CS231N Lecture 14: Generative Models (Part 2)
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Justin Johnson 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2025年5月20日 |

引言:这一讲到底想解决什么
上一讲已经把生成式建模的前半张图铺好了:autoregressive 模型直接分解 \(p(x)\),VAE 用 latent variable 和 ELBO 近似建模数据分布,GAN 走向隐式密度,diffusion 则把生成变成逐步去噪。今天这一讲不是“再加一个模型名字”,而是把这张图的后半边补完整,并且把现代图像、视频生成系统为什么会变成“模块拼装”的样子讲清楚。

来源:Slides 第1页。
本讲主线
这讲的核心不是“哪个模型更酷”,而是把同一个问题拆成四个层次:
- 生成机制:noise 如何变成 data
- 训练机制:监督信号从哪里来
- 采样机制:如何在推理时真正生成样本
- 工程机制:为什么现代系统几乎一定要拼接 VAE、GAN、diffusion、Transformer 和 text encoder
先把生成模型的家族图再看一遍
从讲义角度,最容易混淆的是“显式密度”和“隐式密度”这两个维度。显式密度模型试图直接写出或近似写出 \(p(x)\);隐式密度模型不强调概率值本身,而强调能否从模型里采样出看起来像真的样本。前者重 likelihood,后者重 sample quality。
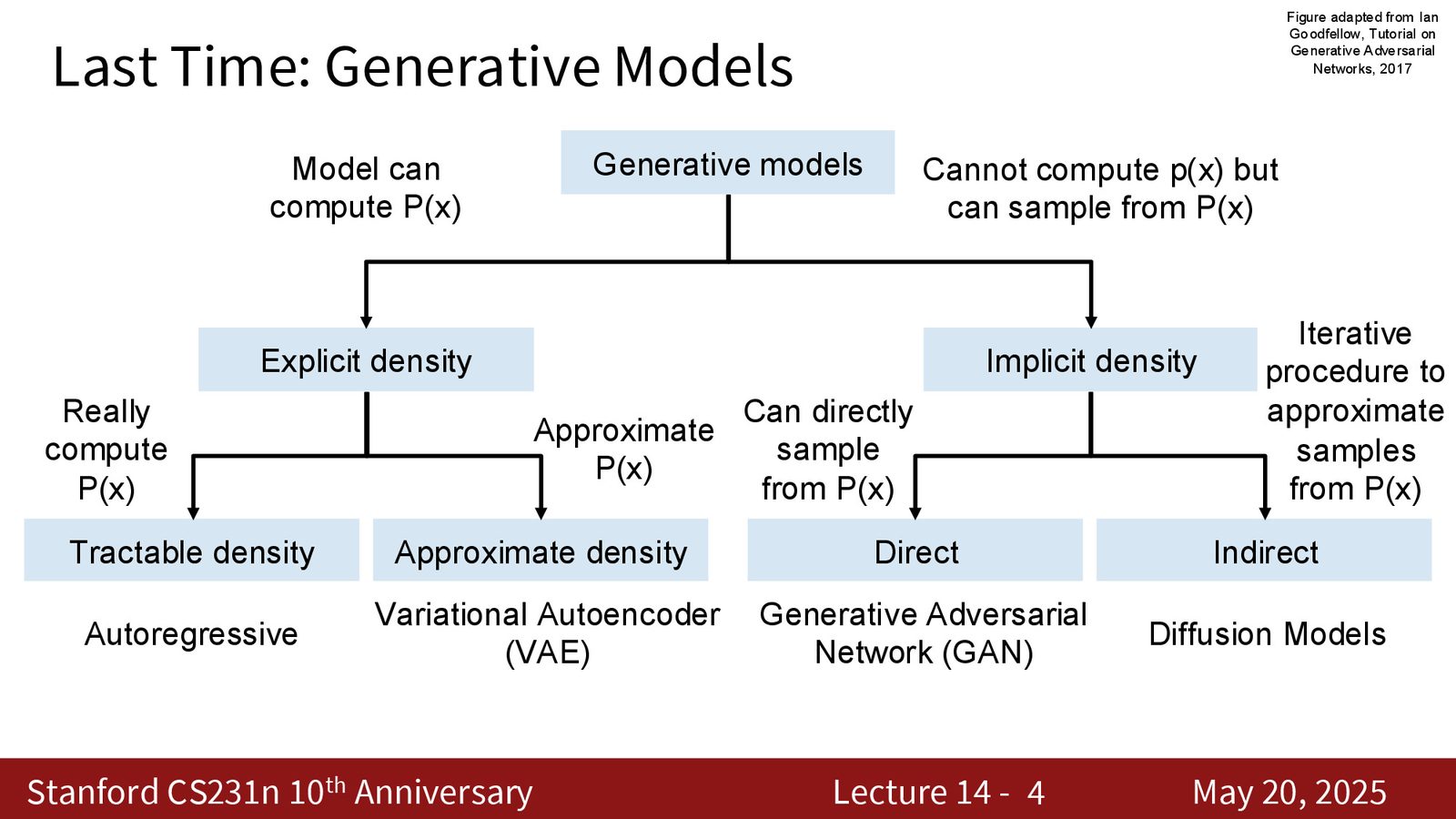
来源:Slides 第3页。

来源:Slides 第4页。
| 方法 | 密度视角 | 训练信号 | 采样方式 | 最典型的工程特征 |
|---|---|---|---|---|
| Autoregressive | 显式密度 | 最大化对数似然 | 逐 token 采样 | 似然好看,但 raw pixels 上极慢 |
| VAE | 近似显式密度 | ELBO | 一步解码 | latent 结构清楚,但重建容易糊 |
| GAN | 隐式密度 | 对抗博弈 | 一步生成 | 样本锐利,但训练极不稳定 |
| Diffusion / flow | 逐步运输 / 去噪 | 回归向量场或 score | 多步积分 | 训练稳,但采样慢 |
| Latent diffusion | 压缩后的 diffusion | 先学 autoencoder,再学 diffusion | latent 上多步采样 | 这是现代图像/视频系统的主干 |
为什么今天的主角是 GAN 和 diffusion
autoregressive 和 VAE 已经在上一讲讲过,这一讲重点是两条后半路:GAN 让我们看到了“不要显式建模密度也能生成很漂亮的样本”,diffusion 则让我们看到“把生成拆成很多个小步骤,训练会稳很多”。这两条路最后没有互相消灭,反而在工业里合流成一套组合拳。
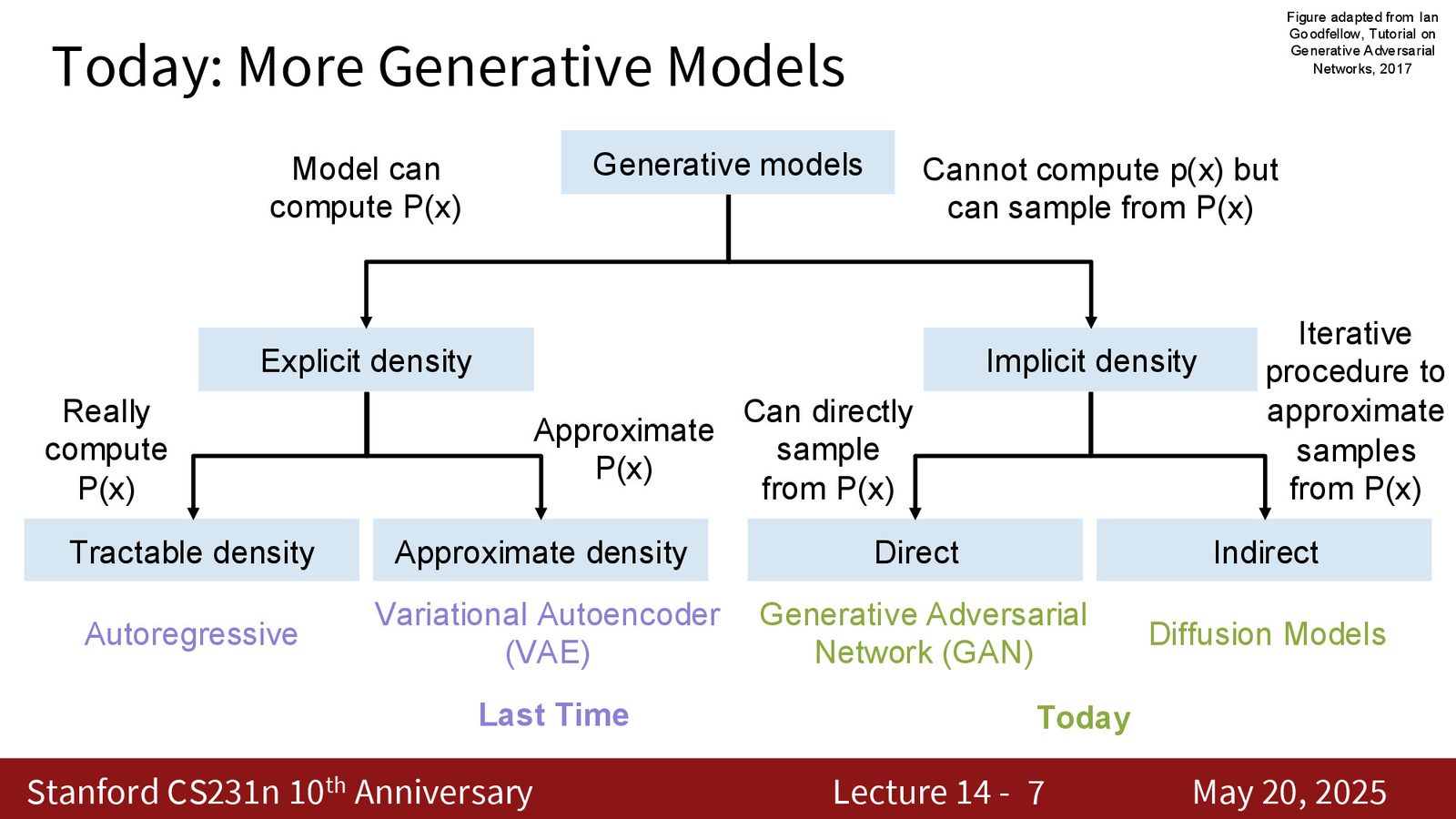
来源:Slides 第7页。
一眼看懂本讲的结论
如果只记一件事,就是这句:现代生成式系统不是“选一个模型”,而是“组合一组互补模块”。GAN 提供锐利感,VAE 提供压缩与 latent,diffusion 提供稳定训练,Transformer 提供可扩展主干,text encoder 提供条件控制。
GAN:隐式密度的经典答案
GAN 为什么重要
GAN 的出现改变了生成模型的主流叙事。它不再强求写出 \(p(x)\),而是让一个生成器 \(G(z)\) 从简单噪声出发直接产出样本,再让判别器 \(D(x)\) 去判断“真还是假的”。这种方法把生成任务改写成一个博弈问题,直观、简洁,而且在图像上能得到非常锐利的结果。

来源:Slides 第11页。
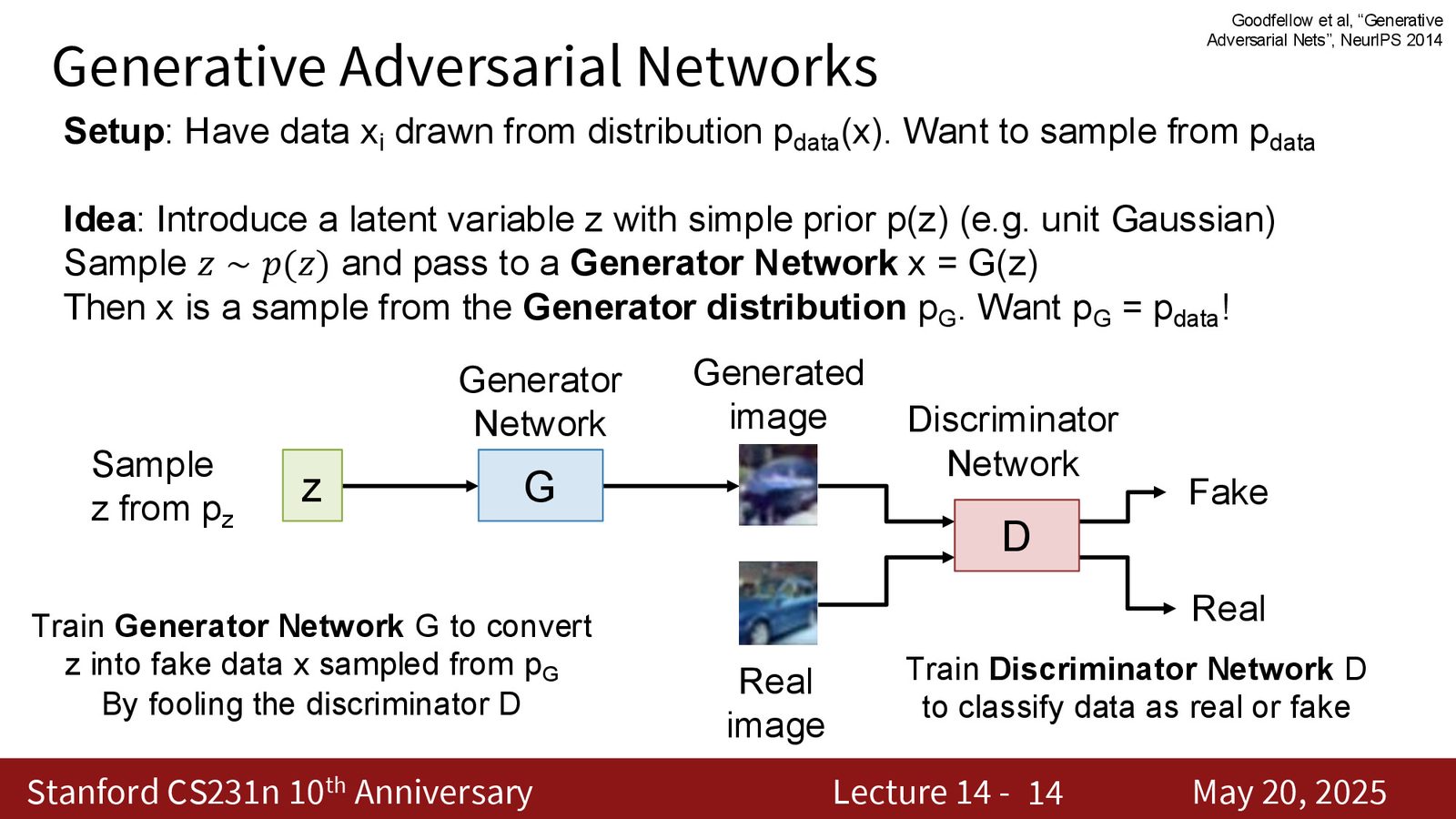
来源:Slides 第14页。
GAN 的关键设定
- \(z \sim p(z)\) 是简单先验,通常是标准高斯。
- \(G(z)\) 把噪声映射成图像或其他样本。
- \(D(x)\) 输出“这个样本是真实数据的概率”。
- 训练目标不是拟合标签,而是让生成分布 \(p_G\) 尽量接近真实分布 \(p_{\text{data}}\)。
GAN 和判别式任务的关系
判别器 \(D\) 看起来像一个二分类器,但它不是我们最终要交付的模型。它的角色更像“训练时的评审员”:通过判断真伪来给生成器提供梯度。真正要学的是生成分布,而不是一个分类标签。
训练目标不是普通 loss
GAN 的经典目标是一个 minimax game:
这个式子很像一个普通 loss,但本质上它不是。它是两个玩家在互相追逐:判别器想把真样本打高分、假样本打低分;生成器想骗过判别器,让假样本看起来像真样本。

