CS231N Lecture 2: Image Classification with Linear Classifiers
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Ehsan Adeli 授课内容整理 |
| 来源 | Stanford CS231N |
| 日期 | 2025年4月3日 |

引言:图像分类——计算机视觉的核心任务
本节课是 CS231N 的第二讲,在第一讲介绍计算机视觉全貌的基础上,本讲将聚焦于图像分类这一核心任务,并介绍两种基本的数据驱动方法:K 近邻分类器(K-Nearest Neighbor)和线性分类器(Linear Classifier)。线性分类器是构建深度神经网络的最重要基础模块。

来源:Slides 第6页。
本讲核心目标
- 定义图像分类任务及其挑战
- 理解数据驱动方法(data-driven approach)的基本范式
- 掌握 K 近邻分类器的原理、超参数选择与局限性
- 深入理解线性分类器的代数、视觉和几何三种视角
- 学习两种损失函数:多类 SVM 损失和 Softmax(交叉熵)损失
什么是图像分类
给定一张图像和一组预定义标签(如 dog, cat, truck, plane 等),图像分类的任务是为该图像指定一个正确的类别标签。

来源:Slides 第7页。
对人类而言,这是一个极其简单的任务——我们的认知系统天然具备对图像的整体理解能力。但对计算机来说,图像只是一个巨大的数字张量。
语义鸿沟(Semantic Gap)
![语义鸿沟:人类看到“猫”,计算机看到的是 \(800 × 600 × 3\) 的整数张量,每个元素取值在 \([0, 255]\)](slides-images/slide-007.jpg)
来源:Slides 第8页。
一张彩色图像在计算机中表示为一个三维张量,维度为 \(H \times W \times 3\)(高度 \(\times\) 宽度 \(\times\) RGB三通道)。每个像素的每个通道是一个 0--255 之间的 8-bit 整数值。人类感知到的“猫”和计算机看到的数字矩阵之间存在巨大的语义鸿沟。
图像的数字表示
图像通常使用 RGB 24-bit 格式存储:每个像素有红(R)、绿(G)、蓝(B)三个通道,每个通道 8 bit(\(2^8 = 256\) 个取值),因此像素值范围为 \([0, 255]\)。有时还有第四个 alpha 通道(透明度),构成 32-bit RGBA 格式。
图像分类面临的挑战
图像分类的困难在于,即使是同一个物体,以下因素的变化都会导致像素值发生巨大变化:

来源:Slides 第9–10页。
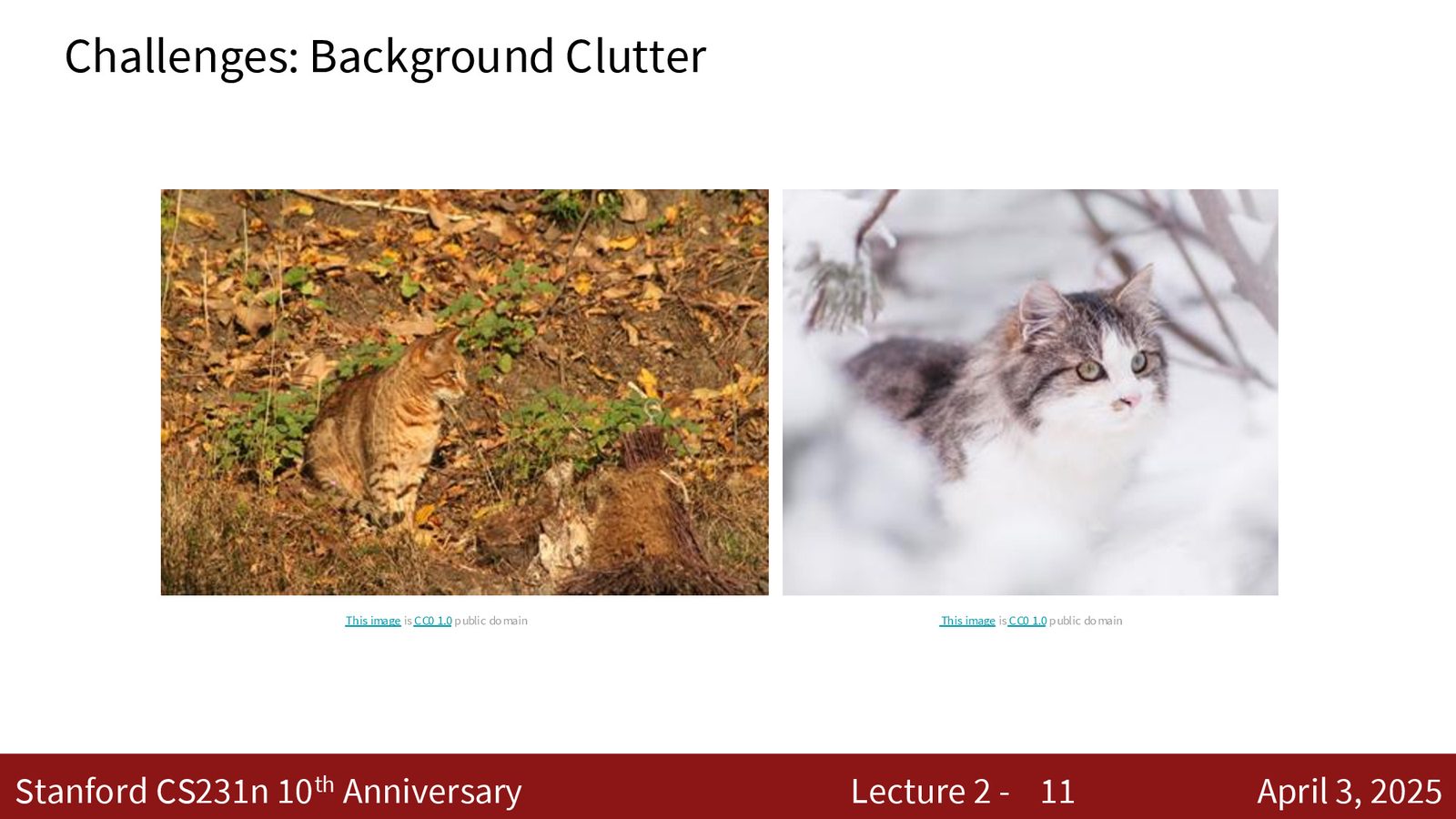
来源:Slides 第11–12页。

来源:Slides 第13–14页。
像素级变化 \(≠\) 语义级变化
即使只是将相机平移一个像素,\(800 \times 600 \times 3\) 张量中的每一个数值都会改变。但从人类感知角度来看,图像内容完全没有变化。这正是基于原始像素的简单距离度量不适合图像分类的根本原因。
本章小结
图像分类是计算机视觉中最基础、最重要的任务之一。它面临的核心挑战来自语义鸿沟——同一物体在不同视角、光照、遮挡等条件下的像素表示差异巨大。传统的基于规则(if-then-else)的方法无法扩展到复杂的现实场景,因此我们需要数据驱动的方法。
数据驱动方法
从规则驱动到数据驱动
传统计算机科学中的许多问题(如排序)可以用明确的算法流程(if-then-else + 循环)解决。但图像分类无法这样做——我们无法为每种物体的每种外观编写规则。

