CS224R Lecture 10: 强化学习用于 LLM 推理
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于公开课程资料整理 |
| 来源 | Stanford Online |
| 日期 | 2025 年春季 |

引言:为什么需要 RL 来做推理
本讲由 CMU 的 Aviral Kumar 客座讲授,聚焦于强化学习(RL)在大语言模型(LLM)推理中的应用。讲者将推理限定在数学问题求解场景下进行阐述,并以时间线为轴将内容分为两大部分:经典 RL 技术和现代扩展。
核心动机
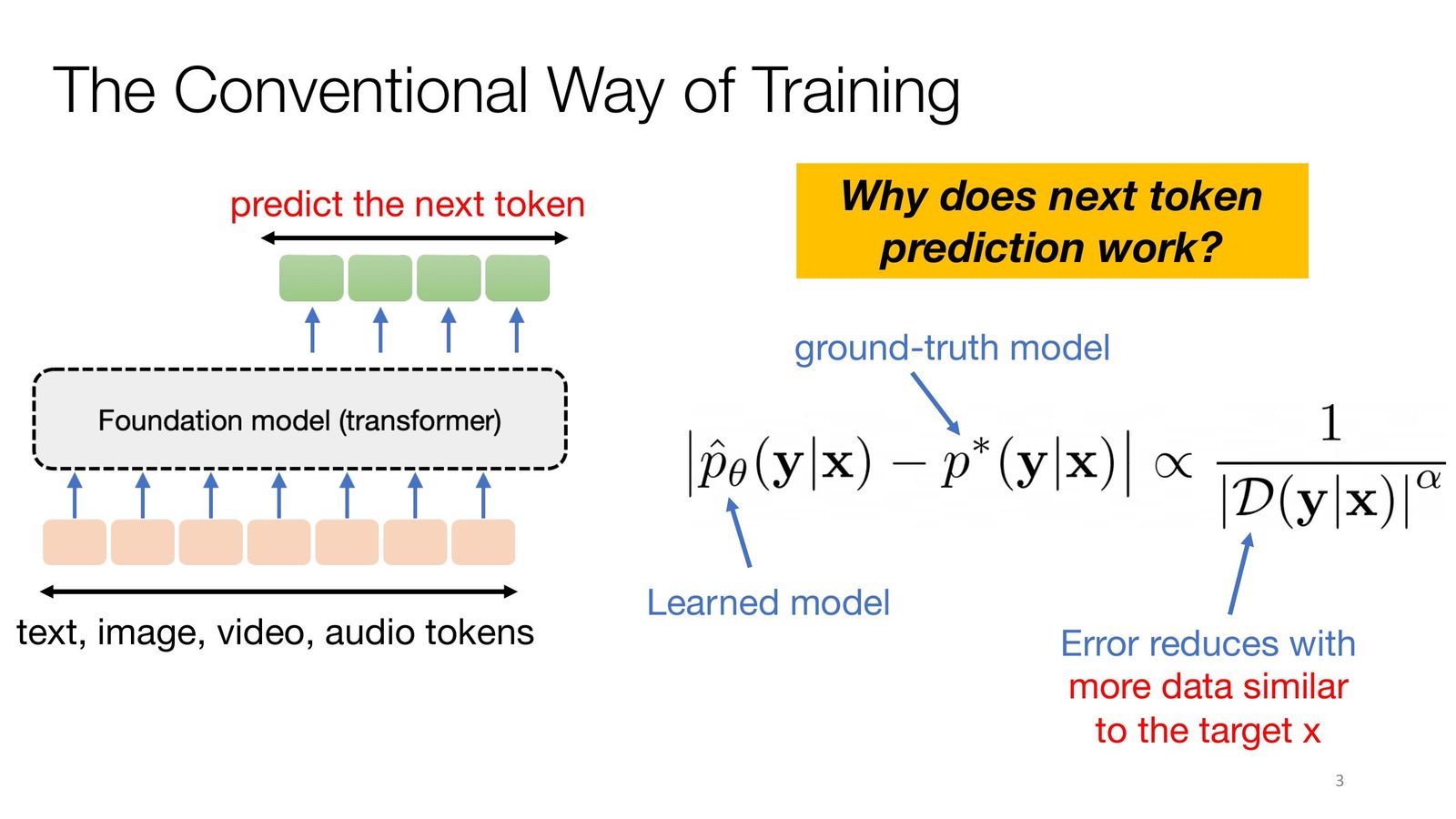
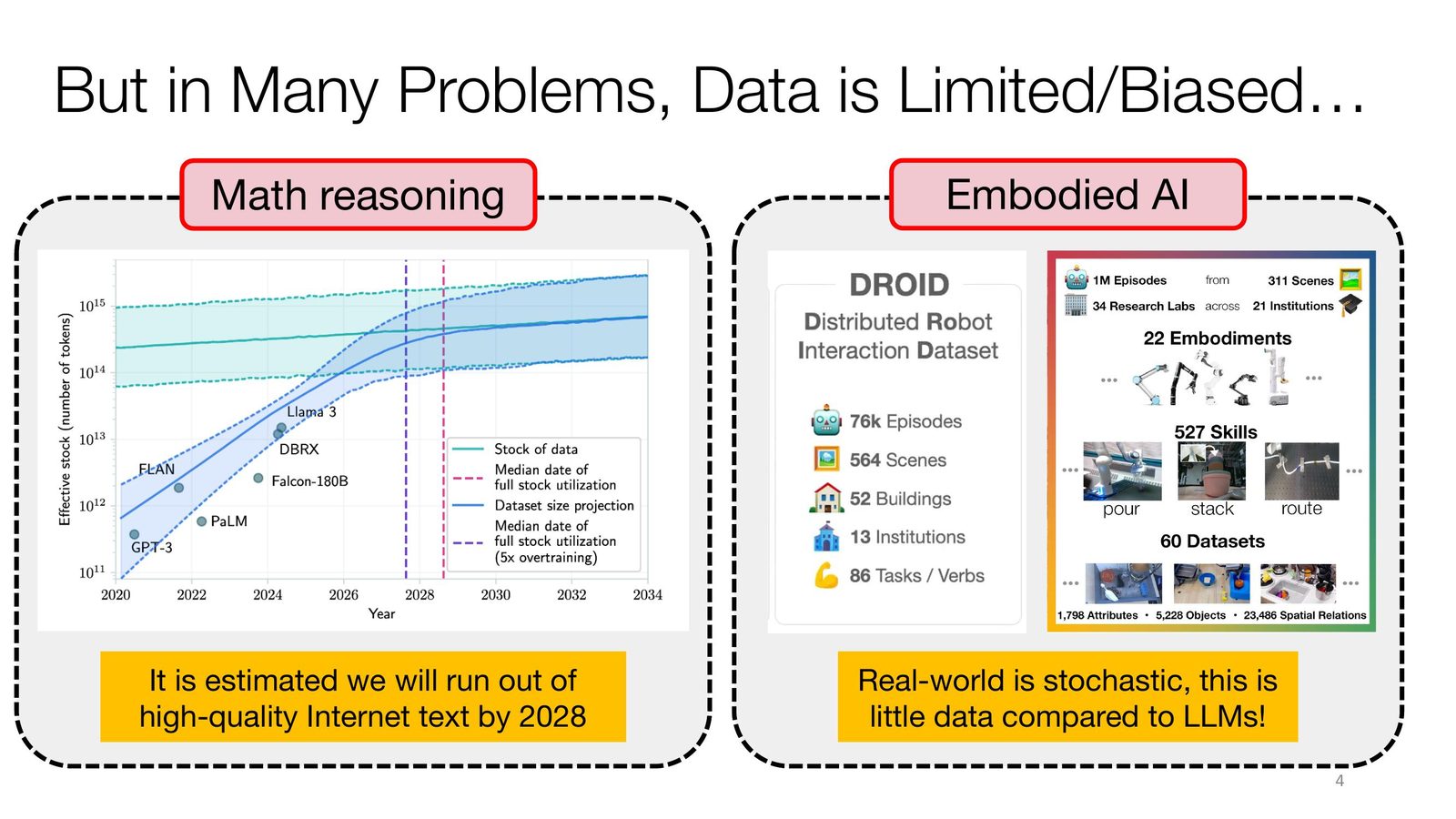
传统的 next-token prediction(NTP)训练范式存在根本性局限:学习到的模型 \(\hat{p}_\theta(\mathbf{y}|\mathbf{x})\) 与真实分布 \(p^*(\mathbf{y}|\mathbf{x})\) 的误差正比于 \(|\mathcal{D}(\mathbf{y}|\mathbf{x})|^{-\alpha}\),即误差随与目标输入 \(\mathbf{x}\) 相似的数据量增加而减小。对于推理问题,高质量的问题--解答数据极其稀缺,预计到 2028 年互联网高质量文本数据将耗尽。
NTP 的失败模式
仅靠监督训练的模型在解决如 AIME(美国数学邀请赛)或 IMO(国际数学奥林匹克)等困难数学问题时,虽然能生成"看上去像解答"的文本,但逻辑推理链条往往存在关键错误。模型会跳过必要的推理步骤,或者在证明过程中对个别项进行分析而忽略整体结构。
来源:Slides 第 3 页。
来源:Slides 第 4 页。
本章小结
NTP 在推理场景下失效的核心原因是高质量推理数据不足。RL 的价值在于不依赖人工标注的完整解答,而是通过奖励信号(如答案是否正确)引导模型自主发现正确的推理路径。
讲座大纲
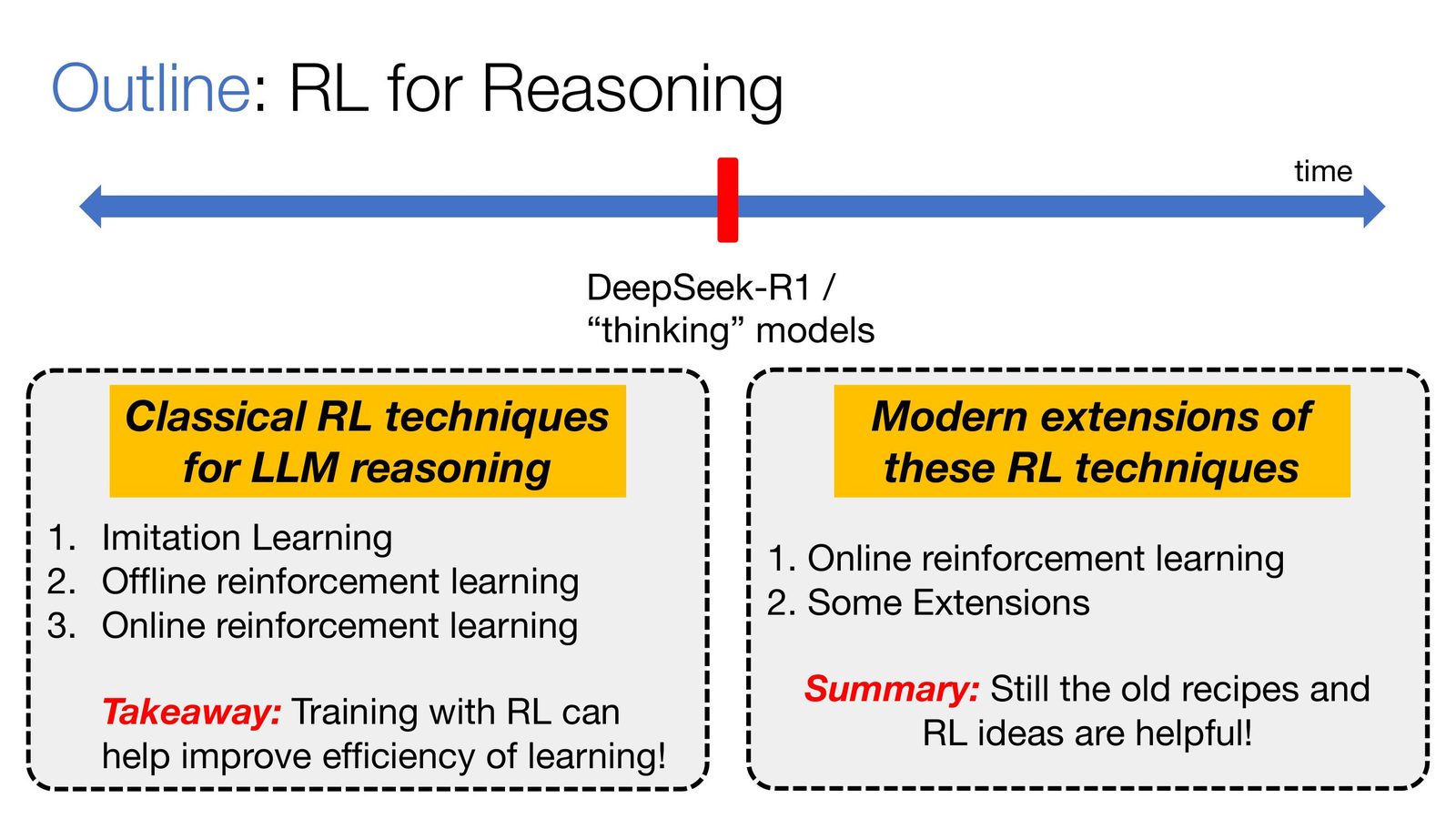
讲者将 RL for Reasoning 以 DeepSeek-R1/"thinking"模型为分界点,分为两个历史阶段:
来源:Slides 第 6 页。
- Part 1 --- 经典 RL 技术:Imitation Learning、Offline RL、Online RL