来源:Slides 第16页。

来源:Slides 第21页。
为什么 GAN 的训练曲线不好看
GAN 没有一个稳定、可解释、可单调下降的总 loss。你看到的 \(D\) loss 或 \(G\) loss 只能说明当前博弈状态的一部分,不能像监督学习那样直接解释为“训练变好了多少”。
为什么早期训练会梯度消失
GAN 初期最常见的情况是:生成器还很弱,判别器一下子就能把真伪分开。于是 \(D(G(z)) \approx 0\),这时候如果生成器直接最小化 \(\log(1-D(G(z)))\),梯度会很弱,更新信号几乎传不回来。
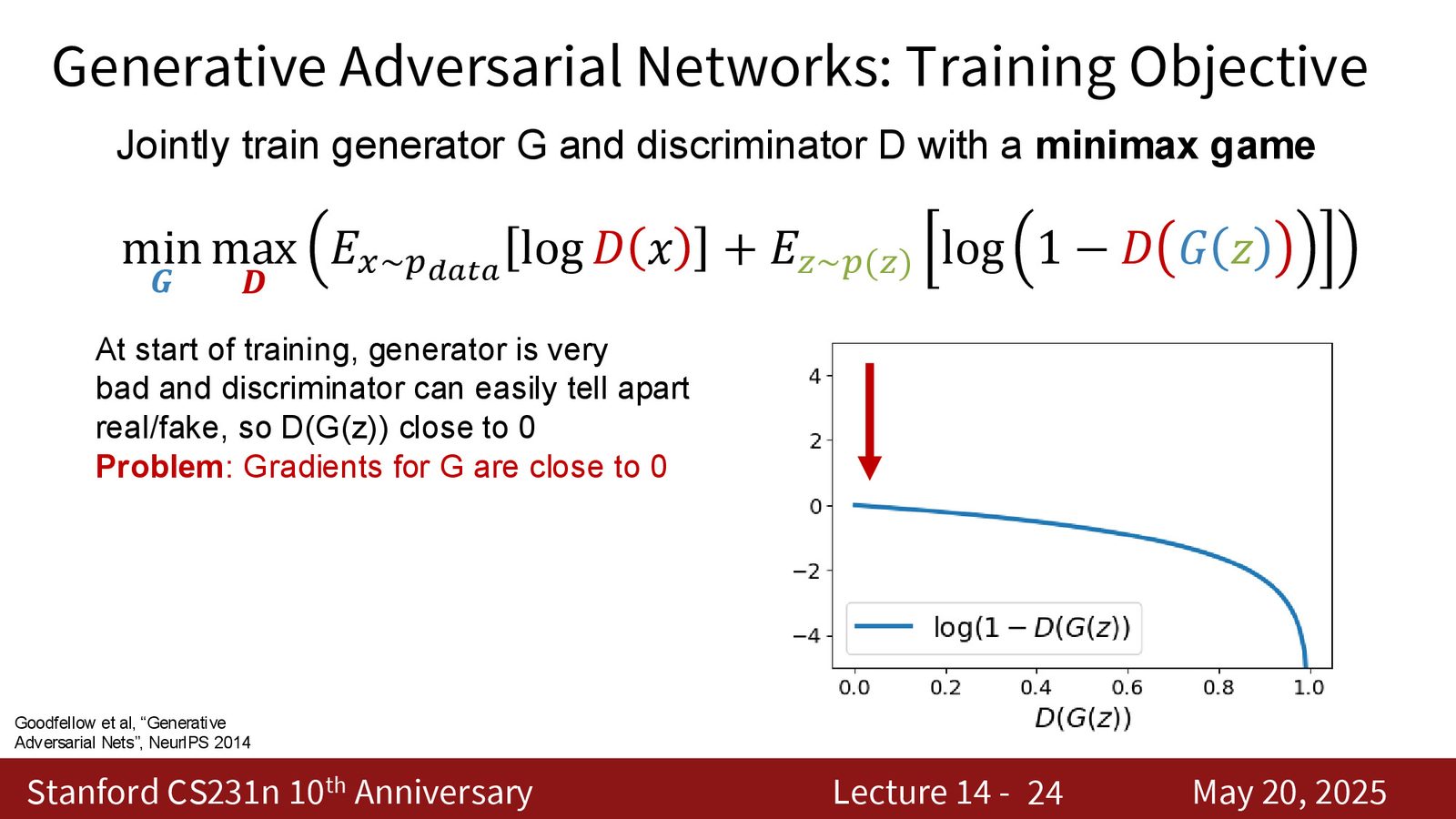
来源:Slides 第24页。
非饱和损失是实战补丁
实践中常用的 generator loss 不是原始的 \(\log(1-D(G(z)))\),而是
这样做的目的很朴素:当判别器很强时,生成器仍然能收到比较有用的梯度,不至于一开始就“学不动”。
为什么这个目标理论上是合理的
如果判别器容量足够、优化足够理想,那么固定生成器时的最优判别器是
把这个 \(D^*\) 代回去,外层目标会变成一个和 Jensen-Shannon divergence 相关的量。于是理想情况下,最小化这个博弈等价于让 \(p_G\) 逼近 \(p_{\text{data}}\)。

来源:Slides 第28页。
理论正确不等于训练可行
这个结论依赖很强的理想化前提:无限模型容量、完美优化、有限样本误差可忽略。现实里这些条件都不成立,所以“理论上能证明”并不等于“训练一定顺利”。
GAN 的优点和缺点
- 优点:采样快,视觉效果往往很好,生成结果锐利。
- 缺点:训练不稳定,模式塌缩明显,loss 很难解释。
- 工程限制:没有显式密度,评估和调参比显式模型更靠经验。
经典架构:DCGAN 和 StyleGAN
GAN 真正能从 toy example 走向真实图像数据,是靠架构上的一系列经验修正。DCGAN 把卷积引入生成器和判别器,让网络更适合处理图像结构;StyleGAN 则进一步把“风格”注入每一层,显著提升了可控性和视觉质量。

来源:Slides 第30页。
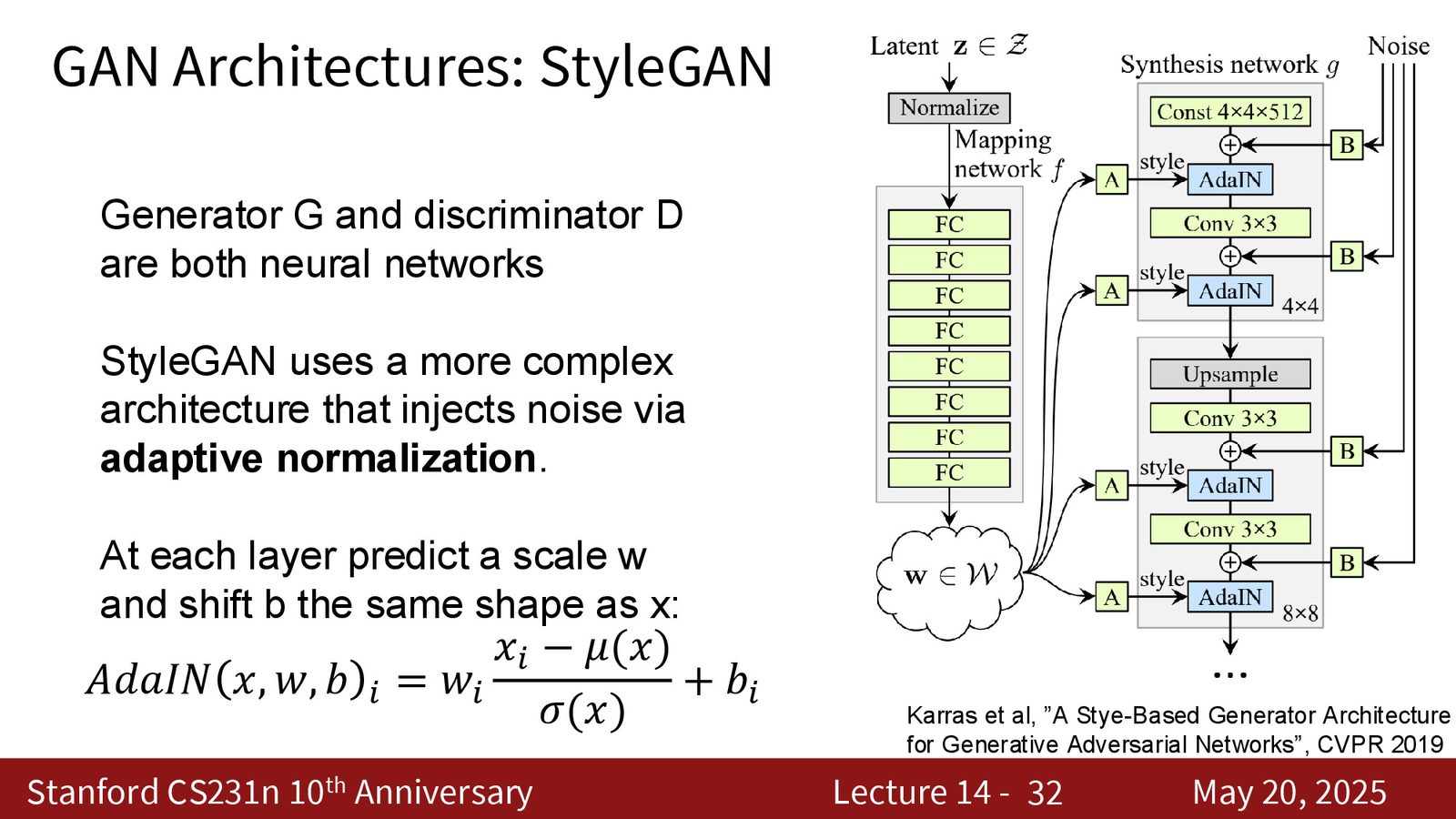
来源:Slides 第32页。
StyleGAN 里最值得读懂的地方不是“名字叫 style”,而是它对每层特征做了可控的 scale 和 shift。可以把它理解成:生成器不只是拿一个 latent 一次性吐图,而是让 latent 在不同尺度上持续影响图像的纹理、局部结构和语义细节。
StyleGAN 的工程含义
分层注入 style 有两个好处:
- 低层更容易控制粗结构,高层更容易控制纹理和细节。
- latent space 往往更平滑,便于插值、编辑和风格混合。
Latent interpolation 和生成空间
GAN 很经典的一个现象是 latent interpolation 平滑。给定两个 latent 向量 \(z_0\) 和 \(z_1\),如果沿线性路径做插值,再送入生成器,图像往往会连续变形,而不是突然跳变。这说明生成器学到的 latent geometry 至少在局部上是有意义的。

来源:Slides 第34页。
这件事为什么重要
平滑插值不是花哨演示,而是说明生成模型学到的 latent 表示不是随机噪声。它至少在局部上组织了语义结构,所以 latent editing、style mixing 和条件控制才有可能成立。
GAN 这一节的结论
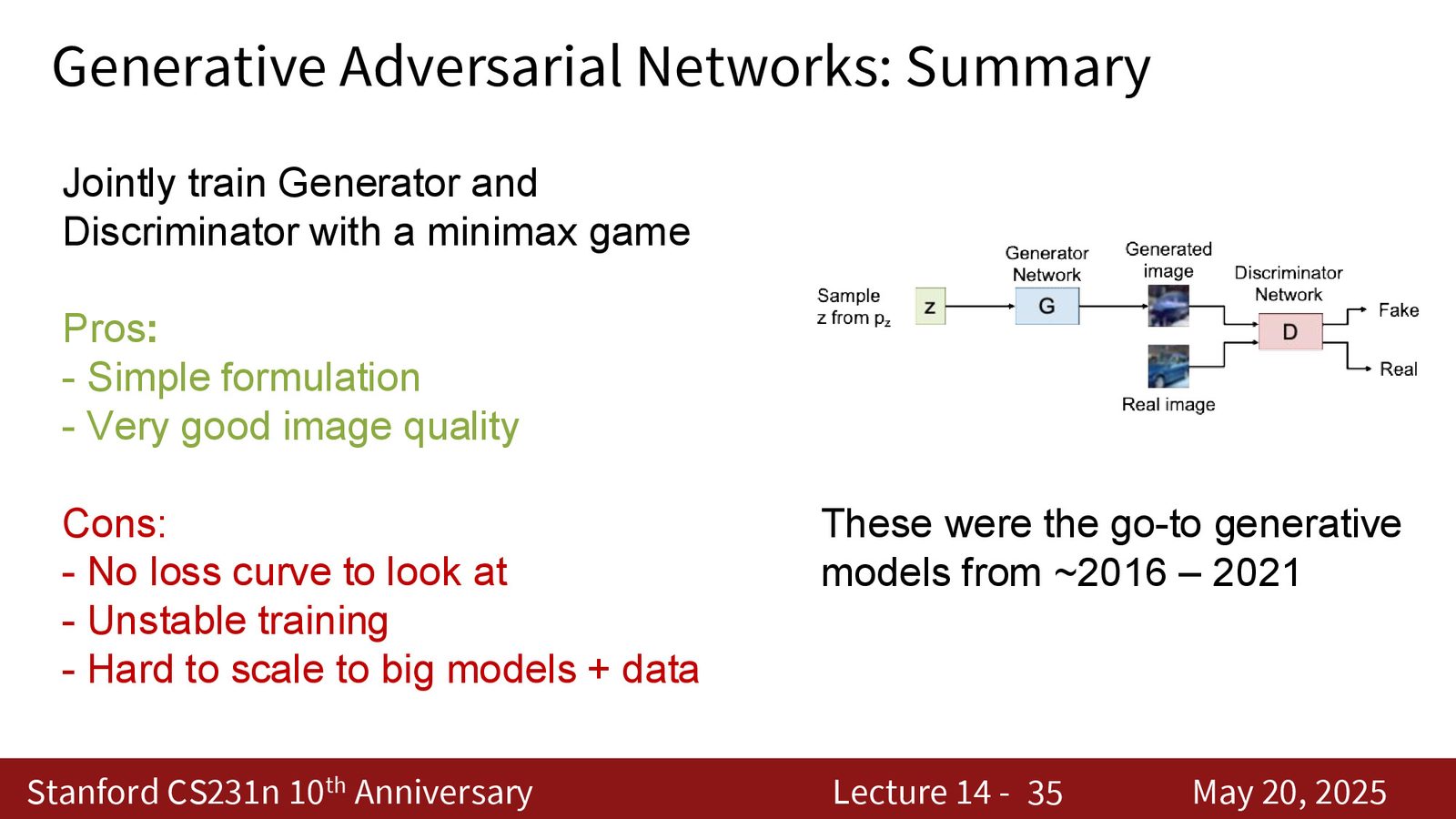
来源:Slides 第35页。
GAN 留下的遗产
GAN 没有消失,它只是退回到了“局部模块”的位置。现代系统仍然会从 GAN 借用:
- 对抗损失来提升局部真实感
- latent space 里的插值和编辑思路
- 对高频细节的偏好
Diffusion:把生成变成逐步去噪
为什么 diffusion 会赢到今天
GAN 给了我们很锐利的图,但训练太难。diffusion 的思路正好相反:别指望一次把噪声变成图,而是把生成拆成很多个小修正。每一步只做一点点“去噪”或“transport”,这样训练就更像回归问题,稳定得多。

来源:Slides 第36页。
这一领域的术语非常乱
Diffusion、score-based model、SDE、DDPM、rectified flow、flow matching,很多时候都在描述近亲算法。名字不同,数学形式也可能不同,但核心都绕不开两件事:往数据里加噪,以及学会把噪声再拿回来。
最朴素的直觉
最简单的理解方式是:先选一个容易采样的噪声分布 \(p_{\text{noise}}\),通常是标准高斯。训练时,把真实样本 \(x\) 按不同噪声强度扰动成 \(x_t\),然后让网络 \(f_\theta(x_t,t)\) 学会在每个噪声水平上“往干净方向推一点点”。

