CS224R Lecture 2: 模仿学习
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Chelsea Finn 讲座与 Stanford CS224R 资料整理 |
| 来源 | Stanford Online |
| 日期 | 2025 年 4 月 9 日 |
模仿学习的基本思想
模仿学习(Imitation Learning)起点是直接复制专家,而非设计复杂的奖励函数。它适合数据充足、专家行为质量高但 reward 不明确的场景。
模仿学习的目标
给定专家策略 \(\pi_{\text{expert}}\) 产生的演示轨迹集 \(\mathcal{D} = \{(s_1,a_1,\ldots,s_T)\}\),目标是找到参数化策略 \(\pi_\theta\),使其预测的动作分布在相同状态下与专家尽量重合,从而保持专家级性能。
Version 0:确定性策略回归
最直接的做法是把模仿学习当成行为映射:
这种方法完全依赖平衡好的演示数据,对 noise 非常敏感。
均值问题与不可逆行为
当专家数据呈现多模态(如左转/右转)时,回归模型会输出“平均”动作,造成在环境中进入危险状态;此问题在城市驾驶、双臂协作等任务中普遍存在。
行为克隆 vs. 逆向强化学习
行为克隆直接建模动作,而逆向强化学习(Inverse RL)则重构 reward,再做 RL 优化。下面对比两个方向的 trade-off:
| 方法 | 优点 | 缺点 |
|---|---|---|
| 行为克隆 | 训练简单,直接使用 supervised learning | 容易失去多模态、受分布偏移影响大 |
| 逆向 RL | 能恢复潜在 reward,具备泛化能力 | 需要大量采样,reward 学习与 policy 训练耦合 |
为何优先行为克隆
在很多工业场景(如自动驾驶)中,专家轨迹足够多且高质量,此时直接做行为克隆可以极大降低上线周期;如果出现分布漂移,再逐步引入 reward 模型。
真实场景中的落地与 caution
实际部署时常见的策略包括:行驶数据的上采样、以 experts 为 baseline 训练 fallback policy,以及建立 human-in-the-loop 的监控机制。在低频故障场景下,先用行为克隆做 warm-start,再用 RL 微调是普遍设计。
行为克隆的可解释性
因为输出是 deterministic/log-prob,方便进行 trace-back;一旦模型输出异常,工程团队可以直接查看最近的 expert sample,快速定位问题源。
本章小结
-
多专家融合与动态权重
- -在大模型时代...
专家混合的价值
将多个专家的 logits 放入 Mixture-of-Experts 框架,可以在少量样本上实现 zero-shot 迁移,因为 gating network 可以自动偏向与当前任务更相关的 expert。
本章小结
行为克隆提供了最快速的入门路径、但 deterministic 回归必须配合多专家 gating 与分布建模才能在复杂场景中泛化。多专家混合提供了针对不同 skill 的自动调度,延展了模仿学习的适用边界。
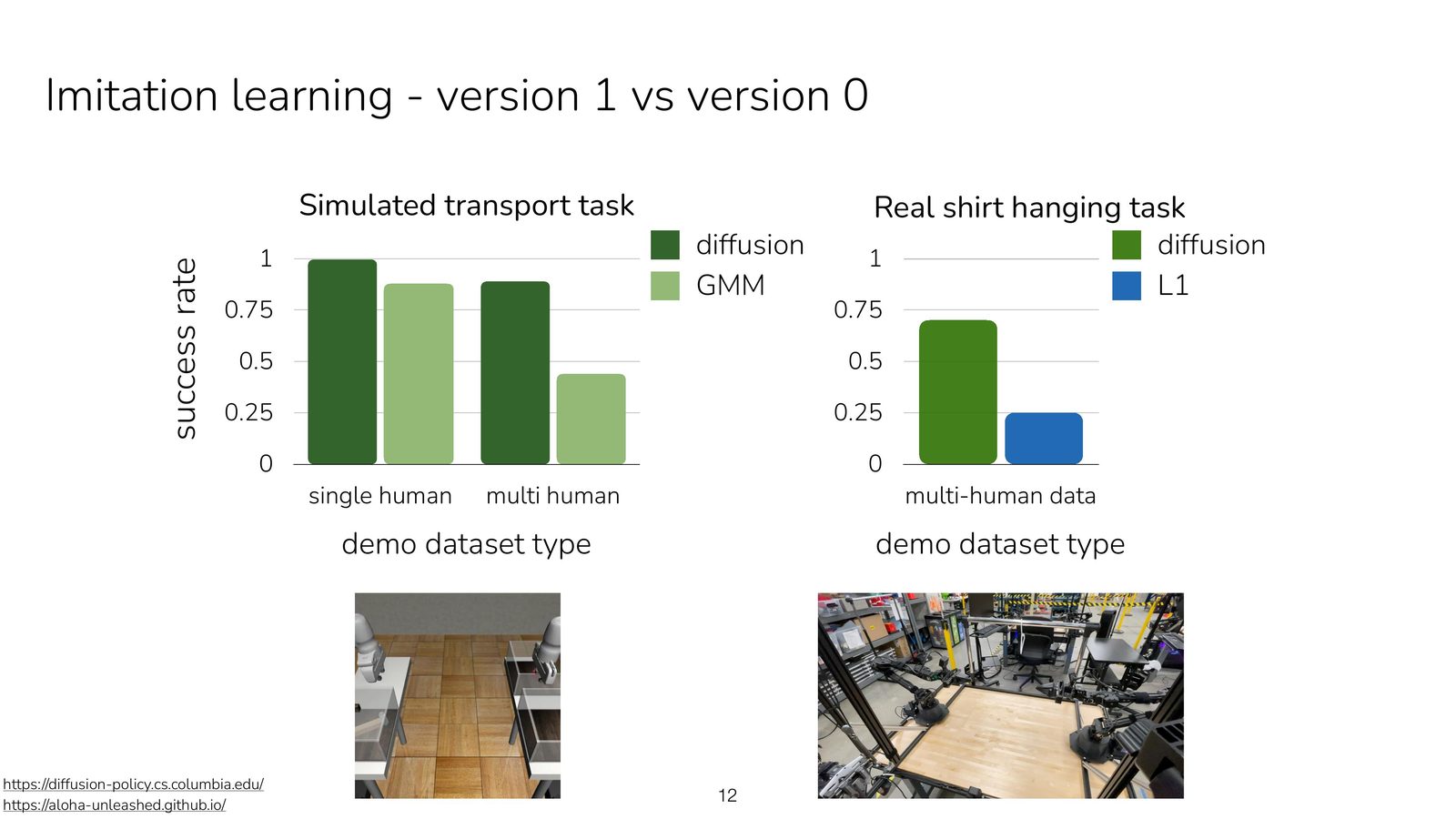
策略表达与生成模型
模仿学习的关键一环是如何表达策略分布。单一的高斯回归只能表示局部、单峰行为,无法匹配多模态专家数据。
分布表示的能力
离散动作可以用 categorical 直接建模,而连续动作层面常见写法也包括 normalizing flow、Mixture Density Network、diffusion model。
生成模型带来的表达力飞跃
将策略视为生成网络 \(p_\theta(a \mid s)\),可以借鉴 diffusion, flow, VAE 等架构,让 policy 自身成为可采样、可推理的概率模型,从而自然适配多模态演示数据。
Diffusion、Mixture 与 Autoregressive 策略
主流表达手段:
- Mixture of Gaussians:同时输出多个 \((\mu_i, \sigma_i, \alpha_i)\),用 softmax 权重混合。
- Autoregressive discretization:将动作空间拆成子维度,递归建模每一维的分布。
- Diffusion Policy:先采样噪声,再迭代去噪,最终生成动作。
| 方法 | 优势 | 典型场景 |
|---|---|---|
| MoG | 提供有限且 interpretable 的混合模式 | 低维连续控制 |
| Autoregressive | 维度分解,捕捉细粒度 correlation | 自动驾驶行为序列 |
| Diffusion | 可做 implicit sampling | 高维机器人操作 |
采样与覆盖诊断
策略参数训练后需要验证它对 expert distribution 的覆盖度。常见做法包括:
- KL divergence sweep:用专家数据和采样数据估计 KL。
- Reject sampling:在 rollout 时如果动作概率低于 threshold,触发 human override。