- Part 2 --- 现代扩展:在线 RL 训练"thinking"模型、DeepSeek-R1、Kimi K1.5 等
Part 1:经典 RL 技术用于 LLM 推理
将推理建模为 RL 问题
MDP 建模
将数学推理问题建模为 MDP:
- 状态 \(s_t\):问题描述 + 到目前为止生成的解答前缀(token 序列)
- 动作 \(a_t\):下一步推理步骤(可以是一个 token 或一个推理步骤/句子)
- 奖励 \(r\):通常是稀疏的终端奖励,仅当完整解答生成后验证答案是否正确(outcome-based reward)
- 策略 \(\pi_\theta(a_t | s_t)\):语言模型本身
数据扩增:扩展问题和解答数量
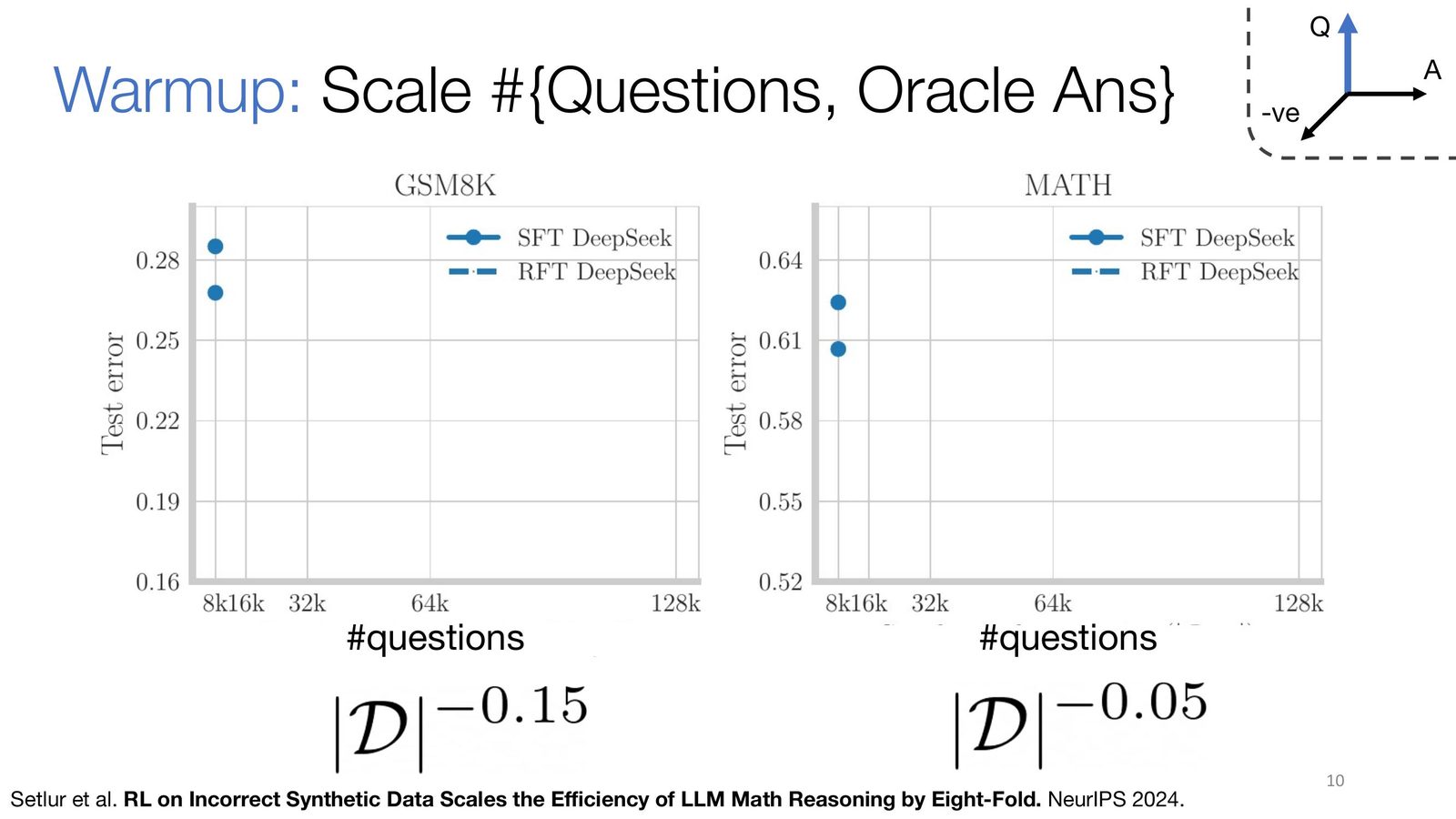
在最简单的设定下,收集更多的 (问题, 解答) 对来做监督微调(SFT)。Setlur et al. (NeurIPS 2024) 的实验表明:
- 在 GSM8K 上,SFT 测试误差随问题数增长的收敛速率约为 \(|\mathcal{D}|^{-0.15}\)
- 在 MATH 上更慢,约为 \(|\mathcal{D}|^{-0.05}\)
来源:Slides 第 10 页。
RFT(Rejection Fine-Tuning)
RFT 是一种简单的利用 RL 信号改进 SFT 的方法:用当前模型采样多个解答,仅保留答案正确的解答用于微调。这等价于一种简化的 offline RL,因为它通过奖励信号过滤了训练数据。
为什么 RFT 继续堆数据会失效
讲者特别强调,RFT 不是 “采样更多、训练更久” 就能无限提升的策略。问题在于:这些 on-policy 正样本来自模型自己的行为分布,它们携带了当前策略已经形成的偏差。模型短期内能在训练提示上学会 “自我修补”,但这种修补往往不是对推理规律的真正掌握,而是对特定轨迹模式的记忆。
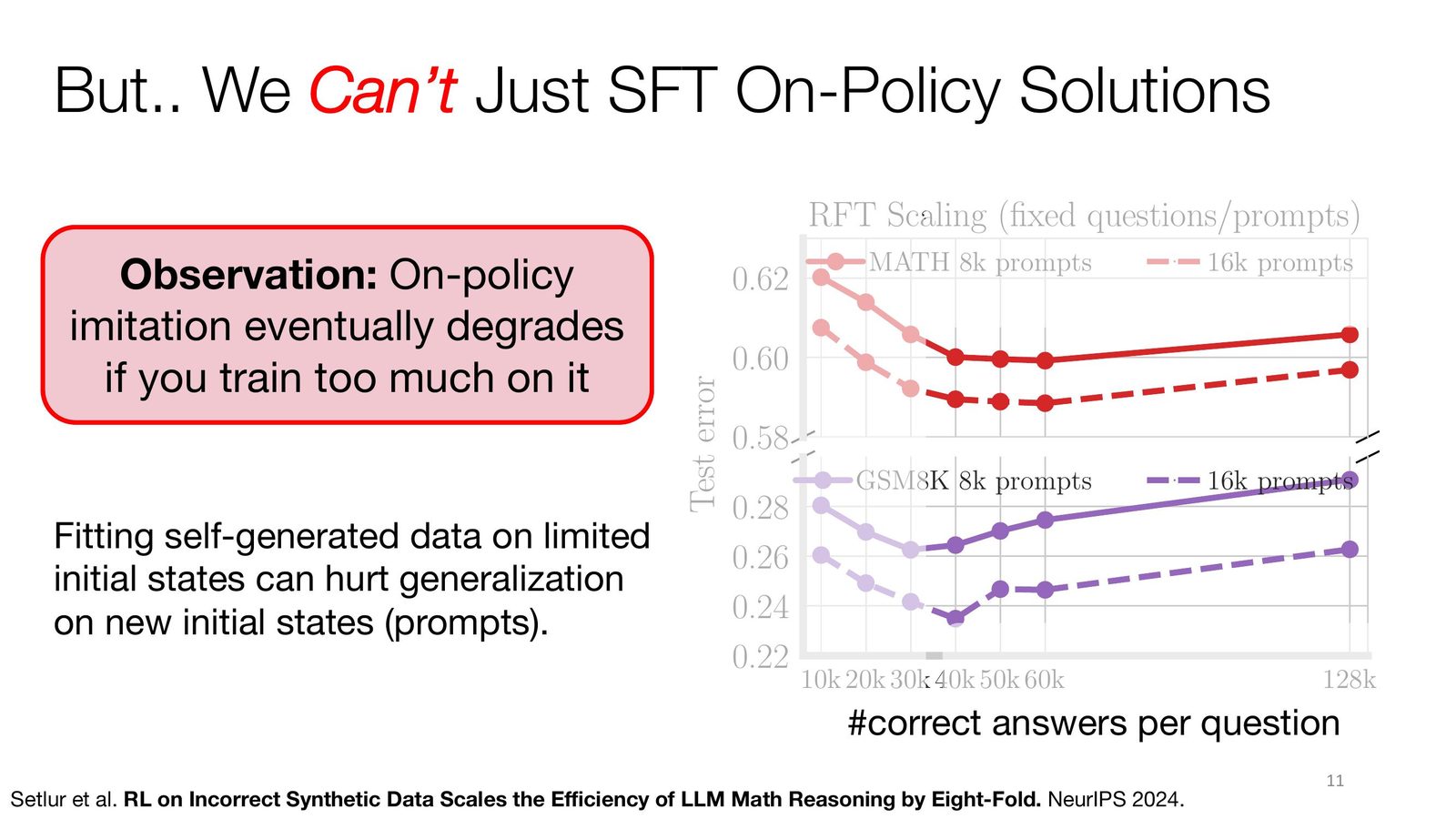
来源:Slides 第 11 页。
RFT 的核心风险是伪步骤被强化
如果模型在某类题目中偶然生成了能通向正确答案、但逻辑上并不稳固的中间步骤,那么 RFT 会把这些步骤也当作 “可学习样本” 一并放大。训练误差下降不代表推理更稳,只可能说明模型更会复述自己原本的习惯。