来源:Slides 第37页。

来源:Slides 第40页。
在这个视角里,生成并不是“凭空画图”,而是一个从噪声空间沿着学习到的方向场逐步回到数据流形的过程。采样的时候,只要从纯噪声开始,不断重复这个修正步骤,就能得到最后的样本。
来源:Slides 第41页。
Diffusion 和判别式任务的关系
diffusion 的核心训练形式不是分类,而是连续值回归:网络要学的是去噪方向、速度场或 score。它和判别式任务的交集主要体现在条件模型里,比如 CFG 早期的 classifier guidance 会借助一个额外分类器来提供梯度,但 CFG 本身已经把这一步收进生成模型里了。
Rectified flow:最清楚的版本
这一讲选 rectified flow 作为“现代 clean implementation”的代表,是因为它足够简单,足够接近工程实践,也足够容易把核心思想讲透。
训练时每次采样:
然后定义中间点和目标速度:
最后让网络回归这个速度场:
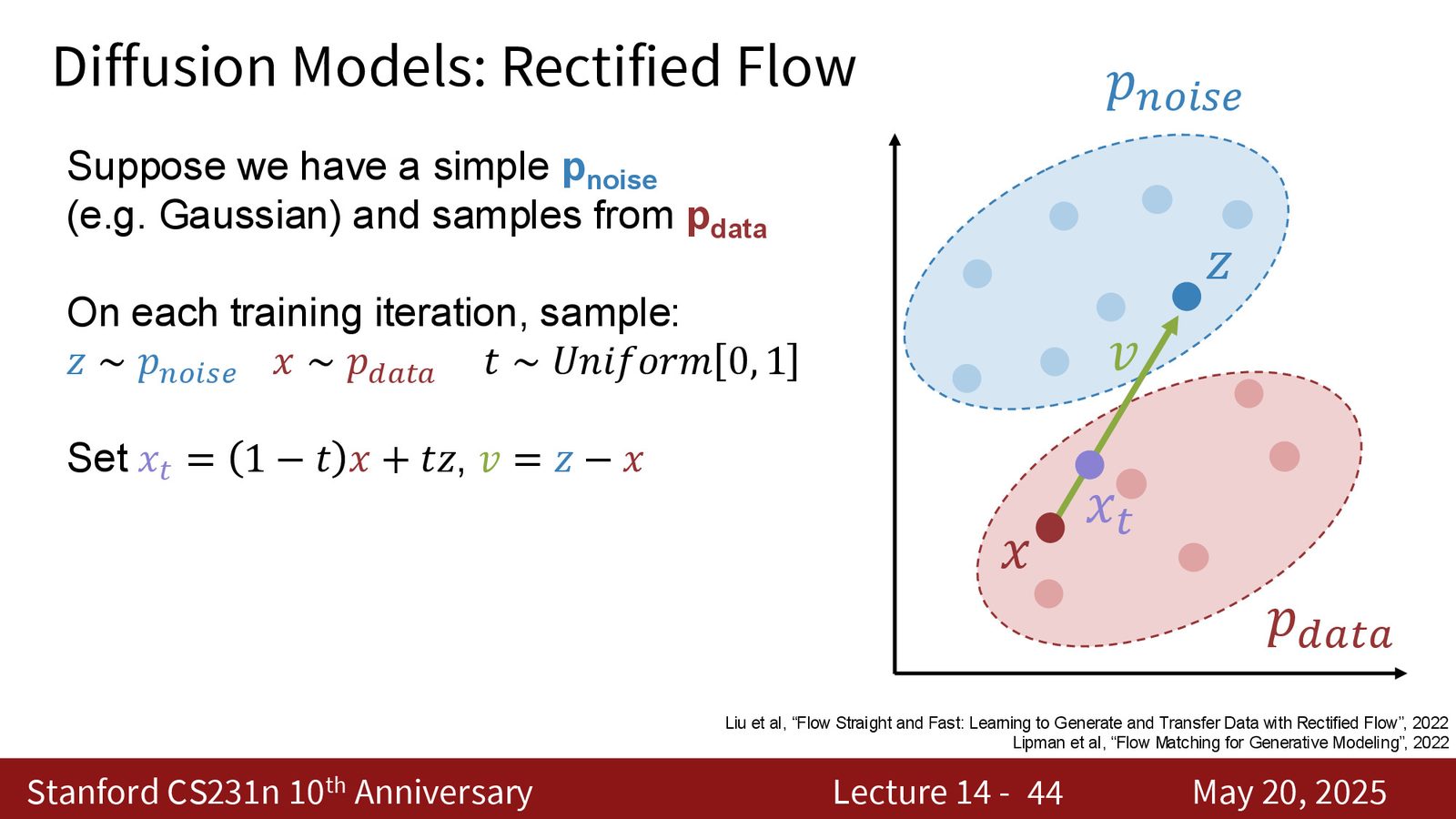
来源:Slides 第44页。
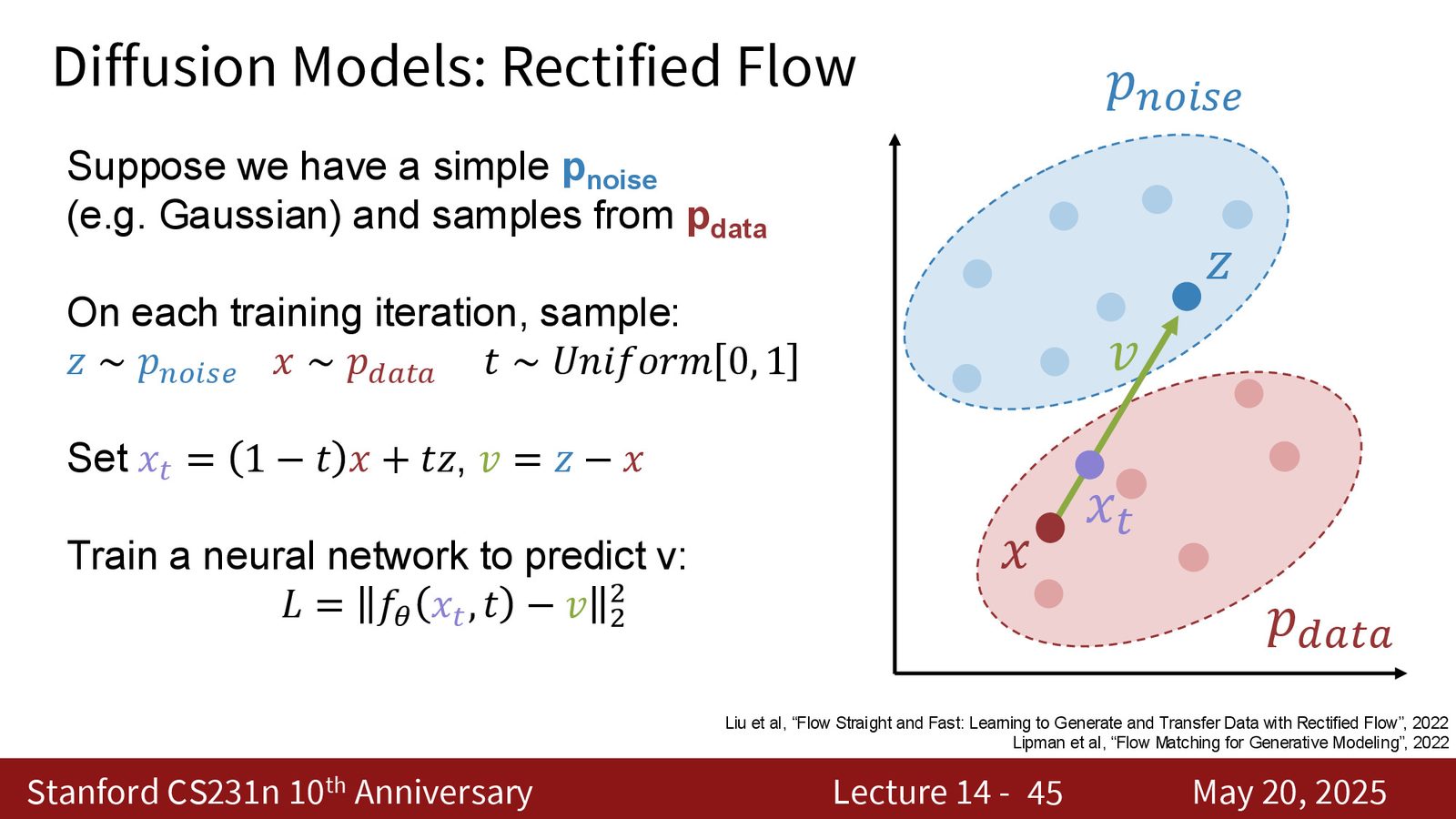
来源:Slides 第45页。
为什么 rectified flow 适合教学
- 训练像普通回归,损失函数直观。
- 采样像数值积分,步骤清楚。
- 既能保留 diffusion 的逐步生成优势,也能把数学和工程解释都压到很低的理解门槛。
采样:从噪声一路积分回数据
采样阶段从噪声 \(x_1 \sim p_{\text{noise}}\) 出发。若把区间 \([0,1]\) 切成 \(T\) 份,就可以做一个简单的 Euler 更新:
从 \(t=1\) 一直走到 \(t=0\)。直觉上,这就是沿着学到的速度场把点从噪声流形搬回数据流形。
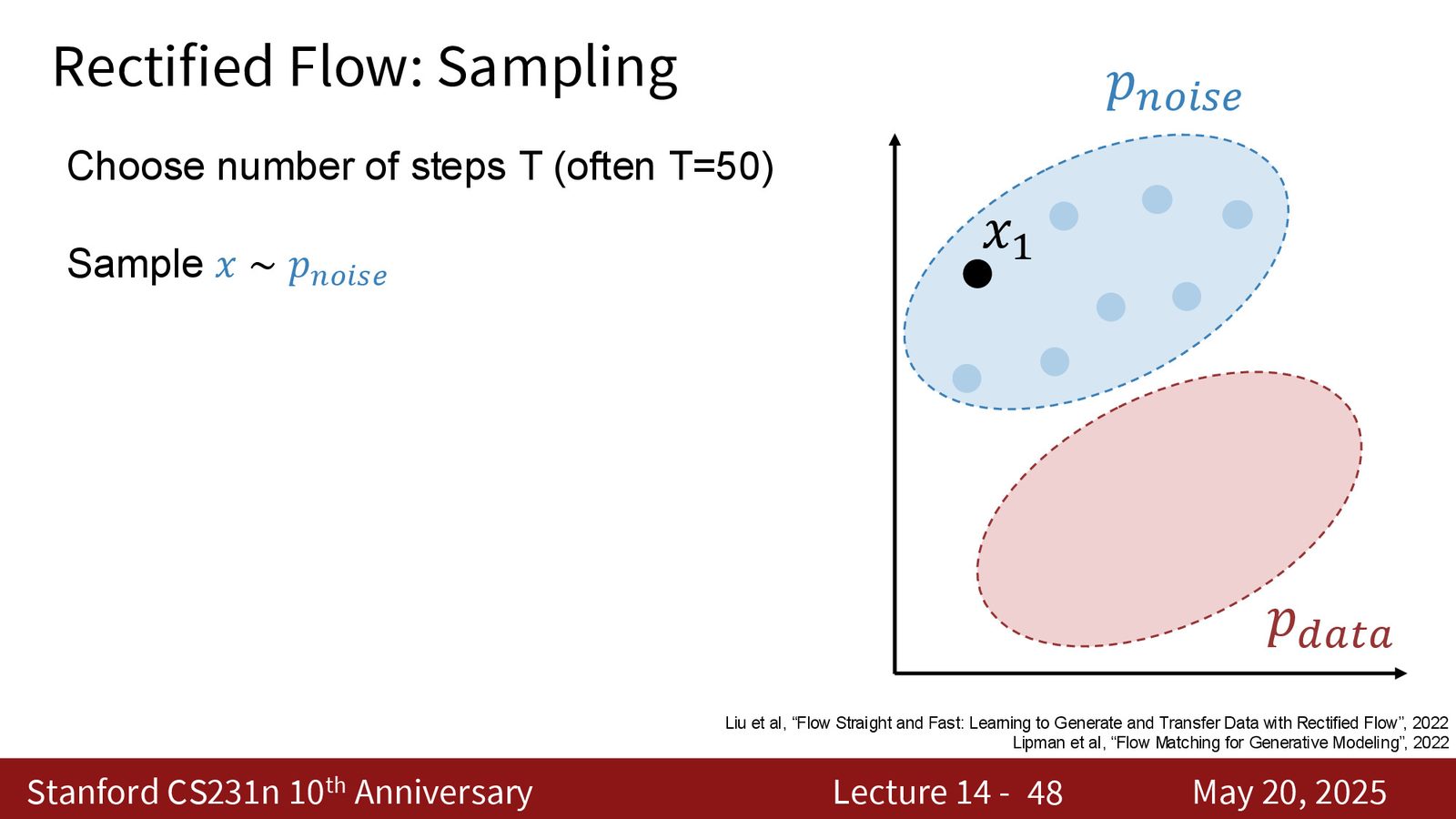
来源:Slides 第48页。
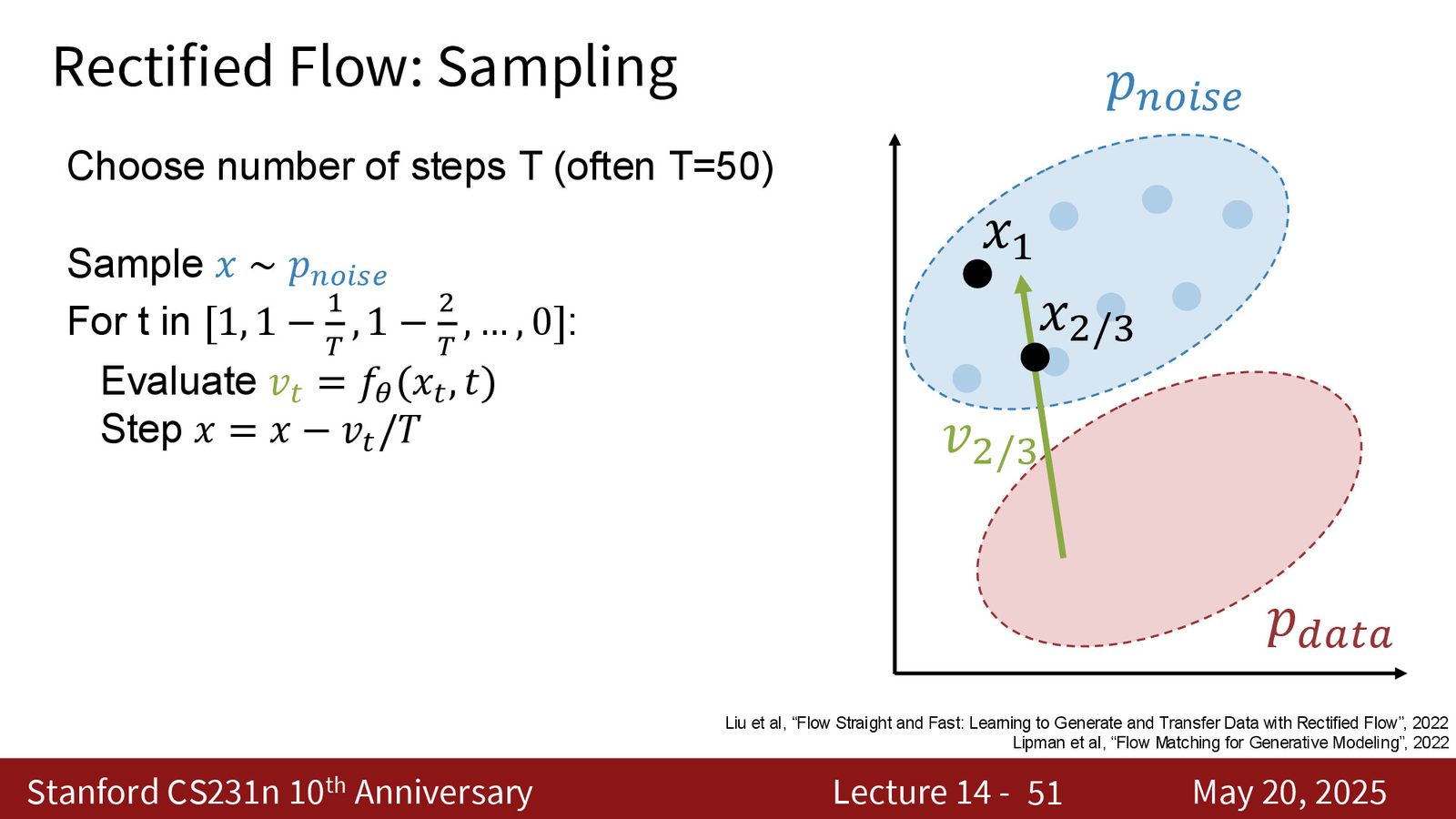
来源:Slides 第51页。
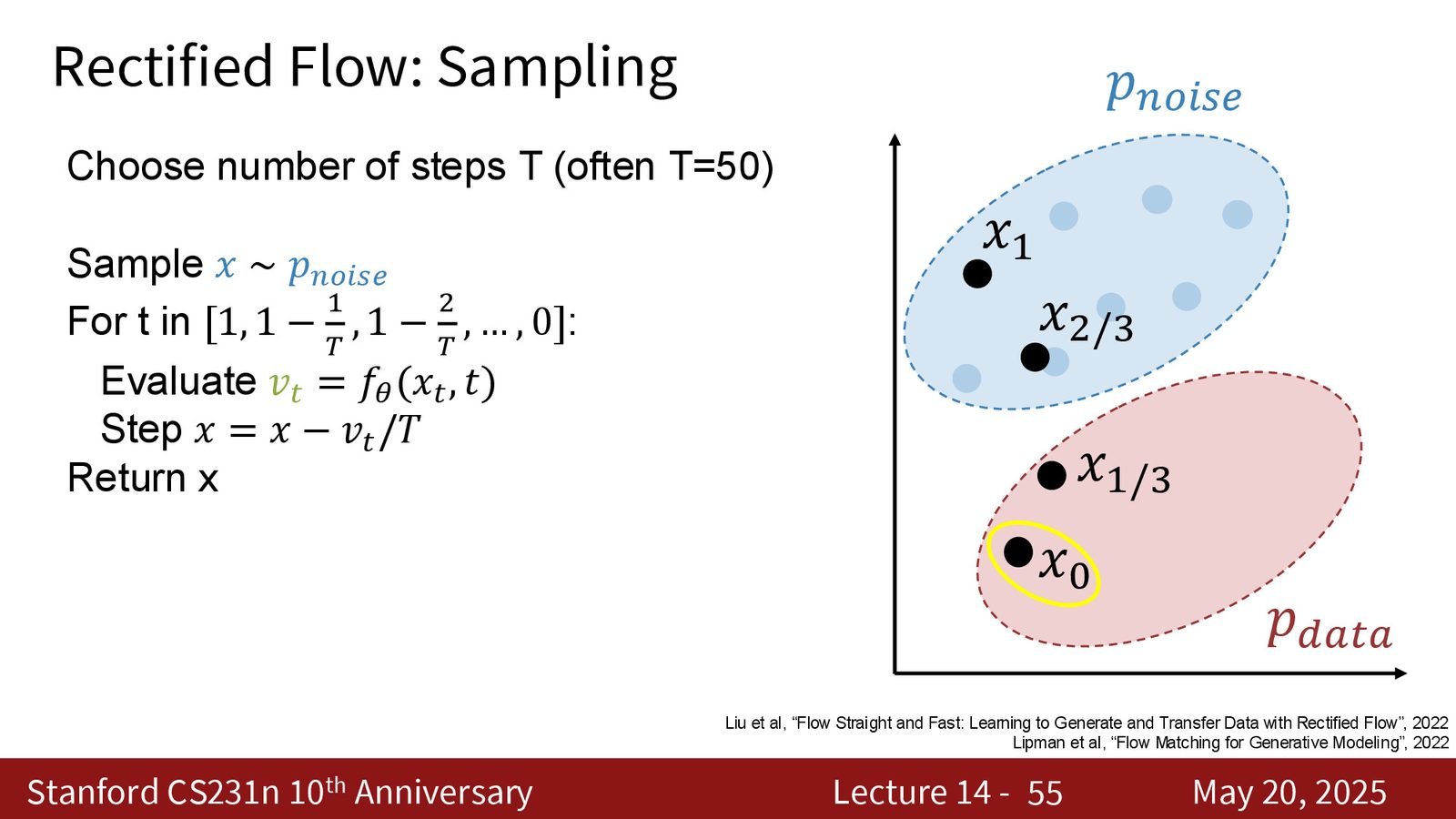
来源:Slides 第55页。
为什么中间噪声最难
rectified flow 里一个很重要的训练观察是:极高噪声和极低噪声相对容易,真正难的是中间噪声。原因很简单:在中间区域,同一个 \(x_t\) 可能对应很多不同的 \((x,z)\) 对,网络必须学会对这些可能性做平均;这比“几乎没噪声”或“几乎全噪声”都更模糊。
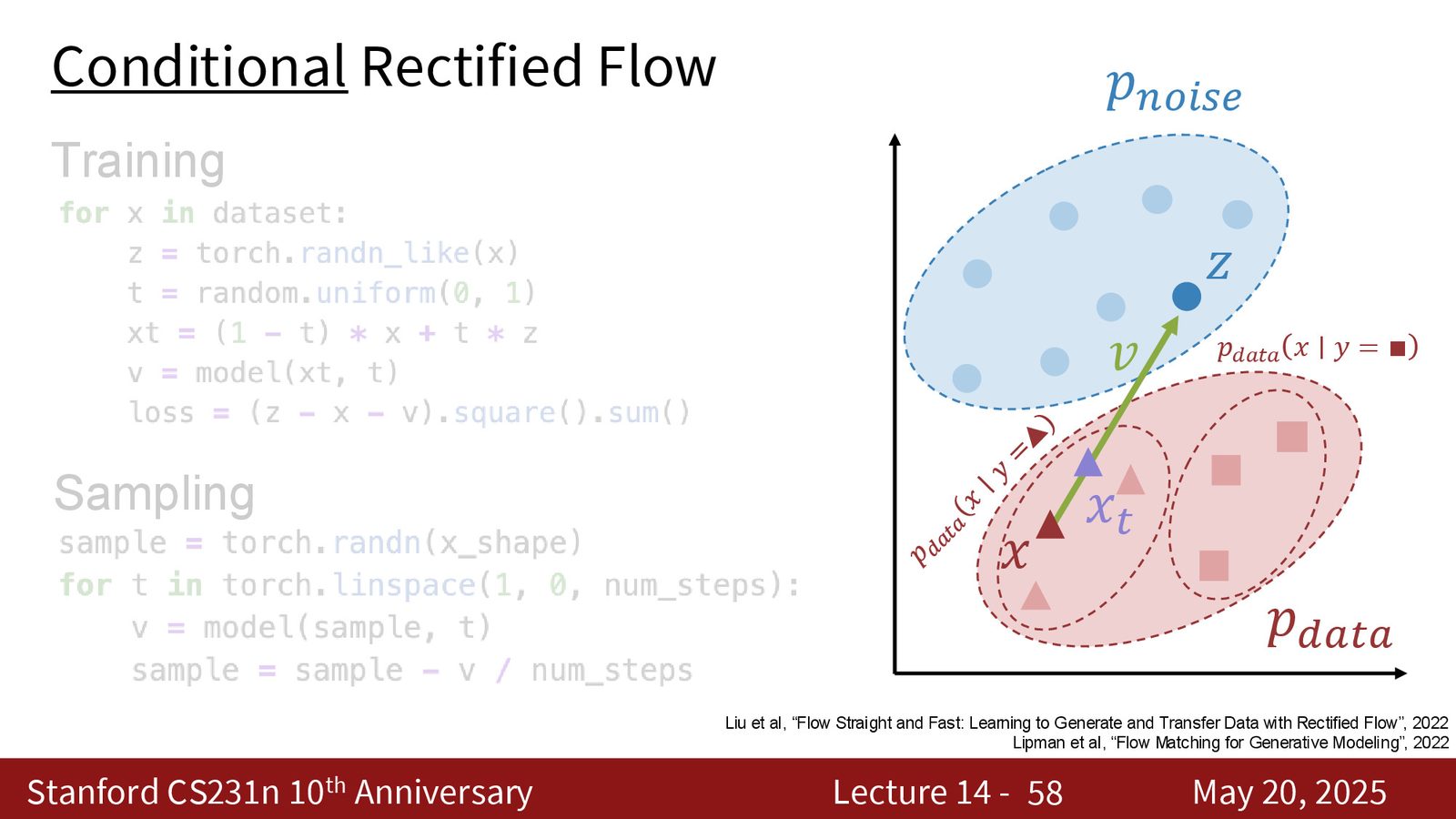
来源:Slides 第58页。
噪声调度不是装饰品
如果总是均匀采样 \(t\),训练会把太多精力浪费在“容易的极端噪声”上。真正影响模型效果的,往往是中间区间的样本。因此噪声 schedule 是模型设计的一部分,不是可有可无的调参细节。
什么是“现代 clean implementation”
这一讲把 diffusion 的教学目标压缩成三个词:训练简单、采样稳定、可以规模化。这也是为什么 diffusion 最后成为主流:它没有 GAN 那么刺激,但训练过程更像一个可控的工程系统。
条件生成与 CFG
从无条件生成到条件生成
真正有用的生成模型几乎都不是无条件的。我们通常想要的是“给定类别、文本、草图、边界框、掩码以后再生成”。在 rectified flow 或 diffusion 里,这很自然:把条件 \(y\) 作为额外输入即可。

