MIT 6.S191 Lecture 2: Recurrent Neural Networks, Transformers, and Attention
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Ava Amini 授课内容整理 |
| 来源 | Alexander Amini (MIT) |
| 日期 | 2025年春季 |

引言:为什么需要序列建模
本讲是 MIT 6.S191(Introduction to Deep Learning)的第二讲,由 Ava Amini 主讲。在上一讲中,Alexander Amini 介绍了神经网络的基础知识,包括感知机(Perceptron)、前馈网络(Feedforward Network)以及反向传播(Backpropagation)算法。本讲将从这些基础出发,系统地讲解如何将神经网络应用于序列数据(Sequential Data)的处理,涵盖三个核心主题:
- Recurrent Neural Networks (RNNs):循环神经网络的基本原理与内部机制
- 训练RNN的挑战:梯度消失/爆炸问题及 LSTM 等改进架构
- Attention 机制与 Transformer:自注意力机制的原理及其在现代大语言模型中的应用
序列建模的核心思想
序列建模的核心目标是:给定一个序列的历史信息,预测该序列未来的状态。这是大语言模型(LLM)、语音识别、机器翻译等众多 AI 应用的基础。
直觉引入:预测球的运动
讲者用一个生动的例子引入序列建模的概念:假设在二维空间中有一个球,我们的任务是预测它接下来的运动方向。

来源:Slides 第3页。
如果只给出球当前的位置而没有任何历史信息,我们的预测只能是随机的——球可能向任何方向移动。但是,如果给出球过去几个时间步的位置序列,问题就变得简单多了:

来源:Slides 第5页。
通过观察球从左到右的历史轨迹,我们可以合理推断它将继续向右移动。这个例子揭示了序列建模的核心:利用过去的信息来预测未来。
序列数据无处不在
序列数据在现实世界中无处不在:

来源:Slides 第7页。
- 音频信号:语音波形可以被分割成一系列声波片段进行序列处理
- 自然语言:文本可以被拆分为单词或字符的序列
- 医学信号:如心电图(ECG)的时间序列
- 金融数据:股票价格的时间序列
- 生物序列:DNA/RNA 核酸序列、蛋白质氨基酸序列
- 天气数据、视频帧序列等
序列建模的任务类型
序列建模的三种基本模式
- Many-to-One:序列输入 \(\rightarrow\) 单一输出。例如:情感分类(输入一段文本,输出正面/负面)
- One-to-Many:单一输入 \(\rightarrow\) 序列输出。例如:图像描述生成(输入一张图片,输出描述文字)
- Many-to-Many:序列输入 \(\rightarrow\) 序列输出。例如:机器翻译(英文序列 \(\rightarrow\) 中文序列)
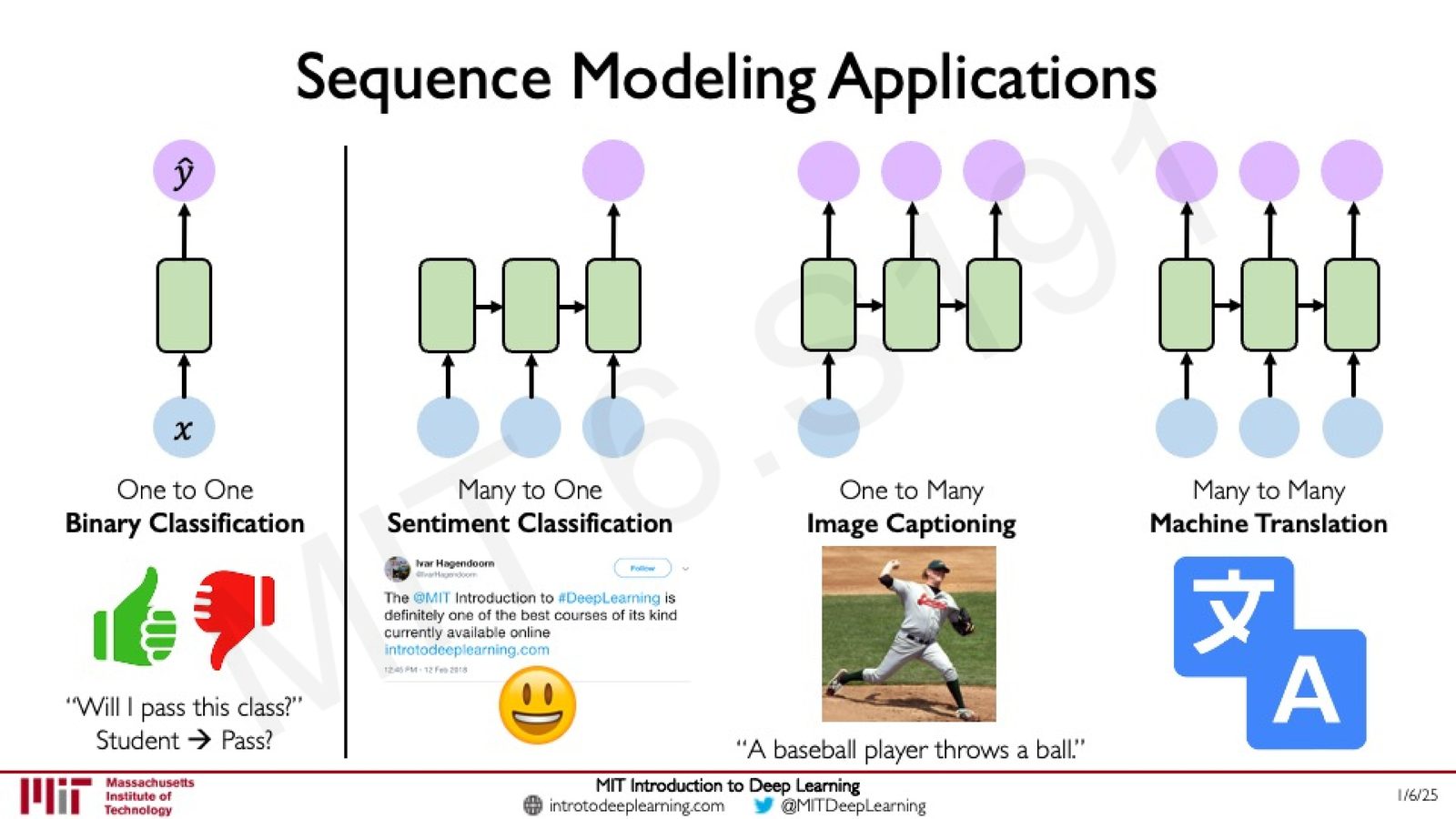
来源:Slides 第8页。
本章小结
