CS231N Lecture 11: Large Scale Distributed Training
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Justin Johnson 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2025年 |

引言:大规模分布式训练的时代
本节课聚焦于大规模分布式训练——这是当今所有神经网络在实践中训练的方式。10 年前,在一块 GPU 上训练模型是常态;而今天,在数千甚至数万块 GPU 上并行训练已成为新常态。课程以 Llama 3 405B 作为贯穿全课的案例研究,因为它是少数公开了详细训练基础设施信息的前沿模型之一。

来源:Slides 第1页。
为什么选择 Llama 3 作为案例
OpenAI 的 GPT-4 论文明确声明“不再分享架构、模型规模、硬件、训练计算、数据集构建、训练方法等任何细节”。这已成为行业新常态。Llama 3 虽非最强模型,但其技术报告详细公开了训练集群和系统基础设施信息,为我们提供了一窥大规模 LLM 训练的珍贵窗口。

来源:Slides 第2页。
课程分为两大部分:
- Part 1:GPU 硬件——理解我们用来训练模型的物理设备
- Part 2:分布式训练算法——如何在大量 GPU 上训练一个神经网络
本章小结
大规模分布式训练已成为深度学习的新范式。理解硬件和并行化算法是构建高效训练系统的必要前提。Llama 3 的开放性使其成为学习这些技术的理想案例。
GPU 硬件剖析
GPU 的起源与演进
GPU(Graphics Processing Unit)最初是为计算机图形学开发的专用协处理器——渲染屏幕上大量像素的过程天然适合大规模并行。在 2000 年代初期,研究者发现这种硬件可以用于通用并行计算。NVIDIA 在 2010 年代初期敏锐地抓住了深度学习的机遇,将 GPU 打造为深度学习训练的主力硬件。

来源:Slides 第3页。
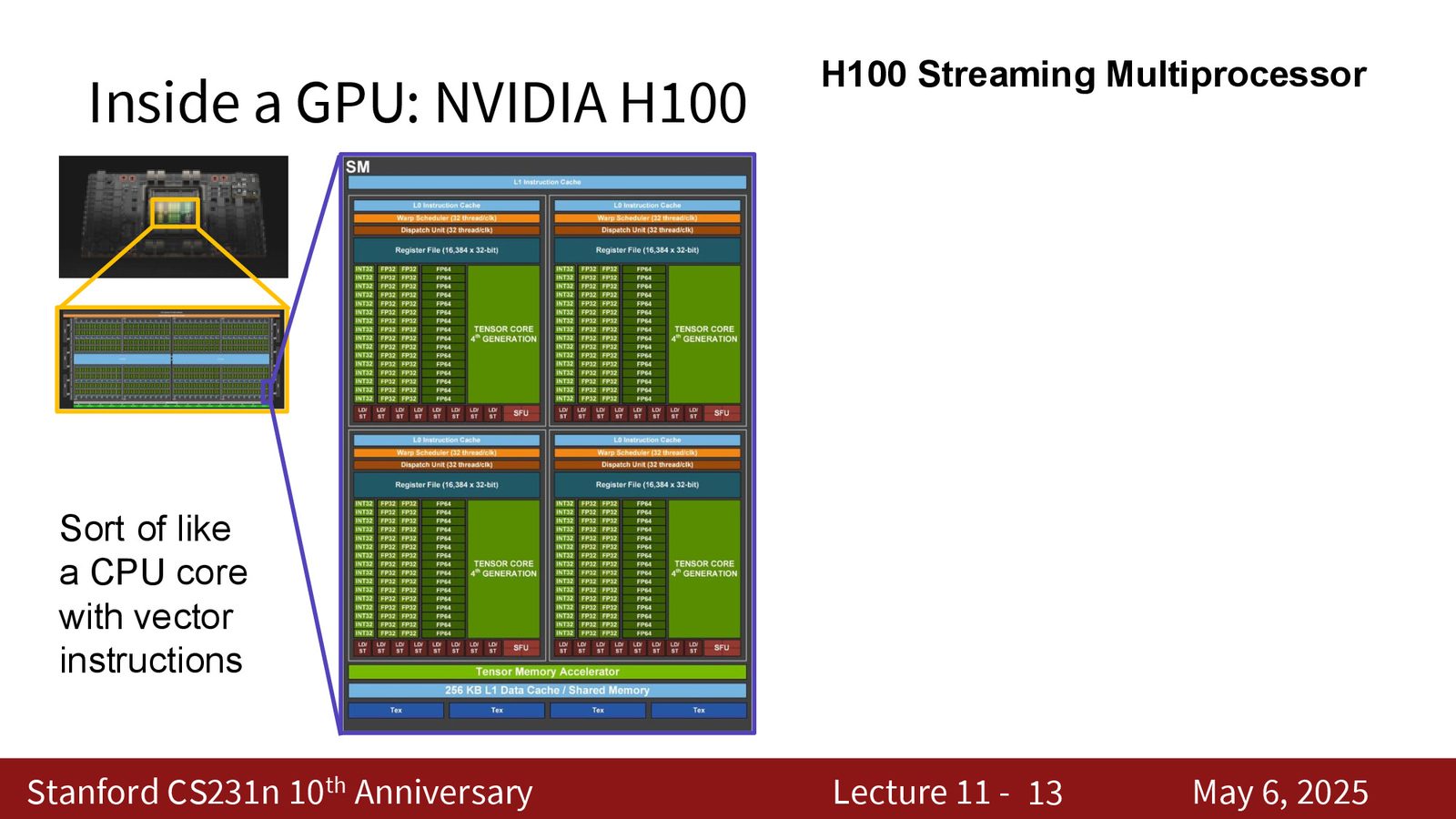
H100 GPU 的内部结构
以当前主力训练硬件 NVIDIA H100 为例,其内部结构呈现出层次分明的设计:

