CS336 Lecture 5: GPUs
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Tatsu Hashimoto 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2025年5月1日 |

引言:为什么要理解 GPU
本节课有两个核心学习目标:(1)理解 GPU 的工作原理,让 CUDA 和 GPU 不再“神秘”;(2)掌握加速算法的基本思路,能够针对新架构设计高性能实现。
课程两大目标
- 理解 GPU 何时变慢、为什么变慢——揭开矩阵乘法性能曲线中那些“诡异波动”的谜底
- 掌握加速算法设计的核心思路——理解 FlashAttention 等算法为何能大幅提升性能
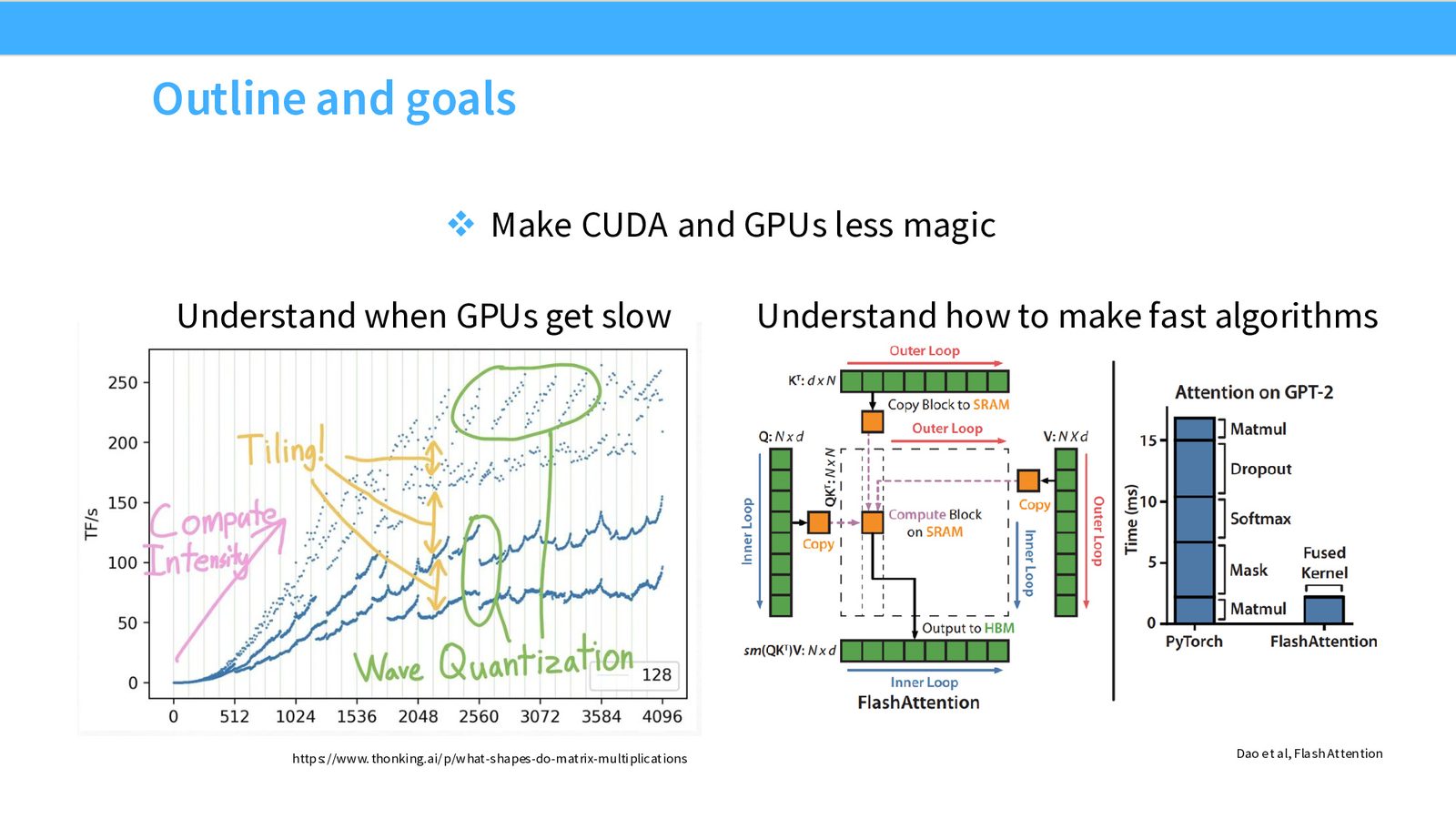
来源:Slides 第2页。矩阵乘法性能数据来自 https://www.thonking.ai/p/what-shapes-do-matrix-multiplications;FlashAttention 图来自 Dao et al.
课程的整体组织分为三部分:
- Part 1:GPU 深度剖析——硬件结构与关键组件
- Part 2:理解 GPU 性能——如何让 ML 工作负载跑得更快
- Part 3:综合应用——拆解 FlashAttention
计算驱动性能提升
Scaling laws 告诉我们:更多的计算资源能带来可预测的语言模型性能提升。Kaplan 等人的研究表明,验证损失与计算量之间存在幂律关系 \(L = 2.57 \cdot C^{-0.048}\)。
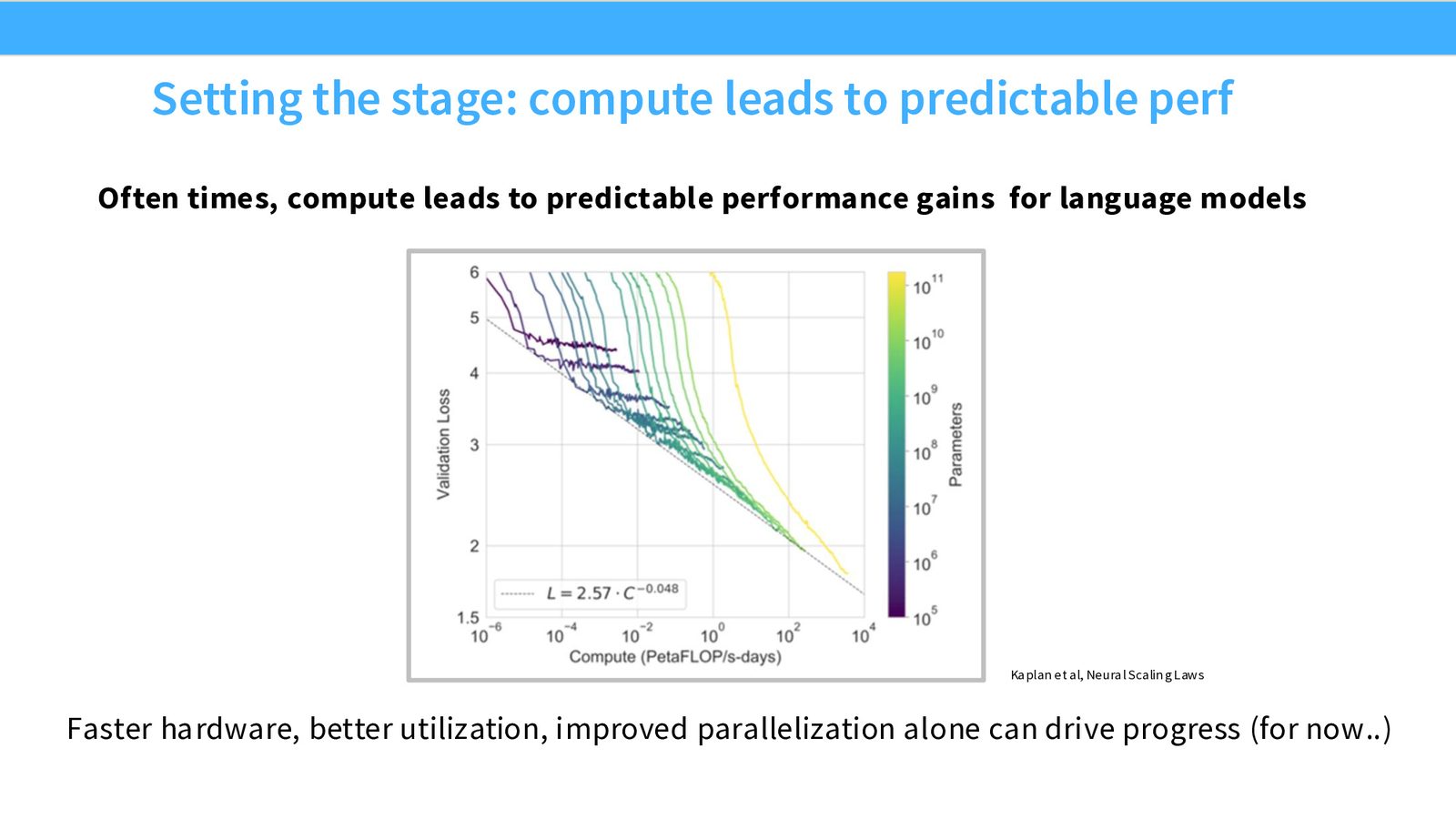
来源:Slides 第5页。图来自 Kaplan et al., Neural Scaling Laws。
更快的硬件、更好的利用率、更高效的并行化,这些才是真正驱动性能进步的因素。因此,理解硬件是构建高效语言模型的必要前提。
从 Dennard Scaling 到并行计算
在半导体发展的早期(1980s--2000s),芯片依靠 Dennard Scaling 来提升性能:更小的晶体管 \(\rightarrow\) 更高的时钟频率 \(\rightarrow\) 更低的功耗 \(\rightarrow\) 更高的性能。但 Dennard Scaling 在 2000 年代初期逐渐失效,单线程性能增长趋于平缓。
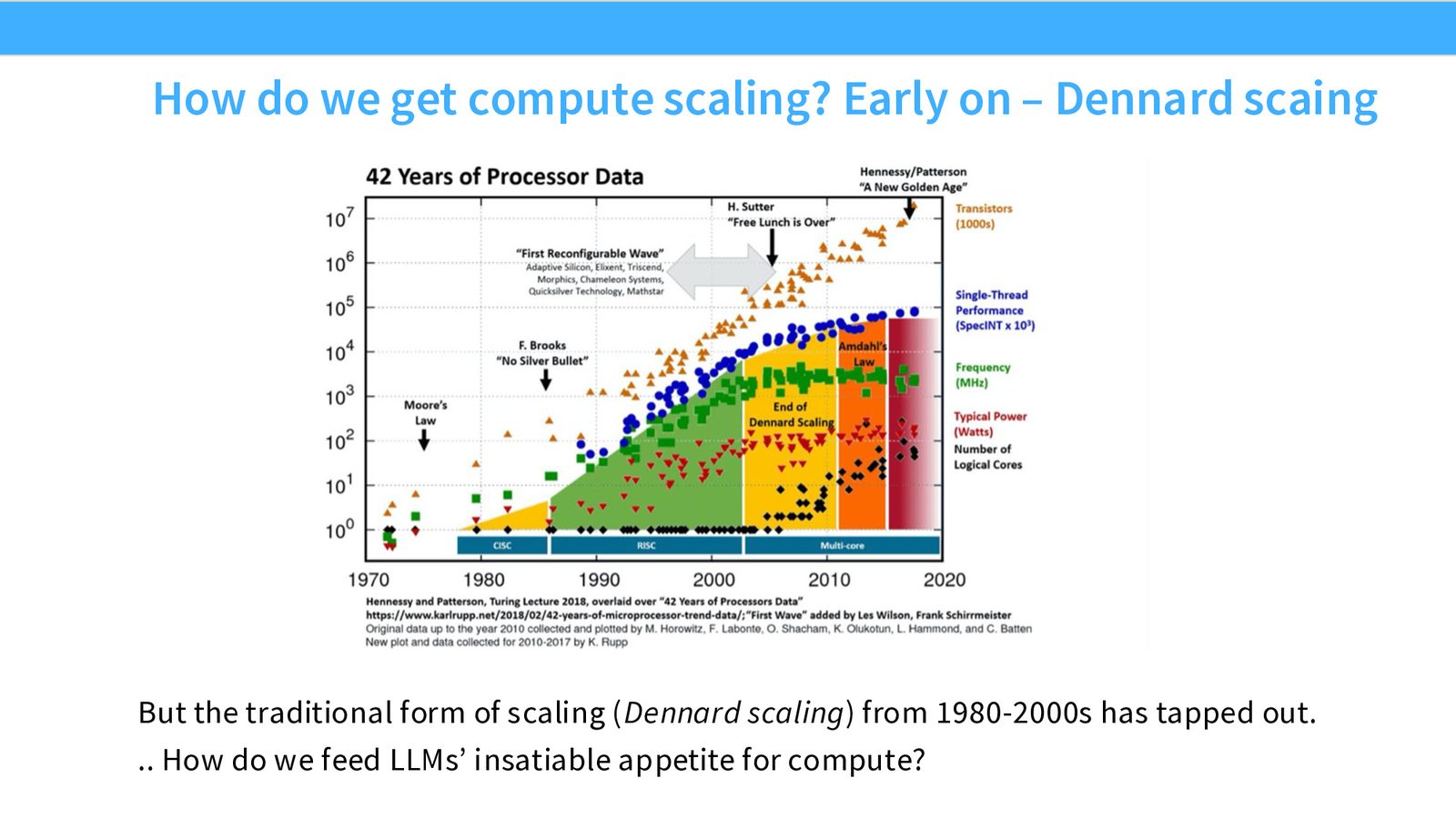
来源:Slides 第6页。
Dennard Scaling 与 Moore's Law
Moore's Law:晶体管数量每1--2年翻倍(仍在延续)。\ Dennard Scaling:更小的晶体管可以在更高频率下以更低功耗运行(已失效)。\ 失效的原因:漏电流增大、散热极限。此后,性能提升转向并行化。
GPU 并行计算的扩展在过去 10 年实现了超过 1000x 的性能提升(从 K20X 到 H100)。这一增长来自四个维度:
