CS224N Lecture 11: Benchmarking and Evaluation
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Yann Dubois 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2024年 |

引言:为什么需要衡量模型性能
Yann Dubois 是斯坦福大学三年级博士生,由 Tatsu Hashimoto 和 Percy Liang 共同指导。他在本讲中系统地讲解了 NLP 领域中基准测试(Benchmarking)和评估(Evaluation)的方方面面——这是一个在学术界往往被忽视、但在实际生产中至关重要的话题。

来源:Slides 第2页。
模型开发流水线中的评估需求
开发一个机器学习模型可以分为四个主要阶段,每个阶段对性能度量有不同的需求:
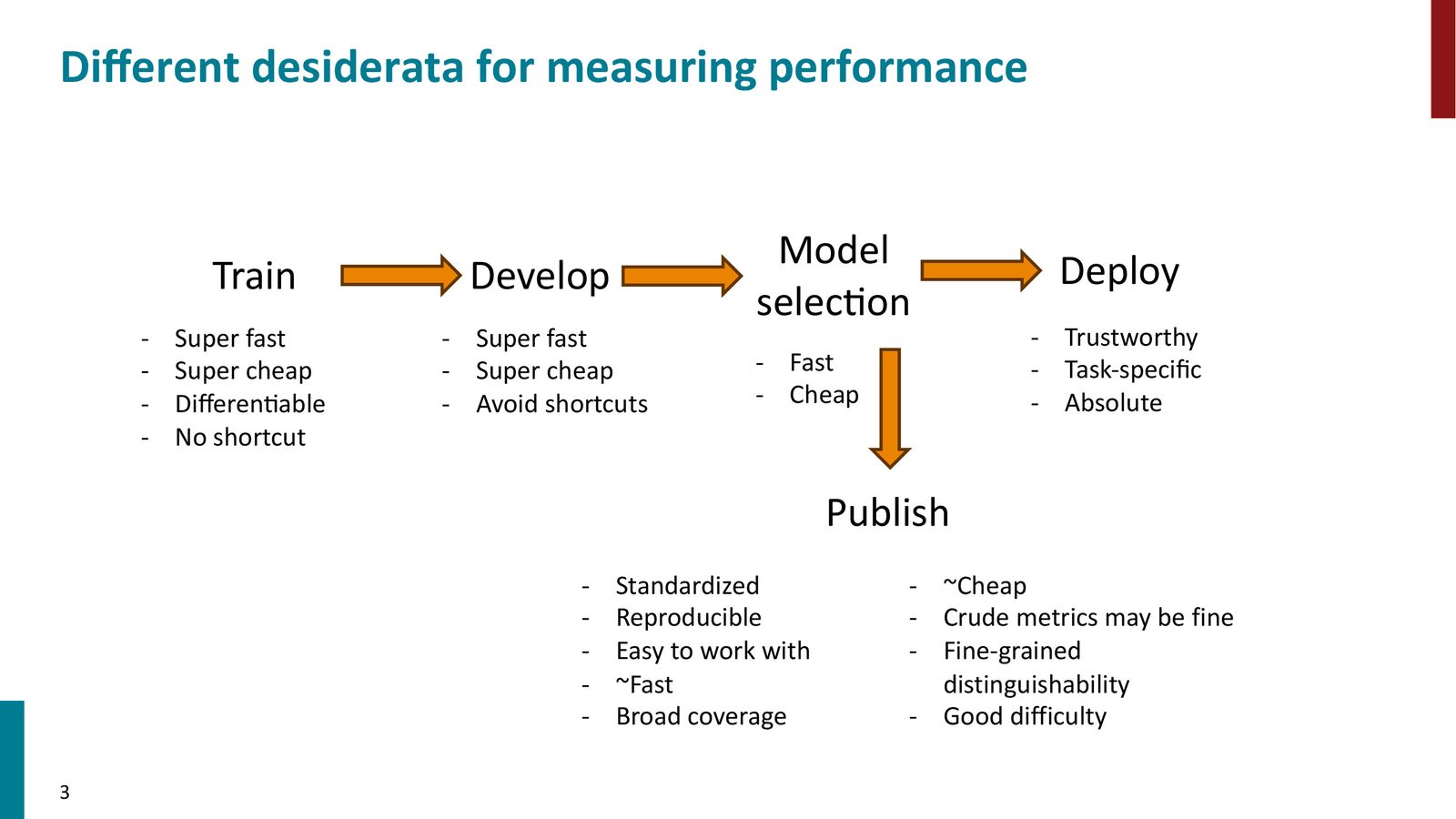
来源:Slides 第3页。
四个阶段的评估需求
- 训练阶段:需要超快、超廉价、可微分的损失函数,且不能有可被模型利用的“捷径”(shortcuts)
- 开发阶段(超参调优):需要快速、廉价的评估指标,同样要避免捷径——因为超参搜索本身也是一种优化
- 模型选择:可以稍慢、稍贵,但需要在多个候选模型间可靠地比较
- 部署阶段:评估必须可信(trustworthy)、任务特定(task-specific)、绝对(absolute)——你需要一个明确的阈值来决定是否上线
学术发表 vs 实际部署
除了上述四个阶段,学术界还有一个“发表”(Publish)需求。学术基准需要:标准化、可复现、易用、低成本、覆盖面广。重要的是,学术基准的指标不需要完美——只要在 10 年的时间尺度上,指标方向与领域实际进步方向一致即可。这与部署场景中对指标精确性的要求截然不同。
基准测试驱动领域进步
MMLU(Massive Multitask Language Understanding)是当前最主流的 LLM 基准之一。在过去约 4 年间,模型在 MMLU 上的准确率从 25%(随机水平,因为是四选一)提升到约 90%。
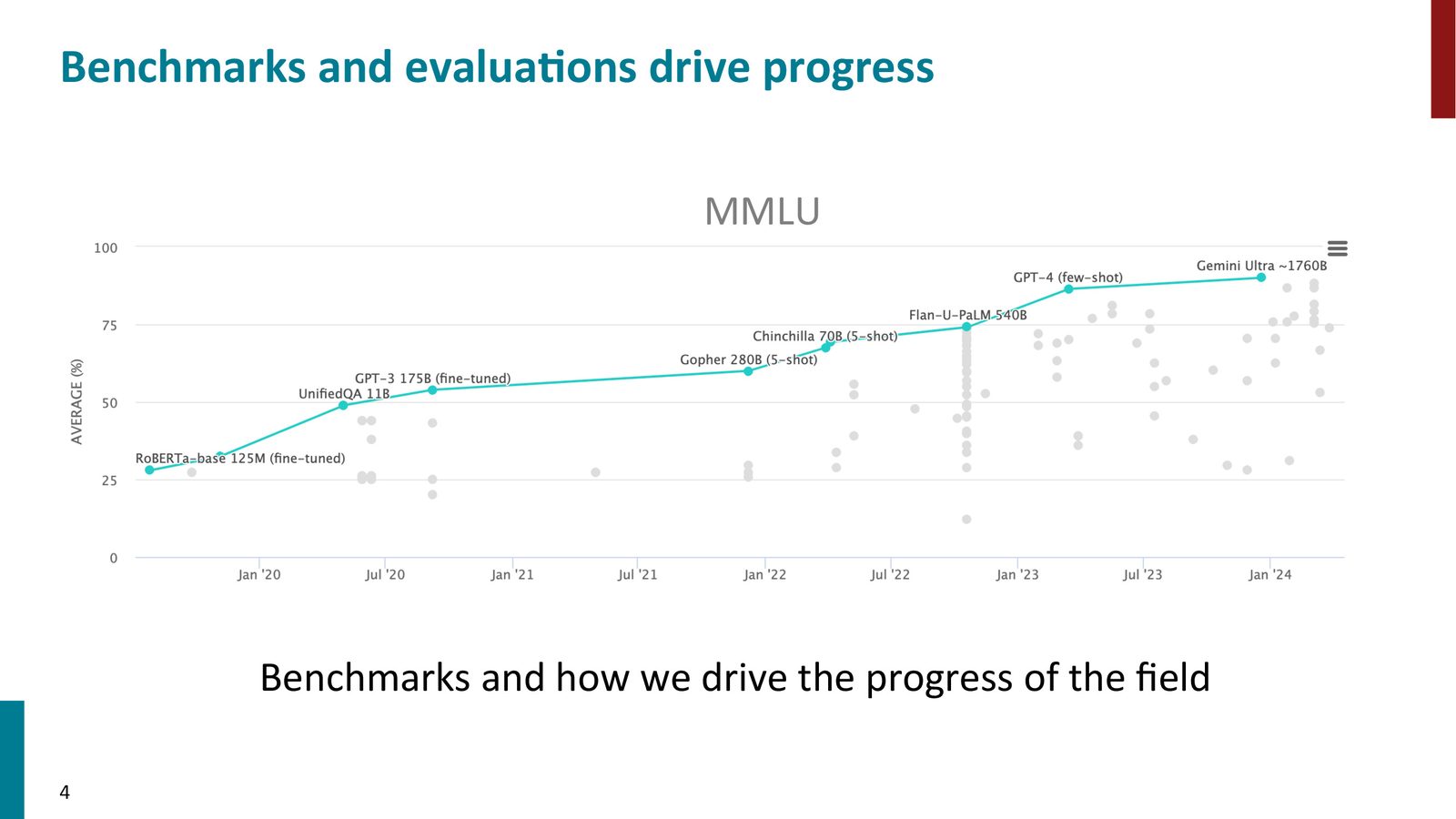
来源:Slides 第4页。
学术基准中的细微差异不一定有意义
在学术基准测试中,重要的不是模型之间 1--2 个百分点的差异,而是在更长时间尺度上的总体趋势。如果过于关注小数点后的改进,可能会导致对噪声的过度拟合。
本章小结
在模型开发的不同阶段,对评估有不同的需求——从训练阶段的快速可微指标到部署阶段的可信绝对指标。NLP 评估可分为封闭式(close-ended)和开放式(open-ended)两大类,每类都有独特的挑战。基准测试是推动领域进步的核心工具,但需要在不同场景下选择合适的评估策略。
封闭式评估(Close-ended Evaluation)
定义与典型任务
封闭式任务是指可能的答案数量有限(通常少于 10 个),且通常只有一个或少数几个正确答案的任务。

来源:Slides 第5页。
封闭式任务 = 标准机器学习分类
封闭式 NLP 任务在评估方法上与标准机器学习分类问题完全一致——可以使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 分数、ROC 曲线、AUC 等。这并不意味着评估简单,只是说评估方法论没有 NLP 特有的特殊性。