来源:Slides 第18页。
早期曾有研究者尝试通过边缘检测器提取边缘、识别角点模式,然后基于这些特征建立分类规则。虽然在有限场景下取得了一些成功,但存在两个根本问题:(1)每种物体都需要单独设计识别规则,无法扩展;(2)规则的设计本身就极其困难。
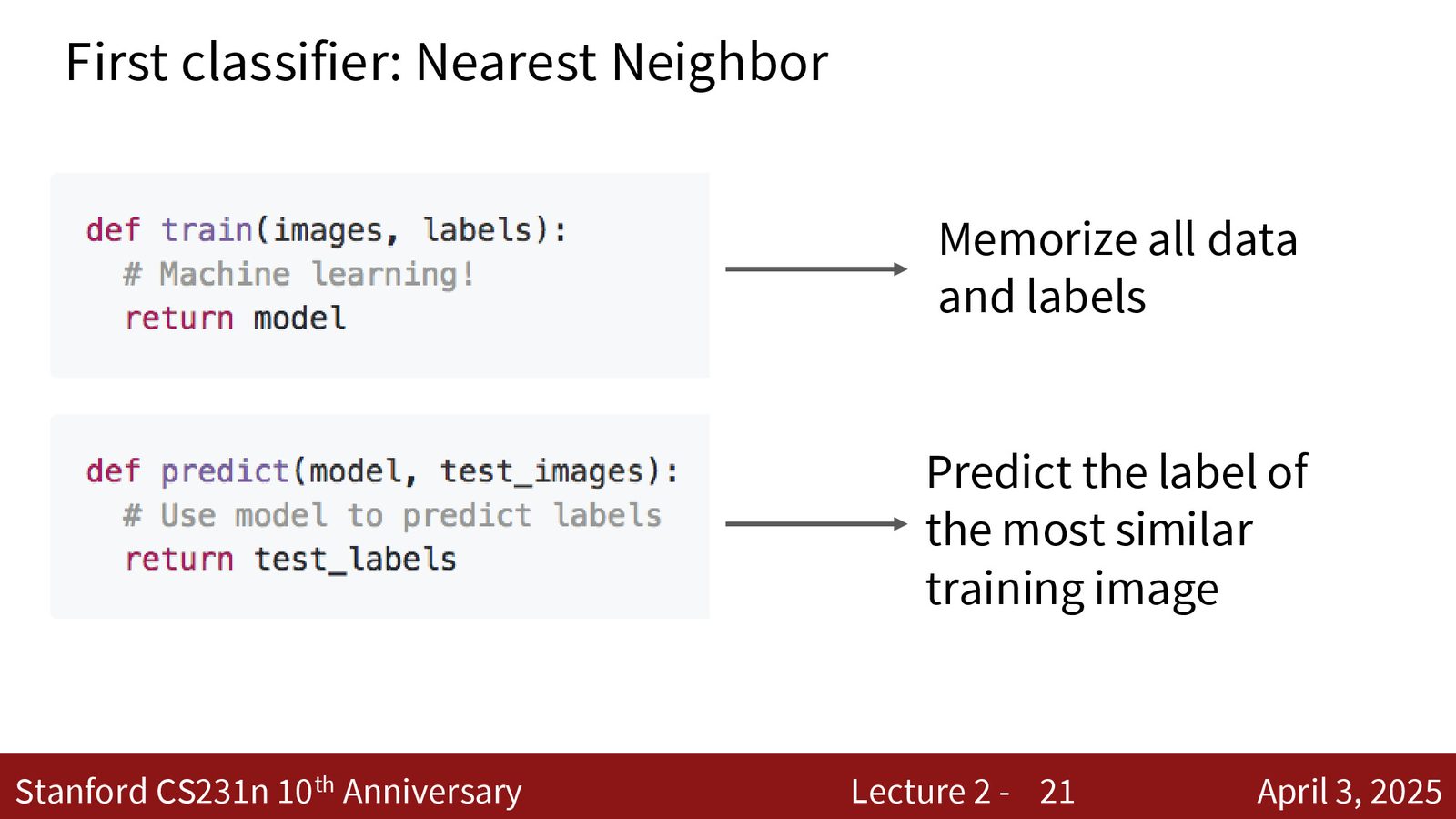
数据驱动方法的三步流程
机器学习提供了一种全新的范式——数据驱动方法(Data-Driven Approach):

来源:Slides 第20页。
数据驱动方法三步流程
- 收集数据:收集大量图像及其对应的标签
- 训练分类器:使用机器学习算法从数据中学习一个模型——实现
train(images, labels) -> model - 评估分类器:在新的、未见过的图像上评估模型性能——实现
predict(model, test_images) -> labels
来源:Slides 第21页。
这种方法的核心优势在于:不需要为每种物体手工设计规则,而是让算法从数据中自动学习区分不同类别的模式。
本章小结
数据驱动方法通过“收集数据 \(\rightarrow\) 训练模型 \(\rightarrow\) 评估预测”的三步流程,替代了传统的手工规则方法。这一范式是现代计算机视觉和深度学习的基础。接下来我们将介绍两种具体的数据驱动分类器。
K 近邻分类器
最近邻分类器的基本思想
最近邻分类器(Nearest Neighbor)是最简单的数据驱动分类方法:
来源:Slides 第21页。
最近邻分类器的工作原理
- 训练阶段:什么都不做,仅将所有训练数据和标签存入内存
- 预测阶段:对于每个测试图像,计算它与所有训练图像的距离,返回距离最近的训练图像的标签
距离函数
要比较两张图像的“相似度”,需要定义距离函数。最基本的两种距离度量是 L1 和 L2 距离。
L1 距离(曼哈顿距离)

来源:Slides 第23页。
其中:
- \(I_1, I_2\):两张图像
- \(p\):遍历所有像素位置
- \(I_1^p, I_2^p\):两张图像在位置 \(p\) 的像素值
L2 距离(欧氏距离)

