CS224N Lecture 13: Brain-Computer Interfaces for Speech
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Chaofei Fan 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2024年 |

引言:为什么需要脑机接口
脑机接口(Brain-Computer Interface, BCI)是一项旨在帮助因神经系统疾病而丧失语言或运动能力的患者恢复沟通能力的前沿技术。本次讲座由斯坦福大学神经假体转化实验室(Neural Prosthetics Translational Laboratory, NPTL)的 Chaofei Fan 主讲,系统介绍了语音脑机接口的发展历程、核心技术原理和最新研究成果。

来源:Slides 第1页。讲者来自 Stanford NPTL 实验室和 BrainGate 研究联盟。
患者的困境
许多神经系统疾病——如脑干中风(brainstem stroke)和肌萎缩侧索硬化症(Amyotrophic Lateral Sclerosis, ALS)——可以导致严重的言语和运动障碍,甚至完全丧失语言能力。

来源:Slides 第3页。
讲者以 Howard Wicks 为例:这位 21 岁的年轻人因严重中风陷入了“闭锁状态”(locked-in state)——大脑功能完好,却无法移动身体、无法开口说话。对于这类患者来说,与外界沟通是最迫切的需求。
闭锁状态的核心矛盾
患者的大脑仍然完全正常运作,拥有完整的思维能力,但身体失去了执行大脑命令的能力。大脑与身体之间的通路被疾病切断了——这正是脑机接口试图“绕过”的环节。
现有辅助沟通手段的局限
目前患者可用的辅助沟通设备主要有两类:

来源:Slides 第4页。
- 字母板:患者通过残余的眼球运动注视字母,由照护者逐字母拼读。这种方式极其缓慢——说一句简单的话可能需要几分钟。
- 眼动追踪设备:患者通过注视屏幕上的虚拟键盘打字。虽然比字母板快,但长时间盯着屏幕对患者非常疲劳,且许多患者的残余眼球运动能力也十分有限。
脑机接口带来的希望