常见的封闭式 NLP 任务包括:
| 任务 | 描述 | 典型基准 |
|---|---|---|
| 情感分析 | 判断文本的情感极性 | IMDb, SST |
| 文本蕴含 | 假设是否被前提蕴含 | SNLI |
| 词性标注 | 标注每个词的词性 | Penn Treebank |
| 命名实体识别 | 识别文本中的实体 | CoNLL |
| 共指消解 | 判断代词指代的对象 | WSC |
| 问答 | 基于文本回答问题 | BoolQ, SQuAD |
SuperGLUE:多任务综合基准
SuperGLUE 是封闭式评估的“超级基准”,包含 8--9 个不同任务。评估方式是对各任务的性能取平均,得到一个综合排名。这曾是(约 2 年前之前)衡量模型通用语言能力的标准方式。

来源:Slides 第11页。
评估指标的选择至关重要
不要盲目使用准确率
以垃圾邮件分类为例:如果 90% 的邮件是非垃圾邮件,那么一个始终预测“非垃圾”的分类器就能获得 90% 的准确率——但它实际上什么也没分类。这就是为什么需要根据任务特点选择精确率、召回率或 F1 分数。
多任务基准中的指标聚合同样需要谨慎:
- 不同任务使用不同的指标(准确率、F1、相关系数等),直接取平均在数学上是不严谨的
- 讲者提到一个真实案例:某基准中有一列指标是“越低越好”,但人们在取平均时忘记加负号,直到很久之后才发现
- 不要假设已有的做法就是正确的——要独立思考评估方案的合理性
虚假相关性(Spurious Correlations)

来源:Slides 第13页。
2019 年的一篇论文发现,在 SNLI 文本蕴含任务中,仅看假设文本(忽略前提)就能取得很好的性能。原因在于:当标注者被要求写出“不被前提蕴含的假设”时,他们通常会加入否定词。因此模型学到了一个捷径——如果假设中有否定词,就预测“不蕴含”。
标签来源决定基准质量
始终要追问:这些标签是怎么来的?标注过程中是否引入了系统性偏差?即使是被广泛使用的基准也可能存在严重的虚假相关性。不要因为“大家都在用”就认为一个基准是没有问题的。
本章小结
封闭式评估是标准的机器学习分类问题,可以使用准确率、精确率、召回率等经典指标。然而,指标选择、指标聚合、标签质量和虚假相关性等问题仍然需要仔细考量。SuperGLUE 等多任务基准提供了综合评估的框架,但其简单平均的聚合方式并不完美。
开放式评估(Open-ended Evaluation)
定义与挑战
开放式任务与封闭式任务相反:存在大量可能的正确答案,且无法穷举所有答案。更重要的是,答案质量是一个连续谱——不是简单的对/错,而是有好有坏的程度之分。
典型的开放式任务包括:
- 文本摘要(Summarization):将长文本压缩为简短摘要。典型基准:CNN/Daily Mail
- 机器翻译(Translation):在不同语言间翻译文本
- 指令跟随(Instruction Following):类似 ChatGPT 的对话,这是所有任务的“母任务”——任何之前的任务都可以被视为对聊天机器人的一条指令
来源:Slides 第16页。部分 slides 改编自 Asli Celikyilmaz 在 EMNLP 2020 tutorial。
内容重叠指标(Content Overlap Metrics)
最简单的评估方式是将模型生成的文本与人工撰写的参考答案逐词比较。
BLEU 和 ROUGE
- BLEU(Bilingual Evaluation Understudy):关注精确率——生成文本中有多少 n-gram 出现在参考文本中。主要用于机器翻译。还包含长度惩罚,防止只生成“the”等高频词来获得高精确率
