CS336 2026 Lecture 13:Data I
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Stanford CS336 Spring 2026 官方可执行讲义重新整理 |
| 来源 | Stanford CS336 |
| 日期 | 2026 年春季 |

Lecture 13: Data I 的核心主线
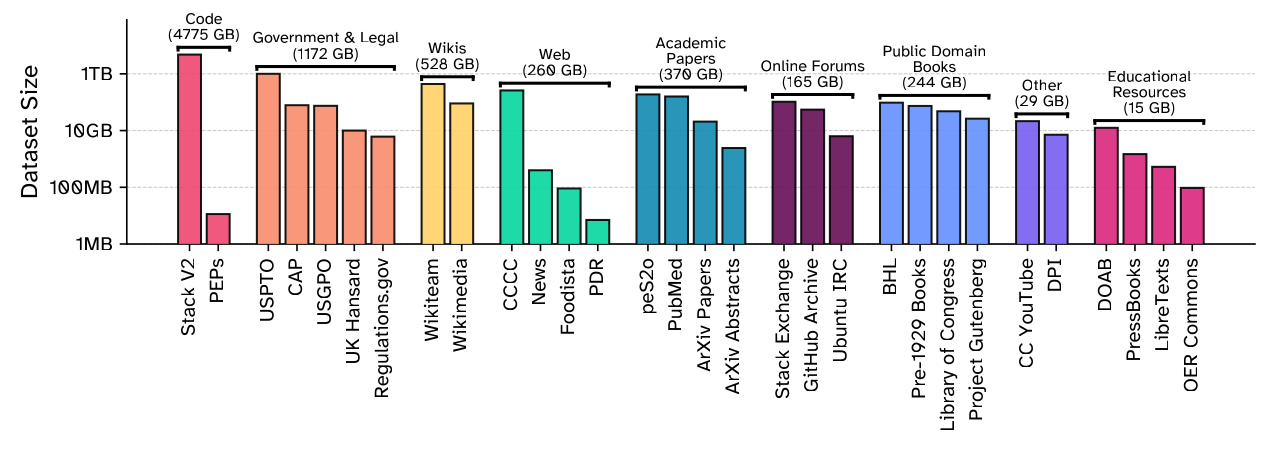
前面的课程默认“给定数据”,然后讨论如何训练语言模型。Lecture 13 开始反过来问:到底训练什么数据? 课程的核心结论很直接:data does not fall from the sky。训练数据不是“整个互联网”的自然副产品,而是一条从 live service 到 raw data,再到 processed data 的工程、法律和伦理管线。
本讲总结先行
- Live service \(\rightarrow\) raw data \(\rightarrow\) processed data,中间有 crawling、HTML extraction、filtering、deduplication、PII handling、license checks。
- 数据是区分语言模型的重要因素,因为架构和训练流程越来越公开,数据细节却常被保密。
- 数据管线涉及 copyright、privacy、robots.txt、ToS、licensing、fair use、shadow libraries 等问题。
- 大部分 pipeline 是启发式的,仍有大量改进空间。
为什么数据最重要
读图:为什么模型公司对 data 更保密
开源权重模型往往公开 architecture、parameter count、training recipe,甚至并行策略;但数据来源、比例、清洗规则、过滤器和法律授权常只给模糊描述。原因包括竞争优势和版权责任。数据成为模型差异化的核心资产。
术语消化:训练阶段和数据质量
| 阶段 | 数据形态 | 目标 |
|---|---|---|
| Pre-training | 大量原始或轻清洗文本、代码、网页、书籍等。 | 建立通用语言和世界知识。 |
| Mid-training | 更高质量、能力导向的数据。 | 强化代码、数学、推理、多语等能力。 |
| Post-training | 聊天、偏好、RL、工具使用轨迹。 | 对齐交互行为和任务偏好。 |
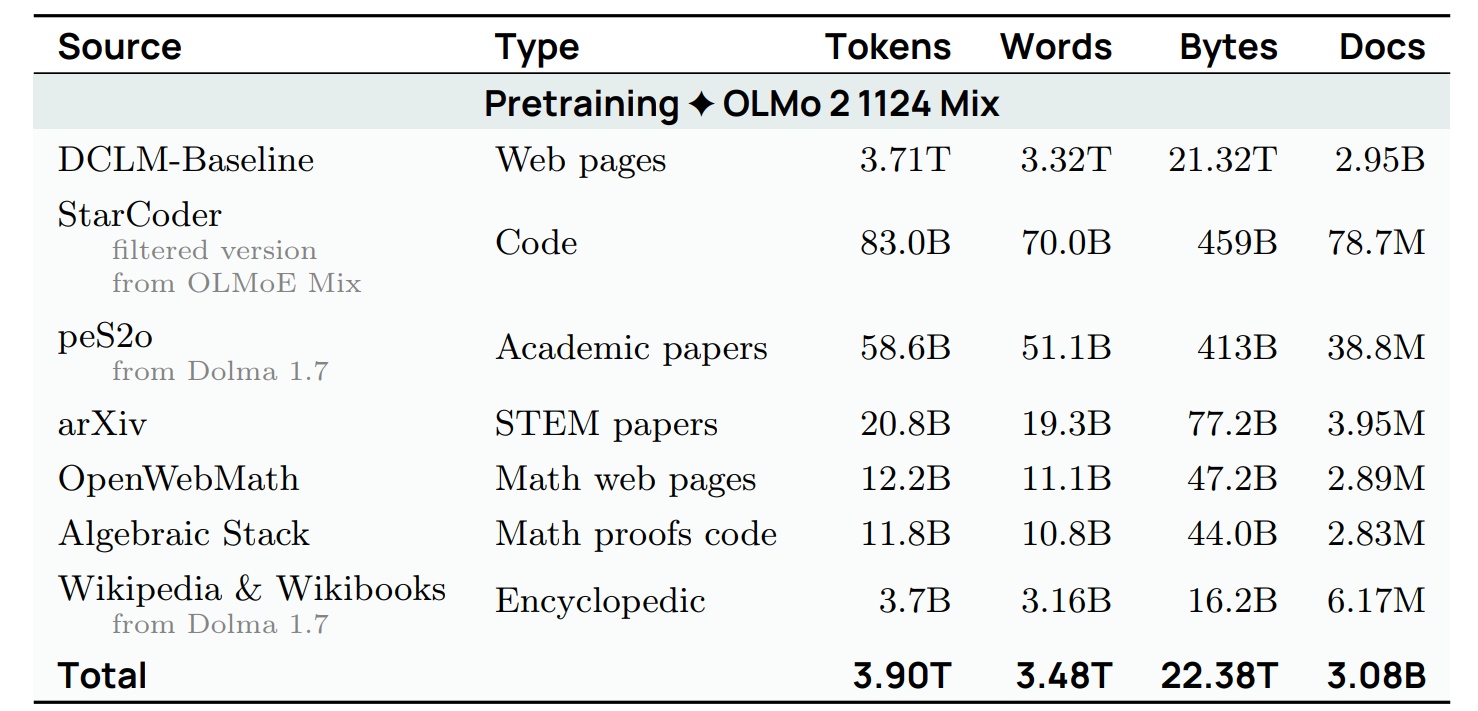
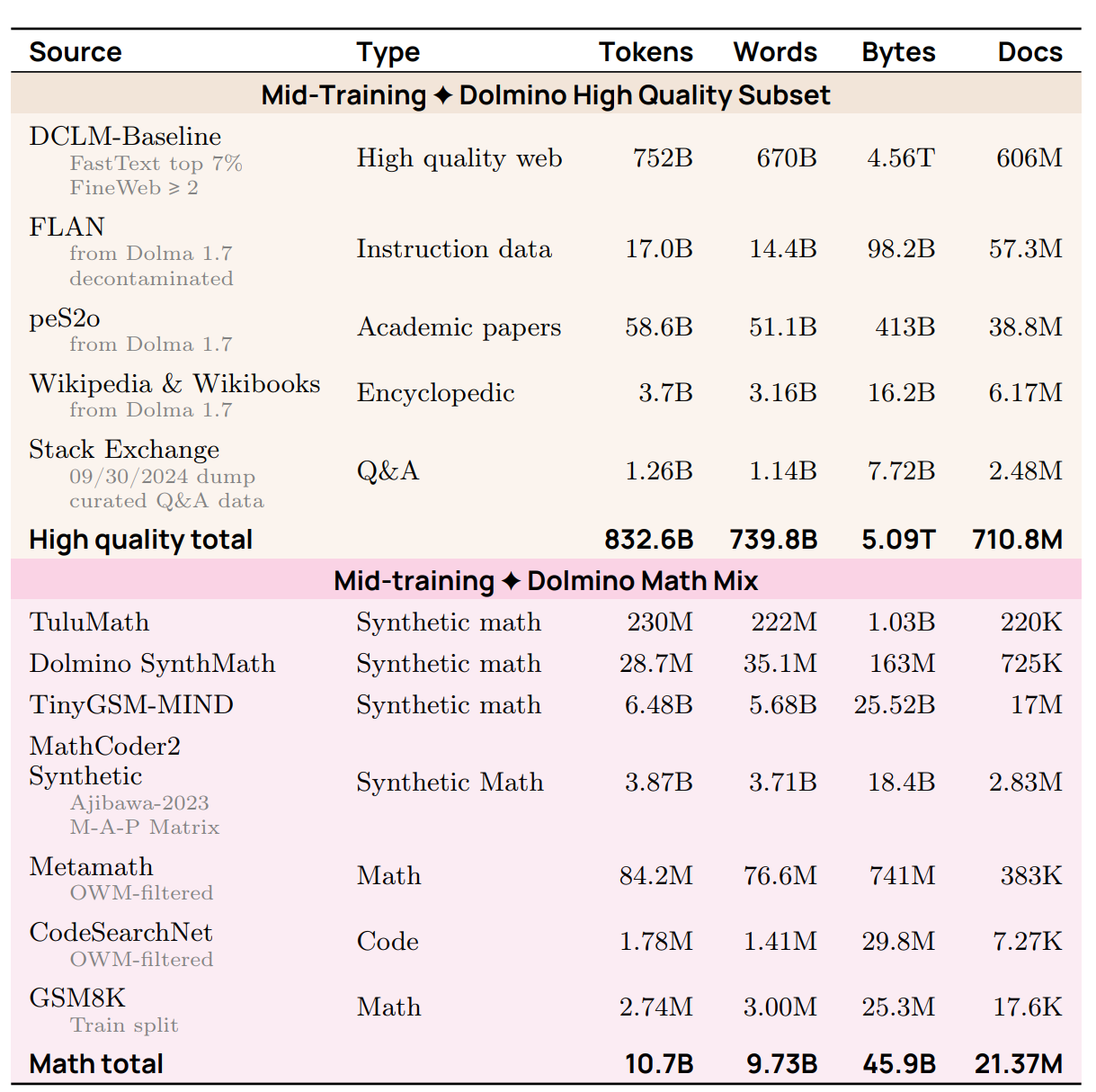
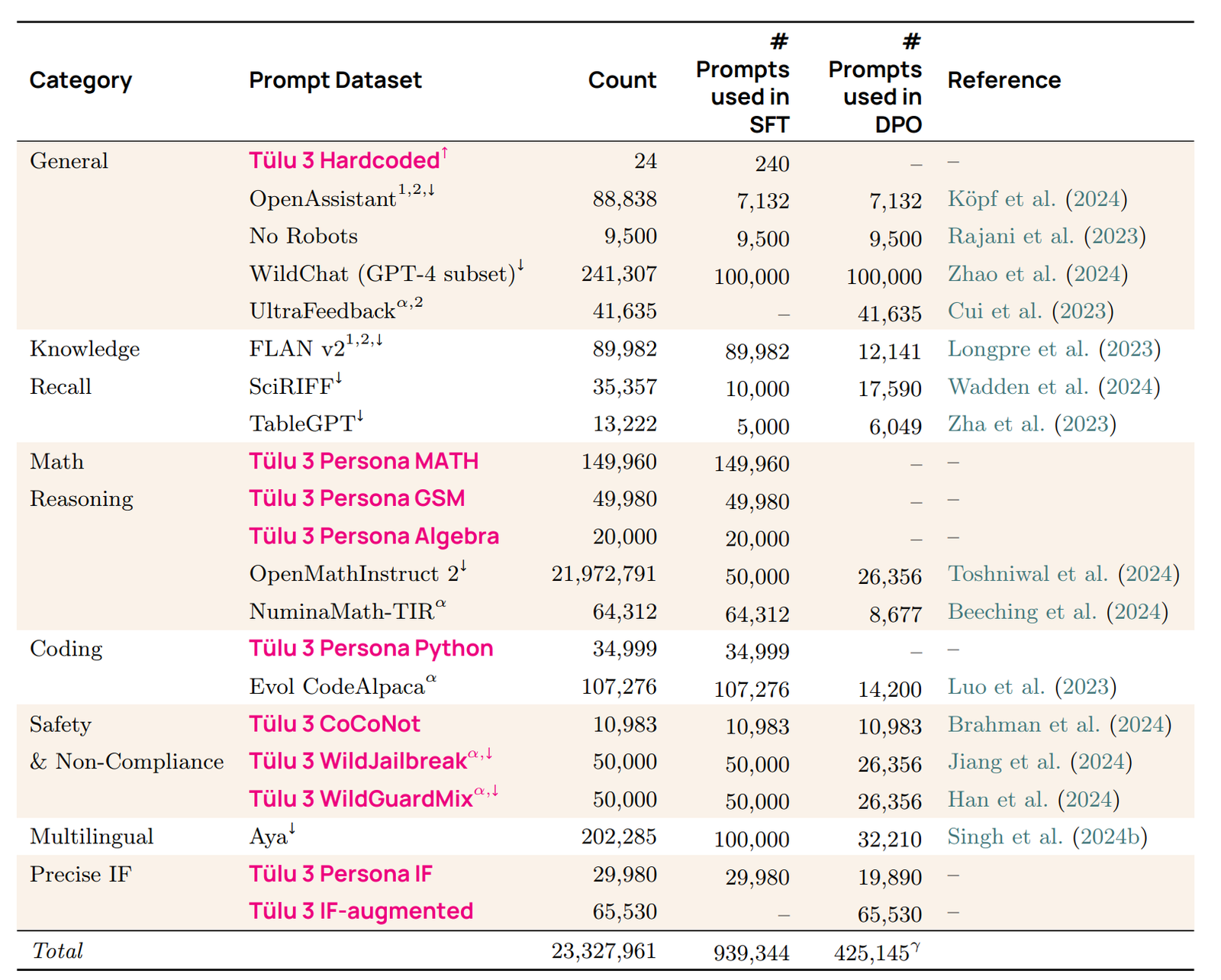
读图:OLMo/Tulu 三张图的教学含义
三张图展示了从大量弱筛网页和通用语料,到更有针对性的高质量数据,再到 instruction/chat 数据的移动。数据量通常下降,人工或模型筛选强度上升,目标也从“预测文本”转向“表现出想要的行为”。
Raw sources:互联网不是一个可直接训练的数据集
“语言模型训练在整个互联网”是非常粗糙的说法。更准确地说,很多原始数据来自 public web 的 crawls,但 live servers 不能直接训练。需要 crawler 发现 URL、下载页面、保存 raw HTTP response,再把 HTML 等格式转换为文本。
术语消化:从 live service 到 processed data
| 层次 | 例子 | 问题 |
|---|---|---|
