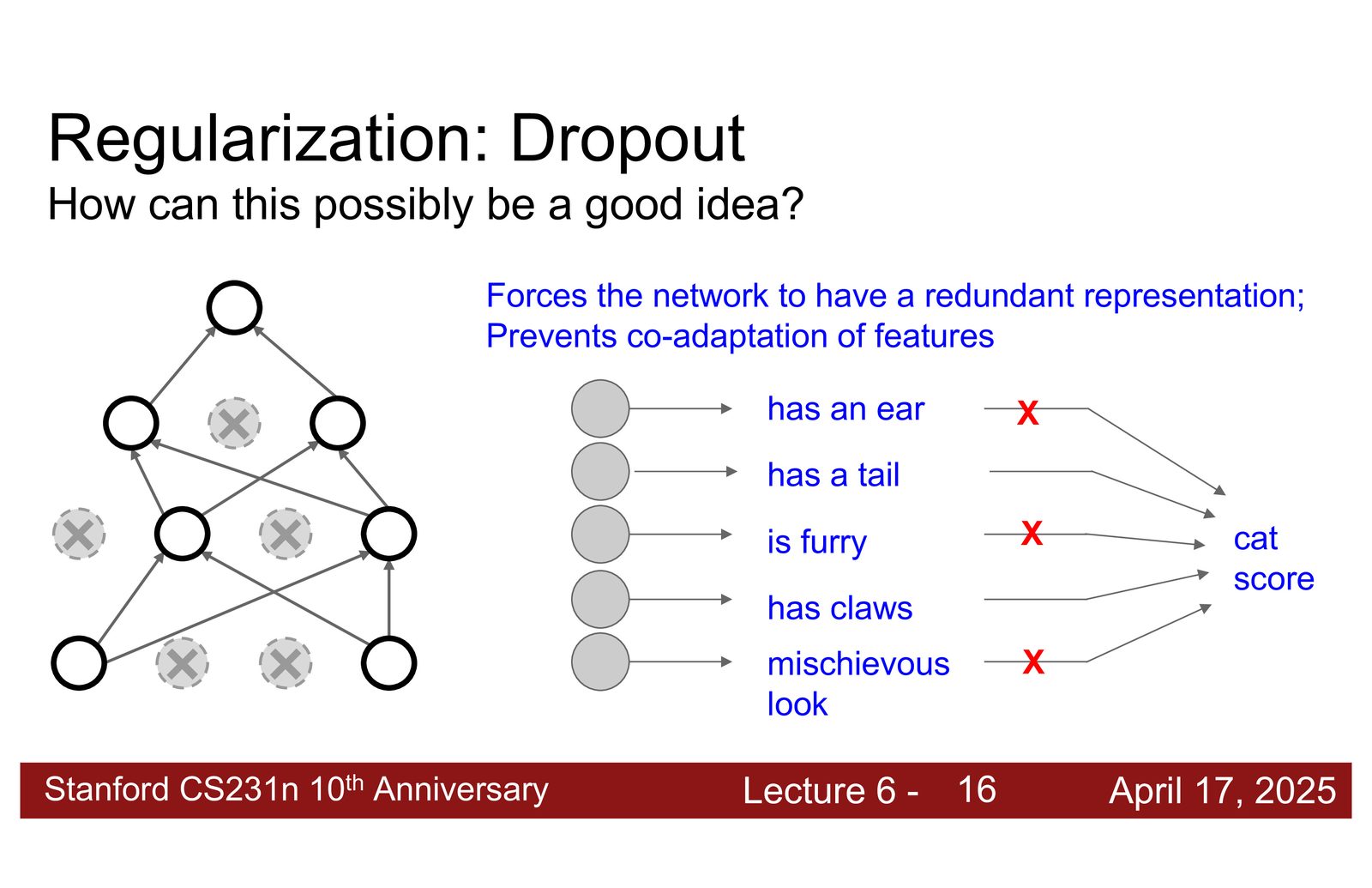
Dropout 为什么有效?
来源:Slides 第12页。
Dropout 有效的直觉
考虑一个猫分类器:模型可能学到“有耳朵 + 有毛皮 = 猫”这样的模式。但如果训练时“耳朵”特征有 50% 概率被丢弃,模型就不能过度依赖耳朵特征,必须同时学会利用尾巴、爪子、毛皮等其他特征。
这迫使模型学习冗余和分布式表示:
- 训练时表现略差(因为只看到部分特征)
- 测试时表现更好(因为学到了更鲁棒的表示)
Dropout 的测试时缩放
如果训练时 \(p = 0.5\)(50% 概率保留),测试时使用全部激活值,那么每个神经元接收的输入总和会翻倍。为了保持训练和测试行为一致,测试时需要将所有激活值乘以 \(p\)。
不做这个缩放会导致测试时输出值远大于训练时,产生严重的行为偏差。
Dropout 的反向传播
Dropout 的反向传播非常简单:被置零的激活值梯度也为零(类似 ReLU 的负半轴),不参与权重更新。这意味着每次训练迭代中,只有一部分参数被更新。
Dropout 与集成学习的联系
Dropout 可以看作一种隐式集成:每次前向传播都在训练一个不同的“子网络”(由存活的神经元构成)。测试时使用全部神经元,相当于对所有可能的子网络进行了(近似的)集成。集成学习是机器学习中经典的提升泛化能力的方法。
