MIT 6.S191 Lecture 5: Deep Reinforcement Learning
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Alexander Amini 授课内容整理 |
| 来源 | Alexander Amini (MIT) |
| 日期 | 2025年春季 |

引言:在动态环境中学习
本讲是 MIT 6.S191(Introduction to Deep Learning)系列课程的第五讲,主题为 Deep Reinforcement Learning(深度强化学习)。在前四讲中,课程已经覆盖了深度学习的核心架构(全连接网络、RNN、CNN)以及两类学习范式(Supervised Learning 和 Unsupervised Learning)。本讲将引入第三类学习范式------Reinforcement Learning(强化学习),并探讨如何将深度学习技术与强化学习相结合,使模型能够在动态环境中通过与环境的交互来学习最优行为策略。

来源:Slides 第2页。
深度强化学习的核心思想与之前的学习范式有本质区别:它不再依赖于预先收集好的静态数据集,而是让模型(Agent)在一个动态环境(Environment)中不断地进行交互------采取行动(Action)、观察环境变化(Observation)、获取奖励信号(Reward)------从而学会如何做出最优决策。这种学习方式在机器人控制、游戏策略、自动驾驶等领域具有广泛的应用价值。
为什么需要强化学习?
在现实世界中,许多任务无法简单地转化为"给定输入预测输出"的监督学习问题。例如,让机器人学会行走、让 AI 学会下棋,都需要智能体在一系列时间步上做出连续决策,并且当前决策会影响未来的状态和奖励。这正是强化学习的核心应用场景。

来源:Slides 第3页。
三类学习范式对比
在正式进入强化学习之前,有必要将其与前面学过的两种学习范式进行系统比较,以便理解其独特定位。

来源:Slides 第7页。
Supervised Learning(监督学习)
- 数据:成对的 \((x, y)\),其中 \(x\) 是输入数据,\(y\) 是标签
- 目标:学习一个从 \(x\) 到 \(y\) 的映射函数
- 类比:给模型展示大量苹果的图片,并告诉它"这是苹果",模型学会识别新的苹果图片
Unsupervised Learning(无监督学习)
- 数据:只有 \(x\),没有标签
- 目标:学习数据的内在结构和分布
- 类比:给模型展示大量相似物体的图片(不告诉它是什么),模型学会发现它们的共同特征
Reinforcement Learning(强化学习)
- 数据:State-Action pairs(状态-动作对)
- 目标:最大化在多个时间步上的未来累积奖励
- 类比:不需要告诉模型"这是苹果",而是让它通过交互学会"吃苹果可以获得营养从而存活"
三种范式的本质区别
- Supervised Learning:从标注数据中学习输入到输出的映射
- Unsupervised Learning:从无标注数据中发现隐藏结构
- Reinforcement Learning:通过与环境的交互学习最优决策策略,目标是最大化长期累积回报
