CS231N Lecture 13: Generative Models 1
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Justin Johnson 授课内容整理 |
| 来源 | Stanford University |
| 日期 | 2025年 |

自监督学习回顾
本节课的开头简要回顾了上一节课讨论的自监督学习(Self-Supervised Learning)内容。自监督学习的核心思想是:在没有人工标签的情况下,通过设计某种 pretext task,让模型从大量无标签数据中学习到有用的特征表示。

来源:Slides 第2页。
对比学习(Contrastive Learning)
对比学习是自监督学习中非常成功的一个范式。其核心思想是:
- 对每张输入图片施加两种随机增强(Random Augmentation),得到一对正样本
- 来自不同图片的增强视为负样本
- 训练网络拉近正样本对的特征距离,推远负样本对的特征距离
来源:Slides 第3页。
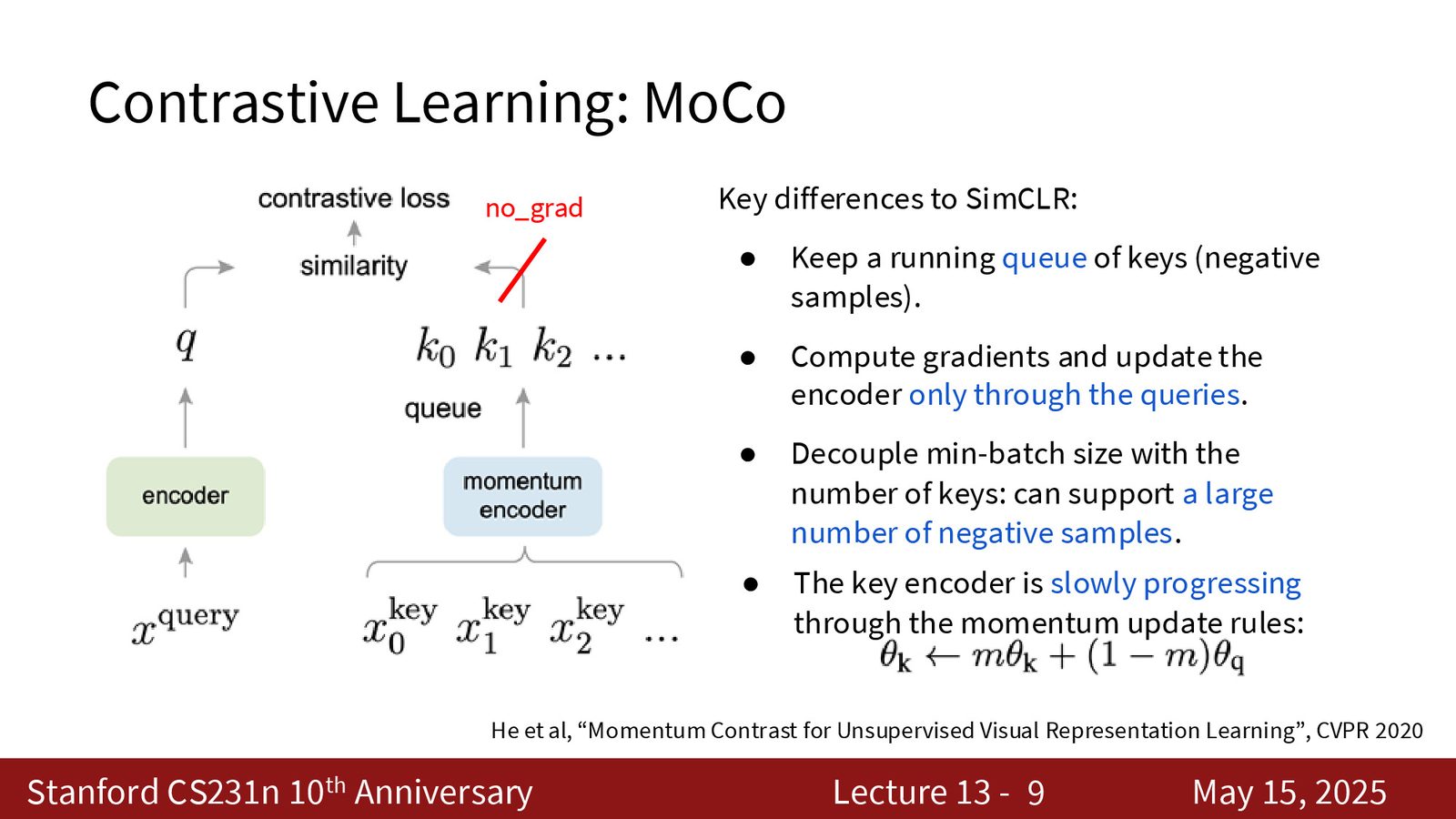
SimCLR 是对比学习的经典工作之一,但它需要非常大的 batch size 才能收敛。后续的 MoCo(Momentum Contrast)通过维护一个负样本队列和动量编码器解决了这个问题。

