CS231N Lecture 17: Robot Learning
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Yunzhu Li 授课内容整理 |
| 来源 | Stanford CS231N |
| 日期 | 2025 |

引言与问题建模
本次客座讲座由哥伦比亚大学助理教授 Yunzhu Li 主讲。他领导着 Robotic Perception, Interaction and Learning(RPIL)实验室,研究方向聚焦在机器人学习——让机器人更好地感知和与物理世界交互。本讲系统介绍了机器人学习的核心范式:从问题建模、感知、强化学习、模型学习、模仿学习,到最新的机器人基础模型。

来源:Slides 第2页。
从监督学习到机器人学习
在 CS231N 课程中,同学们已经学习了监督学习(给定输入 \(X\) 和标签 \(Y\),学习从 \(X\) 到 \(Y\) 的映射)和自监督学习(仅使用无标注数据提取隐含结构)。机器人学习与之有根本性的区别:
机器人学习的核心特征
机器人学习是一个序列决策问题。机器人不仅要理解世界,还要与世界交互——它采取的动作会改变环境状态,环境会给出新的观测和奖励。目标是找到一系列动作,使得累积奖励最大化(或累积代价最小化)。

来源:Slides 第4页。
这一框架由四个核心要素组成:
- 目标(Goal):任务的定义,如自然语言指令或目标函数
- 状态(State):环境的当前描述,如关节角度、图像观测等
- 动作(Action):Agent 对环境施加的操控,如力矩、位移等
- 奖励(Reward):环境对动作效果的反馈信号
问题实例化

来源:Slides 第5页。
同样的框架可以描述极为不同的问题:
| 场景 | 目标 | 状态 | 动作 | 奖励 |
|---|---|---|---|---|
| CartPole | 保持杆平衡 | 角度/角速度/位置 | 水平力 | 每步杆立直=1 |
| 机器人运动 | 向前行走 | 关节角度/速度 | 关节力矩 | 每步前进=1 |
| Atari 游戏 | 最高分 | 游戏画面像素 | 上下左右 | 分数增减 |
| 围棋 | 赢棋 | 棋盘状态 | 落子位置 | 赢=1,输=0 |
| 叠衣服 | 整齐叠放 | 多视角 RGB-D | 夹爪运动 | 叠好=1 |
机器人学习 vs 计算机视觉
计算机视觉主要关注从高维输入中学习表征(如分类、检测)。机器人学习则是一个约束优化问题——物理世界是约束,目标函数定义在任务目标上,决策变量是动作序列。这是两者的根本区别。
奖励设计的微妙之处
即使是“叠衣服”这样看似简单的任务,奖励也可以有多种定义:面积最小?最平整?特定折法?不同用户有不同偏好。奖励设计(reward shaping)本身是一个充满微妙权衡的研究方向。
本章小结
机器人学习的核心是序列决策问题,通过目标、状态、动作、奖励四要素建模。与标准的监督学习不同,机器人的动作会影响后续状态,形成闭环交互。
机器人感知
感知的独特挑战
机器人感知面临的挑战远超传统计算机视觉:

来源:Slides 第10页。
- 观测只包含环境的不完整信息(遮挡、部分可观测)
- 传感器数据存在噪声和误差
- 动作执行可能失败(如抓取滑落)
- 环境包含刚体、可形变物体(布料、液体)、甚至其他智能体(人、动物)
- 环境是动态变化的
多模态感知

来源:Slides 第11页。
在机器人领域,仅依赖摄像头远远不够。研究者会尽可能多地为机器人配备传感器:
- 触觉传感:判断抓取是否稳定
- 音频信息:感知物理接触事件
- 深度信息:获取三维几何
- 摄像头:宏观环境状态
这些传感器互补协作,为机器人提供全面的环境理解。
机器人视觉的三大特征
来源:Slides 第13页。
机器人视觉 \(≠\) 计算机视觉
- 具身性(Embodied):机器人有物理躯体,直接在物理世界中体验,动作会即时影响自身的感知
- 主动性(Active):机器人是主动感知者,它知道自己想感知什么,能选择何时、何处、如何感知(如移动头部看桌子后方)
- 情境性(Situated):机器人处于真实世界中,感知必须与当前任务紧密耦合——扣扣子时只需关注按钮局部区域