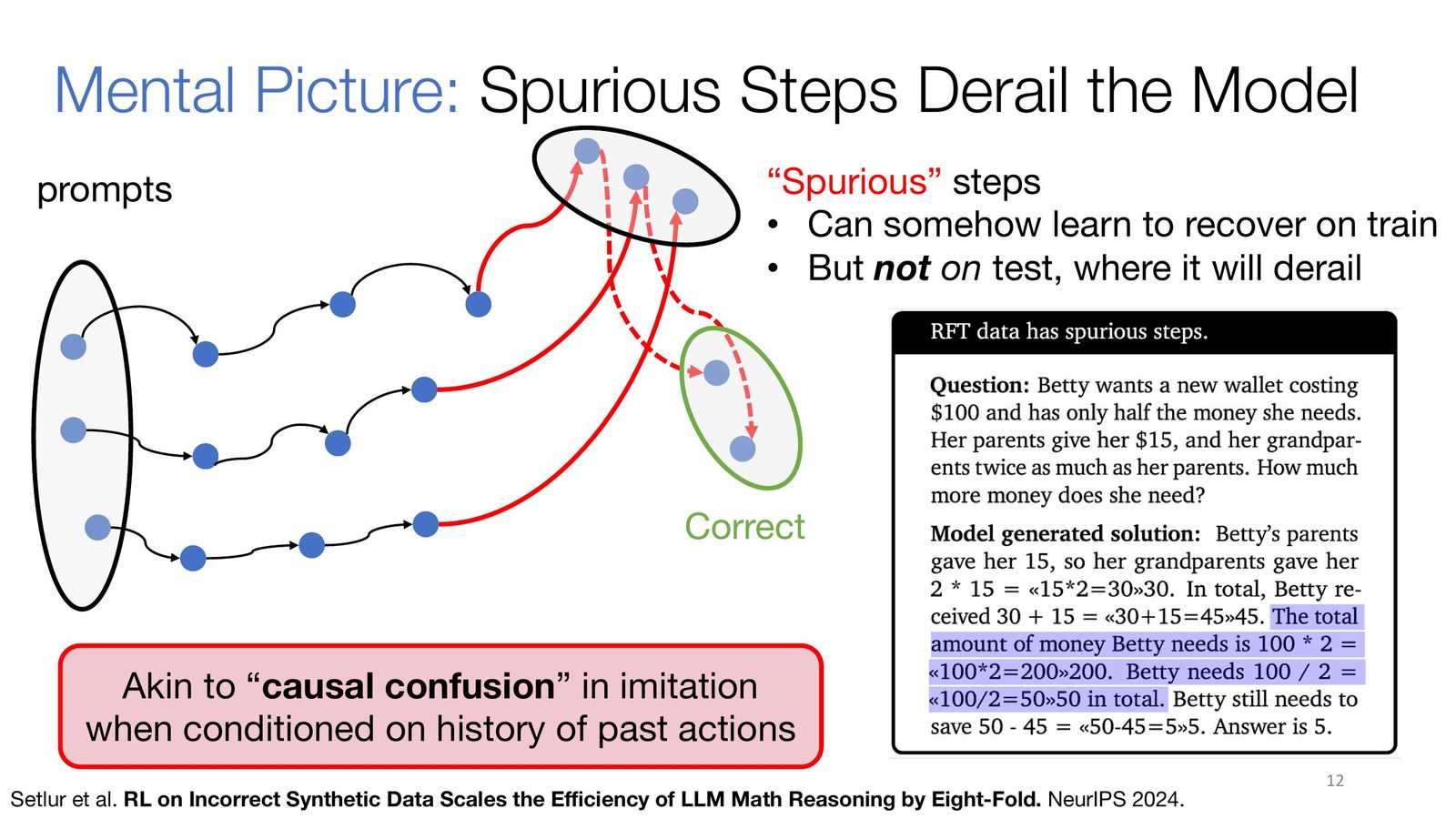
来源:Slides 第 12 页。
离线 RL:利用负样本的优势
关键洞察:不仅使用正确解答(正样本),还应利用错误解答(负样本)来提供对比信号。
Per-Step Advantage 的概念
对于错误解答中的每一步推理,可以通过从该步出发多次 rollout 来估计该步的"优势"(advantage)。如果从某个中间步出发的 rollout 总是失败,说明该步是一个"错误步骤";如果有时成功有时失败,说明该步是"尚可的步骤"。这本质上是在估计 rollout 策略的值函数。
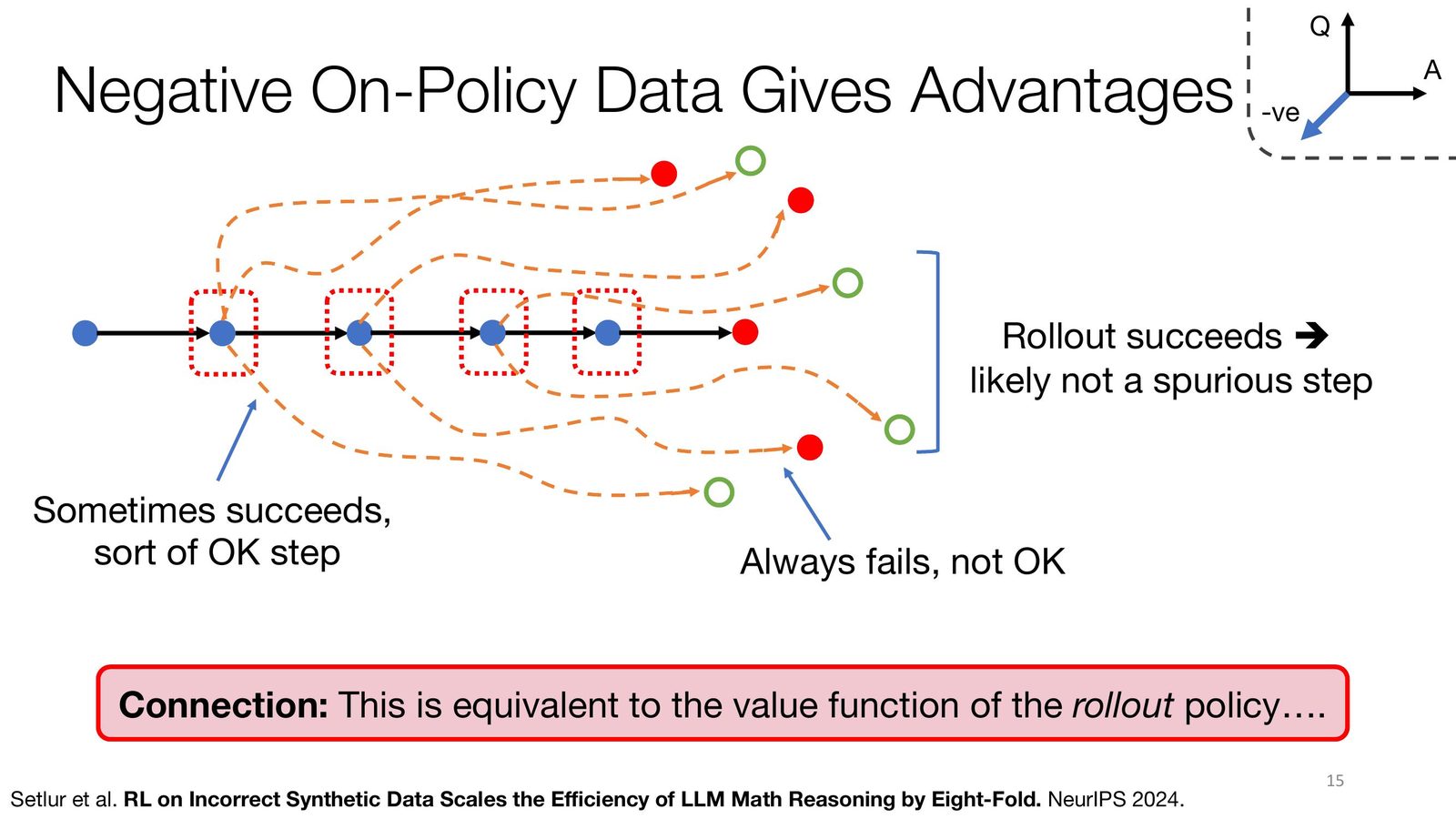
来源:Slides 第 15 页。
离线 RL 使用这些优势估计的两种方式:
- Option 1:仅使用估计的优势进行加权 SFT(对正确步骤加大权重,对错误步骤降低权重)
- Option 2:使用 DPO(Direct Preference Optimization),保留来自 \(\tilde{\pi}\) 的部分 rollout 进行偏好对比训练

来源:Slides 第 20 页。
Advantage 到底在刻画什么
这部分是整场讲座中最值得反复消化的技术点。Aviral Kumar 把 “每一步是否值得保留” 明确转成了一个价值估计问题:固定某个中间步骤后,再从这里继续 rollout,多次观察最终成功率。如果某一步后续几乎总是失败,这一步就应当得到负 advantage;如果后续成功率明显更高,则说明它把搜索过程带向了更好的区域。
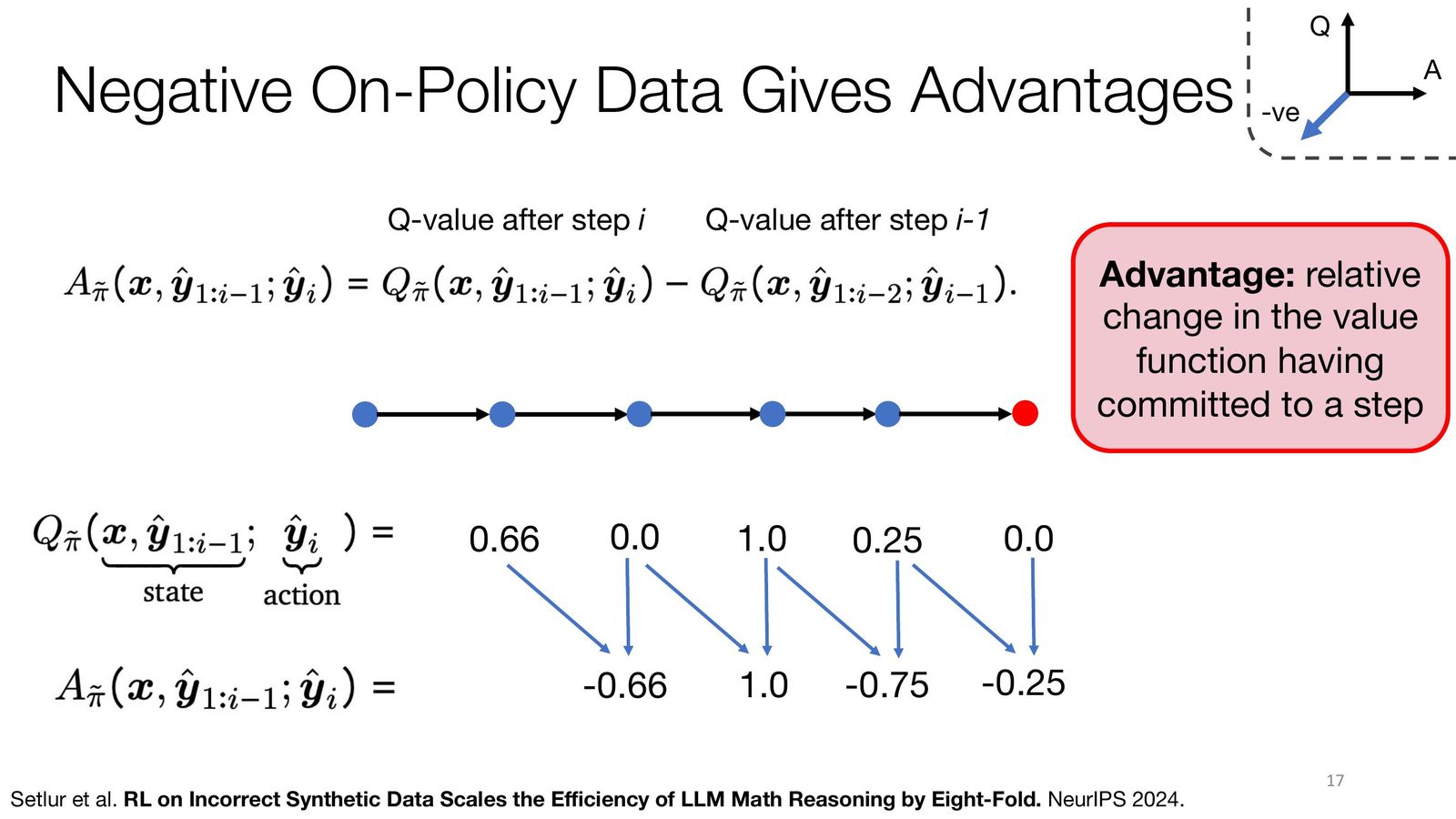
来源:Slides 第 17 页。
从 step filtering 到偏好学习
一旦拿到了 step-level advantage,就有两种非常自然的训练用法:
- 直接过滤:只保留 advantage 高的步骤,形成更干净的 imitation 数据。
- 形成偏好对:把好步骤与坏步骤、好轨迹片段与坏轨迹片段组成 preference pair,再用 DPO 这类目标去优化。
这也是本讲一直在强调的主线:RL 的价值不只是最终 reward,更在于把稀疏结果信号变成更密的训练监督。

来源:Slides 第 19 页。
离线 RL 的局限