序列建模是深度学习中最重要的范式之一,其核心在于利用数据的时间/顺序依赖关系。从简单的球运动预测到复杂的语言模型,序列建模的思想贯穿了现代 AI 的方方面面。
从感知机到循环神经网络
回顾感知机
在上一讲中,我们学习了感知机的基本结构:给定输入 \(x^{(1)}, x^{(2)}, \ldots, x^{(m)}\),每个输入乘以对应权重 \(w_1, w_2, \ldots, w_m\),求和后通过非线性激活函数产生输出。
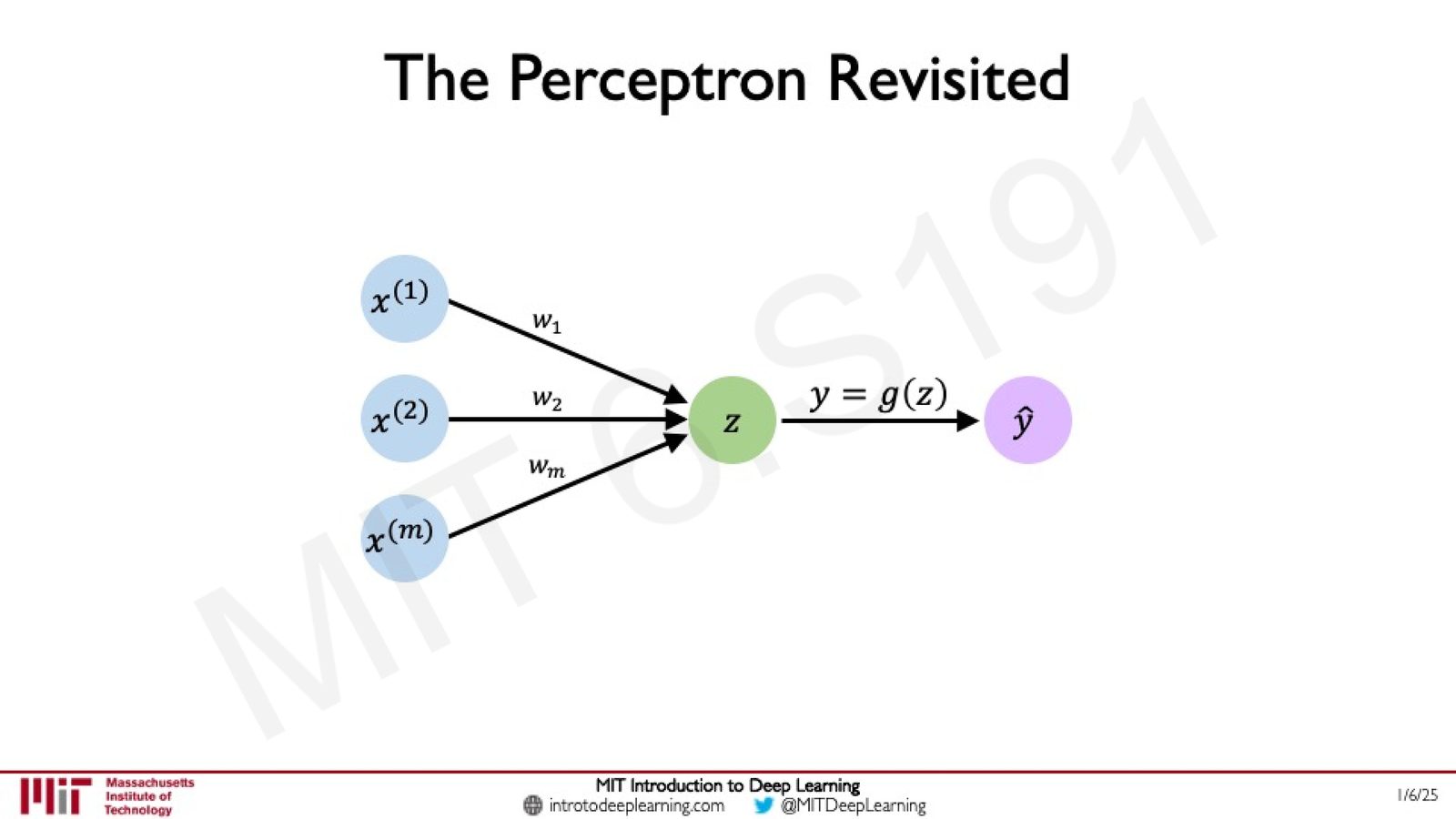
来源:Slides 第10页。
用数学公式表示:
其中:
- \(x^{(i)}\):第 \(i\) 个输入特征
- \(w_i\):对应的权重
- \(b\):偏置项
- \(g(\cdot)\):非线性激活函数
- \(\hat{y}\):预测输出
感知机处理序列数据的局限
将感知机(或前馈网络)直接应用于序列数据时,我们遇到了一个根本性问题:每个时间步的预测完全独立,没有利用其他时间步的信息。
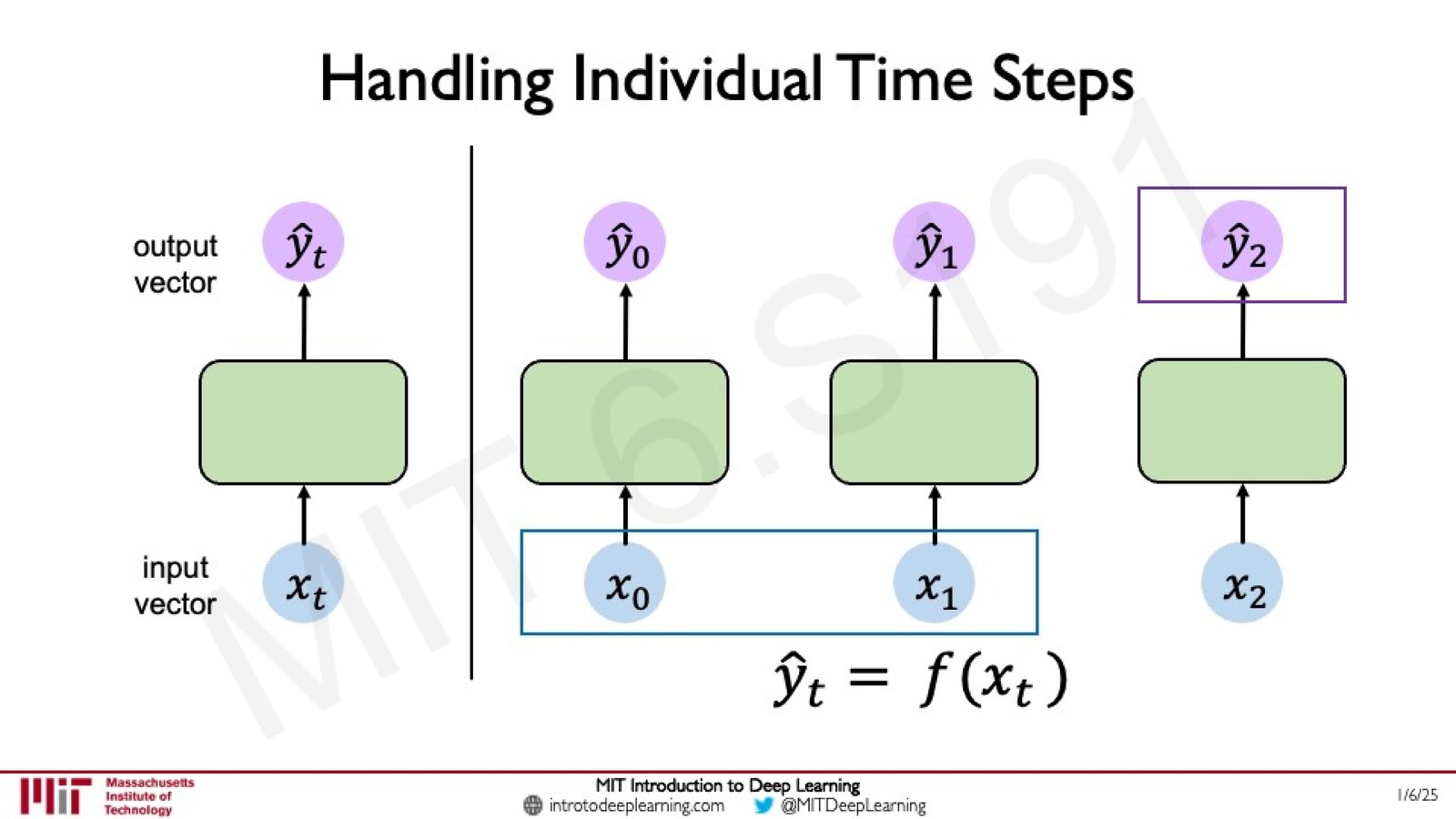
来源:Slides 第13页。
具体来说,如果我们用前馈网络独立处理每个时间步:
那么时间步 \(t=2\) 的预测 \(\hat{y}_2\) 仅仅取决于输入 \(x_2\),完全忽略了 \(x_0\) 和 \(x_1\) 中可能包含的关键信息。
这就好比只看球的当前位置而不考虑历史轨迹——预测必然是盲目的。
引入循环:Recurrence 的核心思想
为了解决这一问题,我们需要一种机制将过去时间步的信息传递给当前时间步。核心思想是:
循环神经网络的核心:隐藏状态
定义一个内部状态(Hidden State)\(h_t\),它在时间步之间传递,携带了网络对过去输入的“记忆”。每个时间步的预测不仅依赖当前输入 \(x_t\),还依赖上一步的隐藏状态 \(h_{t-1}\):
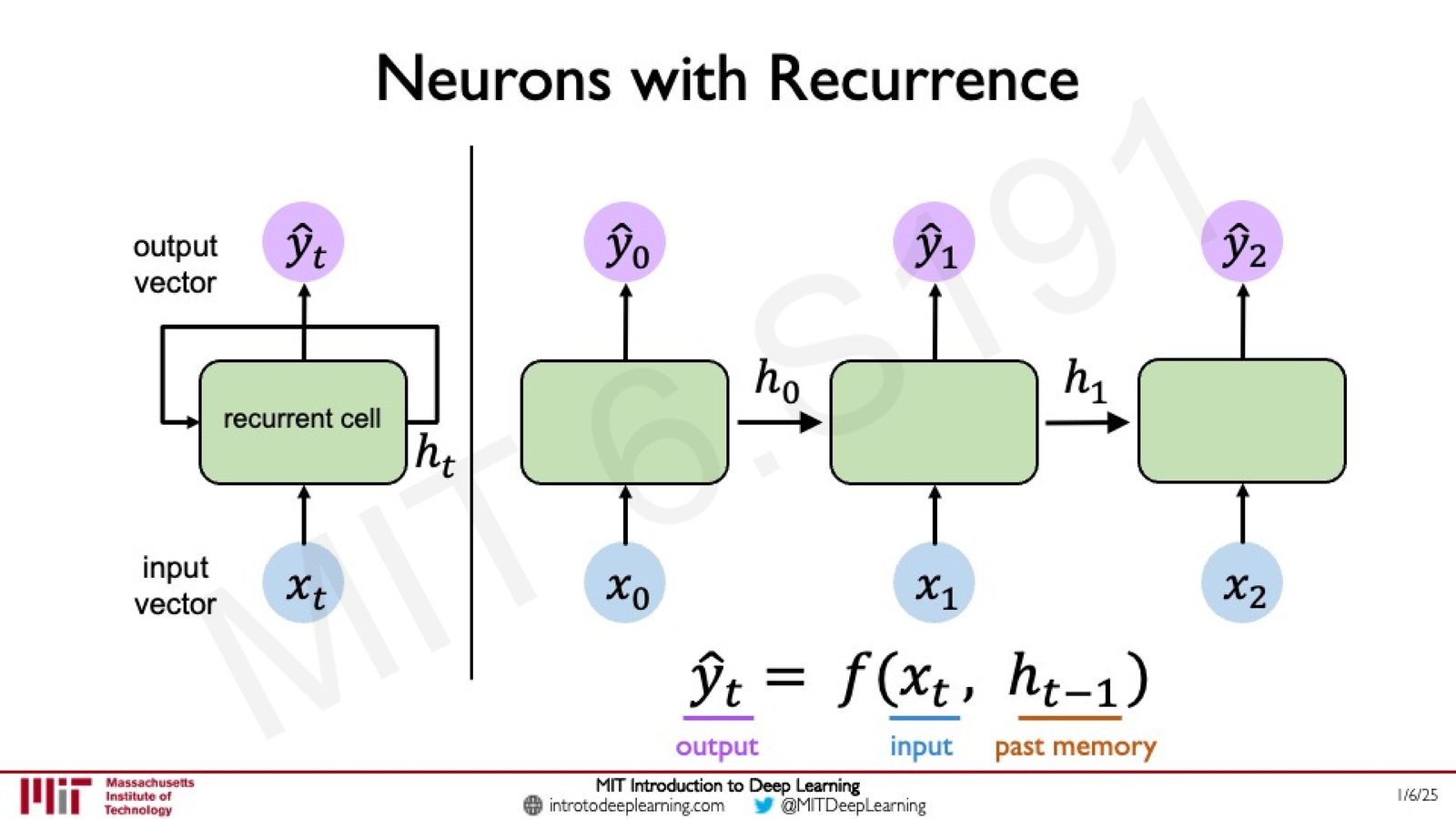
来源:Slides 第15页。
上图左侧展示了 RNN 的折叠视图(Folded View),右侧展示了展开视图(Unrolled View)。隐藏状态 \(h_t\) 像一条链条一样在时间步之间传递,使得网络能够“记住”之前看到的信息。
本章小结
从感知机到 RNN 的演进思路清晰:前馈网络缺乏处理序列的能力,因此我们引入隐藏状态作为时间步之间的信息桥梁,形成了循环(Recurrence)的概念。这是理解所有序列模型的基础。
RNN 的内部机制
RNN 的直觉理解
讲者通过一段 Python 伪代码来建立对 RNN 的直觉理解:
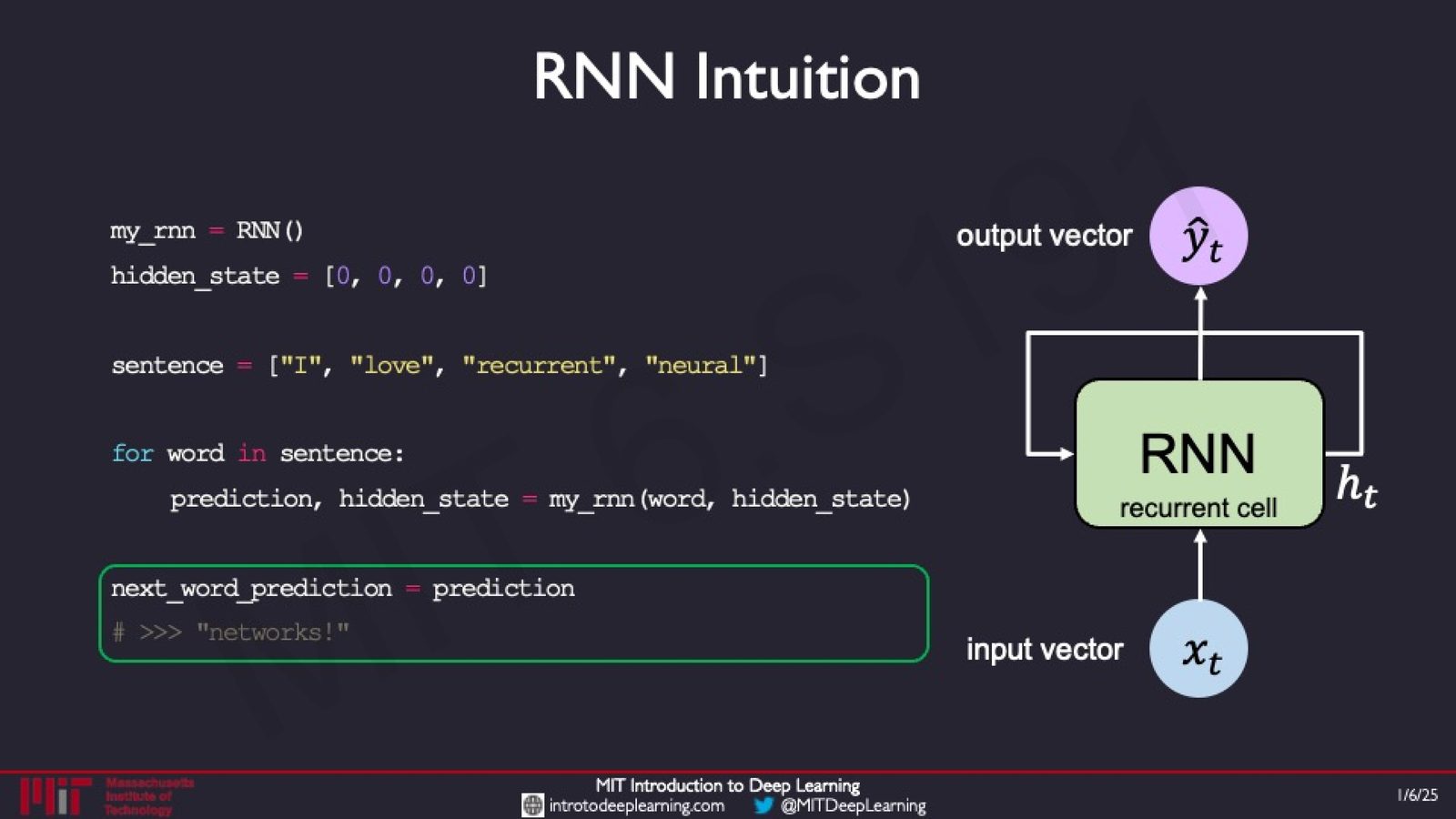
来源:Slides 第20页。
my_rnn = RNN()
hidden_state = [0, 0, 0, 0]
sentence = ["I", "love", "recurrent", "neural"]
for word in sentence:
prediction, hidden_state = my_rnn(word, hidden_state)