来源:Slides 第5页。
DINOv2:当前最强的自监督视觉特征
DINOv2 在 DINO 的基础上将训练数据扩展到 1.42 亿张图片,是目前实践中最常用的自监督视觉特征模型之一。它结合了对比学习和自蒸馏(self-distillation)思想,在多种下游视觉任务上表现优异。如果需要一个通用的视觉特征 backbone,DINOv2 是首选。
本章小结
自监督学习通过 pretext task 在无标签数据上学习特征表示,然后迁移到下游任务。对比学习(SimCLR、MoCo、DINO 系列)是目前最成功的自监督方法之一。DINOv2 通过大规模数据和精心设计的训练策略,成为了当前最强的自监督视觉特征模型。
生成模型基础概念
监督学习 vs 无监督学习
在切入生成模型之前,Justin Johnson 首先梳理了深度学习任务的两个正交维度:
来源:Slides 第9页。
维度一:监督 vs 无监督
- 监督学习:有 \((X, Y)\) 数据对,学习从 \(X\) 到 \(Y\) 的映射(如分类、检测、分割)
- 无监督学习:只有数据 \(X\),从数据本身学习结构(如聚类、PCA、密度估计)
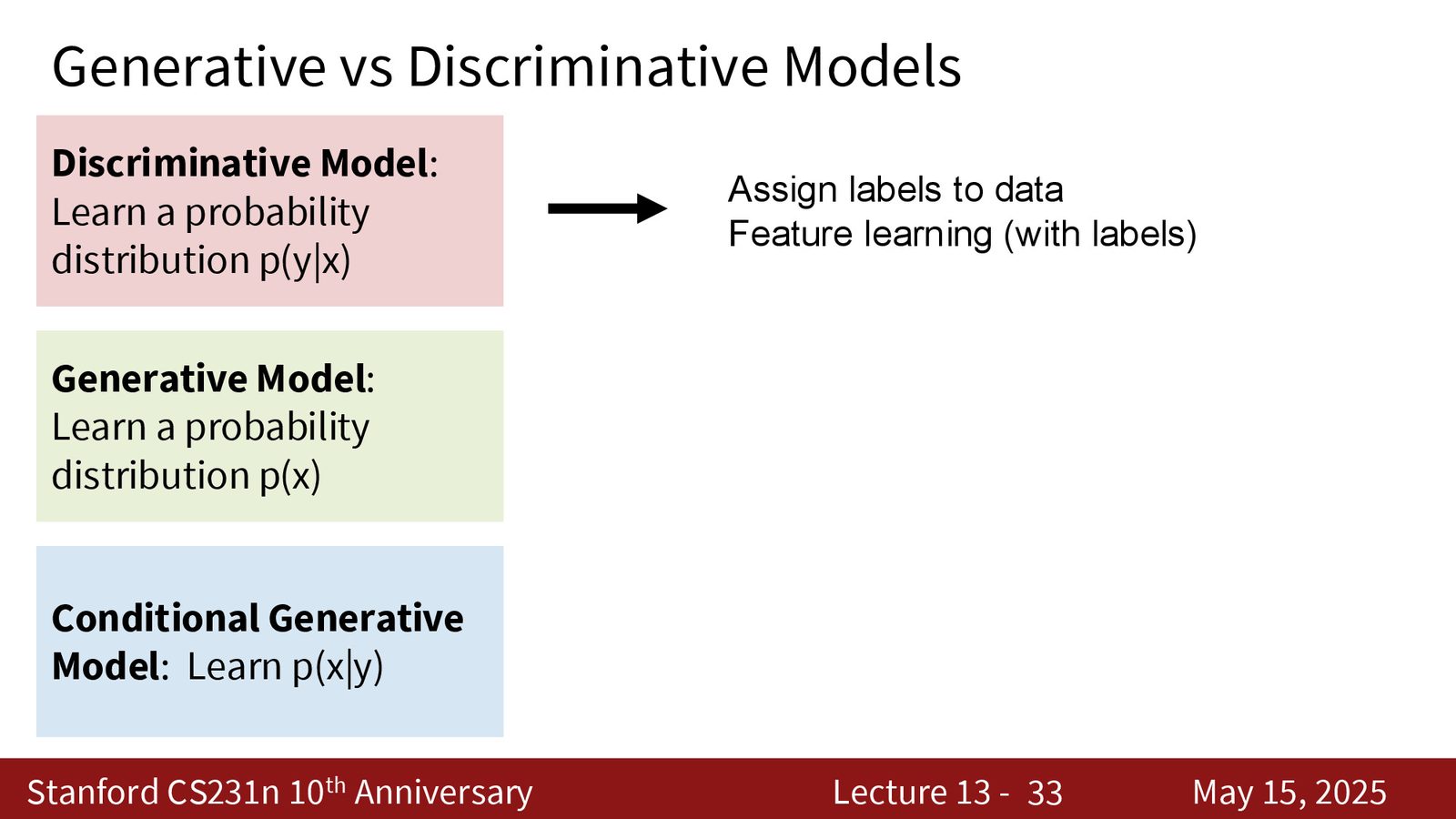
维度二:判别式 vs 生成式
- 判别式模型:学习 \(p(Y|X)\),即给定输入 \(X\) 预测标签 \(Y\) 的概率分布
- 生成式模型:学习 \(p(X)\),即数据本身的概率分布
- 条件生成模型:学习 \(p(X|Y)\),即给定条件 \(Y\) 生成数据 \(X\) 的概率分布
概率分布的归一化约束
理解生成模型的关键在于理解概率分布的归一化约束。

来源:Slides 第11页。
三种概率模型的本质区别
- 判别式模型 \(p(Y|X)\):对于每个输入 \(X\),不同标签 \(Y\) 之间竞争概率质量。图片之间没有竞争——无法拒绝不合理的输入。
- 生成模型 \(p(X)\):所有可能的图片相互竞争概率质量。模型必须思考什么图片更「合理」。可以通过低概率来拒绝不合理的输入。
- 条件生成模型 \(p(X|Y)\):对于每个条件 \(Y\),所有可能的图片相互竞争概率质量。这才是最有实用价值的模型。
论文中常省略条件变量 \(Y\)
大多数生成模型的论文和教程会写 \(p(X)\) 而非 \(p(X|Y)\),这是为了简化数学推导。但在实际应用中,几乎所有有实用价值的生成模型都是条件生成模型。阅读论文时应始终意识到:每个 \(p(X)\) 背后可能隐含着一个条件变量 \(Y\)。
贝叶斯定理连接三种模型
三种概率模型之间通过贝叶斯定理相互关联:
- \(p(Y|X)\):判别式模型
- \(p(X)\):生成模型
- \(p(Y)\):标签先验
- \(p(X|Y)\):条件生成模型
理论上,只要有其中任意两个模型,就能构造出第三个。虽然实践中通常直接训练条件生成模型,但这种关系在扩散模型的 Classifier-Free Guidance 中有重要应用。
为什么需要生成模型
生成模型的核心价值在于处理输出的不确定性和多样性:

来源:Slides 第15页。
- 语言建模:输入文本,输出可能有多种合理的回答
- 文本到图像:一段文字描述可以对应无数张合理的图片
- 图像到视频:一张静态图片可以衍生出多种可能的未来
何时使用生成模型
只要任务的输出存在歧义性(ambiguity)——即给定输入可能有多种合理的输出——就应该考虑使用生成模型。生成模型建模的是输出的分布,而不是单一的确定性映射。
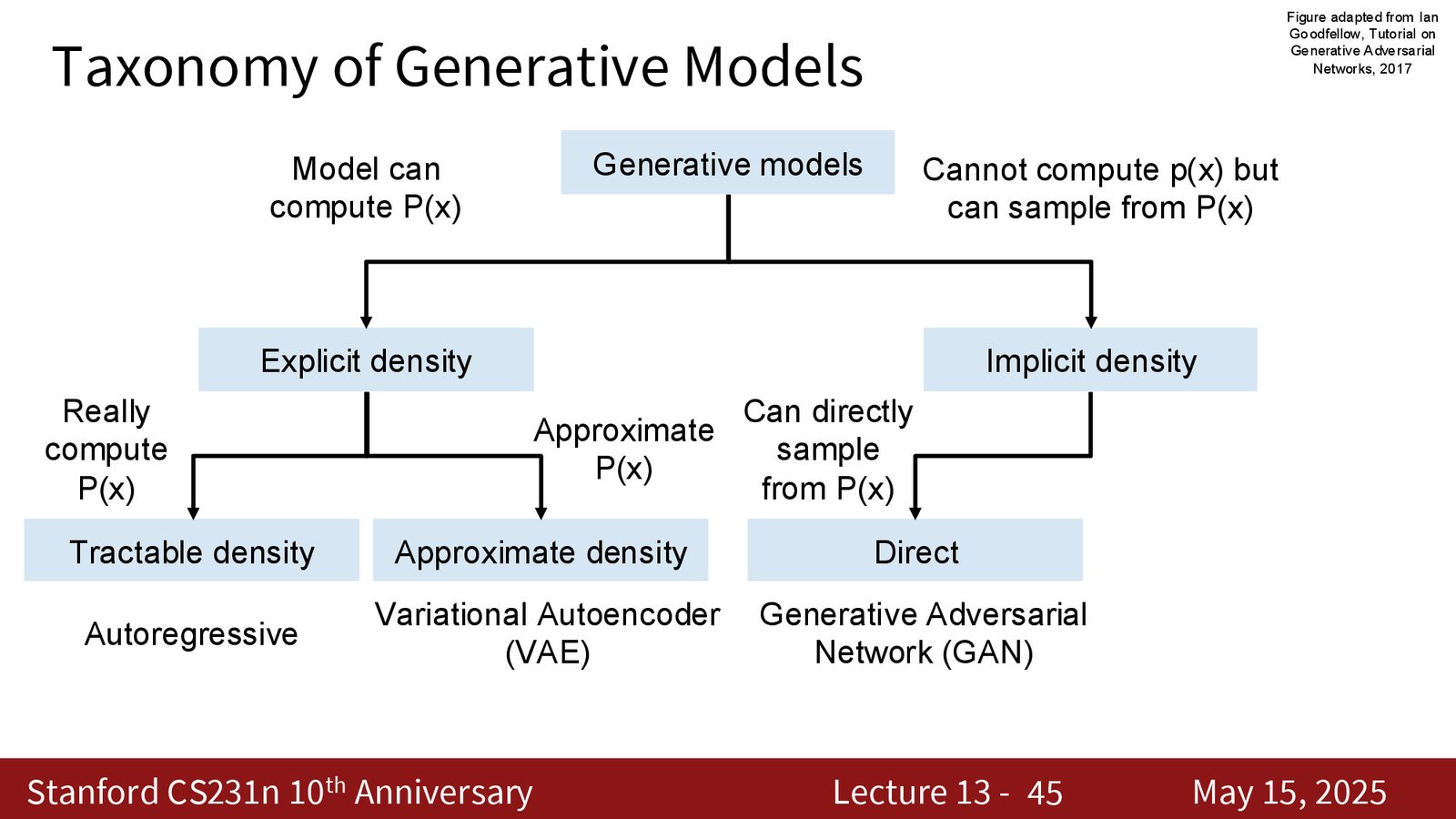
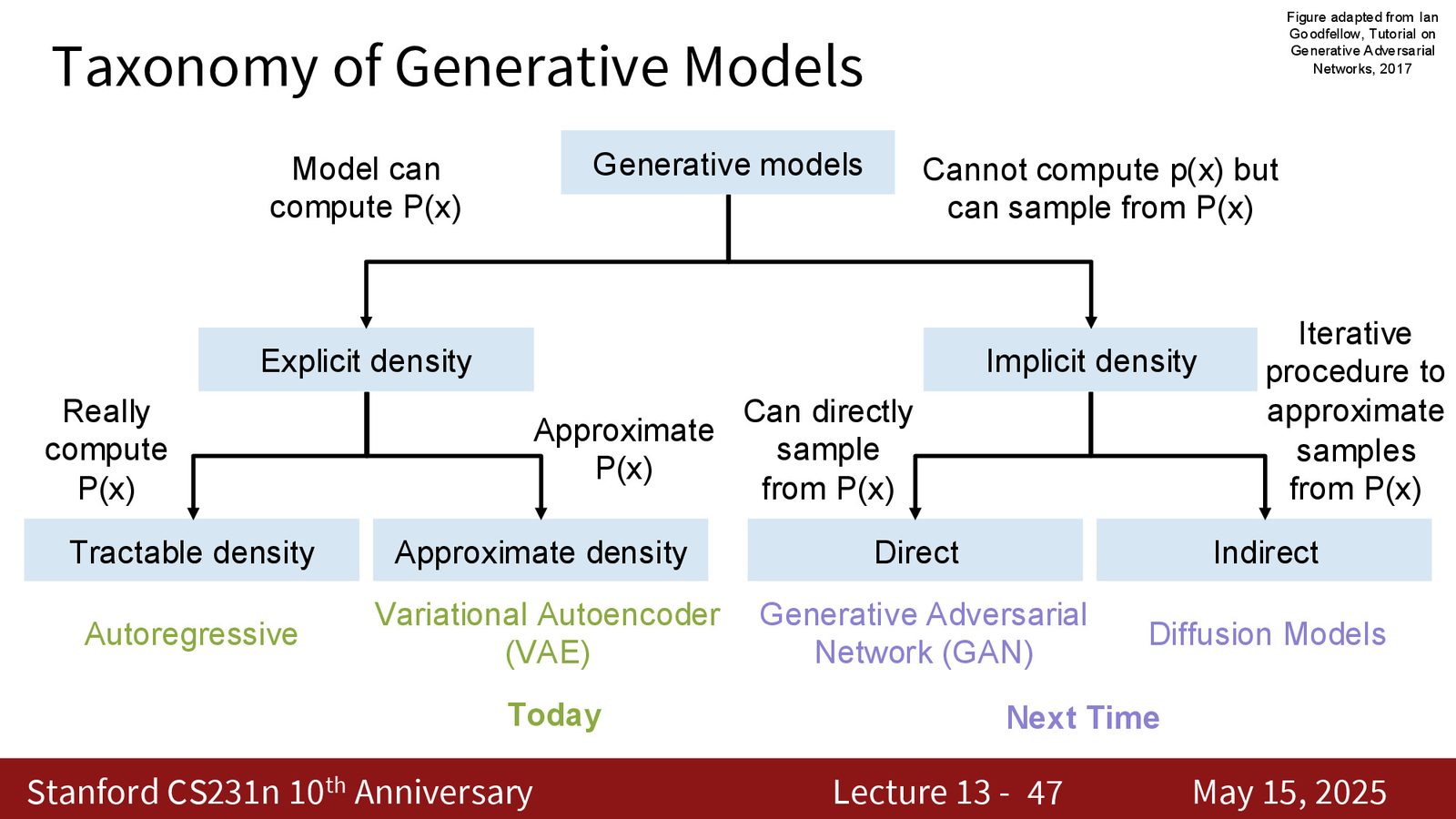
生成模型分类体系