Offline RL 的关键问题在于:用来估计 advantage 的 rollout 策略 \(\tilde{\pi}\) 与当前正在训练的策略 \(\pi_\theta\) 之间存在分布偏移(distribution shift)。随着训练进行,\(\pi_\theta\) 更新后 advantage 估计会变得不准确。
在线 RL:REINFORCE 和 PPO
为了解决离线 RL 的分布偏移问题,在线 RL 在训练过程中持续用当前策略采样新数据。
在线 RL 的基本流程:
- 用当前策略 \(\pi_\theta\) 对问题采样多个解答
- 用奖励模型或验证器评估这些解答
- 估计每步的优势(advantage)
- 用策略梯度方法(如 REINFORCE 或 PPO)更新策略
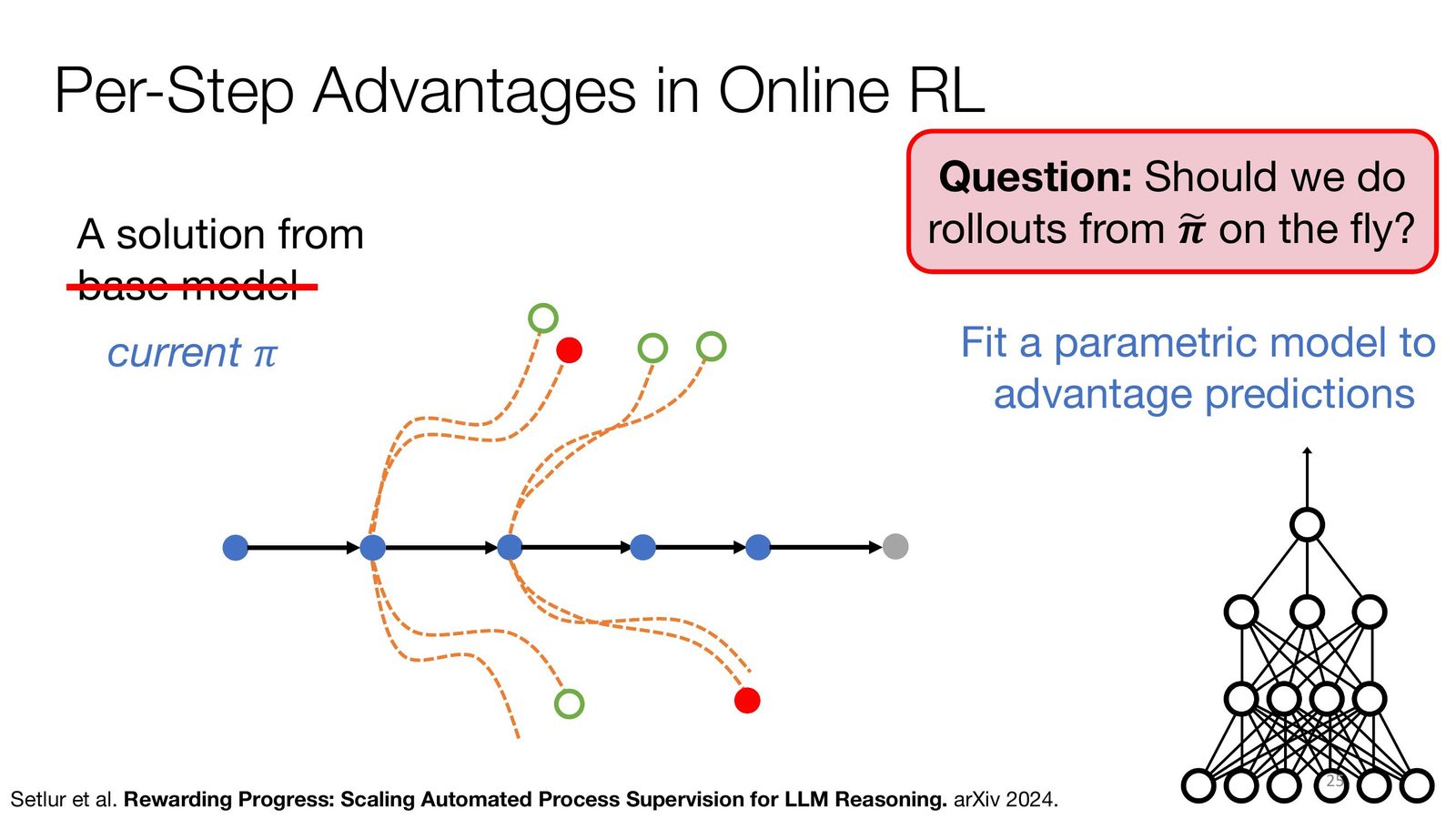
来源:Slides 第 25 页。
一个关键问题是:是否应该在线实时做 rollout 来估计 advantage?讲者提到可以训练一个参数化的过程奖励模型(Process Reward Model, PRM)来预测每步的 advantage,从而避免昂贵的在线 rollout。
PAV:把 outcome reward 变成 dense reward
如果说 offline RL 的关键是把错误轨迹也变成有价值的监督,那么 online RL 的关键就是进一步让奖励信号变密。Setlur et al. 在 “Rewarding Progress” 中提出的 Process Advantage Verifier(PAV)正是为此服务:它学习预测某一步推理给后续成功率带来的边际提升,从而把原本只在答案正确时出现的 0/1 奖励,改写成贯穿整条解答链的 dense bonus。

来源:Slides 第 26 页。
为什么 dense reward 特别适合推理任务
数学与代码推理的搜索空间极大,且正确轨迹非常稀疏。仅靠最终答案 reward,相当于要求模型在几乎没有中途反馈的情况下盲目搜索;而 PAV 提供的 step-level bonus 能持续告诉模型:当前这一步是否把自己带向更可能成功的解空间。
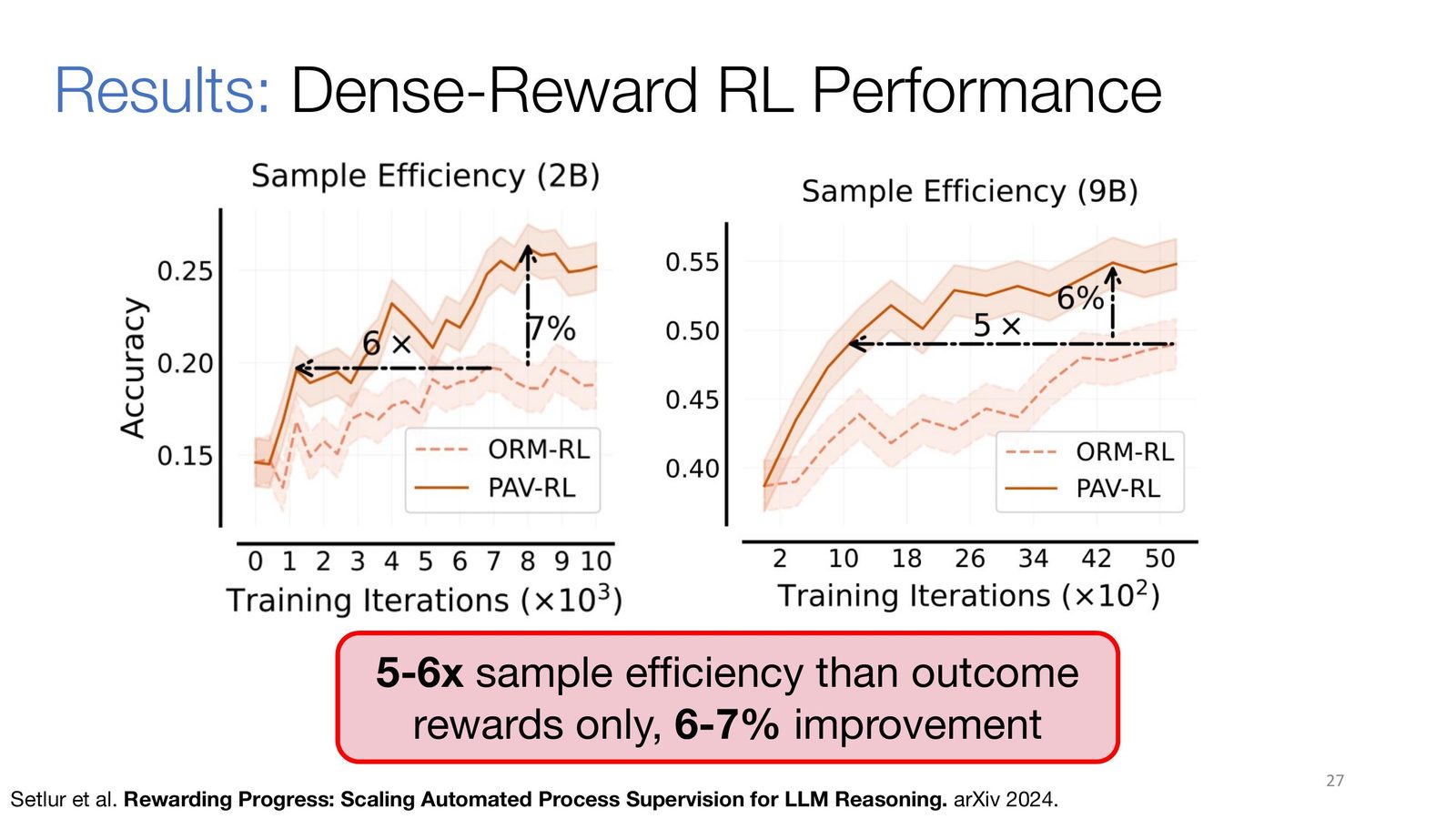
来源:Slides 第 27 页。
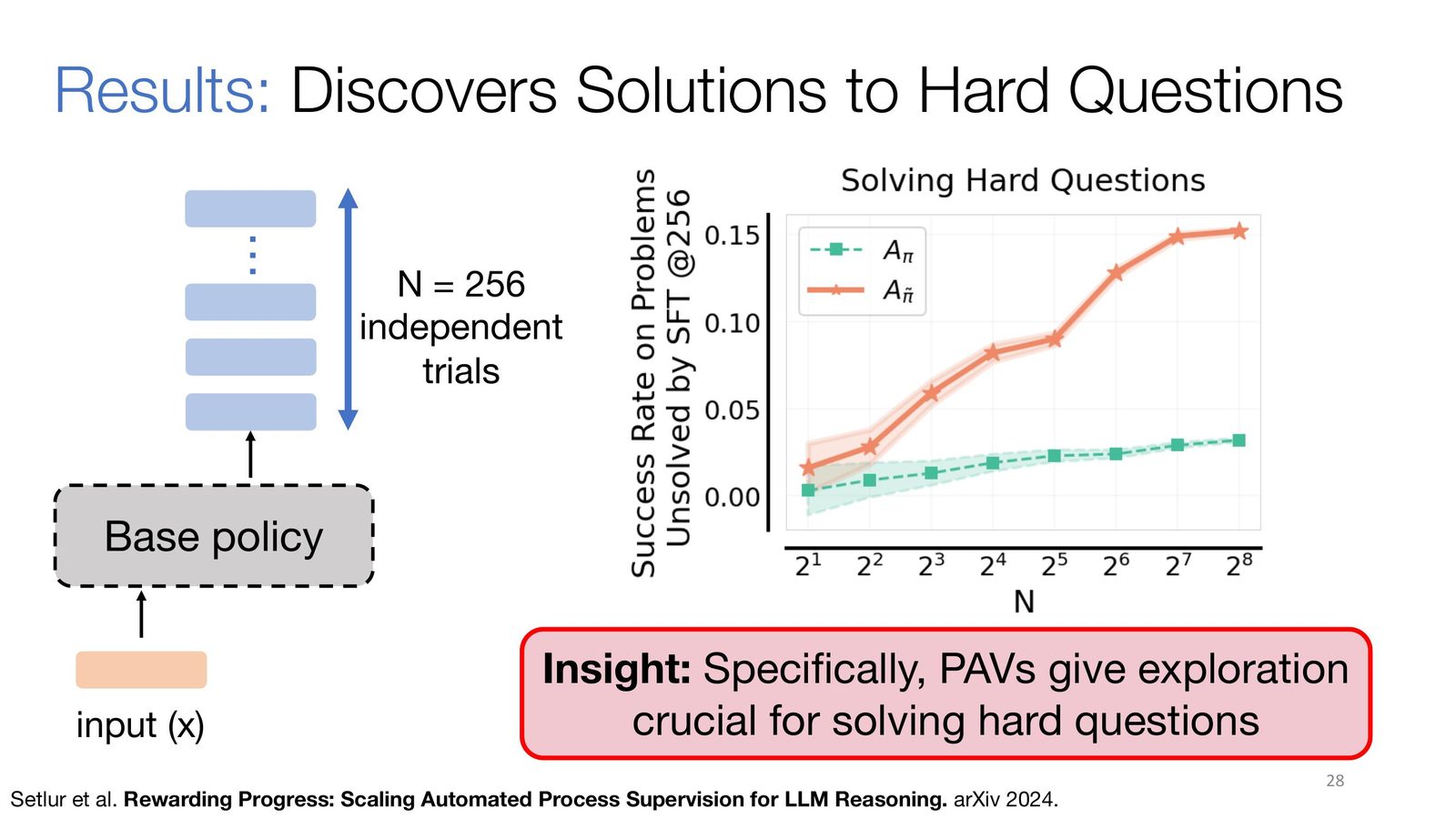
来源:Slides 第 28 页。
本章小结