学习算法(Algorithm)是与网络架构(Architecture)无关的(agnostic)。同一种架构(如 CNN)可以用于不同的学习范式。
本章小结
三种学习范式分别对应不同的数据形式和学习目标。强化学习的独特之处在于:(1)数据不是预先收集的,而是通过交互动态生成的;(2)目标不是预测标签或发现结构,而是学习最优行为策略以最大化长期回报;(3)当前的决策会影响后续能观察到的数据(非 i.i.d.)。
强化学习核心概念
本节详细介绍强化学习中的五个核心概念:Agent(智能体)、Environment(环境)、Action(动作)、Observation/State(观测/状态)、Reward(奖励),以及它们之间的交互关系。
Agent 与 Environment
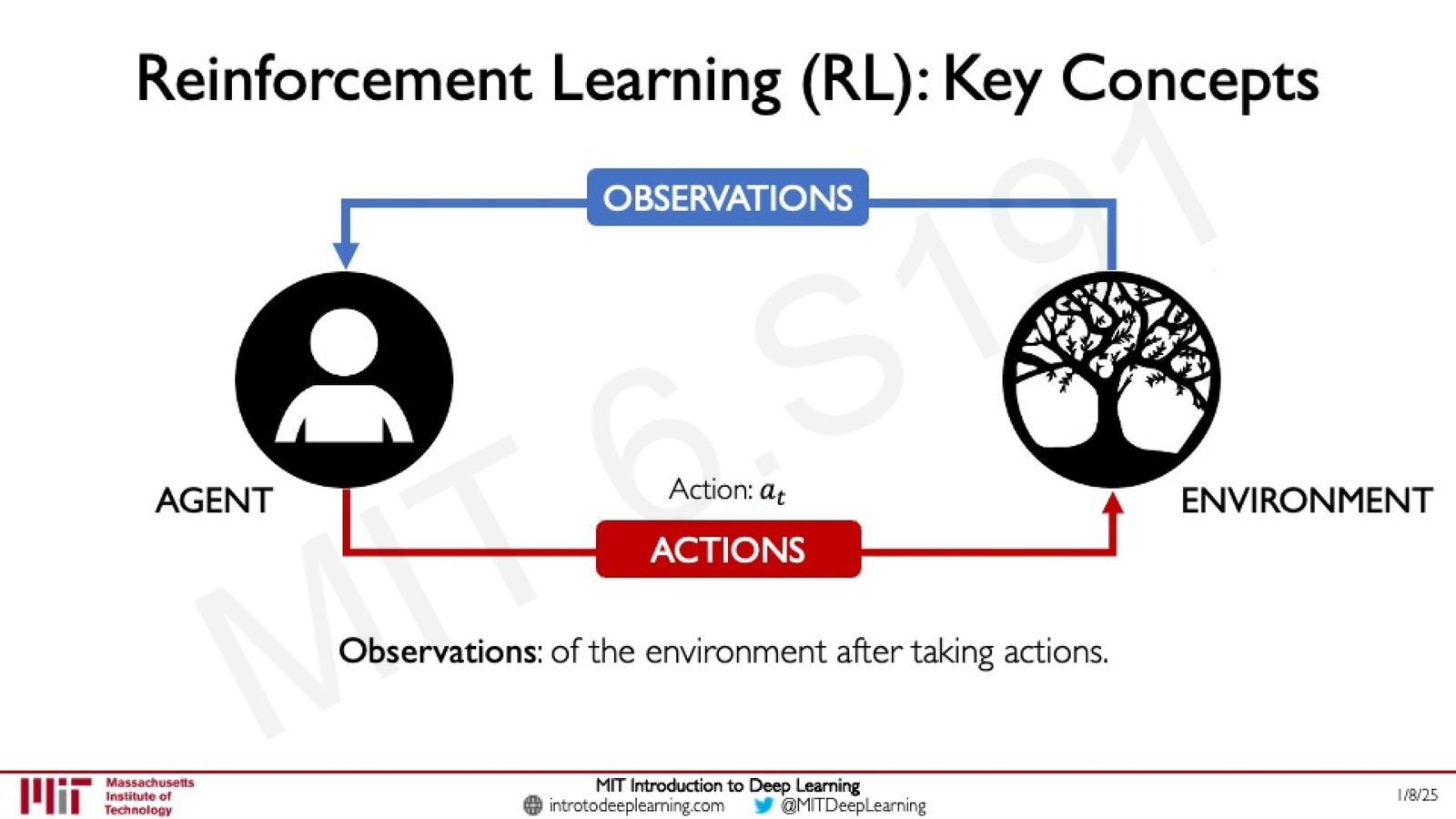
来源:Slides 第11页。
- Agent(智能体):系统中的决策主体,负责根据当前观测采取行动。例如:Super Mario 中的马里奥角色、无人机、自动驾驶汽车的控制器
- Environment(环境):Agent 所存在并运行的世界。环境的规则定义了 Agent 的行动如何影响世界状态
Action 与 Action Space
Action(动作)是 Agent 在环境中可以执行的操作,记为 \(a_t\)(时刻 \(t\) 的动作)。所有可能动作的集合称为 Action Space(动作空间)\(\mathcal{A}\)。
动作空间可以是:
- 离散的(Discrete):如上下左右四个方向
- 连续的(Continuous):如方向盘的转角(任意实数值)
Observation 与 State
Agent 采取行动后,Environment 会返回一个新的观测(Observation),反映环境因该行动而产生的变化。Agent 所感知到的当前情况称为 State(状态),记为 \(s_t\)。
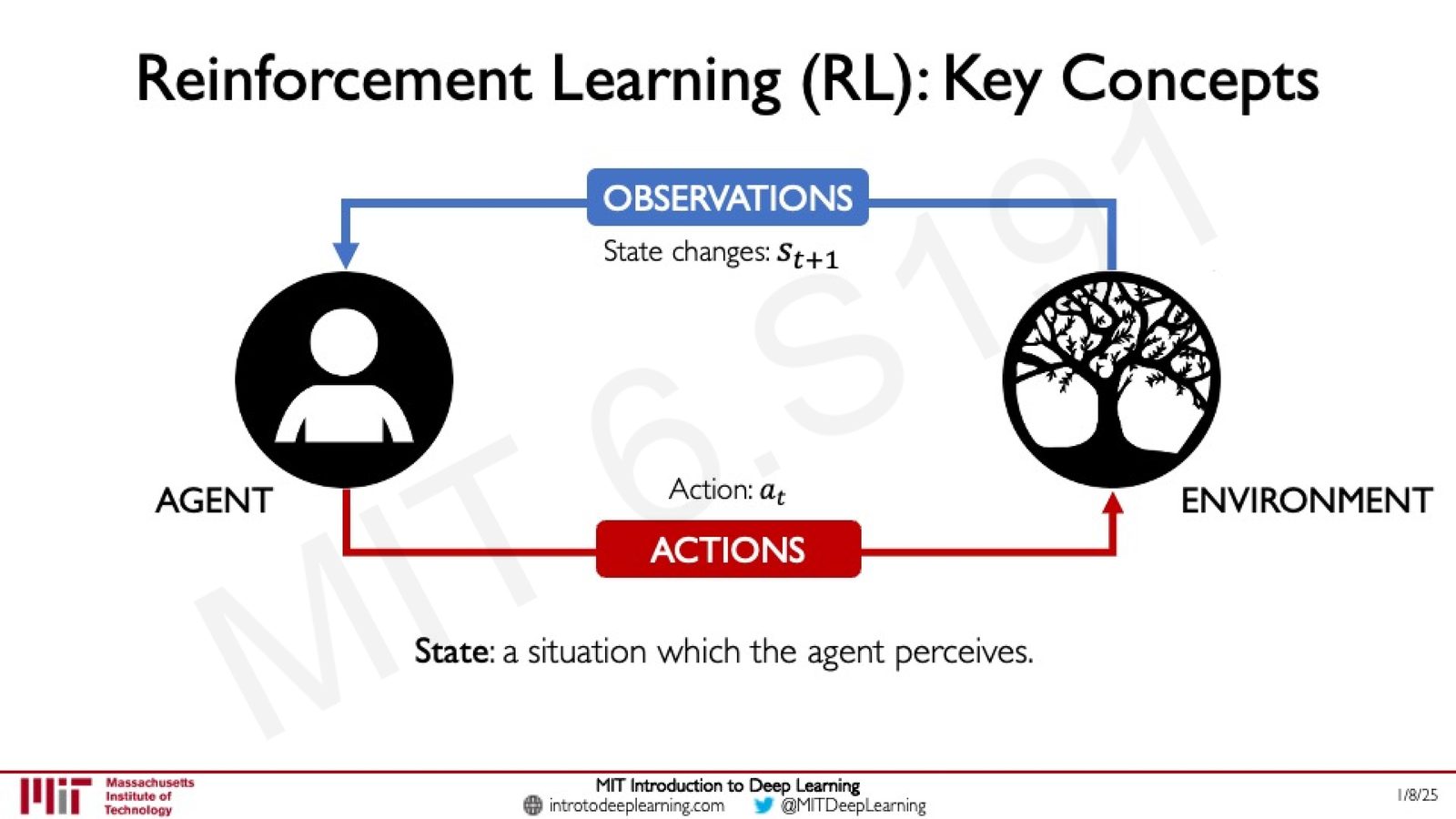
来源:Slides 第12页。
Reward 与 Return
Reward(奖励)\(r_t\) 是环境在每个时间步反馈给 Agent 的标量信号,表示当前状态的"好坏程度"。Agent 的目标是最大化总回报(Total Reward / Return):
- \(R_t\):从时刻 \(t\) 开始的总回报
- \(r_i\):时刻 \(i\) 获得的即时奖励
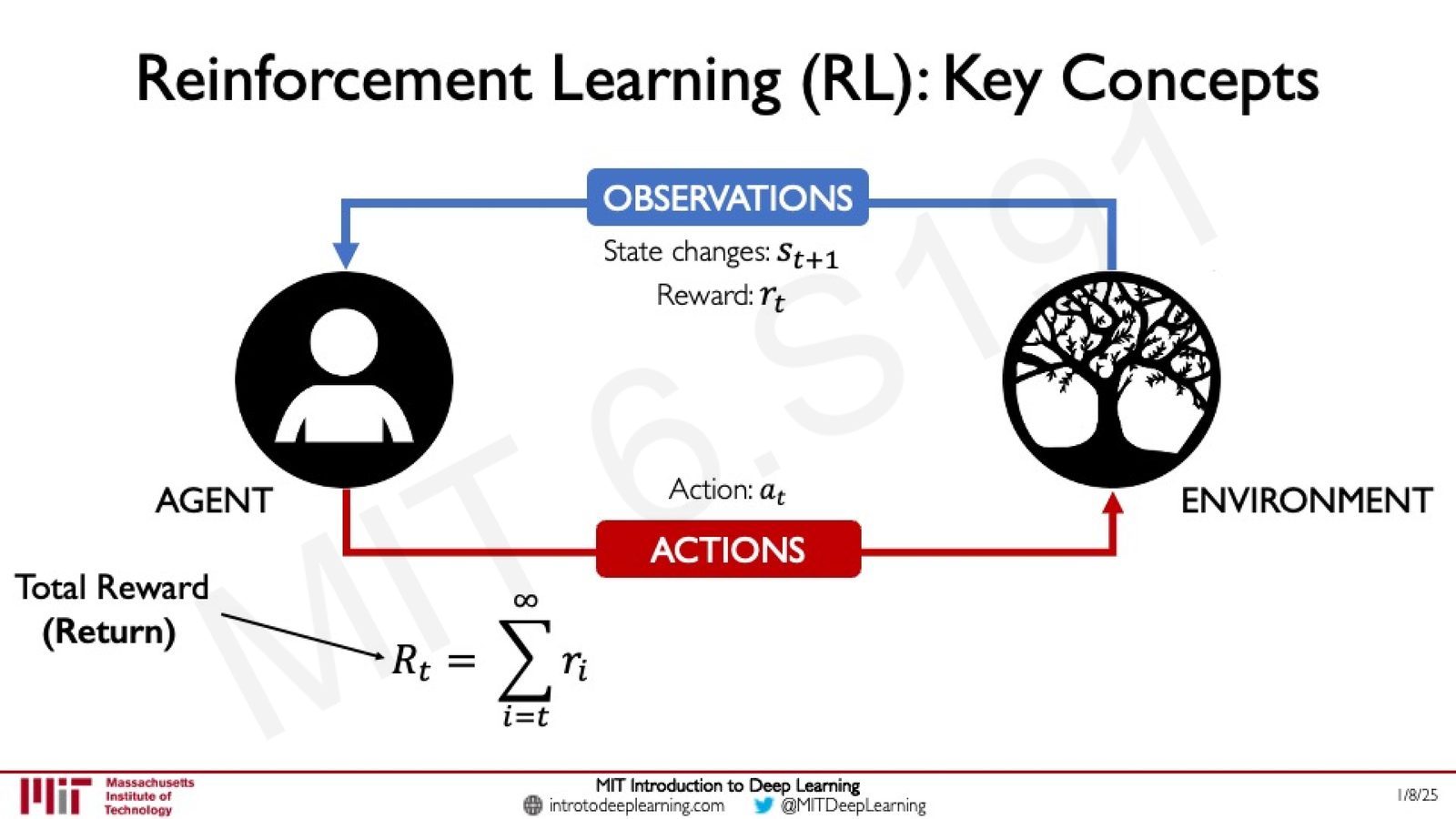
来源:Slides 第14页。
折扣回报(Discounted Return)
在实际应用中,并非所有奖励都同等重要------近期奖励通常比远期奖励更有价值(因为未来具有不确定性)。因此引入折扣因子 \(\gamma \in [0, 1)\) 来对未来奖励进行衰减:
- \(\gamma\):折扣因子(Discount Factor),控制对未来奖励的重视程度
- \(\gamma\) 越接近 0,Agent 越"短视",只关注即时奖励
- \(\gamma\) 越接近 1,Agent 越"远视",更关注长期回报
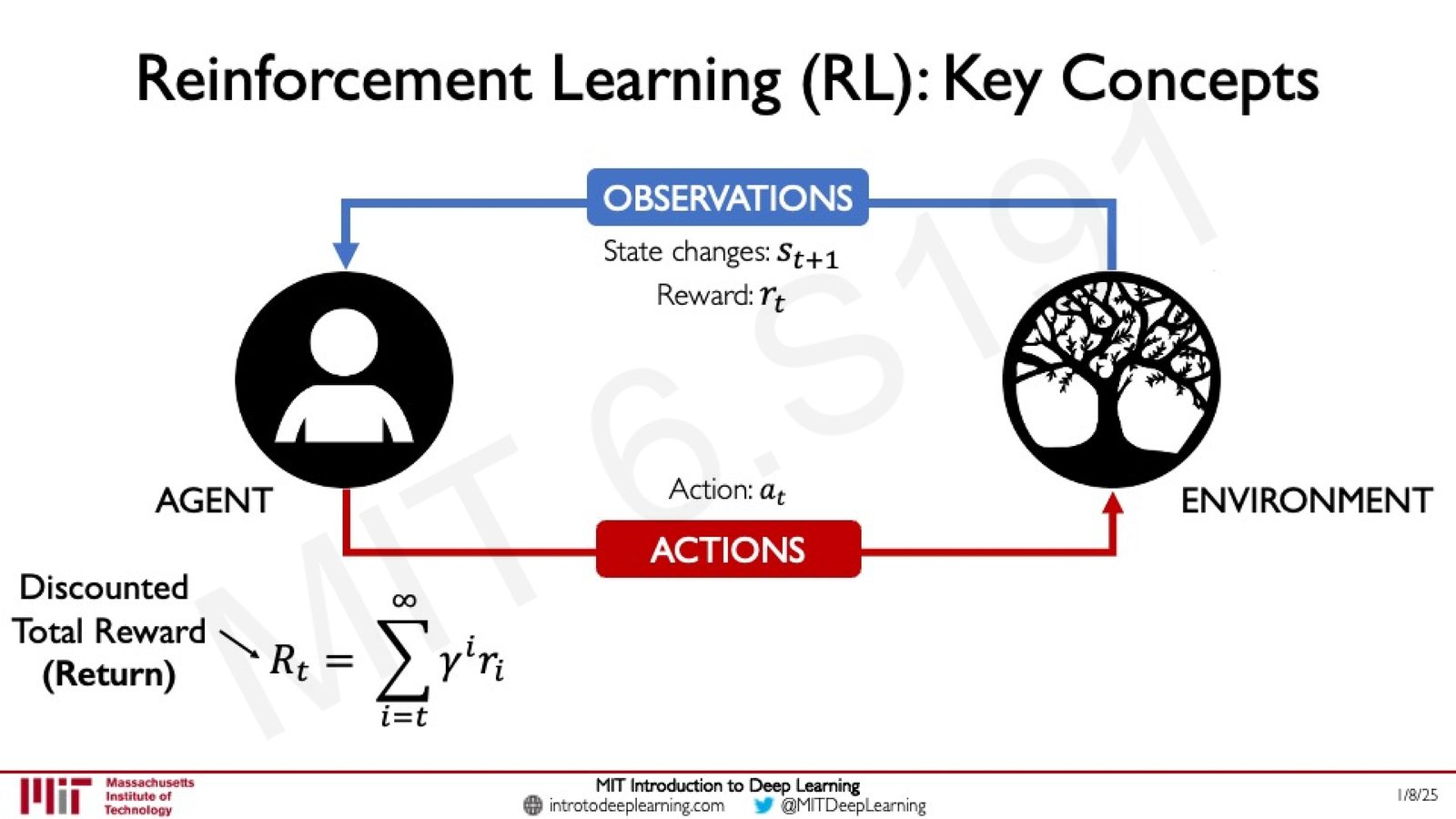
来源:Slides 第16页。
为什么需要折扣因子?