来源:Slides 第6页。Noland Arbaugh 是 Neuralink PRIME 研究的参与者。
脑机接口的核心理念是:既然患者的大脑仍然功能完好,我们是否可以直接从大脑中读取信号,绕过损伤的身体通路,让患者重新控制计算机、机械臂,甚至直接恢复语言能力?
脑机接口的定义
脑机接口(BCI)是一种在大脑与外部设备之间建立直接通信通道的系统。它通过采集和解码大脑神经信号,将用户的意图转化为对外部设备(计算机、机械臂、语音合成器等)的控制命令。BCI 不依赖于身体的自然输出通路(如肌肉运动),因此可以帮助完全瘫痪的患者恢复与外界的交互能力。
本章小结
神经系统疾病可以导致患者完全丧失语言和运动能力,但大脑本身往往仍然功能完好。现有辅助沟通手段速度慢、效率低,远不能满足患者的沟通需求。脑机接口提供了一种全新的解决方案——直接从大脑读取信号,为患者搭建通向外部世界的桥梁。
BCI 简史与神经科学基础
从大脑电信号的发现说起

来源:Slides 第8页。这是最早关于脑电活动的科学记录之一。
BCI 的历史可以追溯到 19 世纪。1875 年,英国科学家 Richard Caton 在动物实验中发现了大脑可以产生电信号,并且这些电信号与动物的行为(如转头、咀嚼)存在对应关系。这是人类首次通过实验证明“大脑以电信号编码信息”。
脑电图(EEG)的发明

来源:Slides 第9页。
1924 年,德国精神科医生 Hans Berger 发明了脑电图(Electroencephalogram, EEG)——一种将电极放置在头皮表面来测量大脑电活动的技术。Berger 发现,大脑产生的电信号呈现出不同频率的波形,且这些波形与患者的精神状态密切相关:
- Alpha 波(\(\sim\)8--13 Hz):出现在安静闭眼时,代表放松状态
- Beta 波(\(\sim\)13--30 Hz):出现在睁眼、进行认知任务时,代表活跃状态
Hans Berger 的故事
Berger 原本是一名士兵。有一天他在训练中从马上摔落,遭受了脑震荡。而就在同一天,他的双胞胎姐妹突然感到不安,发电报向父亲询问弟弟的安危。这件事深深吸引了 Berger,促使他开始研究是否存在“心灵感应”——一种通过脑电波连接两个人的可能性。虽然心灵感应并未被证实,但他因此发明了 EEG,至今仍被广泛用于癫痫等疾病的诊断。