经典 RL 技术(SFT \(\to\) RFT \(\to\) Offline RL \(\to\) Online RL)形成了一个逐步强化的工具链。核心 takeaway 是:RL 训练可以显著提高 LLM 推理的数据效率,相比纯 SFT 可提升约 8 倍。
Part 2:训练"Thinking"模型

来源:Slides 第 30 页。
DeepSeek-R1:通过 RL 激励推理能力
DeepSeek-R1 是"thinking model"范式的标志性工作。其核心发现是:仅通过 RL 训练(不需要人工标注的推理链),模型就能自发涌现出复杂的推理行为。
DeepSeek-R1 的训练流程
- 在基础模型上直接应用 GRPO(Group Relative Policy Optimization)进行 RL 训练
- 奖励仅基于最终答案是否正确(outcome reward)+ 格式奖励
- 模型自发学会了:验证(verification)、回溯(backtracking)、设定子目标(subgoal setting)、反向推理(backward chaining)等元策略
GRPO(Group Relative Policy Optimization)
GRPO 是 PPO 的简化变体。对于每个问题采样一组解答,用组内的相对奖励(减去组内均值后标准化)作为优势估计,避免了训练额外的 critic/value 网络。这在大规模 LLM 训练中更加高效。
从具体轨迹理解 “thinking” 是什么
“Thinking model” 这个说法很容易被说得神秘,但讲者展示的例子其实很具体:模型会在一次回答内部执行更多宏观操作,例如尝试一个方向、发现不对、显式验证、回退并重规划。也就是说,RL 并不是单纯让输出更长,而是提高了模型在固定预算内组织这些宏观动作的能力。

来源:Slides 第 31 页。
真正改变的是动作空间,而非 RL 教科书
讲者在 slides 中专门给出一句很重要的判断:训练目标并没有本质改变,真正变化的是模型已经能执行的 “macro actions”。 DeepSeek-R1 仍在做 policy gradient,Kimi K1.5 也仍然依赖 advantage 驱动的策略更新,但基础模型已经能以更长 token budget 表达验证、回溯、子目标分解等高阶行为,因此同样的 RL 配方能在新的动作空间里产生更强效果。

来源:Slides 第 32 页。
