CS224N Lecture 2: Word Vectors and Language Models
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Chris Manning 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2024年4月 |

优化基础回顾
本节课承接上一讲的内容,首先回顾梯度下降优化的基本思想,然后深入讨论 Word2Vec 的更多细节,介绍基于计数的词向量方法(共现矩阵与 GloVe),探讨词向量的评估方式和词义消歧问题,最后引入神经网络分类器的基本概念。

来源:Slides 第2页。
梯度下降(Gradient Descent)
梯度下降是训练词向量(以及所有神经网络)的核心优化算法。其基本思想是:
- 我们有一个损失函数 \(J(\theta)\),希望找到使其最小化的参数 \(\theta\)
- 计算 \(J(\theta)\) 关于 \(\theta\) 的梯度 \(\nabla_\theta J(\theta)\),得到“下坡”方向
- 沿梯度的反方向走一小步,更新参数
- 重复上述过程
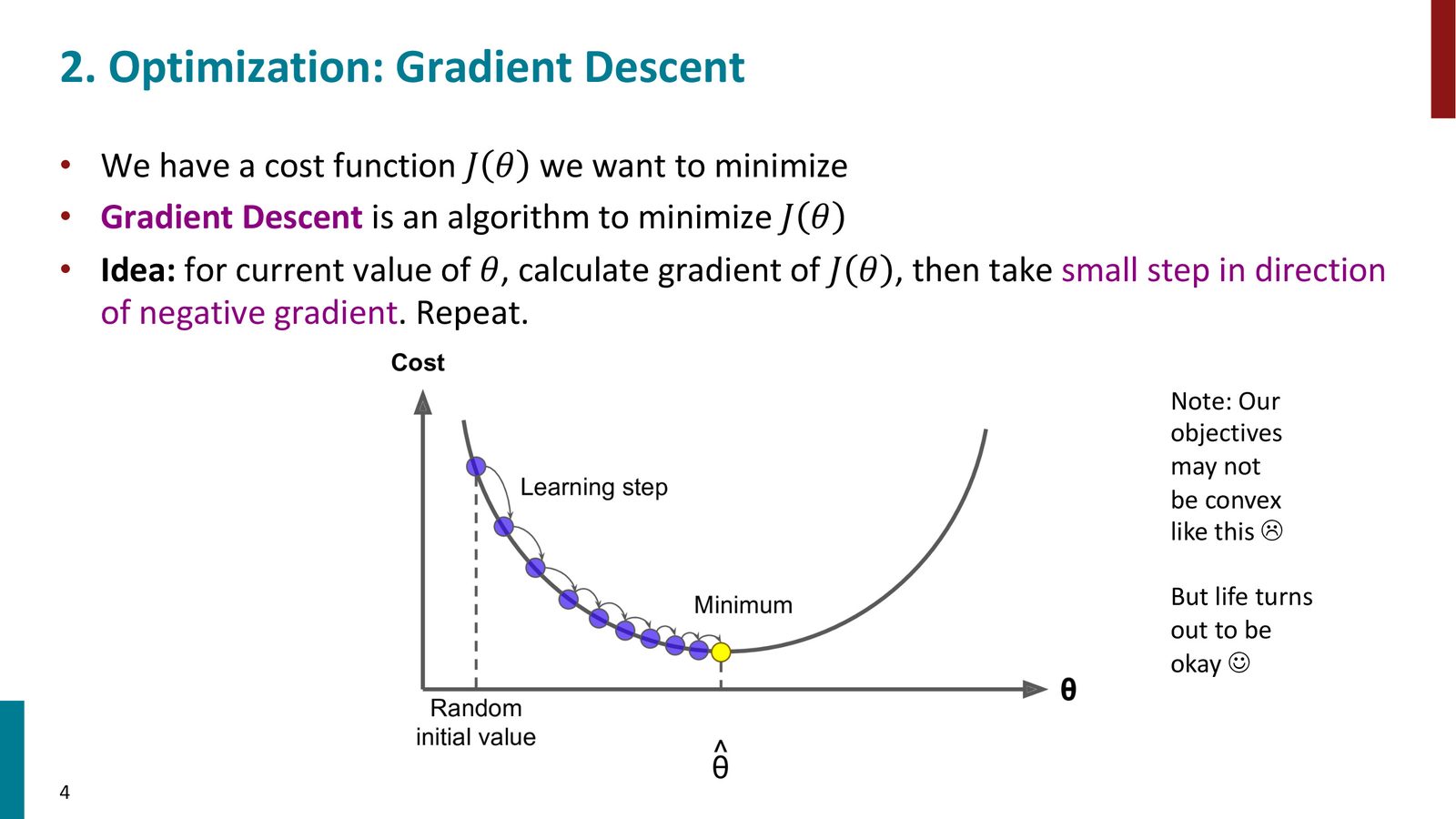
来源:Slides 第4页。
参数更新公式为:
- \(\theta\):模型的所有参数(对于 Word2Vec,就是所有的词向量)
- \(\alpha\):学习率(step size),通常是一个很小的数(如 \(10^{-3}\) 到 \(10^{-5}\))
- \(\nabla_\theta J(\theta)\):损失函数关于参数的梯度

来源:Slides 第5页。
学习率不能太大
如果学习率 \(\alpha\) 过大,参数更新的步幅过大,可能会“跳过”最小值,甚至导致损失函数发散。因此必须选择足够小的学习率,使参数在每一步都朝着正确的方向微调。
随机梯度下降(SGD)
标准梯度下降需要在整个训练语料上计算损失函数和梯度,这在数据量很大时极其耗时。实际中,我们使用随机梯度下降(Stochastic Gradient Descent, SGD):