从头皮到大脑内部:侵入式记录
EEG 虽然安全无创,但其空间分辨率非常有限。头皮上的电极测量的是数百万神经元活动的平均值——就像站在隔壁房间外试图听清里面的谈话,我们只能分辨出大致的情绪和话题,却无法听清具体内容。
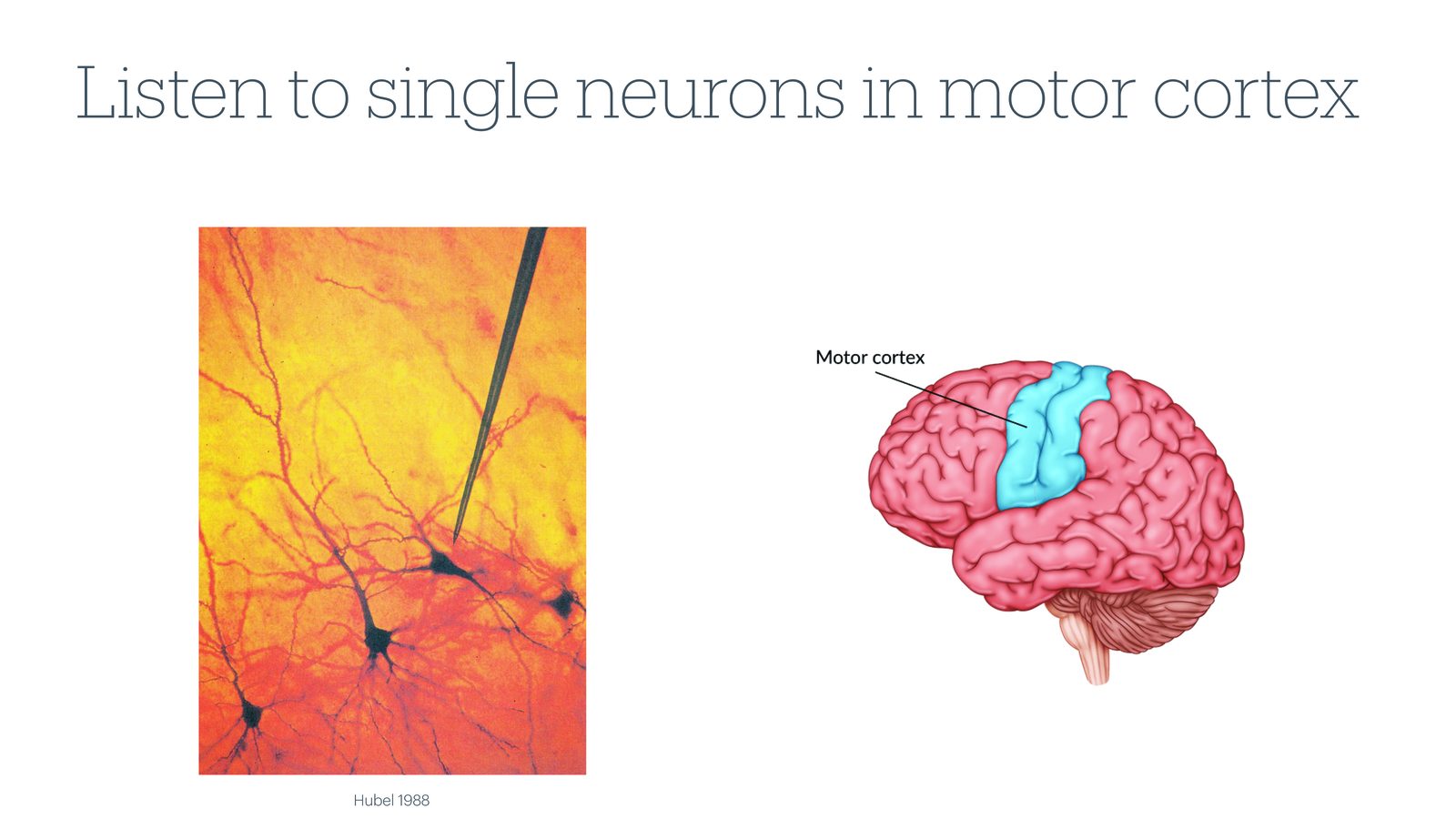
来源:Slides 第11页。左侧为 Hubel 1988 年的单细胞电极记录示意,右侧为运动皮层在大脑中的位置。
为了获取更精确的信号,研究者们开始将电极直接植入大脑内部,紧邻单个神经元进行测量。本讲的研究主要关注运动皮层(motor cortex)——位于大脑中央沟前方的区域,负责控制全身肌肉的运动。
侵入式 vs 非侵入式记录的权衡
侵入式记录(如微电极阵列)能获得单个神经元级别的高质量信号,但需要开颅手术植入电极,存在感染、组织损伤等风险。非侵入式记录(如 EEG、fMRI)安全无创,但信号质量低、分辨率差。当前临床 BCI 研究主要使用侵入式方法,因为高质量信号是实现精确解码的前提。
神经元的基本通信方式
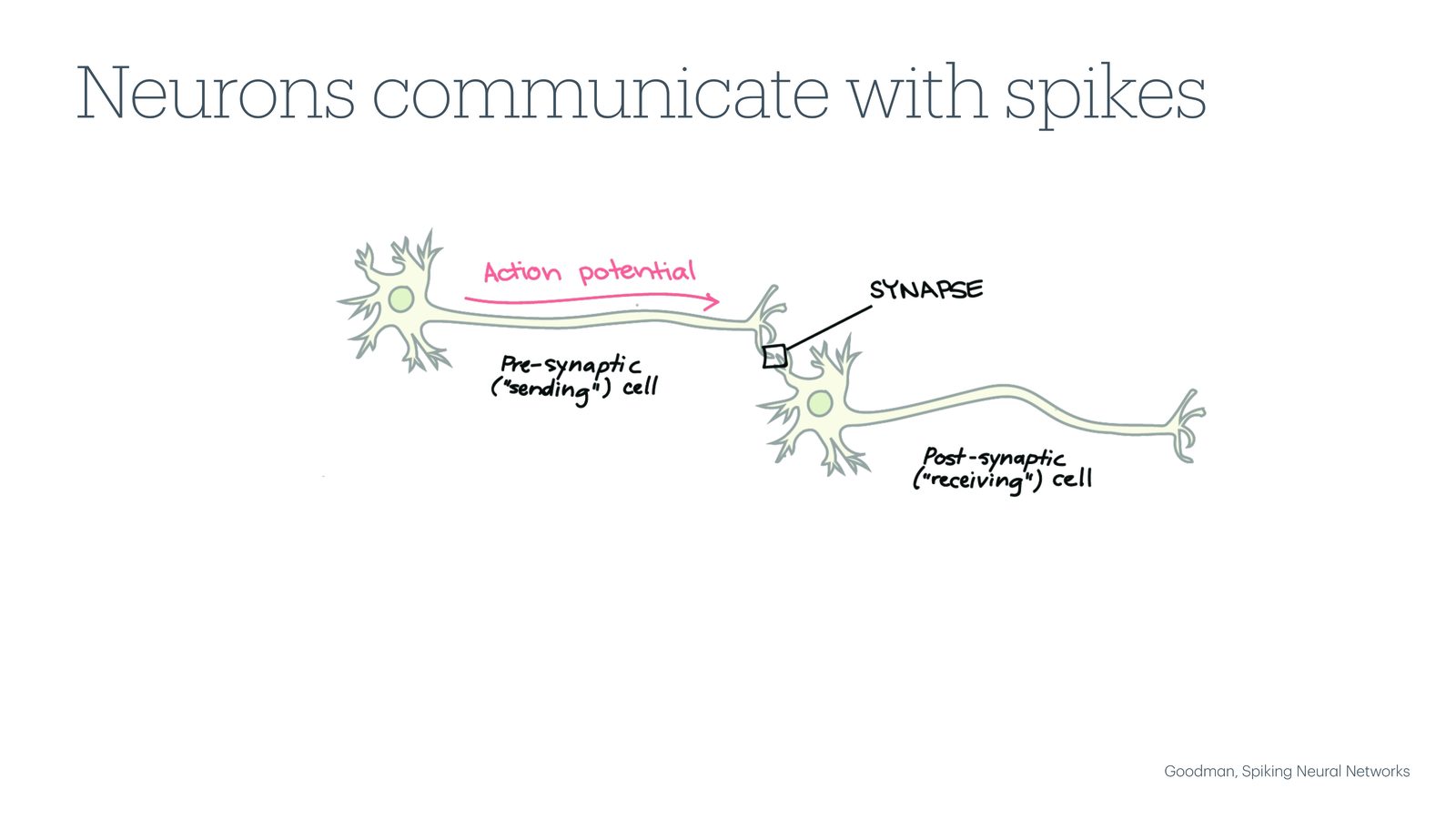
来源:Slides 第12页。来自 Goodman, Spiking Neural Networks。
神经元是大脑的基本计算单元。每个神经元由胞体(soma)、轴突(axon)和树突(dendrite)组成。神经元之间通过突触(synapse)进行通信:当一个神经元需要向下游传递信息时,它会沿轴突产生一个动作电位(action potential),也称为 spike——一个快速的电压脉冲。
如果将微电极放置在神经元轴突附近,就能记录到一系列尖锐的电压尖峰,即脉冲序列(spike train)。这就是 BCI 系统的原始输入数据。
神经元编码的核心特性
- 单个神经元的 spike 出现在毫秒级时间尺度上
- 同一神经元在相同实验条件下的 spike 模式具有试次间变异性(trial-to-trial variability)——这是生物神经元的固有噪声
- 信息不是由单个 spike 携带,而是由 spike 的发放率(firing rate)和群体活动模式共同编码
运动方向的神经编码