- 数值表示(FP32 \(\rightarrow\) FP16 \(\rightarrow\) Int8):\(\sim\)16x
- 复杂指令(DP4, HMMA, IMMA):\(\sim\)12.5x
- 制程进步(28nm \(\rightarrow\) 5nm):\(\sim\)2.5x
- 稀疏性:\(\sim\)2x
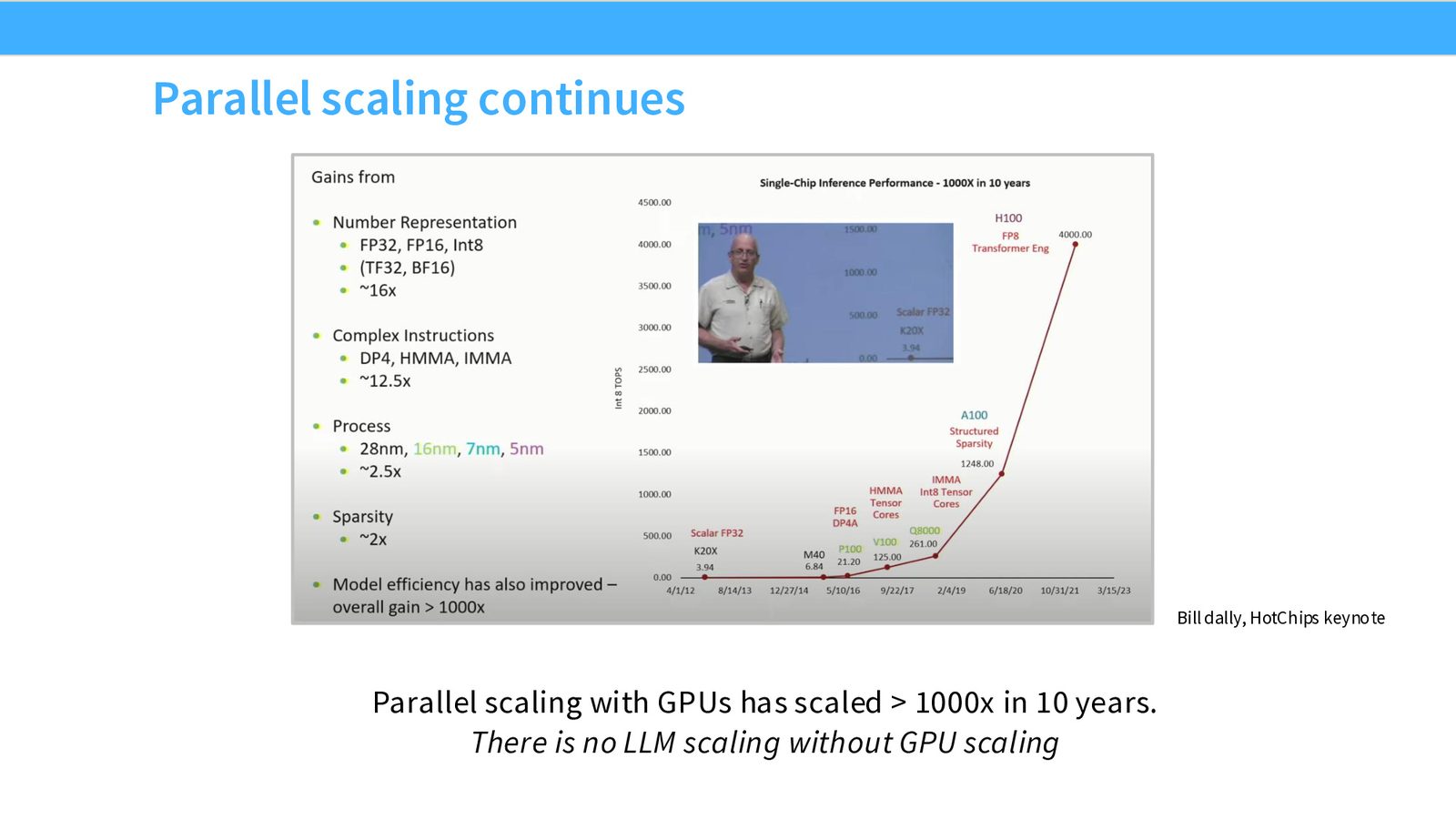
来源:Slides 第7页。
没有 GPU 扩展就没有 LLM 扩展
“There is no LLM scaling without GPU scaling.” GPU 的并行计算能力是大语言模型得以存在的硬件基础。
本章小结
半导体性能提升已从频率驱动转向并行驱动。GPU 通过大规模并行计算实现了指数级的性能增长,是支撑大语言模型训练和推理的核心硬件。理解 GPU 的工作原理和性能特征,是设计高效 ML 系统的必要条件。
GPU 架构剖析
CPU vs GPU:设计哲学的根本差异
CPU 和 GPU 的芯片面积分配方式截然不同:
- CPU:大量面积用于控制逻辑(分支预测、乱序执行)和缓存,少量 ALU。优化目标是延迟(latency)——让单个任务尽快完成。
- GPU:大量面积用于计算单元(ALU),极少的控制逻辑。优化目标是吞吐量(throughput)——在给定时间内处理尽可能多的数据。

来源:Slides 第8页。
右上角的调度示意图清楚地展示了二者的区别:CPU 串行完成 T1\(\rightarrow\)T2\(\rightarrow\)T3\(\rightarrow\)T4(每个任务快速完成),GPU 则让 T1--T4 并行执行(单个任务可能等待数据,但整体吞吐量高)。
GPU 的执行单元:SM 与 SP
GPU 由大量 SM(Streaming Multiprocessor,流式多处理器) 组成,每个 SM 内部包含多个 SP(Streaming Processor,流处理器)。以 A100 为例,拥有 128 个 SM。
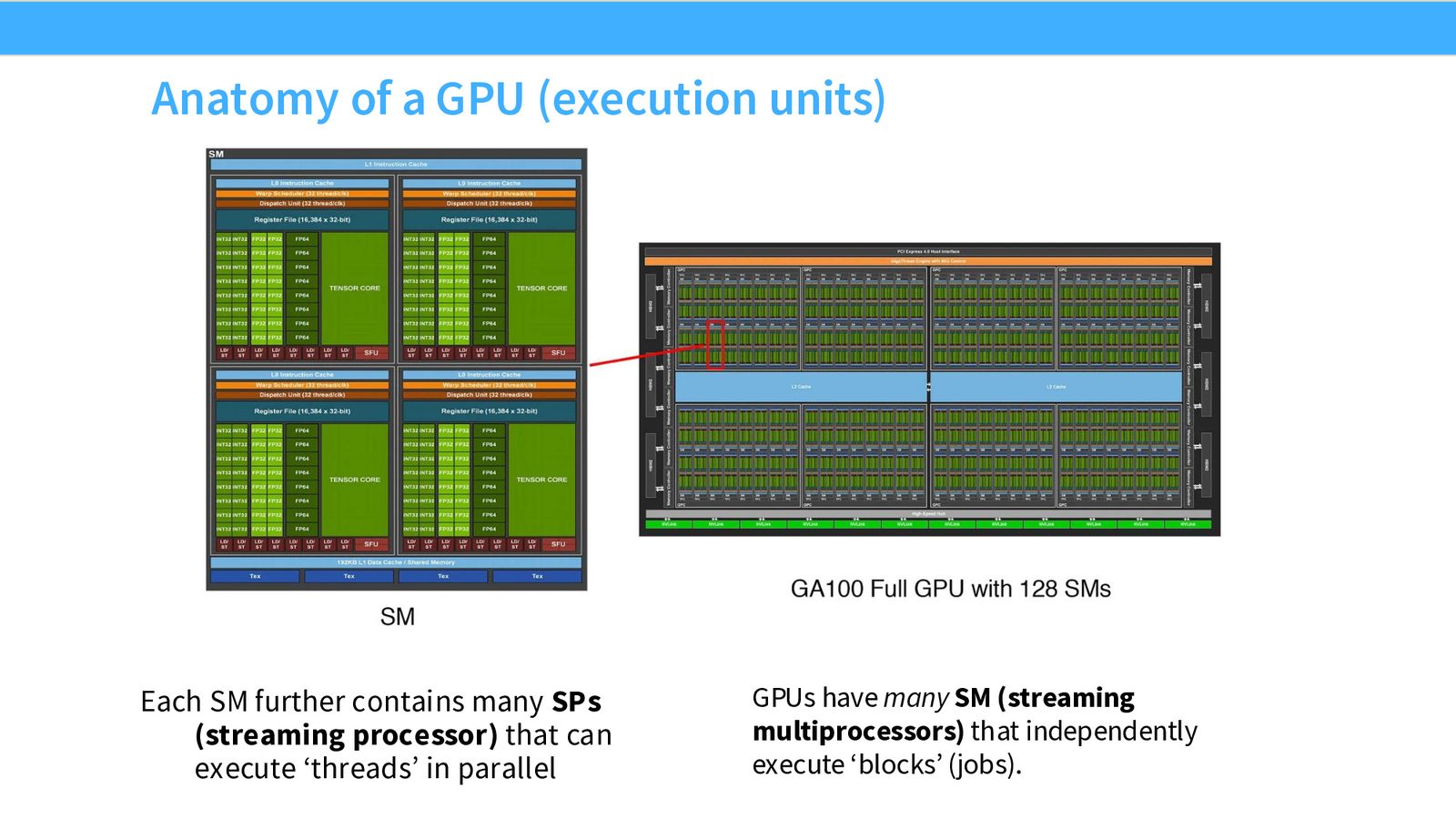
来源:Slides 第9页。
GPU 执行层次
GPU \(\supset\) SM(流式多处理器)\(\supset\) SP(流处理器)\ 每个 SM 独立执行一组“Block”(任务),每个 SP 可以并行执行多个线程。A100 拥有 128 个 SM,每个 SM 含多个 Tensor Core 和大量 FP32/INT32 计算单元。
GPU 内存层次
GPU 性能优化的核心在于内存。越靠近 SM 的内存越快:
| 内存类型 | 访问延迟 (cycles) | 位置 |
|---|---|---|
| Shared Memory (SRAM) | 23/19 (load/store) | SM 内部 |
| L1 Cache | 33 | SM 内部 |
| L2 Cache | 200 | 芯片上 |
| Global Memory (HBM/DRAM) | 290 | 芯片外 |