- Latent space interpolation:在 latent 控制变量中插值,观察生成动作是否落在专家 manifold。
切换采样策略
Archit 提醒:“采样策略决定了我们是否能看到极端行为”。在部署前应把 policy 的 temperature、top-k/top-p 调整写入 runbook 并记录 observational log。
Flow-based policy 用于把动作空间映射到更规则的 latent space,训练时直接拟合 latent 的目标分布,使得采样时只需沿 latent 方向推进再通过 invertible map 还原动作。对于高维动作(如 humanoid 控制),flow 可以显著降低采样难度。
潜在控制的直觉
Flow policy 等价于先在潜在空间做简单的高斯采样,再用 invertible mapping 将其转换为复杂动作。这样可以把模仿学习的目标移到 latent space 中,简化梯度传播。
本章小结
策略表达决定了模仿学习是否能够覆盖 expert space。用生成模型建模多模态分布、Flow-based latent control 以及 rejection sampling,可以在 rollout 端持续纠偏,实现与 expert distribution 的近似,并为 downstream RL 微调提供稳定起点。
误差累积与在线修正
Compounding errors 的根源
模仿学习的核心 challenge 在于,预测的动作 \(\hat{a}\) 会改变下一个状态 \(s'\),从而带来非 i.i.d. 的输入分布。小错会逐步被放大,最终产生 catastrophic failure。
分布偏移与 covariate shift
专家状态分布 \(p_{\text{expert}}(s)\) 与学习策略分布 \(p_{\pi}(s)\) 不一致是系统性风险,如果不干预,即便均值训练 loss 很低也会在少数状态扯断 performance。
DAgger 与 Human-Gated DAgger
解决思路是让策略自己运行,收集新的状态,并用专家在这些状态上提供修正动作:
- Rollout 当前策略 \(\pi_\theta\),记录访问的状态。
- 在每个状态上请求专家动作,并补充到 dataset。
- 重新训练策略或通过 importance weighting 更新参数。
| 阶段 | 关键交付物 | 审查项 |
|---|---|---|
| Observe | Rollout log | state distribution shift |
| Assess | Expert correction | human agreement rate |
| Act | Updated policy checkpoint | performance vs baseline |
Offline vs. Online 模仿学习
- Offline(行为克隆):只使用 static dataset,数据安全但泛化差。
- Online(DAgger/HG-DAgger):涉及 human-in-the-loop,效率高但需要专家权限。
模仿学习与强化学习的协同
实践中常常把 BC 作为 warm-start,再用 RL fine-tune,形成 hybrid pipeline:先用高质量 demonstrations 学习初始 policy,再通过分布式 rollout + reward fine-tuning 提升鲁棒性。
不要放弃 reward 信号
即便目标是模仿专家,也应持续监测潜在 reward(例如 safety penalty、human critique score),以便在奖励出现 drift 时立刻 rollback。
本章小结
Compounding errors 需要数据收集与 human-in-the-loop 策略的结合。DAgger/HG-DAgger 提供了修正路径,结合后续 RL 微调可以让 policy 在 distribution shift 中继续收敛。
演示数据的采集与质量保障
数据采集管线
演示数据来自人类、仿真机器人或 pre-recorded log。常见 pipeline:
- Kinesthetic Teaching:人体直接控制机械臂,低 latency。
- Remote teleoperation:网格化控制,支持地理分布式专家。
- Behavioral cloning from screen recording:视频+键盘鼠标行为同步。
embodiment gap
直接用人类视频代替 robot demonstration 会产生 embodiment gap(自由度差、动力学差),但可以作为 exploration signal,通过 domain randomization 缩小 gap。
数据 QA 与 audit
高质量演示需要 audit pipeline,包括:
- 专家 agreement rate(Cohen's κ);
- 状态-动作对的 variance coverage;
- 误差示范的 labeling;
- Metadata(任务难度、环境 lighting)。
| 维度 | 指标 | 工程应对 |
|---|---|---|
| 一致性 | Pairwise agreement | 不一致样本送审 |