来源:Slides 第6页。
SGD 的核心思想
每次只选取一个小批量(mini-batch,如 16 或 32 个样本)数据,在这个子集上估计梯度,并据此更新参数。虽然每步的梯度估计是有噪声的,但:
- 训练速度大幅提升(不必等待遍历全部数据)
- 噪声反而有正则化效果,帮助模型跳出局部最优,实际上往往能得到更好的结果
while True:
window = sample_window(corpus)
theta_grad = evaluate_gradient(J, window, theta)
theta = theta - alpha * theta_grad
本章小结
梯度下降是所有神经网络训练的基础。在实践中,我们几乎总是使用随机梯度下降(SGD)或其变体(如 Adam),因为它不仅比全量梯度下降快得多,而且由于引入的噪声,往往能找到更好的解。参数初始化必须使用随机小数(而非全零),否则会因为对称性无法学习。
Word2Vec 回顾与深入
Word2Vec 的核心思想回顾
Word2Vec 的 Skip-gram 模型的核心思想非常简单:
- 为词表中的每个词随机初始化一个向量
- 遍历语料中的每个位置,用当前的中心词(center word)预测周围的上下文词(context words)
- 根据预测误差更新词向量,使其逐渐学会捕捉词与词之间的语义关系
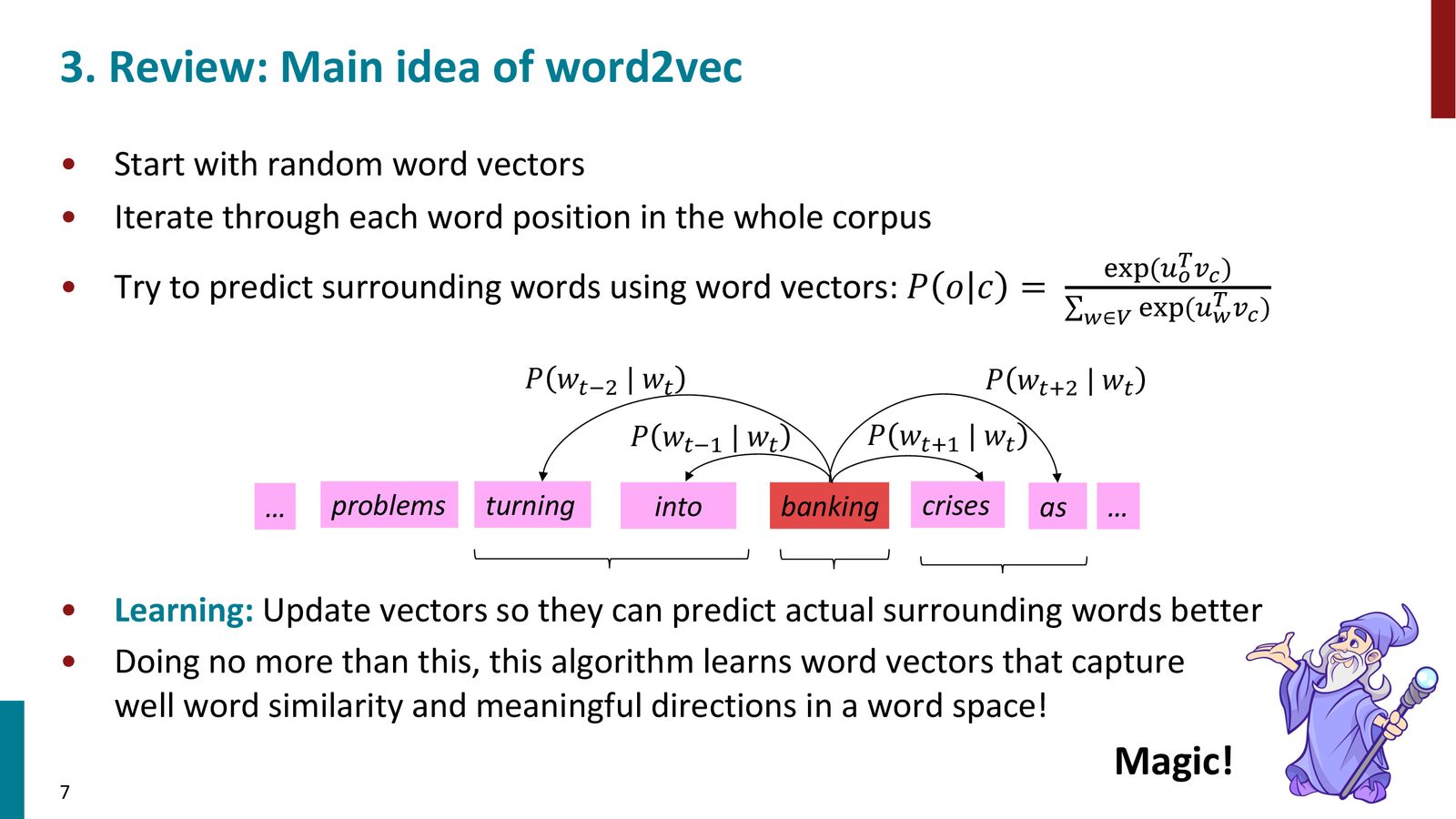
来源:Slides 第7页。
预测概率使用 softmax 函数:
- \(v_c\):中心词 \(c\) 的词向量
- \(u_o\):上下文词 \(o\) 的词向量
- \(V\):整个词表
为什么使用两套词向量?
Word2Vec 为每个词维护两个向量:中心词向量 \(v\) 和上下文词向量 \(u\),这不是为了提升性能,而是为了简化数学推导。如果只用一套向量,当中心词自身出现在归一化求和中时,会产生一个 \(x^2\) 项,使梯度计算变得更复杂。实际上使用一套向量效果略好,但通常的做法是分别训练两套向量,最后取平均。
Word2Vec 参数与计算
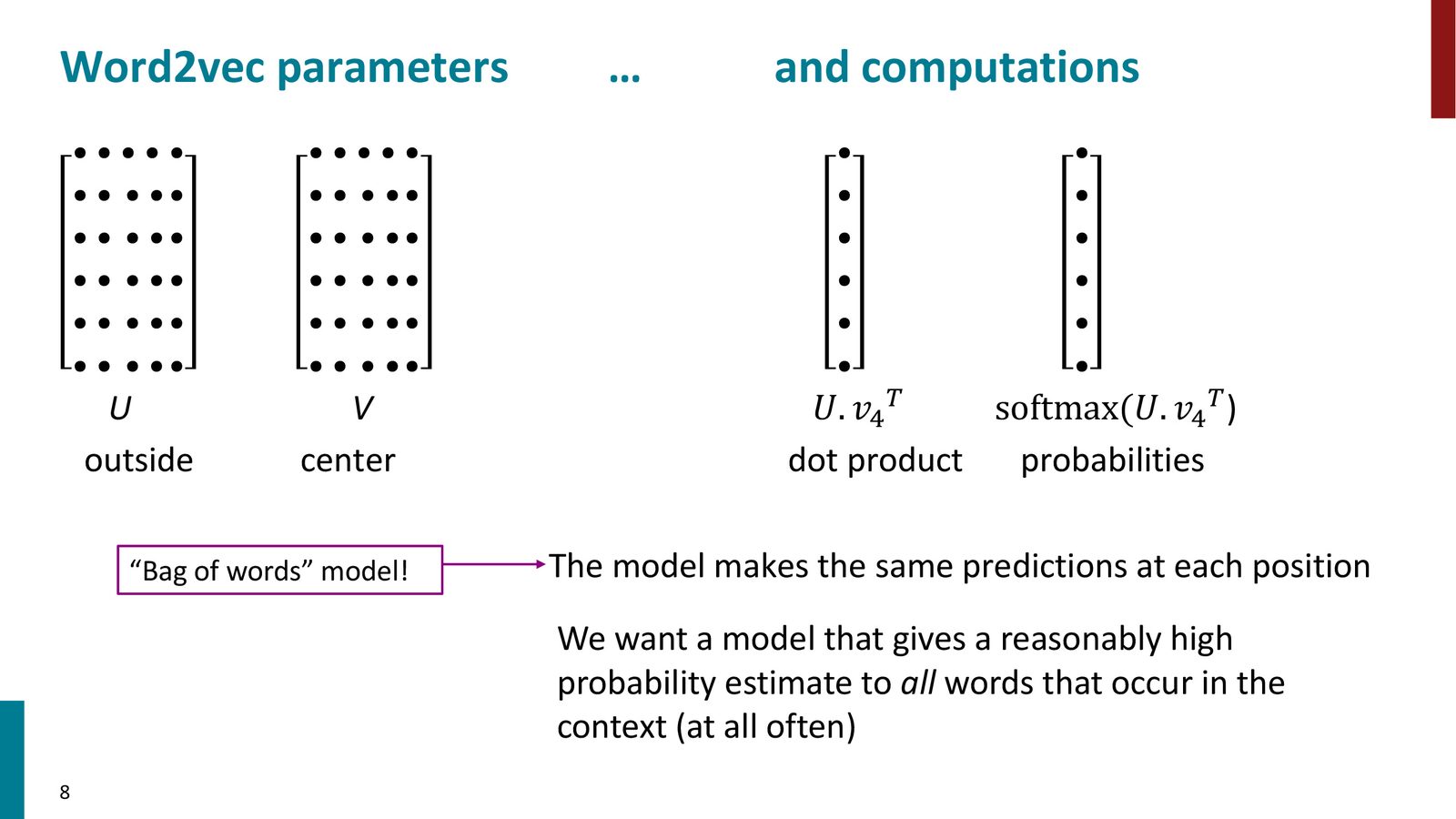
来源:Slides 第8页。
Word2Vec 是一个词袋模型(Bag of Words):它不区分上下文词在左边还是右边,对窗口内所有位置预测相同的概率分布。虽然这看起来是一个很强的简化假设,但仅凭这一点就足以学到非常有用的词向量。
Word2Vec 算法族