如果不使用折扣因子(\(\gamma = 1\)),在无限时间步的情况下总回报可能趋向无穷大,导致优化问题不可解。此外,折扣因子也反映了现实世界中"一鸟在手胜过十鸟在林"的直觉------未来的奖励存在不确定性,当前的确定奖励更有价值。
Q-function(状态-动作价值函数)
Q-function 是强化学习中最核心的概念之一。它衡量了在状态 \(s\) 下执行动作 \(a\) 后,Agent 所能获得的期望未来总回报:

来源:Slides 第18页。
Q-function 的核心含义
\(Q(s, a)\) 回答的问题是:"如果我在状态 \(s\) 下采取动作 \(a\),并且此后一直采取最优策略,我能获得多少总回报?"它不仅考虑当前动作的即时奖励,还考虑了该动作对所有未来状态和奖励的影响。
Policy(策略)
有了 Q-function,Agent 就可以制定策略(Policy),记为 \(\pi(s)\)。最优策略 \(\pi^*(s)\) 是在每个状态下选择使 Q-function 最大化的动作:

来源:Slides 第19页。
本章小结
强化学习的核心框架可以概括为一个闭环交互过程:Agent 观察当前状态 \(s_t\),根据策略 \(\pi\) 选择动作 \(a_t\),环境返回新状态 \(s_{t+1}\) 和奖励 \(r_t\),Agent 的目标是找到使折扣累积回报最大化的最优策略 \(\pi^*\)。Q-function 是连接状态、动作和回报的桥梁,而策略是 Agent 的行为准则。
Deep RL 的两大算法范式
在介绍了 RL 的基本概念之后,本节重点讨论如何用深度神经网络来实现强化学习算法。Deep RL 有两大主要范式:

来源:Slides 第20页。
Value Learning vs. Policy Learning
- Value Learning(价值学习):先学习 Q-function \(Q(s, a)\),再通过 \(a = \arg\max_a Q(s,a)\) 确定最优动作
- Policy Learning(策略学习):直接学习策略函数 \(\pi(s)\),从策略中采样动作 \(a \sim \pi(s)\)
两种方法各有优劣,适用于不同类型的问题。
本章小结
Deep RL 的核心思想是用深度神经网络作为函数逼近器,来学习 Q-function 或 Policy。Value Learning 通过间接方式(先学 Q 再决策),Policy Learning 通过直接方式(直接学策略)来解决决策问题。接下来两节将分别详细介绍这两种范式的代表性算法。
