CS336 Lecture 9: Scaling Laws 1
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Tatsu Hashimoto 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2025年5月 |

引言:为什么需要 Scaling Laws
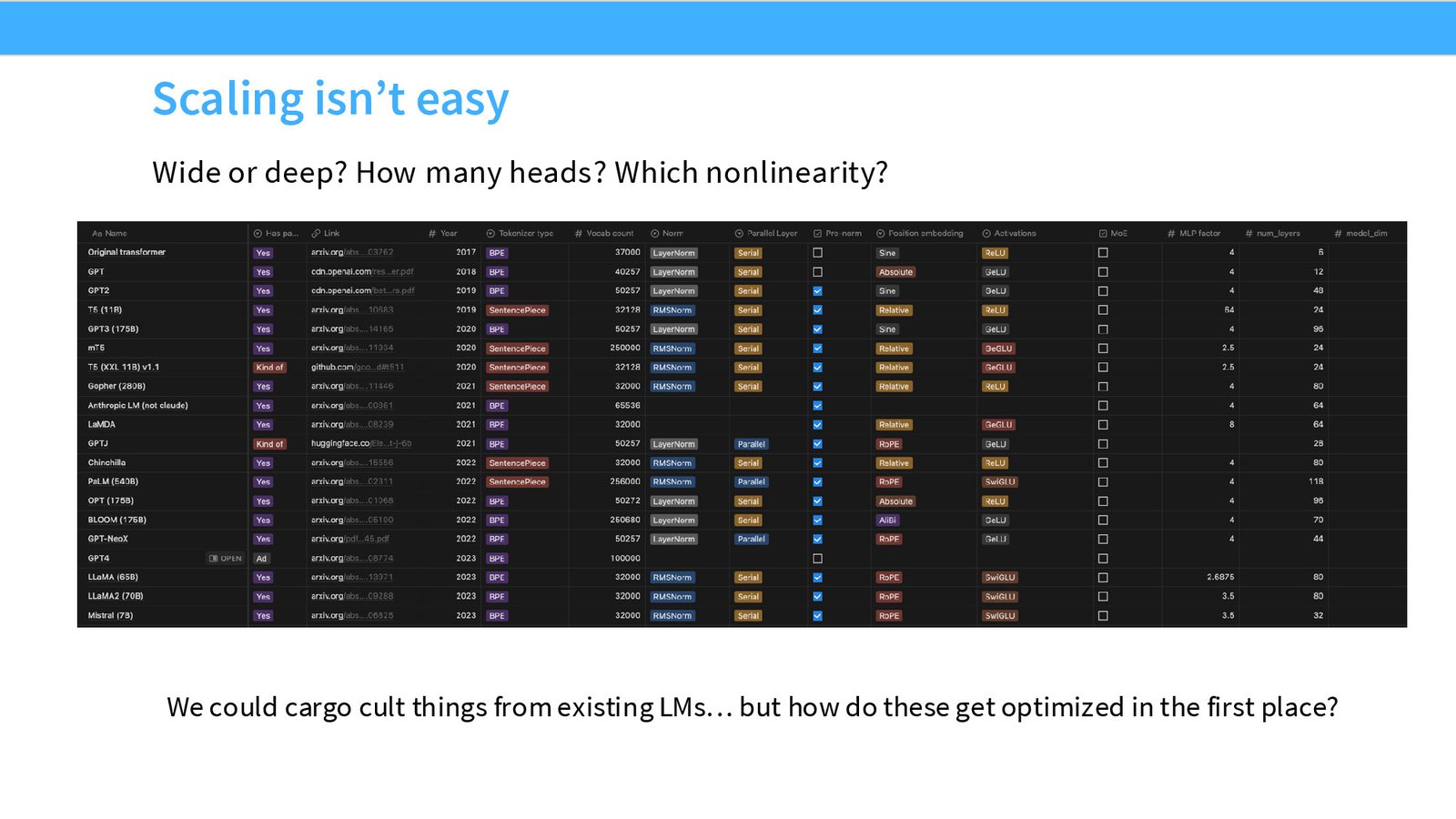
假设你有一位非常有钱的朋友,给了你 100,000 张 H100 GPU 用一个月,目标是构建最好的开源大语言模型。前面的课程已经教会了你分布式训练框架、预训练数据准备、模型架构选择等基本要素。但面对如此庞大的资源,一个核心问题浮现了:如何在不浪费算力的前提下,做出最优的工程决策?

来源:Slides 第2页。
简单地“照搬别人的做法”(如 follow LLaMA 的配置)虽然安全,但无法真正推动前沿。如果你在一家前沿实验室,想要创新和优化,就需要一套系统性的方法来预测不同决策在大规模下的表现。
Scaling Laws 的核心价值
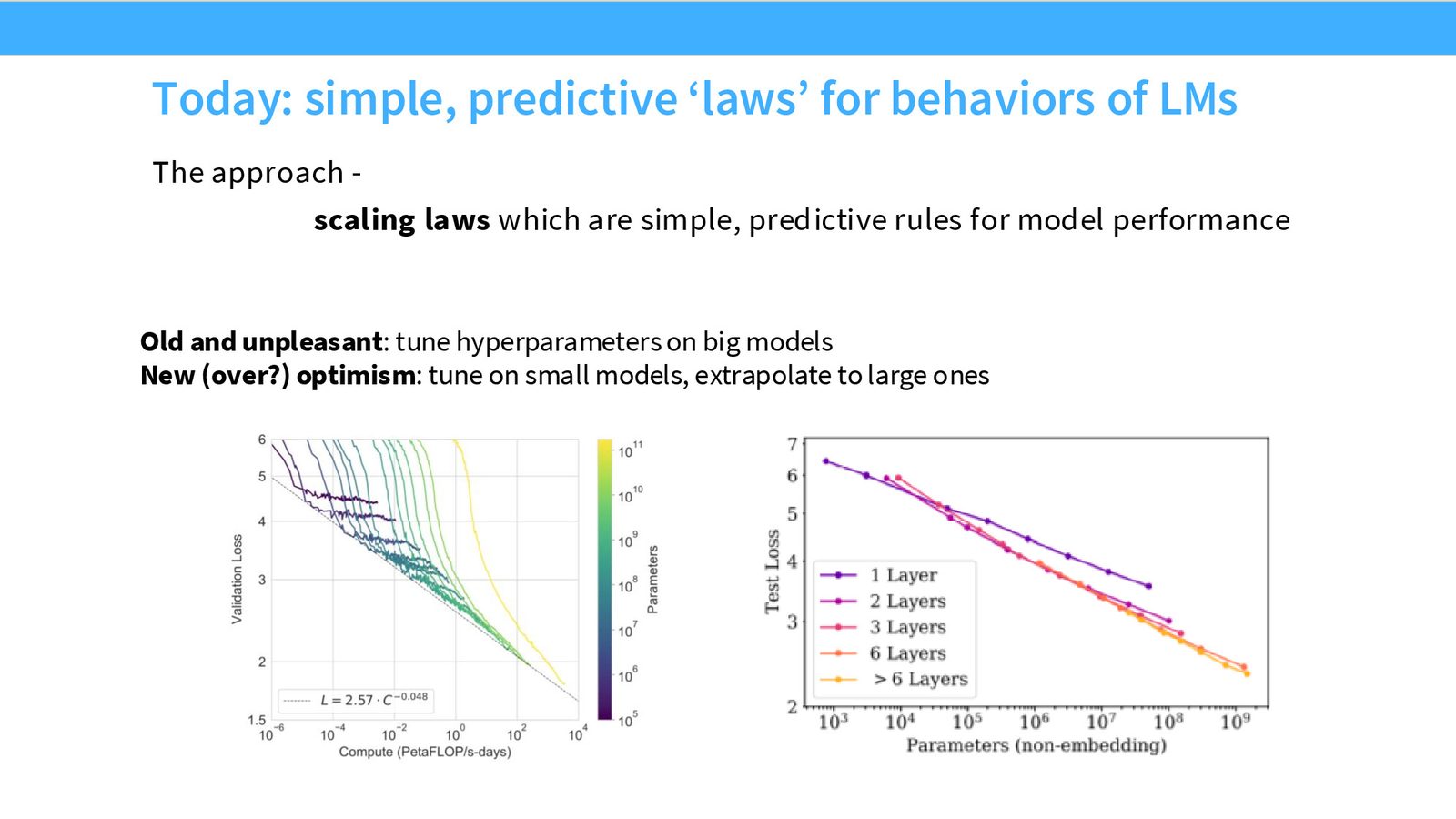
Scaling Laws 的核心思想是:通过训练一系列小模型来预测大模型的行为。不再需要花费巨额算力直接调优大模型,而是在小规模上学习规律,然后外推到大规模,“一次搞定”大模型训练。
传统深度学习的做法是:直接训练大模型、调超参数、发现效果不好、再调——这极其昂贵。新的“乐观主义”方法是:
- 在小规模上训练大量模型
- 从小模型中学习行为规律
- 外推到大规模,一次性训练出最优大模型
来源:Slides 第3页。
本章小结
Scaling Laws 为大语言模型的工程决策提供了一套基于数据驱动的科学方法。其核心前提是:模型在小规模上展示的趋势可以可靠地外推到大规模。这一思想贯穿本节课的所有内容。
Scaling Laws 的历史脉络
理论根源:统计学习理论
Scaling Laws 并非全新概念。在经典统计学习理论中,人们早已研究过“模型性能如何随数据量和模型复杂度变化”的问题。
来源:Slides 第4页。
在有限假设类 \(\mathcal{H}\) 中选择模型时,经典泛化界给出:
其中 \(m\) 是样本数。这告诉我们误差随样本量以 \(1/\sqrt{m}\) 的速率衰减——这本身就是一种“Scaling Law”。
对于更灵活的非参数模型类(如核密度估计),\(\beta\)-光滑函数的 \(L_2\) 估计误差为:
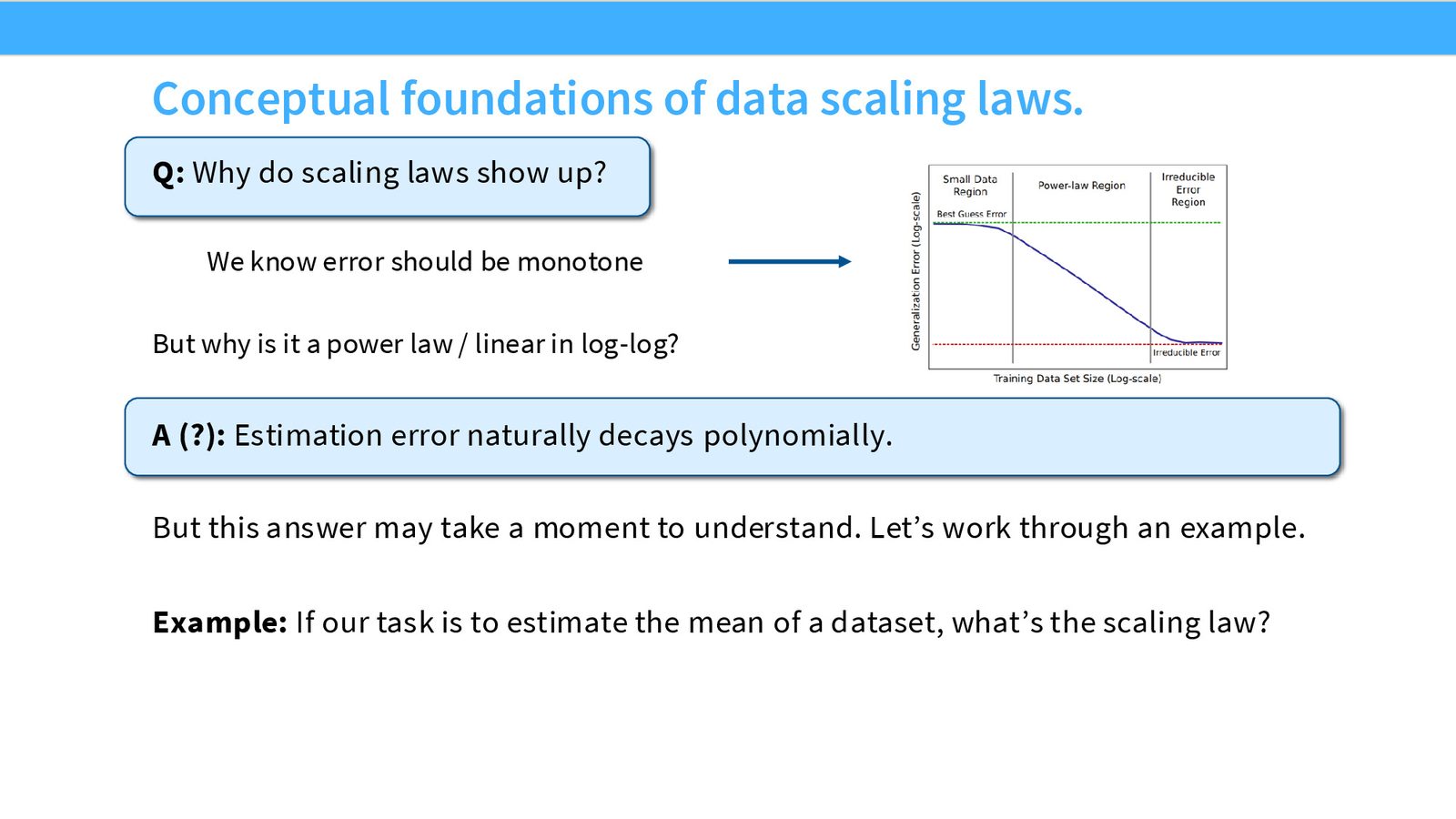
从理论到经验:一个根本性的跃迁
理论给出的是上界(upper bounds),而非实际实现的损失值。Scaling Laws 的真正突破在于:从理论预测的收敛速率出发,转向经验性地拟合模型性能与资源之间的精确关系。理论提供的是“应该期待什么形式的衰减”,经验拟合则告诉我们“具体的系数和指数是多少”。
第一篇 Scaling Law 论文:Bell Labs 1993
Tatsu 认为,历史上第一篇真正的 Scaling Law 论文可能是 1993 年 NeurIPS 上来自 Bell Labs 的工作。论文的作者包括 Vapnik、Cortes 等经典机器学习理论的先驱。

来源:Slides 第5页。
这篇论文的核心思想惊人地超前:
- “训练大规模分类器非常耗费计算资源,需要在训练前预测模型好坏”
- 测试误差可表示为 \(\text{Error} = \epsilon_\infty + a \cdot n^{-\alpha}\)(不可约误差 + 多项式衰减项)
- 通过小模型拟合曲线,可以准确预测大模型的行为
历史的回响
这些想法在 30 年后的今天看来如此自然,但在 1993 年就已经被 Bell Labs 的研究者们清晰地表述出来了。正如许多技术突破一样,Scaling Laws 的种子在很早之前就已播下。
数据缩放的早期研究