本章小结
Dropout 通过在训练时引入随机性来防止过拟合。它的核心机制是:训练时随机丢弃部分神经元(增加难度),测试时使用全部神经元并缩放(获得更好泛化)。Dropout 主要用于全连接层;在现代 CNN 和 Transformer 中,其他正则化方法(如数据增强、权重衰减)更为常用。
激活函数
为什么需要激活函数
激活函数的唯一目的是引入非线性。没有激活函数,无论多少层线性运算(卷积或全连接)的堆叠,整个网络仍然等价于一个线性变换。
激活函数的放置位置:通常在卷积层之后和全连接层之后。
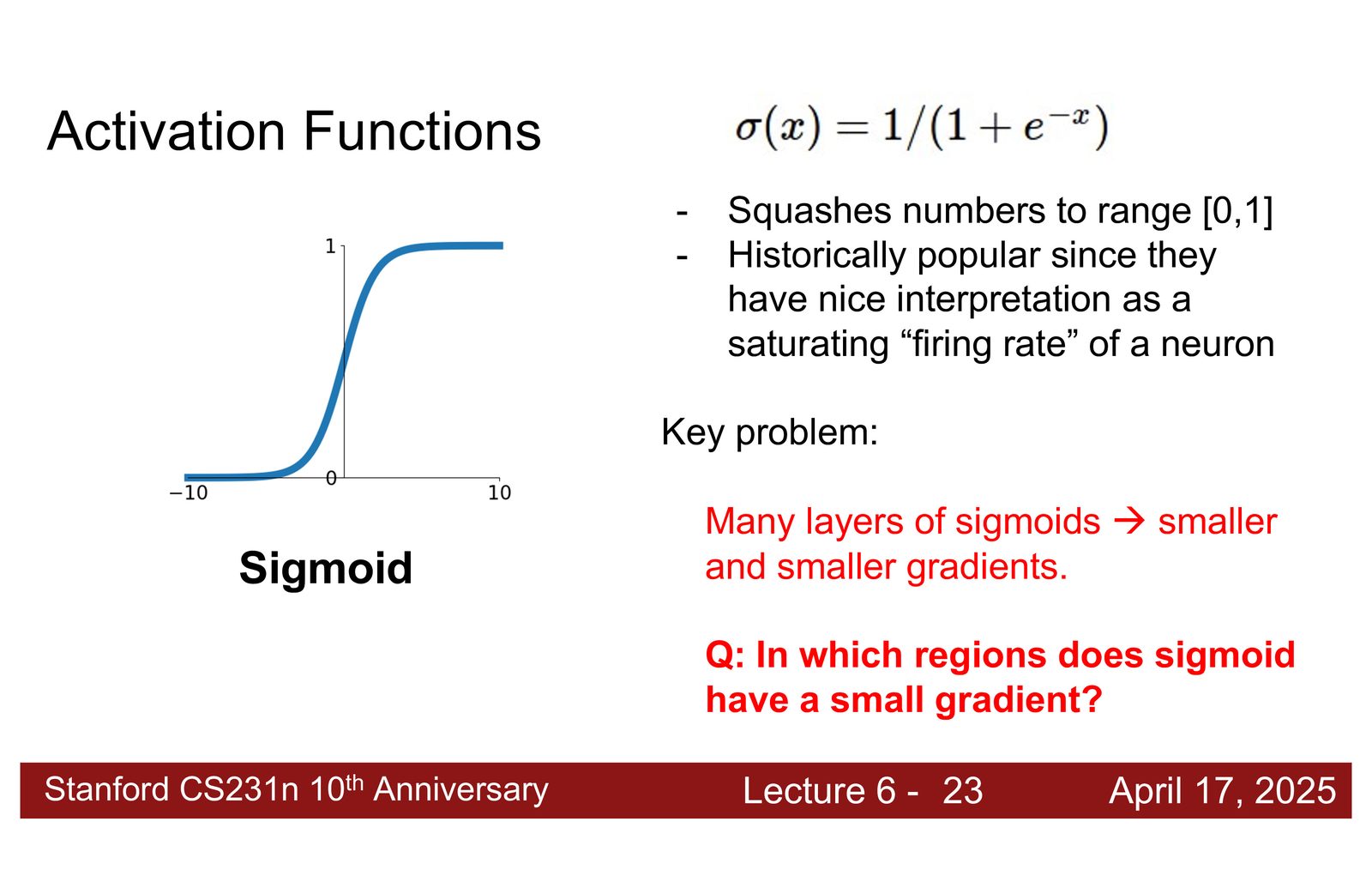
Sigmoid:历史上的经典
来源:Slides 第15页。
Sigmoid 将任意实数映射到 \((0, 1)\) 区间。它在深度学习早期非常流行,但有一个致命缺陷:
Sigmoid 的梯度消失问题
Sigmoid 的导数 \(\sigma'(x) = \sigma(x)(1 - \sigma(x))\) 的最大值仅为 0.25(在 \(x = 0\) 处)。在 \(|x|\) 较大的区域,梯度接近于零。
