[LLM Agents F25] Autonomous Agents — Peter Stone
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Peter Stone 授课内容整理 |
| 来源 | Berkeley RDI |
| 日期 | 2026-04-02 |
![[LLM Agents F25] Autonomous Agents — Peter Stone](cover.jpg)
课程定位与主线
本讲由 UT Austin 的 Peter Stone 主讲,题目是 Autonomous Agents。它并不是在讲一套新的 LLM 框架,而是在把 “Agent” 这个概念重新放回 AI 长期研究脉络:embodiment、interaction、learning。
Stone 在开场明确表示,本讲要覆盖的是一个 broad view,而不是只看 2025 年流行的 “agentic LLM”。因此课程的组织方式也很典型:先给概念和研究版图,再快速扫过实验线索,最后对两个代表性案例做 deeper dive(Slack 与 GT Sophy)。
本讲的核心价值
这节课最关键的贡献不是新算法,而是把 Agent 研究中的三个长期主题重新拧到一起:
- Interaction:单体与多体如何在动态环境中协作与对抗;
- Learning:从 RL 到 human feedback,如何在样本约束下学习可执行策略;
- Embodiment:策略是否真正能落在 physical world,而不是只在 text benchmark 上成立。
为什么这讲对 LLM Agent 仍然重要
尽管讲者大量举的是 robotics 与 autonomous driving 的例子,但这些问题与 LLM Agent 的工程现实高度同构:状态观测不完美、动作后果延迟显现、多人系统中的策略耦合、以及 “高分但不可用” 的评测失真。
本章小结
这是一节 “概念澄清 + 案例复盘” 的课。它要求我们先把 Agent 的定义站稳,再去谈任何看似新的 Agentic 产品形态。
什么是 Autonomous Agent:从 buzzword 回到定义
Stone 给出的定义非常朴素:agent 是通过 sensors 和 actuators 与环境持续交互的智能系统。这一定义故意避免把 Agent 等同于聊天窗口里的 API 调用器,也避免把 Agent 仅仅理解为多工具链路。
连续闭环是关键
在这一讲里,Agent 的最小闭环是:
重点在 “continuous loop”,而不是 request-response。
按照这一定义,chatbot 在某些设置下可以是 Agent,但很多典型 chatbot 仍偏 “被动响应”。Autonomous Agent 更强调主动持续行为,不需要每一步都等用户明确触发。
Robot 与 Agent 的关系
Stone 用了一个非常实用的区分:
- Robot 可以看作是 physical agent;
- 所有 robot 都是 agent;
- 但并非所有 agent 都必须具备 physical embodiment。
这让我们能同时讨论 software agent、game-playing agent、以及 real-world embodied agent。
常见误解
把 Agent 缩减为 “LLM + tool call” 会直接丢掉两类关键问题:
- 真实动作约束(安全、延迟、失败恢复);
- 多体互动约束(协作、竞争、信用分配)。
这两类问题恰好决定系统能否从 demo 走向部署。
本章小结
Agent 的定义不是为了学术形式化,而是决定你后续系统边界怎么画。定义太窄,后面的 benchmark 和工程结论都会失真。
完整智能体栈:Perception, Cognition, Action
Stone 在课里把完整智能体分成三个层次:Perception、Cognition、Action。这个拆法在机器人和 LLM 系统里都非常有用,因为它清晰地分离了 “看见”、“想清楚”、“做出来” 三个失败源。
| 模块 | 在课程中的含义 | 在 LLM Agent 中的对应 |
|---|---|---|
| Perception | 从 raw sensors 到可用状态表示 | context parsing, tool result interpretation |
| Cognition | 规划、推理、队友/对手建模、决策 | decomposition, planning, policy selection |
| Action | 从决策到可执行控制信号 | API call, code execution, UI action |
为什么要强制分层
如果把系统全部扔进 end-to-end black box,会导致以下后果:
- 出错时无法定位是感知问题还是决策问题;
- 奖励设计与评测指标很难有针对性;
- 安全约束无法插在合适位置(例如动作前的 rule check)。
课程里还强调了 Cognition 层不只是 planning。它也包括 teammate/opponent modeling、coordination、tactical adaptation。这一点对多 Agent 任务尤其重要,因为策略质量不再只取决于自身状态,还取决于他人的策略分布。
智能体工程的一个实践准则
在复杂任务里,先保证 Perception 和 Action 管道稳,再提高 Cognition 复杂度,通常比 “一开始就上最复杂 planner” 更容易收敛。
本章小结
Perception-Cognition-Action 不是过时框架,而是今天构建可调试 Agent 的最低工程骨架。
研究问题与应用版图:Stone Lab 的统一问题
Stone 给出的长期研究问题是: “To what degree can autonomous intelligent agents learn in the presence of teammates and/or adversaries in real-time dynamic domains?”
