CS231N Lecture 12: Self-Supervised Learning
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Justin Johnson 授课内容整理 |
| 来源 | Stanford CS231n 10th Anniversary |
| 日期 | 2025年5月8日 |

引言:为什么需要自监督学习
上一讲我们讨论了 GPU、分布式训练和大规模模型训练的工程问题。本讲要回答的是:如果我们有海量原始图像,但没有昂贵的人工标注,能不能先把表示学好?

来源:Slides 第1页。
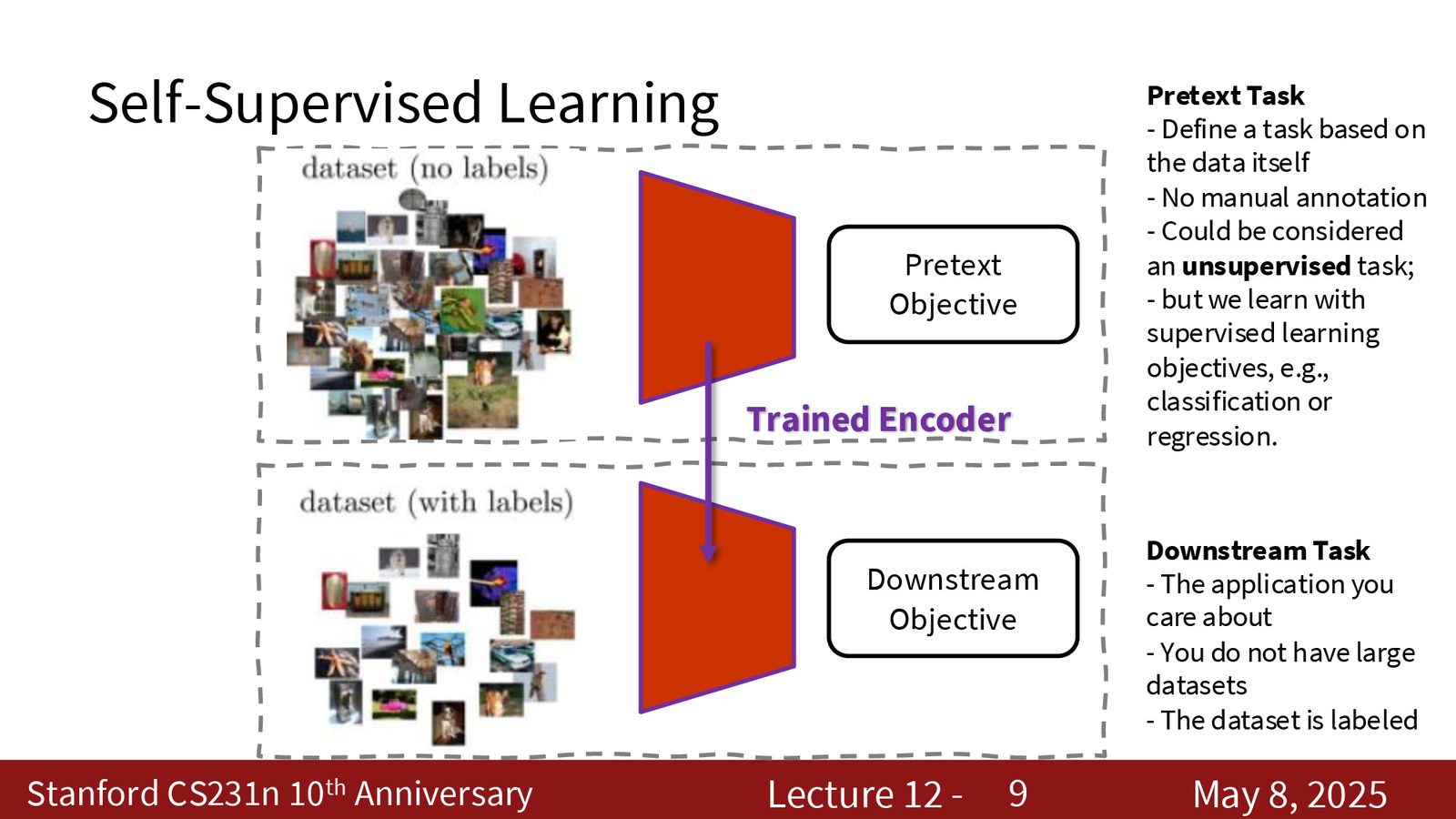
自监督学习的核心目标不是直接解决下游任务,而是先通过一个“预文本任务”(pretext task)让模型学出有用的表示,再把这些表示迁移到分类、检测、分割等下游任务。
为什么需要表示学习
- 直接监督学习需要大量人工标注,尤其是分割、检测这类任务,成本极高。
- 如果模型能从原始数据中学到“视觉常识”,这些表示往往可以迁移到很多任务。
- 评价一个自监督方法时,真正重要的通常不是预文本任务本身,而是它学到的特征对下游任务有多有用。
从特征到标签
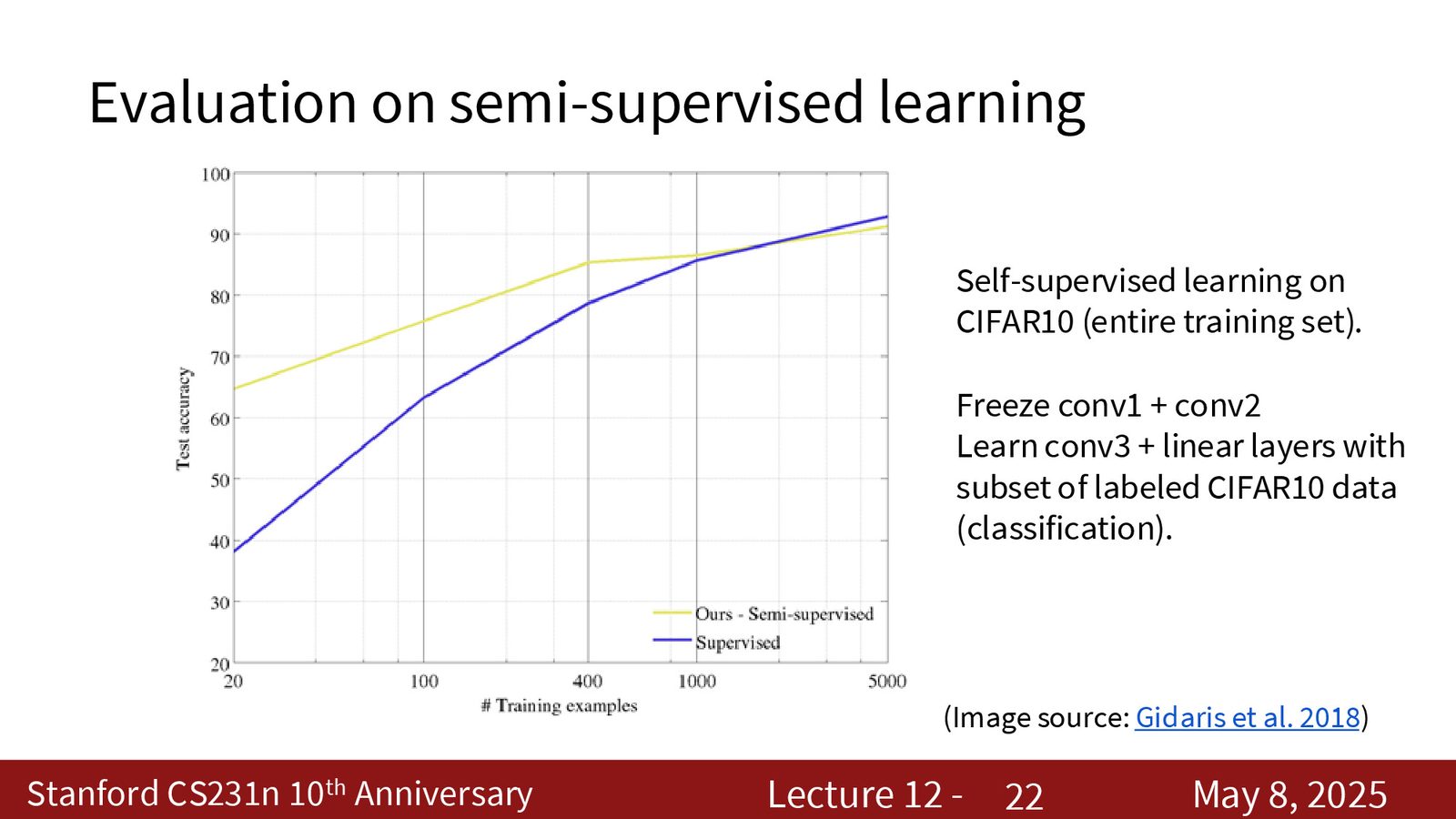
课程前半段我们已经看到,深层网络中间层的特征往往比原始像素更有语义。如果能学到一个好的 encoder,就可以只在少量标注数据上训练一个很浅的分类器,甚至直接做线性 probing。
来源:Slides 第8页。
