[LLM Agents F25] Multi-Agent Systems in Era of LLMs — Oriol Vinyals
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Oriol Vinyals 授课内容整理 |
| 来源 | Berkeley RDI |
| 日期 | 2026-04-02 |
![[LLM Agents F25] Multi-Agent Systems in Era of LLMs — Oriol Vinyals](cover.jpg)
讲座定位与问题设置
这节课的核心,不是给出一个新的 Agent 框架名字,而是回答一个更基础的问题:在 LLM 已经具备 Tool Use、Chain-of-Thought、长上下文和代码执行能力之后,为什么还必须系统性地引入 Multi-Agent 训练视角?Oriol Vinyals 的答案非常明确:如果只做单 Agent 指令优化,系统几乎必然在真实开放环境中出现脆弱性;只有把“协作者”和“对抗者”都纳入训练生态,模型才能获得可持续鲁棒性。
本讲的主命题
课程主线可压缩为一句话:把 AlphaStar 时代对 population training、league dynamics、exploiter discovery 的经验,迁移到 LLM Agent 的 post-training 时代。
讲者给出的历史坐标
本讲并非从零开始设计 LLM Agent,而是沿着 Atari \(\rightarrow\) Go \(\rightarrow\) StarCraft II \(\rightarrow\) LLM Agents 的连续谱系展开。核心是:问题复杂度每上一个台阶,训练目标都会从“单一最优策略”转向“多策略生态中的稳态”。
讲者在 18 分钟附近的表述非常关键:“This is strikingly close to tool use in general.”\footnote{来源:Agentic AI MOOC Lecture 03,字幕区间 00:17:49--00:18:05。} 这里的 “this” 指的是 AlphaStar 中把高维决策拆成 API-like 动作调用序列的机制。换言之,今天 LLM 在 MCP / function calling 里做的事情,在游戏智能里早已出现过结构同构。
不要把本讲理解成“游戏经验照搬”
讲者也反复强调差异:StarCraft 的奖励更清晰、动作接口更结构化,而真实世界 Prompt 与用户目标更含糊。迁移是“借鉴动力学和训练组织方式”,不是“复用原任务定义”。
本章小结
本章给出全讲的评价标准:后续所有技术点都围绕同一目标,即如何让 LLM Agent 从“单点正确”转向“群体互动下的长期稳定正确”。这一目标决定了我们必须讨论 API 设计、IL+RL 混合训练、对抗发现机制和 league 匹配策略。
从复杂度基准到 Agent 评测范式
讲者先通过经典任务对比,解释为什么 StarCraft II 一直被视作现代 Agent 研究的“中间地带”:它既不像 Atari 那样简化,也不像开放互联网任务那样无边界,却已经拥有多主体、部分可观测、长时信用分配和超大动作空间等要素。
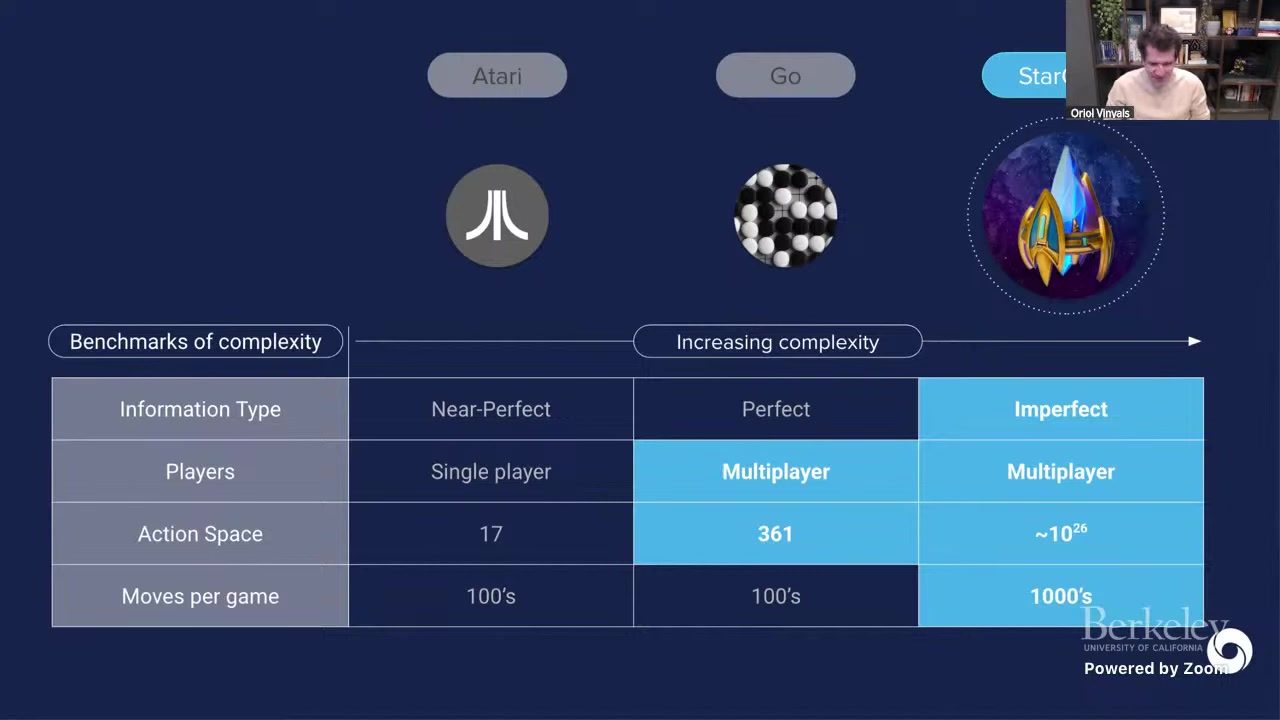