这意味着:当输入值很大或很小时(这在深层网络中经常发生),梯度几乎为零,参数无法更新。经过多层 sigmoid 后,靠近输入层的梯度会指数级衰减——这就是梯度消失(vanishing gradient)问题,曾经严重制约了深度网络的训练。
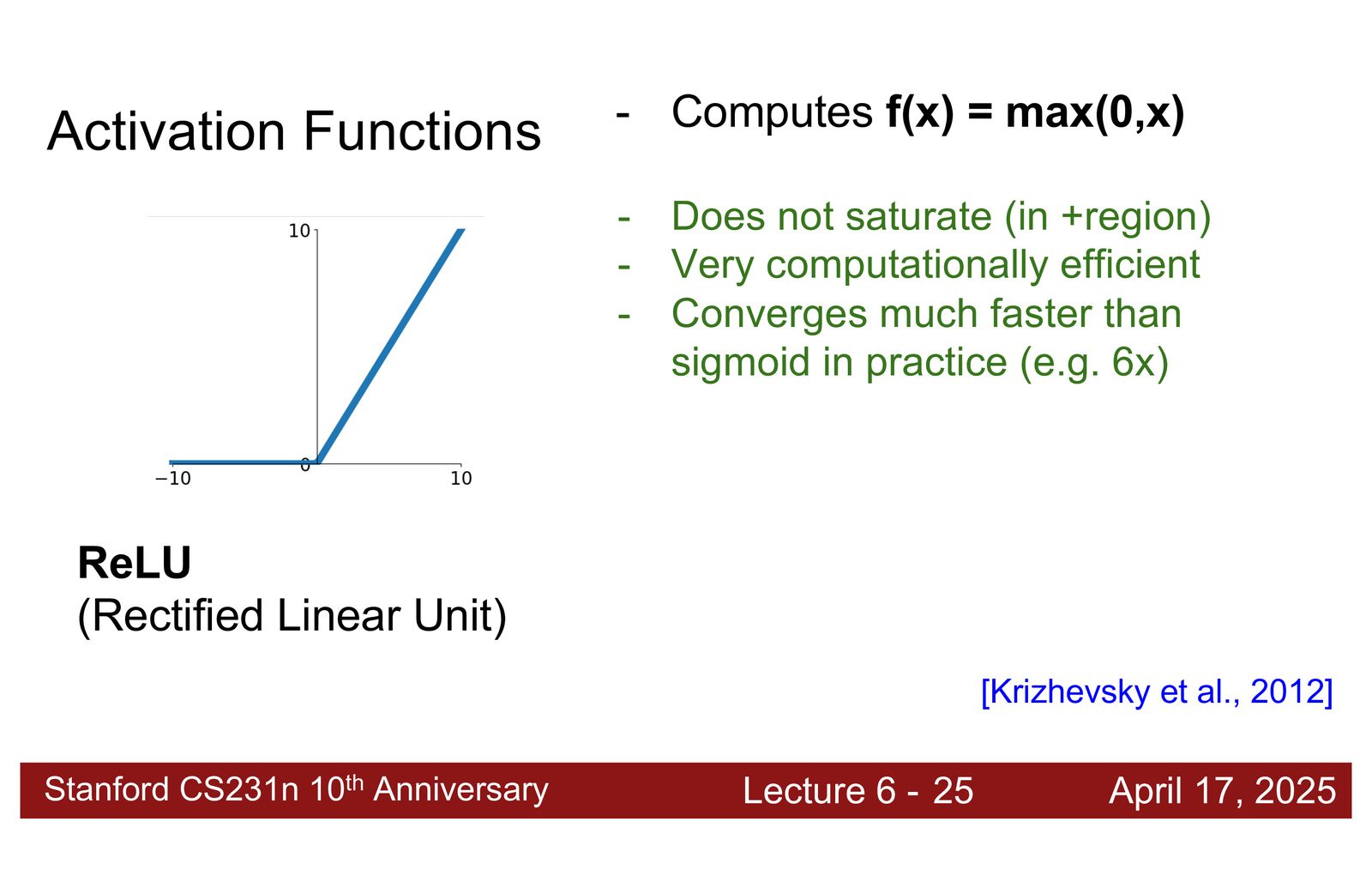
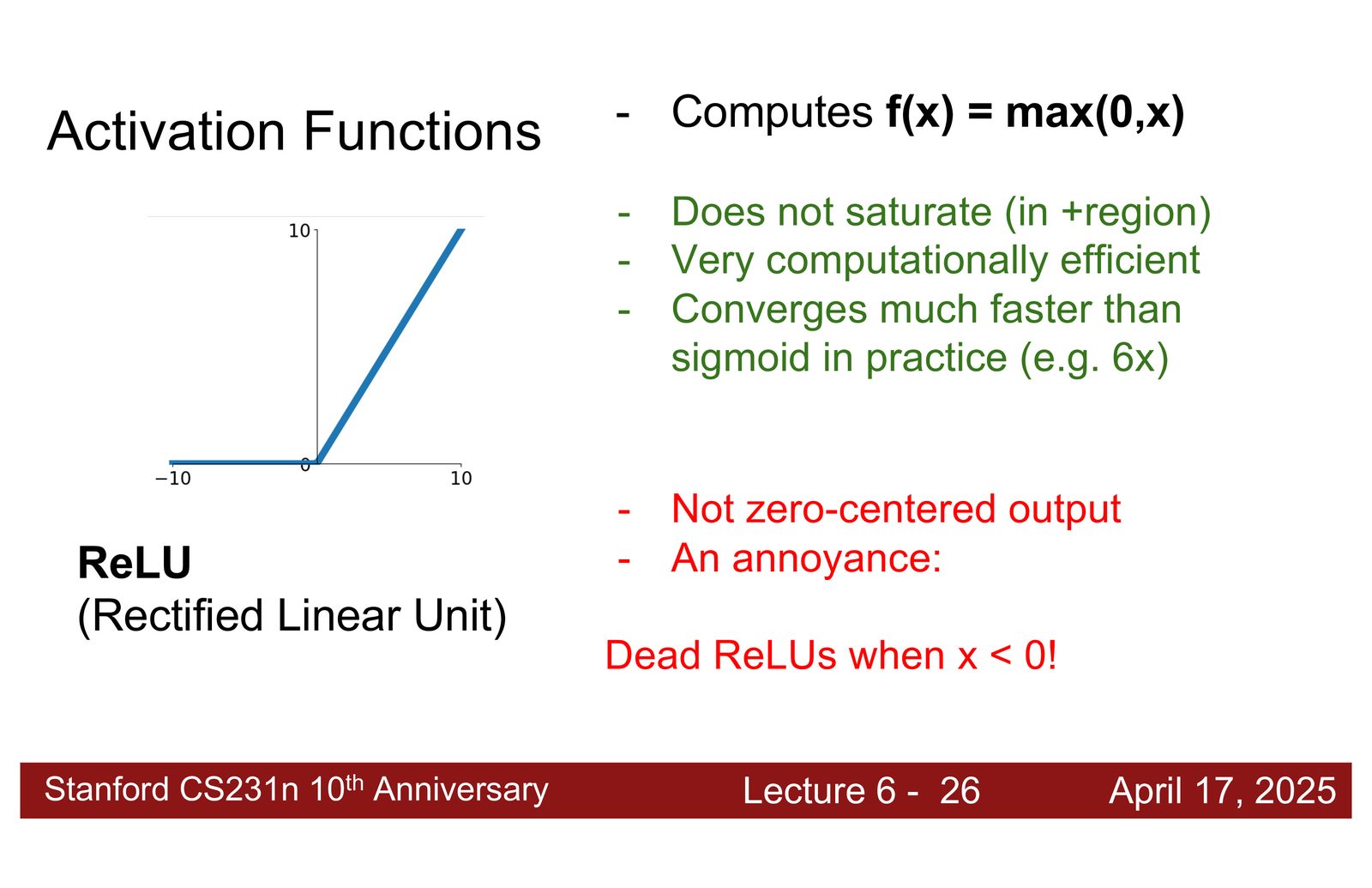
ReLU:简单而有效
来源:Slides 第16页。
ReLU(Rectified Linear Unit)的出现是深度学习发展的关键里程碑:
- 正半轴梯度恒为 1——不会梯度消失
- 计算极其简单——只需一次比较操作
- 引入了恰好足够的非线性
ReLU 的缺点:负半轴梯度为零(“死神经元”问题),一旦某个神经元的输入长期为负,它将永远不再激活。
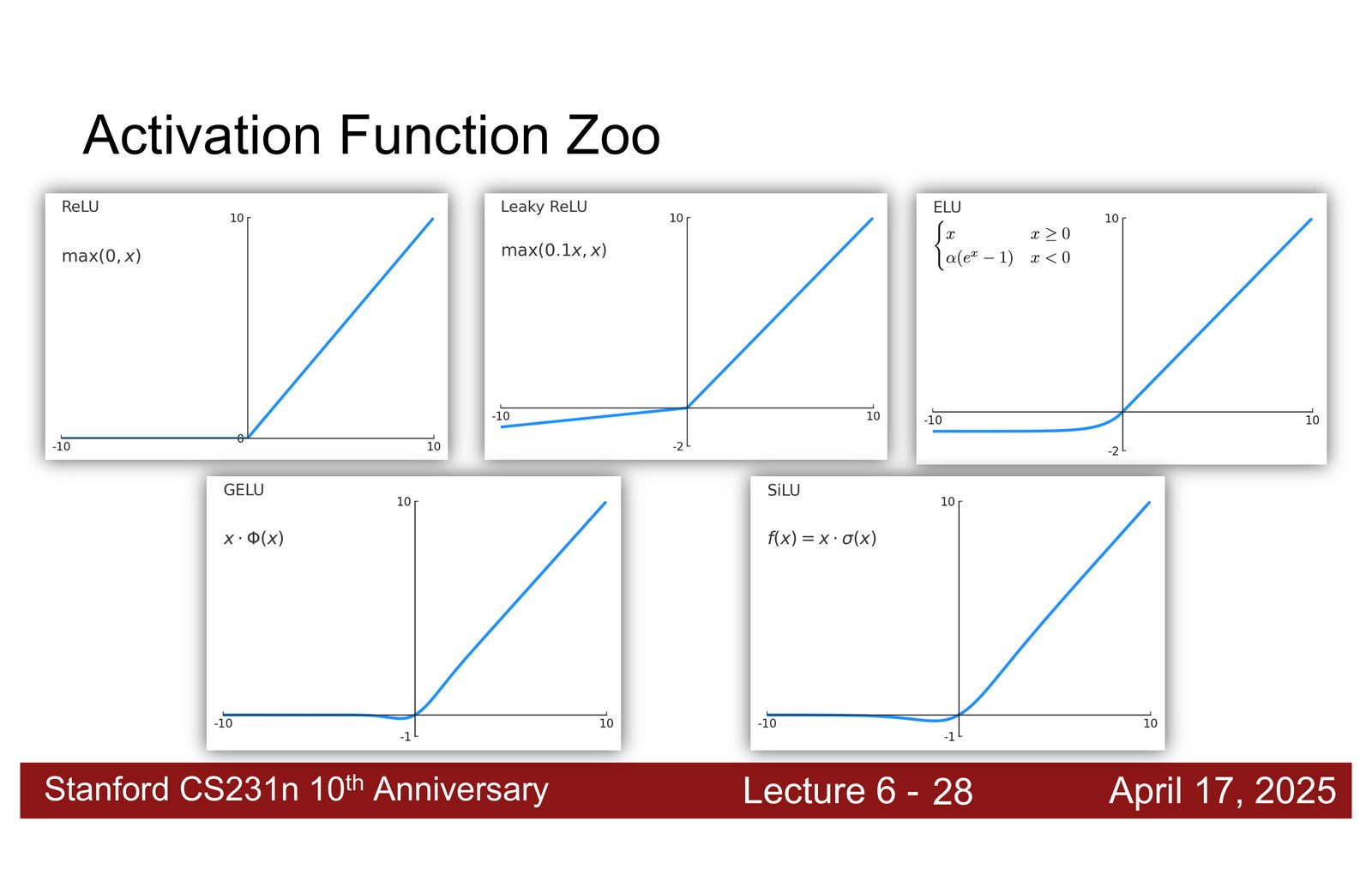
GELU 与 SiLU:现代选择

来源:Slides 第18页。
GELU(Gaussian Error Linear Unit):
其中 \(\Phi(x)\) 是标准正态分布的累积分布函数。
SiLU / Swish:
其中 \(\sigma\) 是 sigmoid 函数。
现代激活函数的设计思路