这个问题从 1998 年延续至今,说明 “Agent” 在学术上并不是新词,而是不断被新计算范式激活的老问题。
统一问题的四个关键词
- learn:不是手工脚本,而是策略学习;
- teammates/adversaries:多体互动不是附加项,而是主问题;
- real-time:控制频率和延迟约束是硬条件;
- dynamic domains:状态分布持续变化,离线最优策略会失效。
围绕这一问题,Stone 的例子覆盖 robotics、robot soccer、autonomous driving、Gran Turismo、human feedback learning、ad hoc teamwork、ethical dataset construction。看上去分散,但都在回答同一个东西:能否在复杂互动环境中持续学习并保持可用行为。
研究叙事中的陷阱
如果只看单一 benchmark 提升,容易误判为能力突破;但在动态多体环境中,很多 “提分” 只是对静态分布的过拟合。
本章小结
统一问题让我们避免被技术热点牵着走。它同时约束了算法目标、系统设计和评测方式。
案例簇 A:Robot Soccer 与服务机器人
RoboCup 作为多体实体智能试验场
Stone 用 RoboCup 展示了多 Agent embodied intelligence 的典型难点:感知噪声、动作延迟、策略协同、对手建模、实时决策。机器人需要 “sensing, deciding, acting” 的完整闭环,且不能靠远程人工遥控。

来源:视频时间区间:00:08:12–00:10:20。
为什么 RoboCup 仍有研究价值
它把多个 AI 子问题耦合在一起:
- 局部感知与全局态势理解;
- 实时控制与长期战术平衡;
- 队内协作与对手对抗;
- 规则约束下的高强度策略竞争。
课程里提到 RoboCup 的长期目标:2050 年 humanoid team 击败人类世界杯冠军队。这个目标是否按时达成并不重要,重要的是它强迫研究者把 “可发表” 转化为 “可比赛”,从而持续暴露系统短板。
服务机器人:从竞赛到家庭任务
另一条线是 RoboCup@Home 场景:做 host、摆台、收纳 groceries、早餐服务等。这些任务难点在于开放环境和长链任务分解,不是单步抓取精度。
服务机器人任务对 Agent 的要求
与标准 manipulation benchmark 不同,服务任务需要:
- 任务层语义理解(不是只有几何控制);
- 跨步骤记忆与状态追踪;
- 出错后的恢复策略;
- 与人类交互中的社会可接受行为。
本章小结
RoboCup 与服务机器人共同说明:当 Agent 进入实体世界,“策略质量” 必须同时在感知、控制、协同和规则约束中成立。
案例簇 B:Autonomous Driving 与交叉口协调
Stone 复盘了自动驾驶研究中的一个代表性问题:当道路系统主体都变成 autonomous agent,交通规则会不会从静态信号灯转向协商式 reservation system。
Reservation-based intersection 的 Agent 含义
每辆车都可视为 agent,进入路口前向调度系统请求时空轨迹槽位(reservation):
- 获批后按保序轨迹通过;
- 未获批则等待;
- 目标是减少全局等待和冲突概率。
这个想法对今天 LLM Agent 也有直接启发:在共享资源系统中,“协作协议” 往往比单 Agent 局部最优更重要。
混合交通是难点
纯 autonomous agent 环境容易优化;human + autonomous 混合环境会引入策略不确定性和行为非平稳性,这是部署中更难的阶段。
本章小结
自动驾驶案例强调了一个事实:Agent intelligence 不是离散任务成功率,而是协议化协同能力。