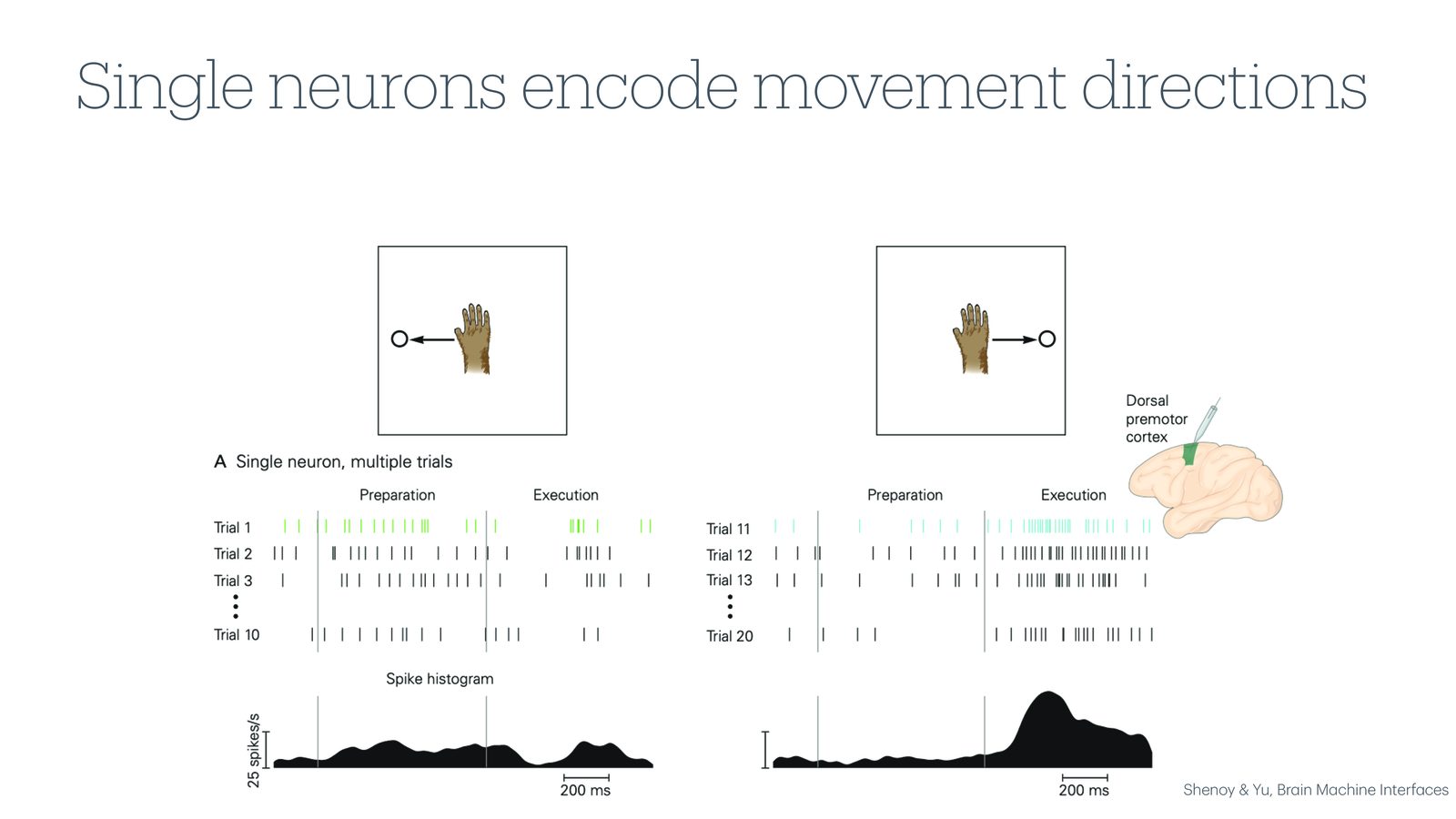
来源:Slides 第13页。来自 Shenoy & Yu, Brain Machine Interfaces。
经典实验表明,运动皮层中的单个神经元对运动方向具有方向选择性(directional tuning)。例如,某个神经元可能在猴子向右移动手臂时大量发放 spike(高发放率),而在向左移动时发放较少。
科学家发现,单个神经元的发放率与运动方向之间的关系可以用余弦调谐曲线(cosine tuning curve)来描述:
其中:
- \(f(\theta)\):神经元在运动方向为 \(\theta\) 时的发放率
- \(\theta_{\text{pref}}\):该神经元的偏好方向(firing rate 最高的方向)
- \(b_0\):基线发放率
- \(b_1\):调制幅度
多神经元群体解码
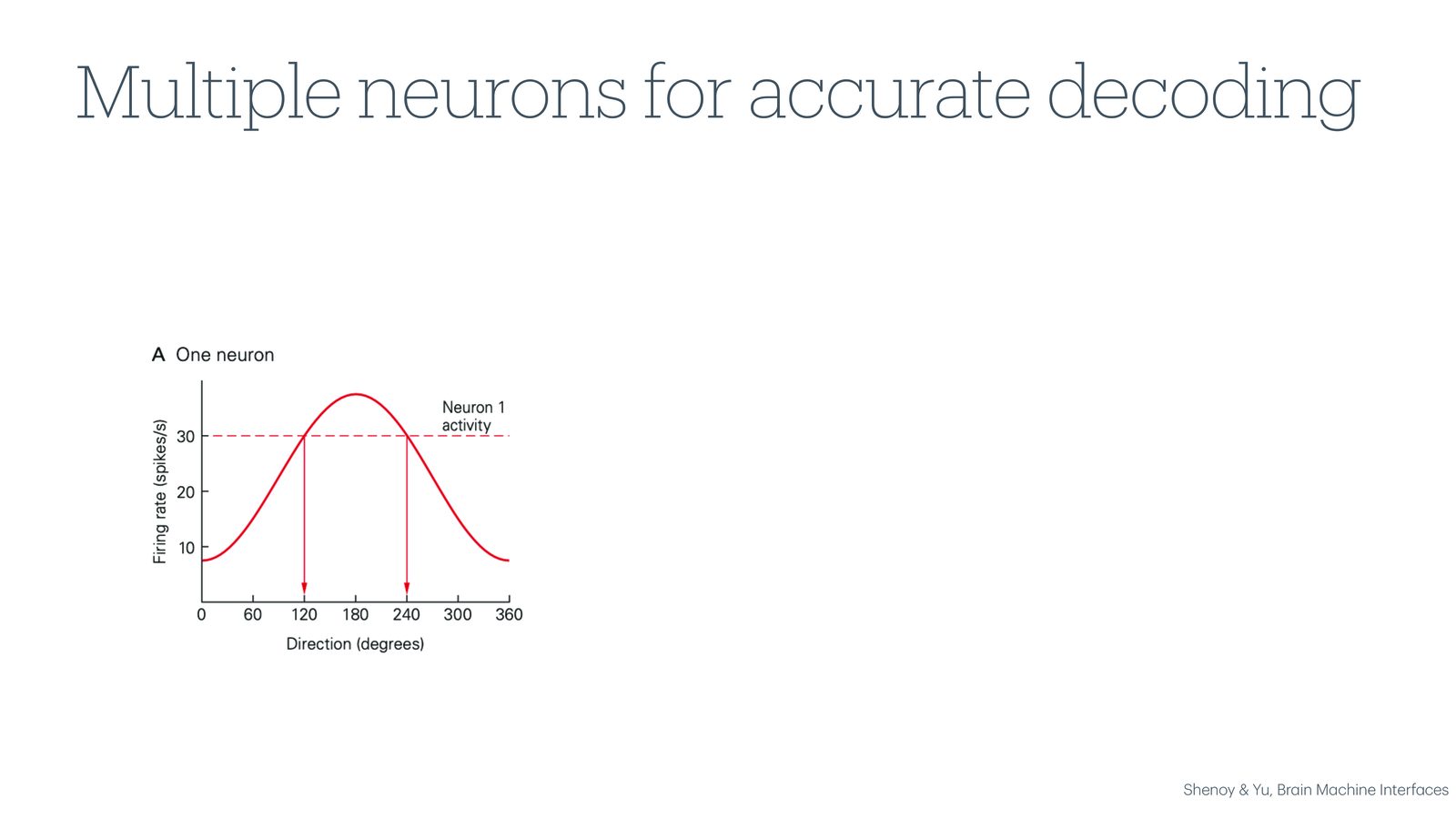
来源:Slides 第14页。来自 Shenoy & Yu, Brain Machine Interfaces。每种颜色代表一个运动方向,虚线为分类决策边界。
由于单个神经元的信号具有固有噪声,仅靠一两个神经元无法精确判断运动方向。但如果同时记录数百个神经元的活动,利用机器学习分类器(如线性分类器、SVM 等)进行群体解码,就可以大幅提高解码精度。
这就是 BCI 的基本范式:
- 在运动皮层植入多电极阵列(Multi-Electrode Array, MEA)
- 记录数百个神经元的同步活动
- 训练机器学习模型,将神经活动模式映射到运动意图
- 在实时场景中使用训练好的解码器,将患者的“想法”转化为设备控制命令
神经活动测量技术概览

来源:Slides 第15页。来自 Belliveau (1992)。x 轴为时间分辨率,y 轴为空间分辨率。
不同的神经记录技术在空间分辨率和时间分辨率两个维度上存在巨大差异:
| 技术 | 空间分辨率 | 时间分辨率 | 是否侵入 |
|---|---|---|---|
| fMRI | mm 级(脑区) | \(≈\)0.5–1 秒 | 否 |
| EEG / MEG | cm 级(多脑区) | \(≈\)毫秒 | 否 |