图 \ref{fig:complexity-benchmark} 是讲者在开场阶段给出的关键图\footnote{来源:Lecture 03 视频帧,时间戳 00:05:45。}。从中可以直接读出一个对后文非常重要的结论:当信息不完全、玩家数量上升、动作空间爆炸时,“单策略+固定对手”训练会迅速失效。
| 任务域 | 状态可观测性 | 对手/用户形态 | 训练关注点 |
|---|---|---|---|
| Atari | 近似完全可观测 | 单环境反馈 | 样本效率、稳定收敛 |
| Go | 完全可观测 | 双人对弈 | 搜索与策略价值协同 |
| StarCraft II | 部分可观测 | 多策略对手生态 | population diversity、counter-strategy |
| LLM Agent 真实场景 | 开放非结构化 | 协作用户 + 对抗用户 | alignment robustness、tool reliability、攻击面收敛 |
评测范式变化
当任务从“封闭规则”走向“开放交互”,评测指标必须从单一平均分转向多维指标:成功率、最坏分位、恢复能力(recovery)、对抗暴露面(attack surface)、策略多样性与长期稳定性。
为什么讲者强调“不是零和”
在 LLM 场景里,用户经常是协作者,不一定是对手。这意味着我们需要同时评估 cooperative efficiency 与 adversarial robustness。仅仅复刻 self-play Elo 曲线并不足够。
本章小结
本章给出的核心启示是:LLM Agent 的评测必须继承多智能体博弈中的“分布视角”,而不是沿用单任务准确率思路。没有分布鲁棒性,就没有可部署性。
动作表示、API 边界与架构可塑性
在 17--18 分钟段,讲者把 AlphaStar 的 action head 与今天 LLM 的 Tool Use 做了直接映射。这是全讲最有工程价值的部分之一:它揭示了“动作接口设计”本身就是能力上限。
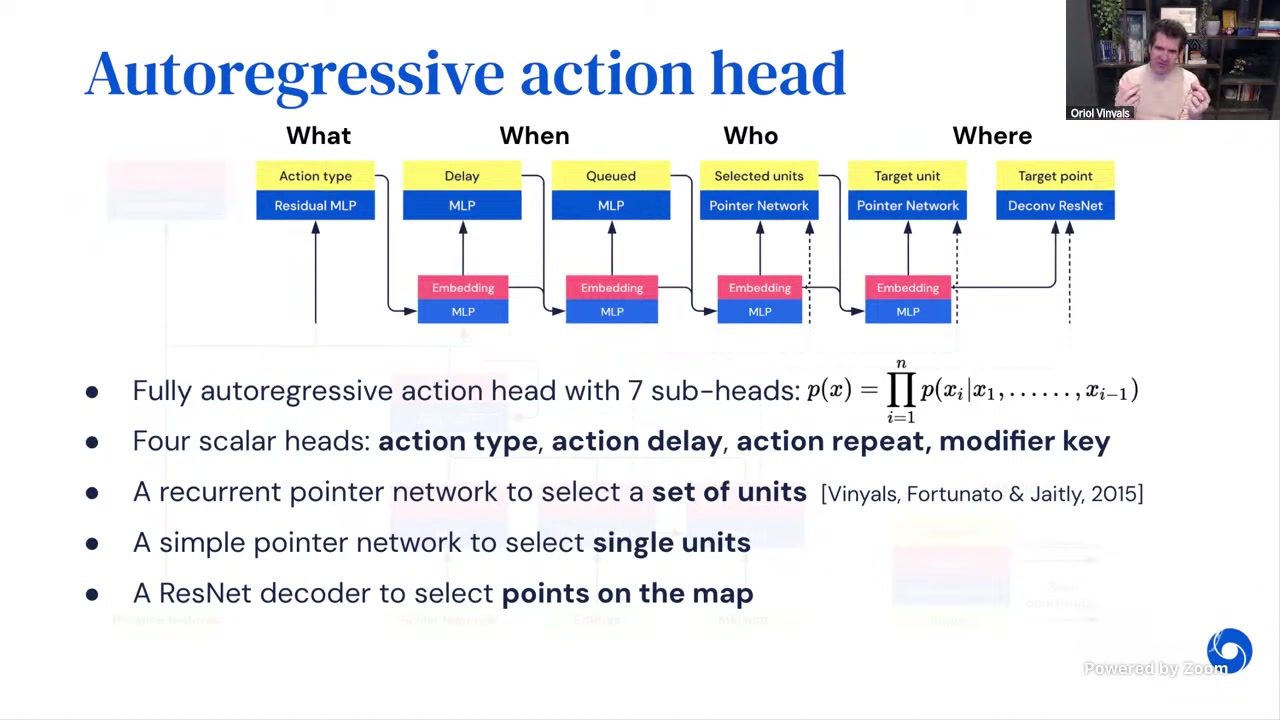
图 \ref{fig:action-head} 展示了动作拆解的结构\footnote{来源:Lecture 03 视频帧,时间戳 00:17:40。}:What(动作类型)、When(时机/延迟)、Who(施加对象)、Where(目标位置)。这与 LLM function calling 中 “tool name + arguments + execution context” 基本同构。
从 StarCraft Action 到 LLM Tool Call 的映射
- What \(\leftrightarrow\) 选择工具(search / code / browser / retrieval)
- When \(\leftrightarrow\) 何时调用(先规划后执行,还是边思考边调用)
- Who \(\leftrightarrow\) 对哪个实体施加动作(文件、进程、用户会话、数据库记录)
- Where \(\leftrightarrow\) 操作落点(参数空间、页面节点、API endpoint)
接口比模型更先成为瓶颈
如果 API 的动作语义过粗,模型无法表达精细计划;如果 API 过细,探索空间会指数增长。课程给出的工程建议是:先建立“可组合原语”,再让策略在原语之上学习分层调用。
常见误区:把 Tool Use 仅当作检索插件
