CS336 2026 Lecture 10:Inference、KV Cache 与服务系统
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Stanford CS336 Spring 2026 官方可执行讲义重新整理 |
| 来源 | Stanford CS336 |
| 日期 | 2026 年春季 |
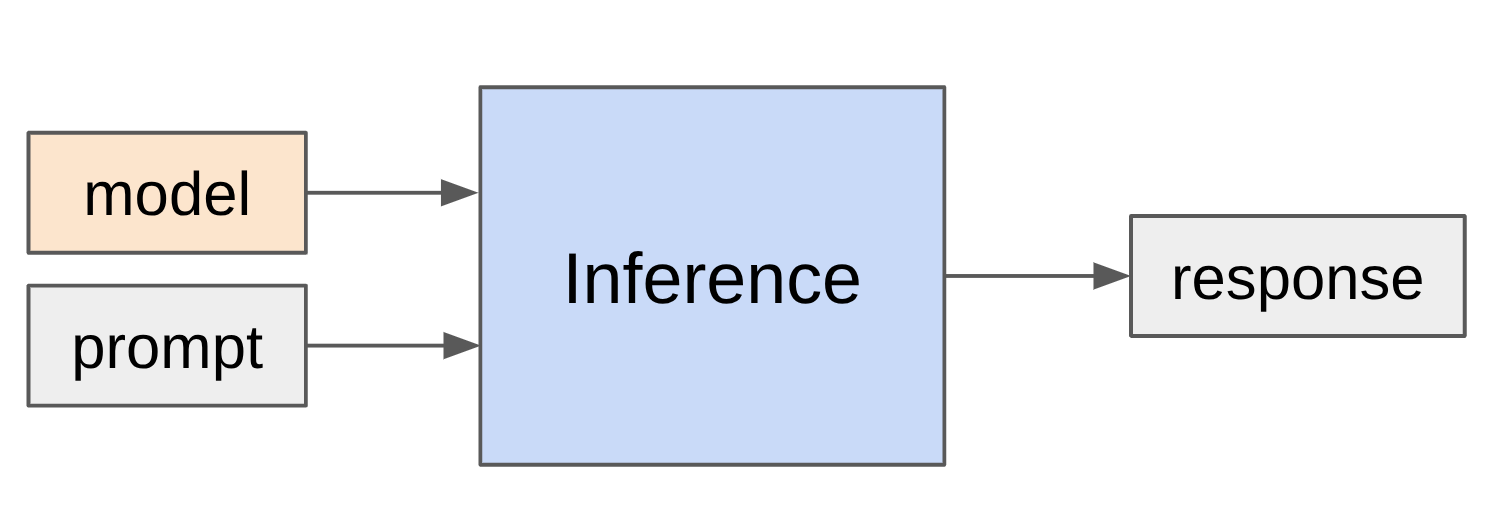
Lecture 10: inference 的总图
读图:inference-schema 如何串起整讲
图里把本讲分成四块。第一块是 Understanding the inference workload:为什么推理和训练不同,为什么 generation memory-bound。第二块是 Taking shortcuts (lossy):GQA/MLA/CLA、local attention、quantization、pruning/distillation 等可能改变模型或精度的做法。第三块是 Use shortcuts but double check (lossless):speculative sampling 利用便宜 draft model 但保持目标模型精确分布。第四块是 Handling dynamic workloads:continuous batching 和 PagedAttention 解决真实请求到达、长度不同、共享前缀和 KV cache 碎片化。
本讲的核心判断
推理优化首先是内存流量优化,其次才是 FLOPs 优化。这里的 HBM 是 High Bandwidth Memory,即 GPU 上的高带宽显存;generation 阶段一次生成一个 token,不断从 HBM 读取模型权重和请求自己的 KV cache,常常 memory-bound。和 ZeRO/FSDP 训练状态分片不同,推理侧通常不维护 optimizer state;若要 shard 模型或 KV cache,目标是降低单卡 HBM 压力或提升吞吐,而不是同步训练梯度。
Understanding the inference workload
推理为什么重要,以及什么叫快
Inference 出现在实际产品、模型评测、agent 内部轨迹、批量数据处理和 RL 采样中。训练是阶段性成本,推理是每次使用都要付的成本。聊天机器人里,人类等待 time-to-first-token;agent 工作流里,内部 trace 可能生成大量不可见 token;RL 中则要采样许多 completions 再打分。换句话说,tokens generated = compute spent。
术语消化:推理服务指标
| 指标 | 含义 | 主要优化方向 |
|---|---|---|