来源:Slides 第31页。
L1 与 L2 距离的核心区别
L1 距离对坐标轴的选择敏感——如果旋转坐标系,L1 距离会发生变化。因此,当特征的每个维度都具有明确的物理意义时,L1 更合适。\ L2 距离对坐标轴的选择不敏感——旋转坐标系不影响 L2 距离。因此,当特征维度之间没有特殊含义、较为任意时,L2 更合适。
最近邻分类器的实现
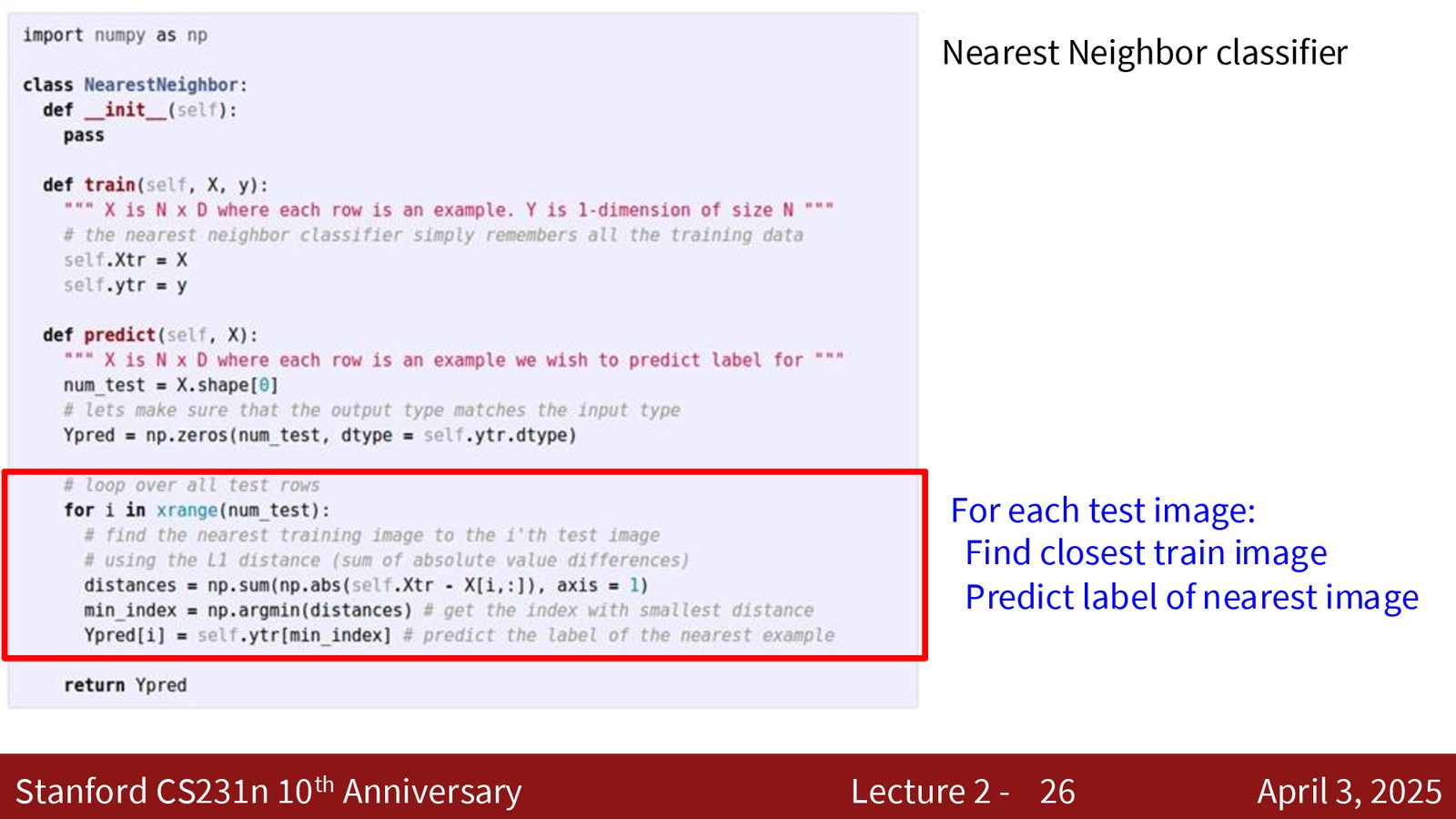
来源:Slides 第26页。
import numpy as np
class NearestNeighbor:
def train(self, X, y):
# X: N x D, y: N x 1
self.Xtr = X
self.ytr = y
def predict(self, X):
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype=self.ytr.dtype)
for i in range(num_test):
# L1 distance
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis=1)
min_index = np.argmin(distances)
Ypred[i] = self.ytr[min_index]
return Ypred
计算复杂度分析
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 训练 | \(O(1)\) | 仅存储数据,无计算 |
| 预测(单样本) | \(O(N)\) | 需要与所有 \(N\) 个训练样本比较 |