把 tool 视为“补充知识”会忽视其控制能力(actuation)。在 Agent 任务里,tool 既是信息通道,也是行为通道。行为通道失控将直接导致越权、幻觉执行、不可逆副作用。
为了使该思想可落地,可以把动作接口写成显式的约束语法:
TOOL_CALL := {
"tool": one_of["search", "terminal", "editor", "web_click"],
"goal": natural_language_intent,
"args": structured_arguments,
"safety_level": one_of["read_only", "bounded_write", "privileged"],
"rollback_plan": optional_steps
}
这类 schema 的价值在于:它让训练目标从“生成像人类的文本”转成“生成可验证的动作计划”。
本章小结
动作空间定义了可学能力边界。AlphaStar 的经验告诉我们,LLM Agent 的架构设计应优先解决动作可分解、可约束、可验证三个问题,否则后续 RL 和多 Agent 训练只是在不稳定接口上叠加复杂度。
IL + RL 混合范式:为什么纯 RL 不够
讲者在 21 分钟段明确提出:“I strongly believe the answer is no.”\footnote{来源:Lecture 03 字幕,区间 00:21:31--00:21:35。} 这里的问题是“纯 RL 能否走完全程”。其论证不是抽象哲学,而是具体失效案例。
混合训练的工程逻辑
- 先用 imitation learning 注入人类先验,获得可用但未最优的初始化策略。
- 再用 reinforcement learning 在真实反馈上超越演示分布。
- 通过 population 对战和对抗样本,修复策略盲区。
字幕在 21:06--22:15 这一段给出一个典型现象:纯 RL 能学出能赢的策略,但可能是“unsatisfactory”的赢法,比如把工人全拉去攻击(worker rush/all-in 变体),以 exploit 方式击败特定对手,却不具备广泛可迁移性。
| 路径 | 优势 | 主要风险 | 适用阶段 |
|---|---|---|---|
| 纯 IL | 稳定、样本效率高、可控性强 | 上限受限于演示质量,难以超越专家 | 冷启动与行为边界塑形 |
| 纯 RL | 可发现新策略,长期可超人 | 容易投机取巧、奖励黑客、收敛脆弱 | 闭环仿真充分且奖励清晰场景 |
| IL + RL | 吸收先验后再探索,兼顾性能与可控性 | 系统复杂度高,需精细调参与评测 | 开放任务、需兼顾安全与性能 |
不要把“赢一局”当作“会这个任务”
在多策略环境里,局部 exploit 成功可能只是偶然匹配,不代表策略掌握。若缺少跨对手分布验证,线上部署后会快速暴露脆弱点。
把这个结论迁移到 LLM Agent:仅依赖 preference optimization 或少量 reward model 信号,同样可能出现“会做 benchmark,不会做真实任务”。因此课程强调 post-training 的核心不是把平均分再抬高一点,而是把失败模式系统性地压缩。
本章小结
IL + RL 的价值在于把“人类先验”和“环境反馈”联合起来。纯 RL 或纯 IL 都能在局部任务表现良好,但都难以单独支撑开放世界 Agent 的长期鲁棒性。
失效模式谱系:从对抗扰动到策略奶酪