| TTFT | Time-to-first-token,用户等到第一个 token 的时间。 | prefill latency,小 batch、prefix cache、prompt 处理。 |
| Latency | 单个请求 token 出现的速度,常以 seconds/token 计。 | generation step time、KV cache 读取、batch size。 |
| Throughput | 系统总体 tokens/second。 | batching、并发、KV memory 管理、kernel efficiency。 |
| Memory-bound | 速度受 HBM 读写限制,而不是算力限制。 | 减少 KV cache、量化、分页、提高复用。 |
Transformer notation 与算术强度
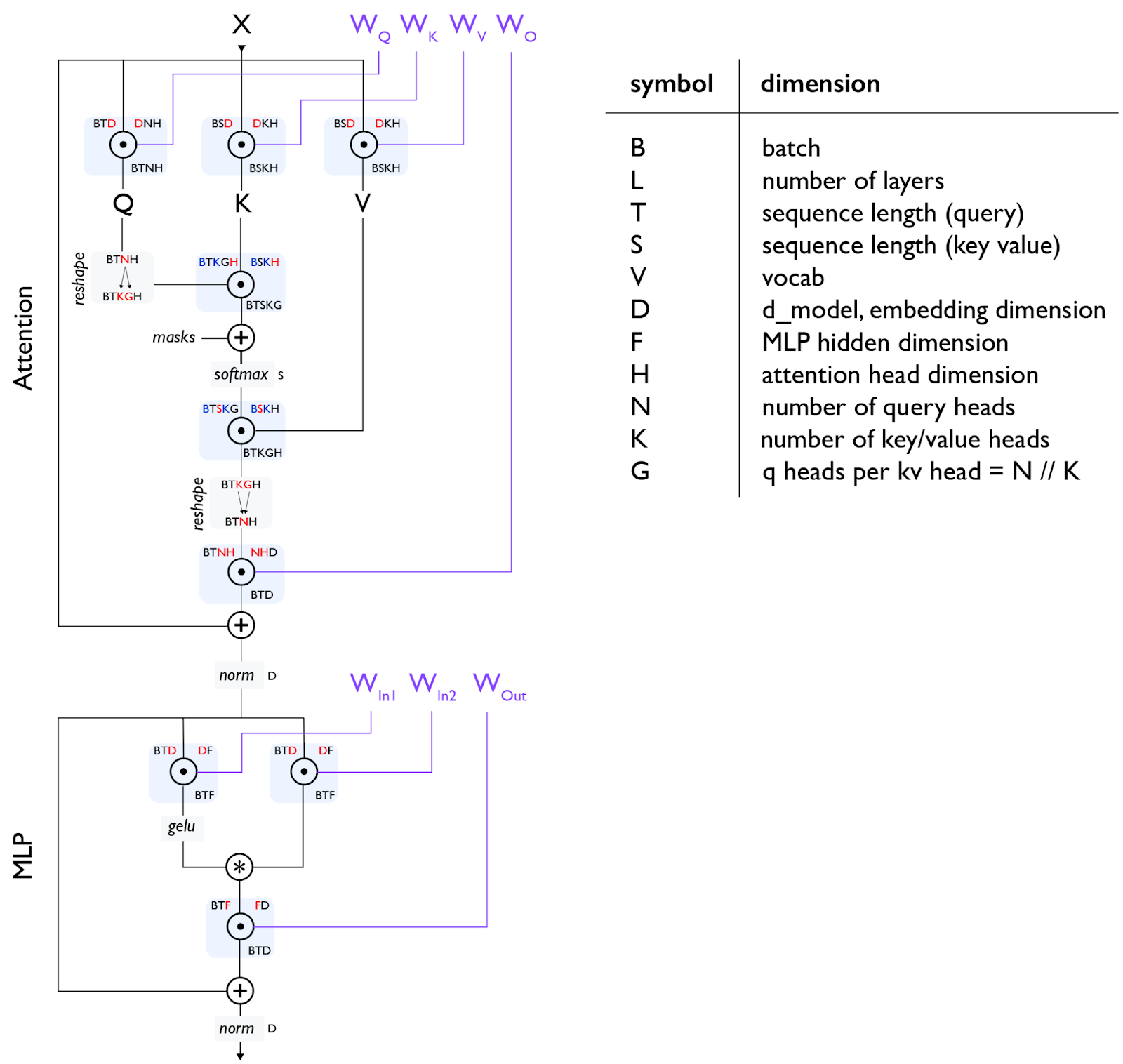
读图:Transformer 维度怎么读
\(B\) 是 batch size,\(T\) 是要计算的 token 数,\(S\) 是已条件化的历史 token 数,\(D\) 是 model dimension,\(H\) 是 head dimension,\(N\) 是 query heads 数,\(K\) 是 key/value heads 数,\(G=N/K\) 是 GQA group 数,\(F=4D\) 是 MLP up-projection width。后面所有推理账本都在追踪这些维度如何进入 FLOPs、HBM 读写和 KV cache。
算术强度 arithmetic intensity 定义为每搬运一个 byte 做多少 FLOPs:
若 \(I\) 高于硬件的 compute/bytes 比,算子 compute-bound;若低于该阈值,算子 memory-bound。矩阵乘 \(X(B,D)W(D,F)\) 的 FLOPs 约为 \(2BDF\),但权重读取约为 \(DF\) 元素。当 \(B=1\) 时,矩阵乘退化成 matrix-vector product,读一整个权重矩阵只服务一个 token,算术强度极低。
为什么 generation 像 batch size 为 1 的矩阵向量乘
训练时 \(B\times T\) 通常很大,同一个权重矩阵服务许多 tokens;generation 时每个请求每步只生成一个新 token,\(T=1\),并发 \(B\) 又由在线流量决定。因此 generation 很难稳定形成大矩阵乘,往往被参数和 KV cache 的 HBM 读取限制。
naive inference、KV cache、prefill 与 generation
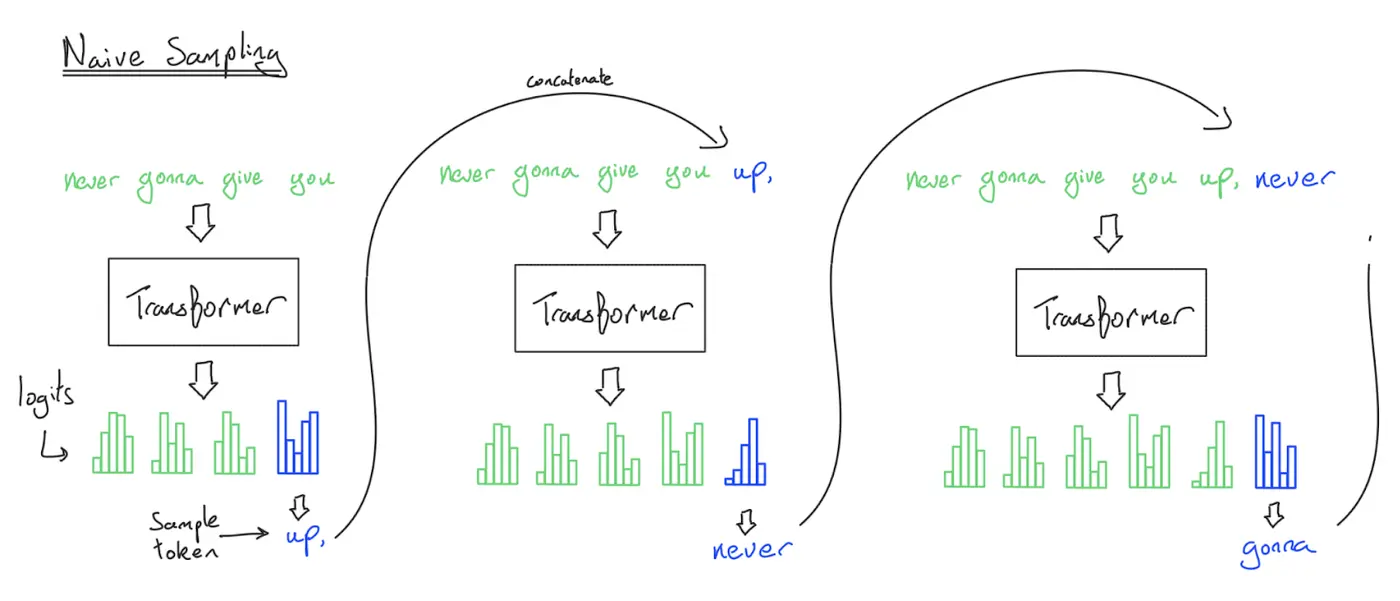
读图:naive inference 为什么是 \(O(T^3)\)
