[CS25] Demystifying Mixtral of Experts — Albert Jiang, Mistral
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Stanford Online 讲座整理 |
| 来源 | Stanford Online |
| 日期 | 2026年04月03日 |
![[CS25] Demystifying Mixtral of Experts — Albert Jiang, Mistral](cover.jpg)
引言:Mixtral 与稀疏的动机
录播背景与议程
Stanford CS25 的第 29 讲由 Mistral AI 的 Albert Jiang 主讲,标题为 “Demystifying Mixtral of Experts”,旨在拆解最新的 Mixtral 8x7B 语言模型:一方面复盘稠密 Transformer 的优化技巧,另一方面解释 Mistral 如何通过 Sparse Mixture of Experts (SMoE) 将 7B 参数级别的专家拆成高效的 router + expert 架构。
Albert 以 “为什么稠密模型成本持续上升” 的命题开场,并以 “Mixtral 将稠密/稀疏合流” 的视角铺陈全场。讲座中穿插多张 slides,结合演示数据、评估曲线、部署案例,为听众提供架构、训练、部署到未来方向的完整教学脉络。
Mixtral 的命题逻辑
稠密模型的推理成本在 13B 以后攀升,而基础仍是在 GPU 内存与 token length 间找到 trade-off;Mixtral 的目标是:让大模型“容量大但活跃参数少”,同时保持与 70B 稠密模型接近的性能。
讲座上下文
讲座发布在 Stanford Online 频道,时长 1小时4分钟,属于 “Transformers United” 系列,面向想把 MoE 带入工业部署的研究者与工程师。Albert Jiang 补充:Mistral 的开源策略让研究者可以直接拿到 Mixtral 权重,便于复现 SMoE 设计。
从稠密到稀疏的认知陷阱
将 Mixtral 视作 “稠密模型的更大版本” 会误判其重点;核心不是参数数量,而是如何在不激活所有参数的前提下仍然表达丰富的语义,因此要关注 router、load balancing 和 inference scheduling。
Mixtral 的使命
本讲将 Mixtral 拆成三层逻辑:1)先复盘 Mistral 7B 的稠密优化(sliding window、GQA、RoPE 等),2)再深入 Mixtral 的 SMoE 设计(experts、router、loss),3)最后讨论训练、评估、部署与未来社区可持续化。每一层都围绕 “如何保持大模型的泛化能力同时控制 latency/成本” 这个教学核心展开。
本章小结
第一章通过讲座背景、目标和风险提示,明确 Mixtral 的价值主张:不追求盲目标规模,而是搭配稀疏路由与工程优化,建成 “大参数、小活跃” 的跨模态基础模型。
Mixtral 架构拆解
Mistral 7B 的稠密起点
Mixtral 的根基还是 Mistral 7B,Jiang 先用 7B 介绍三大稠密优化:Sliding Window Attention 降低 \(O(n^2)\) 的注意力开销;Grouped Query Attention (GQA) 让 KV 缓存共享;RoPE 保持全局位置的旋转不变性。
| 组件 | 主要变化 | 触发点 |
|---|---|---|
| Sliding window | 每层只看 最近 \(W=4096\),推理时长从 \(O(n^2)\) 下降到 \(O(nW)\) | 支撑 long context 的同时降低 attention FLOPs |
| GQA | Key/Value 头被分组共享,减少 KV cache | 降低 KV 内存占用 |
| RoPE | 旋转编码保持 token 间 relative position | 更强的 extrapolated context handling |
Sliding Window 的信息扩散
虽然单层只看 \(W\) 个 token,但经过 \(L\) 层后可以跨越 \(L\times W\) 的有效上下文。例如 32 层 \(\times 4096\) window 约等于 131K token,足以应对长文本。
稀疏专家组的核心
Mixtral 8x7B 将前馈网络替换为 8 个专家,每个 token 通过 Router 选出 Top-2,激活近 12.9B 的参数(约 46.7B 总参数)。激活专家数量少,推理时只更新而非加载全部权重,兼顾参数容量与 latency。
