CS336 2026 Lecture 3:语言模型架构与超参数
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Stanford CS336 Spring 2026 官方讲义整理 |
| 来源 | Stanford CS336 |
| 日期 | 2026 年春季 |

本讲的问题:架构选择到底该听谁的?
Lecture 3 的主题是 architecture and hyperparameters。它回答一个实践问题:当你真的要从零训练语言模型时,哪些 Transformer 设计已经成为强默认值,哪些仍需要实验验证,哪些其实是系统和推理成本驱动的选择?
本讲的核心方法
不要把公开模型的架构表当作“真理列表”。正确做法是把不同模型的选择放在一起,看共识、例外、证据强弱和系统动机。现代默认值是经验均衡,不是数学定理。
本讲目标:从架构动物园中提取默认值
本节建立全讲方法:不要逐个追随 2024--2025 的模型 tweak,而要从公开 dense model 中提取稳定共识和高风险变量。

展开说明:本页是课程定位页:Lecture 3 的任务是把现代 Transformer 架构和超参数经验整理成可执行的工程判断。标题中的 everything you did not want to know 提醒读者,本讲不是单点技巧,而是大量看似细碎但会影响训练稳定性和效率的选择。

展开说明:本页给出全讲路线:先回顾现代 Transformer,再观察大型 LM 共同点和变化点,最后把经验归纳为可操作的架构和超参数默认值。
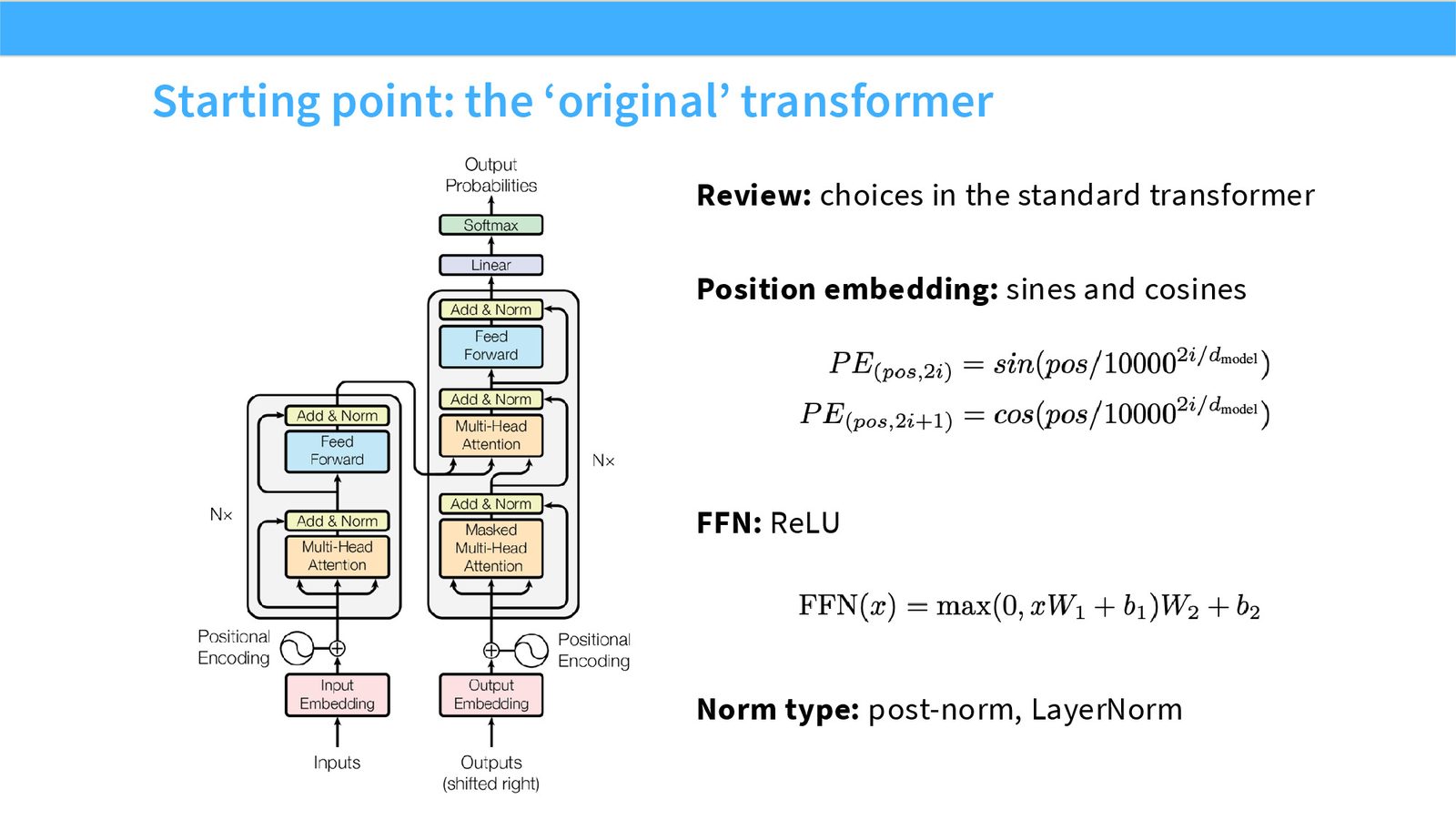
展开说明:本页用原始 Transformer 作为起点:sinusoidal position embedding、ReLU FFN、post-norm LayerNorm。后续所有现代变体都可以看成对这三个默认值的替换。
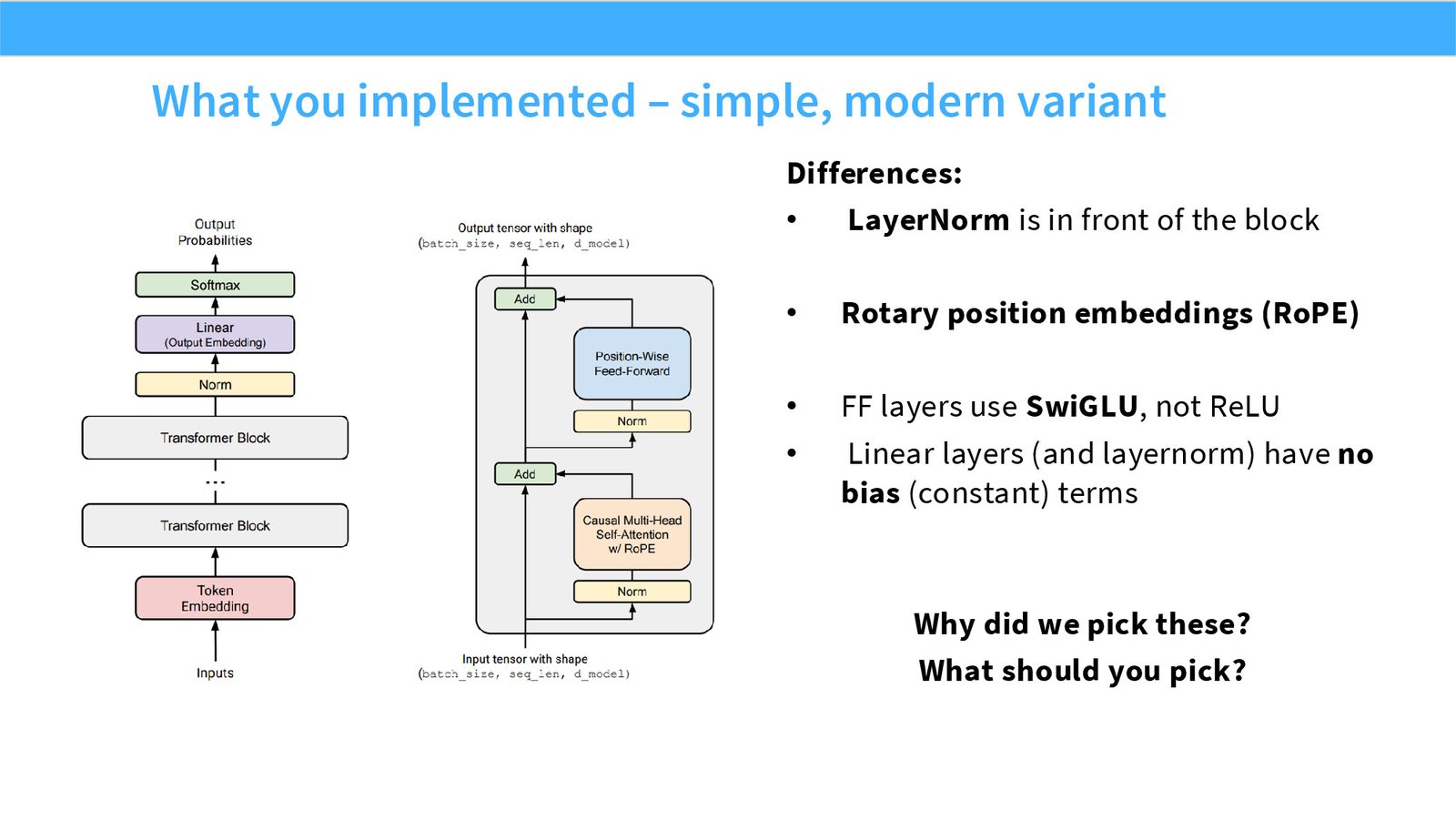
展开说明:本页对应作业中实现的现代化最小模型:pre-norm、RoPE、SwiGLU、无 bias。它不是任意组合,而是近年公开大模型的强共识默认值。

展开说明:本页展示 2024--2025 年 dense model release 的密集程度。教学信号是:架构变化很多,但不应被每个 tweak 牵着走,需要抽取稳定共识。
展开说明:本页用反问强调模型发布速度已经超过个人逐篇消化能力,因此课程采用 empirical survey 的方法,从公开模型中提炼模式。

展开说明:本页说明本讲不是凭偏好讲架构,而是看 dense architectures 的公开数据:哪些共同、哪些变化、哪些能学。

展开说明:本页列出三大主题:architecture variations、hyperparameters、stability tricks。它是本讲 coverage map。