next_word_prediction = prediction
# >>> "networks!"
这段伪代码清楚展示了 RNN 的工作流程:
- 初始化隐藏状态为零向量
- 对序列中的每个元素,调用 RNN 处理当前输入和上一步的隐藏状态
- 每次调用返回一个预测和更新后的隐藏状态
- 序列处理完毕后,最终的预测即为输出
RNN 状态更新的数学公式
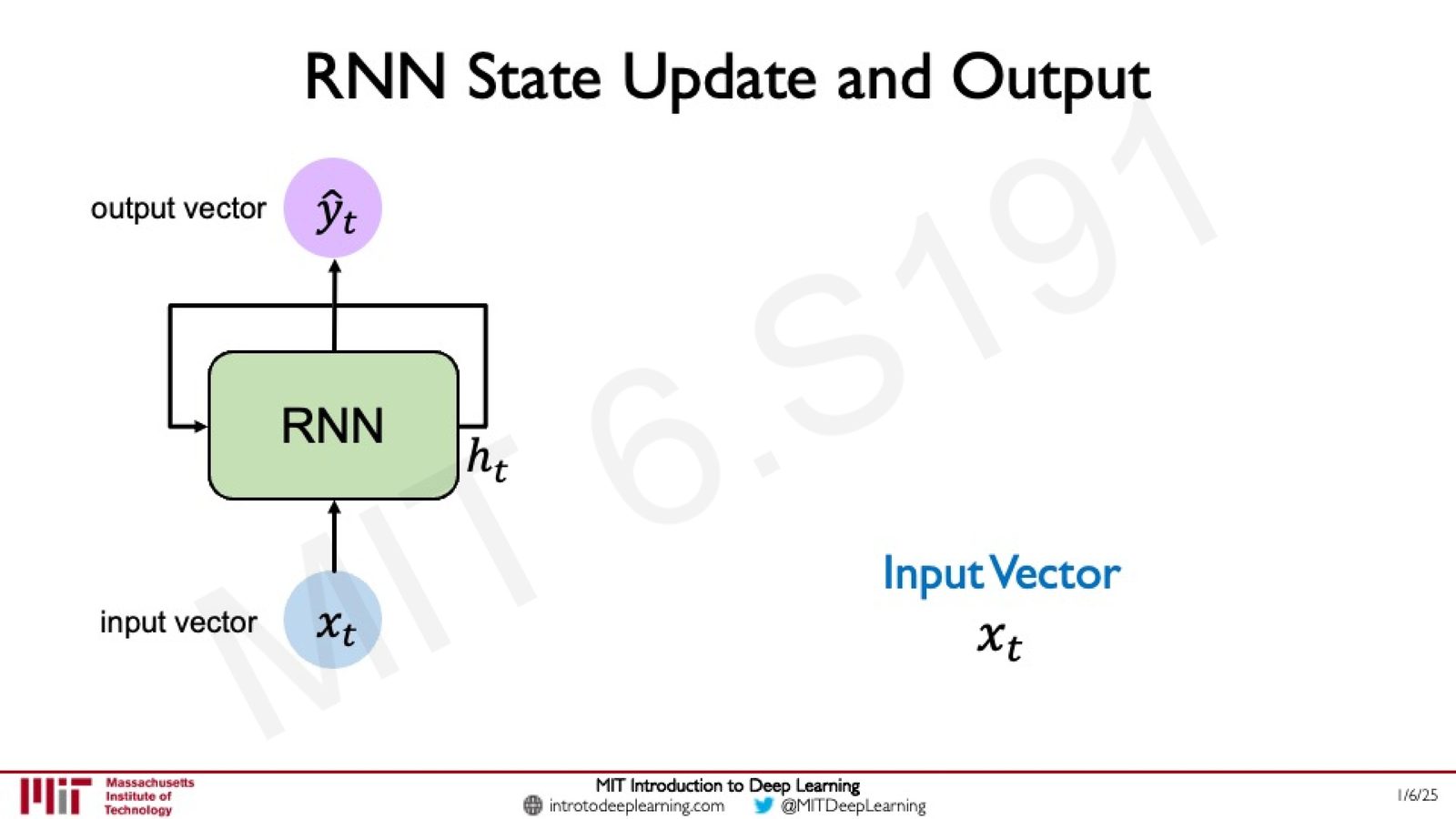
来源:Slides 第22页。
RNN 的前向传播包含两个关键步骤:
Step 1: 更新隐藏状态
- \(W_{xh}\):将输入转化到隐藏空间的权重矩阵
- \(W_{hh}\):隐藏状态自身更新的权重矩阵
- \(b_h\):偏置项
- \(\tanh\):非线性激活函数
Step 2: 生成输出
- \(W_{hy}\):将隐藏状态转化为输出的权重矩阵
- \(b_y\):输出偏置项
权重共享:RNN 的关键特性
在 RNN 中,权重矩阵 \(W_{xh}\)、\(W_{hh}\) 和 \(W_{hy}\) 在所有时间步上共享。这意味着无论序列多长,参数数量不变。这不仅大大减少了模型参数,还使 RNN 能够处理任意长度的序列。
RNN 的计算图展开

来源:Slides 第25页。
将 RNN 在时间轴上展开后,可以清楚地看到:
- 每个时间步接收输入 \(x_t\),通过 \(W_{xh}\) 参与隐藏状态计算
- 隐藏状态 \(h_t\) 通过 \(W_{hh}\) 传递到下一个时间步
- 每个时间步通过 \(W_{hy}\) 产生输出预测 \(\hat{y}_t\)
RNN 的代码实现
class MyRNNCell(tf.keras.layers.Layer):
def __init__(self, rnn_units):
super(MyRNNCell, self).__init__()
self.W_xh = self.add_weight([rnn_units, rnn_units])
self.W_hh = self.add_weight([rnn_units, rnn_units])
self.W_hy = self.add_weight([rnn_units, num_outputs])
def call(self, x, h):
# Update hidden state
h = tf.math.tanh(
tf.linalg.matmul(x, self.W_xh) +
tf.linalg.matmul(h, self.W_hh)
)
# Compute output
output = tf.linalg.matmul(h, self.W_hy)
return output, h
在 TensorFlow/Keras 等框架中,也可以直接使用封装好的 RNN 层:
tf.keras.layers.SimpleRNN(rnn_units)
本章小结
RNN 的核心操作可以归纳为三步:(1) 接收当前输入;(2) 结合上一步隐藏状态更新当前隐藏状态;(3) 基于隐藏状态产生输出。权重在所有时间步共享是 RNN 能够处理变长序列的关键。