Human-in-the-loop 学习:从 TAMER 到 RLHF
Stone 特别回顾了 TAMER 系统(Teaching an Agent Manually via Evaluative Reinforcement)及其后续工作。它在 Tetris 上展示了 “显式人类评价信号” 如何显著加速早期学习。
TAMER 的经验
相对纯随机探索:
- 学习早期收敛更快;
- 人类反馈能快速压制明显坏动作;
- 但最终上限可能受限于反馈噪声与覆盖度。
Stone 也指出后续组合路线:TAMER + RL。先用人类信号快速起步,再用自主 RL 继续提升上限。这几乎就是今天很多 LLM 后训练流程的结构映射:human preference shaping + large-scale policy optimization。
显式反馈与隐式反馈
课程里还讨论了 implicit feedback(如乘客表情、紧张动作):
- 显式反馈:“good move / bad move”,高精度但高成本;
- 隐式反馈:无需额外标注流程,信号自然存在但噪声高。
这对应今天产品中 online telemetry 与 explicit rating 的组合。
只靠 RLHF 不等于解决长期策略问题
RLHF 能优化局部输出偏好,但在长链动作任务里,仍需配合环境反馈、过程奖励与安全约束,才能得到稳定 Agent 行为。
本章小结
TAMER 的历史价值在于证明 “人类反馈是可训练信号”。但完整 Agent 学习需要把人类反馈、环境反馈和自主探索放进同一系统。
Ad Hoc Teamwork:和陌生队友临场组队
Stone 把 ad hoc teamwork 作为 interaction 方向的代表问题:目标是让 agent 在无法预先控制队友策略的情况下,仍能快速形成高质量协作。
问题定义
Ad hoc teamwork 的关键约束是:
- 队友模型不可预训练到固定分布;
- 协同策略必须在线适配;
- 任务成功依赖 “对队友行为的实时解释”。
这和今天多 Agent coding、multi-role planner、企业流程自动化高度一致。你经常要和 “未知策略的外部参与者” 共事,比如新接入 tool、异构模型、甚至人类操作员。
对 LLM Multi-Agent 的直接启发
如果系统只在固定队友配置下验证,部署后经常会遇到协同退化。更稳健的方法是把 “队友分布扰动” 作为训练和评测的一部分。
本章小结
Ad hoc teamwork 把多 Agent 问题从 “是否能协同” 推进到 “是否能和未知协同体稳定协同”,这是落地系统必须面对的版本。
伦理与公平数据:从研究成果到数据治理
很多 “Autonomous Agent” 讨论只聚焦策略最优,但 Stone 在中段专门提到 ethical AI initiative 和 Phoebe 数据集,说明他将伦理治理视为 Agent 系统的一部分,而非部署后补丁。
为什么伦理问题在 Agent 里更尖锐
当系统从 “回答问题” 走向 “持续决策”,伦理风险会被放大。Agent 有状态、可记忆、可长期行动,它造成的偏差不是单条输出,而是策略级行为偏置。
课程中的关键观点
Stone 明确强调了两件事:第一,数据集不只看规模,还要看构建过程是否合规;第二,公平评测应面向全球多样人群,而不是局限于单地区、单语种分布。
“first globally diverse consensually collected fairness evaluation dataset”(约 00:17:07)。
Phoebe 的方法学意义
课程提到 Phoebe(Nature 2025)时,重点并不在 “10,000 图像” 这个数量,而在以下流程要点:
- 先识别数据构建过程中的伦理与法律问题,再定采集协议;