来源:Slides 第9页。Word2Vec 可视化,使用 t-SNE 降维展示。
Mikolov 等人(2013)的论文中描述了一族算法:

来源:Slides 第10页。
Word2Vec 的两种模型与三种损失函数
模型架构:
- Skip-gram(SG):给定中心词,预测上下文词(本课主要介绍的版本)
- Continuous Bag of Words(CBOW):给定上下文词,预测中心词
损失函数:
- Na\"ive softmax:简单但计算代价高
- Hierarchical softmax:用二叉树加速
- Negative sampling:最常用的高效替代方案
负采样(Negative Sampling)
Na\"ive softmax 的分母需要对词表中所有词求和,当词表有 40 万词时,这个计算量很大。负采样提供了一种高效的替代方案。

来源:Slides 第11页。
负采样的目标函数为:
- \(\sigma(x) = \frac{1}{1 + e^{-x}}\):logistic/sigmoid 函数
- 第一项:希望真实上下文词的点积概率尽量高
- 第二项:随机采样 \(K\) 个“噪声”词,希望它们的点积概率尽量低

来源:Slides 第12页。
负样本的采样策略
负样本不是从均匀分布中采样,而是使用调整过的 unigram 分布:
将词频的 \(3/4\) 次方作为采样权重。这个指数使得低频词被采样的概率相对增加,介于均匀分布(指数为 0)和按频率采样(指数为 1)之间。实验表明这种“中间”策略效果最好。通常只采样 \(K = 5 \sim 10\) 个负样本。
梯度的稀疏性

来源:Slides 第13页。
使用负采样后,每个窗口只涉及 \(2m + 1\) 个窗口词加 \(2km\) 个负样本,因此梯度向量极其稀疏——绝大多数词的梯度为零。这意味着:

来源:Slides 第14页。
稀疏更新的实现细节
在分布式训练中,梯度的稀疏性非常重要:我们只需更新出现在当前窗口中的少数词向量,而不是整个嵌入矩阵。在实际的深度学习框架中,词嵌入矩阵通常按行存储(而非列),每行对应一个词的向量。
词向量的“魔力”:类比关系
训练好的词向量展现出令人惊叹的语义属性。最著名的发现是向量类比(vector analogies):
这意味着向量空间中的方向对应于语义关系:“man \(\to\) king” 的方向与 “woman \(\to\) queen” 的方向近似平行,编码了“统治者”这一语义成分。
Chris Manning 在课堂上演示了多个类比示例:
- 性别类比:man : king :: woman : queen
- 文化知识:Australia : beer :: Russia : vodka
- 工具-动作:pencil : sketching :: camera : photographing
- 政治:Obama : Clinton :: Reagan : Nixon
- 语法:tall : tallest :: long : longest
词向量类比的深层含义
仅仅通过“预测上下文词”这一简单任务,在大量文本上训练,就能自动习得丰富的语义知识——这在词向量刚被发现时几乎被视为“魔法”。虽然现在有了更强大的 ChatGPT 等模型,但词向量所揭示的分布式语义表示原理,仍然是现代 NLP 的基石。
本章小结
Word2Vec 通过极其简单的“预测上下文”任务,在大规模语料上学习到的词向量,能够:(1)将语义相近的词映射到空间中相近的位置;(2)通过向量运算执行语义类比。负采样是实际训练中最常用的高效技巧,它用少量二分类(真实对 vs 噪声对)替代了对整个词表的 softmax 归一化。
基于共现计数的词向量方法
从“预测”到“计数”:另一种思路
Word2Vec 是一种基于预测的方法:通过神经网络预测上下文词来学习词向量。但还有一种更直观的思路:既然我们关心的是词与词之间的共现关系,为什么不直接统计它们?
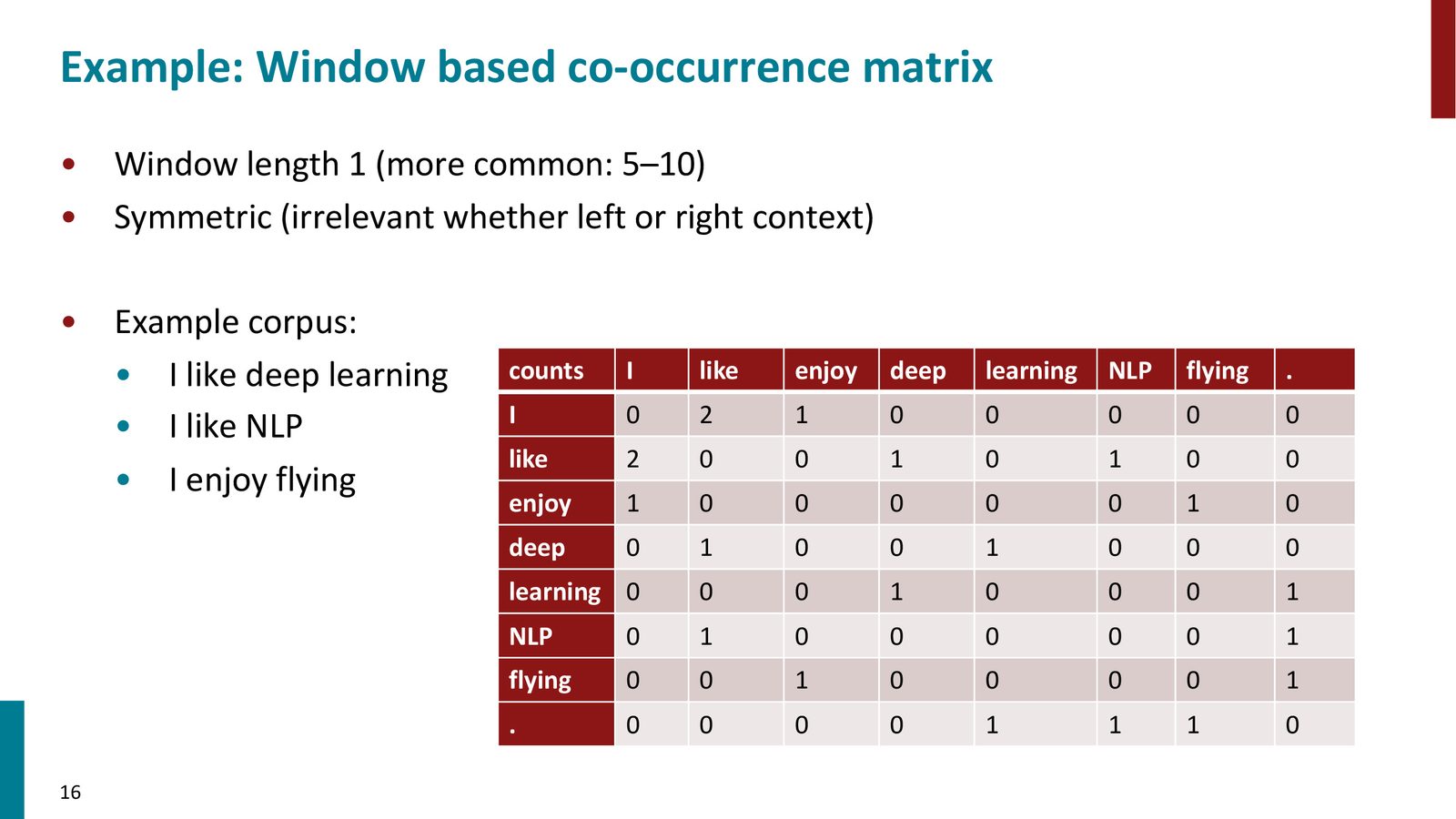
来源:Slides 第15页。
构建共现矩阵 \(X\) 有两种方式:
- 基于窗口:类似 Word2Vec,统计每个词在固定窗口内与其他词的共现次数,捕捉语法和语义信息
- 基于文档:统计词在不同文档中的共现,捕捉主题信息(即潜在语义分析 LSA 的思路)
共现矩阵示例

来源:Slides 第16页。
以一个极小的语料为例(“I like deep learning. I like NLP. I enjoy flying.”),窗口大小为 1,可以构建出如图所示的共现矩阵。矩阵中的每个元素 \(X_{ij}\) 表示词 \(i\) 和词 \(j\) 在窗口内共现的次数。
共现矩阵的维度问题
共现矩阵的大小为 \(|V| \times |V|\)(词表大小的平方)。如果词表有 40 万词,矩阵大小为 \(400{,}000 \times 400{,}000\),远大于 Word2Vec 的 \(400{,}000 \times d\)(\(d\) 通常为 100-300)。因此,直接使用共现矩阵作为词向量既存储浪费,又稀疏低效。
SVD 降维
解决高维问题的经典方法是奇异值分解(Singular Value Decomposition, SVD):
- \(U\) 和 \(V\) 是正交矩阵(列向量互相正交且模为 1)
- \(\Sigma\) 是对角矩阵,对角元素(奇异值)按大小递减排列
通过只保留最大的 \(k\) 个奇异值(将其余的置零),我们得到矩阵 \(X\) 的最优 \(k\) 维近似,从而将高维共现矩阵压缩为低维词向量。
从 LSA 到现代词向量
这种“共现矩阵 + SVD 降维”的方法最早被称为潜在语义分析(Latent Semantic Analysis, LSA),在心理学和信息检索领域有广泛应用。但直接对原始计数做 SVD 效果不佳。Doug Rohde 在 2000 年代的博士论文中发现了一系列改进技巧:对频率取对数、加权窗口距离、使用 Pearson 相关代替原始计数等。他甚至独立发现了线性语义成分的性质,但当时未受到广泛关注。
GloVe:统一计数与预测的模型

