CS336 2026 Lecture 5:GPUs、Roofline 与 FlashAttention
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Stanford CS336 Spring 2026 官方讲义整理 |
| 来源 | Stanford CS336 |
| 日期 | 2026 年春季 |

本讲的问题:GPU 为什么既快又难用?
Lecture 5 把 Lecture 2 的 resource accounting 落到硬件:为什么 GPU 能支撑 scaling?为什么同样是 FLOPs,有的操作飞快,有的操作很慢?为什么 FlashAttention 这种算法能改变 attention 的实际速度?
术语消化:GPU memory hierarchy
HBM 是 High Bandwidth Memory,GPU 上的大容量高带宽显存,容量大但离计算单元远;SRAM 是 Static Random-Access Memory,常对应片上 shared memory/cache,容量小但速度快;register 是每个 thread 私有的最快存储。GPU 优化的核心之一,就是让数据从 HBM 读进来以后尽量在 SRAM/register 附近复用,而不是频繁写回 HBM。
本讲主线
GPU performance 的核心不是“GPU 很快”四个字,而是让数据移动、并行执行和矩阵硬件匹配。低精度、fusion、recomputation、coalescing、tiling、FlashAttention 都是在减少 HBM 往返或提高数据复用。
GPU 为什么适合大规模深度学习
本节从 compute scaling 的历史讲到 GPU 与 CPU 的区别,再拆 SM、SP、warp、block、register、shared memory 和 HBM。
术语消化:SM、SP、warp、block
SM 是 Streaming Multiprocessor,是 GPU 上执行 thread blocks 的主要单元;SP/CUDA core 是 SM 内的标量执行单元;warp 是一组通常 32 个 lockstep 执行的 threads;thread block 是被调度到一个 SM 上的线程组。HBM 是 GPU 的高带宽显存,容量大但离计算单元远;SRAM/shared memory/register 更靠近 SM,容量小但快。
展开说明:GPUS
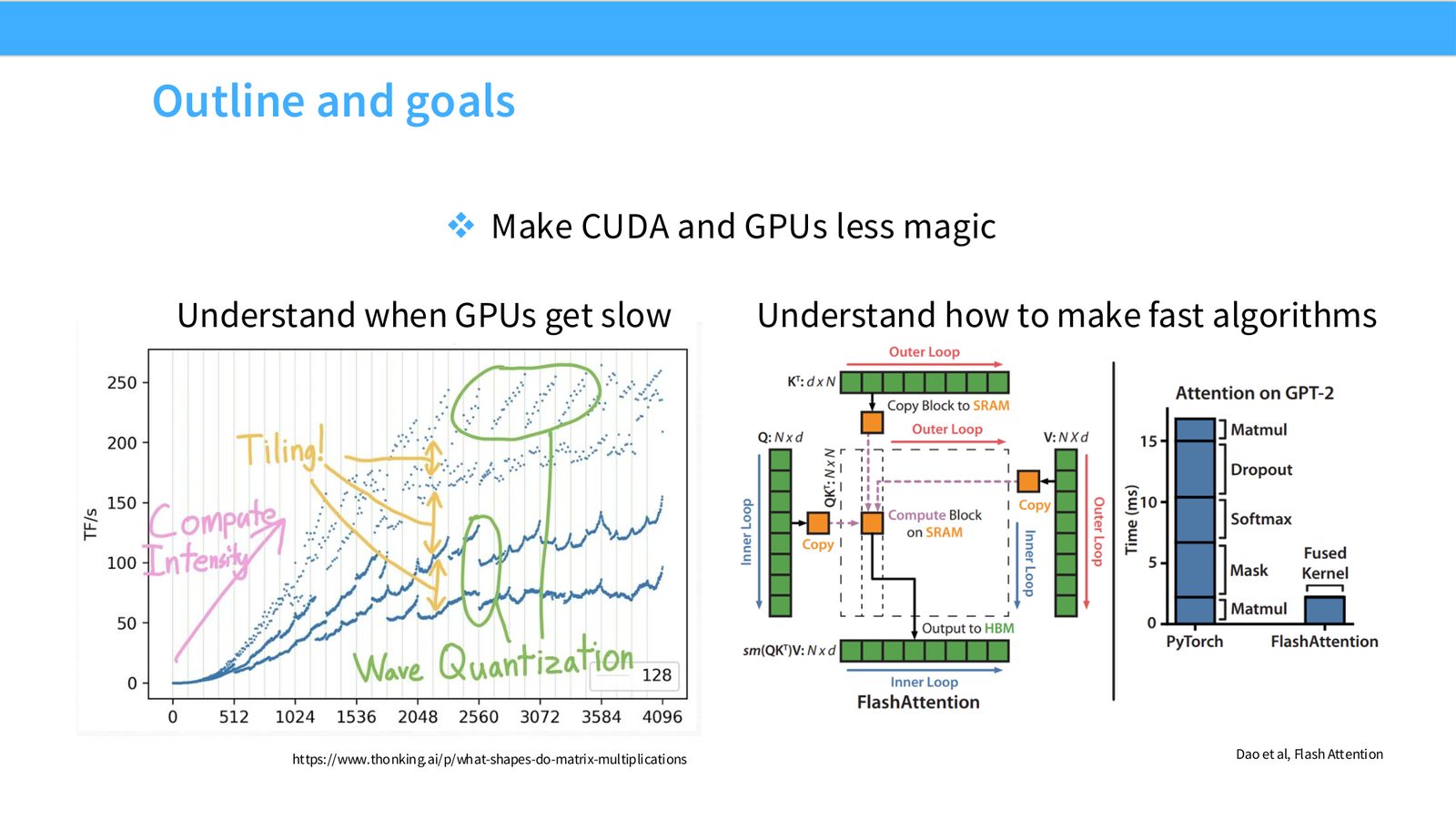
展开说明: Make CUDA and GPUs less magic
展开说明:Substantial credit goes to a few sources that I’d like to highlight..

展开说明: Part 1: GPUs in depth – how they work and important parts
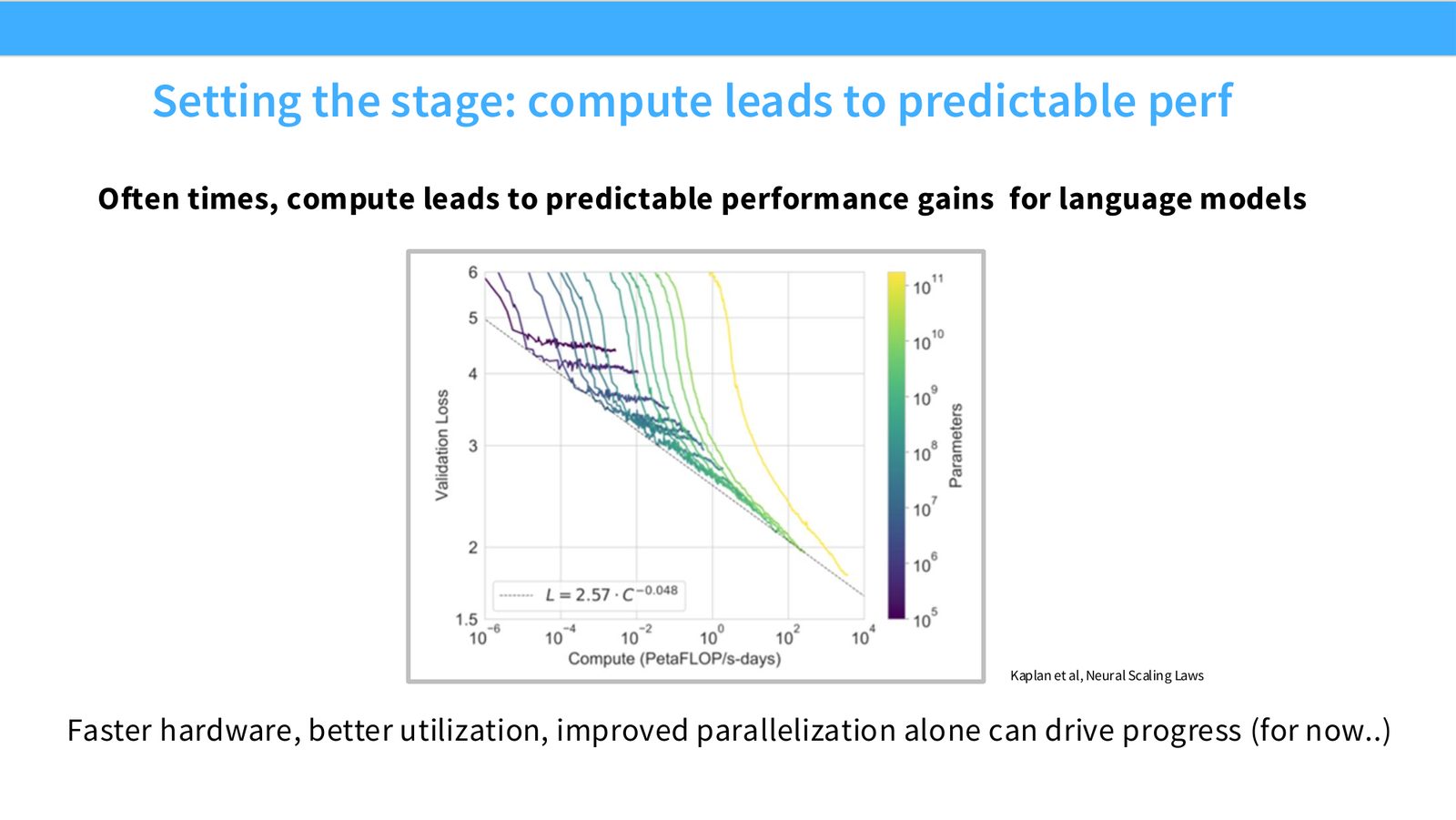
展开说明:Often times, compute leads to predictable performance gains for language models
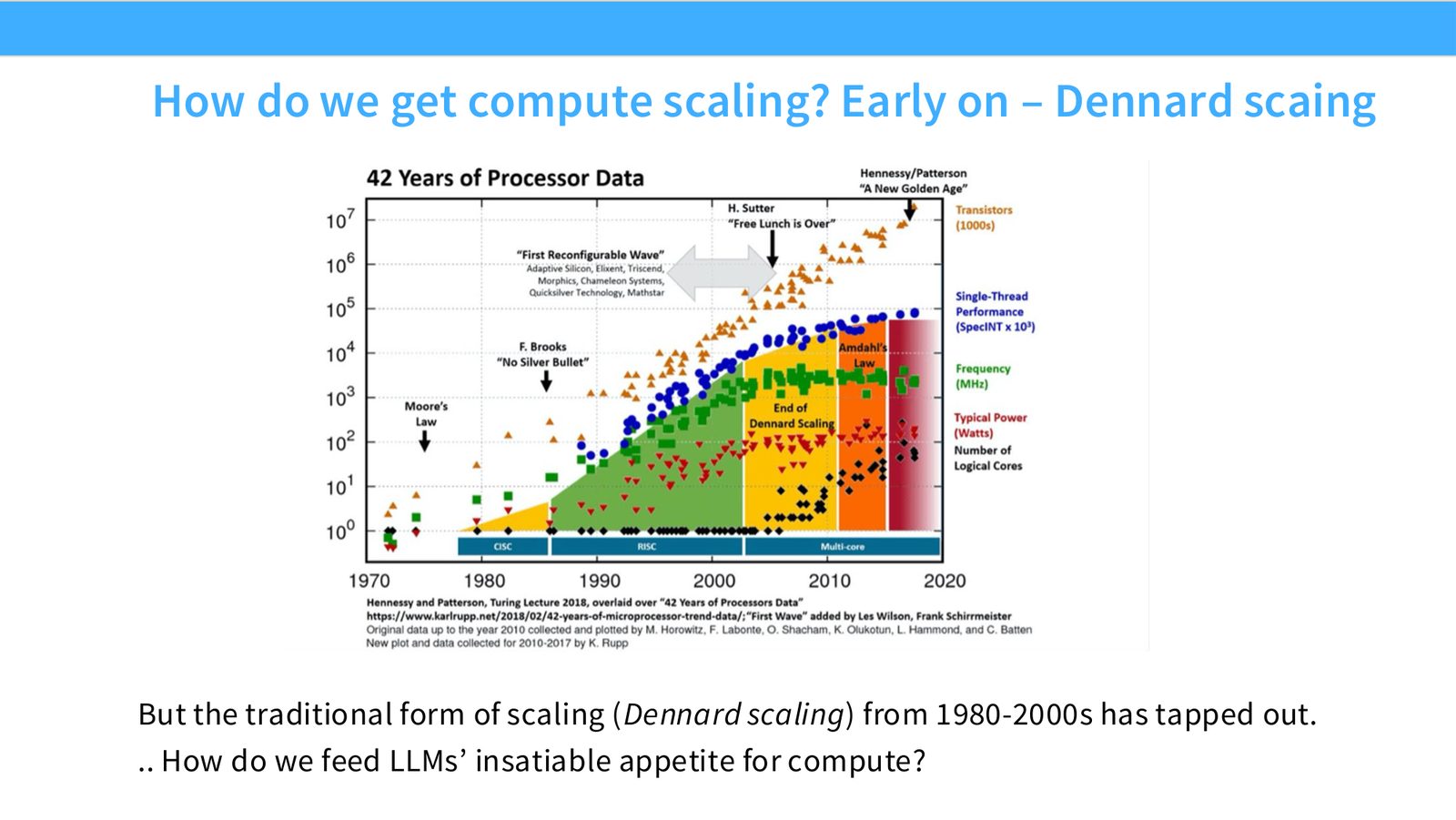
展开说明:But the traditional form of scaling (Dennard scaling) from 1980-2000s has tapped out.