Mixtral 的条件计算事实
$$ \text{Active Params} = N_{\text{tokens}} \times K \times d_{\text{ffn}} \ll \text{Total Params} $$ 只激活 \(K=2\),每个 token 的计算量仍旧集中在 decoder+attention 层,FFN 只是 sparse-gated 的附加层,带来 “参数体量 vs latency” 的折中。
路由与负载均衡的工程细节
Router 通过 softmax 输出概率分布,再用 Top-K 确定激活专家。Jiang 介绍了负载均衡损失(\(\mathcal{L}_{\text{balance}}\))与 auxiliary loss(如 auxiliary load),防止某些专家被 “吃掉”。 $ L_{balance} = \alpha N \sum f_i P_i $ 其中 \(f_i\) 是 token 分配比,\(P_i\) 是 router 给专家 \(i\) 的平均概率。
专家坍缩与 load-balance 失衡
如果 router 一开始只偏重 1 2 个专家,其他专家将 “饥饿”,导致 effective capacity 回到稠密模型。Mixtral 采用 auxiliary loss + random routing 初始化,确保每个专家都有 warm-up 的机会。
Token 级流水线与 routing heuristics
Mixtral 的训练数据在进入 MoE 层前,已经完成 embedding、attention 与 layer norm;router 只对 token embedding 做 scoring,再将 token 分发到 expert-GPU。Jiang 提到一个细节:为了避免 Top-K 路由在 batch 维度上造成 token-skew,还会在 logits 中加入 temperature scheduling,并在 batch 头部呈现 preference token 以引导小概率专家。
Routing heuristics 的实践经验
1)Warm-up 阶段提升 temperature,避免初期 softmax 过于平滑;2)增加 noise 让少数专家获得机会,防止早熟;3)在 logits 上加入 confidence threshold,使低分 token 触发 backup expert。
本章小结
第二章通过稠密基线、MoE 条件计算与负载均衡,展示 Mixtral 是如何在大参数空间里做到 “只激活必要专家”,同时维持信息传播与多样化表达。
Mistral 7B 与 Mixtral 的基线差异
稠密基线的性能剖析
在进入 Mixtral 之前,Albert 先对 Mistral 7B 的推理性能与成本做剖析:Mistral 7B 作为稠密 decoder-only 模型,拥有 \(\sim\)7B 参数,在 MMLU/Mathematics benchmark 上表现出与 13B 稠密模型接近的质量,但随着 context length 上升,其 sliding window attention 仍会带来 \(O(nW)\) 的计算开销。Mixtral 则在此基础上保留 attention stack,并把 FFN 层替换为 MoE,以降低每 token 的激活数据量。

来源:Slide 09 展示了 Mistral 7B 的 decoder stack 与 Mixtral 的 sparse FFN juxtaposition。
稠密 & 稀疏的连续体
Mistral 7B 的 decoder stack 是 Mixtral 的骨架;Mixtral 只在 FFN 处引入 Router+Expert,而保持 attention stack 与 positional encoding 不变,确保稠密和稀疏在表达能力上的连续性。
Mixtral 在 benchmark 上的对比
Mixtral 8x7B 的活跃参数约 12.9B,单 token 推理仅激活 2 个专家,latency 甚至低于 13B 稠密模型,但其总参数接近 46.7B,因此能在 MMLU、HumanEval、GSM8K 上给出接近 70B 的 quality。以下表格对比不同模型的关键维度。
| 模型 | 活跃参数 | latency (token/ms) | 代表 benchmark |
|---|---|---|---|
| Mistral 7B | 7B | 中等 | MMLU 75% |
| Mixtral 8x7B | 12.9B | 低 (13B 稠密水准) | MMLU 80%, HumanEval 41% |