展开说明:本页给出大方向:LLaMA-like architecture 占主导,同时出现 QK norm、hybrid attention 等趋势。
本章小结
本节的关键不是记住所有模型名,而是把公开模型的设计选择转化成可迁移判断:共识默认值可以作为起点,例外需要知道原因,涉及系统和推理成本的选择必须结合资源账本讨论。
Norm 与 residual stream
本节解释 pre-norm、post-norm、RMSNorm、double norm 和 bias removal。核心是保护 residual stream,并减少数据移动。
术语消化:norm 与 residual stream
- Residual stream:Transformer block 中跨层传递的主信号路径,残差连接让梯度和信息更容易穿过深层网络。
- Post-norm:先做 attention/MLP 和 residual add,再 LayerNorm;原始 Transformer 和 BERT 常见。
- Pre-norm:先 LayerNorm,再做子层计算和 residual add;现代大模型常用,训练更稳定。
- RMSNorm:只按 root-mean-square 缩放,不减均值、通常无 bias,减少数据移动和参数。
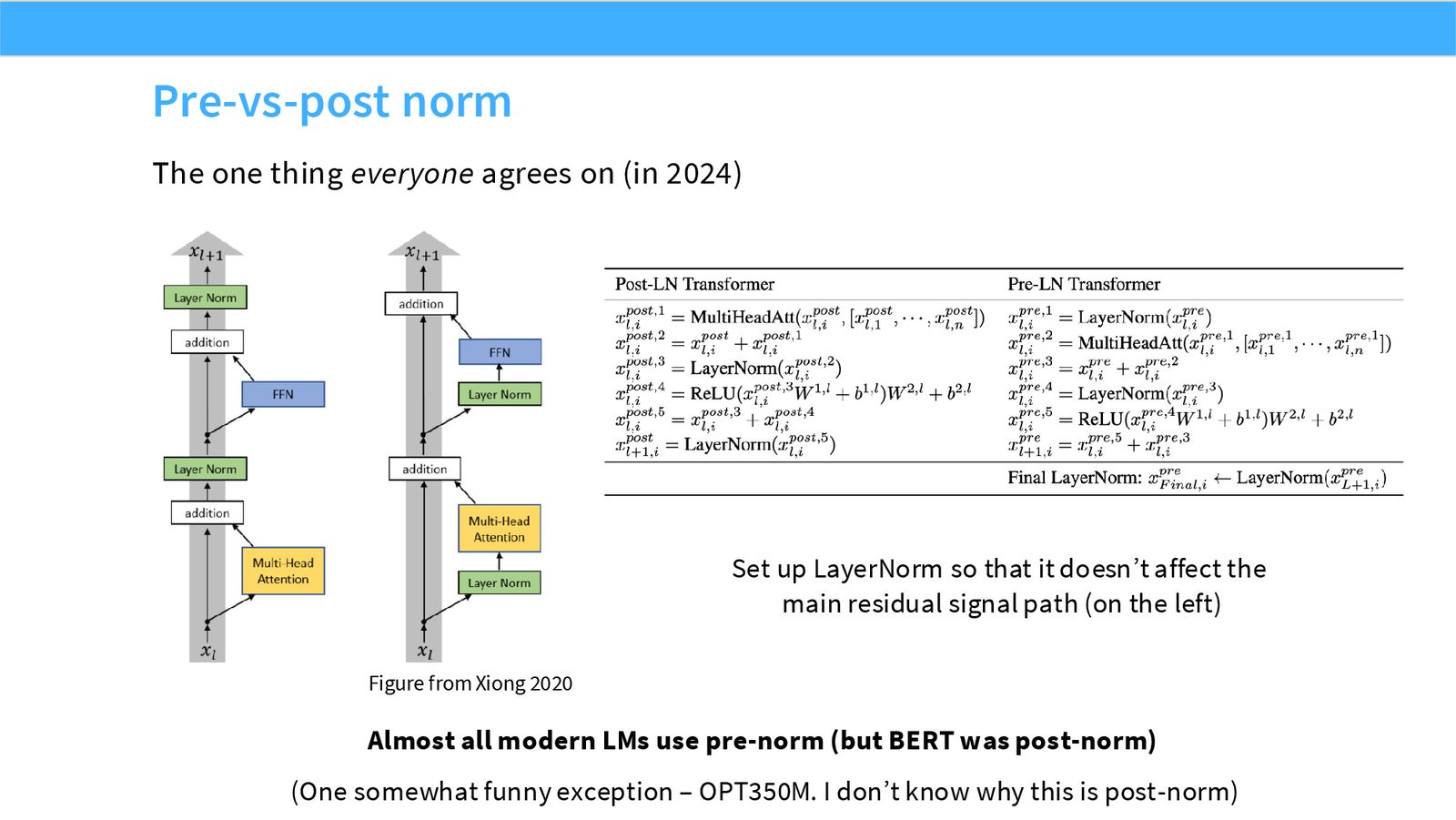
展开说明:本页是 norm 部分的核心共识:现代 LM 几乎都用 pre-norm,使 LayerNorm 不阻断 residual stream 主路径。
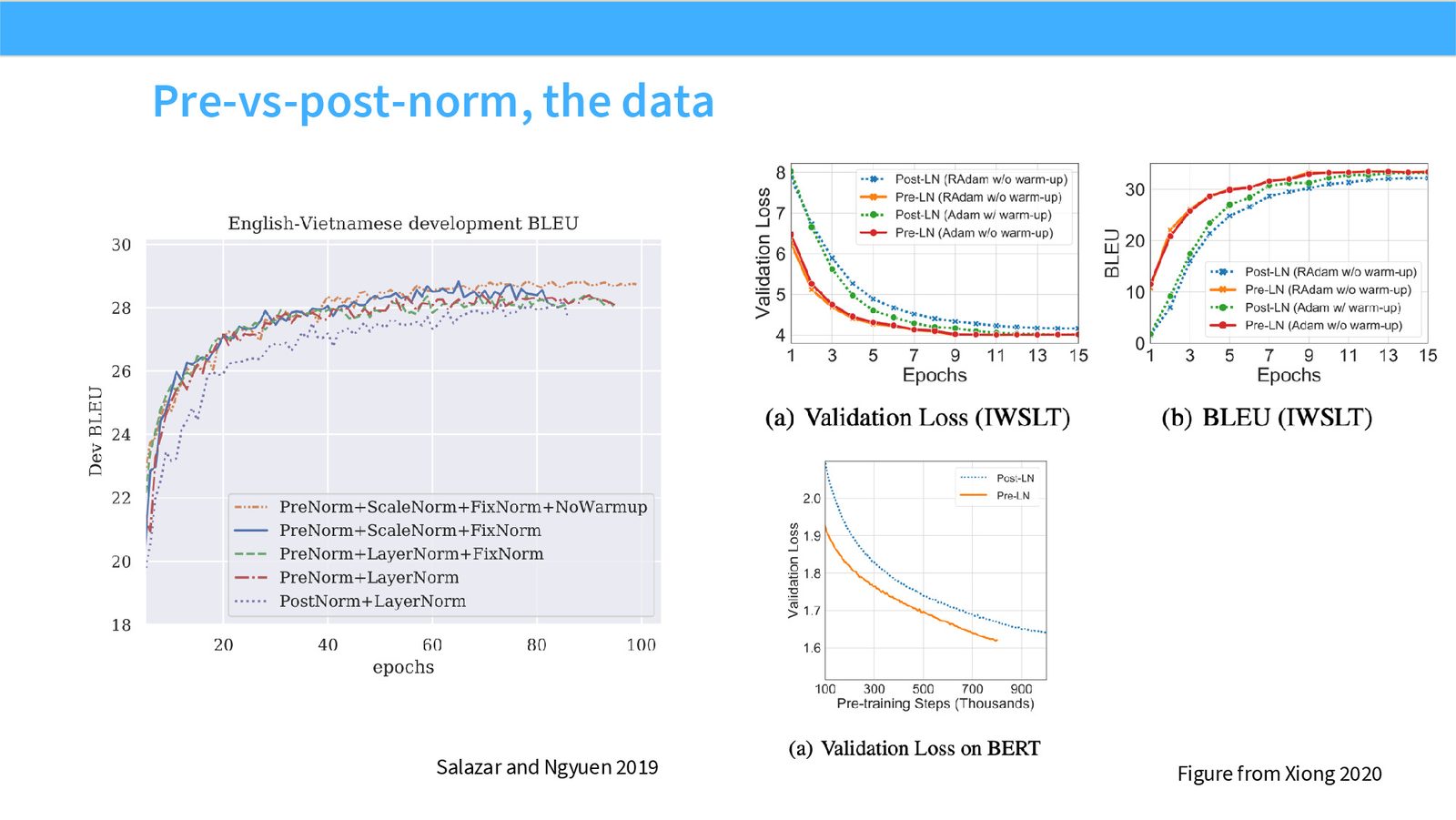
展开说明:本页把经验观察和文献图放在一起:pre-norm 相对 post-norm 有更好的深层训练稳定性证据。
读图:Slide 11 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。
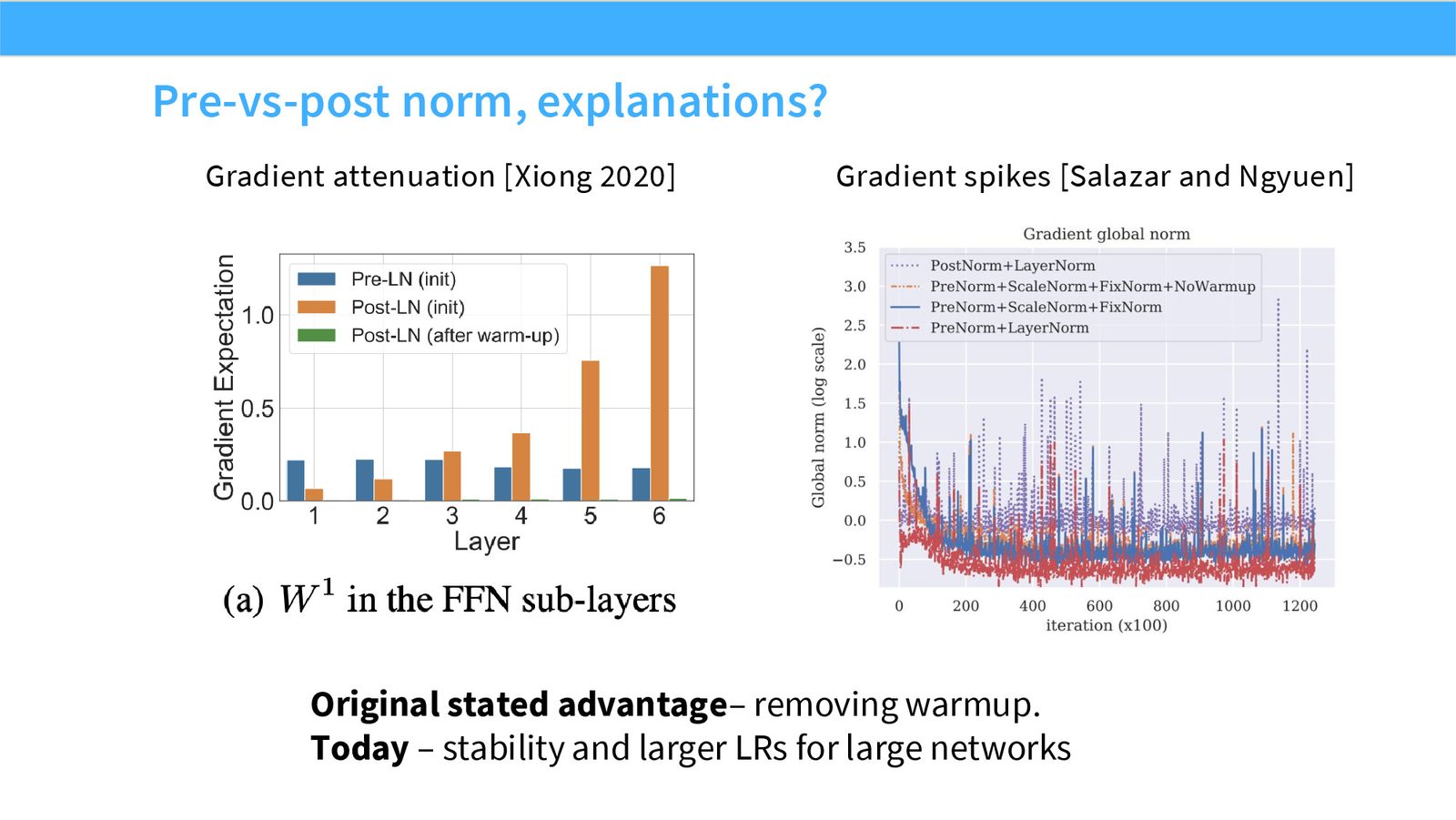
展开说明:本页给出两类解释:Xiong 2020 的 gradient attenuation 与 Salazar/Nguyen 的 gradient spikes。它把经验共识连接到优化动态。
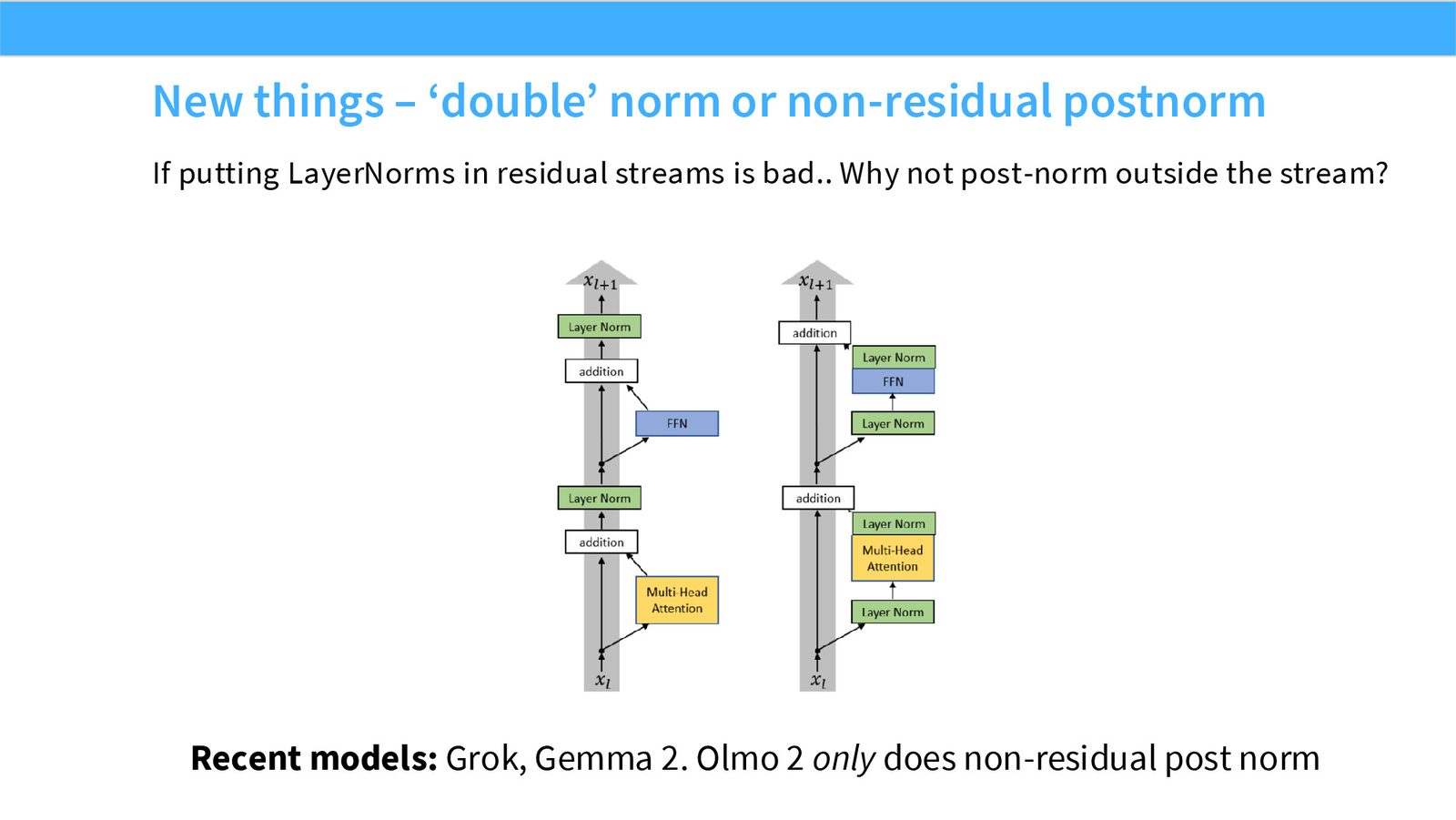
展开说明:本页展示新趋势:既然 residual stream 内放 norm 有风险,一些模型把额外 norm 放到 residual 外侧。

展开说明:本页定义 LayerNorm 和 RMSNorm 的差别:LayerNorm 减均值并归一化方差,RMSNorm 不减均值也不加 bias。

展开说明:本页提出常见解释:RMSNorm 更快、参数更少、效果类似。但它也追问这个 FLOPs 解释是否充分。
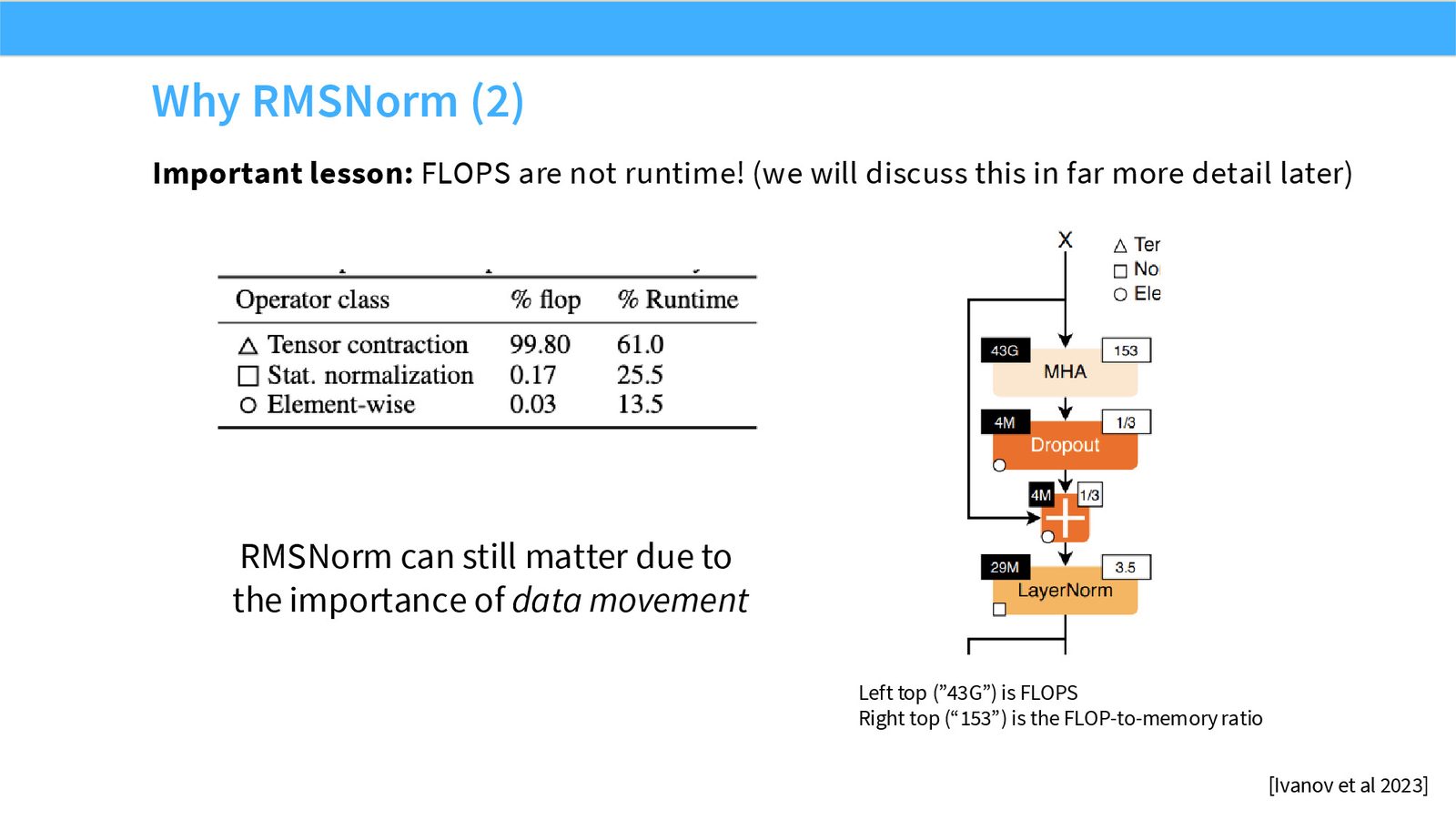
展开说明:本页强调 FLOPs 不是 runtime。RMSNorm 的收益常来自减少数据移动,而不只是少做几个算术操作。
读图:Slide 16 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。
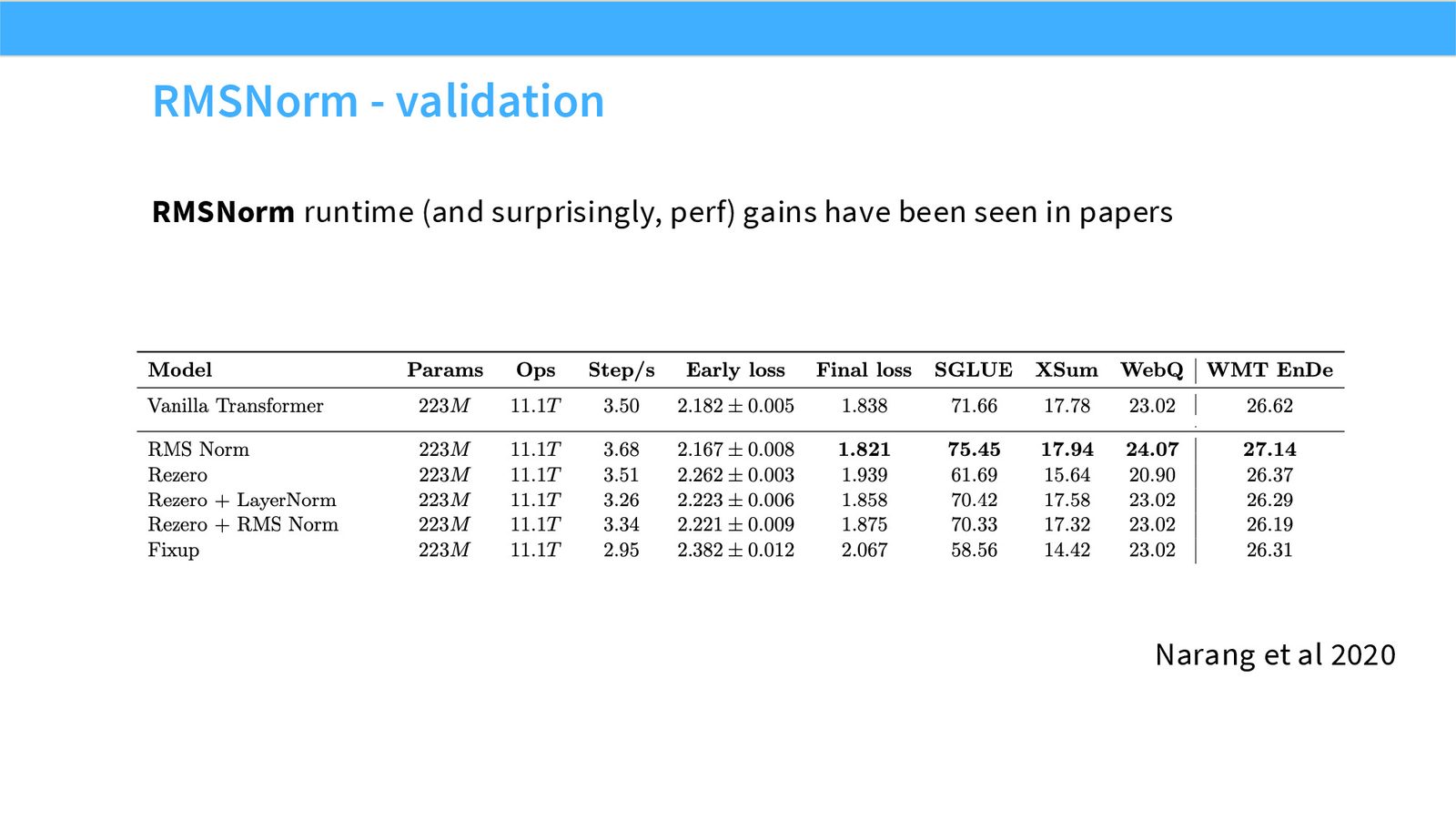
展开说明:本页展示 RMSNorm runtime 和性能增益的文献证据,说明它是经验上可靠的现代默认值。

展开说明:本页把无 bias 扩展到更一般的 linear/FFN 设计:现代 Transformer 常移除 bias,以减少参数移动和稳定性问题。

展开说明:本页总结 norm 部分:pre-norm 或 non-residual norm、RMSNorm、drop bias 构成现代默认组合。
本章小结
本节的关键不是记住所有模型名,而是把公开模型的设计选择转化成可迁移判断:共识默认值可以作为起点,例外需要知道原因,涉及系统和推理成本的选择必须结合资源账本讨论。
Activations、FFN 与 parallel blocks
本节把 ReLU/GeLU/GLU/SwiGLU 放在一个门控 FFN 框架下,并解释 parallel block 更偏系统选择。
术语消化:ReLU、GeLU、GLU、SwiGLU
ReLU 是硬截断非线性,GeLU 用高斯 CDF 做平滑门控。GLU 系列把 FFN 拆成 value 分支和 gate 分支,用逐元素乘法控制哪些 hidden features 通过。SwiGLU 用 Swish 作为 gate,现代 LLaMA/PaLM 风格模型普遍采用。
FFN 公式:普通激活与门控激活
普通 FFN 可以写成
GLU/SwiGLU 类门控 FFN 则写成
其中 \(W_v\) 是 value projection,\(W_g\) 是 gate projection,\(\odot\) 是逐元素乘法。门控结构的代价是多一支投影,所以很多模型会把中间维度缩到约 \(2/3\),让参数量和 FLOPs 与普通 FFN 可比。
符号说明:FFN 与 RoPE 公式
\(x\) 表示当前位置 token 的 hidden state;\(W_1,W_2,W_v,W_g,W_o\) 是可学习投影矩阵;\(\phi\) 是 ReLU/GeLU/Swish 等非线性;\(\odot\) 表示逐元素乘法。RoPE 中 \(i\) 是 token 位置,\(k\) 是第 \(k\) 个二维旋转平面,\(\theta_k\) 是该平面的旋转频率。公式说明的是机制形状,不代表唯一实现细节。