第 \(t\) 个 token 的 forward pass 会处理长度约为 \(t\) 的上下文;单次 attention 近似 \(O(t^2)\)。把 \(t=1\) 到 \(T\) 累加,整体生成 \(T\) 个 token 需要 \(O(T^3)\) 级别的重复计算。图里的关键是 prefix 被反复重算。
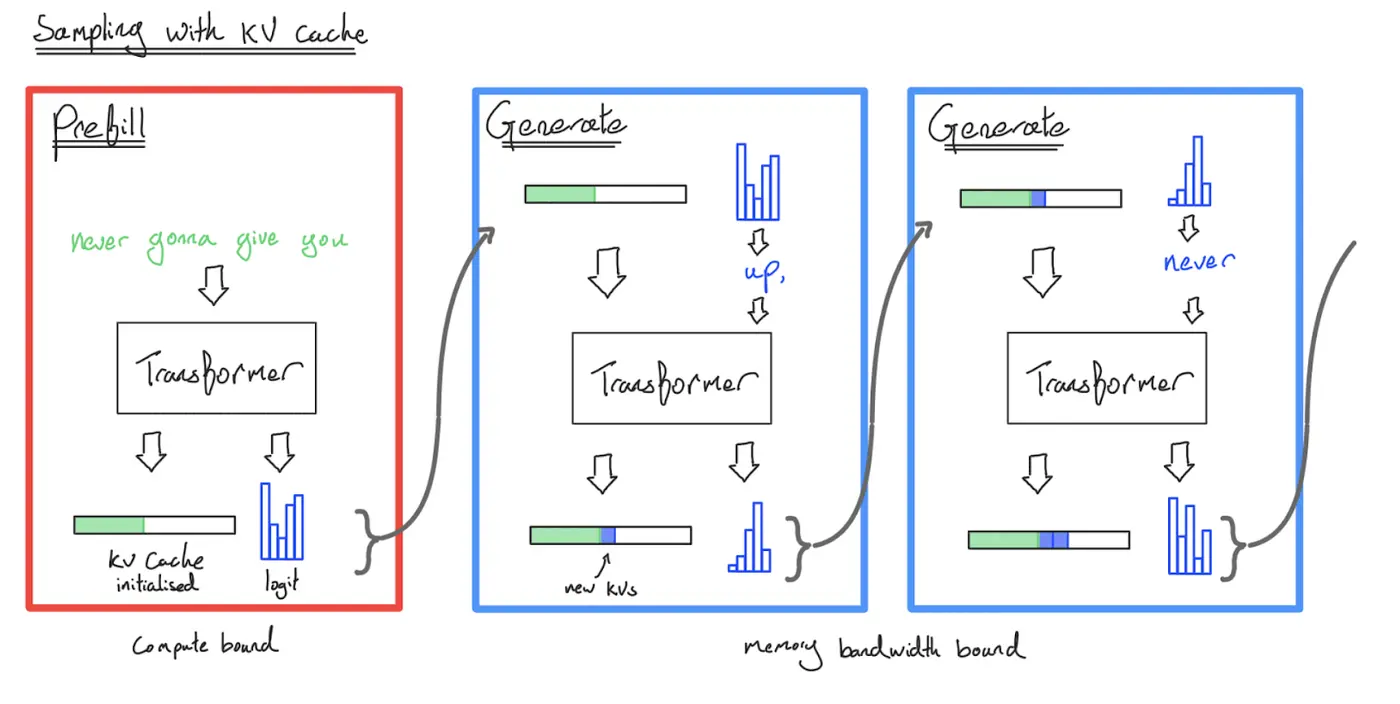
读图:KV cache 省了计算,但制造了内存瓶颈
KV cache 为每个 sequence、token、layer、head 保存 \(K,V\) 向量。它避免历史 token 反复投影,复杂度大幅降低;但每个新 token 都要读取该请求历史的 KV cache。历史越长、batch 越大、层数越多,HBM 读写越重。
其中 \(2\) 来自 key 和 value,\(B\) 是并发请求数,\(S\) 是历史上下文长度,\(L\) 是层数,\(K\) 是 KV heads 数,\(H\) 是 head dimension。这个公式解释了为什么后面 GQA、MLA、CLA、local attention、PagedAttention 都围绕 KV cache 做文章。
prefill 和 generation 的差别
Prefill:给定 prompt,一次性编码 \(S\) 个 tokens,能像训练一样并行,MLP intensity 约随 \(B S\) 提升,attention intensity 约随 \(S/2\) 提升。Generation:每次只生成一个 token,MLP intensity 约随并发 \(B\) 提升,attention generation intensity 小于 1,几乎无法靠 batching 改善,因为每个请求读取自己的 KV cache。
latency-throughput tradeoff
Batch size 增大时,模型权重读取可被更多请求摊薄,throughput 上升;但 KV cache 随 \(B\) 增大,单请求等待和每步读取也变重,latency 变差。一个简单策略是 prefill 用较小 batch 改善 TTFT,generation 用较大 batch 提高吞吐。
复制模型和切分模型的差别
若启动 \(M\) 个完整模型副本,latency 基本不变,throughput 近似乘 \(M\)。若 shard 模型和 KV cache,则能服务更大模型或更大上下文,但每步推理需要跨设备通信,latency 可能上升。
本章小结
理解 inference 的关键是把请求拆成 prefill 和 generation,把算子拆成 FLOPs 与 HBM bytes,把状态拆成 weights 和 KV cache。Generation 的 memory-bound 特性决定了后续所有优化方向。
Taking shortcuts (lossy):减少 KV cache 和模型字节
GQA:按 head 共享 KV