来源:Slides 第12页。
本章小结
机器人感知不同于被动的计算机视觉。它是具身的、主动的、情境化的。机器人需要多模态传感器协同工作,并且感知系统需要与下游决策系统紧密耦合,实现闭环的感知-行动循环。
强化学习
基本框架

来源:Slides 第15页。
强化学习(RL)的核心思想是让 Agent 通过与环境的大量“试错”交互来学习最优策略:执行动作 \(\rightarrow\) 获得奖励 \(\rightarrow\) 调整策略,使高奖励动作出现的概率增大。
强化学习 vs 监督学习

来源:Slides 第16页。
强化学习与监督学习的四大关键差异
- 环境随机性:相同动作可能导致不同结果(如推箱子时因摩擦力不均匀旋转角度不同)
- 信用分配(Credit Assignment):奖励可能延迟到很久之后才出现(如围棋直到终局才知道胜负),需要将结果归因到早期决策
- 不可微分性:物理环境通常不可微,无法直接计算 \(\frac{\partial r}{\partial a}\),需要大量采样做零阶梯度估计
- 非稳态性:Agent 的动作会改变后续状态的分布,与监督学习中数据点互相独立截然不同
Q-Learning 与 DQN

来源:Slides 第19页。
Q 函数 \(Q(s, a)\) 衡量在状态 \(s\) 下执行动作 \(a\) 后的折扣期望未来累积奖励。学习 Q 函数后,决策变得简单:选择使 Q 值最大的动作。
DeepMind 的 DQN 将 Q 函数实例化为深度卷积网络,以 Atari 游戏画面为输入,展示了令人惊叹的结果:训练 4 小时后,Agent 在 Breakout 游戏中发现了人类都不知道的“隧道策略”——将球打穿砖墙上方,实现高效消除。
从游戏到现实:强化学习的突破

来源:Slides 第23页。
Bitter Lesson:简单方法 + 规模化
AlphaGo 到 AlphaGo Zero 的演进体现了 Rich Sutton 提出的“苦涩教训”(Bitter Lesson):找到与规模化最兼容的简单方法,往往比精巧复杂的方法表现更好。AlphaGo Zero 去掉了所有人类知识的初始化,纯靠自我对弈,反而超越了原始 AlphaGo。

来源:Slides 第25页。
在真实物理世界中,ETH 2020 年在 Science Robotics 上发表的工作令人印象深刻:在仿真中训练的四足机器人策略,直接迁移到真实的雪地、泥泞等复杂地形中,依然表现出色。关键技术是域随机化(Domain Randomization)——大量随机化仿真环境的物理参数(摩擦系数、地形几何等),使真实世界成为随机化分布中的一个采样点。
机器人运动控制接近“已解决”
在运动控制(locomotion)领域,强化学习 + Sim-to-Real 迁移已经是成熟的解决方案。仿真不需要完美模拟所有细节(如灌木丛、积雪),只要充分随机化关键物理参数,策略就能在真实环境中鲁棒工作。
强化学习的局限性

来源:Slides 第28页。
尽管在游戏和运动控制中取得了巨大成功,强化学习在操作(manipulation)任务中仍面临严峻挑战:
- 样本效率极低:AlphaGo Zero 需要等价于 3000 年人类知识的计算量
- 安全性:训练过程中的“奇怪行为”在真实机器人上可能导致灾难性失败
- 可解释性差:出错时难以诊断和修正
- 操作任务中 Sim-to-Real 差距更大:仿真中抓取成功但真实中物体滑落,这种“质变”型差异难以通过域随机化消除
本章小结
强化学习通过试错交互学习最优策略,在游戏和运动控制领域取得了超人表现。然而,其在操作任务中因样本效率、安全性和 Sim-to-Real 差距等问题仍受限。这催生了模型学习和模仿学习等替代方案。
模型学习与基于模型的规划
从试错到想象