| Live service | 网站、GitHub、arXiv、Wikipedia。 | 动态页面、认证、rate limit、ToS、robots.txt。 |
| Raw data | WARC、git repo、PDF、LaTeX source、XML dump。 | 格式复杂,噪声大,重复多。 |
| Processed data | WET/text、filtered docs、deduped corpus。 | 转换损失、过滤 bias、PII、版权和质量控制。 |
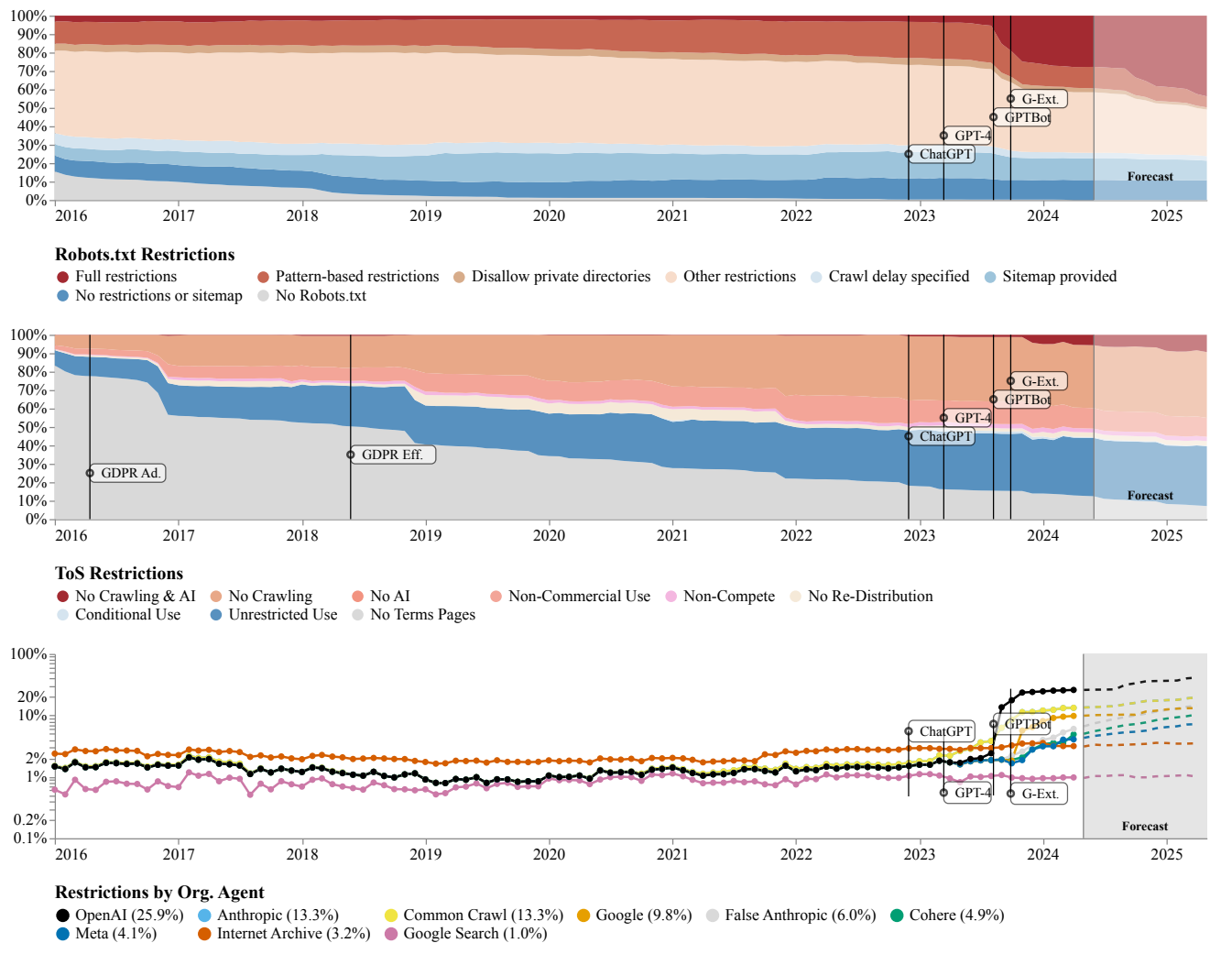
读图:限制增加意味着什么
越来越多网站通过 robots.txt、ToS 或其他方式表达不希望被爬取。即使技术上可访问,也不代表合规、礼貌或可用于训练。未来数据获取的成本会更高,许可数据和自有数据的重要性会上升。
Shadow libraries 的边界
LibGen、Z-Library、Anna's Archive、Sci-Hub 等 technically 是 web 的一部分,但它们绕过版权和付费墙。课程强调从法律角度这是 piracy/copyright infringement。训练数据工程不能把“能下载”当成“能使用”。
本章小结:raw source 不是 raw permission
网页能访问、能下载、能解析,并不意味着能训练。真实数据管线至少要同时处理四种约束:技术可达性、站点意愿、法律授权、社会接受度。这四个维度任一出问题,都可能让数据集不可持续。
Copyright、licenses、fair use 与 lawsuits
几乎互联网上的原创表达都受 copyright 保护。Copyright 保护 expression,而不是 idea;保护门槛很低,不需要注册即存在,但美国起诉通常需要先注册。使用 copyrighted work 的主要路径是获得 license,或主张 fair use。
术语消化:fair use 四因素
- 使用目的和性质:教育用途、transformative use 更有利。
- 作品性质:事实性、非虚构作品更有利。
- 使用数量和实质性:片段比整部作品更有利。
- 对原作品市场的影响:若替代原作品市场,更不利。
这些因素需要具体案件具体分析;本笔记只解释课程内容,不构成法律建议。
课程提到的诉讼包括 The New York Times v. OpenAI、作者诉 Anthropic、作者诉 Meta。讲义中的核心 takeaway 是:截至课程材料所述,一些具体案件中训练被认为 fair use,但盗版复制明确违法,且这一领域仍在快速演化。
训练数据的法律风险不是只看模型是否背诵
复制数据本身可能已经构成争议;训练是否 transformative、模型是否输出受保护表达、是否影响原市场、是否违反 ToS,都是不同问题。数据管线需要记录来源、许可证、过滤规则和使用理由。
术语消化:训练数据法律/合同术语
| 术语 | 课程中的含义 | 数据工程后果 |
|---|---|---|
| Copyright | 保护原创表达,不保护抽象 idea。门槛很低,网页文字通常也受保护。 | 不能把“公开网页”直接等同于“可训练数据”。 |
| License | 权利人承诺在特定条件下不追究使用。 | 需要保存 license、版本、适用范围和限制。 |
| Creative Commons | 一组允许分发/改编的开放许可证,但不同 CC 条款差异很大。 | 需要区分 CC-BY、CC-BY-SA、NC、ND 等条件。 |
| Fair use | 美国法下四因素平衡判断,是否适用取决于具体事实。 | 不能在数据表里简单标成“fair use = yes”。 |