| 多样性 | Different skills, contexts | 用 clustering 识别覆盖 gaps |
| 安全性 | Adversarial prompt | 加入 counterfactual data |
跨模态与跨角色协作
现代模仿学习项目往往涉及数据标注团队、语言专家与 SRE,共同维护 dataset catalog 与 manifest。每次 rollout 都需要把 new prompts 加入 dataset,并把 shift log 记录在 evidence board 中。
本章小结
演示数据质量直接决定模仿学习的下限。通过严格 audit、metadata 和 multi-role feedback,可以把 embodiment gap、adversarial prompt 等问题转化为可治理的风险。
部署与信任
评估栈与监控指标
部署后需要把训练阶段的 evidence 连接到生产指标:
- Benchmark(HumanEval、LongBench)确保能力;
- Guardrail(Hallucination、Forbidden topics)确保安全;
- Ops metrics(Rejection rate、Latency P99)确保体验。
| 类别 | 典型指标 |
|---|---|
| Benchmark | HumanEval、TruthfulQA、Domain-specific tests |
| Safety | Red team rejection、prompt-based filter precision |
| Ops | Rejection rate、Latency P99、Human override count |
幻灯片与视觉证据

可视化仪表盘的作用
把 evidence stacking 可视化成幻灯片上的热力地图,可以让 PM、法律和 SRE 在同一个数据视角下讨论风险,而不是靠零散的 document。
反馈与治理
遵循 Observe-Assess-Act-Document 模式:
- Observe:记录 rollout 表现、reward drift;
- Assess:用 evidence matrix 检查 guardrail;
- Act:human-in-the-loop 开启 mitigation;
- Document:把决策写入 runbook,供后续 audit。
记录比修复更重要
没有 runbook 的反馈 loop,团队很难记住为什么在某个 prompt 上 rollback。Archit 建议:每次 mitigation 要附带 drift snapshot、human override log 和 lesson learned。
本章小结
部署的信任来自 data、policy、ops 之间的闭环。把幻灯片中的 evidence dashboard 变成实际的监控、治理表格,才能让模仿学习系统在 production 中持续稳定。
案例研究与实验设计
机器人示例:Pick-and-place pipeline

该 pipeline 内部将 expert trajectory 聚合、训练 diffusion policy,并在 scoring server 中实时计算 KL drift。部署前 post-mortem 包含: 1) control length 2) intervention log 3) visual replay diff。
| 阶段 | 核心测量 |
|---|---|
| 数据 | Coverage of pick/place, human override rate, sensor noise |
| 训练 | Loss plateau, latent interpolation, sampling temperature drift |
| 部署 | KL drift, rejection rate, human override latency |
录像回放的作用
把 policy rollouts 录成 short clips,与 expert clip 做 diff,有助于 PM 快速识别 drift 来源,从而决定是否 rollback。
Evaluation Matrix 与对齐实验
Evaluation matrix 由三层组成:benchmark scores、safety metrics、ops guardrails。每个版本都需通过如下 tests:
- Benchmark:MMLU-like tasks、LongBench multi-hop。
- Safety:forbidden content rejection、hallucination detectors。
- Ops:latency、human override、drift ticket count。
过拟合 benchmark 的风险
盲目追 benchmark 会让 policy 忽略 rare prompt;一定要把 safety 和 ops guardrail 作为 gating 条件,防止“指标驱动”的 drift。
本章小结
案例研究把演示数据、生成策略、evaluation matrix 和治理转成具体的 artifact(dashboard、table、clips),为后续扩展提供可复制的实验框架。