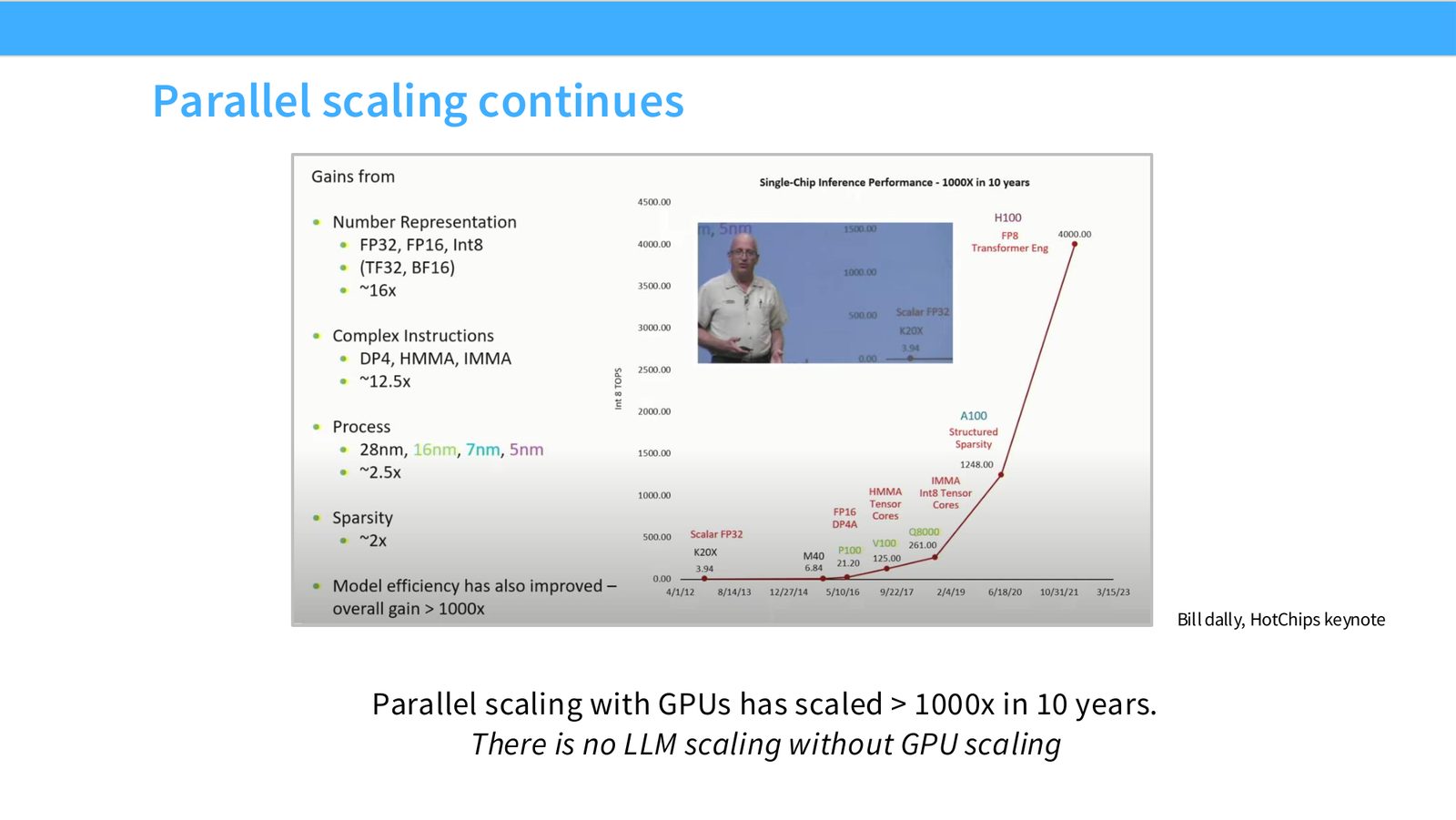
展开说明:Bill dally, HotChips keynote
读图:Slide 7 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
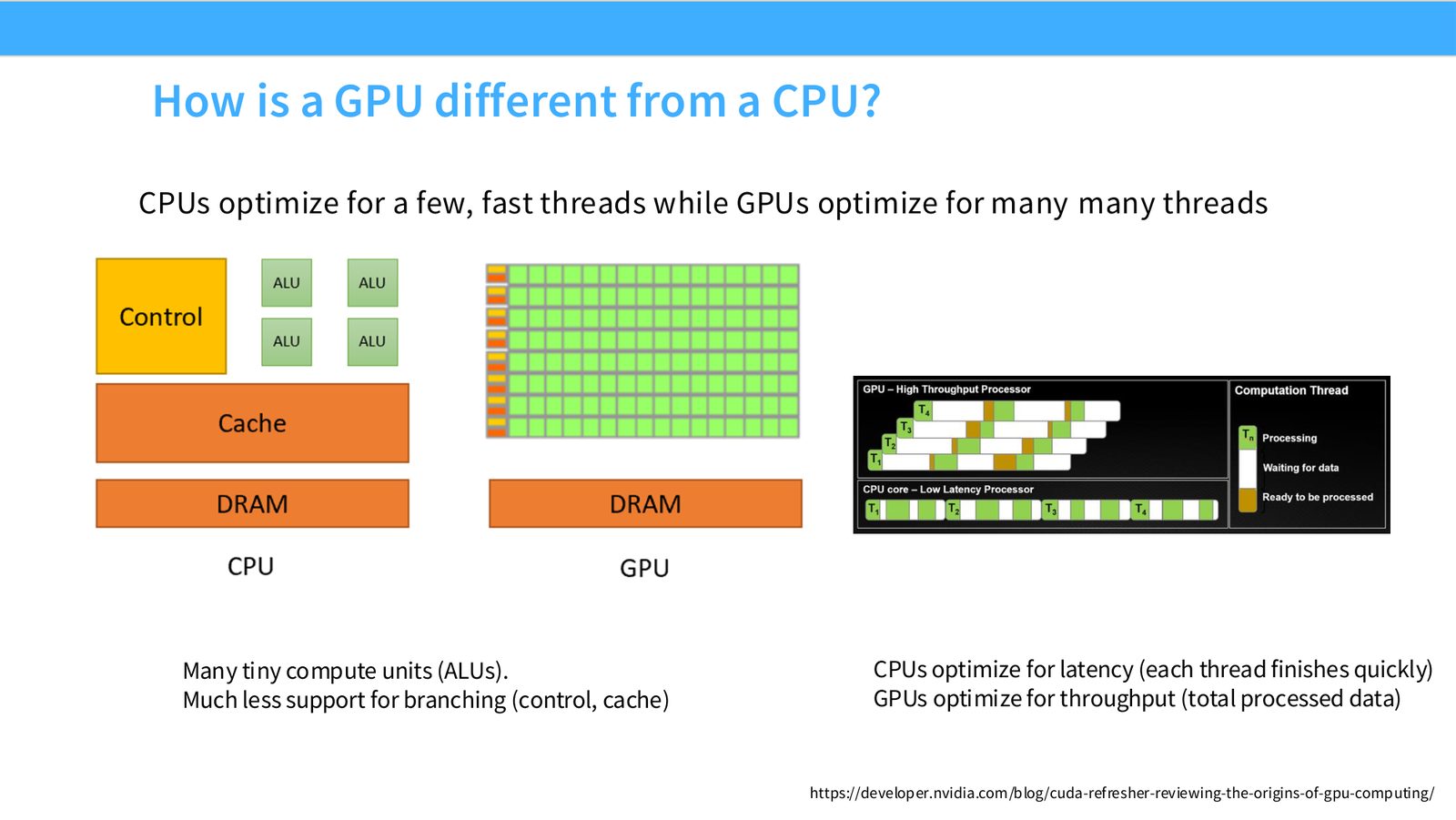
展开说明:CPUs optimize for a few, fast threads while GPUs optimize for many many threads
读图:Slide 8 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
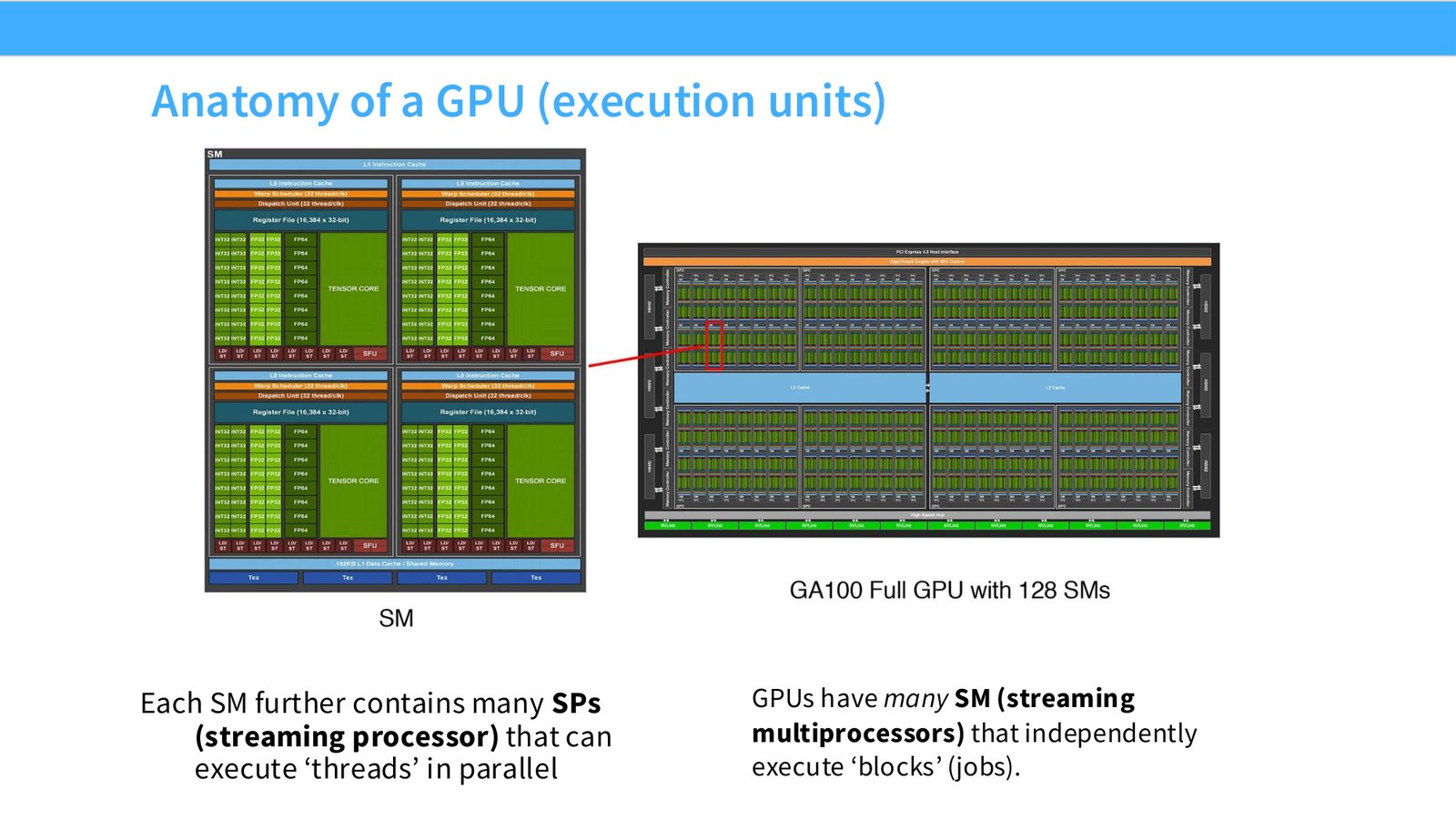
展开说明:Each SM further contains many SPs GPUs have many SM (streaming
读图:Slide 9 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。

展开说明:The closer the memory to the SM, the faster it is – L1 and shared memory is inside
读图:Slide 10 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
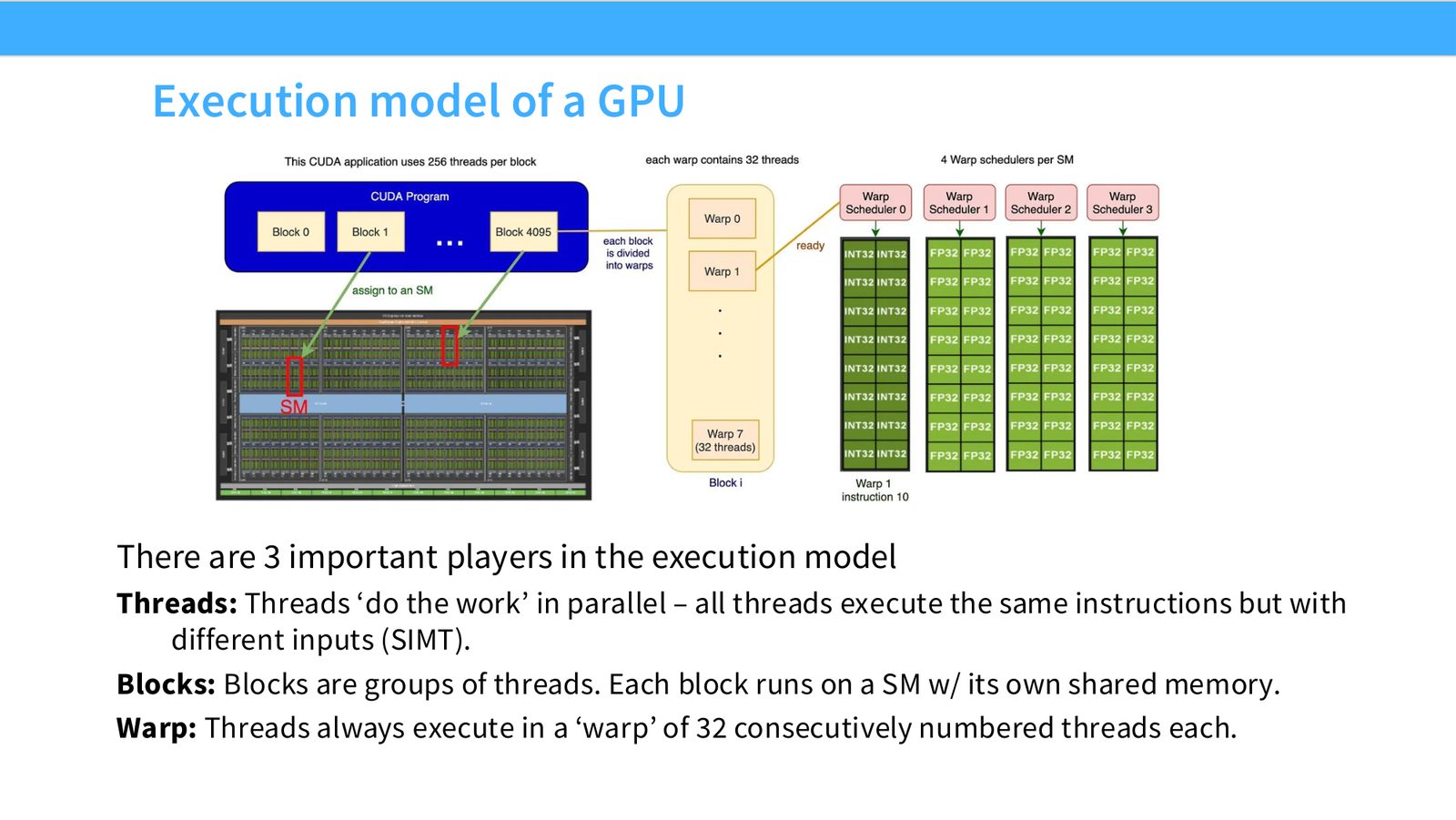
展开说明:There are 3 important players in the execution model
读图:Slide 11 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
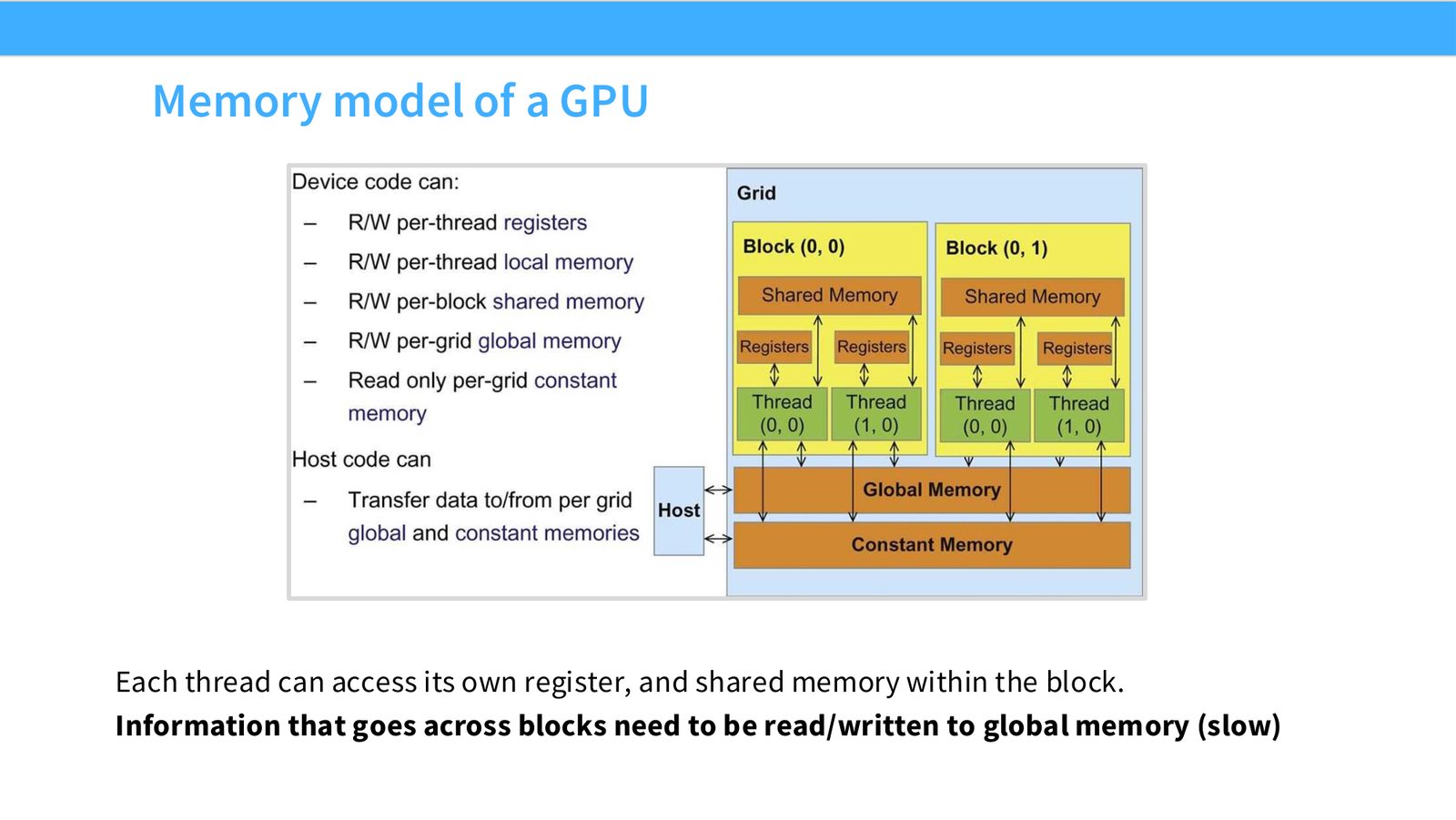
展开说明:Each thread can access its own register, and shared memory within the block.