预测慢、训练快——与实际需求恰好相反
在实际应用中,我们希望训练可以慢(离线完成),但预测必须快(实时响应)。最近邻分类器恰好相反:训练 \(O(1)\),预测 \(O(N)\)。这就像每次问 ChatGPT 一个问题,它都要遍历互联网上的所有答案——完全无法扩展。
从最近邻到 K 近邻
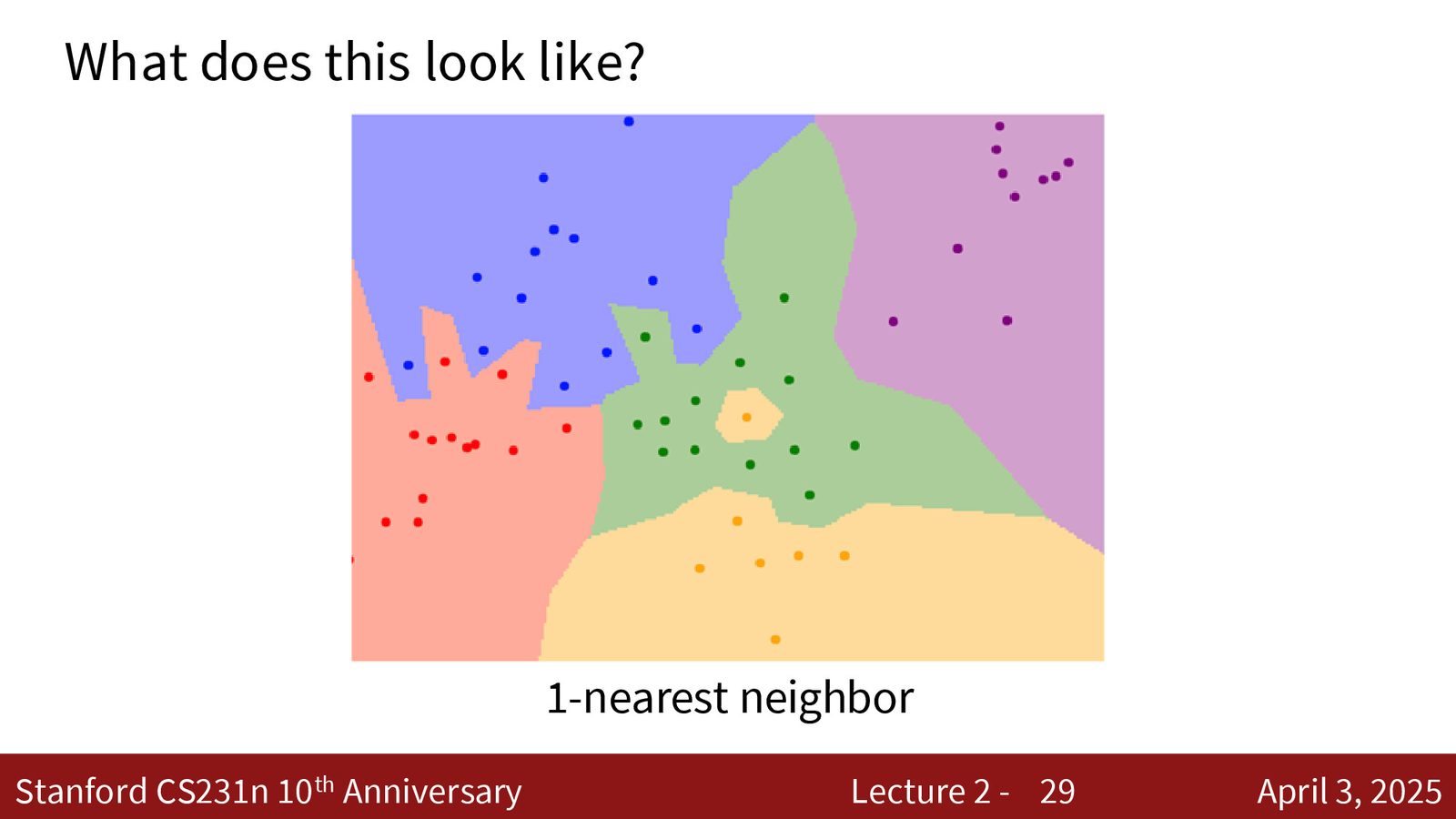
来源:Slides 第29页。
使用 \(K=1\) 时,单个噪声点就会在其周围创建一个错误的决策区域。例如上图中,绿色区域中间有一个黄色点——这很可能是噪声,但 \(K=1\) 会在其周围创建一大块黄色区域。
K 近邻的改进思路
K 近邻(K-Nearest Neighbor, KNN)不再只看最近的一个邻居,而是找到最近的 \(K\) 个邻居,通过多数投票(majority voting)决定分类结果。\(K > 1\) 可以有效减少噪声和异常值的影响,使决策边界更加平滑。
当 \(K\) 较大时,可能出现票数相等的情况(白色区域),此时通常随机选择其中一个类别。这些“不确定区域”也为数据收集提供了有价值的指引——它们指示了需要更多样本的数据空间。
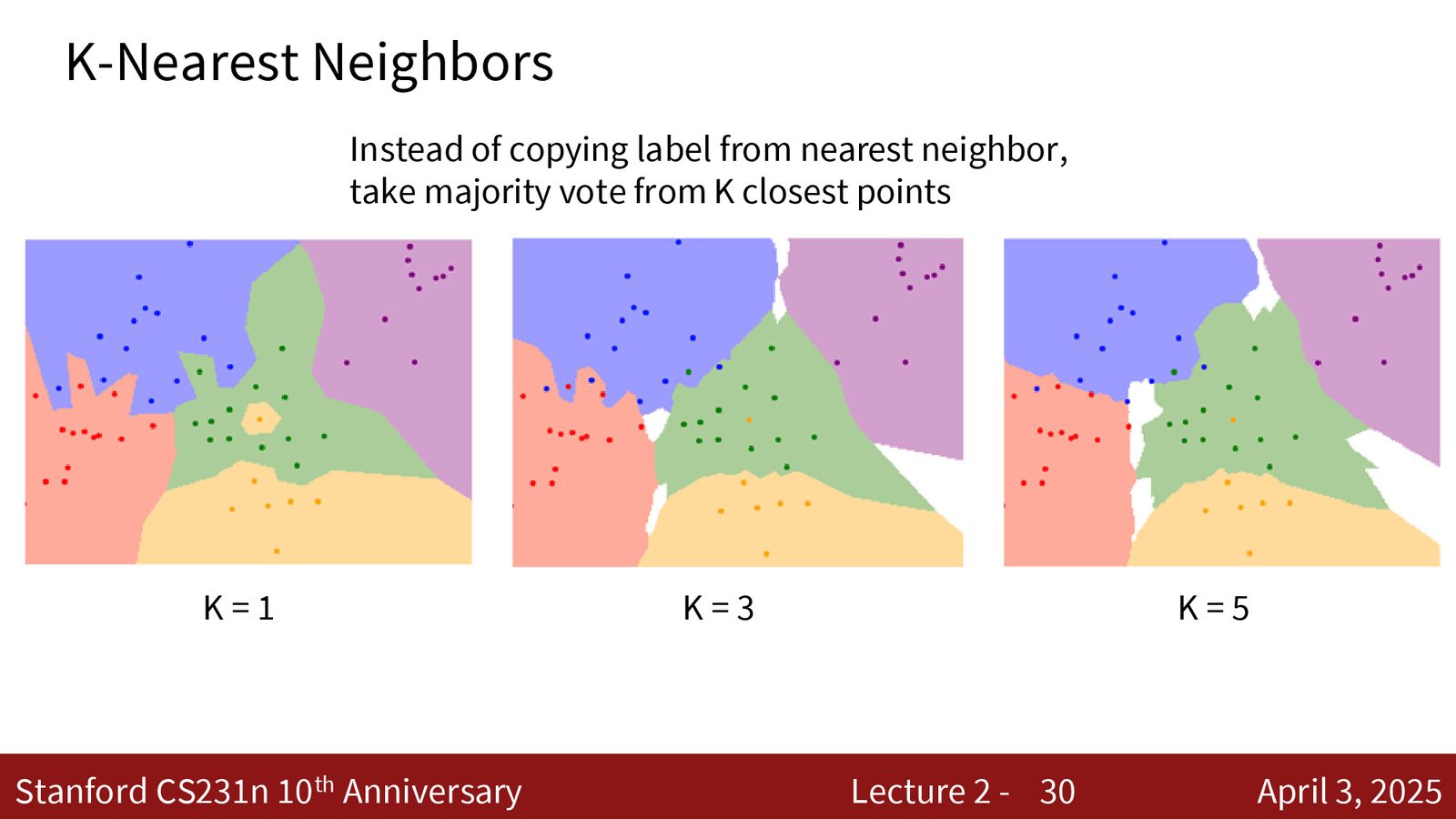
来源:Slides 第30页。
超参数与超参数调优
KNN 中有两个需要选择的超参数(hyperparameters):
- \(K\) 的值:使用多少个近邻
- 距离函数的选择:L1 还是 L2(或其他)
什么是超参数?
超参数是算法运行前需要设定的参数,它们不是从数据中学习得到的,而是由人来选择的。超参数的最优值通常与具体的数据集和问题相关。
错误的超参数选择方法