| Terms of Service | 网站合同条款,可能限制 bot 下载或训练用途。 | 即使版权层面可争辩,合同层面仍可能违规。 |
如何把法律问题变成数据工程字段
高质量数据集至少应记录:source URL、crawl time、license 字段、robots.txt/ToS 状态、是否来自 shadow library、是否包含个人信息、处理步骤、过滤器版本、dedup 策略、下游用途假设。没有这些 provenance 字段,后续很难审计风险。
Common Crawl:web-scale raw source
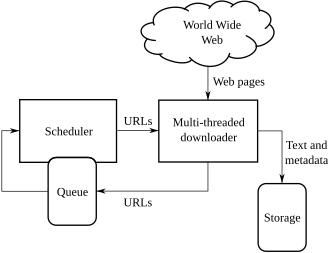
读图:crawler 不是简单 wget 全网
Crawler 需要 selection policy、politeness policy、re-visit policy。它必须决定爬什么、多久重爬、是否尊重 robots.txt、如何避免压垮网站。Common Crawl 每月增加数十亿网页,但 crawl 本身仍只是 raw source。
Common Crawl 提供 WARC 和 WET。WARC 保存 raw HTTP response,例如 HTML;WET 是转换成 text 后的结果。HTML-to-text 是 lossy process,会影响最终模型。
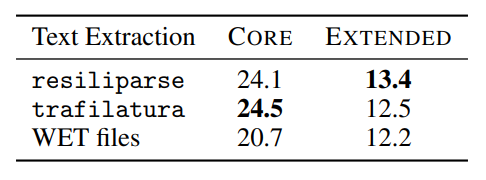
读图:为什么 WET 不是无害中间格式
HTML 包含正文、导航、广告、脚本、评论、页脚。不同 extraction 工具会保留或丢弃不同内容。若正文抽取差,模型会学到网页模板噪声;若抽取过严,又会丢掉有用长尾内容。
术语消化:Common Crawl 到训练文本的处理链
| 步骤 | 做什么 | 主要风险 |
|---|---|---|
| HTML extraction | 从 WARC/HTML 中抽正文。 | boilerplate、广告、导航、评论混入或正文丢失。 |
| Language ID | 判断文档语言。 | 多语混合、代码混合、低资源语言误判。 |
| Quality filtering | 用规则或模型判断是否像高质量文本。 | 过滤掉长尾有用内容,引入 Wikipedia/指令数据偏差。 |
| Deduplication | 移除重复或近重复文档/段落。 | 太弱会重复训练,太强会误删模板相似但内容不同的文本。 |
| Toxicity/PII filtering | 去除有害内容或个人信息。 | 过强会损害分布覆盖,过弱会带来安全和隐私风险。 |
Specialized sources:Wikipedia、GitHub、arXiv
Wikipedia 是高质量知识源:范围有 notability 和 reliable sources 约束,定期 dumps 可直接下载,无需 crawl。但它不是完美源:编辑集中在少数贡献者,且 data poisoning 可能在 dump 前短暂注入恶意内容。
GitHub 对代码能力重要,也可能帮助 reasoning。其数据包括 repository 内容和 metadata,例如 issues、pull requests、comments。代码数据必须处理 forks、重复、license、malware、PII 和 generated files。
arXiv 提供论文 metadata、PDF 和可选 LaTeX source。它适合科学/数学/CS 内容,但不是 peer review,且许可有 all rights reserved 和 Creative Commons 等差异。
源不等于数据集