- 强调 consensually collected,避免 “抓取即合规” 的默认假设;
- 用数据集去评测模型偏见,而不是只做数据陈列。
把 fairness 变成系统接口,而不是论文附录
这部分对 LLM Agent 尤其重要。很多团队在上线前只做一次性安全评审,忽略了上线后策略漂移。Stone 这段内容给出的启发是:应把公平评测做成持续流程与平台能力。
| 治理环节 | 课程线索 | 工程落地点 |
|---|---|---|
| 数据采集 | consensually collected | 用户授权记录、数据来源台账 |
| 标注与描述 | ethical/legal issues first | 敏感属性审查、标注规范审计 |
| 评测目标 | evaluate bias in AI models | 分人群分任务指标看板 |
| 发布与复现 | establish industry standard | 版本化评测基线与复现实验脚本 |
常见短板:把公平只当成离线分数
如果公平只在离线 benchmark 上看一次,部署后很快会失效。Agent 与真实用户交互后,输入分布和行为路径都会变。需要持续监测与回归测试,而不是 “一次过检”。
本章小结
Stone 讨论 Phoebe 的意义在于给出一个 “可执行” 的伦理路线:先治理流程,再谈模型分数;先建立标准,再扩展能力。
Deep Dive I:Slack — 低保真模拟驱动的真实机器人 RL
问题设定
Slack 论文针对的是一个现实痛点:真实机器人 RL 成本高、试错慢、风险大。高保真模拟器难构建,而纯真实世界随机探索几乎不可接受。
真实机器人 RL 的三重约束
- Sample efficiency:电池、硬件寿命和实验时间都有限;
- Safety:随机动作可能造成碰撞与损坏;
- Task diversity:复杂任务需要 base + arm + camera 联动。
方法主干
Slack 的主思路不是先学完整策略,而是先在低保真模拟器里学一个 structured latent action space,再把这个空间用于真实世界任务学习。
方法拆解
- 用 unsupervised RL 在低保真模拟器中发现 task-agnostic skills;
- 通过 disentanglement 学到更结构化的 latent action factor;
- 加入 hand-coded safety reward 约束危险动作;
- 在真实环境中用 factorized SAC 在 latent 空间做高效策略学习。
这条路线的工程含义是:把最贵的探索压缩到一个更可控、更低维的动作空间里,从而把真实世界在线学习时间降到可用区间。
关键帧证据与结果

来源:视频时间区间:00:31:00–00:33:30。
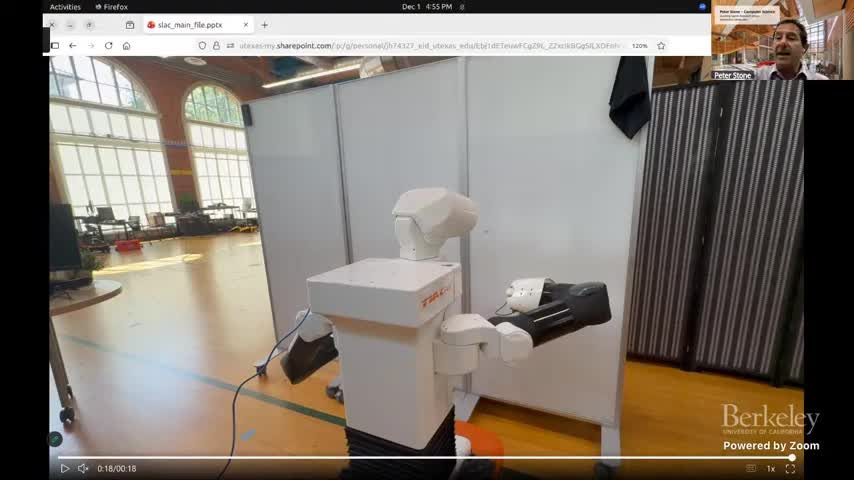
来源:视频时间区间:00:41:30–00:43:20。
课程报告的结果重点有两条:一是多任务(擦白板、扫物入盘、避障等)在 1 小时内可达高成功率;二是安全违规更少。这两条恰好对应真实部署最关心的效率与风险。
Slack 的方法论启发
它不是在说 “模拟器足够真实就能一键迁移”,而是在说 “模拟器可以先学行为结构,再把结构迁移到真实世界做任务学习”。这是一个更现实、更稳健的 sim-to-real middle path。
训练流程拆解:从随机探索到可用技能
字幕里有一段很关键:“if you just use standard state-of-the-art RL, you're going to just flail”(约 00:32:21--00:32:27)。
这句话解释了 Slack 为什么不直接在全动作空间做端到端 RL。对一个移动底盘 + 机械臂系统,随机动作几乎必然导致无效探索和高风险行为。
| 阶段 | 目标 | 主要手段 |