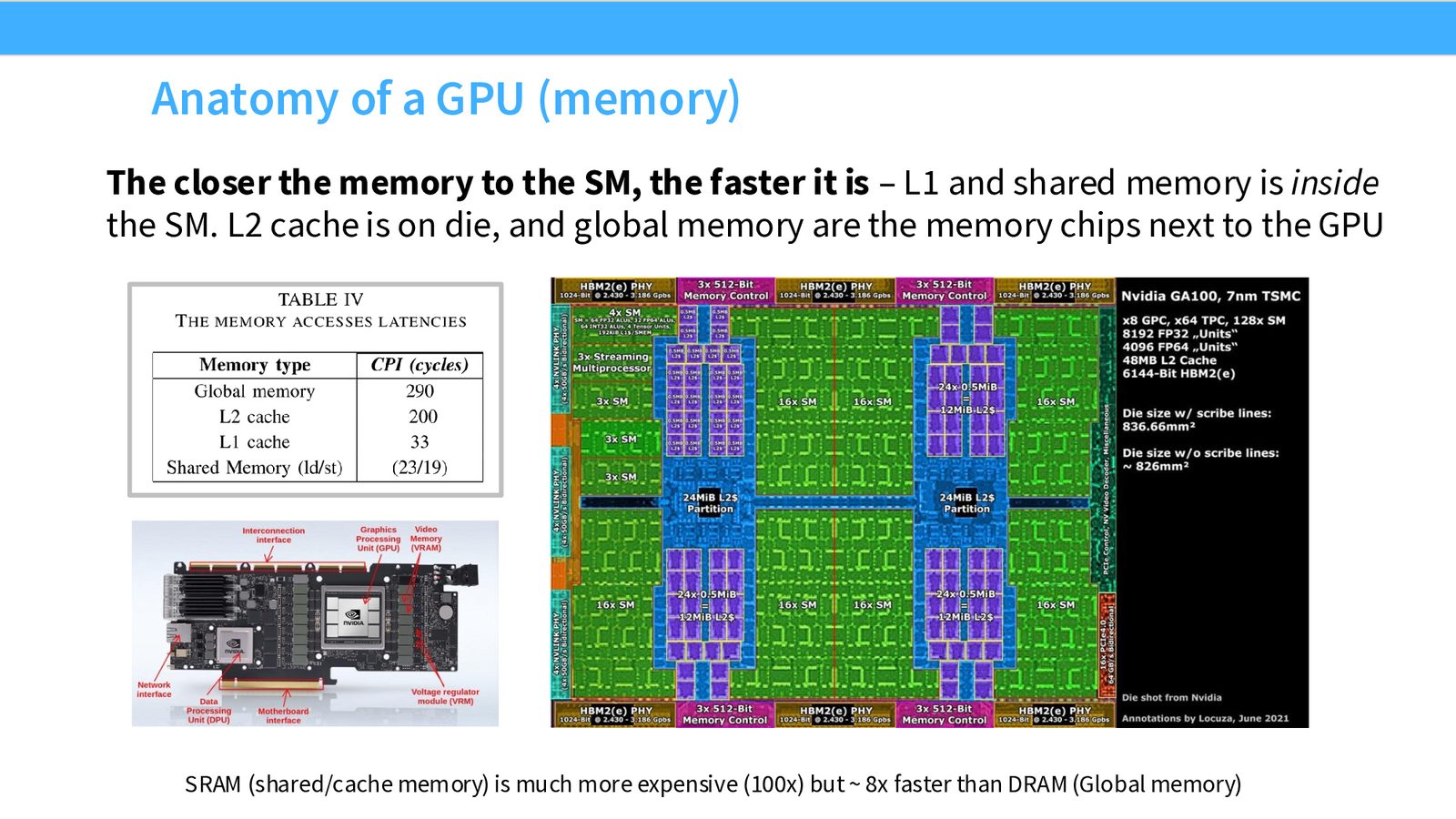
来源:Slides 第10页。PCIe A100 实物照片展示了 GPU 芯片与外部 HBM 芯片的物理距离。
内存是性能的关键瓶颈
SRAM(shared/cache)比 DRAM(global memory)快约 8x,但贵约 100x。全局内存访问延迟(290 cycles)是共享内存(23 cycles)的 12.6 倍。如果你的计算需要频繁访问全局内存,SM 上的计算单元就会空闲等待数据,造成严重的性能浪费。
GPU 执行模型:Thread, Block, Warp
GPU 的编程模型有三个关键概念:
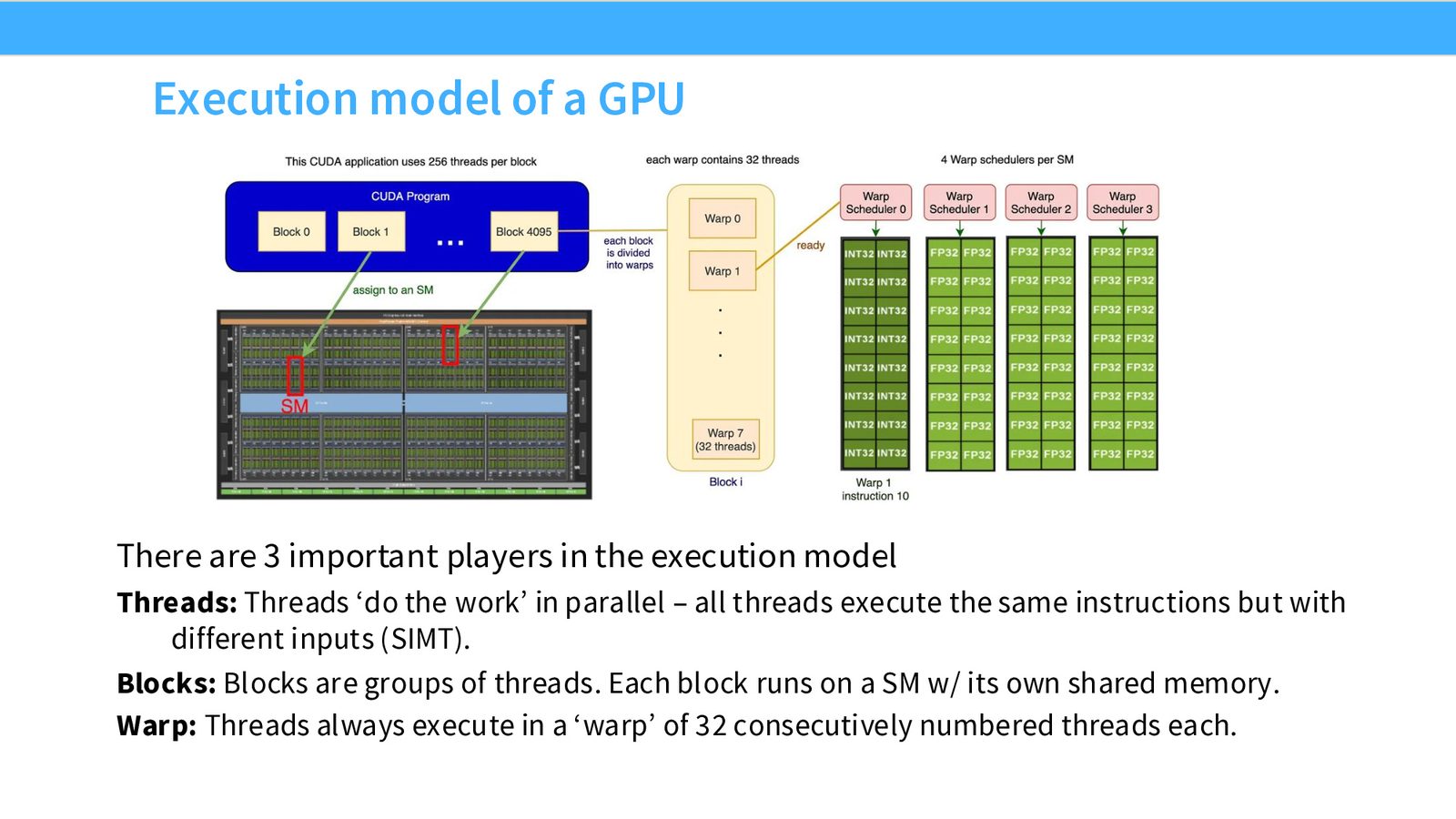
来源:Slides 第11页。
GPU 执行模型三要素
- Thread(线程):执行实际计算的最小单位。所有线程执行相同的指令,但操作不同的数据——这就是 SIMT(Single Instruction, Multiple Threads)模型。
- Block(线程块):一组线程的集合。每个 Block 运行在一个 SM 上,Block 内的线程共享该 SM 的 Shared Memory。
- Warp(线程束):Block 内的线程以 32 个为一组同步执行,称为一个 Warp。Warp 是 GPU 调度的基本单位。
GPU 内存模型
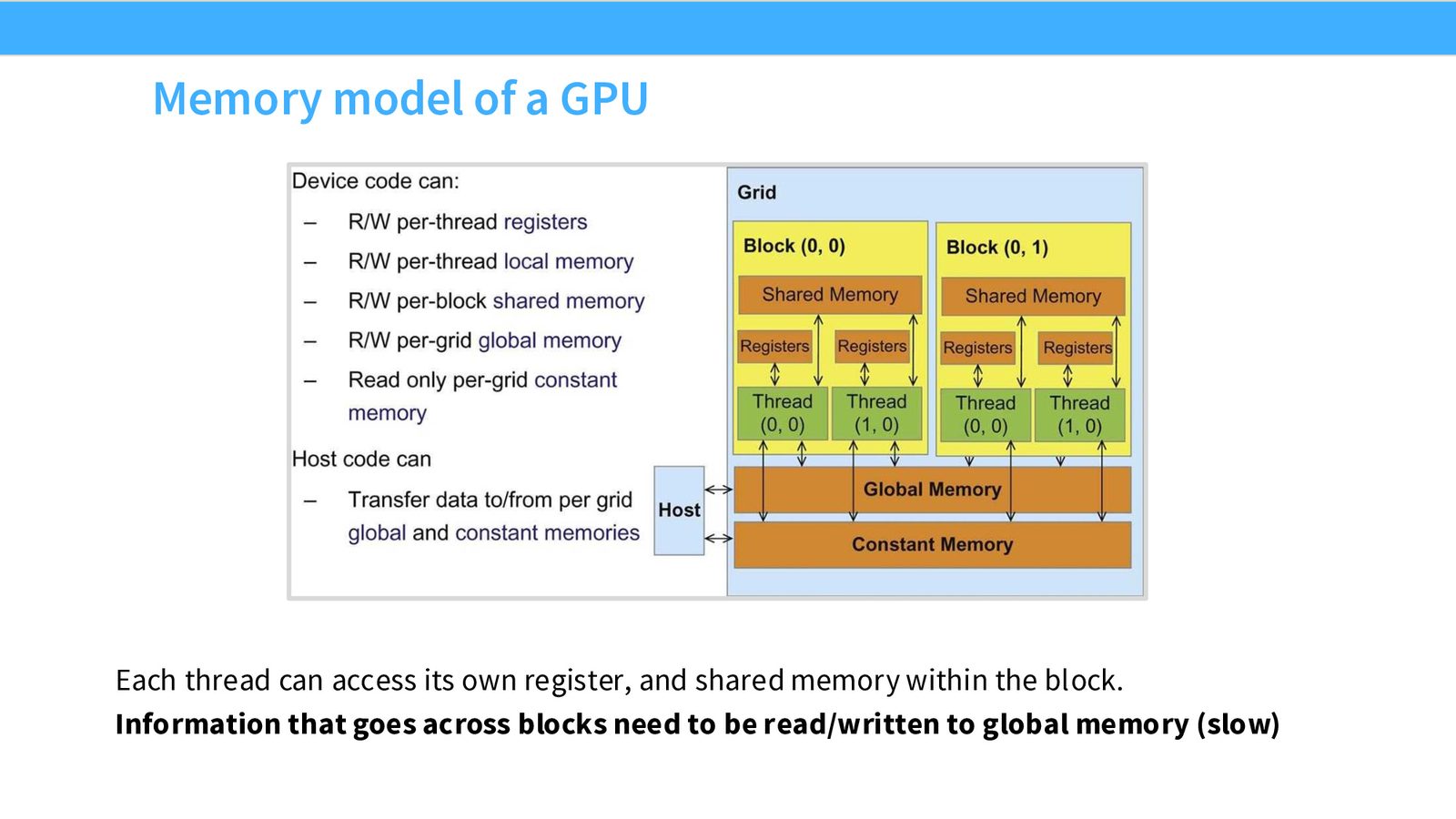
来源:Slides 第12页。
理想的执行模式:每个 Block 的数据都在 Shared Memory 中,Block 内线程高速访问,计算完成后一次性写回全局内存。如果线程需要频繁访问分散在全局内存各处的数据,性能就会急剧下降。
跨 Block 通信代价高昂
Block 之间无法直接通信——必须通过全局内存中转。这意味着算法设计时应尽量让每个 Block 独立完成计算,最小化跨 Block 数据依赖。
TPU 简介
Google 的 TPU(Tensor Processing Unit)与 GPU 在高层架构上非常相似:
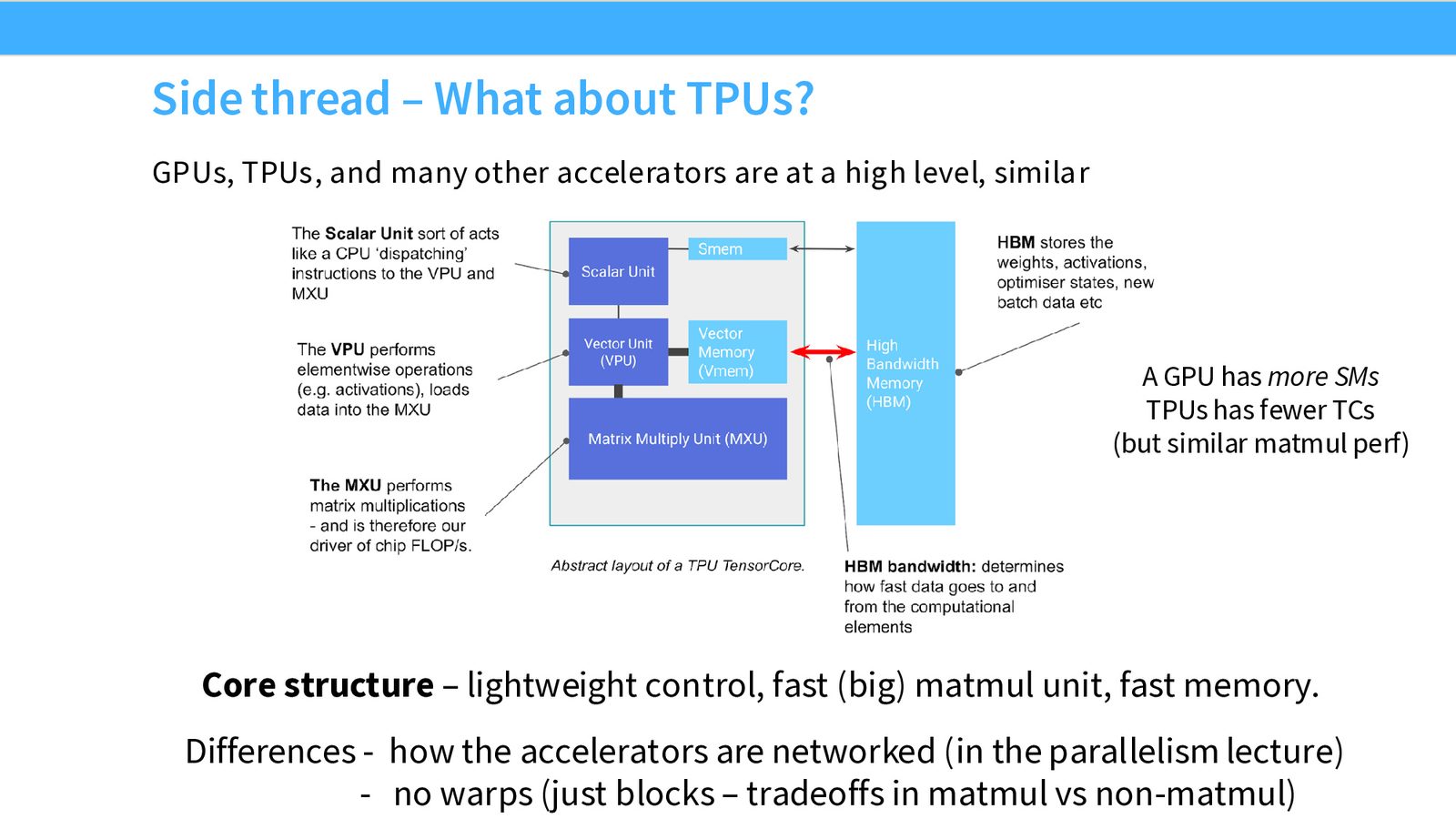
来源:Slides 第13页。
TPU 与 GPU 的核心共同点:轻量控制逻辑 + 大型矩阵乘法单元 + 快速片上内存。 主要差异:(1)TPU 没有 Warp 的概念,编程模型更简单;(2)加速器间的互联方式不同(在并行化课程中详细讨论);(3)GPU 有更多 SM,TPU 有更少但更大的 TensorCore(矩阵乘法性能接近)。
本章小结
- GPU 是大规模并行处理系统,使用 SIMT 模型在大量线程上执行相同指令
- SM 是 GPU 的核心执行单元,Block 映射到 SM,线程以 Warp(32线程)为单位调度
- 计算(尤其是 matmul)的扩展速度远快于内存带宽——这决定了性能优化的核心策略
- 必须尊重内存层次结构:尽量让数据停留在快速的 Shared Memory 中
GPU 性能分析与优化