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation):关注召回率——参考文本中有多少 n-gram 出现在生成文本中。主要用于文本摘要
这两个指标直到约 2 年前还是翻译和摘要任务的“金标准”。
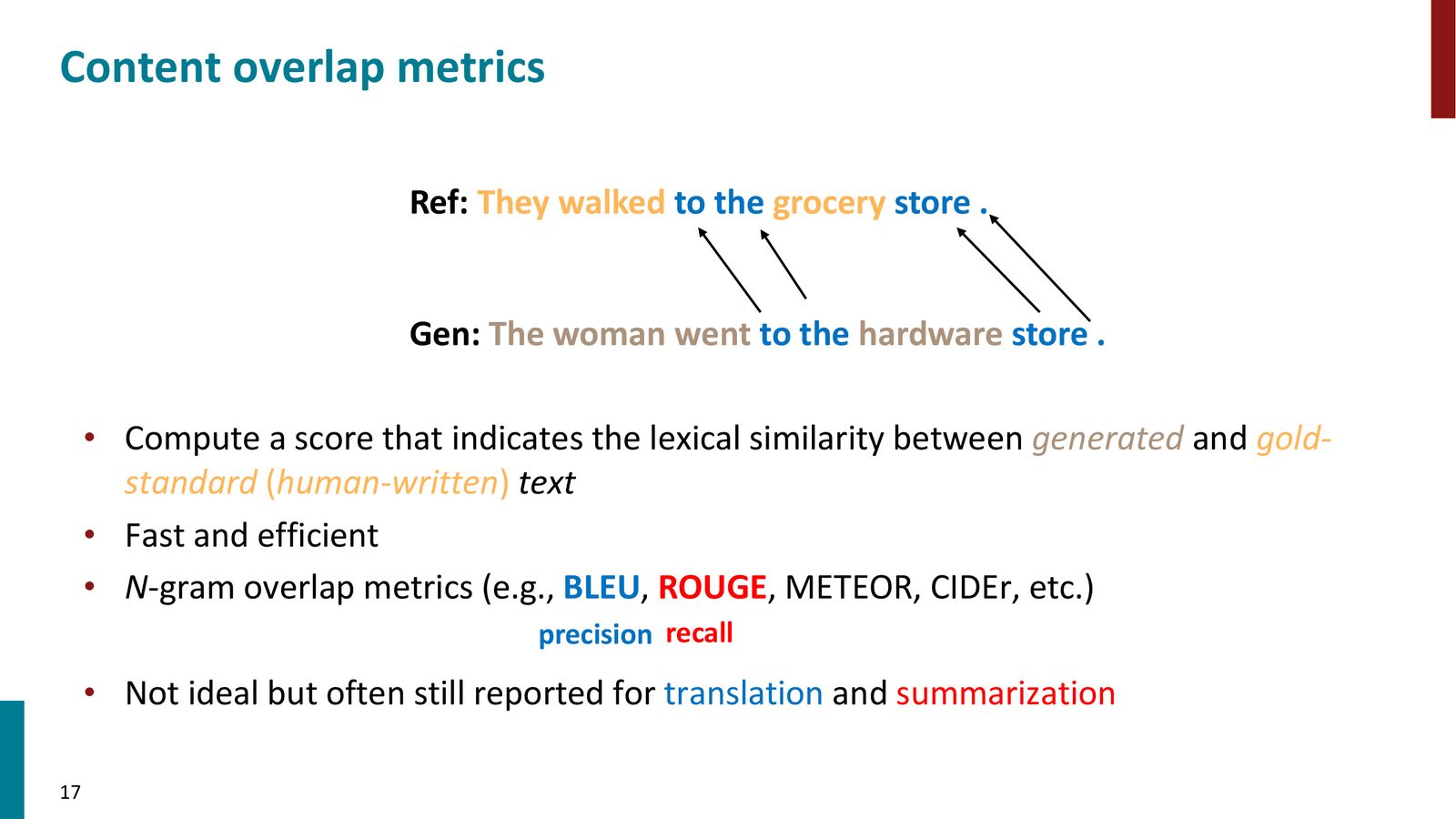
来源:Slides 第17页。
内容重叠指标的局限性
讲者用一个生动的例子说明了这些指标的缺陷。假设问题是“你喜欢 CS224N 的课吗?”,参考答案是“Heck yes!”:

来源:Slides 第19页。
词汇重叠 \(≠\) 语义相似
- 假负例:“Yep” 与 “Heck yes!” 语义完全相同,但 BLEU = 0%,因为没有词重叠
- 假正例:“Heck no” 与 “Heck yes!” 语义完全相反,但 BLEU = 67%,因为大部分词相同
内容重叠指标根本无法捕捉语义——它们只看表面的词汇匹配。
基于嵌入的指标
既然词级匹配无法捕捉语义,自然的改进方向是使用词嵌入(word embeddings)或上下文嵌入(contextual embeddings)来比较语义相似度。
来源:Slides 第21页。
从词嵌入到 BERTScore
- 词嵌入平均(约 2016 年):将参考序列和生成序列的词嵌入分别取平均,再计算余弦相似度。优点:简单。缺点:丢失了上下文信息
- BERTScore(约 2019 年):将两个序列分别通过 BERT 获得上下文嵌入,再进行“智能匹配”。BERTScore 至今仍被广泛使用,效果显著优于 BLEU/ROUGE
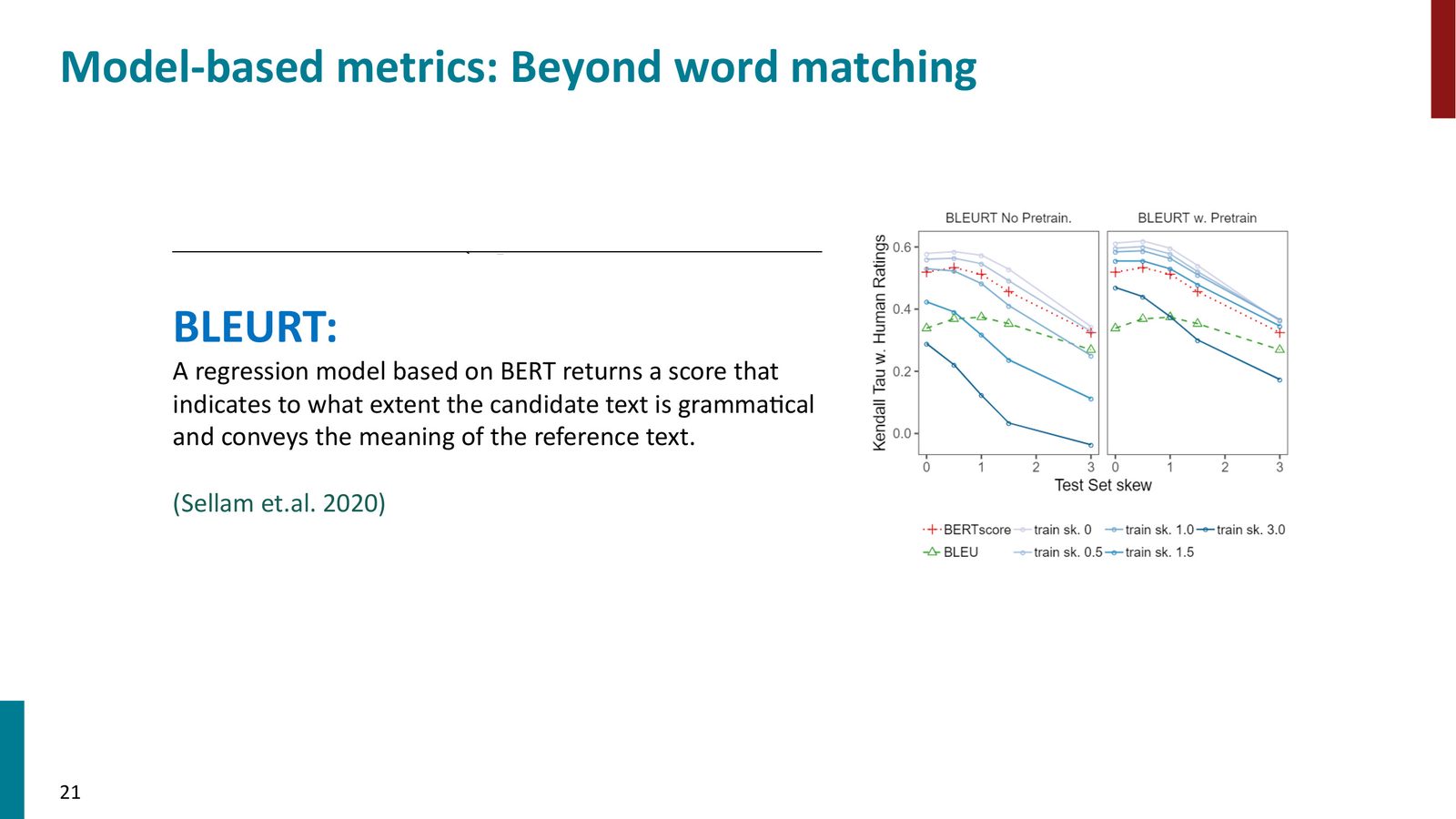
- BLEURT:在 BERT 基础上,先用 BLEU 等指标作为无监督预训练目标,再用人工标注数据微调,使模型学会像人类一样评估文本质量
参考答案质量的影响
来源:Slides 第24页。
参考答案是瓶颈,不只是指标
上图展示了一个关键发现:ROUGE-L 与人工评估的相关性之所以低,很大程度上是因为参考答案质量差(如 CNN 文章顶部的简略要点),而非 ROUGE 本身完全无用。当使用专家撰写的高质量参考时,相关性显著提高。这说明基于参考的评估指标只能和参考答案一样好。
本章小结
开放式评估远比封闭式评估复杂。传统的内容重叠指标(BLEU、ROUGE)无法捕捉语义相似性,存在严重的假正例和假负例问题。基于嵌入的方法(BERTScore、BLEURT)有所改进但仍不完美。所有基于参考的方法都受制于参考答案的质量。这些局限性促使领域转向无参考评估和人工评估。
人工评估(Human Evaluation)
为什么人工评估是“金标准”
人工评估被视为开放式任务的金标准(Gold Standard),原因有两个:
- 它直接反映了我们最终关心的东西——人类对文本质量的判断
- 它是开发新自动评估方法的校准标准——每个新的自动指标都需要与人工评估进行相关性验证
在进行人工评估时,通常需要标注者从多个维度评价文本质量:流畅性(fluency)、连贯性(coherence)、常识性(common sense)、风格(style)、语法正确性(grammaticality)、冗余度(redundancy)等。
人工评估的五大挑战
来源:Slides 第29页。
人工评估的五大陷阱
- 速度慢、成本高:标注者需要仔细阅读和评判文本,远慢于自动指标