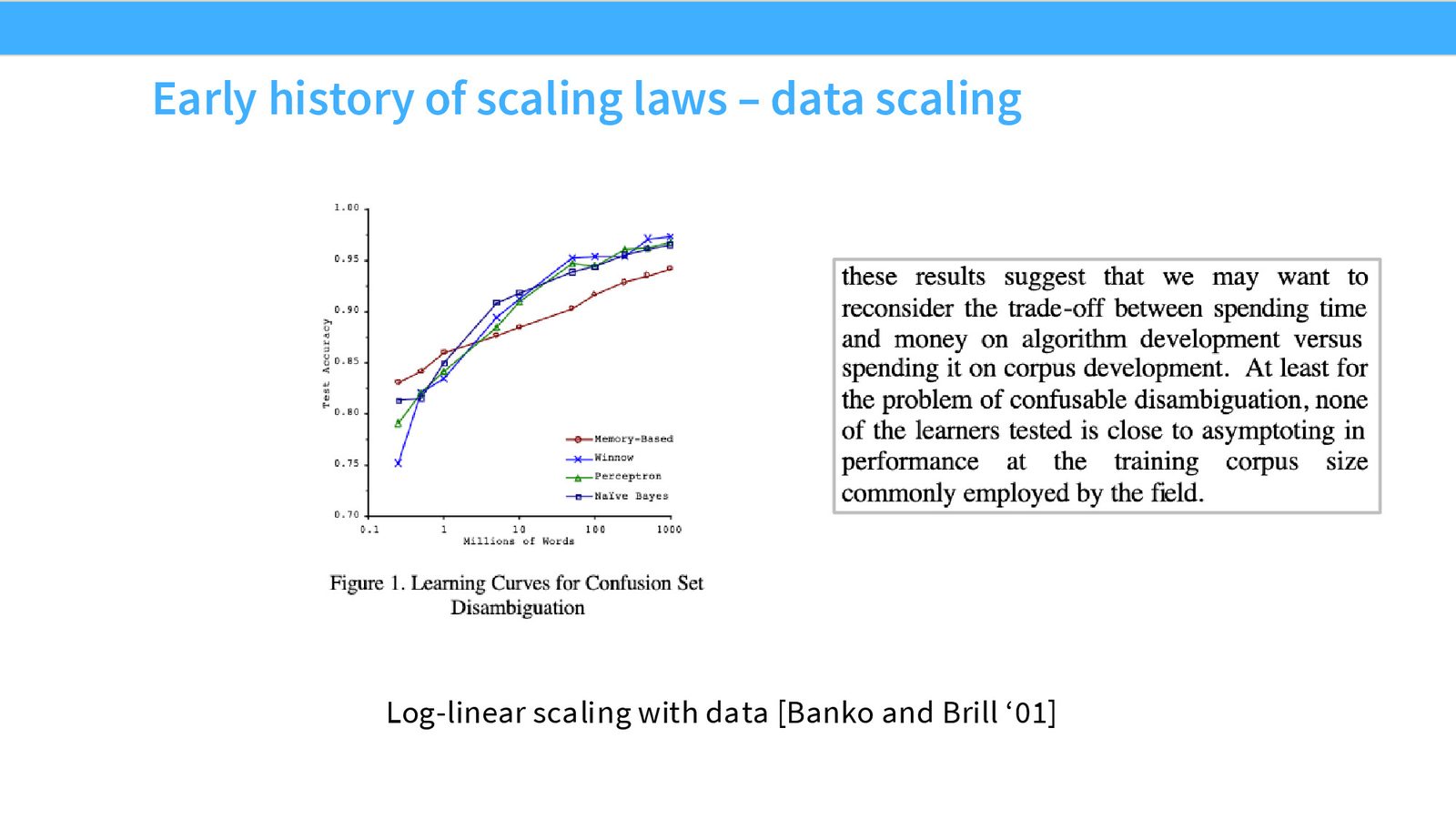
来源:Slides 第6页。
Banko & Brill (2001) 研究了 NLP 系统性能如何随数据量缩放。他们发现性能改善是可预测的,并提出了一个至今仍有争议的问题:应该花时间改进算法,还是只需收集更多数据?
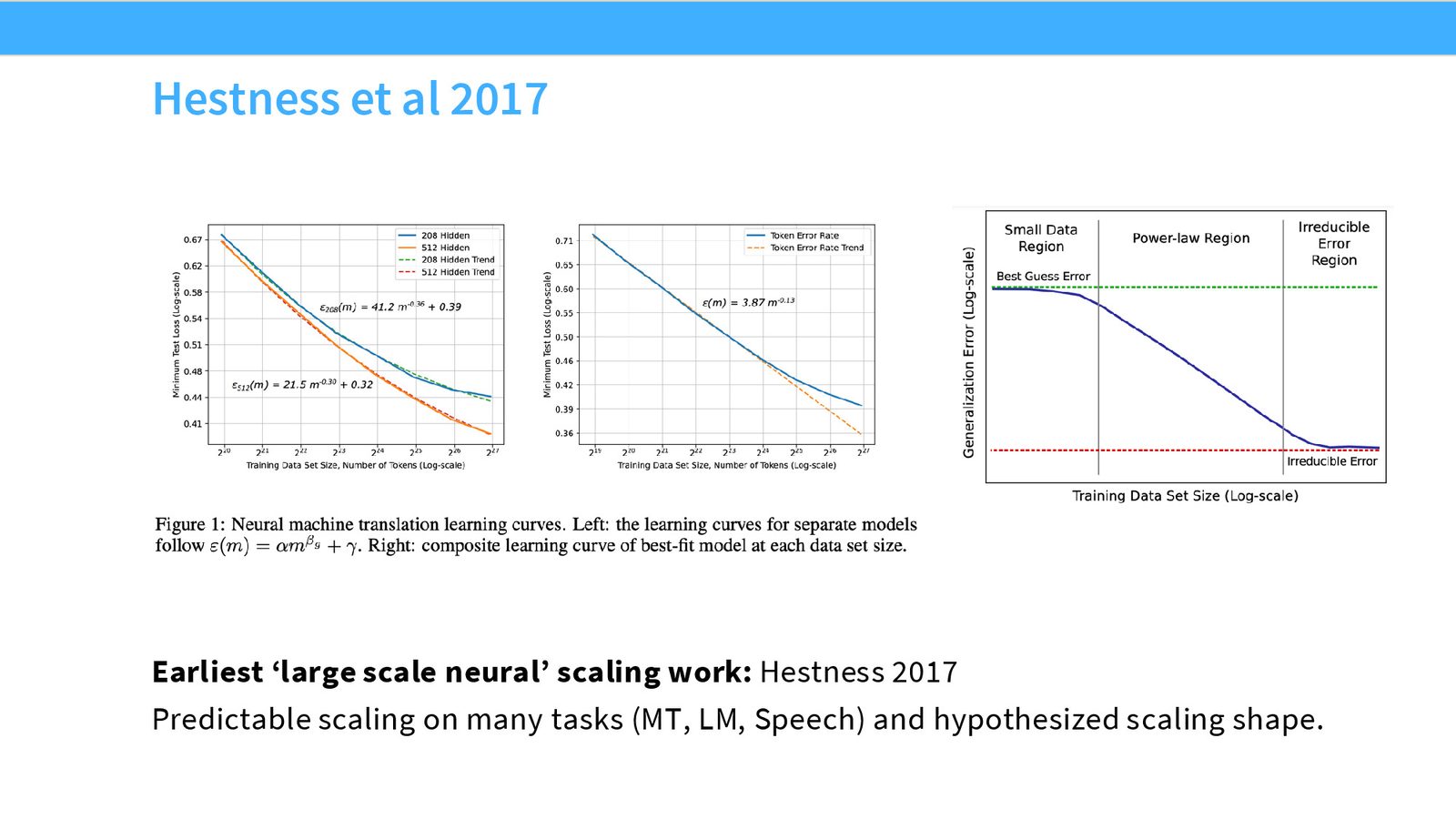
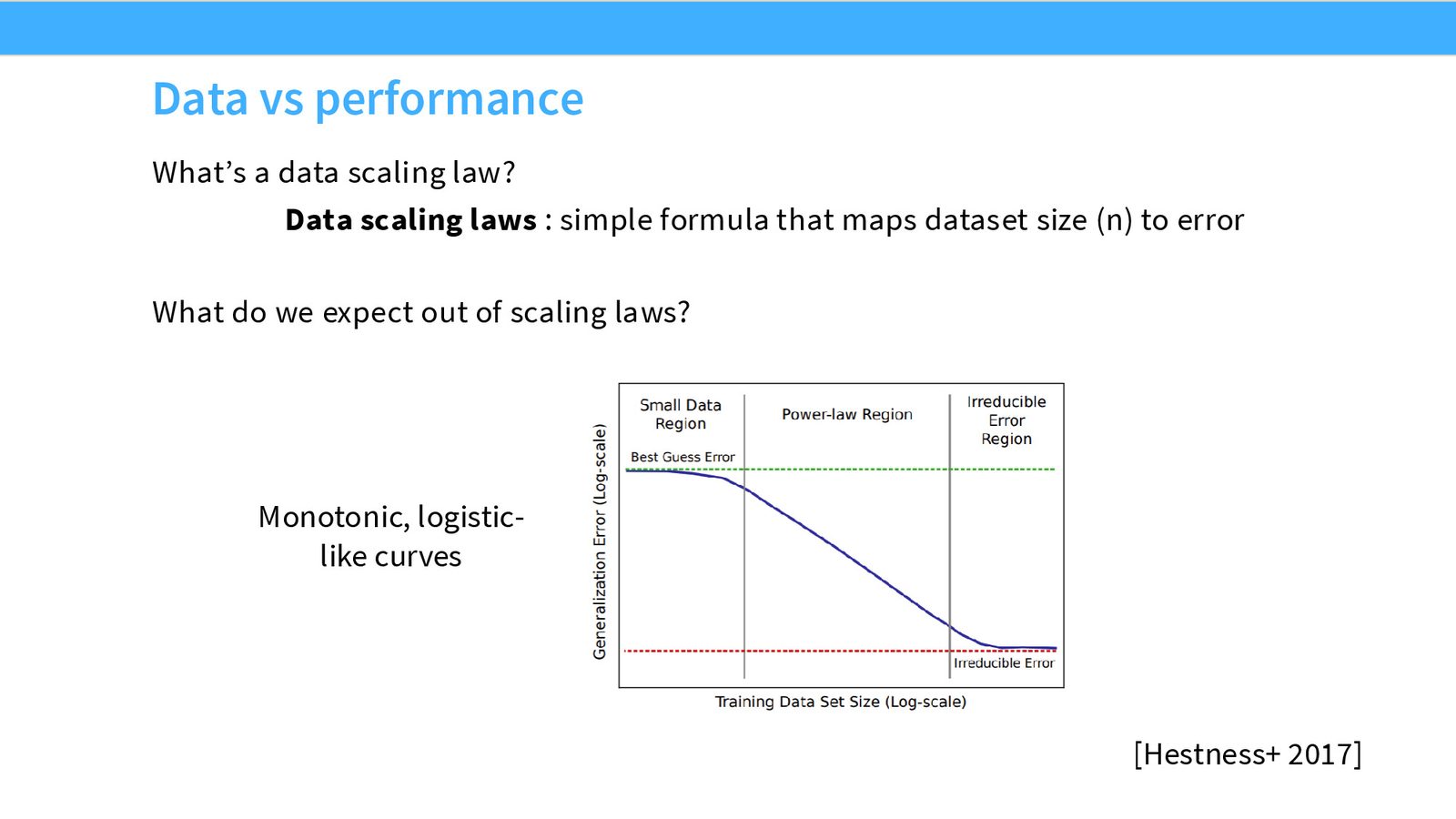
Hestness et al. (2017) 可能是大规模神经网络 Scaling Law 的最早系统研究。他们在机器翻译、语音识别和视觉任务上展示了误差率以幂律衰减的规律,并提出了模型行为的三个阶段:
模型性能的三个阶段
- 随机猜测阶段:数据太少,模型表现接近随机
- 幂律缩放阶段:性能随资源投入可预测地改善(这是 Scaling Laws 最有用的区间)
- 渐近阶段:接近模型类的不可约误差,改善越来越慢