来源:Slides 第16页。
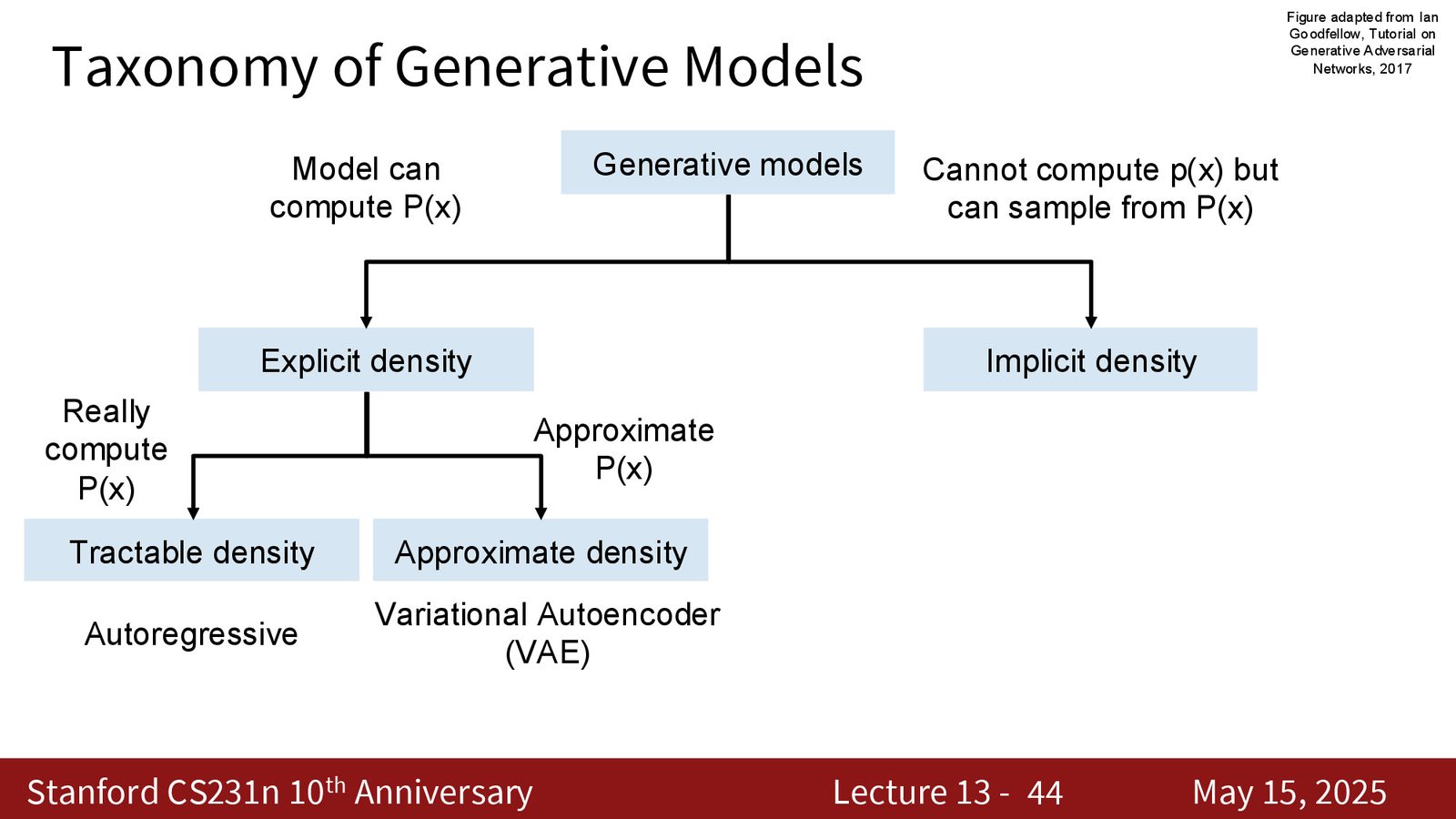
生成模型的四大类别
- 自回归模型(Autoregressive):显式密度,可精确计算 \(p(X)\)
- 变分自编码器(VAE):显式密度,但只能计算 \(p(X)\) 的近似下界
- 生成对抗网络(GAN):隐式密度,直接采样(单次前向传播)
- 扩散模型(Diffusion):隐式密度,迭代采样(需多步推理)
本节课覆盖前三类(自回归、VAE、GAN),下节课讲扩散模型。
本章小结
生成模型学习数据的概率分布 \(p(X)\),使得模型能够生成新的数据样本。判别式、生成式、条件生成式三种模型通过贝叶斯定理相互关联。在实践中,条件生成模型最有价值。生成模型的分类体系根据是否能计算密度值以及采样方式分为四大类。
最大似然估计
基本框架
最大似然估计(Maximum Likelihood Estimation, MLE)是训练显式密度生成模型的通用方法。

来源:Slides 第18页。
假设训练数据 \(\{x^{(1)}, x^{(2)}, \ldots, x^{(N)}\}\) 独立同分布(i.i.d.)地来自某个未知的真实分布 \(p_{\text{data}}\)。我们用神经网络参数化一个密度函数 \(p_W(X)\),目标是找到使训练数据最可能出现的参数 \(W\):
通过取对数(log trick),将乘积转化为求和:
似然(Likelihood)vs 概率(Probability)
概率:固定分布,改变数据点,观察各数据点的概率。\ 似然:固定数据点,改变分布(参数),观察哪个分布让这些数据点最可能出现。\ 最大似然估计本质上是在所有可能的分布中,选择让已观测数据最「合理」的那个分布。
本章小结
最大似然估计通过最大化训练数据在模型分布下的概率来学习模型参数。log trick 将乘积转化为求和,便于优化。MLE 是自回归模型和 VAE 的共同理论基础。
自回归模型(Autoregressive Models)
核心思想:链式分解
自回归模型利用概率论中的链式法则(Chain Rule)将联合分布分解为一系列条件分布的乘积:

来源:Slides 第20页。
自回归模型的两个核心要素
- 将数据分解为序列:定义元素之间的顺序(对语言是自然的,对图像需要人为定义)
- 用神经网络建模条件分布:每一步预测下一个元素的分布 \(p(x_t | x_1, \ldots, x_{t-1})\)
序列建模与采样
训练时,自回归模型通过 Teacher Forcing 的方式并行计算所有条件概率,然后通过 MLE 优化。采样时,则需要逐元素顺序生成:

来源:Slides 第22页。
- 从 \(p(x_1)\) 采样得到 \(x_1\)
- 将 \(x_1\) 输入模型,从 \(p(x_2|x_1)\) 采样得到 \(x_2\)
- 将 \(x_1, x_2\) 输入模型,从 \(p(x_3|x_1,x_2)\) 采样得到 \(x_3\)
- 重复直到序列完成
语言建模
自回归模型天然适合语言建模,因为语言本身就是一维的离散序列。

来源:Slides 第25页。
序列中的每个元素是一个 token(可以是字符、子词或单词),模型输出每个位置上所有可能 token 的概率分布(通常通过 softmax)。ChatGPT 等大语言模型本质上就是超大规模的自回归模型。

来源:Slides 第27页。
- \(s_v\):模型输出的 logit
- \(\tau\):温度参数
- \(\tau \to 0\):趋向 argmax(确定性,低多样性)
- \(\tau \to \infty\):趋向均匀分布(高多样性,低质量)
图像上的自回归模型
将图像展平为像素序列,每个子像素(R/G/B)是 0-255 的离散整数值。一张 \(1024 \times 1024\) 的图片会产生约 300 万个 token 的序列,计算代价极高。