Value Learning:Deep Q-Networks (DQN)
DQN 的基本思想
Deep Q-Network (DQN) 是 Value Learning 的代表性算法。其核心思想是:用一个深度神经网络来近似 Q-function,然后利用学到的 Q-function 来推导最优策略。
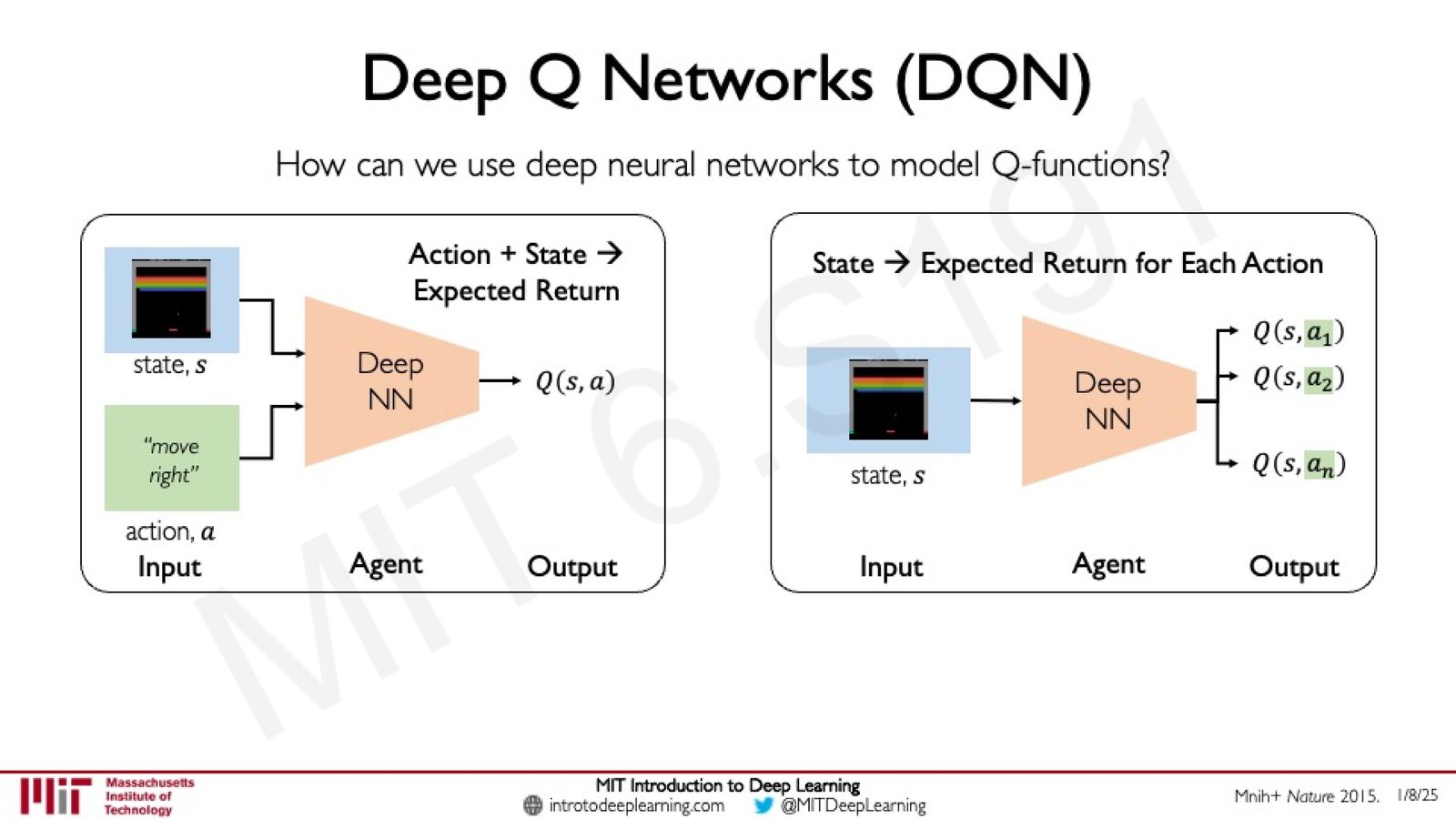
来源:Slides 第26页。
DQN 有两种等价的架构设计:
- 方案一:输入 \((s, a)\),输出单个 \(Q(s,a)\) 值。需要对每个可能的动作调用一次网络。
- 方案二(更高效):输入 \(s\),同时输出所有动作的 Q 值 \(Q(s, a_1), Q(s, a_2), \ldots, Q(s, a_n)\)。只需一次前向传播。
在实践中通常采用方案二,因为它更高效------一次网络调用即可获得所有动作的价值评估。
DQN 的决策过程
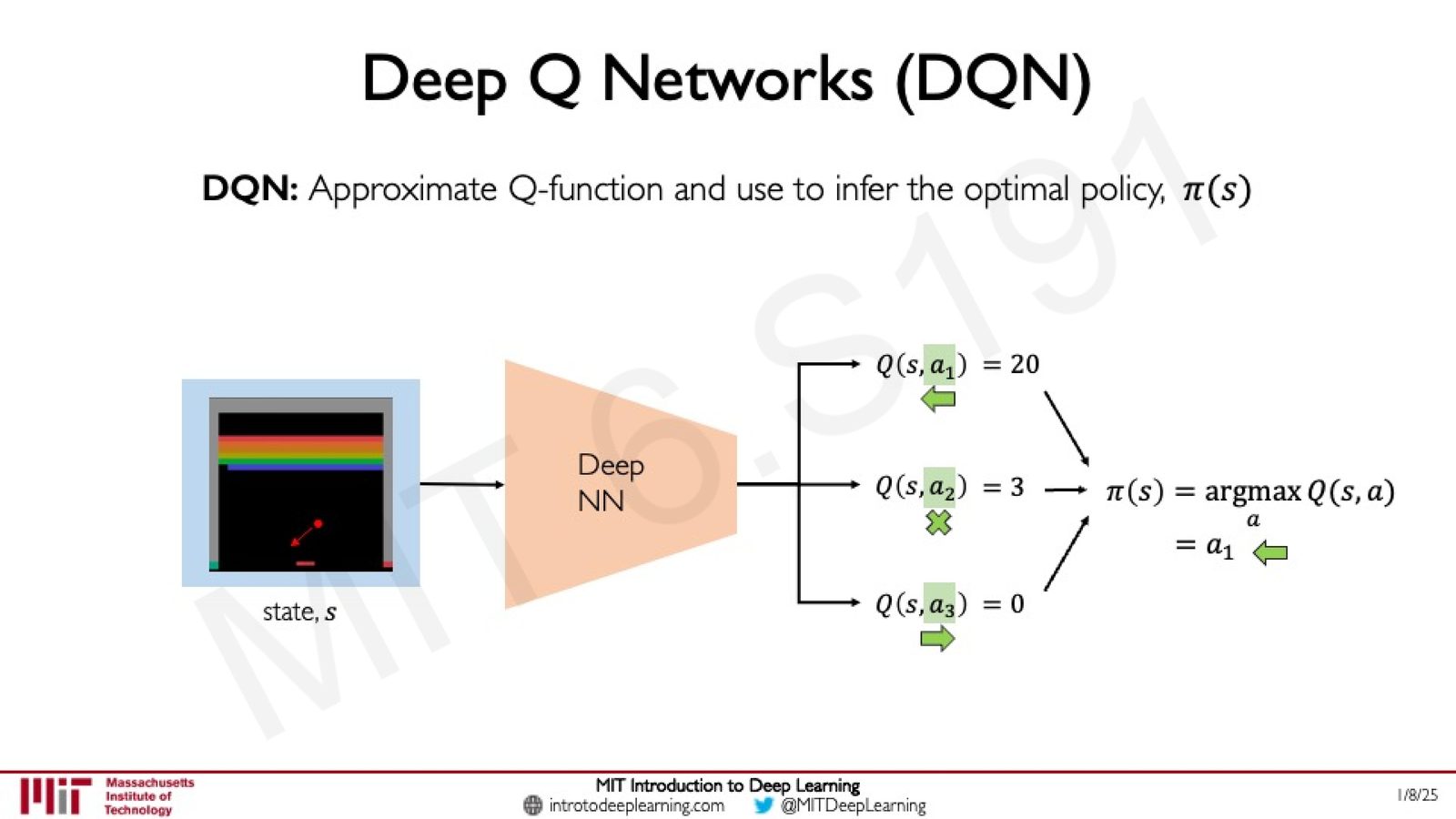
来源:Slides 第36页。
决策过程非常直接:
- 将当前状态 \(s\)(如 Atari 游戏画面)输入 DQN
- 网络输出每个可能动作的 Q 值
- 选择 Q 值最大的动作执行:\(\pi(s) = \arg\max_a Q(s, a)\)
Atari Breakout 示例:理解 Q 值
课上通过 Atari Breakout 游戏来深入理解 Q-function 的含义。考虑两种 state-action pair:
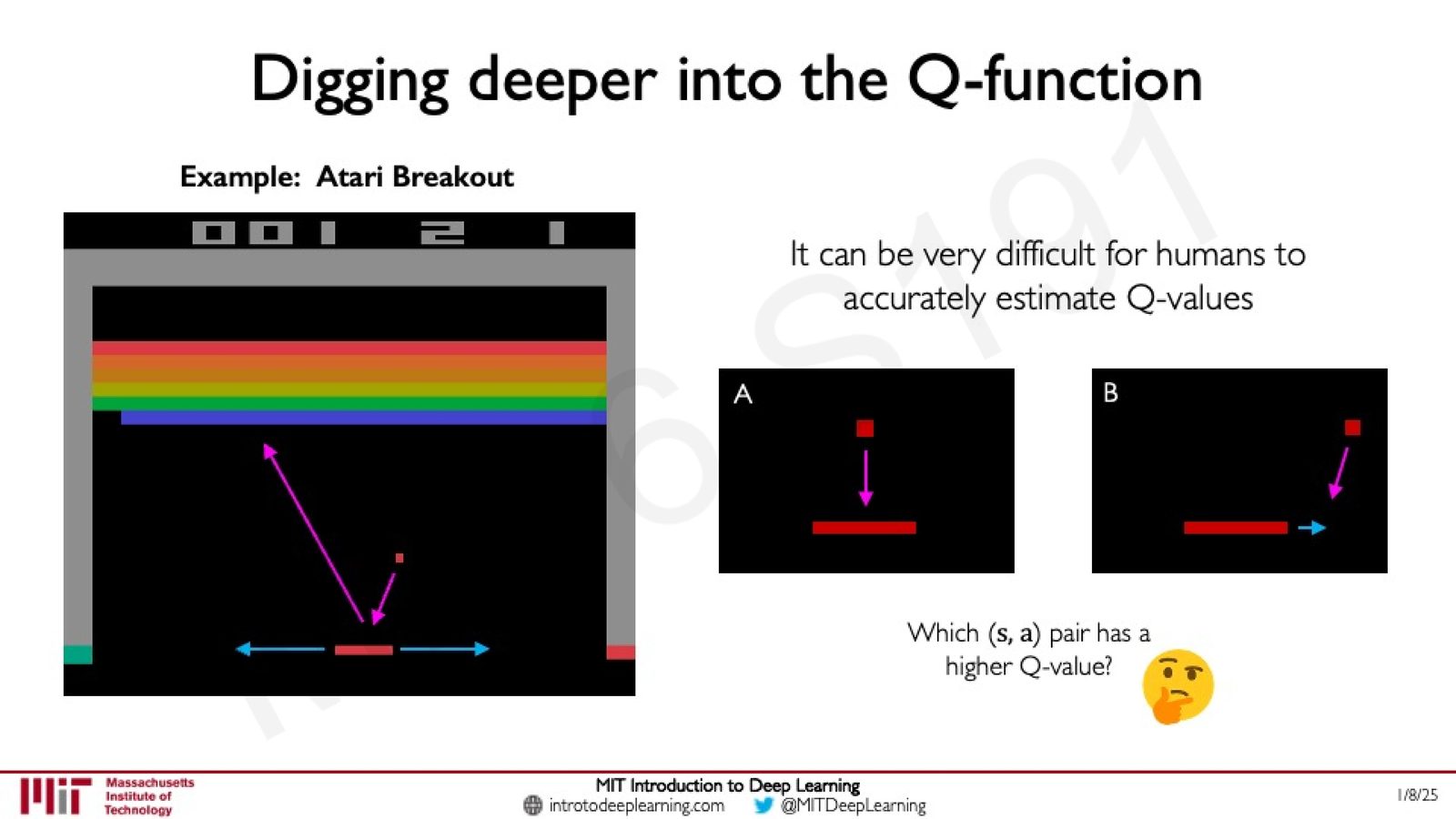
来源:Slides 第22页。
- 场景 A:球直直落向球拍正中央,球拍保持不动
- 场景 B:球飞向侧面,球拍向右移动追赶
Q 值的直觉理解
直觉上场景 B 的 Q 值可能更高(球弹向侧面打到更多砖块),但实际实验表明,场景 B 的策略(侧击)虽然单次得分可能更高,但球拍移动到侧边后回球速度变慢,长期来看反而不利。这说明 Q 值衡量的是长期累积回报而非单步奖励,人类直觉可能无法准确估计 Q 值------这正是需要深度网络来学习的原因。
DQN 的训练
DQN 的训练核心是定义合适的目标值和损失函数。
Target(目标值):利用 Bellman 方程构造训练目标:
- \(r\):当前步获得的即时奖励
- \(s'\):执行动作后到达的新状态