来源:Slides 第62页。
条件生成的真实需求
工程上,条件不是“锦上添花”,而是生成系统是否能落地的关键:
- 文本生成图像需要 prompt
- 图像编辑需要掩码或参考图
- 视频生成需要时间一致性和语义约束
- 产品级系统必须允许用户控制结果
Classifier-free guidance 的核心思想
CFG 的做法非常巧:训练时随机把条件 \(y\) 丢掉,让同一个模型同时学会 conditional 和 unconditional 两种模式。于是推理时我们可以分别得到
然后用线性组合控制“听话程度”:

来源:Slides 第66页。

来源:Slides 第67页。
CFG 的直觉
可以把 \(v_{\emptyset}\) 理解成“往一般数据流形走”,把 \(v_y\) 理解成“往满足条件的子流形走”。CFG 不是重新训练一个模型,而是通过线性外推,把采样方向更强地推向条件分布。
为什么 CFG 如此重要
CFG 之所以几乎成了现代扩散模型标配,是因为它同时解决了两个问题:
- 不需要额外训练一个独立 classifier。
- 采样时可以直接控制 condition strength。

来源:Slides 第71页。
CFG 的代价
CFG 的代价也很直接:采样时通常要跑两次模型,一次 conditional,一次 unconditional,所以推理成本会翻倍。更大的 guidance scale 往往更“听话”,但也更容易牺牲多样性。

