CS336 Lecture 4: Mixture of Experts
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Tatsu Hashimoto 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2025年4月29日 |

引言:为什么要学习 Mixture of Experts
Mixture of Experts(MoE,混合专家模型)是当今最高性能大语言模型的核心架构之一。GPT-4(据 NVIDIA 泄露信息)很可能是 MoE 架构,DeepSeek、Grok、Mixtral、Qwen 以及最新的 Llama 4 都采用了 MoE。2025 年,MoE 相对于 Dense 架构的优势已经非常明确——几乎在所有计算规模上,训练 MoE 模型都能获得比 Dense 模型更好的性能。
来源:Slides 第2页。
MoE 的核心思想
MoE 是一种稀疏激活的架构:模型拥有大量参数(experts),但每次前向传播只激活其中一小部分。这意味着可以在不增加计算量(FLOPs)的前提下,大幅增加模型的总参数量。更多参数 \(\rightarrow\) 更强的知识存储能力 \(\rightarrow\) 更好的性能。
“Experts” 并不真正“专家”
MoE 这个名字极具误导性。你可能会以为有一个“编程专家”、一个“英语专家”、一个“数学专家”,它们各自处理对应领域的内容。但实际情况远非如此——experts 更像是一种稀疏激活的子网络,它们之间的“专业化”程度远没有名字暗示的那么高。甚至用哈希函数随机分配 token 到 expert 都能获得增益。
MoE 架构概述
MoE 的基本思路非常简单:将 Transformer 中的 FFN(Feed-Forward Network)层替换为多个 FFN(即 experts)加上一个路由器(Router)。
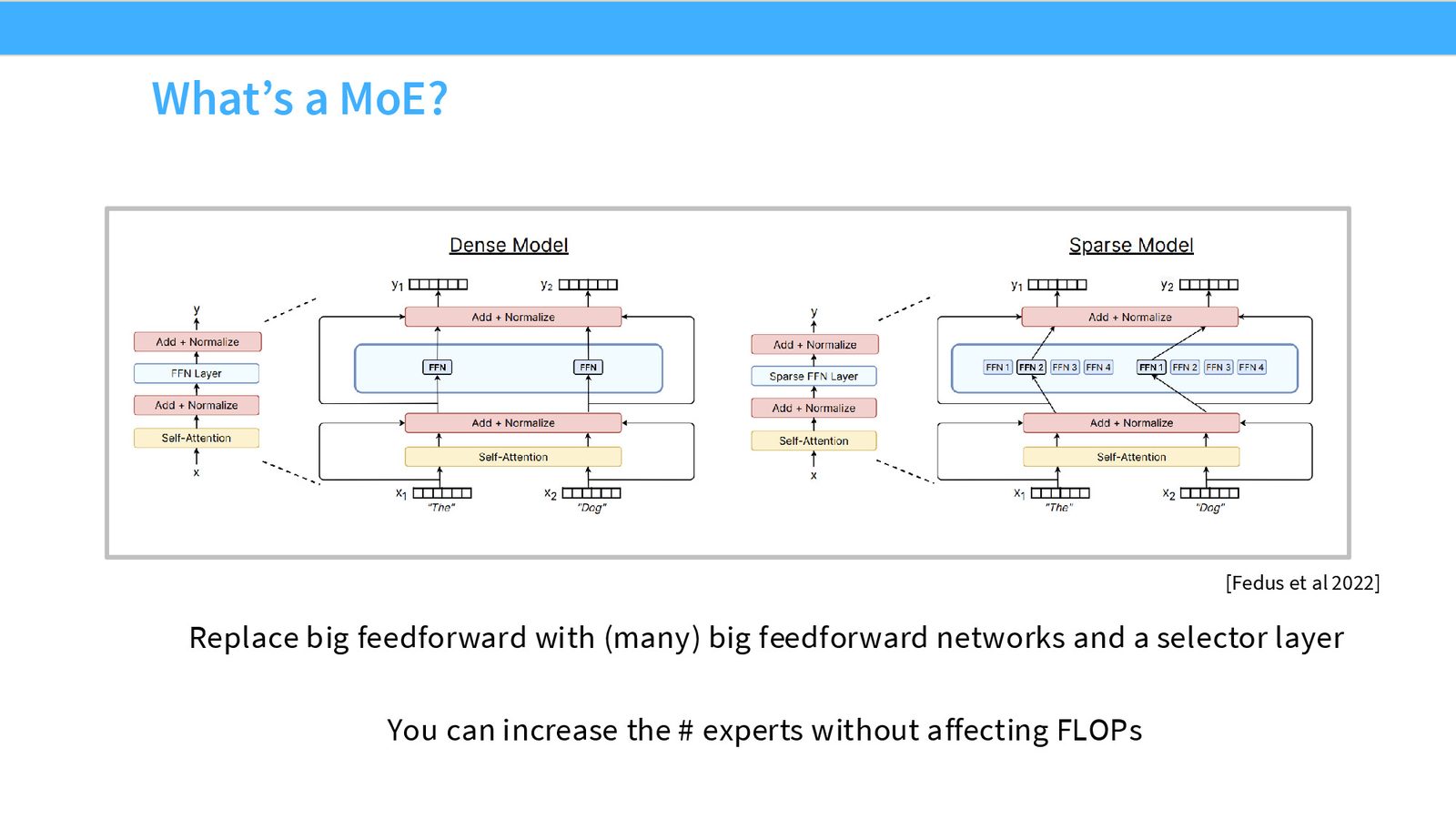
来源:Slides 第3页。来自 Fedus et al. 2022。
MoE 与 Dense 的关键区别
MoE 架构和非 MoE 架构在绝大多数组件上是相同的——Self-Attention、LayerNorm、Embedding 等都不变。唯一的区别在于 FFN 层:
- Dense:一个大的 FFN 处理所有 token
- MoE:多个小的 FFN(experts)+ 路由器,每个 token 只被路由到少数几个 expert
如果只激活一个 expert,且 expert 大小与 dense FFN 相同,那么两者的 FLOPs 完全一致。
MoE 的性能优势
大量实验表明,在相同的训练 FLOPs 下,MoE 模型显著优于 Dense 模型。
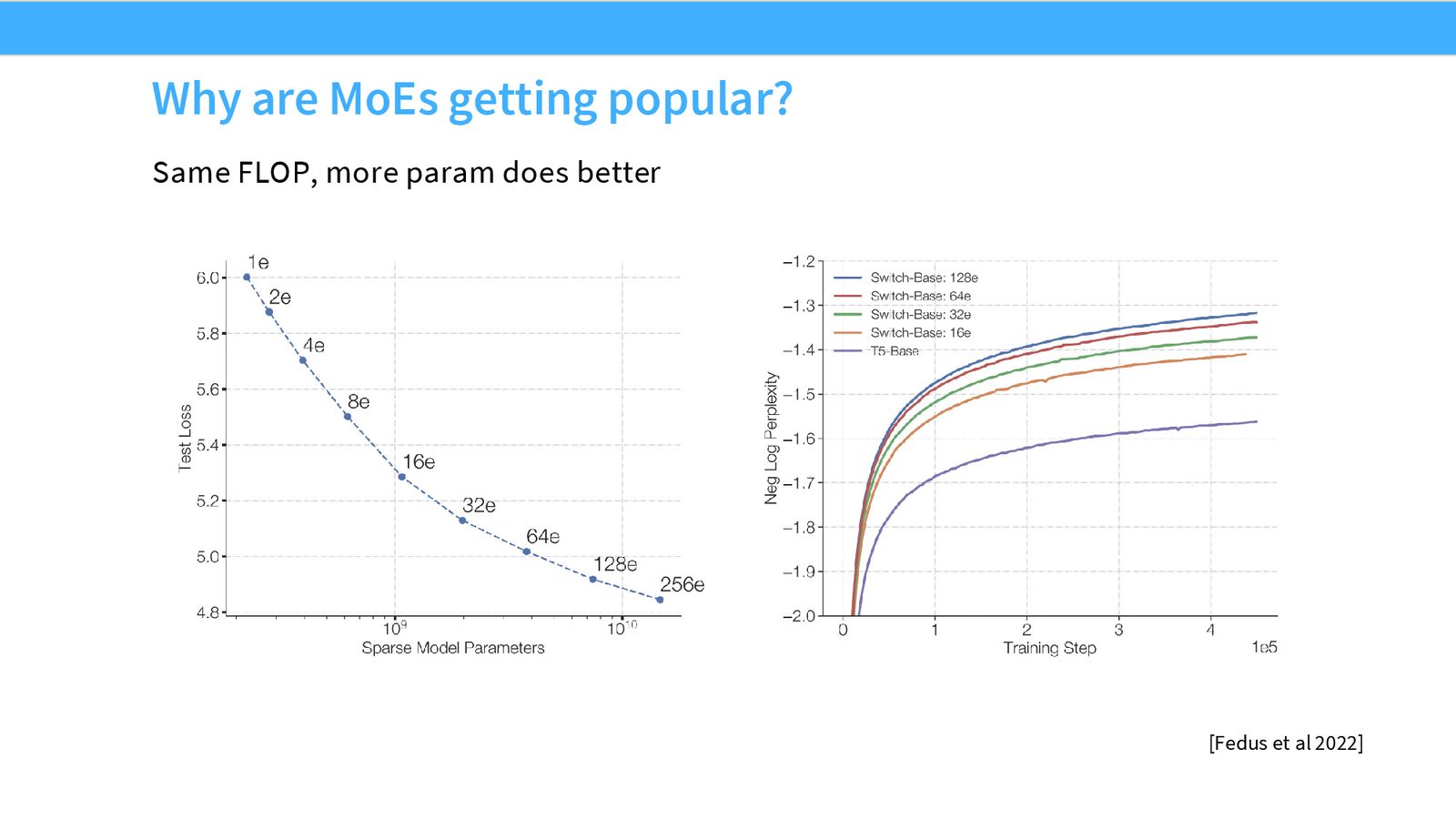
来源:Slides 第4页。来自 Fedus et al. 2022。
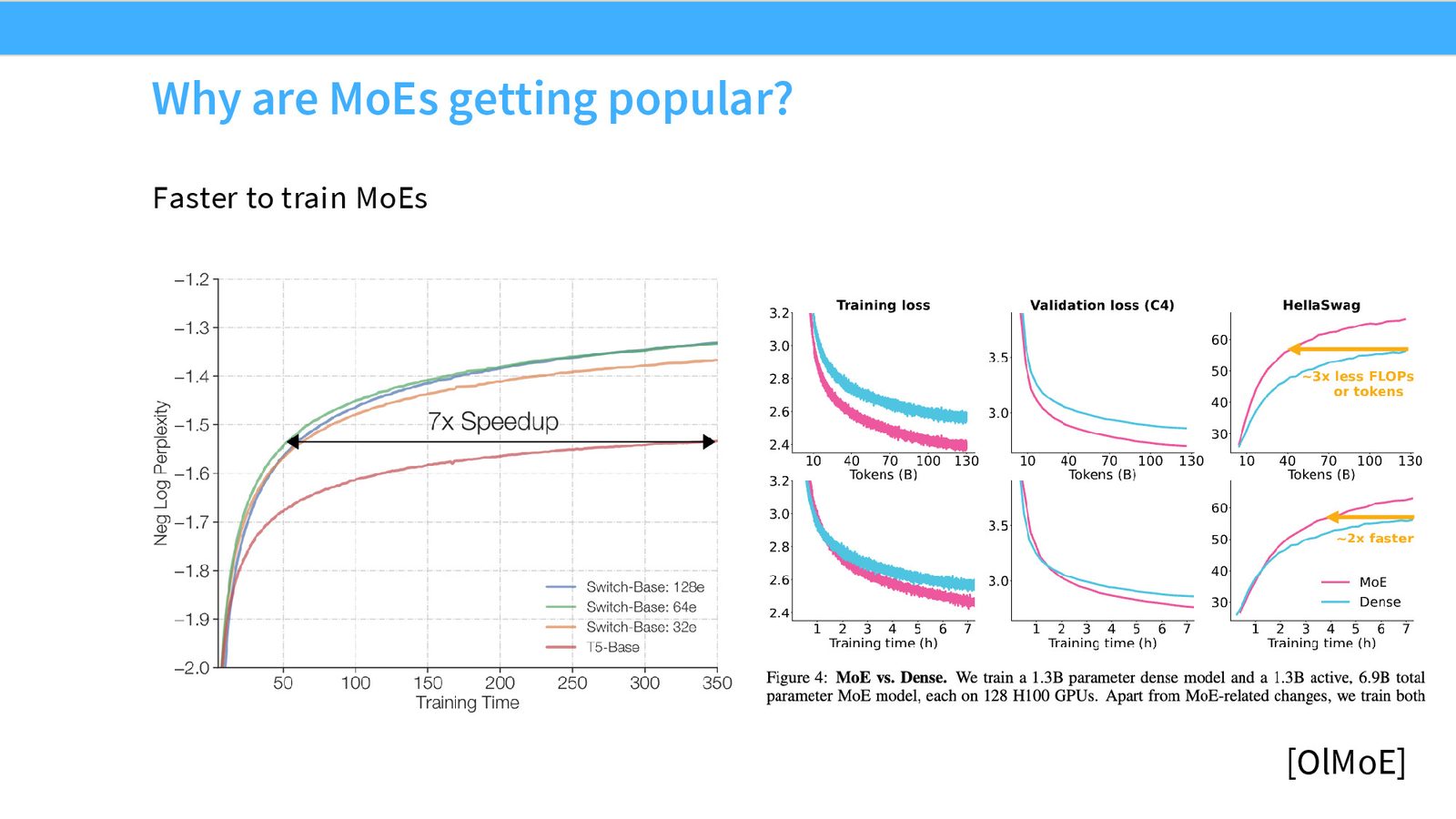
来源:Slides 第5页。左图来自 Fedus et al. 2022,右图来自 OLMoE。
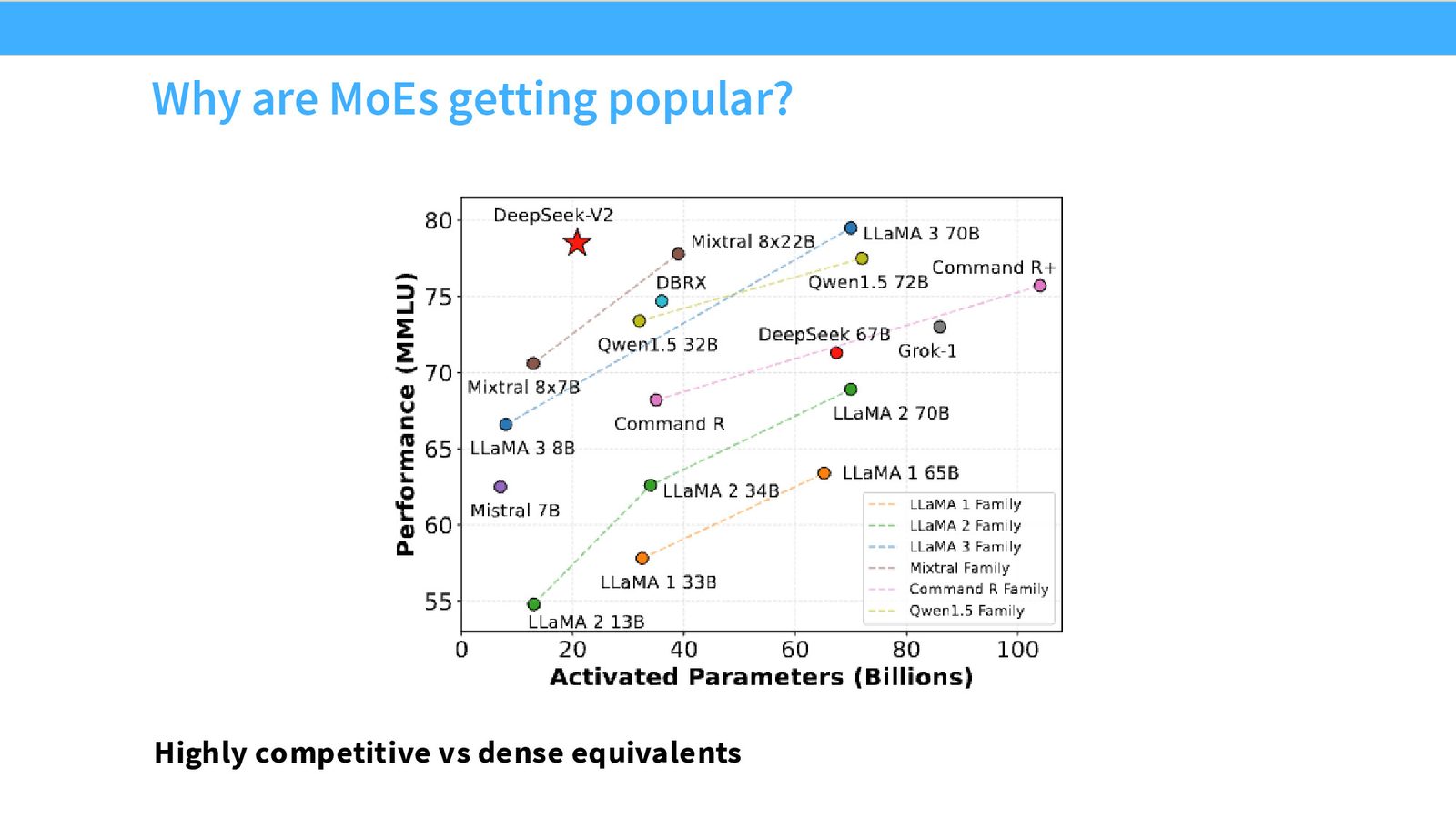
来源:Slides 第6页。来自 DeepSeek-V2 论文。
MoE 的三重优势
- 训练效率:相同 FLOPs 下,MoE 的 loss 下降更快(约 7x 加速)
- 推理效率:只激活部分参数,推理时的 FLOPs 远低于等效 Dense 模型
- 并行化:experts 天然适合分布到不同设备上(Expert Parallelism)
为什么 MoE 没有更早普及?