Matmul 性能的“诡异”曲线
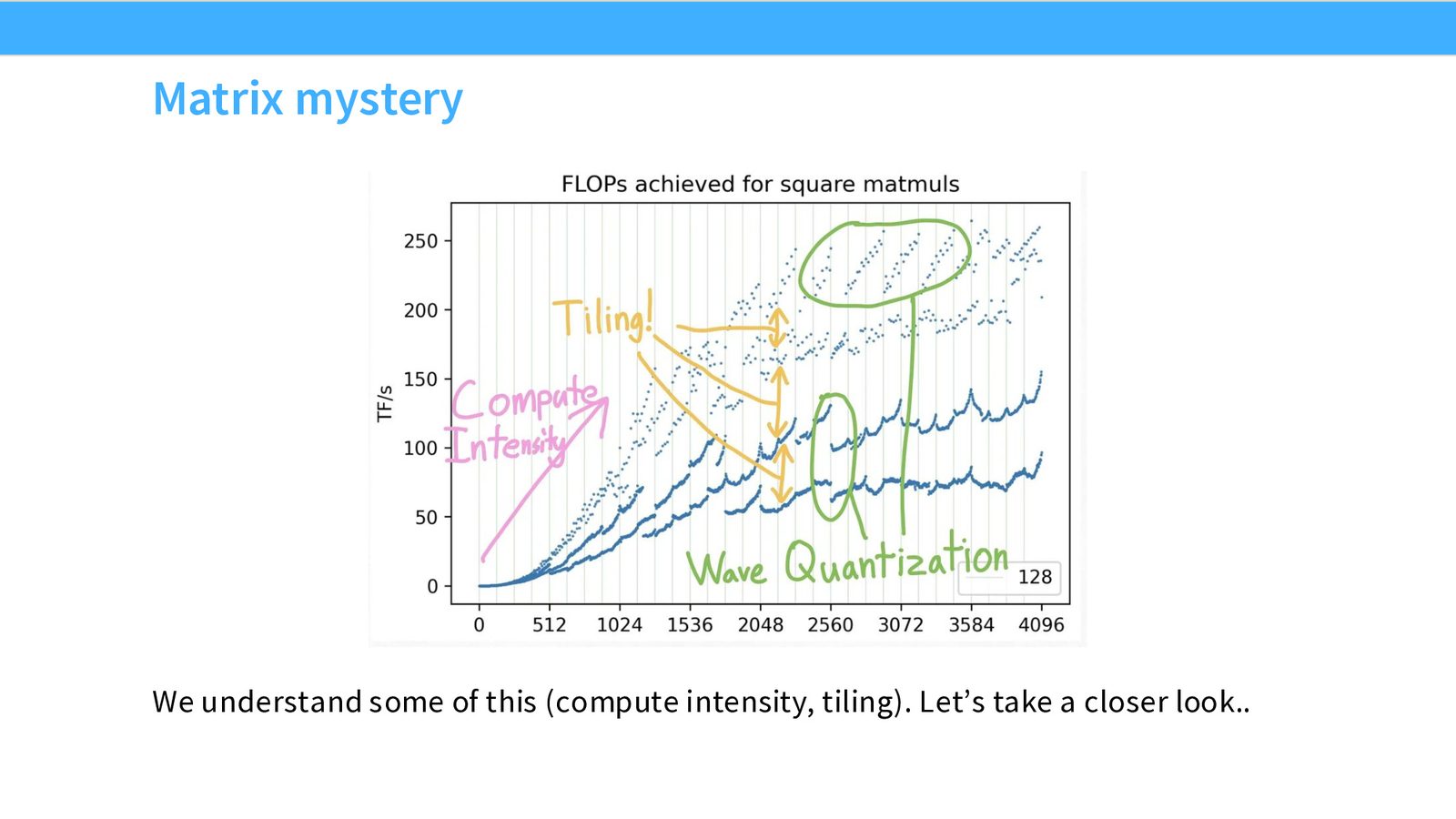
方阵矩阵乘法的性能曲线看起来非常“诡异”——随着矩阵尺寸增大,性能不是单调递增,而是呈现出波浪状的起伏:
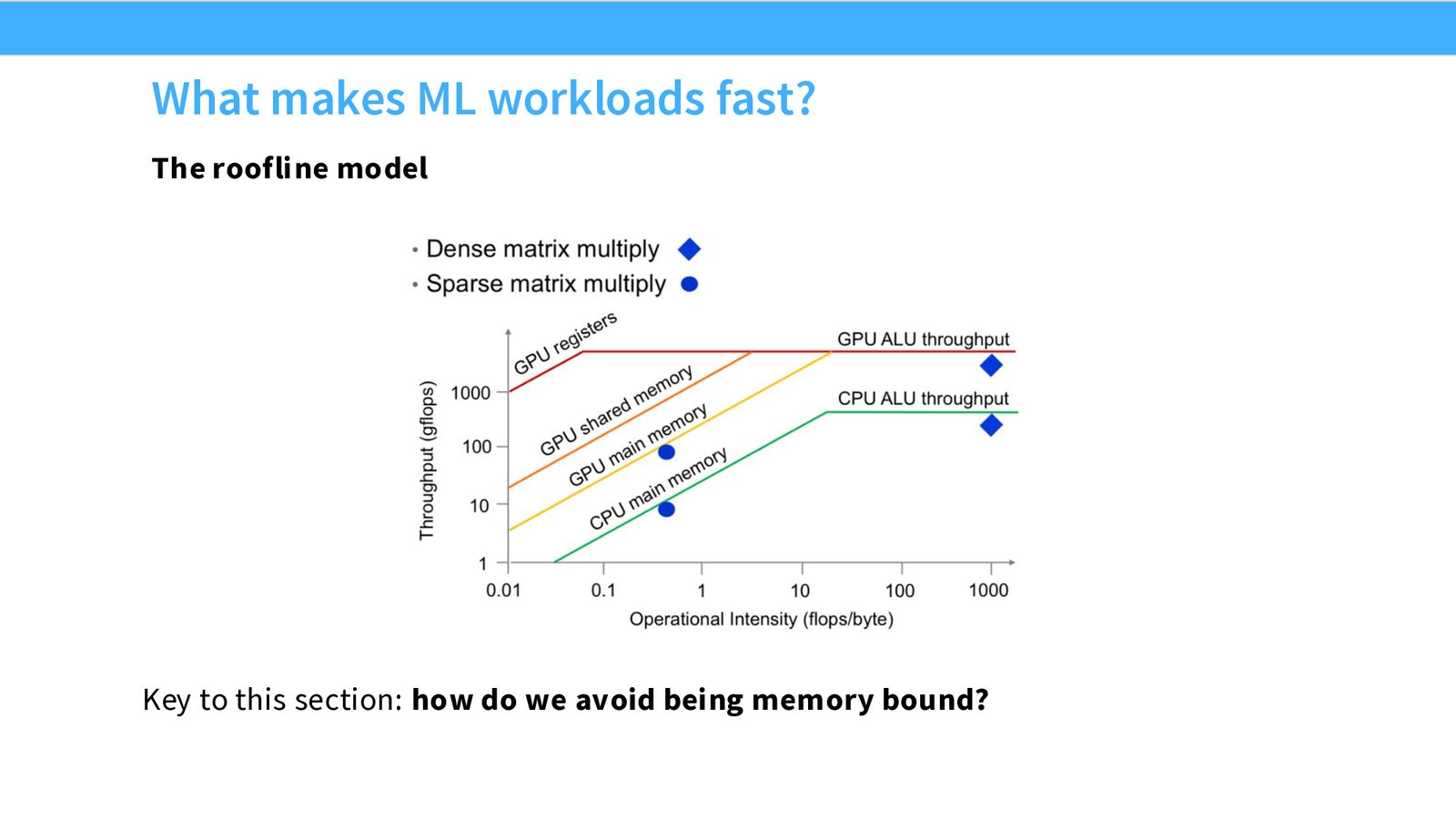
来源:Slides 第20页。数据来自 Horace He 的博客。
本节的目标:到课程结束时,你将完全理解这条曲线中每一个波动的成因。
Matmul 是“特权运算”
现代 GPU 中的 Tensor Core 是专为矩阵乘法设计的硬件电路。Matmul 的峰值吞吐量比普通浮点运算(如加法、ReLU)高 10x 以上。
来源:Slides 第17页。
设计神经网络架构的黄金法则
你的工作负载中,大部分 FLOP 应该花在矩阵乘法上。任何不是 matmul 的操作,相对于 matmul 而言都极其缓慢。这就是为什么 Transformer 架构如此成功——它的核心计算几乎全是矩阵乘法。
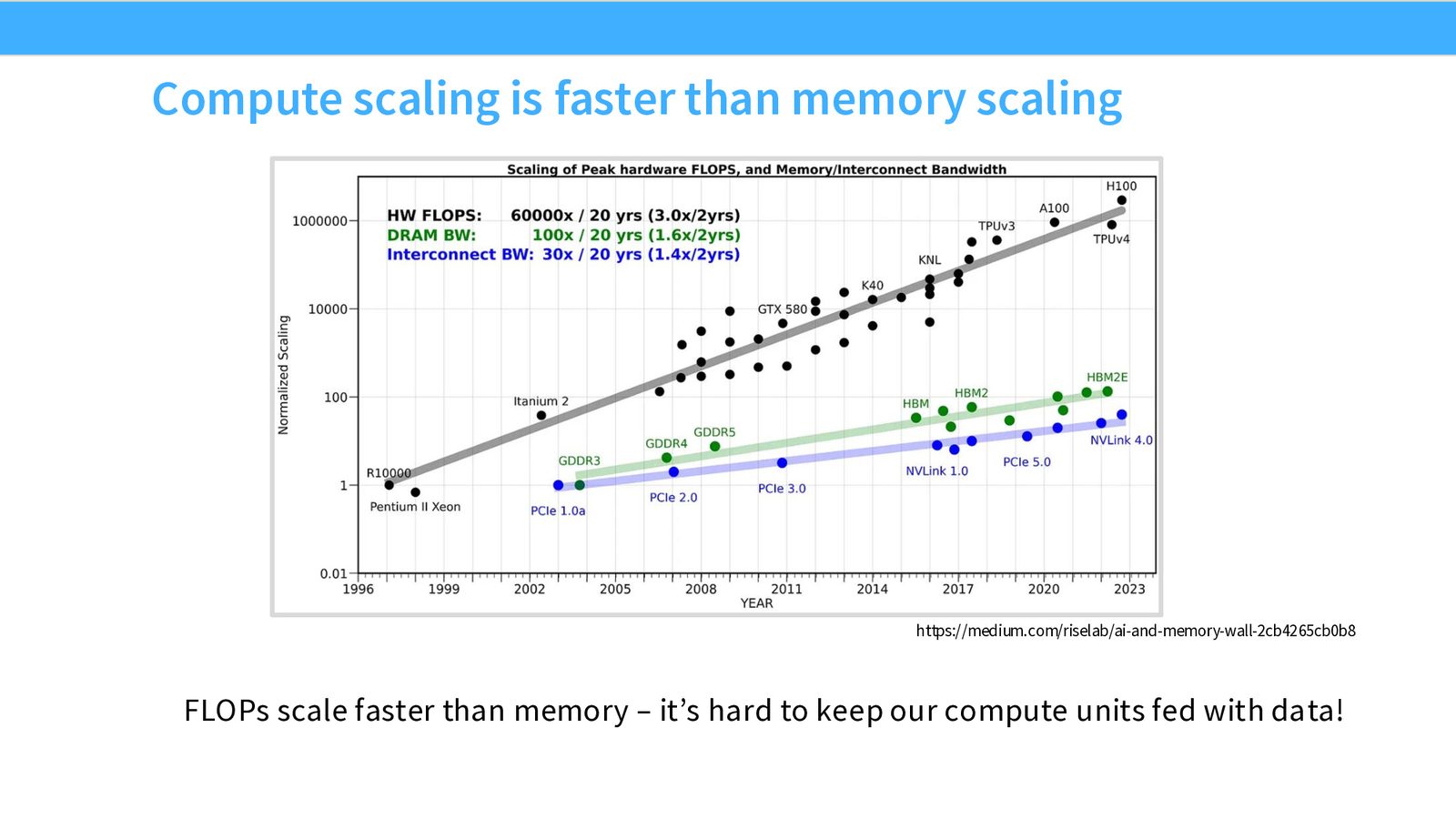
计算扩展快于内存扩展

来源:Slides 第18页。来源:https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b8
Memory Wall:内存墙
计算能力的增长速度(每2年 3.0x)远快于内存带宽(每2年 1.6x)和互联带宽(每2年 1.4x)。这意味着:
- 早期 GPU(如 K80)上,瓶颈往往是计算不够快
- 现代 GPU(如 A100/H100)上,瓶颈越来越多地变成内存带宽不足——数据送不到计算单元
这个差距会越来越大。设计高效算法必须越来越多地关注内存。
Roofline 模型:理解性能上限
Roofline 模型将工作负载分为两个区域:

来源:Slides 第21页。
Roofline 模型的两个区域
- 内存受限区域(Memory-bound,对角线部分):操作强度低,吞吐量受限于内存带宽。增加计算不会更快,因为数据供不上。
- 计算受限区域(Compute-bound,平坦部分):操作强度高,吞吐量受限于计算单元峰值性能。这是理想状态。
本节的核心问题:如何避免被内存带宽限制住?
优化技巧总览
来源:Slides 第22页。
课程介绍了六种核心优化手段:
- Control Divergence(控制分歧)——非内存瓶颈
- Low Precision Computation(低精度计算)
- Operator Fusion(算子融合)
- Recomputation(重计算)
- Coalescing Memory(内存合并访问)
- Tiling(分块计算)
其中第 1 项不涉及内存,其余 5 项都围绕减少或优化内存访问展开。
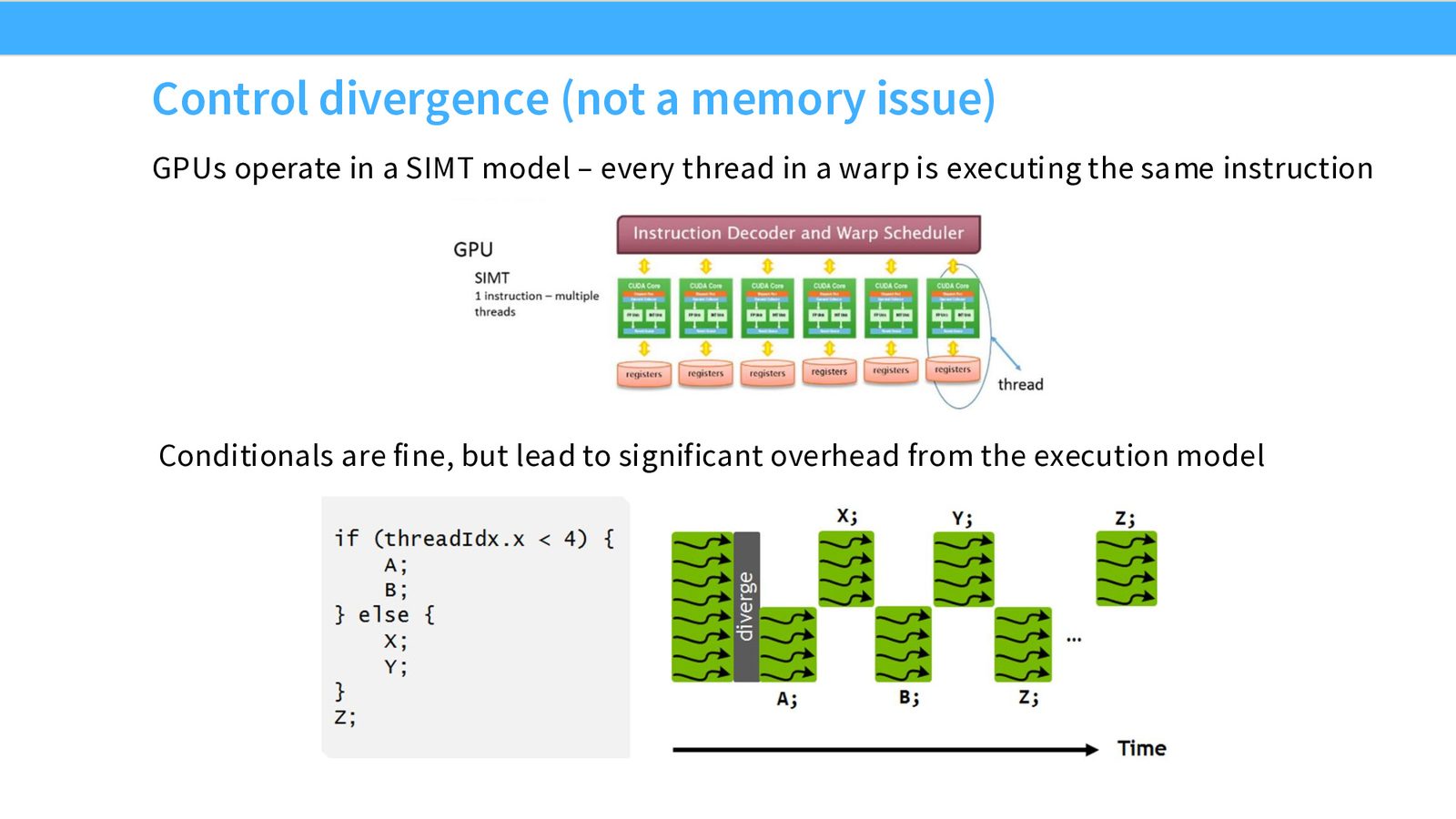
技巧 0:避免 Control Divergence
GPU 的 SIMT 模型要求 Warp 内所有 32 个线程执行相同的指令。如果代码中有条件分支(if-else),会发生什么?