序列建模的实际应用:语言建模
Next Word Prediction 任务
语言建模(Language Modeling)是序列建模最典型、最重要的应用之一。其核心任务极其简单:给定一系列单词,预测下一个最可能的单词。
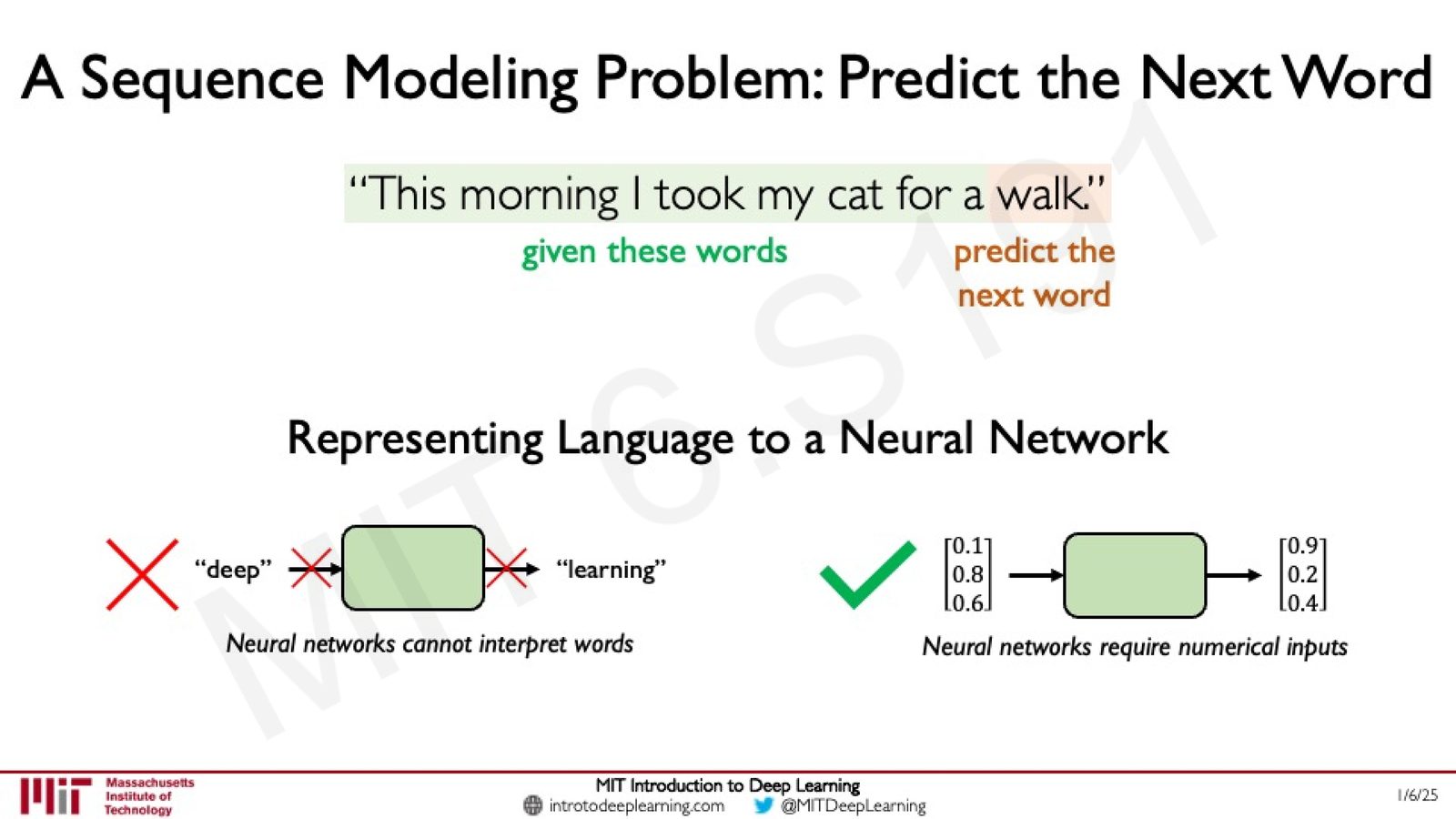
来源:Slides 第35页。
例如给定句子 “This morning I took my cat for a”,模型需要预测下一个词是 “walk”。
Next Word Prediction 是 LLM 的基础
今天的大语言模型(如 GPT 系列)本质上就是在执行这个 Next Word Prediction 任务。通过在海量文本上训练预测下一个词的能力,模型学会了语言的结构和语义。
如何将语言表示为数字
神经网络只能处理数值数据,因此我们需要将单词转化为数值向量。这个过程分为两步:
Step 1: 建立词汇表(Vocabulary)
定义一个包含所有可能单词的有限词汇表,并为每个单词分配一个唯一的索引编号:
- “a” \(\rightarrow\) 1
- “cat” \(\rightarrow\) 2
- “the” \(\rightarrow\) 3
- \(\ldots\)
Step 2: Embedding(嵌入)
将索引映射为固定维度的向量。最简单的方法是 One-Hot Encoding:
One-Hot Encoding 的局限
One-Hot Encoding 有两个严重缺陷:
- 维度灾难:向量维度等于词汇表大小,对于包含数万甚至数十万个词的词汇表,这种表示极其稀疏和低效
- 缺乏语义信息:所有单词之间的“距离”相等,“cat” 和 “dog” 的距离与 “cat” 和 “airplane” 相同,无法捕捉语义相似性
更好的方法是使用Learned Embedding(可学习嵌入):通过训练让网络自动学习一种低维、稠密的向量表示,使语义相近的词在向量空间中距离较近。

来源:Slides 第38页。
Embedding 的本质
Embedding 本质上是一个可学习的查找表(Lookup Table)。它将离散的符号(如单词、字符)映射到连续的向量空间中。经过训练后,语义相似的词(如 “king” 和 “queen”)在嵌入空间中会彼此接近,而语义不同的词则相距较远。这种特性对于下游的序列建模任务至关重要。
序列中的短期与长期依赖
自然语言中存在不同范围的依赖关系:
- 短期依赖:“The clouds are in the \underline{\hspace{1cm}}” \(\rightarrow\) “sky”。答案仅依赖前面几个词。
- 长期依赖:“I grew up in France, \(\ldots\) and I speak fluent \underline{\hspace{1cm}}” \(\rightarrow\) “French”。答案依赖很久之前的上下文“France”。
长期依赖对 RNN 提出了严峻挑战,这直接引出了下一节的主题。
本章小结