来源:Slides 第7页。
Hestness 等人的论文虽然早于后来的大规模 Scaling Law 热潮,但已经包含了许多关键洞察:
- 在随机猜测区域用 Scaling Law 做预测很困难(“涌现能力”的前兆)
- 可预测的缩放意味着计算扩展非常重要
- 量化等效率技术是值得的——如果缩放是可预测的,就应该愿意用计算来换取精度
“涌现能力”与 Scaling Laws 的关系
近年来关于“涌现能力”(emergent capabilities)的讨论非常热烈,但实际上 Hestness 在 2017 年就已经指出:在模型处于随机猜测区域时,Scaling Laws 的预测是不可靠的。所谓“涌现”,可能部分是从随机猜测区域进入幂律区域时的“跳跃”。
本章小结
Scaling Laws 有深厚的历史根基:从 VC 维和非参数收敛率的理论,到 1993 年 Bell Labs 的开创性工作,再到 2017 年 Hestness 的多任务验证。核心发现是:模型性能与数据/计算之间存在可预测的幂律关系,这一规律跨领域、跨模型族普遍成立。
数据 Scaling Laws:理论与经验
Kaplan 论文的经验观察
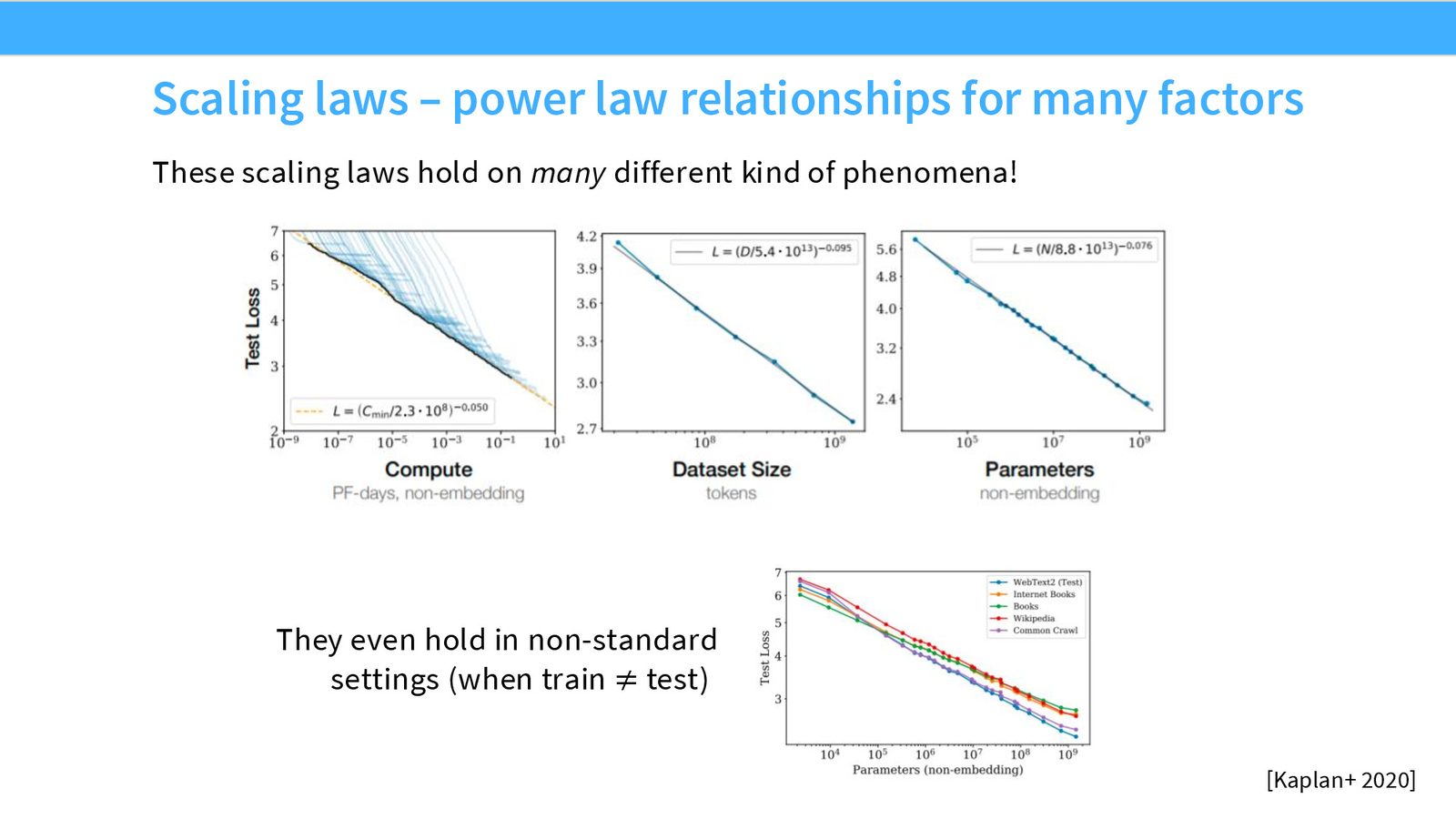
Kaplan et al. 的 Scaling Laws 论文是该领域最全面的参考文献之一。其核心经验发现是:在 log-log 图上,测试损失与计算量、数据量、参数量之间呈线性关系——即存在幂律关系。
来源:Slides 第8页。
幂律关系的数学表达
当在 log-log 图上观察到线性关系时,意味着:
即 \(L = c' \cdot X^{-\alpha}\),其中 \(L\) 是测试损失,\(X\) 是资源量(数据/参数/计算),\(\alpha > 0\) 是缩放指数。
一个重要的细微之处是:当我们单独缩放某个变量(如数据量)时,其他变量必须足够大,以避免进入渐近饱和区域。例如,研究数据缩放时,模型尺寸必须大到不会被数据“填满”。
为什么幂律衰减是自然的?——均值估计
Tatsu 从最简单的统计问题出发,解释为什么幂律衰减是“自然的”。
例子 1:估计高斯均值
给定 \(n\) 个独立同分布样本 \(X_1, \ldots, X_n \sim \mathcal{N}(\mu, \sigma^2)\),用样本均值 \(\hat{\mu} = \frac{1}{n}\sum X_i\) 估计 \(\mu\)。
估计误差为:
取对数后:
来源:Slides 第10页。
这就是最简单的 Scaling Law:在 log-log 图上斜率为 \(-1\)。
为什么实际观测到的指数很小?——非参数回归与维度诅咒
然而,实际观察到的缩放指数远小于理论预期。例如:
- 机器翻译(Hestness):\(\alpha = 0.13\)
- 语音识别(Hestness):\(\alpha = 0.3\)
- 语言建模(Kaplan):\(\alpha \approx 0.095\)
这些指数远远慢于简单估计问题的 \(\alpha = 1\) 或 \(\alpha = 0.5\)。为什么?

来源:Slides 第11页。
例子 2:非参数回归与维度诅咒
考虑在二维空间中估计任意回归函数 \(f\)。最简单的方法是将空间切分成小方块,在每个方块内取均值。

来源:Slides 第12页。
如果有 \(n\) 个样本在 \(d\) 维空间中:
- 将空间切成 \(n^{1/2}\) 个方块(二维)\(\rightarrow\) 每个方块分到 \(n^{1/2}\) 个样本 \(\rightarrow\) 误差 \(\sim n^{-1/2}\)
- 推广到 \(d\) 维:误差 \(\sim n^{-1/d}\)
在 log-log 图上,斜率为 \(-1/d\)。
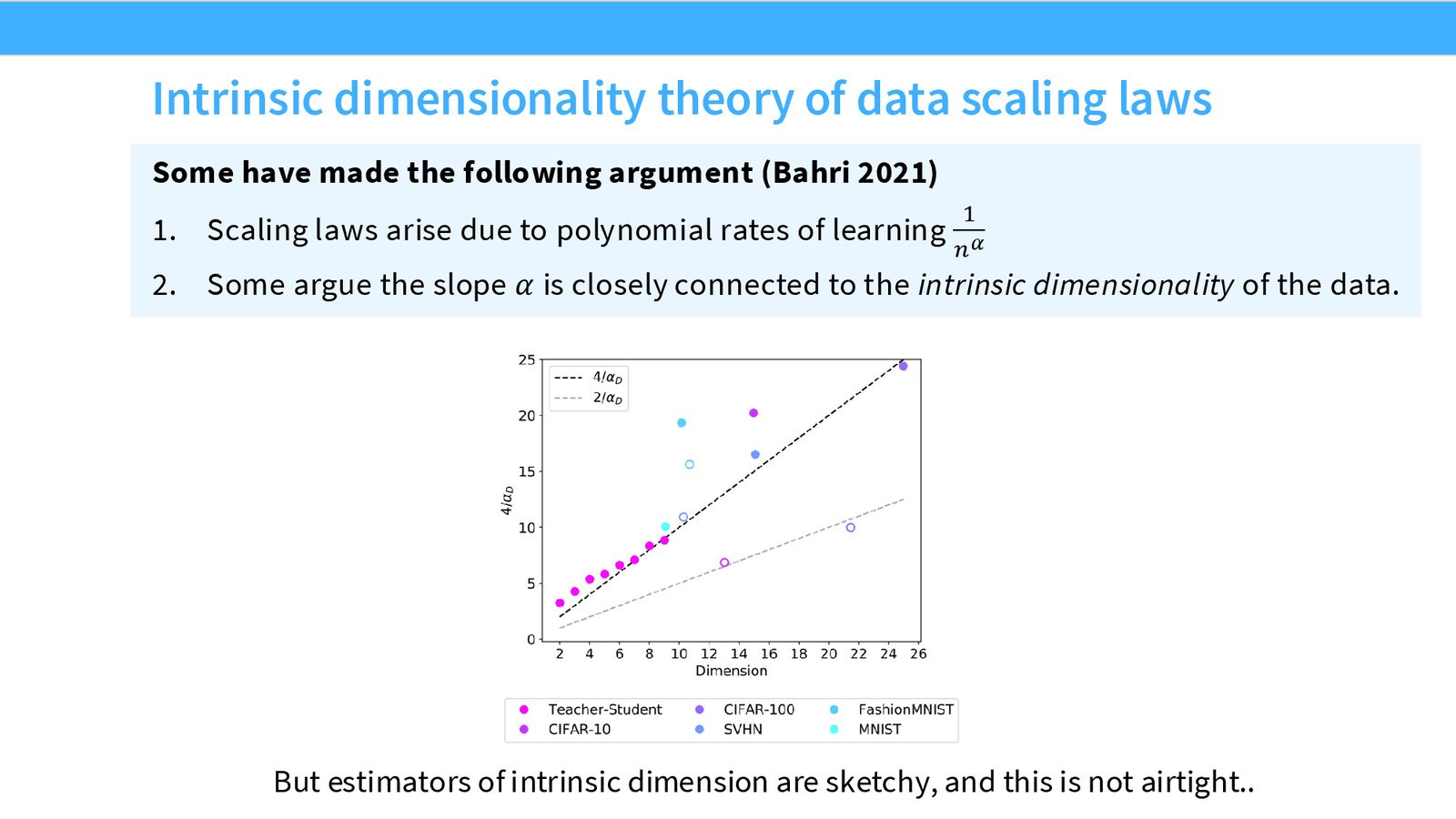
缩放指数反映内在维度
缩放指数 \(\alpha = 1/d\) 直接与数据的内在维度(intrinsic dimensionality)相关。语言建模的缩放指数 \(\alpha \approx 0.095\) 意味着学习任务的有效维度大约为 \(d \approx 10.5\)。换言之,缩放越慢,说明任务越“复杂”(有效维度越高)。
来源:Slides 第13页。
内在维度估计的困难
虽然理论上缩放指数与内在维度密切相关,但直接估计数据的内在维度是一个极其困难的问题——其难度与建模数据本身相当。因此,这种对应关系更多是概念性的,不应过度解读。
数据 Scaling Laws 的实用价值
数据 Scaling Laws 不仅仅是理论上的优美结论,它还有重要的工程应用。
来源:Slides 第14页。
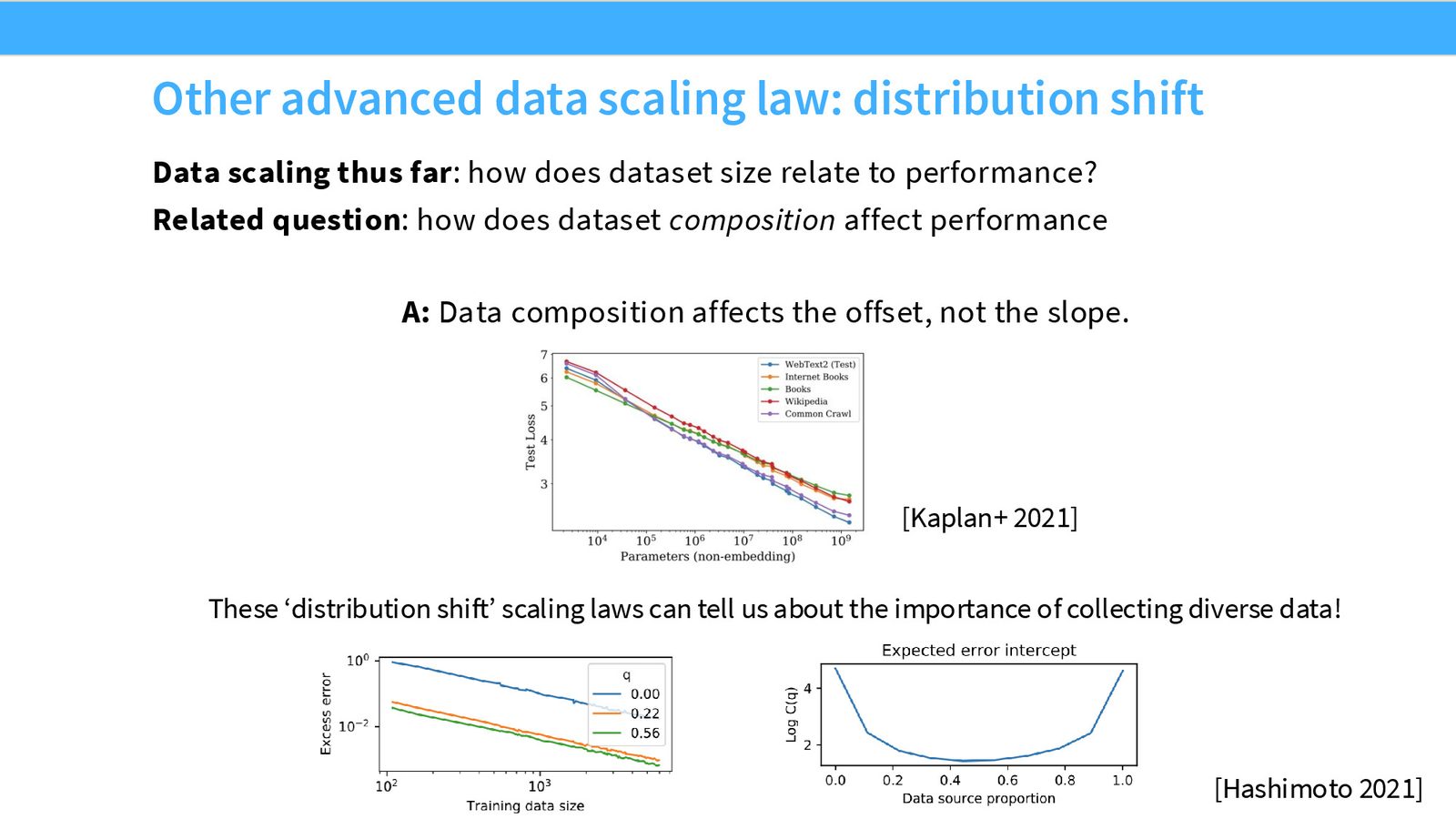
应用 1:数据混合优化
Kaplan 发现数据组成(如 Wikipedia vs. Common Crawl 的比例)只影响 Scaling Law 的偏移量,不影响斜率。这意味着你可以在小模型上做数据选择实验,结论直接迁移到大模型。
应用 2:多轮训练的衰减