| ECoG | mm 级(皮层表面) | \(≈\)毫秒 | 是(皮层表面) |
| 微电极阵列 | m 级(单神经元) | \(≈\)毫秒 | 是(穿入皮层) |
理想情况下,BCI 需要同时具备高空间分辨率和高时间分辨率的记录技术。目前临床 BCI 研究中使用最多的是微电极阵列——一个约指甲大小的硅基芯片,上面排列着 96 根微型针状电极,每根电极可以测量附近几个神经元的活动,总共可以同时记录数百个神经元。
本章小结
- BCI 技术的发展建立在 150 多年的神经科学研究基础上
- 运动皮层中的神经元以发放率编码运动方向信息,具有余弦调谐特性
- 单个神经元信号噪声大,需要多神经元群体解码来提高精度
- 微电极阵列是当前 BCI 临床研究的主要记录技术,提供单神经元级别的高时空分辨率信号
从运动 BCI 到语音 BCI
运动 BCI 的早期成功
基于对运动皮层神经编码的理解,研究者们成功构建了多种运动 BCI 系统。
来源:Slides 第17页。红色问号标示脊髓损伤位置,黄色线路为 BCI 绕行通路。
2D 光标控制与虚拟键盘
NPTL 实验室在 2017 年展示了一项重要成果:瘫痪患者可以通过脑机接口控制虚拟键盘上的光标进行打字,平均速度约为每分钟 20 个正确字符,峰值可达 40 个字符/分钟。这意味着患者不再需要依赖他人帮助字母板拼读,可以独立通过思维控制计算机进行沟通。
机械臂控制
另一个标志性成果是利用 BCI 控制机械臂。Caltech 的研究展示了瘫痪患者通过大脑信号控制机械臂拿起饮料并送到嘴边饮用——这是患者多年来第一次能够自己完成这样的动作。
手写 BCI
2021 年,NPTL 实验室的 Frank Willett 发表论文,展示了手写 BCI:通过解码患者“想象书写”时的运动皮层信号,可以将手写字母转化为文本,速度达到约每分钟 18 个词,远快于 2D 光标方式的 8 个词/分钟。
不同沟通方式的速度对比
- Sip-and-puff 接口:\(\sim\)5 词/分钟
- 2D 光标 BCI:\(\sim\)8 词/分钟
- 手写 BCI:\(\sim\)18 词/分钟
- 自然说话:\(\sim\)150--160 词/分钟
即使最好的运动 BCI 也远未达到自然沟通的速度。问题是:能否直接恢复语音?