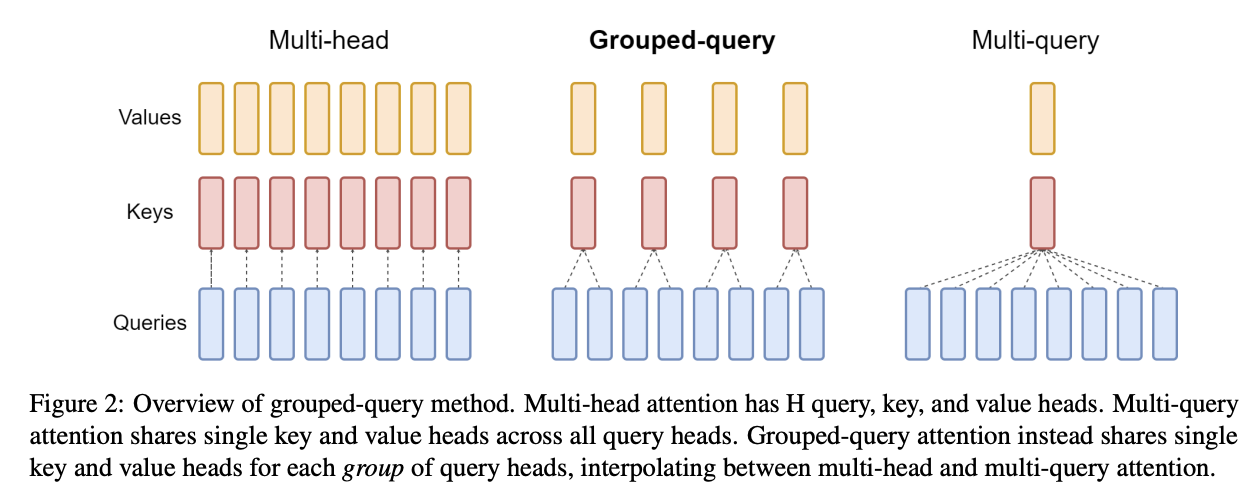
读图:GQA 图应该看 \(N/K\)
MHA 为每个 query head 保存独立 KV;MQA 所有 query heads 共享一个 KV head;GQA 介于两者之间,每组 query heads 共享一组 KV。KV cache 大小约按 \(N/K\) 缩小,因此 latency 和 throughput 改善来自更少 HBM 读取。
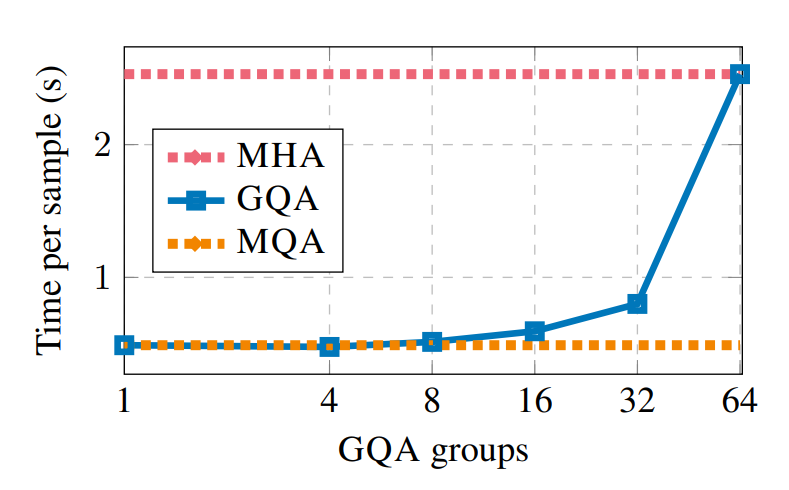
读图:GQA speed 图说明什么
横向比较时,KV cache 小的配置通常 latency 更低或能容纳更大 batch,从而 throughput 更好。若原 MHA 配置不 fit,GQA 首先解决容量;若能 fit,GQA 仍可能通过减少内存流量改善吞吐。
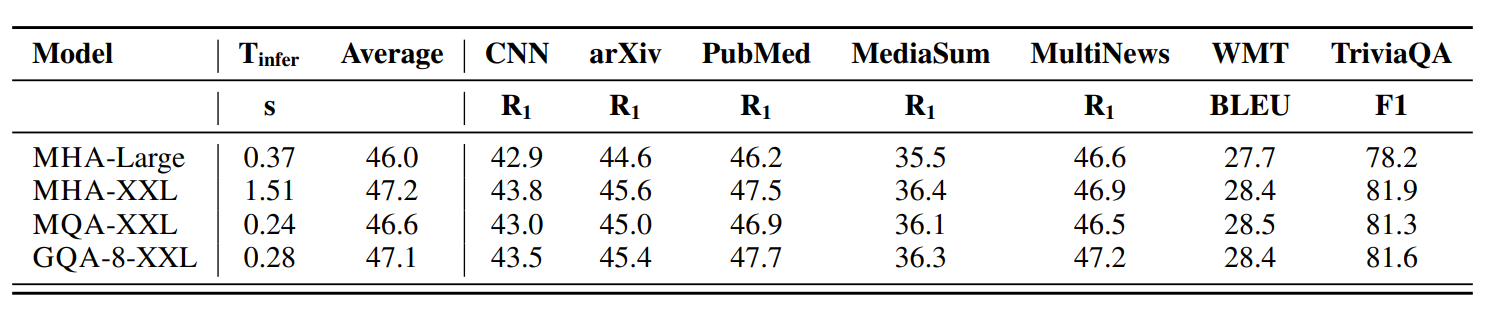
GQA 是 lossy shortcut
GQA 改变 attention 结构,通常会影响模型质量。速度图只说明系统收益,accuracy 图才说明是否值得用。课程主线是:有损 shortcut 必须以质量检查收尾。
MLA 和 CLA:压缩或跨层共享 KV
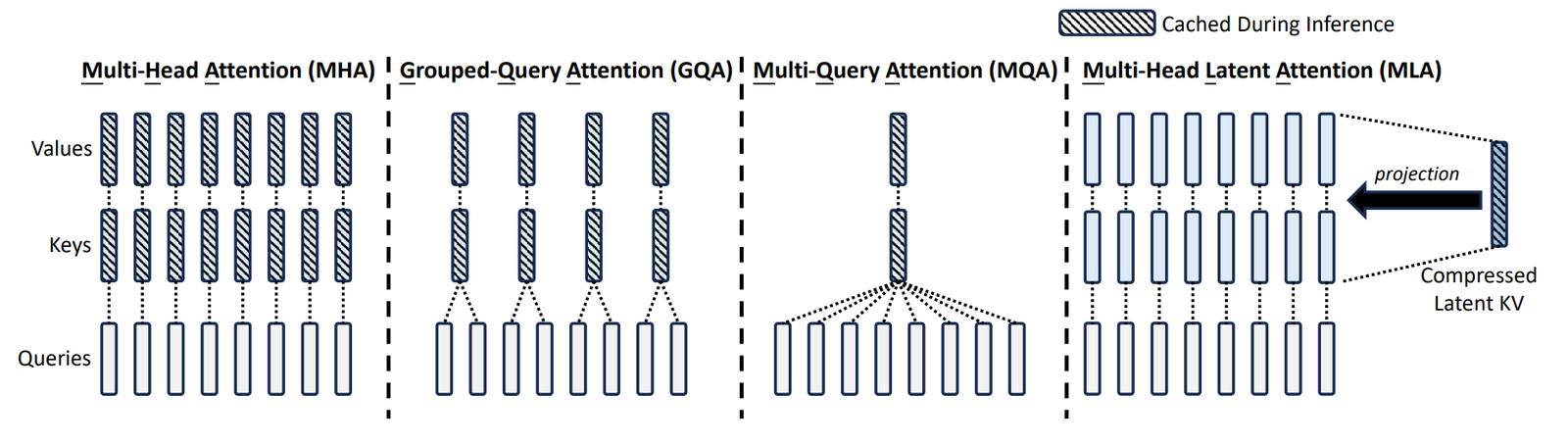
读图:MLA 如何压缩 KV cache
普通 attention 存 \(K=W_Kh,V=W_Vh\),维度约为 \(N H\)。MLA 存低维 latent \(c\),例如 DeepSeek v2 中从 \(16384\) 维压到 \(512\) 维,再额外保留 RoPE 所需维度。它把长期 cache 从高维 KV 变成低维 latent,换来每步投影计算。
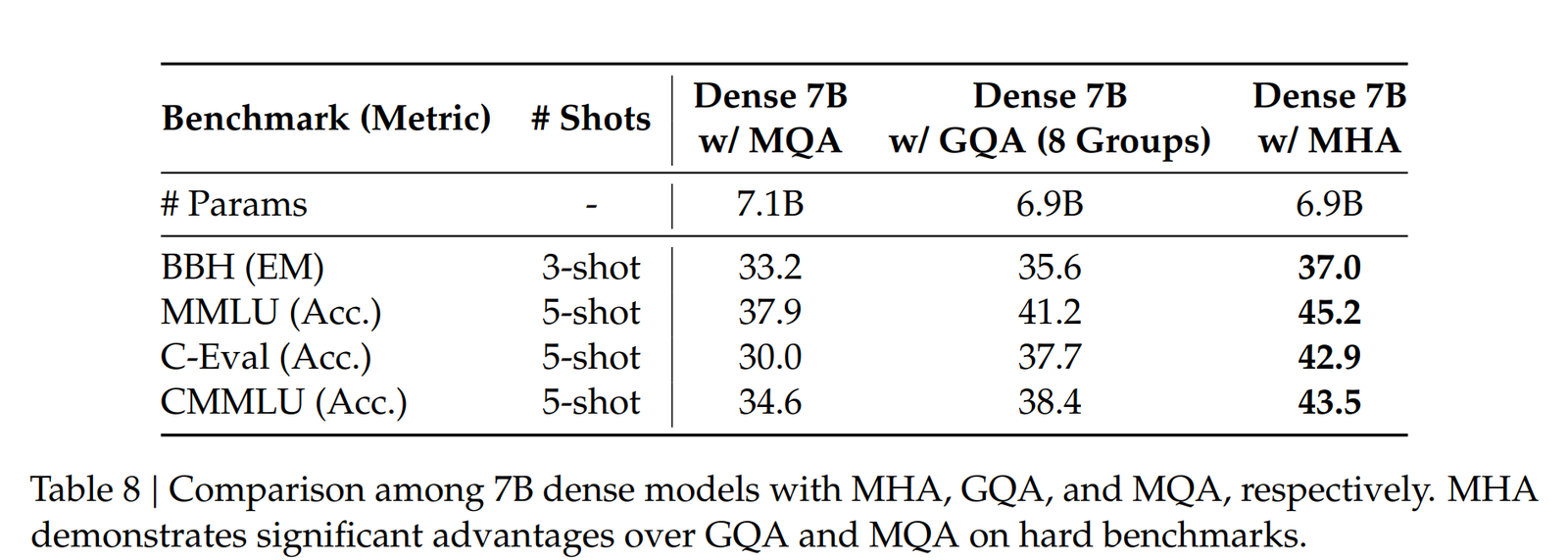
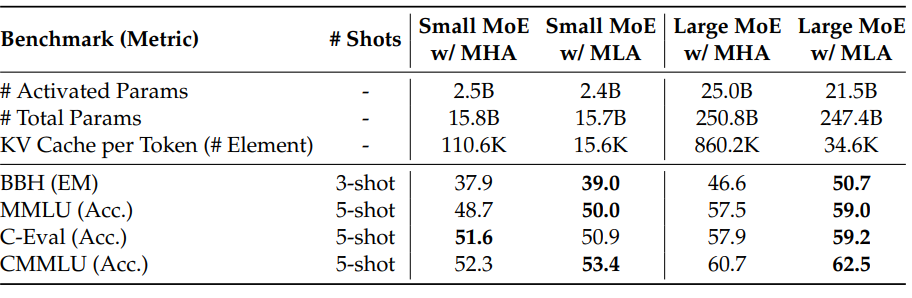
读图:MLA accuracy 两张表一起看
第一张表确认不同 attention 结构的质量基线;第二张表展示 MLA 的质量和成本折中。读表时不能只看平均分,还要看任务类别和模型规模,因为 KV 压缩可能对长上下文、检索或数学任务影响不同。
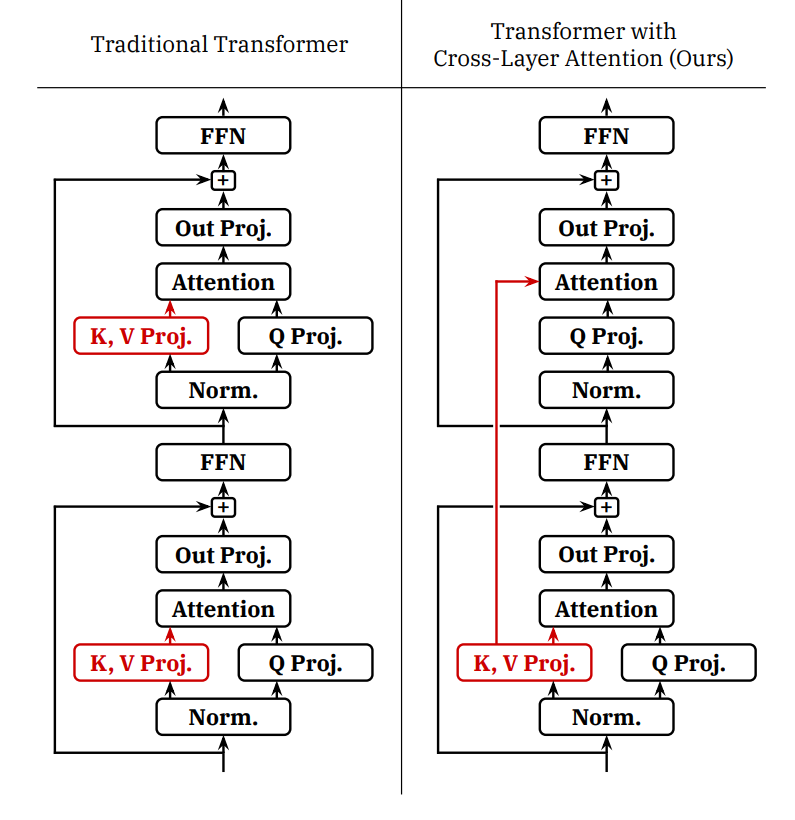
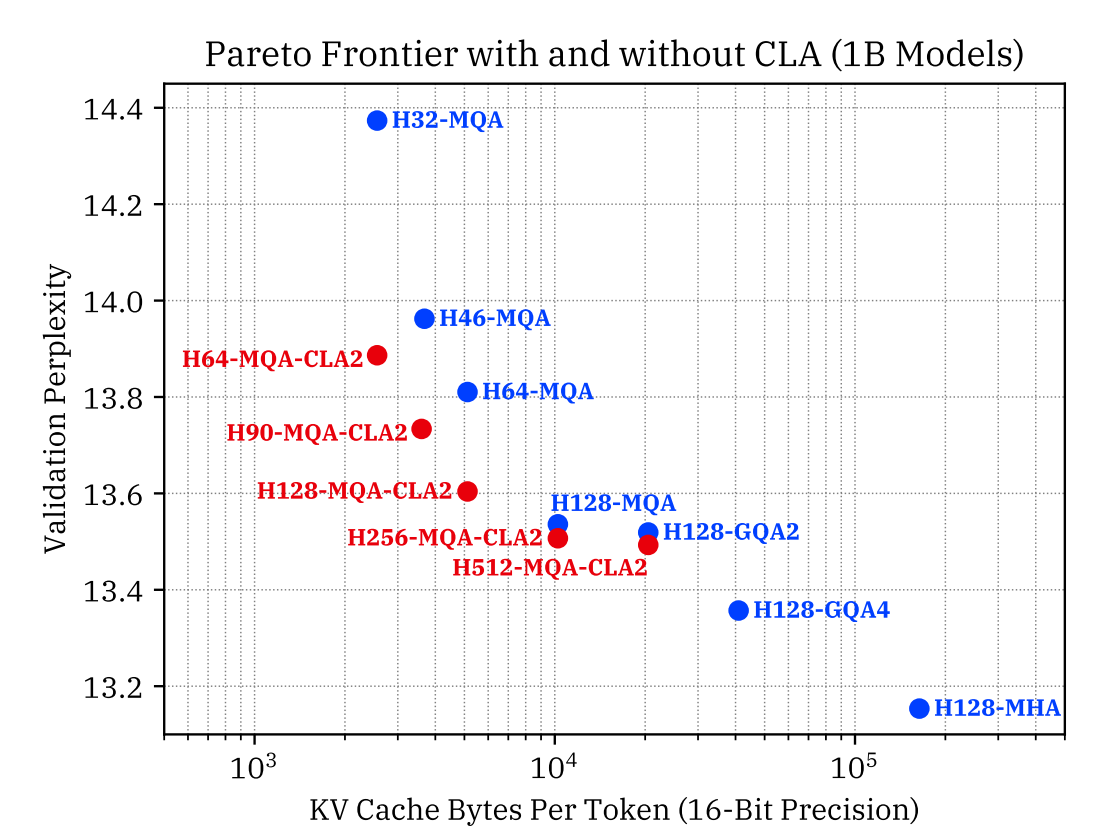
读图:CLA 的 Pareto frontier
CLA 不是只追求最小 KV cache,而是在相同 cache budget 下尽量提高 accuracy,或在相同 accuracy 下减少 cache。Pareto frontier 向左下移动才说明结构改动有系统价值。
Local、hybrid 和 DeepSeek v4 attention
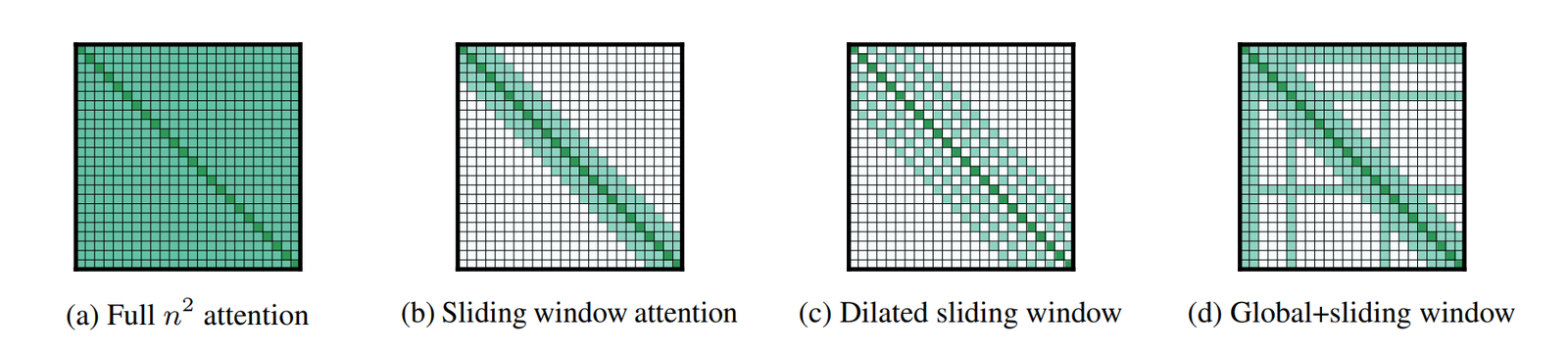