尽管 MoE 优势明显,但直到最近才被广泛采用,原因有两个:
- 系统复杂性高:MoE 的最大优势在多节点训练时才充分体现。当模型必须跨设备切分时,expert parallelism 非常自然;但在小规模训练中,系统开销可能抵消 MoE 的收益。
- 路由决策不可微:选择哪个 expert 是一个离散决策,无法直接通过梯度下降优化。训练目标要么依赖启发式方法,要么不稳定。
MoE 的开源发展历程
MoE 的核心技术主要在 Google 内部发展(Shazeer 2017、Switch Transformer 2021、Fedus et al. 2022)。但在开源领域,中国的实验室走在前面——Qwen 1.5 MoE 是最早的大规模开源 MoE 之一,DeepSeek 从 V1 到 V3 的 MoE 架构演进为整个领域提供了重要参考。西方开源 MoE(如 Mixtral、Llama 4)出现较晚。
MoE 应用于哪些层?
几乎所有主流 MoE 模型都只对FFN 层做稀疏路由。虽然理论上也可以对 Attention 层做 MoE(即 Sparse Attention),但实践中非常少见——有报告称 Attention MoE 的训练更加不稳定,且目前没有大规模开源模型采用这种方案。
本章小结
MoE 通过将 FFN 层替换为多个稀疏激活的 experts,在不增加 FLOPs 的前提下大幅增加模型参数量。实验证据表明,MoE 在几乎所有规模上都优于 Dense 架构。课程接下来将深入讨论三个核心设计问题:如何路由、expert 的数量与大小、以及如何训练路由器。
路由机制(Routing)
路由机制是 MoE 的核心——它决定了每个 token 被分配到哪些 experts。本节将详细讨论路由的设计空间。
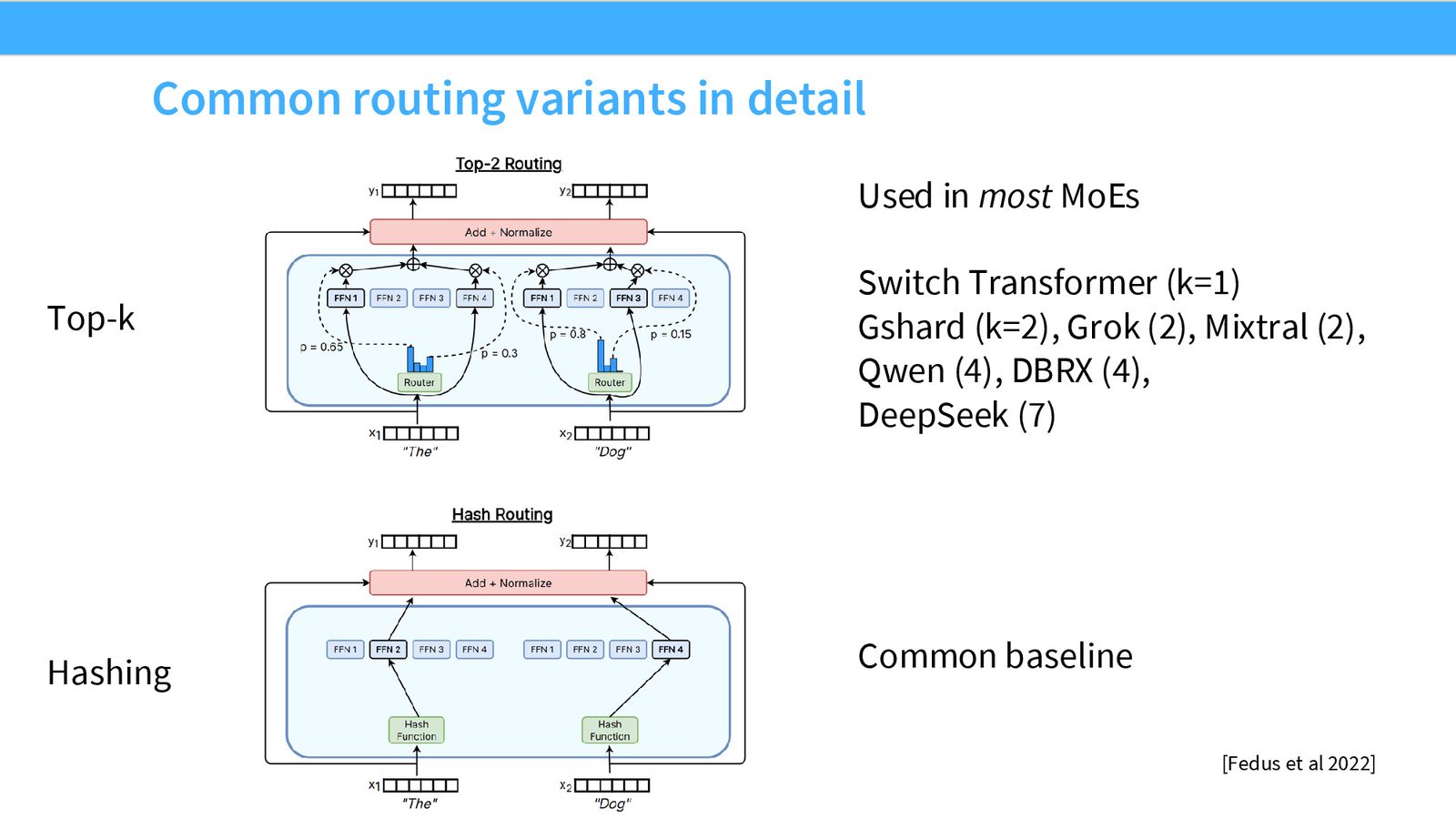
三种路由范式

来源:Slides 第14页。来自 Fedus et al. 2022。
Token Choice Top-K 是事实标准
尽管早期 MoE 研究探索了多种路由方式,但几乎所有大规模部署的 MoE 模型都收敛到了 Token Choice Top-K 路由——DeepSeek V1/V2/V3、Qwen、Grok、Mixtral 等无一例外。
三种路由范式的对比:
| 路由方式 | 优点 | 缺点 |
|---|---|---|
| Token Choice | 每个 token 被路由到最合适的 expert,质量最优 | 可能导致 expert 负载不均衡 |
| Expert Choice | 天然负载均衡,每个 expert 处理相同数量的 token | 某些 token 可能不被任何 expert 处理,或被不合适的 expert 处理 |
| Global Assignment | 理论最优分配 | 计算开销大,实践中收益不足以覆盖成本 |
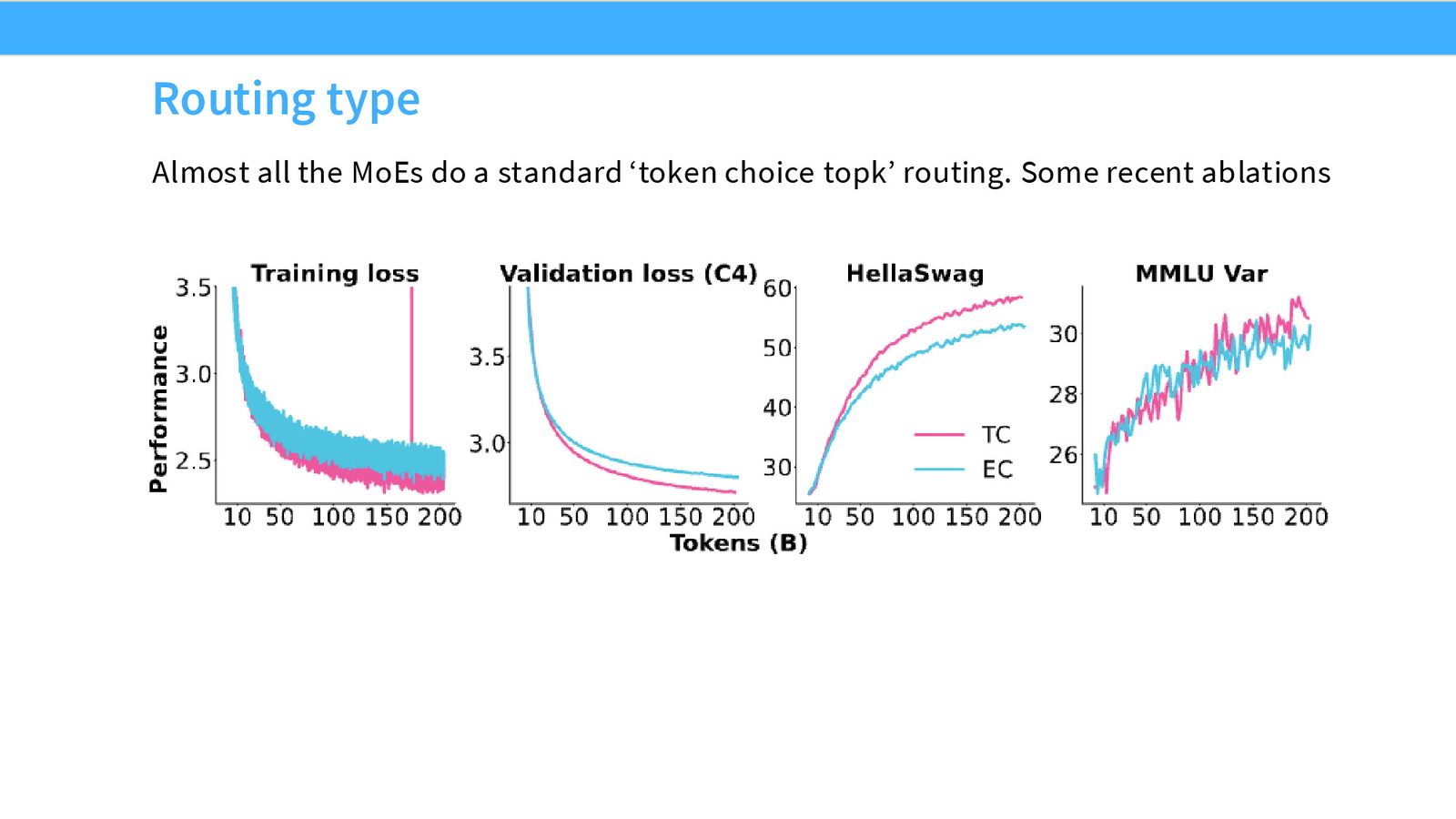
来源:Slides 第16页。来自 OLMoE。
Top-K 路由的数学表达
Token Choice Top-K 路由的具体实现如下:
来源:Slides 第17页。
给定残差流输入 \(\mathbf{u}_t\),路由器首先计算每个 expert 的亲和分数:
其中:
- \(\mathbf{u}_t \in \mathbb{R}^d\):第 \(t\) 个 token 的隐藏状态(残差流输入)
- \(\mathbf{e}_i \in \mathbb{R}^d\):第 \(i\) 个 expert 的可学习向量(路由器参数)
- \(s_{i,t}\):token \(t\) 对 expert \(i\) 的归一化亲和分数
然后通过 Top-K 选择构造门控权重:
最终输出为所有 expert 输出的加权和加上残差连接:
路由器出奇地简单
路由器本质上就是一个线性内积 + Softmax——与 Attention 的 Query-Key 内积非常相似。\(\mathbf{e}_i\) 可以理解为每个 expert 的“名片”,与 token 的隐藏状态做内积来衡量亲和度。没有人使用 MLP 路由器或更复杂的设计,因为:(1)路由器本身的 FLOPs 也要计算在内;(2)路由器的学习信号本身就很间接,即使增加复杂度也不一定能学到更好的路由。
K 值的选择
\(K\)(每个 token 激活的 expert 数量)是一个关键超参数:
- \(K = 1\)(Switch Transformer):最稀疏,FLOPs 最少,但探索不足——router 可能永远只利用最好的 expert,而忽视其他潜在更好的选择
- \(K = 2\)(经典选择):第二个 expert 提供探索信息,有助于学习更好的路由。Mixtral、早期 DeepSeek 使用
- \(K > 2\):更多 FLOPs 但更丰富的梯度信号。DeepSeek V3 使用 \(K = 8\)(配合细粒度 expert)
\(K\) 的增加意味着 FLOPs 的增加
\(K = 2\) 意味着每个 token 要经过两个 expert 的 FFN,FLOPs 翻倍。因此,谈论 MoE 模型时通常使用“激活参数”(activated parameters)而非总参数来衡量计算成本。例如 DeepSeek-V3 有 671B 总参数但只有 37B 激活参数。
Softmax 的位置:一个微妙的设计选择
来源:Slides 第18页。
不同的 MoE 实现对 Softmax 的位置有不同选择:
- DeepSeek V1/V2、Qwen、Grok:先 Softmax 后 Top-K(Softmax 在底部)
- DeepSeek V3、Mixtral、DBRX:先 Top-K 后 Softmax(Softmax 在 gate 上)
先 Softmax 后 Top-K 意味着门控权重不再严格归一化到 1(因为被丢弃的 expert 权重不为零)。但这并不是问题——LayerNorm 可以在后续层补偿尺度变化。部分模型选择在 Top-K 之后重新归一化,但这也是可选的。
令人惊讶的发现:随机路由也有效
Hash 路由也能带来增益
多个研究表明,即使使用哈希函数(完全不含语义信息)来将 token 分配到 expert,MoE 仍然能获得相对于 Dense 模型的性能增益。这说明 MoE 的优势不仅仅来自“智能路由”,而是更根本地来自参数量的增加和稀疏激活本身。这应该深刻影响你对 MoE 本质的理解。
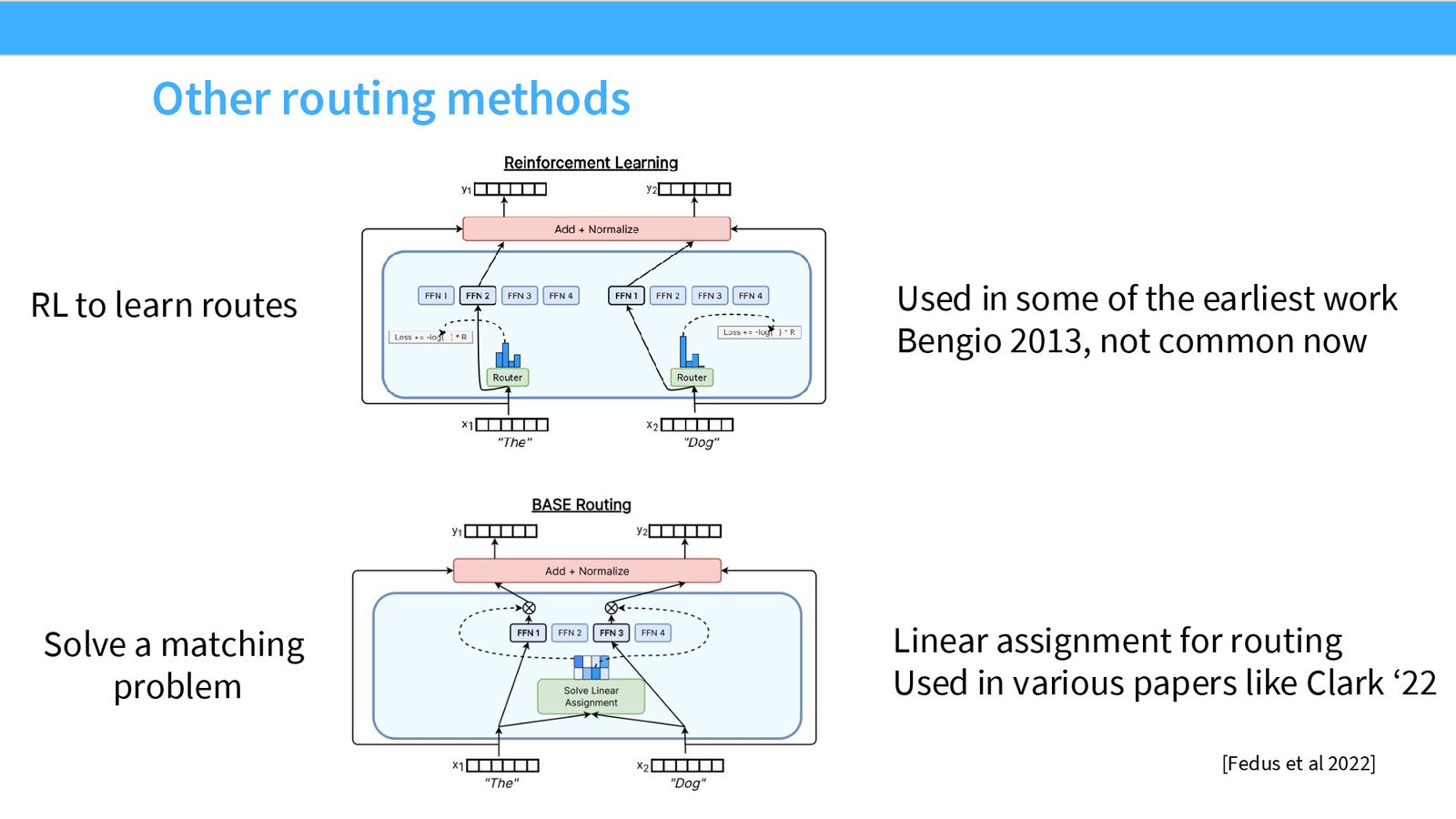
其他路由方法
除了 Top-K 路由外,研究者还尝试过多种其他方法:
- RL 路由:最早期的方法之一,将路由决策视为策略,用强化学习优化。理论上最原则化,但实践中计算开销大、梯度方差高,效果不如更简单的方法。
- 线性分配/最优传输:优雅但计算代价高于收益,未被广泛采用。
- 随机采样:Google 的一篇论文提出“top-1 确定性 + top-2 按概率采样”的方案,增加探索但导致 train-test mismatch。
本章小结
路由机制的设计空间很大,但行业已经收敛到一个简单的方案:线性内积 + Softmax + Top-K 选择。路由器参数量极小(每个 expert 只有一个 \(d\) 维向量),训练通过标准反向传播的间接梯度进行。即使是随机路由也能带来增益,这暗示 MoE 的核心优势来自稀疏参数扩展本身。
Expert 的数量与结构设计
确定了路由方式后,下一个问题是:应该有多少个 expert?每个 expert 应该多大?