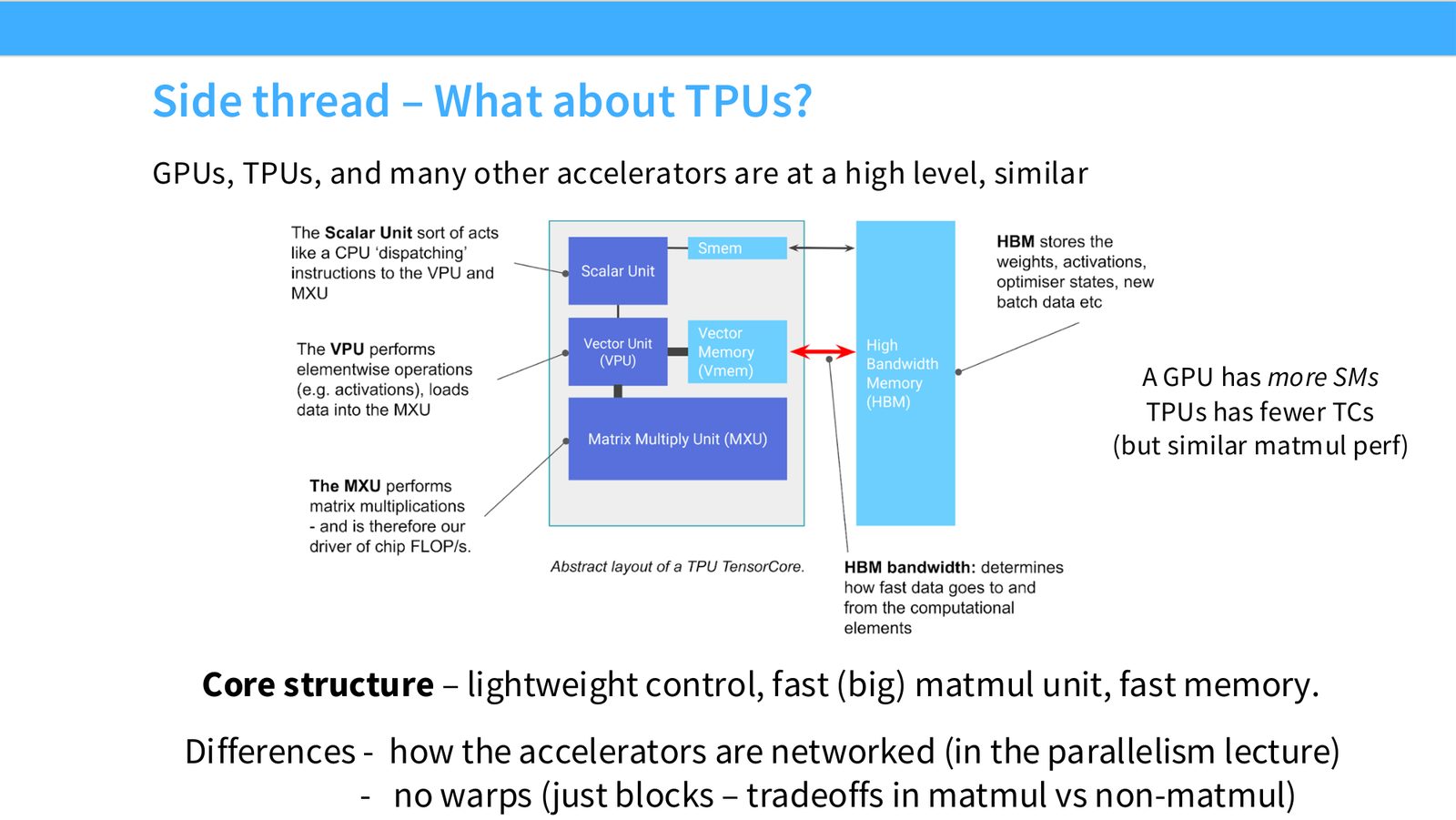
展开说明:GPUs, TPUs, and many other accelerators are at a high level, similar

展开说明:Core structure – lightweight control, fast (big) matmul unit, fast memory.
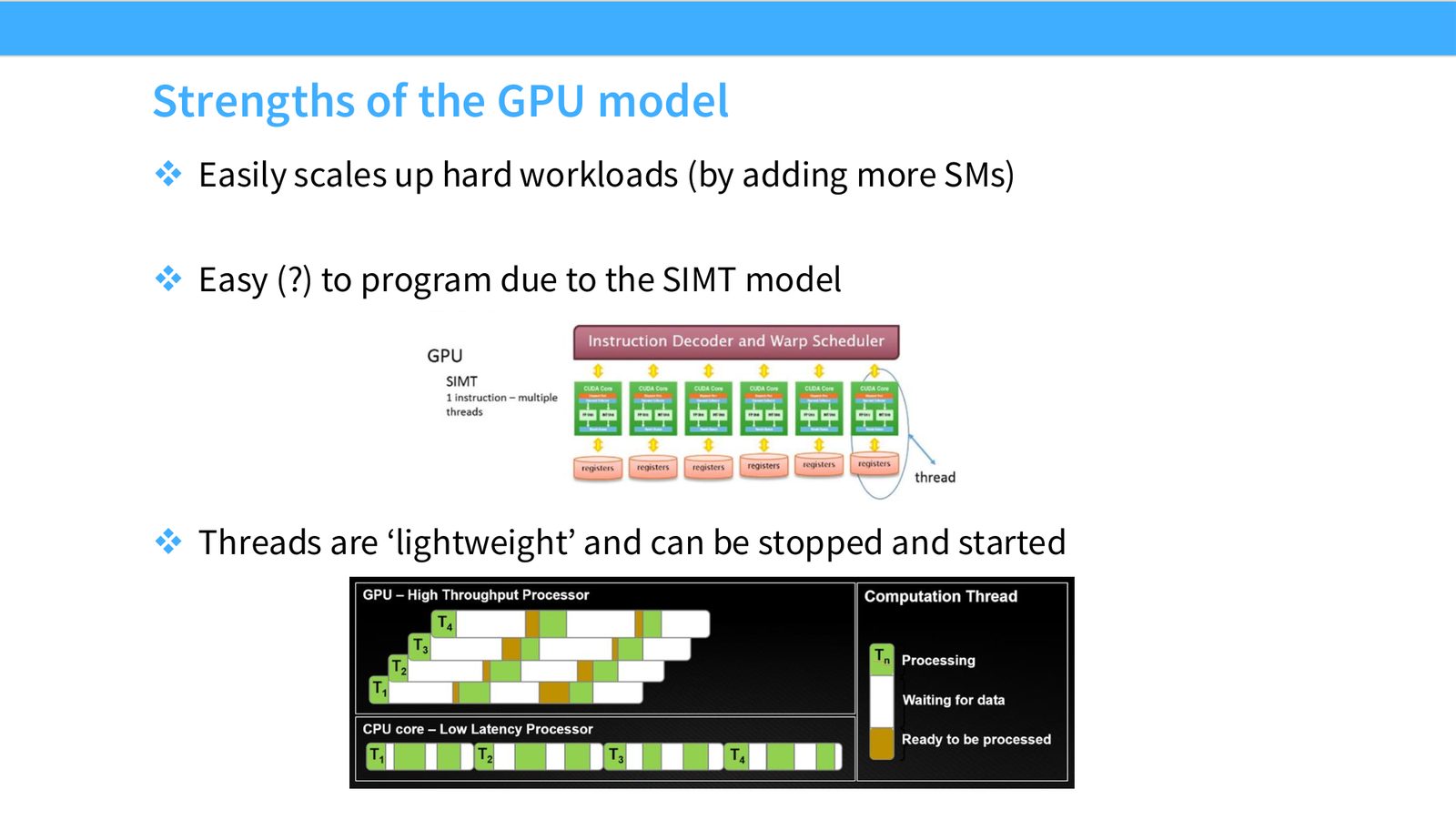
展开说明: Easily scales up hard workloads (by adding more SMs)

展开说明:Early days of NVIDIA GPUs – programmable shaders. Researchers hacked this to do matmuls
读图:Slide 16 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
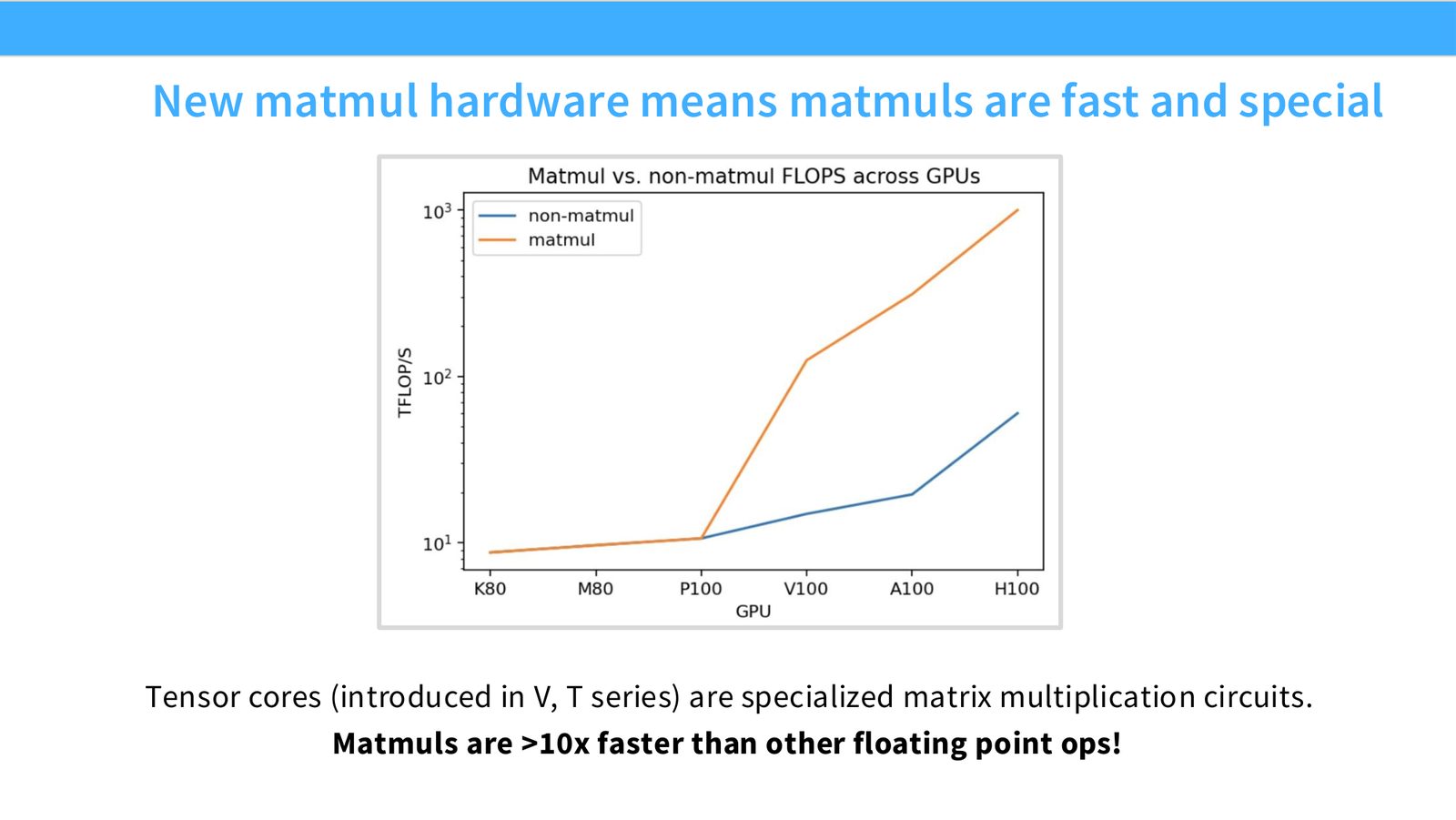
展开说明:Tensor cores (introduced in V, T series) are specialized matrix multiplication circuits.