来源:Slides 第21页。Pennington, Socher, and Manning, EMNLP 2014。
GloVe(Global Vectors for Word Representation)由 Stanford 的 Jeffrey Pennington、Richard Socher 和 Chris Manning 于 2014 年提出。它的核心洞察是:
GloVe 的关键直觉:共现概率的比率
单独看一个词与 ice 或 steam 的共现概率,无法提取出有意义的语义成分。但如果看它们的比率:
- \(P(\text{solid} | \text{ice}) / P(\text{solid} | \text{steam})\) \(\gg\) 1(solid 与 ice 相关)
- \(P(\text{gas} | \text{ice}) / P(\text{gas} | \text{steam})\) \(\ll\) 1(gas 与 steam 相关)
- \(P(\text{water} | \text{ice}) / P(\text{water} | \text{steam})\) \(\approx\) 1(water 对两者无偏)
这些比率编码了 ice 与 steam 之间的“固态 vs 气态”语义差异。
为了将这种比率关系转化为向量空间中的线性关系,GloVe 引入了对数:比率的对数变为差值。因此 GloVe 的目标是学习词向量 \(w_i\) 和 \(\tilde{w}_j\),使得:
- \(X_{ij}\):词 \(i\) 和词 \(j\) 的共现次数
- \(b_i, \tilde{b}_j\):偏置项
这样,两个词向量的差就对应于它们共现概率比率的对数,从而将语义差异编码为向量空间中的线性关系。
GloVe 与 Word2Vec 的关系
表面上看,Word2Vec 是“基于预测”的方法,GloVe 是“基于计数”的方法。但实际上两者深度相关:
- Word2Vec 的 Skip-gram 目标函数可以证明等价于对共现概率矩阵的隐式分解
- GloVe 的优化目标可以看作对共现矩阵的显式分解
- 两者在实践中产生质量相当的词向量
区别更多在于实现细节和训练效率,而非根本原理。
本章小结
基于共现计数的方法(SVD、LSA、GloVe)提供了学习词向量的另一条路径。GloVe 通过建立共现概率比率与向量差之间的对应关系,将“计数”与“预测”两种方法的优势统一起来。其关键洞察是:共现概率的比率(而非绝对值)编码了有意义的语义成分,而取对数将比率转化为向量空间中的线性关系。
词向量的评估
内在评估与外在评估
在 NLP 中,评估方法分为两大类:
两类评估方法
- 内在评估(Intrinsic evaluation):在特定的子任务上直接评估词向量质量(如类比测试、相似度评分)。优点:快速、帮助理解组件行为。缺点:与最终应用的相关性不确定。
- 外在评估(Extrinsic evaluation):将词向量嵌入到真实任务中(如命名实体识别、问答系统),评估任务性能的提升。优点:直接衡量实用价值。缺点:慢、难以隔离词向量本身的贡献。
内在评估:类比任务与相似度
词向量的内在评估主要有两种方式:
1. 向量类比任务:形如 “a : b :: c : ?” 的类比题。例如 “man : king :: woman : ?” 应该得到 queen。通过在大量类比题上的正确率来评估词向量质量。
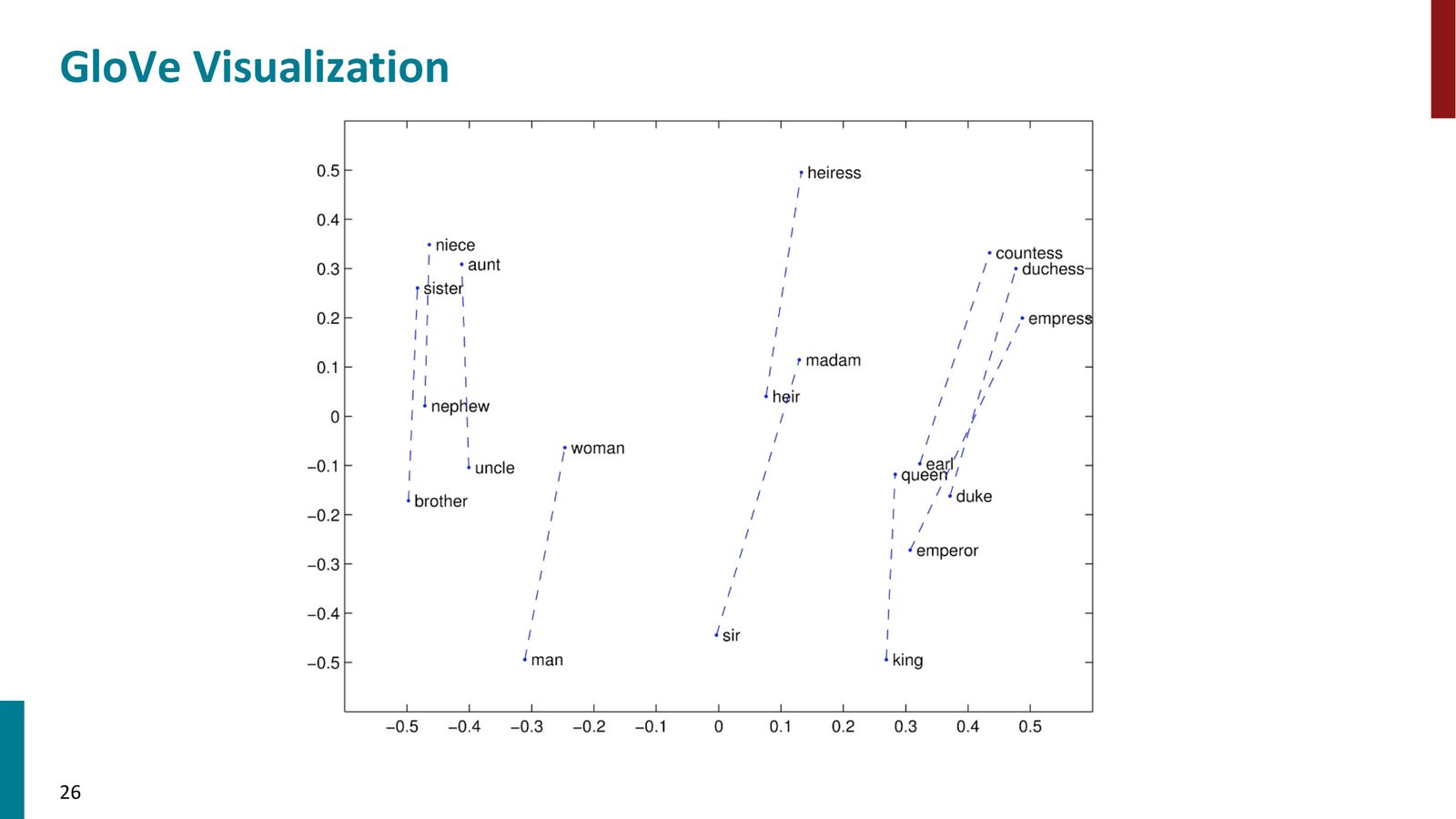
来源:Slides 第26页。
2. 词相似度评分:让人类标注者给词对打相似度分数(0-10 分),然后计算模型给出的余弦相似度与人类评分之间的相关系数。
人类相似度判断的数据集
经典的人类相似度评估数据集包括 WordSim-353、SimLex-999 等。例如:
- tiger/tiger: 10.0(完全相同)
- book/paper: 7.46(高度相关)
- plane/car: 5.77(同为交通工具)
- stock/phone: 1.62(关系较弱)
- stock/jaguar: 0.92(几乎无关)
好的词向量应该与人类判断高度相关。
外在评估:命名实体识别
命名实体识别(Named Entity Recognition, NER)是一个经典的外在评估任务:识别文本中的人名、地名、组织名等实体。
将 GloVe 词向量加入到 NER 系统中,可以显著提升识别准确率——这说明词向量确实捕捉到了对下游任务有用的语义信息。
本章小结
评估词向量需要同时关注内在指标(类比正确率、与人类相似度判断的相关性)和外在指标(在下游任务上的性能提升)。内在评估帮助我们理解词向量的质量,外在评估告诉我们它们在实际应用中是否有用。GloVe 和 Word2Vec 在各类评估中表现相当,远优于简单的 SVD 方法。
词义与多义性问题
一词多义是常态
自然语言中的绝大多数词都有多个含义。Manning 以 “pike” 为例:

来源:Slides 第31页。
- 一种武器(长矛/戟)
- 一种鱼类(梭鱼)
- 一种道路(收费公路,turnpike 的缩写)
- 一种跳水姿势
- 动词:用矛刺
- 澳大利亚俚语:临阵退缩
更常见的多义词如 bank(银行 / 河岸)、star(星星 / 明星)等在日常文本中无处不在。
词义消歧的困难
虽然字典会为每个词列出明确的义项(sense 1, sense 2, ...),但实际上词义之间的边界往往是模糊的。例如 “field” 可以指农田、运动场、学术领域、数学中的域等——这些含义之间有程度不等的关联,硬性划分义项本身就是一种“人为的简化”。
Word2Vec 如何处理多义词?
Word2Vec 为每个词只学习一个向量,不区分不同义项。那么这个唯一的向量代表什么?
词义的叠加(Superposition)
一个多义词的词向量是其各个义项向量的加权平均,权重为各义项在语料中出现的相对频率:
其中 \(f_i\) 是第 \(i\) 个义项的相对频率,\(v_{\text{pike}_i}\) 是该义项如果单独训练会得到的向量。
这种“叠加”看起来会丢失信息——从一个平均向量怎么可能恢复各个义项?但有一个惊人的数学结果:
稀疏编码与义项恢复
由于词向量空间是高维且稀疏的,来自稀疏编码理论的方法可以从单个叠加向量中恢复出各个义项的向量。Arora 等人(其中包括 Stanford 的 Tengyu Ma)在论文中展示了这一技术:从 “tie” 的单一向量中成功分离出了“领带”、“比赛平局”、“电线束扎”、“音乐连接符”等不同义项。
不过在实际应用中,现代 NLP 更倾向于使用上下文词向量(contextual word vectors,如 BERT、GPT),它们为每个词在每次出现时生成不同的向量,从根本上解决了多义性问题。
本章小结
一词多义是自然语言的基本特征。Word2Vec 等静态词向量将多义词表示为各义项的加权平均,虽然看似丢失了信息,但高维空间的稀疏性使得义项在理论上可以被恢复。这一发现为理解词向量的表示能力提供了深刻的数学洞察。后续课程中将介绍的上下文词向量(如 BERT)则从根本上解决了多义性问题。
分类与神经网络入门
命名实体识别:一个分类问题
词向量的一个重要应用是作为分类器的输入特征。以命名实体识别(NER)为例:

来源:Slides 第36页。
例如,判断文本中的 “Paris” 是人名还是地名:
- “Paris Hilton is famous” \(\rightarrow\) Paris 是人名
- “I visited Paris last spring” \(\rightarrow\) Paris 是地名
这需要看上下文才能判断。方法是取中心词及其两侧若干词的词向量,拼接成一个长向量,作为分类器的输入。
从线性分类器到神经网络
传统的统计机器学习分类器(如逻辑回归、SVM、朴素贝叶斯)大多是线性分类器:它们学习权重 \(W\),但输入 \(x\) 是固定的,决策边界是线性的。
神经网络分类器的两大优势
- 学习输入表示:不仅学习分类权重 \(W\),还同时学习词的分布式表示(词向量本身也可以被更新),这使得在原始符号空间中,分类器是非线性的
- 非线性决策边界:通过隐藏层和非线性激活函数,可以表示比线性分类器复杂得多的函数
窗口分类器的神经网络实现
Manning 展示了一个简单但完整的神经网络分类器:
- 输入层:将窗口内 5 个词(如 “museums in Paris are amazing”)的词向量拼接为一个 \(5d\) 维向量(若 \(d = 100\),则为 500 维)
- 隐藏层:将拼接向量乘以权重矩阵 \(W\)(如 \(8 \times 500\)),加偏置 \(b\),通过非线性激活函数(如 sigmoid),得到 8 维隐藏表示
- 输出层:将隐藏表示乘以另一个权重向量,通过 sigmoid 函数输出概率(如“是否为地名”)
神经元与 logistic 回归的类比
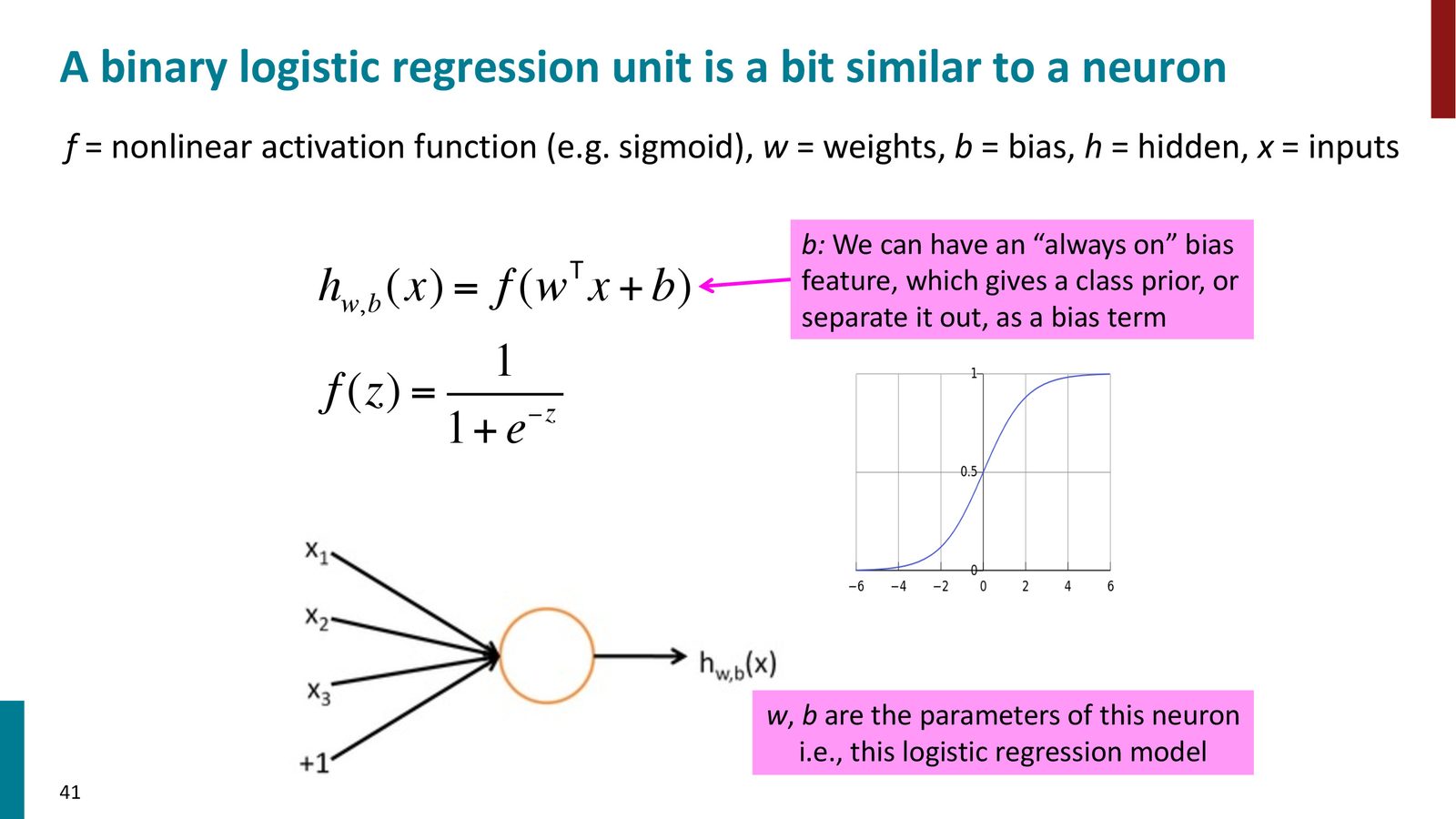
来源:Slides 第41页。
单个人工神经元的数学表达为:
其中 \(f\) 是非线性激活函数(如 sigmoid):
这和 logistic 回归完全相同。神经网络的关键在于:不是只有一个这样的单元,而是有一层这样的单元,它们各自学习不同的权重,提取不同的特征,然后将输出传递给下一层。
非线性激活函数的必要性
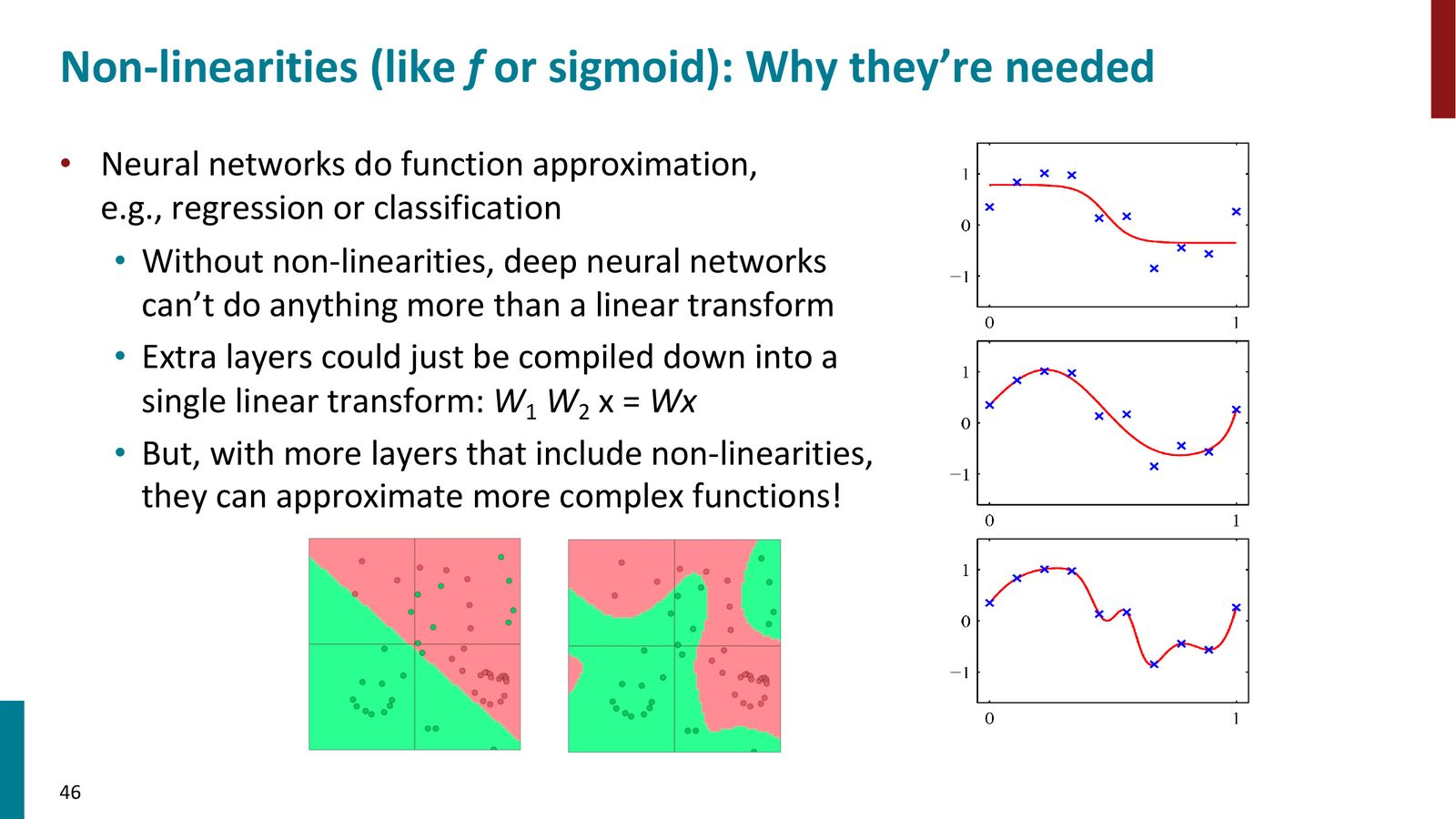
来源:Slides 第46页。
没有非线性,深度毫无意义
如果所有层都是纯线性变换(不加激活函数),那么无论堆叠多少层,整个网络都等价于一个单层线性变换:\(W_1 W_2 x = Wx\)。只有引入非线性激活函数,每增加一层才真正增加了模型的表达能力,使其能够逼近越来越复杂的函数。
交叉熵损失函数
在 PyTorch 中训练分类器时,最常用的损失函数是交叉熵损失(Cross-Entropy Loss):
- \(p\):真实分布(通常是 one-hot 向量,正确类别为 1,其余为 0)
- \(q\):模型预测的概率分布
当真实标签是 one-hot 时,交叉熵简化为:
即负对数似然(negative log-likelihood)——我们已经很熟悉的损失函数形式。
交叉熵与负对数似然的关系
交叉熵损失和负对数似然在分类任务中是等价的。在 PyTorch 中使用 CrossEntropyLoss 时,它已经内置了 softmax 和负对数似然的计算,因此模型输出层不需要再手动加 softmax。
本章小结
神经网络分类器相比传统线性分类器有两个关键优势:(1)可以同时学习输入表示和分类权重,实现端到端的训练;(2)通过非线性激活函数,可以学习任意复杂的决策边界。一个简单的前馈神经网络由输入层、隐藏层和输出层组成,其中隐藏层通过非线性变换将输入重新表示为更适合分类的形式。
总结与延伸
讲者的核心总结
Chris Manning 在本讲中建立了从词向量到神经网络分类器的完整认知链:
- 优化基础:梯度下降(特别是 SGD)是训练所有神经网络模型的基础
- Word2Vec 深入:Skip-gram 与 CBOW 两种架构,负采样作为高效训练技巧
- 计数方法与 GloVe:共现矩阵 + SVD 降维是另一种学习词向量的路径,GloVe 统一了两种方法
- 词向量评估:内在评估(类比、相似度)与外在评估(NER 等下游任务)
- 词义问题:多义词向量是各义项的加权叠加,可通过稀疏编码恢复
- 神经网络入门:从 logistic 回归到多层网络,非线性激活函数是深度的关键
全课知识图谱

