Special Eiqfomoucjs
\begingroup
\setlength{\parskip}{0pt} \renewcommand{\baselinestretch}{0.92}\selectfont
\endgroup
导读:为什么机器人需要基座模型
本节先建立整期的问题。陈建宇的核心判断是,过去机器人常常是“100 个场景、100 个任务、100 套专用模型”,这种方式很难 scale。大语言模型和多模态模型的成功,让机器人领域看到另一条路:能不能为机器人训练一个更通用的 foundation model,让它跨任务、跨本体、跨场景泛化。
本期核心命题
VLA,即 Vision-Language-Action Model,不只是给机器人接一个语言模型,而是让视觉、语言和动作进入同一个可扩展的端到端系统。真正的机器人基座模型,要从“利用现有基础模型做机器人”走向“为机器人预训练基础模型”。

读图:从专用模型到通用模型的压力
图中展示的不是单篇论文,而是整期课的背景:机器人学习长期依赖特定任务、特定数据和特定部署。陈建宇强调,这种方式面对家庭、工厂和人形机器人时不够通用,因而需要基座模型路线。
机器人 AI 的两阶段
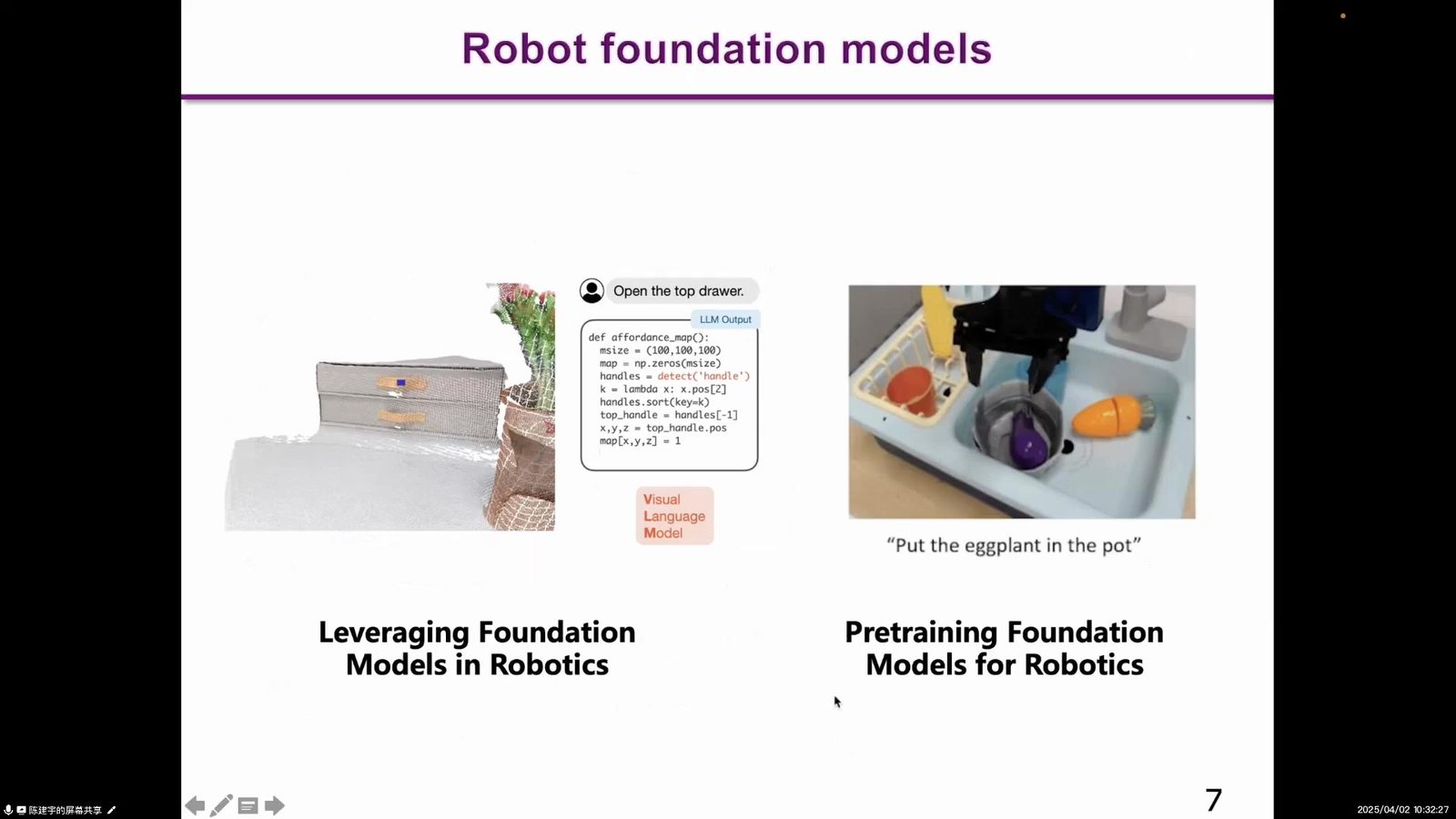
本节把路线分清楚。第一阶段是 leveraging foundation models in robotics,即把 LLM、VLM、Code LM 等现有基础模型拿来替代机器人系统中的某个模块。第二阶段是 pretraining foundation models for robotics,即直接为机器人训练能够输出动作的模型。前者是拼装和借力,后者才是真正的机器人基座模型。
读图:机器人三板块与基础模型替代
图中把 Perception、Actuation 和 LLM 放在一起。传统机器人通常拆成规划、感知和执行;大模型浪潮先替代 Planning,再替代 Perception,最后才试图让 Action 也进入统一模型。
术语消化:VLA、VLM、LLM
| 术语 | 含义 | 本课中的作用 |
|---|---|---|
| LLM | Large Language Model,大语言模型 | 先替代或增强机器人规划。 |