来源:Slides 第23页。
if (threadIdx.x < 4) {
A; B;
} else {
X; Y;
}
Z;
当 Warp 中不同线程走不同分支时,GPU 会先暂停一半线程,执行另一半的分支,然后切换。在上面的例子中,线程 0--3 先执行 A、B(线程 4--7 空闲),然后线程 4--7 执行 X、Y(线程 0--3 空闲),最后所有线程一起执行 Z。
Warp 内的条件分支是性能杀手
Control divergence 会导致 Warp 的有效并行度减半甚至更低。在编写 CUDA kernel 时,应尽量避免在同一个 Warp 内的线程走不同的执行路径。如果必须使用条件分支,尽量让分支按 Warp 边界对齐。
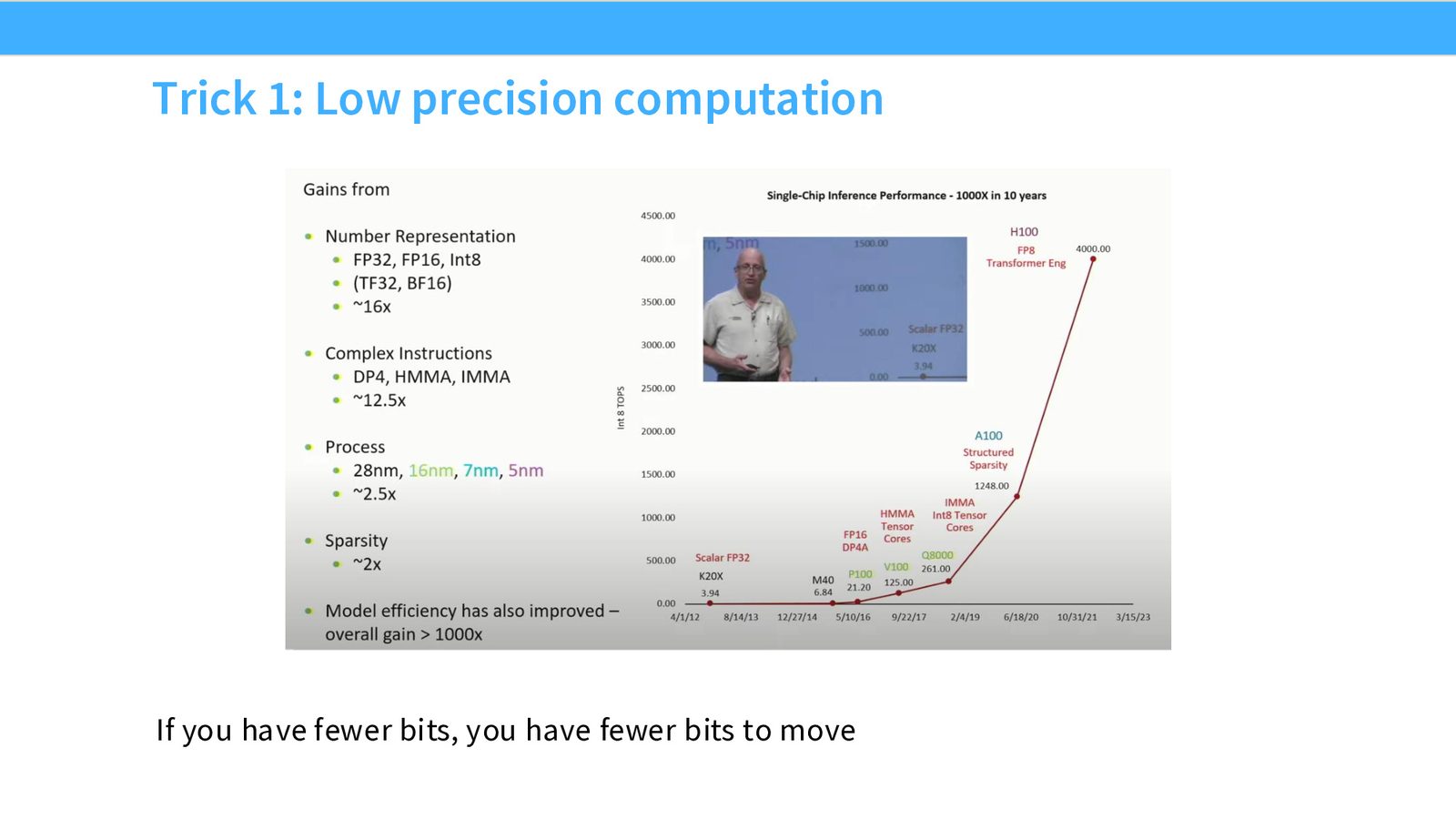
技巧 1:低精度计算
更少的比特 = 更少的数据搬运 = 更高的算术强度(FLOPs/byte)。
以 elementwise ReLU(\(x = \max(0, x)\))为例:
| Float32 | Float16 | |
|---|---|---|
| 内存访问 | 1 read + 1 write = 8 bytes | 1 read + 1 write = 4 bytes |
| 计算量 | 1 comparison, 1 FLOP | 1 comparison, 1 FLOP |
| 算术强度 | 8 bytes/FLOP | 4 bytes/FLOP |
从 FP32 切到 FP16,内存瓶颈直接减半。但并非所有操作都适合低精度:
来源:Slides 第26页。
混合精度训练的三类操作
- 可以用 16-bit(FP16/BF16):矩阵乘法、大多数 pointwise 操作(relu、tanh、add 等)
- 需要更高精度(FP32/FP16 累加器):涉及求和的操作(sum、softmax、normalization)——小值累加会导致舍入误差
- 需要更大动态范围(FP32/BF16):\(|f(x)| \gg |x|\) 的操作(exp、log、pow)以及 loss 函数——否则可能上溢或下溢
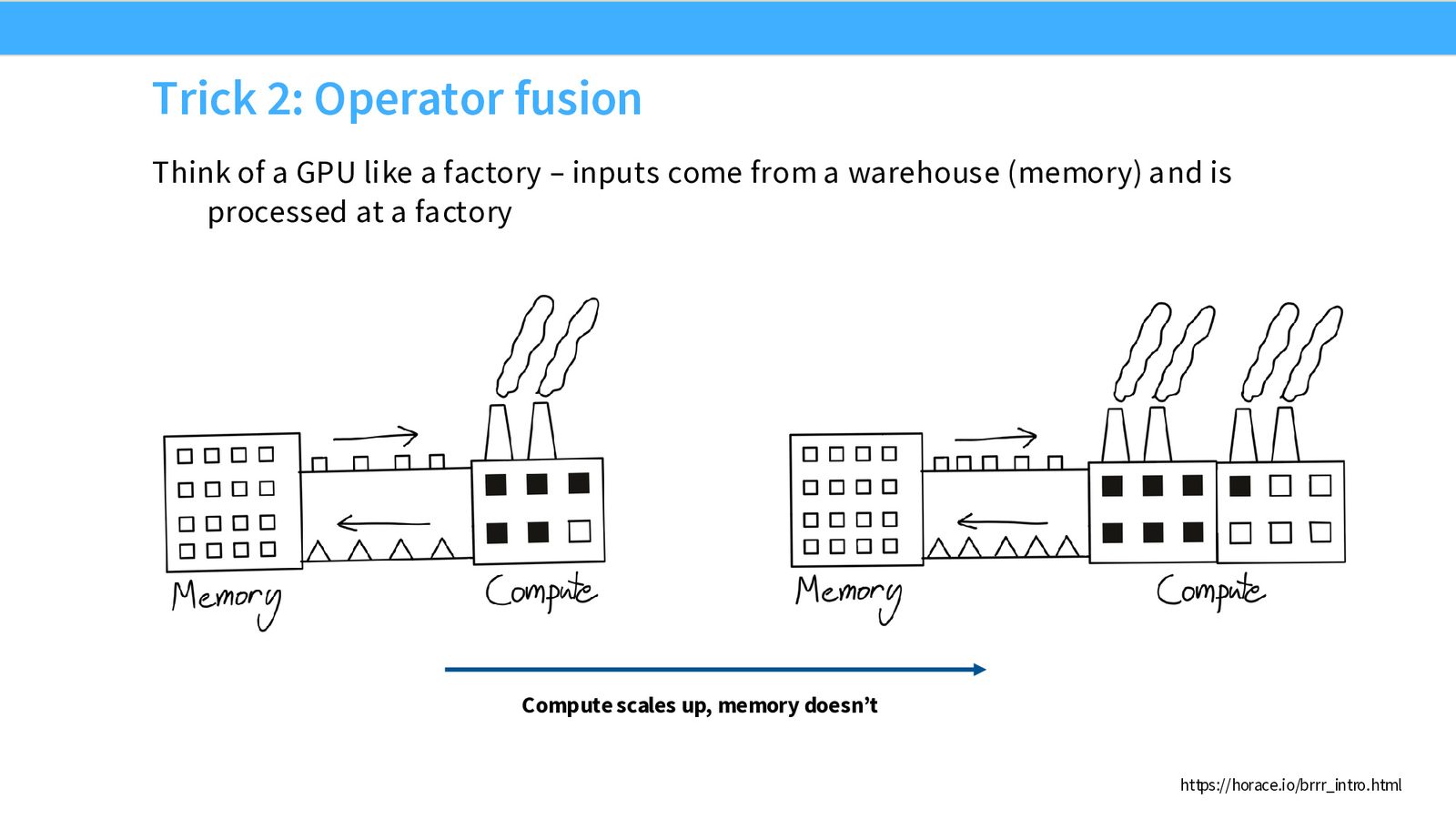
技巧 2:算子融合(Operator Fusion)
Horace He 用工厂比喻来解释内存瓶颈:GPU 就像一个工厂(Compute),原料存放在仓库(Memory)。如果每完成一步加工就要把半成品运回仓库,再从仓库取出来做下一步,搬运成本就会远超加工成本。
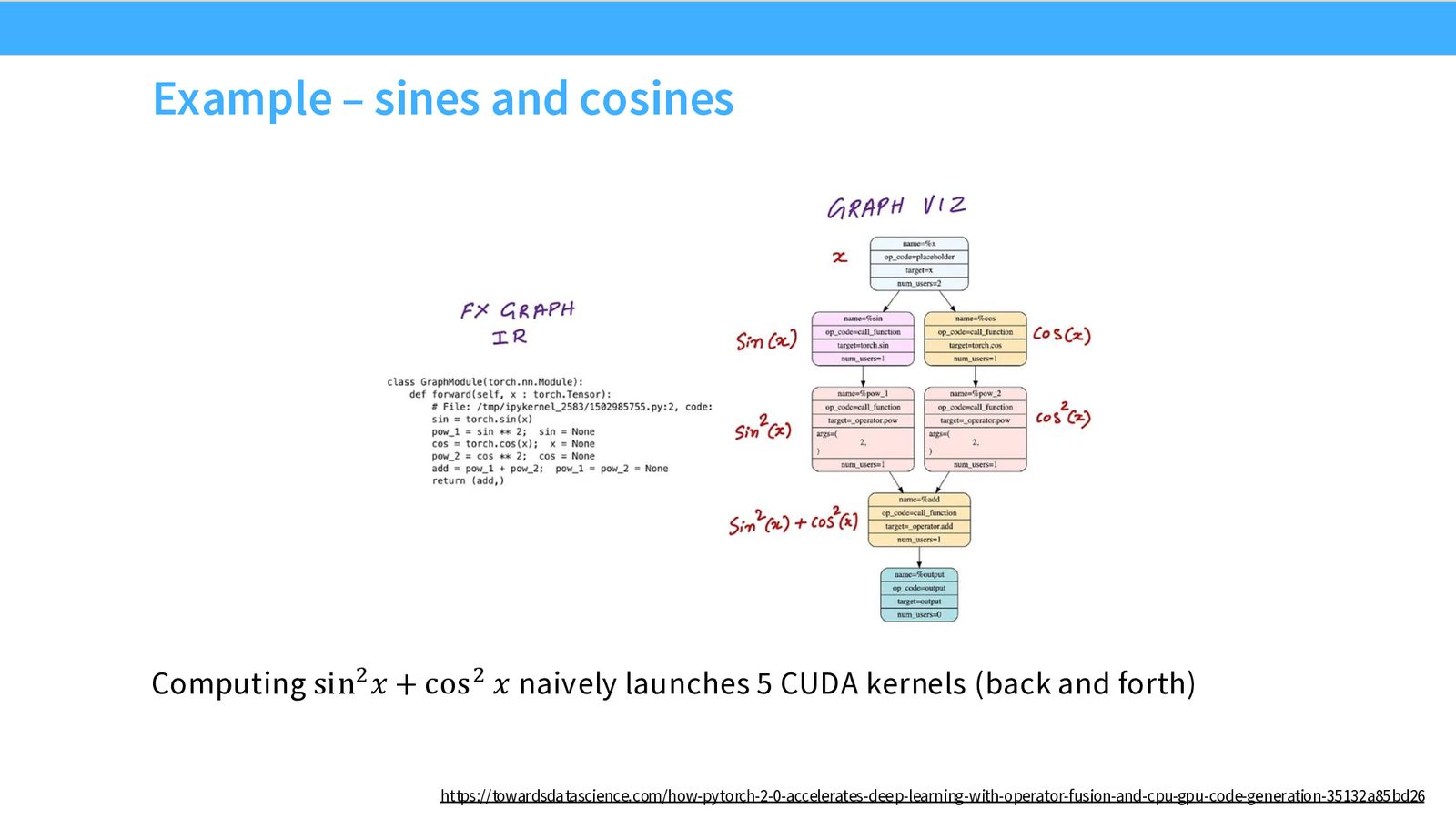
来源:Slides 第28页。
以计算 \(\sin^2(x) + \cos^2(x)\) 为例:朴素实现会启动 5 个 CUDA kernel(sin、pow、cos、pow、add),每次都要从全局内存读写中间结果。使用 torch.compile 进行算子融合后,这 5 个 pointwise 操作可以合并为一次 CUDA kernel 调用,只需一次全局内存读和一次写。
torch.compile 是必备工具
如果你还没有在使用 torch.compile,强烈建议开始使用。它能自动完成大量“简单”的算子融合,显著减少不必要的全局内存往返。
技巧 3:重计算(Recomputation)
在反向传播中,我们需要存储前向传播的中间激活值(activations),以便计算梯度。但存储和读取这些激活值涉及大量全局内存访问。