语言建模的核心任务——预测下一个词——看似简单却极其强大,它是所有现代大语言模型的训练基础。将语言表示为数值向量(Embedding)是实现这一任务的第一步,而处理序列中的长短期依赖关系则是核心挑战。
训练 RNN:反向传播与梯度问题
RNN 的损失函数
与前馈网络类似,RNN 的训练也需要定义损失函数。不同之处在于,RNN 在每个时间步都可以计算一个损失值:
总损失是所有时间步损失的总和:
Backpropagation Through Time (BPTT)
训练 RNN 使用的是反向传播的扩展版本——时间反向传播(Backpropagation Through Time, BPTT)。其核心思想是:
- 前向传播:逐时间步计算隐藏状态和输出
- 在每个时间步计算损失
- 反向传播:将误差沿时间轴从后向前传递,计算每个参数的梯度
- 更新参数
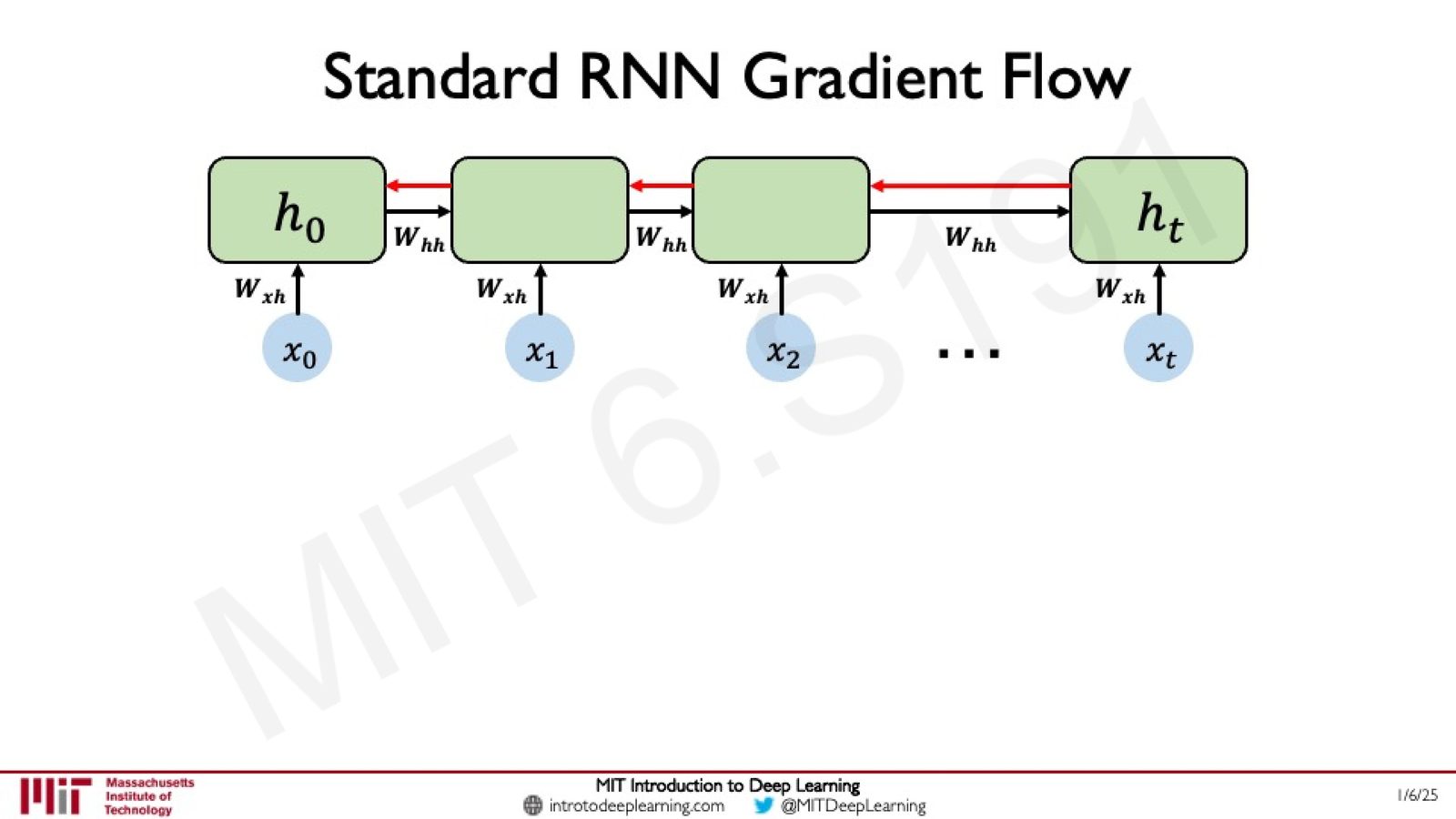
来源:Slides 第45页。
梯度消失与梯度爆炸
在 BPTT 过程中,梯度需要经过多次矩阵乘法(\(W_{hh}\) 的多次连乘)和激活函数导数的连乘。这会导致两个严重的数值问题:
梯度消失与梯度爆炸
- 梯度爆炸(Exploding Gradients):当 \(W_{hh}\) 的特征值 \(> 1\) 时,梯度随时间步呈指数增长,导致参数更新过大,训练不稳定
- 梯度消失(Vanishing Gradients):当 \(W_{hh}\) 的特征值 \(< 1\) 时,梯度随时间步呈指数衰减趋近于零,使得网络无法学习长期依赖关系
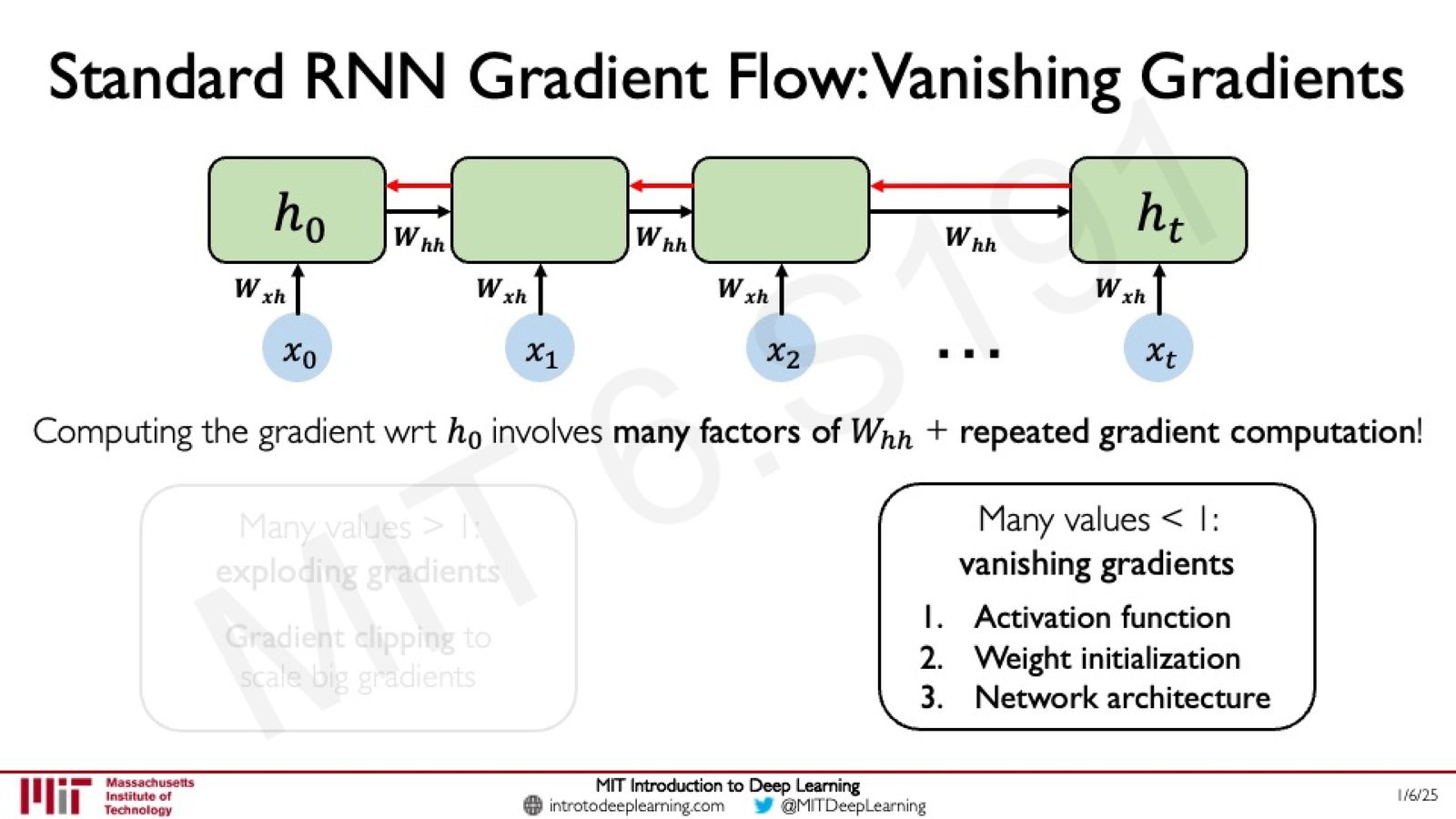
来源:Slides 第48页。
长期依赖的困难
梯度消失问题直接导致 RNN 难以捕捉长期依赖:
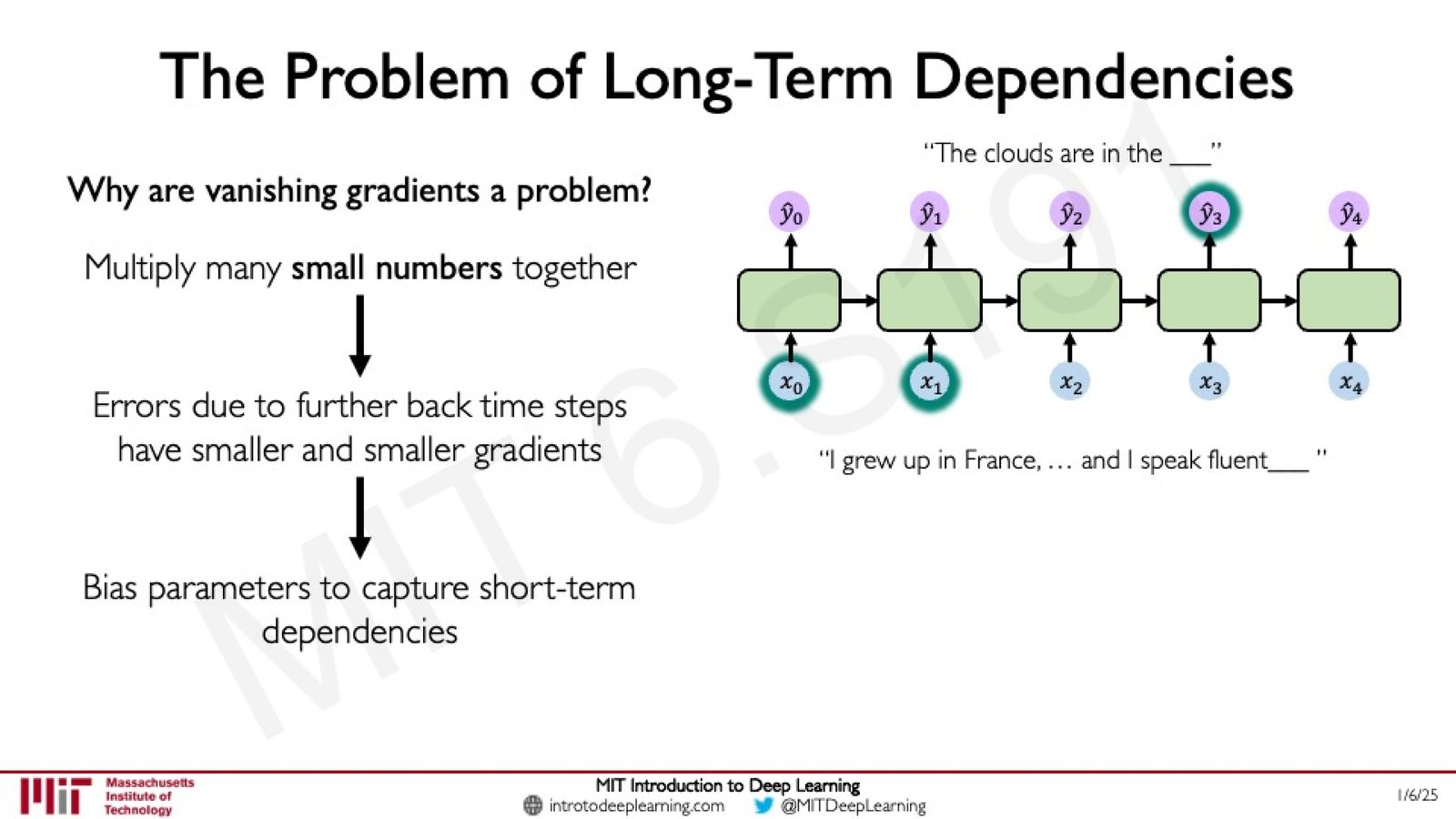
来源:Slides 第52页。
梯度消失 \(≠\) 梯度为零
梯度消失并不意味着梯度完全消失,而是指来自较远时间步的梯度信号变得极其微弱,导致模型的参数更新几乎完全由近期时间步的梯度主导。因此,模型会偏向于学习短期依赖关系,而难以捕捉长期模式。
解决梯度问题的策略
解决梯度消失/爆炸问题有三大类方法:
- 激活函数选择:使用 ReLU 等不会在饱和区压缩梯度的激活函数
- 权重初始化:精心设计权重初始化策略,避免梯度在传播过程中快速缩放
- 网络架构改进:设计专门的门控机制来控制信息流动,如 LSTM 和 GRU
LSTM:长短期记忆网络
Long Short-Term Memory (LSTM) 是解决梯度消失问题最著名的 RNN 变体。其核心思想是在标准 RNN 单元内部添加门控机制(Gates),用以选择性地控制信息的遗忘、存储和输出。
LSTM 的三个门
- 遗忘门(Forget Gate):决定哪些旧信息需要被丢弃
- 输入门(Input Gate):决定哪些新信息需要被存储
- 输出门(Output Gate):决定哪些信息需要被输出到下一个时间步
这些门的值由 sigmoid 函数控制,输出在 \([0, 1]\) 之间,分别表示“完全遗忘”到“完全保留”。