| VLM | Vision-Language Model,视觉语言模型 | 用于感知、场景理解和视觉反馈。 |
| VLA | Vision-Language-Action Model,视觉语言动作模型 | 直接把视觉、语言和动作连接到端到端控制。 |
| Robot Foundation Model | 机器人基座模型 | 目标是跨任务、跨本体和跨场景泛化。 |
本章小结
VLA 的出现,是机器人从模块拼装走向通用基座模型的关键线索。整期课的主线,是从 LLM/VLM 借力,到 RT-2/OpenVLA/HiRT/pi0/GR00T N1,再到 diffusion policy、RDT 和未来统一理解预测模型。
第一阶段:利用现有基础模型改造机器人三板块
上一章提出两阶段路线,本章看第一阶段:把现有 LLM、VLM 和 Code LM 放进机器人系统。传统机器人三板块是 Planning、Perception、Actuation。大模型首先替代规划,因为语言模型擅长把任务拆成步骤;随后 VLM 替代感知,因为它能把视觉场景和语言任务连接起来;再进一步,Code LM 试图把执行也自动化。
SayCan:我能做,而不是我说做
SayCan 的核心问题是:语言模型会提出很多动作,但机器人未必能在当前环境中做到。它将语言模型的任务分解和机器人 affordance 结合起来,既考虑“语言上应该做什么”,也考虑“机器人实际上能不能做”。这是把 LLM 接到机器人规划上的开创性工作。
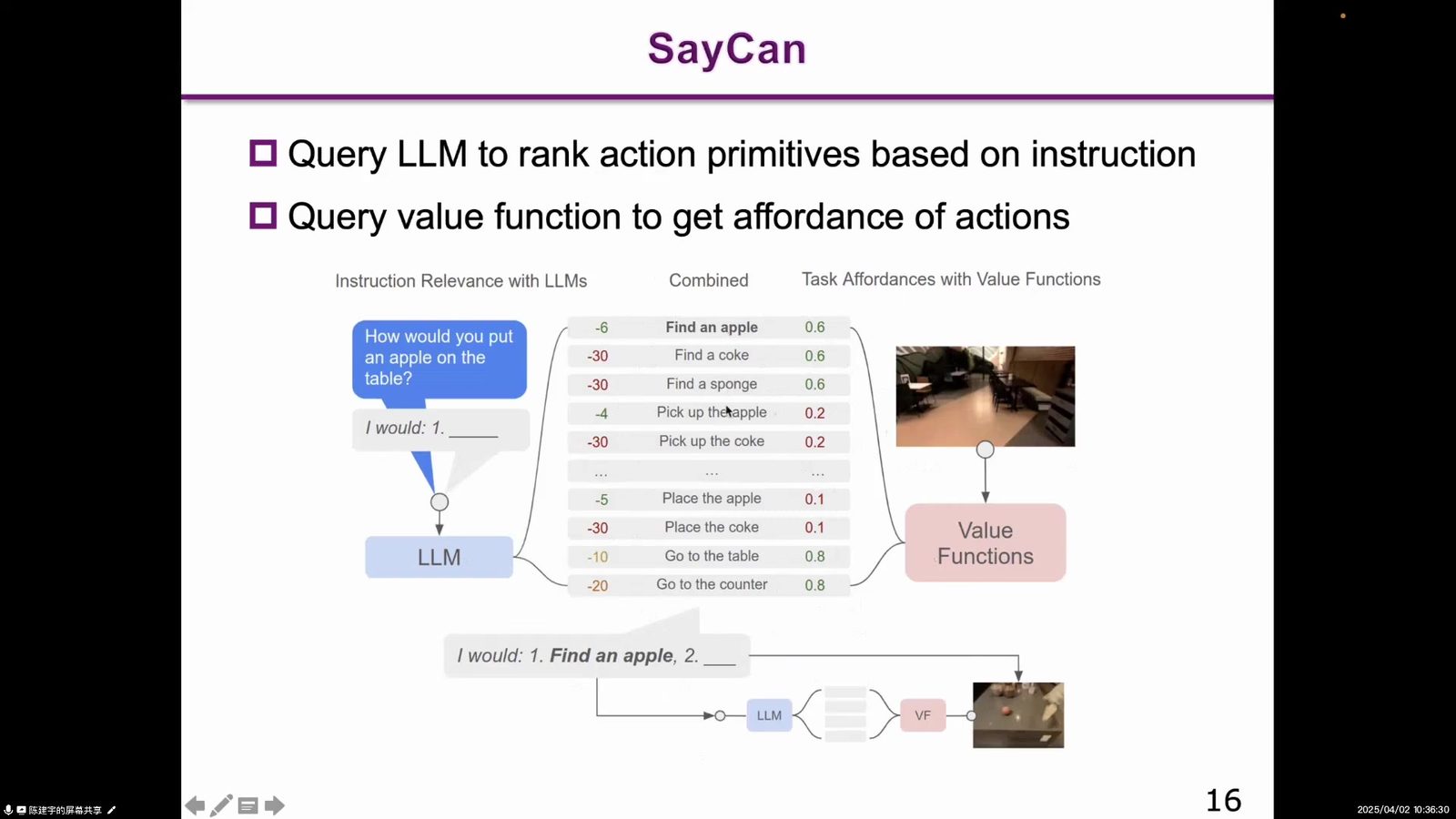
读图:LLM 给目标,affordance 给约束
图中左侧是语言模型对动作的排序,右侧是机器人在现实环境中的可供性判断。读这张图时要注意,SayCan 没有让语言模型直接控制机器人,而是在语言计划和物理可行性之间加了一道约束。
语言计划不能直接等于机器人动作
机器人需要考虑抓取能力、空间位置、物体状态和执行失败。LLM 如果只输出“拿起杯子”,并不知道杯子是否可达、夹爪是否合适、环境是否允许。SayCan 的价值就是把语言意图落地到 affordance。
Inner Monologue、DoReMi 与 VoxPoser
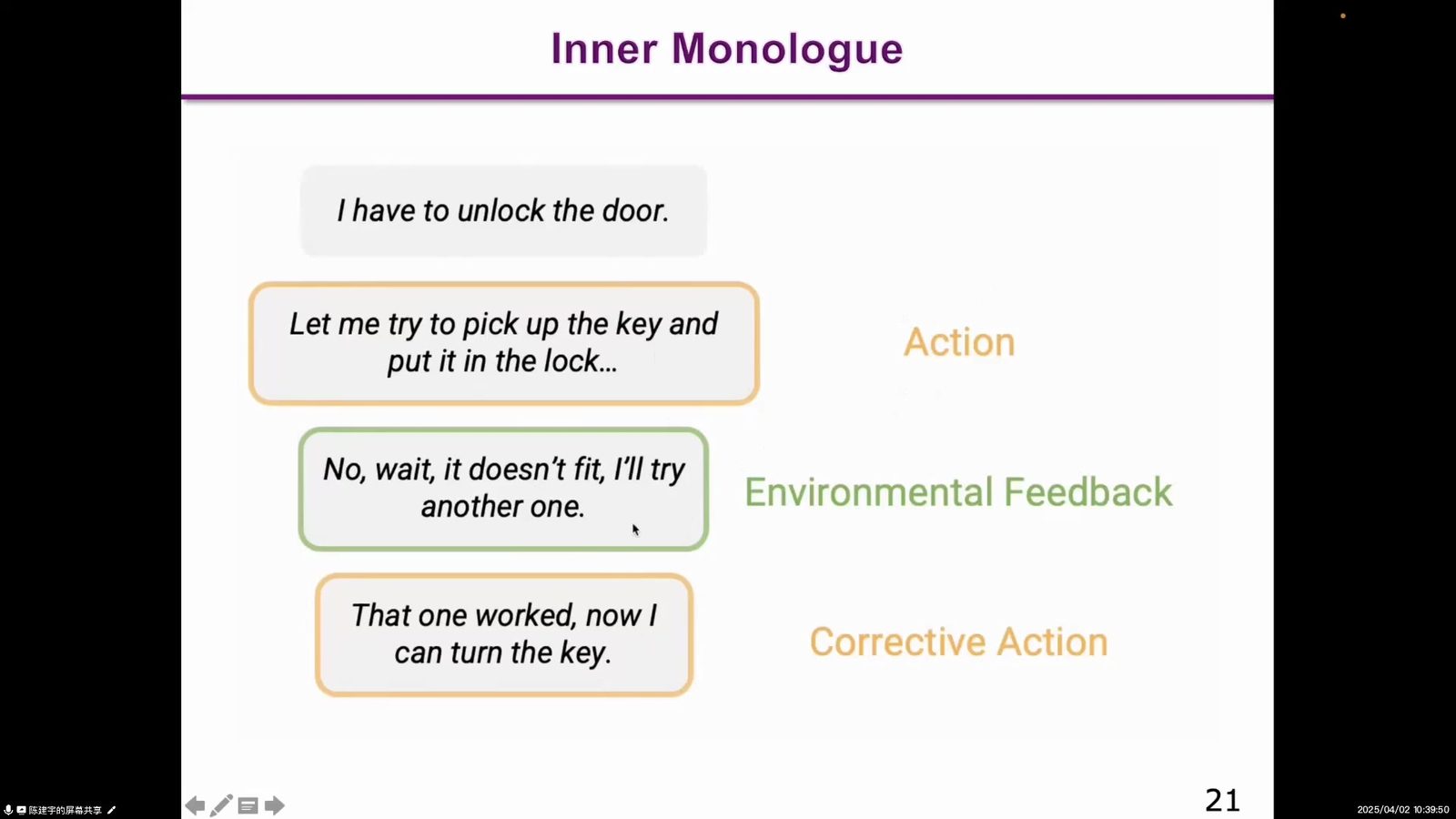