关键 Takeaways
五条核心原则
- 分布式假设是基石:词的含义由其上下文决定——无论是 Word2Vec 的预测方法还是 GloVe 的计数方法,都是这一假设的不同实现
- 向量空间中的方向编码语义:词向量不仅捕捉相似性,还通过向量差编码语义关系(类比性质)
- 预测与计数殊途同归:Word2Vec 和 GloVe 看似不同,实际上都在对共现统计进行建模
- 一词多义不是障碍:静态词向量通过叠加编码多个义项,上下文词向量则彻底解决了这一问题
- 非线性是深度学习的灵魂:没有非线性激活函数,再多的层也只是线性变换
拓展阅读
- Mikolov et al., 2013: “Efficient Estimation of Word Representations in Vector Space” — Word2Vec 原始论文
- Mikolov et al., 2013: “Distributed Representations of Words and Phrases and their Compositionality” — 负采样等技巧
- Pennington, Socher, Manning, 2014: “GloVe: Global Vectors for Word Representation” — https://nlp.stanford.edu/projects/glove/
- Levy & Goldberg, 2014: “Neural Word Embedding as Implicit Matrix Factorization” — 证明 Word2Vec 与矩阵分解的等价性
- Arora et al., 2018: “Linear Algebraic Structure of Word Senses, with Applications to Polysemy” — 从单一词向量恢复义项
- CS224N 课程主页:https://web.stanford.edu/class/cs224n/