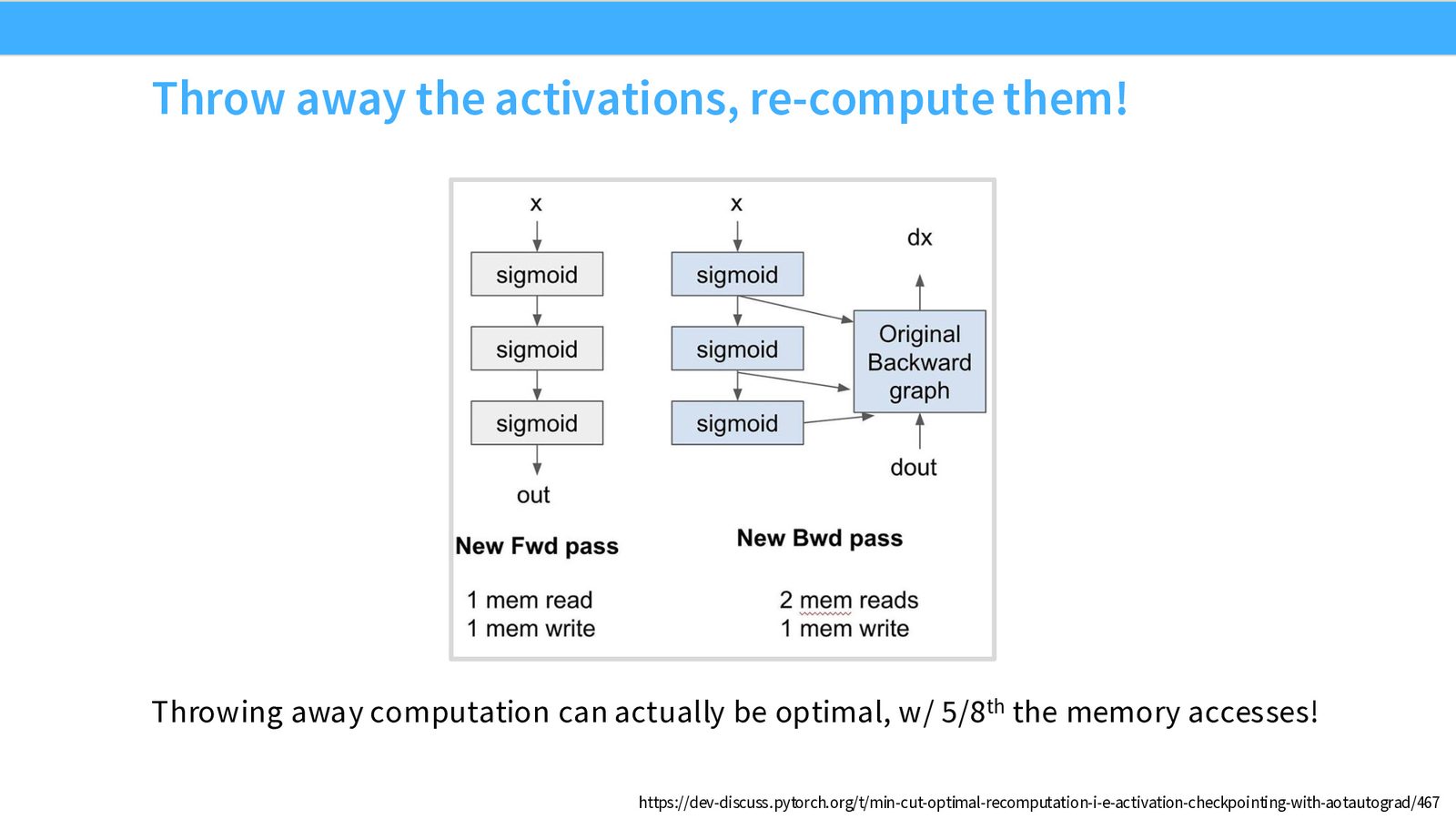
来源:Slides 第32页。
核心洞察:与其存储激活值然后从全局内存读取,不如在反向传播时重新计算它们。这用额外的计算换取了更少的内存访问。

来源:Slides 第33页。
用计算换内存是划算的交易
在 memory-bound 场景下,计算资源是过剩的,内存带宽是稀缺的。重计算用多余的计算能力换取宝贵的内存带宽,减少 \(5/8\) 的内存访问。注意:这与“gradient checkpointing”用的是相同技术,但目标不同——前者是为了加速执行,后者是为了节省显存。
技巧 4:内存合并访问(Coalescing)
DRAM 使用Burst Mode读取数据:每次访问一个地址,硬件会自动返回该地址所在的整个 burst section(通常 128 bytes)内的所有数据。
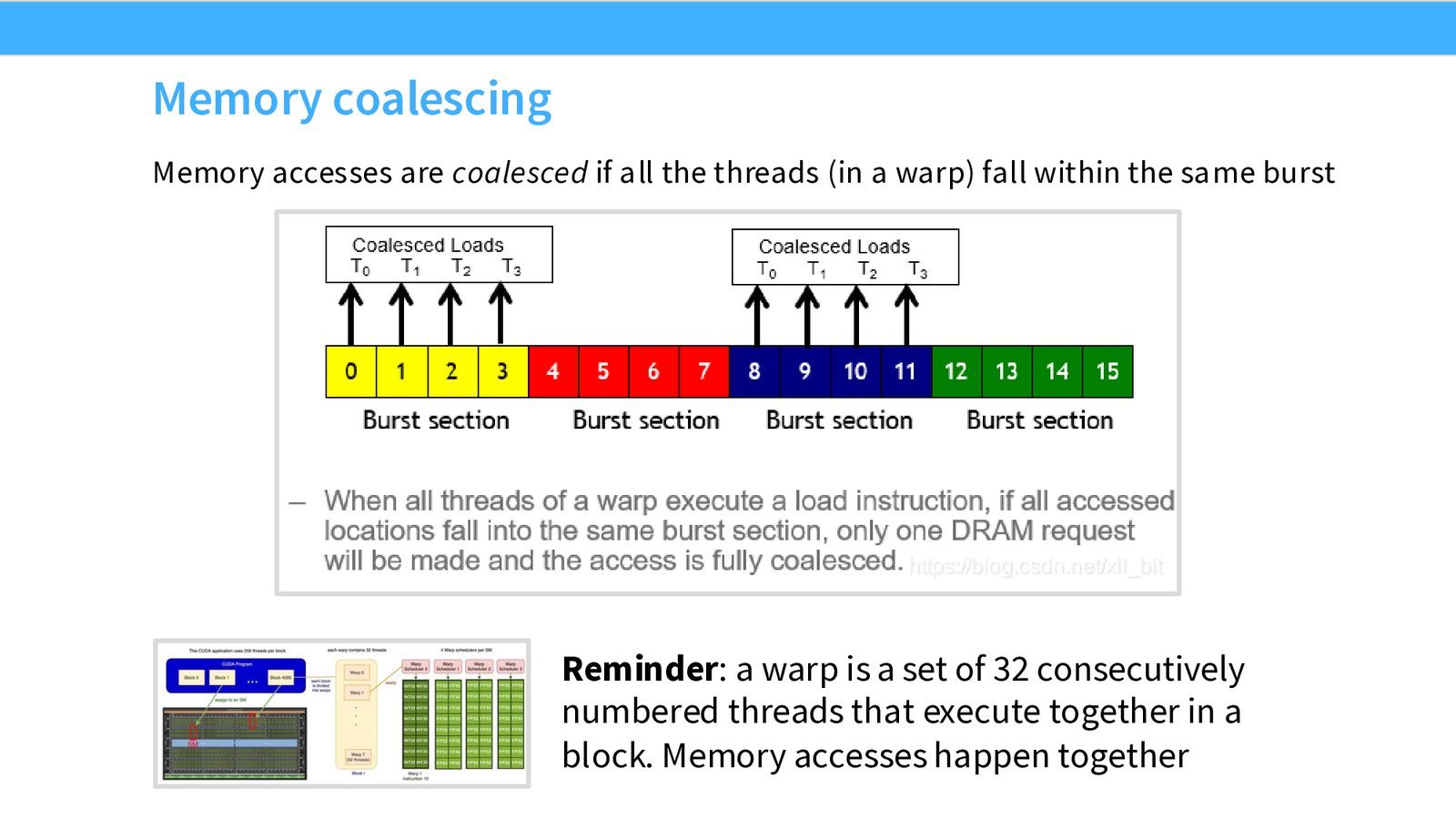
来源:Slides 第34页。
内存合并:当 Warp 中所有线程访问的地址落在同一个 burst section 内时,只需要一次 DRAM 请求即可满足所有线程的需求。
来源:Slides 第36页。
对于 row-major 存储的矩阵,线程沿行方向遍历是非 coalesced 的(每个线程访问不同行的同一列,内存地址不连续),而线程沿列方向遍历是 coalesced 的(相邻线程访问相邻内存地址)。
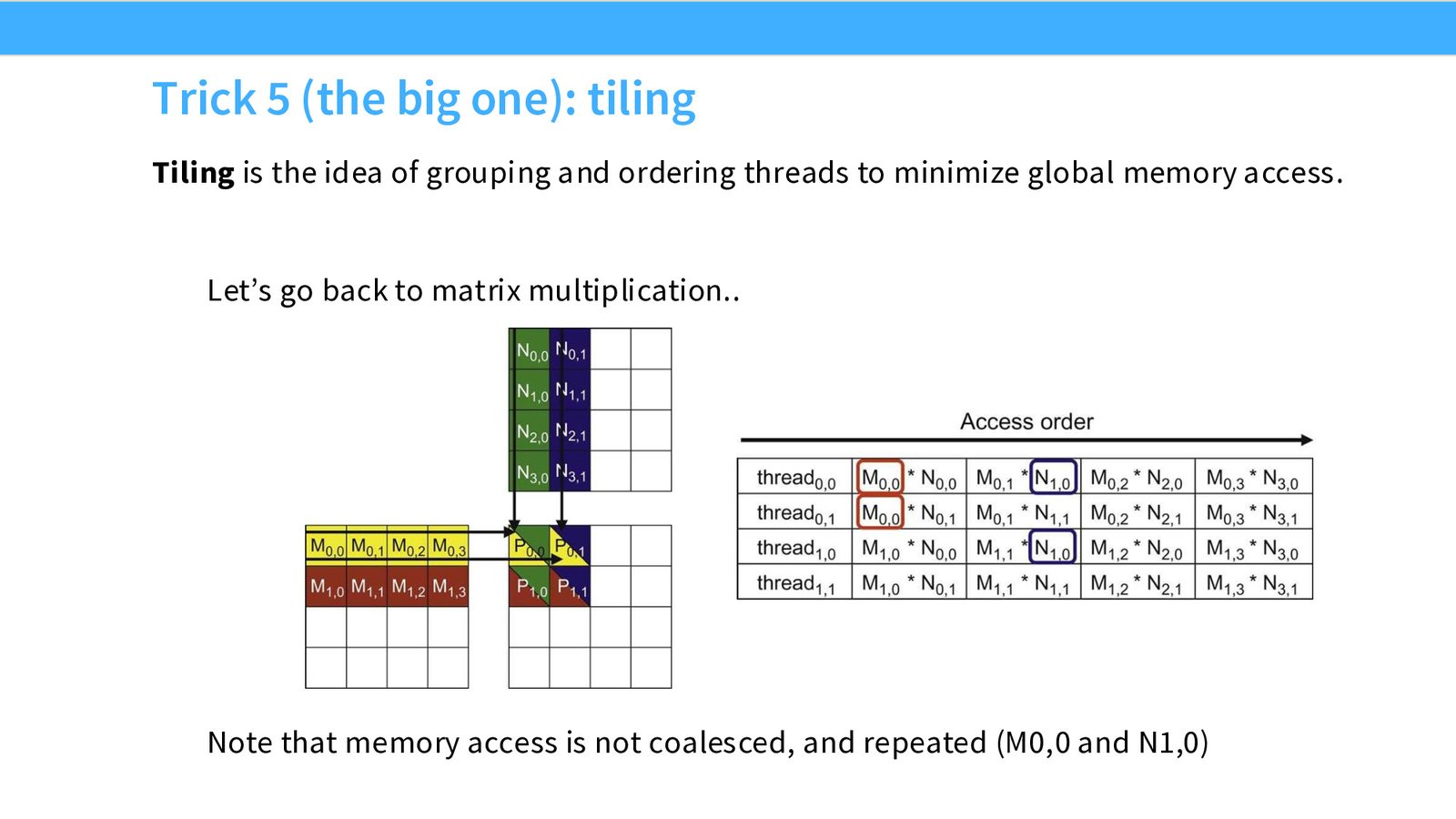
技巧 5(核心):Tiling(分块计算)
Tiling 是本课程中最重要的优化技巧,也是 FlashAttention 的基础。
核心思想:将大矩阵切分为小块(tile),将小块加载到 Shared Memory 中,在高速内存中完成尽可能多的计算,再加载下一块。
来源:Slides 第39页。
来源:Slides 第40页。
- \(N\):矩阵维度
- \(T\):tile 大小(受 Shared Memory 容量限制)
Tiling 将全局内存访问量减少了 \(T\) 倍。如果 Shared Memory 能容纳大的 tile,效果就越显著。
Tiling 的双重优势
- 减少全局内存访问:重复读取从 Shared Memory 而非 Global Memory 进行
- 改善 Coalescing:tile 内的内存访问模式更容易做到连续
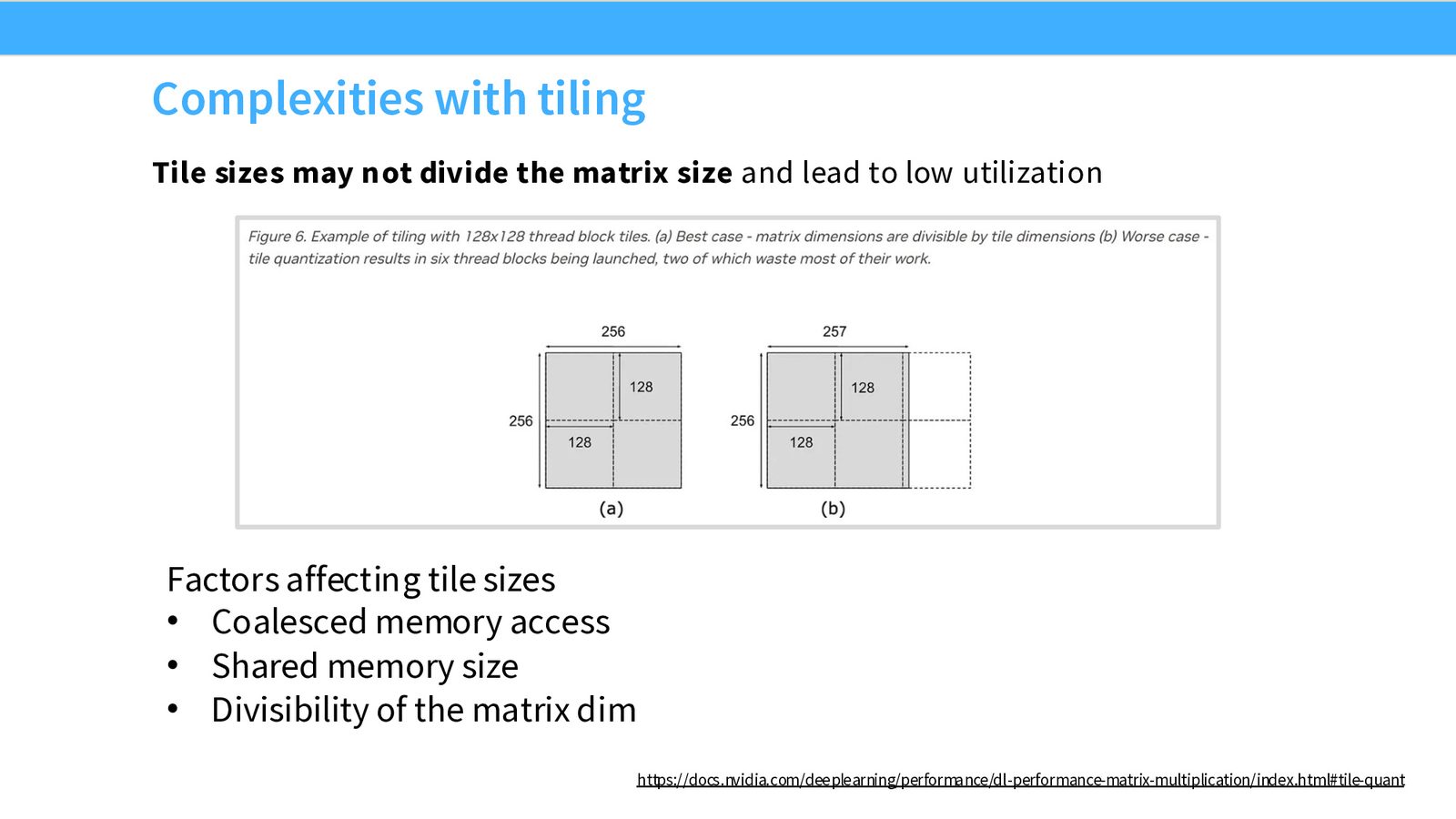
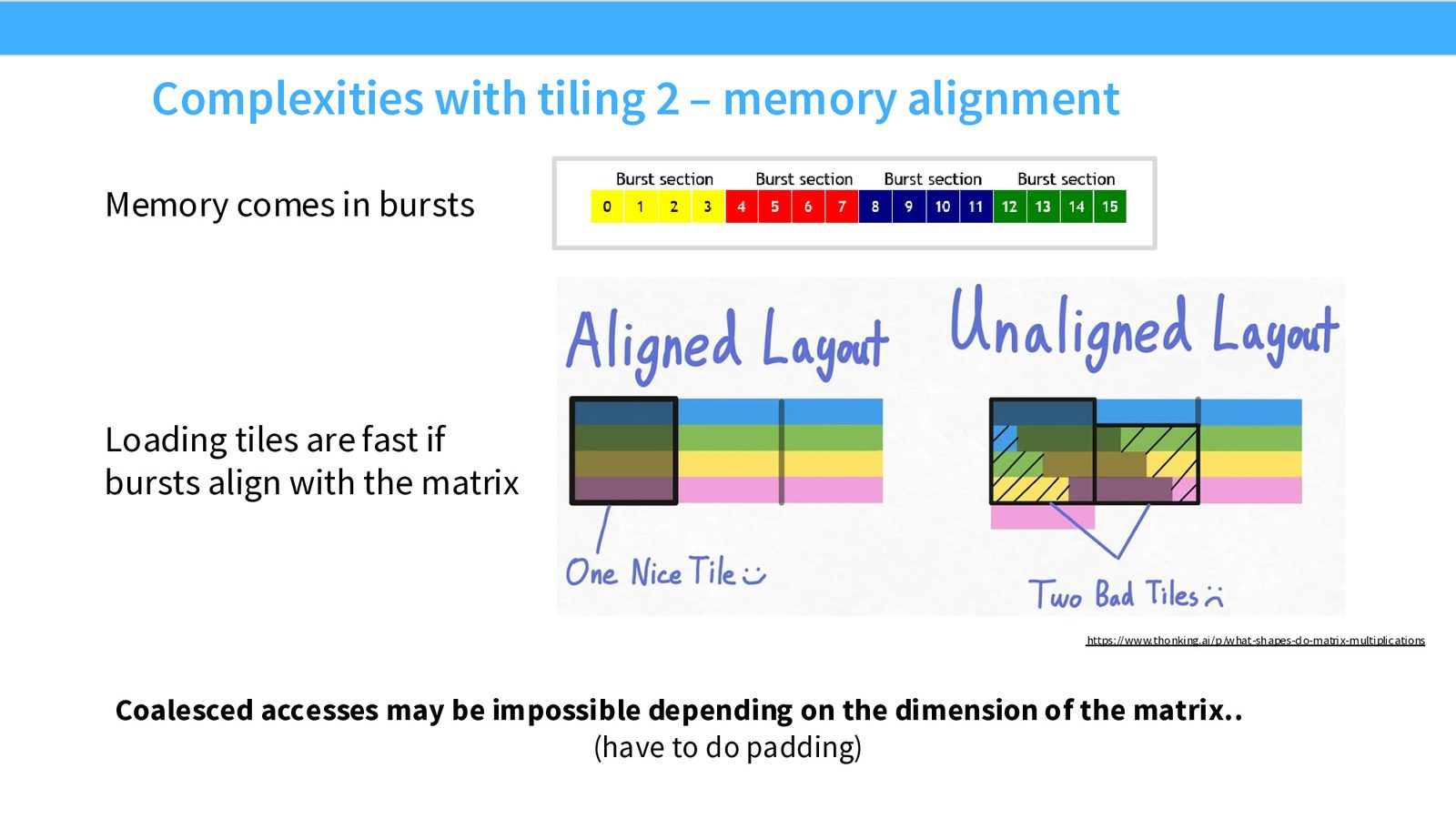
Tiling 的复杂性:Discretization 与 Memory Alignment
来源:Slides 第41页。
如果矩阵维度不能被 tile size 整除,最后的 tile 将大部分为空,浪费 SM 资源。此外,如果 tile 边界与 burst section 不对齐,一次本应只需一次 DRAM 读取的 tile 加载可能需要两次。
来源:Slides 第42页。
不要选择质数维度
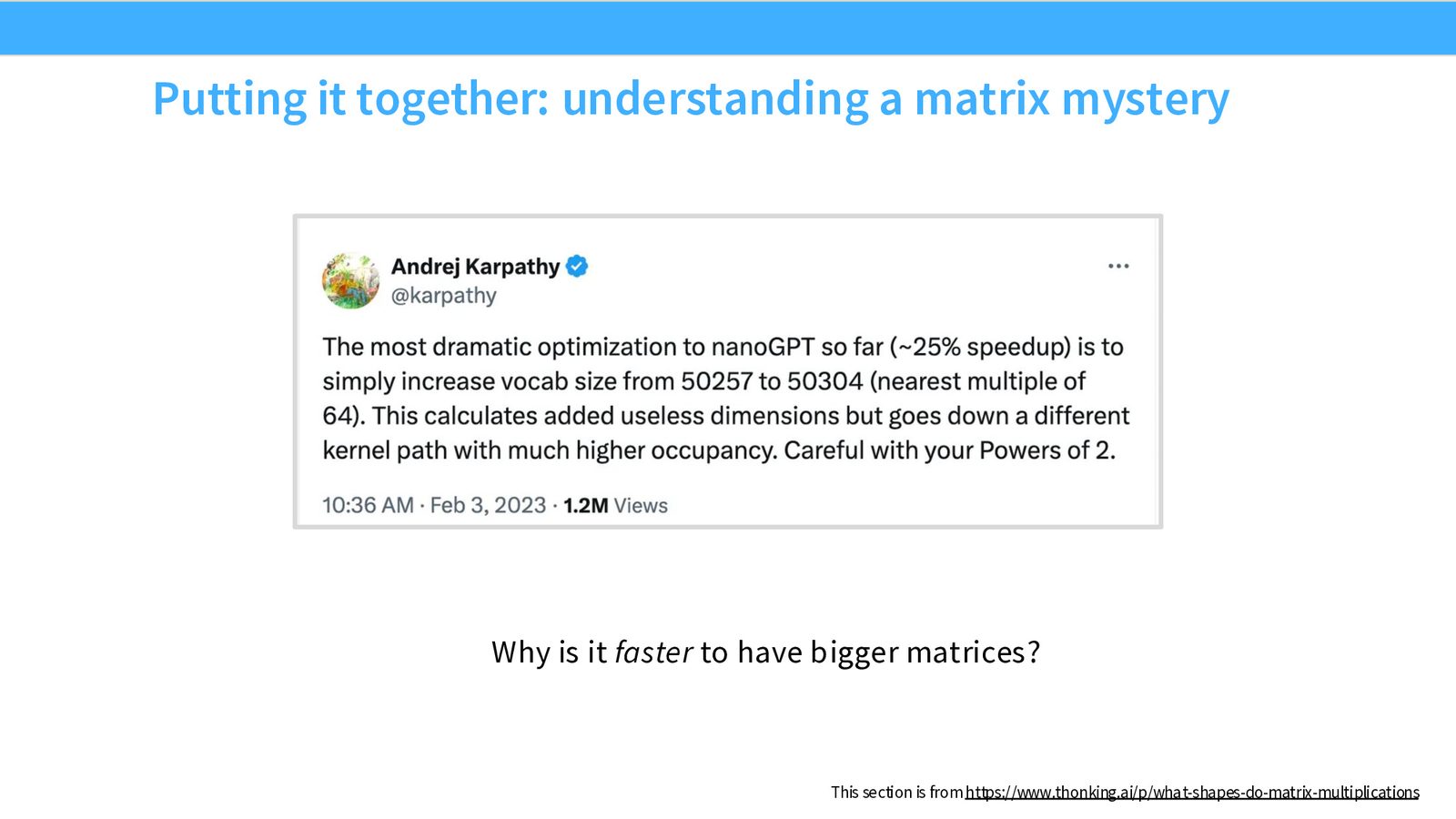
矩阵维度应选择能被常见 tile size(64、128、256)整除的值。Andrej Karpathy 曾分享一个经典案例:将 nanoGPT 的词表大小从 50257 增加到 50304(最近的 64 的倍数),带来了 25% 的速度提升——仅仅是添加了 47 个无用维度!