- \(\max_{a'} Q(s', a')\):在新状态下,所有可能动作中最大的 Q 值(假设后续采取最优策略)
Q-Loss(损失函数):
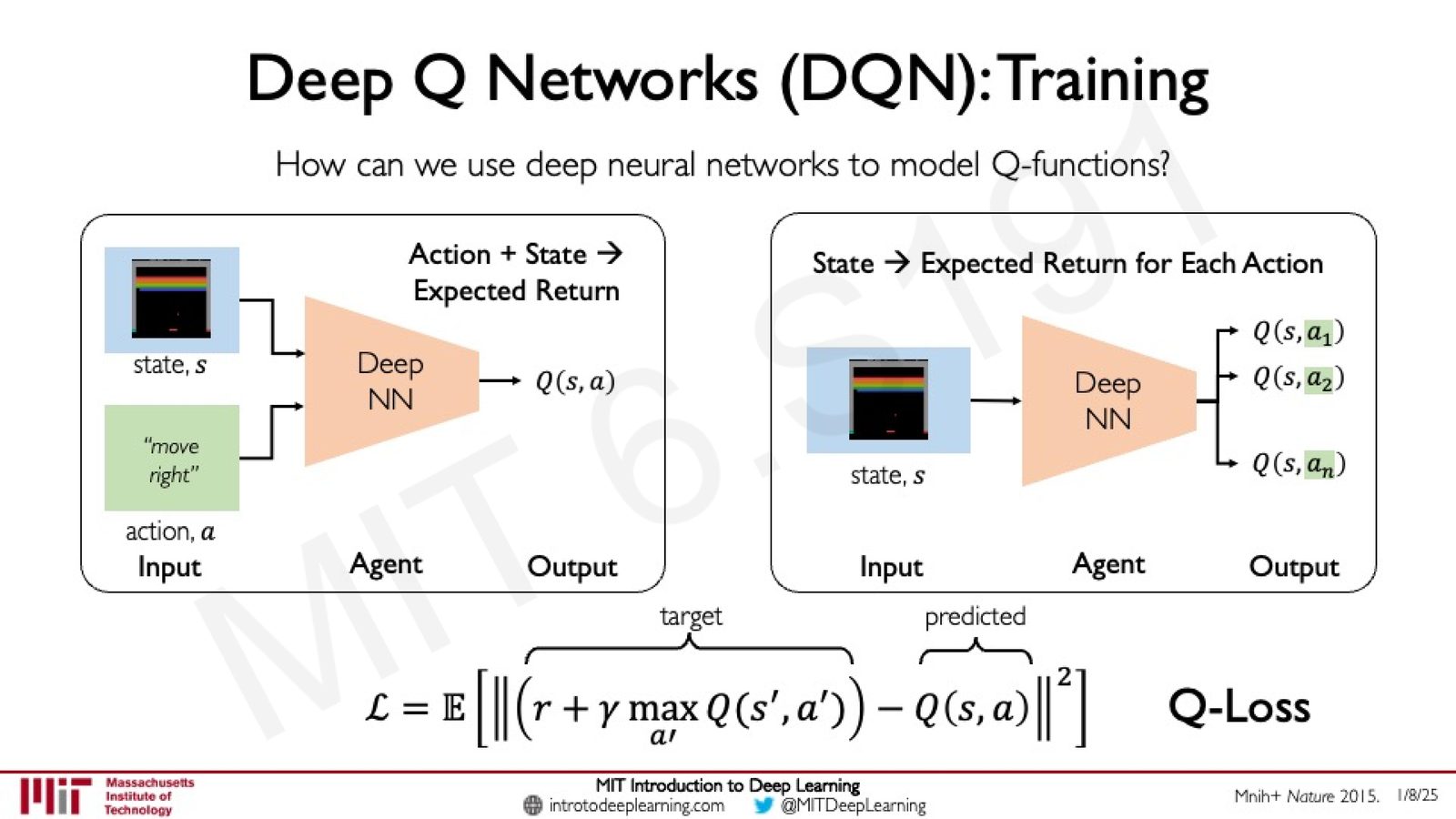
来源:Slides 第30页。
DQN 训练的核心直觉
DQN 的训练本质上是让网络预测的 Q 值逐渐逼近由 Bellman 方程给出的 target 值。target 由"即时奖励 + 折扣后的最优未来回报"构成,这就实现了"用未来回报来指导当前决策"的目标。训练过程通过最小化 predicted Q 与 target Q 之间的均方误差来进行反向传播和参数更新。
DQN 在 Atari 游戏上的成果
Google DeepMind 于 2015 年在 Nature 上发表了 DQN 的里程碑论文,使用相同的网络架构和超参数在 49 种 Atari 游戏上进行测试。
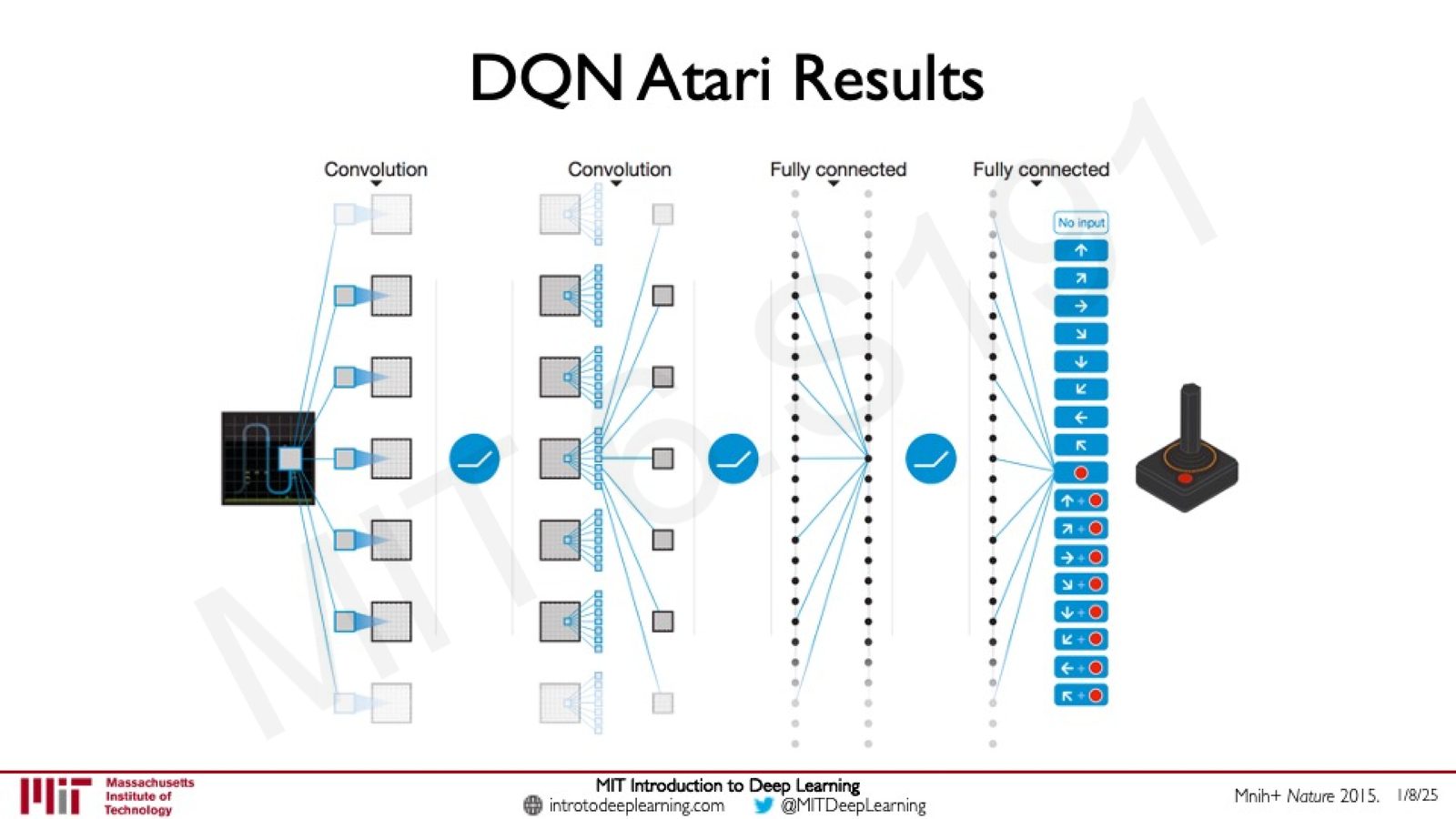
来源:Slides 第32页。Mnih+ Nature 2015.
网络架构包含:
- 多层 Convolution(卷积层):处理原始游戏画面像素
- 多层 Fully Connected(全连接层):将特征映射到各个动作的 Q 值
- 输出层:每个节点对应一个可能的动作(如游戏手柄的各个方向和按键组合)
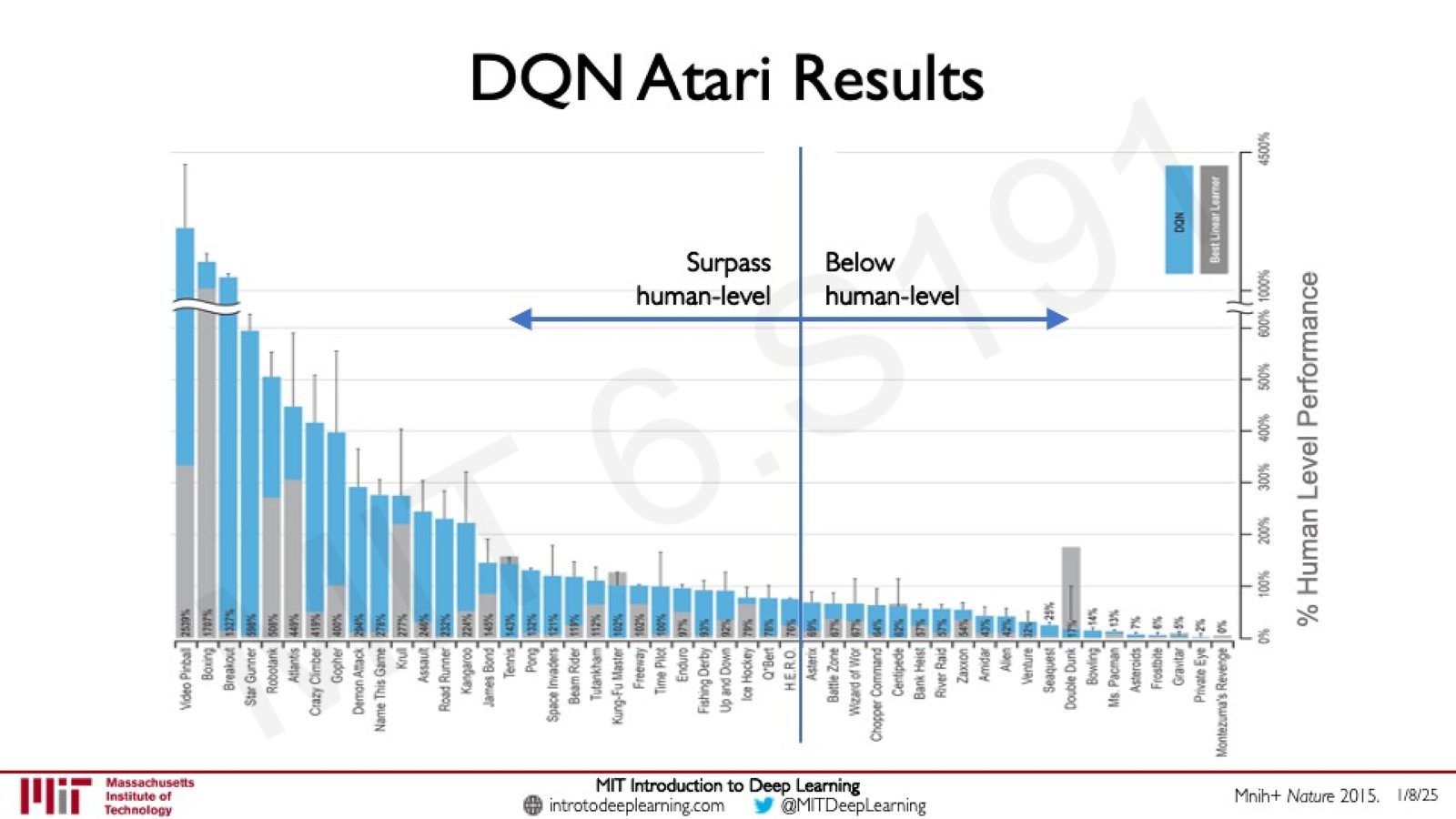
来源:Slides 第33页。Mnih+ Nature 2015.
DQN 的历史意义
DQN 的重要性在于它证明了一个端到端的深度强化学习系统可以直接从原始像素学会复杂的策略。在此之前,RL 通常需要手工设计特征(Feature Engineering)。DQN 开启了 Deep RL 的新时代,也是 DeepMind 被 Google 收购的关键技术之一。
Q-Learning 的局限性

来源:Slides 第34页。
尽管 DQN 取得了巨大成功,Q-Learning 方法存在两个重要局限:
复杂度问题(Complexity):
- 只能处理离散且有限的动作空间
- 对于连续动作空间(如控制方向盘的转角),无法枚举所有可能动作
灵活性问题(Flexibility):
- 策略是通过 \(\arg\max\) 确定性地从 Q-function 推导的
- 无法学习随机策略(Stochastic Policy),而某些场景下随机性是有益的
何时 Q-Learning 不适用?