来源:Slides 第31页。
人类之所以能高效地与环境交互,是因为我们拥有直觉物理模型——能想象动作的后果。模型学习(Model Learning)试图赋予机器人类似的能力。
前向模型与逆规划
- 前向模型(Forward Model):给定当前状态 \(s_t\) 和动作 \(a_t\),预测下一状态 \(s_{t+1}\)
- 规划(Planning):前向模型的逆问题——给定当前状态 \(s_t\) 和目标状态 \(s^*\),求解动作序列 \(\{a_t, a_{t+1}, \ldots\}\) 使预测轨迹尽可能接近目标
规划的优化过程:
其中 \(f\) 是学习到的前向模型。实际执行时采用MPC(模型预测控制)策略:只执行优化出的第一个动作,获取真实环境的新状态后重新规划,以应对模型误差。
状态表征的选择
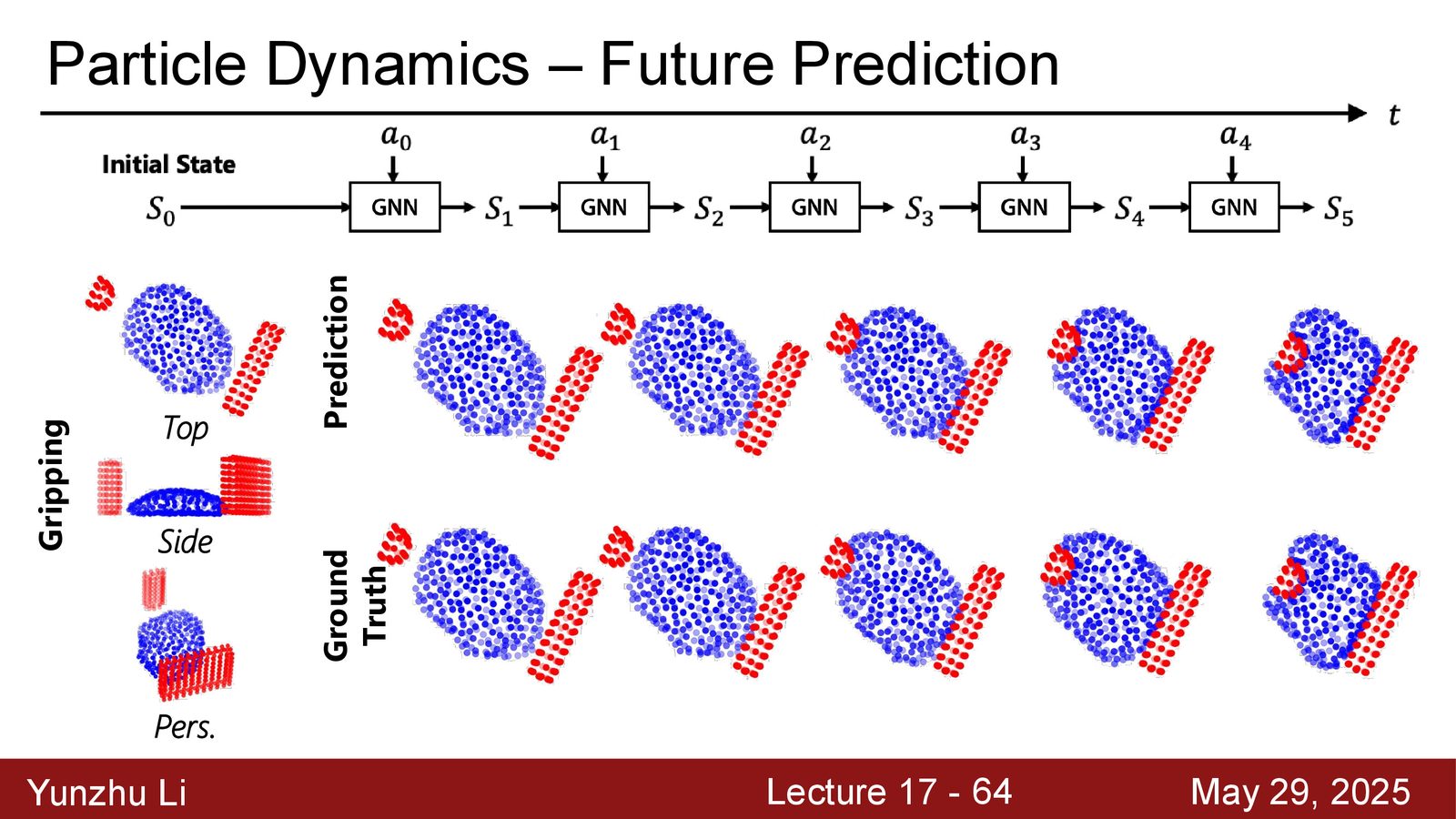
状态表征对模型学习至关重要。不同任务需要不同粒度的表征:
来源:Slides 第35页。
- 像素动力学:直接以 2D 图像为状态,预测动作后图像如何变化。代表工作:Deep Visual Foresight
- 关键点动力学:用 3D 关键点追踪物体,预测关键点的运动。适用于中等自由度的物体操控
- 粒子动力学:用点集表示物体,预测粒子在动作下的运动。适用于高自由度物体(如颗粒物料、可形变物体)
实例:饺子机器人