| LLaMA 2 70B | 70B | 高 | MMLU 83% |
性能/成本的双重尺度
Mixtral 在保持较低 latency 的同时提供接近 70B 稠密模型的 accuracy,说明 MoE 的优势不仅在模型质量,更体现在 unit-token 的成本效率。厂商可以用 Mixtral 替代 70B 以获得更高的 throughput。
本章小结
本章强调 Mixtral 并非完全打破稠密结构,而是借助 MoE 在 FFN 处插入稀疏专家,保持 attention stack 与稠密 encoder 的兼容,从而在成本和质量之间实现可控 trade-off。
训练路线与泛化评估
数据管道与多样性
Mixtral 使用 130k+ 的 human teleop demos、simulated tabletop trajectory、开源网页文本等混合数据。Albert 强调 “data breadth beats depth”,强调任务多样性比重复同一模板更重要。
Mixtral 的数据三角
1)离线 teleoperation demo 提供高质量眼-手对齐;2)Simulated RL trajectory 弥补 edge cases;3)网页与代码语料为语言泛化提供 signal。三者构成覆盖语义广度的 data triangle。
数据调度与清洗
为了保持标注一致性,Mixtral 在期末训练前还会经过三步数据调度:1)按照场景/任务/频率分层采样,确保 color/position/state 每一维维持均匀;2)通过 CLIP-based filtering 清洗 low-quality captions,剔除 success detector 低分的执行片段;3)在 streaming pipeline 中实时监控 per-expert token utilization,一旦某个 expert 在某个任务上失活就补采与之相似的 demo。
数据调度的细节
Mixtral 采用 stratified sampling → CLIP filtering → streaming validation 的组合:先按任务分层再按 timestamp 重采样,接着用 CLIP embedding 删除噪声 caption,最后用 streaming validation 确保训练集不会因为 微小的分布 shift 而让某个 expert 失活。
数据漂移与 expert cold start
若后续数据绝大多数来自同一场景(如 only kitchen),router 会偏向某些 expert,其他 expert 进入 cold start。解决办法是:在采集 pipeline 中强制加入 low-frequency 任务,并用 expert usage 统计触发 on-the-fly data augmentation。
专家专业化与 pseudo label
团队用 3% 的手动 caption + CLIP pseudo label 重新描述 97% 的 demo,将 “pick Coke can” 拆成多个 spatial/状态变体。这种语言扩张 (language-driven relabeling) 让 Router 训练时接收到更细粒度的指令。
语言伪标签作为语义放大器
CLIP embedding 将视觉轨迹映射到自由文本,使每条 demo 经过 pseudo labeling 后拥有多个指令版本,显著提升对 novel command(如 “move lonely red object”)的响应。
评估与 ablation
Mixtral 在数学、代码、推理 benchmark(如 MMLU、HumanEval、GSM8K)上对标 LLaMA 2 70B,但活跃参数不到 13B。Team 还做了 ablation:减少任务类型、减少数据量、减少专家数量,观察 success rate。
| 干预 | 观测 | 结论 |
|---|---|---|
| 减少任务类型 | success rate 迅速下降 | 说明语义多样性关键 |
| 减少示范量 | 下降幅度较小 | duplicate demo 附加价值有限 |
| 减少专家数量 | certain tasks 失速 | 表明 capacity 依赖于多个专家的组合 |
性能/成本比的亮点
Mixtral 生成速度接近 13B 稠密模型,质量接近 70B。对于 API 提供商而言,这意味着在更低成本下提供更高质量输出。
pseudo label 噪声的审慎
虽然 pseudo label 提供更多语义,但过高的噪声可能拖累 Router 的 logits 分布。团队通过 success detector + confidence threshold 过滤低置信 caption。