展开说明:本页列出 ReLU、GeLU、Swish、GLU、GeGLU、ReGLU、SwiGLU 等激活族,提示术语密集,需要统一框架理解。

展开说明:本页把 ReLU、GeLU、SwiGLU/GeGLU 与代表模型对应起来,显示激活函数有明显时代迁移。

展开说明:本页解释 GLU 的机制:一支产生候选值,另一支产生 gate,用逐元素乘法调制 FFN 输出。

展开说明:本页比较 GeGLU、ReGLU、SwiGLU、LiGLU 等变体,核心差异在 gate 分支用什么非线性。
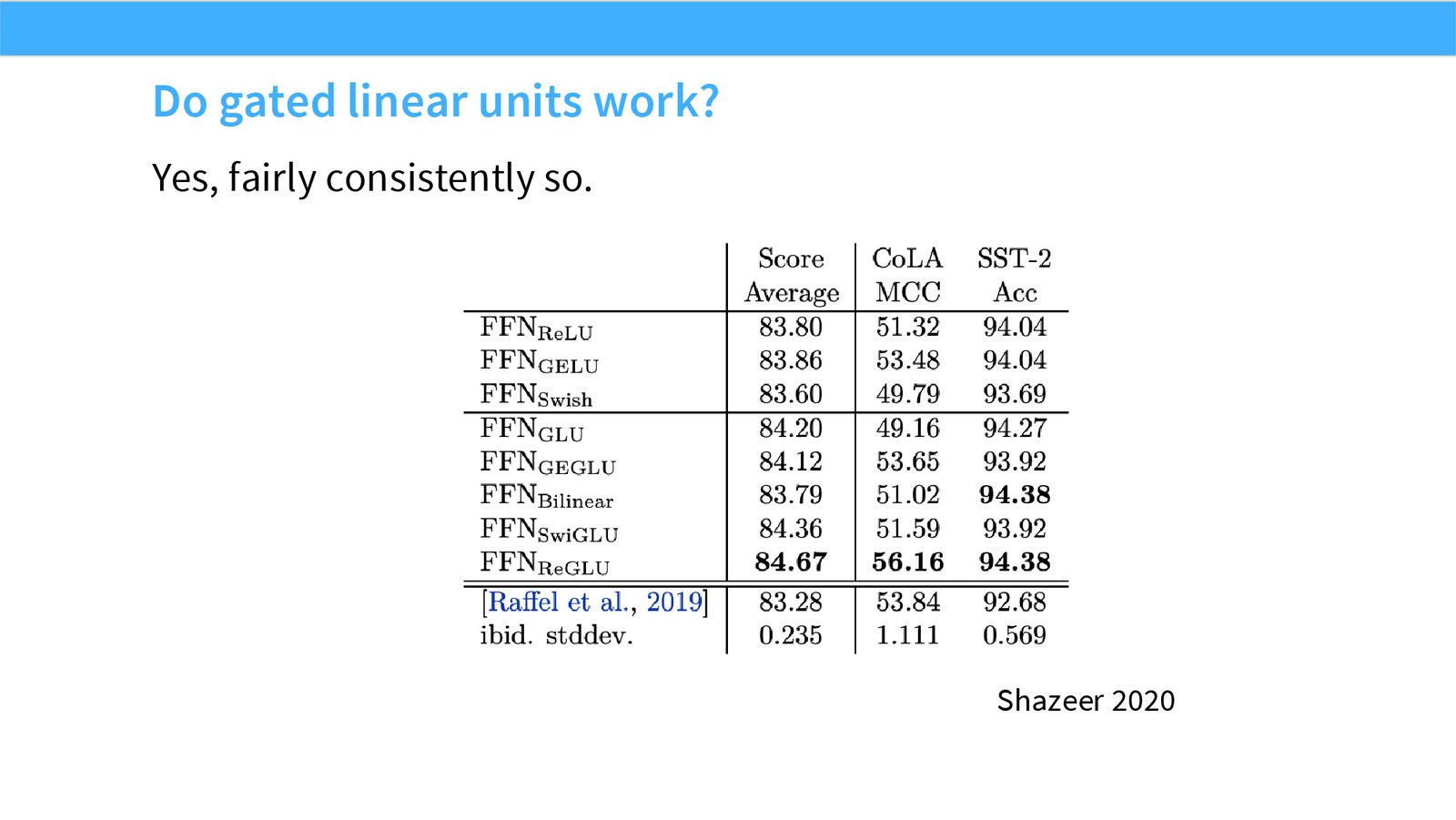
展开说明:本页展示 Shazeer 2020 的证据:gated variants 通常稳定优于普通 FFN。
读图:Slide 24 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。
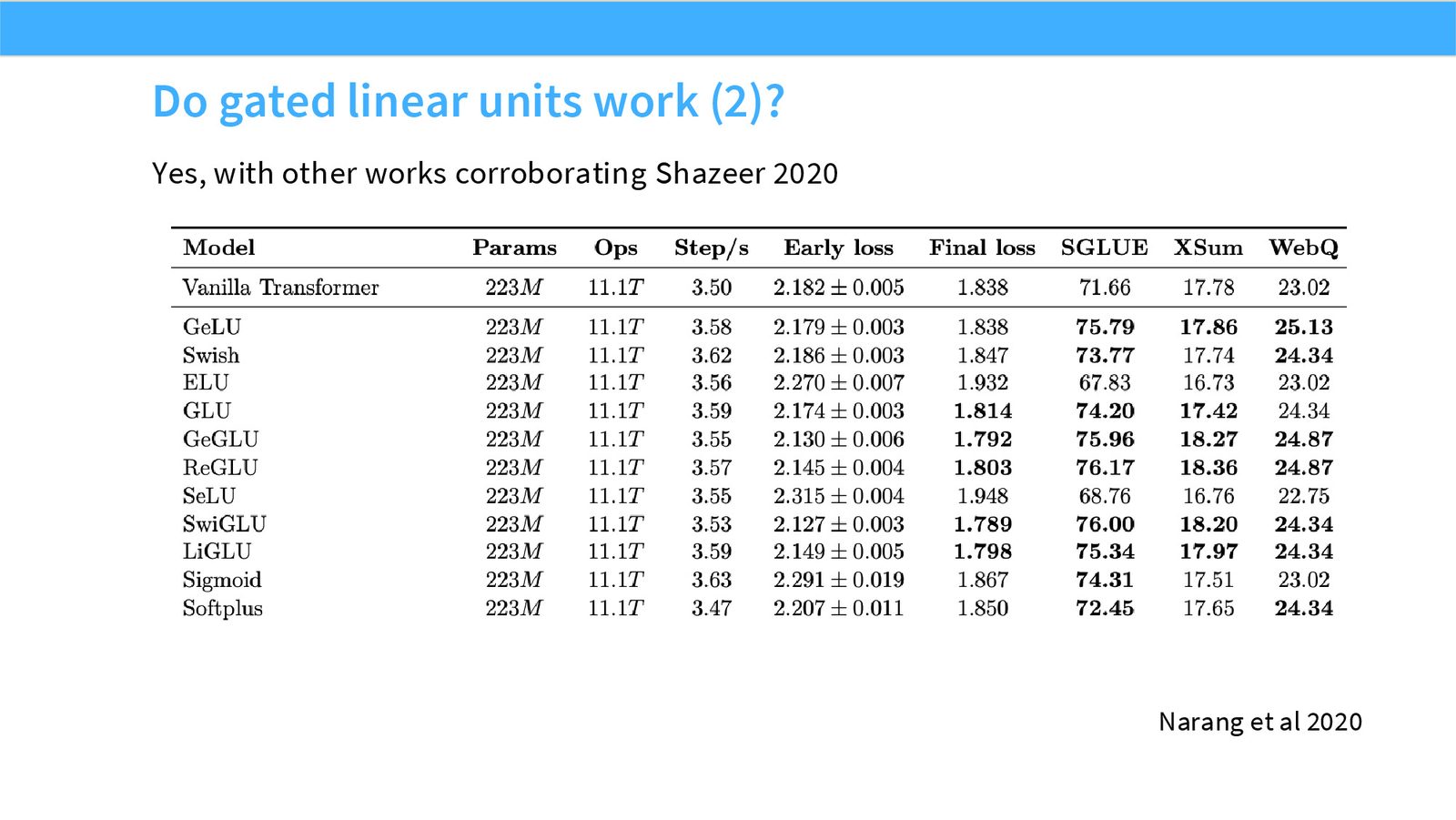
展开说明:本页展示后续工作也验证了 gated FFN 的收益,说明它不是孤立实验结果。
读图:Slide 25 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。

展开说明:本页总结 activation 部分:许多变体存在,但现代主流逐渐收敛到 SwiGLU/GeGLU 类门控 FFN。
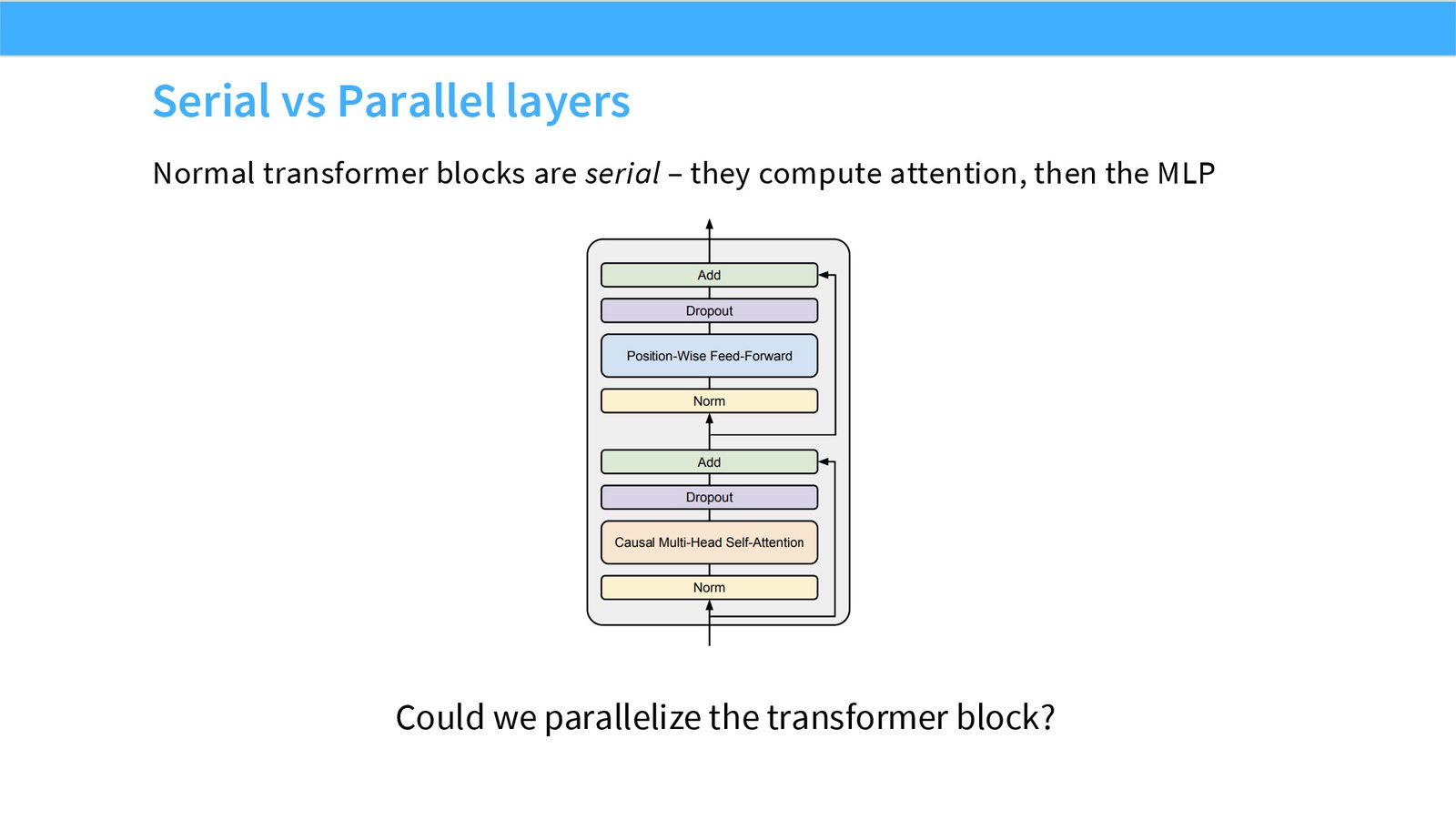
展开说明:本页比较标准串行 block:先 attention 后 MLP。它引出 parallel block 作为系统/延迟选择。

展开说明:本页展示 GPT-J、PaLM、GPT-NeoX 等使用 parallel layers,让 attention 与 MLP 并行或并列汇入 residual。

展开说明:本页总结 architecture variations:pre-norm、RMSNorm、SwiGLU、parallel block 等哪些是强共识,哪些仍是局部选择。
本章小结
本节的关键不是记住所有模型名,而是把公开模型的设计选择转化成可迁移判断:共识默认值可以作为起点,例外需要知道原因,涉及系统和推理成本的选择必须结合资源账本讨论。
Position embeddings 与 RoPE
本节解释从绝对位置到 RoPE 的迁移:相对位置信息通过 Q/K 旋转进入 attention score。
RoPE 的一句话定义
RoPE 把位置信息编码为 query/key 向量的旋转,使 attention score 中自然出现相对位置。它不是把 position embedding 加到 token embedding 上,而是在每层 attention 的 Q/K 空间里改变几何关系。
RoPE 公式链路
把每两个 hidden dimensions 看成一个二维平面。位置 \(i\) 上的向量对 \((x_{2k},x_{2k+1})\) 被旋转角度 \(i\theta_k\):
当 query 和 key 都按各自位置旋转后,它们的点积会依赖相对位移 \(i-j\)。这就是 RoPE 能支持 relative-position behavior 的几何原因。
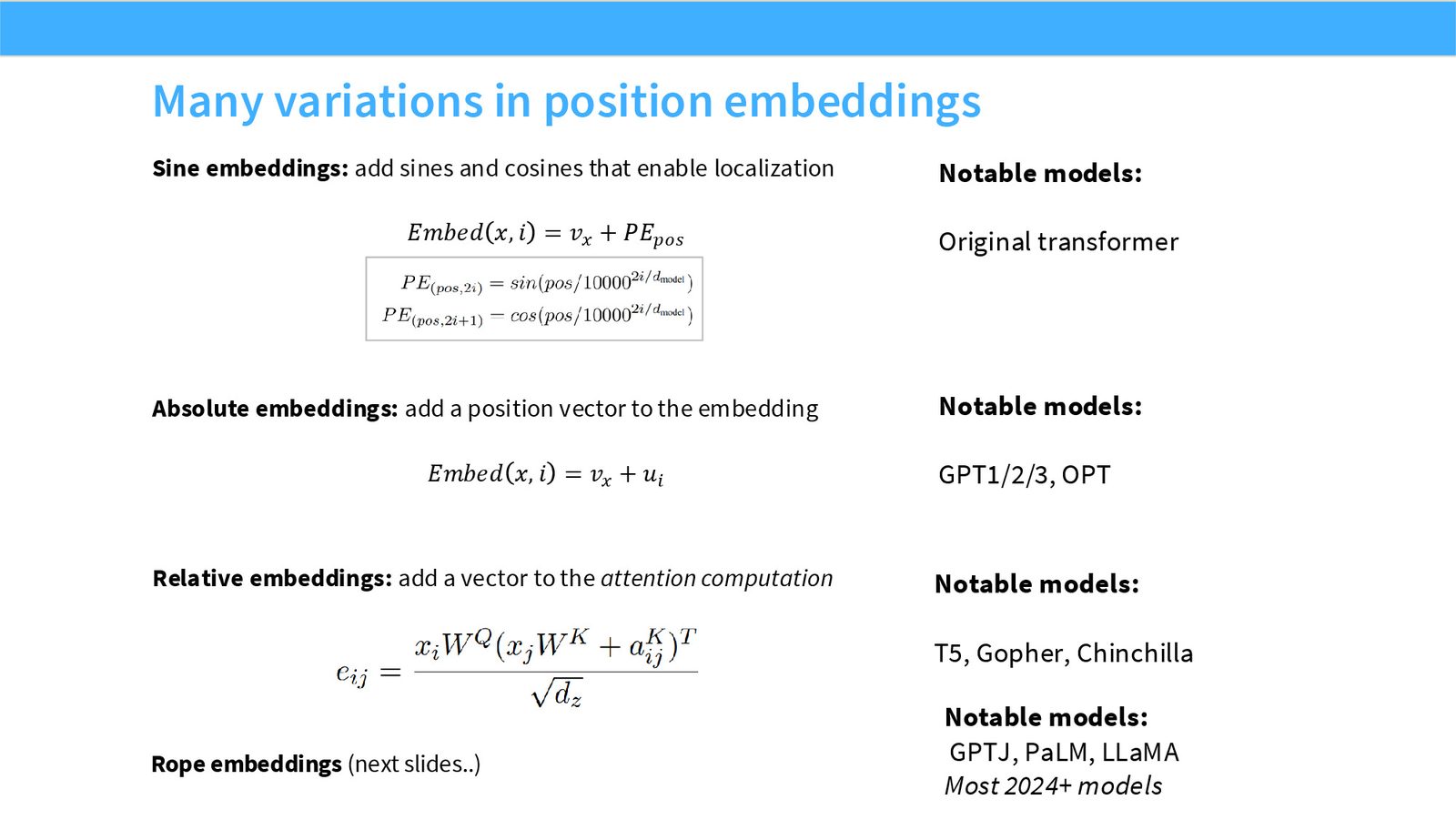
展开说明:本页列出 sinusoidal、learned absolute、relative、ALiBi、RoPE 等位置编码路线。