|---|---|---|
| 阶段 A | 获得可迁移行为结构 | 低保真模拟中无监督技能发现 |
| 阶段 B | 降低动作维度与耦合复杂度 | latent action disentanglement |
| 阶段 C | 控制真实探索风险 | hand-coded safety reward + action constraints |
| 阶段 D | 在真实任务中快速收敛 | factorized SAC 在 latent 空间优化 |
为什么 “低保真” 也能有用
课程给出的核心并不是高保真替代真实世界,而是结构迁移:
- 迁移的是动作组织方式,而非逐像素物理精确性;
- 低保真阶段先学 “怎么动”,真实阶段再学 “为任务而动”;
- 这样做把最昂贵的随机探索从真实机器人上转移出去。
落地风险:latent space 也会失配
如果 latent action 空间覆盖不到真实任务关键操作,后续真实学习会出现 “看似稳定但达不到目标”。因此需要在真实阶段保留重构或扩容机制,而不是把 latent space 视为固定真理。
本章小结
Slack 给了 embodied agent 一个可操作范式:低保真模拟用于学结构,真实世界用于学任务,从而兼顾效率与安全。
Deep Dive II:GT Sophy — 实时竞争场景下的分布式 RL 系统
为什么 GT Sophy 有代表性
Stone 将 GT Sophy 定位为 “实时连续控制 + 多体博弈 + 人类规则约束” 的综合 benchmark。它比很多 turn-based 游戏更接近真实世界策略系统,因为动作频率高、状态连续、战术与礼仪同时存在。
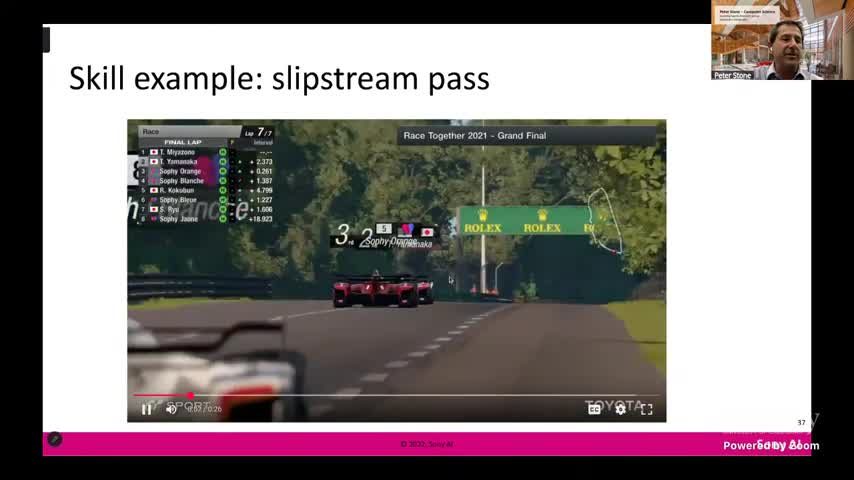
来源:视频时间区间:00:54:00–00:56:30。
任务难点
- Real-time control:10Hz 动作更新,容错窗口极窄;
- Tactics:不仅要快,还要会防守线和 slipstream/crossover;
- Etiquette:不能靠违规碰撞取胜,需通过 steward 规则。
系统架构与算法点
GT Sophy 的成功并非单一算法突破,而是 “计算架构 + 数据策划 + RL 目标” 的组合。课程里强调了 actor-replay-learner 式大规模 rollout,以及 QRSAC(基于 SAC 的分布式价值估计改进)。
可迁移的工程经验
- Distributional value estimation:学回报分布而非仅均值;
- Replay mixture engineering:经验池里不同场景数据配比要精心设计;
- Curriculum-like traffic scenarios:通过 1v1、1v3、多车网格等情形促成战术涌现。
课程中被反复强调的 “数据配比工程”
Stone 在 00:53--00:55 段反复解释,系统并非只靠随机 rollout。团队构造了多种起跑与追车场景:
- 单车跟车、1v2、1v3、1v7 的交通密度梯度;
- 直道跟车学习 slipstream pass;
- 弯道起步学习 crossover 与 double-crossover;
- 特定赛道难点片段的强化采样。
Replay buffer 的核心不是 “大”,而是 “对”
课程中提到,Nature 论文阶段很多配比是人工精调,后续才逐步自动化。这说明在复杂策略学习里,采样分布设计本身就是算法的一部分,而不是数据工程附属工作。
| 经验来源 | 主要学习目标 | 风险 |
|---|---|---|
| 空旷赛道高速圈 | 速度与线路效率 | 忽略交互策略,比赛不稳 |
| 跟车直道片段 | slipstream timing | 过度依赖单一超车模板 |