治理与可解释性
Drift Playbook
Drift Playbook 包括:Detect(alert rules)、Diagnose(cluster drift prompt)、Decide(governance board)、Document(runbook entry)。每次响应都要附带 snapshot、KL 曲线、human override log。
| 阶段 | 核心 artifact |
|---|---|
| Detect | Reward drift alert + latency spike dashboard |
| Diagnose | Prompt clustering report + human override video |
| Decide | Governance board minutes + rollback checklist |
| Document | Runbook entry + postmortem draft |
自动化报警的条目
建议用 KL drift、hallucination flag、human override frequency 三线报警;只有三条同时越界时触发 governance review,避免频繁 false positive。
Automated Evaluation Matrix
Automation coverage包含 unit-level tests(safety prompt injection, allowed domains)、system-level evaluation(trajectory success rate)、ops-level metrics(human override latency)。这些指标要在 dashboard 上分层展示,并与 benchmark/human eval 做 cross-check。
Evaluation matrix 的多层次意义
将 benchmark、safety、ops 分层,再用 color-coded heatmap 表示健康状况,可以让 compliance、ops 和 research 在一次 review 中共享事实感知。
人类监督与治理会议
每个版本都需要指定 alignment owner、ops owner、legal owner。Alignment owner 维护 evidence matrix;ops owner 监控 drift dashboards;legal owner 决定 high-risk prompt 是否需要额外 guardrail。
不要忽视 governance meeting
如果 governance meeting 只是走过场,团队就会在指标冲突时选择对齐最小的那条线(通常是 benchmark)。必须在会前准备 evidence scorecard,并在会后发布 action items。
本章小结
治理与可解释性的闭环是一种 accountability practice:高质量的 drift playbook、automated evaluation matrix 与多角色的 governance meeting 让模仿学习的 deployment 具备 traceability 与迅速响应能力。
调试与可视化
Prompt 级别的仪表盘
在部署后,wrap-around instrumentation 包括:prompt signature fingerprints、action entropy、KL drift trace、human override counter。将这些信号写入 time-series dashboard,可以快速定位哪类 prompt 开始触发 drift。
| 指标 | 说明 |
|---|---|
| Prompt signature | hash + metadata,用于重新播放与 reproduce |
| Entropy | action entropy drop 可能预示 policy collapse |
| KL drift | 当前 policy vs. reference distribution |
| Override count | human 改写提示的次数,衡量 automation trust |
指标要与 runbook 绑定
每个 signal 的 threshold 要写入 runbook,并指定 owner。如果超限,就要自动通知对应的人(ops、alignment、legal),而不是靠 slack 注释。
Rollout 可视化
可视化面板允许 engineer 在一分钟之内判断:1) 该 rollout 是否偏离 expert manifold;2) human override 是否集中在某类 prompt;3) KL/entropy 曲线是否同步下降。把这些图表 embed 到 internal dashboard,用作 gate review。
可视化的诊断价值
当 rollout 出现 drift,visualization 让团队不需翻日志即可看到具体 prompt、KL 路径和 override 位置,大幅缩短 incident response 时间。