破解矩阵乘法性能曲线之谜
现在我们可以完整解释开头那条“诡异”的性能曲线了:
来源:Slides 第44页。
Part 1:Tiling 对齐效应。能被 128 整除的矩阵维度(橙色点)性能最高,能被 32 整除的次之,不能被任何常见因子整除的(如质数维度)性能最差。
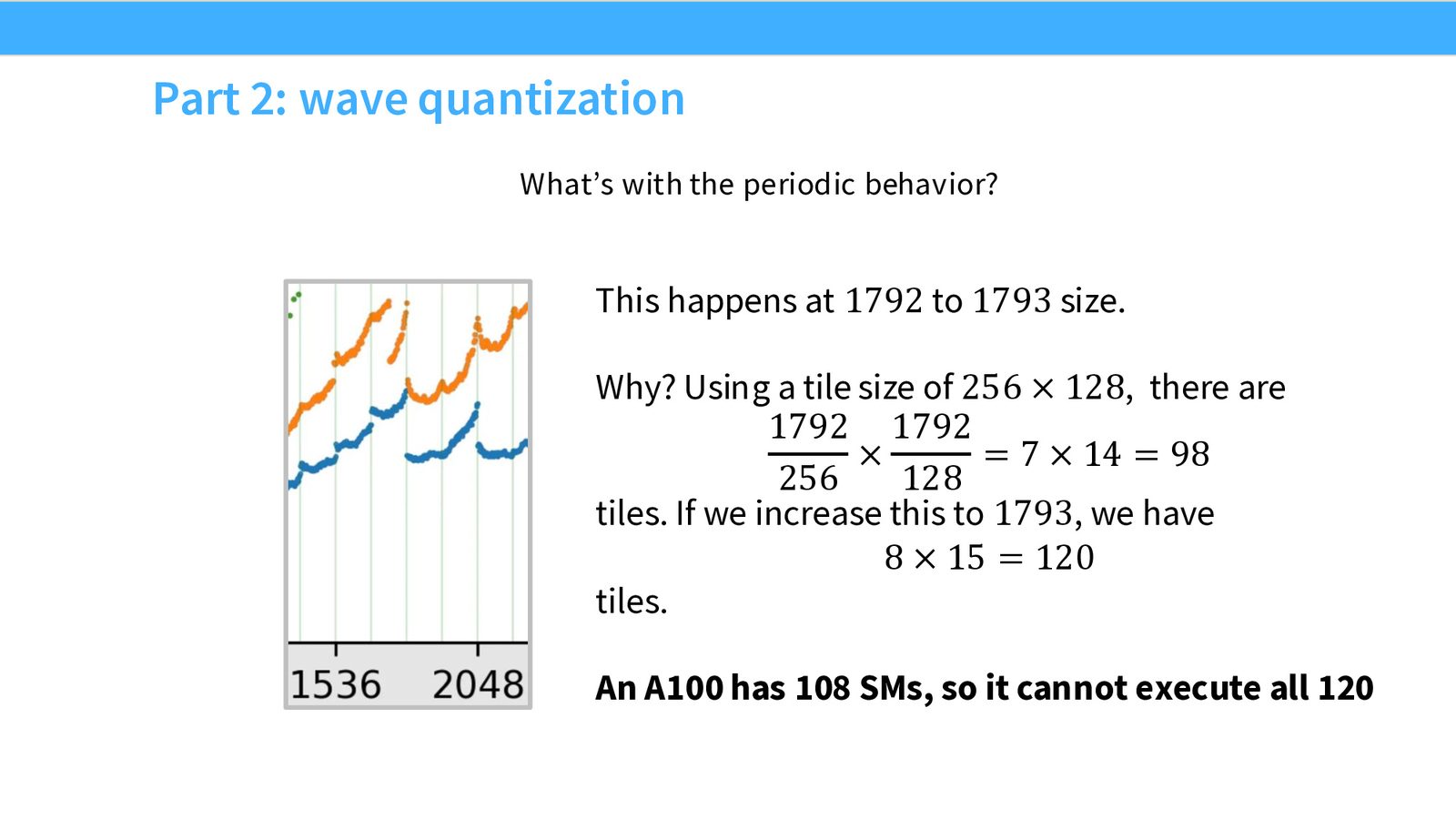
Part 2:Wave Quantization。
来源:Slides 第45页。
A100 有 108 个 SM。当 tile 数 \(\leq\) 108 时,所有 tile 可以一波并行执行(满利用率)。当 tile 数 = 120 时,第一波执行 108 个,第二波只执行 12 个——第二波中 96 个 SM 空闲。这就是周期性的性能骤降。
本章小结
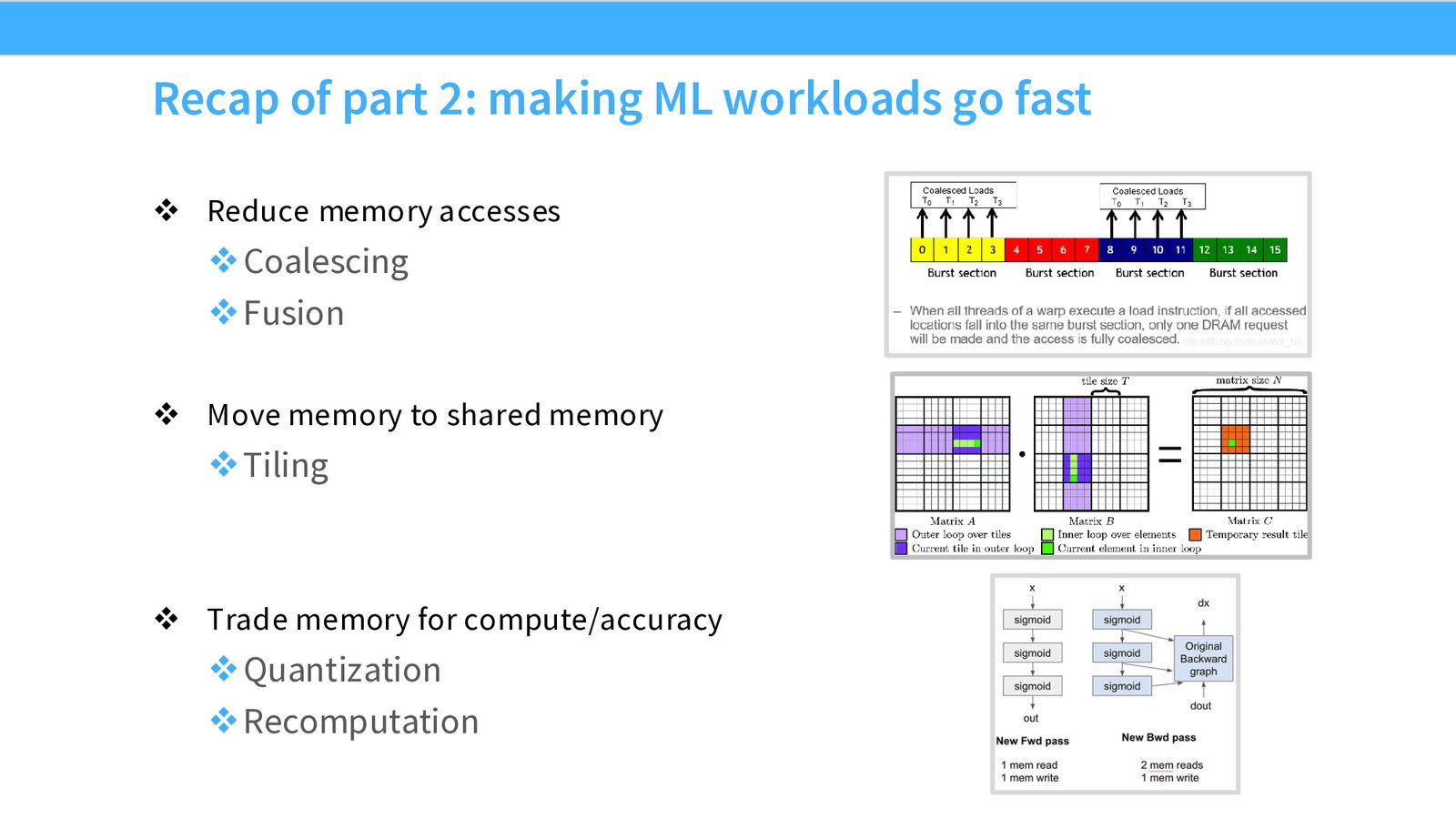
GPU 性能优化的核心策略可以归结为三类:
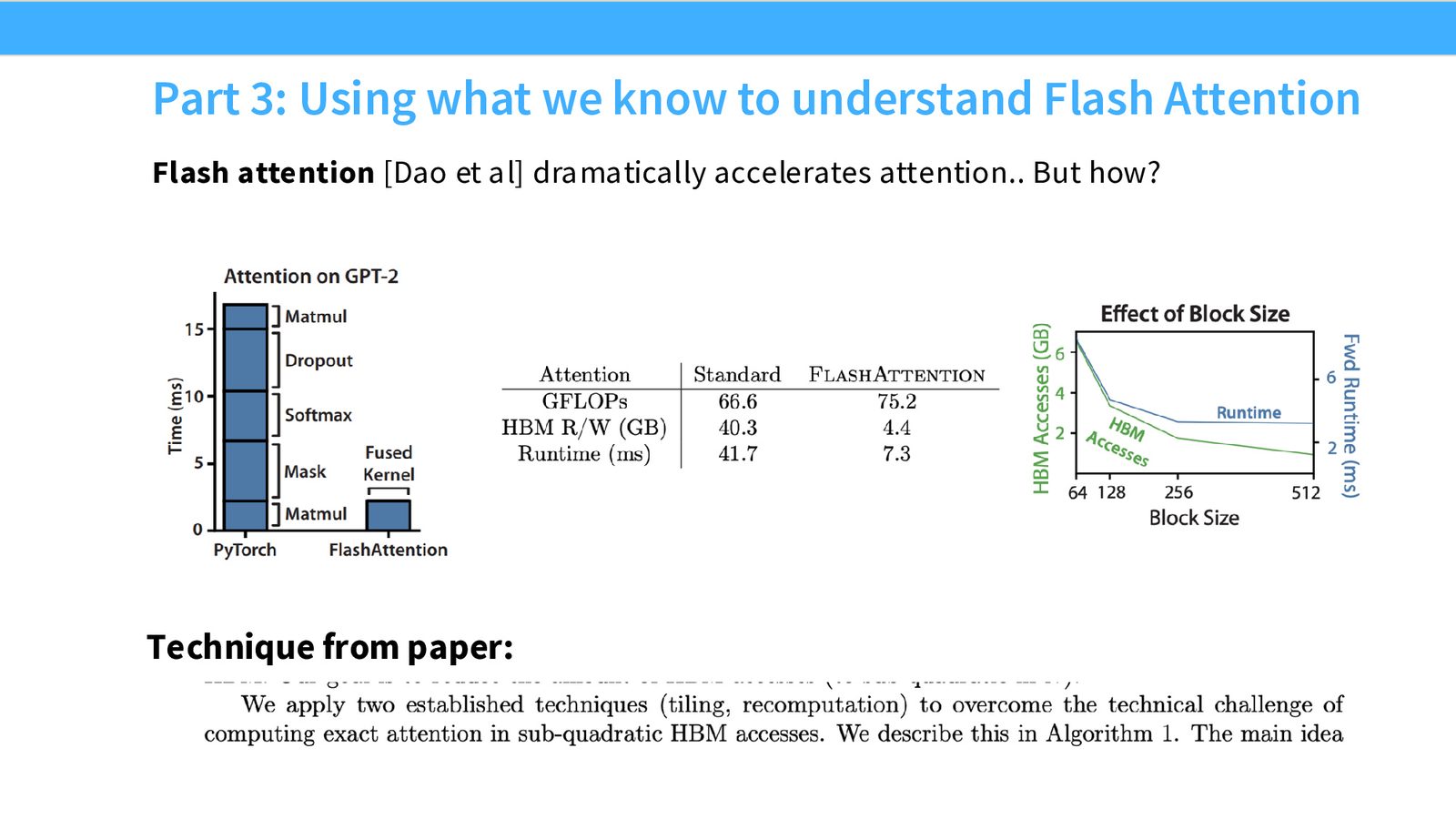
来源:Slides 第46页。
GPU 性能优化三板斧
- 减少内存访问次数:Coalescing(合并访问)+ Fusion(算子融合)
- 将数据移到快速内存:Tiling(分块加载到 Shared Memory)
- 用计算或精度换内存:Quantization(低精度减少数据量)+ Recomputation(重计算避免存储中间结果)
综合应用:拆解 FlashAttention
现在我们用前面学到的所有知识来理解 FlashAttention——一个将前述优化技巧融会贯通的经典算法。
Attention 计算回顾
标准 Attention 计算包含三次矩阵乘法,中间夹一个 softmax:
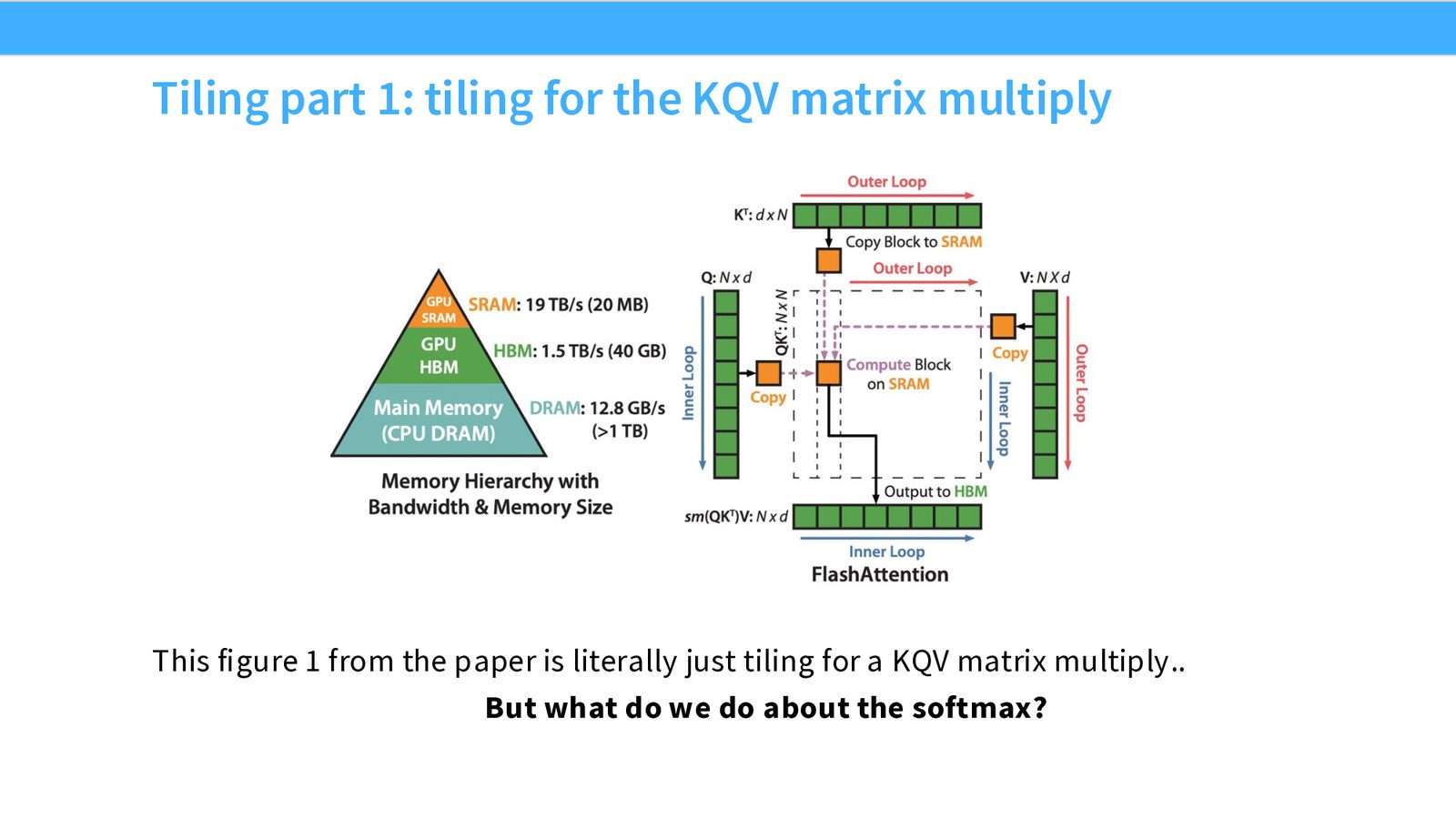
来源:Slides 第48页。
矩阵乘法部分可以直接应用 Tiling 技巧。真正的难点在于 softmax——它是一个全局操作,需要对整行求和和求最大值,这似乎要求所有数据必须同时可用。
FlashAttention 的核心思想
FlashAttention 的关键贡献:通过 Tiling + Recomputation + Online Softmax,实现亚二次方的 HBM 访问量(\(O(N^2 d^2 M^{-1})\) vs 标准实现的 \(O(N^2 d + N^2)\)),同时保持精确计算(非近似)。
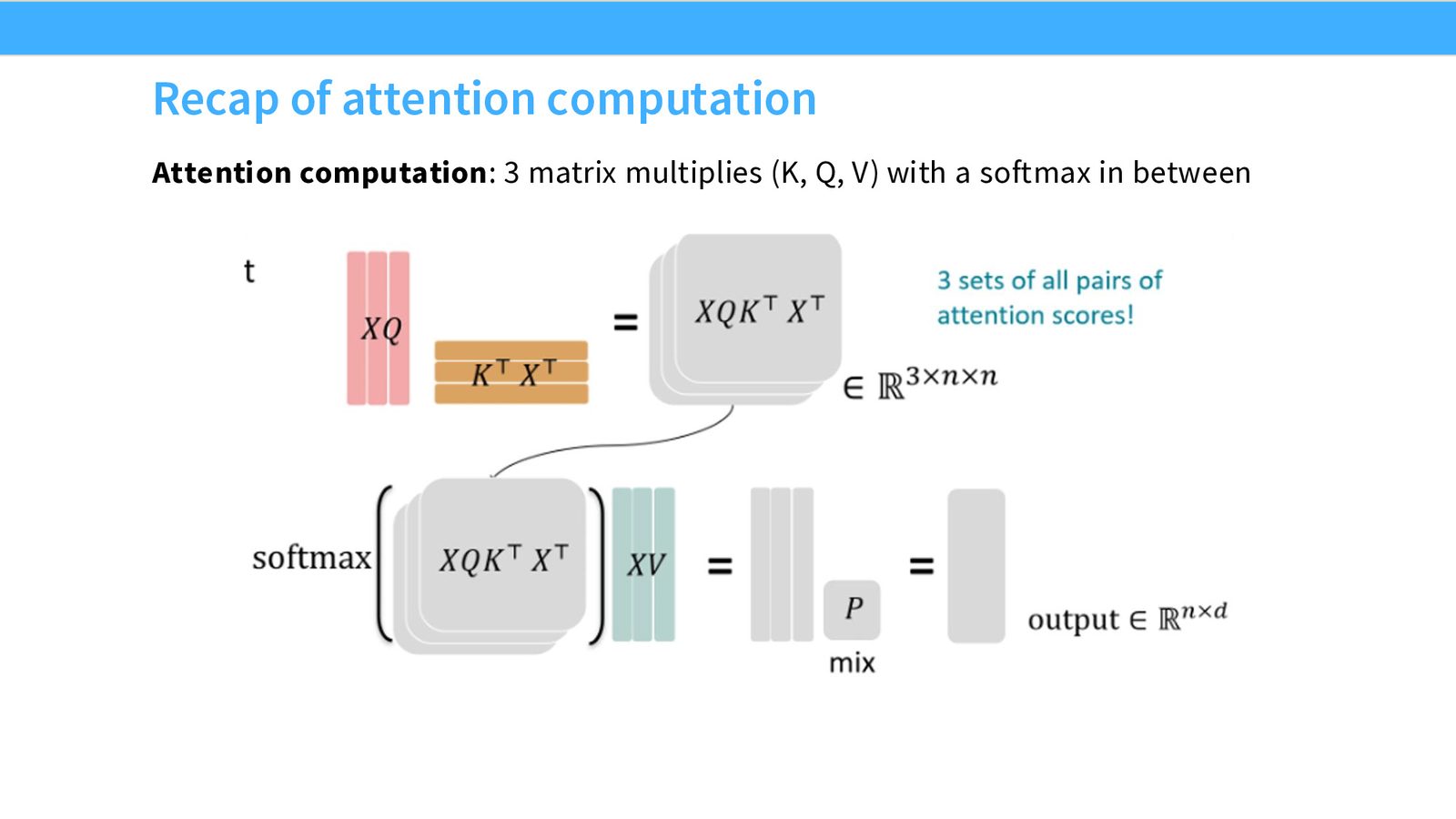
来源:Slides 第47页。

来源:Slides 第49页。FlashAttention Figure 1,Dao et al.
Online Softmax:tile-by-tile 计算全局 softmax
标准 softmax 需要三次遍历数据:(1)求最大值 \(m\),(2)计算 \(\sum e^{x_i - m}\),(3)归一化。Online softmax(Milakov & Gimelshein 2018)将这些步骤融合,只需一次遍历:
来源:Slides 第50页。来自 Milakov and Gimelshein 2018。
Online softmax 的核心在于维护两个运行变量:
- \(m_j = \max(m_{j-1}, x_j)\):当前已见过的最大值
- \(d_j = d_{j-1} \times e^{m_{j-1} - m_j} + e^{x_j - m_j}\):“伸缩求和”——每次更新最大值时,用乘法修正之前的累计量
这使得 softmax 可以逐 tile 增量计算,不需要等到所有数据就绪。
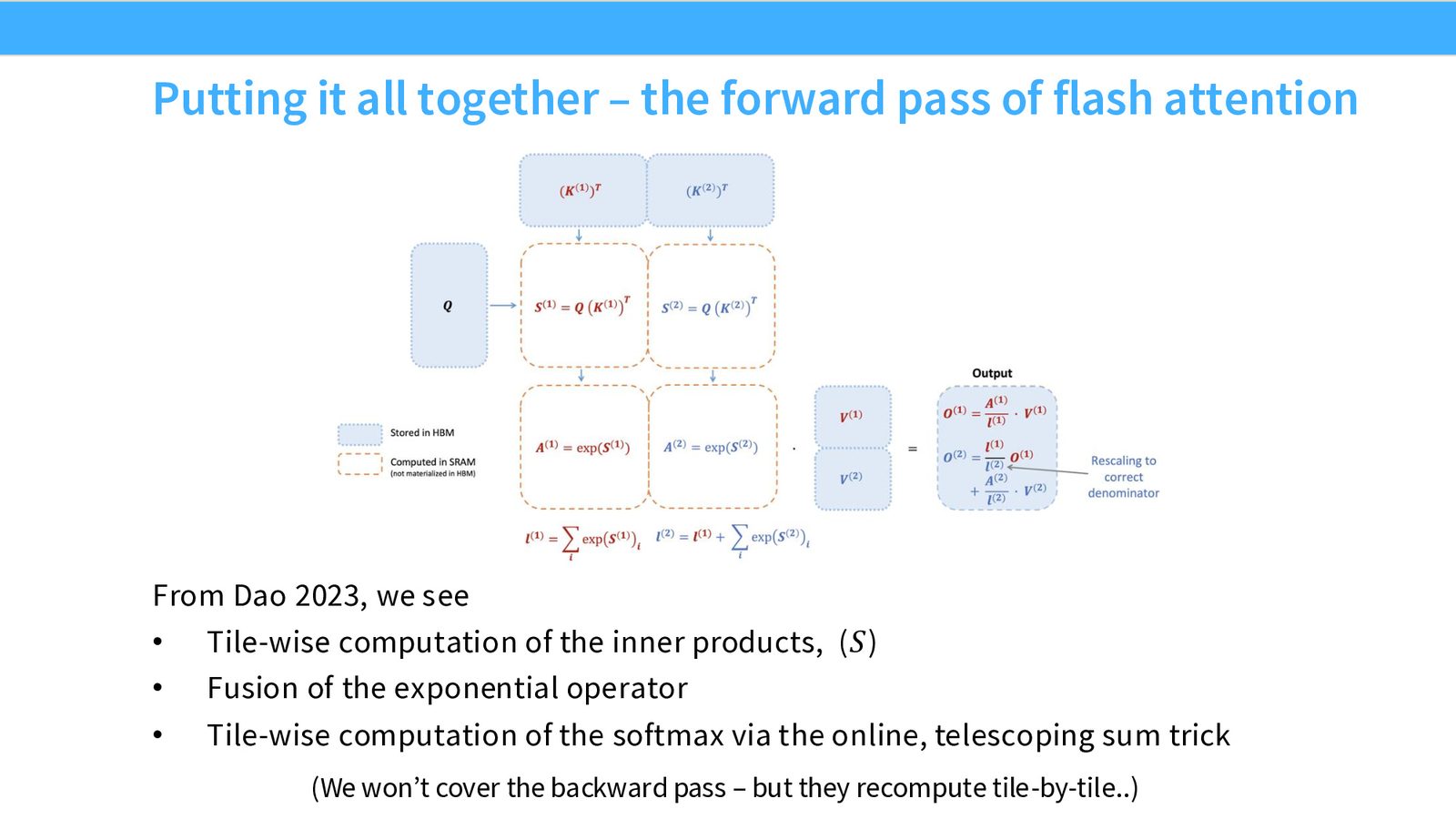