这节课的主要思想可以概括为一句话:
自监督学习的基本范式
先用无标注数据定义一个可自动生成标签的任务,训练 encoder 学表示,再把 encoder 迁移到真正关心的下游任务上。
预文本任务:从图像变换中学习
预文本任务与下游任务
来源:Slides 第9页。
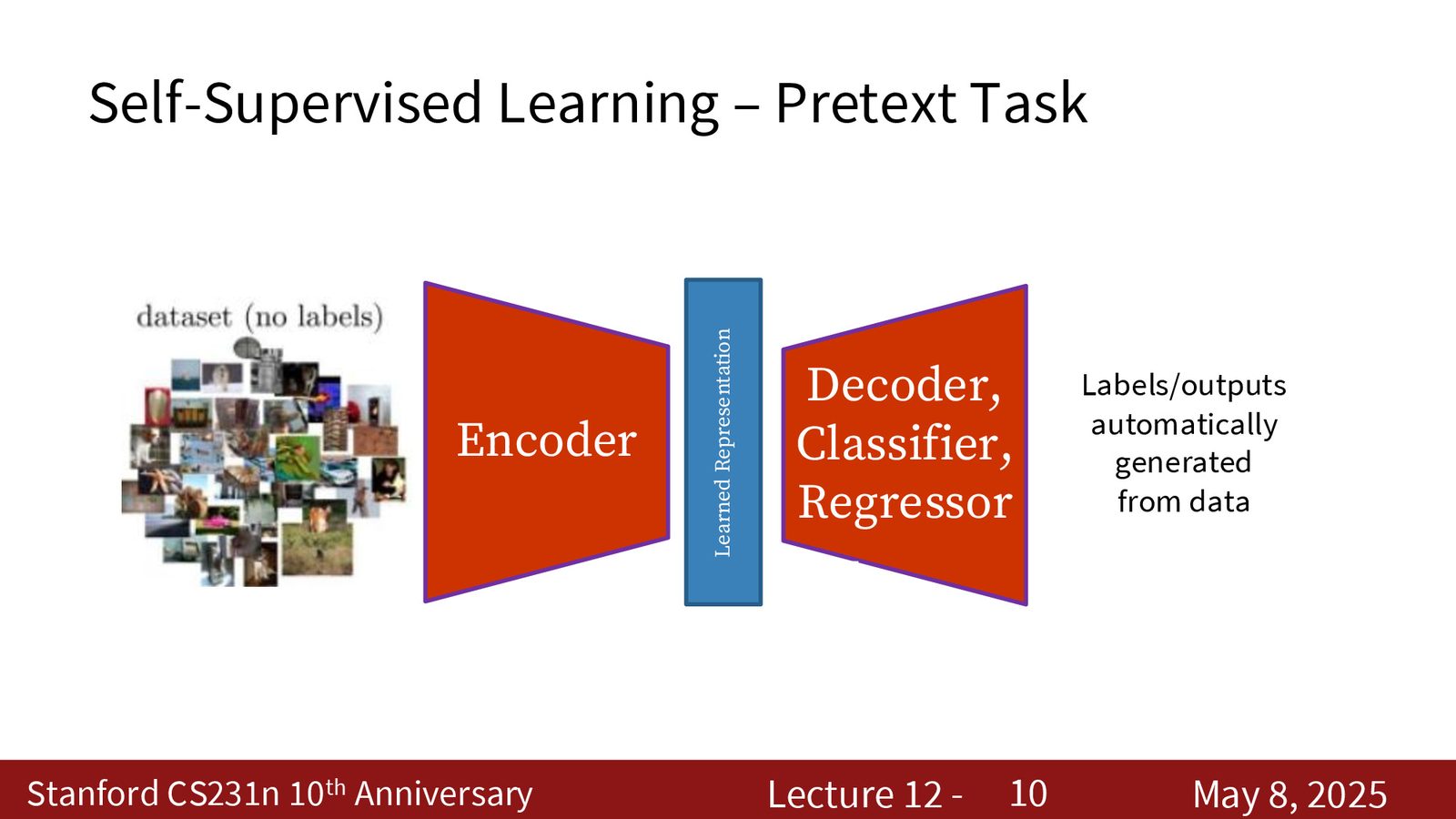
预文本任务的标签不是人工标注,而是从数据本身自动构造出来的。常见模式是:
- 输入:原始图片或视频片段;
- 通过某种变换或遮挡构造任务;
- 输出:旋转角度、patch 位置、缺失像素、颜色通道等;
- encoder 负责学出表征,下游任务再接一个线性层或小型头部。
评价自监督方法时看什么
- 预文本任务能否被很好地解决。
- 学到的表示是否有结构、是否容易聚类或可视化。
- 迁移到分类、检测、分割等下游任务时是否有效。
- 是否足够鲁棒、泛化,并且训练和推理开销合理。
旋转预测
最经典的预文本任务之一是 rotation prediction。给定一张图像,将它旋转 \(0^\circ, 90^\circ, 180^\circ, 270^\circ\) 之一,模型只需要预测旋转类别。
来源:Slides 第21页。
这个任务看似简单,但如果模型真的能分辨物体的朝向,说明它已经学到了一些关于“物体应该长什么样”的语义信息,而不是只看局部纹理。
旋转预测的直觉
如果模型连“这张图是不是倒着的”都能分出来,它通常已经在内部形成了较好的物体级表示。
相对位置与拼图
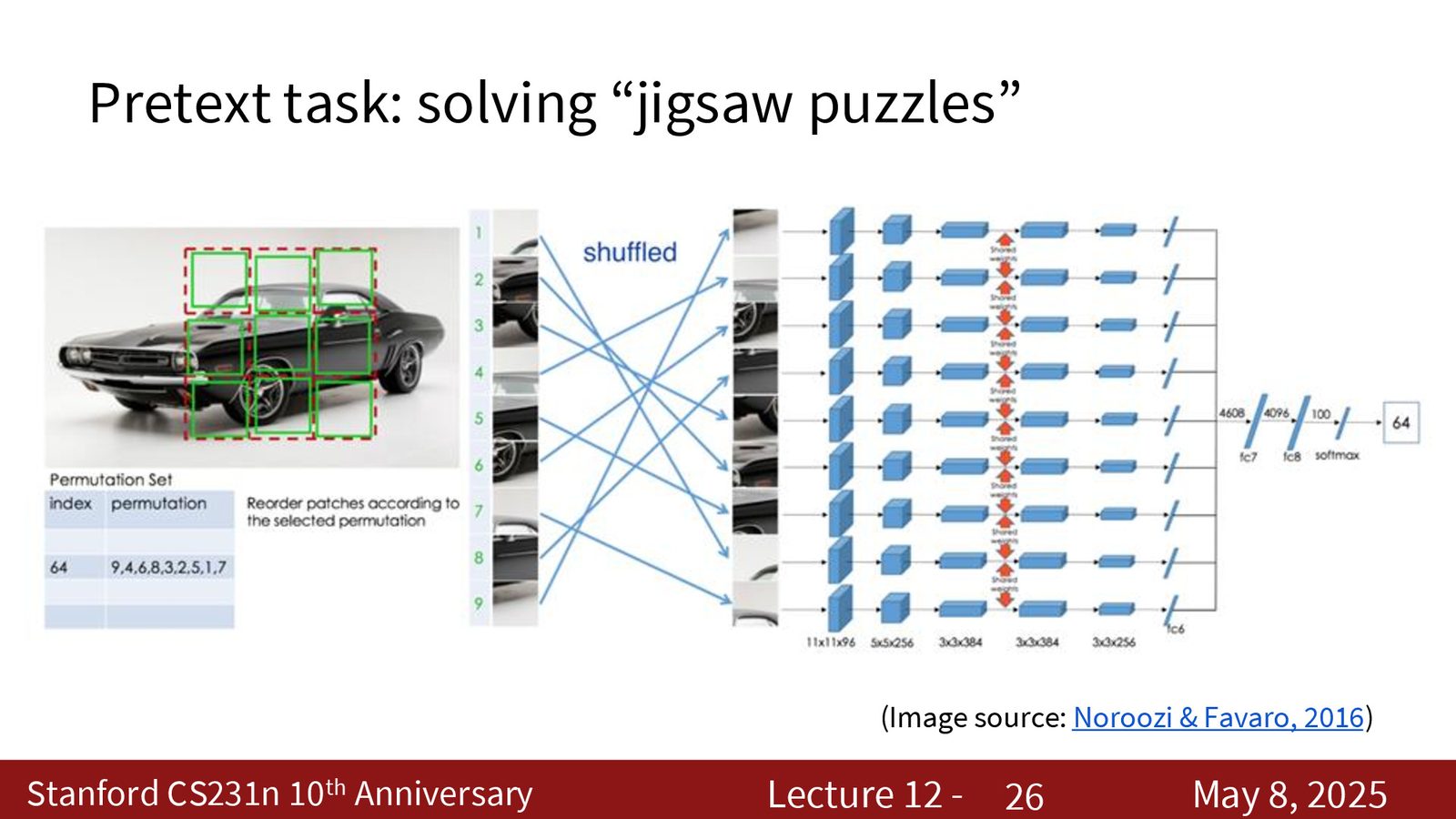