读图:local attention 的收益和代价
局部窗口让每层 KV cache 与可见窗口相关,而不是与完整 sequence length 线性相关。多层堆叠可以传播信息,但远距离精确依赖会变弱。因此实践中常用 hybrid layers:部分层 local,部分层 global。
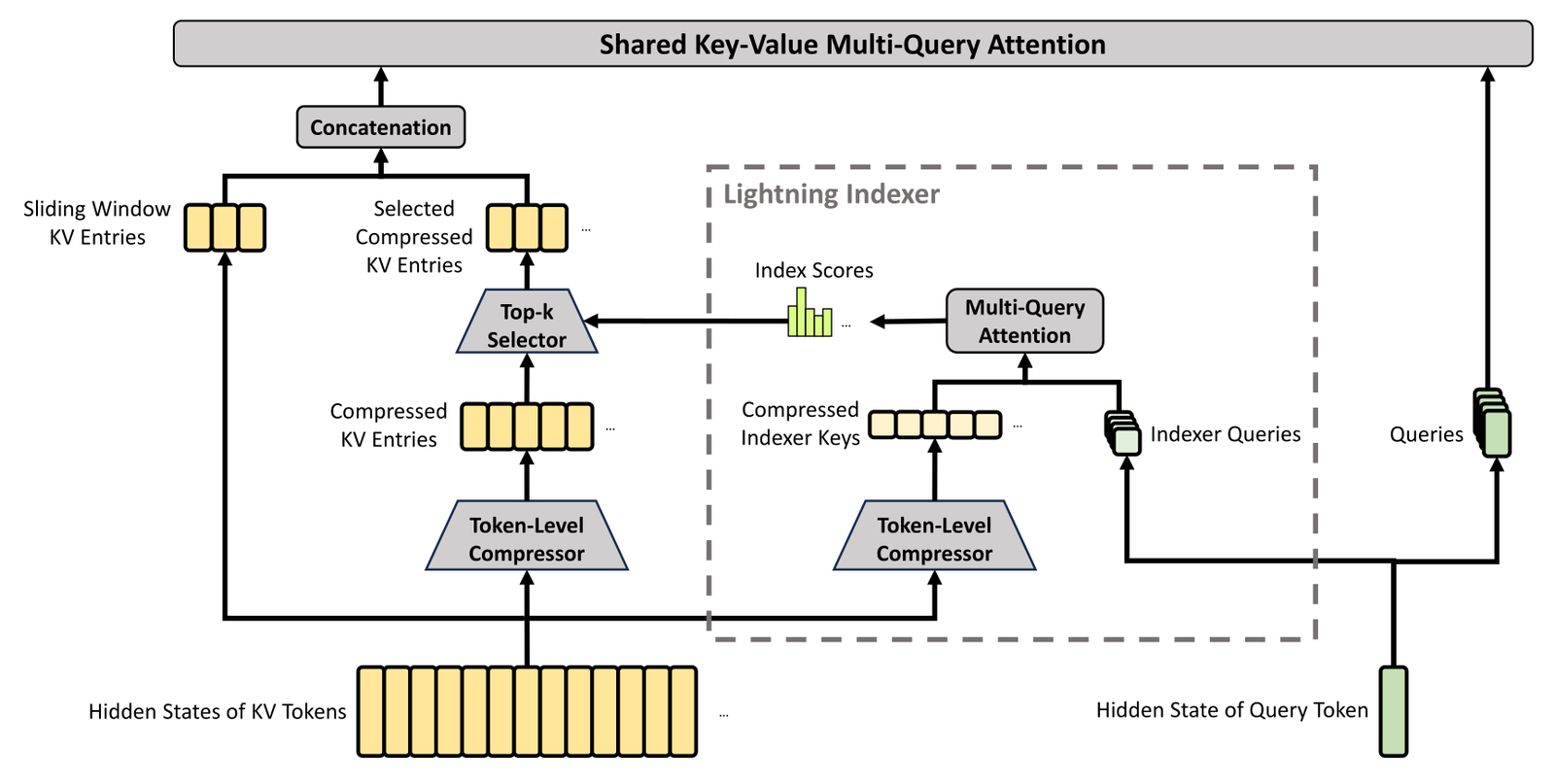
术语消化:DeepSeek v4 attention 三个缩写
| 术语 | 机制 | 推理意义 |
|---|---|---|
| CSA | Compressed Sparse Attention,把每 \(m\) 个 tokens 压成一个表示。 | 降低长上下文 KV 读取。 |
| DSA | DeepSeek Sparse Attention,选择 top \(k\) 相关位置。 | 把注意力集中到更有用 token。 |
| HCA | Heavily Compressed Attention,更激进压缩。 | 服务超长上下文时进一步控成本。 |
quantization 与 AWQ
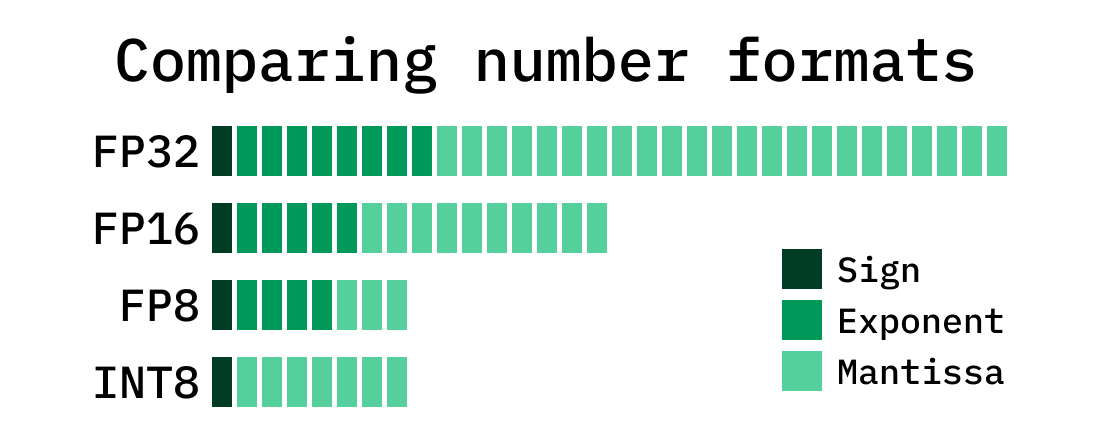
读图:量化为什么直接影响推理
推理 memory-bound 时,参数和 KV cache 的 bytes 直接进入 latency/throughput。bf16 是常见默认;fp8/int8/int4 减少内存流量,但会引入量化误差。位宽越低,越需要校准、补偿或训练时适配。
术语消化:QAT、PTQ、GPTQ、AWQ
| 方法 | 做法 | 代价/适用性 |
|---|---|---|
| QAT | Quantization-aware training,训练中模拟量化误差。 | 质量好但昂贵。 |
| PTQ | Post-training quantization,训练后用校准数据确定 scale/zero point。 | 便宜,常用于部署。 |
| GPTQ | 用 Hessian 信息补偿量化误差。 | 更精细但实现复杂。 |
| AWQ | Activation-aware quantization,保留少量重要权重高精度。 | 关注大 activation channel 命中的权重。 |
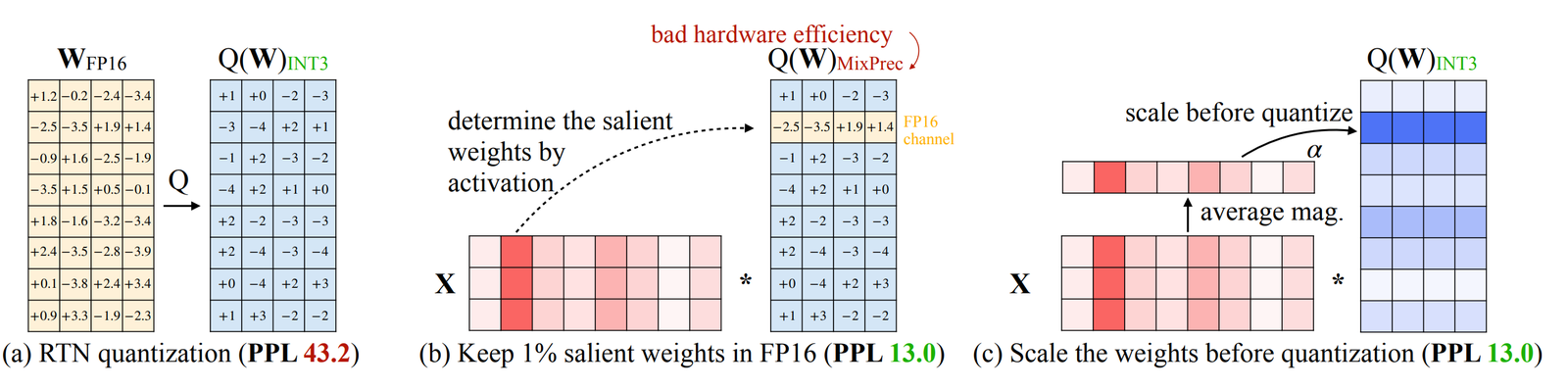
读图:AWQ schema 说明什么
AWQ 的直觉是并非所有权重量化误差同等重要。若某些 activation channels 很大,与其相乘的权重误差会被放大。保留 0.1%-1% 重要权重的高精度,可能用很小内存代价换来明显质量改善。
pruning 与 distillation
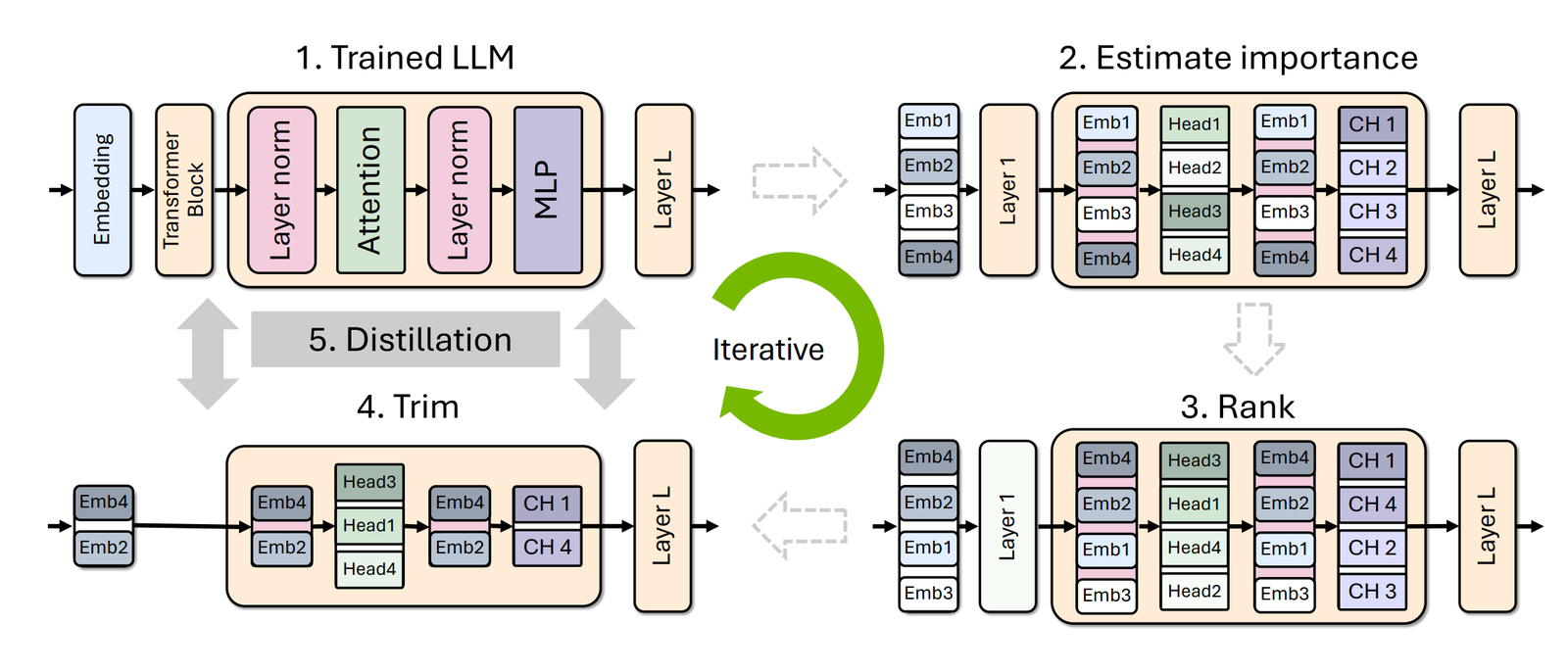
读图:pruning 为什么必须 distill