讲者用游戏术语把失败分成三个层次:adversarial policies、exploiters、cheese。这一分类对 LLM 安全评估极具操作性,因为它对应了不同强度、不同成本的攻击者模型。
三层失效模型
- Adversarial-like:微小扰动触发大幅错误,类似对抗样本。
- Exploiter:持续围绕某一弱点迭代,形成稳定压制。
- Cheese:策略可泛化到多个对手,但不一定是整体最优。
为什么 “How many r in strawberry” 被反复提及
讲者用这个例子强调:系统可能在高难任务表现亮眼,却在基础一致性上失败。这并非“偶发小错”,而是能力分布不均衡,提示我们要做 failure taxonomy,而非只看均值指标。
从失败分层到测试分层
对应三层失效模型,测试也要分层:
- 扰动稳健性测试(格式噪声、提示变体、边界输入)
- 目标导向 exploit 测试(反复 probing、记忆污染、工具串联攻击)
- 分布迁移测试(新任务族、长时交互、跨工具组合)
这部分最重要的一句话是:“You have these models, they do amazing things, but we see them fail often.”\footnote{来源:Lecture 03 字幕,区间 00:32:57--00:33:03。} 这不是悲观论断,而是训练目标需要升级的证据。
本章小结
失败不是单点事件,而是一个分层谱系。只有将其结构化,才能把鲁棒性从“运气”变成“可优化对象”,这也是后续 league 机制存在的根本理由。
League 训练机制:exploiter、不对称博弈与匹配策略
在 44--53 分钟段,讲者详细讲了 AlphaStar league 如何避免策略塌缩。核心机制不是简单“多放几个模型一起打”,而是通过不对称训练目标和精细 match-making 维持压力。
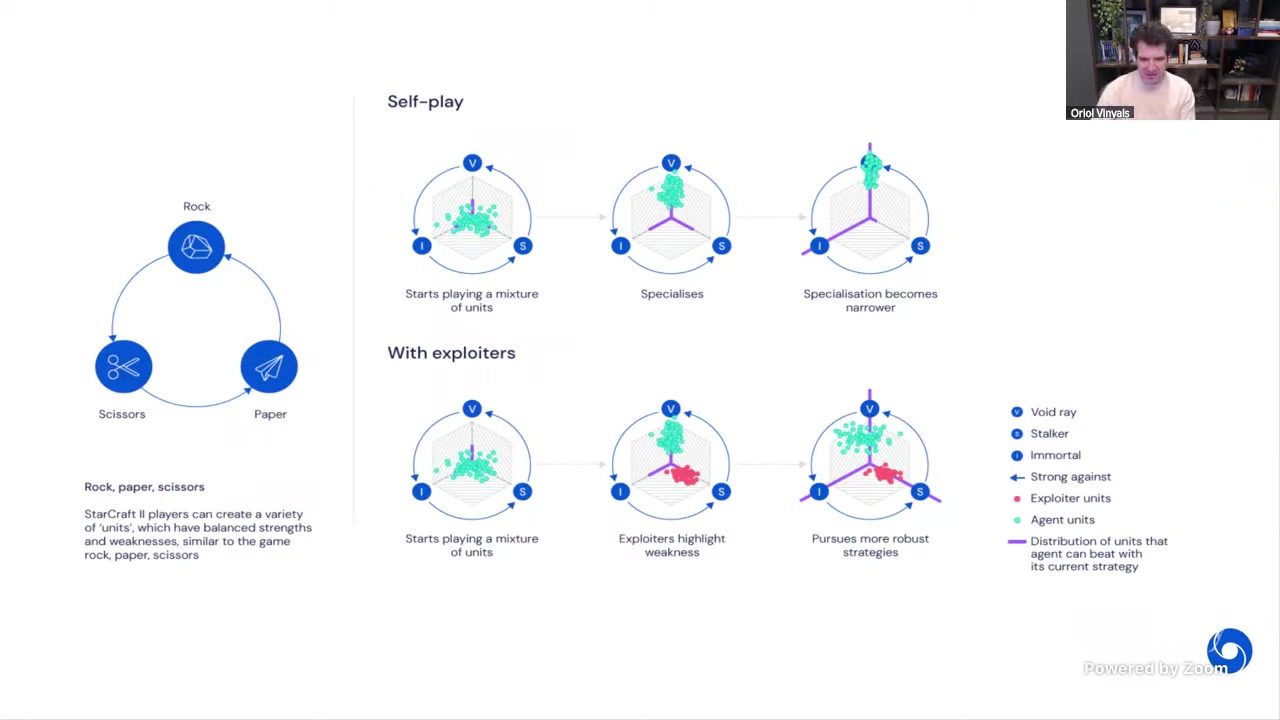
图 \ref{fig:selfplay-vs-exploiter} 对比了两条演化轨迹\footnote{来源:Lecture 03 视频帧,时间戳 00:44:50。}:仅自博弈容易走向狭窄专精,而加入 exploiter 后会被迫寻找更鲁棒策略。
exploiter 的关键设计
讲者描述了一个重要不对称:主策略(main agent)不总能看到 exploiter 的全部训练信息,而 exploiter 专注于击败主策略。这个不对称会持续暴露主策略盲点,抑制过早收敛。
match-making 的两个候选策略
- 对 hardest opponent 训练:直接面对最强压制者,但可能学习信号过稀。
- 对 50/50 opponent 训练:接近最大熵区间,梯度信号更稳定。
字幕中讲者指出 50/50 常带来更平衡的方差与学习信号(00:52:35--00:52:54)。
我们可以用信息论语言表达其直觉:若胜率 \(p\) 接近 0 或 1,策略更新常退化;当 \(p\approx0.5\) 时,不确定性最高,改进空间最大。二元熵
在 \(p=0.5\) 取最大值,这与讲者的经验观察一致。
只追 hardest 不一定最优
如果对手强到长期碾压,模型拿不到有效学习信号;如果对手弱到长期碾压对方,也学不到新东西。match-making 本质是在“挑战性”与“可学习性”之间找平衡。
本章小结
League 的本质是组织学习压力,而不仅是增加算力。exploiter 机制、对手采样和训练不对称性共同决定了策略最终形态,这些思想可直接迁移到 LLM Agent 的 red teaming 与在线优化流程。