GELU 和 SiLU 的共同特点:
- 在 \(x \to +\infty\) 时趋近于 \(f(x) = x\)(线性,梯度为 1)
- 在 \(x \to -\infty\) 时趋近于 \(f(x) = 0\)(类似 ReLU)
- 在 \(x \approx 0\) 附近是平滑的(不像 ReLU 有尖角)
- 在负半轴有非零梯度(避免死神经元问题)
GELU 是当前 Transformer 中使用最广泛的激活函数。

来源:Slides 第19页。
激活函数的选择建议
- 传统 CNN:ReLU(简单高效)
- Transformer:GELU(平滑且有非零负半轴梯度)
- 现代 CNN:SiLU / Swish(与 GELU 性能接近)
- 不要使用:Sigmoid 或 Tanh 作为隐藏层激活(梯度消失风险)
激活函数的放置位置

来源:Slides 第20页。
激活函数总是放在线性运算之后:
- 全连接层 \(\rightarrow\) 激活函数
- 卷积层 \(\rightarrow\) 激活函数
- 归一化层可以放在激活函数之前或之后(具体取决于架构设计)
本章小结
激活函数是深度网络表达能力的关键。从 Sigmoid(梯度消失严重)到 ReLU(简单高效但有死神经元),再到 GELU(平滑且处处可微),激活函数的发展推动了深度学习的进步。选择合适的激活函数对训练稳定性和最终性能都有显著影响。
CNN 经典架构
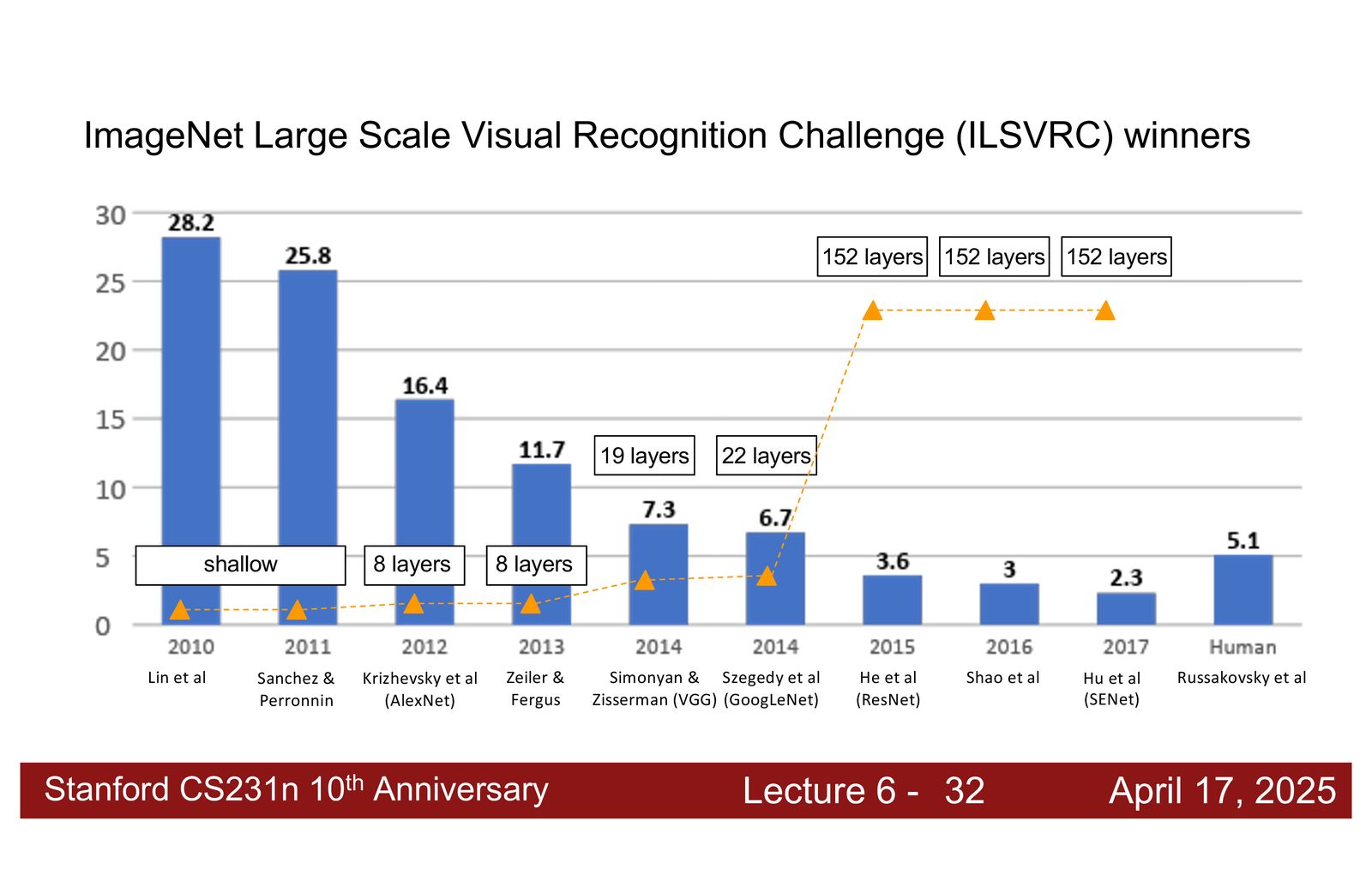
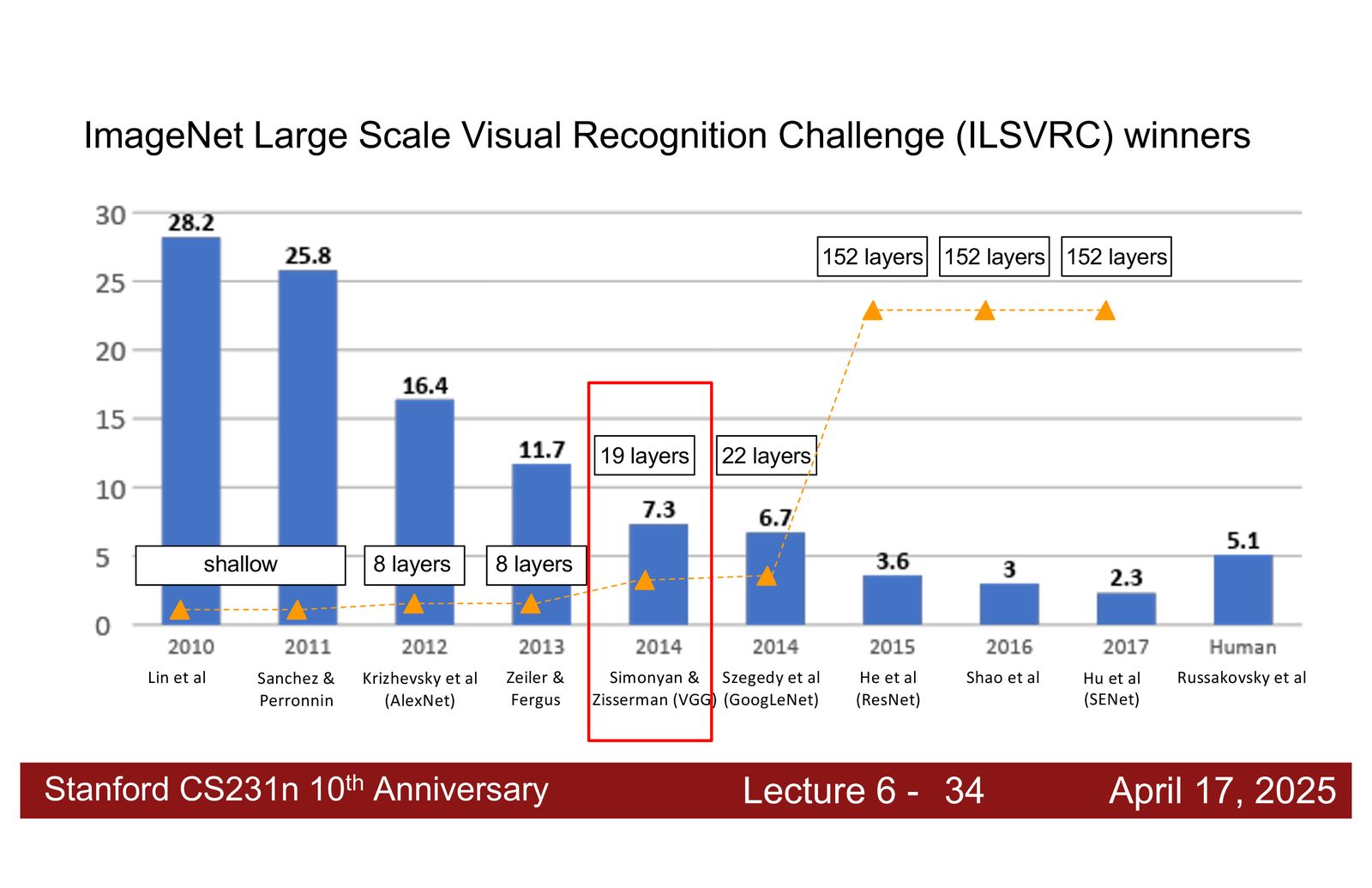
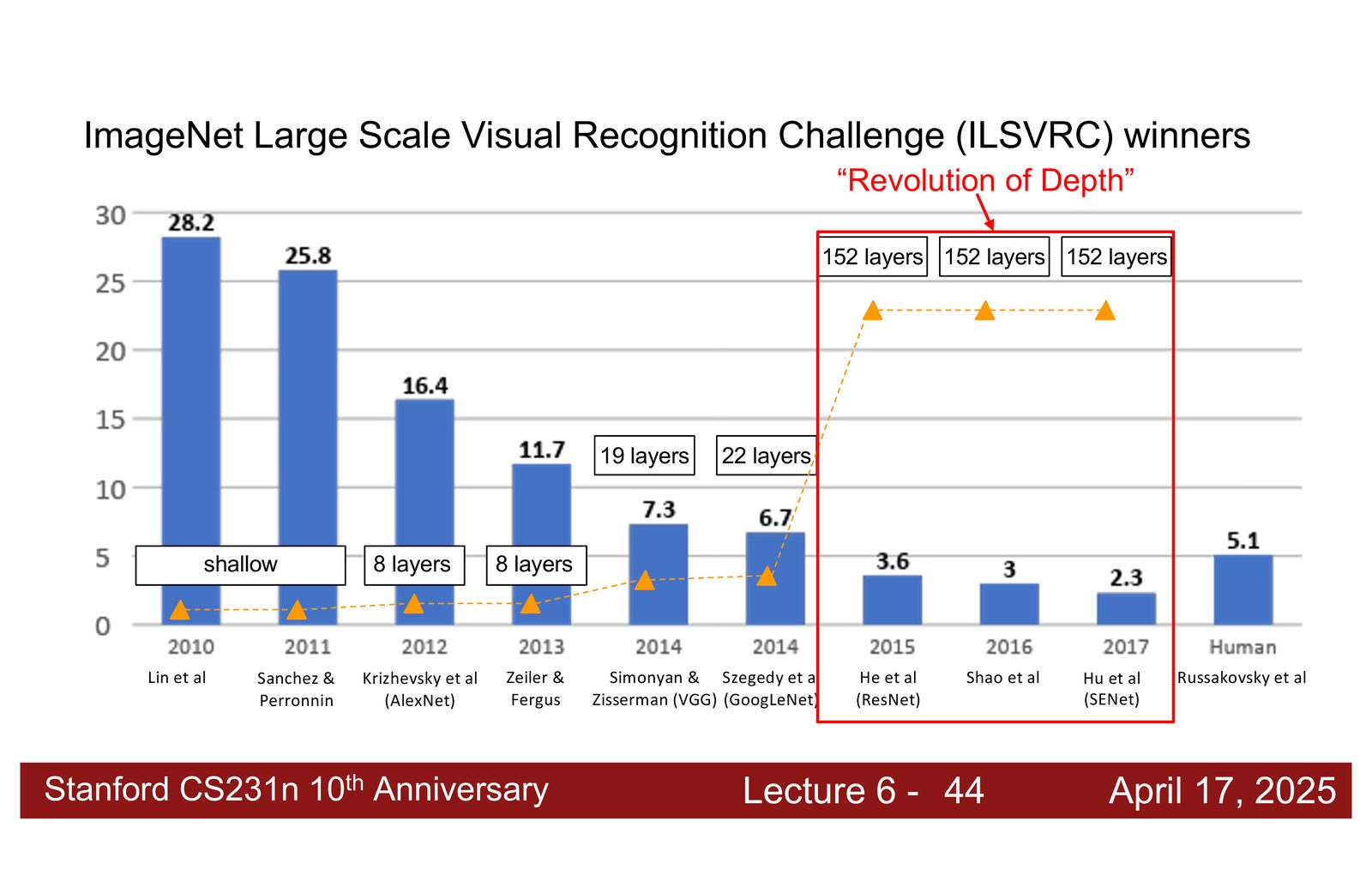
ImageNet 竞赛与架构演进
来源:Slides 第21页。
ImageNet 大规模视觉识别挑战赛(ILSVRC)是推动 CNN 架构发展的重要驱动力。一个清晰的趋势是:随着模型层数的增加和架构设计的改进,错误率持续下降,直到超越人类水平(\(\sim\)5%)。
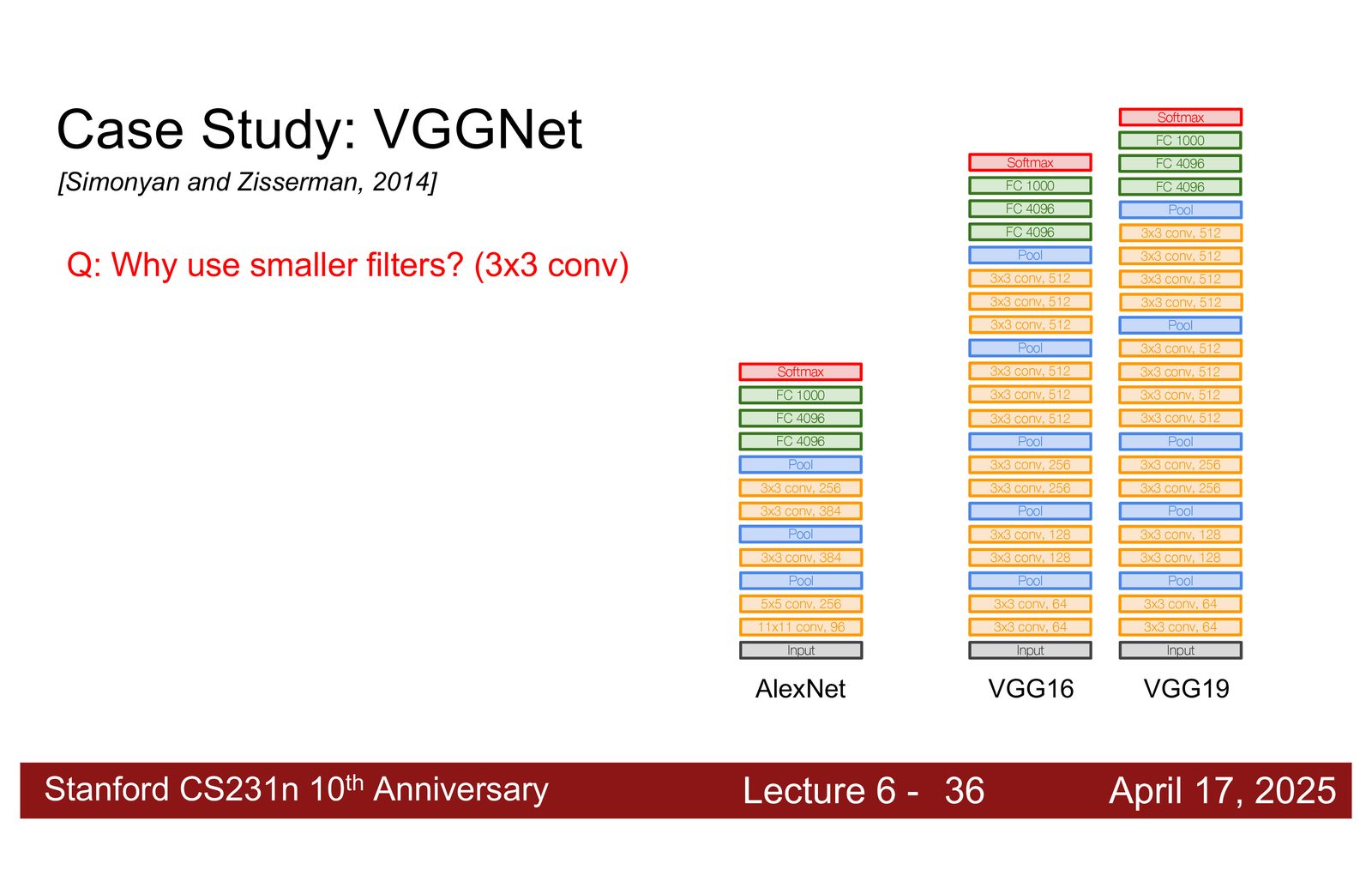
AlexNet vs VGGNet
来源:Slides 第23页。
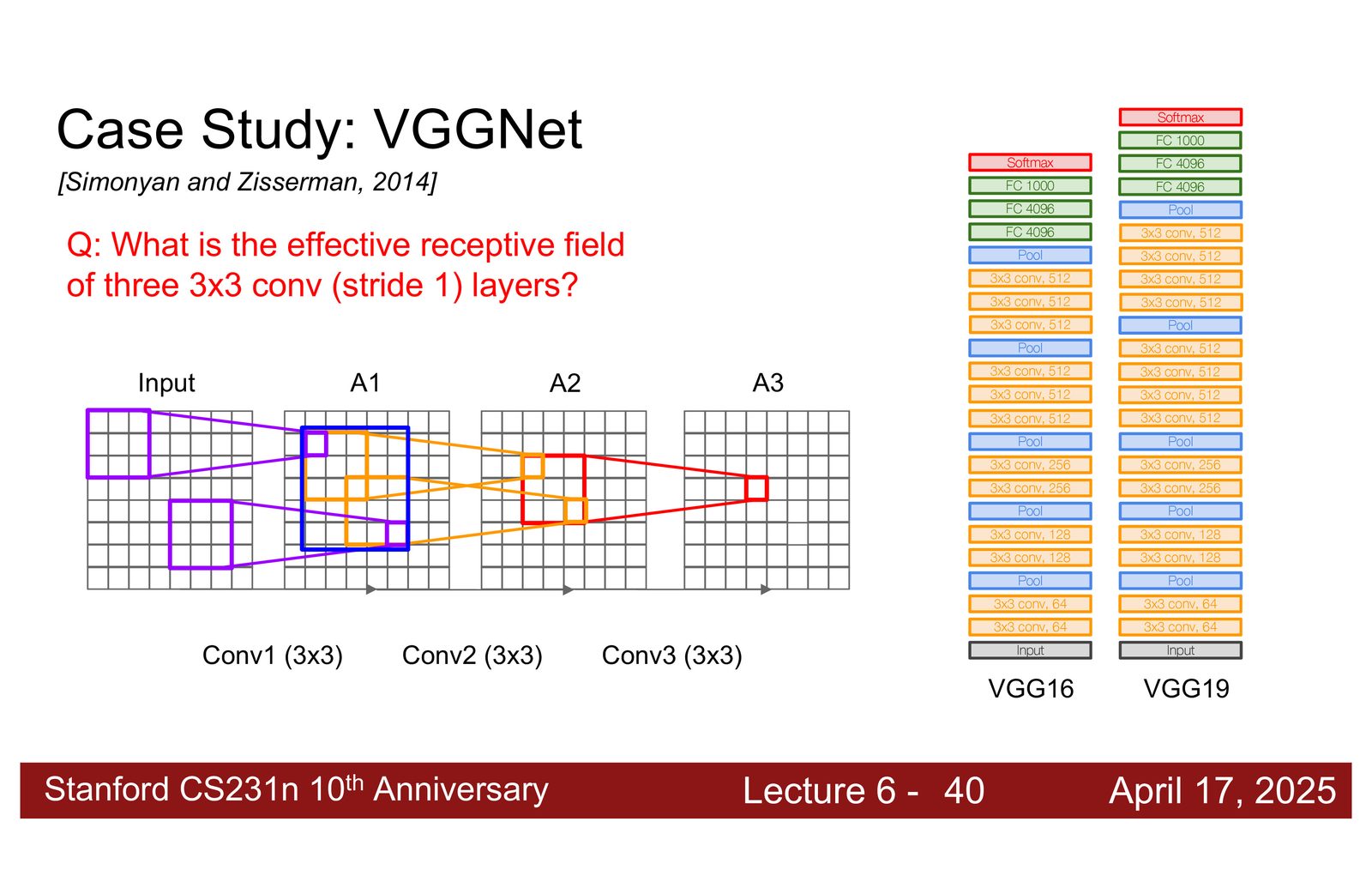
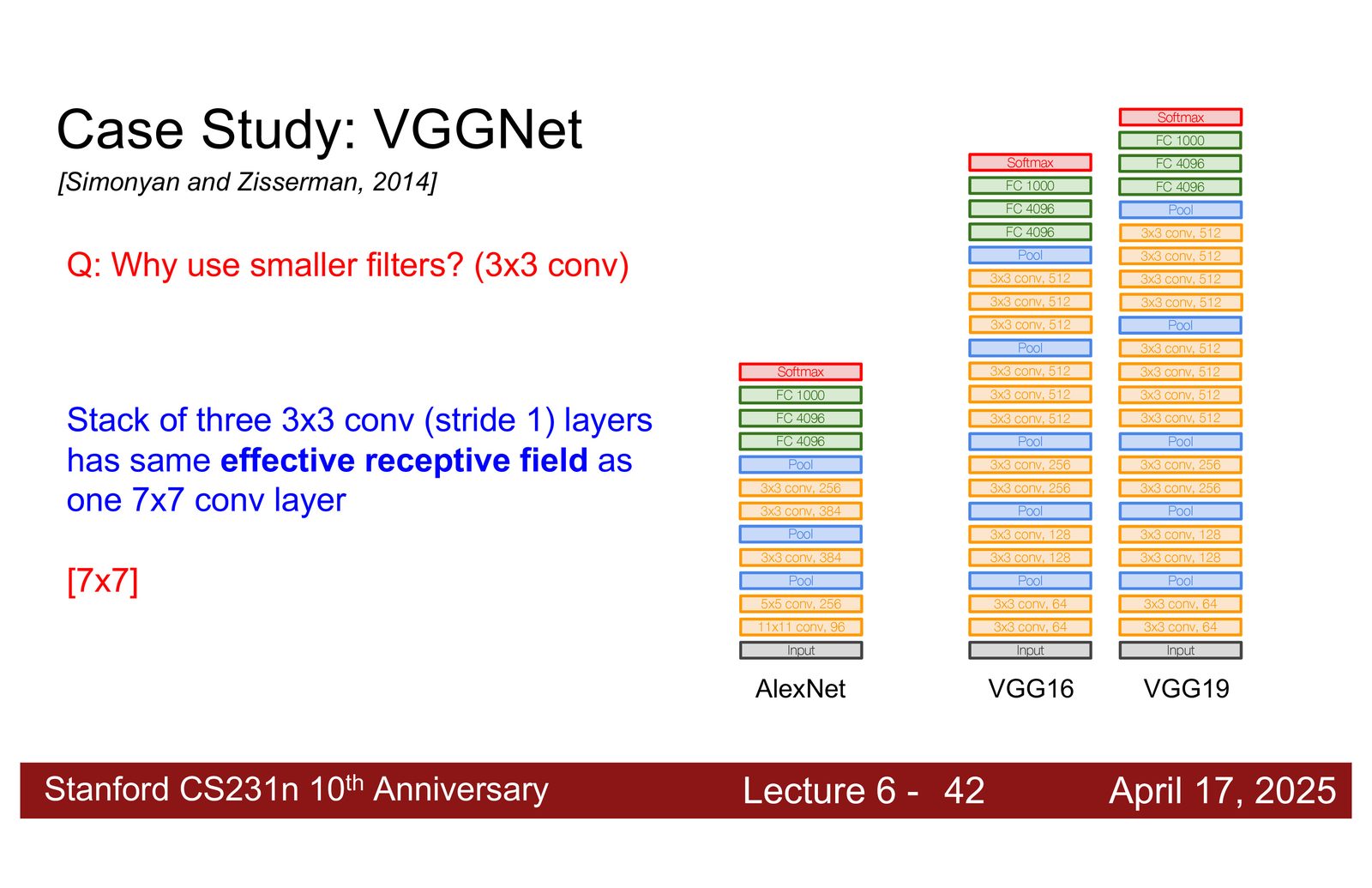
AlexNet(2012)使用了大小不一的卷积核(11x11, 5x5, 3x3),总共约 6000 万参数。VGGNet(2014)提出了一个重要的设计原则:
VGGNet 的核心洞察:小滤波器更好
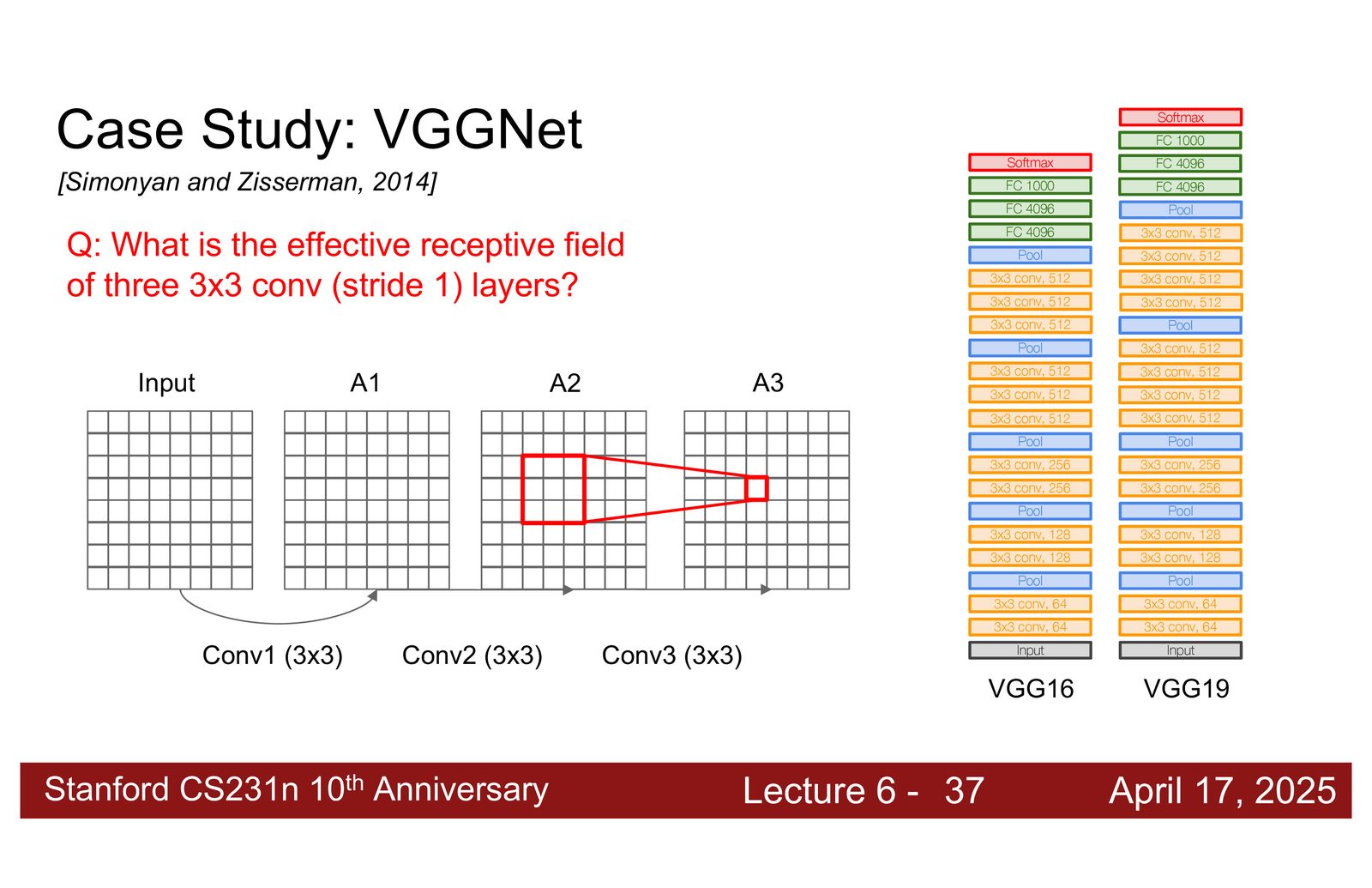
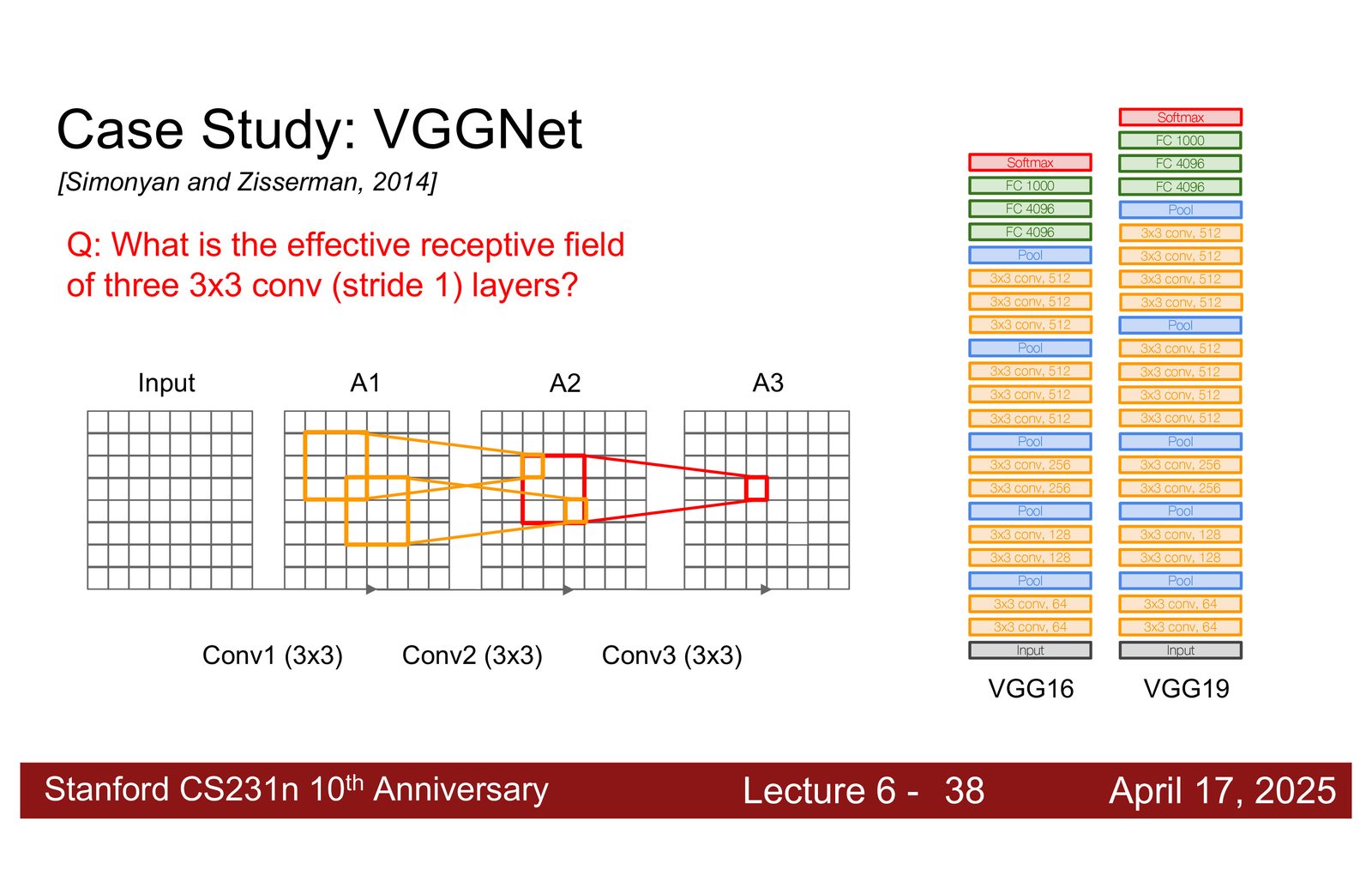
VGGNet 完全使用 \(3 \times 3\) 卷积核代替大卷积核。关键发现:
三个 \(3 \times 3\) 卷积 \(\approx\) 一个 \(7 \times 7\) 卷积(相同的感受野),但:
- 参数更少:\(3 \times (3^2 C^2) = 27C^2\) vs \(7^2 C^2 = 49C^2\),减少 45%
- 表达能力更强:三层之间有激活函数,引入了更多非线性
- 更深的网络:更多层 = 更复杂的特征变换
来源:Slides 第25页。
来源:Slides 第26页。
VGGNet 的架构设计模式清晰而规律:
- 所有卷积层:\(3 \times 3\),stride 1,padding 1(保持空间尺寸)
- 池化:\(2 \times 2\) max pooling,stride 2(空间尺寸减半)
- 每次池化后通道数翻倍:\(64 \rightarrow 128 \rightarrow 256 \rightarrow 512\)