直接移除 layers、heads 或 hidden dimensions 会破坏模型函数。蒸馏让小模型模仿原模型输出,把结构损伤修复回来。它是有损 shortcut,但通过 teacher signal 降低质量损失。
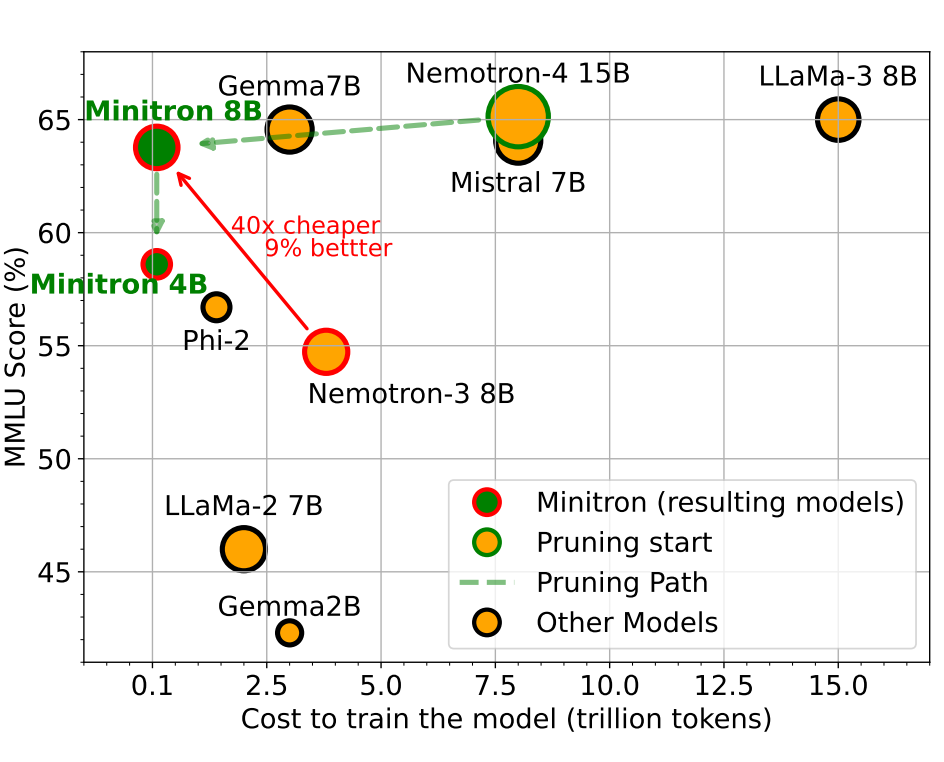
有损 shortcut 的共同风险
GQA、MLA、CLA、local attention、quantization、pruning 都可能改变输出分布。它们的验收不能只看速度,必须看准确率、长上下文能力、校准、下游任务和安全性指标。
Use shortcuts but double check (lossless):speculative sampling
Speculative sampling 利用一个便宜 draft model \(p\) 一次猜多个 token,再让 target model \(q\) 并行检查。直觉是:generation 慢,但 checking 多个候选 token 比逐个生成便宜。关键性质是它仍然精确采样自 \(q\),因此属于 lossless shortcut。

读图:为什么它仍是 exact sample
若 draft \(p\) 对某 token 给出概率高于 target \(q\),该 token 只以 \(q/p\) 的概率接受;被拒绝的概率质量会转移到 residual distribution \(\max(q-p,0)\)。这样最终每个 token 的边际概率仍等于 \(q\),只是把多个候选的校验并行化。
这个两 token 例子说明:如果 \(p(A)>q(A)\),过多提出的 \(A\) 会被拒绝一部分;若 \(p(B)<q(B)\),不足的概率通过 residual 补回来。
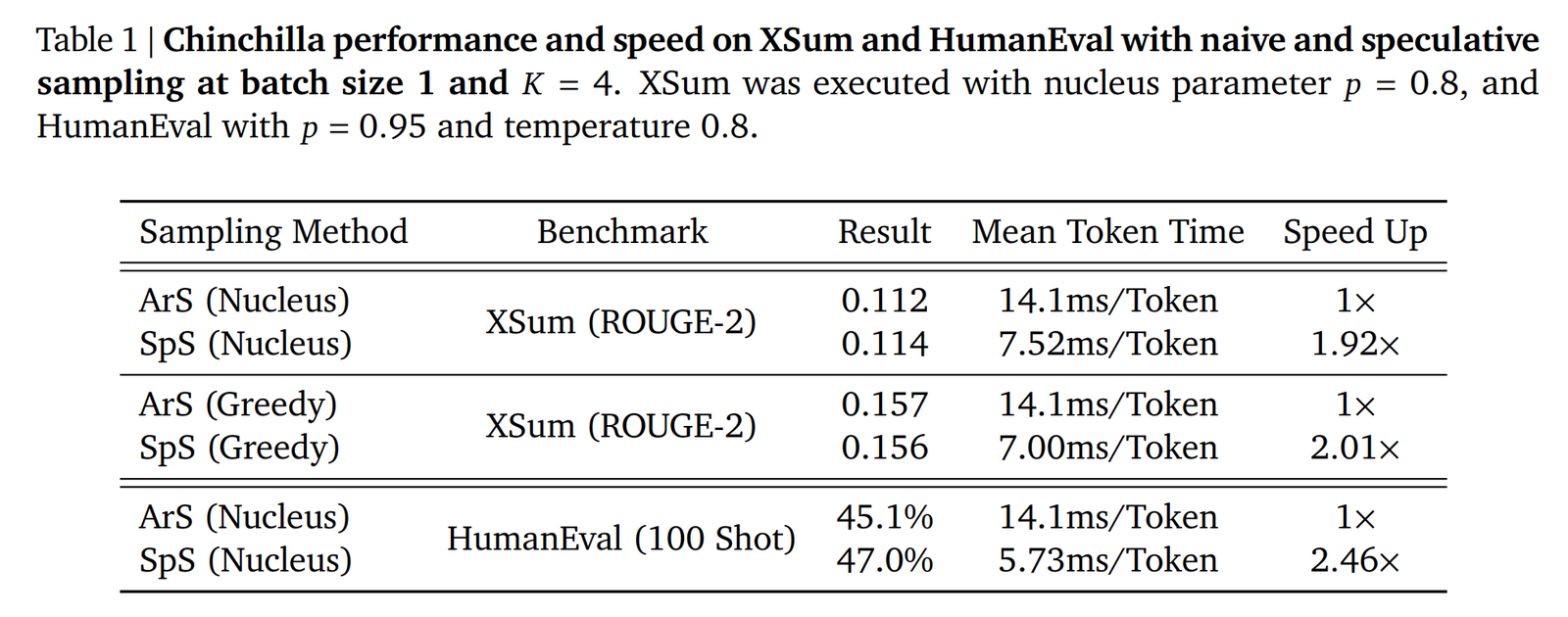
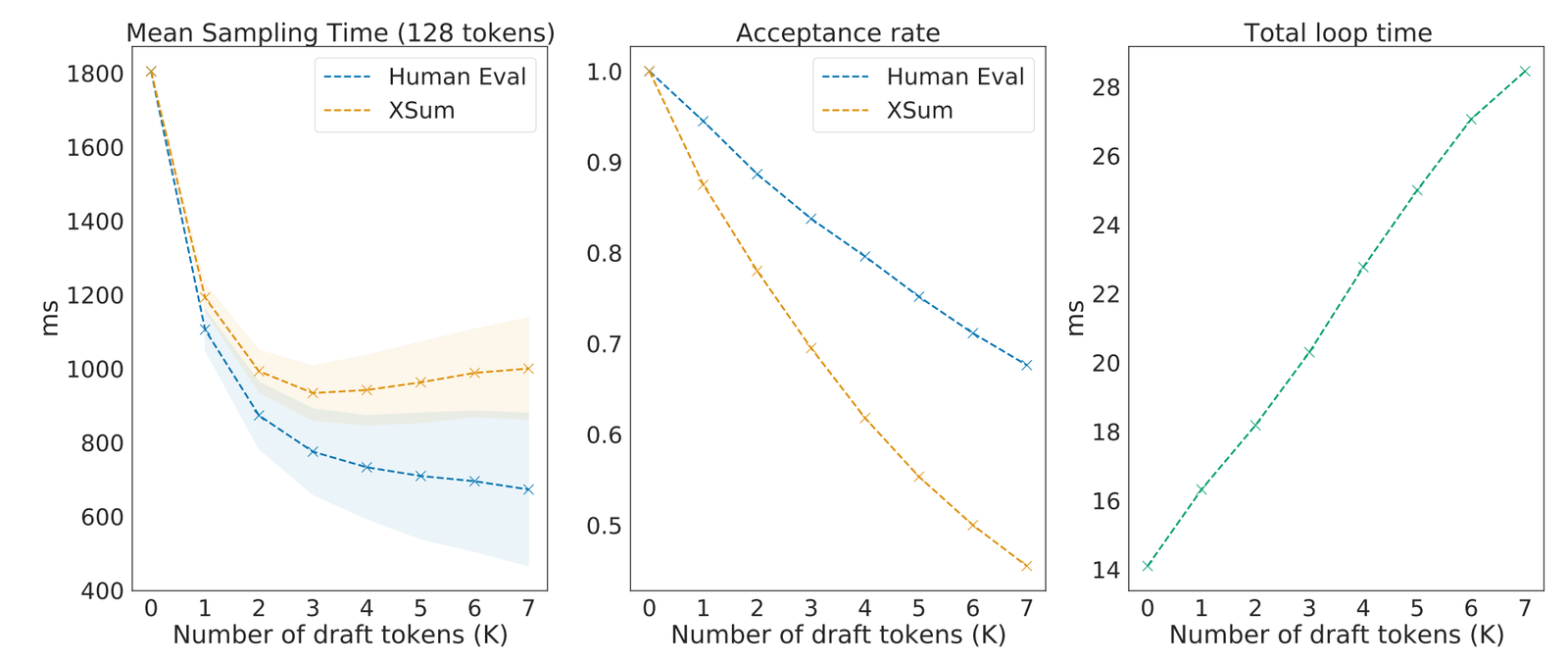
读图:speculative speedup 的两个控制旋钮
Draft model 越接近 target,接受率越高;一次猜的 tokens 越多,潜在并行度越高,但被拒绝时浪费也越多。最佳点取决于 draft 成本、target 成本、接受率和服务端 batch 调度。
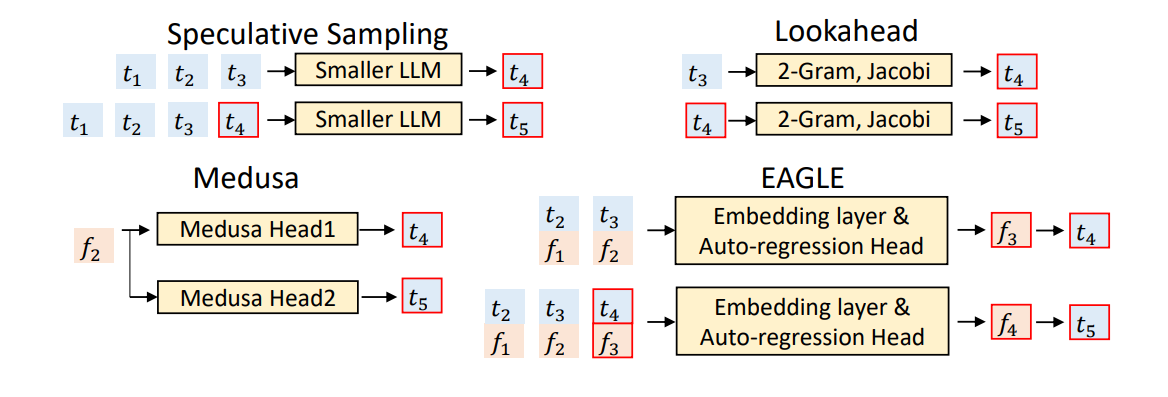
读图:Medusa/EAGLE 的共同目标
Medusa 让 draft 头并行提出多个未来 token;EAGLE 利用 target model 的高级特征帮助 draft。二者都服务同一个目标:提高接受率,同时保持 draft 成本足够低。
本章小结
Speculative sampling 的美感在于:它利用系统不对称性,checking 比 generation 更可并行;又用 rejection-sampling 逻辑保证目标分布不变。它是本讲中最典型的“系统技巧 + 概率正确性”结合。