为什么语音 BCI 比运动 BCI 更难
语言的产生是一个极其复杂的神经过程,涉及大脑多个区域的协调:
- 知识与推理区域(右侧):负责语义理解和高层认知
- 语义和句法区域(中央):负责词语选择和语法组织
- 语音感知区域(左侧):负责言语感知
- 运动规划与执行区域:负责控制口腔面部肌肉产生语音
语音产生涉及的肌肉运动比手臂运动复杂得多、快速得多——嘴唇、舌头、声带、下颌等多个发声器官(articulators)需要在毫秒级时间内精确协调。
语音 BCI 的特殊挑战
- 语音涉及多个发声器官的快速协调运动,远比手臂运动复杂
- 对于丧失语言能力的患者,无法直接测量其发声器官的运动(因为发声器官本身也可能瘫痪)
- 大脑中与语言相关的区域广泛分布,不像手臂运动那样集中在运动皮层的特定区域
- 训练数据采集困难——患者无法正常说话,数据量必然有限
关键突破:从发声器官运动到音素解码
为了降低问题的复杂度,研究者们没有试图直接解码每个发声器官的连续运动轨迹,而是转向解码离散的音素(phoneme)。
音素:语言的基本单位
音素(phoneme)是一种语言中能区分词义的最小语音单位。英语中共有约 39--44 个音素,包括元音(如 /a/、/i/)和辅音(如 /p/、/t/、/s/)。每个音素对应特定的发声器官配置——舌头位置、嘴唇形状、声带振动方式等。
选择音素作为解码目标的优势:
- 音素集合小(\(\sim\)40 个),远少于词汇量(数万个),数据需求少
- 不同音素在运动皮层中具有可区分的神经活动模式
- 从音素可以组合出任意词汇,不受词汇表限制
2021 年,UCSF 的研究者们使用皮层电图(ECoG)技术(电极放在皮层表面、不穿入大脑)首次证明了语音 BCI 的可行性:能够以约 75% 的准确率解码 50 个词的小词汇表。虽然词汇量有限,但这标志着语音 BCI 从概念走向了现实。
本章小结
- 运动 BCI 已经成功帮助瘫痪患者控制光标、机械臂和进行手写输入
- 但运动 BCI 的沟通速度远低于自然说话速度
- 语音 BCI 是下一个目标,但面临更大的技术挑战
- 解码离散音素(而非连续运动轨迹)是降低问题复杂度的关键策略
- UCSF 2021 年首次证明了小词汇量语音 BCI 的可行性
构建高性能语音神经假体
实验设置:参与者 T12
NPTL 实验室在 2022 年招募了一位代号为 T12 的参与者。T12 患有 ALS,虽然还能少量移动手臂,但已经无法产生清晰的语音。研究者在她的大脑中植入了四个微电极阵列:
- 两个阵列植入运动皮层:预期解码语音产生过程中的口腔面部肌肉运动信号
- 两个阵列植入 Broca 区:预期解码语言规划信号
Broca 区与运动皮层
Broca 区位于额叶,传统上被认为与语言产生的规划有关。运动皮层负责控制肌肉运动的执行。假设是:Broca 区编码“想说什么”,运动皮层编码“怎么说”。然而实验结果出人意料——后续将详细讨论。
初步发现:信号主要来自运动皮层
对 T12 进行行为实验后,研究者得到了一个重要发现:
- 运动皮层中的两个阵列能够显著高于随机水平地分类口腔面部运动、单音素和单词
- 而 Broca 区中的两个阵列几乎无法提供高于随机水平的分类信息,尤其是在动作执行阶段
Broca 区的“沉默”——出乎意料的结果
传统神经语言学认为 Broca 区在语言产生中扮演关键角色。然而在本实验中,Broca 区的信号对于解码语音几乎没有帮助。可能的原因包括:(1)电极位置不够精确;(2)Broca 区编码的信息在当前实验范式下不容易被捕获;(3)对 Broca 区功能的传统理解可能需要修正。这一发现仍在进一步研究中。
因此,后续的语音 BCI 系统仅使用运动皮层的两个阵列。
数据采集流程
数据采集是一个需要精心设计的过程:
- 研究者坐在 T12 旁边,屏幕上显示要朗读的句子
- T12 尝试发出语音(虽然不清晰),研究者同步记录其神经活动
- 形成配对数据:输入是神经活动序列,输出是目标句子的文本
- 每个采集 block 包含约 40 个句子,然后休息
- 整个采集过程每个研究 session 持续约 100 分钟
- 总共采集约 10,000 个句子,来自 Switchboard 电话对话语料库(日常对话英语)
数据量的限制
10,000 个句子的训练数据量在机器学习领域算非常少。作为对比,大型语音识别模型通常使用数十万小时的语音数据训练。这一数据限制深刻影响了模型设计的选择——后续会看到为什么不使用 Transformer。
系统架构:两阶段解码
整个语音 BCI 系统采用两阶段解码架构:

- 阶段 1(神经信号 \(\rightarrow\) 音素):使用 GRU 神经网络,以 CTC 损失训练,将神经特征序列解码为音素概率序列
- 阶段 2(音素 \(\rightarrow\) 文本):使用 Beam Search + 语言模型,将音素序列转换为最可能的词序列
阶段 1:为什么使用 GRU 而不是 Transformer
模型选择的理由
在数据量只有 10,000 句的情况下,模型选择需要考虑以下因素:
- 数据效率:Transformer 需要大量数据才能发挥优势;GRU/RNN 在小数据集上表现更好
- 长距离依赖的需求:语音产生主要涉及短程依赖(相邻音素之间的协调),不需要 Transformer 擅长的超长距离建模
- 实时推理效率:系统需要在 20 毫秒内完成一次推理;GRU 的计算效率远高于 Transformer,甚至可以在手机上实时运行
最终选择了 GRU(Gated Recurrent Unit),它是 LSTM 的简化版本,将记忆状态和隐藏状态合并为一个隐藏状态,减少了门控参数,在小数据集上更不容易过拟合。