来源:Slides 第15页。
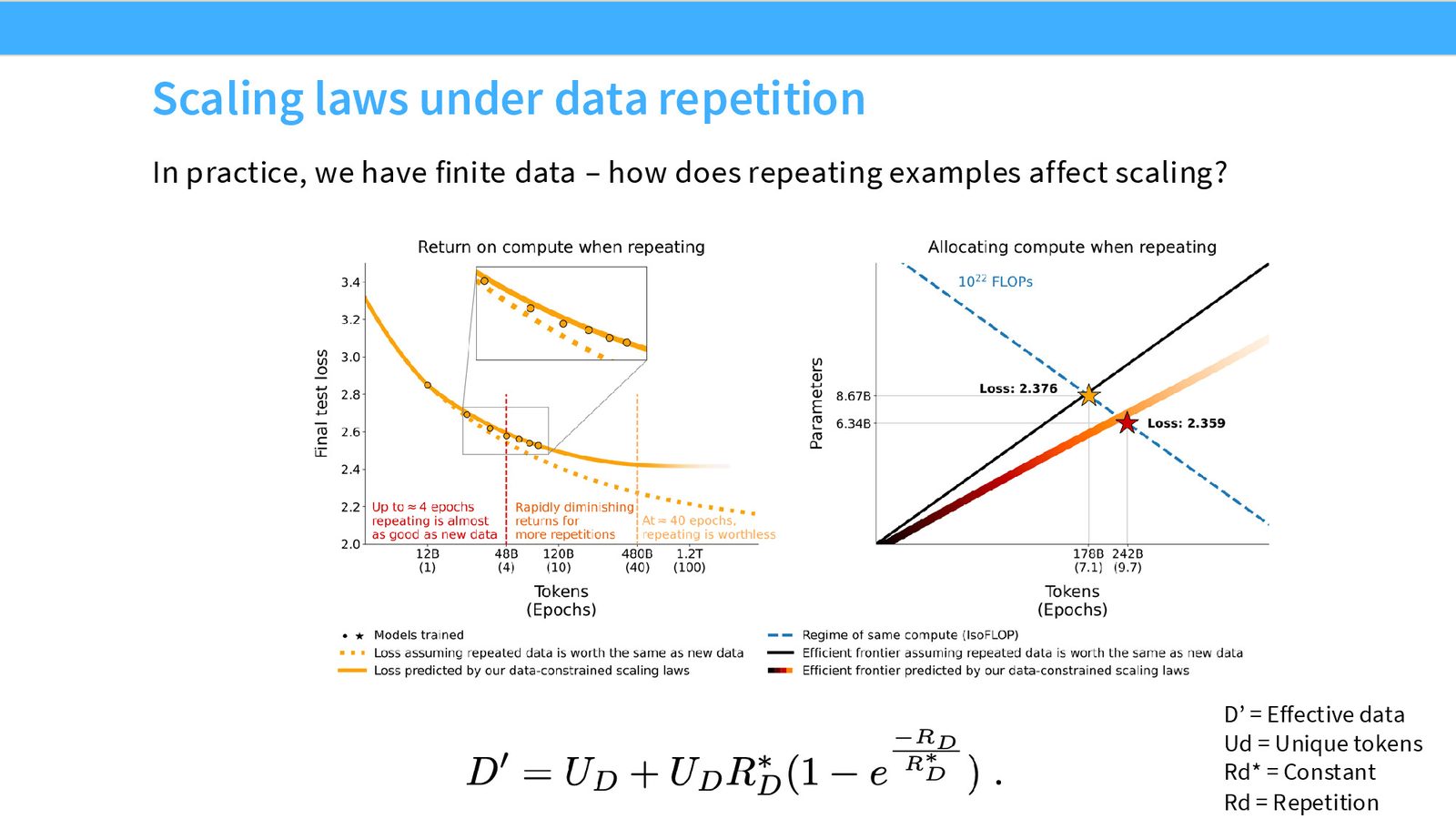
“我们快要用完互联网数据了”的担忧引出了另一个重要问题:重复训练同一批数据的效果如何?研究表明存在一个有效样本量的概念:约 4 个 epoch 之后,重复数据的收益急剧递减。
应用 3:重复高质量数据 vs. 引入低质量新数据
来源:Slides 第16页。
当你需要数万亿 token 进行训练时,面临选择:是重复 Wikipedia 等高质量数据 10 次,还是引入更多低质量但全新的数据?CMU 的研究者们利用 Scaling Laws 框架来分析这种权衡——假设每种数据源都有独立的幂律关系,通过在小规模上拟合每种混合比例的 Scaling Law,就能预测大规模下的最优混合策略。
本章小结
数据 Scaling Laws 是所有 Scaling Laws 中最直观、理论基础最扎实的。幂律衰减可以从简单的统计问题中自然推导出来,而实际观测到的缓慢指数反映了学习任务的内在复杂度。这些规律不仅在经验上极其稳健(跨领域、跨模型族成立),还有重要的工程应用价值。
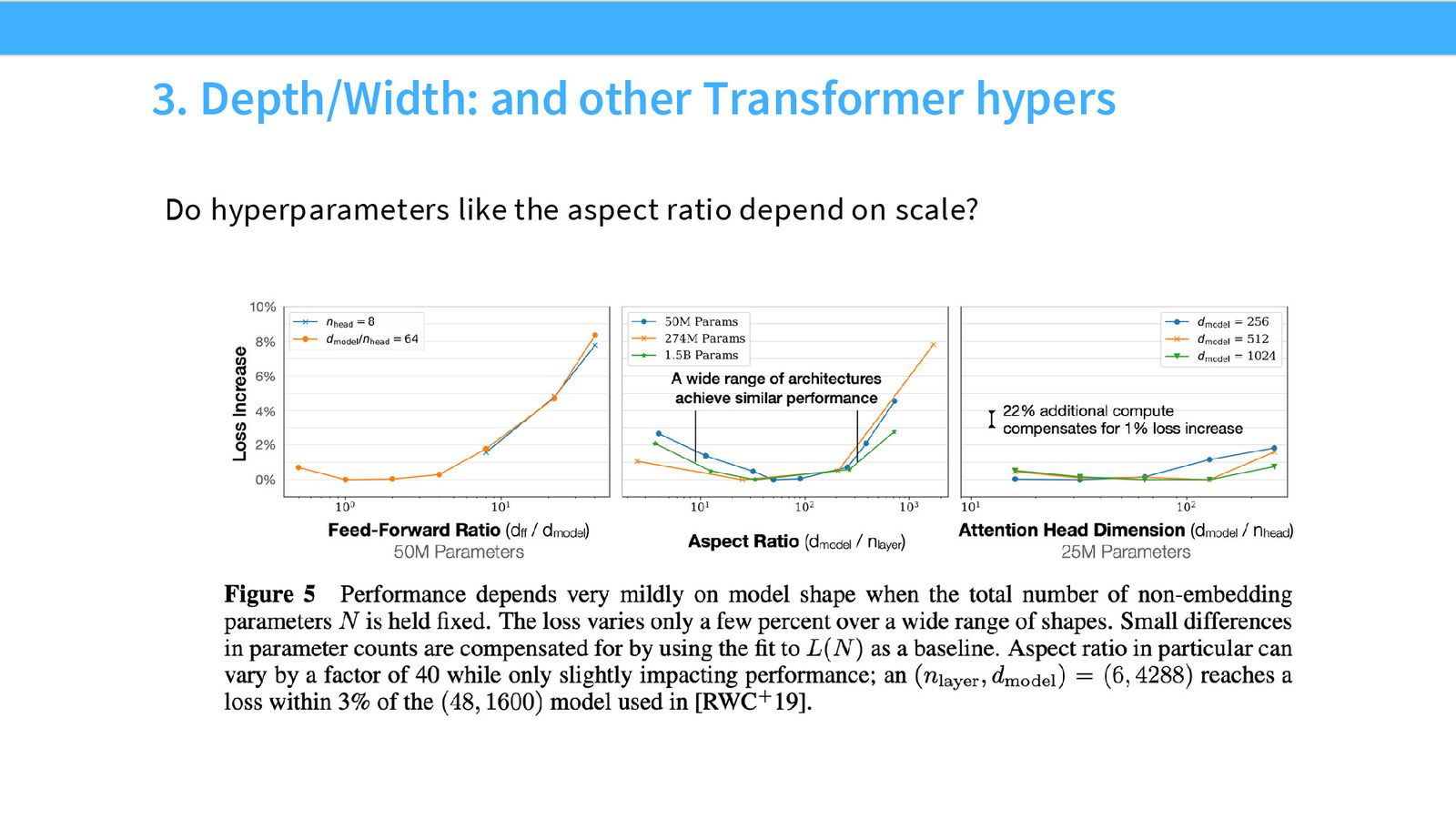
模型 Scaling:架构与超参数选择
从数据 Scaling 转向模型 Scaling,我们面临的是更实际的工程问题:哪种架构更好?用什么优化器?深度和宽度怎么配比?
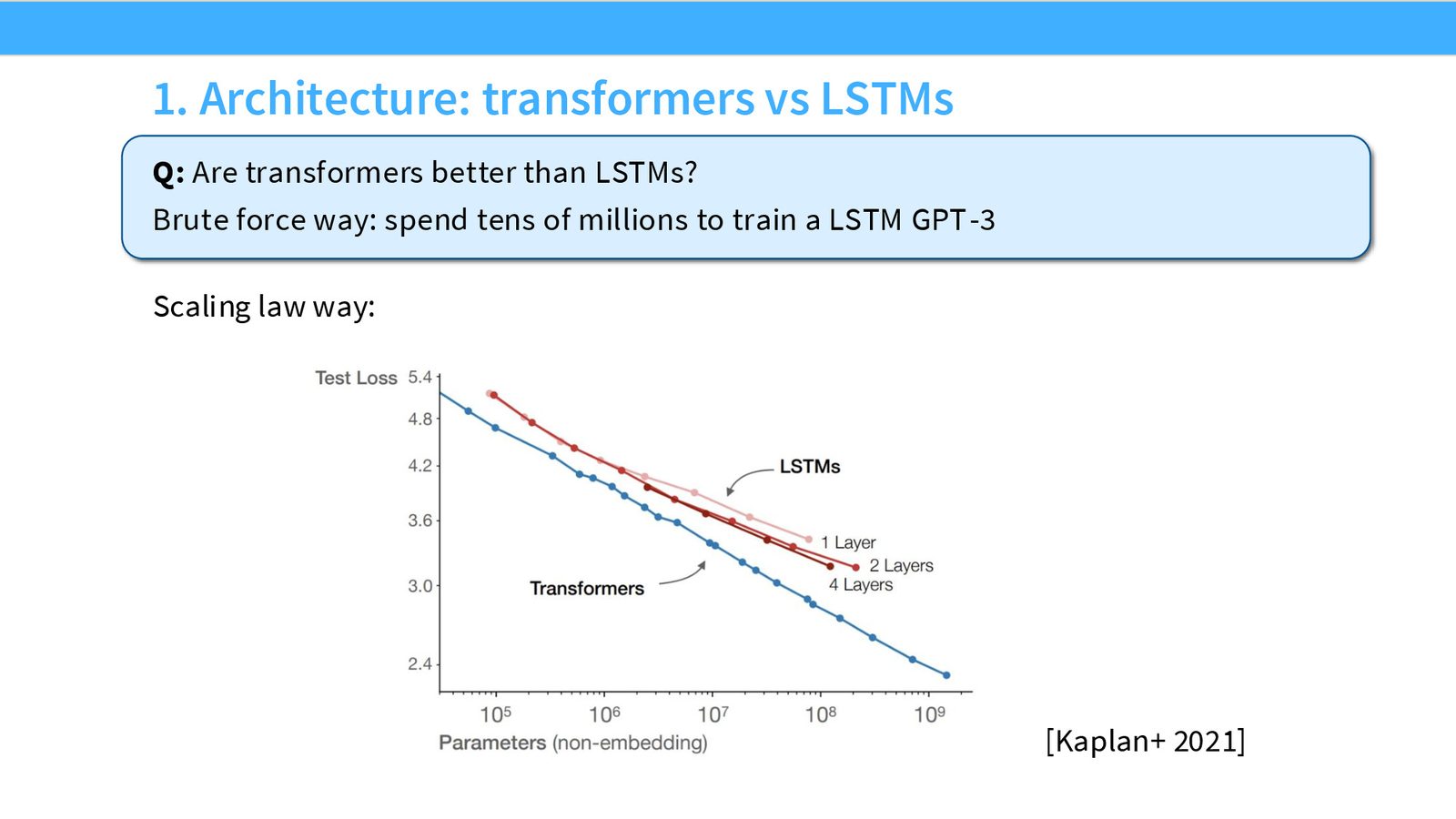
架构比较:Transformer vs. LSTM

来源:Slides 第18页。
Kaplan 的论文清楚地展示了 Transformer 与 LSTM 在 Scaling Law 上的差异。关键观察:
- 两种架构的 Scaling Law 斜率相似(即缩放行为类似)
- 但存在一个常数因子的偏移:LSTM 在计算效率上比 Transformer 差约 15 倍
- 这个差距在 log 尺度上是恒定的,不会随着规模扩大而缩小
Scaling Law 视角下的架构选择
Scaling Law 提供了一种优雅的架构选择方法:训练多种架构的小模型,跨几个数量级的计算量,然后比较它们的 Scaling 曲线。斜率告诉你两种架构的“缩放效率”是否相同;偏移量告诉你在固定计算量下哪个更好。
更广泛的架构比较

来源:Slides 第19页。
Google 的研究者对大量架构进行了系统性的 Scaling 比较。红线代表各种替代架构,绿线代表 Transformer 基线。结果表明:
能可靠超越 Transformer 的改进
在所有测试的架构变体中,只有两类改进能强且可靠地超越标准 Transformer:
- Gated Linear Units (GLU):门控线性单元
- Mixture of Experts (MoE):专家混合模型
这恰好就是当今前沿模型(如 LLaMA、Gemini)中实际使用的技术。Scaling Laws 在几年前就给出了正确的方向指引。
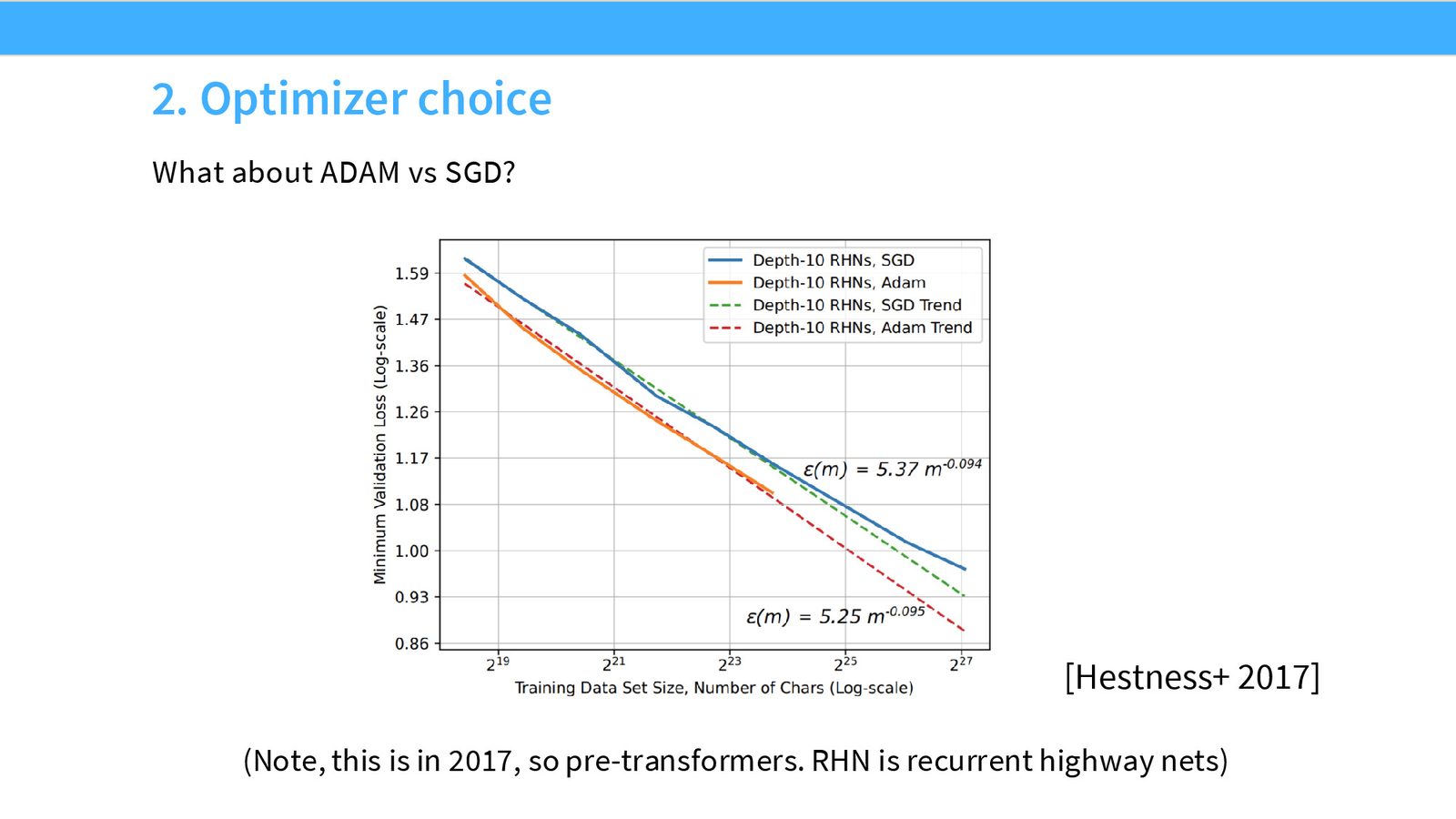
优化器选择:Adam vs. SGD
来源:Slides 第20页。
类似的分析可以应用于优化器选择。Hestness 等人比较了 SGD 和 Adam 优化器,发现二者之间也存在常数因子的计算效率差距,Adam 在相同计算量下能达到更低的损失。
深度 vs. 宽度:Aspect Ratio