为什么 “动作空间升级” 比 “目标函数升级” 更关键
很多讨论把 thinking model 的突破归因于某个新优化器或新损失,但这节课的判断更克制:只要基础模型已经具备一定的元认知雏形,扩大上下文预算、允许更长 rollout、再用 RL 奖励这些行为,就足以显著放大推理表现。换句话说,新能力往往来自已有能力的放大和重组,而不是凭空发明一种全新训练目标。
涌现的推理行为

来源:Slides 第 35 页。
Gandhi et al. (2025) 的研究表明,能否在 RL 训练中涌现认知行为取决于基础模型是否已经具备这些行为的"种子"。DeepSeek 系列模型在 RL 训练过程中,验证和回溯行为的频率先上升后下降;而 Meta 的 Llama 模型则完全没有展现出这些行为,RL 训练也未能改善其推理能力。
RL 并非万能
RL 无法让模型学会它"完全不会"的行为。如果基础模型在预训练阶段没有接触过推理链式思考的数据,单靠 RL 很难从零涌现出复杂推理行为。基础模型的能力是 RL 发挥作用的前提。
固定预算下的训练目标
讲者随后把问题重新表述为一个很工程化的目标:在每道测试题拥有固定总 compute budget 的前提下,训练一个策略,让 sampled response 在这个预算内尽可能提高成功率。这个表述有两个现实含义:
- 推理不是 “越长越好”,而是要在受限预算内决定把算力花在哪里。
- RL、SFT、RFT 本质上都可以被看作这个适应问题的不同求解器,它们差异主要在是否利用奖励以及利用奖励的方式有多充分。

来源:Slides 第 33 页。

来源:Slides 第 34 页。
Kimi K1.5:扩展 RL 训练
Kimi K1.5 的核心贡献在于如何在大规模上有效地进行 RL 训练:
- 更长的上下文窗口(128K tokens)
- 更好的采样策略和奖励设计
- 实验表明 RL 训练的性能随计算量增加而持续提升
长度放大与 test-time scaling 的新范式
RL 训练的另一个直接后果,是模型愿意把更多 token 预算用在真正有价值的地方。讲者引用 Kimi 的报告指出,RL 训练后模型回答长度显著增长,但这不是无意义冗长,而是伴随着更多检查、修正和分支探索。于是,“推理时多给一些计算” 开始成为一条可与 “继续增大模型参数” 并列的性能提升路线。
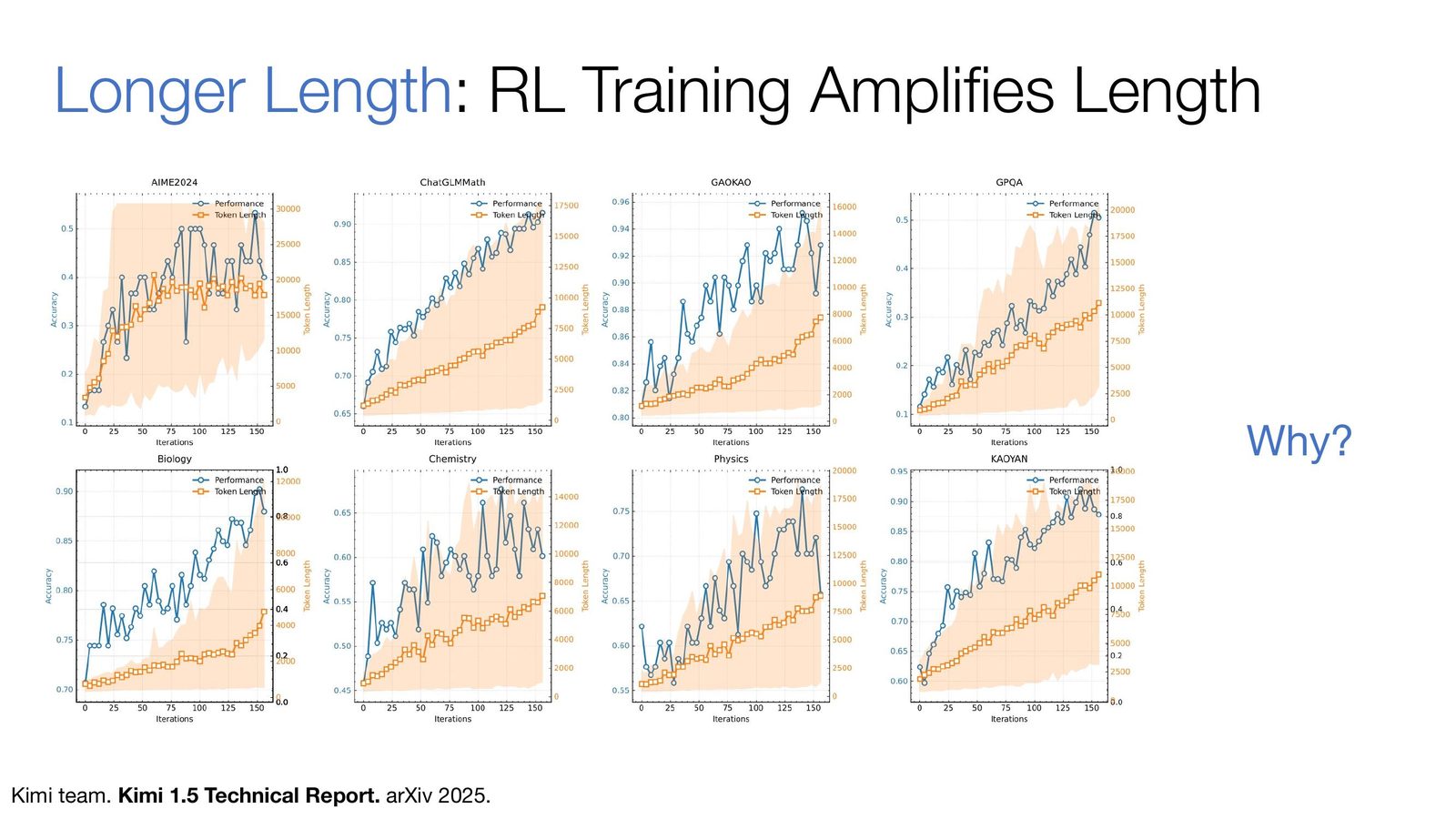