展开说明:本页给出 RoPE 的相对位置目标:让 attention score 能感知相对距离。
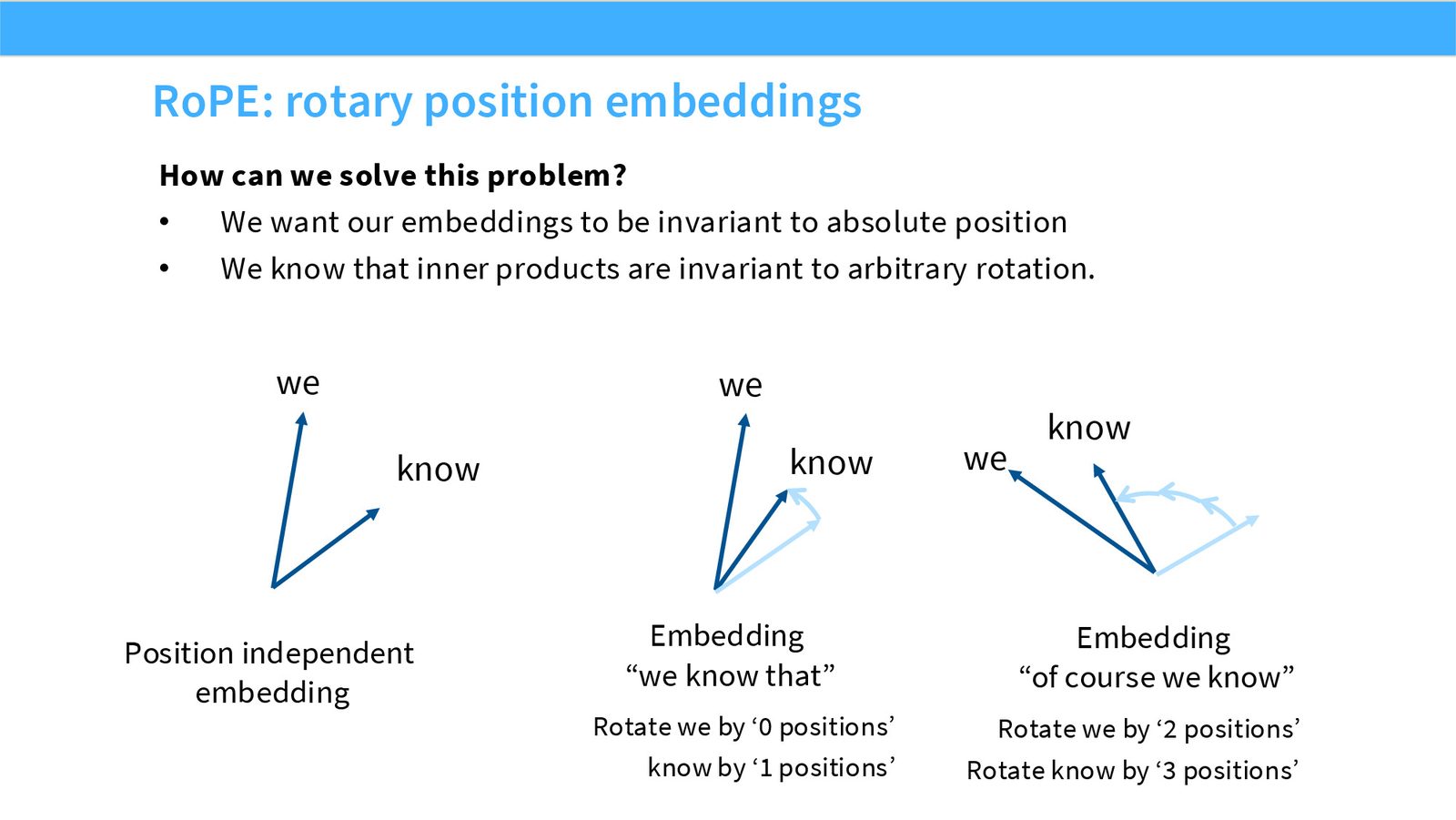
展开说明:本页说明用旋转矩阵满足相对位置性质:不同位置对应不同旋转,点积中体现相对偏移。
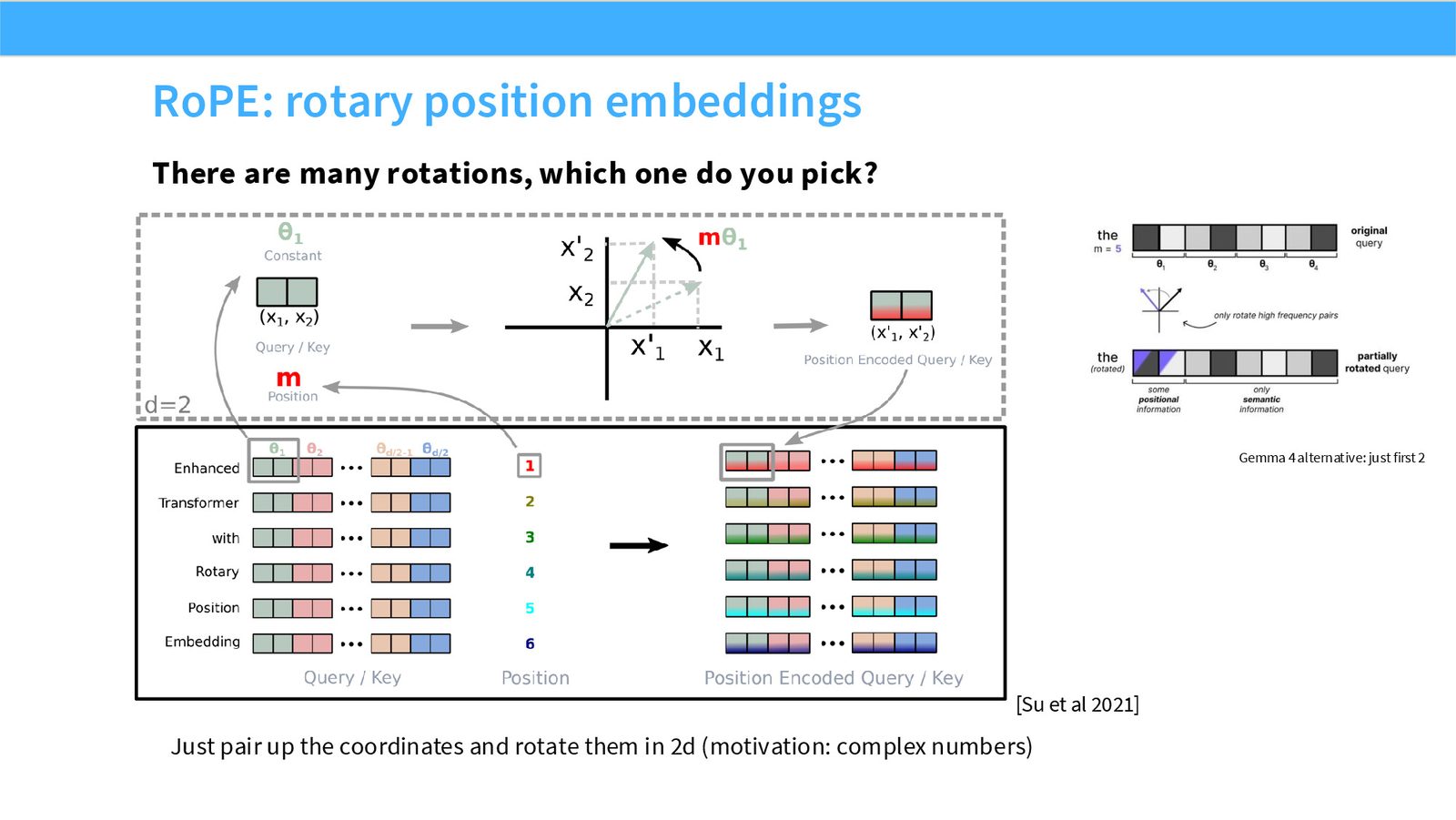
展开说明:本页指出旋转频率选择不是唯一的,需要多频率覆盖不同距离尺度。
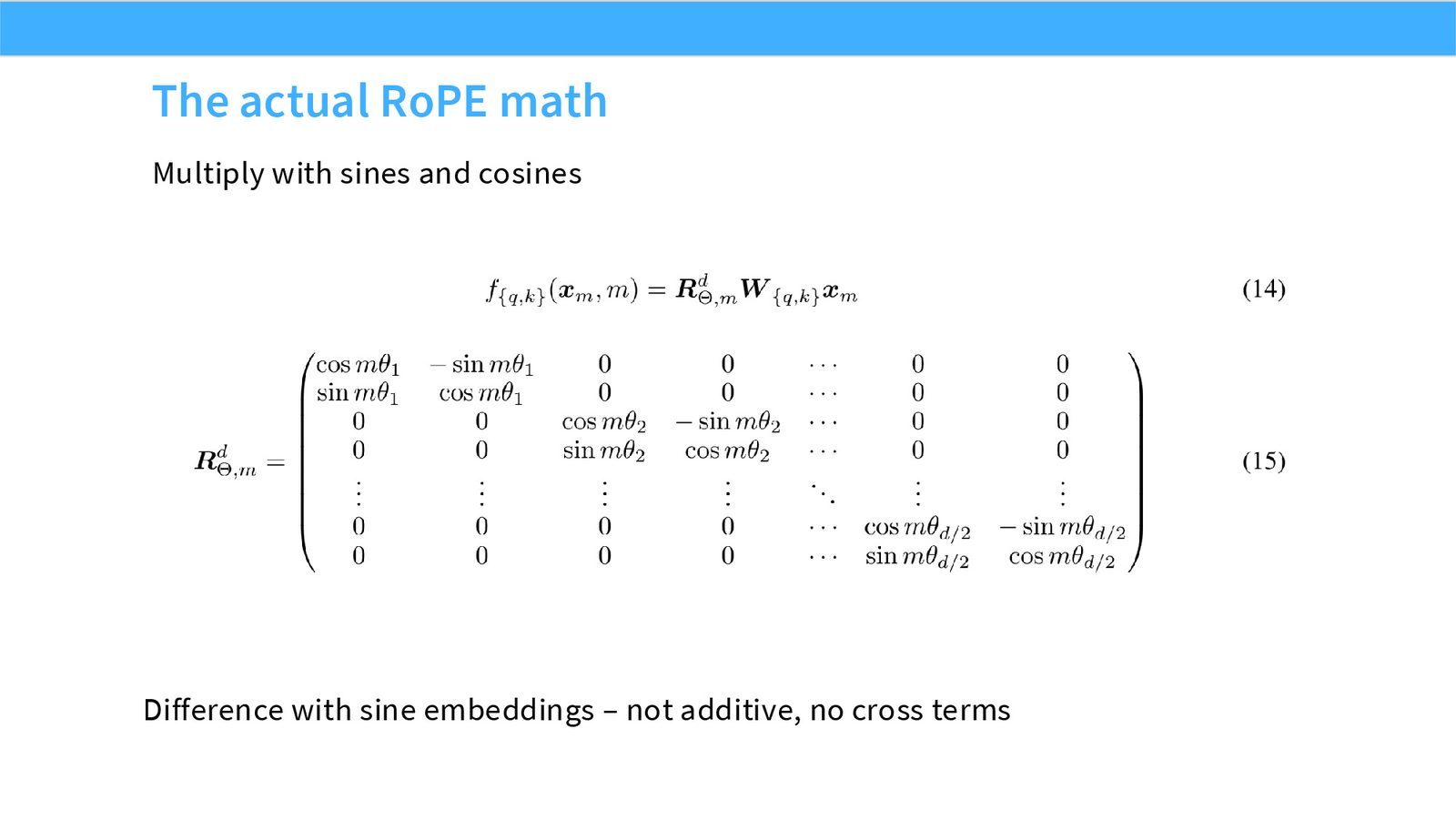
展开说明:本页给出 RoPE 公式:把偶/奇维组成二维平面,用 sin/cos 对每对维度旋转。

展开说明:本页说明 RoPE 在 attention 的 Q/K 上实施,通常不直接改 V。实现细节会影响 shape 和广播。
本章小结
本节的关键不是记住所有模型名,而是把公开模型的设计选择转化成可迁移判断:共识默认值可以作为起点,例外需要知道原因,涉及系统和推理成本的选择必须结合资源账本讨论。
Hyperparameter defaults
本节整理 FFN ratio、head dim、aspect ratio、vocab size、dropout、weight decay 的现代默认值和例外。
超参数默认值的读法
本节所有比例都应读作“保守起点”,不是“唯一正确”。若模型规模、数据、硬件、上下文长度或推理目标不同,就需要用小规模实验验证这些默认值是否仍适用。

展开说明:本页转入超参数:ff_dim、head dim、vocab size、depth/width 等看似平凡但影响资源和质量。

展开说明:本页展示 FFN hidden dim 与 model dim 的常见比例,传统 dense FFN 常用约 4 倍。
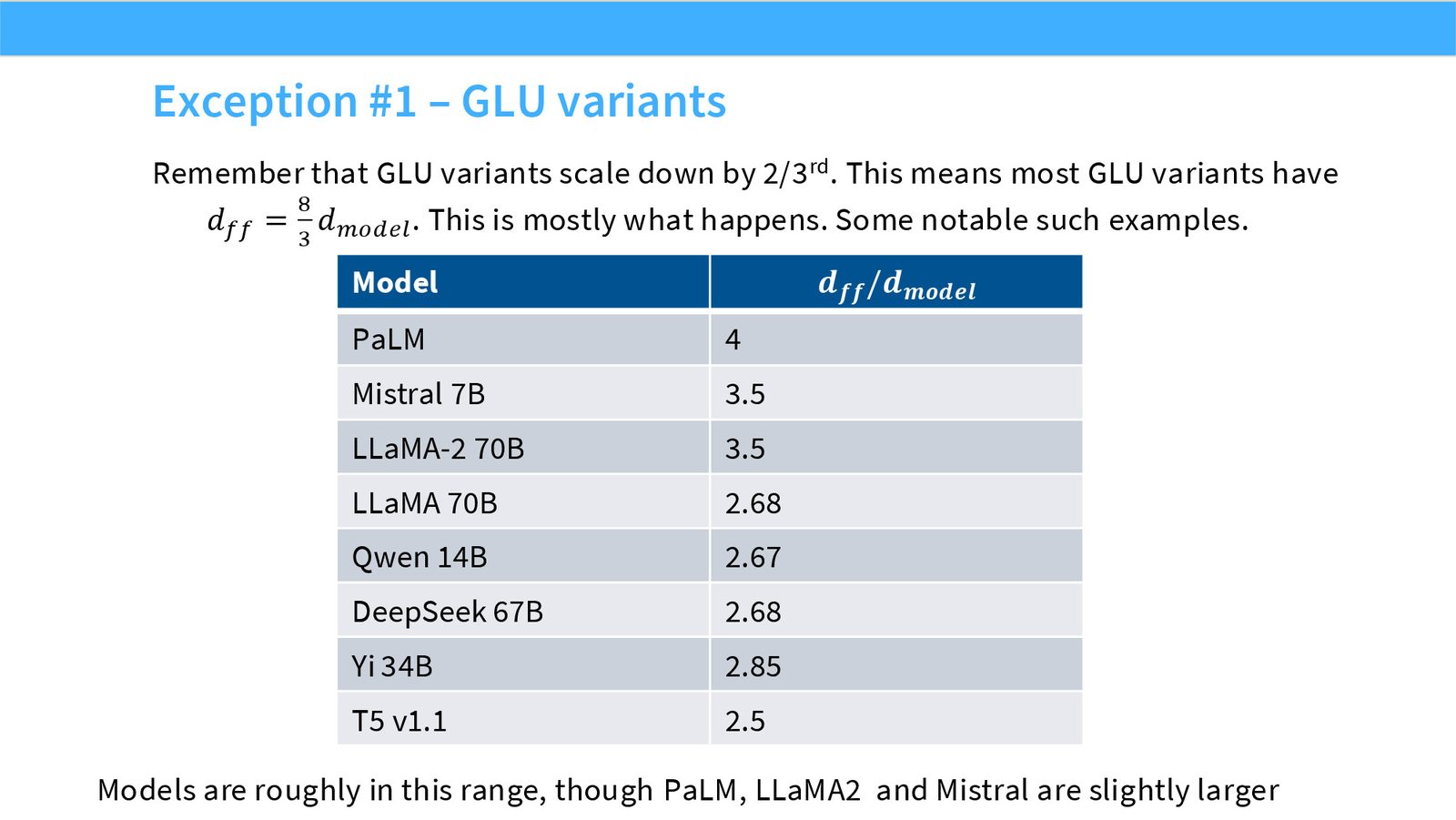
展开说明:本页提醒 GLU variants 常把维度缩到约 2/3,因为门控结构有两支投影,参数/计算要对齐。