Wikipedia、GitHub、arXiv 都是 sources。真正进入模型的是经过选择、清洗、格式转换、去重、分片和混合权重设定后的 datasets。数据集设计是模型设计的一部分。
三类专门数据源的互补性
| 来源 | 强项 | 局限 |
|---|---|---|
| Wikipedia | 高密度百科知识、结构清晰、多语 dumps。 | 不是原创思想库,主题受 notability 和编辑群体影响。 |
| GitHub | 代码、工程过程、issues/PR/comments。 | license、fork/duplicate、malware、PII、bot activity。 |
| arXiv | 科研论文、LaTeX source、metadata permissive。 | 未同行评审,PDF/LaTeX 解析复杂,领域分布不均。 |
经典数据集:BERT、WebText、CCNet、C4
BERT 使用 Wikipedia 和 BooksCorpus。BooksCorpus 来自 Smashwords 上免费的自出版书籍,后来因违反 ToS 等问题下线。GPT-2 的 WebText 则用 Reddit 高 karma 外链作为 quality surrogate,并产生 OpenWebText 的开源复刻。
CCNet 试图自动构造大规模高质量预训练数据:去重、语言识别、用 KenLM 5-gram 模型筛出像 Wikipedia 的文本。C4 从 Common Crawl 2019 snapshot 出发,用手工规则过滤自然语言文本,成为 T5 的重要贡献之一。
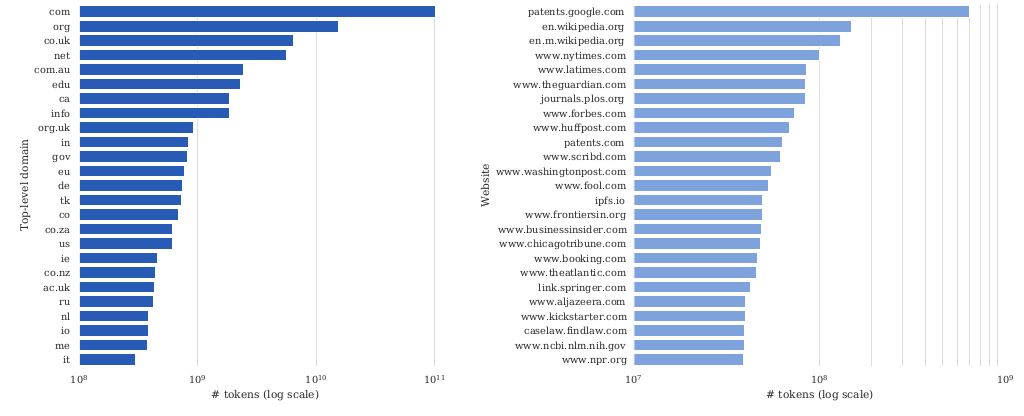
读图:C4 domains 告诉我们什么
C4 不只是“网页文本”。它的 domain distribution 反映了 crawl、HTML extraction 和过滤规则共同造成的选择偏差。模型学到的风格、知识和价值取向会受这些 domain 比例影响。
经典数据集的谱系
| 数据集 | 主要来源 | 关键处理 | 教学结论 |
|---|---|---|---|
| BERT data | Wikipedia + BooksCorpus | 文档级序列,BooksCorpus 来自免费自出版书。 | 早期 LM 数据更窄、更人工。 |
| WebText | Reddit 高 karma 外链网页 | 英文过滤、近重复移除。 | 用社交信号做代理质量筛选。 |
| CCNet | Common Crawl | 去重、fastText 语言识别、KenLM 质量过滤。 | 自动化 web filtering 的早期范式。 |
| C4 | Common Crawl snapshot | 手工规则、坏词/非英文/短页过滤。 | 简单规则可规模化,但偏差明显。 |
| GPT-3 data | CC、WebText2、Books、Wikipedia | 质量分类器、fuzzy dedup。 | 私有数据细节开始变模糊。 |
GPT-3、The Pile、Gopher、LLaMA、RefinedWeb
GPT-3 数据包括 processed Common Crawl、WebText2、神秘 books corpora 和 Wikipedia,总计约 400B tokens。处理上使用 quality classifier 区分 WebText/Wikipedia/Books 与其他网页,并做 fuzzy deduplication。
The Pile 是开源模型社区对 GPT-3 数据不透明的回应,聚合 22 个高质量 domain,包括 Pile-CC、PubMed Central、arXiv、Enron emails、Project Gutenberg、Books3、StackExchange 等。