本节看三篇继续把基础模型用于机器人推理的工作。Inner Monologue 强调机器人执行过程中需要语言化的反馈和内心独白,把环境反馈重新纳入规划。DoReMi 关注计划和执行不一致时如何检测并恢复。VoxPoser 则用语言模型构造 3D value maps,把语言目标转成可组合的空间价值场,用于 manipulation。
读图:机器人需要执行后的自我叙述
Inner Monologue 的图把 Action、Environmental Feedback、Corrective Action 连成闭环。它不是简单让机器人“会说话”,而是让执行结果回到语言规划过程,形成可修正的中间状态。
读图:错配检测是具身智能的现实问题
DoReMi 处理的是规划与执行错配:计划里说 A,执行中环境变成 B,或者机器人没有按预期完成。它提醒我们,机器人系统不是一次生成计划就结束,而是要持续检测、纠错和恢复。

读图:从语言目标到 3D 操作场
VoxPoser 图中把语言指令转成空间中的 value map。读图时要看“可组合”二字:不同约束可以叠加成一个操作目标,例如接近物体、避开障碍、保持姿态等。
从 Code LM 到真正的机器人模型
Code LM 替代 Actuation 的想法,是让模型写机器人代码或调用底层 API。但陈建宇指出,这仍然不是完整的机器人 foundation model。它更多是在现有工具和现有控制器上做编排;真正的 VLA 需要模型本身具备从视觉和语言直接输出动作的能力,而不是只会写调用代码。
第一阶段的边界
Leveraging foundation models 能快速增强规划、感知和工具调用,但它本质上仍是模块化系统。通用机器人最终需要在机器人数据上训练能够处理 action 的模型。
本章小结
第一阶段的贡献,是证明 LLM/VLM 能帮助机器人理解任务、计划行动、检测错配和构造空间目标。但这些方法仍依赖传统机器人模块,尚未真正形成端到端 VLA。
第二阶段:VLA 与机器人基座模型
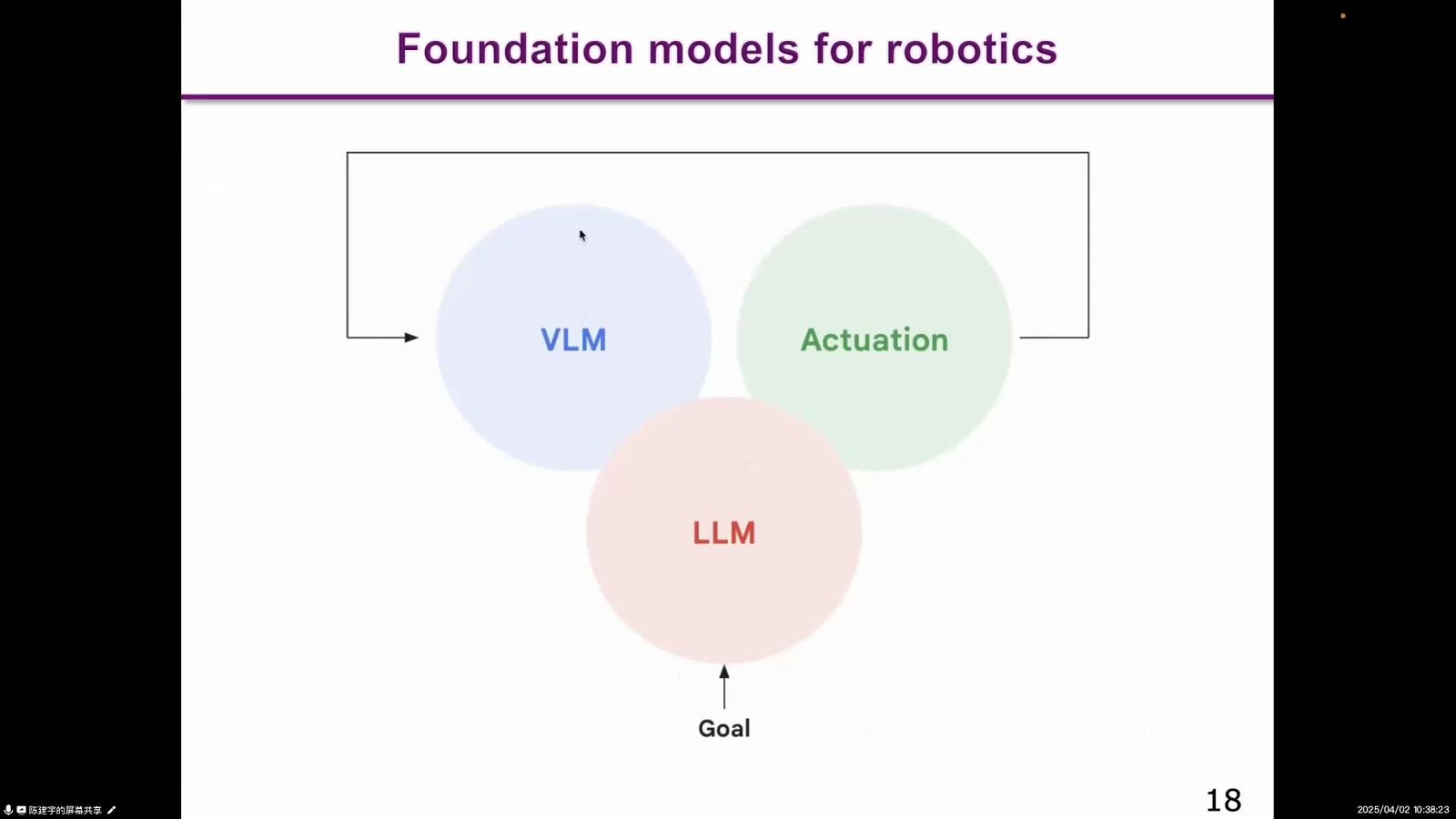
上一章讲现有基础模型如何进入机器人,本章进入第二阶段:直接为机器人预训练 foundation model。VLA 的目标是把视觉、语言和动作放进一个模型中,让模型从观察和指令直接产生机器人动作。陈建宇用“人就是很智能的 VLA Agent”来解释:人看到世界、理解语言、输出动作,本身就是通用 VLA。
