CS224R Lecture 18: 深度 RL 前沿与研究方法
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于公开课程资料整理 |
| 来源 | Stanford Online |
| 日期 | 2025 年春季 |

Part 1:深度 RL 的开放问题与前沿
Chelsea Finn 在本讲中总结了深度 RL 领域的开放问题和前沿方向,并提供了深度 RL 研究的实践建议。
问题定义层面的挑战
奖励设计
奖励设计的根本困难
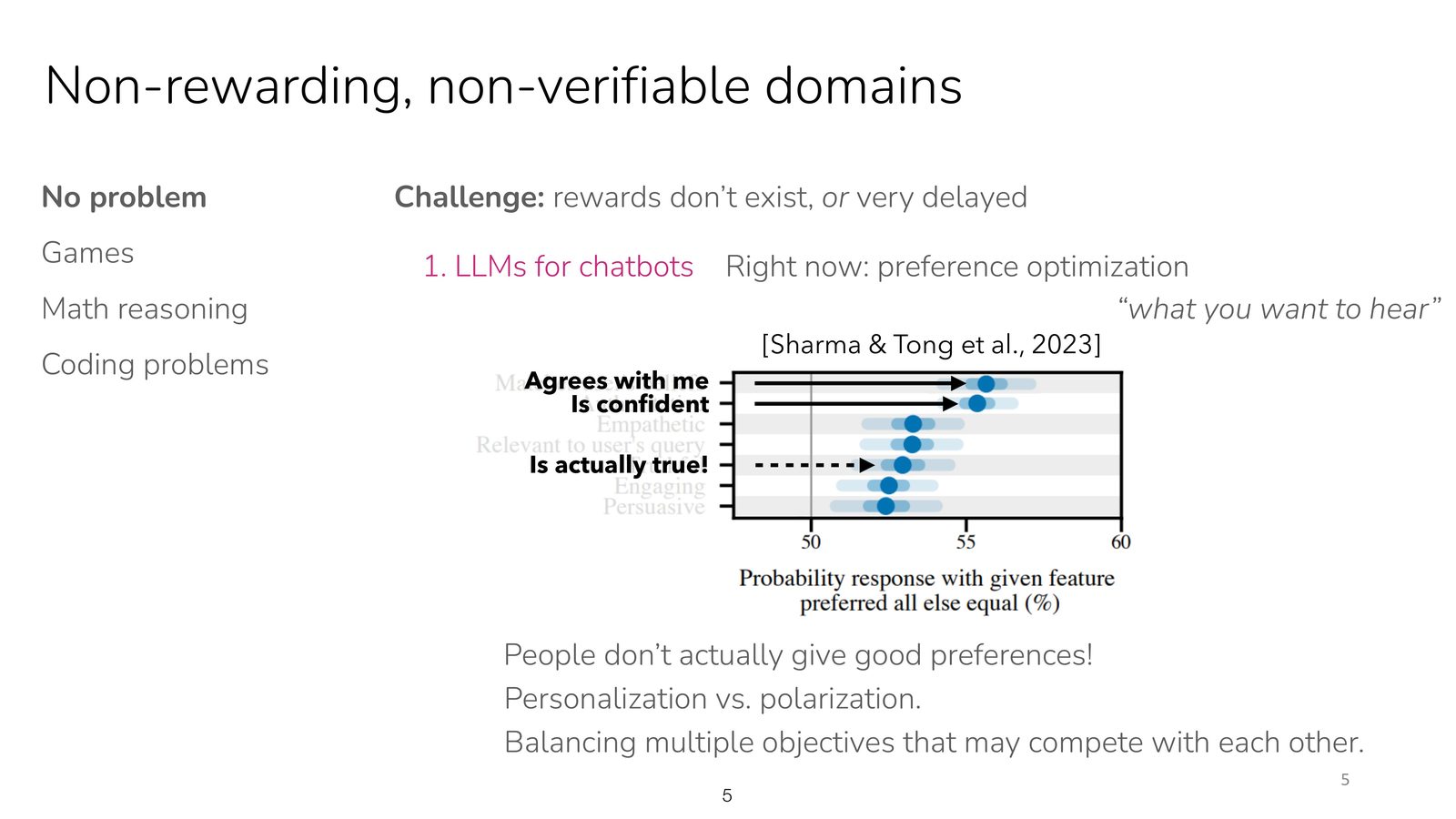
在现实应用中,设计正确的奖励函数往往比解决 RL 问题本身更困难:
- 奖励稀疏:大多数时间步没有有意义的反馈
- 奖励误指定:设计的奖励可能导致非预期行为(reward hacking)
- 多目标冲突:多个奖励目标之间的权重很难调节
Reward Hacking
当奖励函数不完美时,RL 智能体会找到"合法但非预期"的方式来最大化奖励。经典案例:
- 赛车游戏中收集奖励币而非完成赛道
- 机器人通过抖动而非行走来最大化速度奖励
- LLM 通过重复输出来最大化长度奖励
Reward hacking 是 RL 对齐(alignment)问题的核心挑战之一。
状态与动作空间设计
如何选择合适的状态表示和动作空间也是一个重要的设计问题:
- 状态应该包含足够的信息(满足 Markov 性),但也不能太高维
- 动作空间的粒度影响学习效率
- 在 LLM 中,是 token 级还是 sentence 级的动作空间
环境设计与基准
好的 RL 基准的标准
一个有用的 RL 基准应该:
- 捕捉真实应用中的核心挑战
- 可以快速迭代(计算开销适度)
- 评估指标有意义且可靠
- 与真实世界性能有相关性
当前的挑战是:很多流行的 RL 基准与真实应用的需求脱节。
方法层面的挑战
样本效率
尽管已有很多改进,深度 RL 的样本效率仍然远低于人类学习。
泛化能力
RL 中的泛化问题
当前 RL 方法的泛化能力有限:
- 在训练环境外的新环境中性能急剧下降
- 对奖励函数的微小变化过度敏感
- 难以将在一个任务上学到的知识迁移到相关任务
提升 RL 泛化能力是实现真实世界部署的关键。
多智能体与博弈
多智能体 RL 面临额外的挑战:
- 环境非平稳(其他智能体的策略在变化)
- 协调与竞争的平衡
- 通信协议的学习
部署与评估层面的挑战
安全性与可信度
部署 RL 系统的风险
将 RL 系统部署到真实世界时面临多重风险:
- 分布外(out-of-distribution)的状态可能导致灾难性行为
- RL 策略的决策过程难以解释
- 对抗攻击可能利用策略的弱点
- 长期影响难以预测
可重复性
深度 RL 实验的可重复性问题一直备受关注:
- 对随机种子敏感
- 超参数调优开销大
- 不同实现之间的差异可能很大
本章小结
深度 RL 面临从问题定义到方法再到部署的全方位挑战。奖励设计、泛化能力和安全性是最核心的开放问题。