来源:Slides 第30页。
直接在像素空间做自回归效率极低
一张 \(1024 \times 1024\) 的 RGB 图像有 \(\sim\)3M 子像素值。这意味着自回归序列的长度达到 300 万,对 Transformer 而言计算代价极其昂贵。解决方案是先将图像编码为更短的 latent token 序列,然后在 latent 空间上做自回归——这正是现代 token-based 图像生成方法的核心思路。
来源:Slides 第33页。
本章小结
自回归模型利用链式法则将联合分布分解为条件分布的乘积,可以精确计算 \(p(X)\) 并用 MLE 训练。它天然适合语言建模,但在图像上面临序列过长的问题。现代方法通过 latent tokenization 缓解这一问题。
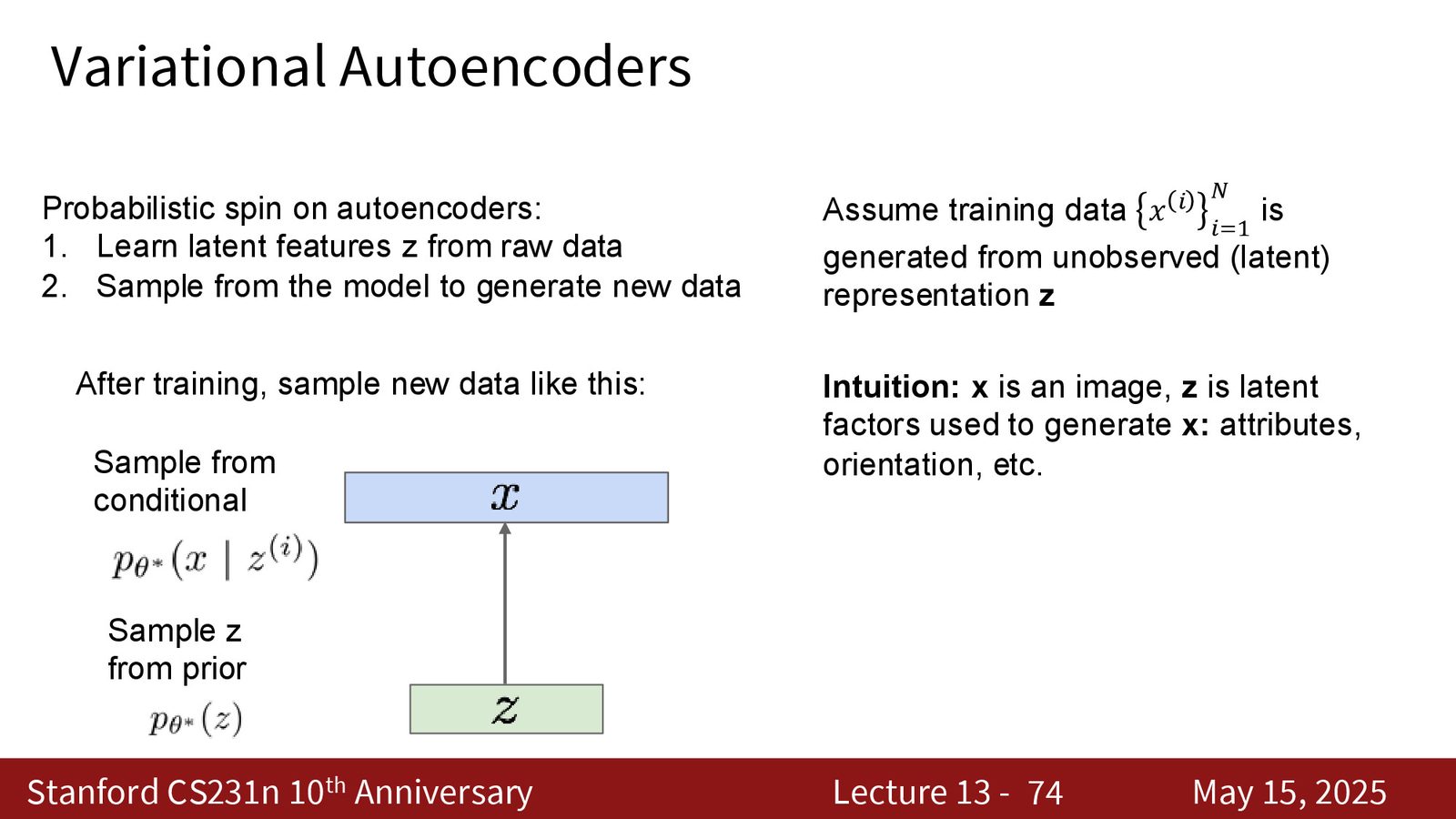
变分自编码器(VAE)
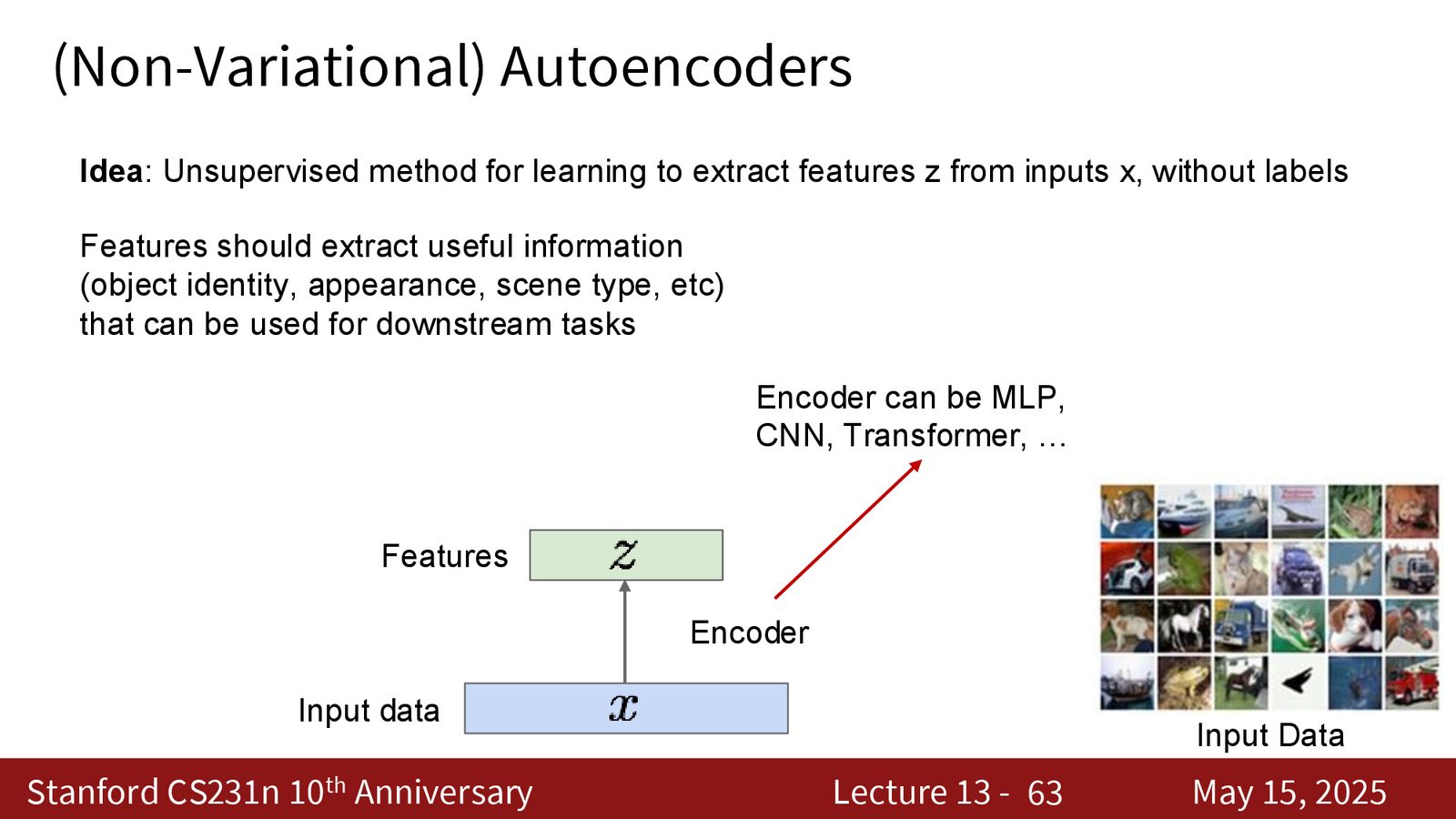
从自编码器到 VAE 的动机
传统自编码器(Autoencoder)通过 encoder-decoder 架构学习数据的压缩表示:encoder 将输入 \(X\) 映射到低维 latent code \(Z\),decoder 从 \(Z\) 重构 \(X\)。