LSTM 通过这种门控机制,使梯度能够沿着一条“高速公路”(Cell State)在时间步之间传递,大大缓解了梯度消失问题,使网络能够学习更长期的依赖关系。
LSTM 的历史意义
LSTM 由 Hochreiter 和 Schmidhuber 于 1997 年提出,是深度学习历史上最重要的架构创新之一。在 Transformer 出现之前(2017年),LSTM 及其变体(如 GRU)是处理序列数据的主流选择,广泛应用于机器翻译、语音识别、文本生成等领域。
本章小结
训练 RNN 的核心挑战是梯度消失/爆炸问题,它限制了标准 RNN 学习长期依赖的能力。LSTM 通过门控机制有效缓解了这一问题,但其本质仍然是逐时间步处理序列,存在计算效率和长序列建模能力上的局限。
RNN 的应用与局限
RNN 的应用实例:音乐生成
讲者介绍了 RNN 在音乐生成中的应用。这是一个天然适合序列建模的任务:给定音乐音符的历史序列,预测下一个最可能的音符。
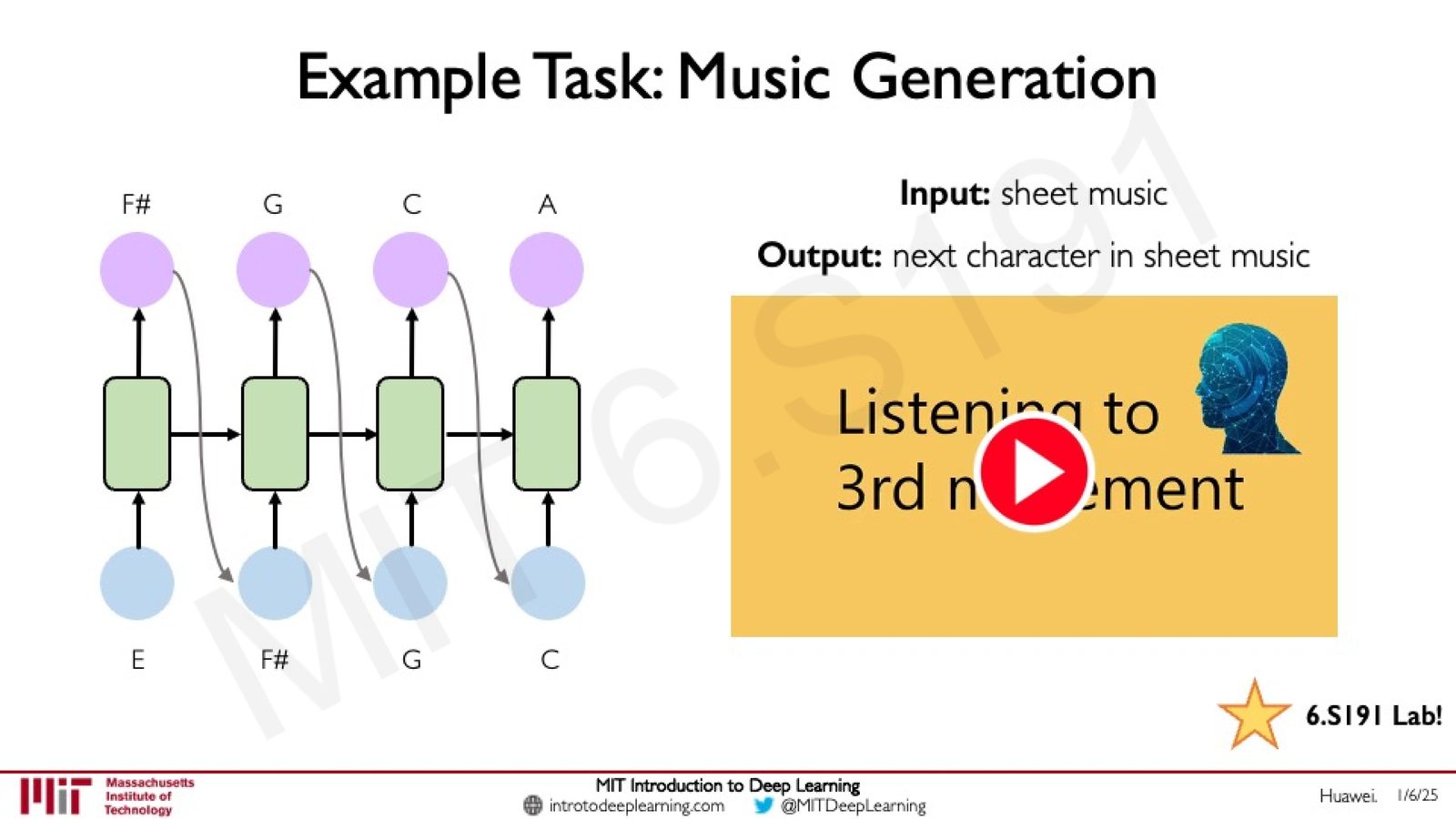
来源:Slides 第56页。
讲者提到了一个有趣的案例:有团队训练神经网络模型学习古典音乐,然后让模型尝试完成舒伯特(Franz Schubert)著名的“未完成交响曲”的第三乐章。这展示了 RNN 在创造性任务中的潜力。
序列建模的设计标准
讲者总结了序列建模的四个关键设计标准:
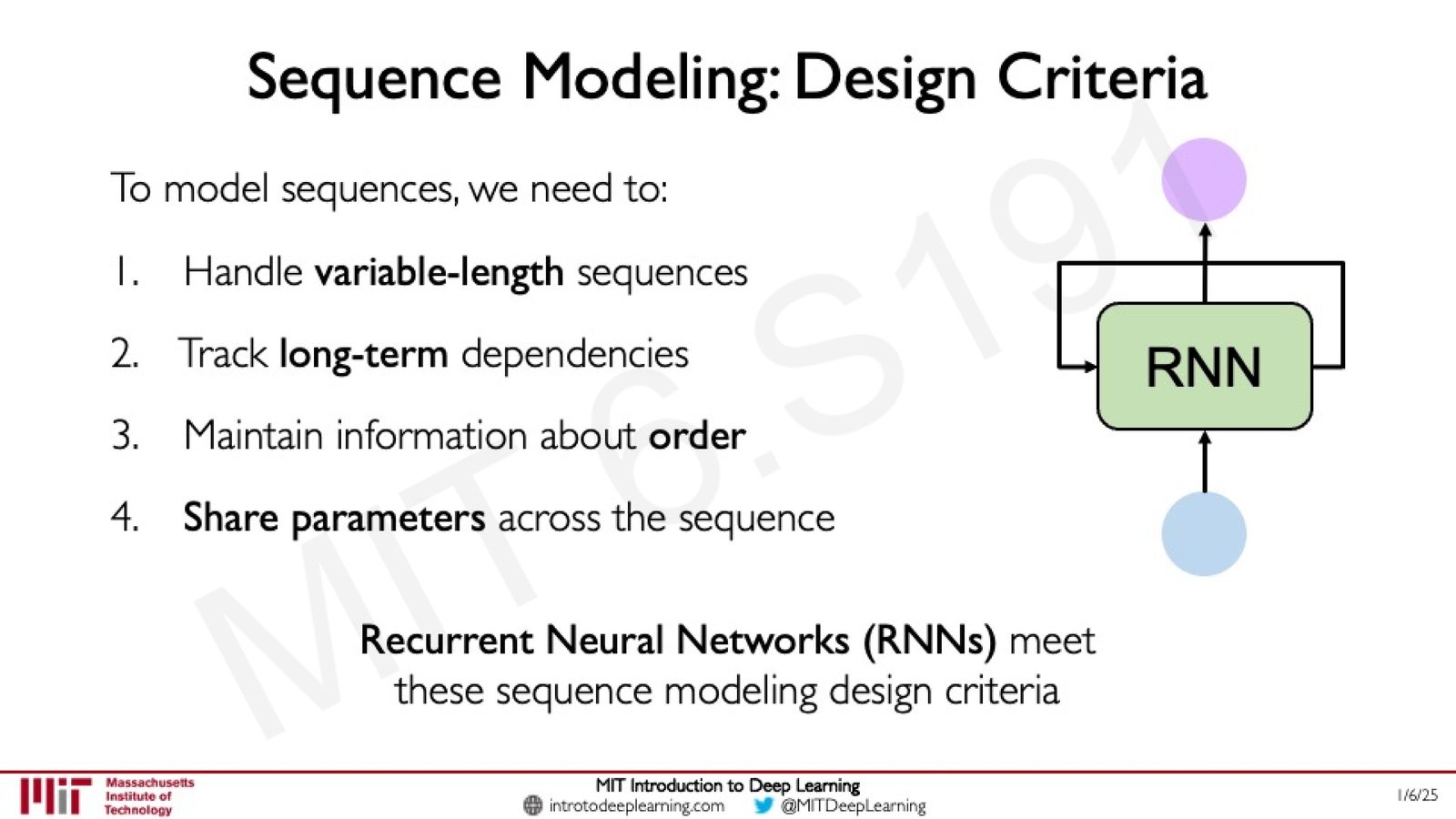
来源:Slides 第30页。
- 处理变长序列(Variable-length sequences)
- 追踪长期依赖(Long-term dependencies)
- 维护顺序信息(Maintain information about order)
- 跨序列共享参数(Share parameters across the sequence)
RNN 满足了这四个标准,但在实际应用中仍然存在重要局限。
RNN 的核心局限
RNN 的三大局限
- 顺序计算瓶颈:RNN 必须逐时间步处理数据,无法并行化。对于长序列,训练和推理都非常缓慢
- 长期依赖困难:尽管 LSTM 缓解了梯度消失问题,但对于非常长的序列,信息仍然会逐渐衰减
- 编码瓶颈:在 Encoder-Decoder 架构中,整个输入序列的信息必须压缩到一个固定大小的隐藏状态向量中,这对于长序列是不够的
这些局限促使研究者思考:能否完全放弃循环机制(Recurrence),用一种全新的方式处理序列数据?
本章小结
RNN(含 LSTM/GRU)在序列建模中取得了巨大成功,但其顺序处理的特性限制了计算效率,梯度传播的困难也制约了其处理超长序列的能力。这些局限直接推动了 Attention 机制和 Transformer 架构的诞生。
Attention 机制:注意力是你所需要的一切
超越循环:寻找新范式
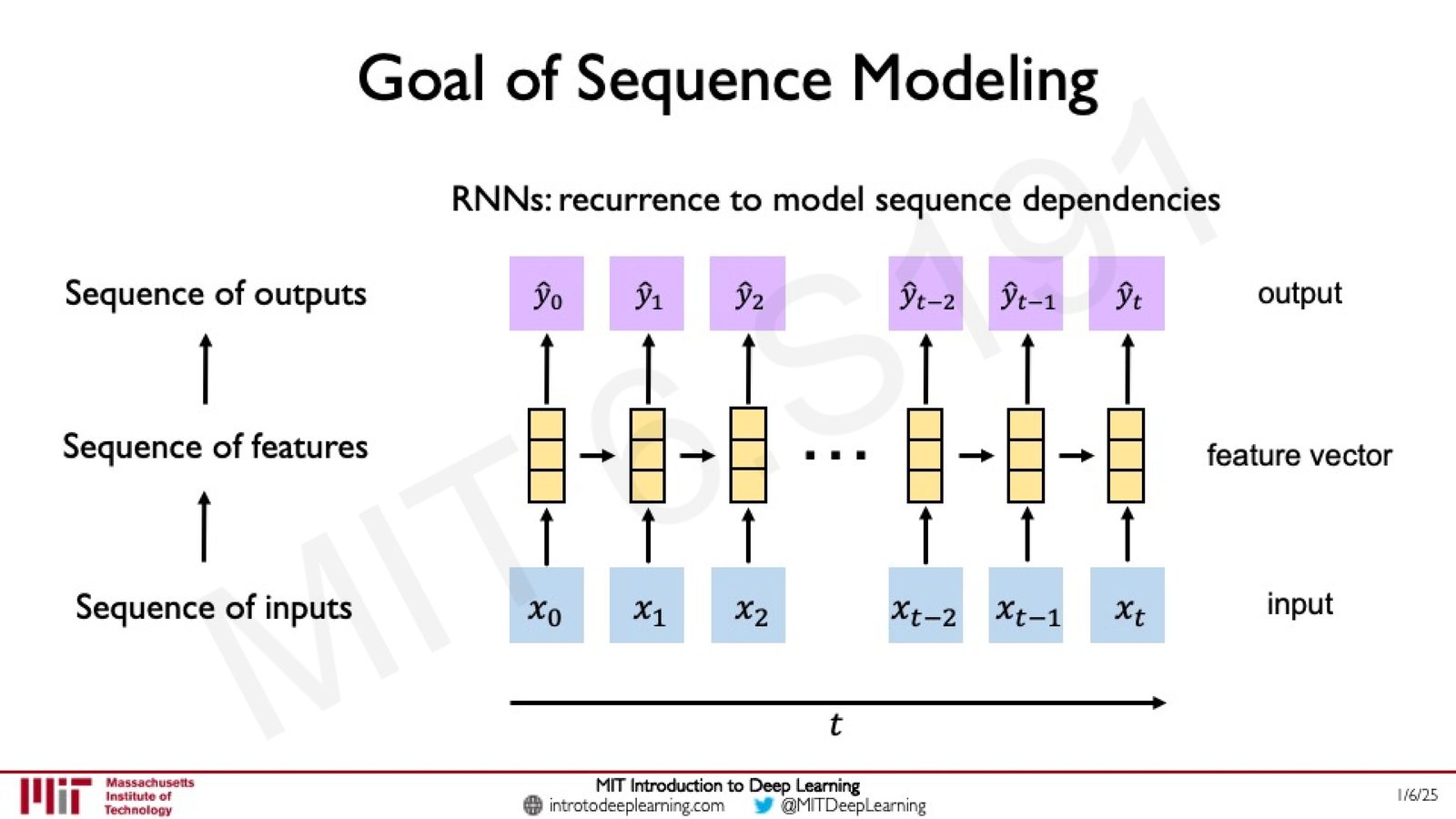
来源:Slides 第60页。
让我们回到序列建模的根本目标:给定输入序列,提取特征,生成预测。RNN 通过逐步处理来捕捉序列依赖,但如果我们能同时看到整个序列,并自动识别其中重要的部分,是否能做得更好?