另外一类预文本任务是预测 patch 的相对位置,或者把图像切成拼图后预测正确排列。
来源:Slides 第25页。
相对位置任务会迫使模型理解局部 patch 与整体结构之间的关系。拼图任务更难,因为输出空间更大,但它也更强调全局布局和对象结构。
为什么拼图任务常常要限制候选排列
如果直接让 9 个 patch 做全排列,输出空间是 \(9!\),太大了。因此很多工作会预先挑选一小组“足够不同”的排列,把问题变成有限类别分类。
修补缺失区域
inpainting 任务会随机遮掉图像的一部分,让模型根据上下文补全缺失内容。
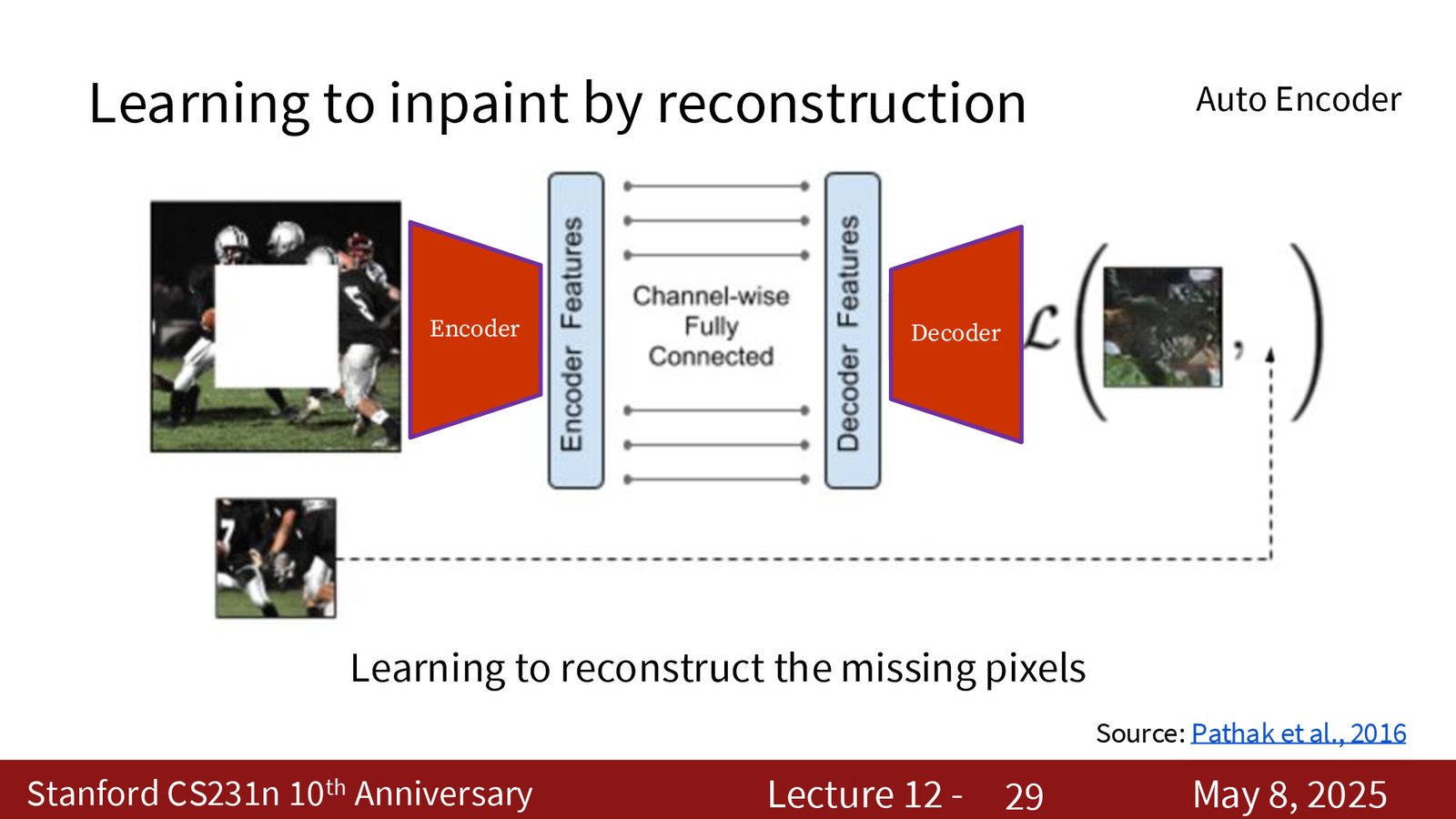
来源:Slides 第28页。
这类方法通常是一个 encoder-decoder 结构。encoder 编码可见区域,decoder 尝试重建被 mask 的部分。训练时直接对重建误差做回归即可。
重建任务的一个问题
像素级重建往往会鼓励模型输出“模糊的平均答案”,因为真实的缺失区域常常有多种合理补全。后面我们会看到,MAE 仍然沿用遮挡重建思路,但做法更现代。
颜色预测与 Split-Brain
另一个经典预文本任务是 image colorization。做法是把图像转到 LAB 颜色空间,只输入亮度通道 \(L\),让模型预测颜色通道 \(A, B\)。

来源:Slides 第34页。
这类任务之所以有用,是因为预测颜色不只是局部回归,它要求模型理解物体语义。比如“草通常偏绿”、“天空通常偏蓝”,这些都是物体层面的信息。
Split-Brain Autoencoder 的思想