从 AlphaStar 到 LLM:协作用户与对抗用户共存
在 54 分钟后,讲者转入直接对照:LLM 环境不是标准零和博弈,用户大多是协作者,但对抗用户同样真实存在。对应地,训练系统必须同时处理两类目标。

图 \ref{fig:contrast-llm} 的要点非常清晰\footnote{来源:Lecture 03 视频帧,时间戳 00:56:30。}:用户通常合作,但必须假设 adversarial probing 常态化;现实任务复杂度远高于游戏;多 Agent red teaming 已在使用,但整体仍处于早期。
迁移时最容易忽视的差异
- 奖励函数模糊:真实任务很少有明确胜负信号。
- Prompt 空间无界:自然语言比离散动作接口复杂得多。
- 用户目标异质:同一模型同时服务效率、创造力、安全、合规等多目标。
双生态训练目标
迁移后的 LLM 多 Agent 训练至少应同时优化两类分布:
- Collaborative distribution:正常用户任务成功率、成本和体验。
- Adversarial distribution:越权、诱导、注入、策略欺骗下的稳健性。
单看一类分布会导致另一类指标崩塌。
错误策略:把 red teaming 当作发布前一次性流程
讲者强调 “users probe it”,意味着攻击会持续演化。red teaming 必须从项目流程角度变成持续对抗循环,而不是 QA 阶段的 checklist。
这里的关键引语也很值得保留:“Users are in general collaborative... That being said, we also have adversarial users.”\footnote{来源:Lecture 03 字幕,区间 00:54:47--00:55:12。}
本章小结
LLM 时代的多 Agent 问题不是把所有人当敌人,也不是把所有人当朋友,而是承认二者共存。训练、评测与上线监控都必须对应这一现实分布。
可扩展性判断:post-training 仍在早期
讲者在结尾给出一个强信号:“in this AlphaStar league we use 10 to the 10 training steps in post training”\footnote{来源:Lecture 03 字幕,区间 00:58:21--00:58:29。}。这句的分量在于,它把讨论从算法偏好拉回到训练资源分配问题。
计算资源分配的结论
在 AlphaStar 类型系统中,post-training 的计算投入可以远超 pretraining;而当前 LLM 体系往往把绝大部分预算放在 pretraining,post-training 仍偏轻量。讲者据此判断:多 Agent RL 可能是下一轮 scalability breakthrough 的来源。
为什么这对课程项目重要
如果把后训练看成“微调收尾”,那你会设计出静态评测和短周期迭代;如果把后训练看成“主战场”,你会优先投资:
- 大规模交互数据回放与筛选;
- exploit discovery 自动化;
- population-level 评估与调度基础设施。
规模化不等于盲目加算力
讲者也指出 reward fuzziness 是核心难点。若奖励定义失真,算力只会放大偏差。扩展前必须先回答:我们到底在优化什么行为?