来源:Slides 第39页。
这项在 Stanford 完成的工作展示了模型学习的强大能力:机器人配备 15 种 3D 打印工具和 4 个 RGBD 相机,通过学习面团的粒子动力学模型,自主决策工具选择和动作规划,从一团面团制作出完整的饺子。
该系统的决策分为两个层次:
- 高层决策:选择使用哪种工具(分类器)
- 低层决策:给定工具,规划具体的运动轨迹
学习模型 vs 物理仿真器
实验表明,直接从真实世界交互数据学习的神经动力学模型,比精心调参的基于物理的仿真器(如 MPM 材料点方法)预测精度更高。这为“数据驱动的物理模型”提供了有力证据。
本章小结
模型学习通过学习环境的前向预测模型,让机器人能“想象”动作的后果,从而进行高效规划。关键要素包括:合适的状态表征(像素/关键点/粒子)、准确的前向模型、以及 MPC 式的闭环执行。这种方法比纯强化学习更数据高效、更安全。
模仿学习
从试错到示教

来源:Slides 第47页。
模仿学习(Imitation Learning)是当前机器人学习中最实用的方法。其核心思想:收集大量人类执行任务的示教数据 \((o_t, a_t)\),用监督学习训练策略网络 \(\pi_\theta\),直接从观测映射到动作。
行为克隆(Behavior Cloning)
最简单的模仿学习算法。给定专家示教数据集 \(\{(o_i, a_i)\}\),通过最小化预测动作与专家动作之间的损失来训练策略:
优点是简单高效——早上收集数据,下午训练模型,晚上就有工作策略。
级联误差问题

来源:Slides 第49页。
行为克隆的致命缺陷:级联误差
由于机器人学习是序列决策问题,一个微小的预测误差会导致状态偏离训练数据的分布,在新状态下策略产生更大的误差,进而更大偏离——误差沿时间轴指数级放大。这与标准监督学习中数据点独立的假设截然不同。
解决方案是迭代式数据收集:
- 收集初始专家示教
- 训练策略并在真实环境中执行
- 观察失败案例,收集纠正行为数据
- 将纠正数据加入训练集,重新训练
- 重复上述过程直到策略足够鲁棒
逆强化学习
除了直接学习动作映射,另一条思路是逆强化学习(Inverse RL):从示教数据中推断隐含的奖励函数,再用标准强化学习来学习策略。经典案例包括 Stanford 的 Pieter Abbeel 和 Andrew Ng 利用此方法控制遥控直升机完成极限飞行动作。
扩散策略(Diffusion Policy)

来源:Slides 第55页。
近年来模仿学习最重要的进展之一是扩散策略(Diffusion Policy),将扩散模型引入策略函数类:
从生成模型到策略学习
- 隐式行为克隆(Implicit BC):借鉴能量基模型(EBM),学习 \((o, a) \mapsto \text{score}\),通过优化推理动作
- 扩散策略:借鉴扩散模型,通过逐步去噪生成动作序列,天然处理多模态分布
两者都从深度学习的生成模型发展中汲取灵感,显著提升了对复杂操作任务的处理能力。
扩散策略展示了极为丰富的操作能力:涂抹黄油、煎蛋、削土豆皮、滑动书本等精细操作,都能在真实世界中可靠执行。
本章小结
模仿学习是目前获得真实世界工作策略的最高效途径。行为克隆虽然简单,但面临级联误差问题,需要迭代式数据收集来缓解。扩散策略等新方法从生成模型领域引入先进技术,显著提升了策略的表达能力和鲁棒性。
机器人基础模型
从专用策略到基础模型