当动作空间是连续的(如机器人关节角度、汽车油门刹车力度),Q-Learning 无法直接应用,因为它需要对所有可能动作计算 Q 值并取最大值。在连续空间中动作有无穷多个,这在计算上不可行。此时需要转向 Policy Gradient 方法。
本章小结
DQN 通过深度神经网络近似 Q-function,实现了从原始像素到决策的端到端学习。其训练基于 Bellman 方程构造 target,通过最小化 Q-Loss 来更新网络参数。DQN 在 Atari 游戏上取得了超越人类的成绩,但受限于离散动作空间和确定性策略,无法直接处理连续控制等更复杂的问题。
Policy Learning:Policy Gradient 方法
为了克服 Q-Learning 的局限,本节介绍另一类 Deep RL 算法------Policy Gradient(策略梯度),它直接学习策略函数 \(\pi(s)\),无需学习中间的 Q-function。
Policy Gradient 的核心思想

来源:Slides 第38页。
与 DQN 不同,Policy Gradient 方法不再估计每个动作的 Q 值,而是直接输出一个动作上的概率分布。网络的输入是状态 \(s\),输出是 \(P(a|s)\)------在该状态下采取每个动作的概率。
对于离散动作空间,输出是一个 softmax 概率分布(类似分类任务):
处理连续动作空间
Policy Gradient 最大的优势在于能够自然地处理连续动作空间。
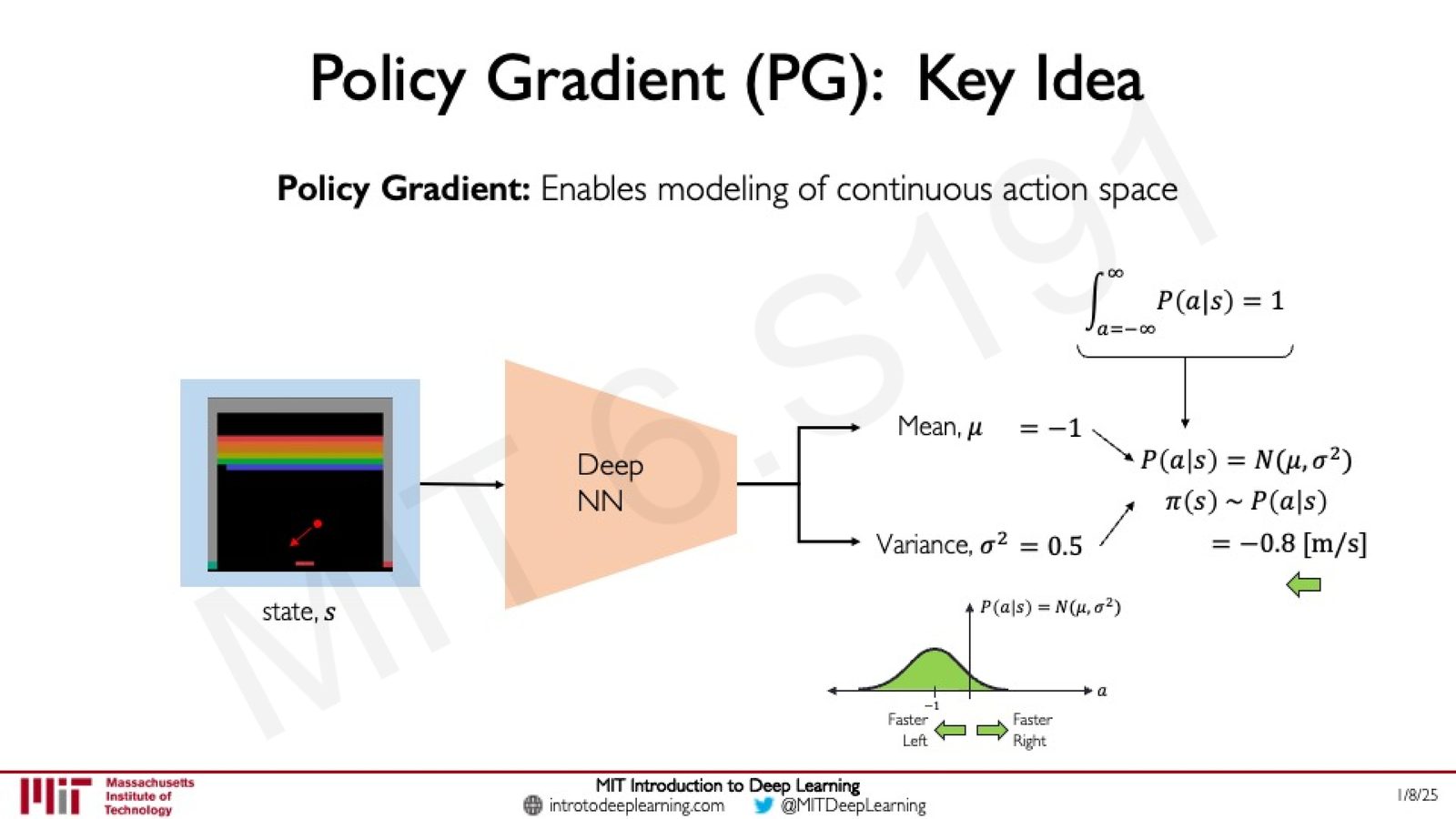
来源:Slides 第40页。
对于连续动作空间,网络不再输出各动作的概率,而是输出一个概率分布的参数。例如,假设动作服从高斯分布:
网络输出均值 \(\mu\) 和方差 \(\sigma^2\),然后从该分布中采样得到具体动作:
Policy Gradient 的关键优势
- 处理连续动作空间:通过输出概率分布的参数(如高斯分布的 \(\mu\) 和 \(\sigma^2\)),可以自然地处理连续控制问题
- 学习随机策略:输出的是概率分布而非确定性动作,天然支持 Stochastic Policy
- 直接优化目标:直接优化策略以最大化期望回报,无需学习中间的 Q-function
Policy Gradient 的训练算法
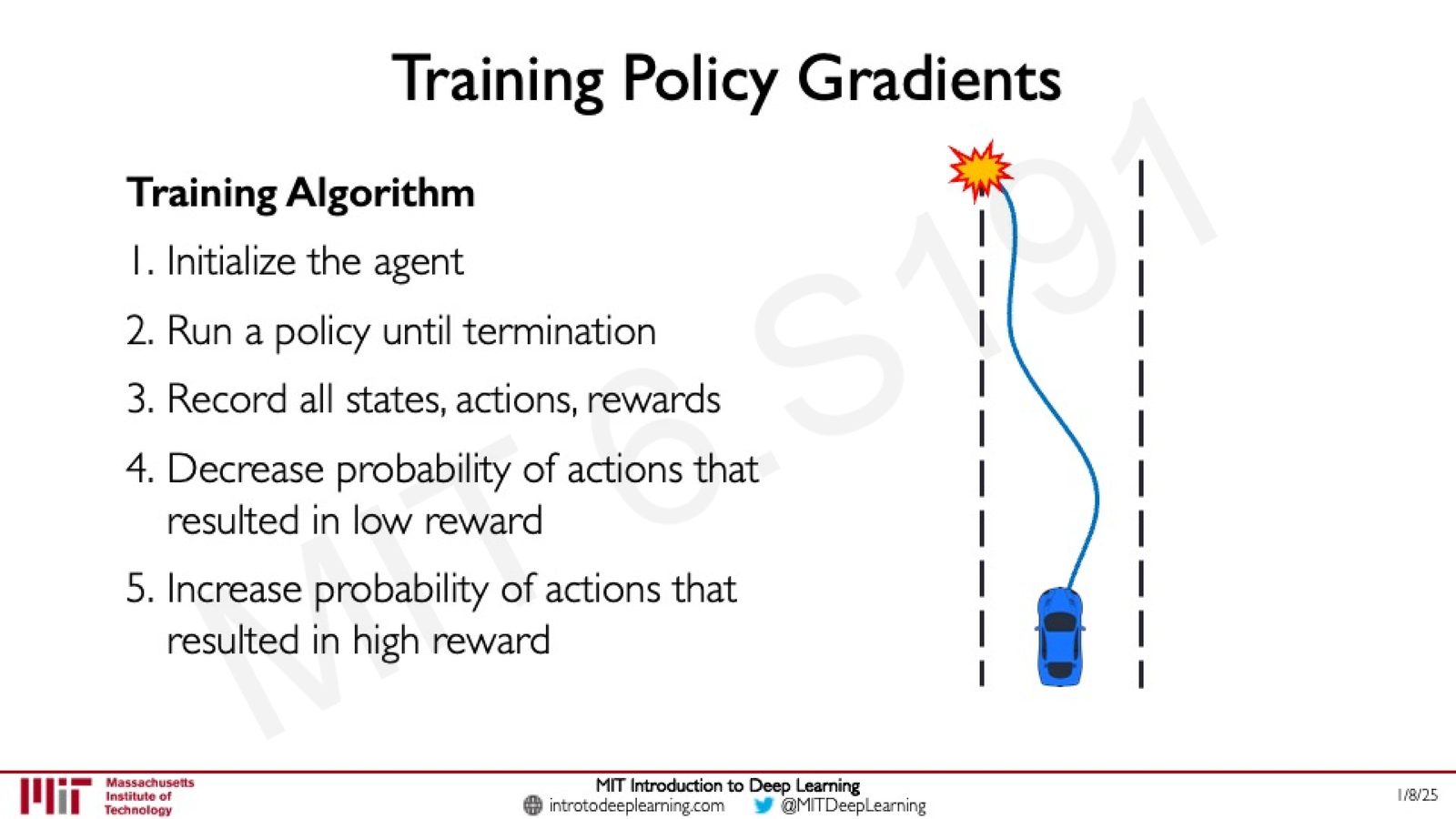
来源:Slides 第44页。
Policy Gradient 的训练遵循以下五步流程:
- 初始化 Agent:随机初始化策略网络的参数
- 运行策略直到终止:让 Agent 按照当前策略在环境中运行一个完整的 episode
- 记录所有 (state, action, reward):收集整个 episode 中的所有轨迹数据
- 降低低奖励动作的概率:对于导致低回报的动作,减少其被选中的概率
- 提高高奖励动作的概率:对于导致高回报的动作,增加其被选中的概率
Policy Gradient 的损失函数
训练的数学核心在于定义合适的损失函数:

来源:Slides 第46页。Williams Reinforcement Learning 1992.
- \(-\log P(a_t | s_t)\):选择动作 \(a_t\) 的负对数似然(log-likelihood)
- \(R_t\):从时刻 \(t\) 开始的折扣累积回报
梯度下降更新规则为:
Policy Gradient 损失函数的直觉理解
这个损失函数的设计非常精巧:
- 当 \(R_t > 0\)(高回报)时,loss 的负号使得梯度更新增大 \(P(a_t|s_t)\),即提高该动作的概率
- 当 \(R_t < 0\)(低回报/惩罚)时,梯度更新减小 \(P(a_t|s_t)\),即降低该动作的概率
- \(R_t\) 的绝对值大小决定了更新幅度------回报越大,对策略的调整越强
这就是 REINFORCE 算法(Williams, 1992)的核心思想。
Policy Gradient 的高方差问题
Policy Gradient 方法的一个已知问题是高方差(High Variance)。由于使用 Monte Carlo 采样来估计回报,不同 episode 之间的回报波动可能很大,导致梯度估计噪声较大、训练不稳定。常见的缓解方法包括:使用 baseline 减小方差(如 Actor-Critic 方法)、增加采样数量、使用 reward normalization 等。
本章小结
Policy Gradient 方法直接学习策略函数,通过"提高高回报动作的概率、降低低回报动作的概率"来优化策略。其最大优势是能够处理连续动作空间并学习随机策略。损失函数由动作的对数似然和折扣回报的乘积构成,通过梯度上升来优化期望回报。
强化学习在真实世界中的应用
本节介绍深度强化学习的三个重要应用:自动驾驶中的端到端 RL、围棋中的 AlphaGo 与 AlphaZero,以及近年来 LLM 对齐中的 RLHF。
自动驾驶:从仿真到真实部署

来源:Slides 第48页。Amini+ IEEE RA-L 2020.