来源:Slides 第37页。
方法 1:在训练集上选择最优超参数——这是最差的做法。对于 KNN,\(K=1\) 在训练集上永远能达到 100% 准确率(因为每个样本的最近邻就是自己),但这完全没有意义。
方法 2:在测试集上选择最优超参数——这也是错误的。虽然比方法 1 好一些,但它相当于用测试集“作弊”,无法保证模型在真正未见过的数据上的泛化能力。
绝对不要在测试集上调超参数
测试集应该只在最终评估时使用一次。如果在测试集上反复调参,模型的性能评估将不可靠——你只知道它在这个特定测试集上表现如何,但不知道它能否泛化到其他数据。
正确的超参数选择方法
方法 3:训练集 + 验证集 + 测试集

来源:Slides 第40页。
从训练数据中划分出一部分作为验证集(validation set)。在训练集上训练模型,在验证集上评估不同超参数的效果,选择验证集上表现最好的超参数,最后在测试集上评估一次得到最终结果。
方法 4:交叉验证(Cross-Validation)
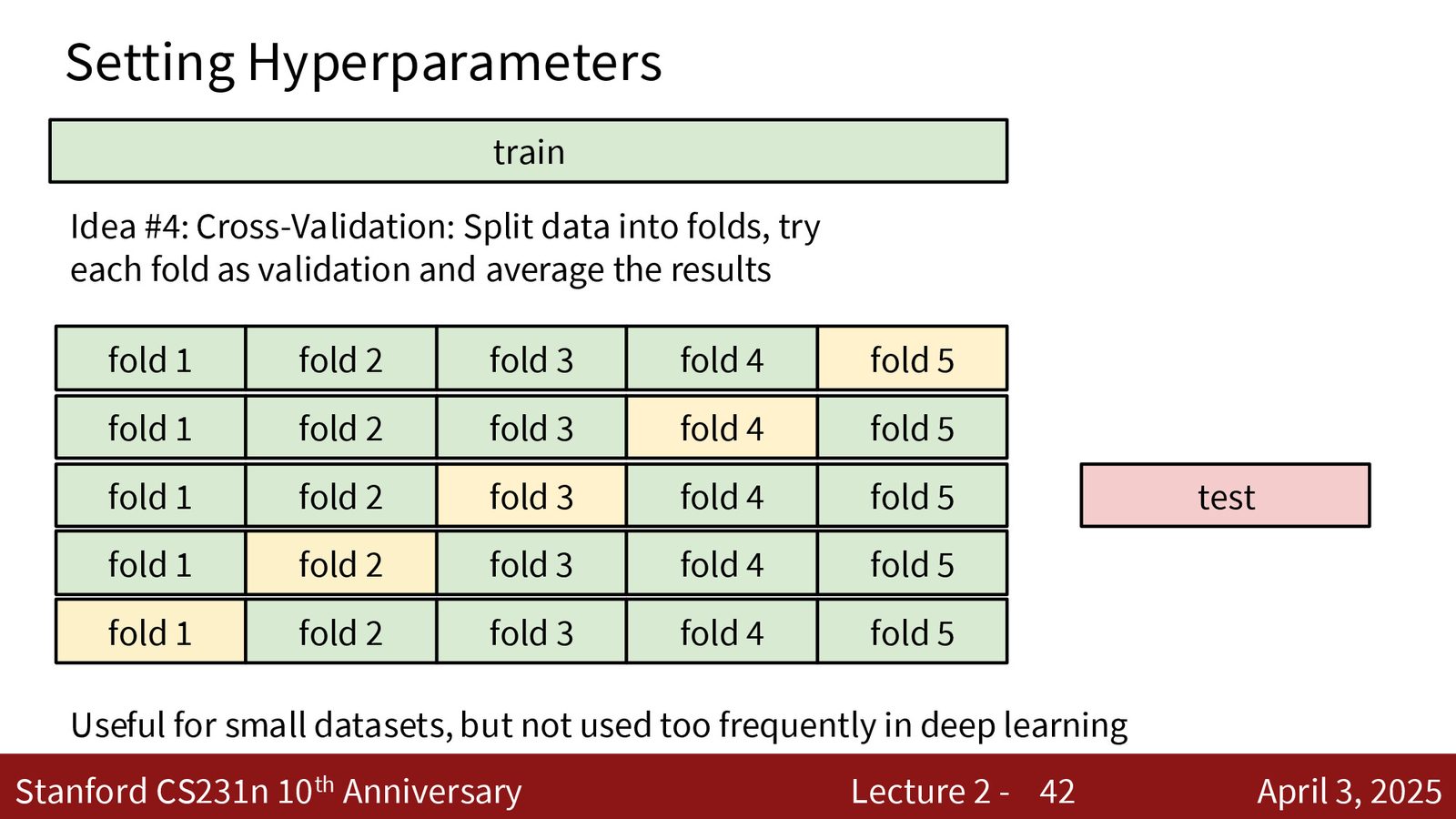
来源:Slides 第42页。
交叉验证流程
- 将训练数据分成 \(K\) 等份(folds)
- 对于每一轮,用其中一份作为验证集,其余 \(K-1\) 份作为训练集
- 对每种超参数设置,运行 \(K\) 轮,取平均准确率
- 选择平均准确率最高的超参数
- 用选定的超参数在全部训练数据上重新训练,在测试集上评估
交叉验证结果更可靠,但计算开销是单次验证的 \(K\) 倍。在大规模深度学习中,由于计算成本过高,交叉验证较少使用,通常采用单一验证集的方法。
KNN 在 CIFAR-10 上的表现
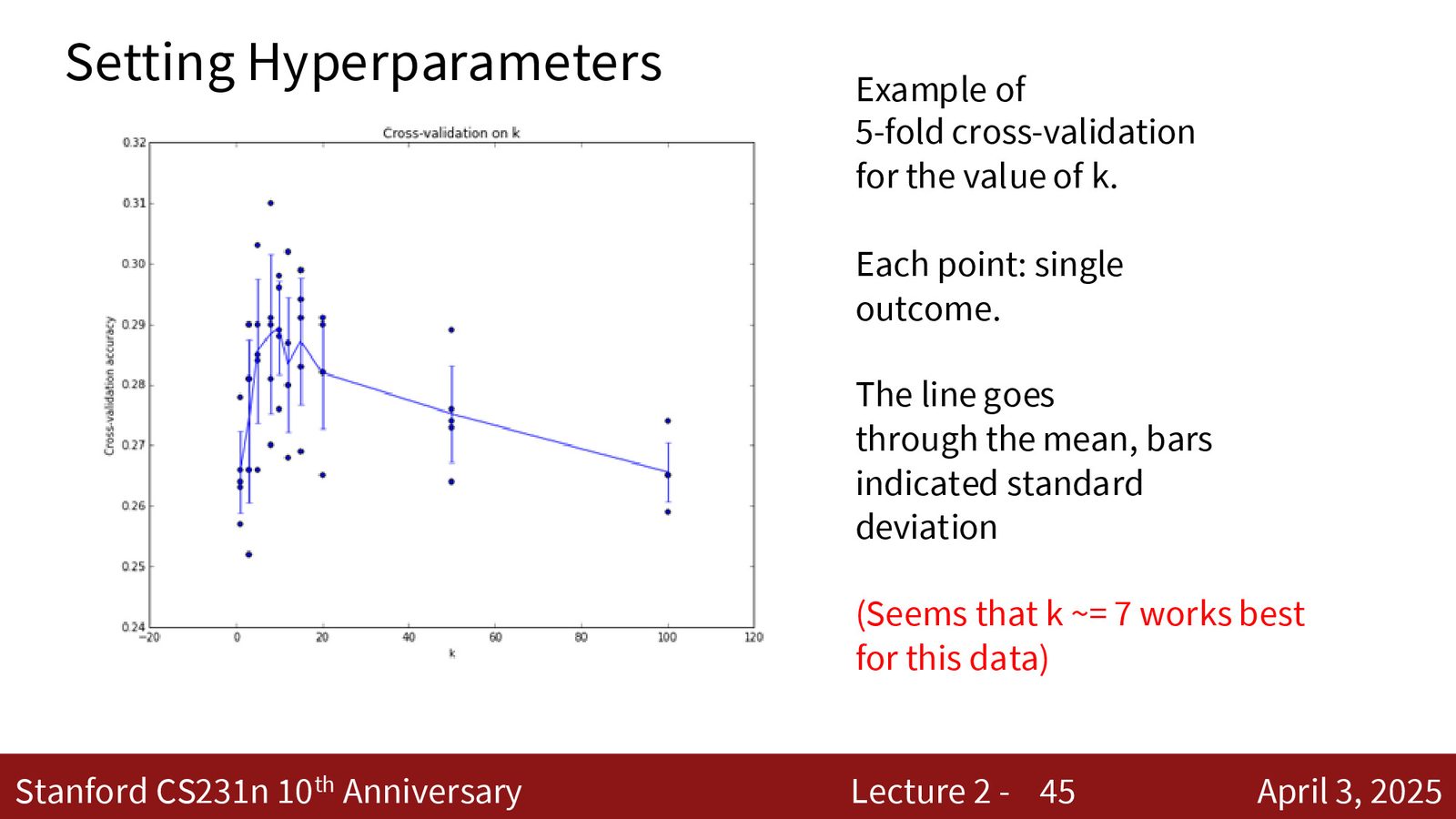
来源:Slides 第45页。

来源:Slides 第47页。

来源:Slides 第48页。
在 CIFAR-10 上,KNN 最佳准确率约为 28%。考虑到随机猜测的准确率为 10%(10 个类别),KNN 确实在“做一些事情”,但还有很大提升空间。
观察检索结果可以发现,基于像素距离的匹配存在严重问题:颜色分布相似的图像会被认为“相近”,但它们在语义上可能完全不同。例如,一只绿色青蛙的最近邻可能是一只绿色背景的狗。
来源:Slides 第51页。
像素距离不适合图像分类
将整张图像向右平移一个像素、改变颜色、或添加遮挡,都可能产生与原图相同的像素距离。像素级距离无法捕捉图像的语义信息,因此在实际中几乎不使用 KNN 进行图像分类。
KNN 小结