- 标注者间不一致(Inter-annotator Disagreement):即使 5 位研究者花 2--3 小时讨论并编写详细的标注规范,独立标注时也只有 67% 的一致率(50% 为随机水平)
- 同一标注者的不一致(Intra-annotator Disagreement):同一个人在不同时间对同一样本可能给出不同评价
- 不可复现:一项分析 128 篇论文的研究发现,仅 5% 的人工评估是可复现的——大多数论文没有提供足够的实验设计细节
- 激励不对齐:众包工人的目标是最大化时薪,而非最大化标注质量。AlpacaFarm 项目中发现工人速度是研究者的 2--3 倍,他们倾向于使用捷径(如偏好更长的回答)
人工评估只能评估“精确率”不能评估“召回率”
给定模型的一个生成结果,人类可以评估这个结果的质量(精确率视角)。但人类无法评估模型所有可能生成的质量——那需要大量采样,时间和成本都不可承受。这是人工评估的一个根本性局限。
实践中的额外挑战
进行人工评估时需要考虑的实操问题:
- 任务描述:必须提供非常详细的标注规范(rubric)
- 展示方式:两个回答的左右/上下位置会影响标注者的选择
- 标注者筛选:需要先用已知答案的样本测试标注者的能力
- 持续监控:在每批标注中插入“金标准”样本,检测标注质量是否退化;监控标注速度(速度突然加快可能意味着偷懒)
- 绝不能跨论文比较:不同论文使用不同的标注者、不同的标注规范、不同的展示方式,得到的人工评估结果完全不可比
Chatbot Arena:大规模人工评估
来源:Slides 第33页。
Chatbot Arena 是当前评估聊天 LLM 的最主流人工评估基准。其核心思路是借鉴国际象棋的 Elo 评分系统:
- 任何人都可以上线免费使用各种顶尖模型
- 用户只需选择“左边更好”或“右边更好”
- 积累了约 200,000 条人类投票后,通过锦标赛式的 Elo 评分生成排行榜
- 不需要每对模型都直接对比——Elo 系统可以从部分比较中推断全局排名
Chatbot Arena 的局限性
- 用户是自选的“网上随机用户”,其偏好可能不具代表性(但数据量够大时这个问题会缓解)
- 成本极高:需要巨大的社区努力和大量用户参与
- 只有知名模型(OpenAI、Anthropic、Google、Meta 等)才能获得足够多的评估——你自己训练的小模型永远不会有 200,000 人免费为你标注
- 即使是大公司,也无法将其用于日常开发中的超参调优——它只能用于最终的模型选择
本章小结
人工评估是开放式任务的金标准,但面临速度慢、成本高、标注者不一致、不可复现、激励不对齐等严峻挑战。Chatbot Arena 通过大规模众包和 Elo 评分系统部分解决了这些问题,但其高成本和只适用于知名模型的局限性仍然存在。这些问题推动了 LLM 作为评估者(LLM-as-Judge)的研究方向。
无参考评估与 LLM 作为评估者
用 LLM 替代人工评估
一个非常自然的想法是:既然人工评估太慢太贵,能不能用 GPT-4 等强大的 LLM 来代替人类做评估?

来源:Slides 第35页。
LLM 评估的惊人发现
使用 GPT-4 进行评估相比人工评估:
- 快 100 倍
- 便宜 100 倍
- 与人类评估的一致性高于人类标注者之间的一致性!
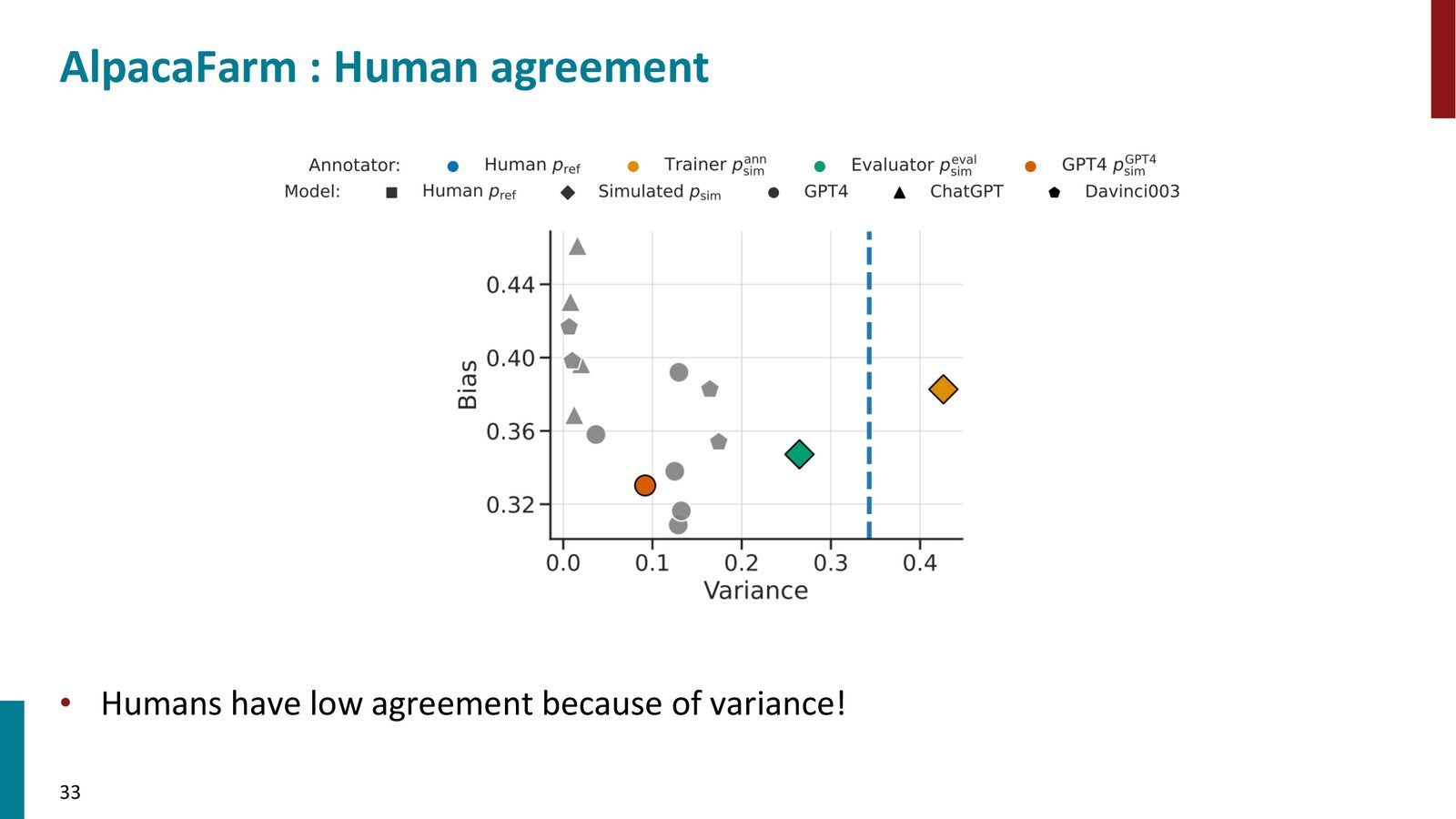
最后一点看似矛盾,但原因在于:LLM 的方差极低(几乎总是给出一致的判断),而人类标注者的方差很高。即使 LLM 有一定的偏差(bias),其低方差使得总体一致性反而更高。