来源:Slides 第21页。
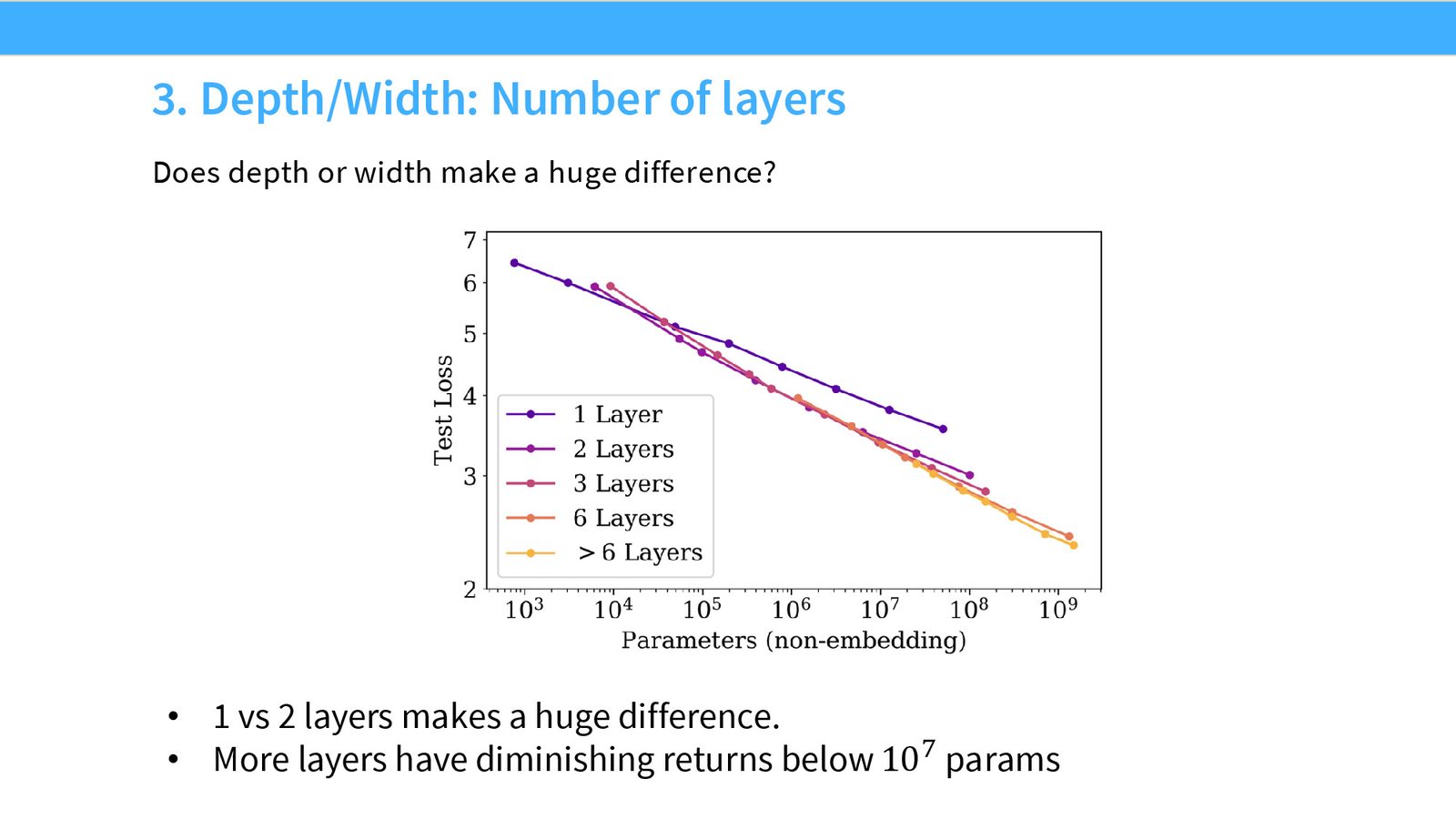
Kaplan 论文中关于深度与宽度比例的分析很有意思:
- 1 层的模型明显很差
- 但从 2 层开始,不同层数的 Scaling 曲线非常接近
- 存在一个“很宽的最优盆地”:宽度/深度比在 4--16 之间都接近最优
不是所有参数都相同
在做参数缩放分析时,一个容易犯的错误是将 embedding 层参数也计入总参数量。Kaplan 发现:
- 如果包含 embedding 参数,Scaling 曲线会在某处“弯曲”,不再保持清晰的 log-log 线性
- 如果只考虑非 embedding 参数,曲线干净得多
原因是 embedding 层参数与 Transformer 层参数的“学习效率”不同。类似的问题也出现在 Mixture of Experts 中——稀疏激活的参数需要转换为“等效密集参数”。
来源:Slides 第22页。
超参数的跨尺度迁移
来源:Slides 第23页。
一个关键发现是:许多 Scaling Law 曲线在不同超参数设定下斜率相同、不交叉,只有常数偏移。这意味着:
超参数选择可以在小规模完成
如果 Scaling 曲线对于不同超参数值只有常数偏移(斜率相同、不交叉),那么在任意一个计算尺度上选择最优超参数,结论就能迁移到所有更大的尺度。这大大降低了超参数搜索的成本。
Kaplan 论文对多种超参数进行了这样的分析:Aspect Ratio(宽度/深度比)在不同规模的模型上表现一致;Feed-forward 维度比和注意力头维度也表现出类似的跨尺度稳定性。
本章小结
模型 Scaling Laws 为工程决策提供了强大的工具:通过在小规模上系统比较不同架构、优化器和超参数,可以可靠地预测大规模下的最优选择。关键洞察是大多数设计选择在 Scaling Law 中表现为常数偏移,使得小规模实验的结论可以直接迁移。
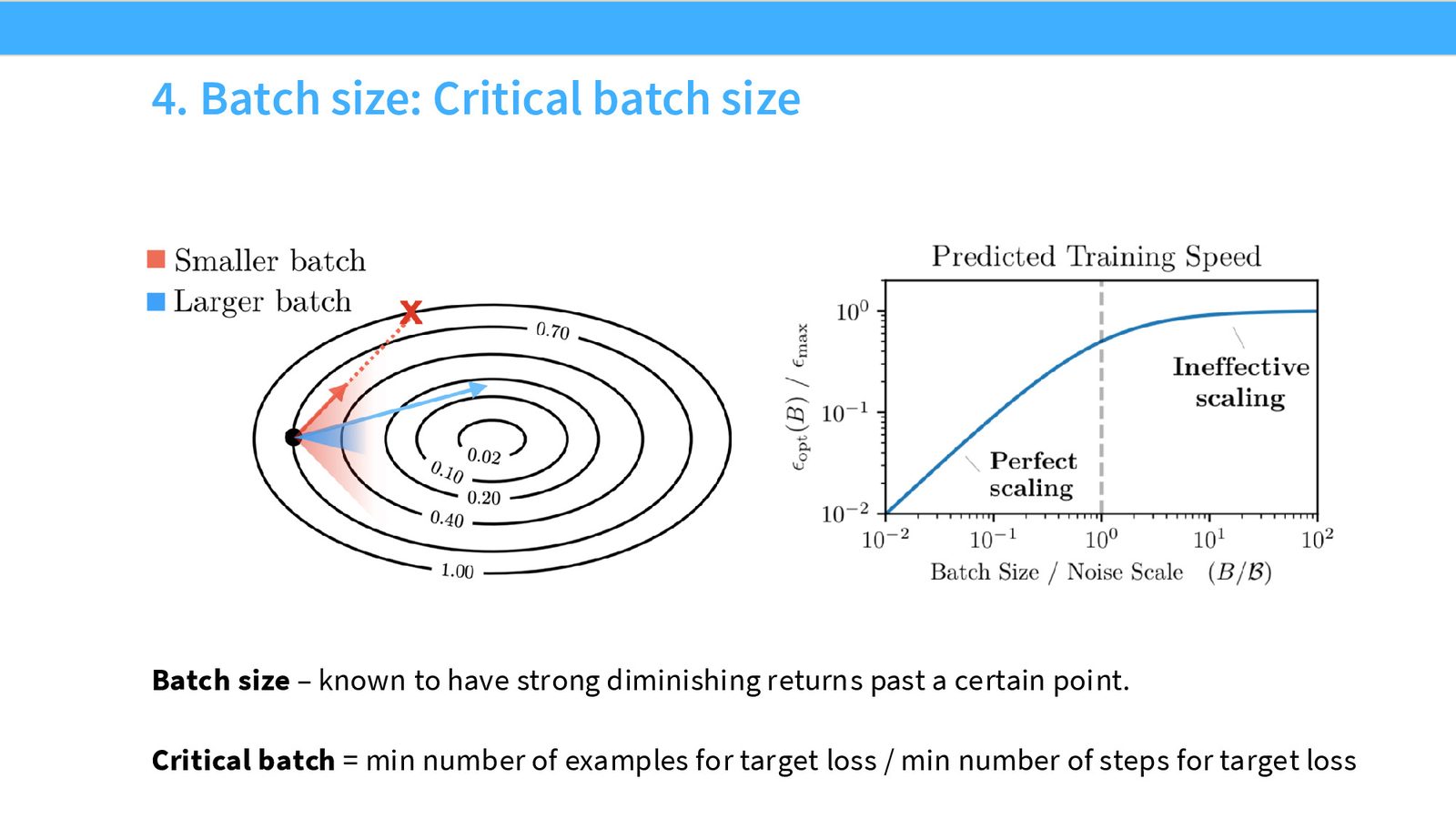
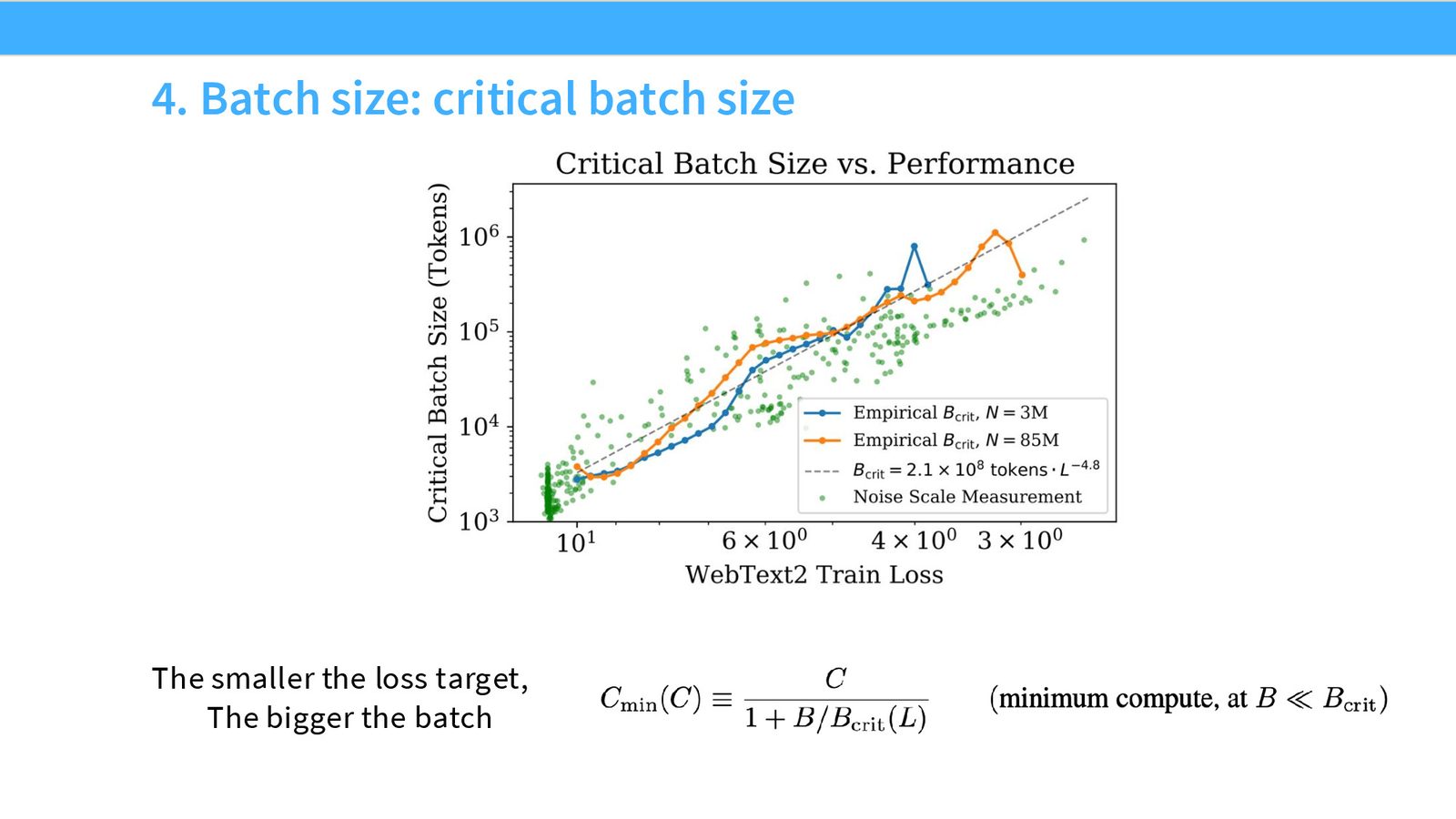
批量大小与学习率的 Scaling
Critical Batch Size
批量大小(batch size)是一个同时涉及系统效率和优化效率的超参数。

来源:Slides 第25页。
批量大小的关键行为分为两个阶段:
- 完美缩放阶段:当 batch size $< $ noise scale(梯度噪声尺度),增大 batch size 几乎等效于增加梯度步数——这是最理想的状态,因为并行化带来了真正的加速
- 收益递减阶段:当 batch size \(>\) noise scale,额外的样本不再有效减少噪声,性能改善被优化景观的曲率限制
Critical Batch Size 就是这两个阶段之间的转折点。