来源:Slides 第52页。
- KNN 是最简单的数据驱动分类方法,帮助我们理解了超参数和距离度量的概念
- 训练 \(O(1)\),预测 \(O(N)\)——与实际需求恰好相反
- 像素级距离不适合图像分类
- 在实际中几乎不使用 KNN 处理图像,但它引出的概念(超参数、验证集、交叉验证)贯穿整个课程
本章小结
KNN 通过“记忆 + 查表”的方式工作,核心是距离函数的选择和 \(K\) 值的设定。通过学习 KNN,我们掌握了数据驱动方法的基本范式、超参数调优的正确方法论(训练集/验证集/测试集的划分),以及交叉验证技术。同时,我们也认识到了基于原始像素距离的方法的根本局限性,这引出了更强大的参数化方法——线性分类器。
线性分类器:深度学习的基石
线性分类器是深度学习中最重要的基础模块。几乎所有的神经网络架构都以线性变换为核心组件。
从非参数到参数化方法
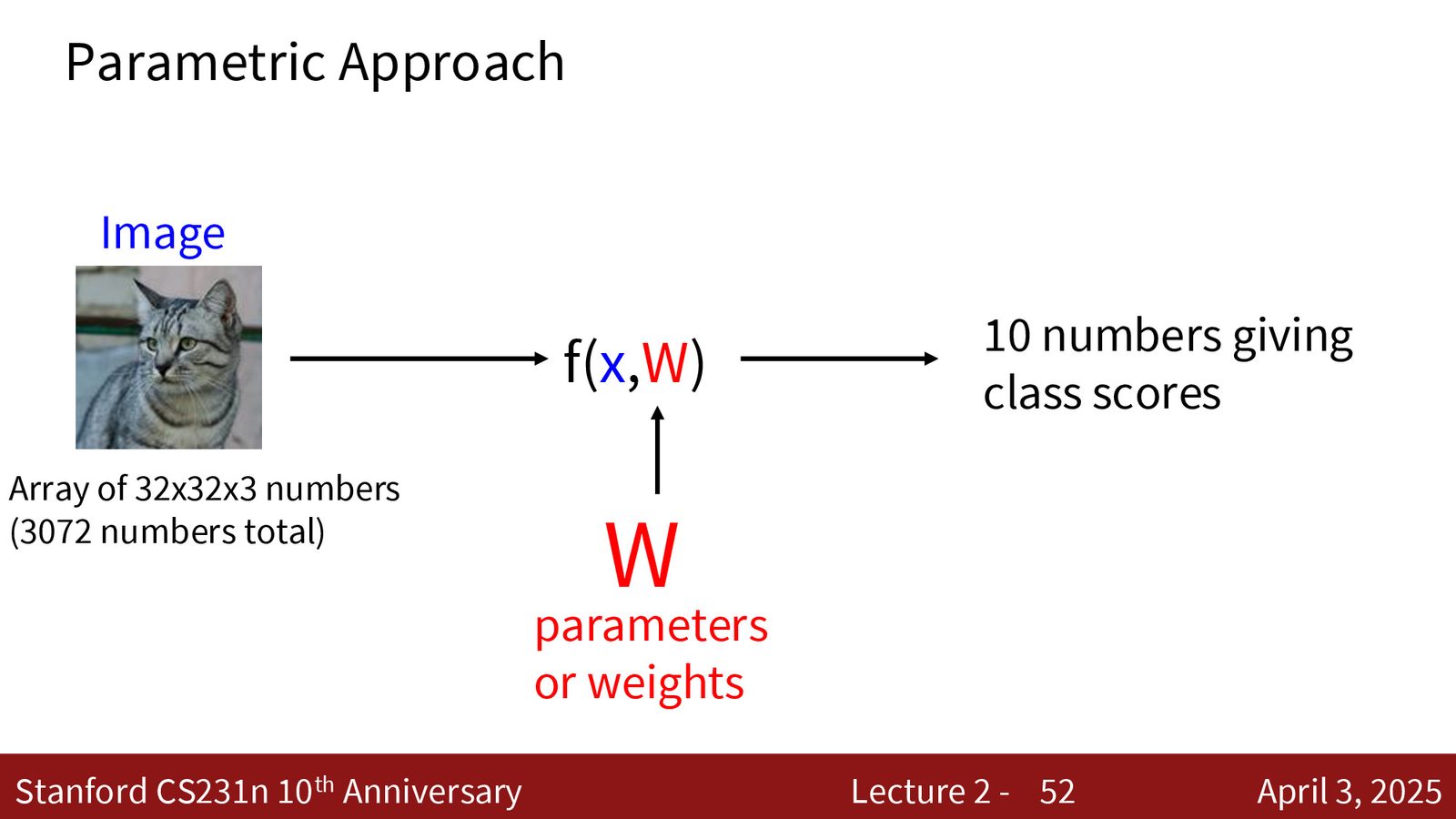
KNN 是非参数方法——它不学习任何参数,而是直接存储所有训练数据。线性分类器是参数化方法——它学习一组参数 \(W\)(权重矩阵),将输入图像映射到输出类别分数。
来源:Slides 第53页。
参数化方法 vs 非参数方法
- KNN(非参数方法):训练 \(O(1)\),预测 \(O(N)\)。模型就是全部训练数据。
- 线性分类器(参数化方法):训练时间较长(需要优化),但预测极快——只需一次矩阵乘法。模型是学习到的参数 \(W\) 和 \(b\),训练数据在预测时不再需要。
线性分类器的数学定义

来源:Slides 第55页。
线性分类器的核心公式为:
其中:
- \(x \in \mathbb{R}^{D \times 1}\):输入图像展平为列向量(例如 CIFAR-10 中 \(D = 32 \times 32 \times 3 = 3072\))
- \(W \in \mathbb{R}^{C \times D}\):权重矩阵(\(C\) 为类别数,例如 \(C = 10\))
- \(b \in \mathbb{R}^{C \times 1}\):偏置向量,与输入无关
- \(f(x, W) \in \mathbb{R}^{C \times 1}\):每个类别的分数

来源:Slides 第58页。
偏置项 \(b\) 的作用
偏置向量 \(b\) 提供了一个与输入无关的类别偏好。例如,如果训练数据中猫的样本远多于其他类别,偏置项会自动调整,使“猫”类的分数整体偏高。在几何上,偏置项允许决策超平面不必经过原点,从而提供更灵活的分类边界。
线性分类器的三种解读视角
理解线性分类器有三种互补的视角:代数视角、视觉视角和几何视角。
代数视角(Algebraic Viewpoint)
来源:Slides 第58页。
从代数角度看,\(f = Wx + b\) 就是一个简单的矩阵-向量乘法加上偏置。\(W\) 的第 \(i\) 行 \(w_i\) 与输入 \(x\) 做内积再加上 \(b_i\),得到第 \(i\) 类的分数。
视觉视角(Visual Viewpoint)