来源:Slides 第72页。
噪声调度:为什么中间区域最值得关注
为什么要重新采样 \(t\)
训练 diffusion 或 rectified flow 时,不能把所有噪声水平一视同仁。最难的区域通常在中间噪声附近:信息既不够清晰,也没到完全随机。这个区域才是模型真正要“学会平均”的地方。
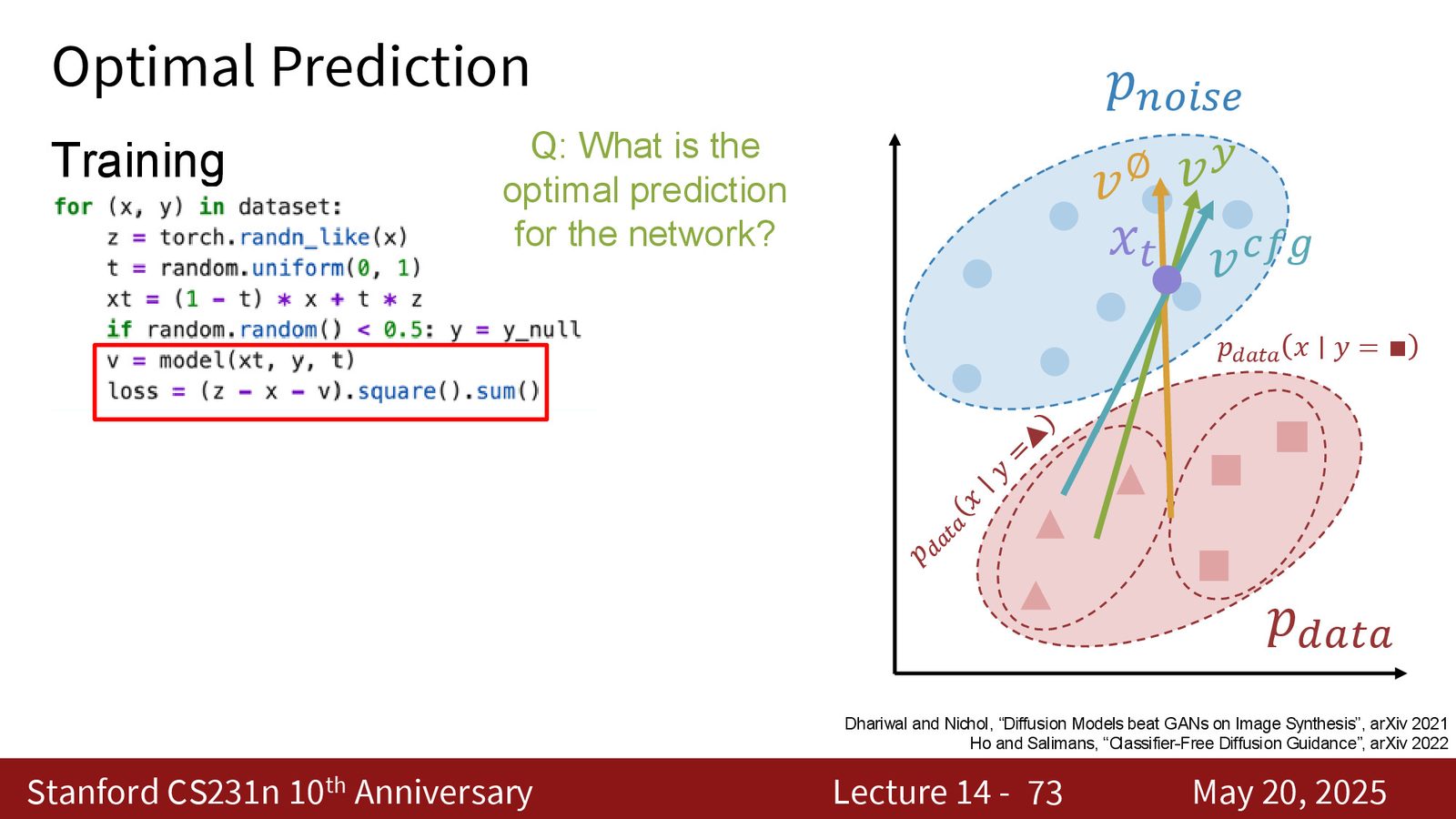
来源:Slides 第73页。
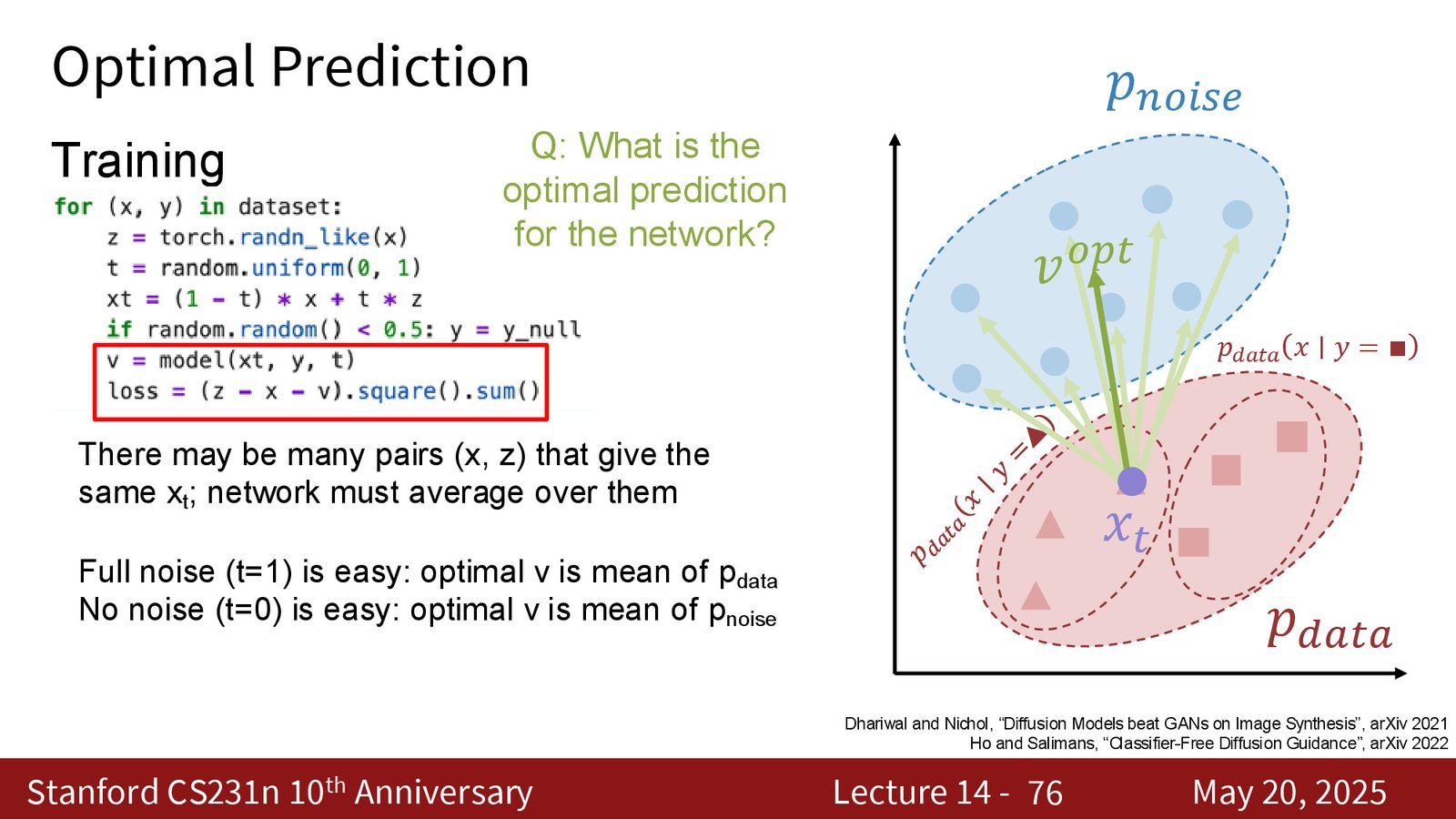
来源:Slides 第76页。
为什么中间噪声最难
在中间噪声区域,输入还保留一部分结构,但又不足以唯一决定答案。模型在这里要处理的是“多对一”的平均问题,而不是简单复原。这也是噪声 schedule 设计最关键的地方。
非均匀 schedule 不是细节,而是模型设计
如果训练时对所有噪声水平等权处理,就会让模型在大量“容易样本”上浪费算力。于是更好的做法是用非均匀噪声分布,比如 logit-normal sampling,甚至在高分辨率任务里把分布往更高噪声区域偏一点。
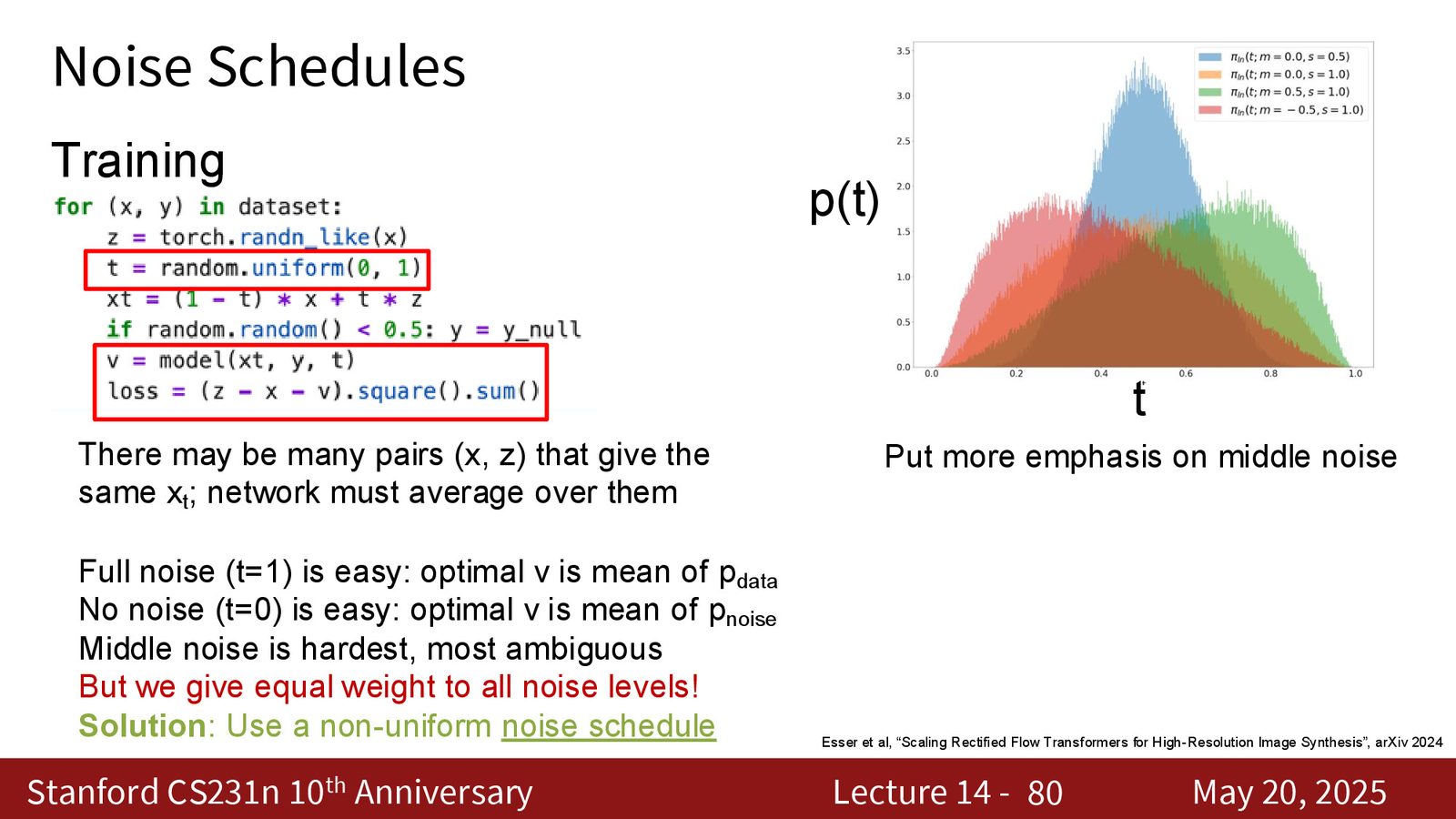
来源:Slides 第80页。
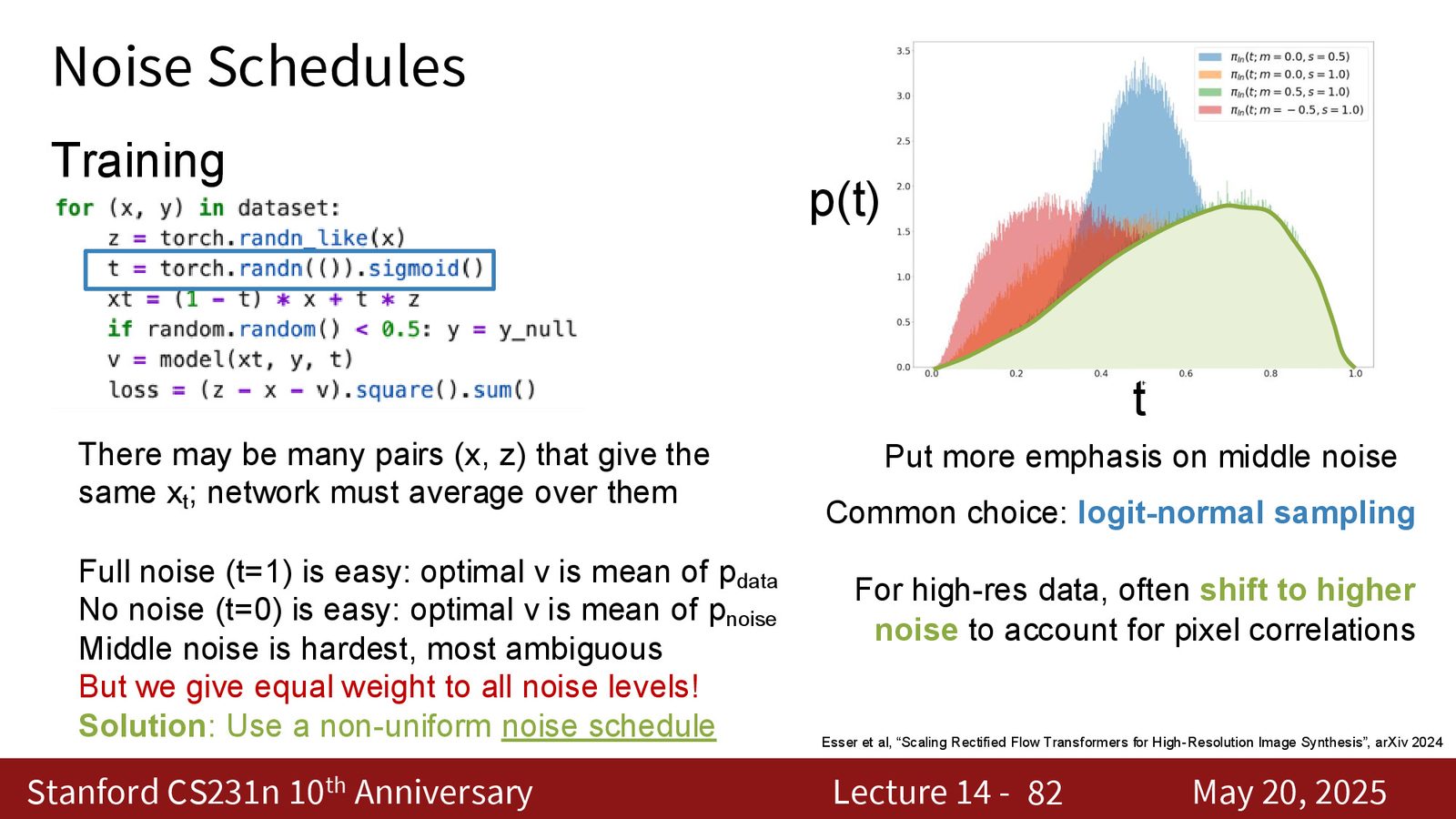
来源:Slides 第82页。
schedule 影响的不只是收敛速度
schedule 不只是“调收敛快慢”,它直接影响网络看到的数据难度分布。换句话说,schedule 改变了你到底在教模型先学什么、后学什么。
Latent diffusion:把贵的部分压缩掉
为什么要进 latent space
把 diffusion 直接跑在高分辨率像素上太贵了。空间分辨率一高,token 数量和计算成本就会迅速膨胀。于是一个很实用的策略出现了:先用 encoder 把图像压缩到更小的 latent,再在 latent 上做 diffusion,最后再用 decoder 还原。

来源:Slides 第85页。

来源:Slides 第86页。
latent diffusion 为什么成为工业主流
这一步不是“稍微省点显存”这么简单,而是把生成难题转移到了更适合建模的空间里。latent 维度更低,模型更容易学到语义结构,采样成本也明显下降。
VAE 是 latent diffusion 的前半段
latent diffusion 里 encoder / decoder 通常来自 VAE。训练时需要同时优化重建项和 KL prior,但 KL 往往会被压得很小,因为这里的目标是压缩和保真,而不是强约束 latent 服从某种过强的先验。