来源:Slides 第36页。
传统自编码器的局限
传统自编码器可以学习到数据的压缩表示,但存在两个核心问题:
- 无法从 latent space 中采样生成新数据——因为 latent space 没有已知的概率结构
- latent space 可能不连续、不平滑——相邻的 \(Z\) 值不一定对应相似的 \(X\)
VAE 正是为了解决这两个问题而提出的。
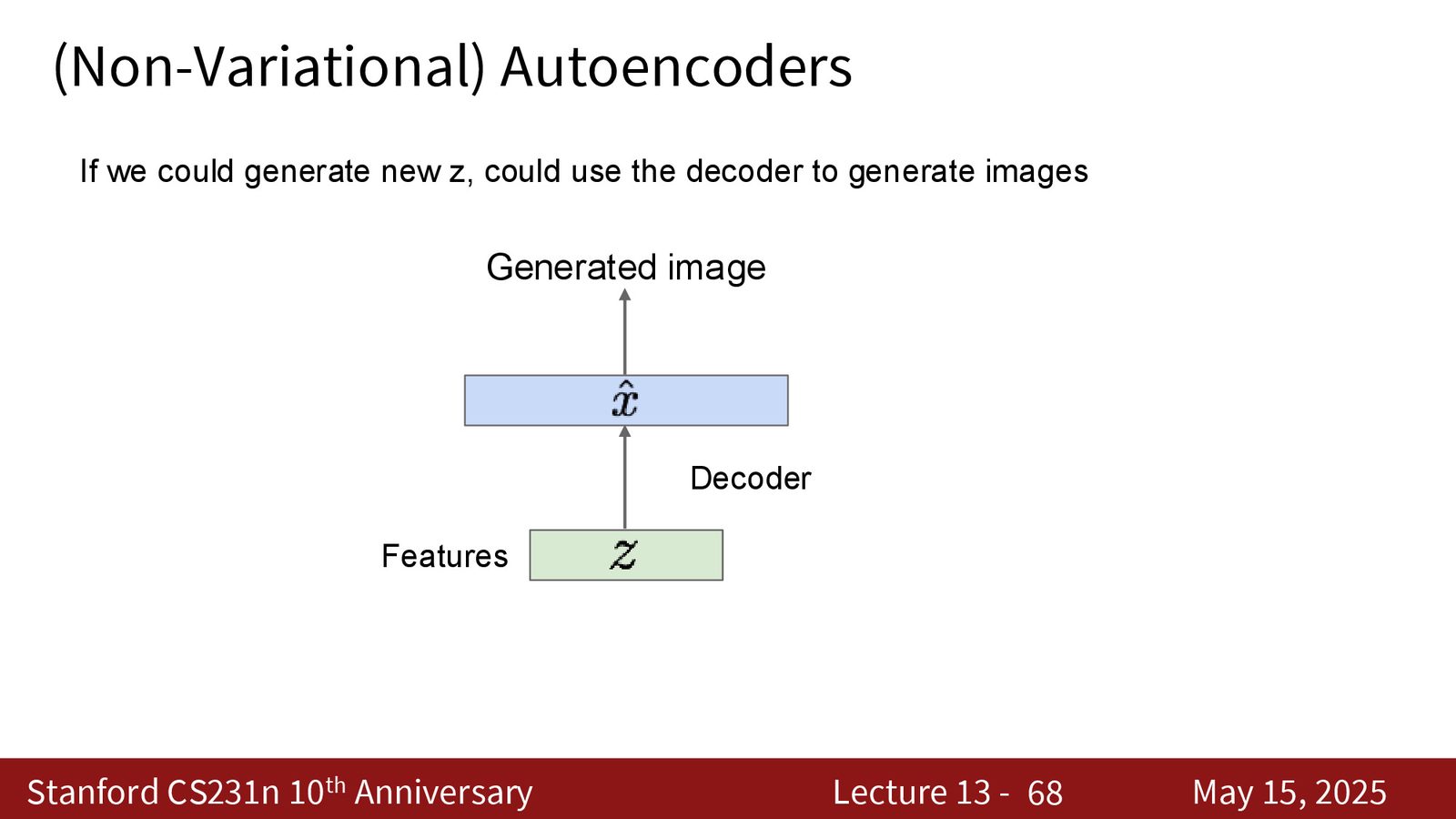
如果想用自编码器生成新数据,需要能在 latent space 中采样 \(Z\),然后通过 decoder 生成 \(X\)。但问题是:latent space 没有已知的分布结构,无法进行有意义的采样。
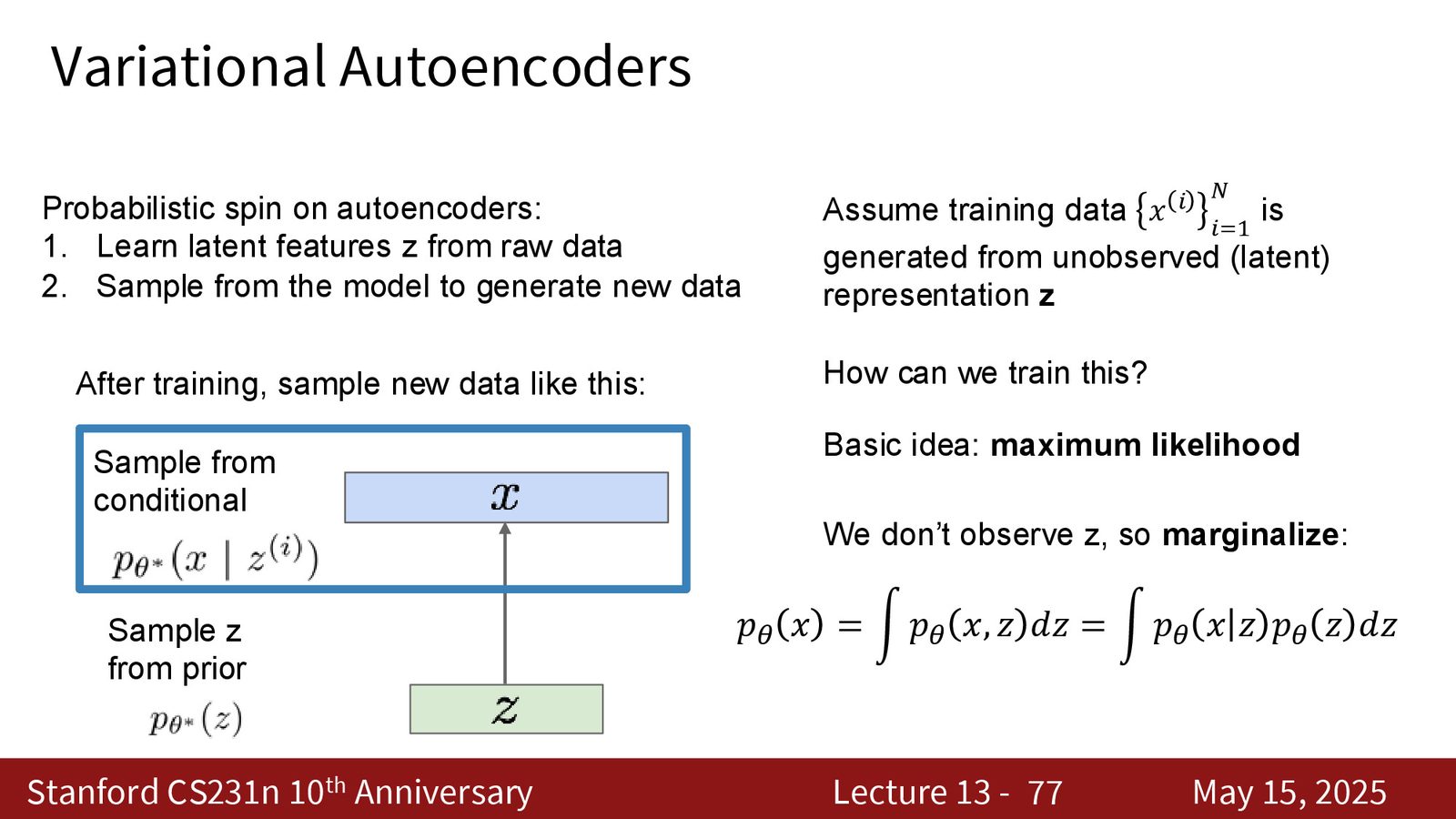
VAE 的概率框架