展开说明:本页给出 T5 例外,说明默认值有历史和架构条件,不能机械套用。
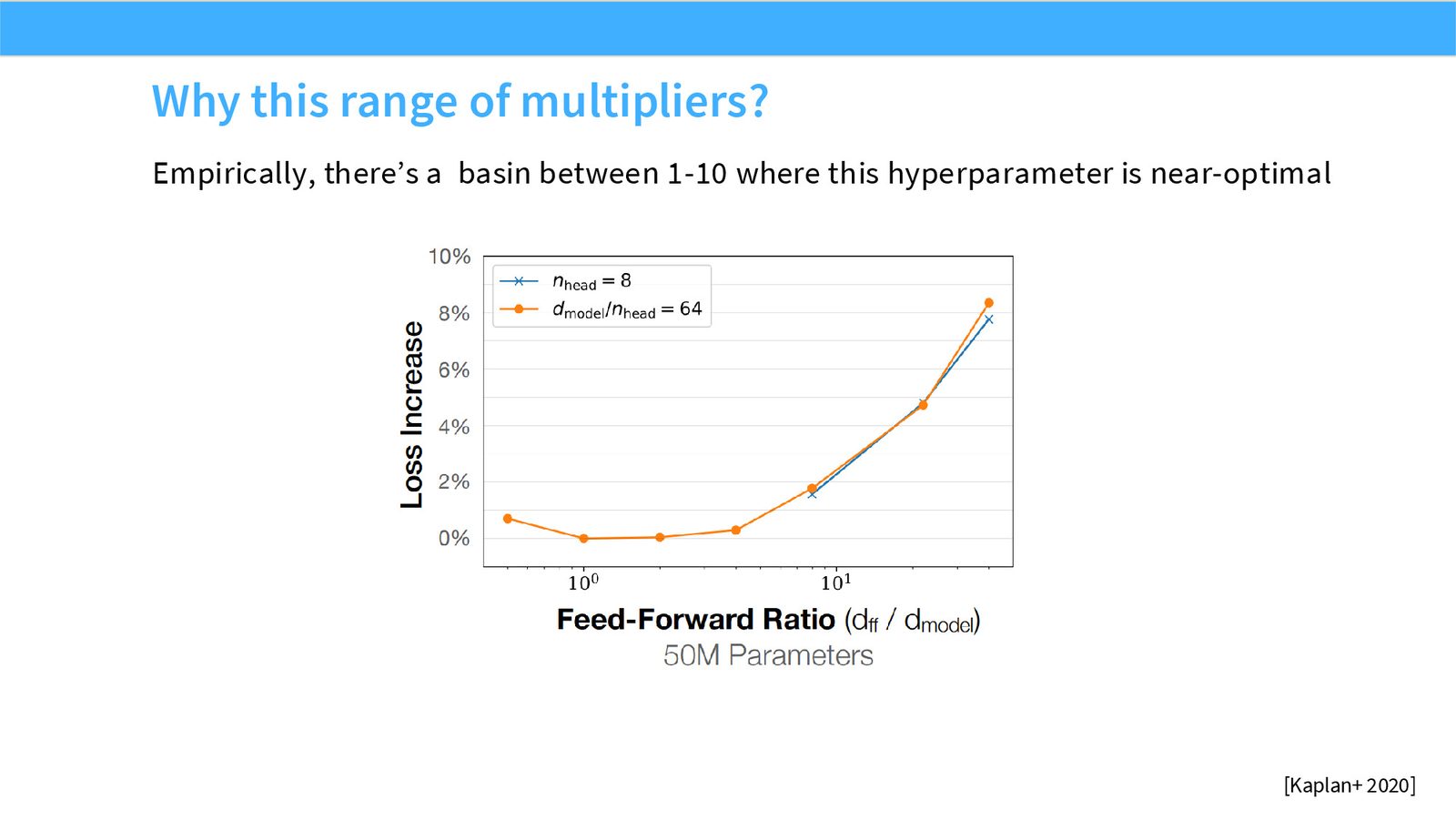
展开说明:本页展示 ff_dim multiplier 在一定盆地内都可行,超参选择不是尖锐单点,而是宽容区间。
读图:Slide 40 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。

展开说明:本页总结:保守默认值好用,但应通过小规模实验验证,不要把公式当法律。

展开说明:本页讨论 head_dim × num_heads 与 model_dim 的关系,现代模型通常让总 head dim 接近 model dim。
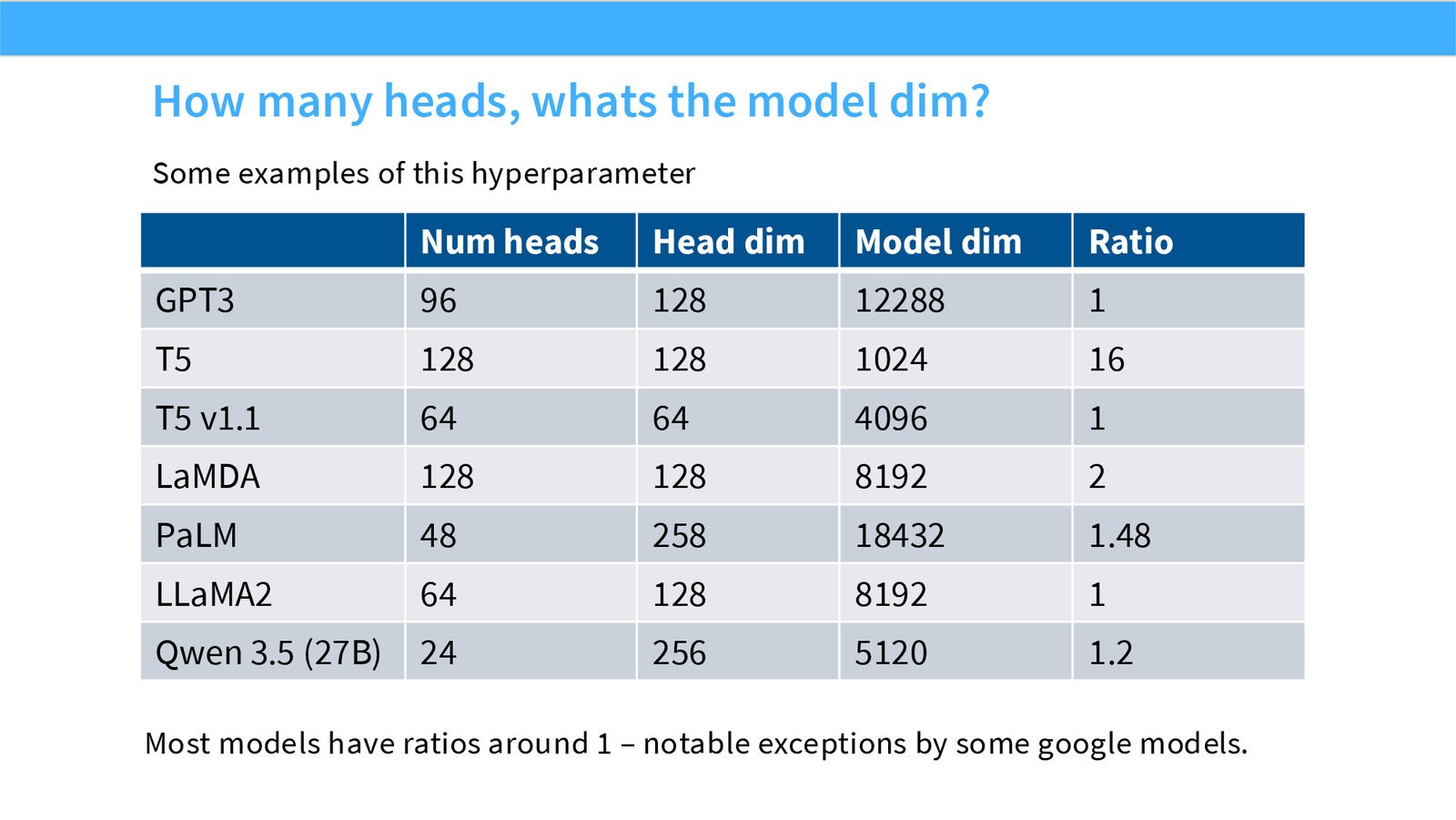
展开说明:本页列出不同模型的 head 数、head dim、model dim 实例,展示公开模型如何选 attention shape。
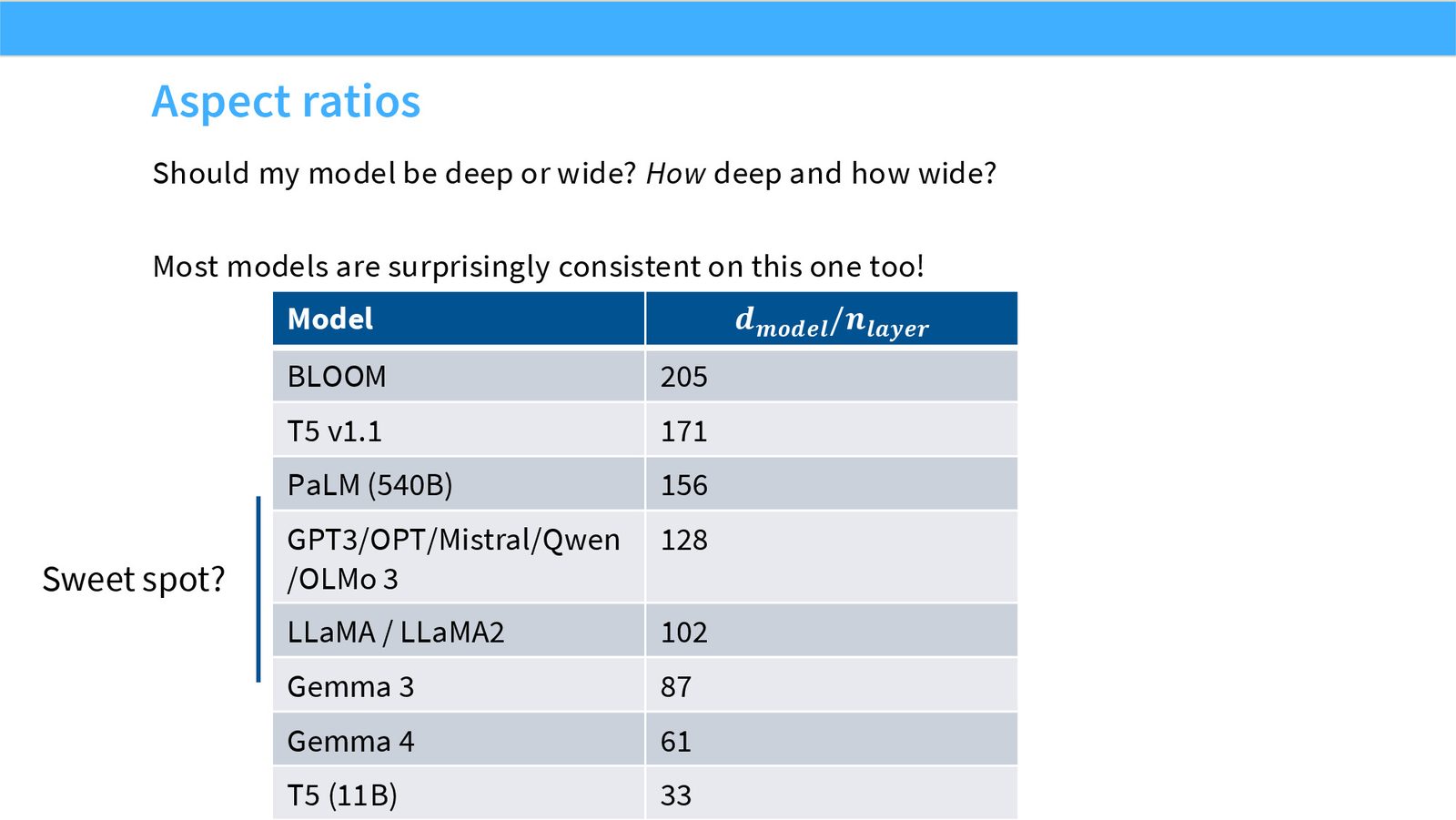
展开说明:本页提出 depth vs width 问题:同样参数量下,模型可以更深或更宽。
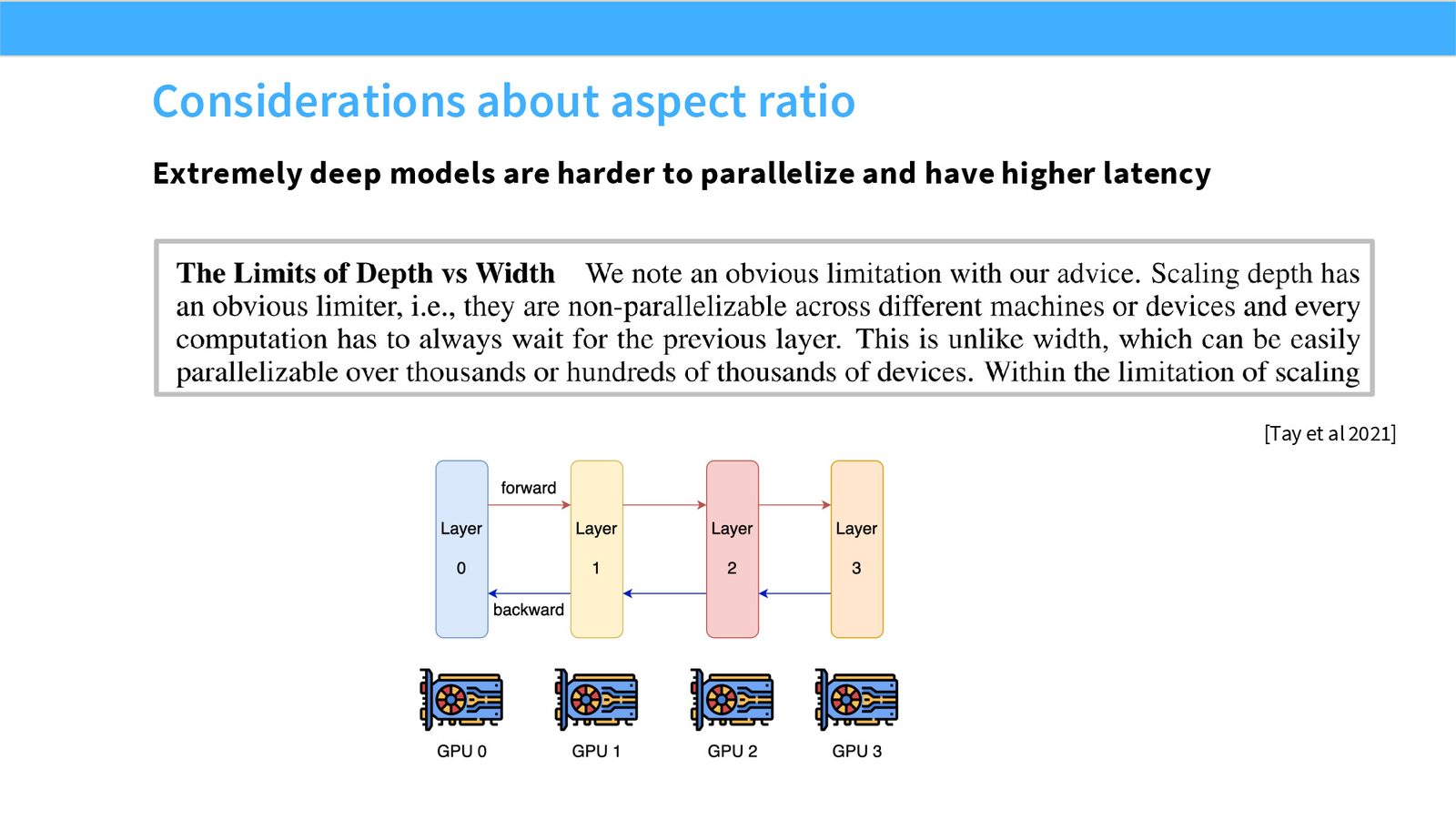
展开说明:本页解释极深模型并行和延迟更难,极宽模型单层矩阵更大,aspect ratio 同时是优化和系统问题。
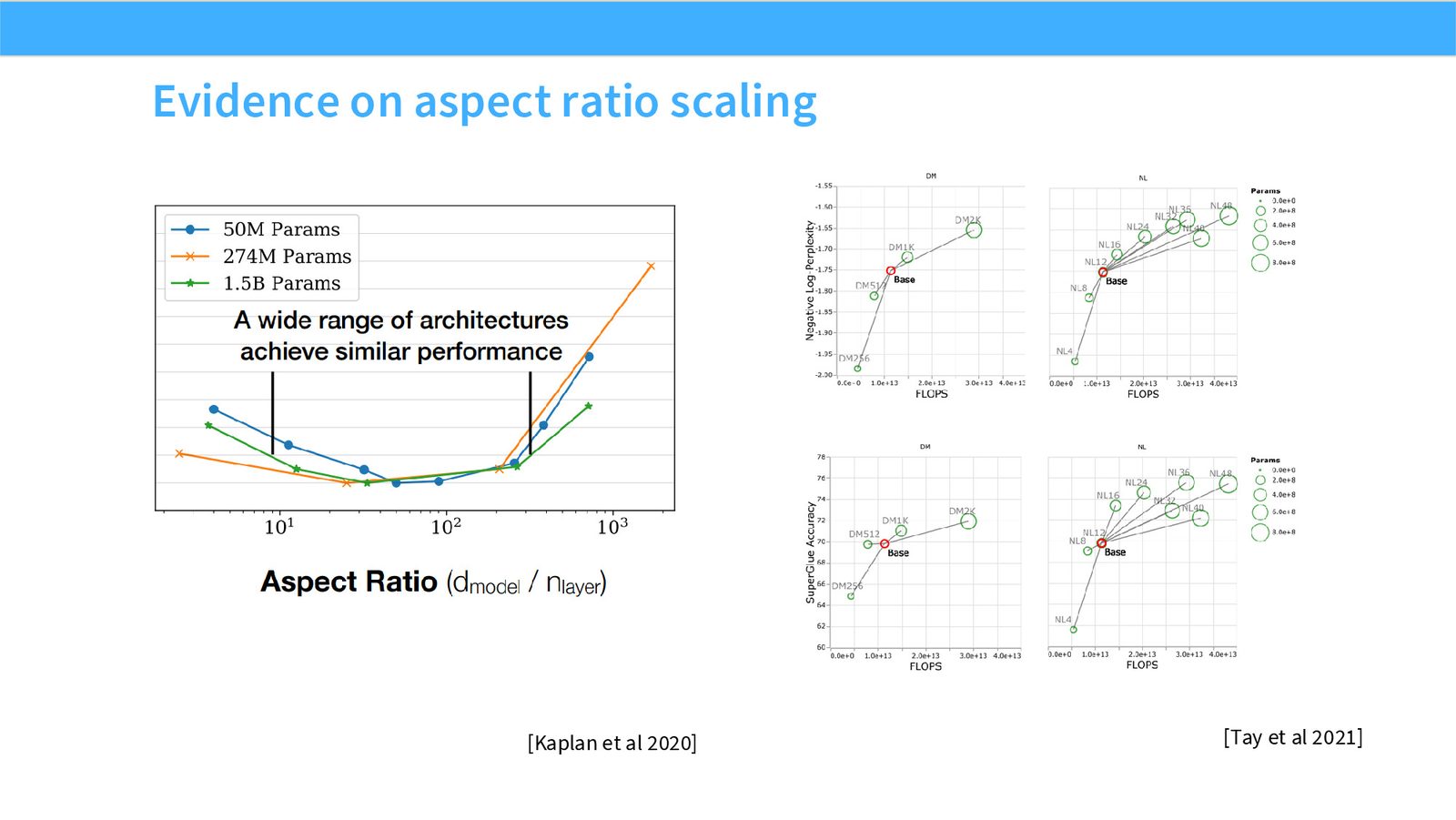
展开说明:本页引用 Kaplan/Tay 等证据说明 depth/width scaling 有经验趋势,但仍依赖任务和规模。
读图:Slide 46 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。