读图:Slide 17 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
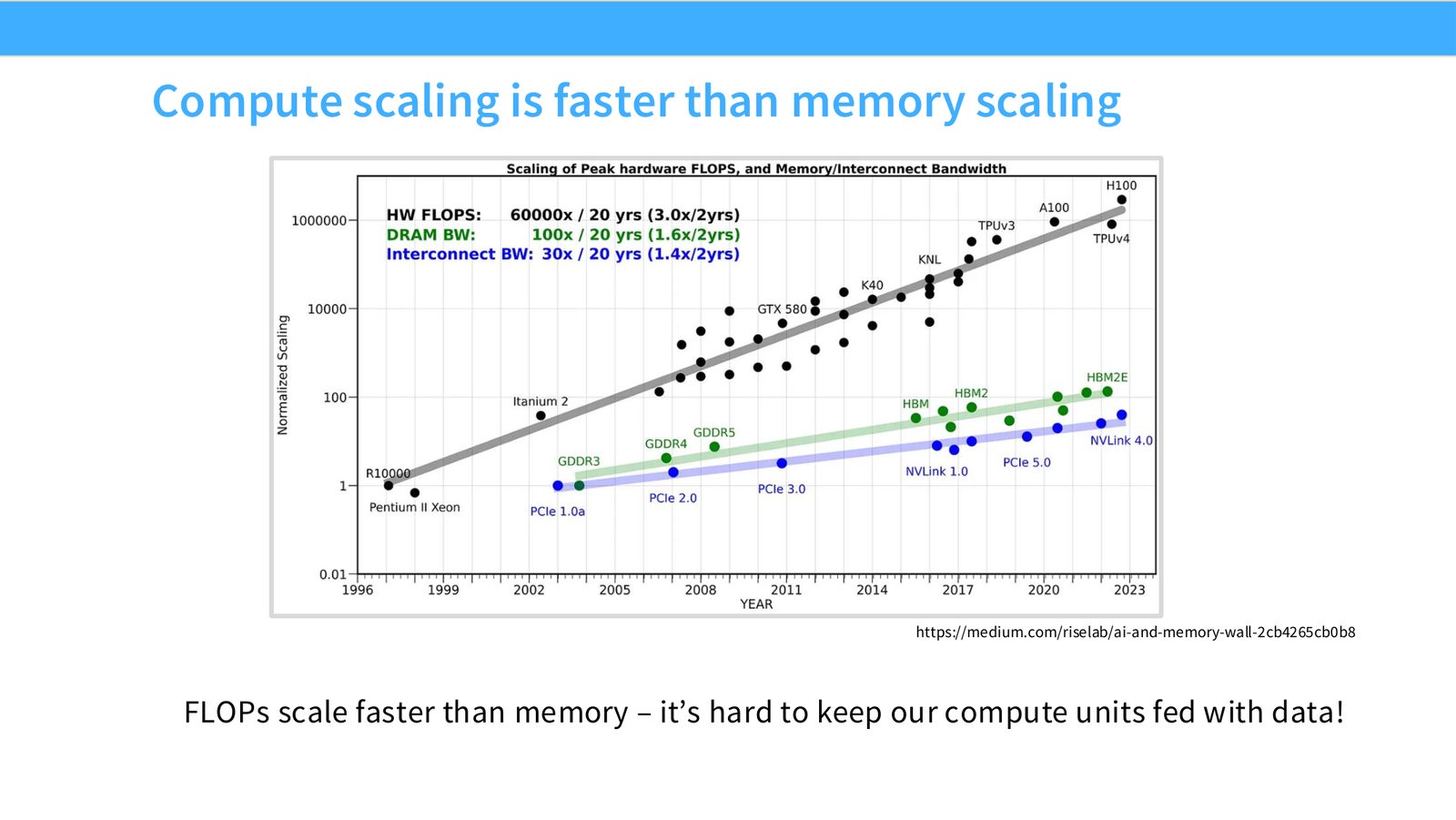
展开说明:https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b8
本章小结
本节的共同问题是如何减少昂贵的数据移动并提高硬件利用率。GPU 的速度来自海量并行和专用矩阵硬件,但只有当 memory access、shape、precision 和 kernel 组织匹配时,这些速度才会真正出现。
Roofline 与低精度:让 ML workload 跑快
本节解释 GPU 性能模型、divergence、低精度如何提高 arithmetic intensity。随后再看 FP8、MXFP8、MXFP4 的实际含义。
性能公式:roofline 心智模型
低精度减少 bytes moved,也可能启用 tensor cores,因此同时影响 memory traffic 和 peak compute。

展开说明: GPUs are massively parallel – same instructions
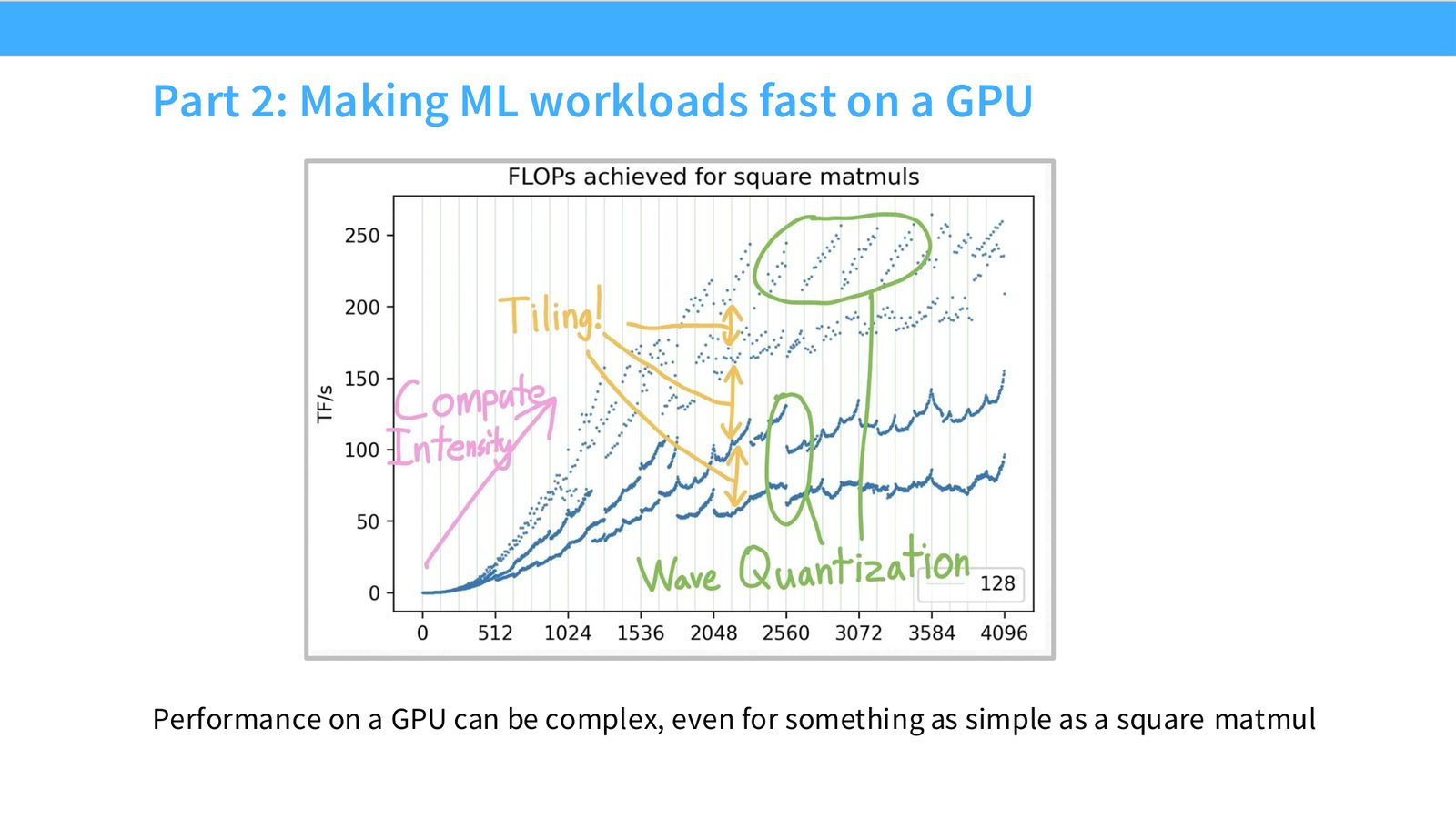
展开说明:Performance on a GPU can be complex, even for something as simple as a square matmul
读图:Slide 20 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
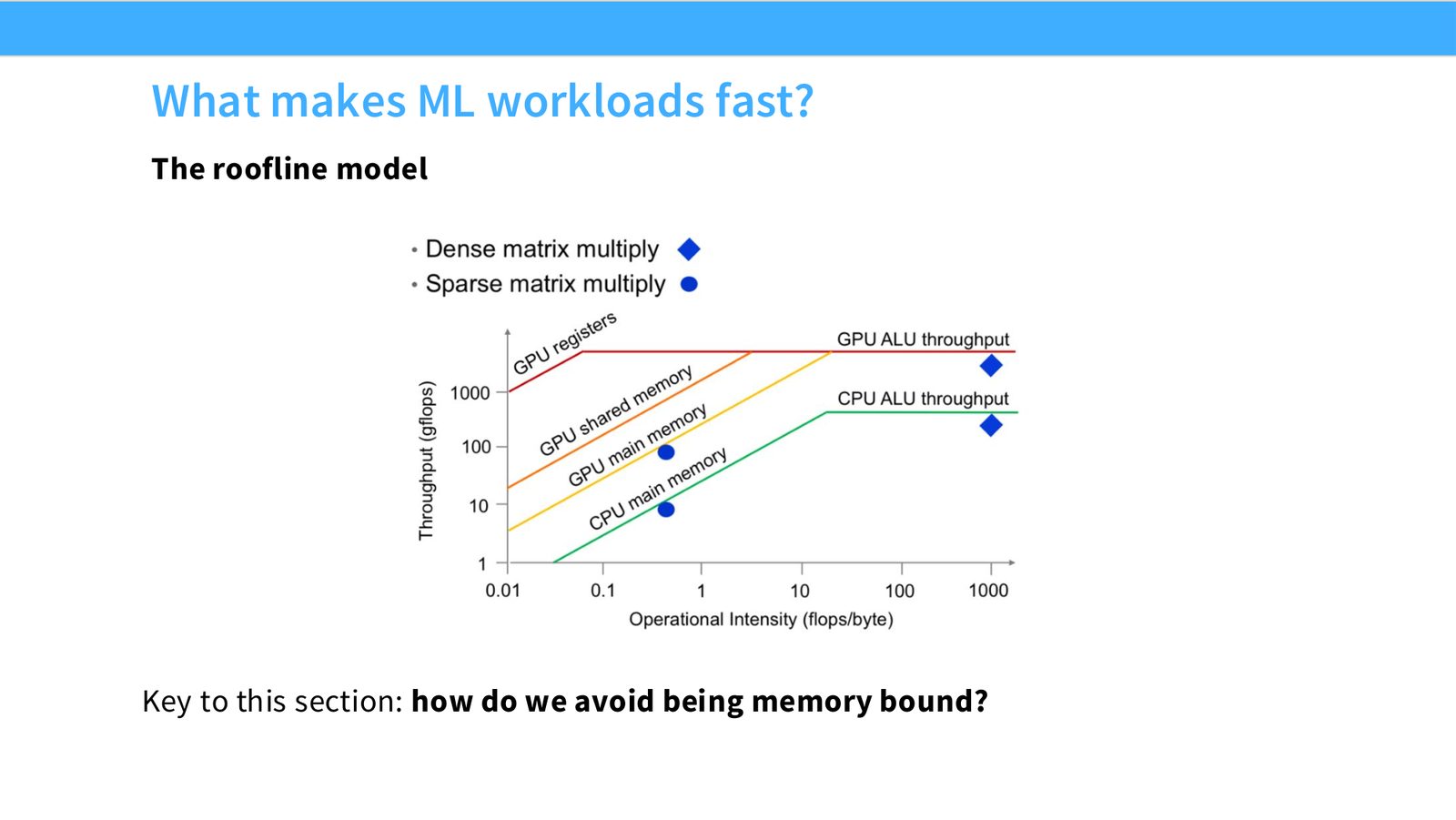
展开说明:The roofline model
读图:Slide 21 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。

展开说明:1. Control divergence (not a memory bottleneck..)
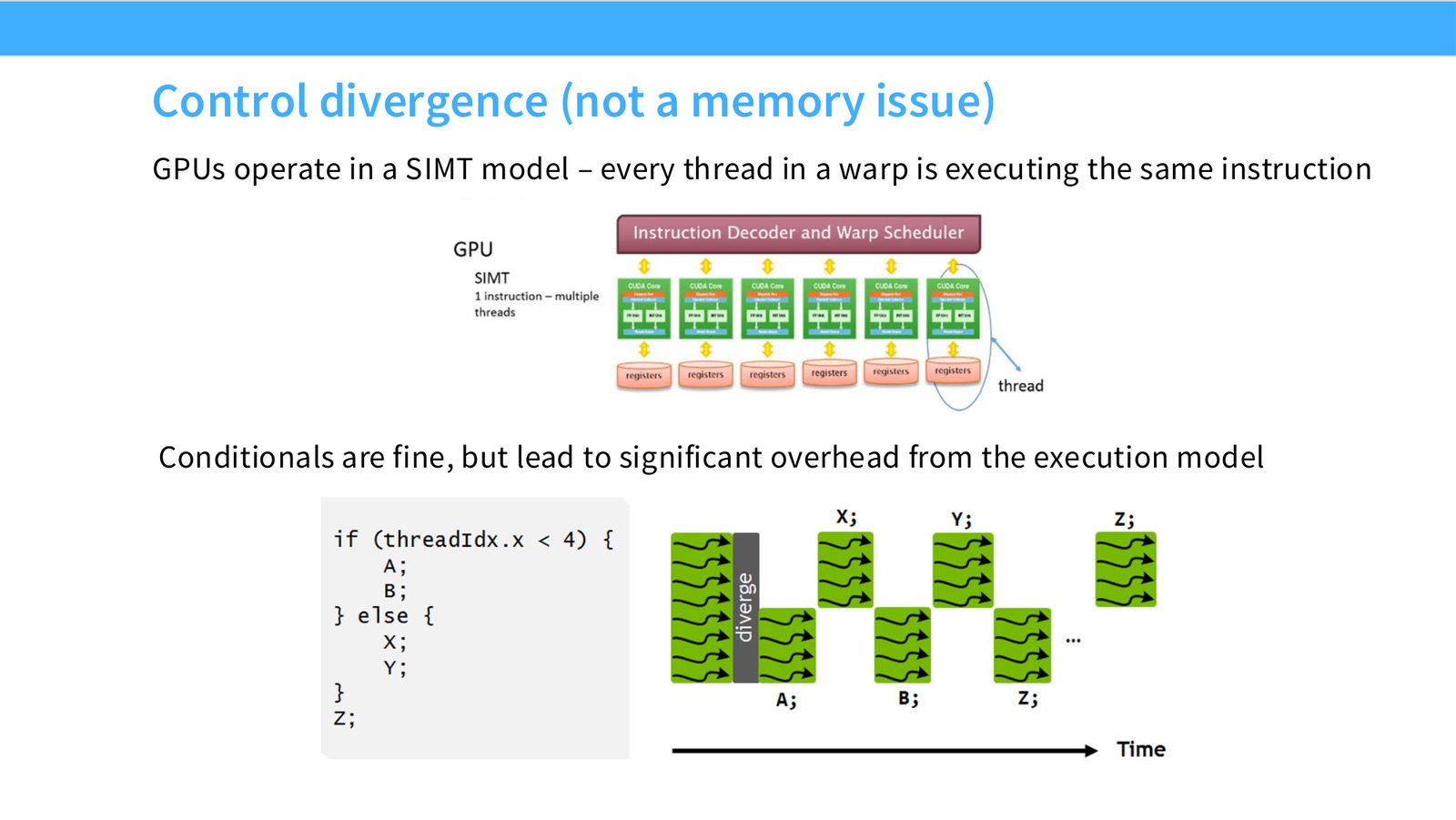
展开说明:GPUs operate in a SIMT model – every thread in a warp is executing the same instruction
读图:Slide 23 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
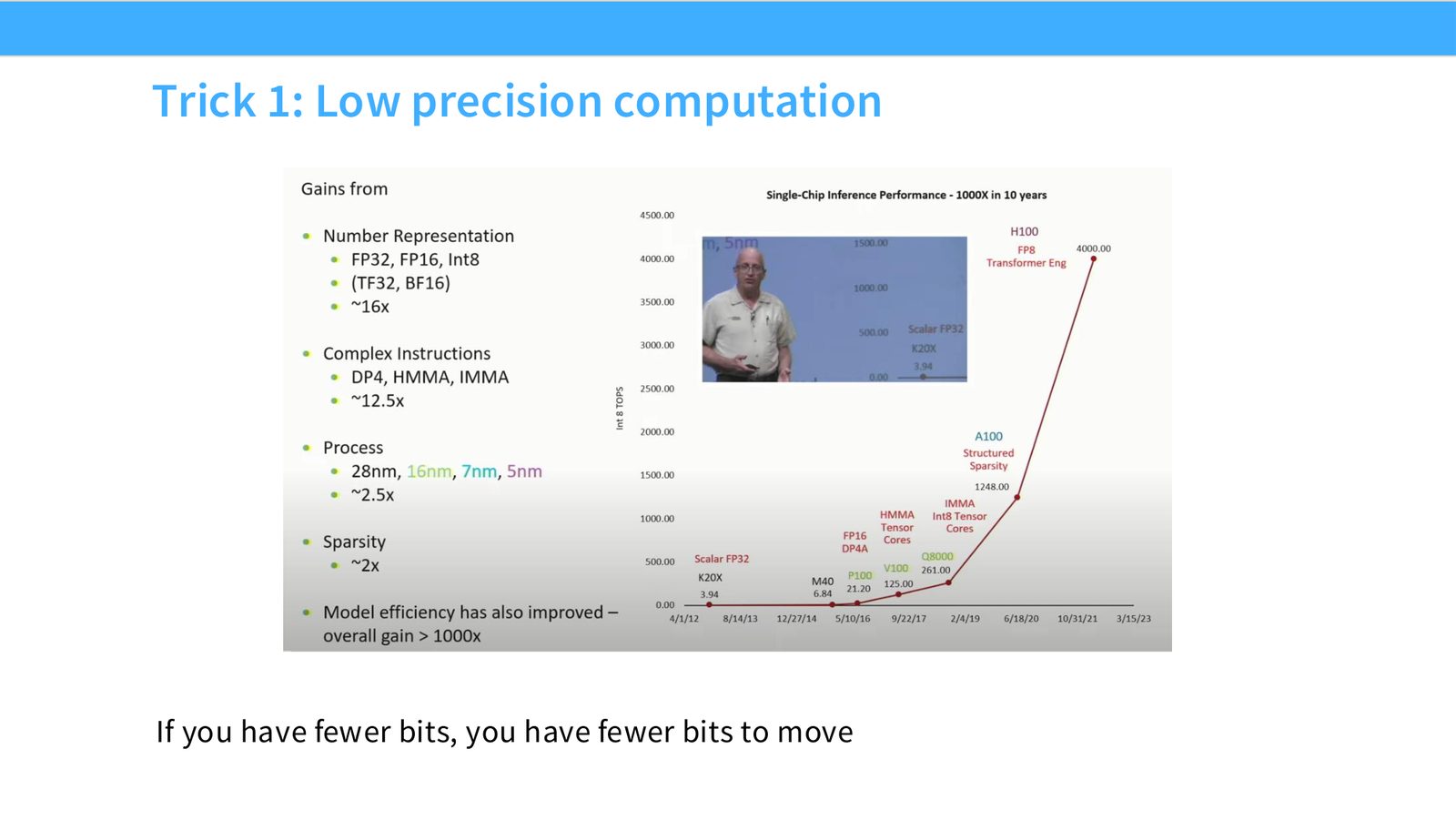
展开说明:If you have fewer bits, you have fewer bits to move
读图:Slide 24 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。

展开说明:Example: elementwise ReLU (\(x\) = max(0, \(x\))) on a vector of size \(n\).