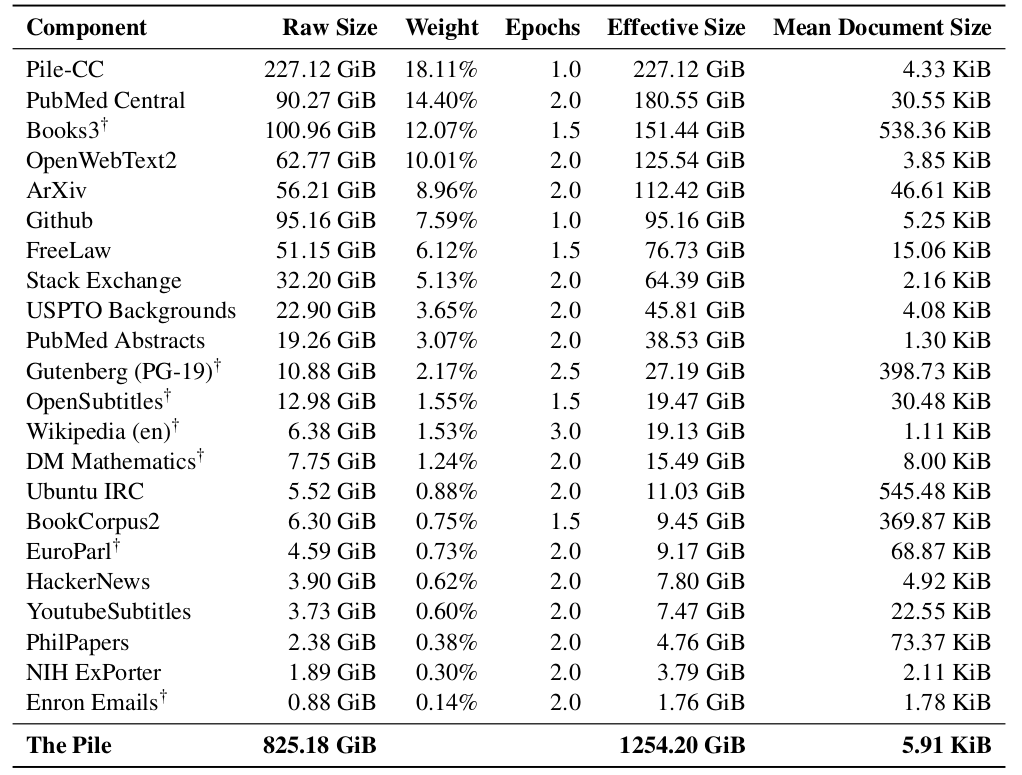
读图:The Pile 的价值和争议
The Pile 让数据组成更透明,推动开源模型训练。但其中 Books3 来自 shadow library Bibliotik,后来因 copyright lawsuits 下线。透明不等于没有法律/伦理风险。
Gopher 的 MassiveText 说明数据描述本身也很有价值:MassiveWeb、C4、Books、News、GitHub、Wikipedia,并使用 English filtering、deduplication、train-test overlap、manual quality rules 和 Google SafeSearch toxicity filtering。LLaMA 则使用 CommonCrawl/CCNet/C4/GitHub/Wikipedia/Project Gutenberg/Books3/arXiv/StackExchange,总计约 1.2T tokens,并被 RedPajama/SlimPajama 复刻。
RefinedWeb 的主张是 web data is all you need:使用 WARC 和 trafilatura 抽取文本,Gopher rules 过滤,避免 ML-based filtering 以减少 bias,并用 MinHash over 5-grams 做 fuzzy deduplication。FineWeb 在此基础上扩展到 95 个 Common Crawl dumps,结果达到 15T tokens。
这些数据集的代际变化
早期数据集强调“有一批可训练文本”:Wikipedia、BooksCorpus、WebText。GPT-3 之后,数据集开始强调“大规模 web + 多源混合 + 去重过滤”:The Pile、MassiveText、LLaMA data、RefinedWeb。到 Dolma/DCLM/Nemotron-CC 阶段,重点进一步变成“过滤器和数据处理算法本身”:谁能从巨大 raw pool 中筛出更高质量、更少偏差、更可审计的数据。
不要把 token 数当成唯一质量指标
15T tokens 不必然优于 3T tokens,3T tokens 也不必然优于 800GB。数据价值取决于覆盖、质量、去重、许可证、语言分布、代码/数学/学术比例、污染控制和与目标能力的匹配。Scaling laws 只能在数据分布相对稳定时外推;换数据 pipeline 会改变曲线。
手工规则和模型过滤的偏差不同
手工规则透明、便宜、可解释,但可能粗糙,例如删除包含代码符号的页面。模型过滤更强,但会把训练 classifier 的正负例偏差扩散到整个语料。数据过滤没有中立方案,只有可审计的 trade-off。
案例复盘:同一个 raw source 可以长成完全不同的数据集
Common Crawl 是最典型例子。C4、CCNet、RefinedWeb、FineWeb、Dolma、DCLM、Nemotron-CC 都可以从 Common Crawl 或 web crawl 出发,但它们的目标和处理哲学不同。C4 强调简单可复制规则;CCNet 强调 Wikipedia-like quality;RefinedWeb 强调 WARC 抽取和弱模型过滤;DCLM 强调标准化数据处理竞赛;Nemotron-CC 则强调不要过度过滤,宁可用 ensemble classifier 和 synthetic rephrasing 提升质量。
同源不同集的关键差异