展开说明:本页对比单语、多语、生产系统的 vocab size,显示 tokenizer/词表也是架构超参。

展开说明:本页询问预训练是否需要 dropout。大型 LM 预训练常少用 dropout,因为数据量巨大且目标不是小数据过拟合。
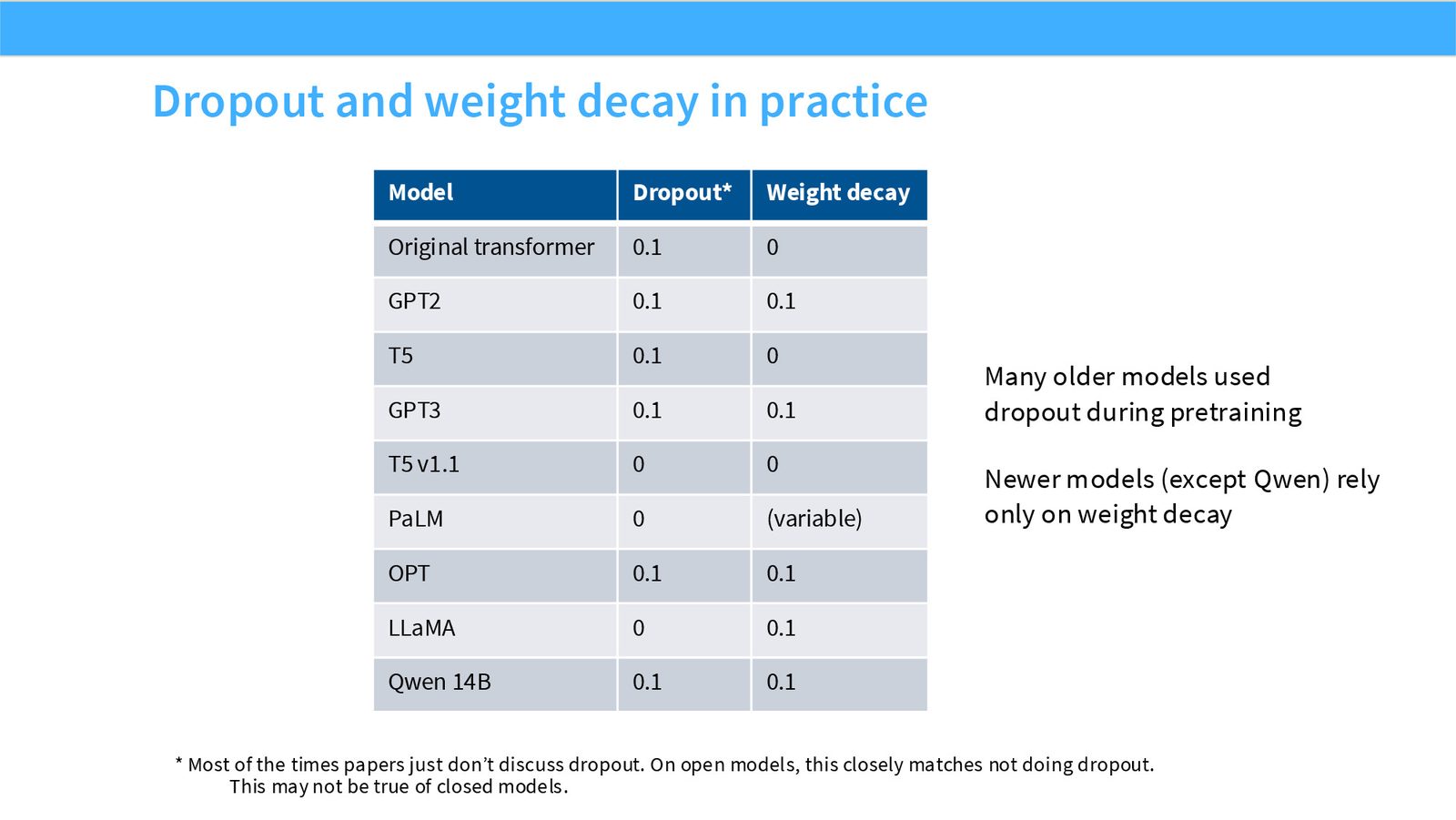
展开说明:本页列出模型的 dropout 和 weight decay 实践,说明 weight decay 更常保留。
读图:Slide 49 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。
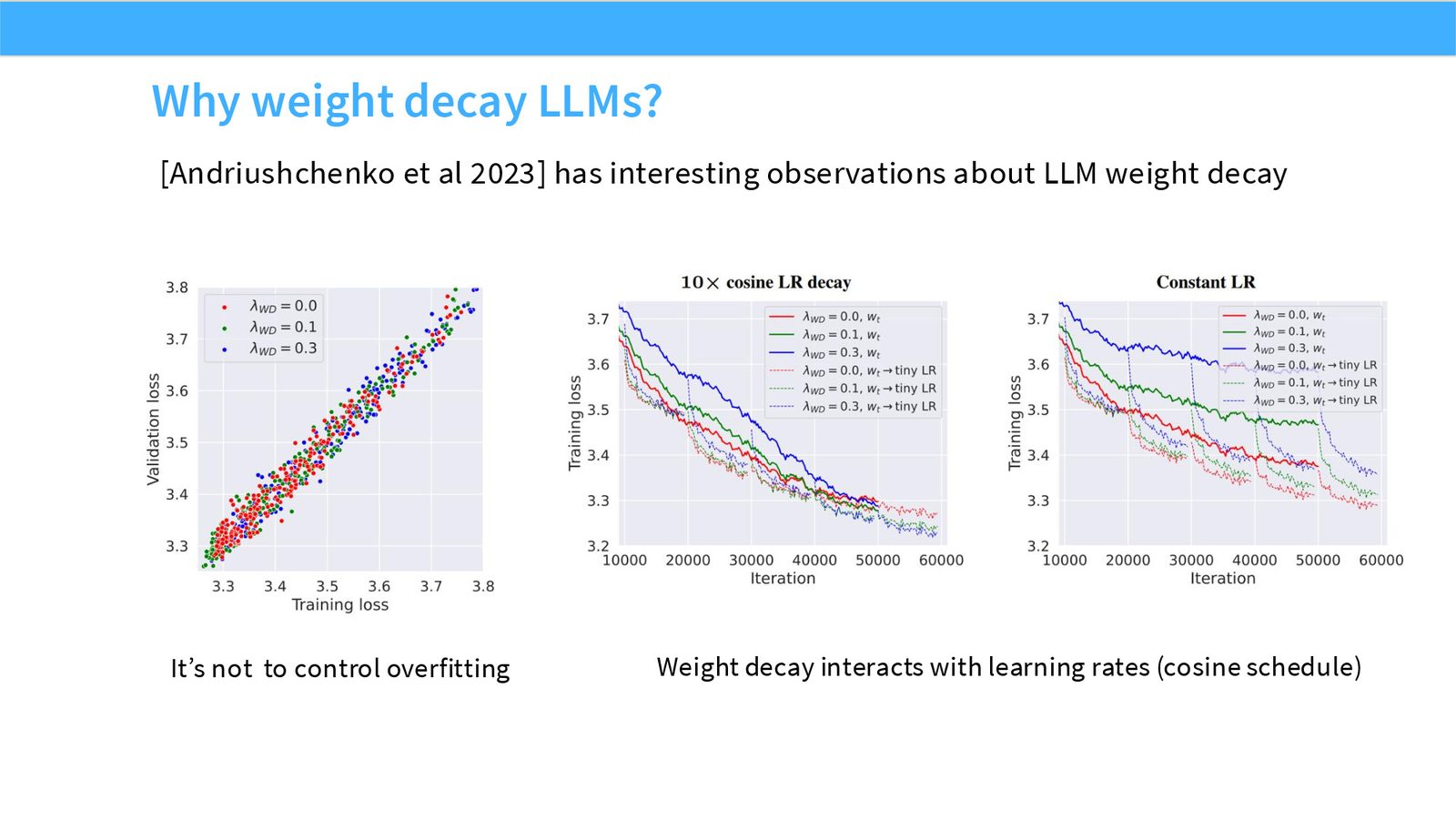
展开说明:本页引用 Andriushchenko 等工作,提示 weight decay 可能影响 logit/表示尺度和泛化。

展开说明:本页总结 FFN ratio、head ratio、aspect ratio、vocab、dropout、weight decay 的现代保守默认。
本章小结
本节的关键不是记住所有模型名,而是把公开模型的设计选择转化成可迁移判断:共识默认值可以作为起点,例外需要知道原因,涉及系统和推理成本的选择必须结合资源账本讨论。
Stability tricks
本节处理 softmax 和 logits 的稳定性:z-loss、QK norm、logit soft-capping。
稳定性技巧的共同风险
z-loss、QK norm、logit soft-capping 都在限制数值尺度。它们能减少训练爆炸或 softmax 饱和,但也可能改变模型表达范围。稳定性补丁必须和 loss 曲线、梯度 norm、下游指标一起看。
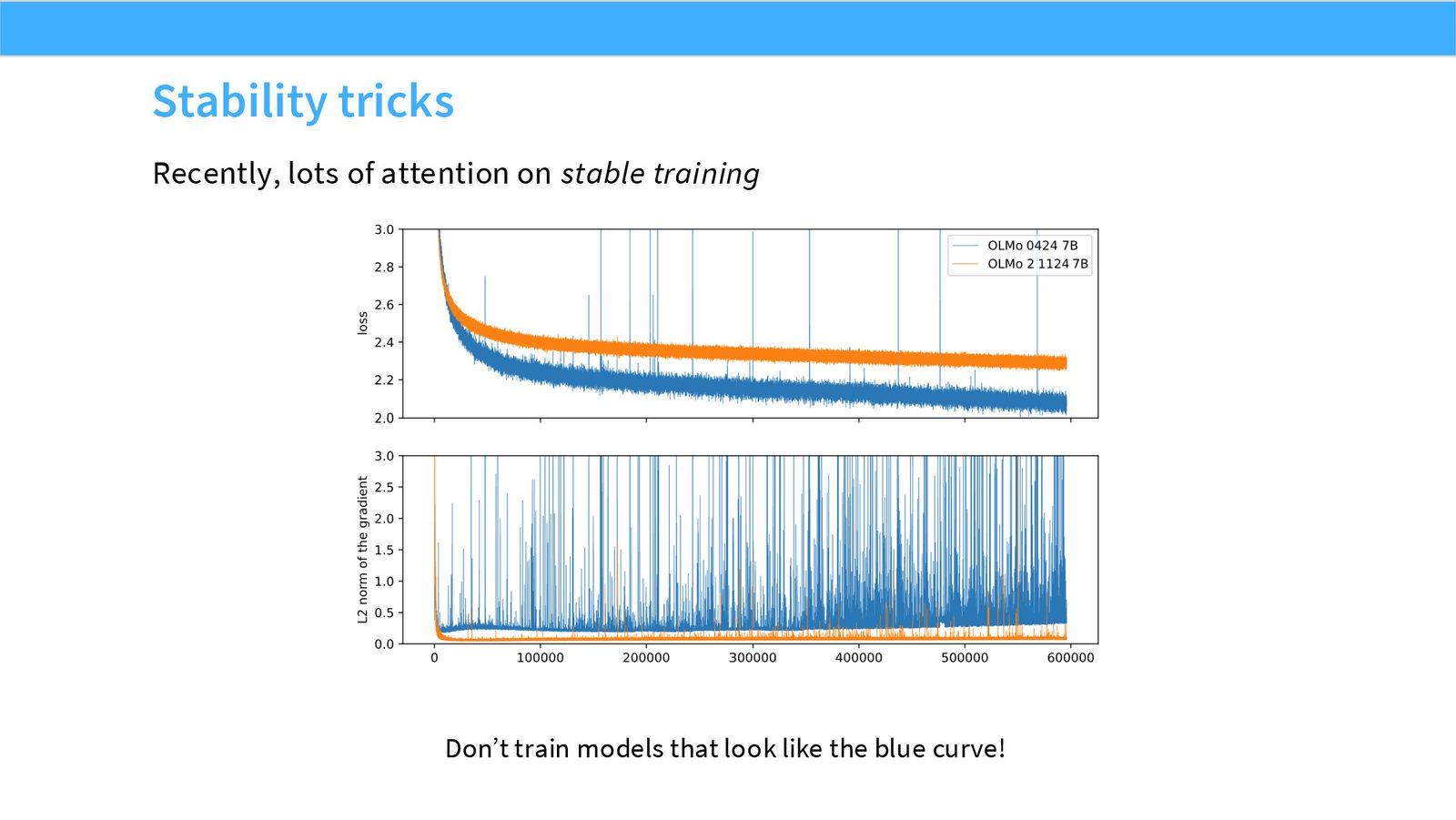
展开说明:本页转入稳定性技巧:越大模型越需要关注 softmax、logits、attention score 的数值稳定。
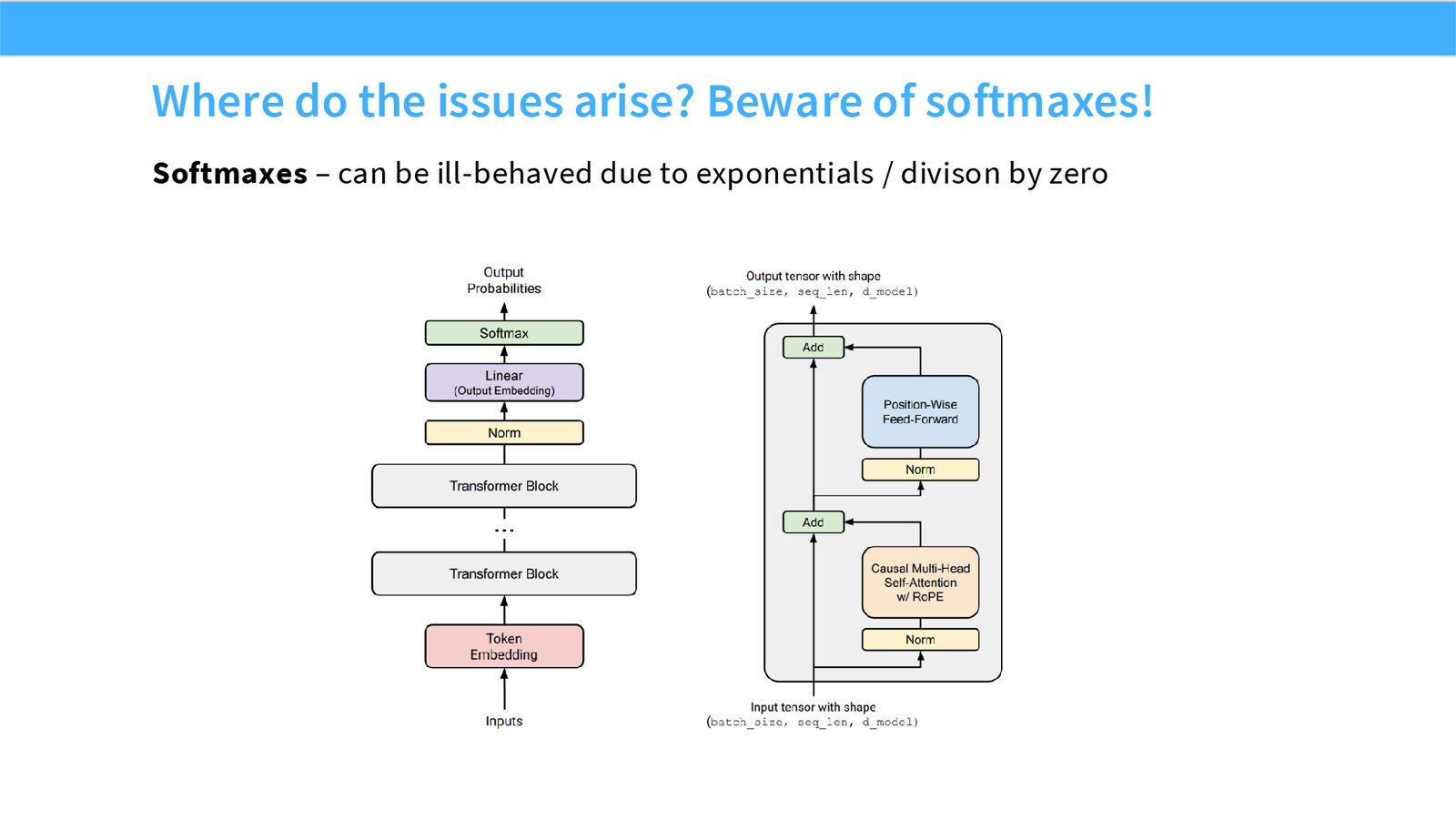
展开说明:本页指出 softmax 因指数和除法容易数值不稳定,是 output 和 attention 两处的共同风险。