读图:Slide 25 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
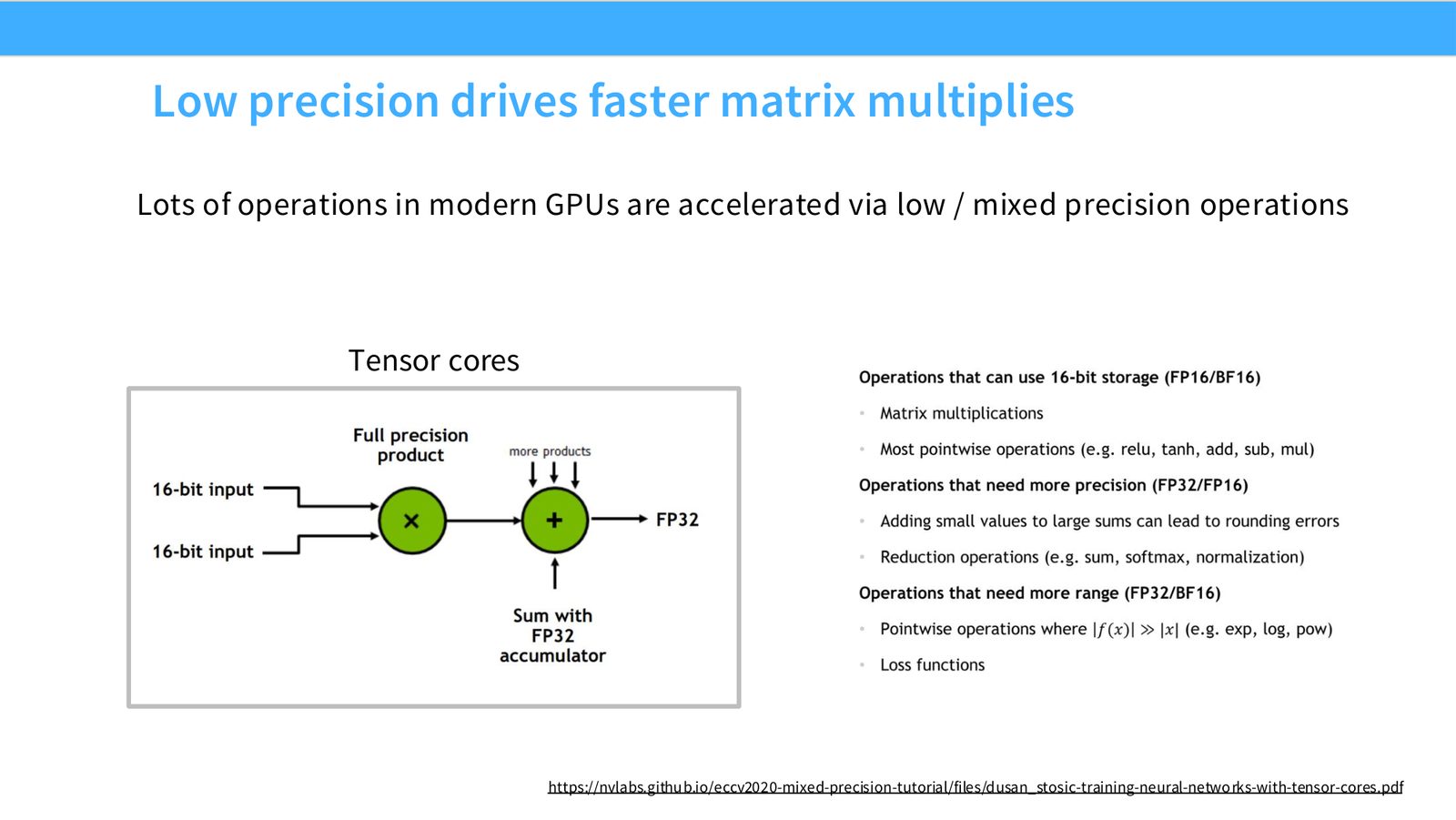
展开说明:Lots of operations in modern GPUs are accelerated via low / mixed precision operations
读图:Slide 26 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
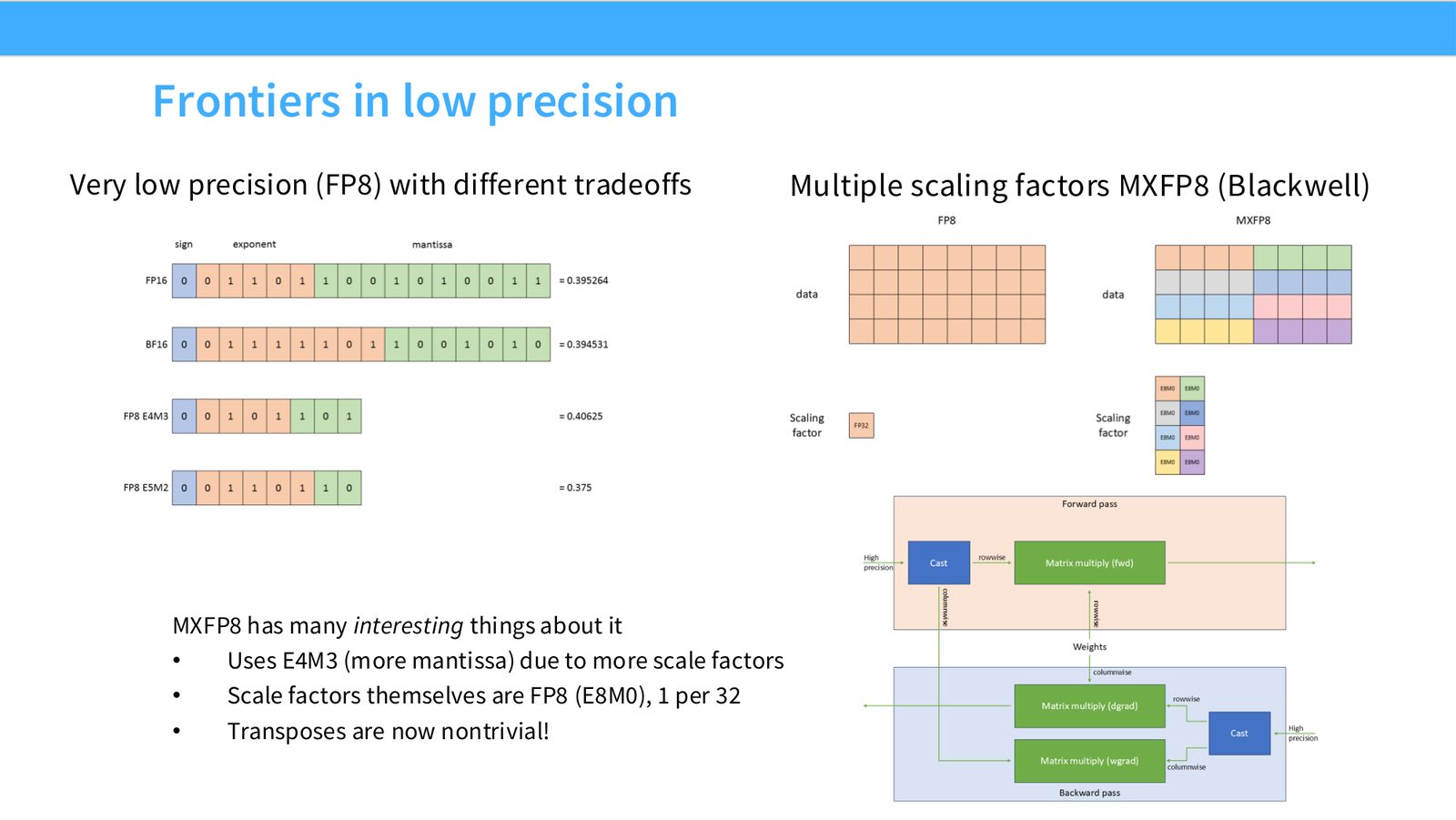
展开说明:Very low precision (FP8) with different tradeoffs Multiple scaling factors MXFP8 (Blackwell)
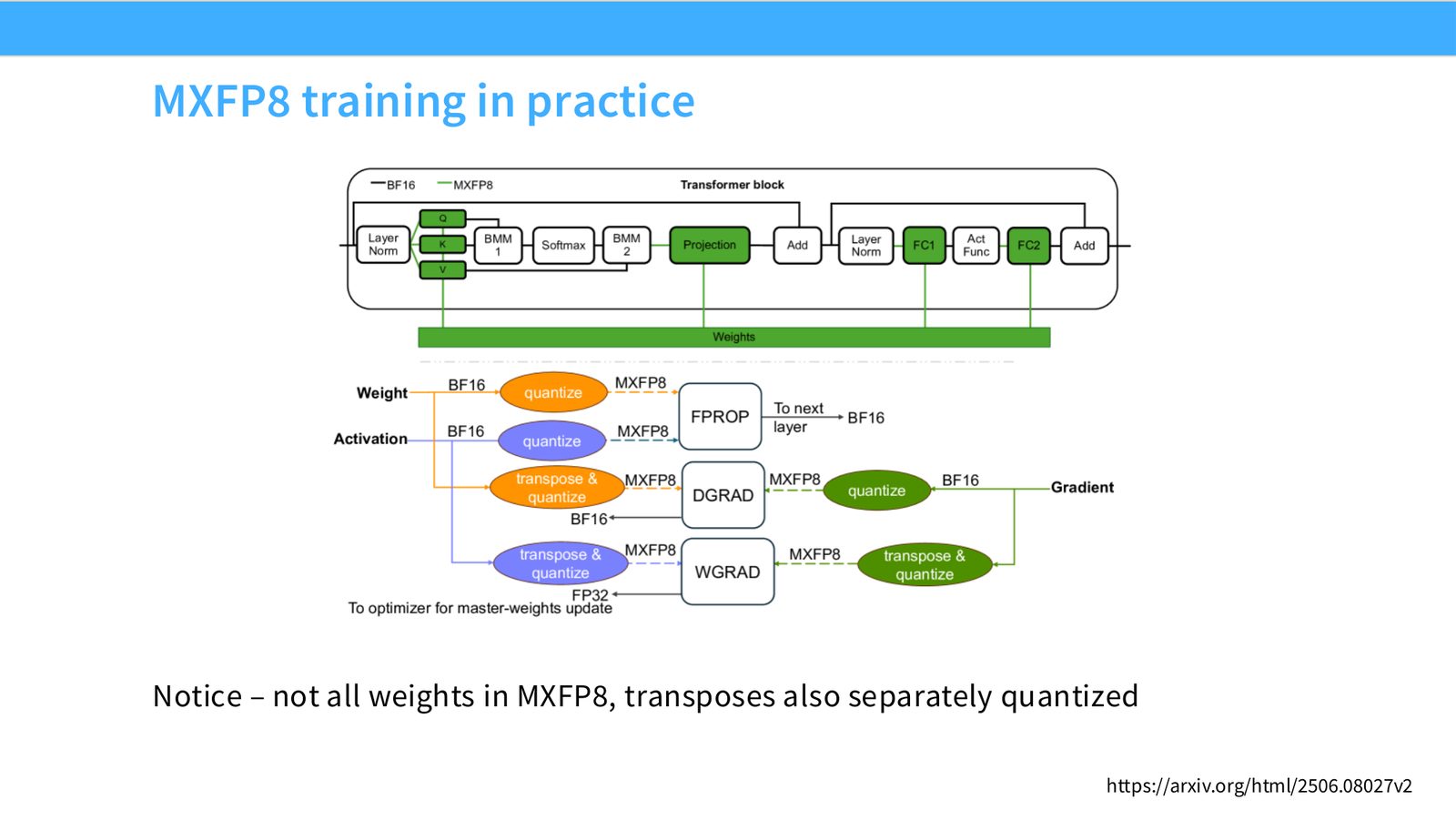
展开说明:Notice – not all weights in MXFP8, transposes also separately quantized
本章小结
本节的共同问题是如何减少昂贵的数据移动并提高硬件利用率。GPU 的速度来自海量并行和专用矩阵硬件,但只有当 memory access、shape、precision 和 kernel 组织匹配时,这些速度才会真正出现。
Operator fusion 与 recomputation:少搬数据
本节用工厂/仓库类比说明 HBM 往返为什么贵,再解释 fusion 和 recomputation 如何减少 memory access。
first-use glossary:operator fusion 与 recomputation
Operator fusion 把多个小 kernel 合成一个 kernel,让中间结果留在寄存器/shared memory 中,减少 HBM 读写。Recomputation 是丢弃某些中间 activations,在需要时重算,用额外 compute 换更低 memory traffic 或 peak memory。
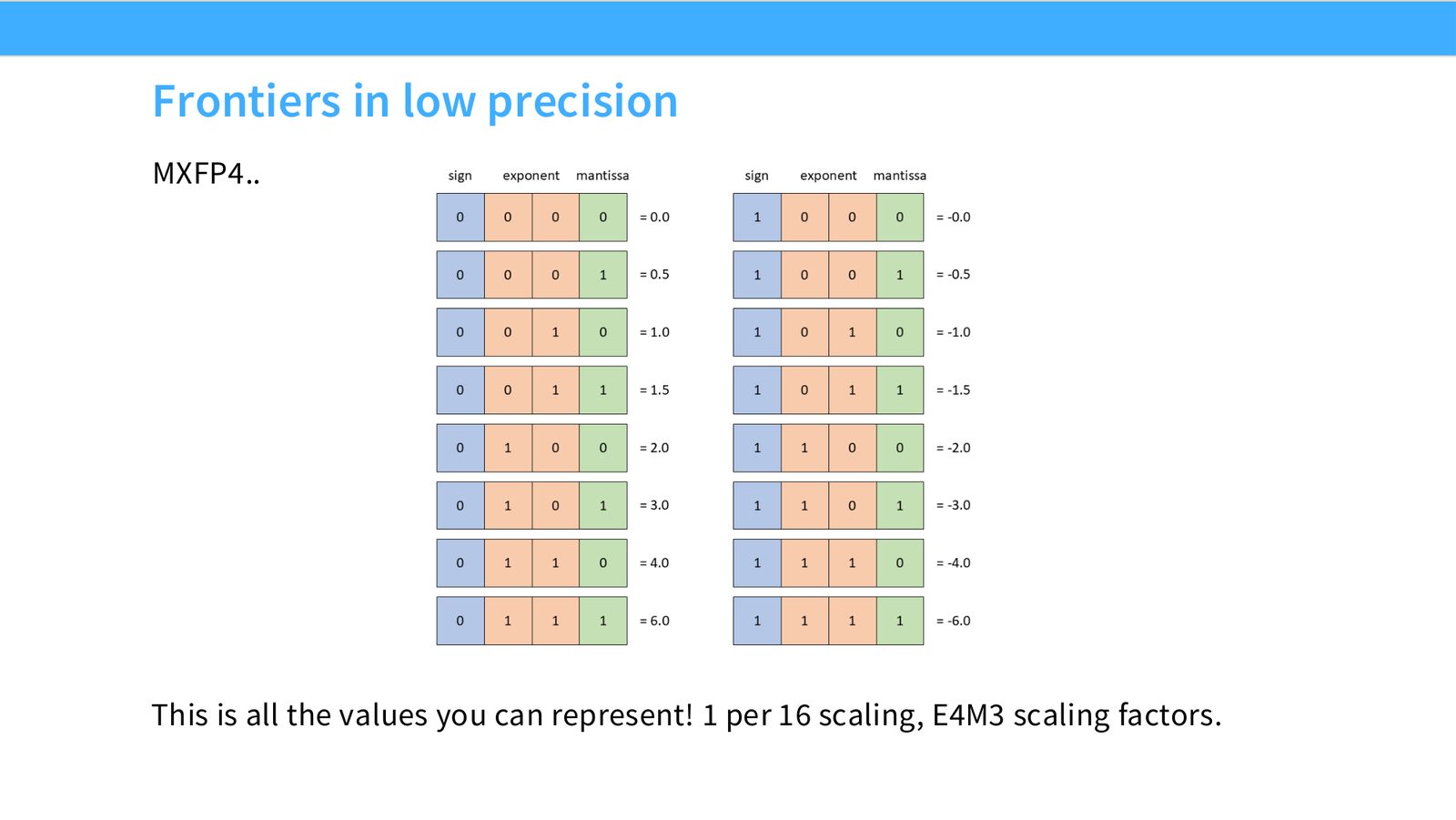
展开说明:MXFP4..