来源:Slides 第26页。
一个非常有趣的发现是:目标损失越低,Critical Batch Size 越大。直觉是:当你追求更低的损失时,模型处于更“精细”的优化区域,梯度噪声的影响更大,因此需要更大的 batch size 来去噪。
LLaMA 3 的 Batch Size 策略
LLaMA 3 训练报告中实际采用了“逐步增大 batch size”的策略。这正是基于 Critical Batch Size 随目标损失变化的洞察:训练初期(损失高)用较小 batch size,训练后期(损失低)增大 batch size,兼顾优化效率和系统效率。
Batch Size 与 Compute 的关系
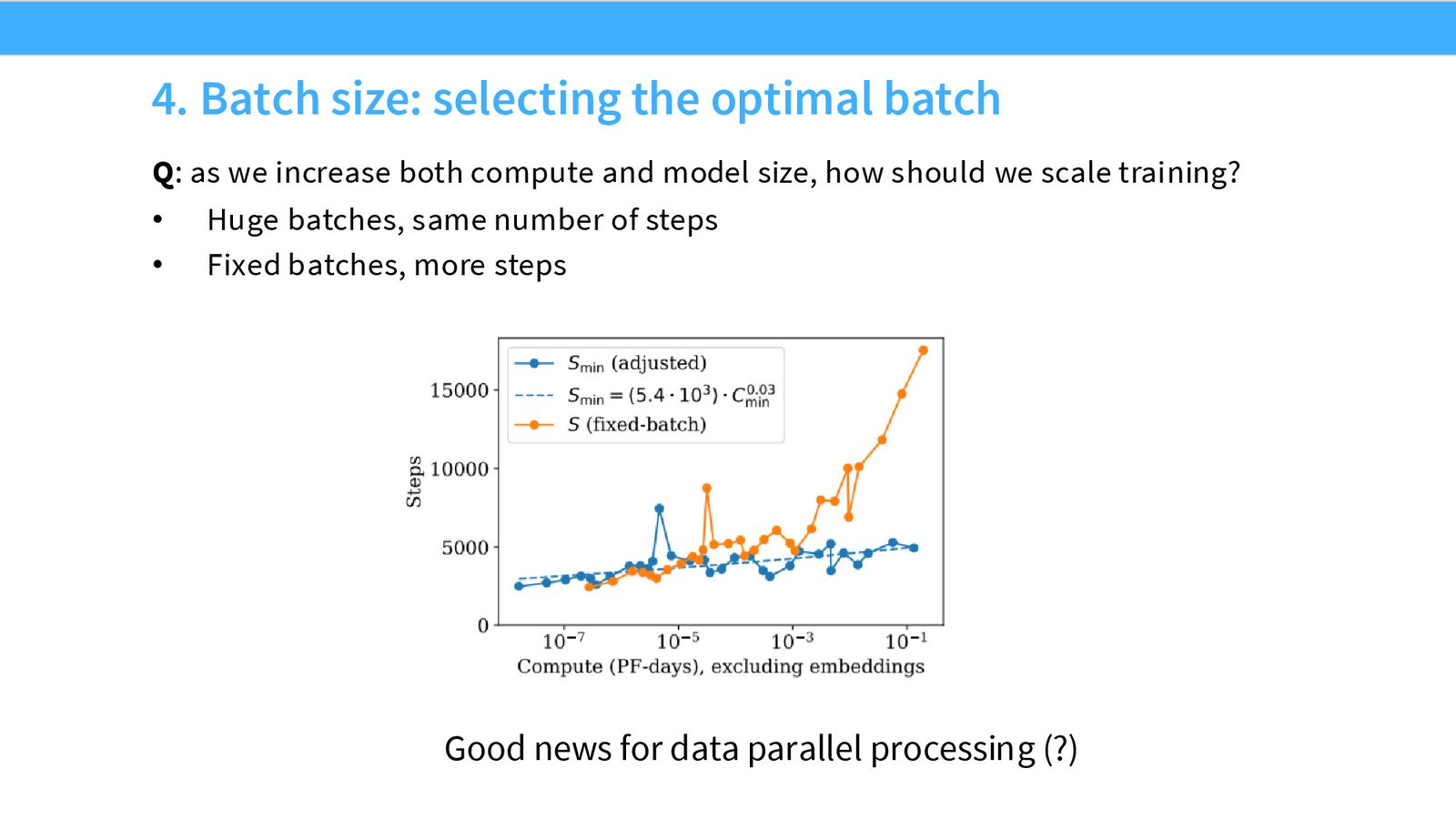
来源:Slides 第27页。
Kaplan 的分析表明:随着计算预算增大,最优 batch size 也增大,但总训练步数可以基本保持不变。这对数据并行系统来说是好消息——意味着可以通过增加 GPU 数量(增大 batch size)而不是增加训练时间来利用更多计算资源。
学习率 Scaling 与 MuP
学习率是另一个与模型规模紧密相关的超参数。
来源:Slides 第28页。
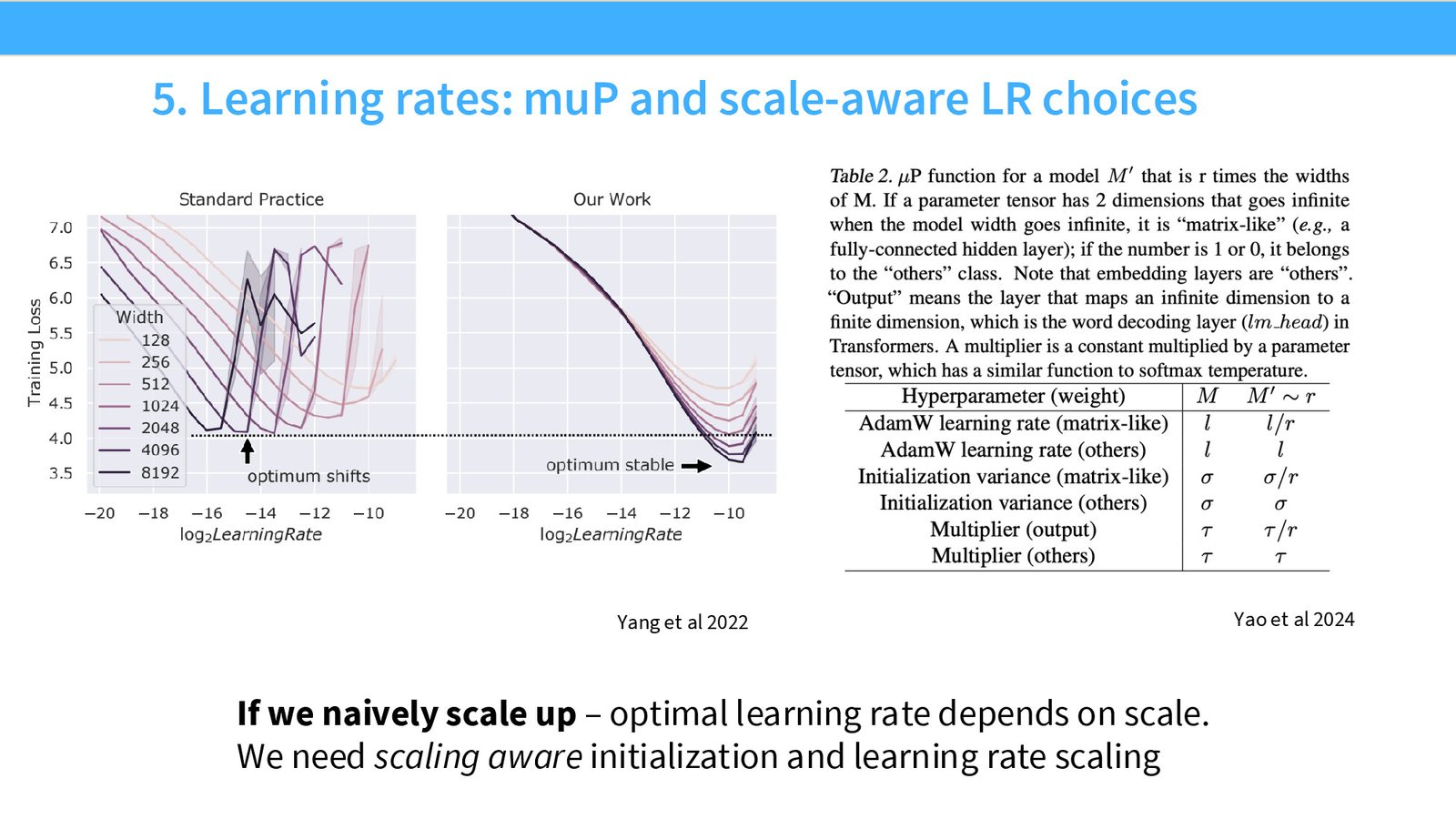
标准做法下,最优学习率随模型宽度增大而递减。经验法则是学习率 \(\propto 1/\text{width}\)。这意味着每次改变模型大小都需要重新搜索最优学习率。
MuP(Maximal Update Parameterization) 提供了一种更优雅的解决方案:通过重新参数化模型——调整不同层的初始化方差和学习率缩放,使得最优学习率在不同宽度下保持不变。
MuP 的核心思想
MuP 通过以下方式重新参数化模型:
- 根据模型宽度缩放每层的初始化方差
- 根据模型宽度缩放每层的学习率
- 在前向传播中乘以宽度相关的缩放因子
效果是:在最小模型上调好的学习率,直接迁移到最大模型,无需重新搜索。
MuP 的行业采用
Meta 在发布 LLaMA 4 时声称使用了一种叫做 “MetaP” 的类似技术。越来越多的实验室认识到,如果不得不依赖预测最优学习率的 Scaling Law 拟合,那么拟合误差可能导致次优结果。通过 MuP 这样的重新参数化,可以从根本上避免这个问题。
本章小结
Batch size 和学习率是两个与模型规模高度耦合的超参数。Critical Batch Size 的概念提供了一个理解“何时可以安全增大 batch size”的框架。MuP 等重新参数化方法则从根本上解决了学习率跨尺度迁移的问题。在实践中,许多前沿实验室已经采用了这些技术来优化训练流程。
Scaling Laws 的局限性
训练损失 vs. 下游任务
来源:Slides 第30页。
Scaling Laws 在训练损失(交叉熵/困惑度)上表现极好,但在下游任务上的预测能力差得多。
困惑度 \(≠\) 下游性能
左图显示:不同架构和超参数的模型,其参数量与负对数困惑度几乎完美线性相关——意味着“只要计算量够,什么配置都差不多”。
但右图显示了完全不同的情况:在下游任务(如 SuperGLUE)上,不同架构之间存在显著差异,某些模型远好于其他模型。
不要将困惑度的 Scaling 等同于下游能力的 Scaling!
这一现象在 State Space Models 上也有体现:SSM 在困惑度上可以与 Transformer 匹配甚至超越,但在 in-context learning 和 QA 等能力上可能明显落后。
反缩放与分布外行为
还有一类被称为“反缩放”(inverse scaling)的现象:模型变大后某些行为反而变差。例如,更大的模型更擅长复制训练数据中的模式,因此如果你希望抑制复制行为,这会变得更困难。
反缩放的本质
反缩放通常出现在分布外(out-of-distribution)区域:当期望的行为与训练数据不一致时,更大的模型更倾向于遵循训练数据的模式,而非人类期望的行为。从某种意义上说,这是经典深度学习鲁棒性问题在大模型时代的延伸。
本章小结
Scaling Laws 最可靠的预测对象是训练损失(如交叉熵、困惑度),而非下游任务性能。在使用 Scaling Laws 做工程决策时,需要清楚地区分这两者。对于需要特定能力的应用场景,单独验证是必不可少的。
联合数据–模型 Scaling Laws 与 Chinchilla
联合 Scaling 的动机
前面我们讨论的 Scaling Laws 都是单变量的:固定其他变量,只看一个变量(数据、参数或计算)对损失的影响。但在实际训练中,计算预算是固定的,你需要决定如何在模型大小和数据量之间分配。
来源:Slides 第33页。
两个极端都不好:
- 极小模型 + 海量数据 \(\rightarrow\) 模型容量不足,数据被浪费
- 极大模型 + 极少数据 \(\rightarrow\) 严重过拟合,计算被浪费
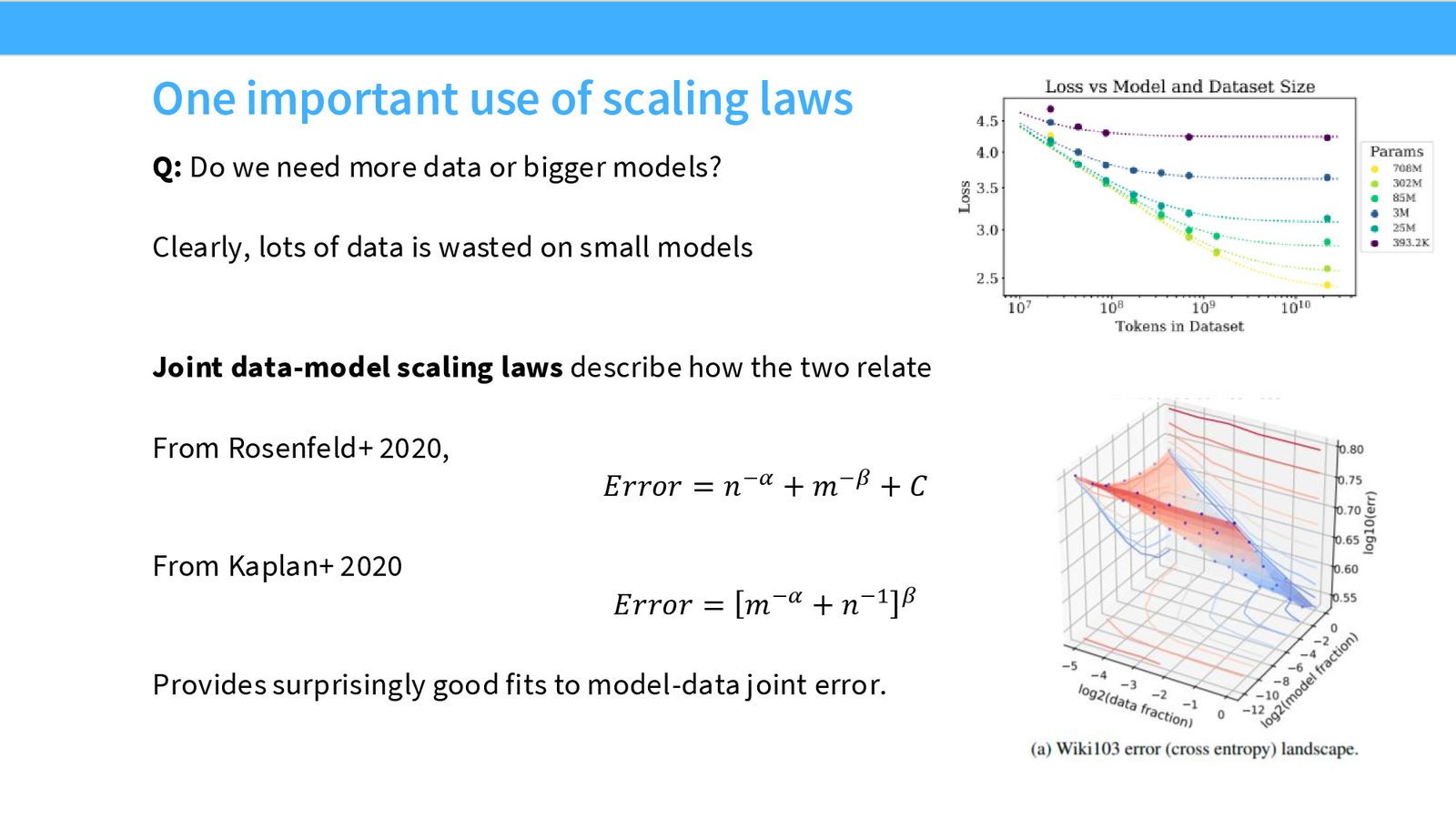
联合 Scaling Law 的函数形式
来源:Slides 第34页。
Rosenfeld et al. 提出的函数形式:
其中 \(N\) 是参数量,\(D\) 是数据量(token 数),\(\epsilon_\infty\) 是不可约误差。每项分别描述了模型容量不足(\(N\) 项)和数据不足(\(D\) 项)带来的误差。
Kaplan et al. 使用了类似但稍有不同的形式(聚焦于可约误差而非不可约误差)。
来源:Slides 第35页。
令人惊讶的拟合精度
尽管联合 Scaling Law 的函数形式是“凭经验拍脑袋”(ad hoc)的,但它对实际训练结果的拟合几乎完美。Rosenfeld 展示了只用小模型+少数据拟合的 Scaling Law,可以非常准确地外推到大模型+多数据的区域。
来源:Slides 第36页。
Kaplan 的固定计算预算分析
来源:Slides 第37页。
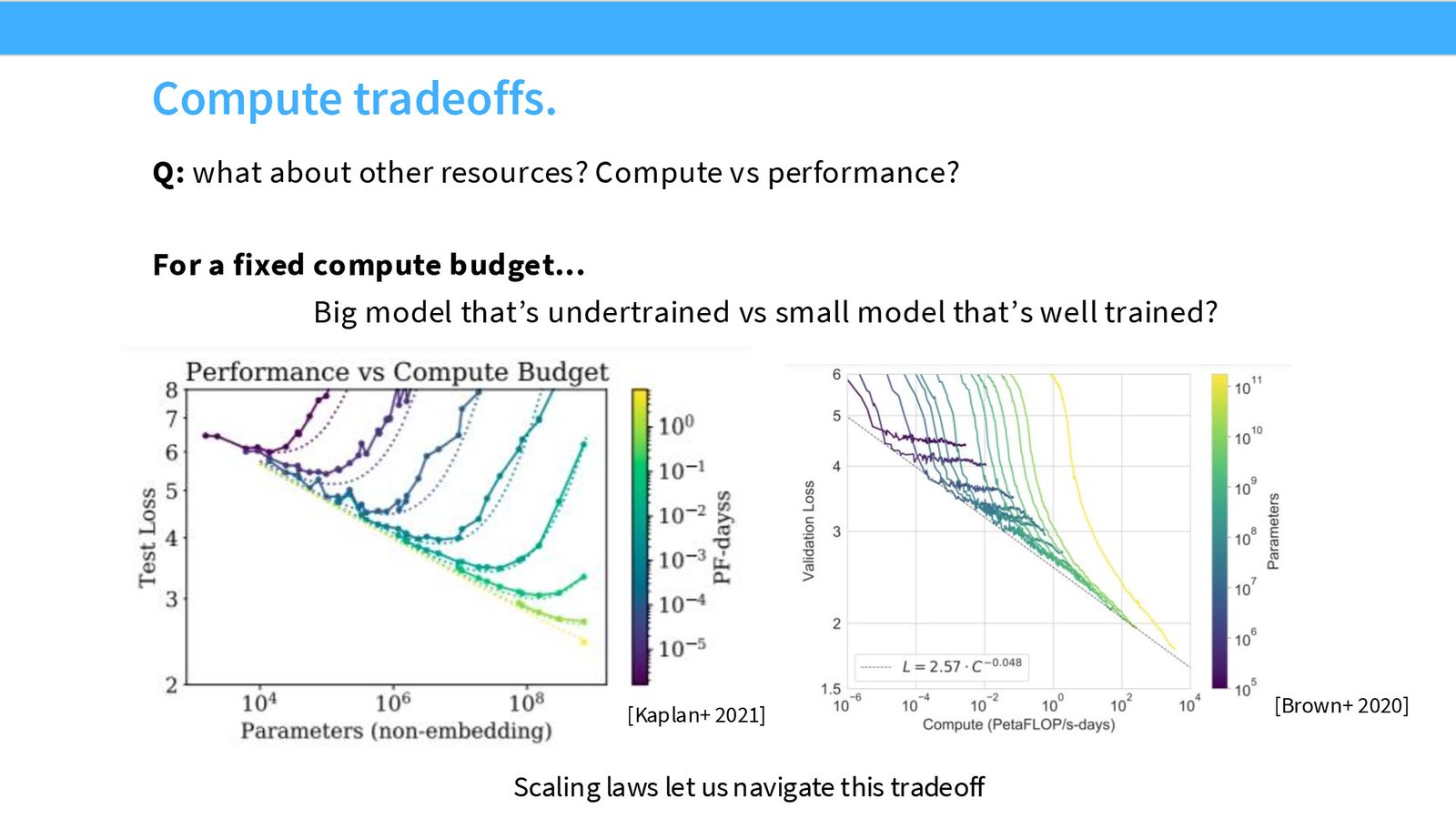
在 Kaplan 的论文中,固定计算量(颜色编码),变化参数量(x轴),可以看到每条等计算曲线上都有一个最优点——对应着在该计算预算下的最优模型大小。
然而,Kaplan 的最优估计后来被发现有较大偏差。原因之一是学习率 schedule 的影响(cosine schedule 不能被提前截断),导致在不同计算预算下比较模型时引入了系统性偏差。
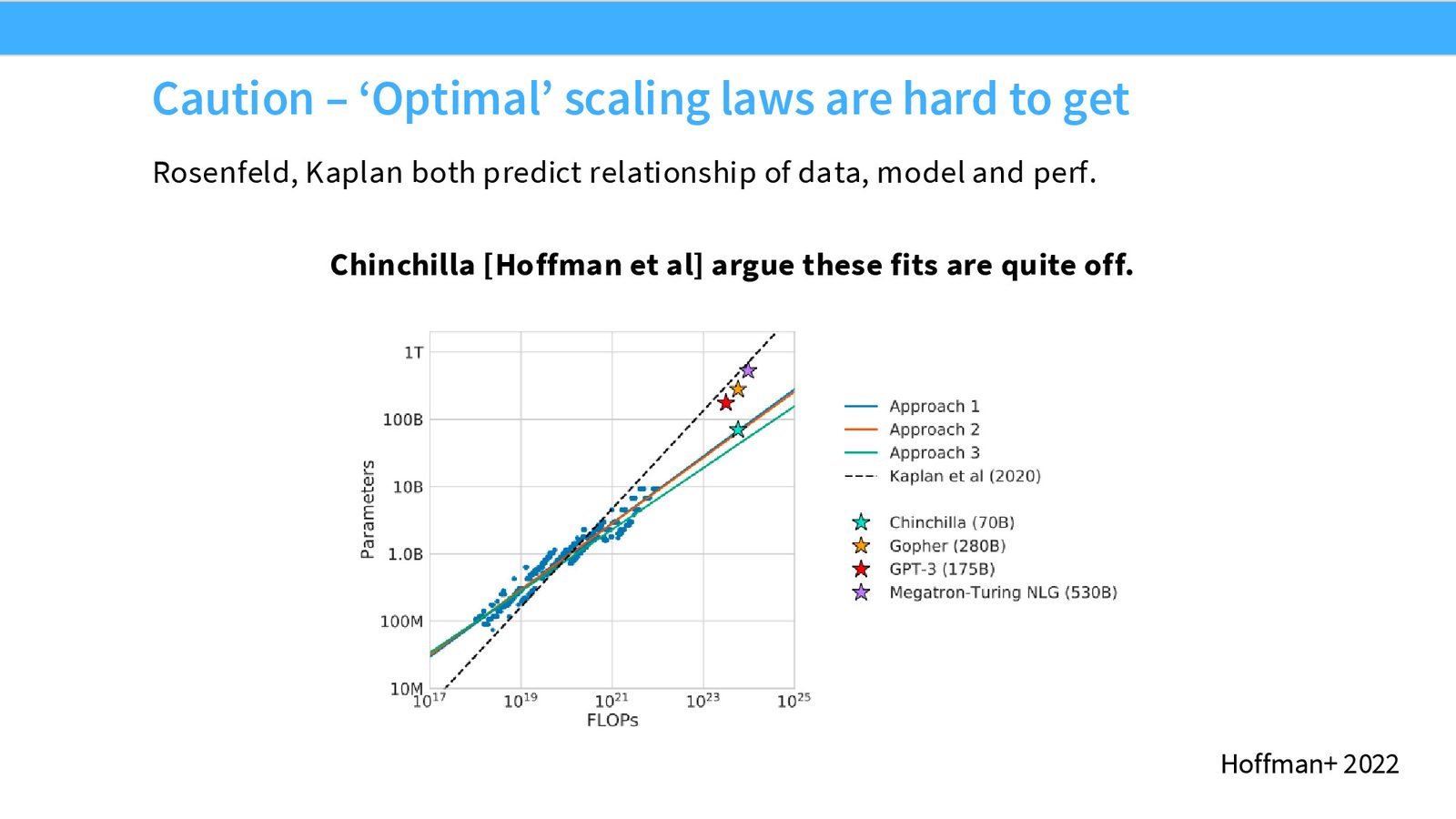
Chinchilla:三种方法
Chinchilla 论文(Hoffmann et al., Google DeepMind)是确定最优数据/模型比例的权威参考。
来源:Slides 第39页。
| 方法 | 参数 Scaling 指数 \(a\) | 数据 Scaling 指数 \(b\) |
|---|---|---|
| Chinchilla 方法 1 | 0.50 | 0.50 |
| Chinchilla 方法 2 | 0.50 | 0.50 |
| Chinchilla 方法 3 | 0.46 | 0.54 |
| Kaplan et al. | 0.73 | 0.27 |
方法 1:最小包络法
来源:Slides 第40页。
在所有不同大小的模型训练曲线上,取下包络线(lower envelope)——即对于每个 FLOP 值,选择达到最低损失的那个模型。然后分析这些最优点的参数量和 token 数如何随 FLOP 缩放。
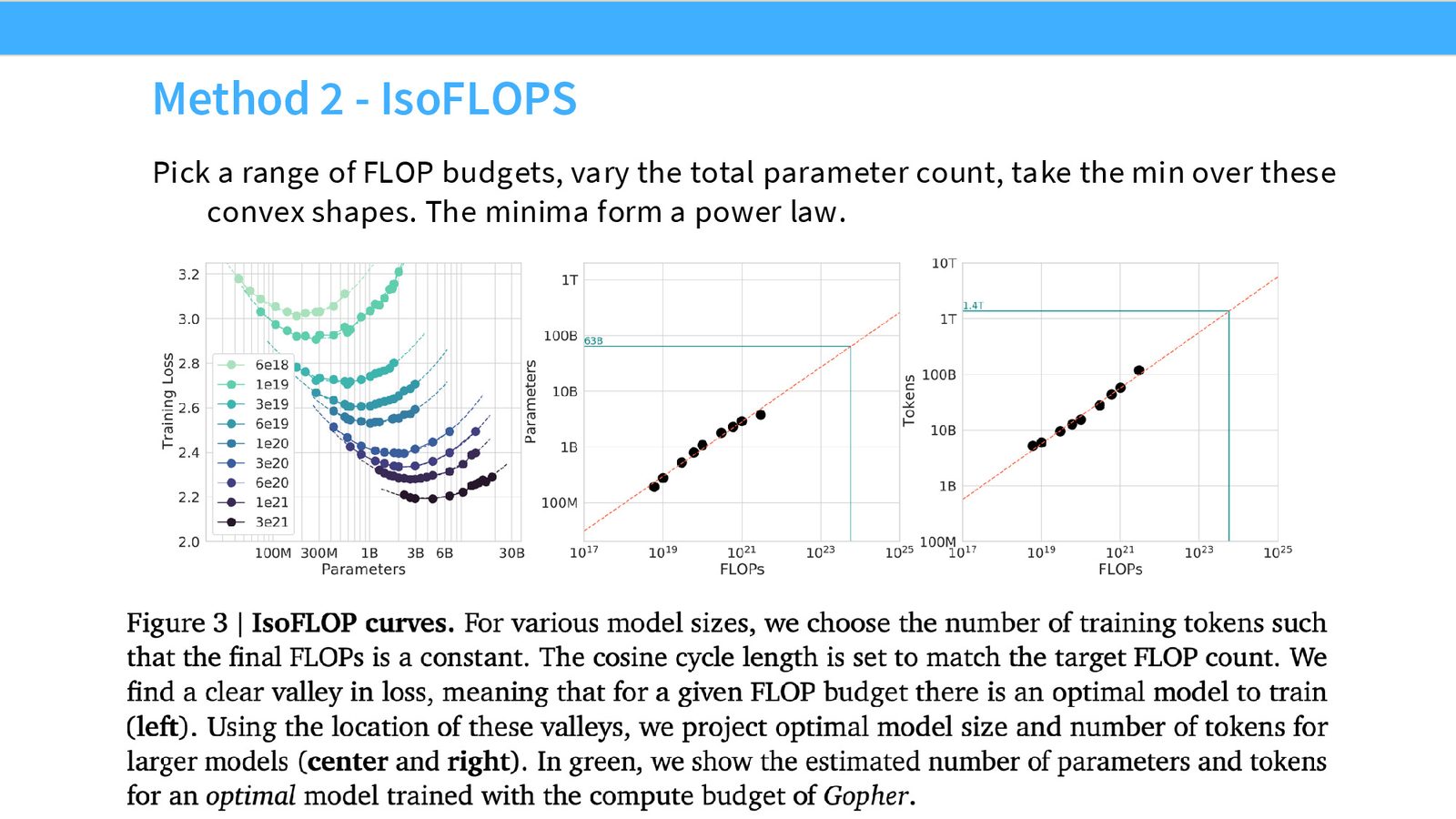
方法 2:IsoFLOP 分析
来源:Slides 第42页。
IsoFLOP 分析——最规范的方法
IsoFLOP 分析可能是最直观、最规范的 Chinchilla 方法:
- 选择多个计算尺度(每种颜色代表一个固定的 FLOP 预算)
- 在每个尺度上,训练不同大小的模型(小模型+多数据 到 大模型+少数据)
- 找到每条等 FLOP 曲线的最小值点
- 分析最小值点如何随 FLOP 缩放 \(\rightarrow\) 得到最优参数量和最优 token 数的缩放关系
来源:Slides 第43页。
方法 1 和方法 2 给出了高度一致的结果:对于 Chinchilla 的训练预算,最优模型约 63--67B 参数。
方法 3:参数化曲面拟合
来源:Slides 第44页。
方法 3 是直接拟合 Rosenfeld 式的联合 Scaling Law 函数。训练大量模型(不同参数量 \(\times\) 不同数据量),拟合 3D 曲面,然后求最优。但这个方法的拟合质量明显不如前两种。
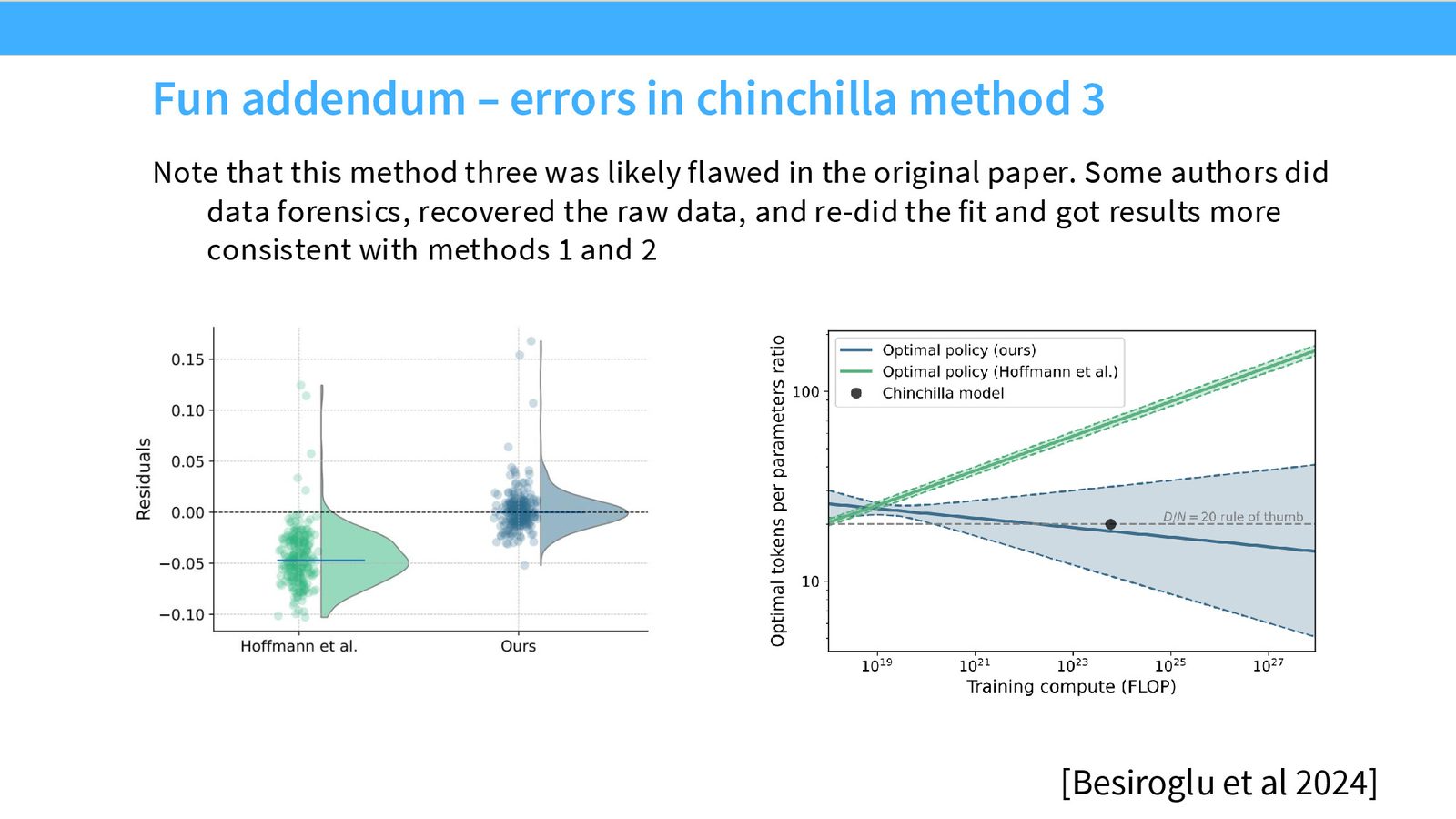
Chinchilla 方法 3 的曲线拟合 bug
Epoch AI 的研究者在 2024 年试图复现 Chinchilla 方法 3 的结果。由于无法获取原始数据,他们甚至用“图表取值器”从论文图表中提取数据点。结果发现:
- 原始论文的残差不是零均值的——这是曲线拟合有问题的标志
- 修正拟合后,方法 3 的估计与方法 1、2 几乎完全一致
- 即原始结果是正确的,只是拟合过程中有小错误
这是一个“复现反而证实了原始结论”的罕见案例。
Chinchilla 比例与 Cosine Schedule 的陷阱