可以把输入拆成两路,让一部分通道预测另一部分通道,或者反过来。比如 RGB-D 传感器里,可以用 RGB 预测 Depth,也可以用 Depth 预测 RGB。
视频颜色化与跟踪
静态图像颜色化还可以扩展到视频。给定一个有色参考帧,再去给后续灰度帧上色,模型就需要建立跨帧对应关系。

来源:Slides 第42页。
这里隐含的难点其实是 tracking。如果模型能把某个对象在不同帧中的对应区域对齐,就能把颜色或其他信息传播过去。于是,颜色化不仅是一个重建任务,也能间接逼出跟踪能力。
颜色化为何会诱发跟踪
要把参考帧中的颜色传到目标帧,模型必须先知道哪些像素属于同一对象或同一部位。这种对应关系本质上就是跟踪。
Masked Autoencoder
课程后半段特别强调了 MAE。它仍然是重建式任务,但 masking 更激进、结构更大,也更适合现代 ViT。
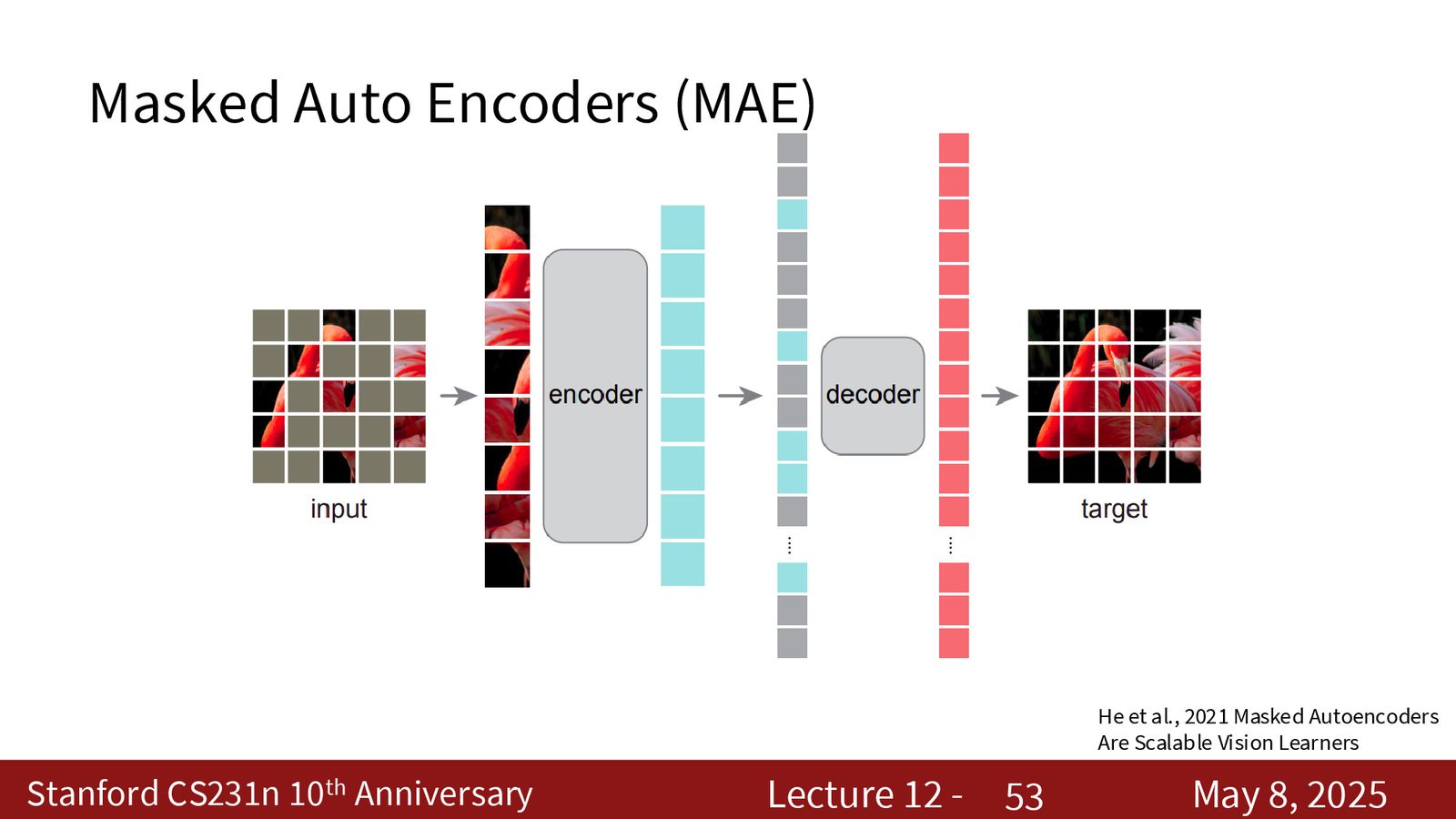
来源:Slides 第52页。
MAE 的关键设计是:
- 先把图像切成 patch;
- 随机遮掉大部分 patch,常见遮挡率可高达 75%;
- encoder 只处理可见 patch;
- decoder 用 mask token 复原完整图像;
- 损失只算在被 mask 的 patch 上。
MAE 的两个优势
- 遮挡率高,等于对同一张图做了大量随机增强,训练信号丰富。
- encoder 只看少量可见 patch,因此训练效率高,表示质量也往往很好。
如何评价预文本任务