| 方向 | 关键问题 | 预期价值 |
|---|---|---|
| Population RL for LLMs | 如何构造多用户/多代理交互分布并稳定训练 | 提升真实场景鲁棒性与泛化 |
| Reward grounding | 模糊奖励如何转化为可学习信号 | 降低目标漂移和 reward hacking |
| Adaptive matchmaking | 在线选择最有学习价值的对手与任务 | 提升训练效率,降低无效对抗成本 |
| Controllable exploit generation | 如何可控地产生高价值 counter-strategy | 缩短脆弱性发现周期 |
本章小结
本章核心是资源观:当前 LLM 的后训练强度与 AlphaStar 式系统相比仍偏早期。下一阶段突破很可能来自 “多 Agent + 强后训练 + 可控对抗” 的联合设计,而非单点提示技巧。
面向课程实践的落地框架
为了把讲座理念转成可执行路径,这里给出一个可用于课程项目或团队内部试验的最小实践框架。该框架不追求一步到位的 AGI,而是优先构建可闭环迭代能力。
四层工程栈
- 接口层:定义可组合 Tool API 与权限边界。
- 策略层:主策略 + exploiter 策略 + evaluator 策略协同。
- 训练层:IL 冷启动 + RL 强化 + match-making 调度。
- 评估层:协作成功率、对抗稳健性、恢复速度、成本曲线。
一套可复用的实验循环
- 采集真实任务轨迹,构建 IL 数据与失败标签。
- 启动主策略,使用固定安全规则做第一轮上线。
- 用 exploiter 代理自动挖掘脆弱点,生成 counter episodes。
- 以 50/50 类似准则做任务采样,避免训练信号塌缩。
- 周期性回归评估,分离“平均性能提高”与“尾部风险下降”。
课程项目里最容易被忽略的环节
很多项目只记录最终成功率,不记录失败路径与修复时间。没有 failure replay 和修复时延统计,就很难判断系统是否真的更鲁棒,还是只是在测试集上更幸运。
| 指标组 | 代表指标 | 解释 |
|---|---|---|
| 协作效率 | 任务成功率、平均步数、工具调用次数 | 反映正常用户体验与成本 |
| 对抗稳健性 | 攻击成功率、越权率、注入生效率 | 反映安全边界真实强度 |
| 恢复能力 | 失败后重试成功率、平均恢复轮数 | 反映系统弹性而非一次命中 |
| 分布泛化 | 新任务族成功率、跨工具迁移性能 | 反映是否过拟合既有任务 |
如果把上述框架与本讲观点对应,可以得到一个务实判断:Multi-Agent 的真正价值不在于多模型并行本身,而在于它能够持续制造“有学习价值的压力”。
本章小结
从实践角度看,最重要的是先搭建可闭环系统:能发现弱点、能生成反制、能验证改进。只有这样,讲座里的理论迁移才会转化为可复现的工程收益。
课堂案例精读:四个关键时间片
为了避免笔记停留在概念层,本章按视频中的四个关键时间片做精读,分别对应“问题定义”、“架构映射”、“鲁棒机制”、“扩展判断”。每个时间片都可以直接转化为后续研究任务。
时间片 A(00:17–00:18):Action Head 与 Tool Use 的结构同构
讲者在该段明确指出 AlphaStar 的动作序列与今天 LLM Tool Use 的结构近似一致。真正值得重视的是“近似”二字:它提示我们可复用训练组织思想,但必须重新定义动作与奖励。
精读结论 A
把动作看成“可组合 API 调用序列”之后,模型优化目标就从语言流畅性转向策略可执行性。也就是说,生成质量的主导变量不再是 token 困惑度,而是任务闭环成功率与错误恢复能力。
对于课程实验,建议把 action trace 单独存储并可重放。最小字段包括:工具名、参数、触发上下文、执行结果、回滚信息。这样可以做两个关键分析:一是失败是否由策略选择错误导致;二是失败是否由工具接口定义不良导致。
时间片 B(00:21–00:22):纯 RL 的投机陷阱
这一段的 worker rush 案例非常典型:系统找到短期可赢路径,却损失长期泛化能力。换到 LLM Agent 语境,可类比为模型在某些 benchmark 上形成固定提示套路,一旦用户目标略微偏移就失效。
精读结论 B
任何看起来“很聪明”的策略,都必须通过跨分布验证。若训练中没有足够多样的对手/任务,模型会把环境缺陷当能力上限,最终形成不可部署的脆弱策略。
讲者强调 “unsatisfactory”,意味着评价函数不能只记录最终胜负,还要约束策略质量。对 LLM Agent 而言,这可落地为过程约束(例如工具调用预算、权限边界、解释一致性、拒答一致性)。
时间片 C(00:44–00:53):exploiter 与匹配策略
讲者在这段提供了最有实践价值的训练组织经验:主策略如果长期在舒适区自博弈,会快速收敛到窄策略;exploiter 通过定向攻击打破舒适区;而 match-making 决定攻击压力是否转化为有效学习信号。
精读结论 C
exploiter 不是“坏样本生成器”,而是“学习信号放大器”。它把难以自然采样到的失败区域,主动拉到训练主路径上。对于 LLM 系统,这对应自动化 red teaming 的核心价值。
| AlphaStar 概念 | 功能 | LLM Agent 对应实现 |
|---|---|---|
| Main agent | 维持主任务表现 | 主服务策略(在线请求主路由) |
| Main exploiter | 专门挖掘主策略弱点 | 定向攻击代理(prompt injection / policy bypass) |
| League exploiter | 在群体分布中找新弱点 | 多任务多工具组合攻击代理 |
| Match-making | 控制学习难度与信号密度 | 动态任务采样与在线数据再加权 |
| Population update | 防止策略塌缩 | 周期性多策略蒸馏/集成与回归评估 |
时间片 D(00:58 附近):10\^10 级后训练步数与可扩展性
这段最值得记录的是资源配置观。讲者给出的对照不是某个算法细节,而是训练预算重心:如果后训练太轻,系统很难学到真实环境所需的鲁棒行为。
精读结论 D
下一代 Agent 系统的差距,很可能首先体现在“谁能持续运营高质量后训练循环”,而不是“谁先提出新术语”。后训练基础设施本身将成为核心竞争力。
图 \ref{fig:contrast-llm} 与 58 分钟附近字幕放在一起看,可以得到一个清晰判断:当前社区已经理解问题,但尚未在算力、数据组织、持续对抗机制上投入到 AlphaStar 级别。
从精读到行动
如果团队预算有限,优先顺序应是:先提升 failure discovery 密度,再提升模型规模。因为没有失败发现能力,更多参数只会更快过拟合现有任务分布。
本章小结
四个时间片共同构成了一条闭环链路:接口定义 \(\rightarrow\) 训练范式 \(\rightarrow\) 失败发现 \(\rightarrow\) 规模化运营。缺任一环,Multi-Agent 在 LLM 场景都难以产生稳定收益。
研究议程与实验蓝图
本章把课堂观点进一步转成可立项的研究议程。目标不是追求概念完整性,而是给出可在 4--12 周内复现实验信号的方案。
议程一:协作分布与对抗分布的联合优化
研究问题:同一模型同时服务正常用户和攻击用户时,如何避免一端优化拉垮另一端?