评估矩阵与运营指标
Albert 介绍了一套 latency / quality / stability 的运营矩阵,既监控 Mixtral 在 benchmark 上的 accuracy,也把 success detector confidence、expert load 平衡纳入日常 dashboard。Slide 10 呈现了 mixtral 在 MMLU、HumanEval、GSM8K 上与其他模型的对比,以及 router health 的可视化指标。

来源:Slide 10 同时展示 accuracy table 与 router load dashboard,用以支撑运营矩阵的 monitoring 视角。
| 指标 | Mixtral 8x7B | LLaMA 2 70B | 目标偏差 |
|---|---|---|---|
| MMLU | 80% | 83% | latency 低 |
| HumanEval pass@1 | 41% | 44% | cost/prompt 更优 |
| GSM8K | 79% | 82% | 更高 sample efficiency |
运营矩阵的三角
1)Quality:accuracy 由 benchmark + Long-context stability 组成;2)Latency:router/top-K 影响 per-token latency;3)Stability:expert load balancing + success detector confidence 防止 catastrophic routing failure。
监控仪表盘的盲区
只看 accuracy 会忽略 expert imbalance;若某个 expert load 持续 1% 以下,说明 router 已经 drift,需要通过 temperature bump 或 pron noise 重新分发 token。
Router 稳定性与 regularization
为了稳定 Top-K routing,Mixtral 在 router logits 上施加 auxiliary entropy loss,并且使用 dropout 让某些 token 在训练阶段盲目尝试少数专家。Regularization 还能防止 router 对高频 token 过度自信,保持每个专家都能接收到足够 diverse 的 token stream。
Router regularization 的经验
1)Entropy loss 让 softmax 输出更平滑;2)Dropout + noise 让少见 token 被随机分配到不同专家;3)Early epochs 强调 load balancing,后期再减少 auxiliary loss 权重以恢复 sharp logits。
本章小结
第三章强调 Mixtral 的训练从数据组合、语言 relabeling 到 ablation,始终围绕 “任务多样性 + pseudo label 低噪声”,确保 sparse experts 在训练与评估阶段都能发挥作用。
工程与部署实践
推理内存与量化策略
尽管每个 token 只激活 2 个专家,所有专家参数仍需常驻内存;Mixtral 采用 4-bit 量化与 动态分片机制,避免 inference 时 load 一次全部 46.7B 权重。
Mixtral 的内存 + 量化策略
1)将专家参数存入巨大但可分页的 tensor;2)在 activation 时只加载 Top-K;3)配合 4-bit/8-bit 量化,控制 GPU memory < 40GB;4)量化后再 finetune 避免精度损失。
多节点推理与 API 架构
Deploy 时 Mixtral 通常以 pipeline parallel + tensor parallel 方式分布于多个 GPU,每个 GPU 管理 subset of experts。Albert 指出 “router 所在的 GPU 需要快速 gather logits,再 dispatch token 到对应 expert GPU”,因此通信 pipelining 与 NCCL bandwidth 是决定性资源。
分布式 inference 的关键
- Router GPU 承担 logits 计算与 Top-K 路由决策。
- Expert GPU 接收 token 并输出 slice,必须在下一个 micro-batch 前完成。
- NCCL bandwidth 影响 token exchange latency,因此需要 overlap communication 和 computation。