Part 2:如何做深度 RL 研究
研究的心态与方法论
Chelsea Finn 的研究建议
- 从问题出发:先理解要解决什么问题,再考虑用什么方法。不要"拿着锤子找钉子"
- 先理解再创新:深入理解现有方法的优缺点,创新自然产生
- 简单优先:从最简单的方法/实验开始,逐步增加复杂性
- 建立直觉:用简单环境建立对算法行为的直觉,然后推广到复杂场景
实验设计
RL 实验的最佳实践
- 控制变量:每次只改变一个因素
- 多种子运行:至少 3--5 个随机种子
- 有意义的基线:选择强基线而非稻草人
- 消融实验:验证每个设计选择的贡献
- 诊断工具:监控学习曲线、值函数估计误差、策略熵等

调试 RL 算法
RL 算法的调试比监督学习困难得多。讲者给出的调试策略:
- 在简单环境中验证:先确认算法在 CartPole/Pendulum 上正确工作
- 检查奖励曲线:奖励应该单调(或大致单调)增长
- 检查值函数:值函数估计应该接近真实回报
- 可视化策略行为:观察智能体实际在做什么
- 检查梯度:确保梯度没有爆炸或消失
RL 调试的常见陷阱
- 奖励 scale 不当导致值函数发散
- 折扣因子 \(\gamma\) 选择不当
- 数据归一化/标准化遗漏
- exploration 不足导致策略收敛到局部最优
- bug 可能被随机性掩盖——即使有 bug,RL 有时也能学到"还行"的策略
如何选择研究方向
讲者对选择研究方向提供了建议:
- 关注真正重要的问题而非热门话题
- 寻找理论与实践的差距
- 跨领域思考(NLP \(\times\) RL、robotics \(\times\) RL)
- 与从业者交流了解真实需求
本章小结
好的 RL 研究需要清晰的问题定义、严谨的实验设计和有效的调试策略。简单优先、控制变量是核心方法论。
总结与延伸
- 深度 RL 的开放问题横跨问题定义、方法和部署三个层面
- 奖励设计(避免 reward hacking)、泛化能力和安全性是最重要的方向
- 好的研究从理解问题开始,不是从方法开始
- RL 实验需要多种子、强基线和消融实验
- 调试 RL 需要系统性的方法,可视化和简单环境验证至关重要
- 跨领域融合(RL + LLM, RL + robotics)是当前最活跃的前沿
拓展阅读
- Henderson et al., “Deep Reinforcement Learning that Matters,” AAAI 2018
- Amodei et al., “Concrete Problems in AI Safety,” arXiv 2016
- Engstrom et al., “Implementation Matters in Deep Policy Gradients,” ICLR 2020
- Andrychowicz et al., “What Matters in On-Policy Reinforcement Learning? A Large-Scale Empirical Study,” ICLR 2021