来源:Slides 第94页。

来源:Slides 第95页。
为什么纯 VAE 容易模糊
VAE 的 decoder 追求的是条件平均意义上的重建最优,而不是感知质量最优。对于多解的高频细节,平均往往意味着“糊”。这就是为什么后续工程里经常要引入 GAN 式的对抗约束来补锐度。
为什么现代系统是 VAE + GAN + diffusion
当 decoder 细节不够锐利时,就可以加一个 discriminator 帮它把输出推向更自然的图像外观。于是 latent diffusion 的前半段是 VAE,后半段是 diffusion,局部细节修正则借用了 GAN 的思路。
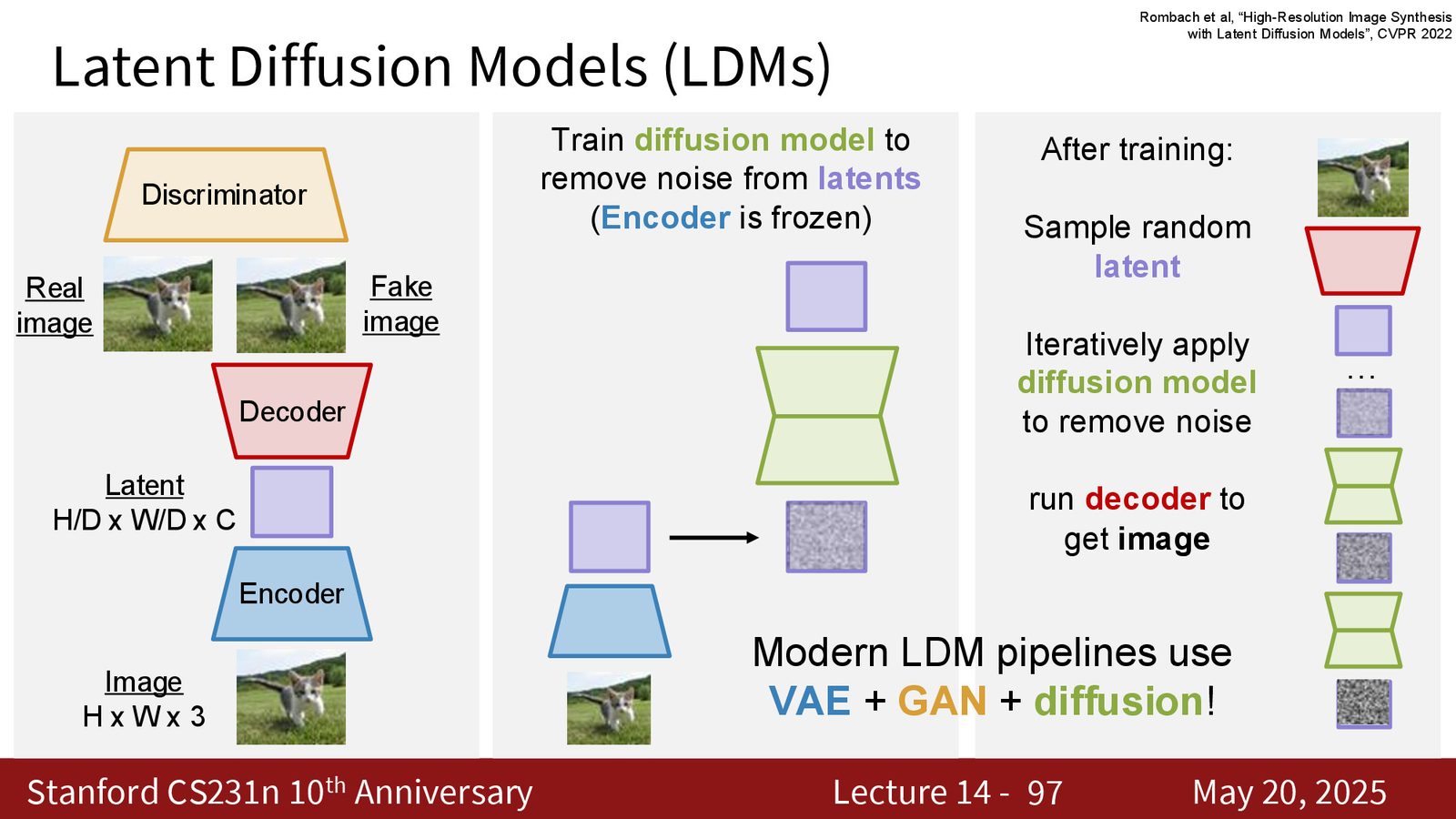
来源:Slides 第97页。
现代 LDM 管线的分工
- VAE 负责压缩和还原
- GAN 负责局部质感和清晰度
- diffusion 负责全局生成和条件控制
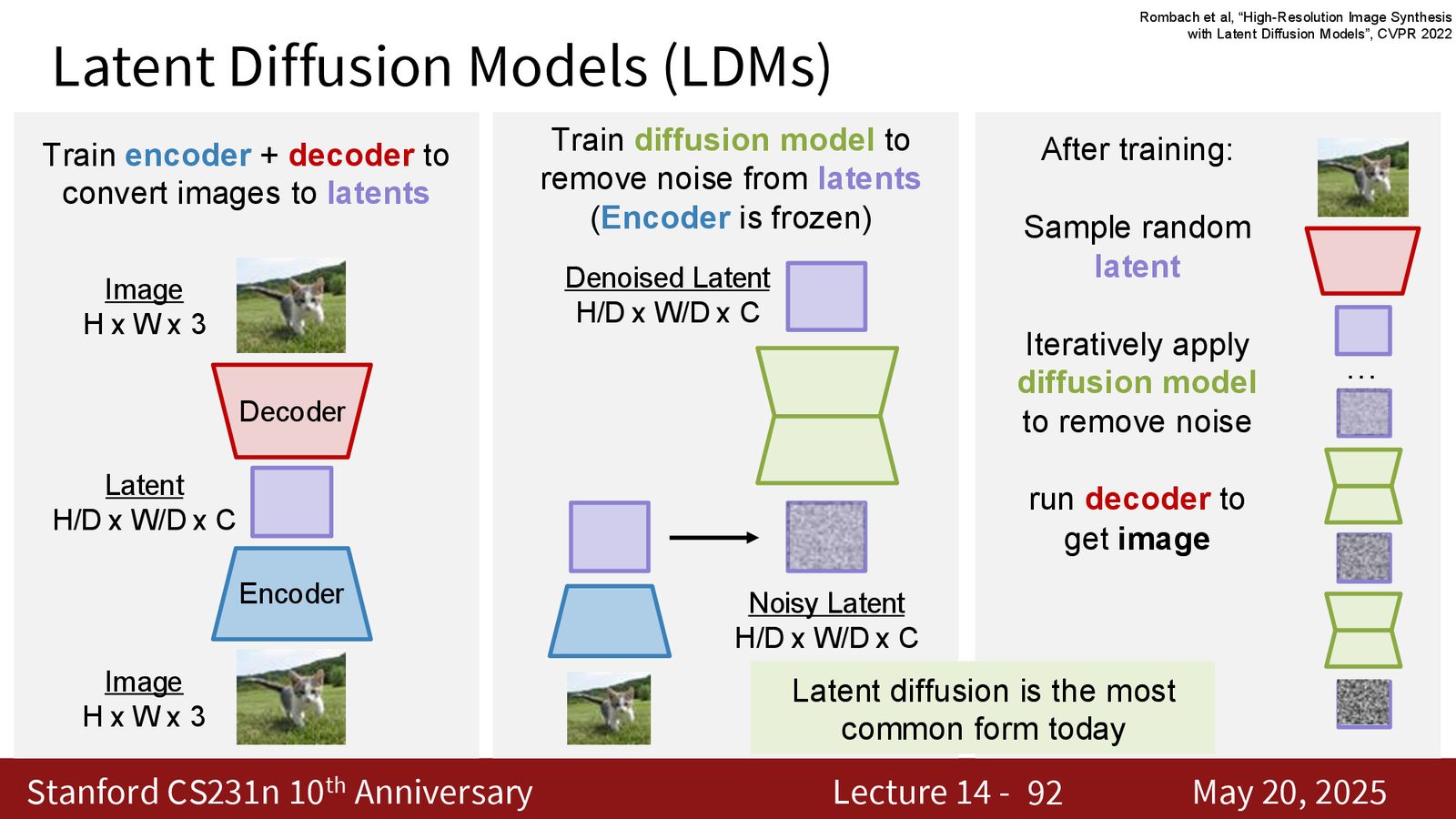
来源:Slides 第92页。
DiT、Text-to-Image 和 Text-to-Video
为什么 Transformer 又回来了
当 diffusion 进入 latent space 后,主干网络就越来越像一个序列建模问题。于是 Transformer 再次变得非常自然:token 序列、时间步条件、文本条件,都可以比较统一地接进去。DiT 的关键问题不是“能不能用 Transformer”,而是“怎么把条件信号优雅地注入进去”。

来源:Slides 第98页。
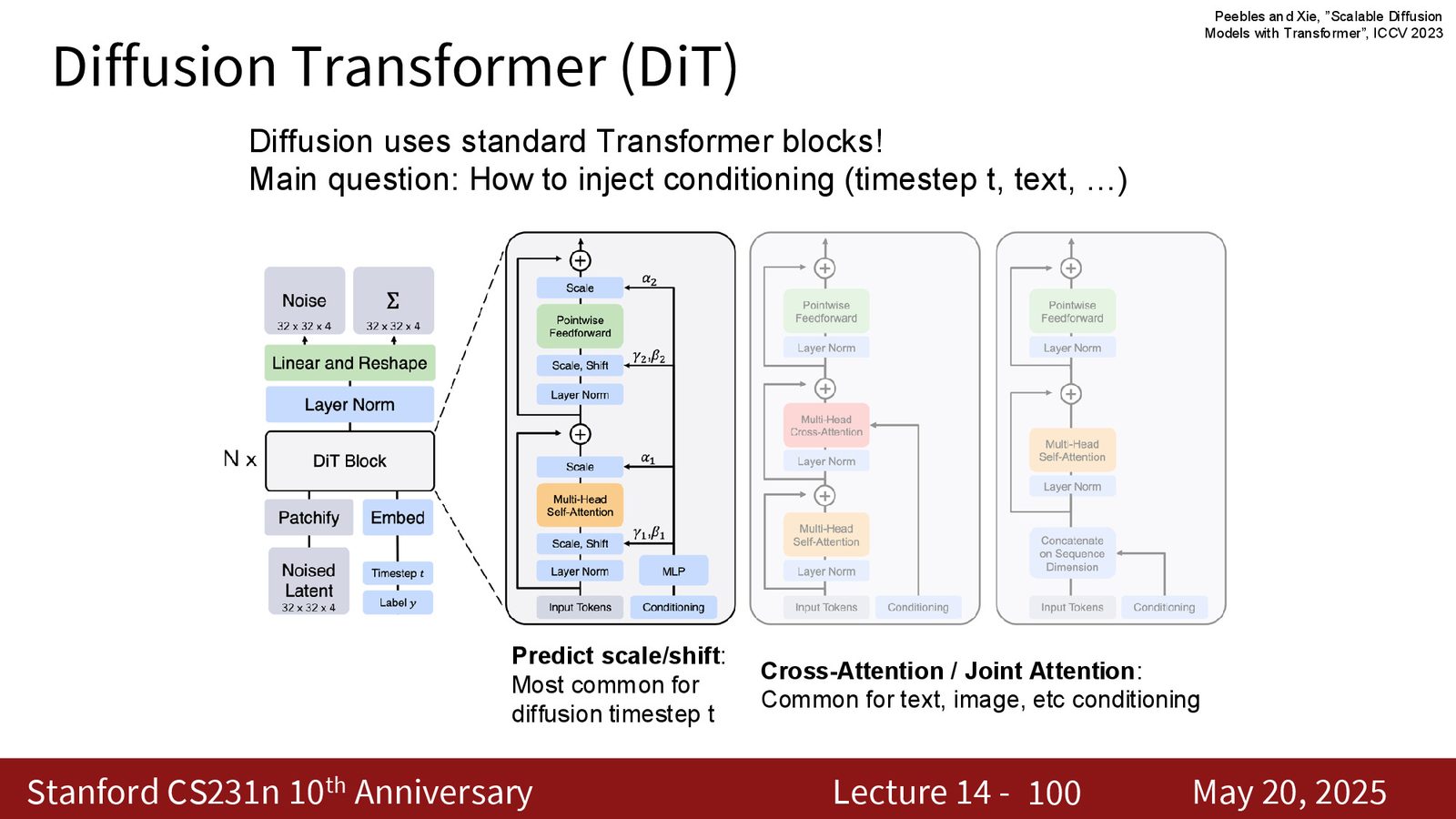
来源:Slides 第100页。
DiT 里最重要的两类 conditioning
- timestep conditioning:通常用 scale-shift / AdaLN 方式注入
- text or multimodal conditioning:通常用 cross-attention 或 joint attention
Text-to-Image
文本到图像的标准管线非常清楚:prompt 先进入预训练 text encoder,然后 text embedding 和 noisy latent 一起进入 diffusion transformer,最后经过 decoder 还原成图像。这里最关键的不是“把文字转成图片”这么一句话,而是“让条件信号真的参与了生成轨迹的每一步修正”。
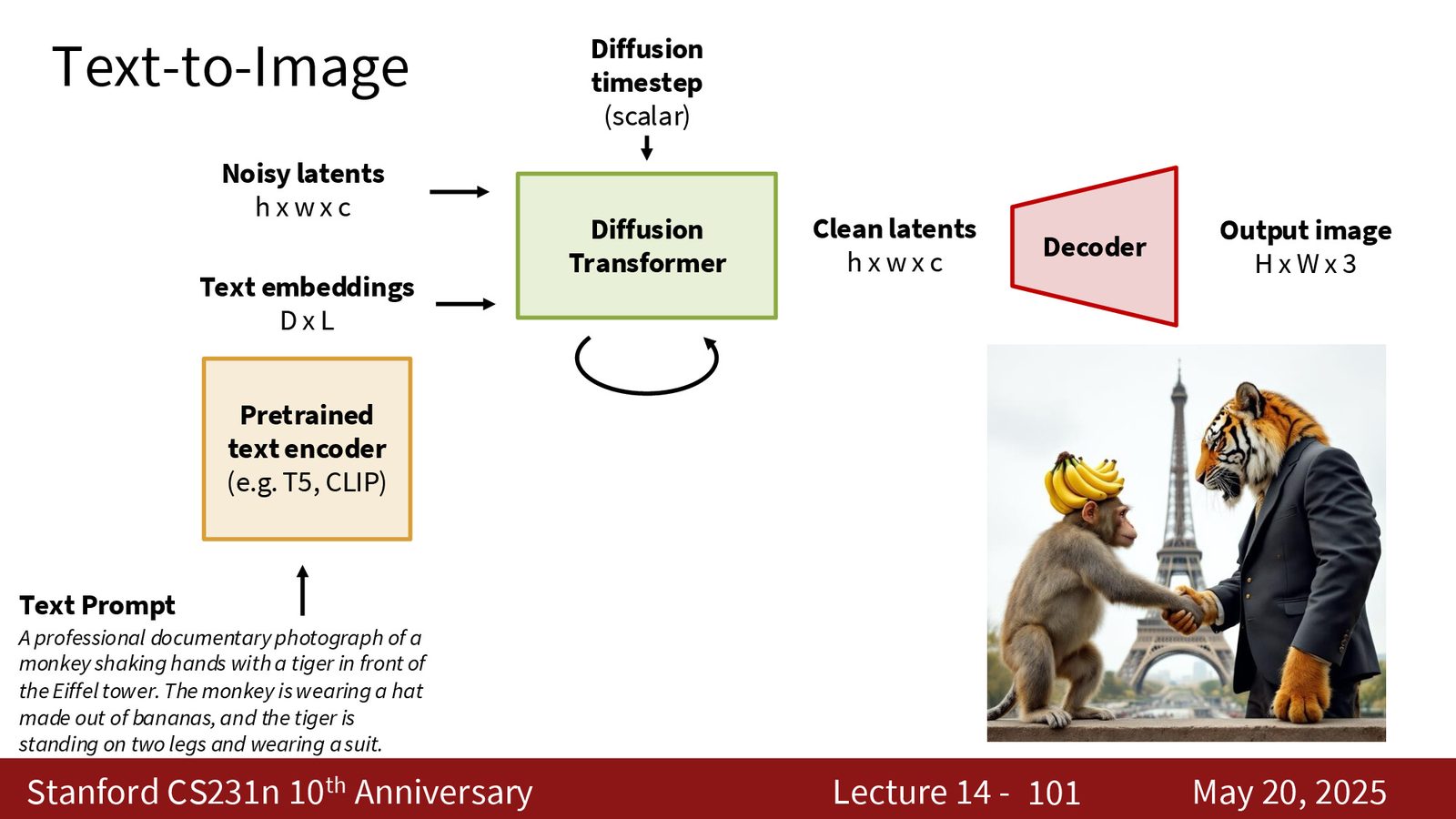
来源:Slides 第101页。
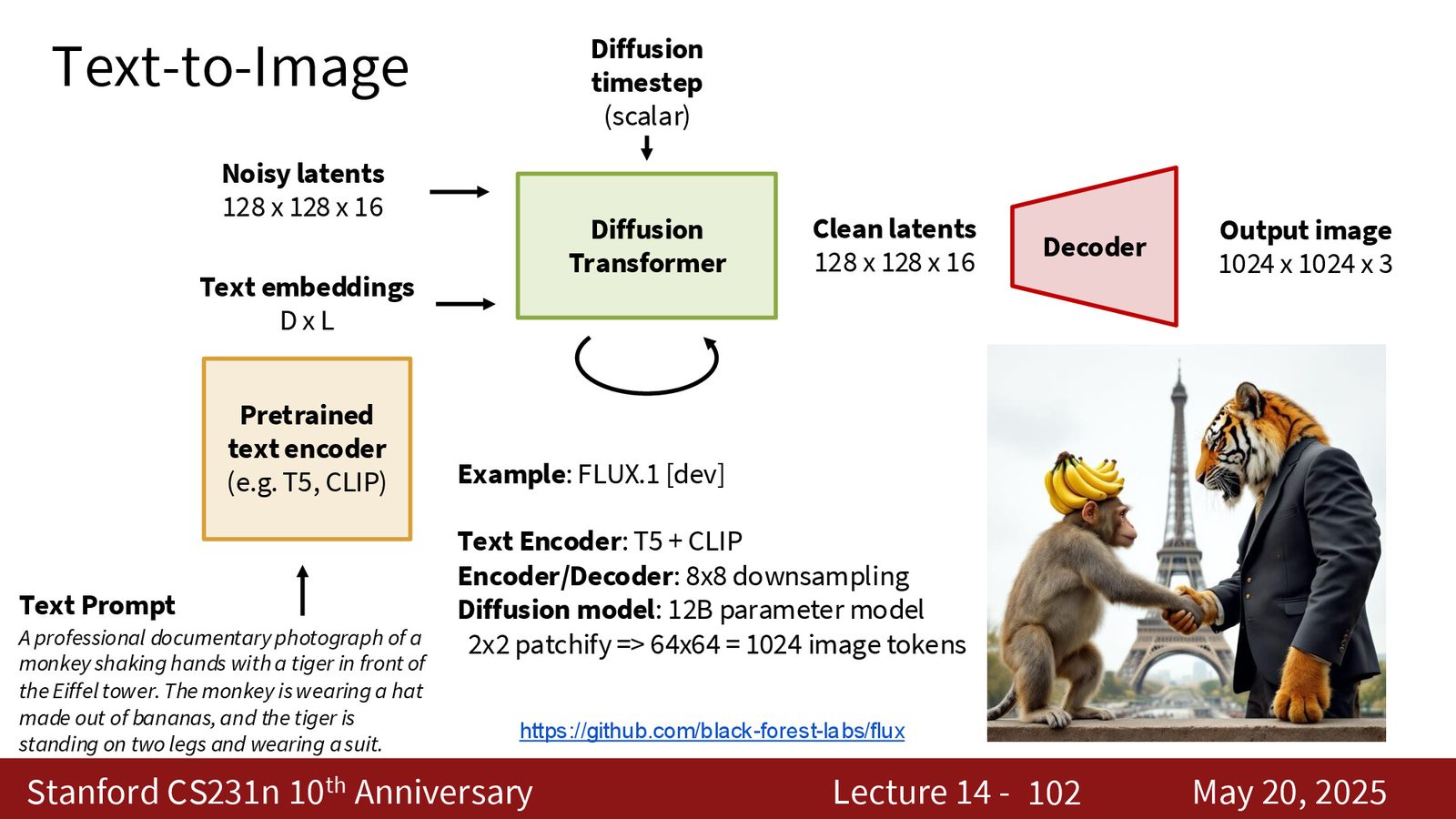
来源:Slides 第102页。
为什么 text-to-image 看起来像“多模型拼装”
因为它本来就是。文本编码器通常是预训练并冻结的;latent encoder / decoder 负责压缩和还原;真正学生成过程的是 diffusion 主干。工程上,每个模块都在做自己最擅长的事。
Text-to-Video
视频生成比图像生成贵得多,原因不是“多了一维”这么简单,而是时序一致性、运动一致性、跨帧语义一致性都会把 token 数和计算成本推高。到了视频场景,latent 往往是 \(t \times h \times w \times c\),模型要同时处理空间和时间。
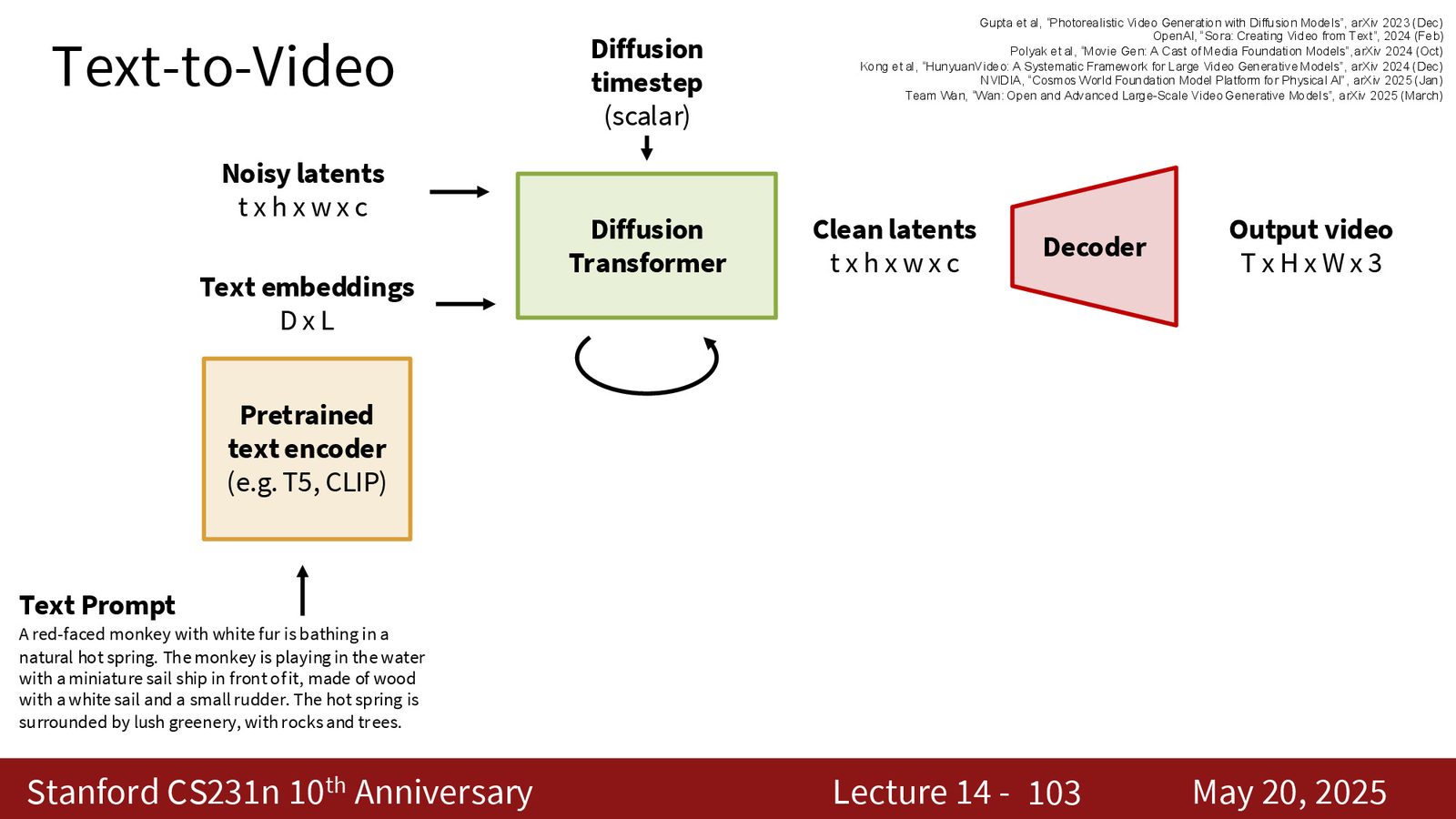
来源:Slides 第103页。