建议实验设置
- 构建双数据池:\(D_c\)(collaborative episodes)与 \(D_a\)(adversarial episodes)。
- 训练时按比例混采:\(D = \lambda D_c + (1-\lambda)D_a\),并周期性扫描 \(\lambda\)。
- 指标分开报:协作成功率 \(S_c\)、对抗防御率 \(R_a\)、综合成本 \(C\)。
这种设置的重要性在于,它把“安全性”从发布门槛变成训练一等公民。对于课程团队而言,这也能避免仅凭单一 leaderboard 做错误结论。
议程二:基于 exploiter 的自动发现与修复循环
研究问题:如何让系统自动发现新失败模式,并在可控范围内迭代修复?
最小可运行修复循环
- 由 exploiter 生成挑战任务并执行攻击。
- 将失败轨迹归因到策略错误、工具错误或规则错误。
- 按归因类型进行 targeted finetuning 或 policy patch。
- 用冻结评测集验证是否真实修复、是否引入新回归。
可用如下伪代码描述循环逻辑:
for round in training_rounds:
attack_batch = exploiter.generate(main_agent, task_pool)
failures = evaluate(main_agent, attack_batch)
labeled = root_cause_label(failures) # policy / tool / rule
main_agent = targeted_update(main_agent, labeled)
report = regression_eval(main_agent, fixed_benchmark)
if report.safety_drop:
rollback(main_agent)
议程二的风险点
如果只关注攻击成功率下降,可能出现“过拟合现有攻击脚本”。必须持续引入新攻击策略,并保留不可见测试集,否则很快形成虚假安全感。
议程三:match-making 与学习信号密度
研究问题:如何在任务极难与极易之间保持稳定学习?
| 策略 | 预期优点 | 潜在缺点 |
|---|---|---|
| Hardest-first | 快速暴露上限缺陷 | 易出现无梯度区,训练不稳定 |
| 50/50-first | 学习信号密度高,收敛平稳 | 暴露极端风险速度较慢 |
| Curriculum hybrid | 兼顾稳定与极端覆盖 | 调度规则复杂,参数敏感 |
建议的课程实验路线
先用 50/50-first 建立稳定基线,再逐步注入 hardest-first 任务;最后用 curriculum hybrid 做全局平衡。每步都固定随机种子与任务池版本,确保结果可复现。
议程四:可控性(controllability)与可解释性
讲者在 53 分钟附近提到 “having controllability mattered”。这点在 LLM Agent 中尤其重要,因为任务语言开放、动作后果复杂,可控性直接关联到安全合规。
可控性设计清单
- 行为前置约束:权限级别、调用白名单、预算上限。
- 行为中可观测:每步动作理由、输入输出摘要、风险标签。
- 行为后可追溯:轨迹存档、异常聚类、快速回滚。
可解释性不是附加报告
如果解释数据不进入训练回路,它就只是审计文本。真正有价值的解释,必须能反向驱动数据再采样、奖励修正和策略更新。
本章小结
本章给出的研究议程可以概括为四件事:联合优化双分布、构建自动修复循环、设计有效匹配策略、把可控性写进训练系统。做到这四点,课堂理念就能从“观点”变成“生产力”。
边界条件与反例检验
到这一步,一个自然问题是:既然 Multi-Agent 这么重要,是否所有 LLM 系统都应该立刻采用 league + exploiter 的重型方案?答案是否定的。工程上必须先识别边界条件,再决定投入强度。

图 \ref{fig:current-llm-limits} 展示了讲者在后半段对现状的判断\footnote{来源:Lecture 03 视频帧,时间戳 00:30:55。}:奖励难以完备定义、计算分配偏向 pretraining、任务和数据覆盖仍有限。换句话说,问题并不是“要不要多 Agent”,而是“何时、以何种成本和治理方式引入”。
哪些场景不应立即上重型 Multi-Agent
如果任务满足以下特征,先做单 Agent 基础能力打磨更划算:任务边界固定、工具集合很小、错误成本可控、用户行为高度同质。这些条件下,引入多策略生态的收益可能不足以覆盖复杂度成本。
反例 1:小而确定的自动化任务
例如固定格式报表生成、单 API 数据同步、只读检索问答。此时首要瓶颈通常是数据清洗、接口稳定性和监控,而不是对抗学习能力。过早引入 league 机制会显著增加维护负担。
反例不等于否定
即便暂不使用 multi-agent 训练,也应保留最小化的对抗评测接口。因为业务一旦扩展到开放用户交互,系统会迅速进入讲者描述的“协作+对抗共存”状态。