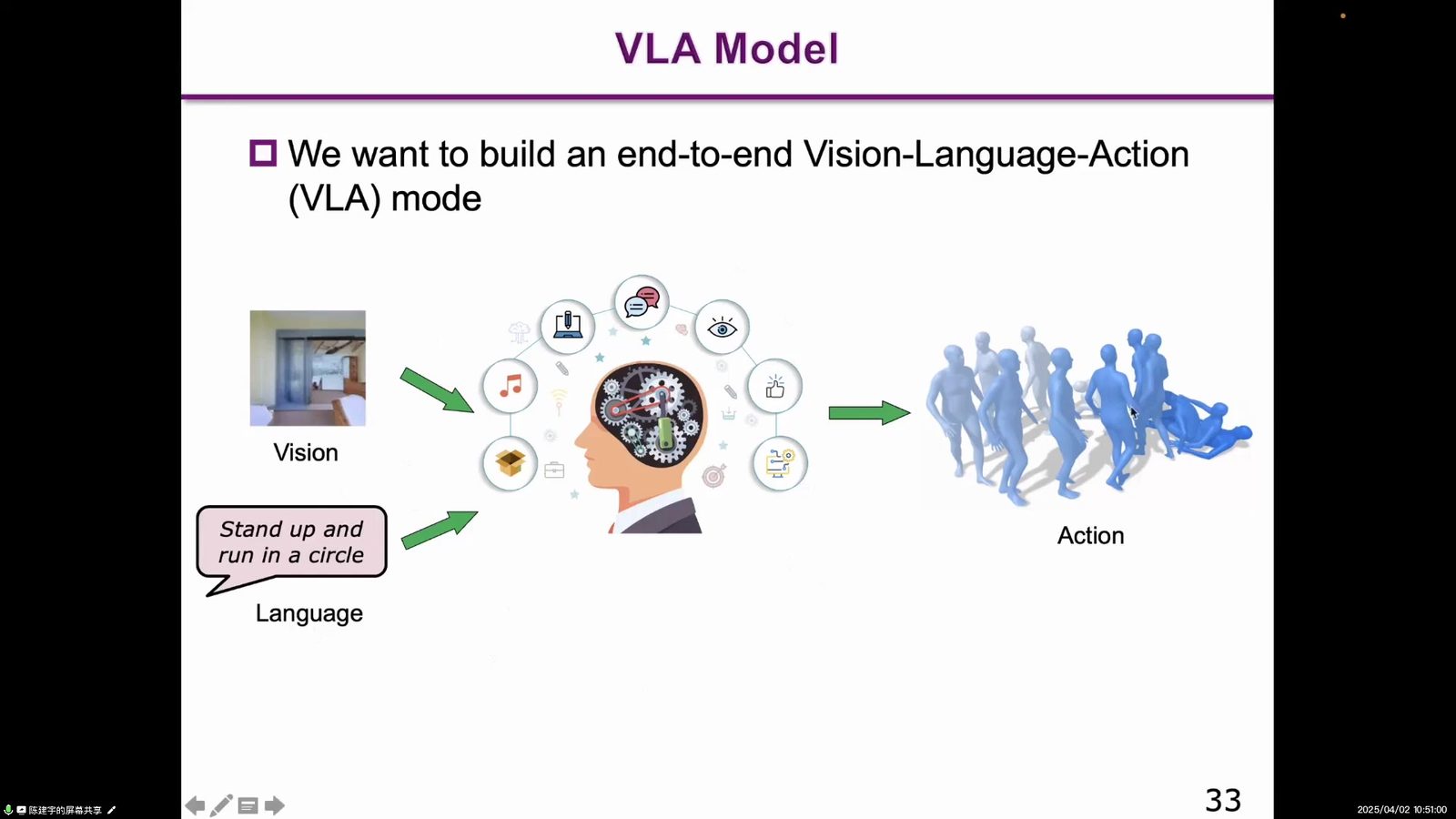
读图:VLA 的 A 是真正难点
图中从 vision 和 language 到 action,展示的是 VLA 的最小形态。V 和 L 可以借用 VLM/LLM 的进展,但 A 需要处理频率、连续控制、轨迹、稳定性和本体差异。
ALOHA 与 Mobile ALOHA:低成本硬件和示范数据
本节从 VLA 概念回到数据和硬件底座。原因是,机器人基座模型不是只靠论文里的大模型结构就能出现,它首先需要便宜、可复制、能稳定采集示范的系统。ALOHA 在这里承担的是“把真实双手操作数据做出来”的角色,为后续讨论 action chunk、模仿学习和跨任务泛化提供具体参照。
ALOHA 系列不是严格意义上的现代 VLA,但它对机器人学习很重要:低成本双臂硬件、teleoperation 示范、Action Chunking Transformer,以及让机器人模仿细粒度双手操作。Mobile ALOHA 加上移动底盘,把双臂操作扩展到更复杂的移动场景,并以大量演示视频出圈。
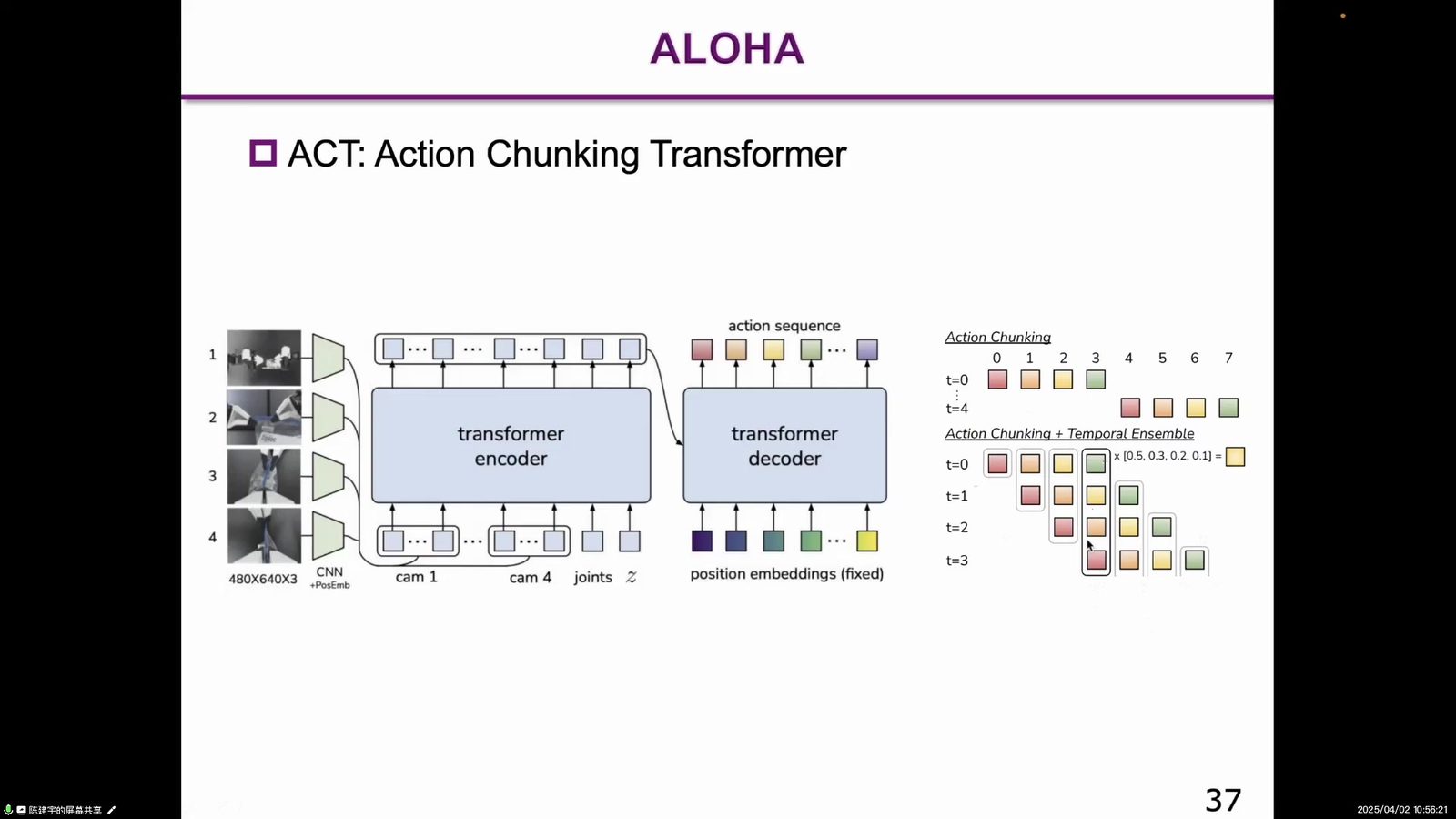
读图:Action Chunking 是动作序列预测
图中展示 ACT 的结构:输入观测,输出未来一段动作序列。关键是 chunking:模型不是只预测下一步动作,而是预测一段动作轨迹,再滚动执行。这和模型预测控制有相似直觉。

ALOHA 的局限
ALOHA 很强,但更像高质量模仿学习系统。它仍然偏任务和数据驱动,不等于能跨大量机器人和任务泛化的 VLA 基座模型。
Gato、RT-1 与 Octo
接下来这一组工作把问题从“能否收集高质量示范”推进到“能否训练一个更通用的策略”。从 Gato 到 RT-1,再到 Octo,核心变化是通用代理的想法逐步落到真实机器人数据和开源 policy 框架上。老师强调,这些工作不一定都是今天意义上的 VLA,但它们共同铺出了统一建模、多任务训练和机器人控制规模化的路径。
Gato 是“一个模型处理多种任务”的早期通用代理尝试,思想非常早,但当时模型、数据和算力还不够成熟。RT-1 则更直接面向机器人控制,在真实世界控制数据上训练 Robotics Transformer。Octo 是开源通用机器人策略,强调把不同任务和数据放进一个可复用的 policy 框架。