来源:Slides 第105页。
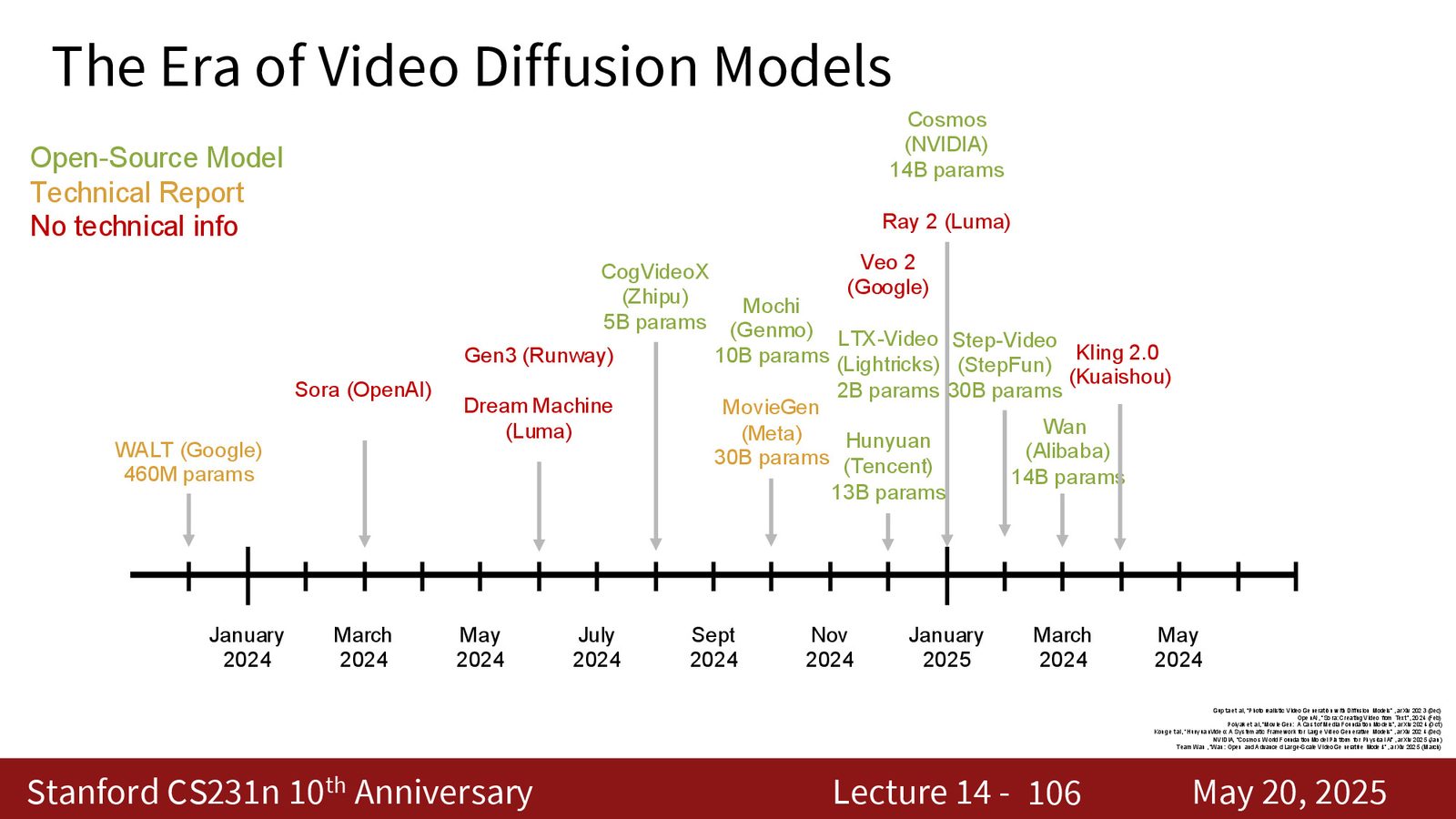
来源:Slides 第106页。
为什么还要 distillation
Diffusion 的采样成本本来就高。latent diffusion 好不容易把每一步便宜化了,但如果还要跑 30--50 步,推理依旧会慢。于是 distillation 成为必需:把多步采样压成更少步,甚至一步,并且有时还能把 CFG 一起蒸馏进去。

来源:Slides 第108页。
蒸馏在这里解决的是什么
蒸馏不改变“模型学什么”,主要是在改变“模型怎么被执行”:
- 把多步采样压缩成少步
- 把 CFG 的效果直接 bake 进学生模型
- 让 diffusion 系统更接近产品级时延要求
Generalized diffusion:不同公式,其实同一思想
统一写法
到这里,diffusion 的不同流派已经足够多了。lecture 里进一步给了一个统一写法。把不同版本的 noising path 和预测目标都写成同一个模板后,很多看起来不同的算法会突然变得可比:
训练目标就是让 \(y_{\text{pred}}\) 逼近 \(y_{\text{gt}}\)。

来源:Slides 第109页。

来源:Slides 第110页。
几个最重要的特例
在这个统一模板里,不同方法只是对 \(a,b,c,d\) 的选择不同:

来源:Slides 第111页。

来源:Slides 第112页。

来源:Slides 第113页。

来源:Slides 第114页。
为什么这些写法本质上是同一件事
- x-prediction 直接预测干净样本
- epsilon-prediction 预测噪声
- v-prediction 预测二者的线性组合
它们看起来不同,但都在学同一条“从噪声回到数据”的路径,只是参数化方式不同。
Diffusion 的三种解释
lecture 进一步指出,diffusion 不只是“一个训练技巧”,它还有三种常见解释。
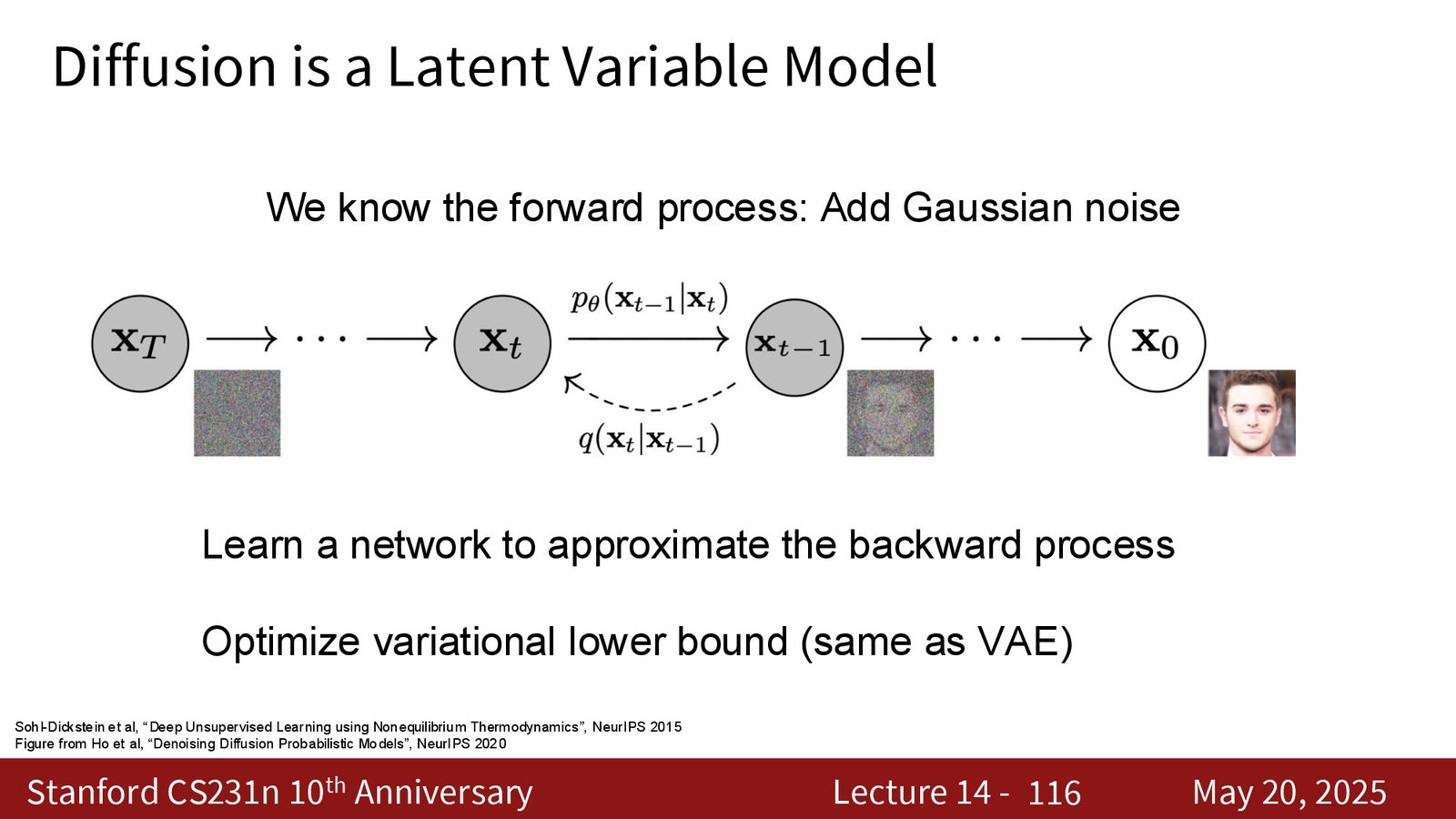
来源:Slides 第116页。
第一种是 latent variable model 视角:前向过程把数据变成 latent trajectory,反向过程则通过 ELBO 或相关目标去拟合。第二种是 score matching 视角:模型学习的是 \(\nabla_x \log p(x)\),也就是指向高密度区域的向量场。第三种是 SDE / ODE 视角:噪声演化可以写成连续时间动力系统,采样就是数值积分。