细粒度 Expert(Fine-Grained Experts)

来源:Slides 第19页。
早期 MoE 的逻辑演进:
- 基础 MoE:将 Dense FFN 复制为多份,每份与原始 FFN 大小相同,Top-2 路由 \(\rightarrow\) 激活参数翻倍
- 更多 experts 更好:实验表明增加 expert 数量能持续降低 loss
- 但不想付出参数代价:因此将每个 expert 切小——例如将 FFN 的中间维度从 \(4d\) 缩小到 \(2d\) 或更小,同时 expert 数量翻倍
- FLOPs 不变:因为激活的总 FFN 参数量保持不变
细粒度 Expert 是目前最重要的 MoE 创新之一
DeepSeek 最早系统性地提出并验证了细粒度 expert 的优势。以 DeepSeek MoE V1 为例:64 个细粒度 routed experts(中间维度为标准的 \(1/4\)),激活其中 6 个。总 expert 数量增加的同时,每个 expert 更小,带来更灵活的组合能力。这已经被所有主流 MoE 模型采纳。
共享 Expert(Shared Experts)
DeepSeek 的另一个重要创新是共享 expert:在 routed experts 之外,额外设置 1--2 个始终激活的 expert(不经过路由器)。
共享 Expert 的设计动机
不管输入是什么 token,可能都有一些“通用处理”是必须做的。如果把这些通用计算也交给 routed experts,会浪费路由和参数资源。共享 expert 的作用类似于一个“公共基础设施”,处理所有 token 都需要的通用变换,让 routed experts 专注于差异化处理。
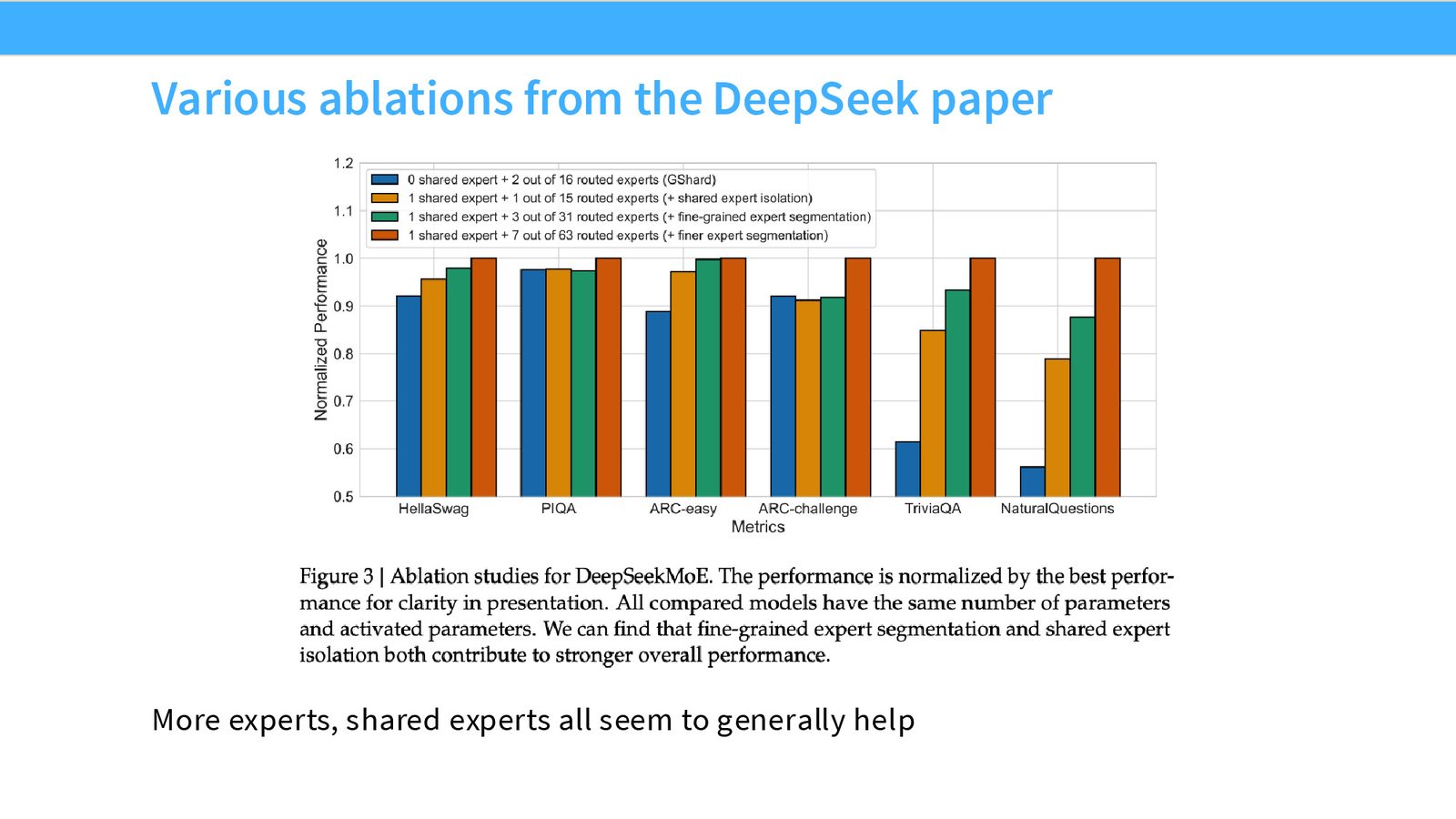
来源:Slides 第21页。来自 DeepSeek MoE 论文。
不过,关于共享 expert 的价值,业界仍有分歧:
- DeepSeek V1/V2/V3 使用 2 个共享 expert
- OLMoE 的消融实验表明,1 个共享 expert 的增益并不总是显著
- 一些中国 LLM 公司曾尝试多个共享 expert,后来又回到 0 或 1 个
- 共享 expert 的实际价值可能在于让所有 expert 大小一致,简化系统实现
OLMoE 消融:更多 experts vs 更大 experts
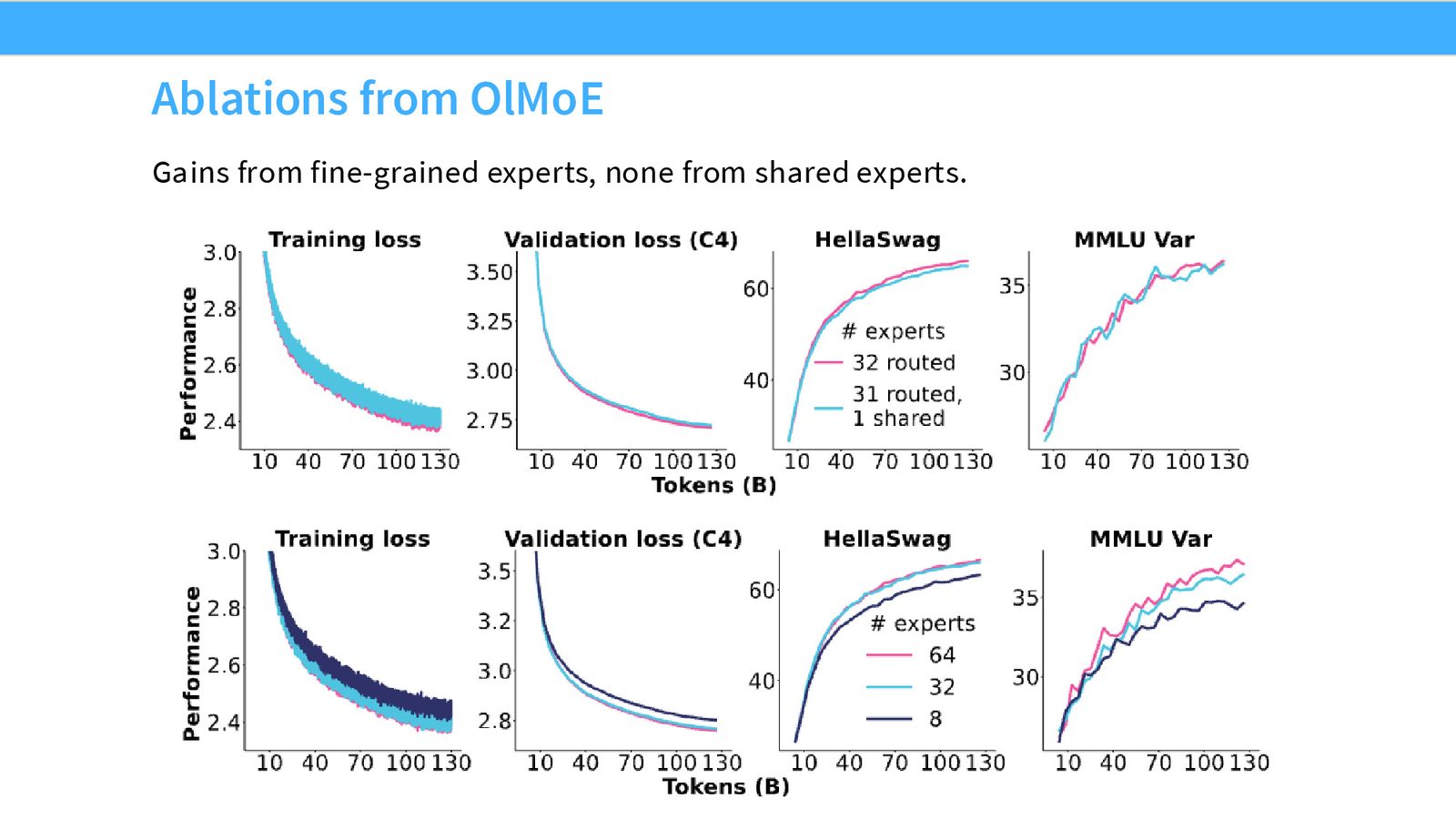
来源:Slides 第22页。来自 OLMoE。
OLMoE 的系统性消融验证了以下结论:
- 从 8 到 64 个细粒度 experts:持续降低验证 loss
- 共享 expert:在某些任务上有帮助,但不如细粒度 expert 那样一致
- 增加 activated experts:当 expert 更细粒度时,增加 \(K\) 是“免费”的(因为每个 expert 更小)
本章小结
- 细粒度 expert 是 MoE 最重要的设计创新——将 expert 切小、数量增多,在不增加 FLOPs 的前提下获得更灵活的组合能力
- 共享 expert 捕获通用处理需求,但其边际收益仍有争议
- 更多 experts 几乎总是更好,只要系统能高效支持
MoE 的训练挑战
MoE 的训练远比 Dense 模型复杂。核心挑战在于:训练时必须保持稀疏激活(否则 FLOPs 与 Dense 无异),但稀疏路由决策不可微。
三种训练策略

来源:Slides 第24页。
- 强化学习(RL):最原则化——将路由视为策略,用 policy gradient 优化。但计算开销大、梯度方差高,实践中效果不如更简单的方法。
- 随机近似(Stochastic Approximation):在路由分数上添加噪声,实现探索-利用权衡
- 启发式辅助损失(Heuristic Auxiliary Loss):添加额外的损失项鼓励负载均衡——这是目前所有主流系统使用的方法
随机路由:Shazeer 2017

来源:Slides 第26页。来自 Shazeer et al. 2017。
Shazeer 2017 的方案在标准路由分数上添加可学习幅度的高斯噪声:
其中 \(W_{\text{noise}}\) 控制噪声的幅度,可以通过学习来调节探索-利用权衡。
随机路由的权衡
- 优点:噪声使每个 expert 随机接收一些“意外” token,减少过度专业化,增强鲁棒性
- 缺点:随机性降低了专业化程度,导致效率损失;如果训练时有随机性但测试时没有,会产生 train-test mismatch
辅助损失(Auxiliary Loss):负载均衡的启发式方法
辅助损失是目前最广泛使用的训练策略。核心问题是:如果没有负载均衡约束,MoE 训练会发生什么?