一种朴素的想法是:将所有输入拼接成一个大向量,用前馈网络处理。但这有两个问题:
- 参数规模会随序列长度爆炸式增长,不具有可扩展性
- 拼接操作破坏了位置/顺序信息
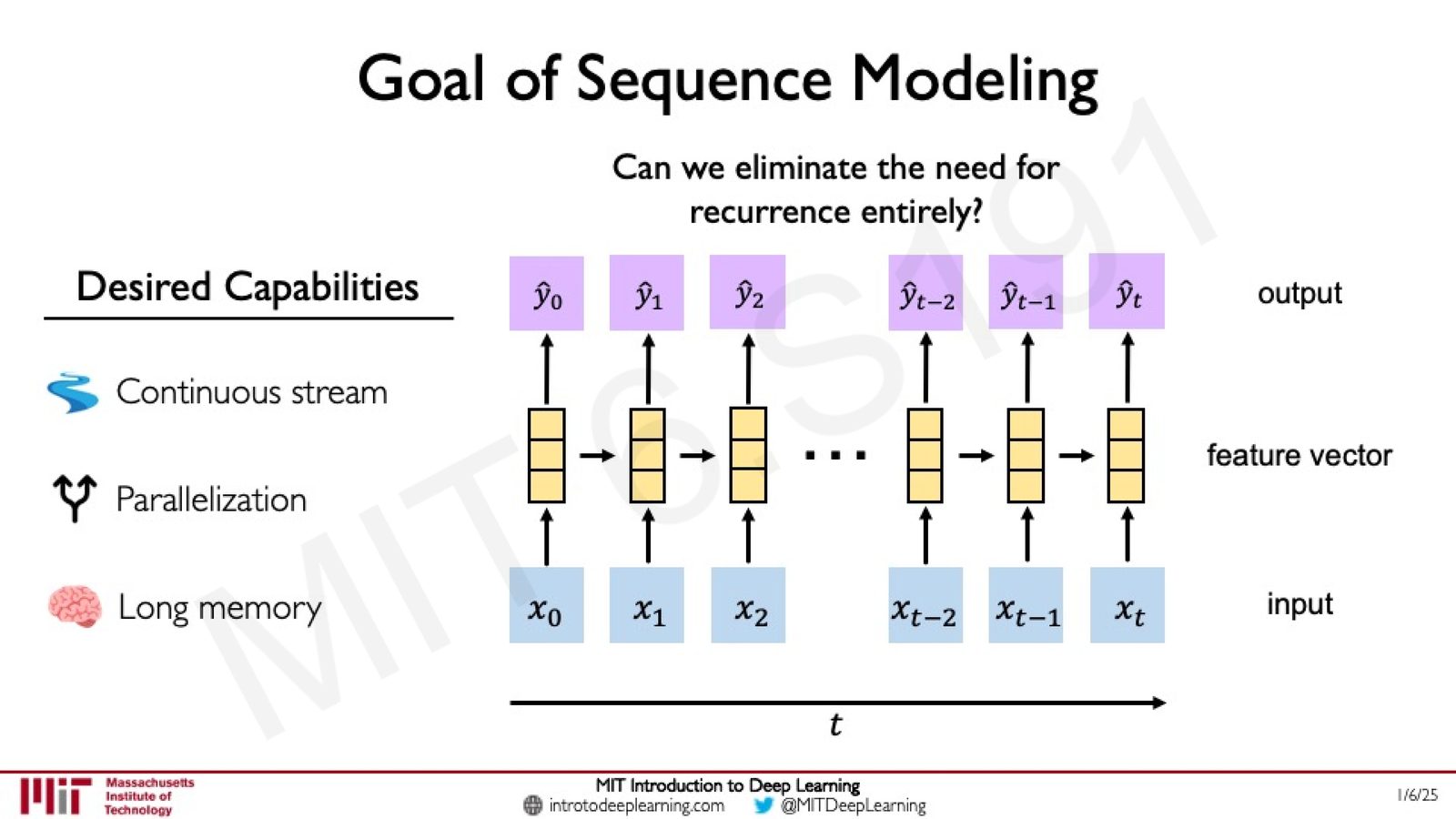
来源:Slides 第62页。
什么是 Attention
Attention(注意力)机制的核心思想源自人类认知:当我们观察一个场景时,不会均匀地关注所有内容,而是自动聚焦于最相关、最重要的部分。
Attention 的核心定义
Attention 是一种让网络能够自动识别并聚焦于输入中最重要部分的机制。它通过计算输入不同部分之间的相关性得分(Attention Score),来决定在生成输出时应该“关注”哪些输入。
搜索引擎类比:Query-Key-Value
讲者用一个非常直观的搜索引擎类比来解释 Attention 的工作原理:

来源:Slides 第67页。
假设你在视频搜索引擎中搜索“deep learning course”(Query):
- 数据库中每个视频都有一个标签/描述(Key)
- 搜索引擎计算 Query 与每个 Key 的相似度
- 找到最匹配的 Key 后,提取对应的视频内容(Value)
Query-Key-Value 的三元组
Attention 机制中的三个核心概念:
- Query (Q):你正在寻找什么——当前需要被回答的“问题”
- Key (K):数据库中每个条目的“标签”——用于匹配的索引
- Value (V):与每个 Key 关联的实际内容——匹配成功后要提取的信息
Attention 的过程就是:用 Query 在 Keys 中搜索最匹配的条目,然后提取对应的 Values。
本章小结
Attention 机制的核心是一个“搜索与检索”的过程:通过计算 Query 和 Key 之间的相似度来确定应该关注哪些输入,然后从 Value 中提取相关信息。这种机制不需要逐步处理序列,可以直接建模任意两个位置之间的依赖关系。
Self-Attention 与 Transformer
Self-Attention 的四个步骤
Self-Attention(自注意力)是 Attention 的一种特殊形式:Query、Key、Value 都来自同一个输入序列——即序列对自身的不同位置进行注意力计算。

来源:Slides 第70页。
Self-Attention 的完整计算过程分为四步:
Step 1: 编码位置信息(Positional Encoding)
由于我们不再逐步处理序列,而是一次性输入所有元素,我们需要显式地编码位置信息:
其中 \(p_i\) 是位置编码向量,它为每个位置提供唯一的标识。
Positional Encoding 的必要性
没有位置编码,Self-Attention 将无法区分 “the cat sat on the mat” 和 “the mat sat on the cat”——因为 Attention 操作本身对输入的顺序是置换不变(Permutation Invariant)的。位置编码打破了这种对称性,让模型能够感知序列中的顺序关系。
Step 2: 提取 Query、Key、Value
对位置编码后的输入,通过三个不同的线性变换层分别生成 Q、K、V 矩阵:
- \(W_Q, W_K, W_V\) 是三个可学习的权重矩阵
- 同一个输入 \(\tilde{X}\) 经过不同的线性变换,捕捉不同方面的信息
Step 3: 计算 Attention 权重
使用缩放点积(Scaled Dot-Product)计算 Query 和 Key 之间的相似度:
- \(Q \cdot K^T\):Query 与 Key 的点积,衡量相似度
- \(\sqrt{d_k}\):缩放因子(\(d_k\) 为 Key 的维度),防止点积值过大导致 softmax 梯度消失
- \(\text{softmax}\):将相似度归一化为概率分布
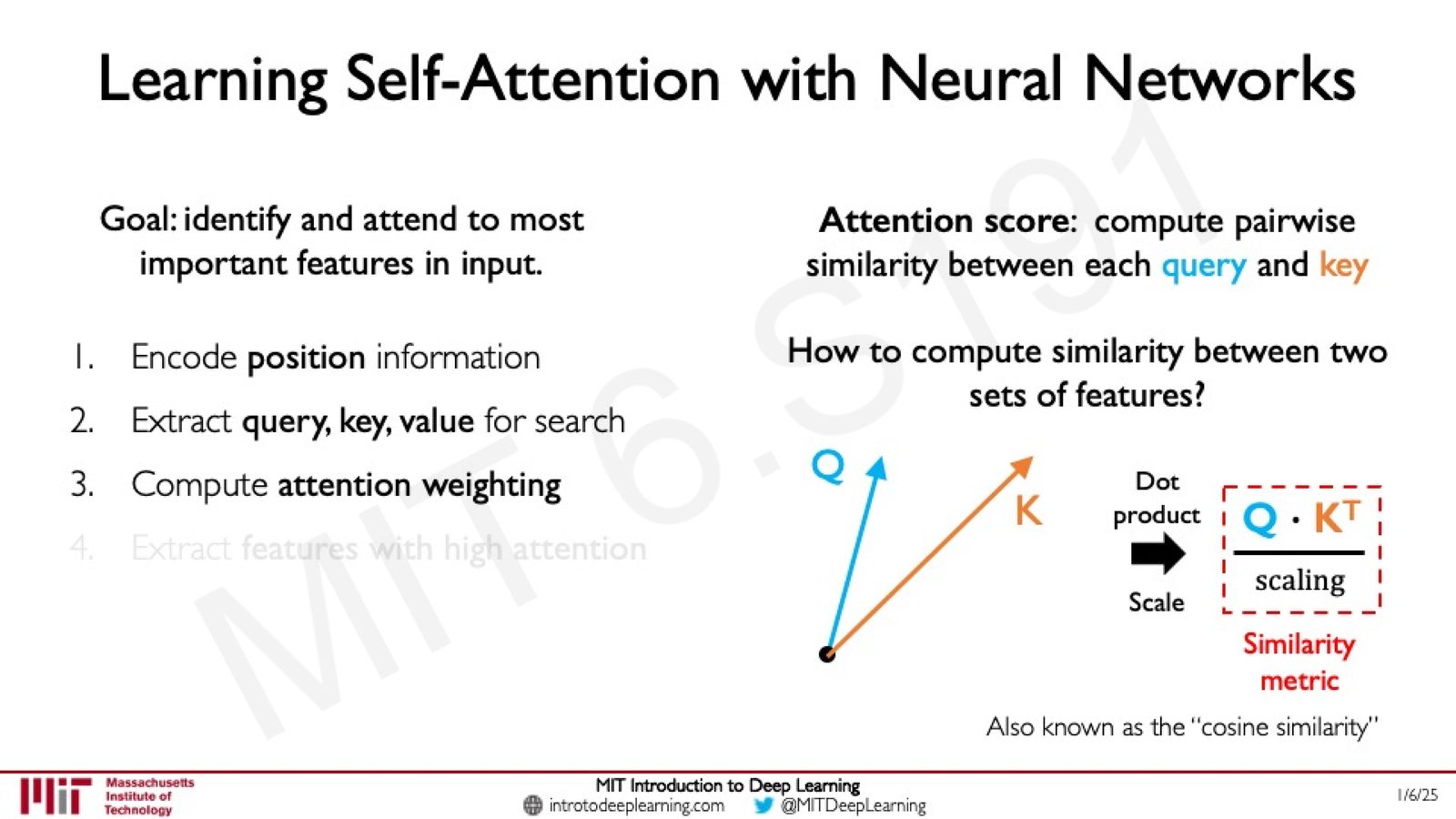
来源:Slides 第73页。
Step 4: 提取高注意力特征
用 Attention 权重对 Value 进行加权求和,得到最终输出:
Self-Attention 的完整公式
这个公式被称为 Scaled Dot-Product Attention,是 Transformer 架构的核心计算单元。
Attention 权重的可解释性
Attention 权重矩阵提供了一种直观的可解释性:矩阵中的每个元素 \(a_{ij}\) 表示位置 \(i\) 对位置 \(j\) 的“关注程度”。

来源:Slides 第75页。
例如,在句子 “He tossed the tennis ball to serve” 中,“ball” 这个词可能对 “tennis” 和 “tossed” 有较高的注意力权重,因为这些词对于理解 “ball” 的语义最为关键。
从 Attention Head 到 Transformer
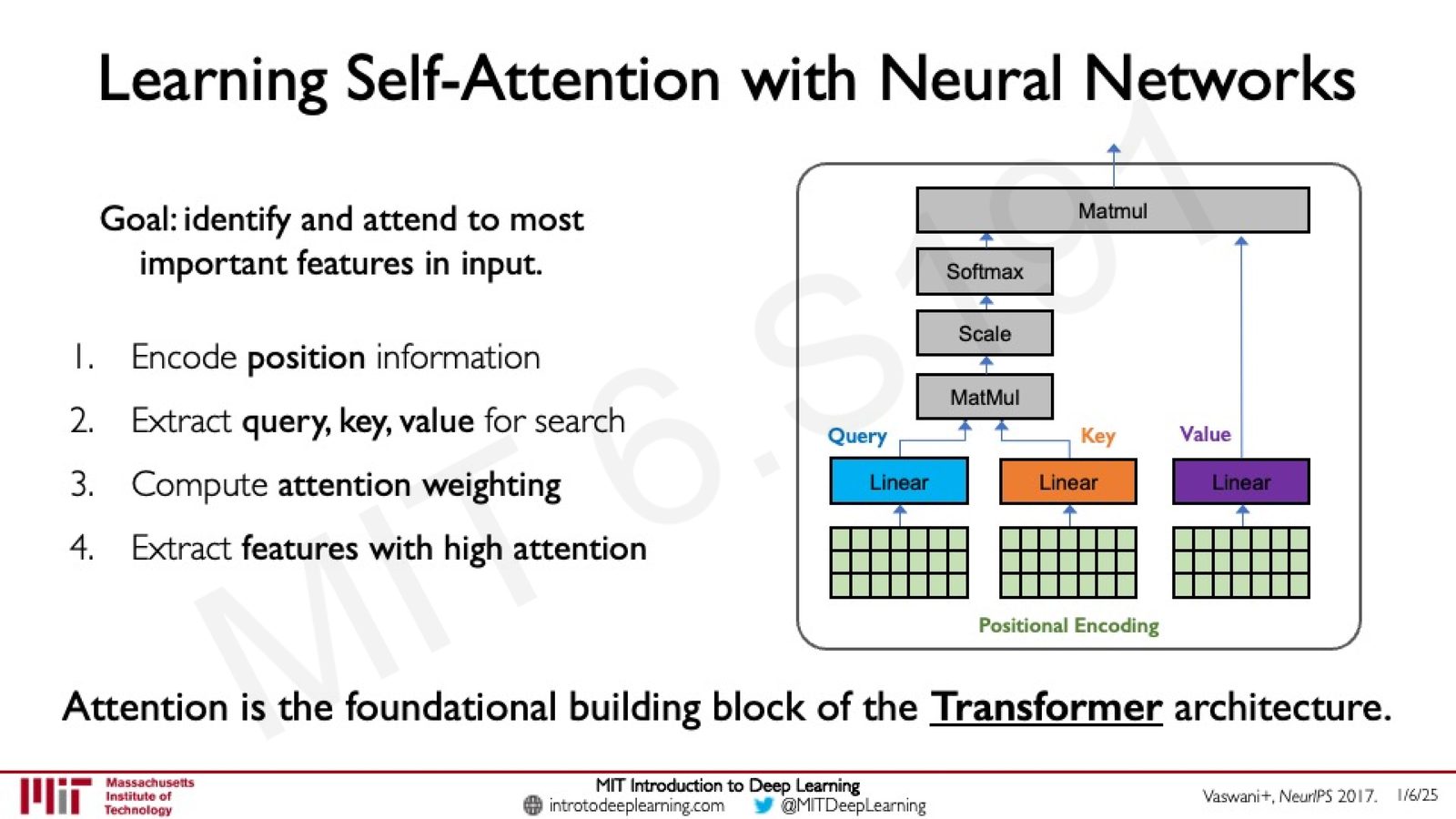
来源:Slides 第78页。
一个完整的 Self-Attention 计算(从位置编码到 Q/K/V 提取再到加权输出)构成一个 Attention Head。
Multi-Head Attention
实际的 Transformer 不只使用一个 Attention Head,而是使用多个并行的 Attention Head——这就是 Multi-Head Attention:
其中每个 head 使用不同的 \(W_Q^i, W_K^i, W_V^i\):
Multi-Head Attention 的优势
多头注意力让模型能够同时从不同的角度关注输入的不同方面。例如,在处理一个句子时:
- 一个 Head 可能专注于捕捉语法结构关系
- 另一个 Head 可能专注于语义相关性
- 第三个 Head 可能关注指代消解(谁指代谁)
多个 Head 的输出被拼接并通过线性变换融合,使模型能够综合利用多种关注模式。
本章小结
Self-Attention 通过四步操作(位置编码、Q/K/V 提取、相似度计算、加权求和)实现了对序列内部依赖关系的直接建模。它不需要逐步处理序列,可以并行计算,且能直接捕捉任意距离的依赖关系。Multi-Head Attention 进一步增强了模型从多个角度理解输入的能力。这些机制构成了 Transformer 架构的核心。
Transformer 的应用与影响