| 弯道拥挤片段 | defensive/crossover 决策 | 碰撞风险上升 |
| 发车网格片段 | 多车起步博弈 | 学到激进行为倾向 |
Stone 明确提到,初版系统并非一上来就赢。通过复盘失败、调整奖励和数据配比,才在后续 rematch 中稳定超过顶级人类车手。这说明高水平 Agent 的迭代方式是 “系统级闭环调参”,而非单步神奇优化。
速度最优不等于比赛最优
如果只优化 lap time,策略会忽略规则与交互;如果过度惩罚碰撞,又会变得过于 timid。真正可用策略必须在速度、战术和规则之间平衡。
Etiquette 约束:从 “能赢” 到 “应当这样赢”
在 00:55:39--00:56:18 附近,Stone 讨论了比赛礼仪(etiquette):避免可避免碰撞、不能恶意挤出赛道、但也不能保守到不会竞争。
这部分非常像真实世界 Agent 的 “policy + governance” 联合优化。
规则约束设计原则
- 仅靠结果奖励会催生漏洞利用(rule exploitation);
- 仅靠硬惩罚会让策略过度保守(timid policy);
- 需要把行为规则、对抗目标与长期胜率放在同一目标函数里联合权衡。
部署层面的误区
把 etiquette 放到后处理(例如只在推理后做规则过滤)通常不够。课程案例显示,更稳妥的方法是训练期就把规则信号注入策略学习,减少 “先学坏再纠正” 的代价。
部署反馈
GT Sophy 后续被纳入游戏产品线,说明其价值不仅是论文成绩,还包括玩家体验维度:可调难度、可解释行为风格、可持续内容更新。这与今天 LLM Agent 需要 “可产品化” 的诉求一致。
本章小结
GT Sophy 展示了竞争型 Agent 的真实难点:你需要一个完整训练系统去学策略分布、场景配比、战术行为和规则边界,而不是只追一个分数。
从课程到工程:Agent 系统实施清单
前面各案例看似分散,但可以收敛成一套实施路径。下面给出一份可直接用于项目 kickoff 的 checklist,帮助团队把 “概念正确” 落到 “系统可交付”。
阶段化建设路线
| 阶段 | 必做事项 | 验收信号 |
|---|---|---|
| 定义阶段 | 明确 observe/decide/act 闭环与环境边界 | 关键状态与动作可枚举 |
| 基线阶段 | 建立可运行的分层管道(P-C-A) | 能定位失败在何层出现 |
| 训练阶段 | 设计场景分布与反馈体系(human + env) | 策略改进曲线稳定上升 |
| 评测阶段 | 引入多体互动与异常扰动评测 | 非 IID 情况下性能不过度塌缩 |
| 治理阶段 | 纳入安全/公平/合规约束与审计日志 | 违规率可量化并可追踪回放 |
常见失败模式与修复策略
失败模式 A:只做离线 benchmark
症状:离线分数高,但线上多步任务失败率高。
修复:补充交互式评测,强制覆盖恢复路径与协同路径。
失败模式 B:忽视队友/对手分布漂移
症状:固定环境里表现稳定,换协作方后性能骤降。
修复:把 ad hoc teamwork 思想引入训练,加入未知队友策略扰动。
失败模式 C:安全策略完全后置
症状:模型本体仍产生危险决策,外层拦截频繁触发。
修复:把安全与规则奖励前置到训练期,降低策略与守卫冲突。
一句话原则
先保证系统可诊断,再追求策略最优;先保证行为可治理,再追求局部指标极致。
证据索引:课程片段与结论对照
| 时间戳 | 课程片段 | 提炼结论 |
|---|---|---|
| 00:08–00:10 | RoboCup 多机器人自主对抗 | 多体协作必须在实时闭环下验证 |
| 00:12–00:13 | reservation-based intersection | 协议化协调优于局部最优 |
| 00:21–00:23 | TAMER 与 implicit feedback | 人类反馈可作为可训练信号 |