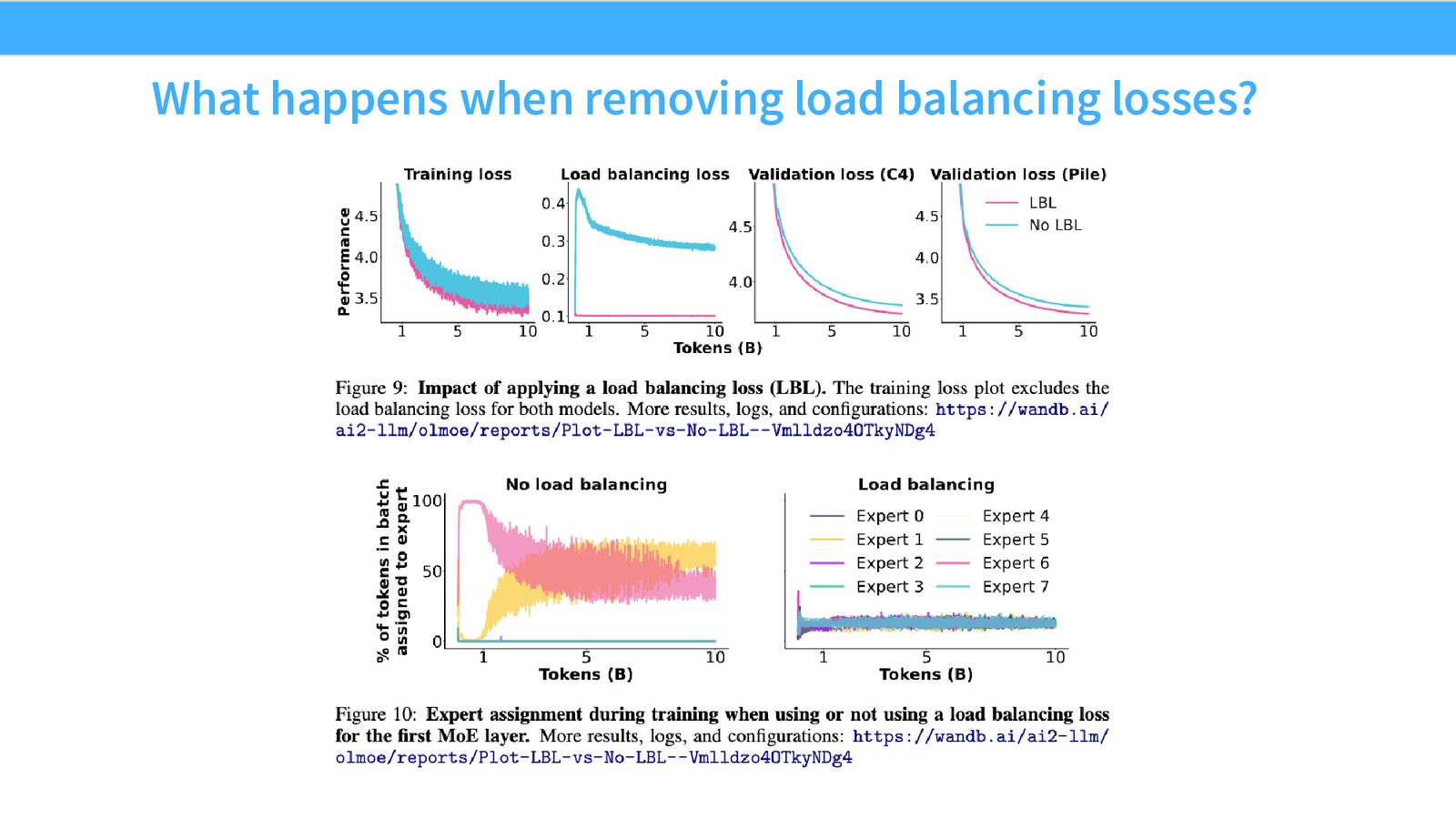
来源:Slides 第31页。来自 OLMoE。
Expert Collapse:MoE 训练的最大敌人
没有负载均衡约束时,路由器会进入正反馈循环:某个 expert 获得更多 token \(\rightarrow\) 获得更多训练 \(\rightarrow\) 变得更好 \(\rightarrow\) 吸引更多 token。最终只有 2--3 个 expert 处理所有 token,其余 expert “死亡”。这被称为 Expert Collapse,会严重浪费模型容量。
标准辅助损失(Load Balancing Loss)

来源:Slides 第28页。来自 Fedus et al. 2022。
标准负载均衡损失的形式为:
其中:
- \(f_i = \frac{1}{T} \sum_{t=1}^{T} \mathbf{1}(\text{Token } t \text{ selects Expert } i)\):expert \(i\) 被选中的频率
- \(P_i = \frac{1}{T} \sum_{t=1}^{T} s_{i,t}\):expert \(i\) 的平均路由概率
- \(\alpha\):辅助损失权重(超参数)
辅助损失权重 \(α\) 需要精心调节
\(\alpha\) 过大会过度干扰语言模型的主损失,降低模型质量;\(\alpha\) 过小则无法有效防止 Expert Collapse。这是 MoE 训练中最需要调参的超参数之一。
Z-Loss:稳定路由器
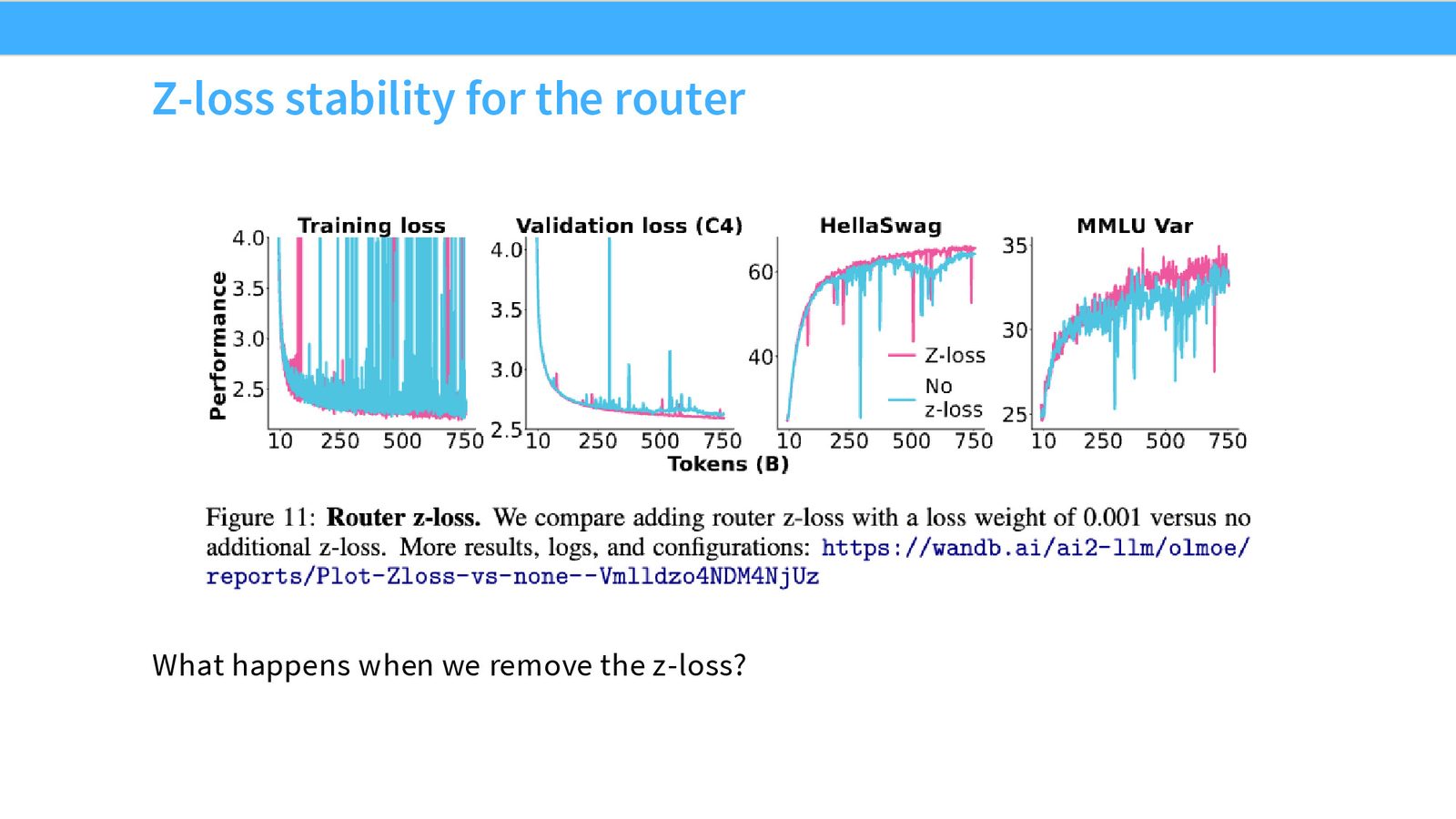
来源:Slides 第36页。来自 OLMoE。
Z-Loss(来自 ST-MoE)通过惩罚路由器 logits 的绝对值来防止数值不稳定:
Z-Loss 对训练稳定性至关重要
OLMoE 的实验表明,去掉 Z-Loss 会导致训练出现灾难性的 loss 尖峰——Validation loss 骤升、HellaSwag 性能暴跌。Z-Loss 是 MoE 训练的“安全网”。
DeepSeek V3 的创新:Auxiliary-Loss-Free Balancing
来源:Slides 第34页。来自 DeepSeek V3 论文。
DeepSeek V3 提出了一种优雅的替代方案:
- 在路由分数上添加一个per-expert 偏置 \(b_i\):\(s'_{i,t} = s_{i,t} + b_i\)
- 用 \(s'_{i,t}\) 做 Top-K 路由决策,但门控权重仍然使用原始的 \(s_{i,t}\)
- \(b_i\) 通过简单的在线学习更新:如果 expert \(i\) 的 token 不足,增大 \(b_i\)(\(b_i \mathrel{+}= \gamma\));如果过多,减小 \(b_i\)(\(b_i \mathrel{-}= \gamma\))
DeepSeek V3 的“非完全无辅助损失”
尽管 DeepSeek V3 论文大力宣传 Auxiliary-Loss-Free Balancing 的稳定性优势,但细读论文会发现他们仍然保留了一个 sequence-level 的辅助损失来实现序列级别的负载均衡。因此这个方法并非完全“loss-free”。
多层次负载均衡
DeepSeek 实践中使用多层次的负载均衡:
- Per-Expert Balancing(每批次):确保每个 expert 在每个 batch 中获得大致相同数量的 token
- Per-Device Balancing:确保每个设备上的 expert 总共获得大致相同数量的 token,优化硬件利用率
- Per-Sequence Balancing(DeepSeek V3):确保在序列级别也保持均衡
Token Dropping 与容量因子
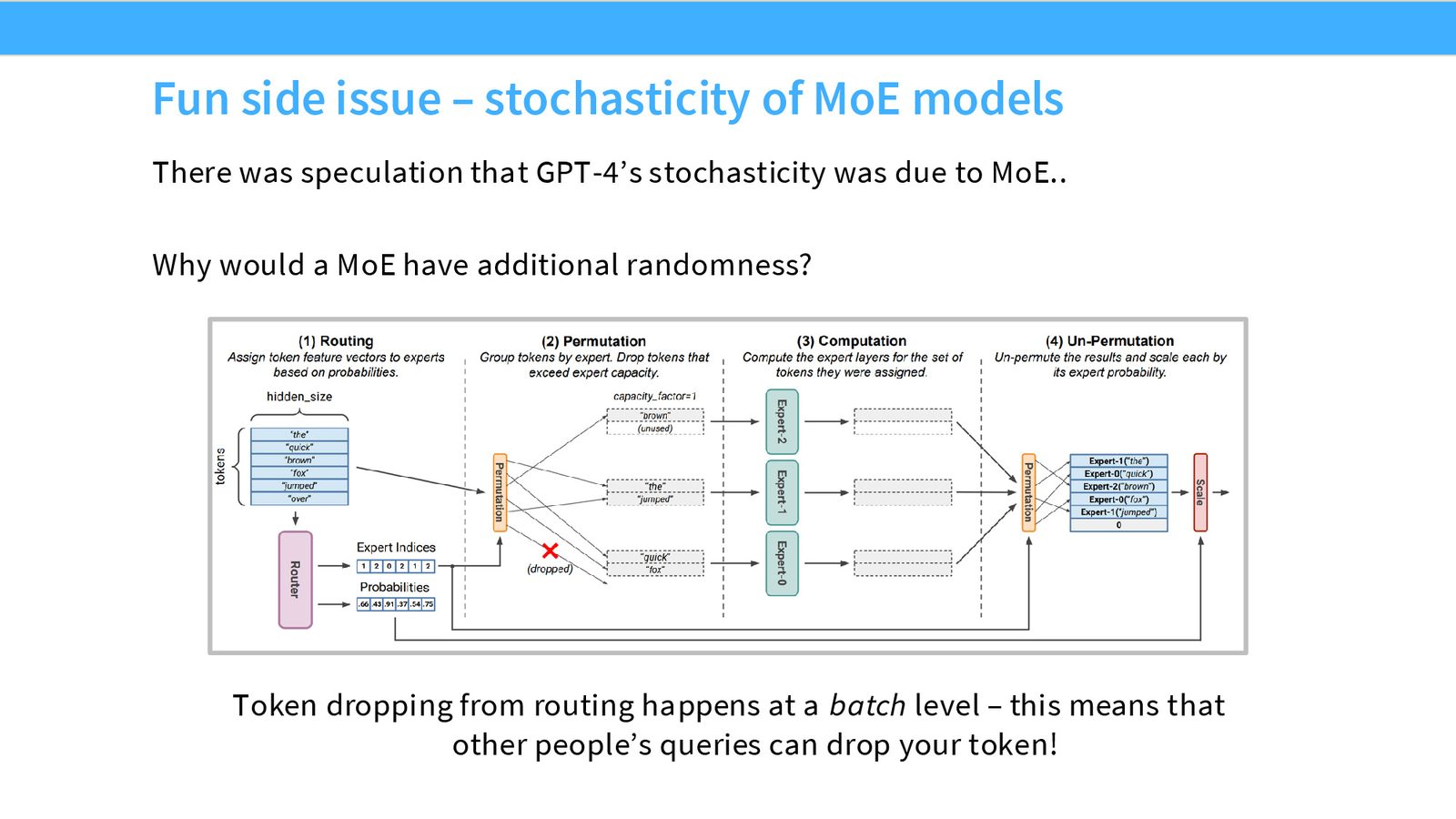
来源:Slides 第37页。
当某个 expert 接收到过多 token 时,超出容量的 token 会被“丢弃”——它们不经过任何 expert,直接通过残差连接传递。这引入了一个容量因子(Capacity Factor)超参数,控制每个 expert 能接受的最大 token 数。
Token Dropping 会导致推理时的非确定性