来源:Slides 第45页。
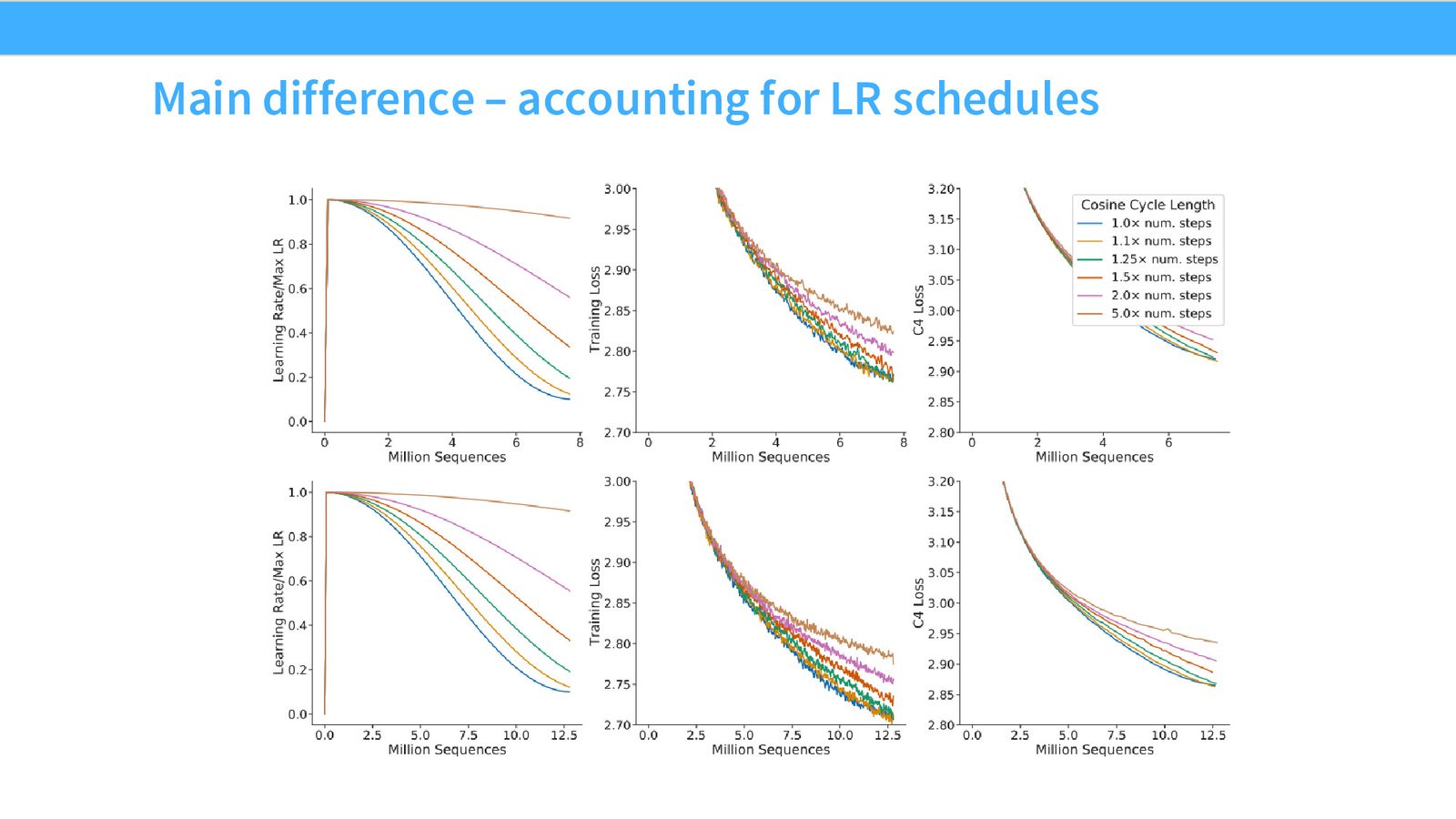
Kaplan 估计偏差较大的一个重要原因是 cosine learning rate schedule 不能提前截断:
Cosine Schedule 的不可截断性
Cosine 学习率先升后降,必须完整运行到冷却(cool-down)阶段才能得到有效的模型。如果在中途截断,模型仍处于高学习率状态,性能远差于完整训练的模型。因此,在做 Scaling Law 实验时,每个模型必须用完整的 schedule 训练到底,不能简单地取训练中间的 checkpoint 来做对比。
著名的 Chinchilla 比例约为 20 tokens/parameter。这意味着一个 70B 参数的模型最优应训练 1.4T tokens。
本章小结
联合数据--模型 Scaling Laws 解答了大语言模型训练中最核心的资源分配问题。Chinchilla 的三种分析方法从不同角度收敛到了相似的结论(\(a \approx b \approx 0.5\)),确立了约 20 tokens/parameter 的黄金比例。
从训练最优到推理最优
Chinchilla 比例的局限
Chinchilla 比例回答的是:给定固定训练 FLOP 预算,如何获得最低的训练损失?但这并非企业真正关心的问题。
来源:Slides 第47页。
当 Chinchilla 和 Kaplan 的论文发表时(2020--2022),LLM 还不是产品,不需要考虑推理成本。但如今 LLM 已经是创收产品,推理成本是核心关切:
训练成本是一次性的,推理成本是持续的
训练一个模型的计算成本只需付一次,但部署后的推理成本随用户使用量持续累积。因此,企业宁愿在训练时多花计算(“过度训练”小模型),也不愿部署一个推理昂贵的大模型。
tokens/parameter 比例的历史演进:
- GPT-3 (2020):约 2 tokens/parameter(严重“训练不足”)
- Chinchilla (2022):约 20 tokens/parameter(训练最优)
- LLaMA 系列 (2023--):100--200 tokens/parameter
- 最新模型 (2024--2025):可能超过 1000 tokens/parameter(如 Qwen 用 30T tokens 训练 7B 模型)
趋势非常明确:业界正在大幅增加 tokens/parameter 比例,用更多的训练计算换取更小、更便宜的推理模型。
Scaling Laws 作为通用工具
来源:Slides 第49页。
Tatsu 以自己学生 Isan 的文本扩散模型研究为例,说明 Scaling Laws 的方法论并非局限于自回归 Transformer。即使在一个全新的生成模型家族上:
- IsoFLOP 分析依然产生清晰的 U 型曲线
- 最优点依然可靠地遵循幂律 Scaling
- 不同模型类型之间仅有常数偏移