来源:Slides 第62页。
\(W\) 的每一行 \(w_i \in \mathbb{R}^D\) 可以被 reshape 为与输入图像相同的形状(如 \(32 \times 32 \times 3\)),得到一个模板图像(template)。分类过程本质上是用每个类别的模板与输入图像做匹配(内积越大,匹配度越高)。
在 CIFAR-10 上训练后,可以可视化这些模板:
- “car” 模板呈现出红色的车辆正面轮廓
- “airplane” 模板呈现出蓝色背景上的飞机形状
- “horse” 模板呈现出绿色背景上的马的轮廓
线性分类器只能学习一个模板
线性分类器的根本局限在于:每个类别只有一个模板(\(W\) 的一行)。如果同一类别有多种外观(如红色汽车和蓝色汽车),线性分类器只能学习到一个“平均”的模板。这就是为什么我们后续需要神经网络——它们可以学习多层次、多模式的特征表示。
几何视角(Geometric Viewpoint)
来源:Slides 第63页。
在像素空间中,线性分类器对每个类别学习一个线性决策边界(在 2D 中是直线,在高维中是超平面)。\(W\) 的第 \(i\) 行定义了超平面的法向量,\(b_i\) 定义了超平面的偏移量。

来源:Slides 第65页。
线性分类器的局限性

来源:Slides 第66页。
存在多种线性分类器无法处理的数据分布模式:
- XOR 问题:两个类别分别占据第一三象限和第二四象限,无法用一条直线分开
- 环形分布:一个类别包围另一个类别
- 多模态分布:一个类别的数据分布在空间中多个不相连的区域
线性不可分问题
当数据不是线性可分的时候,线性分类器无论怎么优化参数都无法得到正确的分类结果。解决方法包括:(1)引入非线性特征变换;(2)堆叠多个线性层并加入非线性激活函数——这就是神经网络的基本思想。
本章小结
线性分类器通过学习权重矩阵 \(W\) 和偏置 \(b\),实现从输入图像到类别分数的参数化映射。它有三种等价的理解方式:代数上是矩阵乘法;视觉上是模板匹配;几何上是超平面分割。线性分类器训练后只保留参数,预测极快,但其表达能力有限——只能学习线性决策边界,每类仅一个模板。它是构建更复杂神经网络的基石。
损失函数:量化分类器的好坏
有了线性分类器的结构 \(f(x, W) = Wx + b\),下一个关键问题是:如何找到最优的 \(W\)?为此需要定义一个损失函数(loss function),也称目标函数(objective function),来量化当前参数 \(W\) 下分类器的表现有多差。

来源:Slides 第68页。
损失函数的一般形式
给定训练数据集 \(\{(x_i, y_i)\}_{i=1}^N\),其中 \(x_i\) 是图像,\(y_i\) 是整数标签,总损失定义为所有样本损失的平均值:
其中 \(L_i\) 是单个样本的损失函数,\(f(x_i, W)\) 是模型对样本 \(x_i\) 的预测分数向量。不同的 \(L_i\) 定义方式产生不同的分类器。
多类 SVM 损失(Hinge Loss)

来源:Slides 第88页。
SVM 损失(也称 Hinge Loss)的核心思想是:对于每个样本 \(i\),正确类别的分数 \(s_{y_i}\) 应该比任何错误类别的分数 \(s_j\) 至少高出一个安全边距(margin)\(\Delta\)(通常取 1)。
其中:
- \(s = f(x_i, W)\):输入 \(x_i\) 的分数向量
- \(s_{y_i}\):正确类别 \(y_i\) 的分数
- \(s_j\):其他类别 \(j\) 的分数
- \(\Delta\):安全边距,通常取 1
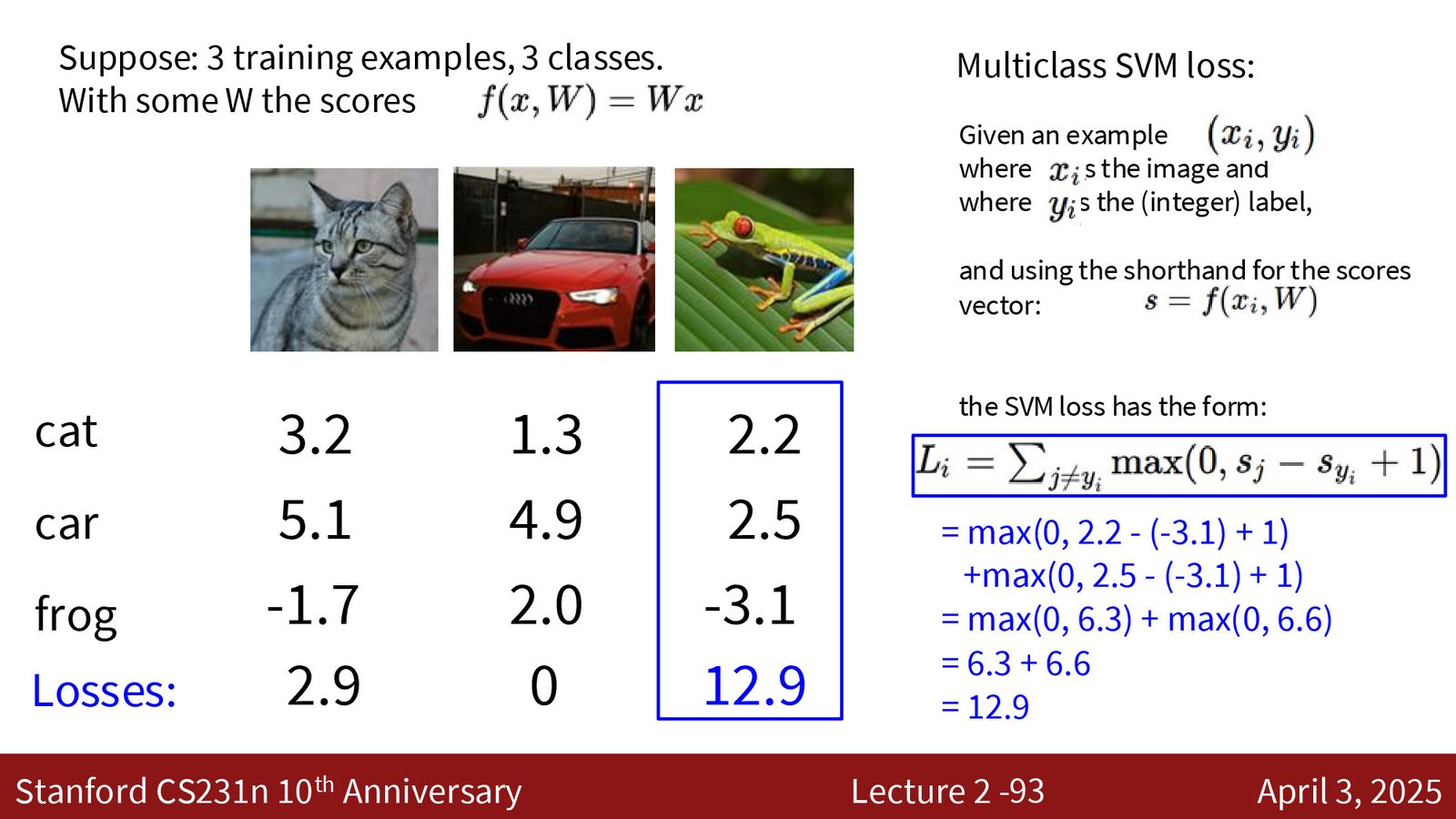
来源:Slides 第93页。
SVM 损失计算示例
来源:Slides 第93页。
考虑三个类别(cat, car, frog)和三个样本的分数:
样本 1(cat,\(y_i = 0\)):分数 \(s = [3.2, 5.1, -1.7]\)
样本 2(car,\(y_i = 1\)):分数 \(s = [1.3, 4.9, 2.0]\)
样本 3(frog,\(y_i = 2\)):分数 \(s = [2.2, 2.5, -3.1]\)
总损失:\(L = \frac{1}{3}(2.9 + 0 + 12.9) = 5.27\)
关于 SVM 损失的几个重要问题
- \(L_i\) 的最小值是多少? 答:\(0\)。当正确类别的分数比所有错误类别至少高出边距 \(\Delta\) 时。
- \(L_i\) 的最大值是多少? 答:\(+\infty\)。当正确类别的分数远低于错误类别时。
- 初始化时 \(W\) 很小,所有分数接近 0,此时 \(L_i \approx\) ? 答:\(C - 1\)(类别数减1)。因为每个错误类别贡献约 \(\max(0, 0 - 0 + 1) = 1\),共 \(C-1\) 个错误类别。这是一个有用的sanity check。