本章小结
从 AlexNet 到 VGGNet,CNN 架构设计的趋势是:用更小的滤波器和更深的网络取代大滤波器和浅网络。小滤波器参数少、非线性更强,但需要更多层才能达到相同的感受野。VGG 确立了“\(3 \times 3\) 卷积 + 每阶段下采样并翻倍通道数”的设计范式。
ResNet:残差学习
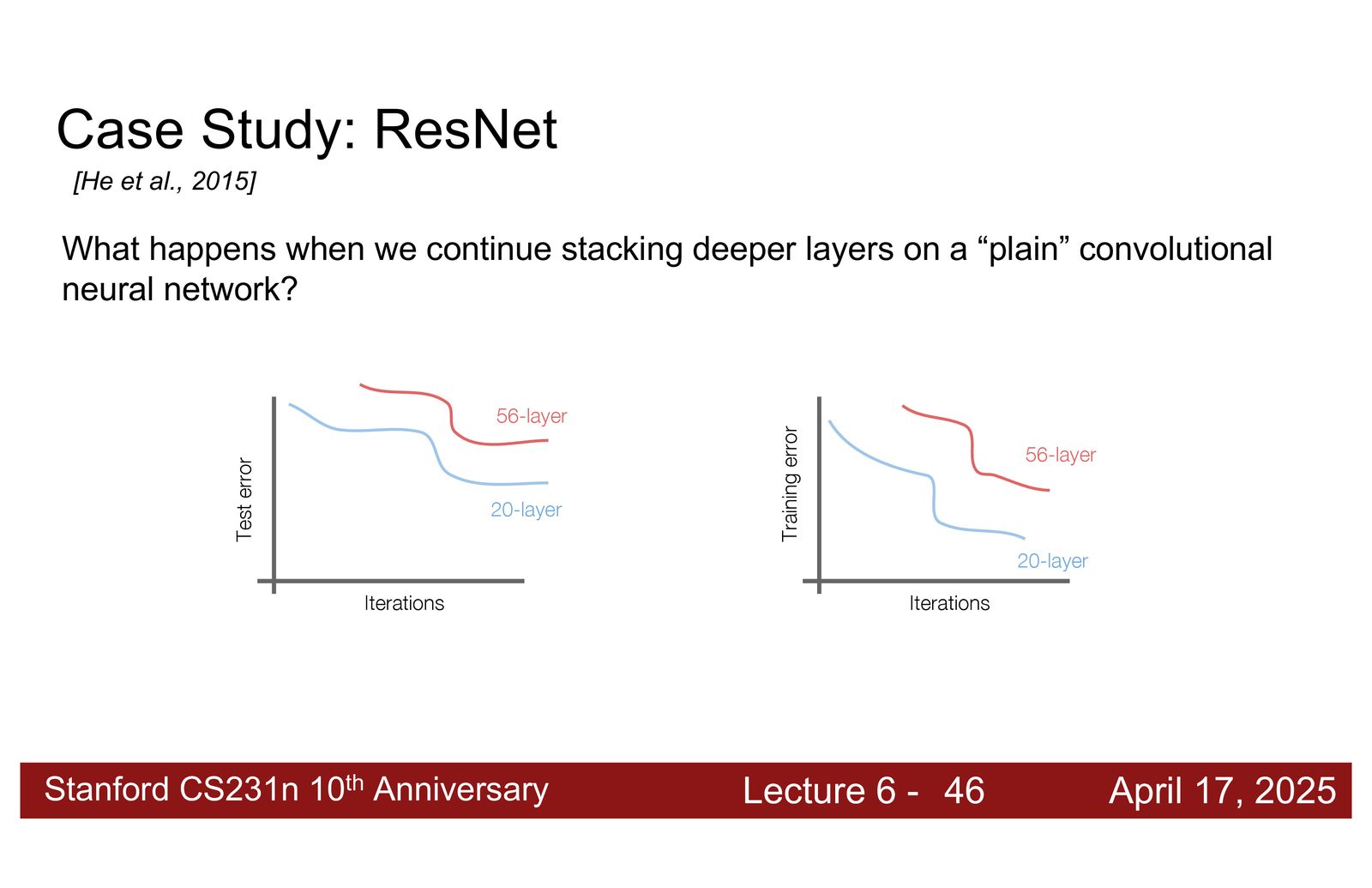
深度退化问题
来源:Slides 第28页。
一个令人困惑的发现:当把普通的 CNN(没有残差连接)从 20 层加深到 56 层时,训练误差和测试误差都变高了。
这不是过拟合!
如果是过拟合,我们会期望看到:训练误差下降(模型“记住”了训练数据),但测试误差上升。然而实际观察到的是训练误差也更高——56 层网络在训练集上的表现甚至不如 20 层网络。
这说明问题出在优化上,而非模型容量上。更深的网络包含了更浅网络能学到的所有函数(理论上可以将多余的层设为恒等映射),但优化算法找不到好的解。
残差连接的核心思想
来源:Slides 第30页。
ResNet 的核心创新:不让网络直接学习目标映射 \(H(x)\),而是学习残差 \(F(x) = H(x) - x\)。网络输出为:
残差连接解决了什么问题?