Handling dynamic workloads:continuous batching
真实推理流量不是训练中的矩形 batch。请求到达时间不同、prompt 长度不同、生成长度不同,还可能共享 system prompt 或要求多样本生成。静态 batching 会让早到请求等待,也会因 padding 浪费大量计算。
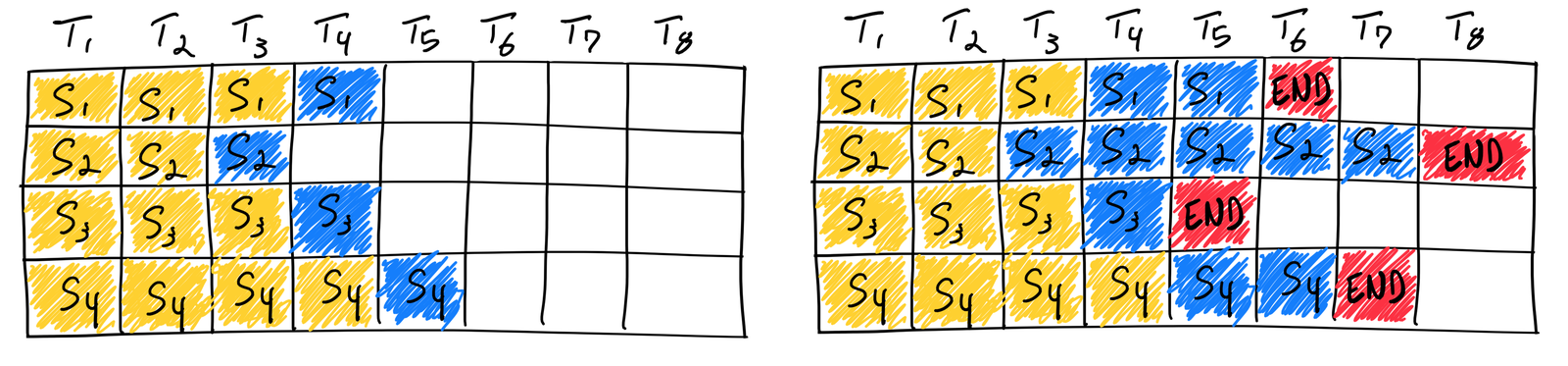
读图:continuous batching 解决哪个问题
图中不同请求像长度不一的条带。训练可以把 \(B\times S\times H\) 看成稠密矩形;推理则是 ragged array。Iteration-level scheduling 每个 decode step 都可以加入新请求、移除完成请求,让 GPU 更持续地工作。
selective batching 的核心
Attention 需要按 sequence 单独处理,因为每个请求历史长度不同;non-attention MLP 等操作可以把所有 active tokens concatenate 成 \([3+9+5,H]\) 这样的矩阵统一计算。服务系统要在“保持语义正确”和“形成大矩阵乘”之间拆算子。
PagedAttention:用操作系统思想管理 KV cache
fragmentation 与 blocks

读图:KV cache fragmentation
如果为每个请求按最大长度预留连续空间,实际生成较短时会产生 internal fragmentation;不同请求释放/分配后,空洞之间不连续,又会产生 external fragmentation。显存看似充足,却无法容纳新的长请求。
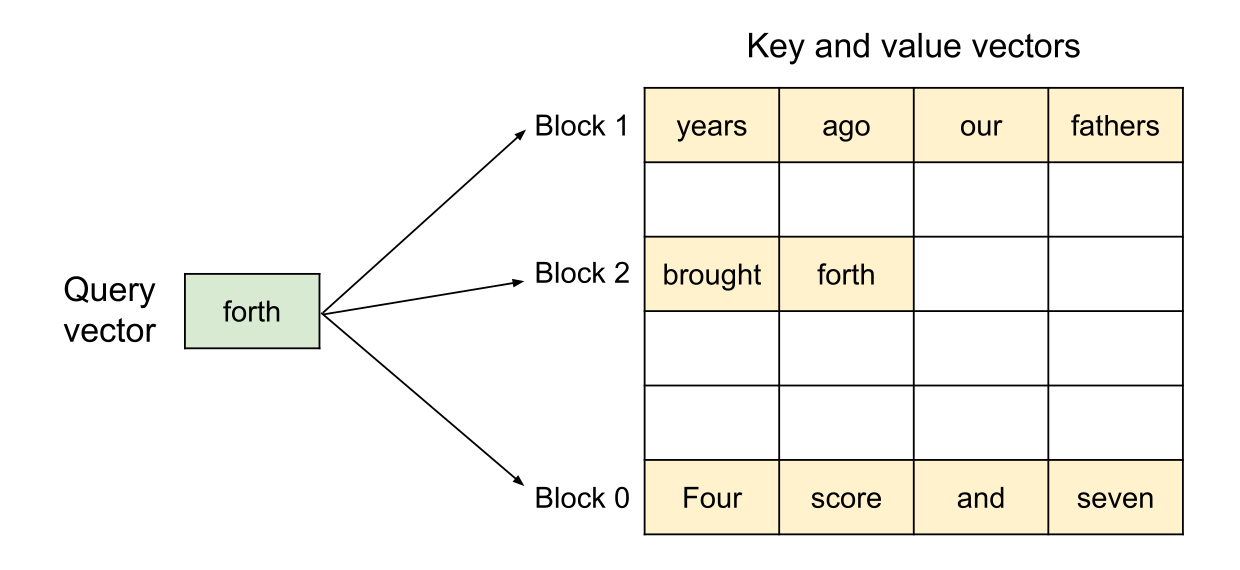
读图:blocks 像虚拟内存页
每个请求看到的是逻辑连续的 token 序列,但物理 KV blocks 可以分散在显存里。调度器维护 block table,把逻辑位置映射到物理块。这样可以按需增长,而不是一开始预留最大长度。
sharing、copy-on-write 与并行读取
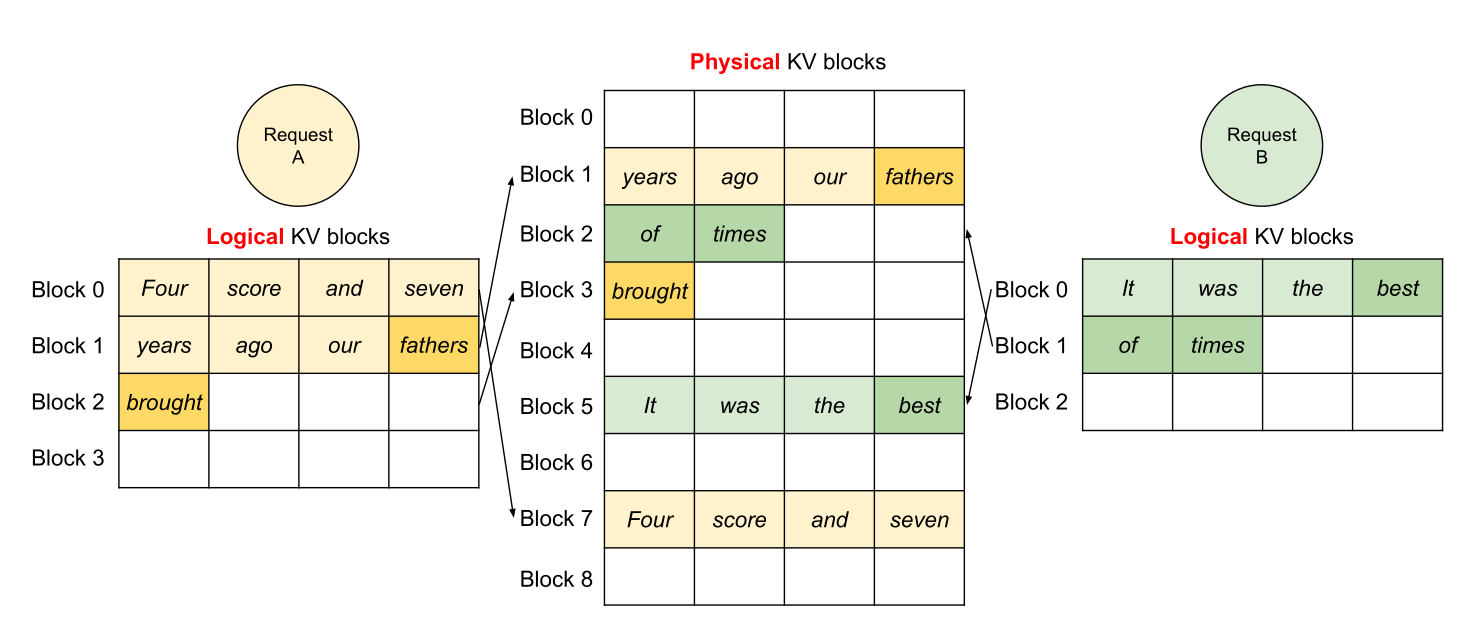
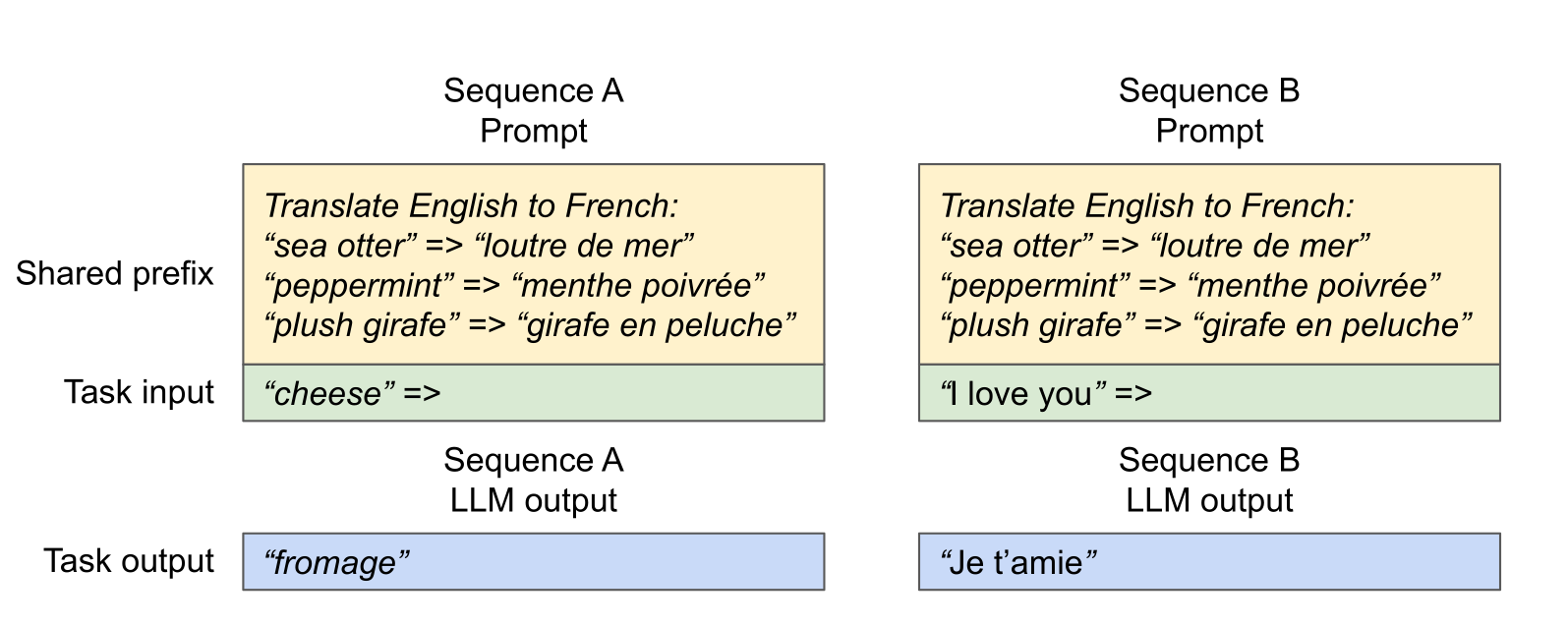
读图:prefix sharing 为什么省显存
多个请求若有相同 system prompt 或同一 prompt 的多个 samples,前缀 KV 完全相同。PagedAttention 可让它们共享同一批 blocks;当某个请求继续生成并发生分叉时,再 copy-on-write 新 blocks。这和操作系统共享内存页的思路一致。
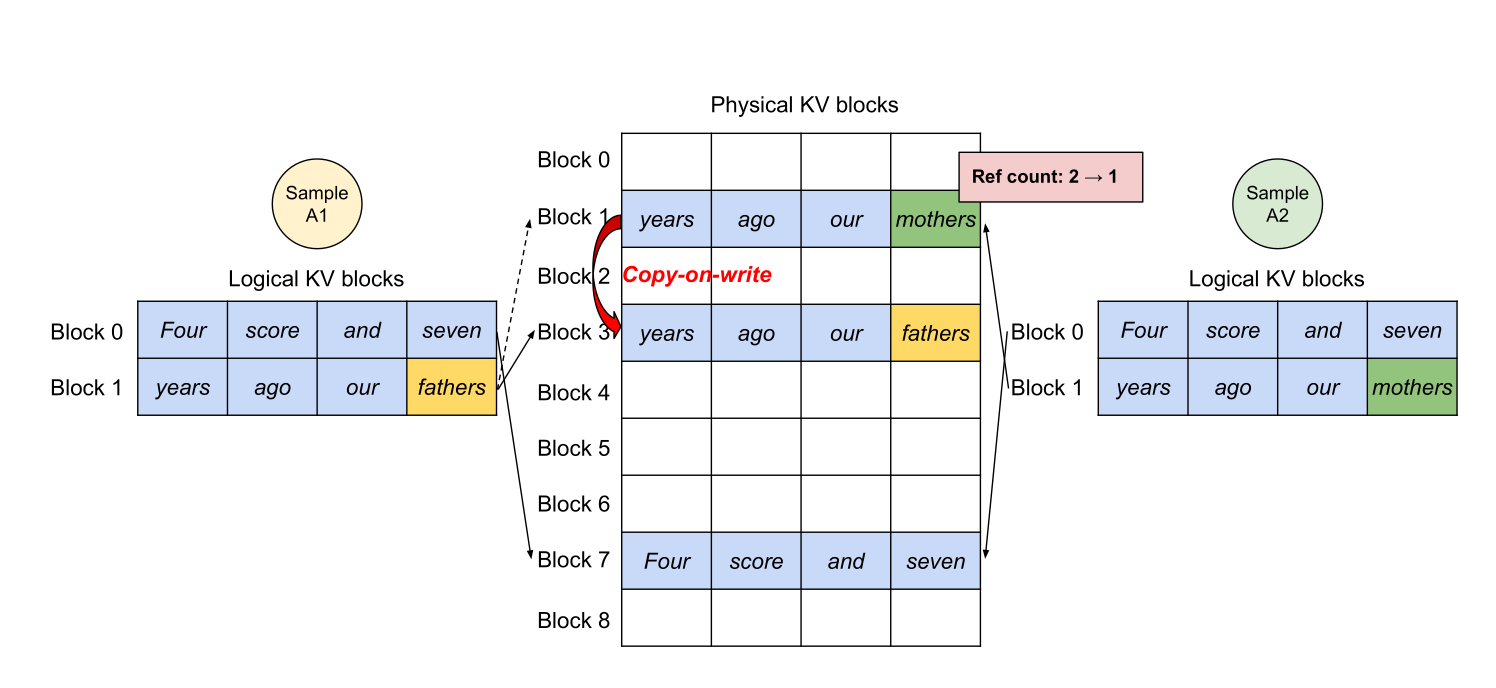
读图:PagedAttention 不只是内存分配器