来源:Slides 第4页。
- HBM 内存:80 GB 高带宽内存,位于芯片外部,与计算核心以 \(\sim\)3 TB/s 带宽连接
- L2 Cache:约 50 MB,位于芯片上,比 HBM 更接近计算单元
- 132 个 SM(Streaming Multiprocessor):GPU 的核心计算单元
GPU “binning” 工艺
H100 芯片设计有 144 个 SM,但由于制造过程中不可能每个晶体管都完美,NVIDIA 只保证 132 个 SM 正常工作。这种“binning”策略让 NVIDIA 能将更多芯片作为合格产品出售,是半导体行业的通用做法。
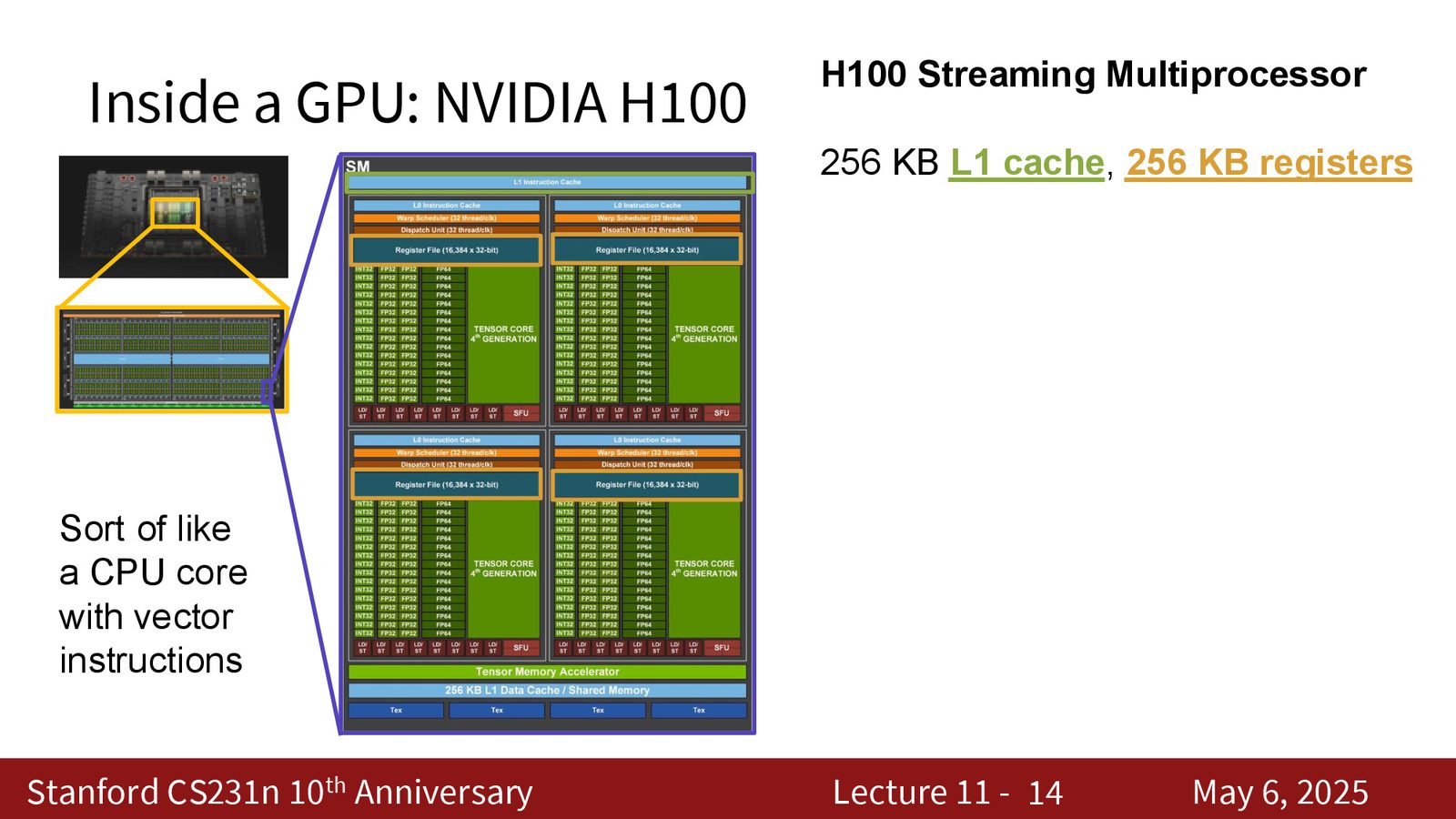
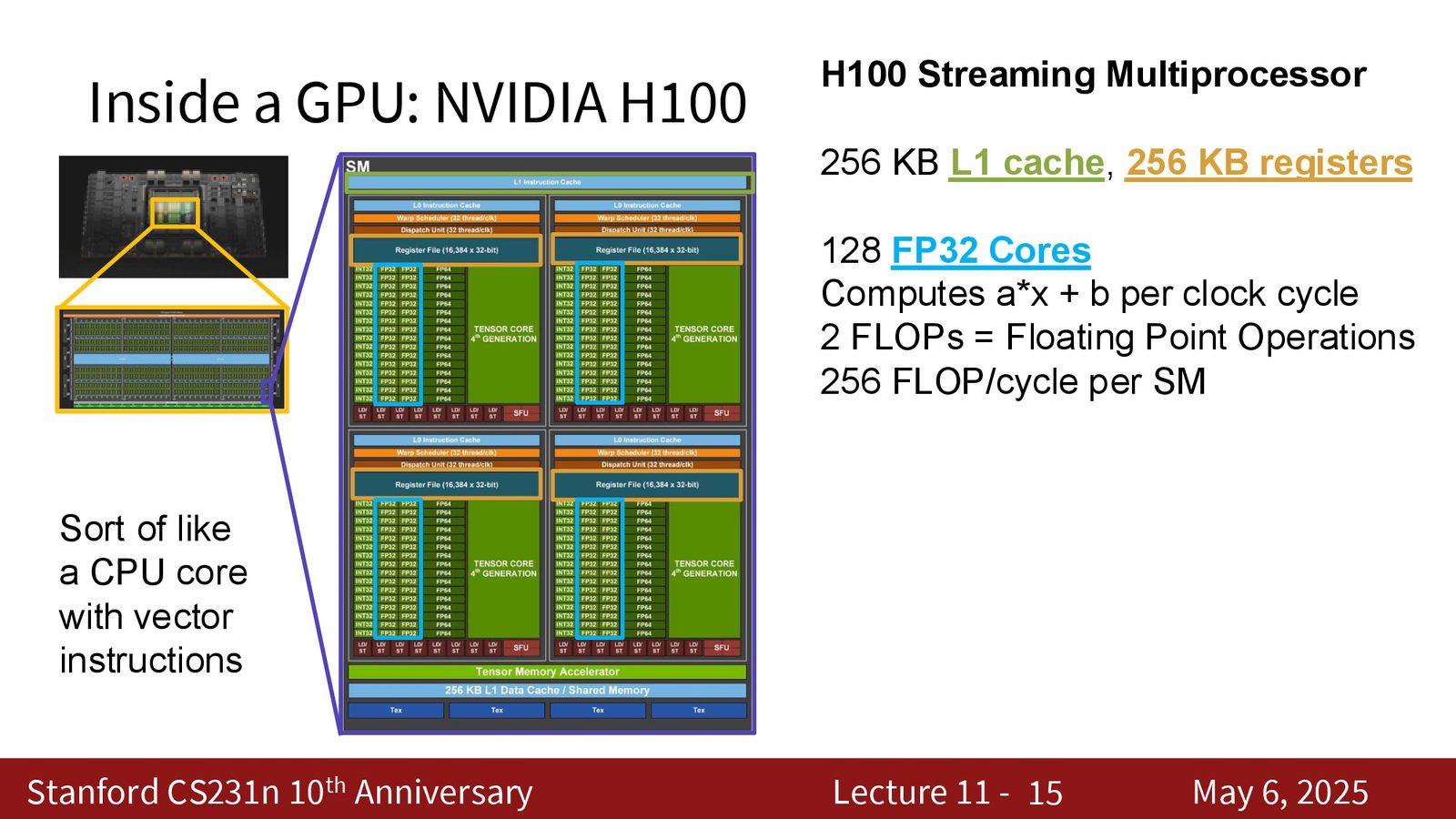
SM 的内部结构:FP32 核心与 Tensor Core
每个 SM 内部包含两种关键计算单元:

来源:Slides 第5页。
FP32 核心 vs Tensor Core
- 128 个 FP32 核心:每个可在一个时钟周期内计算 \(ax + b\)(标量),整个 SM 每周期可执行 256 FLOP
- 4 个 Tensor Core:专为矩阵乘法设计的硬件电路。每个可在一个时钟周期内计算 \(16 \times 4 \cdot 4 \times 8 + 16 \times 8\) 的矩阵乘加运算,整个 SM 每周期可执行 4,096 FLOP
Tensor Core 的吞吐量是 FP32 核心的 16 倍。这就是为什么在 PyTorch 中忘记将模型转换为 16-bit 精度会导致运行速度慢 20 倍——因为它会使用 FP32 核心而非 Tensor Core。
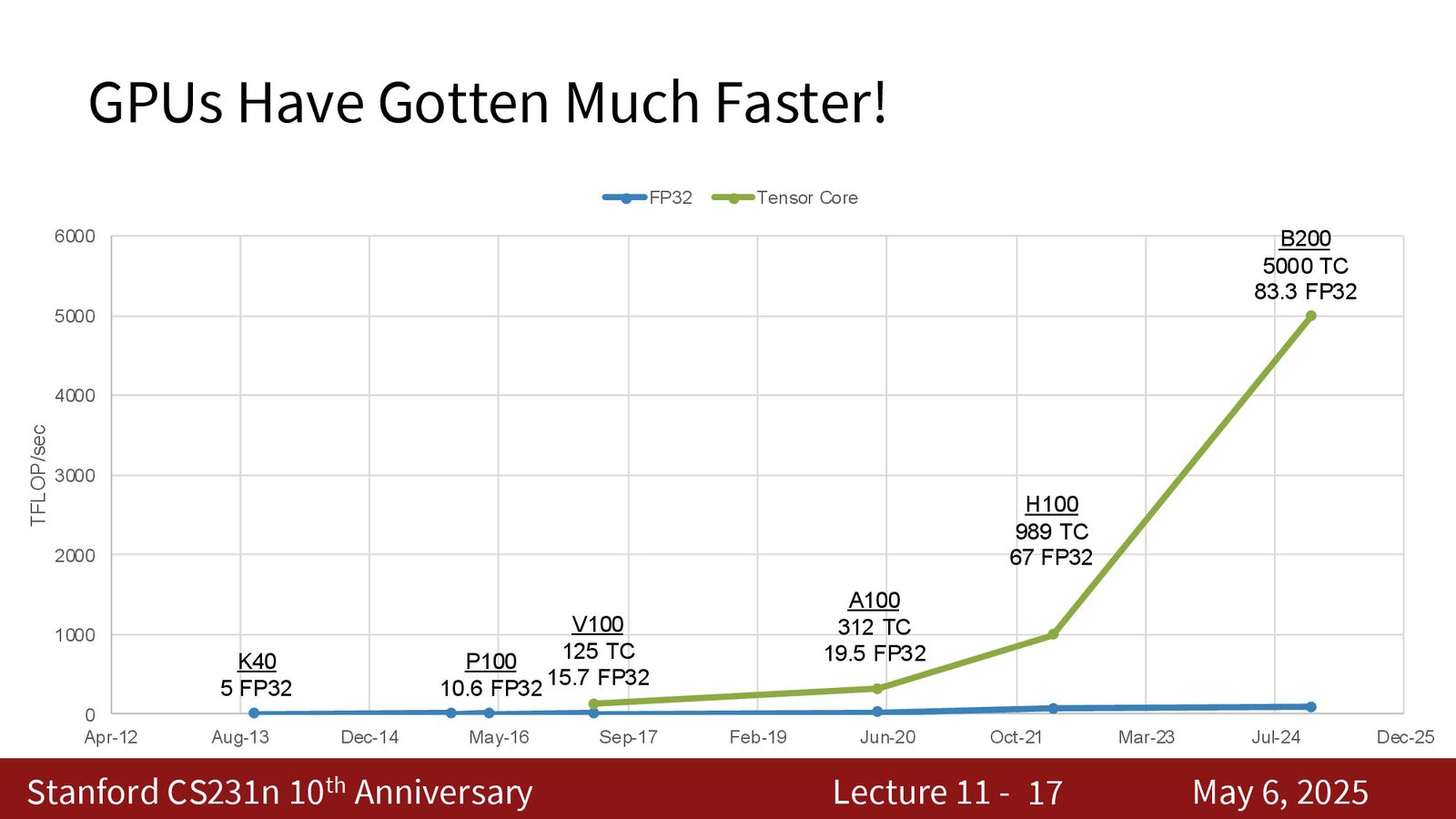
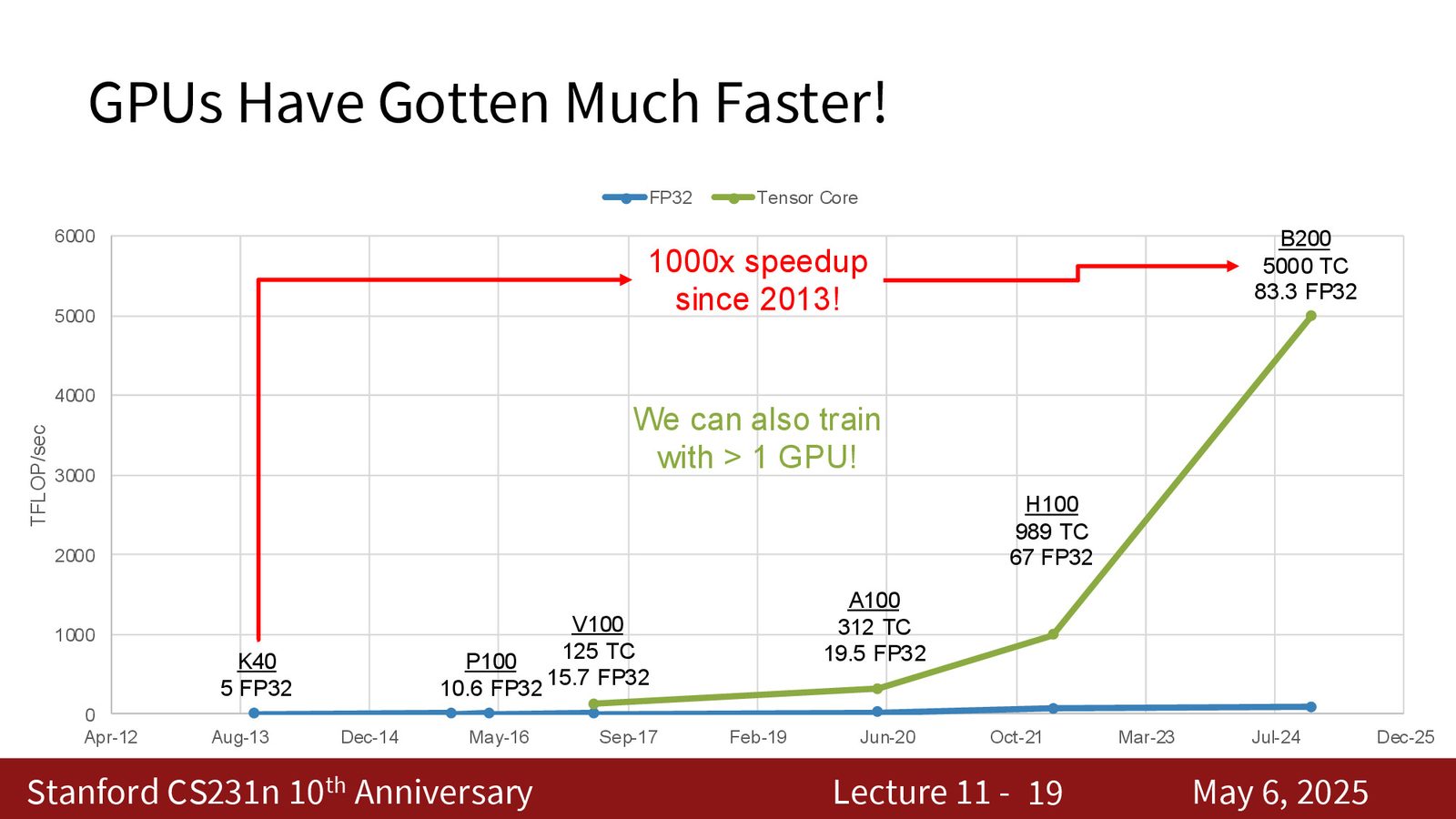
GPU 计算能力的指数级增长
从 2013 年的 K40 到 2024 年的 B200,GPU 的计算吞吐量在过去十余年间增长了约 1000 倍:

来源:Slides 第6页。
Tensor Core 与混合精度
Tensor Core 使用混合精度计算:输入为 16-bit(FP16/BF16),乘法在低精度下执行,累加在 32-bit 精度下完成。V100(2017年)是第一个引入 Tensor Core 的 GPU,此后每一代 GPU 的 Tensor Core 都更多、更大、更快。
1000 倍增长还不够
单设备 1000 倍的计算能力增长已经很惊人,但更疯狂的是:我们现在不是在一块 GPU 上训练,而是在数万块 GPU 上并行训练。单设备增长叠加多设备并行,这就是过去十年 AI 能力爆发式增长的硬件基础。
GPU 集群的层次结构
从单个 GPU 扩展到完整的训练集群,内存层次结构不断延伸:

来源:Slides 第8页。
| 层级 | GPU 数量 | 带宽 | 带宽衰减 |
|---|---|---|---|
| GPU 内部(HBM \(≤ftrightarrow\) 计算核心) | 1 | 3 TB/s | 基准 |
| Server 内部(GPU \(≤ftrightarrow\) GPU) | 8 | 900 GB/s | \(≈\)3x |
| Pod 内部(GPU \(≤ftrightarrow\) GPU) | 3,072 | 50 GB/s | \(≈\)60x |
| Cluster(Pod \(≤ftrightarrow\) Pod) | 24,576 | \(<\)50 GB/s | \(>\)60x |

来源:Slides 第9页。
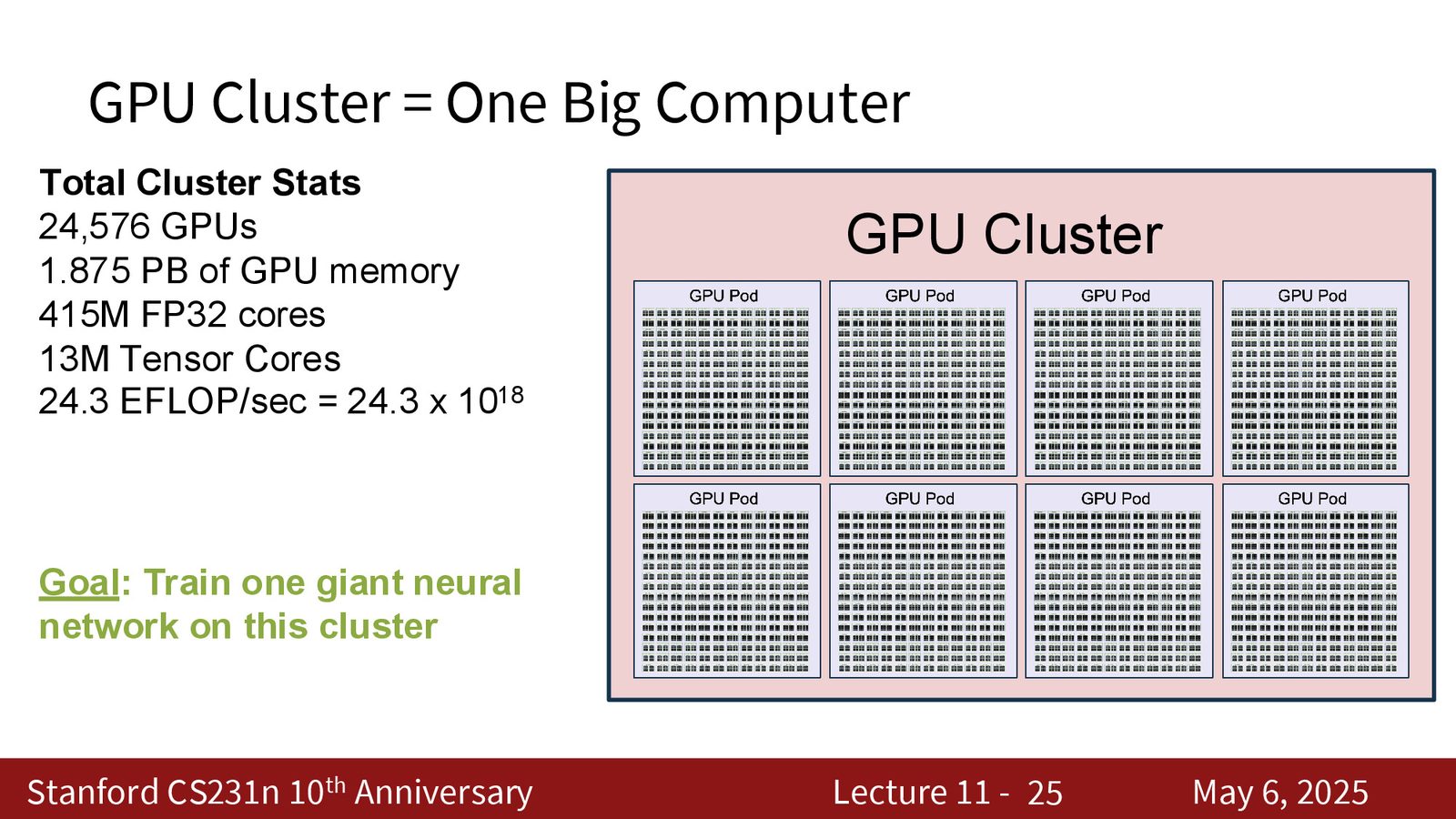
将整个数据中心视为一台巨型计算机
Llama 3 的训练集群拥有:24,000 块 GPU、1.8 PB HBM 内存、4.15 亿个 FP32 核心、1,300 万个 Tensor Core,总计算能力达 24 ExaFLOP/s(\(24 \times 10^{18}\))。我们的目标是将这个巨大的集群当作一台超级计算机来使用,在上面训练一个巨型神经网络长达数月。
其他训练硬件
虽然 NVIDIA GPU 目前占据主导地位,但还有其他竞争者:

来源:Slides 第10页。
- Google TPU:已迭代六代,V5P 性能与 H100 同一量级。Google 的 Gemini 模型几乎可以肯定在 TPU 上训练。但 TPU 只能通过 Google Cloud 租用或在 Google 工作才能使用
- AMD MI325X:纸面规格与 H100 相当,但实际影响力远不及
- AWS Trainium:Anthropic 用于部分训练
本章小结
- GPU 通过大量并行计算单元(SM/Tensor Core)实现超高吞吐量
- Tensor Core 是 GPU 的“魔力所在”,其矩阵乘法吞吐量是 FP32 核心的 16 倍
- GPU 集群呈层次结构,带宽随距离快速衰减——从 3 TB/s(GPU 内部)到 50 GB/s(跨 Pod)
- 算法设计必须尊重这种层次结构,将高通信需求放在高带宽连接上
分布式训练:五种并行策略
并行化的四个维度
Transformer 模型本质上是 \(L\) 层的堆叠,每层操作一个三维张量 \((\text{batch}, \text{sequence}, \text{dim})\)。这为我们提供了四个天然的并行化轴:
来源:Slides 第12页。
五种并行策略
- 数据并行(Data Parallelism, DP):在 batch 维度上切分
- 全分片数据并行(FSDP):DP + 模型权重分片
- 混合分片数据并行(HSDP):FSDP + DP 的二维组合
- 上下文并行(Context Parallelism, CP):在 sequence 维度上切分
- 流水线并行(Pipeline Parallelism, PP):在 layers 维度上切分
- 张量并行(Tensor Parallelism, TP):在 dim 维度上切分
本章小结
Transformer 模型的四个维度(batch、sequence、dim、layers)为分布式训练提供了天然的并行化轴。不同维度的并行策略具有不同的通信需求和适用场景,需要根据模型规模、GPU 数量和集群拓扑进行选择。
数据并行(Data Parallelism)
基本原理
数据并行是最简单也是最基础的分布式训练方法。其核心思想:每块 GPU 持有模型的完整副本,但处理不同的数据子集。
来源:Slides 第13页。
数学上,设总损失为各样本损失的平均:
由于梯度是线性算子,可以重新排列为:
- \(M\):GPU 数量
- \(N\):每块 GPU 上的 mini-batch 大小
- 蓝色括号内的部分可以在每块 GPU 上完全独立计算
- 外层求和需要跨 GPU 通信(All-Reduce)
数据并行的执行流程
来源:Slides 第14页。
- 每块 GPU 持有模型权重的独立但相同的副本
- 每块 GPU 加载不同的 mini-batch 数据
- 每块 GPU 独立执行前向传播,计算局部损失
- 每块 GPU 独立执行反向传播,计算局部梯度
- All-Reduce:所有 GPU 交换并平均梯度
- 每块 GPU 独立更新权重(因为起点相同、梯度相同,更新后的权重仍然相同)
不同 GPU 必须加载不同的数据
这是数据并行中最容易犯的 bug:所有 GPU 意外加载了相同的 mini-batch。这不会导致程序报错,但会使训练完全无效——你相当于在浪费 \((M-1)\) 块 GPU 的计算资源。
计算与通信的重叠
反向传播和 All-Reduce 可以流水线化执行:当 GPU 在计算第 \(L-1\) 层的梯度时,第 \(L\) 层的梯度已经可以开始 All-Reduce。这种重叠隐藏了大部分通信开销。PyTorch 的 DistributedDataParallel(DDP)类自动实现了这一优化。
来源:Slides 第16页。
数据并行的瓶颈:内存限制
数据并行要求每块 GPU 存储模型的完整副本。对于每个模型参数,需要存储:
- 权重本身(2 bytes,16-bit)
- 梯度(2 bytes)
- 优化器状态——Adam 的 \(\beta_1\) 和 \(\beta_2\)(各 2 bytes)
即每个参数需要 \(\sim\)8 bytes。H100 有 80 GB 内存,因此数据并行最多支持约 10B 参数的模型——远远不够。
本章小结
数据并行是分布式训练的基础,数学上完全等价于单 GPU 大 batch 训练。它简单有效,但受限于 GPU 内存——每块 GPU 必须能容纳完整的模型参数、梯度和优化器状态。
全分片数据并行(FSDP)
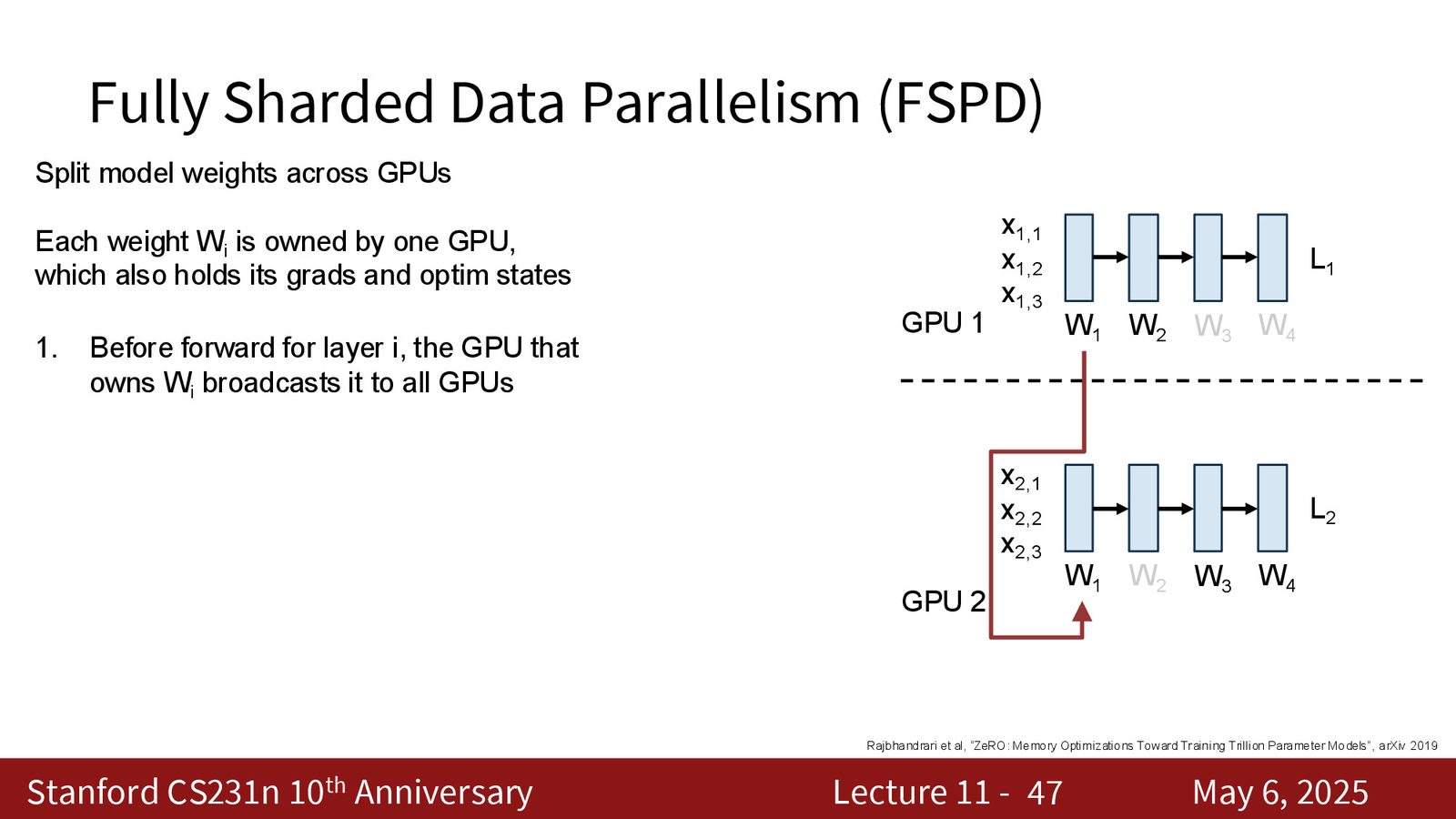
核心思想:分片存储
为突破数据并行的内存瓶颈,FSDP 将模型权重分片存储在不同 GPU 上:每个权重矩阵只有一个“所有者” GPU 负责存储其权重、梯度和优化器状态。
来源:Slides 第18页。
FSDP 的执行流程
FSDP 在前向和反向传播中需要额外的通信步骤:

来源:Slides 第19页。
前向传播:
- 权重所有者广播第 \(i\) 层的权重给所有 GPU
- 所有 GPU 执行第 \(i\) 层的前向传播
- 非所有者 GPU 删除第 \(i\) 层权重的本地副本
- 同时预取第 \(i+1\) 层的权重(计算-通信重叠)
反向传播(每层需要三件事同时进行):
- 权重所有者广播权重(用于计算梯度)
- 各 GPU 执行反向传播
- 各 GPU 将局部梯度发送回权重所有者,由所有者聚合并更新权重

来源:Slides 第21页。
FSDP 的通信开销
在一次完整的前向+反向传播中,FSDP 需要通信 3 倍模型权重的数据量:前向传播广播一次权重,反向传播广播一次权重 + 回传一次梯度。相比之下,普通数据并行只需通信 1 倍(All-Reduce 梯度)。
混合分片数据并行(HSDP)
HSDP 将 GPU 组织为二维网格,结合 FSDP 和 DP 的优势:

来源:Slides 第22页。
- 组内(同一服务器内的 GPU,高带宽连接):使用 FSDP,需要 3 倍权重通信
- 组间(跨服务器的 GPU,低带宽连接):使用普通 DP,只需 1 倍梯度通信
网络拓扑感知的算法设计
HSDP 是第一个将并行策略与物理网络拓扑对齐的例子。高通信需求(FSDP)放在高带宽连接(服务器内部)上,低通信需求(DP)放在低带宽连接(跨服务器)上。这种“拓扑感知”的设计思想贯穿整个大规模训练系统。
本章小结
FSDP 通过分片存储突破了数据并行的内存瓶颈,代价是更多的通信。HSDP 进一步将 FSDP 与 DP 组合为二维并行,根据网络拓扑分配不同的并行策略,平衡了通信开销与内存需求。
激活检查点(Activation Checkpointing)
即使使用 FSDP 解决了权重存储问题,激活值的存储仍会成为瓶颈。以 Llama 3 405B 为例(126 层、维度 16384、序列长度 4096),前向传播的隐藏状态需要大量 GPU 内存。
来源:Slides 第24页。
三种策略的计算-内存权衡
对于 \(n\) 层网络:
| 策略 | 计算 | 内存 |
|---|---|---|
| 存储所有激活 | \(O(n)\) | \(O(n)\) |
| 不存储任何激活 | \(O(n^2)\) | \(O(1)\) |
| 每 \(c\) 层检查点一次 | \(O(n^2/c)\) | \(O(c)\) |
| \(c = √n\)(最优) | \(O(n√n)\) | \(O(√n)\) |
激活检查点会降低训练速度
激活检查点通过在反向传播时重新计算中间激活来节省内存,但这会引入额外的计算开销。典型设置(\(c = \sqrt{n}\))会增加约 \(\sqrt{n}\) 倍的前向计算量。这“不太爽”,但它让我们能训练更大的模型。
本章小结
激活检查点是一种用计算换内存的技术,在 FSDP 之上进一步扩展了可训练模型的规模。最优策略是每 \(\sqrt{n}\) 层保存一次检查点,实现 \(O(n\sqrt{n})\) 计算和 \(O(\sqrt{n})\) 内存的平衡。
实用扩展指南
从 1 GPU 到 10,000 GPU 的扩展路径

来源:Slides 第26页。
扩展配方
- DP(\(\leq\)128 GPU,\(\leq\)1B 参数):最简单,将局部 batch size 调到最大化 GPU 内存
- FSDP(\(>\)1B 参数):权重分片,突破单 GPU 内存限制
- FSDP + 激活检查点:激活值内存瓶颈时启用
- HSDP(\(>\)256--512 GPU):利用网络拓扑,减少跨服务器通信
- TP + CP + PP(\(>\)1,000 GPU,\(>\)50B 参数,序列 \(>\)10K):高级并行策略
MFU:分布式训练的北极星指标
当面对如此多的并行策略和超参数时,Model FLOP/s Utilization (MFU) 是你的指路明灯:

来源:Slides 第28页。
- \(>\)30%:良好
- \(>\)40%:优秀(接近当前最优水平)
- \(<\)30%:可能存在严重瓶颈
更快的 GPU 可能导致更低的 MFU
从 A100 到 H100,计算吞吐量提升约 3 倍,但内存带宽仅提升约 2 倍。通信速度跟不上计算速度的增长,导致 H100 上的 MFU(\(\sim\)40%)反而低于 A100(\(\sim\)50%)。这个差距在未来的 GPU 上可能继续扩大。
本章小结
扩展分布式训练是一个渐进的过程,随着 GPU 数量和模型规模的增加逐步引入更复杂的并行策略。MFU 是衡量训练效率的核心指标,所有并行策略的调优都应以最大化 MFU 为目标。
高级并行策略
上下文并行(Context Parallelism)
上下文并行在序列维度上切分,将长序列分配给不同 GPU 处理。

来源:Slides 第32页。
- LayerNorm、FFN、残差连接在序列维度上天然独立,可以直接切分
- Attention 是难点:因为需要计算所有 token 对之间的交互
- 两种解决方案:Ring Attention(按 block 轮转计算)和 Ulysses Attention(按 head 并行)
Llama 3 在长上下文训练阶段(序列长度 131,072)使用了 16-way 上下文并行。
流水线并行(Pipeline Parallelism)
流水线并行将网络的不同层分配给不同 GPU。主要挑战是层间的顺序依赖:

来源:Slides 第35页。
朴素实现中,\(n\)-way 流水线并行的利用率仅为 \(1/n\)(8-way 时最大 MFU 仅 12.5%)。

来源:Slides 第37页。
缩小 Bubble 的关键:微批次
通过同时处理多个 micro-batch,让不同 GPU 在同一时刻处理不同 micro-batch 的不同层,可以显著提高 GPU 利用率。micro-batch 越多,bubble 越小,但每个 micro-batch 的激活值都需要存储——又需要激活检查点。
张量并行(Tensor Parallelism)
张量并行将单个权重矩阵切分到多块 GPU 上,每块 GPU 只计算矩阵乘法的一个“切片”:

来源:Slides 第40页。
两层 TP 的巧妙技巧
对于 Transformer 的两层 MLP(\(Y = \sigma(XW_1)W_2\)),可以将 \(W_1\) 按列切分、\(W_2\) 按行切分。这样两层之间不需要通信,只在两层 MLP 结束后做一次 All-Reduce。这正好适配 Transformer 中 FFN 的两层 MLP 结构。

来源:Slides 第41页。
N 维并行:全部用上
实际的大规模训练系统同时使用所有并行策略:

来源:Slides 第43页。
Llama 3 的 4D 并行
在 16,384 块 GPU 的最大训练阶段:
- 8-way 张量并行:在单服务器的 8 块 GPU 上(最高带宽)
- 16-way 上下文并行:处理 131K 长序列
- 16-way 流水线并行:将 126 层分配给 16 个阶段
- 8-way 数据并行:跨 Pod 复制(最低带宽)
关键原则:高通信需求的并行策略放在高带宽连接上。TP 通信最密集,放在服务器内部(900 GB/s);DP 通信最稀疏,放在跨 Pod 连接上(50 GB/s)。

来源:Slides 第44页。
本章小结
上下文并行、流水线并行和张量并行分别从序列、层、维度三个方向切分计算。在实际的大规模训练中,四种并行策略同时使用,形成 4D 并行。不同策略的通信需求不同,应与集群的物理网络拓扑对齐。
大规模训练的工程挑战
硬件故障与容错
在 24,000 块 GPU 上训练数月,硬件故障是必然的:
来源:Slides 第46页。
大规模训练的故障率
Llama 3 在 54 天训练中经历了 466 次任务中断,平均每天 8--9 次。硬件故障占 58.7%(GPU 故障 30.1%、主机维护 14.1%、网络问题 5.5%)。这意味着训练系统必须能够自动检测故障、重启并从检查点恢复,否则大规模训练根本不可能完成。
本章小结
大规模训练不仅是算法和硬件的挑战,更是系统工程的挑战。自动故障检测、快速检查点恢复和训练监控是使训练在数万 GPU 上稳定运行数月的关键基础设施。
总结与延伸
讲者的核心总结
Justin Johnson 在课程结尾强调了以下关键信息:
- GPU 计算能力 1000 倍增长是过去十年 AI 能力爆发的核心驱动力
- 内存层次结构(从 SRAM 到跨 Pod 网络)决定了算法设计
- 数据并行 + FSDP + 激活检查点可以覆盖大多数实际场景(\(\leq\)1,000 GPU)
- MFU 是优化分布式训练的北极星指标
- 真正的大规模训练(\(>\)10,000 GPU)需要 4D 并行 + 拓扑感知 + 自动容错
全课知识图谱

关键 Takeaways
五条核心原则
- Tensor Core 是 GPU 的灵魂:确保你的计算尽量走 Tensor Core(使用 16-bit 精度、矩阵乘法为主的架构)
- 带宽随距离急剧衰减:算法设计必须尊重 GPU 集群的层次化带宽结构
- DP/FSDP/HSDP 覆盖大多数场景:这是你最可能在实践中使用的技术
- MFU 是唯一的优化指标:面对众多并行策略和超参数时,MFU 告诉你方向
- 容错是大规模训练的必需品:在数万 GPU 上训练数月,硬件故障不是“如果”的问题,而是“何时”的问题
拓展阅读
- Llama 3 技术报告:https://arxiv.org/abs/2407.21783
- PyTorch FSDP 文档:https://pytorch.org/docs/stable/fsdp.html
- Megatron-LM 论文(张量并行):Shoeybi et al., https://arxiv.org/abs/1909.08053
- Ring Attention:Li et al., https://arxiv.org/abs/2310.01889
- GPipe(流水线并行):Huang et al., https://arxiv.org/abs/1811.06965
- ZeRO(FSDP 的前身):Rajbhandari et al., https://arxiv.org/abs/1910.02054