预文本任务本身并不是终点。真正重要的是它学到的 encoder 是否对下游任务有帮助。
来源:Slides 第67页。
通常会看三类指标:
- linear probing:冻结 encoder,只训练一个线性分类器;
- fine-tuning:在下游任务上继续微调部分或全部参数;
- feature quality:做可视化、聚类、检索等分析。
预文本任务的局限
很多预文本任务都很“手工”,每设计一种任务就要额外调一套方法。更严重的是,学到的表示可能过度绑定某个具体任务,不够通用。
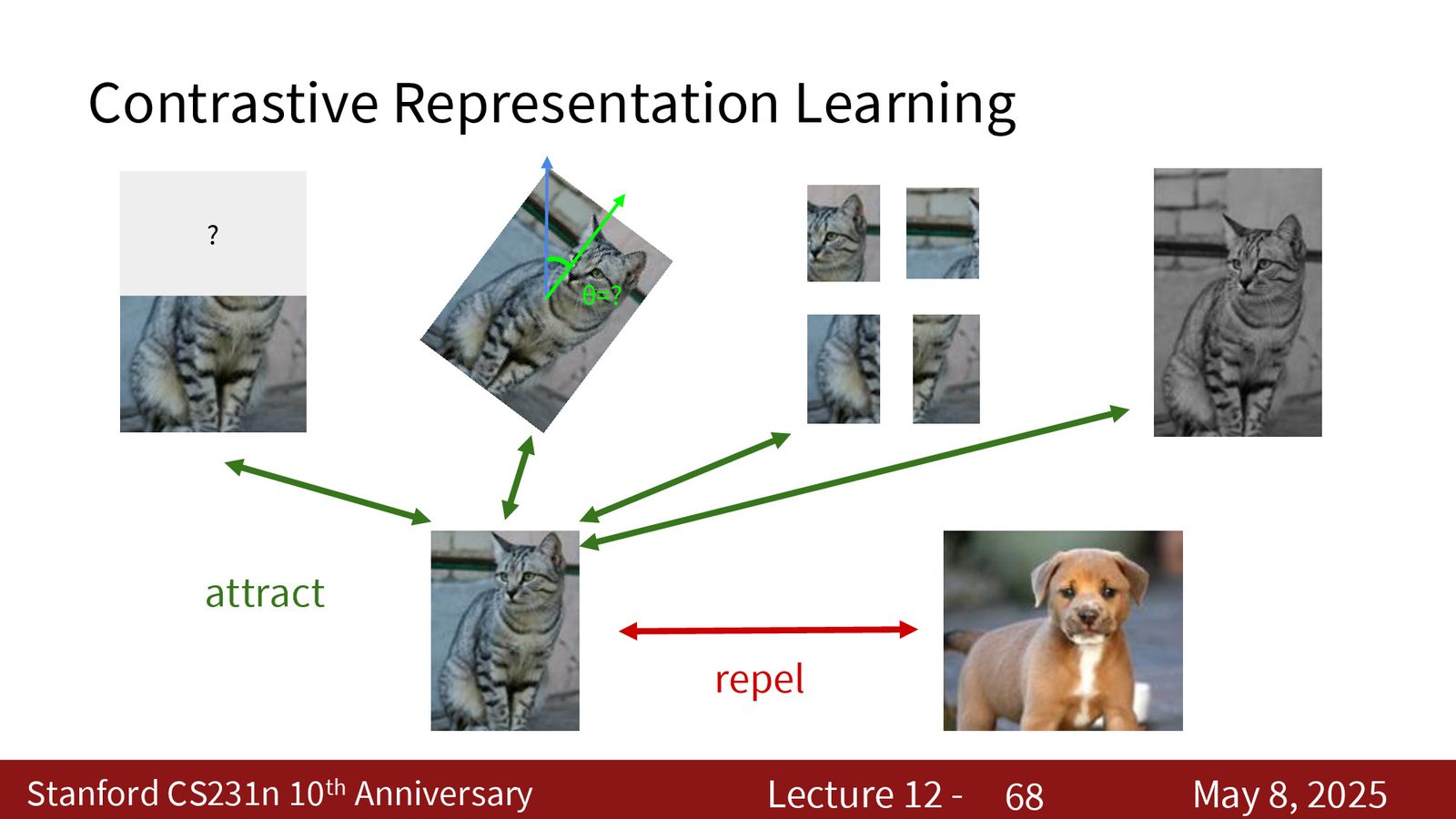
对比学习:更通用的表示目标
从“同一对象的不同视图”出发
如果说图像变换类预文本任务是在问“这张图被怎么变了”,那么对比学习问的是“哪些样本应该被拉近,哪些样本应该被推远”。

来源:Slides 第66页。
对比学习的目标
- 正样本:同一对象的不同增强视图;
- 负样本:其他对象;
- 目标:正样本在表示空间里更近,负样本更远。
InfoNCE 形式化
给定参考样本 \(x\)、正样本 \(x^+\)、负样本 \(x^-\),令编码器为 \(f(\cdot)\),打分函数为 \(s(\cdot,\cdot)\)。希望
对应的常见损失就是 InfoNCE:

来源:Slides 第74页。
从形式上看,它和多分类交叉熵几乎一样:模型要在一堆候选里把“正确的那个正样本”挑出来。
为什么 InfoNCE 有效
它等价于“把正样本当作正确类别、把所有负样本当作其他类别”的分类问题,因此特别适合端到端优化。
为什么需要大 batch