展开说明:本页定义 z-loss:约束 log-sum-exp normalizer,防止 logits 尺度失控。
读图:Slide 54 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。
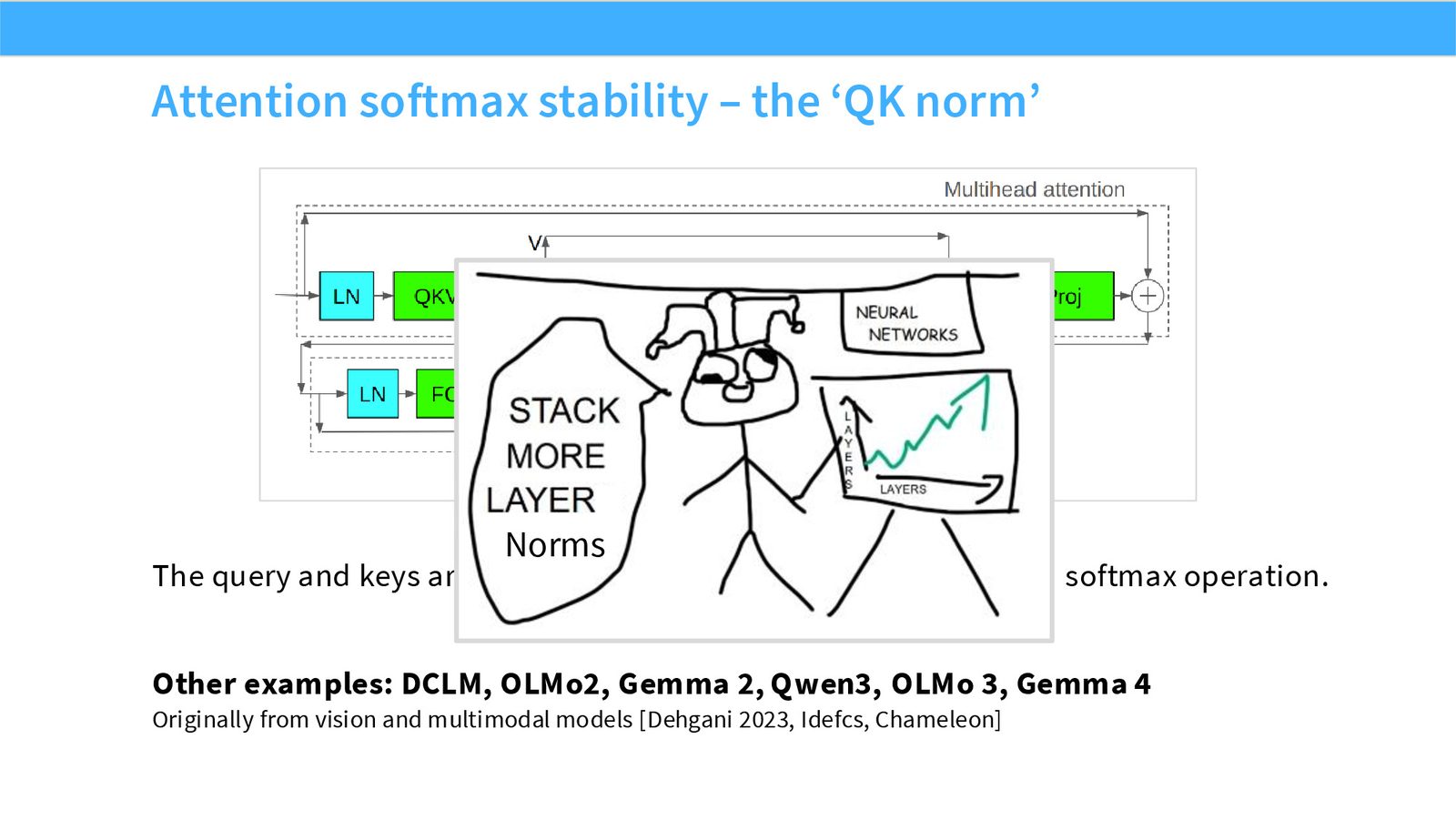
展开说明:本页讲 QK norm:对 query/key 做 norm 控制 attention logits,减少 softmax 极端值。
读图:Slide 55 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。

展开说明:本页展示用 tanh 对 logits 做 soft cap,限制极端 logits。
本章小结
本节的关键不是记住所有模型名,而是把公开模型的设计选择转化成可迁移判断:共识默认值可以作为起点,例外需要知道原因,涉及系统和推理成本的选择必须结合资源账本讨论。
Attention variants and inference pressure
本节解释 attention head 设计为何被推理成本重新打开:MQA、GQA、local/sliding-window attention。
术语消化:MHA、MQA、GQA、local attention
- MHA:每个 query head 都有自己的 key/value head,表达力强但 KV cache 大。
- MQA:多个 query heads 共享一组 key/value,显著降低推理 KV cache,但可能轻微损失质量。
- GQA:介于 MHA 与 MQA 之间,多个 query heads 共享一组 KV heads,是现代推理友好的折中。
- Local/sliding-window attention:只 attend 附近窗口,降低长上下文成本,但需要周期性 full attention 或其他机制维持全局信息。

展开说明:本页说明大多数模型不太改 attention heads,但 inference-driven 例外越来越重要。
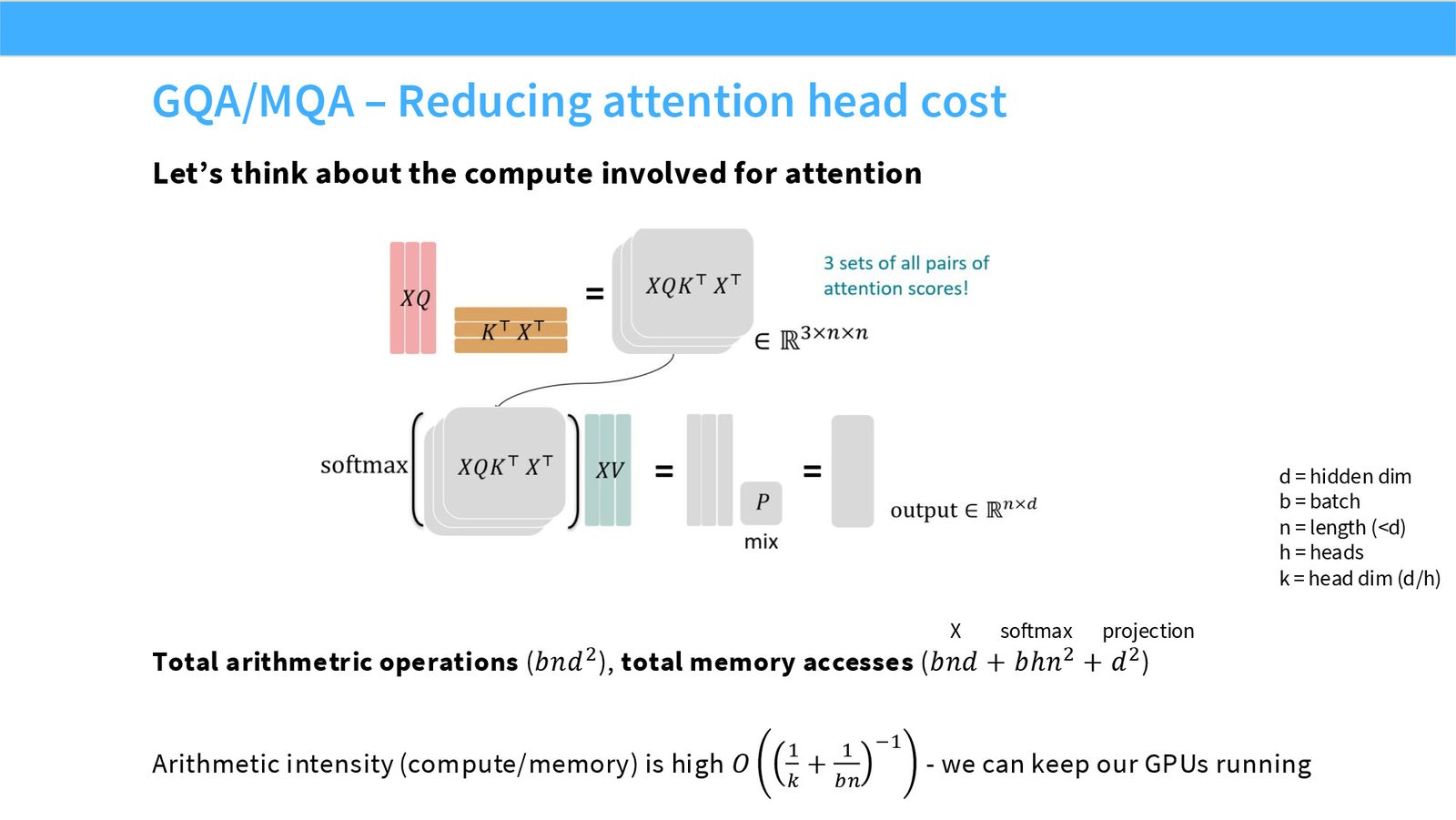
展开说明:本页从 attention compute 角度引入 GQA/MQA,关注 key/value head 成本。
读图:Slide 58 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。
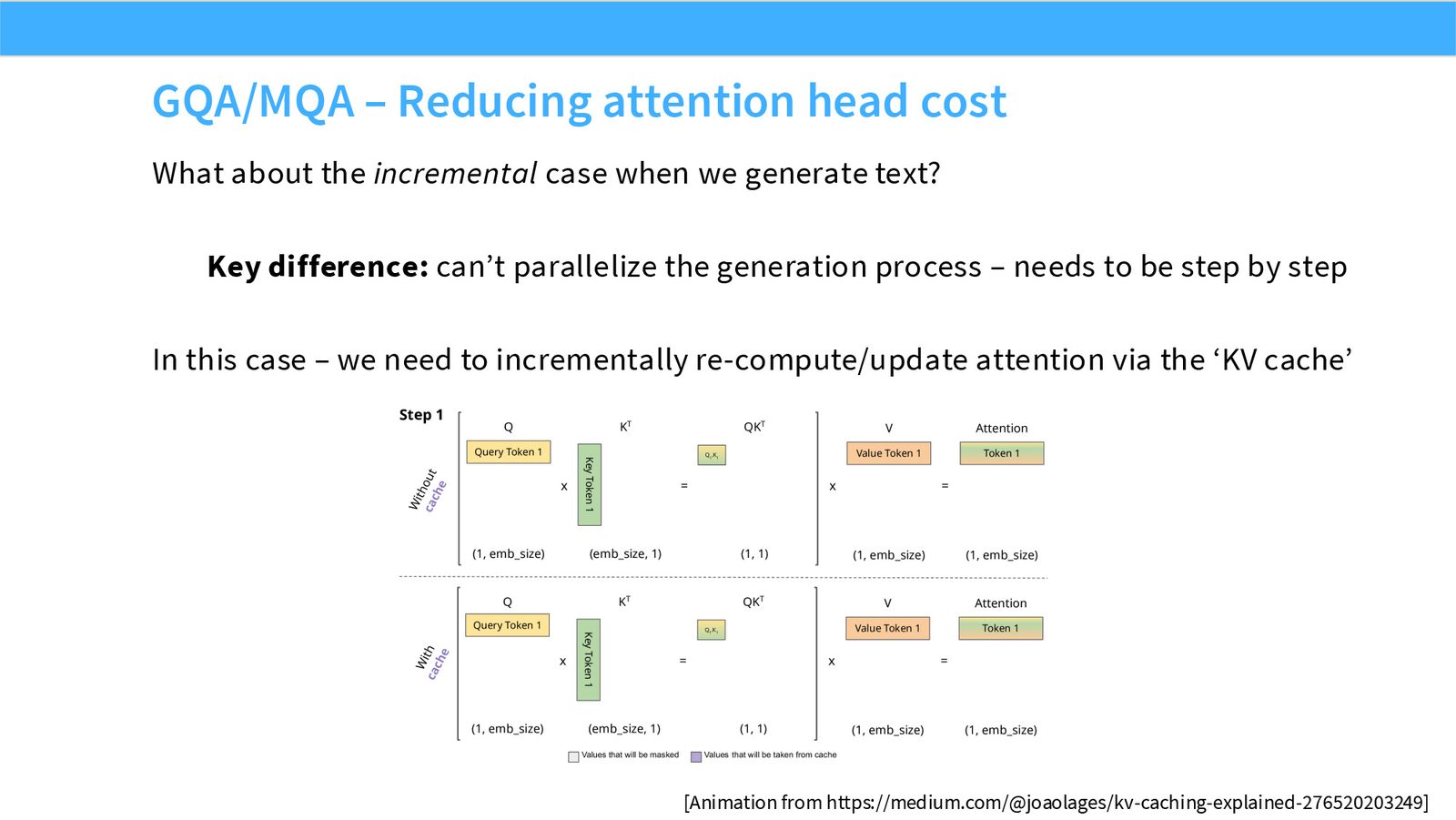
展开说明:本页把问题转到生成时的 incremental case:每次只生成一个 token,KV cache 成本突出。
读图:Slide 59 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。