边缘 vs 云的部署边界
边缘设备无法一次性加载 46.7B 参数,因此 Mixtral 的 edge-version 仍是稠密 13B 或更小模型。云端 API 则可利用 MoE 的 sparse expertise,换取更低 cost-per-token。部署团队还需不断监控 load imbalance,避免某些 expert 成为 GC bottleneck。
边缘部署的内存陷阱
若在边缘直接运行 Mixtral 的参数集,会因 sequential page fault 造成 latency 峰值。解决方案是:先用 distillation 缩小模型,再用 router 故意降 expert count。
观测与指标雷达
Albert 建议在生产环境构建 router health radar,通过 success detector confidence、expert load fraction、token latency 三个维度的折线图持续监控。如果某个 expert 的 load 比例 < 2%,则通过 temperature bump + noise injection 让其重新恢复活跃。Slide 22 展示了这样的 dashboard(图中带有 NCCL link 图标)。

来源:Slide 22 的监控 dashboard用于跟踪 expert usage、router confidence 以及 cross-node latency。
Observability 三叉柱
1)Expert usage:每个 expert 的 token count;2)Router confidence:softmax 温度与 entropy;3)Latency:token end-to-end 延迟。三者一起构成 MoE 的观测仪表盘。
Latency 预算与批次规划
Mixtral 的 inference pipeline 严格控制三率(compute、memory、communication):1)Router 在每个 micro-batch 激活 2 个 expert,2)每个 expert 至少处理 8 16 token,才会触发 NCCL reduce;3)通过 gradient accumulation 把 forward/backward 分拆到 2 4 个 stage 以减少 peak memory。Albert 建议在部署前先做 latency budget sheet,把 router latency + expert compute + NCCL flush 下好行,确保 token latency 不超过 20ms。
Latency 预算清单
- Router forward: 2 3 ms
- Expert forward: 4 5 ms per expert
- NCCL synchronization: 3 ms
- Total per token: 15 18 ms
本章小结
本章解释部署 Mixtral 时的 memory/quantization、multi-node inference 与边缘/云差异,突显工程团队需在 latency、通信与成本之间做出精细抉择。
Slide-driven Insights
Slide 08:架构一览
Slide 08 用 flowchart 展示 Mixtral 的 router → expert → aggregator 流程,强调 “few activated experts” 在 decoder 之后被 concat 聚合。配图显示 token 先经过 embedding、attention,再到 sparse FFN。

来源:来源:Mixtral 官方 slides,第 8 页。
Slide 08 的视觉要点
图中将 router 置于 attention 之后,明确了 routing 结果只影响 FFN 片段,并通过 concat 汇总多个 expert 的输出,便于理解 sparse prefix 与 dense tail 的连续性。
Slide 21:评估与部署视角
Slide 21 给出 benchmark 表格与 multi-GPU 部署概览。表格体现 Mixtral 在 MMLU、HumanEval 上与 70B 稠密模型的 score 接近,而部署图示显示 router-expert partition 需要 dedicated NCCL stream。

来源:来源:Mixtral 官方 slides,第 21 页。
Slide 21 的提示
用一个表格同时展示 accuracy、latency 与 cost,帮助工程团队评估 “是否值得用 MoE”;图示中的 NCCL channel 体现 router-expert synergy,是讨论多节点部署时不可忽略的细节。