本章小结
调试与可视化把抽象的 drift 信号具体化:Prompt dashboard 提供定量监控,Rollout visualization 则提供触发点的 qualitative insight,两者结合,才能在下一次 release 前完成根因分析。
团队协作与持续演进
Roles & responsibilities 矩阵
成功的模仿学习系统需要 alignment、ops、data、legal 四个团队协作。下面的矩阵列出了每个角色的 output 和 checkpoint:
| 角色 | 交付物 | 核心 checkpoint | 频率 |
|---|---|---|---|
| Alignment Engineer | Evidence matrix, policy checkpoint | KL drift < θ, preference score | per model release |
| Ops/SRE | Drift dashboard, latency log | alert resolution time | daily |
| Data Engineer | Demo catalog, metadata | coverage report | weekly |
| Legal/Compliance | Guardrail doc, review minutes | high-risk prompt gating | per sprint |
不要把责任模糊化
如果某条 guardrail 既不是 ops 的责任也不是 compliance 的责任,就会在 incident 中无人响应。要用矩阵明确 owner,并把流程写入 team handbook。
持续演进与研究方向
模仿学习在 research 轨道上可以迈向 sim-to-real、multi-agent collaboration、自动化 reward inference。Slide 02-11 强调了 multi-agent scenario 中的 cooperative imitation、competitive imitation 以及 dynamic gating。
Future experiments 的关键
每次 research experiment 都要陪同 evaluation matrix,确认实验结束后 metric 是否回到 baseline;如果 metrics drift 严重,就要延迟 production rollout。
本章小结
团队协作与 research planning 构成持续演进的双车轴:责任矩阵保证每次 release 有人在看数据,研究方向则通过 structured experiment 让模仿学习 pipelines 在多 agent、sim-to-real 的未来场景中稳健。
Sim-to-Real 与验证实验
仿真校准与现实验证

为了让 policy 从仿真迁移到真实环境,常用的策略包括 domain randomization、dynamics randomization、fidelity tuning。每次迁移都要记录 randomization 参数与 reality gap 监控指标。
| 验证点 | 说明 |
|---|---|
| Domain gap | 动力学/感知差异的 distribution drift score |
| Simulator fidelity | 视觉/控制 fidelity 与 real world log 的 L2 误差 |
| Transfer success | real world rollout 的 task success rate |
记录 transfer meta-data
用 metadata 记录每次 transfer 的 simulator seed、randomization range、hardware configuration,有助于复现某次 jump 的成功或 failure。
Cross-environment evaluation
不同环境(lab、field、cloud)会有不同 constraints。需要规定 evaluation order,例如:先在 lab environment run benchmark,再到 field environment 检查 sensor noise 和 drift,再最后在 cloud pipeline 里收集 logs。
不要在 field rollouts 上直接用 baseline
Field environment 一旦 drift,就非常 expensive。要在 lab 中先验证 metric,然后 incremental expansion 到 field,最后在 cloud 把 logs 收集到 evidence board 中。
本章小结
Sim-to-Real pipeline 要靠 structured validation matrix 与 metadata,才能在不同环境之间安全迁移 policy;在每次 field rollout 之前必须验证 domain gap。
持续学习与多 agent 协作
Multi-Agent 体现与 imitation