来源:Slides 第60页。
机器人基础模型的定义
机器人基础模型是一种广泛泛化的策略,其输出的动作可能不是最优的,但在给定任何合理的观测和语言指令条件下,总是能生成平滑、合理、可在真实世界执行的动作轨迹。这类似于大语言模型——回答可能不完美,但总是“有道理”的。
这些模型有多种名称(Vision-Language-Action Models / VLAs、大行为模型 / Large Behavior Models),但本质相同:从观测和任务指令映射到可广泛泛化的动作输出。
\(_0\):一个具体案例

来源:Slides 第63页。
\(\pi_0\)(Physical Intelligence 于 2024 年 10 月发布)的设计包含三个关键阶段:
- 数据聚合:汇集学术界和自采集的大量多机器人、多任务数据
- 预训练:从预训练的视觉语言模型出发,用动作预测和 VQA 双重目标共同微调——既保留语义知识,又学会预测动作
- 后训练(Post-training):收集特定任务数据,对基座模型进行微调以达到高性能
来源:Slides 第64页。
为什么基础模型路线可行?
机器人基础模型的成功来自三个因素:
- 视觉语言模型的语义知识迁移:预训练 VLM 已理解“抽屉”、“把手”等概念,这些知识可直接用于机器人任务
- 大规模多源数据:跨机器人、跨任务的数据带来泛化能力
- 扩散模型等表达力强的策略类:能处理多模态动作分布
当前挑战
来源:Slides 第69页。
尽管进展迅速,机器人基础模型仍面临重大挑战:
- 数据不足:机器人数据的规模远不及语言/视觉数据。数据收集依赖人类遥操作,速度比人类直接操作更慢
- 泛化不够:在“野外”环境(非实验室设置)中的泛化能力仍不足
- 评估困难:缺乏标准化的大规模评估基准,难以客观比较不同方法的进展
- 执行效率:当前机器人执行任务远慢于人类
本章小结
机器人基础模型借鉴大语言模型的成功经验,通过大规模多源数据预训练和任务特定后训练,追求广泛泛化的机器人策略。\(\pi_0\) 等工作展示了令人鼓舞的进展,但数据规模、泛化能力和评估标准仍是关键瓶颈。
总结与延伸
全课知识图谱
本讲构建了机器人学习的完整认知框架:

关键 Takeaways
五条核心洞见
- 机器人学习 \(\neq\) 计算机视觉:它是序列决策问题,动作影响未来状态,需要处理随机性、延迟奖励和不可微环境
- 运动控制接近解决,操作仍是开放问题:RL + Sim-to-Real 在 locomotion 中非常成功,但 manipulation 中 Sim-to-Real 差距更大
- 模型学习是“想象力”:学习环境的前向模型,让机器人能预测动作后果,比纯试错更高效
- 模仿学习是最实用的方法:通过人类示教快速获得工作策略,扩散策略等新方法大幅提升表达能力
- 基础模型是未来方向:融合视觉语言知识和大规模机器人数据,追求广泛泛化的通用策略
拓展阅读
- Mnih et al., “Playing Atari with Deep Reinforcement Learning” (DQN), 2013
- Silver et al., “Mastering the game of Go” (AlphaGo), Nature 2016
- Lee et al., “Learning quadrupedal locomotion over challenging terrain”, Science Robotics 2020
- OpenAI, “Solving Rubik's Cube with a Robot Hand”, 2019
- Chi et al., “Diffusion Policy”, RSS 2023
- Black et al., “\(\pi_0\): A Vision-Language-Action Flow Model for General Robot Control”, 2024
- Yunzhu Li AAAI 2025 Tutorial: Robotic Foundation Models