Slide 31:router load 与 trust
Slide 31 展示了 pairwise expert usage heatmap 和 router confidence band,说明 router 在 high-entropy input 时需要更高温度,并在 fallback expert 条件下使用 softmax noise(图中展示了 backup expert 的语义分支)。
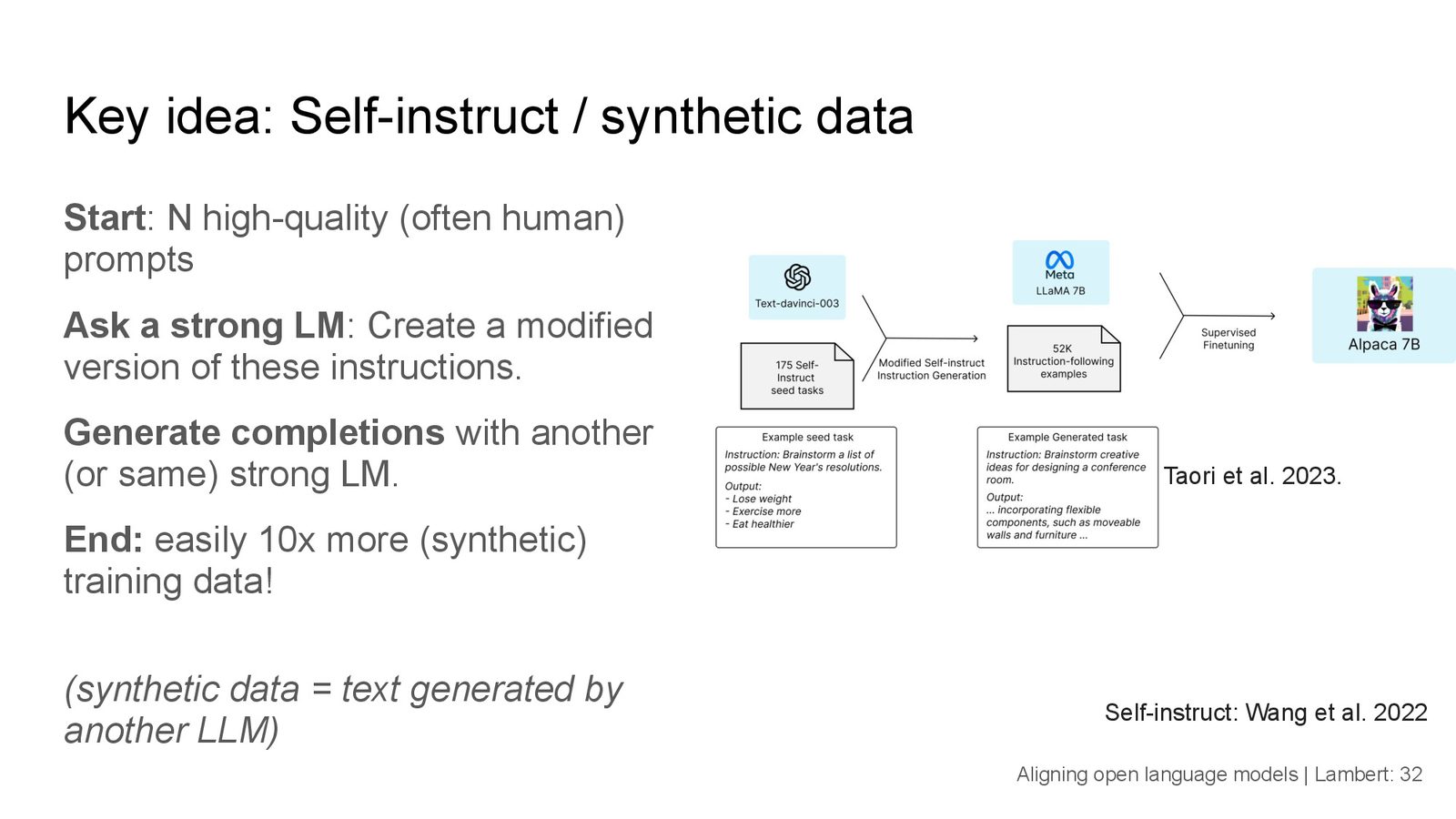
来源:Slide 31 强调 router 在 high-entropy 输入时会激活
backup expert,以防少数 expert 过载。
Slide 31 的 router 教训
1)High-entropy token 需要 higher temperature + noise injection;2)添加 backup expert 可以避免 softmax collapse;3)实时 heatmap 帮助找出 expert hot spots。
Slide 38:量化与 Multi-modal stack
Slide 38 提供了 Mixtral 与 multi-modal stack 的整合图,展示 router 之外还可以接入 vision encoder & speech encoder,再由 aggregator 输出给 agent stack。图中也提示 4-bit/8-bit 量化与 pipeline parallel 的协作细节。

来源:Slide 38 展示 Mixtral 如何与 vision/speech 模块拼接,形成 agent-ready stack。
Slide 38 的系统视角
Mixtral 可以视为 multi-modal scaffolding 的语言 backbone:language & vision encoder 提供 token,router/expert 输出 action-level embedding,agent stack 则实现 downstream policy。
本章小结
Slide-driven Insights 让讲座不仅有口头讲解,还通过视觉图示强化 router/expert 流水线与评估对比,帮助听众把抽象架构具象化。
未来方向与社区实践
研究挑战与开放问题
Albert 将 Mixtral 的未来定位在更大规模的 expert(128+)、更稳健的 router(非 softmax)、更精致的 load balancing 以及跨语言 transfer。关键问题包括 “如何避免 router 对 token 重新打分时的 jitter” 与 “如何把 MoE 训练推向多模态”。
研究议题速递
1)更细粒度的 router logits regularization;2)expert-level prompt tuning;3)multi-modal tokens 共享 expert;4)非平滑 routing(如 Gumbel-softmax)。这些议题既涉及理论也需要大规模实验。
产业协同与开源实践
Mixtral 权重开源在 Hugging Face,并提供 inference API。Albert 提到:社区可以借助 mixtral tag 的 LoRA 模块快速在自己数据上 finetune,同时用 https://huggingface.co/mistralai/Mixtral-8x7B 作为基准 checkpoint,协同改进 router、data prep、LLM + agent stack。
社区实践可复用路径
- 下载 Mixtral checkpoint。
- 用 LoRA 或 QLoRA 对 router/train heads 做轻量微调。
- 结合 LangChain/Agentic API 构造 open-source assistant。
本章小结
第六章强调 Mixtral 不是闭源黑盒,而是社区合作的基座:研究者可以在 Hugging Face 继续探索 router、专家 routing fairness 与 multi-modal 整合。
案例与实践
Mixtral 在 Hugging Face 上的复现路径
Hugging Face 上的 mistralai/Mixtral-8x7B checkpoint 已经开源,Albert 建议复现流程如下:
- 下载 Mixtral checkpoint 与 tokenizer,确保与 official config 对齐。
- 使用 LoRA 或 QLoRA 在 router/FFN 上做轻量微调(无需重写所有专家)。