CTC 损失函数
CTC(Connectionist Temporal Classification)
CTC 是一种专门为输入输出长度不匹配的序列到序列问题设计的损失函数。它的核心特性包括:
- 长度不匹配处理:神经特征序列可能有数千帧,而对应的音素序列只有几十个 token
- 单调对齐:CTC 假设输入输出之间存在单调对齐关系——即前面的输入帧对应前面的输出 token(这与机器翻译的任意对齐不同)
- 空白符:引入特殊的 blank token 作为“填充”,使输出序列长度与输入一致
- 解码方式:输出时合并重复 token 并移除 blank,得到最终的 token 序列
CTC 最初被广泛应用于手写识别和语音识别(如 CS224S 中介绍的),在语音 BCI 场景中被自然地借鉴过来。
CTC 的工作方式可以用一个简单例子说明:假设 GRU 的输出为 [-H-HH-EE-LL-LL-OO-](其中 - 表示 blank),经过合并重复和移除 blank 后,得到 HELLO。
阶段 2:Beam Search 与语言模型
得到音素概率序列后,需要将其转换为实际的词序列。这一步使用修改版的 Beam Search,结合两种语言模型:
最终的解码目标函数为:
其中:
- \(P(Y|X)\):GRU + CTC 解码器给出的音素序列概率
- \(P_{\text{LM}}(Y)\):语言模型给出的句子概率
- \(|Y|\):句子长度(词数)
- \(\alpha\):语言模型权重
- \(\beta\):词插入奖励(word insertion bonus),用于平衡长短句子的概率差异
两层语言模型的设计
- 实时解码阶段使用 N-gram 语言模型:N-gram 模型所有计算都是内存查找,可以在 20ms 内评估上百个候选假设
- 后处理阶段使用 Transformer 语言模型(如 GPT 级别):对 Beam Search 产出的 Top-K(如 100 个)候选句子进行重排序(reranking),选出最终结果。此步骤可以在 \(\sim\)0.5 秒内完成
这种“先粗后精”的两层策略,既满足了实时性要求,又利用了 Transformer 的强大语言建模能力。
系统表现
最终系统的表现:
- 在句子复制任务中,系统可以实时将 T12 的脑信号解码为文字,词错误率约为 25%
- 在问答任务中,系统同样可以解码出 T12 想要表达的回答
- 静默语音(silent speech)模式——T12 只移动口腔但不发声——系统仍然能够较好地解码
静默语音解码的意义
静默语音解码意味着患者不需要实际发出声音,只需要“尝试”做出说话的口腔动作,系统就能解码。这对于完全丧失发声能力的患者尤为重要——即使声带完全瘫痪,只要运动皮层中仍然编码着语音运动的意图信号,BCI 就有可能解码出来。
本章小结
- 语音 BCI 采用两阶段架构:GRU + CTC 解码音素,Beam Search + 语言模型生成文本
- 在小数据(10,000 句)场景下,GRU 比 Transformer 更合适
- CTC 损失函数处理了输入输出长度不匹配和单调对齐的问题
- N-gram 语言模型保证实时性,Transformer 语言模型提升最终精度
- 系统实现了 \(\sim\)25% 词错误率的实时脑到文本解码
最新进展与未来方向
多模态 BCI
UCSF 的研究团队进一步探索了多模态 BCI:不仅解码文字,还同时解码语音(声音波形)和面部动作,从而驱动 3D 数字化身(avatar)进行“说话”。这使得 BCI 的输出从冰冷的文字变成了有表情、有声音的虚拟形象,大大提升了沟通的自然性和情感表达能力。
UC Davis 的最新突破
UC Davis 与 NPTL 的合作者将四个微电极阵列全部植入运动皮层(而非像 T12 那样分配给 Broca 区),获得了更强的神经信号。他们展示了:
- 通过持续训练,系统的词错误率可以接近零
- 参与者每天都在使用这个系统与家人交流
- 系统的实用性已经接近临床可用水平
从实验室到日常生活
UC Davis 的工作标志着语音 BCI 正在从实验室演示走向临床实用。参与者已经将 BCI 作为日常沟通工具,而非仅在实验中使用。这是 BCI 领域的一个重要里程碑。
内部语音解码:下一个前沿
目前所有语音 BCI 都要求患者“尝试”说话(attempted speech)或至少做出说话的口腔动作(mimed/silent speech)。但许多患者的发声器官已经瘫痪多年,“尝试说话”对他们来说非常困难且费力。
内部语音(inner speech)——即“心里说话”——是一个更具吸引力的解码目标:
- 每个人都有内部语音的体验(默读、自言自语)
- 内部语音不需要任何肌肉运动,对患者来说更加自然和轻松
- 初步研究表明,在小词汇量条件下,内部语音的解码准确率显著高于随机水平,虽然不如 attempted speech
内部语音解码的挑战
- 内部语音的神经信号比外显语音弱得多——因为没有实际的运动执行
- 不是所有人都有清晰的内部语音体验
- 内部语音可能是多维度的,不像外显语音那样是线性的声音序列,更像是思维的“压缩表示”
- 在大脑中,内部语音可能涉及比运动皮层更广泛的区域
伦理考量
随着 BCI 技术越来越强大,一系列伦理问题开始浮现:
- 隐私权:如果 BCI 能够解码内部语音,是否会读取用户不想表达的私人想法?
- 记忆解码:如果可以读取记忆,是否应该允许?这对阿尔茨海默病患者可能是福音,但也可能被滥用
- 认知增强:如果 BCI 能让人控制机械臂比自然手臂更快,这算“增强”还是“辅助”?边界在哪里?
- 公平性:如果可以“购买记忆”来跳过学习过程,这对社会公平意味着什么?