在 multi-agent 场景下,每个 agent 可以 imitating 不同 specialist,彼此之间通过 gating network share policy logits。CSI gating 允许在 runtime 选择最合适的 expert。
Multi-agent imitation 的力量
通过 multi-agent imitation,系统可以在单 agent 模型无法覆盖的复杂任务中分工协作。每个 agent 负责一段 trajectory,最后通过 aggregator 合成一致策略。
持续学习与自我改进

Continuous improvement loop 里,每次 deployment 都需把 human override 作为 new training data,并在 nightly retrain pipeline 中引入 multi-agent critic 作为 auxiliary loss。
Self-supervised critic
使用 self-supervised critic 可以在缺乏 human comparison 的情况下估计 reward gap,配合 human override 形成 stratified preference signal。
本章小结
多 agent imitation 与 continuous improvement loop 让模仿学习变成一个不断自我校准的系统;只要在 evaluation → retrain → deployment 中加上 traction guardrails,就能持续提升。
总结与延伸
- 行为克隆提供最快的入门,但是需要警惕均值行为与 covariate shift。
- 生成模型使策略具备多模态表达力,需要在采样阶段做 KL/temperature 调整。
- DAgger/HG-DAgger/混合 RL 策略是解决 compounding errors 的有效路径。
- 高质量演示数据的 audit、metadata、multi-role 协同是落地的基础。
- 部署环节要以 evidence board 为中心,把 benchmark、safety、ops 三条线绑定到监控迭代。
- 记录每次 mitigation 与 rollback 事件,让 governance audit 有据可依。
落地路线图

落地路线图将模仿学习 pipeline 拆成三个阶段:1) 数据准备(demo catalog + metadata),2) 策略训练(diffusion/MoG + flow calibration),3) 灾难恢复(drift playbook + governance review)。每个阶段都要定义 guardrail、evaluation metric 与 artifacts。
| 阶段 | Key artifact |
|---|---|
| 数据准备 | Metadata-rich demo catalog + coverage report |
| 策略训练 | KL drift sweep + sampling temperature record |
| 部署恢复 | Drift playbook + rollback checklist |
别把 roadmap 当计划书
Roadmap 应该不断更新,从 evidence dashboard 获取实际 delay 和 drift,再把 lesson learned 反向写回 timeline,才能持续前进。
总结表
| 主题 | 核心 takeaway | 工程行动 |
|---|---|---|
| 行为克隆 | 快速上线但需注意 covariance shift | 训练后跑 KL sweep、部署前做 sanity check |
| 策略表达 | 生成分布需要被采样探索 | 使用 diffusion/MoG 并记录 sampling temperature |
| 在线修正 | DAgger 弥补未见状态 | 建立 Observe-Assess-Act-Document runbook |
| 数据 QA | Multi-role audit | 用 metadata + clustering 识别 coverage gaps |
| 部署治理 | Evidence dashboard | 绑定 benchmark/safety/ops 3 条线 |
拓展阅读
- Chi et al., Diffusion Policy:将 diffusion model 引入机器人策略。
- Ross et al., A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning:DAgger 原文。
- Brohan et al., RT-2:展示多模态模仿学习的效果。
- Rajeswaran et al., Behavioral Cloning with Expert Interventions:将 human interventions 系统化。
本章小结
本讲从行为克隆到生成策略、从 DAgger/online pipeline 到 data QA 与部署治理,形成一个 end-to-end 的模仿学习实践框架。只有把各个阶段都打通,才能让模仿学习在生产环境中真正可靠地执行。