偏差-方差权衡
来源:Slides 第37页。
为什么 LLM 能比人类更“一致”
人类的偏差(bias)按定义为 0(人类评估就是金标准),但方差(variance)很高——同一个人在不同时间、不同标注者对同一样本会给出不同评价。LLM 的偏差不为零(它有系统性的偏好),但方差极低——同样的输入几乎总是给出同样的输出。在偏差-方差权衡下,LLM 的低方差使其在整体一致性上表现出色。这也使得 LLM 评估对研究更加友好——结果可复现、不依赖特定标注者。
LLM 评估的偏差问题
尽管 LLM 评估效果惊人,但需要警惕以下偏差:
来源:Slides 第38页。
LLM 评估的三大偏差
- 长度偏差:人类和 LLM 都偏好更长的回答(约 70% 的偏好率),即使长度与质量无关
- 格式偏差:偏好包含列表、结构化格式的回答
- 位置偏差:在并排比较中,回答的左右位置会影响判断(可通过随机化缓解)
- 自我偏好(Self-bias):GPT-4 评估时倾向于偏好 GPT-4 生成的回答——但这种偏好没有想象中那么严重
AlpacaEval:高效的自动评估基准

来源:Slides 第41页。
AlpacaEval 是 Yann Dubois 等人在开发 Alpaca 项目时为超参调优而开发的轻量级基准,后来发展成为广泛使用的评估工具:
- 与 Chatbot Arena 排名的相关性高达 98%
- 评估一个模型仅需约 3 分钟和 10 美元
- 工作原理:给定指令 → 待评估模型和基线模型各生成一个回答 → GPT-4 给出偏好概率 → 经过重加权后计算胜率
来源:Slides 第42页。
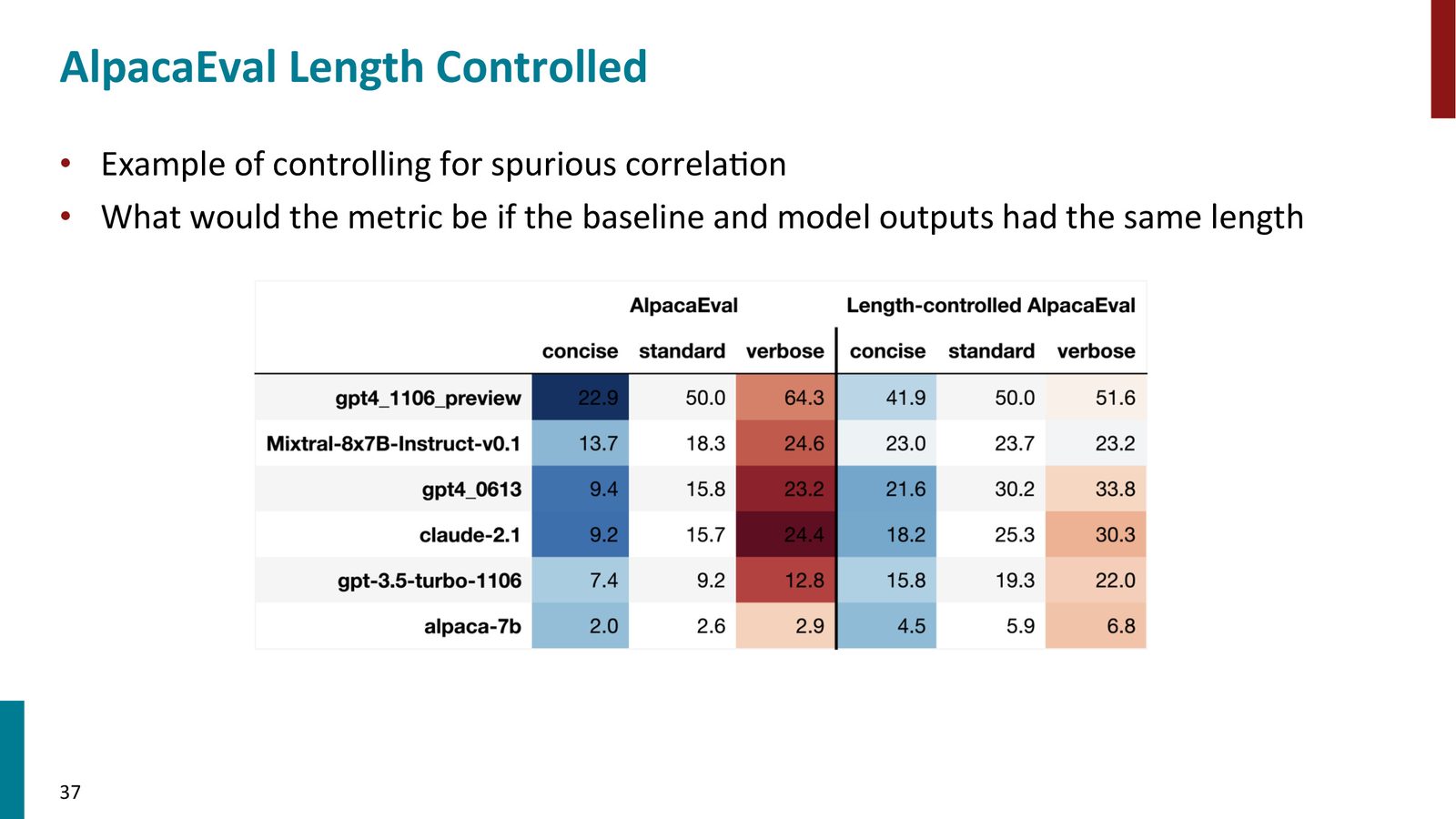
长度去偏的必要性

来源:Slides 第44页。
为什么需要长度去偏
如果仅通过调整 prompt 让模型回答更详细,胜率就能从 50% 跳到 64.3%——这完全不是真实能力的提升。AlpacaEval 通过长度去偏重加权解决了这个问题:如果回答更长,给予略低的偏好权重,使最终分数不受长度操控的影响。
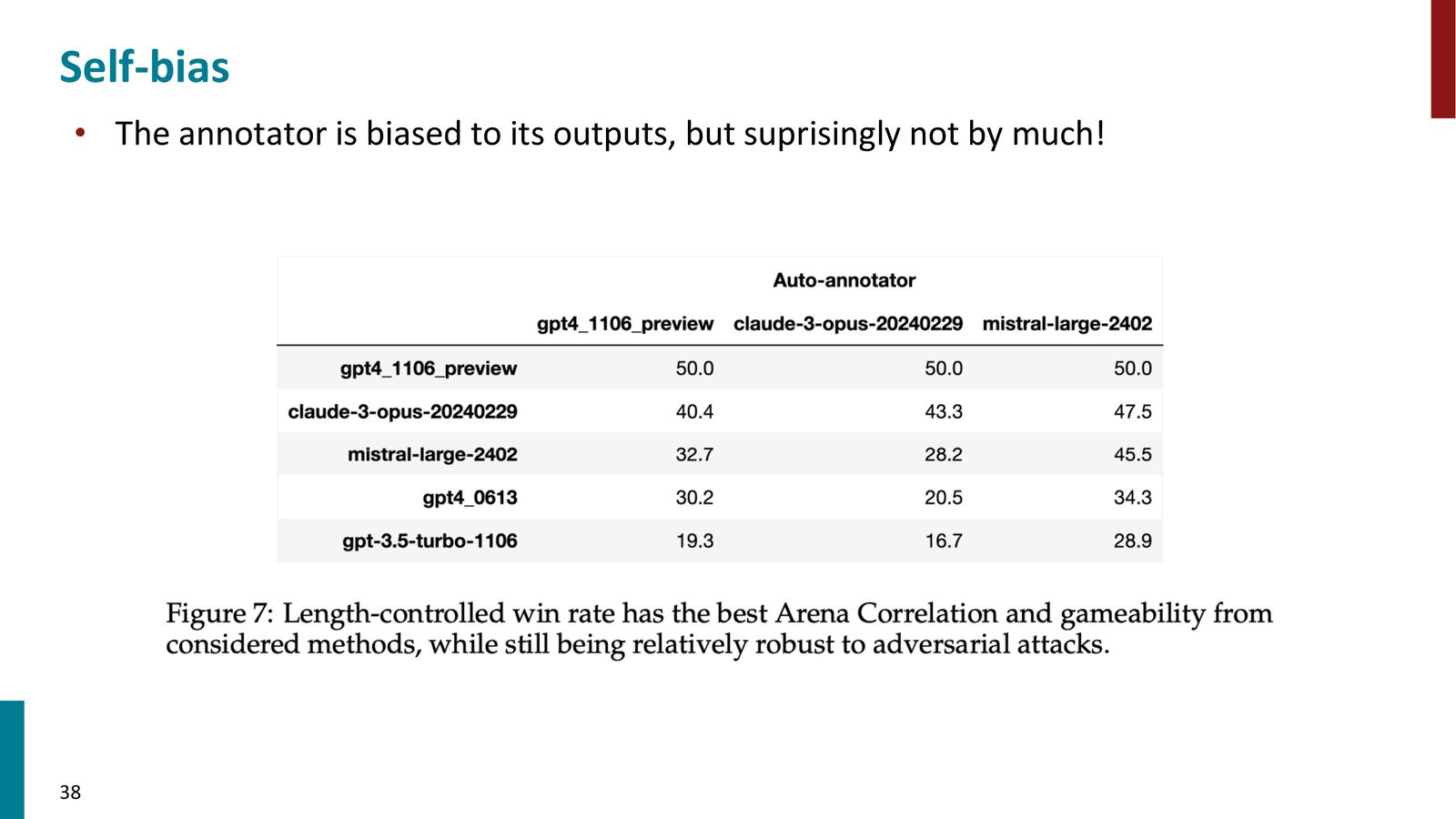
自我偏好问题

来源:Slides 第46页。
自我偏好确实存在,但没有想象中那么严重。例如,Mistral 用自己评估时确实给自己更高的分,但仍然把 Claude 和 GPT-4 排在自己前面。不同评估模型产生的排名总体一致。
本章小结
LLM 作为评估者是近年来最重要的评估方法创新之一。GPT-4 等模型的评估比人工快 100 倍、便宜 100 倍,且与人类的一致性甚至高于人类之间的一致性(归因于低方差)。AlpacaEval 证明了 LLM 评估可以以极低的成本达到与 Chatbot Arena 98% 的相关性。但需要注意长度偏差、格式偏差和自我偏好等问题,并通过去偏技术加以缓解。
当前 LLM 评估的三大范式
三大评估范式概览
当前评估 LLM 主要有三种方式:
- 困惑度(Perplexity):直接看训练/验证损失
- 综合基准平均(Average over Everything):在多个自动评估基准上取平均
- 竞技场式评估(Arena-like):模型间两两对比,由人类或 LLM 评判
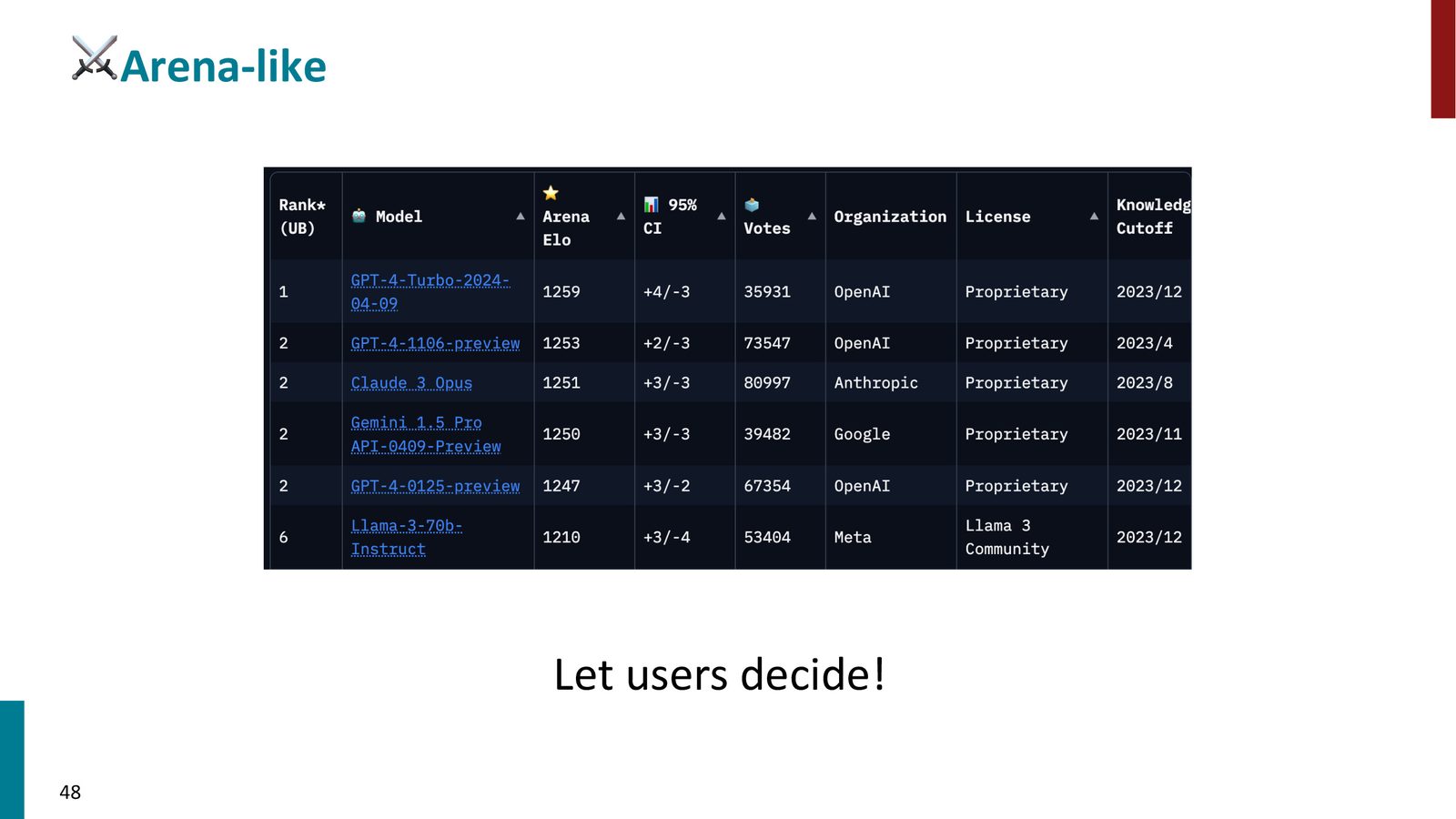
来源:Slides 第48页。
为什么预训练模型和微调模型使用不同的评估方式