- 恒等映射变得容易:如果某层不需要做任何变换,网络只需让 \(F(x) \approx 0\)(将滤波器权重学到接近零),输出就自然等于输入 \(x\)。
- 学习增量而非全量:网络从“从头学习完整映射”变成“在输入基础上学习一个微小的修正量”,这个优化问题更容易。
- 梯度传播更顺畅:反向传播时,梯度可以通过跳跃连接直接回传到前面的层,缓解了梯度消失问题。
残差块的结构
一个标准的残差块包含:
- 输入 \(x\)
- \(3 \times 3\) 卷积 \(\rightarrow\) ReLU \(\rightarrow\) \(3 \times 3\) 卷积 得到 \(F(x)\)
- 跳跃连接:将 \(x\) 直接复制过来
- 相加:\(F(x) + x\)
- ReLU
来源:Slides 第32页。
残差连接要求张量形状一致
\(F(x) + x\) 要求两者形状完全相同。这就是为什么残差块内部使用 \(3 \times 3\) 卷积、stride 1、padding 1——保持空间尺寸不变。当需要下采样或改变通道数时,需要在跳跃连接上也做相应的变换(通常用 \(1 \times 1\) 卷积)。
ResNet 的设计模式
来源:Slides 第34页。
ResNet 的整体设计:
- 入口:一个较大的 \(7 \times 7\) 卷积层(stride 2)+ max pooling
- 主体:多个阶段(stage),每个阶段包含若干残差块
- 阶段之间:空间尺寸减半,通道数翻倍
- 出口:全局平均池化 \(\rightarrow\) 全连接层 \(\rightarrow\) 分类
ResNet 家族提供了不同深度的变体:
| 模型 | 层数 | Top-5 错误率 |
|---|---|---|
| ResNet-18 | 18 | 10.9% |
| ResNet-34 | 34 | 8.6% |
| ResNet-50 | 50 | 7.1% |
| ResNet-101 | 101 | 6.4% |
| ResNet-152 | 152 | 6.2% |
ResNet 的历史影响
ResNet(2015)是第一个成功训练超过 100 层的深度网络。它赢得了 ILSVRC 2015 的冠军,首次在 ImageNet 上超越了人类水平。更重要的是,残差连接不仅用于 CNN——现代 Transformer 架构中也广泛使用残差连接,原因完全相同:帮助梯度在非常深的网络中有效传播。
Kaiming He 的贡献
ResNet 的第一作者何恺明(Kaiming He)是计算机视觉领域最有影响力的研究者之一。除了 ResNet 之外,他还发明了 Kaiming 初始化方法(本节课后面会讲到),两者同出一人之手——这并非巧合,因为残差连接和正确的初始化都是为了解决深度网络的训练稳定性问题。
本章小结
ResNet 通过残差连接解决了深层网络的优化困难。残差学习的核心思想是“学习增量而非全量”——让网络在输入的基础上学习一个小的修正量。这个看似简单的改变使得训练超过 100 层的网络成为可能,并且其影响远超 CNN 领域,成为现代深度学习架构的标准组件。
权重初始化
为什么初始化很重要
来源:Slides 第36页。
权重初始化是训练深度网络的关键步骤。不恰当的初始化会导致训练完全失败。
以一个 6 层全连接网络(每层 4096 维,ReLU 激活)为例,考虑两种极端情况:
- 初始化太小(\(W \sim \mathcal{N}(0, 0.01^2)\)):激活值随层数指数衰减,到最后几层几乎全为零。梯度也几乎为零,网络无法学习。
- 初始化太大(\(W \sim \mathcal{N}(0, 0.05^2)\)):激活值随层数指数增长,最终溢出。梯度也会爆炸。
来源:Slides 第37页。
Kaiming 初始化
来源:Slides 第38页。
Kaiming He 等人提出的初始化方法(He Initialization):
其中 \(D_{in}\) 是该层输入的维度。因子 2 是为 ReLU 激活函数量身定制的(ReLU 平均将一半的值置零,所以需要额外的 \(\sqrt{2}\) 来补偿)。
Kaiming 初始化的效果
使用 Kaiming 初始化后,各层激活值的均值和标准差保持大致恒定——既不会衰减也不会爆炸。这使得:
- 前向传播中信号强度稳定
- 反向传播中梯度大小稳定
- 训练从一开始就在良好的区域进行
Xavier 初始化 vs Kaiming 初始化
- Xavier 初始化(Glorot, 2010):\(W \sim \mathcal{N}(0, 1/D_{in})\) 或 \(\mathcal{N}(0, 2/(D_{in} + D_{out}))\)。适用于 Sigmoid/Tanh 激活。
- Kaiming 初始化(He, 2015):\(W \sim \mathcal{N}(0, 2/D_{in})\)。适用于 ReLU 激活(因子 2 补偿 ReLU 的零化效应)。
在实践中,PyTorch 的大多数层默认使用 Kaiming 初始化。
本章小结
权重初始化虽然只影响训练的第一步,但它决定了优化的起点,对训练能否成功有着决定性影响。Kaiming 初始化通过根据层的输入维度和激活函数类型来校准初始权重的标准差,确保信号和梯度在深层网络中稳定传播。
CNN 训练实用技巧
学习率调度
来源:Slides 第40页。
学习率是训练中最关键的超参数之一。常见的调度策略:
- 阶梯衰减(Step Decay):每隔固定 epoch 将学习率乘以衰减系数(如 0.1)
- 余弦退火(Cosine Annealing):学习率按余弦曲线从初始值平滑衰减到接近零
- 线性预热(Linear Warmup):训练初期从很小的学习率线性增加到目标学习率
- 预热 + 余弦退火:先线性预热,再余弦衰减——这是现代训练中最常用的策略
学习率调度的直觉
- 初期需要预热:刚开始时,网络权重随机,梯度方向不稳定。大学习率可能导致训练不稳定。
- 中期需要较大学习率:快速探索参数空间,找到好的区域。
- 后期需要小学习率:在好的区域内精细调整,收敛到更优的解。
数据增强
来源:Slides 第42页。
数据增强通过对训练图像施加随机变换来人工扩大数据集,是最有效的正则化技术之一:
- 随机裁剪(Random Crop):在略大的图像中随机裁出目标大小的区域
- 水平翻转(Horizontal Flip):50% 概率左右镜像翻转
- 颜色抖动(Color Jitter):随机调整亮度、对比度、饱和度
- 随机擦除(Random Erasing):随机遮挡图像的一部分
- Mixup / CutMix:将两张图像混合或拼接
数据增强的核心原则
数据增强的变换应该满足:
- 标签不变性:变换后的图像应该仍然属于同一类别(水平翻转的猫还是猫)
- 合理性:变换应该生成可能出现在现实中的图像
- 训练时使用,测试时不用(或使用确定性版本,如中心裁剪)
正则化方法汇总
来源:Slides 第44页。
防止过拟合的主要手段:
- L2 正则化 / 权重衰减:损失函数中加入 \(\lambda \|W\|^2\) 惩罚项
- Dropout:训练时随机关闭神经元
- 数据增强:增加训练数据的多样性
- 提前停止(Early Stopping):在验证集性能开始下降时停止训练
- Batch Normalization:也有一定的正则化效果
迁移学习
来源:Slides 第46页。
当目标任务的数据量有限时,迁移学习是最有效的策略:
- 在大规模数据集(如 ImageNet)上预训练一个 CNN
- 将预训练模型的卷积层作为特征提取器
- 替换最后的全连接层(匹配目标任务的类别数)
- 用目标数据集微调(fine-tune)——可以只训练最后几层,也可以全网络微调(通常用较小的学习率)
迁移学习的经验法则
- 数据很少 + 与预训练域相似:只训练最后一层
- 数据较多 + 与预训练域相似:微调全网络(小学习率)
- 数据较多 + 与预训练域不同:微调全网络(较大学习率)
- 数据很少 + 与预训练域不同:最困难的情况,考虑使用更多数据增强
本章小结
训练一个高性能的 CNN 不仅需要好的架构设计,还需要一系列工程技巧的配合:Kaiming 初始化确保训练稳定启动,学习率调度控制训练节奏,数据增强增强泛化能力,正则化防止过拟合,迁移学习利用已有知识加速新任务的学习。
总结与延伸
全课知识图谱
本节课覆盖了从 CNN 组件到完整训练流程的全部内容:

关键 Takeaways
七条核心原则
- 归一化稳定训练:Layer Norm(Transformer)或 Batch Norm(CNN)让激活值分布可控
- Dropout 防止过拟合:通过随机丢弃强制学习冗余表示
- GELU 取代 ReLU:平滑且无死神经元,已成为 Transformer 标配
- 小滤波器更好:\(3 \times 3\) 卷积参数少、非线性强,VGG 证明了这一点
- 残差连接使深度成为可能:学习增量 \(F(x)\) 比学习完整映射 \(H(x)\) 容易得多
- 正确初始化至关重要:Kaiming 初始化根据维度和激活函数校准权重标准差
- 训练是系统工程:学习率调度、数据增强、迁移学习缺一不可
拓展阅读
- Simonyan & Zisserman, “Very Deep Convolutional Networks” (VGGNet, 2014)
- He et al., “Deep Residual Learning for Image Recognition” (ResNet, 2015)
- He et al., “Delving Deep into Rectifiers” (Kaiming 初始化, 2015)
- Ioffe & Szegedy, “Batch Normalization” (2015)
- Ba et al., “Layer Normalization” (2016)
- Hendrycks & Gimpel, “Gaussian Error Linear Units (GELUs)” (2016)
- Srivastava et al., “Dropout: A Simple Way to Prevent Neural Networks from Overfitting” (2014)