展开说明:本页解释 decode 的 arithmetic intensity 低,attention KV 读取会成为推理瓶颈。
读图:Slide 60 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。
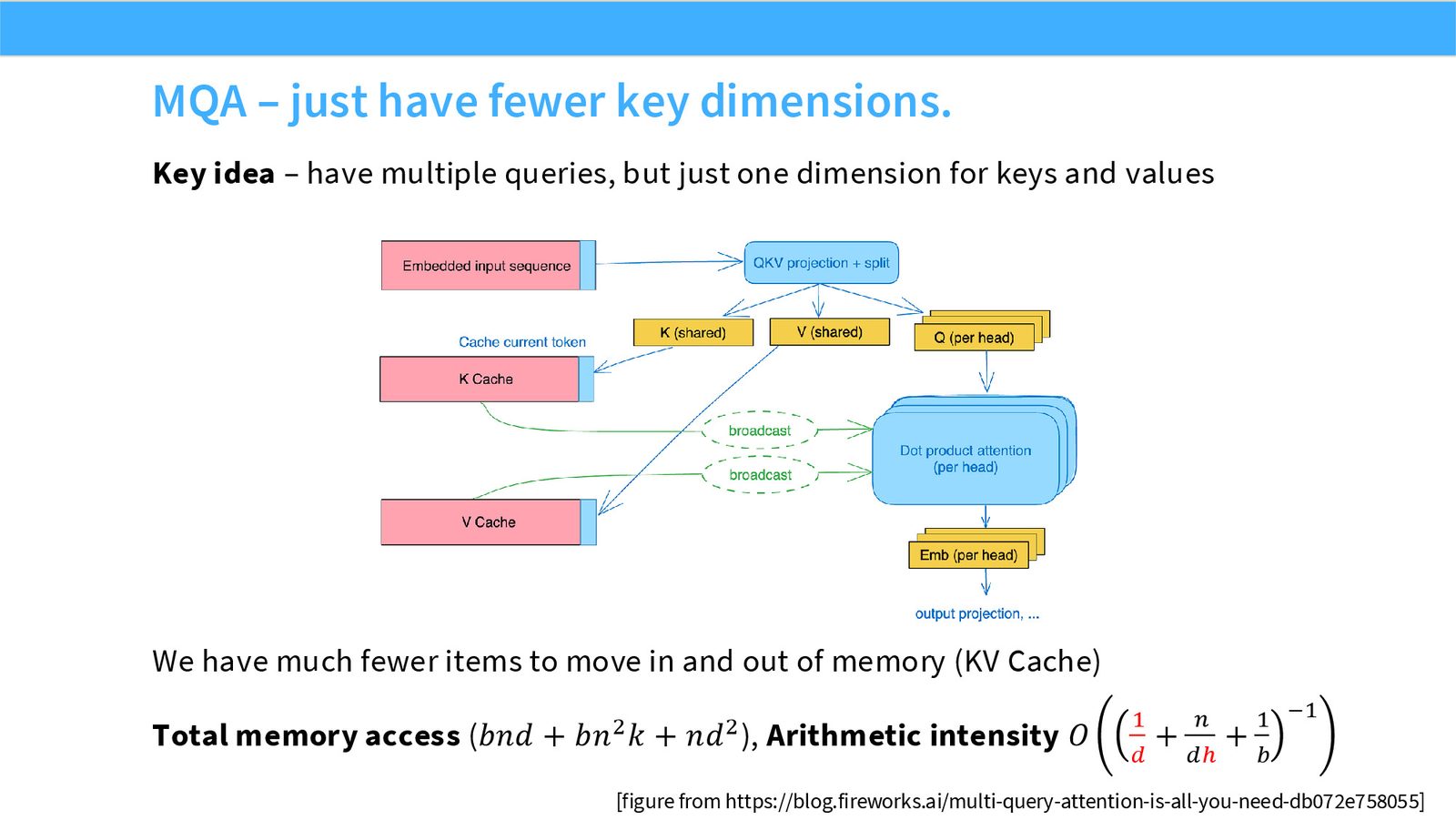
展开说明:本页给出 MQA 核心:多个 query heads 共享更少的 key/value heads。
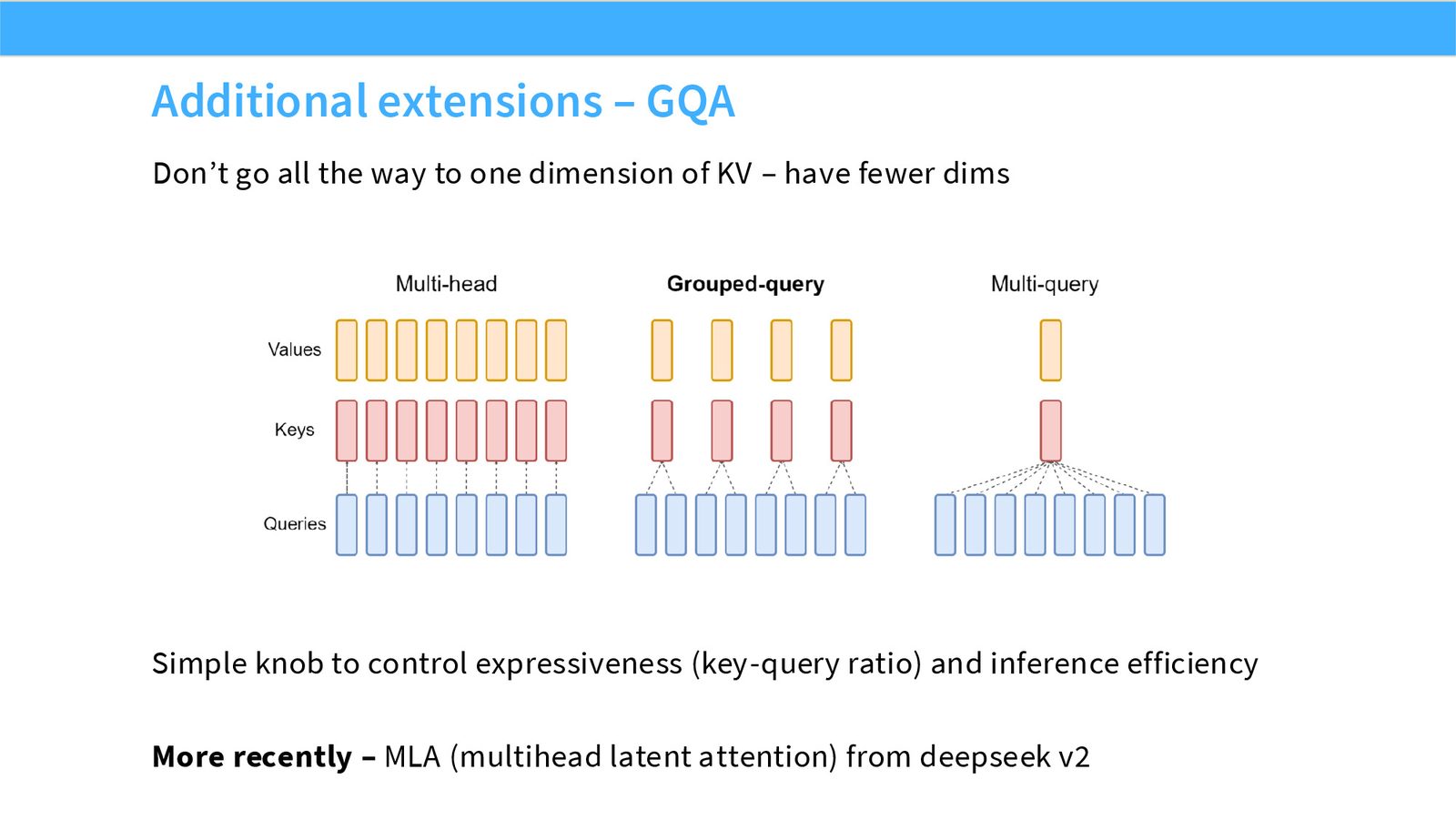
展开说明:本页给出 GQA:不极端共享到一个 KV head,而是分组共享,质量和成本折中。
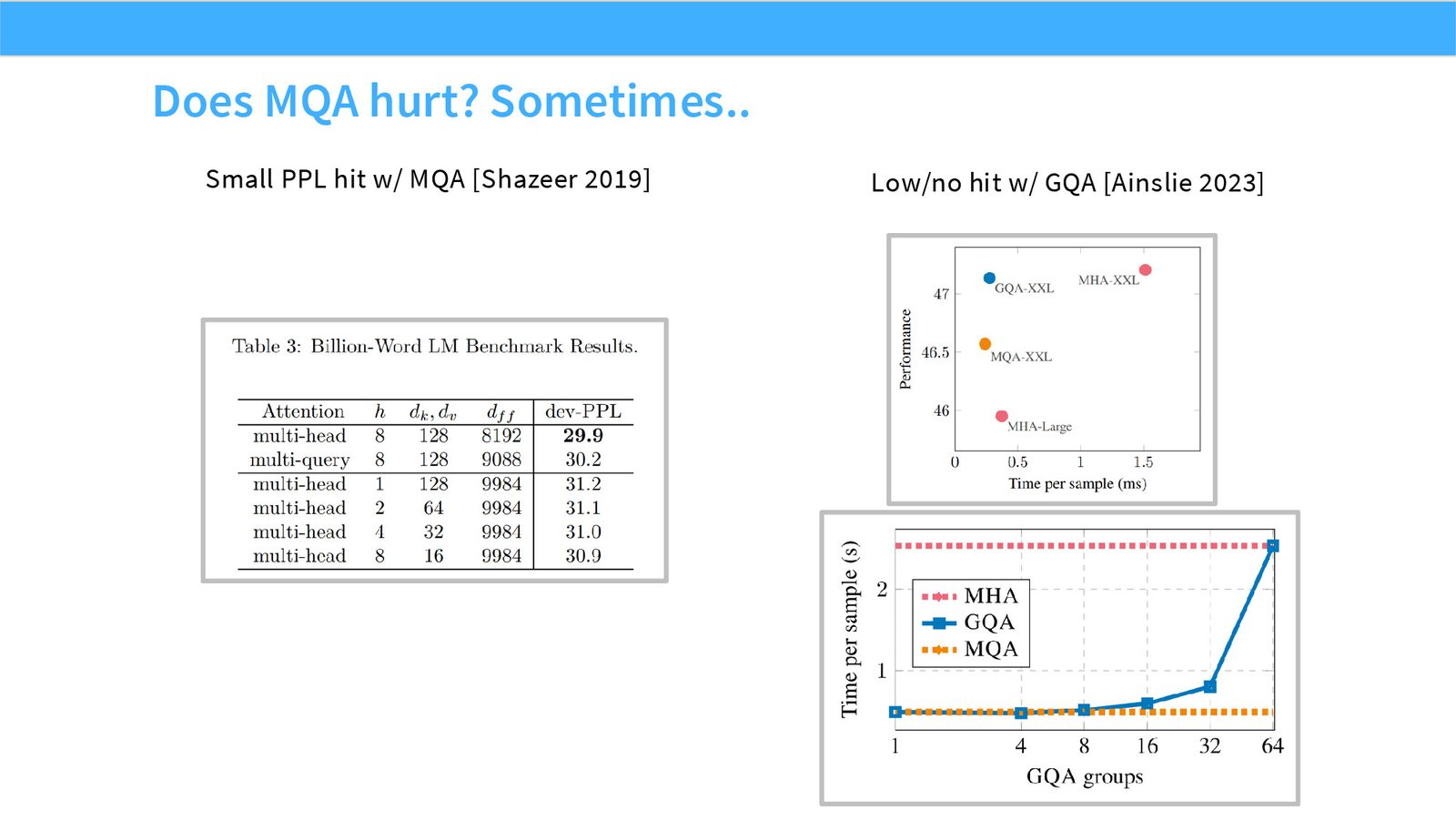
展开说明:本页展示 MQA/GQA 的 PPL 影响证据,说明质量损失通常小但不能忽略。
读图:Slide 63 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。
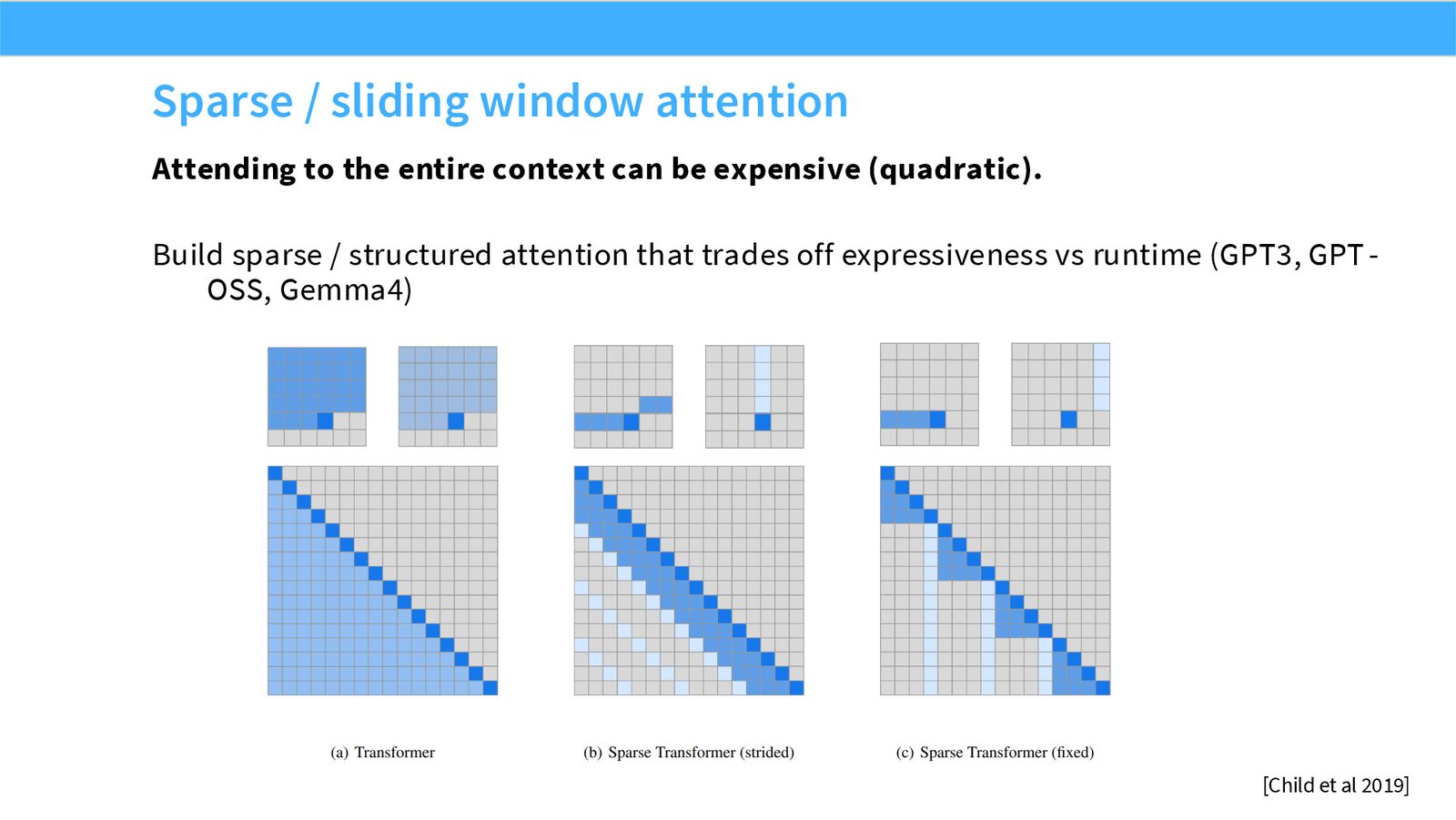
展开说明:本页引入 sliding-window/local attention,降低长上下文完整 attention 的二次成本。

展开说明:本页展示混合策略:多数层 local,周期性 full attention 保持全局信息流。
读图:Slide 65 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。
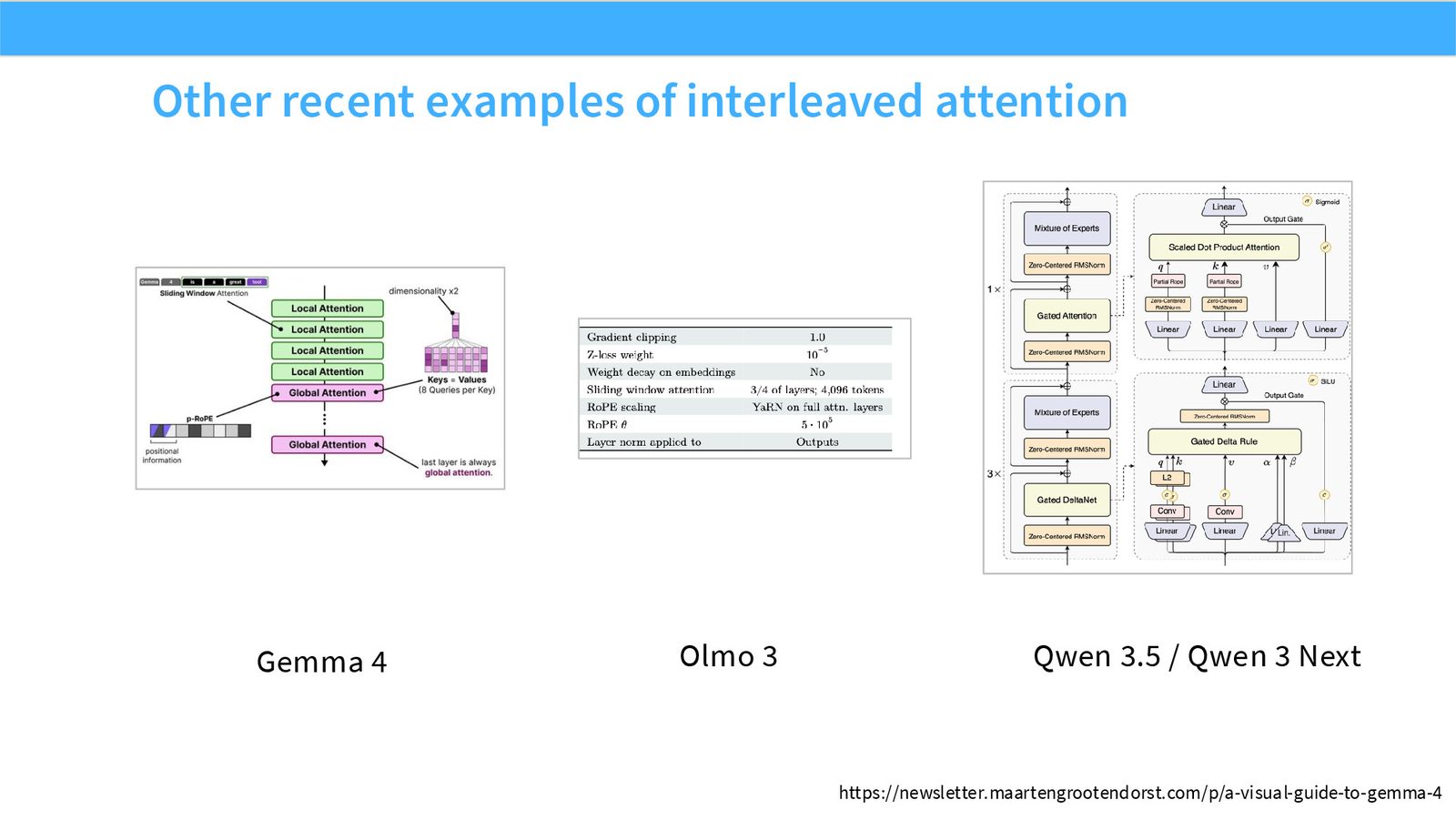
展开说明:本页列出 Gemma、Olmo、Qwen 等近期模型的 interleaved attention 实践。
读图:Slide 66 应该怎么看
这页不是装饰性截图,而是本节论点的证据页。先看图中模型/论文/曲线或表格的比较对象,再看它们支持的趋势:哪些设计已经形成共识,哪些只是局部实验结果,哪些主要由运行时或推理成本推动。读这类页时要区分 quality evidence、runtime evidence 和 stability evidence,不能把一种证据直接替换成另一种。
本章小结
本节的关键不是记住所有模型名,而是把公开模型的设计选择转化成可迁移判断:共识默认值可以作为起点,例外需要知道原因,涉及系统和推理成本的选择必须结合资源账本讨论。
Recap
最后回到本讲总问题:哪些默认值稳,哪些选择依赖规模、系统和任务。

展开说明:本页总结:现代 LM 有许多共同架构默认值,也有受推理、稳定性、系统约束驱动的新变化。
本章小结
本节的关键不是记住所有模型名,而是把公开模型的设计选择转化成可迁移判断:共识默认值可以作为起点,例外需要知道原因,涉及系统和推理成本的选择必须结合资源账本讨论。
跨章节综合:如何选择自己的 architecture recipe
| 决策层 | 保守默认值 | 什么时候需要重新实验 |
|---|---|---|
| Norm | pre-norm + RMSNorm + no bias | 极深模型、训练不稳定、需要 QK norm 或额外 postnorm 时 |
| FFN | SwiGLU / GeGLU,按参数量调整 hidden dim | 小模型、特殊硬件、不同 activation kernel 性能差异明显时 |
| Position | RoPE | 超长上下文 extrapolation、局部 attention、特殊多模态输入时 |
| Head shape | 总 head dim 接近 model dim,head dim 取硬件友好值 | 推理 KV cache 成本高,考虑 GQA/MQA/MLA 时 |
| Regularization | 预训练少用 dropout,保留 weight decay | 数据很小、fine-tuning、过拟合明显时 |
| Stability | 监控 logits、QK norm、gradient norm | 出现 loss spikes、softmax 饱和、长上下文训练不稳时 |
最终 takeaways
现代 LM 架构已经形成一组强默认值:pre-norm、RMSNorm、SwiGLU、RoPE、bias-free linear layers、保守 FFN/head/aspect ratio、GQA 或 hybrid attention 的推理友好变体。但这些默认值不是理论定律,而是公开模型、硬件、数据和训练稳定性共同塑造的经验均衡。
不要把架构选择和系统选择分开
RMSNorm、bias removal、parallel layers、GQA、sliding-window attention 看起来是 architecture,但常常由 memory bandwidth、kernel fusion、KV cache、latency 和 parallelism 驱动。Lecture 3 和 systems/inference 单元是相互嵌套的。
总结与延伸
本讲把现代 Transformer 的大量细节组织成四类问题:norm 和 residual stream 保证训练稳定,FFN/activation 决定表达和参数效率,position embedding 决定序列几何,hyperparameters 和 attention variants 则把模型质量、训练效率和推理成本连在一起。
- 共识默认值:pre-norm、RMSNorm、SwiGLU、RoPE、no bias 已经是现代大模型常见起点。
- 经验证据:很多选择来自公开模型和消融结果,而不是完备理论证明。
- 系统动机:FLOPs 少不一定 runtime 少;数据移动、KV cache 和 kernel shape 经常决定真实收益。
- 实验原则:保守默认值用于起步,真正 recipe 需要小规模可控实验验证。
拓展阅读
- Xiong et al. 2020 on pre-norm and warmup.
- Zhang and Sennrich 2019 on RMSNorm.
- Shazeer 2020 on GLU variants and SwiGLU.
- Su et al. 2021 on RoPE.
- Shazeer 2019 and Ainslie et al. 2023 on MQA/GQA.