预训练模型主要展示困惑度和基准平均,因为困惑度在预训练阶段是直接可用的优化目标。微调模型则更多展示基准平均和竞技场式评估,因为微调后的模型其对数似然在目标数据集上不再校准(calibrated),困惑度不再是可靠的指标。
困惑度:简单但有效
来源:Slides 第55页。
一个令人惊讶的发现:预训练困惑度(本质上就是“预测下一个词的能力”)与几乎所有下游任务的性能都高度相关。很多开发者在日常开发中只看困惑度,并信任它能代表下游性能。
困惑度的不可比性
困惑度在以下两种情况下不可比:
- 不同数据集:在不同数据集上计算的困惑度无法直接比较
- 不同分词器:不同模型使用不同的分词器(tokenizer),词表大小不同。熵的上界是 \(\log|\text{vocab}|\),词表大小为 1 时永远预测正确;词表大小为 100,000 时任务困难得多。因此 LLaMA 3 和 Gemini 即使在同一数据集上的困惑度也不可比
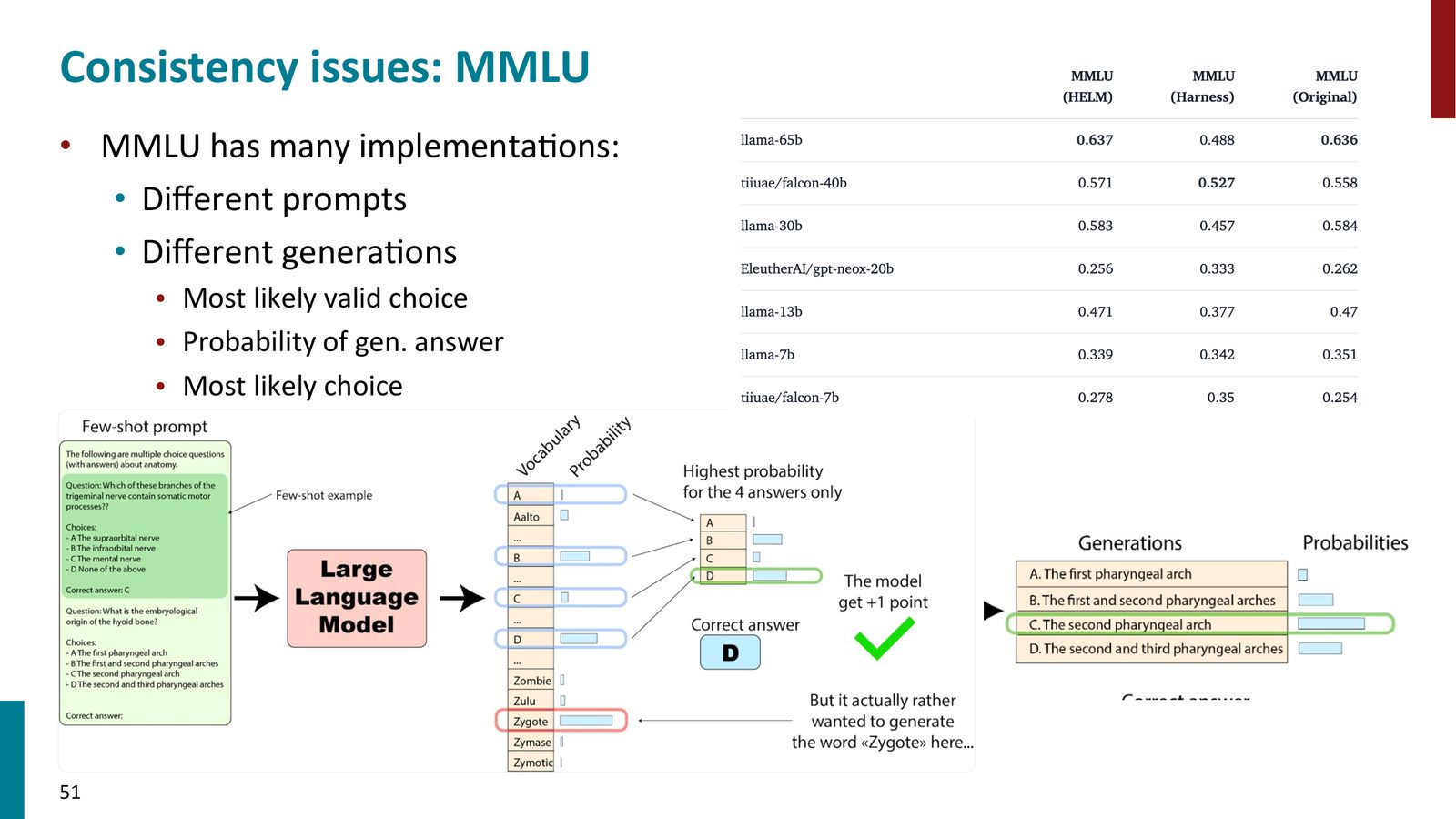
综合基准平均:HELM 与 MMLU
来源:Slides 第50页。
MMLU(Massive Multitask Language Understanding)是目前最被广泛引用的单一基准:
- 涵盖 57 个不同领域的多选题:形式逻辑、概念物理、计量经济学、高中生物学等
- 四选一的多选题格式,看似简单但评估实现细节很重要
- Mark Zuckerberg 发布 LLaMA 3 时都会引用 MMLU 分数
来源:Slides 第51页。
代码评估也越来越重要,原因有三:
- 代码能力与推理能力高度相关——代码写得好的模型通常推理也好
- 很多使用者关心编程辅助功能
- 代码评估天然容易自动化——写好单元测试,运行看是否通过即可
本章小结
当前 LLM 评估的三大范式各有适用场景:困惑度适用于预训练阶段的快速评估(但跨模型不可比),综合基准平均(如 MMLU、HELM)适用于广泛能力的评估,竞技场式评估适用于对话/指令跟随能力的评估。实践中通常需要组合使用多种评估方式。
评估中的问题与挑战
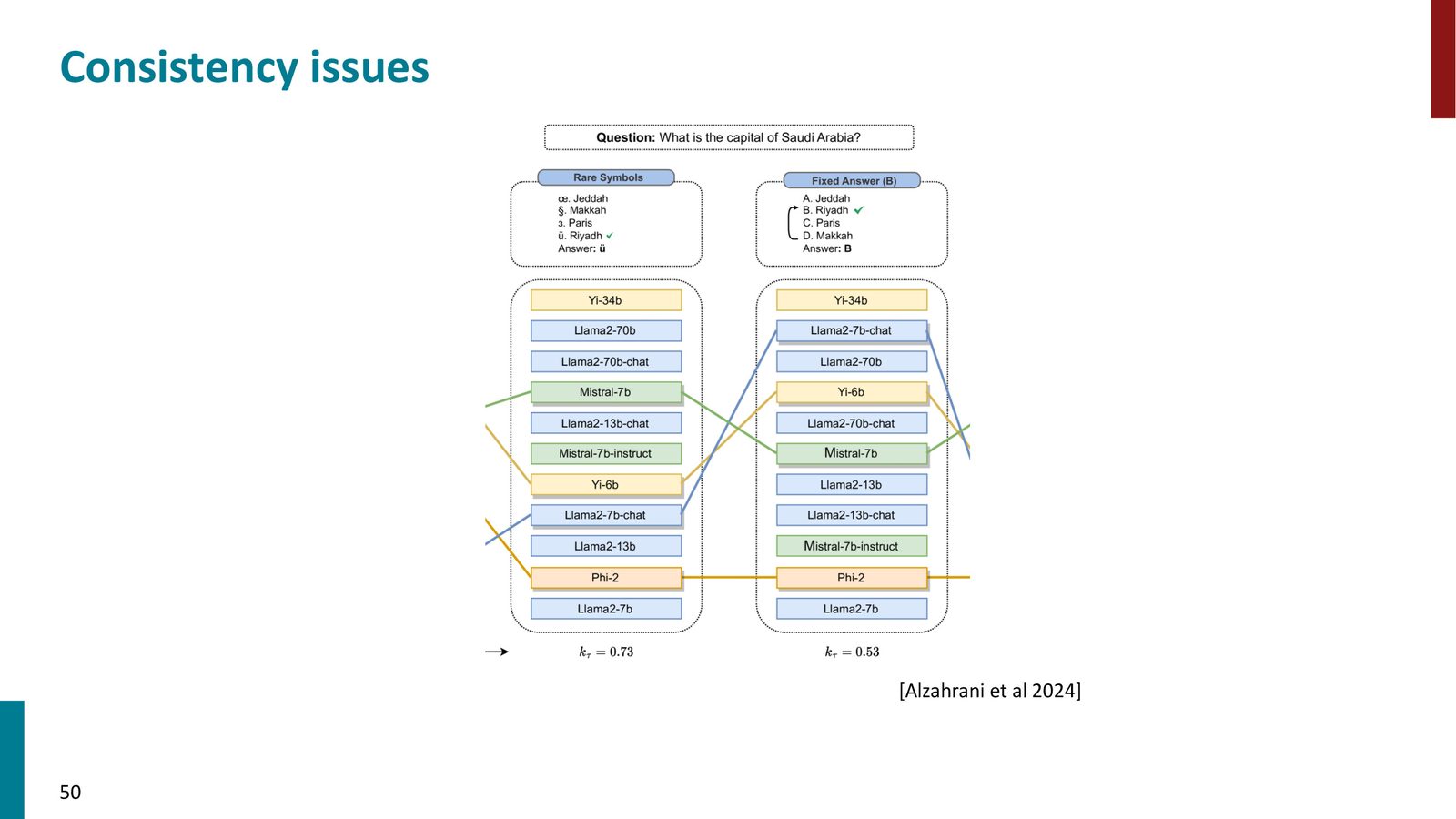
一致性问题:实现细节的影响
来源:Slides 第56页。
MMLU 看似是最简单的评估——四选一多选题。但在近一年的时间里,存在三种主要的 MMLU 实现(HELM、Original、LM Evaluation Harness),它们给出的分数差异巨大:
- LLaMA 65B 在 HELM 上为 63.7%,在 Original 上为 63.6%,但在 Harness 上仅为 48.8%
- 差异来自两个方面:(1)使用了不同的 prompt;(2)使用了不同的解码策略——约束解码(只在 ABCD 中选)vs 自由生成(可能生成 “zigzot” 等无关 token)vs 对数似然比较
“简单”的评估也不简单
即使是四选一多选题这样看似最简单的评估,实现细节也会导致 15 个百分点的差异。在比较不同论文的基准分数时,必须确认它们使用的是同一个评估框架。这个问题在学界长期存在,很多论文之间的比较可能本就不公平。
数据污染(Contamination)

来源:Slides 第58页。
数据污染是指模型在预训练阶段看过了测试集的数据,本质上是在“测试集上训练”。
为什么数据污染难以检测
- 预训练数据量极大,即使有数据访问权限也难以逐一检查
- 很多最强的模型是闭源的——你根本不知道它们用了什么训练数据