FlashAttention Forward Pass 全貌

来源:Slides 第51页。来自 Dao 2023。
FlashAttention 综合了本课所有优化技巧:
- Tiling:对 KQV 矩阵乘法进行 tile-wise 计算,最小化 HBM 访问
- Fusion:将指数运算与矩阵乘法融合在同一个 kernel 中
- Online Softmax:通过伸缩求和实现 tile-by-tile 的精确 softmax
- Recomputation(反向传播中):不存储 \(N^2\) 大小的注意力矩阵,在反向传播时 tile-by-tile 重新计算
FlashAttention = Tiling + Fusion + Online Softmax + Recomputation
FlashAttention 不是一个全新的算法,而是将 GPU 性能优化的所有经典技巧巧妙组合的结果。理解了本课介绍的每一种优化手段,你就能理解 FlashAttention 的每一个设计决策。
本章小结
FlashAttention 通过 tiling 将 attention 的 HBM 读写从 40.3 GB 减少到 4.4 GB,运行时间减少 5.7x。它的成功完全建立在对 GPU 内存层次的深刻理解之上:将数据保持在 SRAM 中,通过 online softmax 避免全局同步,通过 recomputation 避免存储 \(N^2\) 中间矩阵。
拓展阅读
- Horace He's Blog: https://horace.io/brrr_intro.html —— GPU 性能优化入门必读
- “What shapes do matrix multiplications”: https://www.thonking.ai/p/what-shapes-do-matrix-multiplications —— 矩阵维度对性能的影响
- CUDA Mode Group: https://github.com/cuda-mode —— CUDA 学习社区
- Dao et al., FlashAttention: https://arxiv.org/abs/2205.14135
- Dao, FlashAttention-2: https://arxiv.org/abs/2307.08691
- Milakov & Gimelshein, Online Softmax: https://arxiv.org/abs/1805.02867
总结与延伸
讲者的核心总结
来源:Slides 第51页(最后一页)。
Tatsu Hashimoto 在课程结尾强调了三点:
- 硬件驱动规模化:底层硬件细节决定了什么能规模化、什么不能
- 以 matmul + 数据搬运为中心思考:当前基于 GPU 的计算体系,要求算法设计者时刻关注矩阵乘法和数据移动
- 细致的 GPU 优化带来真正的性能提升:Coalescing、Tiling、Fusion 等看似底层的技巧,是 FlashAttention 等突破性算法的基石
全课知识图谱
本课建立了一条从硬件到算法的完整认知链:

关键 Takeaways
五条核心原则
- 内存是新的瓶颈:现代 GPU 上,计算速度远快于内存带宽,大多数优化围绕减少内存访问展开
- Matmul 是“特权运算”:尽量让你的工作负载以 matmul 为主,避免大量非 matmul 操作
- 矩阵维度要“友好”:选择 64/128/256 的倍数,避免质数维度
- 数据要尽量留在 SRAM:通过 Tiling 将工作数据加载到 Shared Memory,最小化全局内存访问
- FlashAttention 不是魔法:它是 Tiling + Fusion + Online Softmax + Recomputation 的精妙组合