读图:Gato 早在思想上接近 VLA
Gato 图中显示多任务、多模态输入统一进一个模型。它的历史价值是提出 generalist agent 的方向,但还没有今天 VLM/VLA 的模型规模、数据和机器人执行能力。
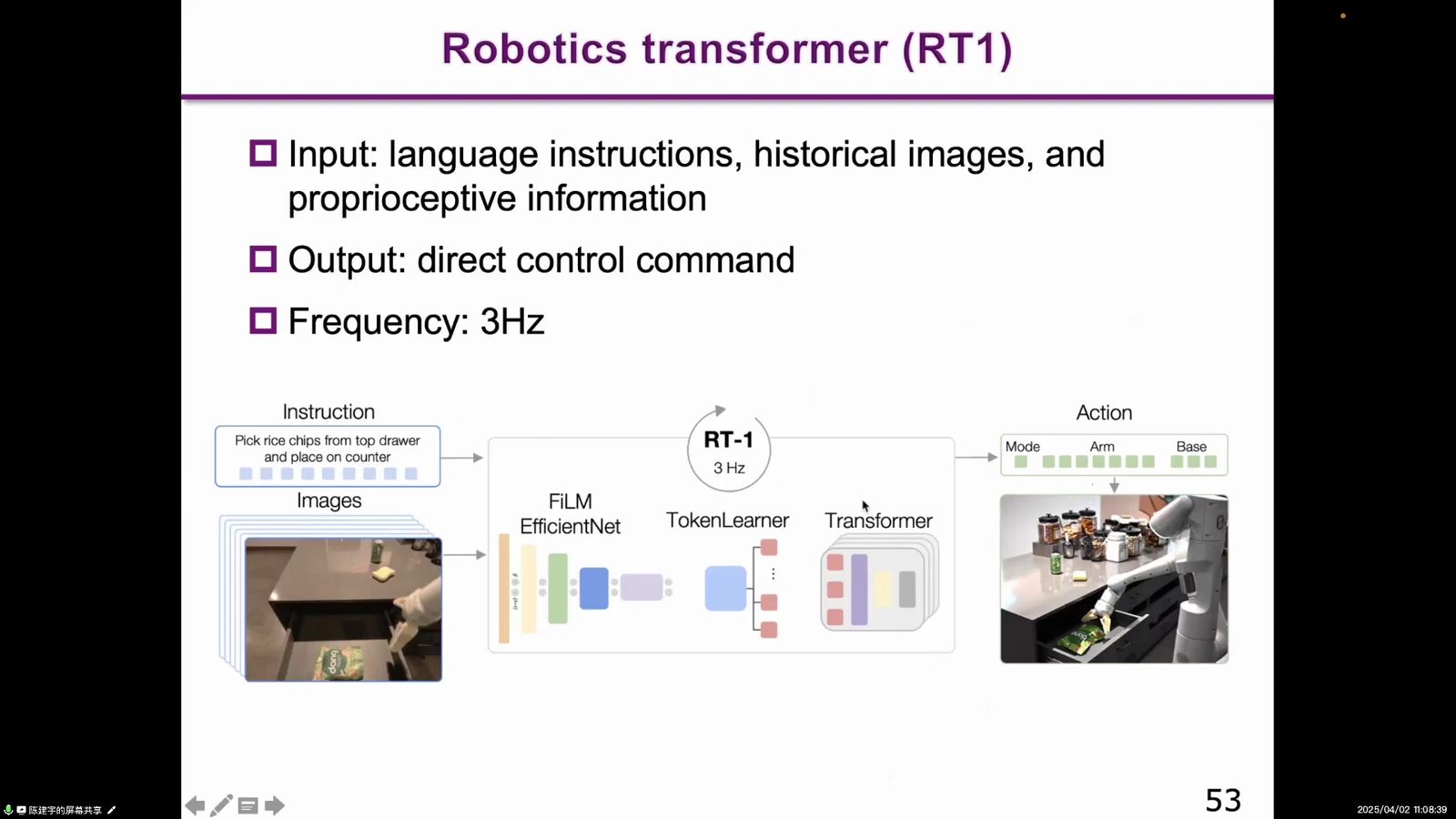
读图:RT-1 是机器人数据规模化的重要节点
RT-1 把任务说明、图像观测和动作 token 放进 Transformer。它的贡献不只是模型结构,还在于真实机器人控制数据和可扩展训练流程。
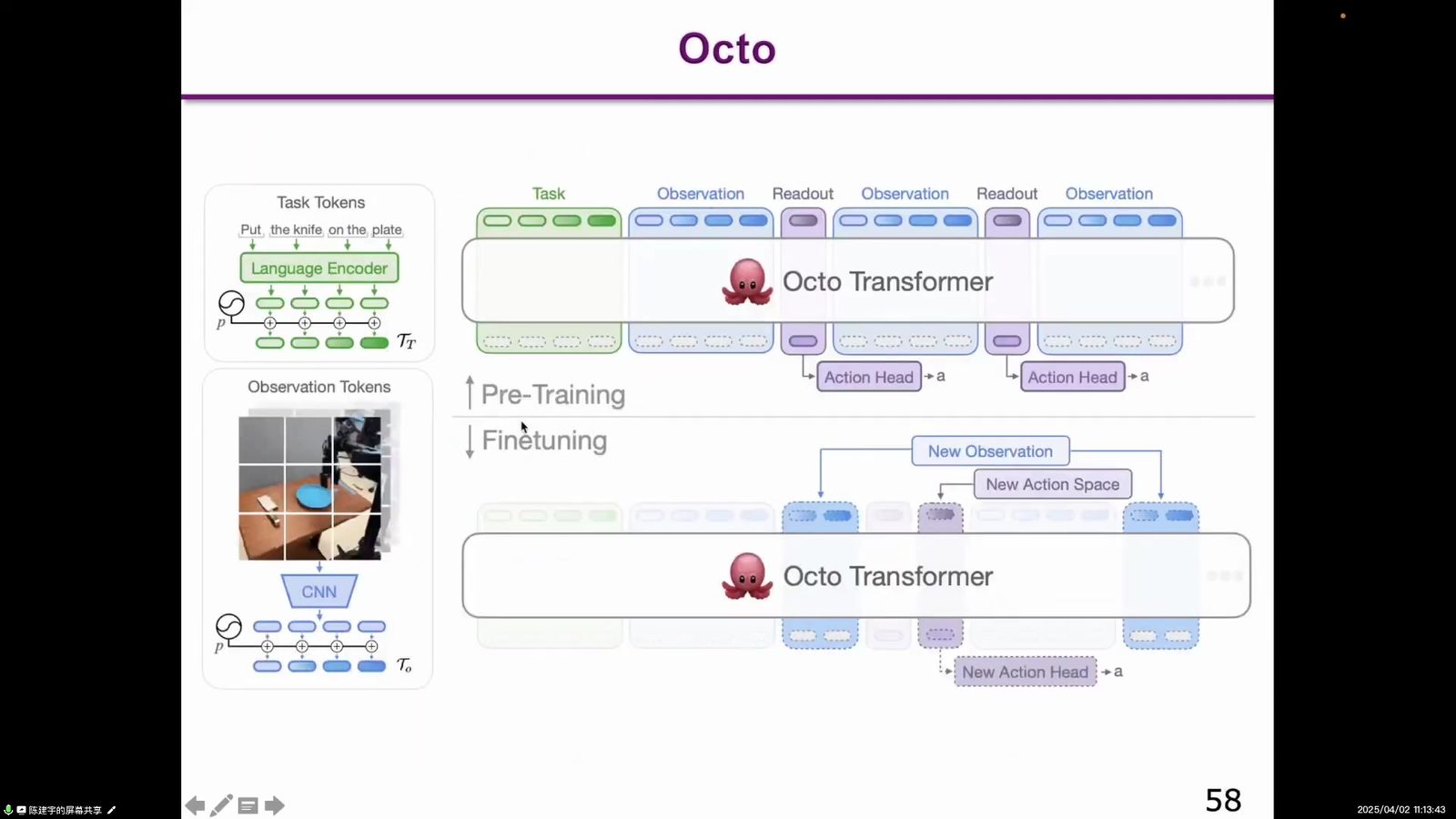
跨本体学习:CrossFormer 与 GR 系列
通用机器人模型不能只会一种机械臂或一种任务。CrossFormer 关注 cross-embodied learning,希望一个 policy 覆盖 manipulation、navigation、locomotion 和 aviation 等不同本体。字节 AI Lab 的 GR-1/GR-2 则把视频生成预训练、video-language-action 和 web-scale knowledge 引入机器人操作,强调从大规模视频和知识中学习。
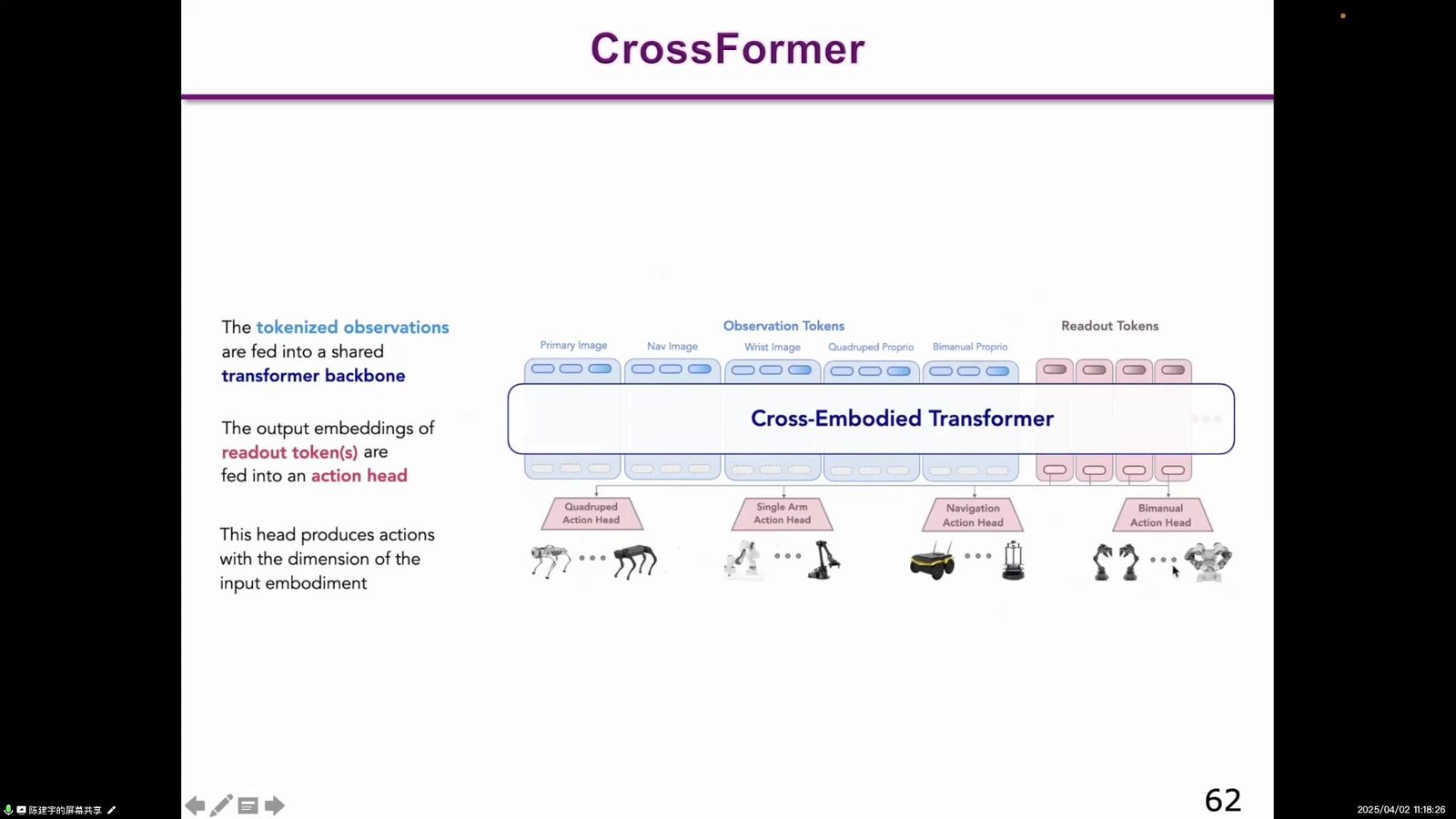
读图:跨本体是 VLA 泛化的关键
CrossFormer 图示强调不同机器人本体之间的共享策略。真正通用的机器人基座模型不能只服务单一硬件,否则仍然会退回“一个机器人一个模型”。

本章小结
第二阶段开始把机器人数据、动作输出和跨本体泛化放到核心位置。ALOHA 提供低成本示范和动作序列学习,RT-1/Octo/RT-X/OpenVLA 等工作把 VLA 推向更通用的机器人策略。
RT-2、RT-X、OpenVLA 与 Action Head
前面已经说明,机器人基座模型需要真实机器人数据和跨任务策略;本章进一步进入最接近当前 VLA 主线的论文群。这里的问题变成:既然 VLM 已经从互联网图文中学到大量视觉语言知识,机器人能否把这部分知识迁移到动作输出,而不是从少量机器人数据重新学习世界常识?