来源:Slides 第 36 页。
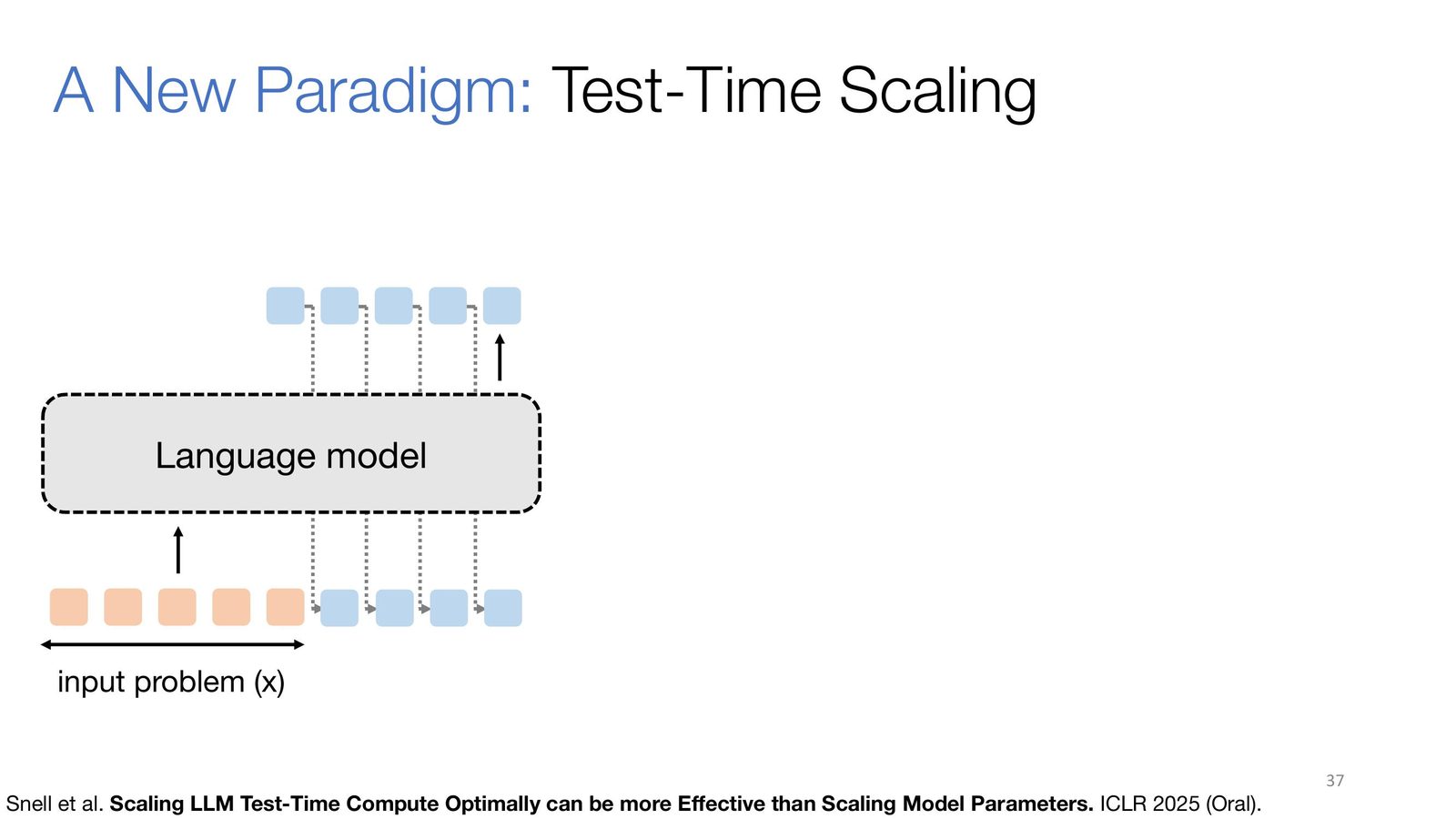
来源:Slides 第 37 页。
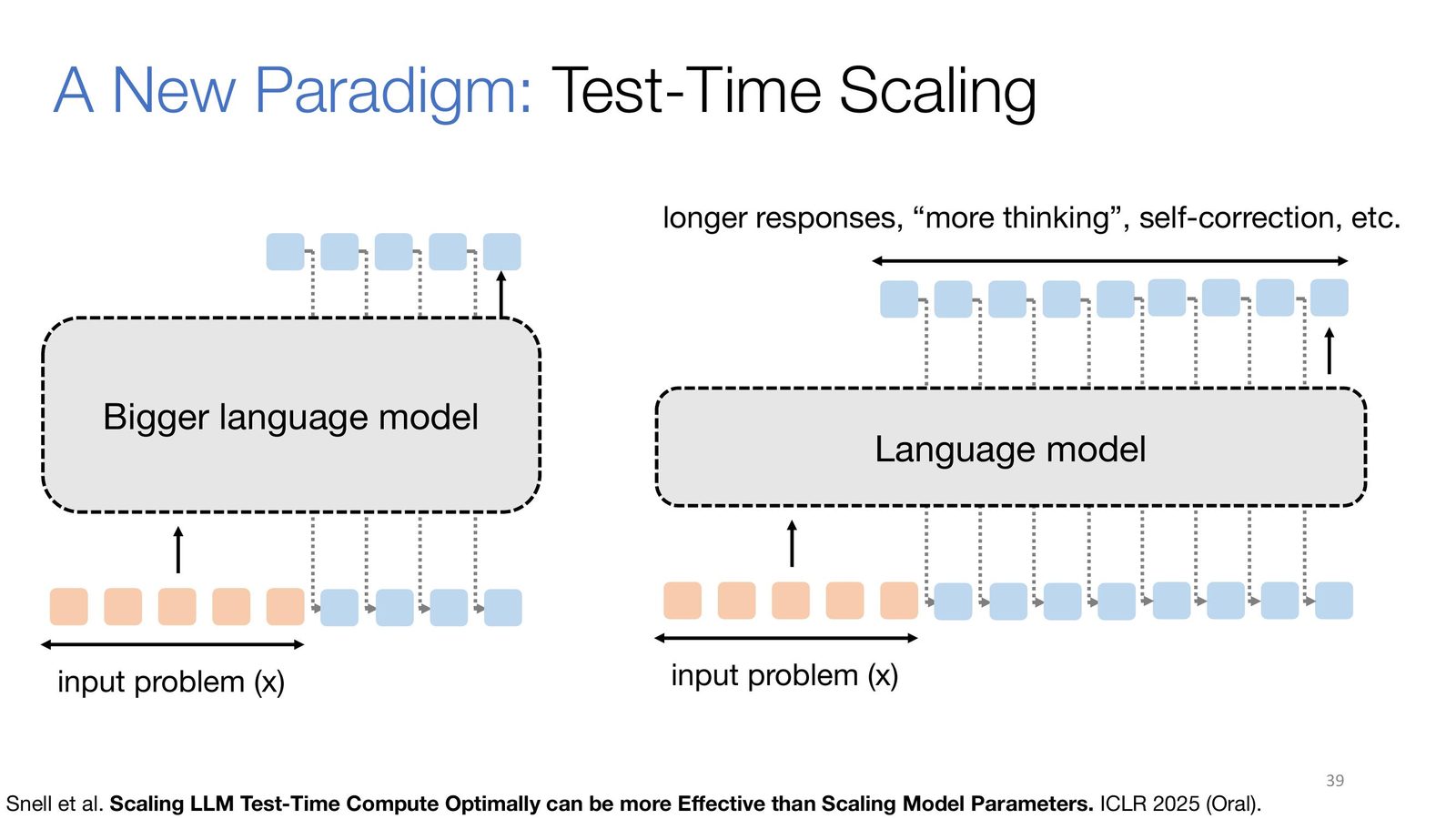
来源:Slides 第 39 页。
Thinking 模型的效果
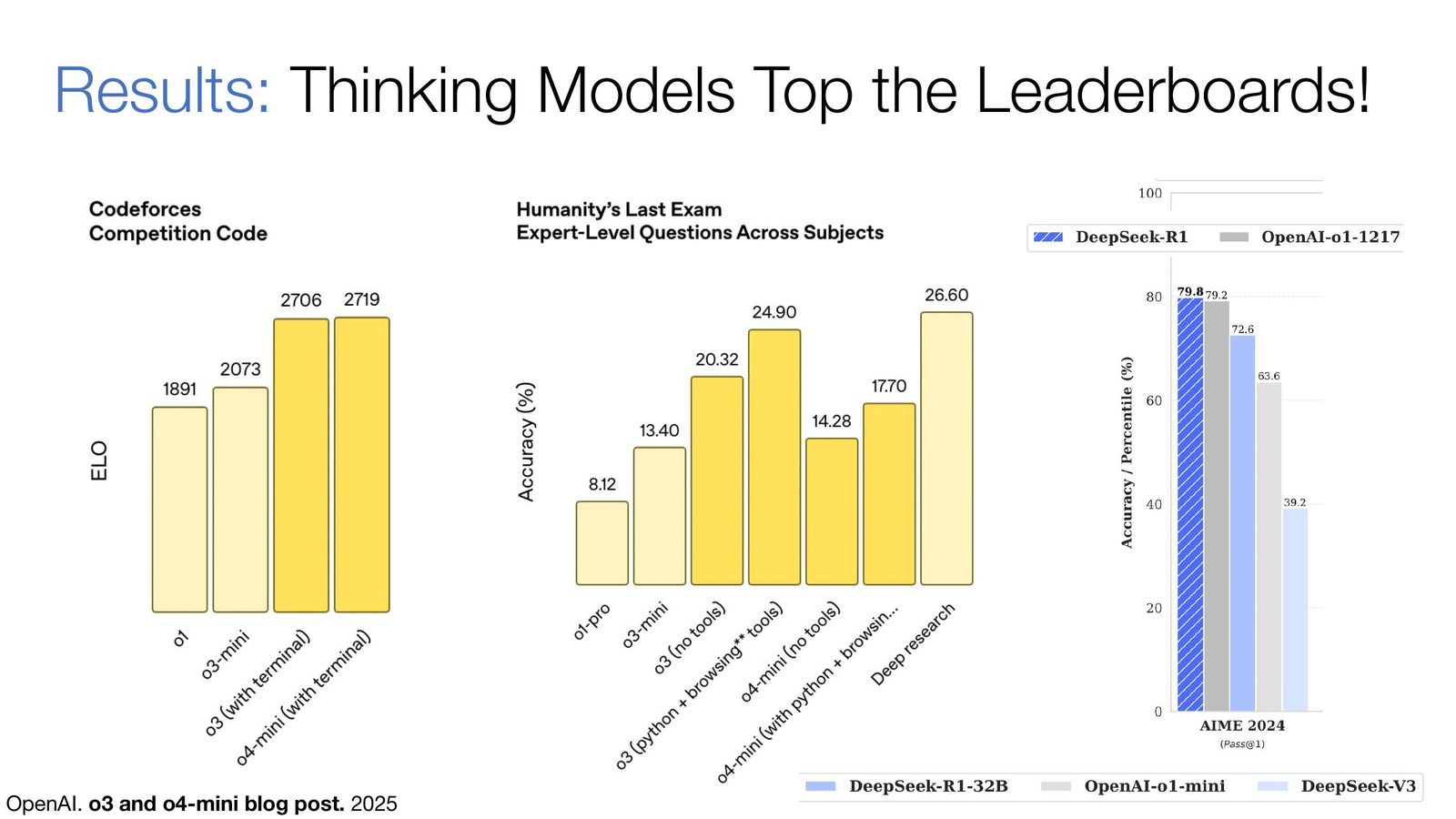
来源:Slides 第 40 页。
Thinking 模型在 Codeforces 竞赛编程、Humanity's Last Exam、AIME 等多个基准上取得了显著提升。DeepSeek-R1 在 AIME 2024 上达到 79.8% 的 Pass@1,与 OpenAI o1-1217 的 79.2% 相当。
Test-Time Compute 与 Meta-RL
讲者最后提到,优化 test-time compute(推理时计算量分配)本质上是一个 Meta-RL 问题:模型需要学习在推理时如何"花费"计算预算。
还没有解决的问题
尽管 leaderboard 成绩已经很亮眼,这节课最后一页反而是警告意味最强的一页:当前 thinking model 仍然缺乏统一而清晰的 formulation。我们还没有彻底回答三件事:第一,是否存在比 outcome reward 更稳健的 dense reward 设计;第二,在什么条件下 RL 的收益会稳定超过 SFT;第三,如何把 “推理增强” 严格表述为一个适应问题,而不是一组经验技巧的堆叠。
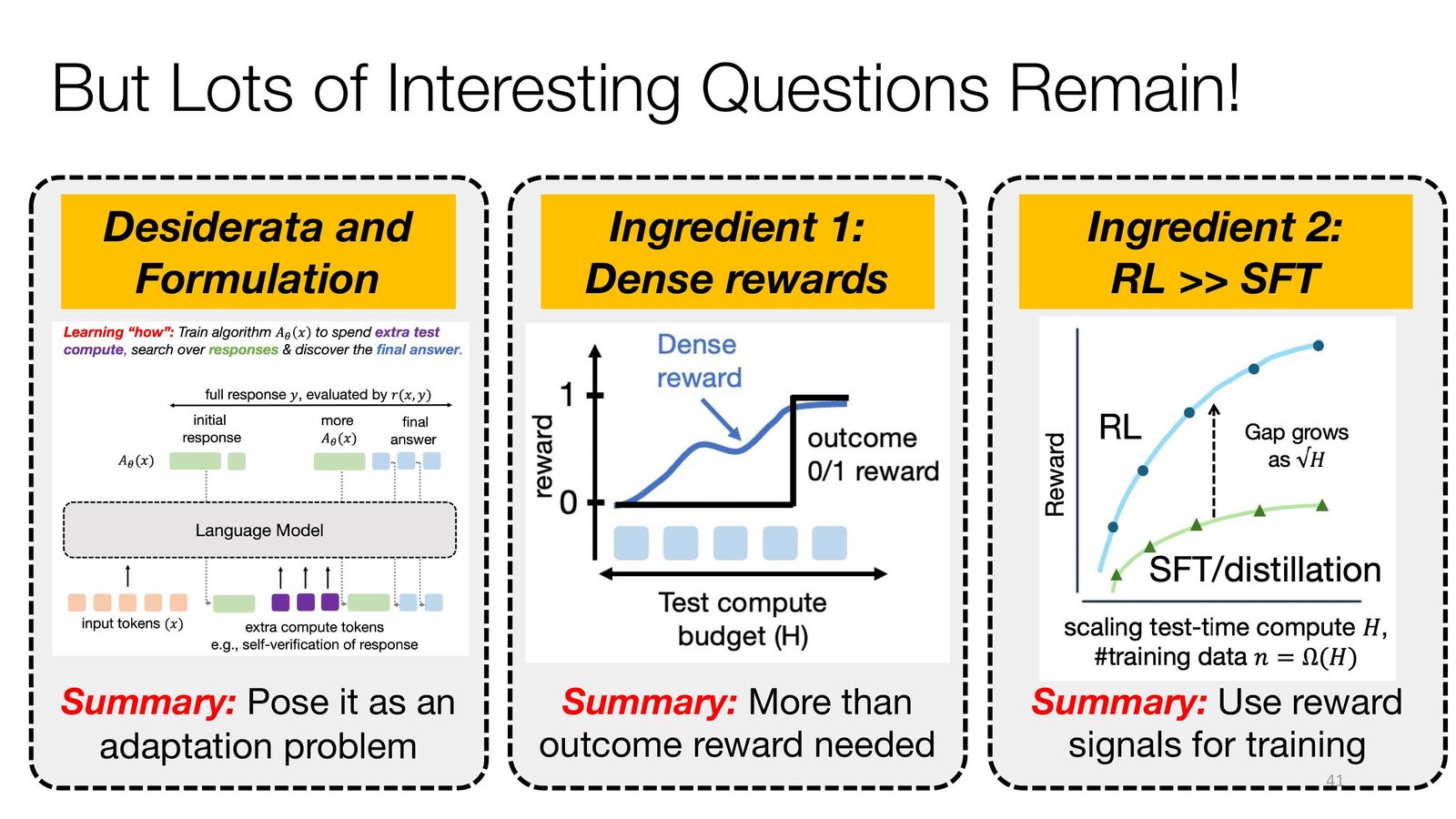
来源:Slides 第 41 页。
真正的挑战不在于复刻一篇 DeepSeek-R1
如果只盯着某个公开模型或某条 benchmark 曲线,很容易把问题误解成 “找到同款 recipe”。但 Aviral Kumar 的收束方式更像研究问题清单:我们仍然需要弄清楚奖励信号的形状、搜索与验证的耦合方式、以及不同基础模型为何对 RL 的响应差异如此巨大。
本章小结
DeepSeek-R1 等 thinking model 证明了:(1) RL 可以激励 LLM 自主发展推理能力;(2) 关键前提是基础模型需具备推理行为的"种子";(3) GRPO 等简化的策略优化方法在大规模训练中既高效又有效。
总结与延伸