Amini 教授介绍了他在 MIT 的研究工作------使用 Policy Gradient 方法训练自动驾驶系统。这项工作的关键创新包括:
VISTA 仿真器:一个基于真实驾驶数据的高保真仿真环境。与传统的计算机图形学仿真不同,VISTA 使用真实驾驶视频来合成新的视角,确保仿真画面具有照片级真实感。
端到端 RL 训练:
- Agent 的状态是驾驶摄像头的画面
- 动作是连续的方向盘转角
- 奖励设计极为稀疏:只在车辆驶出车道或发生碰撞时给予惩罚
- 策略网络输出高斯分布的参数,从中采样得到具体的转向角度

来源:Slides 第49页。Amini+ IEEE RA-L 2020.
从仿真到现实的迁移(Sim-to-Real Transfer)
这项工作的突破性在于:模型完全在仿真环境中训练,从未接触真实道路数据,但可以直接部署到真实汽车上并安全行驶。这是全球首辆完全通过仿真 RL 训练并在现实世界中部署的全尺寸自动驾驶汽车。关键在于 VISTA 仿真器的高保真度弥合了仿真与现实之间的差距(Domain Gap)。

来源:Slides 第47页。
真实环境中训练 RL 的风险
Policy Gradient 训练算法的第2步"运行策略直到终止"在真实环境中可能非常危险。对于自动驾驶来说,"终止"可能意味着碰撞或事故。因此仿真环境是 RL 在安全关键领域落地的前提------Agent 可以在仿真中安全地犯错和学习,而不会造成真实的损害。
围棋:AlphaGo 与 AlphaZero
围棋(Go)是 Deep RL 最引人注目的应用之一。围棋的复杂度远超国际象棋------19x19 棋盘上合法位置数约为 \(2.08 \times 10^{170}\),比宇宙中的原子数量还多。
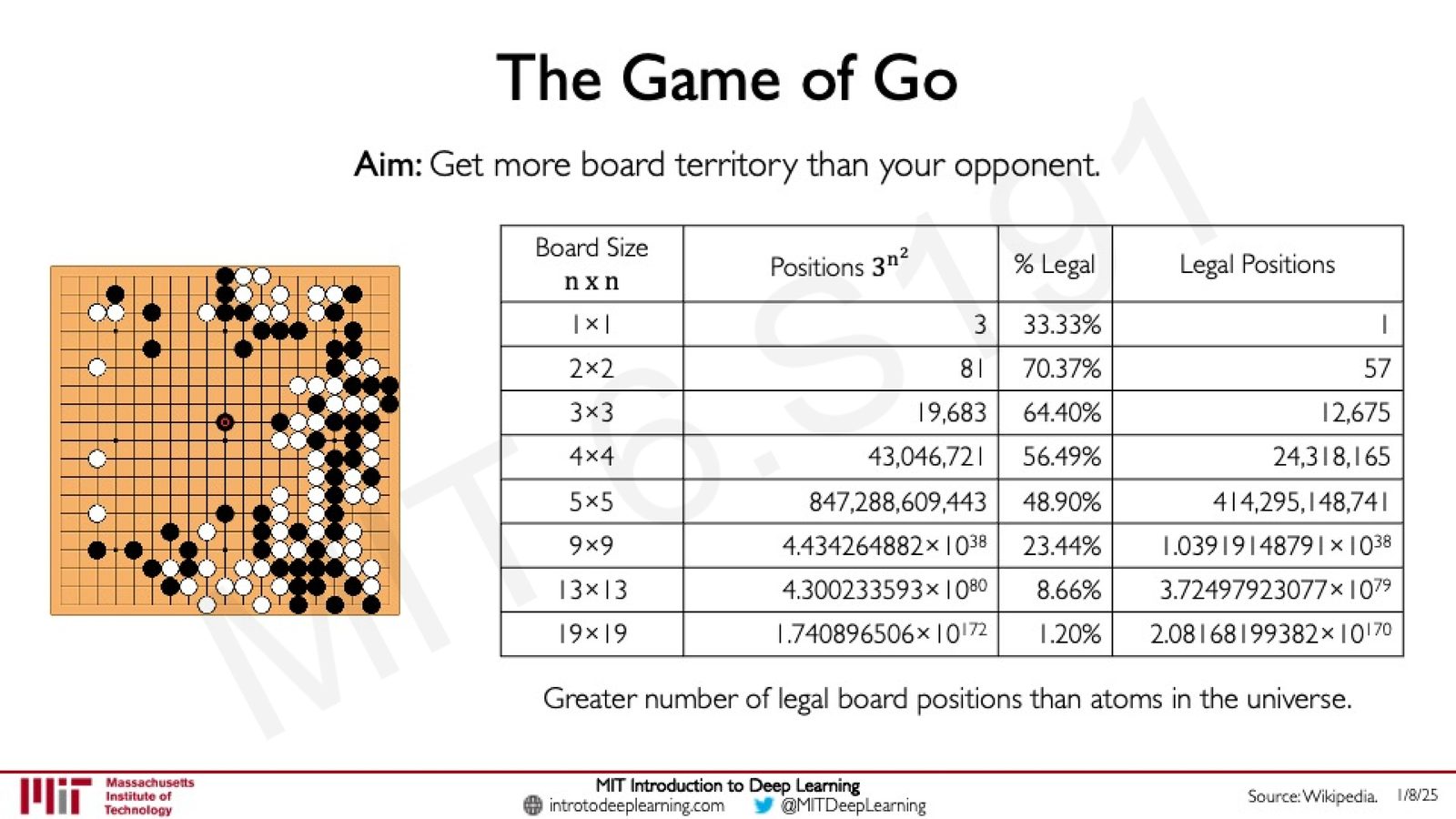
来源:Slides 第52页。Source: Wikipedia.
AlphaGo(Silver+ Science 2016)采用了多阶段训练流程:
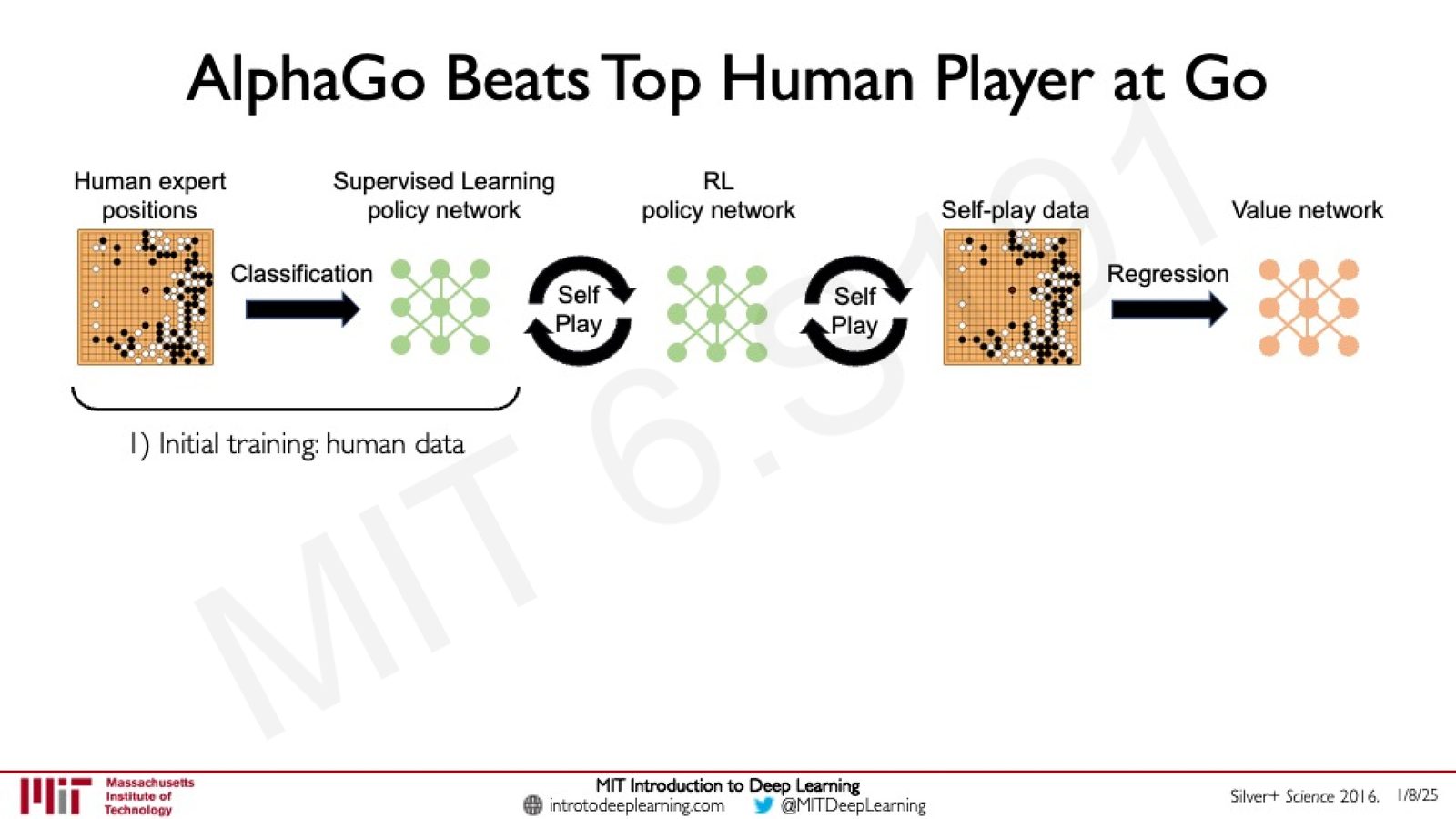
来源:Slides 第54页。Silver+ Science 2016.