本章进入当前 VLA 主线。RT-2 被视为 VLA 的开山工作之一,它把 web-scale 的视觉语言知识迁移到机器人控制中。关键思想是:一个预训练好的 VLM 已经掌握大量视觉和语言知识,能否通过机器人动作数据,让它直接输出 action?这把互联网知识和机器人控制连接起来。

读图:RT-2 用 VLM backbone 输出机器人动作
图中可以看到 RT-2 把 VLM 和机器人 action 连接起来。核心是迁移:模型不是只在机器人数据上从零学,而是把互联网视觉语言知识迁移到机器人控制。
RT-X 与 Open X-Embodiment
本节把焦点从单个模型结构移到数据基础设施。RT-2 证明了 VLM 迁移到机器人控制有价值,但如果训练数据只来自少数机器人和少数任务,模型仍然容易被本体、场景和动作空间锁死。因此 RT-X/Open X-Embodiment 的核心问题,是怎样把分散在不同实验室、不同机器人上的经验汇成可训练的通用数据。
RT-X 和 Open X-Embodiment 强调数据集和跨本体模型。机器人数据稀缺且碎片化,单一实验室很难覆盖足够多任务和机器人本体。Open X-Embodiment 通过汇集多机器人、多任务数据,尝试训练跨本体模型,显示通用策略优于单任务专用策略的可能性。
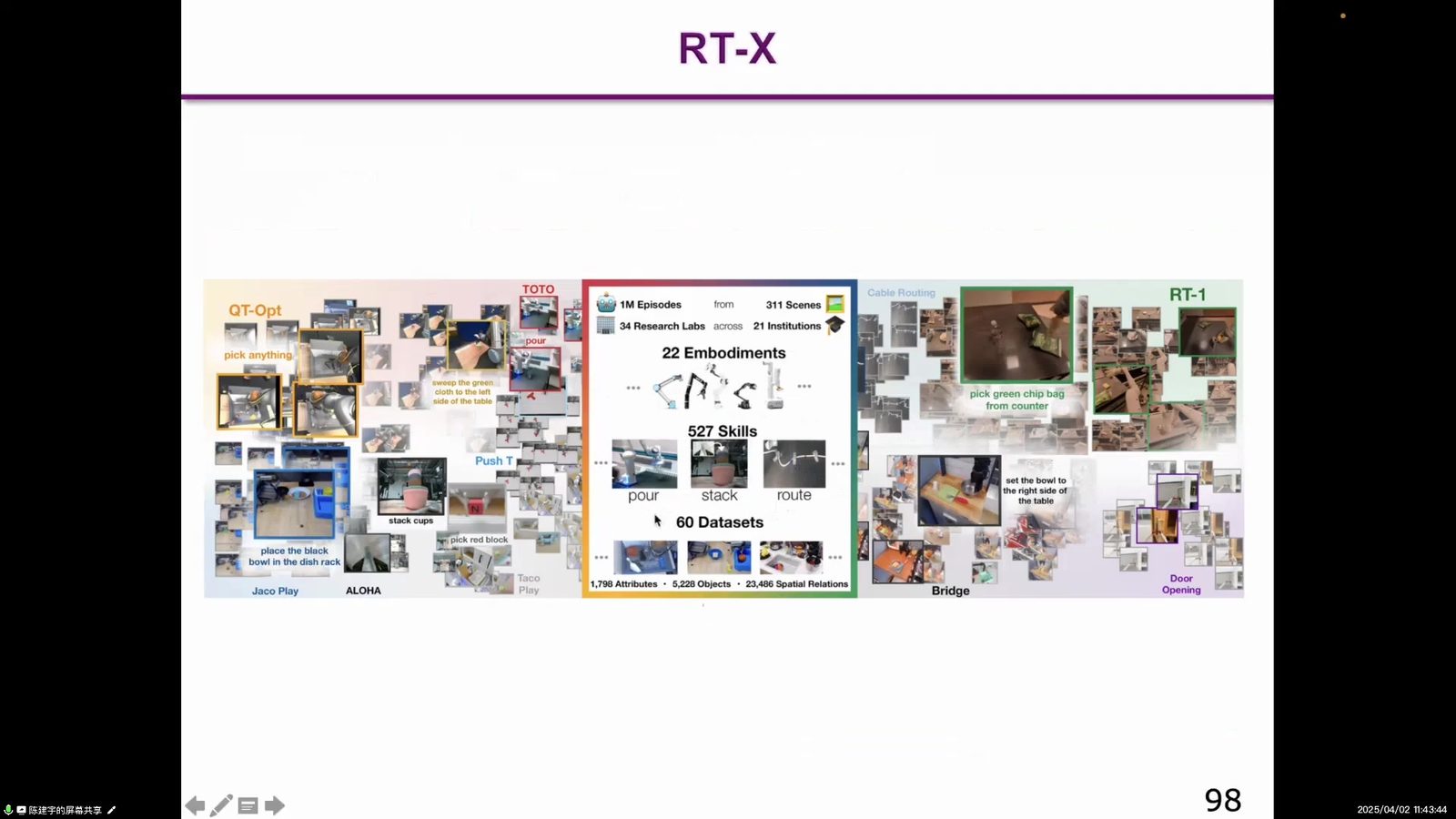
读图:数据集本身就是基础设施
图中拼接了大量机器人和任务场景。读这张图要注意,VLA 的瓶颈不只是模型结构,还包括跨实验室、跨硬件、跨任务的数据标准化。
OpenVLA 与 HiRT:开源和层级动作处理
OpenVLA 近似开源版 RT-2,把 VLM 接上动作输出,并开源模型与训练流程。HiRT 则指出,直接用 VLM 输出 action 存在动作频率和精细控制问题,因此加入专门处理 Action 的 policy/head:VLM 低频理解和规划,Action Policy 高频执行控制。
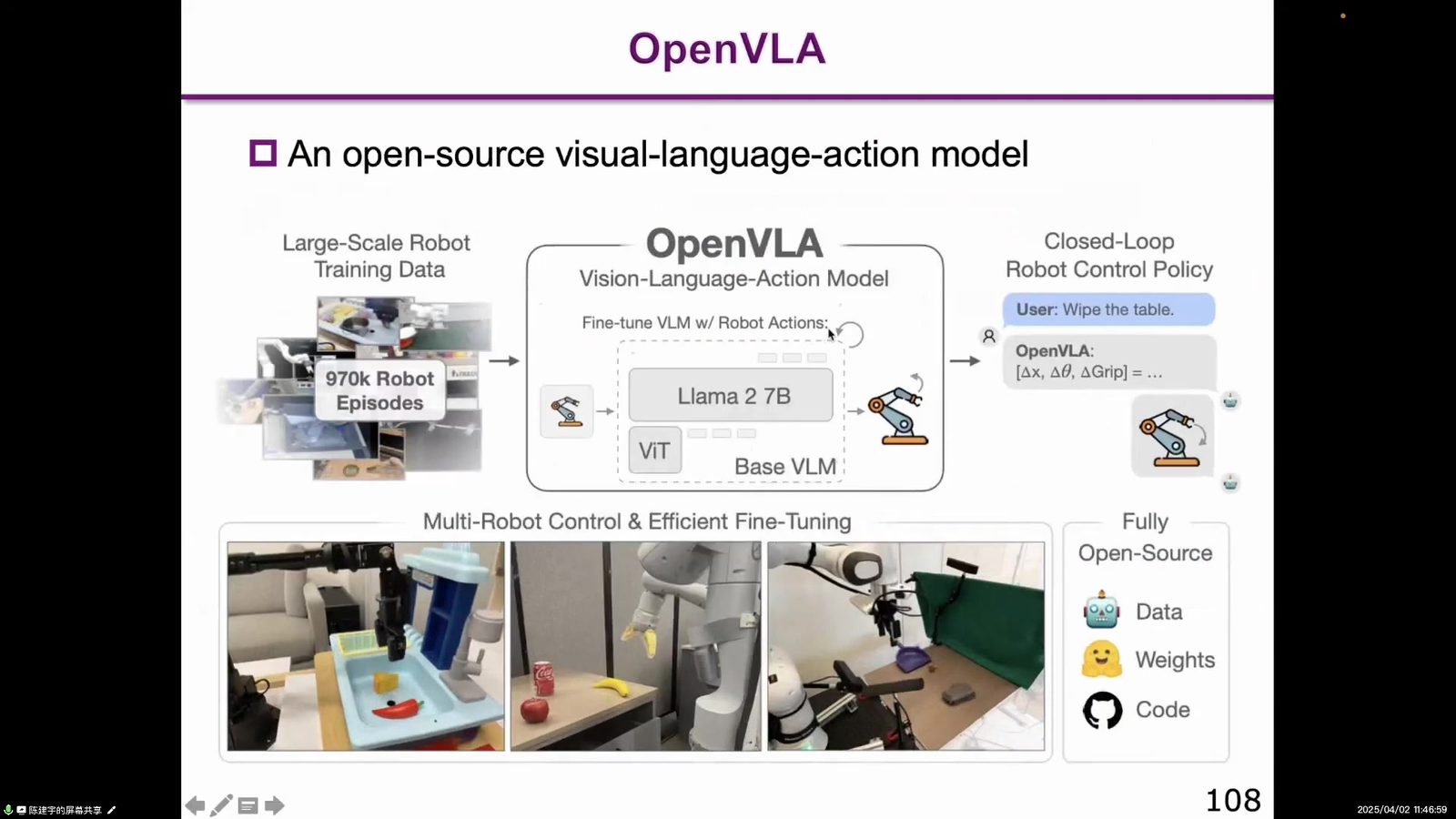

读图:Action Head 是 VLA 工程化的重要补丁
HiRT 图中把高层 VLM 信息传给 Action Policy。它对应一个工程事实:大 VLM 推理慢,机器人控制频率高,动作输出需要专门模块来处理连续控制和局部视觉反馈。
Figure Helix、pi0 与 GR00T N1
接下来这一段进入企业界和更接近产品化的系统。前面的 OpenVLA 与 HiRT 已经暴露出一个核心张力:VLM 擅长低频理解和语义规划,但真实机器人需要高频、连续、稳定的 action。Figure Helix、pi0 和 GR00T N1 的共同点,是把“理解模块”和“动作模块”更明确地拆开,再用系统设计把两者重新接起来。
Figure Helix 虽未发论文,但代表企业界最新架构:上层系统二像预训练 VLM,下层系统一像实时动作控制。pi0 把 flow model 引入 VLA,用 Action Expert 做通用机器人控制。NVIDIA GR00T N1 则强调人形机器人开放基础模型,也采用 VLM 加 action 处理的结构。
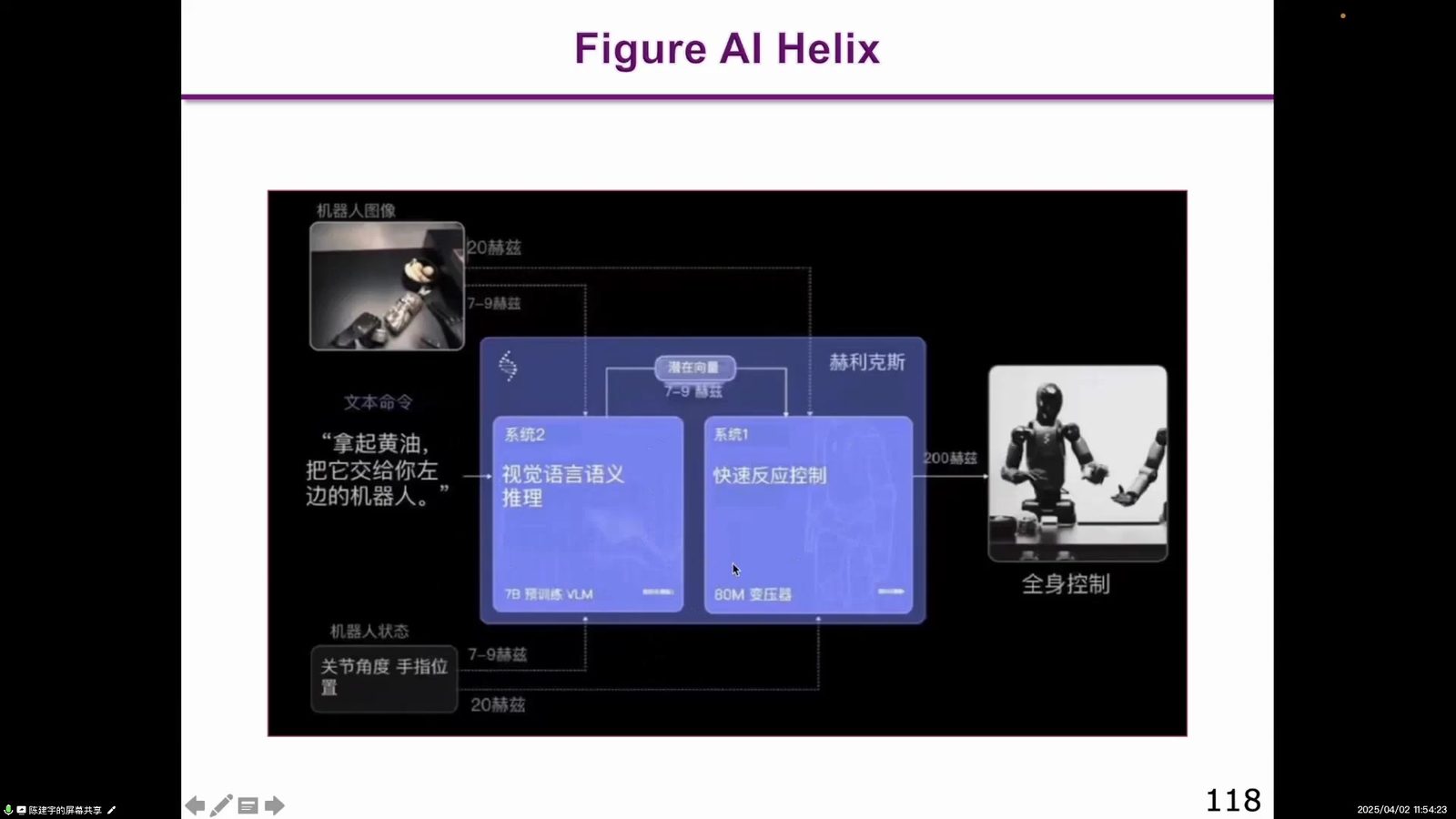

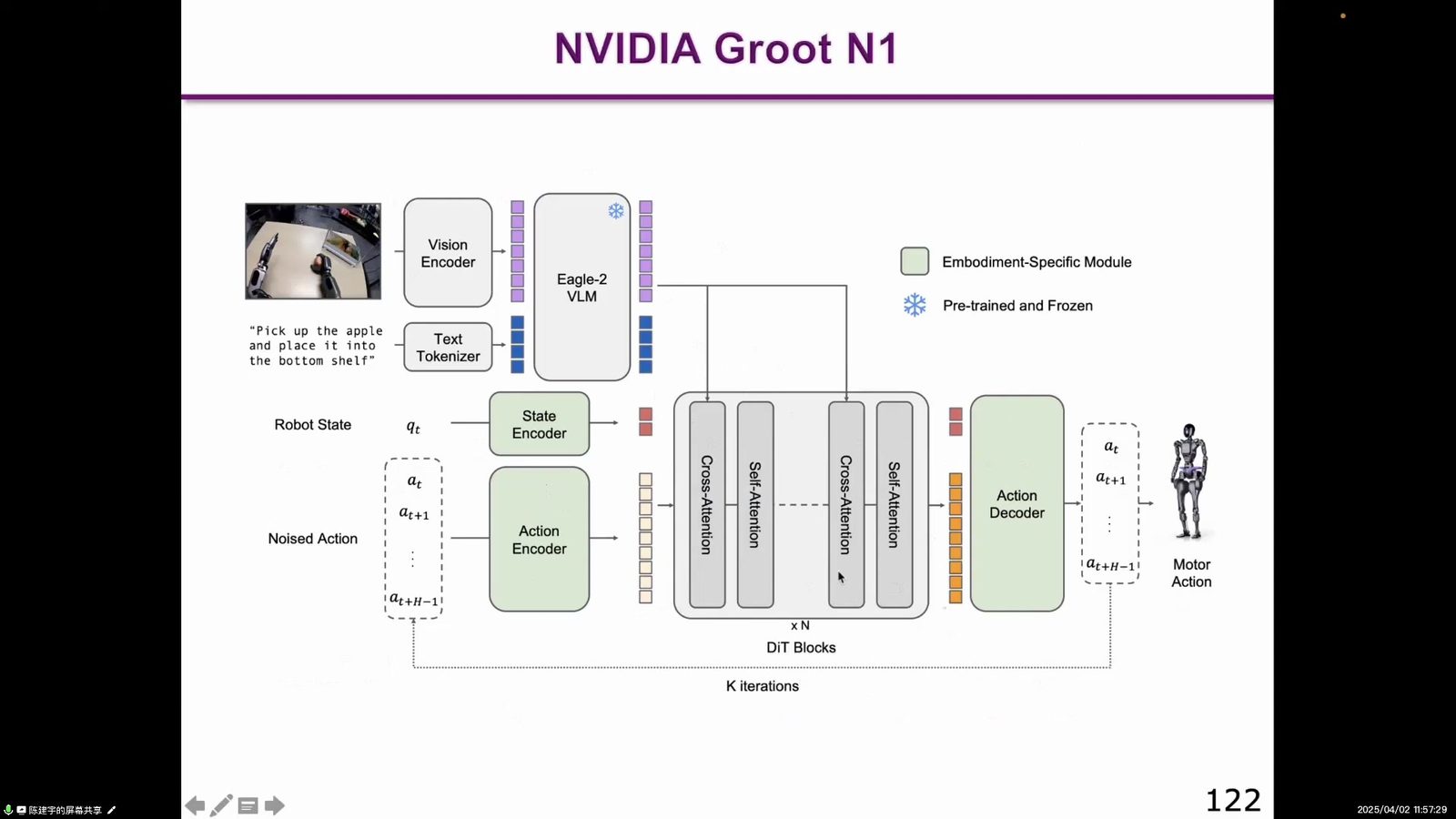
本章小结