来源:Slides 第98页。
将 Hinge Loss 的线性部分替换为平方:\(L_i = \sum_{j \neq y_i} \max(0, s_j - s_{y_i} + 1)^2\),会得到一个不同的分类器。平方版本对大的违规(margin violation)惩罚更严厉,对小的违规惩罚更轻。选择哪种形式取决于你对错误的“容忍度”。
Softmax 分类器(交叉熵损失)
SVM 损失只关心正确类分数是否比错误类分数高出安全边距,不对分数赋予概率意义。Softmax 分类器则将分数转换为概率分布。
Softmax 函数

来源:Slides 第73页。
给定分数向量 \(s = f(x_i, W)\),Softmax 函数将其转换为概率分布:
Softmax 函数的两步操作
- 指数化:\(e^{s_k}\) 确保所有值为正
- 归一化:除以所有指数值之和,确保概率总和为 1
输出可以解释为:“根据当前参数 \(W\),模型认为图像 \(x_i\) 属于类别 \(k\) 的概率。”
交叉熵损失
Softmax 分类器的损失函数定义为正确类别概率的负对数:

来源:Slides 第83页。
直觉理解:
- 我们希望最大化正确类别的概率 \(P(Y = y_i | X = x_i)\)
- 等价于最小化其负对数 \(-\log P\)
- 取负号将最大化问题转为最小化问题
- 取对数使数值更易处理(对数函数是单调递增的,不改变最优解)
交叉熵损失计算示例
以之前的例子(cat,分数 \(s = [3.2, 5.1, -1.7]\)):
Step 1:指数化
Step 2:归一化
Step 3:计算损失
当前模型认为这张猫的图片是猫的概率只有 13%——说明 \(W\) 还需要优化。
交叉熵损失的取值范围与 Sanity Check
- 最小值:\(0\)(当正确类别的概率为 1 时,\(-\log(1) = 0\))
- 最大值:\(+\infty\)(当正确类别的概率趋近于 0 时)
- Sanity Check:初始化时所有分数接近相等,每个类别概率约为 \(1/C\),此时 \(L_i \approx -\log(1/C) = \log(C)\)。对于 CIFAR-10(\(C=10\)),\(L_i \approx \ln(10) \approx 2.3\)。如果初始损失远大于这个值,说明实现可能有 bug。
交叉熵的多种等价解释

来源:Slides 第81页。
同一个损失函数有多种等价的理论解释:
- 最大似然估计(MLE):选择使观测数据出现概率最大的参数 \(W\)
- KL 散度最小化:最小化真实分布 \(p\)(one-hot)与预测分布 \(q\)(softmax 输出)之间的 KL 散度
- 交叉熵最小化:\(H(p, q) = H(p) + D_{KL}(p \| q)\)。由于 one-hot 分布的熵 \(H(p) = 0\),所以 \(H(p,q) = D_{KL}(p \| q) = -\log q_{y_i}\)
Softmax 分类器 = 多项逻辑回归
Softmax 分类器本质上就是多项逻辑回归(Multinomial Logistic Regression)。如果你在其他课程中学过二分类的逻辑回归,Softmax 是它在多分类场景下的自然推广。在深度学习框架中,这个损失函数通常被称为 CrossEntropyLoss 或 BCE(Binary Cross Entropy,用于二分类)。
SVM 损失 vs Softmax 损失

来源:Slides 第103页。
| 特性 | SVM 损失 | Softmax 损失 |
|---|---|---|
| 公式 | \(_j ≠ y_i (0, s_j - s_y_i + 1)\) | \(-≤ft(e^s_y_i/_j e^s_j)\) |
| 分数解释 | 无特殊含义 | 概率(经 softmax 归一化后) |
| 关注点 | 正确类是否比错误类高出边距 | 正确类的概率有多高 |
| 满足条件后 | 损失为 0,不再优化 | 永远不会精确为 0,持续优化 |
| 最小值 | 0 | 0(理论极限) |
| 初始化 sanity check | \(C - 1\) | \((C)\) |

来源:Slides 第104页。
两种损失的核心差异
SVM 损失只关心“正确类是否够好”——一旦正确类分数超过所有错误类分数加上边距,损失就为 0,不再有进一步优化的动力。\ Softmax 损失永远在优化——即使正确类概率已经很高(如 99%),损失仍然大于 0,模型会继续尝试推高正确类的概率。
本章小结
损失函数是连接“分类器结构”和“参数优化”的桥梁。本节介绍了两种重要的损失函数:
- SVM/Hinge 损失:基于边距的思想,要求正确类分数比错误类至少高出 \(\Delta\)
- Softmax/交叉熵损失:将分数转化为概率,最大化正确类别的概率(等价于最小化 KL 散度/交叉熵)
两种损失在实践中都被广泛使用,Softmax 损失在现代深度学习中更为常见。下一讲将介绍如何通过优化算法(如梯度下降)来找到使损失函数最小的参数 \(W\)。
总结与延伸
讲者的核心总结
Ehsan Adeli 在本讲中构建了从最简单分类器到深度学习基石的完整链条。本讲的核心信息可以总结为:
- 图像分类是计算机视觉的核心:几乎所有视觉任务(检测、分割、生成等)都建立在分类的基础上
- 数据驱动是正确范式:从手工规则转向从数据中学习
- 线性分类器是神经网络的基石:理解 \(f = Wx + b\) 是理解整个深度学习的起点
- 损失函数定义了“好”的标准:没有损失函数就没有优化,没有优化就没有学习
全课知识图谱
本讲建立了一条从最简单到最核心的认知链条:

关键 Takeaways
五条核心原则
- 图像分类的挑战来自语义鸿沟:计算机看到的是数字张量,而非人类理解的语义内容
- 数据驱动方法取代手工规则:让算法从大量标注数据中自动学习分类模式
- 超参数调优必须使用验证集:永远不要在测试集上选择超参数
- 线性分类器是深度学习的基石:\(f = Wx + b\) 是所有神经网络的基本组件
- 损失函数定义优化目标:SVM 损失关注边距,Softmax 损失关注概率——两者在实践中各有适用场景
拓展阅读
- CS231N 课程官网:http://cs231n.stanford.edu/
- CS231N KNN 在线交互式演示:可在课程网站上体验不同 \(K\) 值和距离函数的效果
- Bishop, Pattern Recognition and Machine Learning, Chapter 4 —— 线性分类器的经典参考
- Stanford CS229 Machine Learning —— 关于逻辑回归、SVM、交叉验证的更深入讲解
- CIFAR-10 数据集:https://www.cs.toronto.edu/ kriz/cifar.html
- Deng et al., ImageNet: A Large-Scale Hierarchical Image Database, CVPR 2009