在推理时,如果请求被 batch 处理,不同请求的 token 可能竞争同一个 expert 的容量。这意味着相同的输入在不同 batch 中可能产生不同输出——这可能是 GPT-4 在 temperature=0 时仍然非确定性的原因之一。
本章小结
MoE 训练的核心挑战是平衡路由质量和负载均衡。行业共识是使用辅助损失 + Z-Loss 的组合。DeepSeek V3 的 bias-based balancing 是一个有趣的替代方案,但并非完全取代辅助损失。Expert Collapse 是最需要警惕的问题——没有负载均衡约束的 MoE 训练几乎必然失败。
系统优化与推理
MoE 模型的系统实现涉及独特的挑战和优化机会。
Expert Parallelism
来源:Slides 第38页。
Expert Parallelism 是 MoE 特有的并行化方式:
- 每个 expert(或一组 expert)放在不同设备上
- 路由器决定 token 的 expert 分配后,通过 All-to-All 通信将 token 发送到对应设备
- 各设备独立计算 FFN
- 再通过 All-to-All 通信将结果收集回来
Expert Parallelism 是 MoE 流行的系统原因
当模型大到必须分布在多个设备上时,Expert Parallelism 提供了一种非常自然的切分方式。与 Tensor Parallelism(需要在每步都同步)不同,Expert Parallelism 只在路由点和聚合点需要通信。它与 Data Parallelism、Pipeline Parallelism、Tensor Parallelism 可以自由组合,为大规模训练提供了更多灵活性。
Grouped GEMM:设备级稀疏计算
当多个 expert 位于同一设备上时,可以利用 Grouped GEMM(分组矩阵乘法)来高效处理稀疏的 expert 计算。现代库(如 Meta 的 Megablocks)可以将多个小矩阵乘法合并为一个大的 grouped operation,避免浪费 GPU 计算资源。
MoE 的推理特性
MoE 在推理时有独特的优势和挑战:
MoE 推理的核心特性
- 优势:每个 token 只需要激活部分 expert 的参数,FLOPs 远低于等效 Dense 模型
- 挑战:所有 expert 的参数都需要存储在内存中,内存需求远高于激活参数暗示的水平
- 权衡:MoE 是“用内存换 FLOPs”的典型例子——更多参数、更少计算
MoE 与后训练(Post-Training)
来源:Slides 第42页。
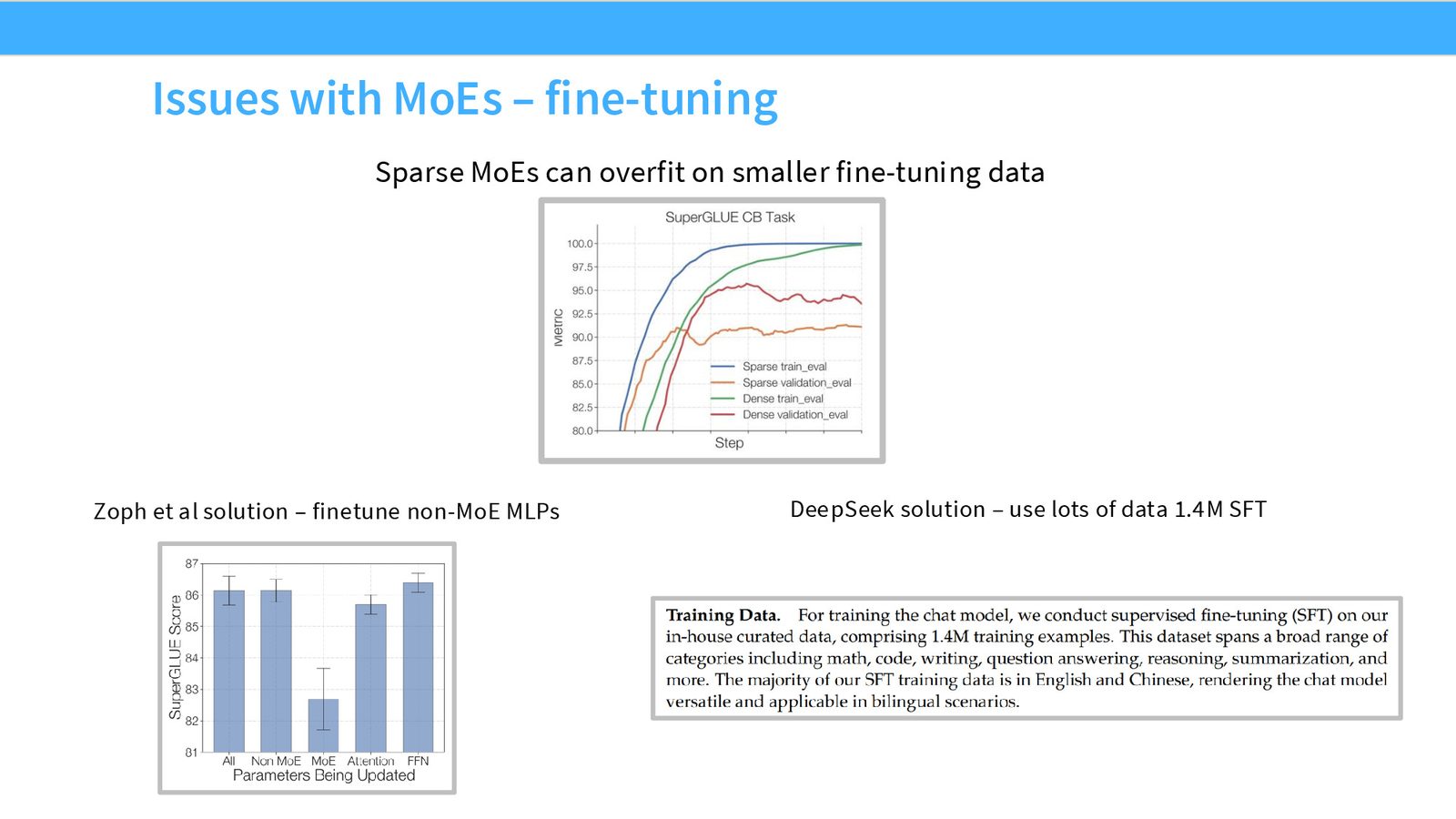
MoE 模型在微调(SFT)和 RLHF 阶段面临特殊挑战:
MoE 更容易在后训练中过拟合
MoE 的总参数量远大于激活参数量。在后训练数据量有限的情况下,大量未充分训练的参数容易导致过拟合。DeepSeek 的解决方案很务实:使用大量 SFT 数据(1.4M 样本)来缓解过拟合问题。
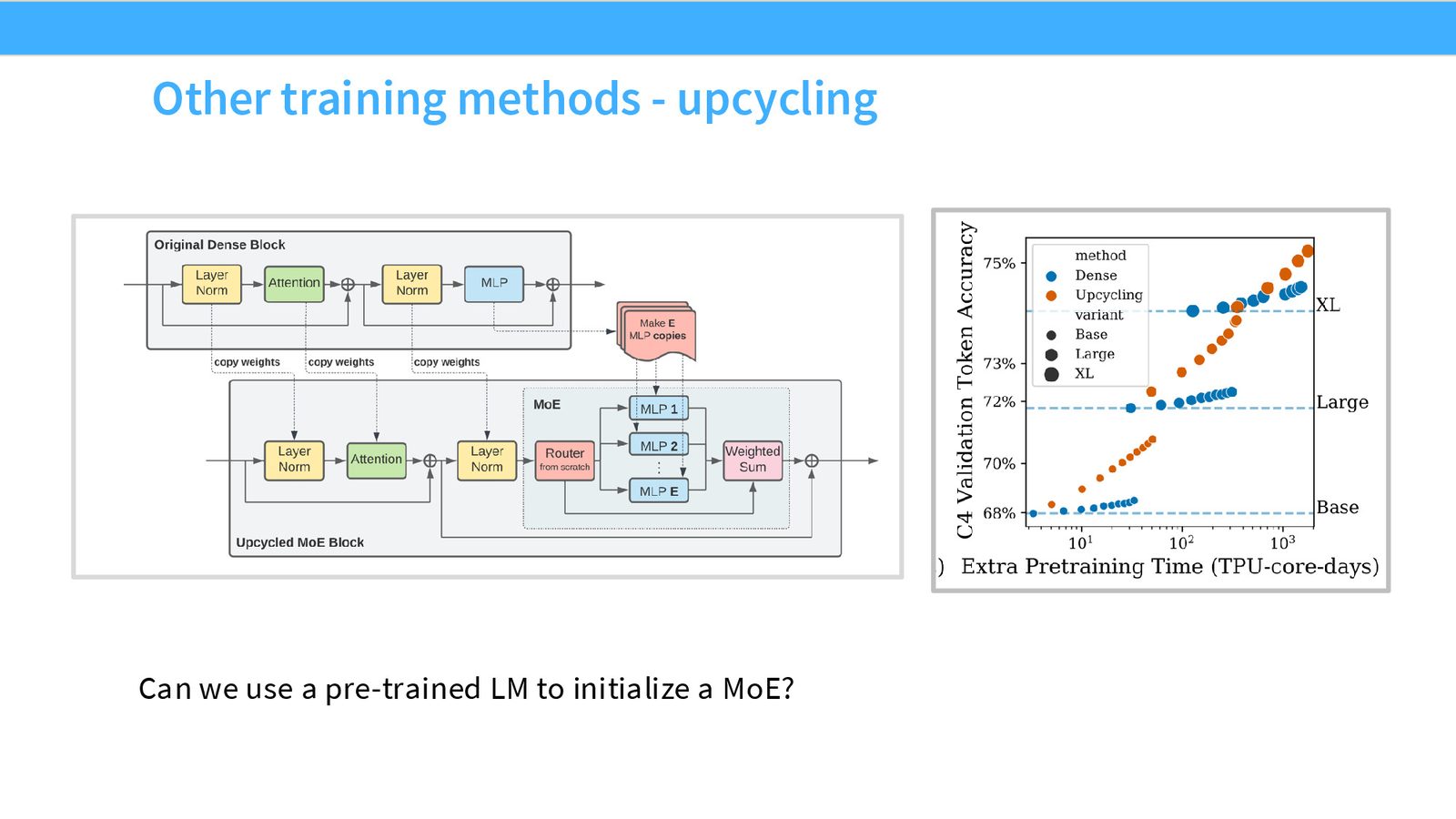
Upcycling:从 Dense 到 MoE 的低成本转换
来源:Slides 第44页。
Upcycling 是一种将现有 Dense 模型转换为 MoE 模型的技巧:
- 取 Dense 模型的 MLP 权重
- 复制多份(每份加少量随机扰动)
- 随机初始化路由器
- 以 MoE 模式继续预训练
成功案例:
- MiniCPM:Dense \(\rightarrow\) MoE upcycling,显著提升性能
- Qwen 1.5 MoE:从 Qwen 1.5 Dense 模型 upcycle,2.7B 激活参数达到 7B Dense 模型水平
本章小结
MoE 的系统实现需要精心设计的 Expert Parallelism、高效的 Grouped GEMM、以及多种并行策略的组合。推理时 MoE 用内存换 FLOPs,后训练时需注意过拟合。Upcycling 提供了一条从 Dense 到 MoE 的低成本升级路径。
案例分析:DeepSeek MoE 架构演进
本节追溯 DeepSeek 从 V1 到 V3 的 MoE 架构变化,展示一个现代高性能 MoE 系统是如何逐步构建的。