来源:Slides 第117页。

来源:Slides 第118页。
这三种视角不是互斥的
把 diffusion 解释成 latent model、score model 或 SDE,并不意味着它们是三种不同算法。更准确的说法是:它们是同一套生成过程的不同投影。工程上,你只需要选一个最方便实现和调参的参数化。

来源:Slides 第119页。
Autoregressive models strike back
为什么 AR 又回来了
raw pixels 上的 autoregressive 模型太慢了,因为序列太长。但如果把图像先压到离散 latent 空间,AR 就重新变得可行。也就是说,AR 不是被 diffusion 完全淘汰了,而是换了赛道:它更适合做离散 token 的序列建模。
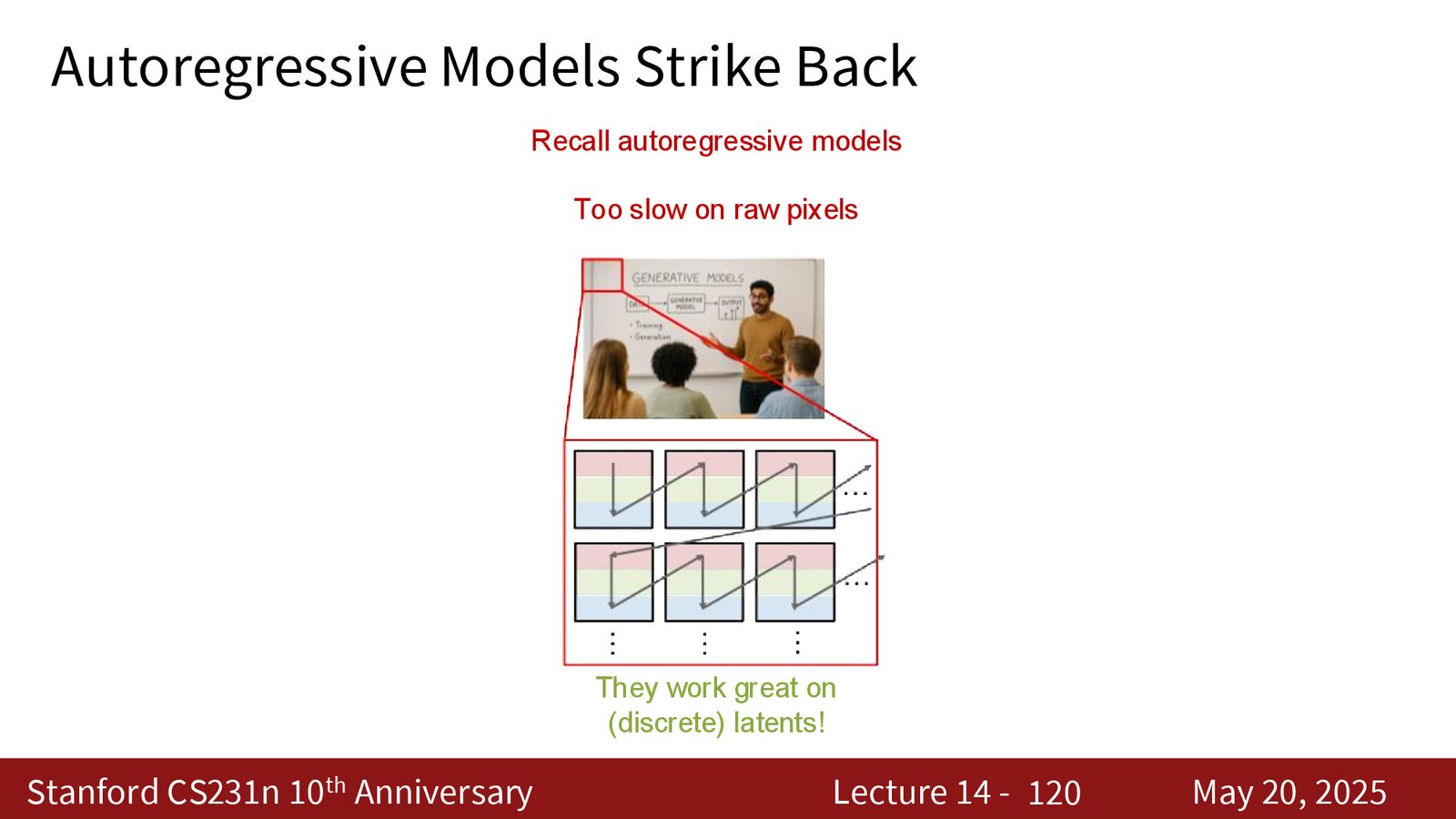
来源:Slides 第120页。
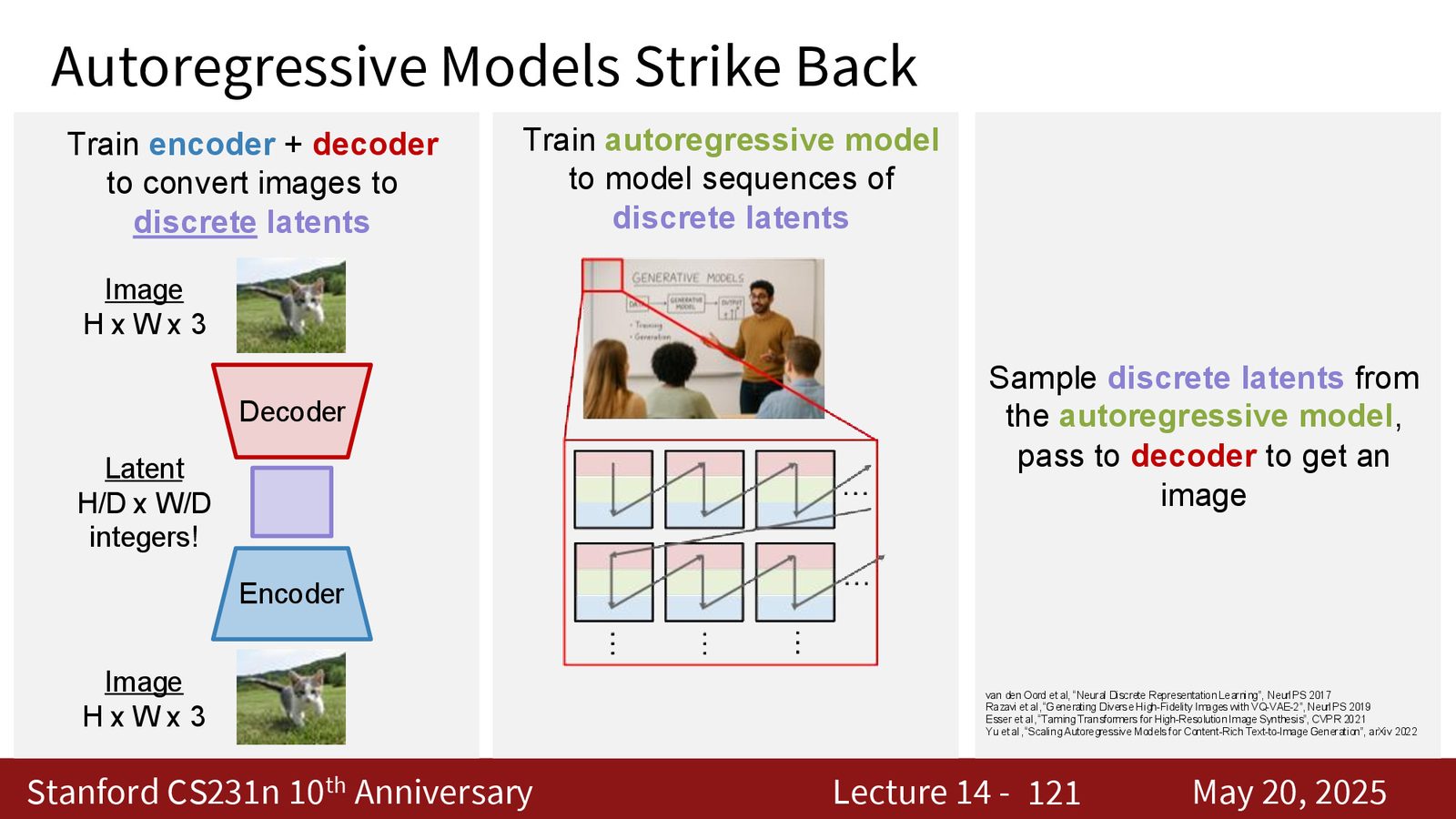
来源:Slides 第121页。
为什么离散 latent 很有吸引力
离散 latent 把图像压缩成更短的 token 序列,序列建模任务就从“生成几十万像素”变成“生成一小串离散码”。这对 Transformer 特别友好,也让高质量文本到图像生成再次有了 AR 路线。
总结与延伸
本章小结
从四条线收束成一条主线
这一讲虽然看起来覆盖了很多东西,但其实只有一条核心主线:从噪声到样本的变换,最终都可以看成一条可学习的运输路径。GAN 用对抗博弈逼近这条路径,diffusion / rectified flow 用逐步去噪或速度场积分来实现它,latent diffusion 把这条路径搬到更便宜的表示空间里,Transformer 则负责把条件和序列建模接起来。
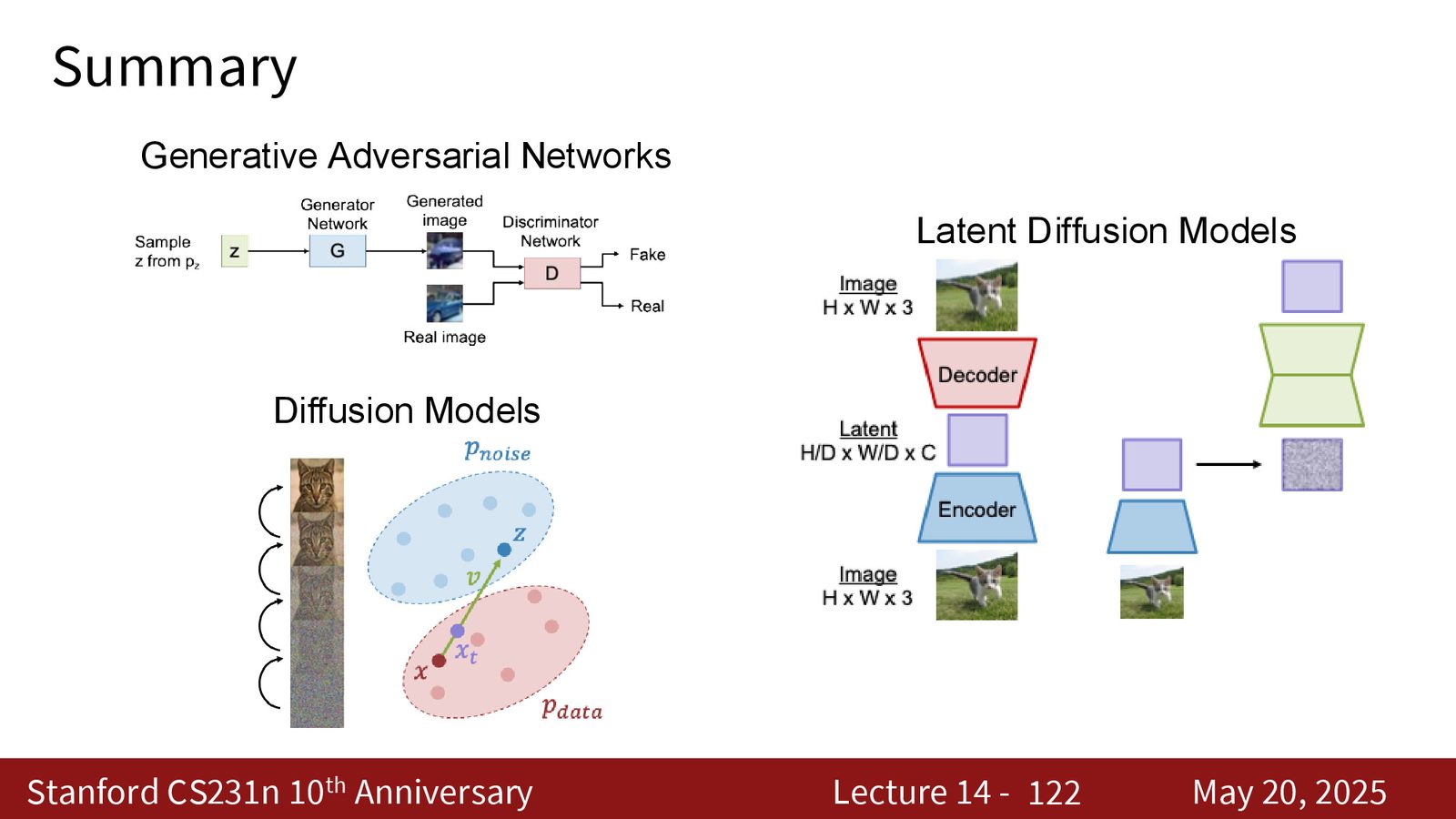
来源:Slides 第122页。
最后的 takeaways
- GAN 的核心价值是高质量样本,但它训练不稳,且不适合把自己当作标准监督学习来理解。
- Diffusion / rectified flow 把生成拆成多个小步,训练更稳,数学和工程解释都更清楚。
- CFG 几乎是现代条件扩散的标配,它让“听话程度”成为可调参数。
- Latent diffusion 让高分辨率生成变得可承受,是今天最常见的图像和视频生成范式。
- Generalized diffusion 告诉我们:很多名字不同的方法,本质上只是同一套运输问题的不同参数化。
- AR on discrete latents 说明 autoregressive 并没有过时,只是从 raw pixels 迁移到了更合适的表示空间。
和前两讲的联系
如果把上一讲和这一讲合起来看,就会发现生成式建模其实一直在做同一件事:用可计算的方式把简单分布变成复杂数据分布。区别只在于,你是选择直接分解概率、通过 latent 变分近似、用对抗博弈、还是用逐步去噪。现代系统之所以复杂,是因为它们已经不满足于“能生成”,而要同时满足“质量高、可控、可扩展、可部署”。

来源:Slides 第123页。
延伸阅读
- Goodfellow et al., Generative Adversarial Nets (2014)
- Ho et al., Denoising Diffusion Probabilistic Models (2020)
- Song et al., Score-Based Generative Modeling through SDEs (2021)
- Liu et al., Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow (2022)
- Rombach et al., High-Resolution Image Synthesis with Latent Diffusion Models (2022)
- Peebles and Xie, Scalable Diffusion Models with Transformers (2023)