- 抽取器不同:WET、trafilatura、jusText、resiliparse 会改变保留正文的边界。
- 语言识别不同:阈值高会损失多语和 code-mixed 文本,阈值低会混入噪声。
- 质量定义不同:像 Wikipedia、像 instruction data、像教育内容、像高投票网页,是四种不同的“好”。
- 去重粒度不同:文档级去重、段落级去重、MinHash 近重复、benchmark decontamination 对模型记忆和泛化影响不同。
- 安全过滤不同:bad-word lists、toxicity classifiers、PII redaction 会改变社会偏见和内容覆盖。
数据管线如何影响模型行为
如果过滤器偏好百科式文本,模型可能更正式但长尾对话能力弱;如果偏好 Reddit 外链,模型可能更了解网络文化但噪声和偏见更重;如果偏好代码和 PR metadata,模型会更擅长软件工程;如果大量使用合成 instruction data,模型会更会“回答问题”,但风格和事实分布会向 teacher model 靠拢。数据处理不是清洁工序,而是行为塑形。
可复现性不只需要发布 URL 列表
即使公开所有 URLs,如果没有 crawl time、HTML extraction version、过滤器权重、dedup hash、语言识别阈值和删除策略,别人仍然无法复现同一数据集。网页会变,robots.txt 会变,内容会消失,许可证会改。数据集复现比代码复现更脆弱。
术语表:数据处理方法
| 方法 | 做什么 | 什么时候会出问题 |
|---|---|---|
| Language ID | 判断文本语言,常用 fastText 等分类器。 | 多语混合、代码、专有名词、低资源语言会被误判。 |
| Exact dedup | 删除完全相同文档或段落。 | 只能去掉显式重复,模板改写和轻微变化仍保留。 |
| Fuzzy dedup | 用 MinHash/Jaccard 等检测近重复。 | 阈值太低误删,阈值太高重复训练。 |
| Quality rules | 按标点、词数、坏词、HTML 特征等过滤。 | 透明但粗糙,容易删掉代码、列表、非标准文本。 |
| Quality classifier | 用模型判断文本是否高质量。 | 继承训练正负例偏差,可能把“像某数据集”当成“好”。 |
| PII redaction | 删除邮箱、电话、地址、公开 IP 等个人信息。 | 规则漏检或误删真实技术内容。 |
| Benchmark decontamination | 移除与评测集重叠的训练文本。 | 近似匹配难,时间戳和复制传播会破坏假设。 |
为什么 Data I 值得单独一讲
模型能力常被解释为参数量、架构或训练 FLOPs 的结果,但这些变量背后还有一个更不透明的变量:模型到底读过什么。数据源决定知识覆盖,过滤器决定语言风格和价值偏好,去重决定记忆压力,许可证决定可持续性,PII/安全过滤决定社会风险。忽略数据,就无法真正解释模型行为。
现代 filtering:Dolma、DCLM、Nemotron-CC
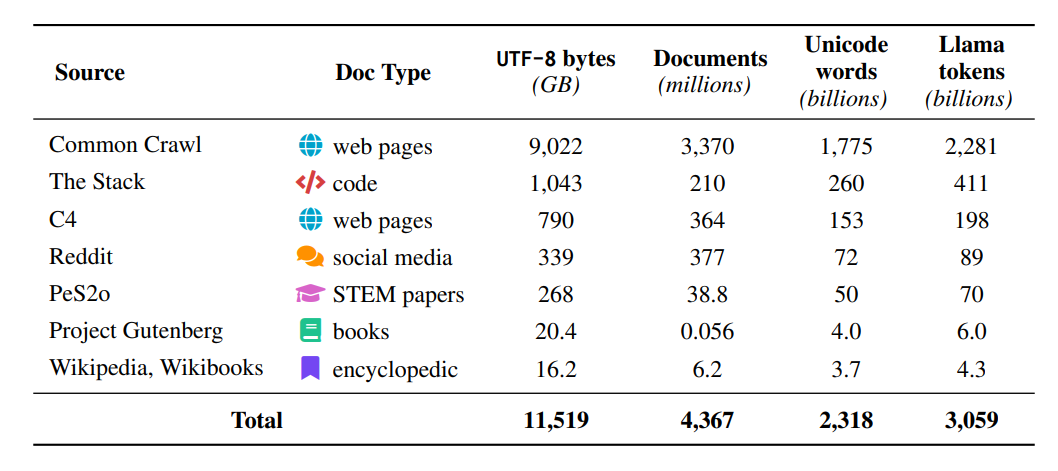
读图:Dolma 的 pipeline
Dolma 的 Common Crawl 处理包括语言识别、Gopher/C4 规则过滤、toxicity filtering、Bloom filter deduplication。它体现了现代开源数据集的折中:不用强模型过滤以减少 bias,但仍大量依赖启发式。

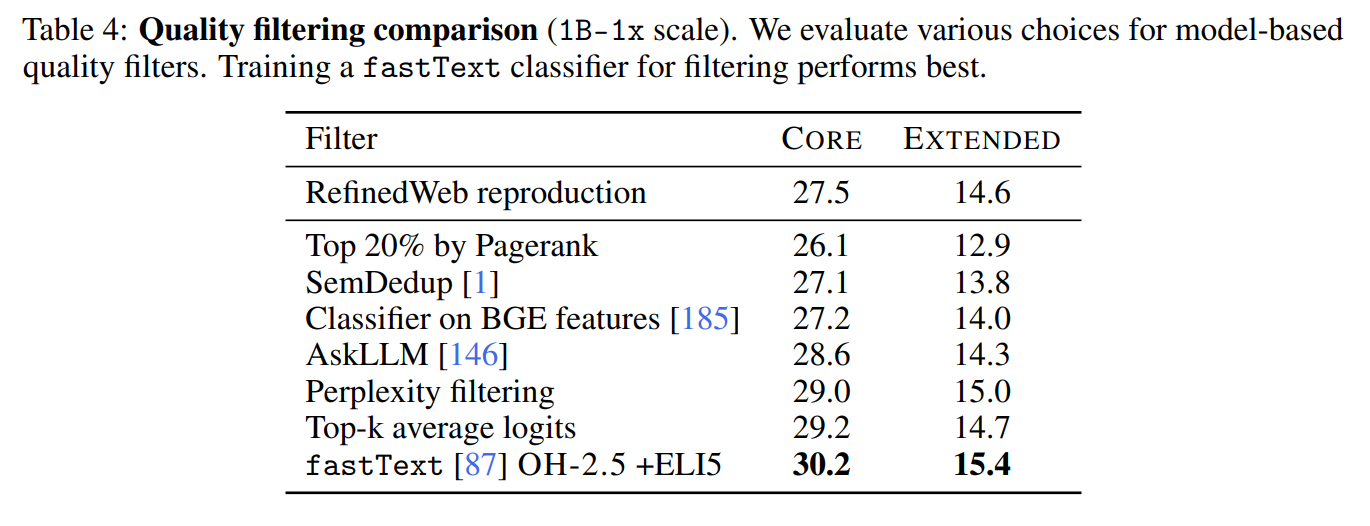
读图:model-based filtering 的优缺点