RT-2 把 VLM 知识迁移到机器人控制,RT-X/Open X-Embodiment 强调数据规模和跨本体,OpenVLA 提供开源路线,HiRT/pi0/GR00T N1 则开始更认真地处理 Action 模块。这说明 VLA 的核心难点正在从“接上语言和视觉”转向“动作如何高频、稳定、可泛化地输出”。
Diffusion Policy、RDT 与世界模型方向
前面几章主要围绕 Transformer/VLM/VLA,本章看 action 生成路线。Diffusion Policy 把扩散模型用于视觉运动策略学习:不是生成图像,而是生成动作轨迹。它对机器人很自然,因为动作序列本身也可以看成需要逐步去噪和生成的对象。

读图:扩散模型也可以生成 action
图中展示了 Diffusion Policy 的训练与推理过程。关键迁移是:扩散模型不只用于图像生成,也可以用于 action trajectory 生成,尤其适合连续动作和多峰轨迹。
RDT-1B:扩散基础模型用于双手操作
本节继续追问 action 本身应该如何建模。前面 VLM+Action Head 的路线把动作模块作为高频控制器,但仍需要一个更适合连续轨迹、多峰选择和双手协同的生成机制。RDT-1B 的意义在于把 Diffusion Policy 的直觉放大到基础模型尺度,让“动作生成”不再只是一个小策略网络的附属环节。
RDT-1B 将 Diffusion Policy 扩展到更大的双手操作基础模型。它试图处理 unified action space、不同 action head 和双臂 manipulation。它的意义在于,把小模型式动作扩散推进到更大规模、更接近 foundation model 的方向。
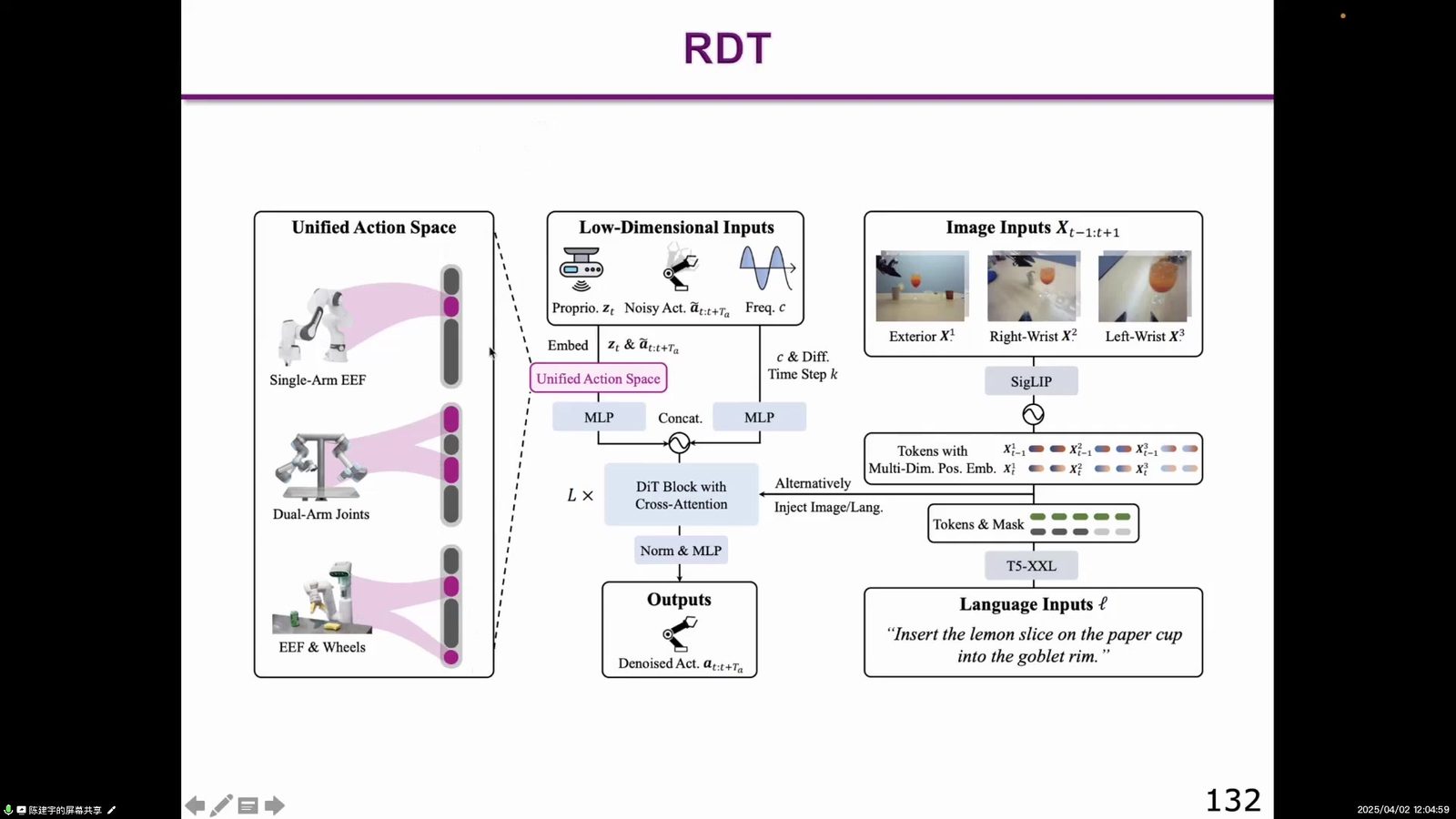
Prediction with Action 与 VPP
Prediction with Action 把视觉预测和动作预测放进联合去噪过程,试图把世界模型和 VLA 连接起来。续作 VPP 强调用 predictive visual representations 形成 generalist robot policy。这里的核心不是只输出 action,而是同时理解未来视觉变化和动作后果。

读图:世界模型进入 VLA
图中包含视频预测、动作和去噪过程。读这张图时要抓住一点:机器人不只需要知道下一步动作,还需要预测动作会如何改变视觉世界,这就是世界模型方向。
未来方向:UP-VLA 与在线强化学习
本节从已有系统转向下一阶段问题。当前 VLA 已经能连接视觉、语言和动作,但还没有稳定解决“理解世界”和“预测动作后果”之间的统一,也没有解决真实环境中持续改进的闭环。因此陈建宇把未来方向压缩为两条线:更统一的模型结构,以及更安全可控的在线学习。
最后,陈建宇列出两个未来方向。UP-VLA 试图统一 understanding 和 prediction,把理解与预测合到 embodied agent 的一个模型中。另一个方向是 online reinforcement learning,用在线反馈继续改进 VLA。难点在于,如果直接对整个 VLM/VLA 做 RL,训练可能不稳定;一种策略是先冻结 VLM,只训练 action head,再逐步放开。
未来两条线
第一条线是统一理解、预测和动作,让模型不仅看懂世界,还能预测动作后果;第二条线是在线强化学习,让机器人在真实或仿真环境反馈中持续改进。
本章小结
Diffusion Policy 和 RDT 把动作生成建模推向更强的连续控制;Prediction with Action/VPP 把世界模型引入 VLA;UP-VLA 和在线 RL 则指向未来的统一模型和持续学习。