Attention Is All You Need
2017 年,Vaswani 等人发表了划时代的论文 Attention Is All You Need,提出了 Transformer 架构。该架构完全摒弃了循环机制,仅基于 Self-Attention 和前馈层构建序列模型。

来源:Slides 第65页。
GPT 中的 T 代表 Transformer
如果你使用过 ChatGPT,那么名字中的 “T” 就代表 Transformer。GPT 全称是 Generative Pre-trained Transformer——一种基于 Transformer 架构的生成式预训练模型。Transformer 是当今几乎所有大语言模型的底层架构。
Transformer vs. RNN:优势对比
| 特性 | RNN/LSTM | Transformer |
|---|---|---|
| 处理方式 | 逐时间步(Sequential) | 全序列并行(Parallel) |
| 长期依赖 | 困难(梯度消失) | 直接建模(Self-Attention) |
| 训练效率 | 低(无法并行化) | 高(可充分利用 GPU) |
| 位置信息 | 隐式(通过时间步顺序) | 显式(Positional Encoding) |
| 可扩展性 | 有限 | 强(支持超大规模) |
Self-Attention 的广泛应用
Self-Attention 和 Transformer 的影响远超自然语言处理:
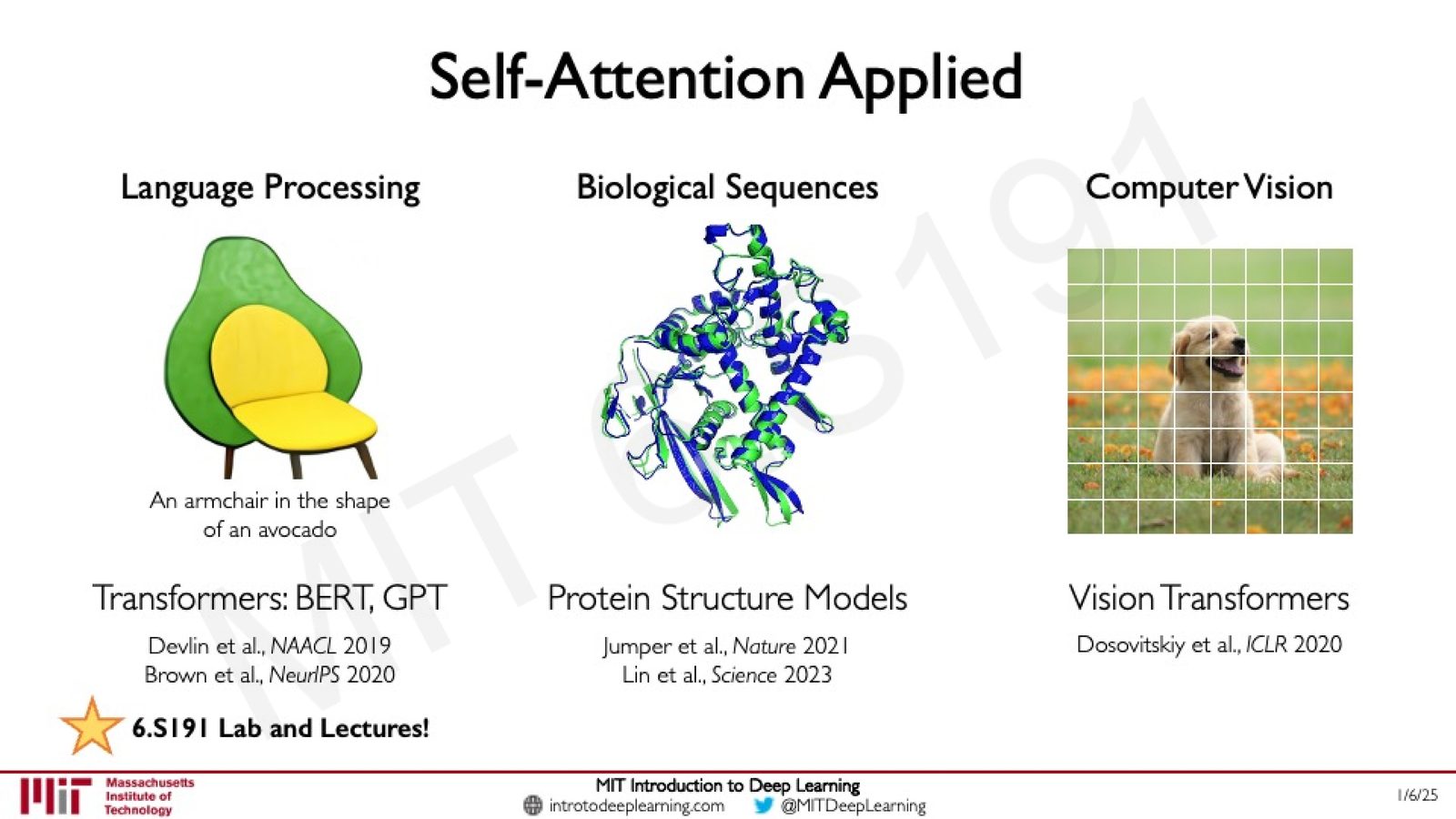
来源:Slides 第80页。
- 自然语言处理:BERT(Devlin et al., NAACL 2019)、GPT(Brown et al., NeurIPS 2020)等大语言模型
- 生物序列:AlphaFold(Jumper et al., Nature 2021)用 Attention 预测蛋白质三维结构;ESMFold(Lin et al., Science 2023)
- 计算机视觉:Vision Transformer / ViT(Dosovitskiy et al., ICLR 2020)将图像切分为 Patch 序列,用 Transformer 处理,性能媲美甚至超越卷积神经网络
- 多模态:跨模态的 Attention 机制实现了图文生成(如 DALL-E)、视频理解等任务
Transformer 的通用性
Transformer 的成功关键在于其与领域无关(Domain-agnostic)的架构设计。无论输入是文字、图像、蛋白质序列还是音频,只要能将其表示为一系列向量(Token),就可以用 Transformer 进行处理。这种通用性使得 Transformer 成为了“基础模型”(Foundation Model)时代的标准架构。
本章小结
Transformer 彻底改变了序列建模的格局。它通过 Self-Attention 机制消除了对循环结构的依赖,实现了高效的并行计算和直接的长距离依赖建模。从自然语言处理到蛋白质结构预测,从计算机视觉到多模态生成,Transformer 的影响无处不在。
总结与延伸
本讲核心线索
本讲从最基本的感知机出发,沿着一条清晰的演进路线逐步构建了对序列建模的完整理解:
- 感知机/前馈网络:能处理单个时间步的输入,但无法利用历史信息
- RNN:通过隐藏状态引入“记忆”,实现了时间步之间的信息传递
- LSTM:通过门控机制缓解梯度消失问题,改善长期依赖的学习
- Attention/Transformer:完全放弃循环结构,通过自注意力机制直接建模全局依赖关系
从 RNN 到 Transformer 的范式转变
这一演进路线体现了深度学习中一个重要的设计哲学转变:
- RNN 哲学:按时间顺序处理,维护一个压缩的记忆状态
- Transformer 哲学:一次看到全局,让网络自己决定关注什么
Transformer 的成功表明:与其让人类设计信息流动的方式(如循环),不如让网络通过学习自行发现数据中的重要模式。
关键概念速查
| 概念 | 核心要点 |
|---|---|
| Hidden State (\(h_t\)) | RNN 在时间步之间传递的内部记忆 |
| Recurrence Relation | \(h_t = f_W(x_t, h_t-1)\),循环更新隐藏状态 |
| BPTT | 沿时间轴反向传播梯度的算法 |
| Vanishing Gradient | 梯度随时间步衰减,阻碍长期依赖学习 |
| LSTM | 通过门控机制保护梯度流的 RNN 变体 |
| Embedding | 将离散符号映射为连续向量的可学习表示 |
| Positional Encoding | 为 Transformer 输入注入位置信息 |
| Self-Attention | 序列内部的 Query-Key-Value 注意力计算 |
| Scaled Dot-Product | \(softmax(QK^T/√d_k)V\) |
| Multi-Head Attention | 多组并行 Attention,捕捉多种关注模式 |
| Transformer | 完全基于 Attention 的序列模型架构 |
拓展阅读
- Vaswani et al., Attention Is All You Need, NeurIPS 2017. Transformer 的开创性论文。
- Hochreiter & Schmidhuber, Long Short-Term Memory, Neural Computation 1997. LSTM 的原始论文。
- Devlin et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019.
- Brown et al., Language Models are Few-Shot Learners (GPT-3), NeurIPS 2020.
- Dosovitskiy et al., An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT), ICLR 2021.
- MIT 6.S191 课程官网:http://introtodeeplearning.com
- MIT 6.S191 Lab 1:Deep Learning in Python and Music Generation with RNNs