- 监督学习预训练:使用人类专家棋谱,以分类任务训练 Policy Network(预测人类棋手的落子位置)
- 强化学习自我对弈:用 RL 的 Policy Gradient 方法让 Policy Network 通过自我对弈进一步提升,达到超越人类的水平
- Value Network 训练:用自我对弈产生的数据训练 Value Network,评估局面的胜率(回归任务)
AlphaGo 在 2016 年以 4:1 击败围棋世界冠军 Lee Sedol,成为 AI 历史上的里程碑事件。
AlphaZero(Silver+ Science 2018)更进一步,完全抛弃了人类数据,从零开始仅通过自我对弈的强化学习来训练:
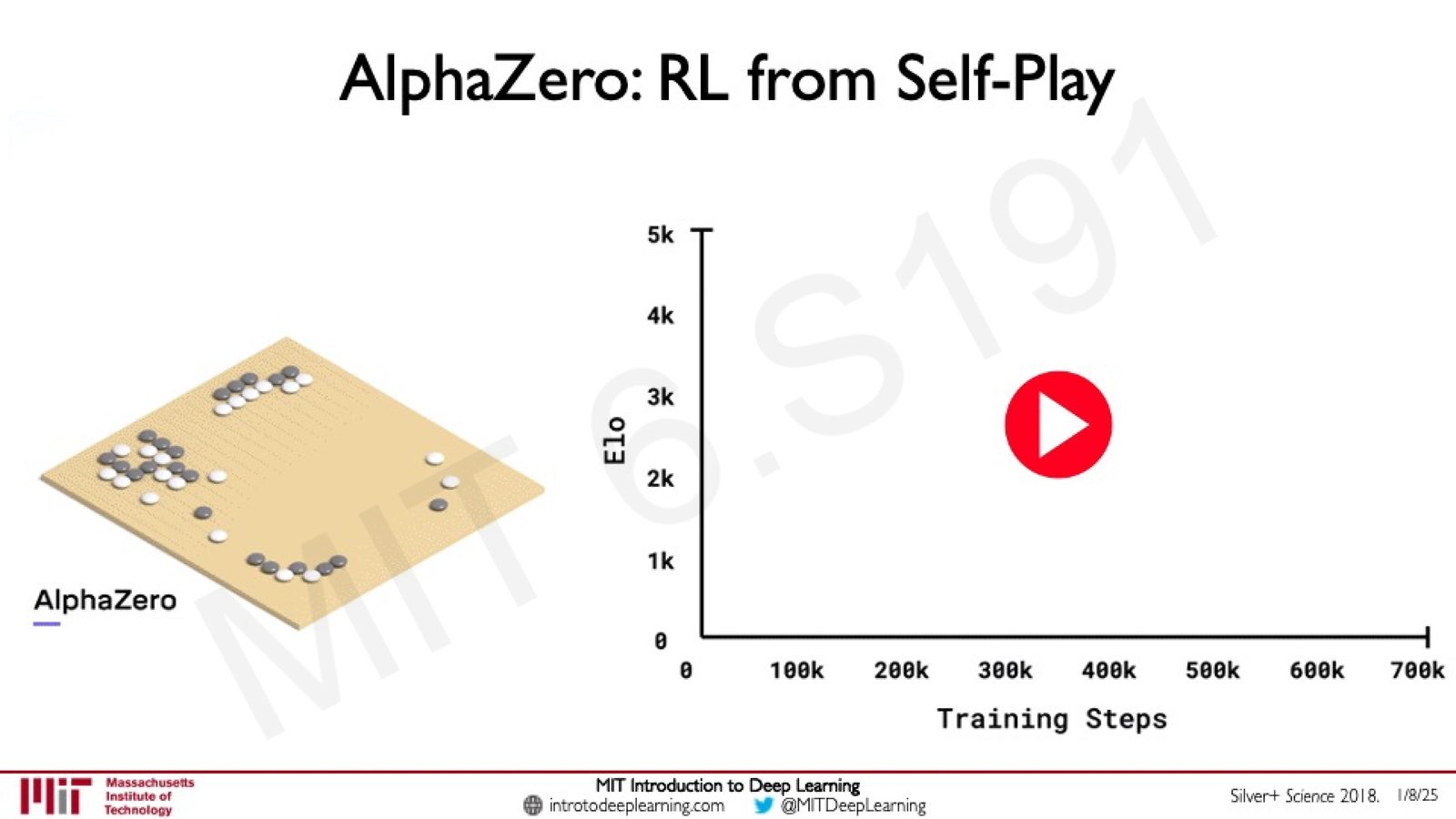
来源:Slides 第57页。Silver+ Science 2018.
从 AlphaGo 到 AlphaZero 的飞跃
- AlphaGo:需要人类专家棋谱作为起点(监督学习预训练 + RL 微调)
- AlphaZero:完全从零开始(tabula rasa),不使用任何人类数据,仅通过自我对弈 + 强化学习达到超越所有前任版本的水平
- AlphaZero 证明了:在完美信息博弈中,纯 RL 的自我对弈可以发现人类从未想到的策略,突破人类认知的局限
本章小结
Deep RL 在自动驾驶和围棋等领域取得了突破性成果。自动驾驶中的端到端 RL 展示了 Policy Gradient 处理连续控制任务的能力,而仿真器是确保安全训练的关键。AlphaGo 和 AlphaZero 系列证明了 Deep RL + 自我对弈可以在极其复杂的决策问题上达到甚至超越人类水平。
RL 的挑战与前沿:奖励函数设计
课上在讨论 DQN 和 Policy Gradient 的实际应用时,特别强调了一个在 RL 中被广泛低估但极其关键的问题------奖励函数的设计(Reward Design / Reward Engineering)。
奖励的来源
在 Atari 游戏中,奖励由游戏规则天然定义(如打掉砖块得分、失去生命扣分),设计者无需操心。但在真实世界应用中,奖励的定义远非显而易见:
- 自动驾驶中,什么是"好的驾驶"?安全?高效?舒适?
- 机器人操控中,如何量化任务完成的质量?
- 语言模型中,什么是"好的回答"?
奖励设计不当的后果(Reward Hacking)
如果奖励函数设计不当,Agent 可能找到钻奖励函数漏洞的方式来获得高回报,但并未真正完成预期任务。例如:
- 清洁机器人发现"把垃圾藏起来"比"真正清扫"获得更高奖励
- 赛车 AI 发现"反复绕圈收集加速道具"比"完成比赛"得分更高
这被称为 Reward Hacking 或 Reward Misspecification,是 RL 应用中最常见的陷阱之一。
稀疏奖励与密集奖励
奖励信号的稀疏程度直接影响学习效率:
- 密集奖励(Dense Reward):每步都有明确的反馈(如 Atari 中每打掉一块砖都得分),学习较快
- 稀疏奖励(Sparse Reward):只有在最终成功/失败时才有反馈(如自动驾驶中只有碰撞时才有惩罚),学习困难但奖励设计更简单
RLHF:用人类反馈来定义奖励
对于语言模型等任务,"好的输出"很难用简单的数学公式定义。RLHF(Reinforcement Learning from Human Feedback)通过让人类对模型输出进行排序和评分,训练一个 Reward Model 来近似人类偏好,然后用该 Reward Model 指导策略优化。这是 ChatGPT 等现代 LLM 对齐(Alignment)的核心技术之一,本质上就是 Policy Gradient + 人类定义的奖励模型。
本章小结
奖励函数是 RL 系统的灵魂------它定义了 Agent 的优化目标。奖励设计过于简单可能导致 Reward Hacking,过于复杂则难以工程化。RLHF 为难以形式化的任务提供了一种利用人类判断来定义奖励的方法,是当前 AI alignment 的重要技术路线。
总结与延伸
课程总结
来源:Slides 第58页。
本讲系统介绍了 Deep Reinforcement Learning 的核心内容,主要分为三个部分:
一、RL 基础概念
- Agent 在 Environment 中通过 Action 进行交互
- State-Action pairs 构成学习的基本数据
- 目标是最大化折扣累积回报 \(R_t = \sum \gamma^i r_i\)
- Q-function \(Q(s,a)\) 衡量状态-动作对的期望未来回报
二、Value Learning / Q-Learning
- 用 DQN 近似 Q-function
- 策略通过 \(\arg\max_a Q(s,a)\) 确定性推导
- 适用于离散动作空间
- 在 Atari 游戏中取得了超越人类的表现
三、Policy Gradient
- 直接学习和优化策略函数 \(\pi(s)\)
- 适用于连续动作空间
- 通过 \(\text{loss} = -\log P(a_t|s_t) \cdot R_t\) 训练
- 在自动驾驶、围棋等复杂应用中取得突破
延伸阅读
- DQN 原始论文:Mnih et al., “Human-level control through deep reinforcement learning,” Nature, 2015
- REINFORCE 算法:Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,” Machine Learning, 1992
- AlphaGo:Silver et al., “Mastering the game of Go with deep neural networks and tree search,” Nature, 2016
- AlphaZero:Silver et al., “A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play,” Science, 2018
- VISTA 仿真器:Amini et al., “Learning Robust Control Policies for End-to-End Autonomous Driving From Data-Driven Simulation,” IEEE RA-L, 2020
- RLHF:Ouyang et al., “Training language models to follow instructions with human feedback,” NeurIPS, 2022
- PPO:Schulman et al., “Proximal Policy Optimization Algorithms,” 2017------当前最流行的 Policy Gradient 变体
- Actor-Critic 方法:结合 Value Learning 和 Policy Gradient 的优势,同时学习价值函数和策略函数
- 课程官网:https://introtodeeplearning.com
Deep RL 的未来方向
深度强化学习仍然是一个快速发展的领域。当前的研究热点包括:
- Sample Efficiency:如何用更少的交互数据达到同等性能
- Multi-Agent RL:多个 Agent 同时学习和协作/竞争的场景
- Offline RL:利用已有的历史数据进行离线训练,避免在线交互的成本和风险
- Foundation Models + RL:将大规模预训练模型的知识融入 RL,加速学习
- RLHF & AI Alignment:通过人类反馈训练更安全、更有用的 AI 系统