InfoNCE 的一个现实问题是:负样本越多,通常效果越好。因此很多方法都依赖大 batch 或者大字典/队列来提供更多负样本。
负样本越多通常越好
更多负样本通常会带来更紧的互信息下界,也让模型更难走捷径,因此学习到的表示往往更强。但代价是显存和训练复杂度都会上升。
SimCLR
SimCLR 是一个非常简洁但很强的实例级对比学习框架。

来源:Slides 第76页。
它的关键点有三个:
- 用强数据增强生成正样本对;
- 在 encoder 后加一个 projection head \(g(\cdot)\),只在投影空间做对比学习;
- 用一个大 batch,把 batch 里其他样本都当作负样本。
为什么要 projection head
对比损失有时会丢掉一些对下游任务有用的信息。projection head 允许模型把“对比学习所需的表示”和“下游任务最有用的表示”适当分开。
SimCLR 的训练细节
SimCLR 的训练流程可以理解为:
- 对每张图做两次随机增强;
- 得到 2N 个视图;
- 每个视图把另一个增强视图当正样本,其余 2N-2 个当负样本;
- 用 InfoNCE 逐个计算损失并平均。
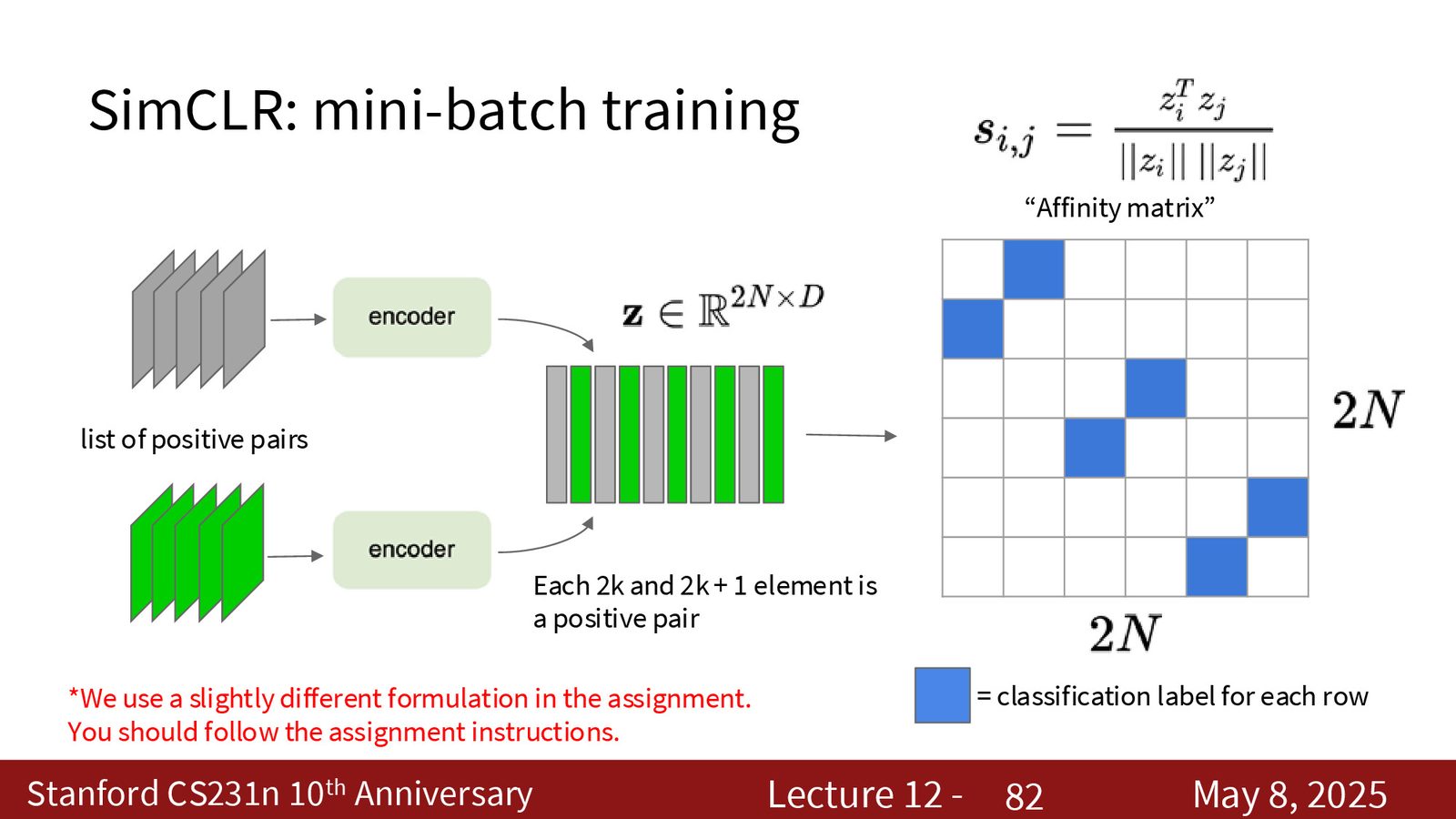
来源:Slides 第81页。
SimCLR 的另一个重要结论是:强增强和大 batch 都非常重要。没有足够多负样本,效果会明显下降。
MoCo 与 MoCo v2
SimCLR 很强,但对 batch size 和显存要求很高。MoCo 的思路是把负样本从当前 batch 里“解耦”出来,使用一个队列来持续维护大量 key。