DeepSeek MoE V1(16B, 2.8B active)
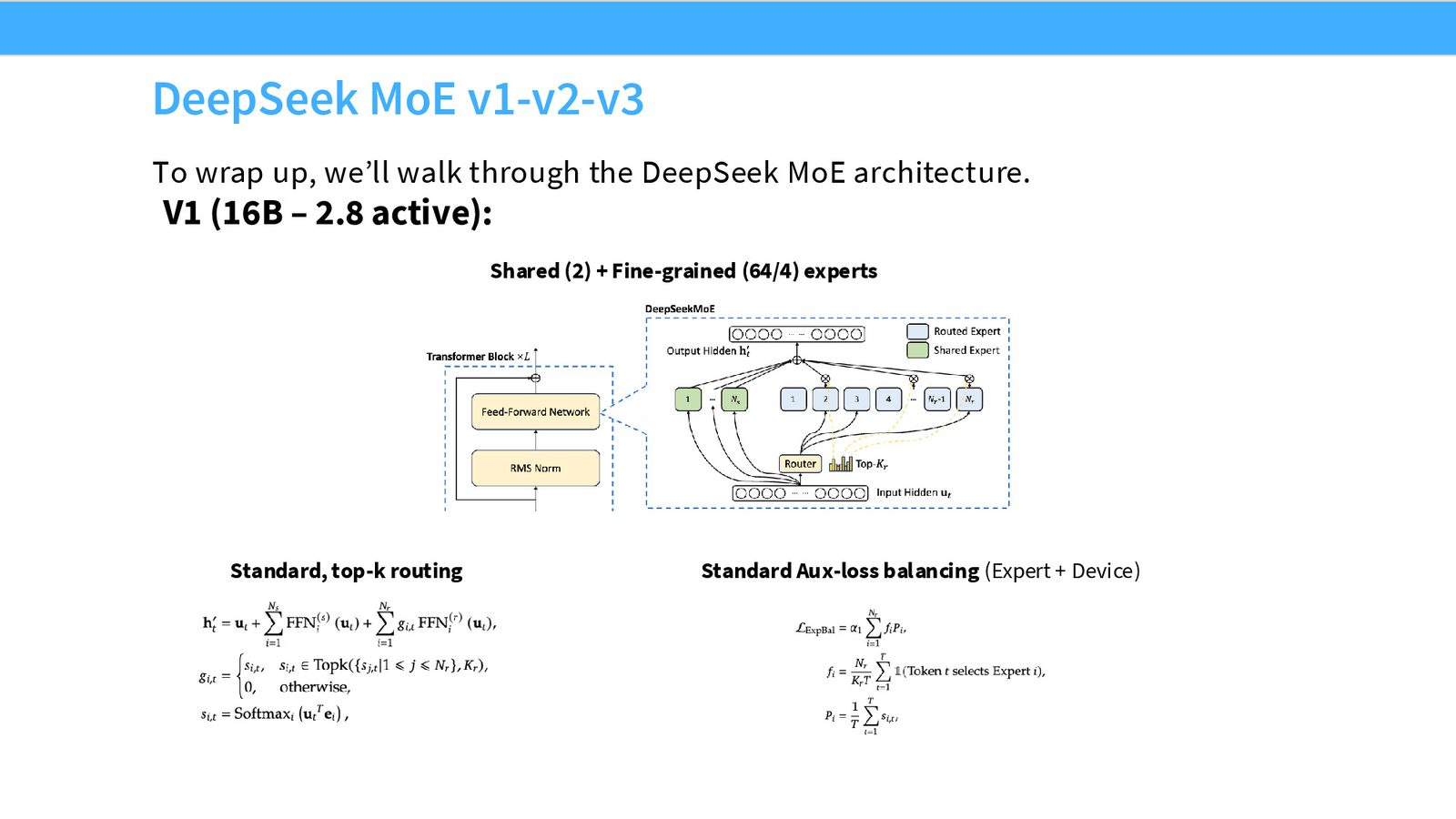
来源:Slides 第41页。来自 DeepSeek MoE 论文。
V1 的关键设计:
- 16B 总参数,2.8B 激活
- 2 共享 expert + 64 细粒度 routed expert,激活 \(K_r = 4\) 个
- 标准 Top-K 路由:Softmax 在 Top-K 之前
- 标准辅助损失:Expert-level + Device-level 均衡
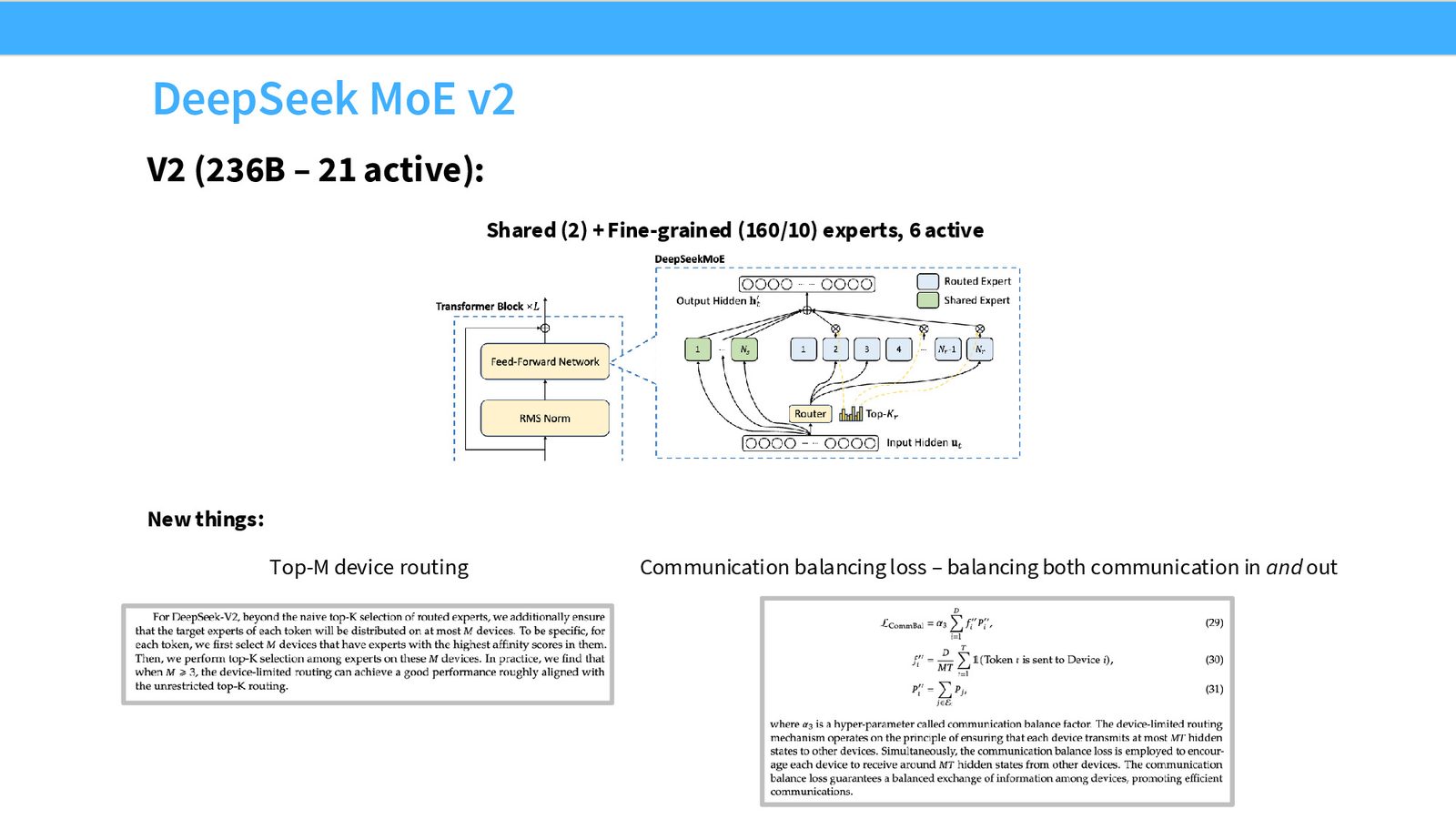
DeepSeek V2(236B, 21B active)
V2 是 V1 的直接放大版本:
- 236B 总参数,21B 激活——规模增长一个数量级
- MoE 架构完全不变——同样的共享+细粒度 expert 结构、同样的路由、同样的辅助损失
- 唯一变化是 expert 数量和模型规模的增大
- 新增 Multi-head Latent Attention (MLA)——一种压缩 KV Cache 的注意力机制
架构的稳定性
从 V1 到 V2,DeepSeek 在 MoE 部分没有做任何架构修改——他们在 V1 时就已经找到了正确的架构。这说明好的架构设计可以在小规模验证后直接放大,体现了 DeepSeek 团队扎实的工程和研究能力。
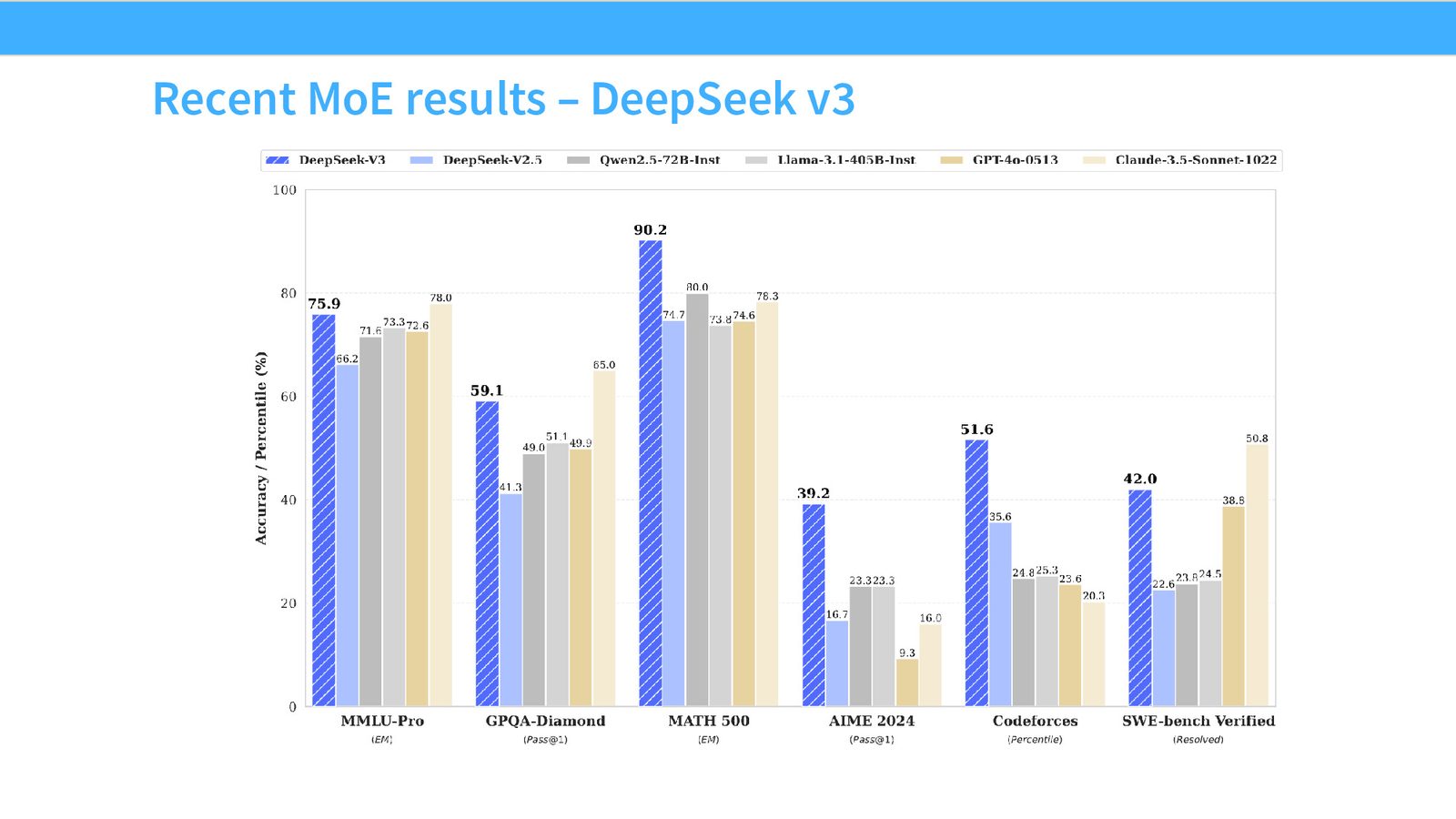
DeepSeek V3(671B, 37B active)

来源:Slides 第47页。来自 DeepSeek V3 论文。
V3 相对于 V2 的变化:
- 规模继续放大:671B 总参数,37B 激活
- Auxiliary-Loss-Free Balancing:用 per-expert bias + 在线学习替代部分辅助损失(但保留了 sequence-level 辅助损失)
- Multi-Token Prediction (MTP):使用轻量级单层 Transformer 同时预测下一个 token(虽然论文展示了预测多个 token 的框架,实际只预测了 1 个额外 token)
- Multi-head Latent Attention (MLA):继承自 V2 的 KV Cache 压缩技术
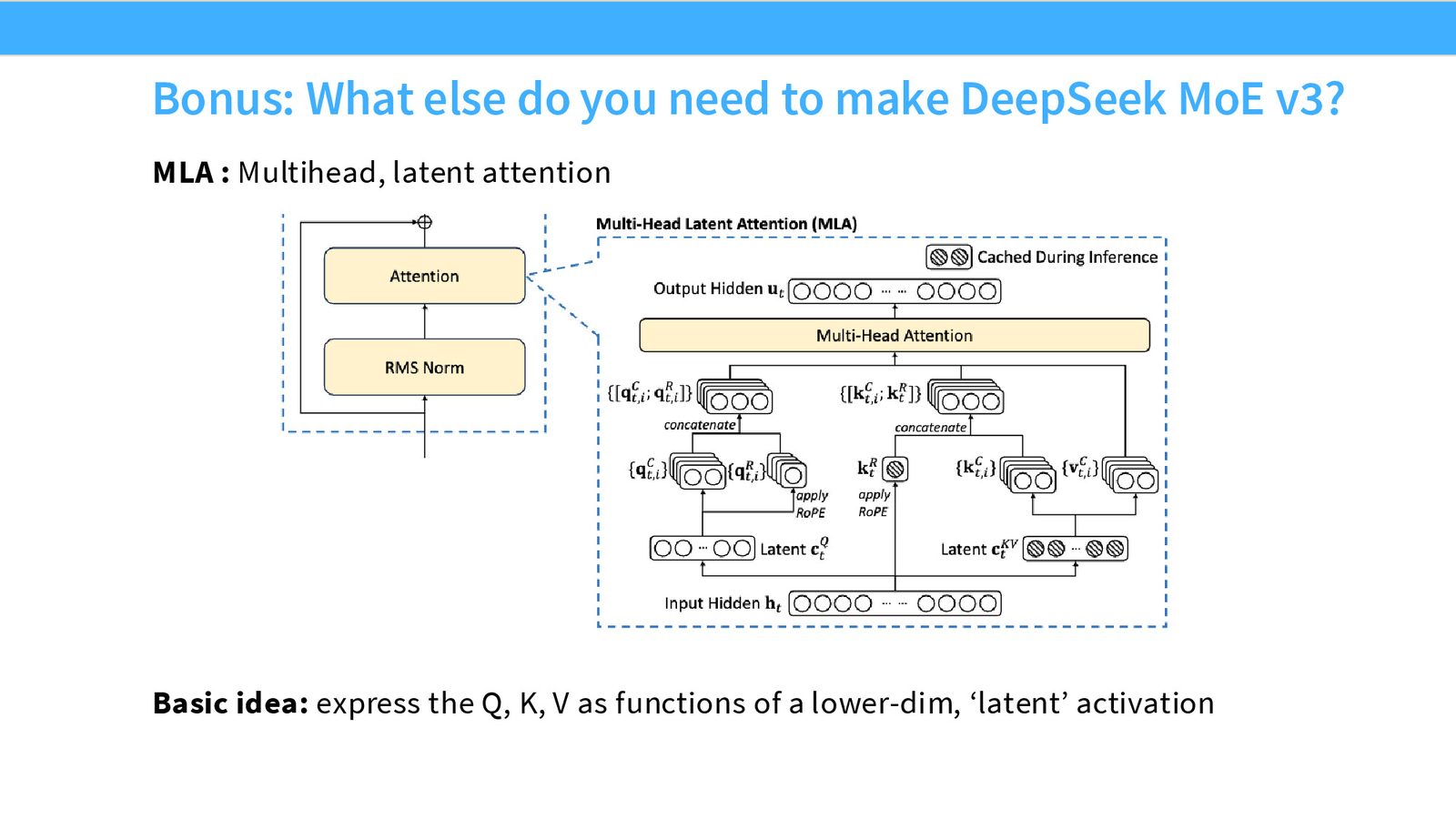
来源:Slides 第11页。来自 DeepSeek V3 论文。
Multi-head Latent Attention (MLA)
MLA 是 DeepSeek V2/V3 中的另一个重要创新,虽然不直接属于 MoE 范畴,但值得简要介绍:

来源:Slides 第45页。来自 DeepSeek V2 论文。
MLA 的核心思路:
- 将隐藏状态 \(\mathbf{h}_t\) 投影到低维 latent vector \(\mathbf{c}_t = W_{\text{DKV}} \mathbf{h}_t\)
- 只缓存 \(\mathbf{c}_t\)(维度远小于 \(\mathbf{h}_t\))
- 需要 K/V 时,从 \(\mathbf{c}_t\) 上投影恢复:\(\mathbf{k}_t = W_{UK} \mathbf{c}_t\),\(\mathbf{v}_t = W_{UV} \mathbf{c}_t\)
- 利用矩阵乘法结合律,将 \(W_{UK}\) 合并到 Q 的投影矩阵中,不增加额外的矩阵乘法
MLA vs GQA
GQA(Grouped Query Attention)通过减少 KV head 数量来压缩 KV Cache。MLA 采取完全不同的思路——保持所有 head 但将 KV 投影到低维空间。两者目标相同(减少 KV Cache),但 MLA 在理论上可以保留更多信息。
MLA 与 RoPE 不兼容
标准 MLA 中,因为 RoPE 的旋转矩阵夹在 Q 投影和 K 上投影之间,矩阵乘法不能自由交换顺序,导致无法合并矩阵。DeepSeek 的解决方案是在非压缩维度上应用 RoPE,或为 RoPE 添加专门的非压缩维度。
Multi-Token Prediction (MTP)
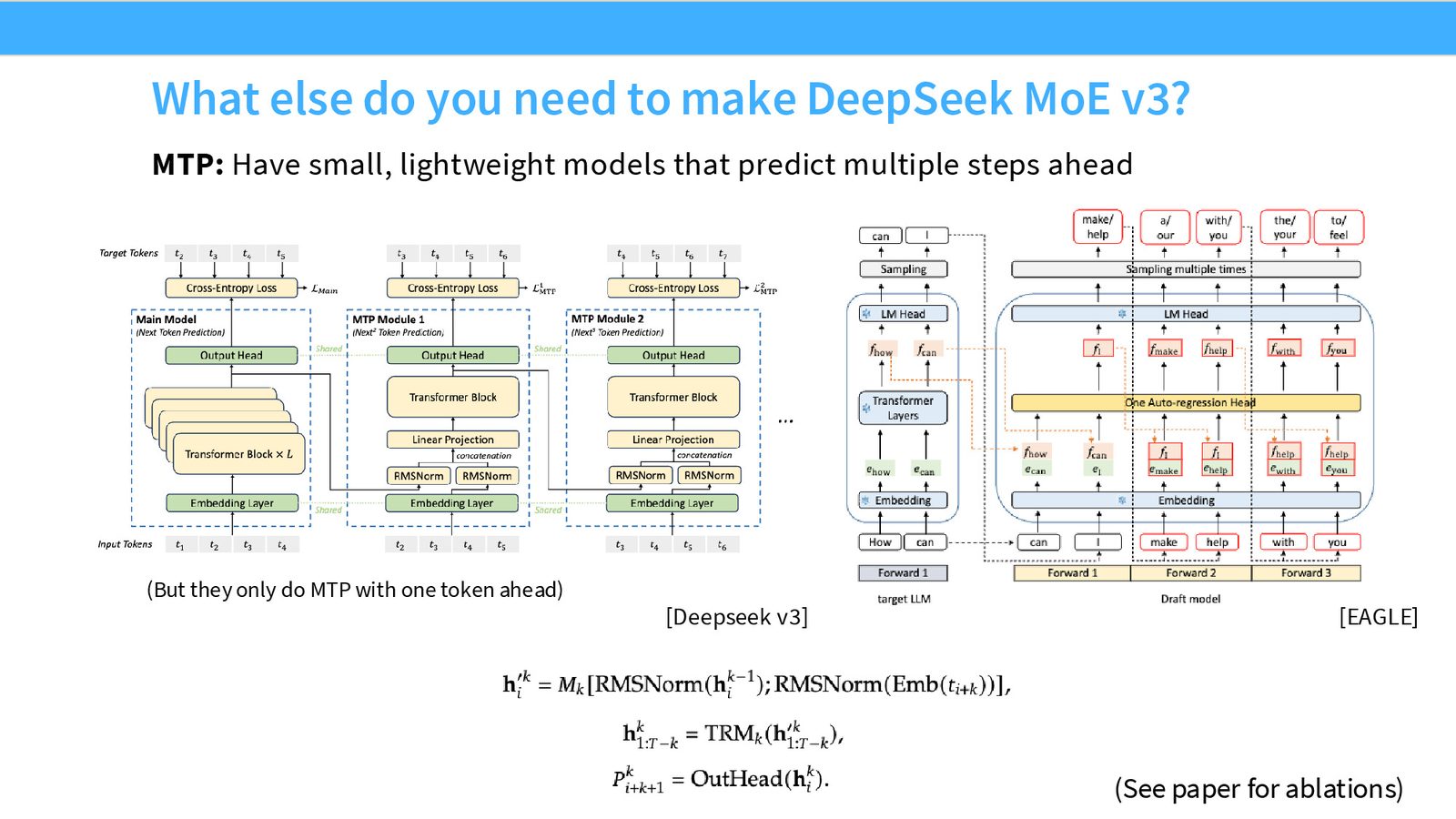