| 00:31–00:33 | Slack 任务设定与难点 | 低保真结构学习可降真实成本 |
| 00:53–00:56 | GT Sophy 策略涌现与 etiquette | 数据配比与规则设计决定上限 |
本章小结
把 Stone 的课程真正落地,需要把算法、系统、评测、治理四条线并行推进。任意一条缺失,都会导致 “可演示但不可部署”。
对 LLM Agent 的系统启发
把 Stone 这节课映射回 2025 年 LLM Agent,至少有四个直接结论。
启发 1:Agent 评测必须包含 interaction outcome
仅看单轮回答质量会误导。应评估:
- 长链任务完成率;
- 与人/工具/其他 agent 的协同稳定性;
- 出错恢复路径是否可控。
启发 2:分层动作空间可以显著降本
Slack 的 latent action 思想在软件 Agent 里也成立:不要总是直接生成低层动作序列,可以先学高层 action primitives,再做下游任务优化。
启发 3:数据策划和 replay 配比决定战术能力
GT Sophy 证明了 “看到什么分布,就学到什么策略”。在 coding/ops agent 里,同样需要精心构造困难场景、对抗场景和边界场景的训练比例。
启发 4:安全约束应显式进入训练目标
无论是机器人避障还是竞速 etiquette,本质都是 “把合规从后处理挪到训练过程”。LLM Agent 也应把权限、审计、风险动作约束前置。
本章小结
这节课不是在和 LLM Agent 竞争叙事,而是在提供一套更稳的工程母框架:定义闭环、分层建模、场景化训练、系统级评测。
总结与延伸
核心内容总表
| 主题 | 课程结论 | 对 LLM Agent 启发 |
|---|---|---|
| Agent 定义 | 连续感知-决策-行动闭环 | 评测要覆盖多步行为结果 |
| 智能体架构 | Perception-Cognition-Action 分层 | 系统可调试性优先于端到端神化 |
| 多体互动 | 协作与对抗是核心难题 | 多 Agent 场景需建模队友分布变化 |
| Human feedback | TAMER/RLHF 可加速早期学习 | 人类偏好与环境反馈需联合优化 |
| Embodied RL | Slack 通过结构化动作空间降本提效 | 高层 action primitive 可迁移到软件 Agent |
| 竞争型 RL | GT Sophy 依赖系统工程和数据策划 | replay/curriculum 设计是策略质量关键 |
进一步思考
- 当 Agent 要在真实业务里长期运行时,哪些失败模式必须在训练阶段提前暴露?
- 如何把 “ad hoc teamwork” 形式化到今天的 multi-agent coding pipeline?
- 在 LLM Agent 里,哪些能力应留在系统外层,哪些应内化到策略模型?
拓展阅读
- Peter Stone 个人主页与公开讲座(含 Autonomous Agents、GT Sophy、robot learning 系列)
- TAMER / Deep TAMER / human-in-the-loop reinforcement learning 相关论文
- Ad Hoc Teamwork challenge paper(AAAI 2010)与后续多智能体协作研究
- Slack(Sim-to-real latent action learning)与 factorized RL 相关论文
- Outracing champion Gran Turismo drivers with deep RL(Nature 2022)
- Phoebe dataset(human-centric fairness benchmark,Nature 2025)