什么时候必须升级为 population 训练
当系统出现以下信号时,应尽快引入 exploiter 与动态匹配:
- 线上 failure mode 的长尾持续增长,且人工规则修补速度跟不上。
- 模型在基准集表现稳定,但在真实用户多轮交互中回归明显。
- 同一漏洞在不同 prompt 变体下反复出现,表明是策略结构问题而非样本噪声。
升级触发器
升级的核心触发器不是“模型分数高低”,而是“失败发现速度是否超过修复速度”。一旦失败发现速度长期更快,说明系统已进入需要 population dynamics 的阶段。
治理与成本:课程之外的现实问题
讲者谈的是研究范式,但产品侧还要面对治理和成本问题。Multi-Agent 系统往往引入更多执行链路、更多状态和更多权限边界,因此必须把安全治理与审计能力前置。
| 维度 | 收益 | 成本/风险 |
|---|---|---|
| 鲁棒性 | 更快发现并修复长尾漏洞 | 训练与评测流水线复杂度上升 |
| 泛化性 | 对新策略/新任务迁移更稳健 | 需要持续数据运营与任务调度 |
| 安全性 | 可系统化 red teaming | 若权限设计不当,攻击面可能扩大 |
| 可解释性 | 轨迹更完整,便于审计 | 追踪与存储成本显著增加 |
治理底线
任何引入自动执行能力的代理系统,都必须具备最小回滚机制与高风险操作熔断机制。没有这两项,模型再强也不应进入高权限生产环境。
本章小结
本章给出一个务实判断:Multi-Agent 不是默认答案,而是阶段性答案。先识别业务所处阶段,再决定训练复杂度;一旦进入开放交互与高风险执行场景,就应尽早升级到 population 视角,并同步建设治理能力。
总结与延伸
本讲把 AlphaStar 的成功经验抽象成 LLM Agent 时代的三条硬结论:第一,动作接口与训练组织方式同等重要;第二,鲁棒性来自 population dynamics 而非单模型“聪明”;第三,post-training 的强度与质量决定了系统是否具备真实可扩展性。
| 主题 | 课堂结论 | 对 LLM Agent 的直接行动项 |
|---|---|---|
| 复杂度迁移 | 从 Atari/Go 到 StarCraft,问题从单策略优化转向生态鲁棒性 | 评测从单分数升级为分布稳健性面板 |
| 动作表示 | Action head 与 Tool API 结构同构 | 先定义可验证动作 schema,再训练策略 |
| 训练范式 | IL + RL 优于单一路径,纯 RL 易学到投机策略 | 建立冷启动演示集与持续对抗回放机制 |
| 失败分层 | adversarial / exploiter / cheese 各自对应不同风险形态 | 将红队测试分层,避免单一攻击脚本 |
| League 机制 | exploiter 与 match-making 决定最终策略质量 | 引入动态任务采样与 50/50 学习信号区间 |
| 用户生态 | 协作用户与对抗用户共存 | 联合优化 usefulness 与 safety,两者不可偏废 |
| 扩展路径 | 多 Agent RL + 强后训练可能带来下一次跃迁 | 增加 post-training 投入并强化奖励定义质量 |
进一步阅读
- Vinyals et al., Grandmaster level in StarCraft II using multi-agent reinforcement learning (Nature, 2019).
- Silver et al., Mastering the game of Go with deep neural networks and tree search (Nature, 2016).
- Ouyang et al., Training language models to follow instructions with human feedback (NeurIPS, 2022).
- Bai et al., Constitutional AI: Harmlessness from AI Feedback (2022).
- Anthropic / OpenAI / DeepMind 公开的 red teaming 与 system card 文档(关注 adversarial evaluation 方法学)。
- Berkeley CS294/CS285 系列关于 RL、offline RL、multi-agent learning 的课程资料。
- Tool-use agent 开源框架(LangGraph, AutoGen, OpenHands)中的执行安全与评测设计文档。
延伸思考题
- 若奖励函数不可完全定义,哪些 proxy signals 能稳定替代?
- 在真实产品里如何构造“不泄露风险、但有效暴露弱点”的 exploiter?
- 当对抗样本持续演化时,何种在线学习机制能避免灾难性遗忘?