读图:Slide 29 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
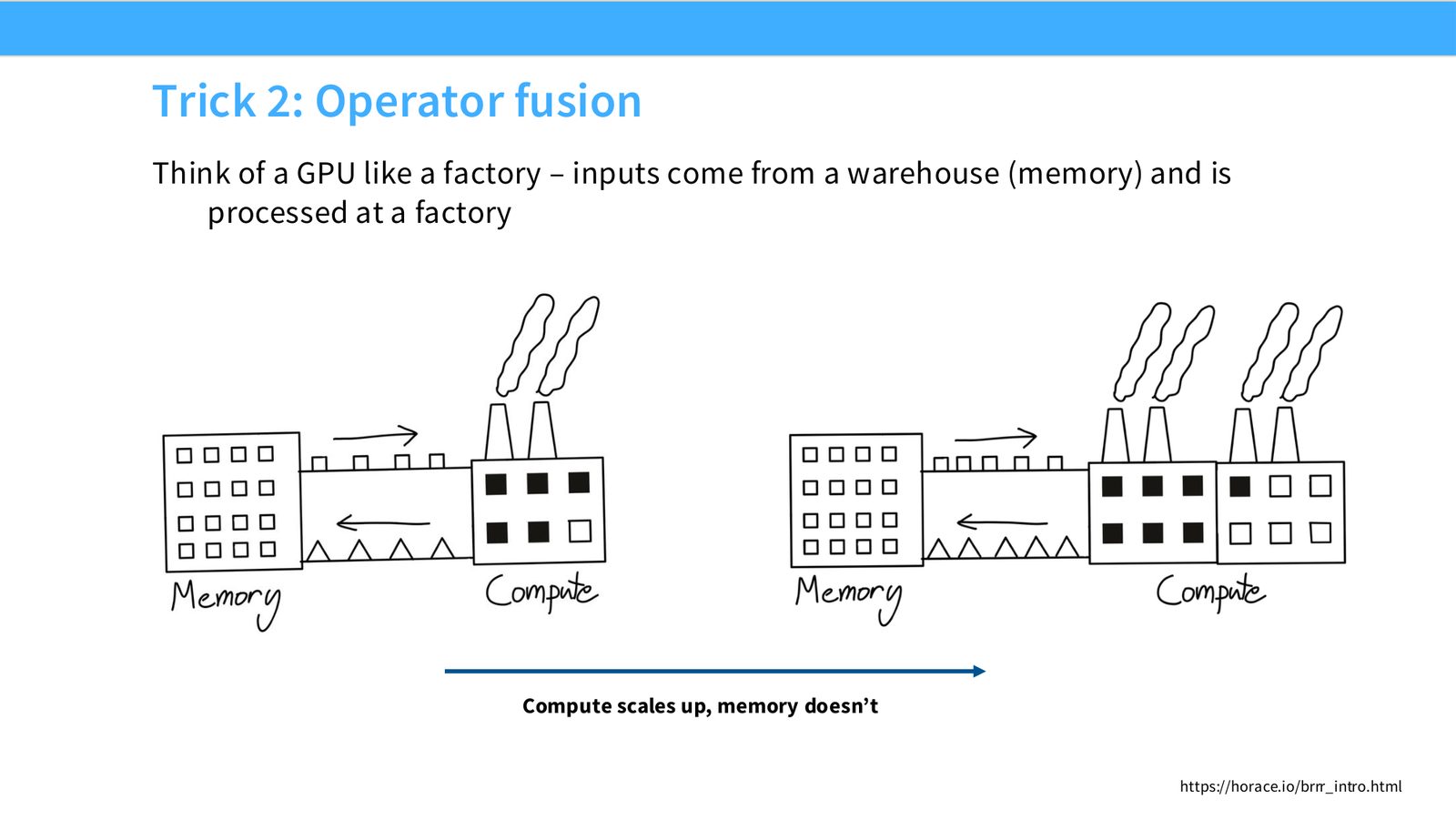
展开说明:Think of a GPU like a factory – inputs come from a warehouse (memory) and is
读图:Slide 30 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
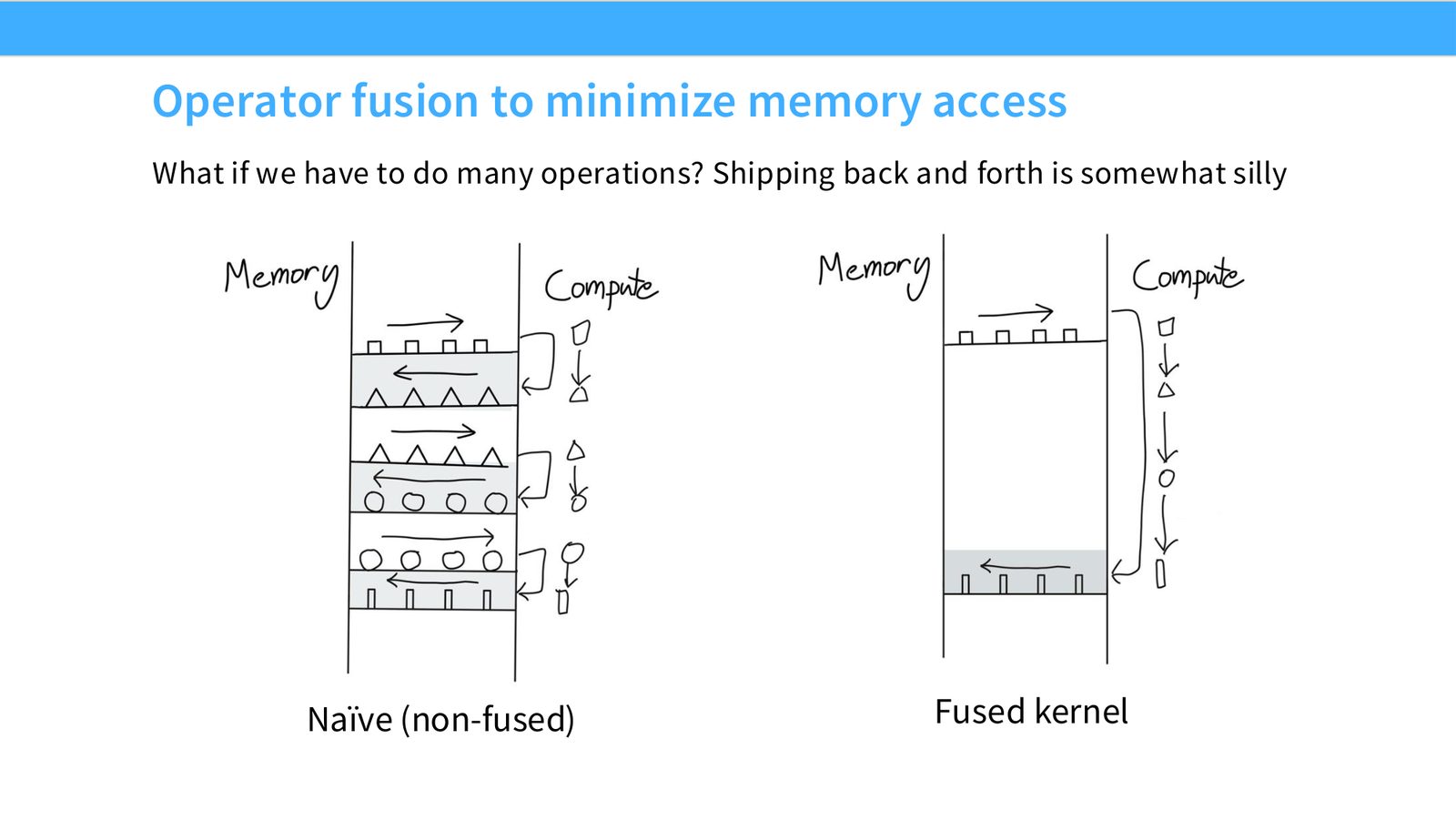
展开说明:What if we have to do many operations? Shipping back and forth is somewhat silly
读图:Slide 31 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
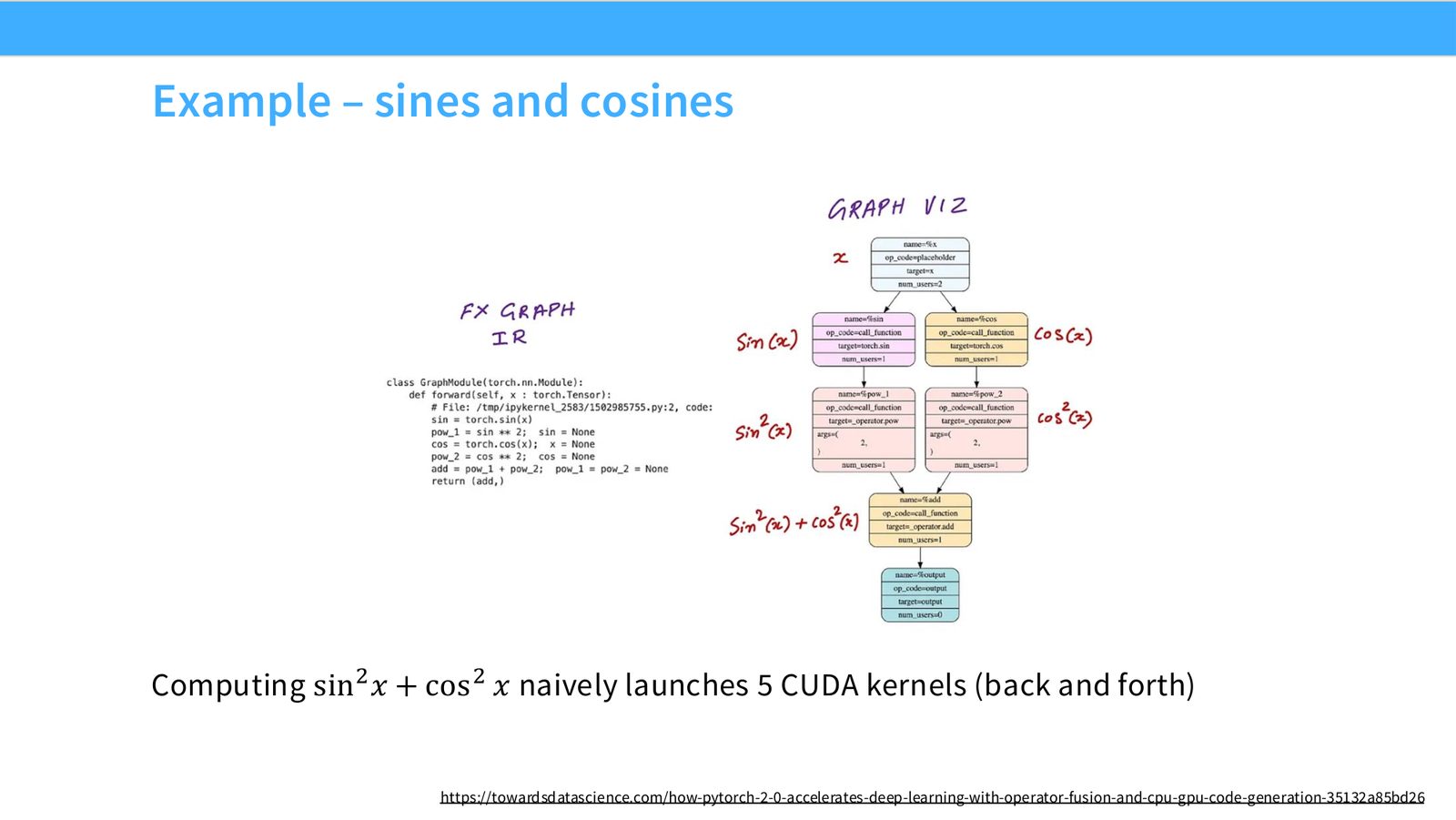
展开说明:Computing sin 2 \(x\) + cos 2 \(x\) naively launches 5 CUDA kernels (back and forth)
读图:Slide 32 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
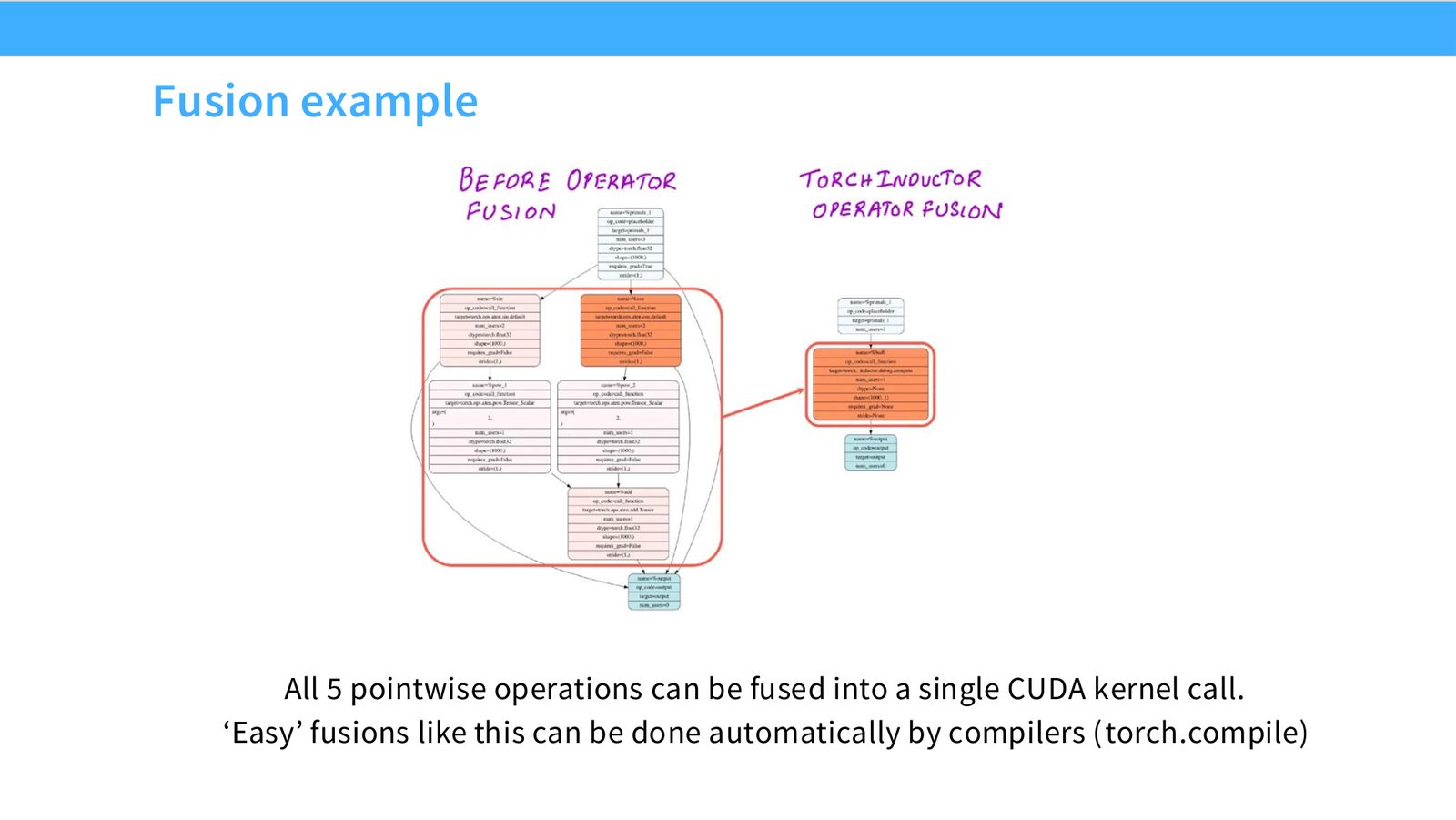
展开说明:All 5 pointwise operations can be fused into a single CUDA kernel call.