开放式讨论而非封闭答案
讲者引用教科书中的观点强调:这些伦理问题目前没有标准答案。重要的是保持科学家、工程师和政策制定者之间的持续对话,确保 BCI 技术被用于帮助真正需要它的人,同时充分意识到潜在的风险。
本章小结
- 多模态 BCI 正在实现文字、语音、面部动作的同步解码
- UC Davis 的系统已接近零词错误率,正在被参与者日常使用
- 内部语音解码是下一个前沿方向,但信号弱、定义模糊,挑战巨大
- BCI 技术的发展需要同步考虑隐私、公平等伦理问题
NLP/ML 技术在语音 BCI 中的关键角色
本节系统梳理语音 BCI 中使用的核心 NLP 和机器学习技术,帮助读者将 CS224N 的知识与 BCI 应用联系起来。
序列到序列建模
语音 BCI 的核心任务本质上是一个序列到序列(seq2seq)问题:
与 NMT(神经机器翻译)的对比:
| NMT | 语音 BCI | |
|---|---|---|
| 输入 | 源语言 token 序列 | 神经特征向量序列 |
| 输出 | 目标语言 token 序列 | 音素/词序列 |
| 对齐方式 | 任意(可重排) | 单调(时间顺序) |
| 数据量 | 百万级句对 | \(≈\)10,000 句 |
| 延迟要求 | 可容忍数百 ms | 必须 \(<\) 20 ms |
| 模型选择 | Transformer | GRU + CTC |
不要盲目照搬 NLP 模型
虽然语音 BCI 在形式上是 seq2seq 问题,但其约束条件与典型 NLP 任务差异巨大:数据量小三个数量级、延迟要求严格百倍、对齐是单调的。直接使用 NLP 领域的“最强模型”(如 Transformer encoder-decoder)往往不是最优选择。问题特性决定模型选择,而非模型的“先进程度”。
语言模型的角色
语言模型在语音 BCI 中扮演着至关重要的角色——它弥补了神经解码器的不足:
- 神经解码器产生的音素序列可能包含错误(如将 /b/ 误认为 /p/)
- 语言模型知道“I can speak”比“I can speke”更可能,从而纠正解码错误
- N-gram 模型在 Beam Search 中实时引导搜索方向
- Transformer 语言模型在后处理中进行全局重排序
语言模型是“免费的先验知识”
语言模型本质上编码了语言的统计规律——哪些词组合更常见、哪些句子更自然。这些知识不需要从患者的稀缺脑数据中学习,而是从海量文本语料中预训练获得的。在数据极度稀缺的 BCI 场景中,语言模型提供的先验知识尤为宝贵。
Beam Search 的适配
标准 Beam Search 直接应用于 CTC 输出时需要特殊处理:
- CTC 输出中包含大量blank token,需要在 Beam Search 中正确处理前缀合并
- 需要集成发音词典(pronunciation dictionary),将音素序列映射到词
- 需要在每个时间步同时维护音素级和词级的假设
- 需要平衡解码速度和搜索质量——在 20ms 内完成
本章小结
- 语音 BCI 本质上是一个带有严格约束的 seq2seq 问题
- CTC 损失函数、GRU 编码器、Beam Search、语言模型——这些都是 NLP 领域的经典技术
- 但 BCI 的数据量和延迟约束要求对这些技术进行针对性适配
- 语言模型提供的先验知识对于弥补神经解码器的错误至关重要
总结与延伸
讲者的核心总结
Chaofei Fan 在课程结尾总结了三点核心信息:
- BCI 是一个令人振奋的跨学科研究方向:它处于 AI/机器学习、神经科学和神经工程的交汇处
- 可用的临床系统即将到来:语音 BCI 已从实验室演示发展到接近日常使用的水平
- 最重要的是:BCI 正在为像 Howard 和 T12 这样的患者带来真实的希望——帮助他们在沉默多年后重新“发声”
全课知识图谱

关键 Takeaways
五条核心要点
- 大脑信号可以被解码:运动皮层的神经活动编码了丰富的运动意图信息,包括语音产生过程中的口腔面部肌肉运动
- 音素是解码的“中间表示”:直接解码词汇需要海量数据,而 40 个音素的集合大大降低了数据需求,且可以组合出任意词汇
- 模型选择应服从问题约束:在小数据 + 低延迟场景下,简单的 GRU + CTC 优于复杂的 Transformer encoder-decoder
- 语言模型是关键的“外部知识源”:预训练语言模型弥补了神经解码器的不足,显著提高了整体系统的准确性
- BCI 正在从实验走向临床:语音 BCI 已经帮助患者在日常生活中恢复沟通能力,这项技术正在改变真实的人生
拓展阅读
- Willett, F. et al. (2021). High-performance brain-to-text communication via handwriting. Nature. https://doi.org/10.1038/s41586-021-03506-2
- Willett, F. et al. (2023). A high-performance speech neuroprosthesis. Nature. https://doi.org/10.1038/s41586-023-06377-x
- Moses, D. A. et al. (2021). Neuroprosthesis for decoding speech in a paralyzed person with anarthria. New England Journal of Medicine. https://doi.org/10.1056/NEJMoa2027540
- Metzger, S. L. et al. (2023). A high-performance neuroprosthesis for speech decoding and avatar control. Nature. https://doi.org/10.1038/s41586-023-06443-4
- Card, N. S. et al. (2024). An accurate and rapidly calibrating speech neuroprosthesis. UC Davis / NPTL.
- Shenoy, K. V. & Carmena, J. M. (2014). Combining decoder design and neural adaptation in brain-machine interfaces. Neuron. https://doi.org/10.1016/j.neuron.2014.08.038
- BrainGate 研究联盟: https://www.braingate.org/
- Stanford NPTL 实验室: https://nptl.stanford.edu/