DCLM 使用正例 OpenHermes/ELI5、负例 RefinedWeb 训练 fastText classifier,在大池子上过滤。优点是质量提升明显;风险是 classifier 会继承正负例选择偏差,把“像某些高质量数据”误当成“真正有用数据”。
Model-based filtering 的机制
把一个小的人工/模型选定数据集当作“好文本”正例,把普通 web 文本当作负例,训练 classifier 后打分整个 Common Crawl pool。这个过程实质上是在定义“模型应该多学哪类文本”。因此 classifier 的训练集就是隐含的数据价值观。
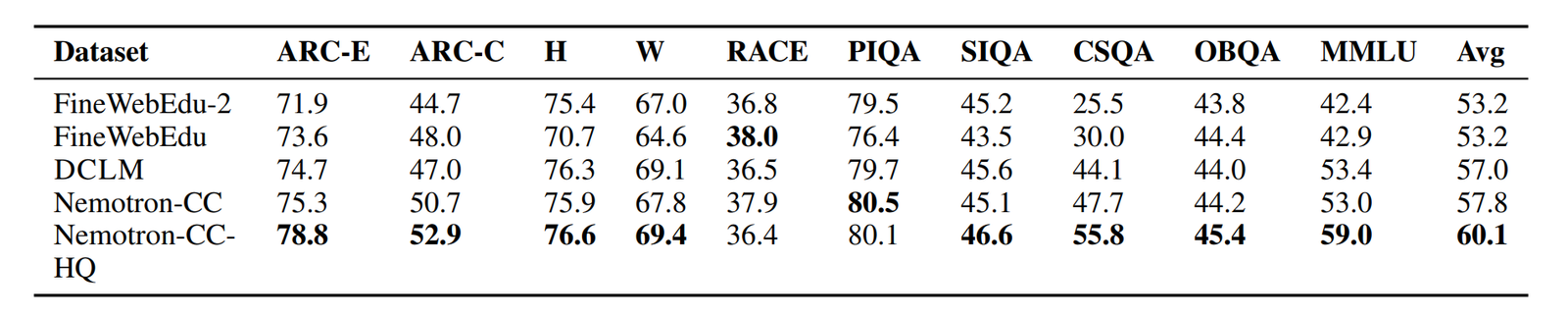
读图:Nemotron-CC 的动机
FineWebEdu 和 DCLM 可能移除 90% 数据,质量高但 token 少。Nemotron-CC 试图“need more tokens but preserve quality”:用 Nemotron-340B-instruct 打分并蒸馏 classifier,结合 DCLM classifier,对低质量数据重写,对高质量数据生成任务。
合成数据和重写的风险
用 LM rephrase 低质量数据或从高质量数据生成 QA pairs,可以提高可学信号密度;但也可能引入 teacher model 的风格偏差、事实错误、重复模板和版权继承问题。合成数据应记录生成模型、prompt、过滤器和去重策略。
Code data:The Stack 与 Stack v2
The Stack 从 GitHub Archive 获取 repo names,git clone 大量 repositories,只保留 permissively licensed 代码,用 go-license-detector 检测 license,并用 MinHash/Jaccard 去重。Stack v2 扩展到 issues、comments、PRs、Software Heritage repos 和 docs crawls。
读图:为什么 PR metadata 有价值
代码文件教模型语法和 API,PR/issue/comment 教模型软件工程过程:bug report、review、patch rationale、discussion。Agentic coding models 很可能受益于这种过程数据,但也要处理 PII、bot activity、malware 和 license。
代码数据的特殊性
代码不是普通文本:它有许可证、依赖、可执行语义、测试、提交历史和安全风险。高质量代码数据不只是 .py/.js 文件,还包括 README、issue、PR、review、diff context、CI log。面向 coding agents 的数据尤其需要过程信息。
CommonPile:只用 permissively licensed data 可行吗
读图:permissive data 也有细节
License laundering 可能把 copyrighted work 重新包装成 permissive license;collection license 不一定延伸到单个文档;合成数据若来自未授权数据训练的模型,法律状态也不清楚。只说“permissive”不够,仍需 provenance 审计。
实操视角:设计一个训练数据管线要问什么
数据管线 checklist
- 来源:每个 source 是 live service、public dump、licensed corpus、synthetic data 还是 user data?