本讲的核心信息是:经典 RL 的基本思想(策略梯度、advantage estimation、on/off-policy 区分)在 LLM 推理中同样适用且至关重要。
关键 takeaway:
- SFT 受限于数据稀缺,纯靠扩展数据的 scaling 速率很慢
- RL 通过利用负样本和 advantage 信号,将数据效率提升了约 8 倍
- 在线 RL(如 GRPO/PPO)通过持续采样避免了分布偏移
- Thinking 模型展示了 RL 可以从简单的 outcome reward 中涌现复杂推理行为
- 基础模型的预训练质量是 RL 成功的前提条件
方法脉络总表
| 方法 | 使用的数据/信号 | 主要收益 | 主要风险 |
|---|---|---|---|
| SFT / NTP | 问题 + 参考解答 | 训练简单、稳定、易扩展 | 受高质量数据规模限制,容易学到表面模式 |
| RFT | on-policy 正样本 + 结果筛选 | 能快速放大已有正确轨迹 | 伪步骤会被一并强化,泛化可能变差 |
| Offline RL | 错误轨迹 + advantage / preference | 能利用负样本,显著提升数据效率 | 依赖 rollout 策略,存在分布偏移 |
| Online RL / GRPO / PPO | 当前策略采样 + outcome / dense reward | 直接优化当前行为分布,适合 thinking model | 成本高,对奖励设计和基础模型质量敏感 |
拓展阅读
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via RL (2025)
- Kimi K1.5: Scaling Reinforcement Learning with LLMs (2025)
- Setlur et al., “RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold,” NeurIPS 2024
- Gandhi et al., “Cognitive Behaviors that Enable Self-Improving Reasoners,” arXiv 2025
- Setlur et al., “Rewarding Progress: Scaling Automated Process Supervision for LLM Reasoning,” arXiv 2024