来源:Slides 第38页。
VAE 的核心假设是:每个数据点 \(x^{(i)}\) 是由某个不可观测的隐变量 \(z^{(i)}\) 生成的。数据的生成过程为:
- 从先验分布 \(p(Z)\)(通常是标准高斯分布 \(\mathcal{N}(0, I)\))中采样 \(Z\)
- 从条件分布 \(p_\theta(X|Z)\)(decoder)中生成 \(X\)
数据的边际似然为:
积分不可解(Intractable)
\(p_\theta(X) = \int p_\theta(X|Z) p(Z) dZ\) 这个积分在高维空间中无法直接计算。同样,后验分布 \(p_\theta(Z|X) = \frac{p_\theta(X|Z) p(Z)}{p_\theta(X)}\) 也因为分母不可解而无法直接计算。这正是 VAE 需要引入变分推断的根本原因。
变分下界(ELBO)
为了绕过不可解的积分,VAE 引入一个编码器网络 \(q_\phi(Z|X)\)(也叫推断网络),用它来近似真实的后验分布 \(p_\theta(Z|X)\)。

来源:Slides 第41页。
通过数学推导,可以将对数似然分解为:
由于 KL 散度 \(\geq 0\),丢弃最后一项得到下界:
这就是变分下界(Variational Lower Bound),也叫证据下界(Evidence Lower Bound, ELBO)。
ELBO 的两个组成部分
- 重构项(Reconstruction):\(\mathbb{E}_{q_\phi(Z|X)}[\log p_\theta(X|Z)]\)——encoder 编码的 \(Z\) 应该能让 decoder 重构出原始数据 \(X\)。等价于最小化重构误差(固定方差时等价于 L2 loss)。
- 先验匹配项(Prior Matching):\(D_{KL}(q_\phi(Z|X) \| p(Z))\)——encoder 输出的 \(Z\) 分布应该接近先验 \(p(Z) = \mathcal{N}(0, I)\)。这保证了 latent space 的结构化。
训练过程
来源:Slides 第44页。
训练 VAE 的具体步骤:
- Encoder:输入数据 \(X\),输出高斯分布的参数 \((\mu, \sigma)\)
- KL 项:计算 \(D_{KL}(q_\phi(Z|X) \| \mathcal{N}(0,I))\),鼓励 \(\mu \to 0\),\(\sigma \to 1\)
- 采样:使用 reparameterization trick \(Z = \mu + \sigma \odot \epsilon\)(\(\epsilon \sim \mathcal{N}(0,I)\)),使梯度可以回传
- Decoder:输入 \(Z\),输出重构的 \(\hat{X}\)
- 重构项:计算重构误差 \(\|X - \hat{X}\|^2\)
重参数化技巧(Reparameterization Trick)
直接从分布 \(q_\phi(Z|X)\) 采样是不可微的,无法进行反向传播。解决方法是将采样操作改写为确定性变换加外部噪声:\(Z = \mu + \sigma \odot \epsilon\),其中 \(\epsilon \sim \mathcal{N}(0, I)\)。这样梯度可以通过 \(\mu\) 和 \(\sigma\) 回传到 encoder。
重构损失 vs 先验损失的博弈
VAE 训练中两个损失项存在有趣的对抗关系:
- 重构损失希望:\(\sigma \to 0\)(减少噪声),\(\mu\) 对每个数据点都不同(编码更多信息)
- 先验损失希望:\(\sigma \to 1\),\(\mu \to 0\)(都变成标准高斯)
来源:Slides 第45页。
这种博弈迫使模型在保留足够信息以重构数据和保持 latent space 结构化之间找到平衡。
采样与 Latent Space 操作
训练完成后,可以直接从先验 \(p(Z) = \mathcal{N}(0, I)\) 采样 \(Z\),然后通过 decoder 生成新数据。此外,由于 latent space 是连续且结构化的,可以在 latent space 中进行插值。
来源:Slides 第47页。
VAE 生成的样本通常偏模糊
VAE 使用对角高斯分布建模 \(p(X|Z)\),假设像素间独立。这意味着 VAE 倾向于预测像素值的均值,导致生成的图像看起来偏模糊。此外,L2 重构损失也会惩罚高频细节。要获得清晰的生成结果,通常需要结合其他技术(如对抗训练或更强的 decoder)。
本章小结
VAE 在传统自编码器基础上引入概率框架:encoder 输出 latent 分布的参数,通过 KL 散度强制 latent space 接近标准高斯。ELBO 是由重构项和先验匹配项组成的变分下界,两者在训练中相互博弈。VAE 的主要贡献是提供了结构化的 latent space,但生成的样本通常较模糊。
生成对抗网络(GAN)
GAN 的基本思想