- 结合 Helix/Data2Vec 等串流 pipeline,把 inference 输出接入 LangChain/Agent。
| 阶段 | Key 操作 | 注意事项 |
|---|---|---|
| 下载与验证 | git lfs clone + huggingface-cli login |
保持 checksum,与 repo release 一致 |
| LoRA/QLoRA | 只微调 routerffn, 维持 expert weights freeze | 群调阶段可用 8-bit Adam 以节省内存 |
| 集成 Agent | LangChain + Mistral FastAPI | 监控 token cost |
复现的黄金路径
重用官方 tokenizer + config,先做 router/adapter 的低成本微调,再借助 LangChain 之类的 agent stack 进行可视化调试,可以快速验证 Mixtral 在自有对话任务中的效果。
企业部署与 metrics 监控
实际部署者需要围绕 latency、cost、reliability 三个维度进行监控。Albert 建议构建 router health dashboard,用 success detector 的 confidence 统计每个 expert 的活跃 token 数,并在网络抖动时自动调整 temperature。
production 中的 router health 脚本
若某个 expert 的 token 分配持续低于阈值,说明 routing 机制已经偏向少数专家,必须通过 temperature bump 或 fallback expert 让其他专家恢复活跃,否则会出现 expert cold start。
本章小结
第七章给出了 Mixtral 的复现与部署步骤:快速复制 Hugging Face checkpoint、用 LoRA 微调 router、用 dashboard 监控 router health,确保 MoE 不只是研究,而是可持续生产级模型。
问答与实践策略
常见质询与解答
在 Q&A 环节,Albert 收到的问题集中在 “router fairness、quantization 之后的精度、以及 expert 数量扩张”。他强调:1)负载均衡 loss 保证每个 expert 最少接收一定比例的 tokens;2)量化后要先做小批量 calibration 再上线,避免低精度引起 success detector 报警;3)增加专家不一定更好,应该先扩展数据宽度再优化 expert 数量。
Debugger 关注点
在 production 中,若发现某些 expert 无法逃出 cold-start,应优先检查 router logits 的 entropy,如果持续低于 0.5,表明 softmax 已经过于锋利;此时可临时引入 backup expert 模式,或者降低 temperature 让更多 expert 被激活。
实践策略与复现手册
Albert 也建议工程团队在复现 Mixtral 时沿用 data → router → observability 的三步手册:先构建 coverage 达标的数据池,再用 Router+Expert pipeline 训练,最后用 router health dashboard + metric alert 保持长期可观察。他还提到 huggingface 的 inference script 可以直接连接 LangChain agent,便于验证 Mixtral 在 downstream assistant 中的表现。
实践策略三板斧
1)Data coverage:用 multi-task + multi-domain 语料;2)Router training:保留 entropy loss + auxiliary load;3)Observability:用 success detector confidence + NCCL latency 设定警戒线。
本章小结
本章总结了现场问答中的常见顾虑与 Albert 给出的应对策略,重点在于 router fairness calibration、量化后的验收流程,以及复现 pipeline 的三大阶段。
实践检查与后续
模型调优清单
在 Mixtral 从研究到生产的过程中,建议坚持以下调优清单:1)data breadth:每个新任务必须保证至少 5k 个高质量 demo;2)router fairness:用 auxiliary loss 控制 expert distribution 并记录 load variance;3)evaluation:human-in-loop success detector + benchmark guardrails;4)deployment:每次发布前执行 quantization + NCCL burn-in。