来源:Slides 第50页。
Scaling Laws 的普适性
Scaling Laws 不是针对特定架构或任务的特殊现象,而是深度学习中的一种普遍规律。只要你的模型足够灵活、数据足够多、训练足够长,就很可能观察到幂律缩放行为。这使得 Scaling Law 的方法论成为通用的工程工具。
本章小结
Chinchilla 比例(20 tokens/parameter)只是训练最优的起点。在产品化时代,推理成本的重要性使得 tokens/parameter 比例不断增大。同时,Scaling Laws 的方法论作为通用工具,已经被成功应用到扩散模型等全新领域,展现了其普适性。
基于 Scaling Laws 的工程决策流程
来源:Slides 第31页。
综合本讲所有内容,基于 Scaling Laws 的模型开发流程可以总结为:
Scaling Law 驱动的设计流程
- 训练小模型:跨越几个数量级的计算量,训练一组小模型
- 建立 Scaling Law:验证 log-log 线性关系确实成立
- 基于预测设置超参数:利用 Scaling Law 的外推,确定大模型的最优配置
在许多情况下,Scaling 曲线对不同超参数的斜率相同,仅有常数偏移。这意味着你甚至不需要拟合完整的 Scaling Law——只需在任意一个小尺度上选出最优超参数,结论就能直接迁移。
但有一个重要例外:学习率需要特殊处理(通过 MuP 等方法或通过专门的学习率 Scaling Law)。
本章小结
Scaling Law 驱动的工程流程将大模型开发从“试错”转变为“预测+验证”。虽然并非所有决策都能完美迁移(特别是学习率和下游任务性能),但这套方法论大幅降低了探索成本。
总结与延伸
讲者的核心总结
来源:Slides 第52页。
Tatsu Hashimoto 在本讲中传达了以下核心信息:
- 数据 Scaling 有坚实的理论基础:幂律衰减可以从非参数统计的基本定理中推导出来,缩放指数与数据的内在维度相关
- 模型/架构 Scaling 提供了强大的工程工具:通过在小规模上比较不同选择,可以可靠地预测大规模下的最优方案
- Chinchilla 确立了资源分配的基本框架:联合数据--模型 Scaling Laws 回答了“给定预算,模型应该多大”的核心问题
- 实践已超越 Chinchilla:推理成本的考量使得业界大幅“过度训练”小模型,tokens/parameter 比例从 20 增长到数百甚至数千
全课知识图谱

拓展阅读
- Kaplan et al., Scaling Laws for Neural Language Models: https://arxiv.org/abs/2001.08361 —— Scaling Laws 领域最全面的参考论文
- Hoffmann et al., Training Compute-Optimal Large Language Models (Chinchilla): https://arxiv.org/abs/2203.15556 —— 确立 20 tokens/parameter 比例的里程碑论文
- Hestness et al., Deep Learning Scaling is Predictable, Empirically (2017): https://arxiv.org/abs/1712.00409 —— 大规模神经网络 Scaling Law 的早期系统研究
- Rosenfeld et al., A Constructive Prediction of the Generalization Error Across Scales (2020): https://arxiv.org/abs/1909.12673 —— 联合 Scaling Law 函数形式的重要参考
- Epoch AI, Chinchilla Scaling: A Replication Attempt (2024): https://epochai.org/blog/chinchilla-scaling-a-replication-attempt —— 对 Chinchilla 方法 3 的复现与修正
- Yang et al., Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer (MuP): https://arxiv.org/abs/2203.03466 —— 跨尺度学习率迁移的理论与方法
- Muennighoff et al., Scaling Data-Constrained Language Models: https://arxiv.org/abs/2305.16264 —— 多 Epoch 训练的 Scaling Laws
- Banko & Brill, Scaling to Very Very Large Corpora for Natural Language Disambiguation (2001) —— 数据缩放的早期 NLP 研究