来源:Slides 第46页。来自 DeepSeek V3 论文。
MTP 的思路简单但有效:
- 在主模型的隐藏状态基础上,添加一个轻量级单层 Transformer
- 这个小模型预测下一个 token 之后的 token(即 “next-next token”)
- 额外的预测损失可以为主模型提供更丰富的梯度信号
- 推理时,MTP 模块还可以用于 speculative decoding(类似 EAGLE)
本章小结
| V1 | V2 | V3 | |
|---|---|---|---|
| 总参数 | 16B | 236B | 671B |
| 激活参数 | 2.8B | 21B | 37B |
| 共享 Expert | 2 | 2 | 2 |
| Routed Expert | 64 | 160 | 256 |
| Top-K | 6 (4 routed) | 6 | 8 |
| 路由方式 | Top-K + Softmax | Top-K + Softmax | Top-K + Sigmoid |
| 均衡策略 | Aux Loss | Aux Loss | Bias + Seq Aux Loss |
| 注意力 | MHA | MLA | MLA |
| MTP | – | – | 1 token ahead |
总结与延伸
讲者的核心总结
Tatsu Hashimoto 在课程结尾强调了以下几点:
- MoE 已成标配:在 FLOP 约束的设置下,MoE 几乎总是优于 Dense 模型。这一结论在 2025 年已经有大量经验证据支持。
- 稀疏性是关键:MoE 的核心优势来自“不需要所有参数同时工作”——这使得模型可以拥有大量参数而不按比例增加计算成本。
- 离散路由是核心挑战:Top-K 路由决策的不可微性使得训练变得复杂,但启发式方法(辅助损失、bias balancing)在实践中表现良好。
- 架构变化有限:DeepSeek 从 V1 到 V3,核心 MoE 架构几乎未变——好的架构在小规模验证后可以直接放大。
全课知识图谱

关键 Takeaways
六条核心原则
- MoE 用参数换 FLOPs:更多参数、更少计算,是当前最高效的 scaling 方式
- 路由器越简单越好:线性内积 + Softmax + Top-K 已经足够,复杂路由器收益有限
- 细粒度 Expert 是关键创新:将 expert 切小、数量增多,是提升 MoE 性能的最有效手段
- 负载均衡是训练成败的关键:没有均衡约束,Expert Collapse 几乎不可避免
- 好的架构在小规模就能验证:DeepSeek V1 的架构直接放大到 V3,证明了小规模实验的价值
- Expert 并不真正“专业化”:随机路由也有效,MoE 的核心优势来自稀疏参数扩展本身
拓展阅读
- Fedus et al., “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity”: https://arxiv.org/abs/2101.03961
- Fedus et al. 2022, “A Review of Sparse Expert Models in Deep Learning”: https://arxiv.org/abs/2209.01667
- Shazeer et al. 2017, “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer”: https://arxiv.org/abs/1701.06538
- DeepSeek-MoE: https://arxiv.org/abs/2401.06066
- DeepSeek-V2: https://arxiv.org/abs/2405.04434
- DeepSeek-V3: https://arxiv.org/abs/2412.19437
- OLMoE: https://arxiv.org/abs/2409.02060
- Mixtral of Experts: https://arxiv.org/abs/2401.04088
- Zoph et al., “ST-MoE: Designing Stable and Transferable Sparse Expert Models”: https://arxiv.org/abs/2202.08906