| 阶段 | 核心任务 | 验收指标 |
|---|---|---|
| 数据 | Multi-task coverage + CLIP filter | low-error < 2% 的 pseudo label |
| Router | Auxiliary load + dropout regularization | max load imbalance < 1.6x |
| Evaluation | Benchmark + success detector confidence | MMLU/HumanEval/GSM8K 录入 |
| Deployment | Quantization + NCCL pipeline test | 运行 latency < 20 ms/token |
调优的黄金法则
先从 data + router 做好 coverage,再把 evaluation metric 做到位,最后才是 deployment 的 latency/quantization。每一步都应有客观指标,不要只凭 subjective judgment。
Slide 44:实验时间轨迹
Slide 44 展示了 Mixtral 从数据收集、router 训练到部署的时间线,每个阶段都伴随指标更新(如 success detector recall 80%、expert entropy 0.7)。图中还强调 warm-up、full training、production rollout 三个里程碑。

来源:Slide 44 将 Mixtral 工程分为 three-phase 计划,并为每个阶段注记 KPI。
Slide 44 的时间管理
模型训练节奏应遵循 collect → train → monitor → iterate:在 collect 阶段完成 data breadth,train 阶段提升 router entropy,monitor 阶段确保 observability,iterate 阶段再回到数据 + pseudo label。
时间线的失配风险
若在 train 阶段没有完成 monitor 准备,就匆忙上线,会导致 production router 频繁 retransmit;必须全程维持 automation + alert,否则 latency jitter 会影响 downstream agent。
本章小结
本章提供可执行的调优清单与时间线,帮助研发团队追踪 Mixtral 的数据、router、metric、部署四个维度,确保每次迭代都有明确的验收标准。
总结与延伸
关键层级回顾
以下表格归纳本讲关键层级:稠密的 optimization 仍是基础,稀疏专家让模型发挥更高 capacity,工程实践则决定 MoE 能否大规模部署。
| 层级 | 核心内容 | 影响 |
|---|---|---|
| 基础优化 | Sliding window + GQA + RoPE | 控制长上下文的 attention FLOPs |
| 稀疏架构 | Router + Top-K experts + auxiliary loss | 只激活必要参数,以 46.7B 上换取 12.9B 计算 |
| 工程部署 | Quantization + multi-node routing + load balancing | 让 Mixtral 在云端低成本运行 |
拓展阅读
- Jiang et al., “Mixtral of Experts”, 2024.
- Brohan et al., “RT-1: Robotics Transformer for Real-World Control at Scale”, RSS 2023.
- Ahn et al., “Do As I Can, Not As I Say: Grounding Language in Robotic Affordances (SayCan)”, 2022.
- Huang et al., “Inner Monologue: Embodied Reasoning through Planning with Language Models”, CoRL 2022.
本章小结
整场讲座围绕 “稠密优化 → 稀疏 MoE → 工程部署” 形成闭环,Mixtral 用 router/expert、pseudo label 和 quantization 使大模型可部署,社区则可通过 open-source checkpoint 持续优化语言模型生态。