- 权限:是否有 license?ToS 是否允许?robots.txt 怎么处理?是否含 shadow-library 风险?
- 抽取:HTML/PDF/LaTeX/code/XML 如何转文本?转换器版本和失败率是什么?
- 过滤:使用手工规则、语言识别、quality classifier、toxicity filter 还是 PII filter?阈值怎么定?
- 去重:document-level、paragraph-level、MinHash、Bloom filter、benchmark overlap 分别怎么做?
- 混合:web、code、math、academic、books、Q&A、multilingual、synthetic data 的比例如何决定?
- 审计:能否追踪某条训练样本的 provenance?能否删除某类数据?能否复现实验?
数据配比不是静态表格
Pre-training 早期可能需要最大覆盖和多样性;mid-training 可能提高代码、数学、高质量学术文本或教育文本比例;post-training 则加入 instruction、preference、tool-use、RL trajectories。数据 mix 应服务训练阶段和目标能力,而不是一次性固定。
数据工作最容易隐藏在“清洗过”三个字里
论文常写“we cleaned and deduplicated the data”,但这句话可能包含数百个规则、多个模型过滤器、人工审计、legal review 和大量失败样本。对复现和安全来说,清洗规则和过滤器版本与模型 architecture 一样重要。
数据质量评估与反馈闭环
数据管线不是一次性脚本,而是一个需要闭环优化的系统。训练前可以用静态统计检查语料,例如语言分布、重复率、平均文档长度、域名分布、许可证比例、PII 命中率、毒性分数、代码/数学/学术文本比例;训练中可以看 loss 曲线和 domain-level loss;训练后再用 evaluation suite 反推哪些能力缺口对应哪些数据缺口。
从 eval 回到 data 的闭环
- 如果代码 benchmark 弱,检查代码数据比例、license 过滤是否过严、是否缺少 issue/PR/文档数据。
- 如果数学推理弱,检查是否有足够高质量 LaTeX、竞赛题、步骤化解答和去重后的合成数据。
- 如果多语能力弱,检查 language ID 阈值是否把 code-switching 和低资源语言误删。
- 如果模型幻觉强,检查高权威来源比例、重复低质网页、知识密度和事实性过滤。
- 如果安全性差,检查 harmful data、jailbreak data、refusal data 和 policy data 的覆盖及标注质量。
数据审计指标
| 指标 | 看什么 | 为什么重要 | |
|---|---|---|---|
| Domain mix | web、books、code、academic、forums、Q\ | A、news 的比例。 | 决定模型知识和风格来源。 |
| Duplication rate | exact/near duplicate 的比例和重复 token 权重。 | 重复会浪费 compute,也可能导致 memorization。 | |
| Document quality score | 规则分、classifier 分、人审样本。 | 过滤策略是否过强或过弱。 | |
| License coverage | permissive、unknown、restricted、licensed 的比例。 | 决定法律和发布风险。 | |
| PII/toxicity rate | 隐私和有害内容命中率。 | 决定安全和合规处理需求。 | |
| Benchmark overlap | 与 eval/test 集的 exact/fuzzy overlap。 | 避免评价污染和能力高估。 |
数据闭环也可能过拟合
如果只根据现有 benchmark 补数据,模型会越来越适合 benchmark,而不一定更适合真实用户。数据迭代应该同时看 held-out eval、fresh eval、private eval、真实使用反馈和安全审计。
本章小结
Lecture 13 的后半部分说明,同样叫“web data”可以有完全不同的数据哲学:C4 偏规则过滤,RefinedWeb/FineWeb 偏大规模 web,DCLM 偏模型质量分类器,Nemotron-CC 偏保留更多 token 和合成增强,CommonPile 偏许可可审计。数据集不是自然物,而是价值判断和工程约束的产物。
Data I 的根本观点
如果说前几讲讨论的是“如何更有效地训练模型”,这一讲讨论的是“训练目标从哪里来”。数据决定模型看见什么语言、知识、代码、价值观、错误、重复和法律风险。架构可以复现,GPU 可以租,优化器可以开源;但高质量、合规、目标明确的数据管线最难复制。
和下一讲的连接
Data I 主要讲来源、法律边界和经典/现代数据集谱系。下一步自然是更细的数据处理问题:如何做 dedup、contamination removal、PII filtering、quality classifiers、data mixing、curriculum、post-training data 和 evaluation-driven data iteration。
总结与延伸
Lecture 13 的核心是把“数据”从抽象名词还原成生产系统。网页不是直接可训练文本,Common Crawl 不是高质量数据,许可证不是一行元数据,过滤器不是中立工具。数据工程涉及来源、转换、过滤、去重、版权、隐私、质量和长期维护。
最终 takeaways
- Data does not fall from the sky;数据获取和清洗需要大量工程和人类判断。
- 模型公司常公开架构和训练流程,却隐藏数据细节,说明数据是核心竞争力。
- Public web 受动态内容、认证、robots.txt、ToS、rate limit 和法律限制约束。
- Copyright/fair use/licensing 是训练数据管线不可回避的一部分。
- Common Crawl 是 raw source,不是成品训练集;HTML extraction 和 filtering 会塑造模型。
- 现代数据集在规则过滤、模型过滤、合成重写、dedup、license 审计之间折中。
- 下一步数据课程自然会进入更细的 processing、mixing 和 post-training 数据设计。
拓展阅读
- Common Crawl, C4, CCNet, RefinedWeb, FineWeb.
- The Pile, Dolma, DCLM, Nemotron-CC, The Stack, CommonPile.
- Copyright Act, Creative Commons, fair use, Terms of Service.
- LLaMA, GPT-3, Gopher, OLMo 2, Tulu data reports.