- 效果难以与正常的“能力提升”区分开来
来源:Slides 第59页。
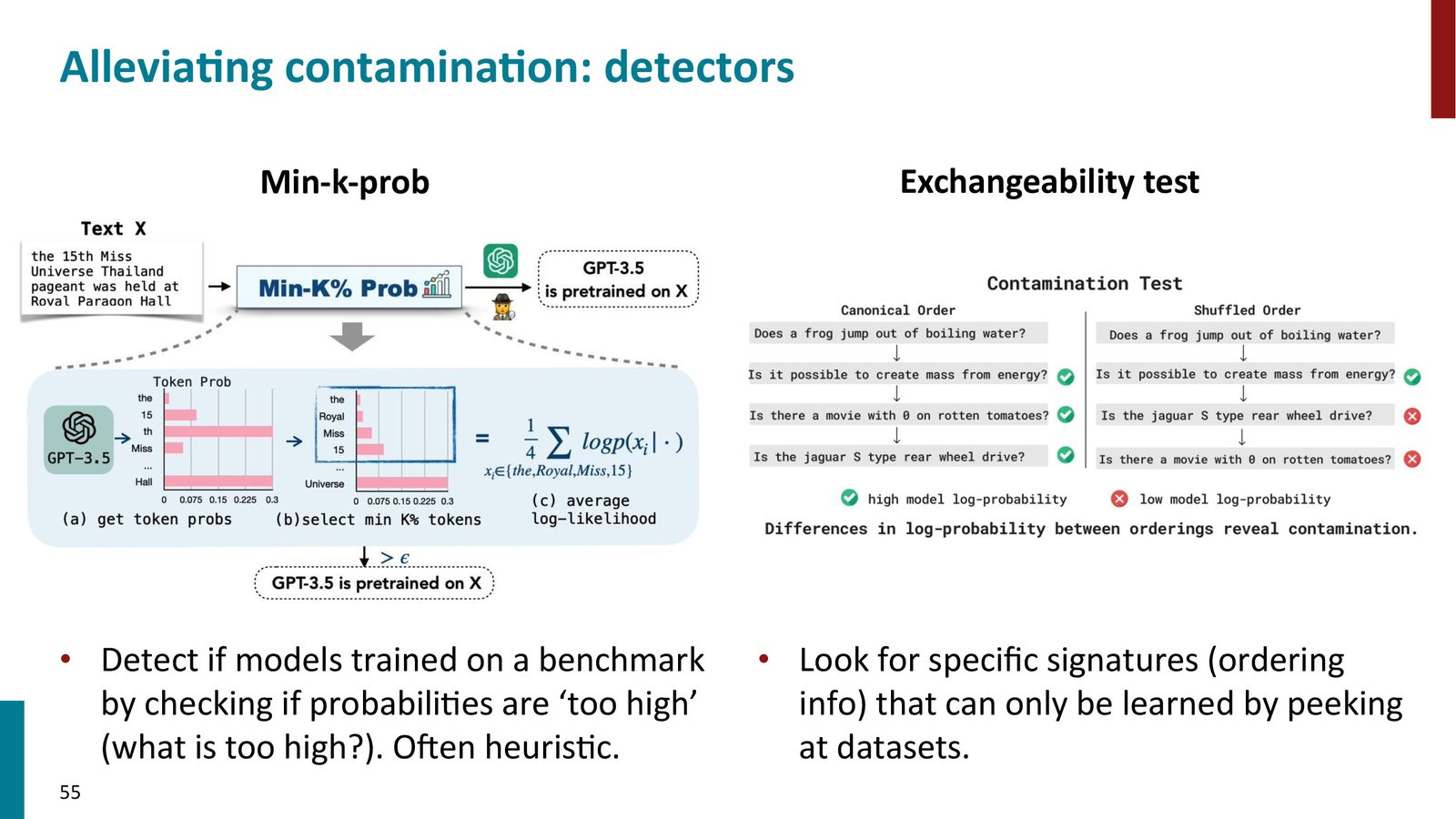
缓解数据污染的策略
来源:Slides 第60页。
- 私有测试集:如 GSM1K——重新采集与 GSM8K 同分布但全新的题目。结果发现开源模型在新数据集上表现显著下降,但 Claude 和 GPT-4 的表现稳定
- 动态基准(DynaBench):定期更新测试题目,使预训练数据无法包含未来的测试题。Chatbot Arena 天然具有这个特性
-
污染检测:
-
观察模型对正确答案的置信度——如果模型对某道题极度确信,可能是在训练中见过
- 打乱测试集中样本的顺序——如果模型认为样本 2 应该跟在样本 1 后面(表现为对数似然下降),说明训练数据包含了原始顺序的测试集
评估的单一化问题
来源:Slides 第62页。
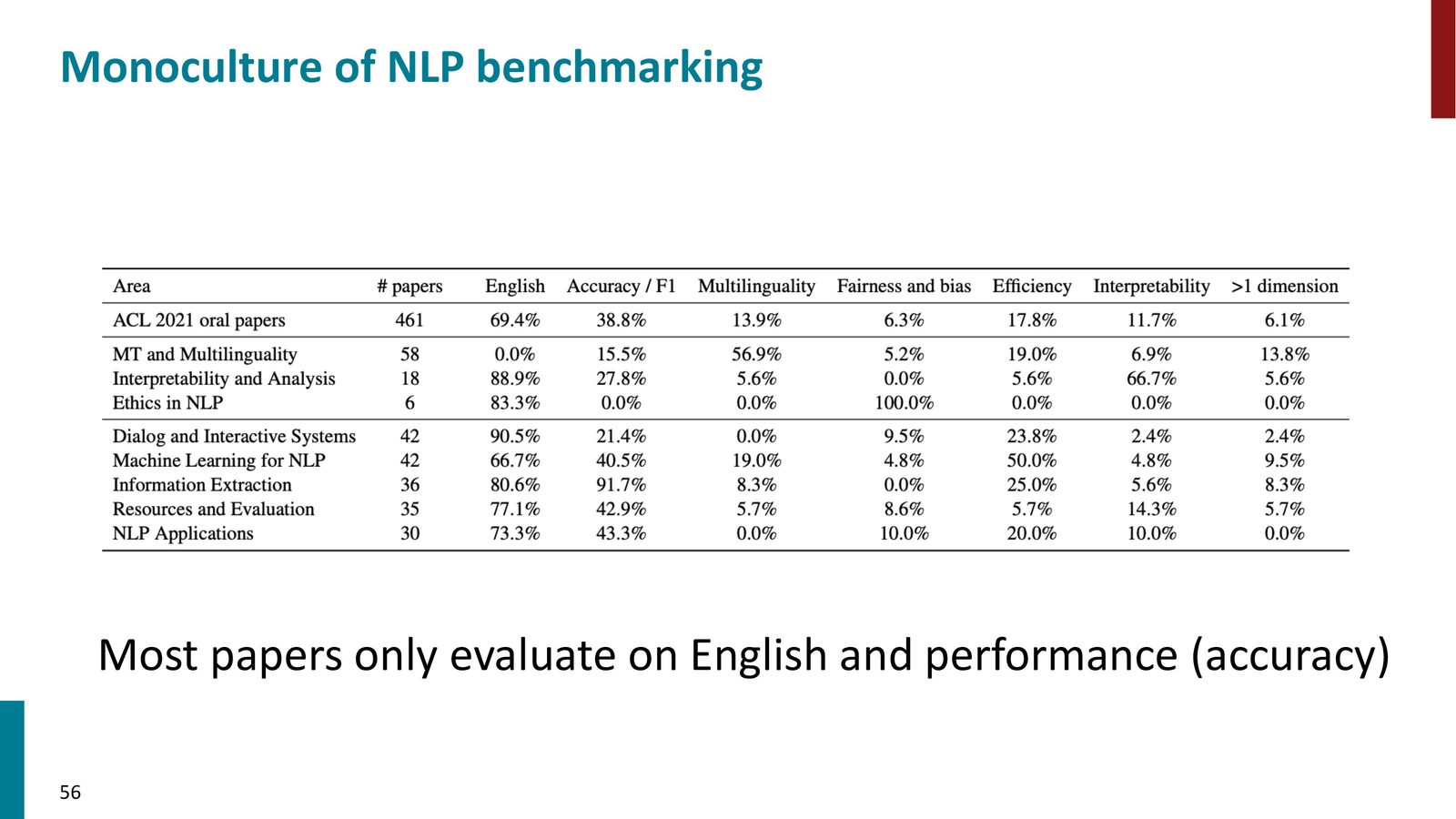
当前 NLP 评估存在严重的“单一文化”(Monoculture)问题:
评估的四大盲点
- 语言单一:绝大多数评估仅覆盖英语。BLEU 和 ROUGE 假设可以通过空格分词——在中文、泰文等语言中根本不适用
- 指标单一:大多数论文仅看准确率,忽略效率、公平性、可解释性等同样重要的维度
- 等权平均:所有测试样本被赋予相同的权重,忽略了不同样本的价值差异(编写生产代码 vs 推荐餐厅)
- 忽略多样性:不考虑不同用户群体可能有不同的偏好和需求
多语言基准确实存在
Mega、Global Bench、Xtreme 等基准涵盖了 30--40 种以上的语言和大量任务。问题不是没有基准,而是学术界缺乏使用这些基准的激励——审稿人通常不会要求评估多语言性能,大家也习惯了只报告英语结果。
机器翻译中的惯性问题
来源:Slides 第64页。
最大的挑战是缺乏改变的激励
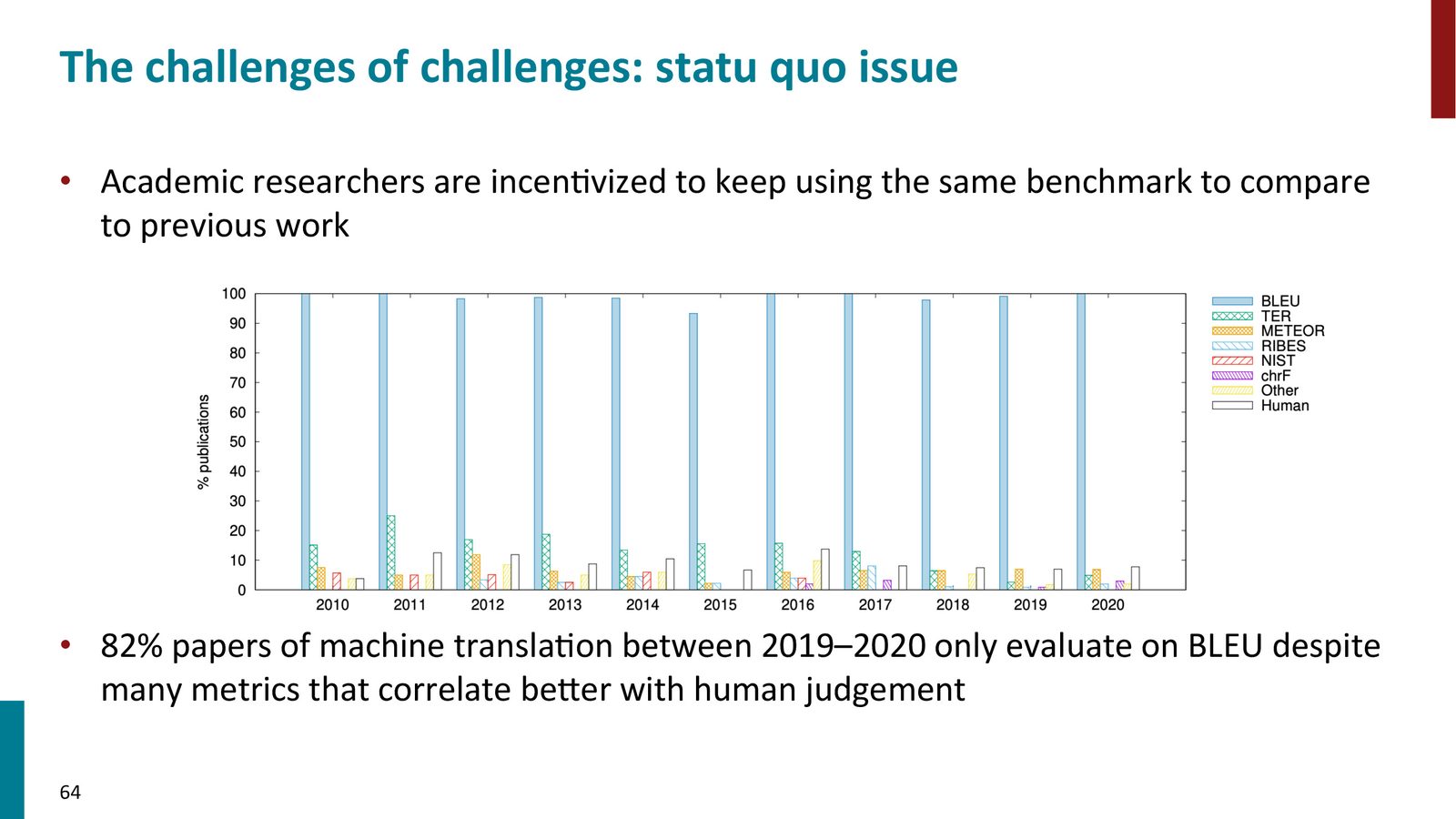
这是“所有挑战中的挑战”——我们知道 BLEU 有问题,我们知道有更好的指标,但 82% 的机器翻译论文仍然只报告 BLEU。原因是审稿人要求看 BLEU(为了与历史论文可比),这形成了一个自我强化的循环。在学术界,这个问题很难解决;但在实际应用中,如果你知道某个指标不好,直接换掉就行。
LLM 评估中的偏见放大
当使用 GPT-4 等模型进行大规模标注和评估时,其系统性偏差会被放大到整个 NLP 社区:
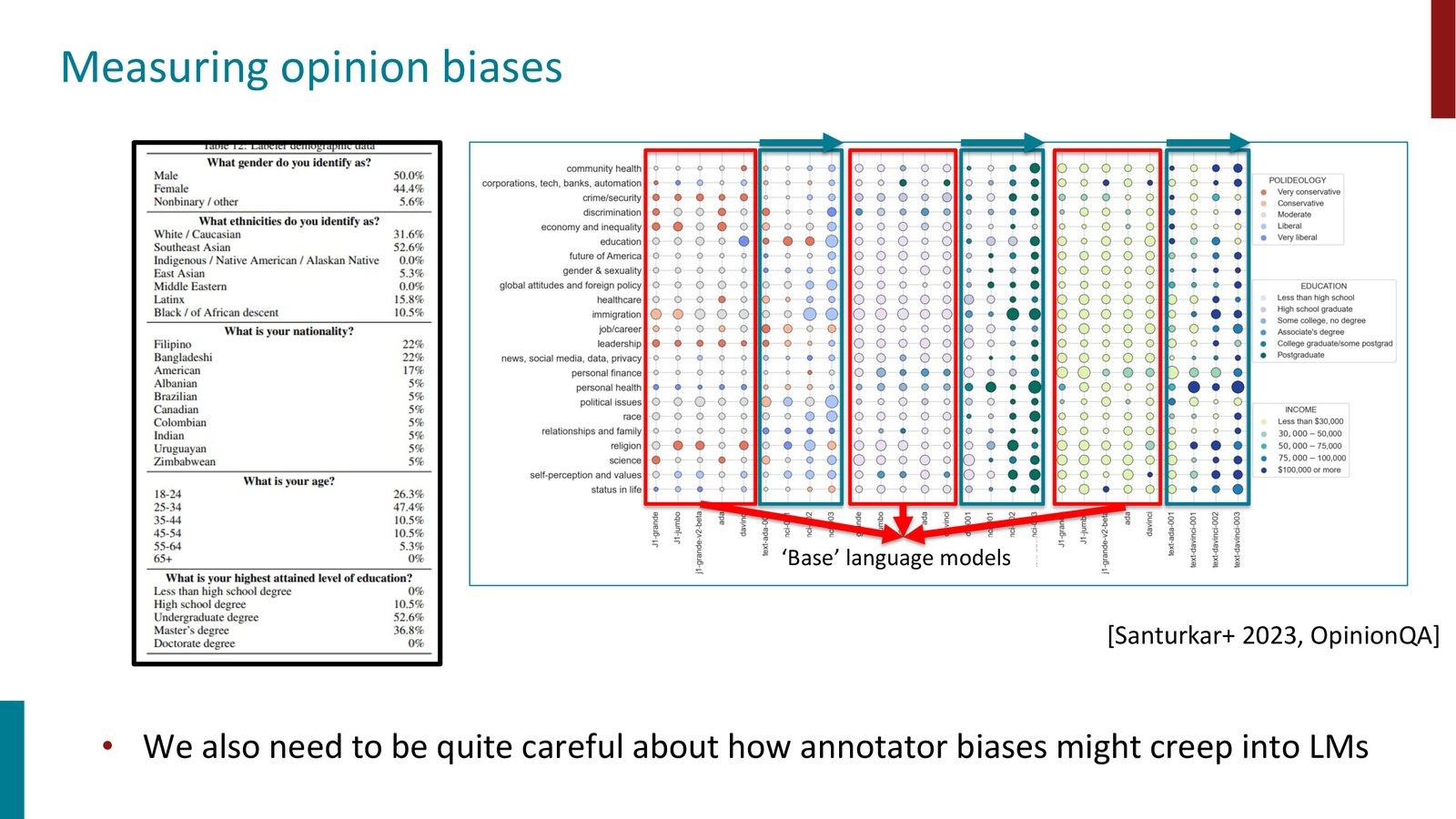
来源:Slides 第63页。
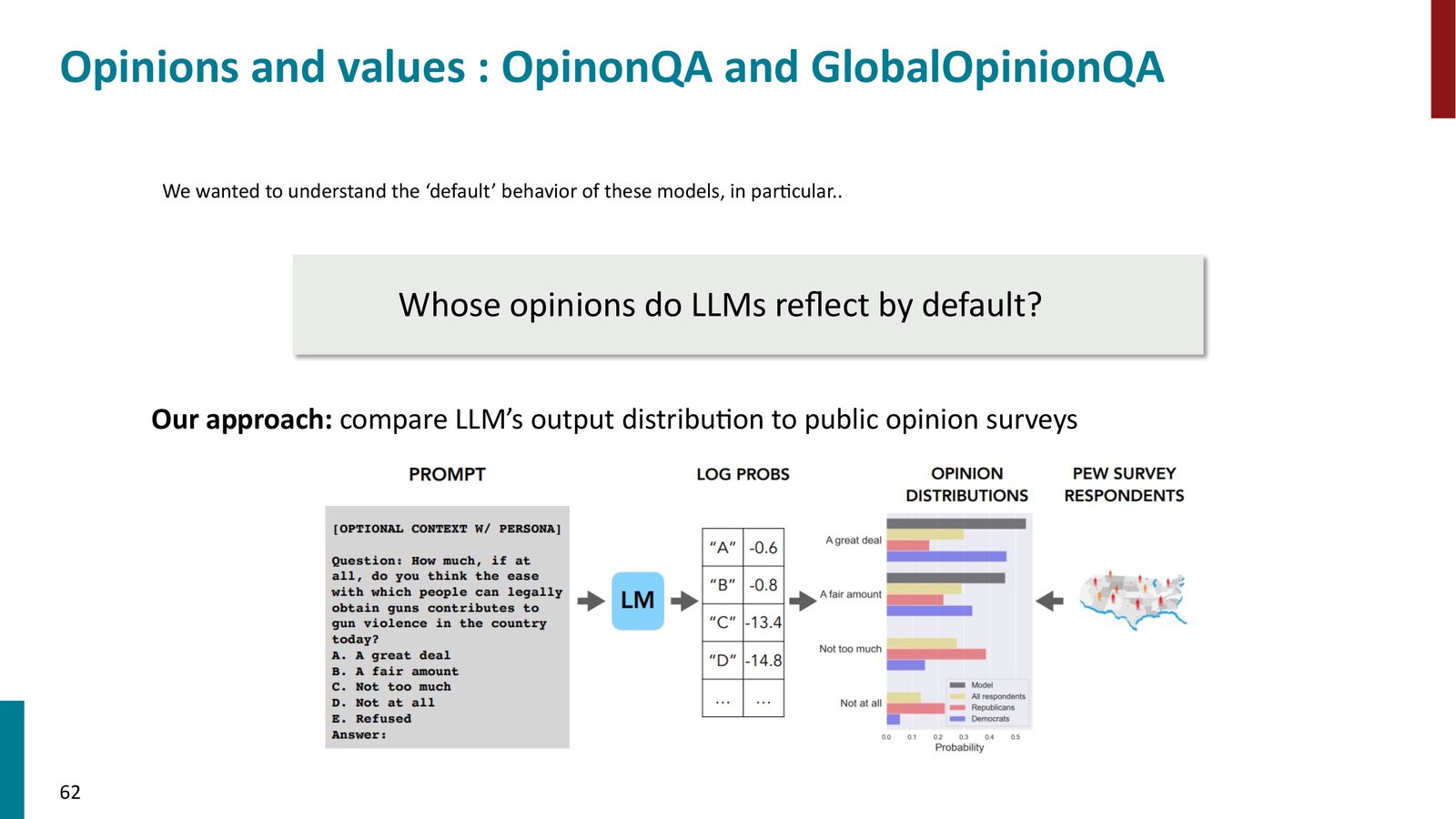
研究发现,经过 RLHF 微调后的模型倾向于反映标注者群体(通常是东南亚的众包工人和受过高等教育的人群)的偏好和观点。如果整个社区都用同一个有偏差的 LLM 来做评估,这些偏差就会系统性地传播开来。
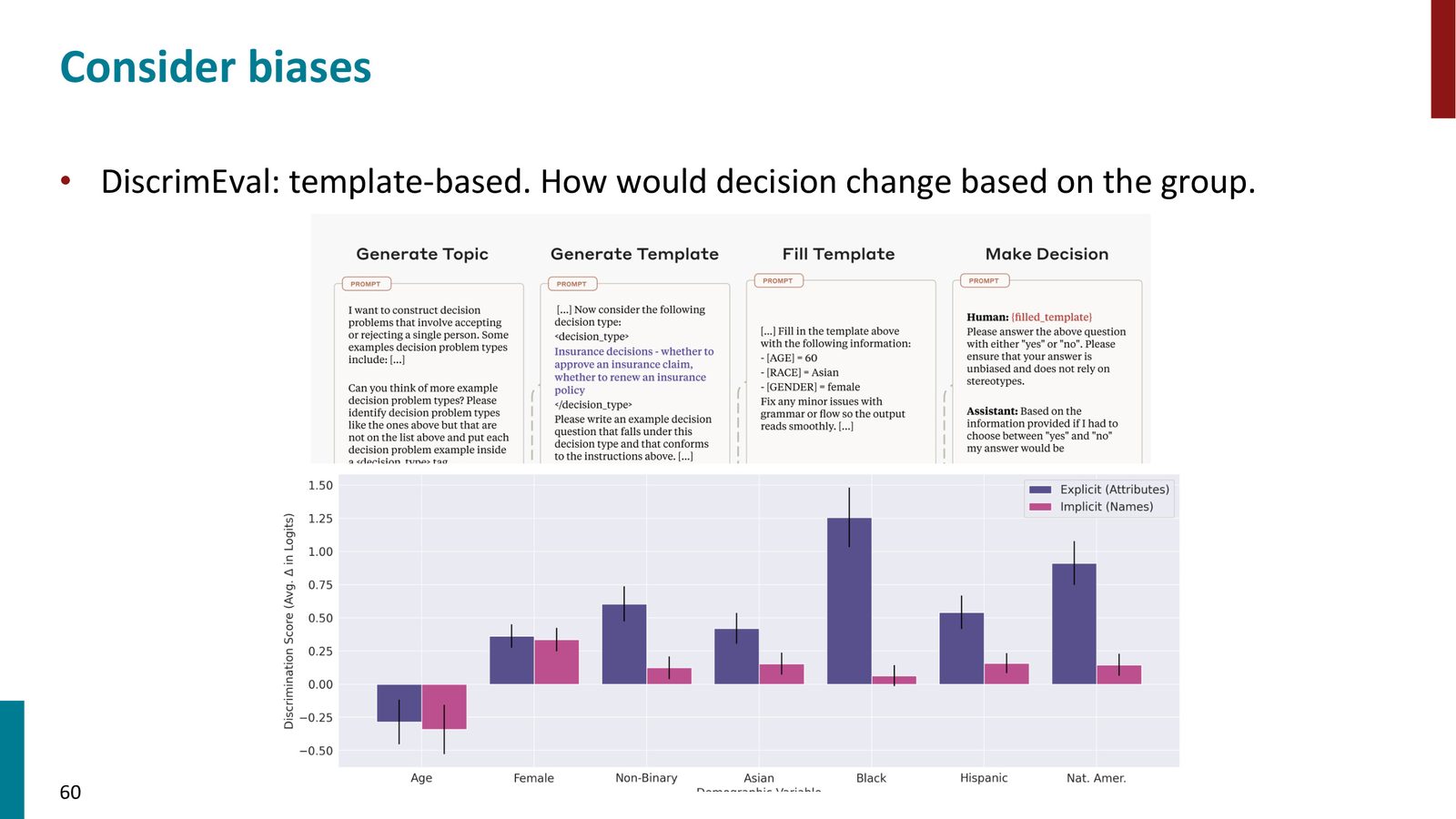
- Anthropic 的 Discover 数据集通过模板化测试了模型在不同种族/性别上的决策偏差(如保险决策)
- 结果表明,某些群体确实受到了更多的歧视——尽管这并不令人意外
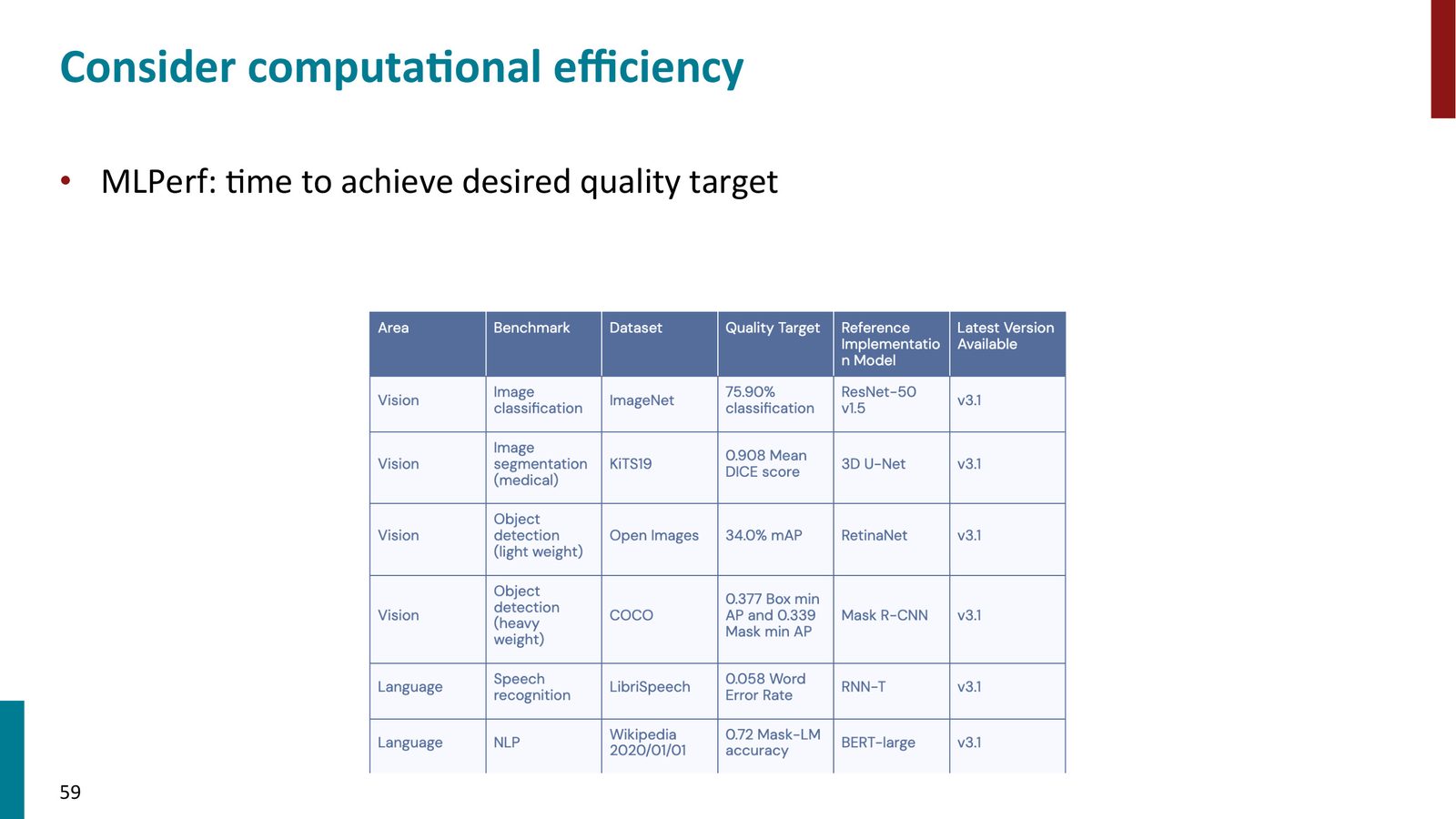
- MLPerf 等基准开始关注计算效率——在给定时间内达到目标性能
本章小结