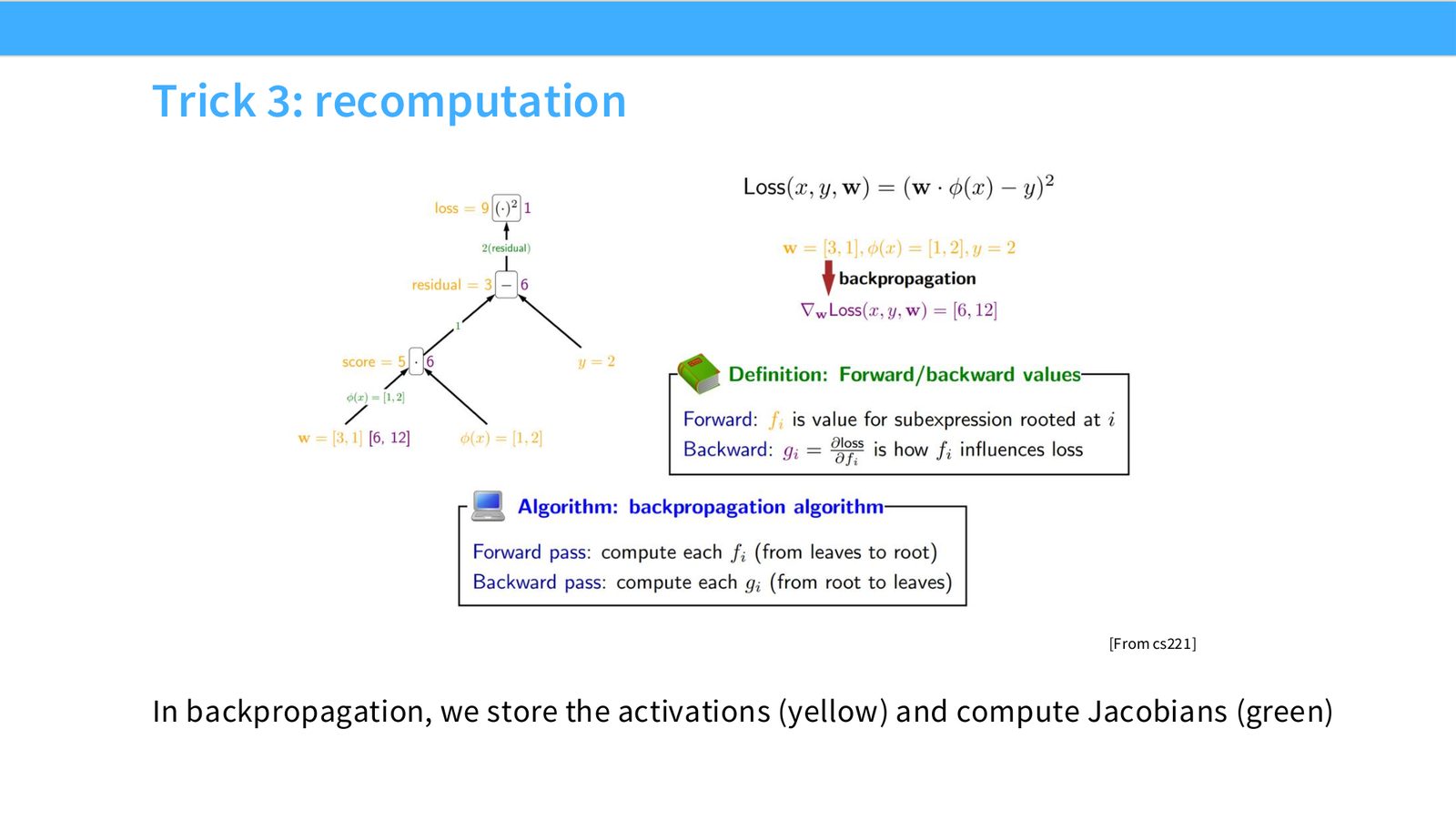
展开说明:[From cs221]
读图:Slide 34 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
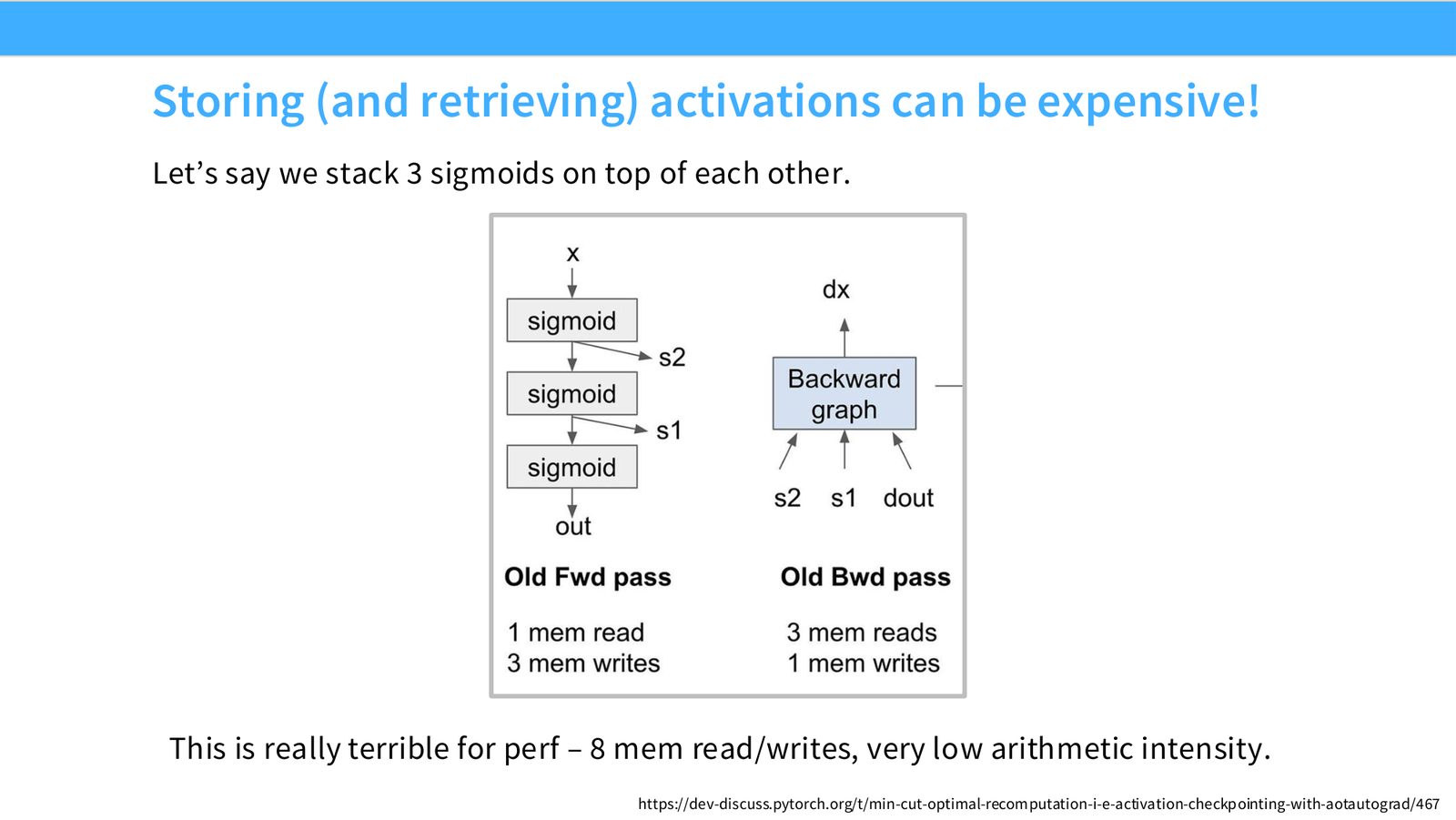
展开说明:Let’s say we stack 3 sigmoids on top of each other.
读图:Slide 35 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
本章小结
本节的共同问题是如何减少昂贵的数据移动并提高硬件利用率。GPU 的速度来自海量并行和专用矩阵硬件,但只有当 memory access、shape、precision 和 kernel 组织匹配时,这些速度才会真正出现。
Coalescing、tiling 与矩阵性能异常
本节解释 DRAM burst、memory coalescing、row-major matmul、tiling、alignment、wave quantization 和 matrix mystery。
first-use glossary:coalescing、tiling、wave quantization
Memory coalescing 指同一个 warp 的 memory accesses 落在连续 burst 中,从而合并成高效访问。Tiling 把大矩阵切成小块放入 shared memory 重复使用。Wave quantization 指 thread blocks 数量不能完美填满 SM waves 时产生的周期性利用率波动。
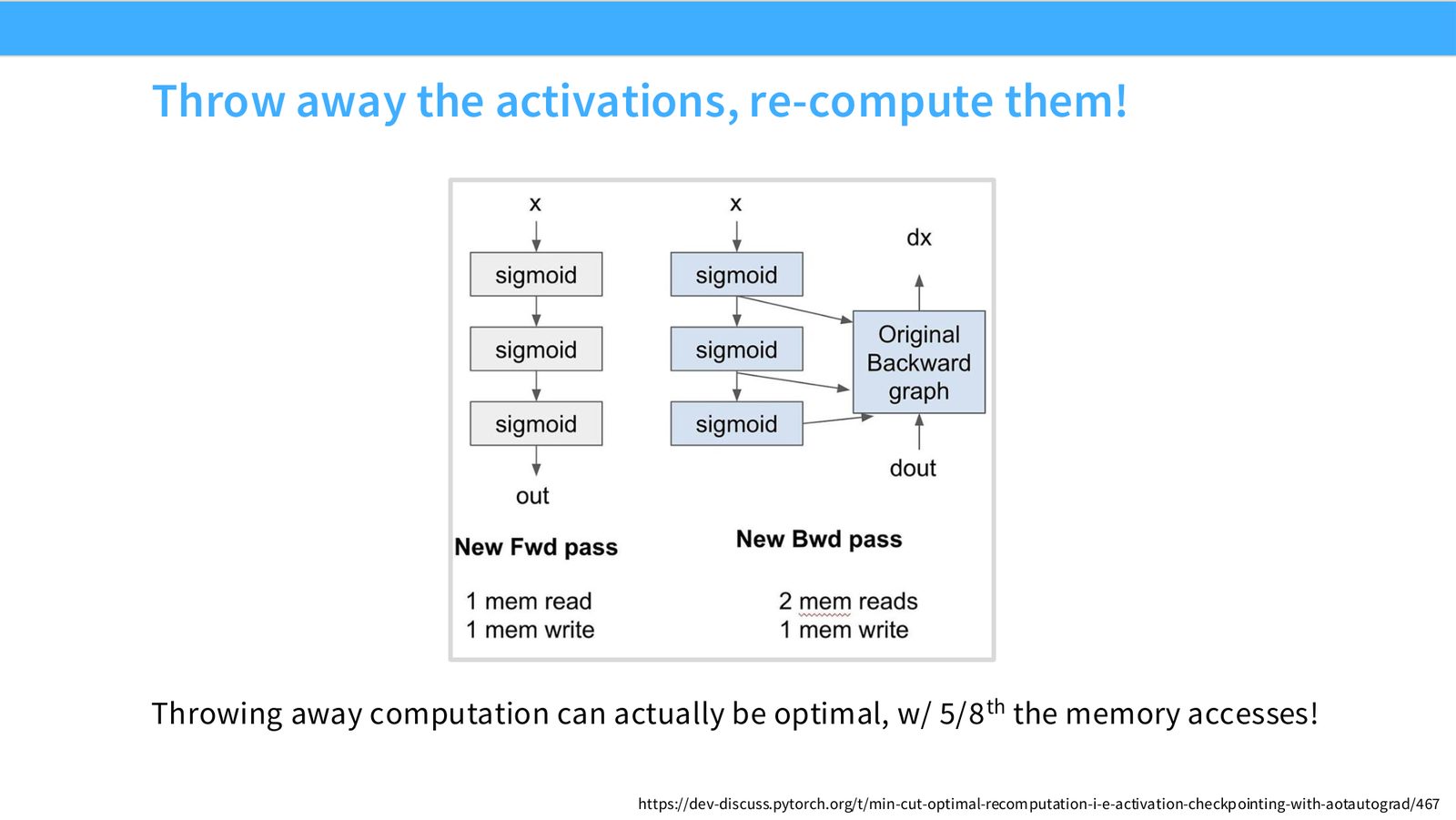
展开说明:Throwing away computation can actually be optimal, w/ 5/8 th the memory accesses!
读图:Slide 36 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
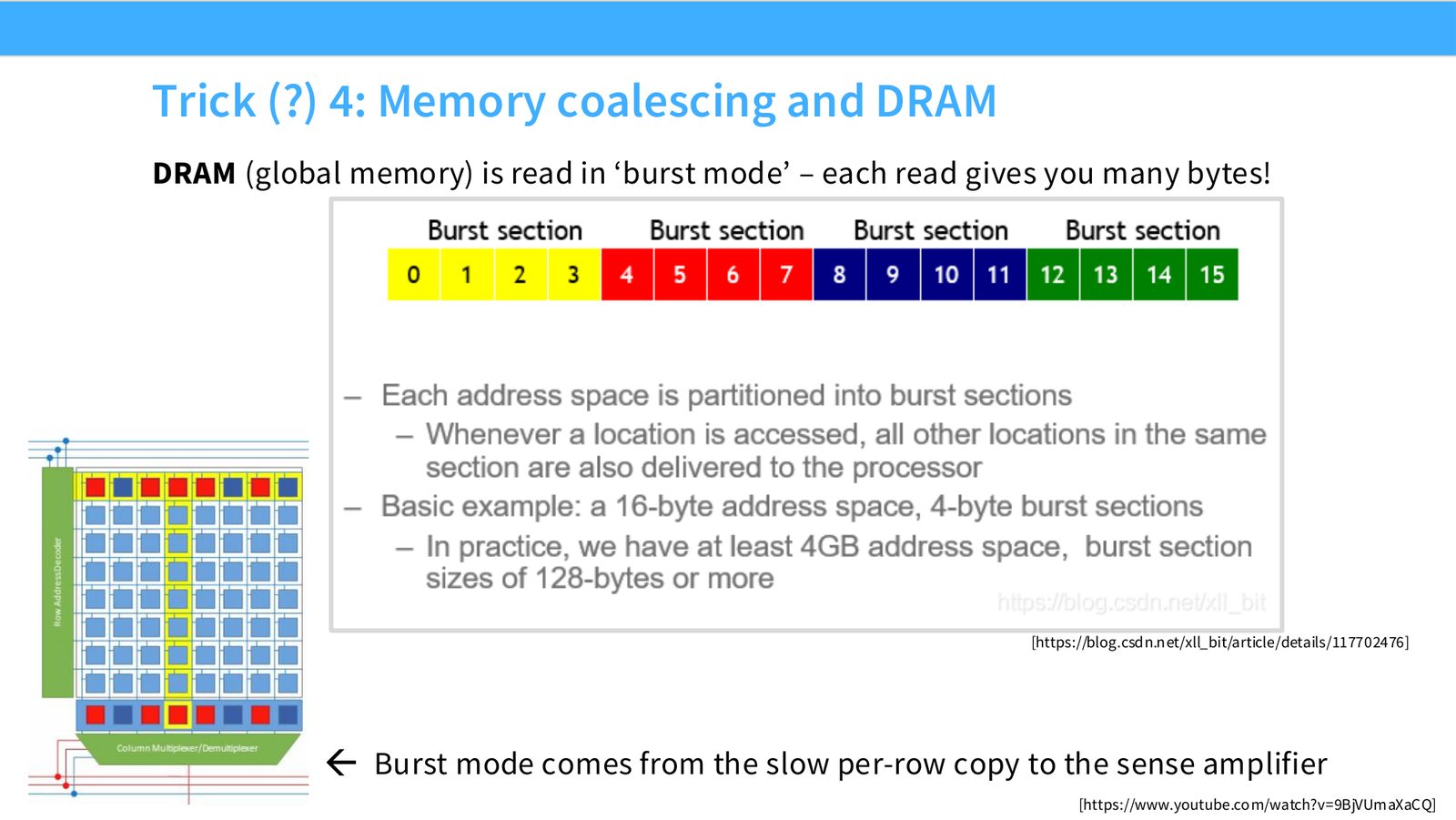
展开说明:DRAM (global memory) is read in ‘burst mode’ – each read gives you many bytes!