总结与延伸
本节把整期压缩成六个结论。第一,机器人革命的关键是从专用模型走向通用模型。第二,早期路线是用 LLM/VLM/Code LM 改造 Planning、Perception、Actuation。第三,真正的 VLA 要把 Vision、Language、Action 放进端到端模型。第四,RT-2/OpenVLA 等路线借助 VLM 迁移互联网知识,但 action 高频控制仍需要专门处理。第五,Diffusion Policy/RDT 说明动作本身可以用生成模型建模。第六,未来方向是世界模型、统一理解预测和在线强化学习。
把 VLA 投屏课放进张小珺 AI/互联网队列
这期是 EP106、EP109、EP121 等具身智能访谈的技术底座。它不是创业故事,而是机器人基座模型路线图,解释了为什么 VLA 会成为 2025 年机器人讨论里的关键词。
经典论文速查表
| 论文/系统 | 关键贡献 | 本课位置 |
|---|---|---|
| SayCan | LLM 规划 + affordance 可行性 | 用语言模型替代 Planning 的代表。 |
| Inner Monologue | 环境反馈和语言化自我修正 | 让执行反馈回到规划。 |
| DoReMi | 检测和恢复计划执行错配 | 处理真实机器人执行失败。 |
| VoxPoser | 3D value maps | 把语言目标转成空间操作场。 |
| ALOHA | 低成本双臂操作和 ACT | 示范数据和动作序列学习。 |
| RT-1/RT-2 | 机器人 Transformer / VLA 迁移 | Google Robotics 主线。 |
| RT-X/OpenVLA | 跨本体数据和开源 VLA | 数据与开源基础设施。 |
| HiRT/pi0/GR00T N1 | VLM + Action Head/Expert | 更认真处理 action。 |
| Diffusion Policy/RDT | 动作扩散和双手操作基础模型 | 生成式 action policy。 |
| UP-VLA/iRe-VLA | 统一理解预测和在线 RL | 未来方向。 |
后续观察问题
最后回到张小珺这组 AI/互联网访谈的长期观察框架:VLA 不是一个单点模型名,而是一组围绕数据、模型、硬件、商业落地和安全训练的系统问题。下面这些问题适合作为后续追踪清单,用来判断机器人基座模型是否真的进入类似大语言模型的 scale 阶段。
- VLA 的 scaling law 是否会像语言模型一样稳定出现?
- 跨本体数据集能否足够大、足够标准化,支撑真正通用策略?
- VLM backbone 直接输出 action,和 VLM + Action Head,哪条路线更可扩展?
- 世界模型是否会成为机器人泛化的关键,还是 action policy 本身就足够?
- 在线强化学习能否在真实机器人上安全、高效、可持续地运行?
- 人形机器人是否会先靠本体和遥操作落地,还是必须等待 VLA 能力成熟?
拓展阅读
- 对具身智能学术史感兴趣,可对照 EP106 王鹤访谈。
- 对仿真和合成数据感兴趣,可对照 EP109 谢晨/光轮访谈。
- 对多模态世界模型和视觉推理感兴趣,可对照 EP102 张祥雨访谈。
- 对机器人产业化和硬件入口感兴趣,可对照 EP104 Rokid 与 EP121 谭捷访谈。