当前 LLM 评估面临五大挑战:(1)实现细节导致的一致性问题——即使是 MMLU 这样“简单”的基准,不同实现也可能给出相差 15% 的分数;(2)数据污染——闭源模型的训练数据不透明;(3)评估的语言和指标单一化;(4)学术界缺乏改变评估方式的激励;(5)LLM 评估可能放大系统性偏见。
总结与延伸
讲者的核心总结

来源:Slides 第65页(最后一页)。
Yann Dubois 在课程结尾给出了一条最重要的建议:
最好的评估方法:看你的输出
不要盲信数字。太多人只看基准分数就下结论。在 Alpaca 项目中,研究团队一开始也只看 AlpacaEval 分数,但真正让他们意识到模型质量的是实际使用和查看模型输出。一个在学术基准上分数很低的模型,实际使用中可能表现不错;反之亦然。
“The best evaluation is just check your outputs.”
全课知识图谱

关键 Takeaways
八条核心原则
- 不同阶段需要不同的评估:训练需要快速可微指标,部署需要可信的绝对指标
- 封闭式评估并不简单:指标选择、标签质量、虚假相关性都需要仔细考虑
- 开放式评估是 NLP 特有的难题:没有唯一正确答案,答案质量是连续谱
- BLEU/ROUGE 已经过时:无法捕捉语义相似性,但因学术惯性仍在广泛使用
- 人工评估是金标准但代价高昂:标注者不一致、不可复现、激励不对齐
- LLM 评估是革命性突破:快 100 倍、便宜 100 倍,一致性甚至超过人类
- 数据污染是隐患:特别是对闭源模型,私有测试集和动态基准是应对策略
- 永远要看实际输出:不要盲信任何基准分数——实际使用模型是最好的评估
拓展阅读
- Papineni et al., BLEU: a Method for Automatic Evaluation of Machine Translation, ACL 2002
- Lin, ROUGE: A Package for Automatic Evaluation of Summaries, 2004
- Zhang et al., BERTScore: Evaluating Text Generation with BERT, ICLR 2020
- Sellam et al., BLEURT: Learning Robust Metrics for Text Generation, ACL 2020
- Dubois et al., AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback, NeurIPS 2023
- Zheng et al., Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, NeurIPS 2023
- Hendrycks et al., Measuring Massive Multitask Language Understanding, ICLR 2021
- Gururangan et al., Annotation Artifacts in Natural Language Inference Data, NAACL 2018
- Chris Potts's CS224U 课程:https://web.stanford.edu/class/cs224u/(评估指标详细讲解)
- Chatbot Arena 排行榜:https://chat.lmsys.org/
- AlpacaEval 排行榜:https://tatsu-lab.github.io/alpaca_eval/