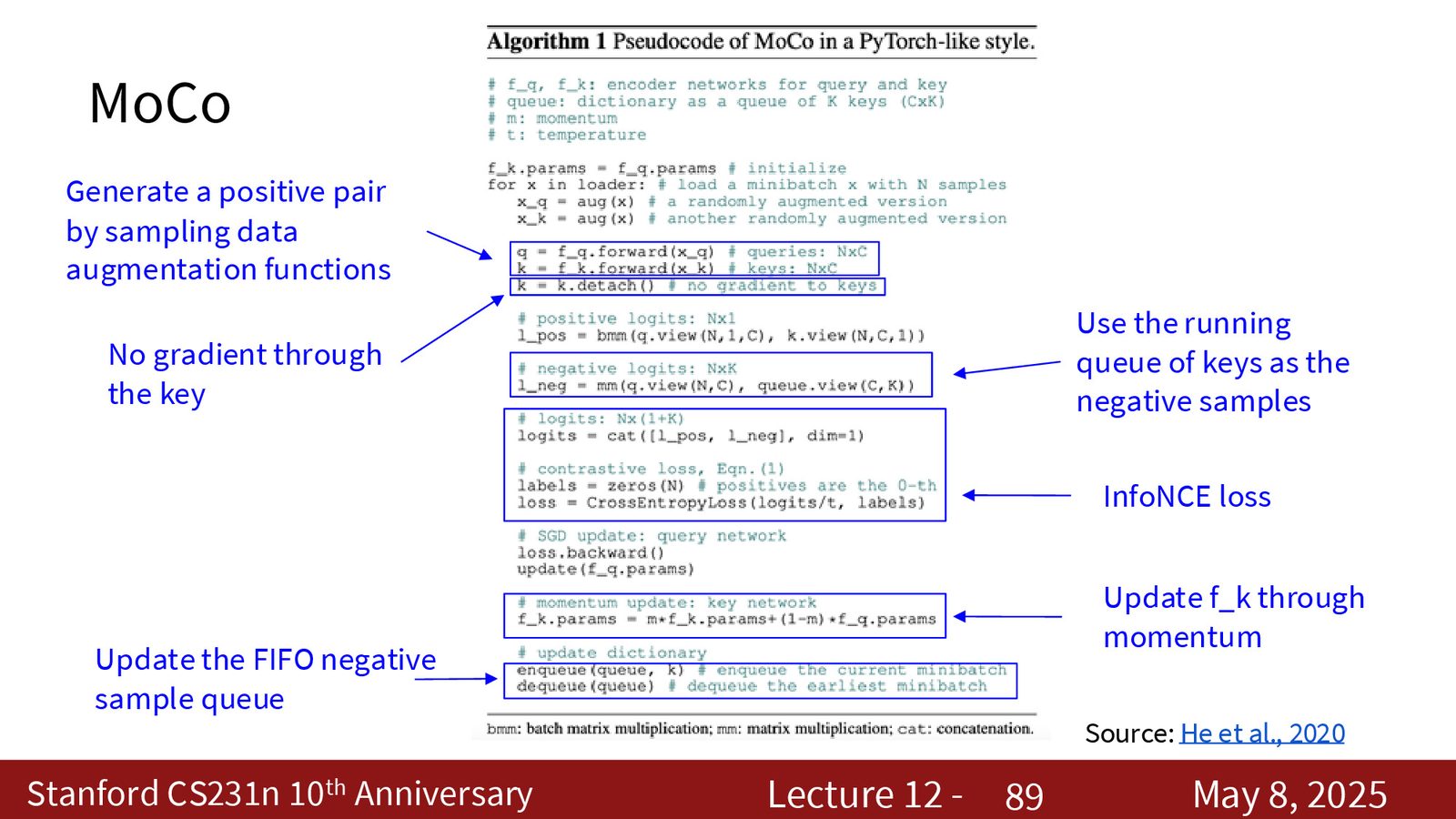
来源:Slides 第88页。
MoCo 的要点是:
- query 分支负责反向传播;
- key 分支不直接回传梯度,而是用 momentum update 慢慢更新;
- 队列里的旧 key 作为负样本,解决了 batch 受限的问题。
MoCo 的工程价值
MoCo 把“负样本规模”和“batch size”分开了,因此比 SimCLR 更省显存,也更适合普通硬件。

来源:Slides 第90页。
MoCo v2 本质上是一个混合体:既保留 MoCo 的队列和 momentum encoder,又吸收了 SimCLR 的非线性投影头和更强的数据增强。
序列级对比学习:CPC
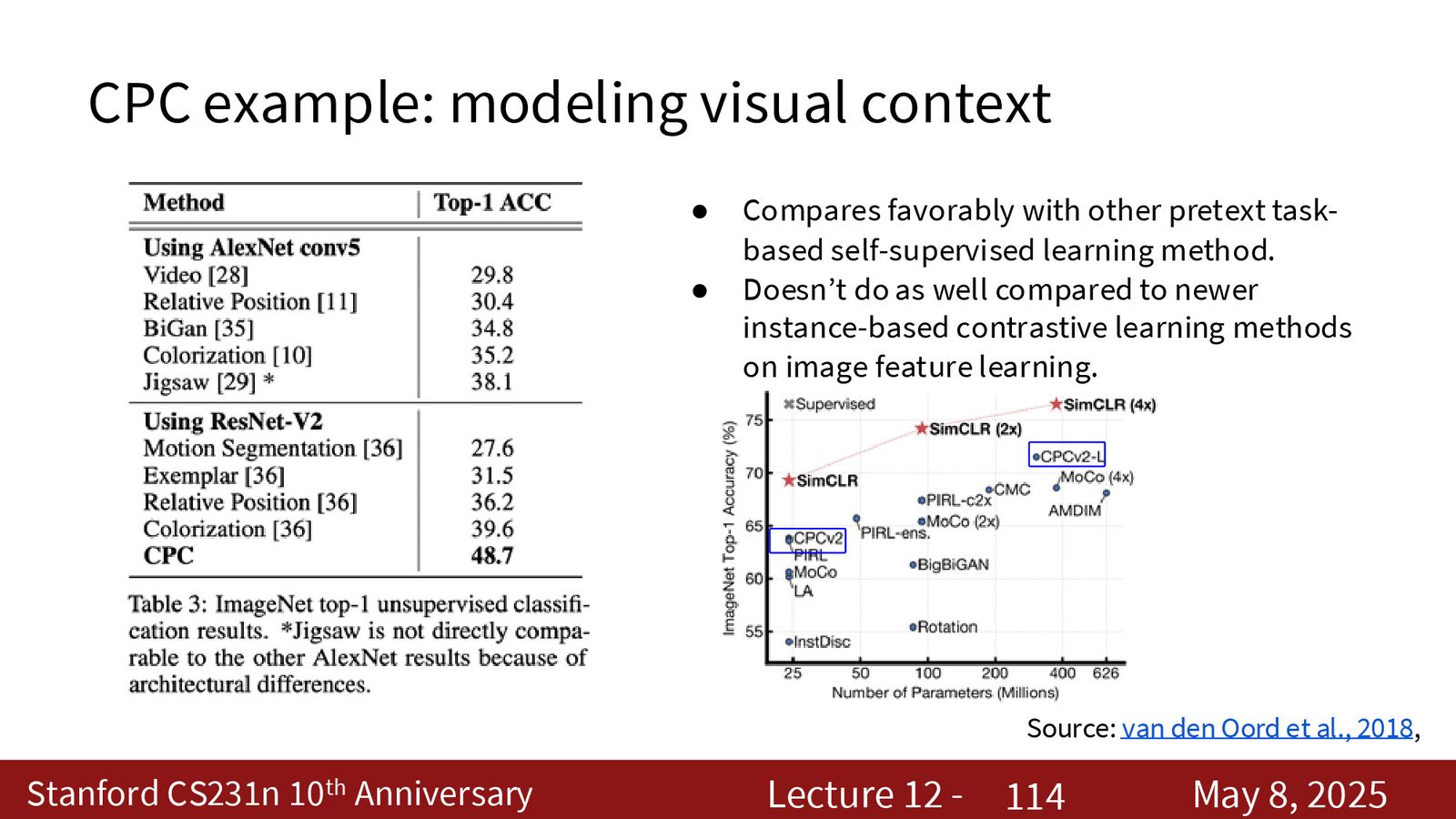
前面的 SimCLR 和 MoCo 都是 instance-level 对比学习。CPC 则把对比目标放在时序上。
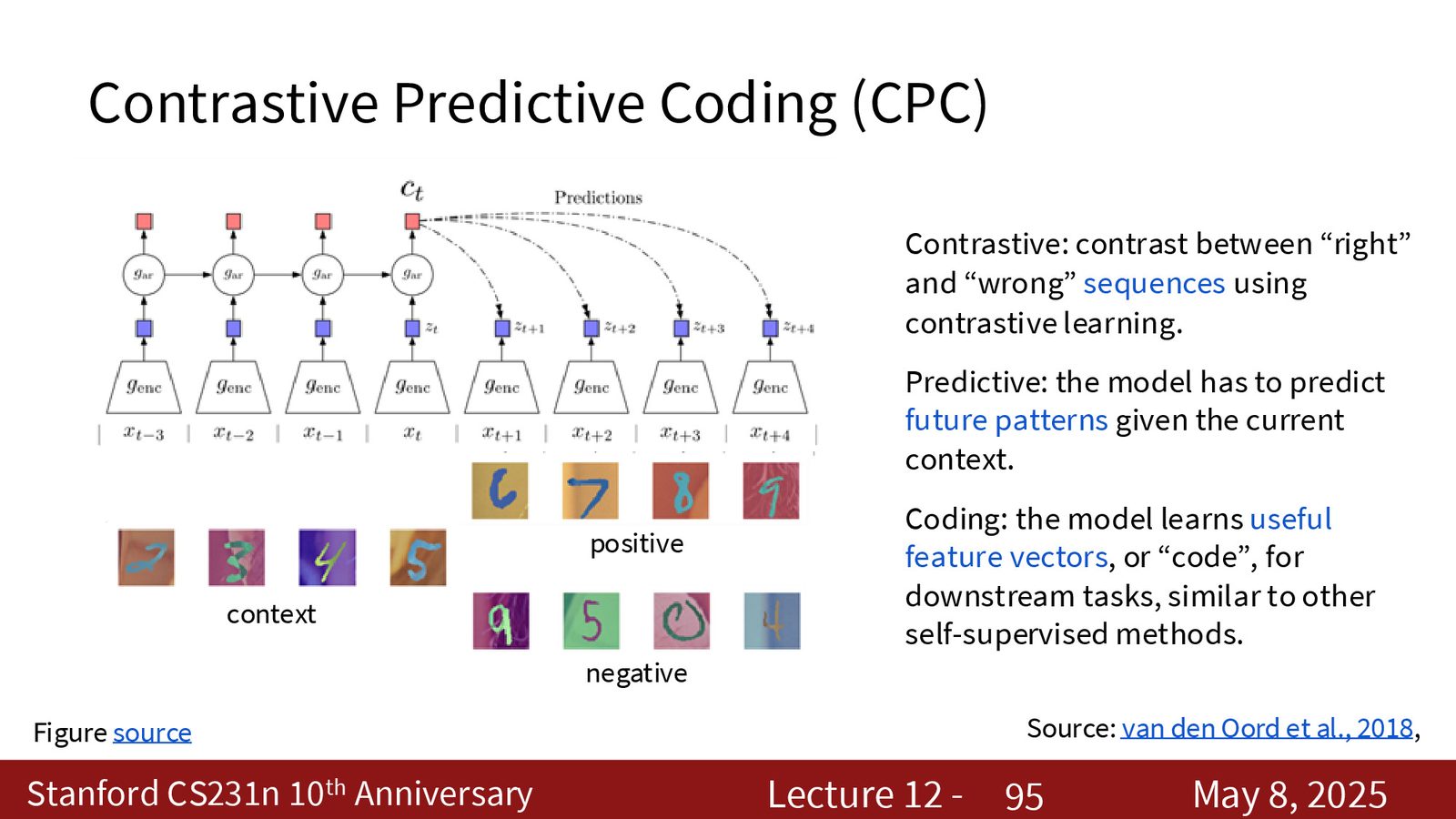
来源:Slides 第94页。
CPC 的思路是:先把一个序列编码成局部向量 \(z_t\),再把前半段上下文汇总成 context code \(c_t\),最后用 InfoNCE 让 \(c_t\) 更容易预测未来的 \(z_{t+k}\),而不是错误的 future code。
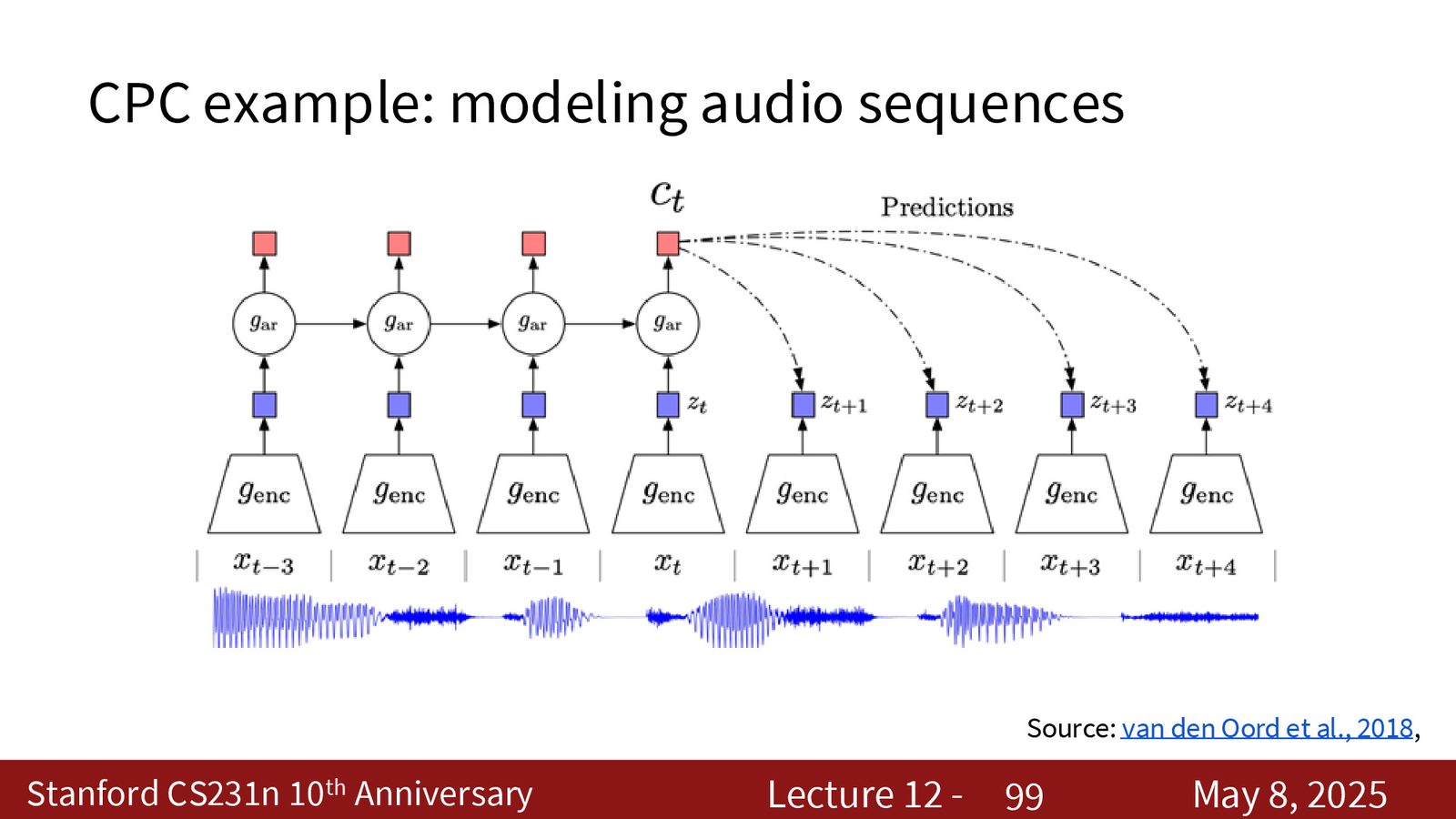
来源:Slides 第98页。
CPC 的适用场景