来源:Slides 第49页。
GAN 属于隐式密度模型——放弃显式建模 \(p(X)\),转而通过一个博弈过程隐式地学习数据分布。
GAN 包含两个神经网络:
- Generator \(G\):输入噪声 \(Z \sim \mathcal{N}(0,I)\),输出生成数据 \(G(Z)\)
- Discriminator \(D\):输入数据(真实或生成),输出「真实」的概率 \(D(X) \in [0,1]\)
目标函数

来源:Slides 第52页。
GAN 的训练是一个 minimax 博弈:
- Discriminator 的目标(最大化):正确分类真实数据为真(\(D(X) \to 1\)),生成数据为假(\(D(G(Z)) \to 0\))
- Generator 的目标(最小化):让 Discriminator 把生成数据误判为真(\(D(G(Z)) \to 1\))
训练过程

来源:Slides 第54页。
训练交替进行两个步骤:
- 训练 Discriminator:固定 Generator,用真实数据和生成数据训练 Discriminator 做二分类
- 训练 Generator:固定 Discriminator,通过 Discriminator 的反馈优化 Generator
GAN 训练的梯度消失问题
在训练初期,Generator 产生的样本质量极差,Discriminator 很容易将其识别为假。此时 \(D(G(Z)) \approx 0\),而 \(\log(1 - D(G(Z)))\) 在 \(D(G(Z)) \approx 0\) 处梯度非常小。这意味着 Generator 在训练初期几乎收不到有效的梯度信号。实践中常用的替代目标是最大化 \(\log D(G(Z))\)(而非最小化 \(\log(1 - D(G(Z)))\)),因为前者在 \(D(G(Z)) \approx 0\) 处梯度更大。

来源:Slides 第56页。
GAN 的训练难点

来源:Slides 第59页。
GAN 训练是出了名的不稳定
- 没有有意义的损失曲线:与其他模型不同,GAN 的损失值不能直观反映生成质量。数百篇论文试图解决这个问题,但至今仍未有完美方案。
- 模式坍缩(Mode Collapse):Generator 可能只学会生成少数几种样本,忽略数据分布的多样性。
- 训练不收敛:Generator 和 Discriminator 的对抗可能导致训练震荡而非收敛。
- 超参数敏感:对学习率、网络架构、训练步数等超参数极为敏感。
GAN 生成的图像质量
尽管训练困难,GAN 在生成图像质量上曾长期领先。

来源:Slides 第61页。
来源:Slides 第63页。
来源:Slides 第68页。
GAN 在约 2016--2021 年间是图像生成的主流方法。它的优势在于:
- 单次前向传播即可生成样本(推理速度快)
- 生成的样本清晰、锐利
条件 GAN
通过向 Generator 和 Discriminator 输入条件信息 \(Y\)(如类别标签、文本描述),可以将 GAN 扩展为条件生成模型。

来源:Slides 第71页。
GAN vs VAE 的权衡
来源:Slides 第74页。
VAE 和 GAN 的权衡
- VAE:可以计算(近似的)\(p(X)\);有结构化的 latent space(可做编码和插值);但样本通常偏模糊
- GAN:样本质量高、清晰锐利;推理速度快(单次前向);但训练困难、无有效损失指标、容易模式坍缩、没有 encoder(无法从 \(X\) 到 \(Z\) 的映射)
本章小结
GAN 通过 Generator 和 Discriminator 的对抗训练隐式地学习数据分布。它放弃了密度估计的能力,换来了更清晰的生成样本。GAN 在 2016--2021 年间主导了图像生成领域,但其训练不稳定性是重大缺陷。后来被扩散模型取代成为主流方法。
总结与延伸
讲者的核心总结
来源:Slides 第77页。
Justin Johnson 在课程结尾总结了本节课的三大主题:
- 生成模型的概率基础:判别式 vs 生成式 vs 条件生成式,归一化约束的含义
- 显式密度方法:自回归模型(可精确计算密度),VAE(可计算近似密度下界)
- 隐式密度方法:GAN(直接采样,但不可计算密度)
下一节课将覆盖家族树的另一半——扩散模型,它属于隐式密度的迭代采样方法。
全课知识图谱

关键 Takeaways
五条核心原则
- 归一化约束是生成模型的核心:不同概率模型的本质区别在于什么东西在竞争概率质量
- 条件生成模型最有实用价值:\(p(X|Y)\) 才是真正有用的模型,\(p(X)\) 更多是理论工具
- MLE 是显式密度方法的统一框架:自回归和 VAE 都在(直接或间接地)最大化数据的对数似然
- 每种方法都有其权衡:自回归(精确但慢)、VAE(有 latent space 但模糊)、GAN(清晰但难训练)
- 扩散模型最终统一了质量与稳定性:解决了 GAN 的训练问题,同时达到甚至超越 GAN 的生成质量
拓展阅读
- Kingma & Welling, “Auto-Encoding Variational Bayes” (2013): https://arxiv.org/abs/1312.6114 --- VAE 原始论文
- Goodfellow et al., “Generative Adversarial Nets” (2014): https://arxiv.org/abs/1406.2661 --- GAN 原始论文
- van den Oord et al., “Pixel Recurrent Neural Networks” (2016): https://arxiv.org/abs/1601.06759 --- PixelRNN
- Karras et al., “A Style-Based Generator Architecture for GANs” (2019): https://arxiv.org/abs/1812.04948 --- StyleGAN
- Lilian Weng's Blog, “From Autoencoder to Beta-VAE”: https://lilianweng.github.io/posts/2018-08-12-vae/ --- VAE 详解