为了让非连续 blocks 不拖慢 attention,系统还需要 kernel 支持:融合 block read 和 attention,减少 launch overhead,配合 FlashAttention/FlashDecoding/CUDA graphs。内存管理和 kernel design 必须一起做。
PagedAttention 的系统意义
PagedAttention 把 KV cache 从“连续大数组”变成“可分页的逻辑地址空间”。它直接服务动态 workload:变长请求、共享前缀、多样本生成、早停、长上下文。vLLM 的成功说明,LLM serving 的关键创新不只在模型结构,也在操作系统式资源管理。
本章小结
Continuous batching 解决时间维度的动态性,PagedAttention 解决空间维度的动态性。前者让 batch 随请求到达和完成不断变化;后者让 KV cache 随序列增长和共享动态分配。
总结与延伸
Lecture 10 的主线是:推理不同于训练,因为它反复发生、在线动态、generation sequential 且 memory-bound。优化方向可以分三类:改变模型或精度以减少内存流量,利用概率校验保持 exact sampling,借鉴系统思想管理动态请求和 KV cache。
最终 takeaways
- 推理成本长期重复发生,TTFT、latency、throughput 是不同目标。
- Prefill 通常较 compute-bound,generation 通常 memory-bound。
- KV cache 大小约为 \(2BSLKH\cdot\text{bytes}\),是推理显存和带宽的核心对象。
- GQA、MLA、CLA、local/hybrid attention 都在减少 KV cache,但需要质量检查。
- Quantization、AWQ、pruning、distillation 减少模型字节或计算,但属于有损 shortcut。
- Speculative sampling 用 draft model 提案、target model 校验,能保持 exact target distribution。
- Continuous batching 和 PagedAttention 把在线 serving 变成调度和内存管理问题。
拓展阅读
- vLLM and PagedAttention paper.
- Speculative decoding / speculative sampling papers.
- GQA, MLA, CLA and DeepSeek attention reports.
- AWQ, GPTQ, QAT/PTQ quantization references.
- Orca continuous batching serving system.