- 音频序列;
- 视频帧序列;
- 一些可以按顺序组织的视觉任务。
不过在图像表示学习上,CPC 往往不如更直接的实例级方法强。这也是为什么后来的主流更多转向 SimCLR、MoCo、MAE 和 DINO 这类方法。
DINO
DINO 不是严格意义上的 contrastive learning,但它借用了“student/teacher、视图一致性”的思想。
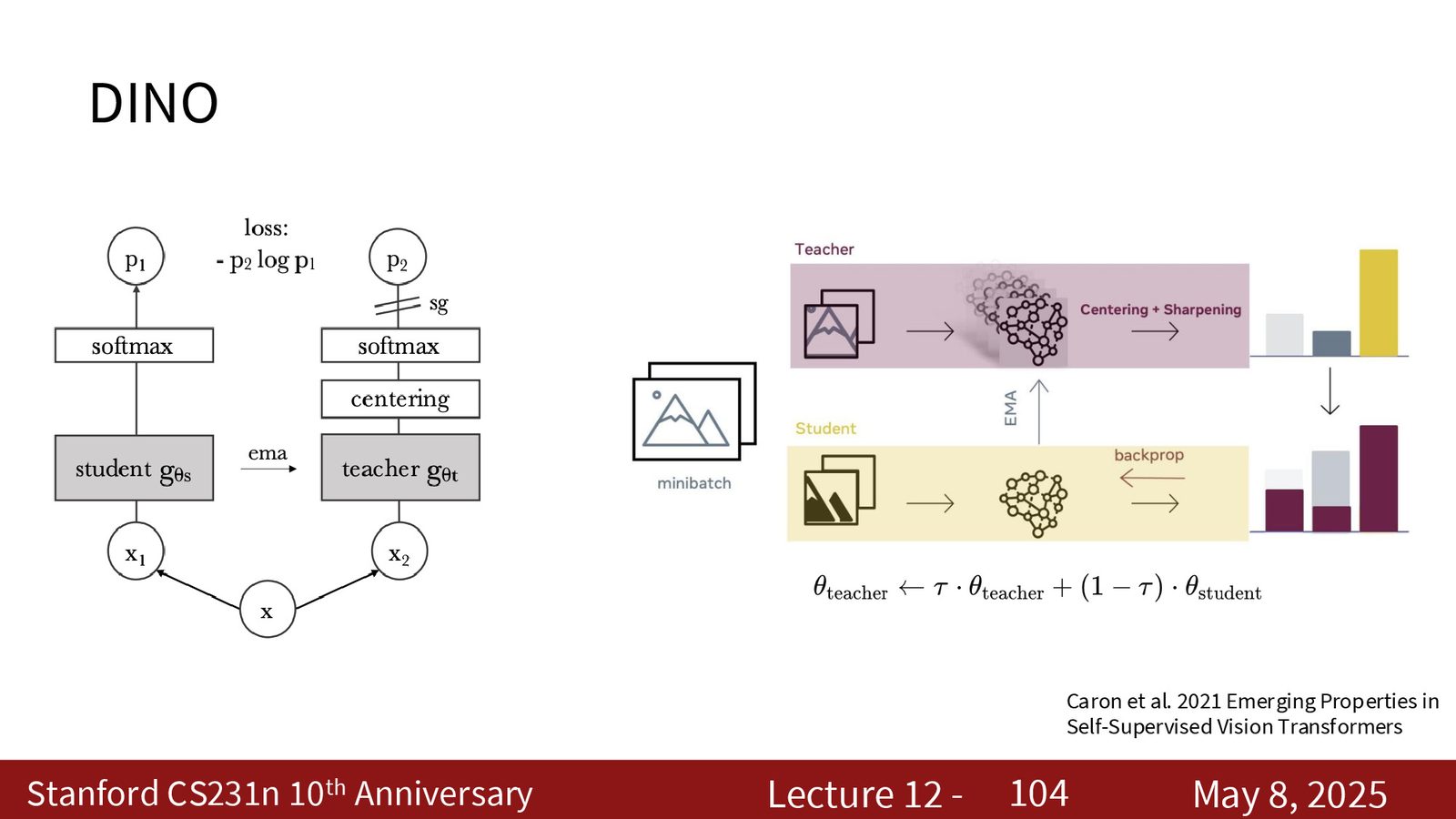
来源:Slides 第103页。
它的主要特点是:
- 不显式构造传统的正负样本对;
- 通过 teacher-student 机制让不同视图输出一致;
- 常与 ViT 结合,学习到的特征往往非常适合可视化和下游迁移。
DINO 的位置
DINO 继承了对比学习的“让不同视图保持一致”的思想,但它更接近自蒸馏,而不是标准的负样本对比框架。
总结与延伸
本章小结

来源:Slides 第107页。
本讲核心结论
- 预文本任务利用数据本身自动生成监督信号,能在没有人工标签时学到有用表示。
- 图像变换类任务关注视觉常识,包括旋转、拼图、修补、颜色化和 MAE。
- 对比学习把问题抽象成“拉近正样本、推远负样本”,InfoNCE 是核心目标。
- SimCLR、MoCo、CPC、DINO 分别代表了不同的实现路径,但共同目标都是学到可迁移的视觉表示。
- 评价自监督方法时,最终还是要看下游任务表现,而不是只看预文本损失。
下一讲预告
来源:Slides 第111页。
下一讲我们会转向生成模型,讨论如何从“学表示”进一步走向“生成内容”。