读图:Slide 37 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
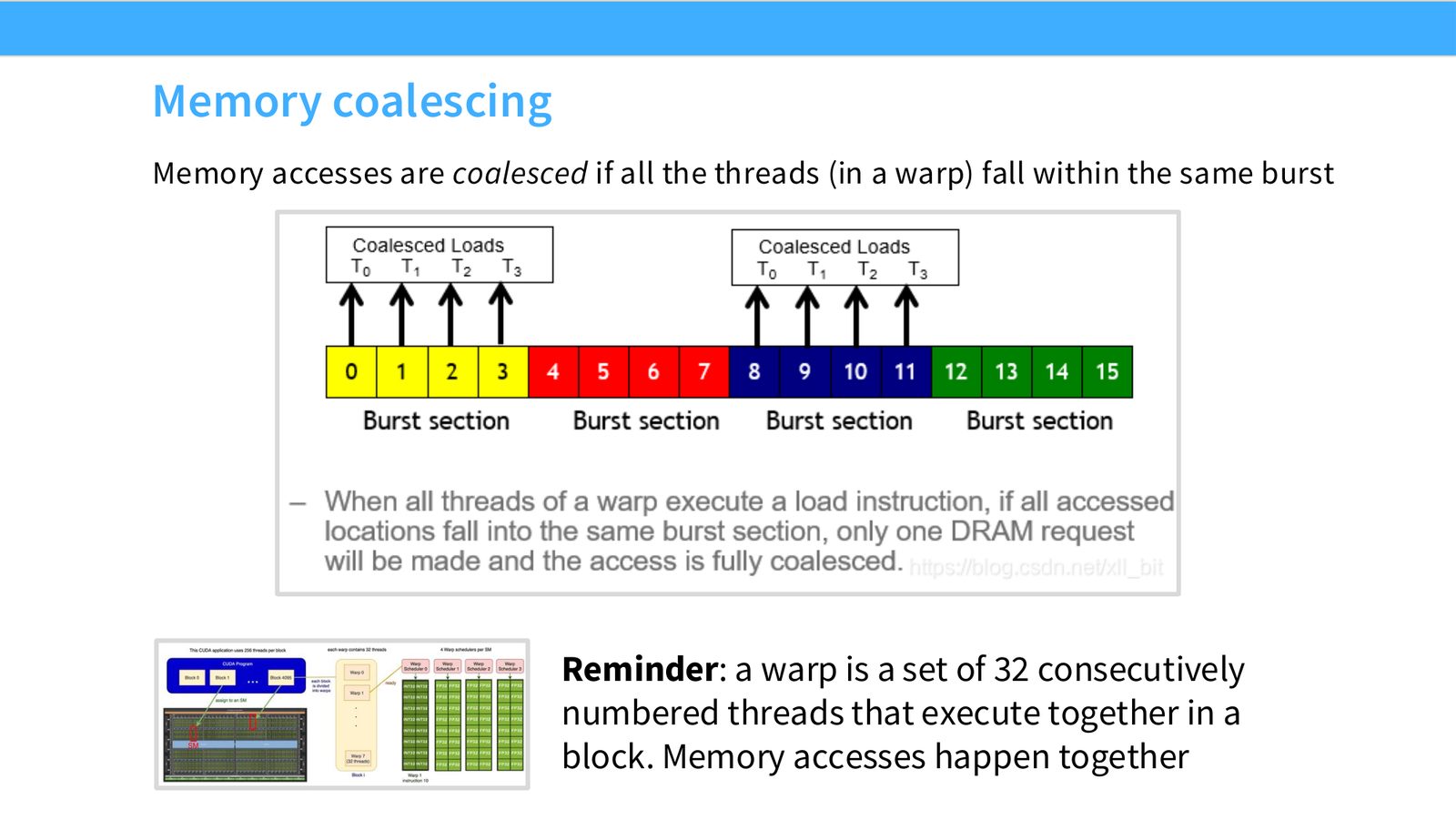
展开说明:Memory accesses are coalesced if all the threads (in a warp) fall within the same burst
读图:Slide 38 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
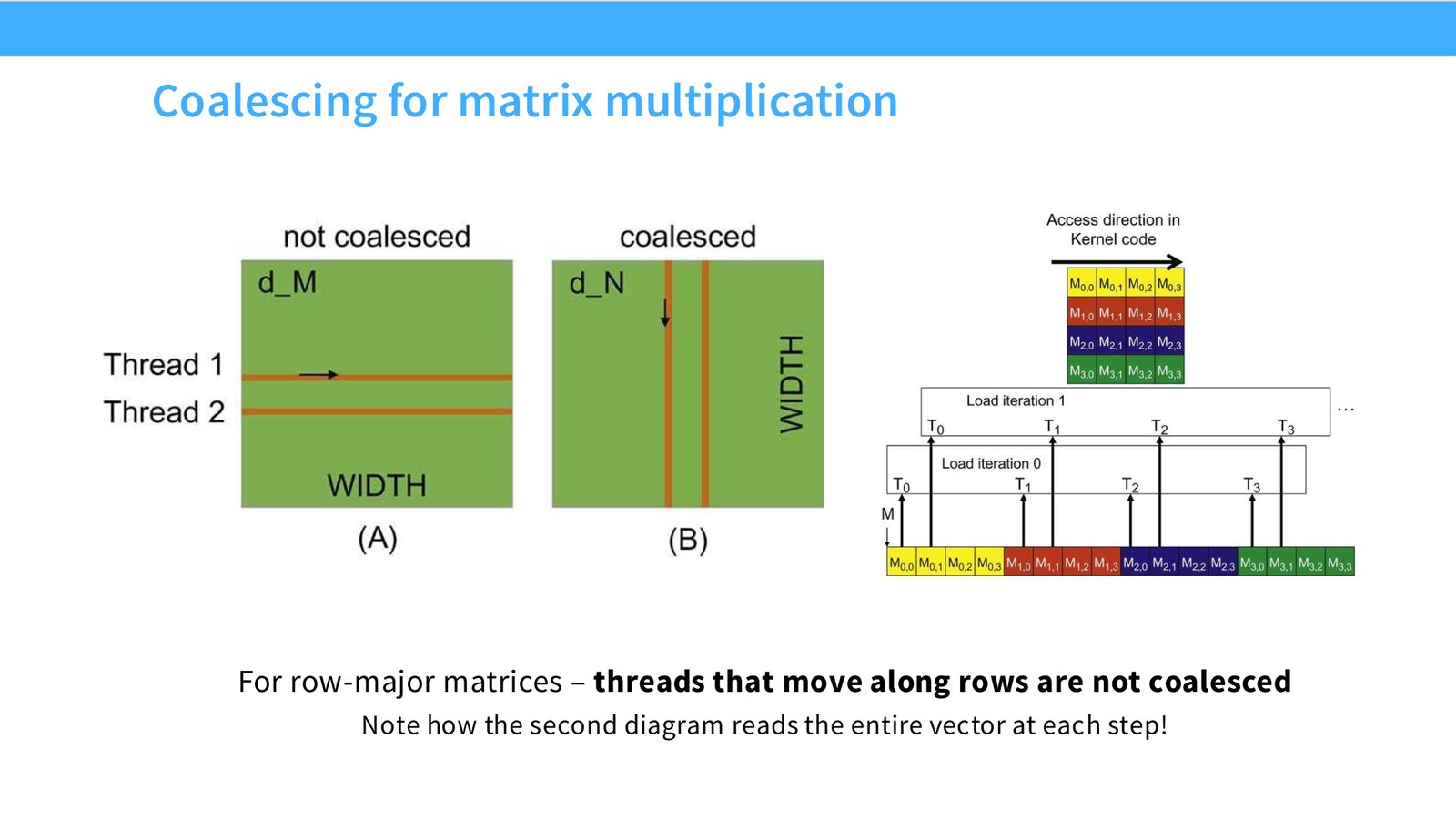
展开说明:For row-major matrices – threads that move along rows are not coalesced
读图:Slide 39 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
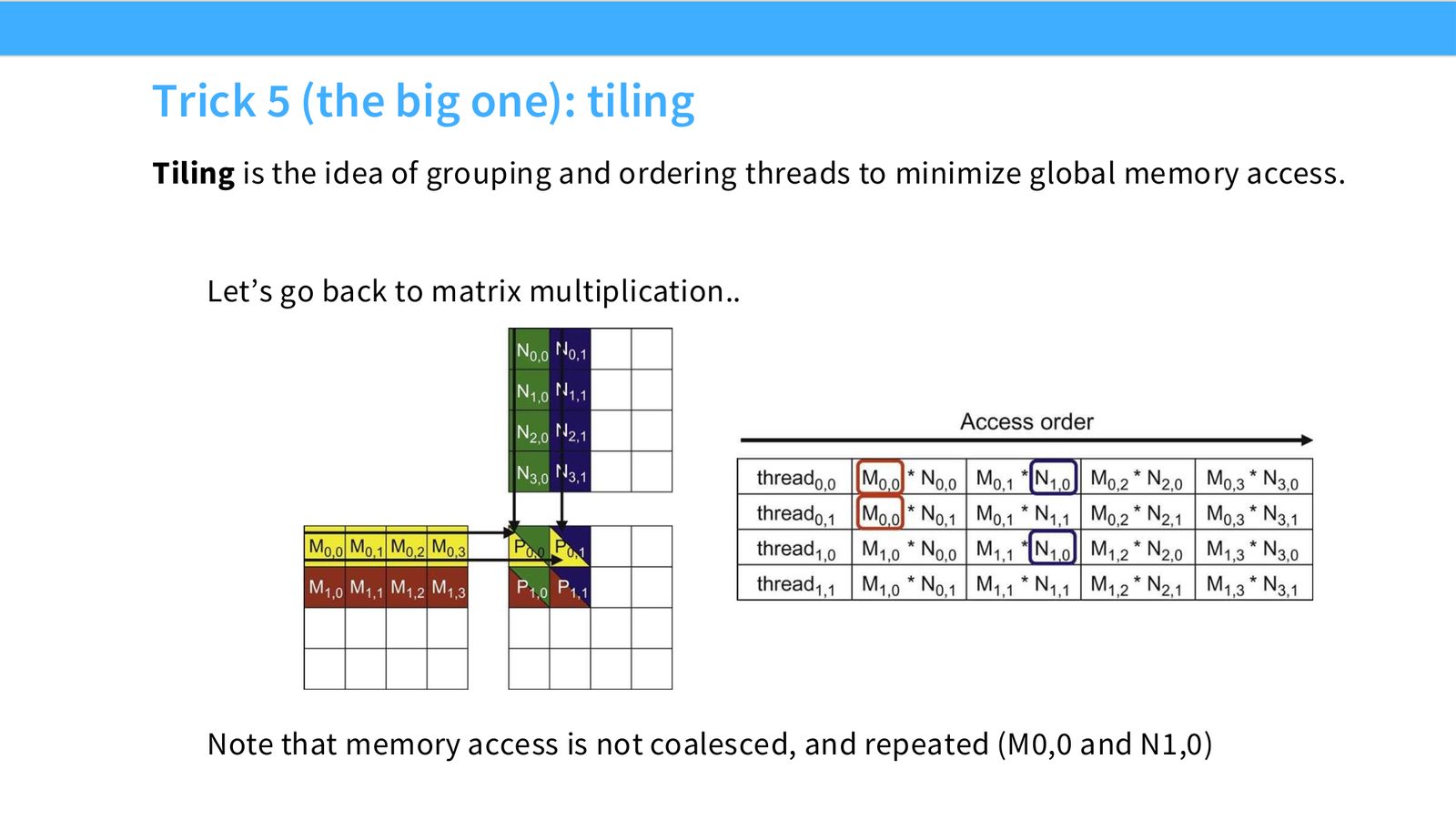
展开说明:Tiling is the idea of grouping and ordering threads to minimize global memory access.
读图:Slide 40 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
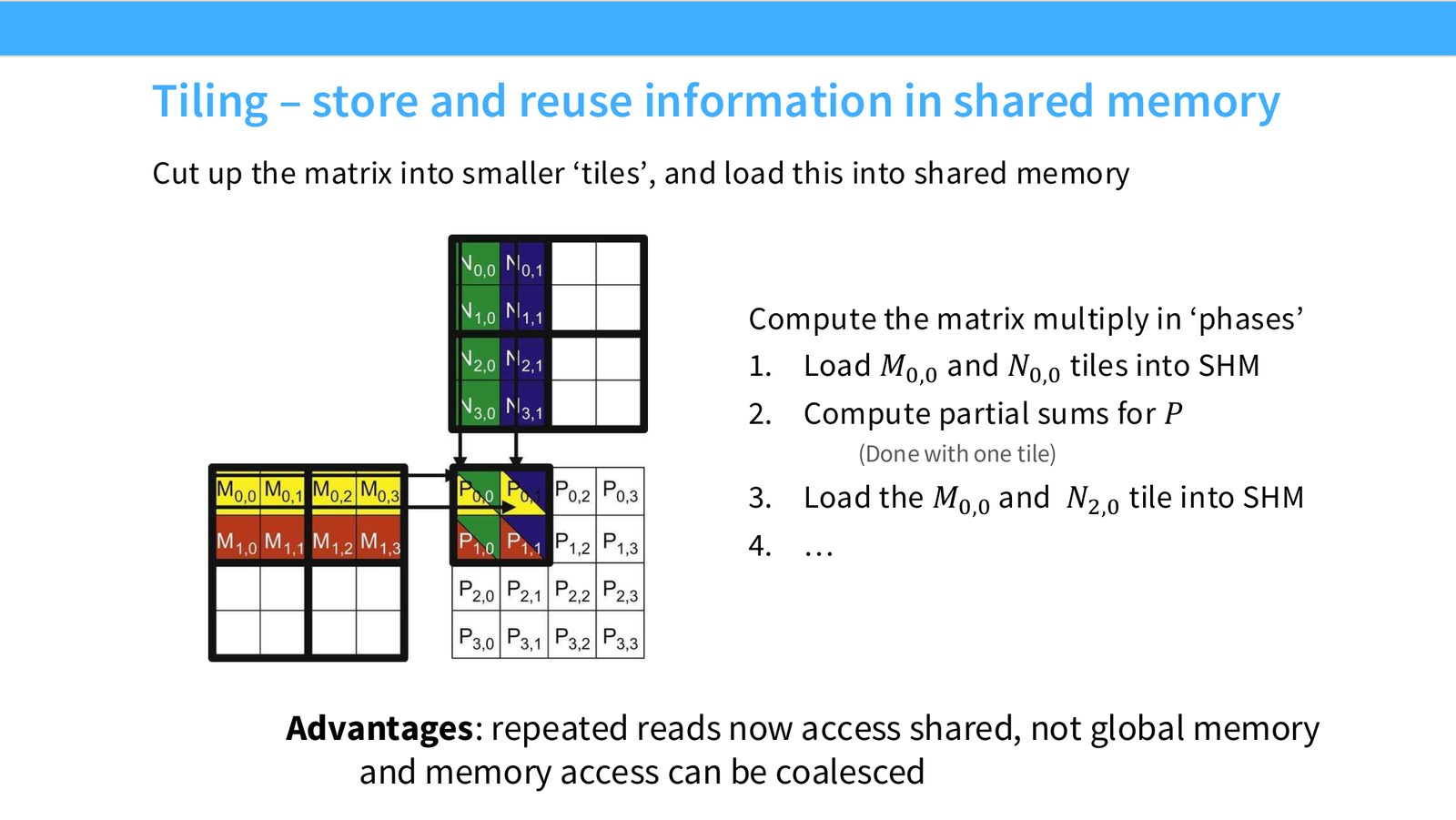
展开说明:Cut up the matrix into smaller ‘tiles’, and load this into shared memory
读图:Slide 41 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
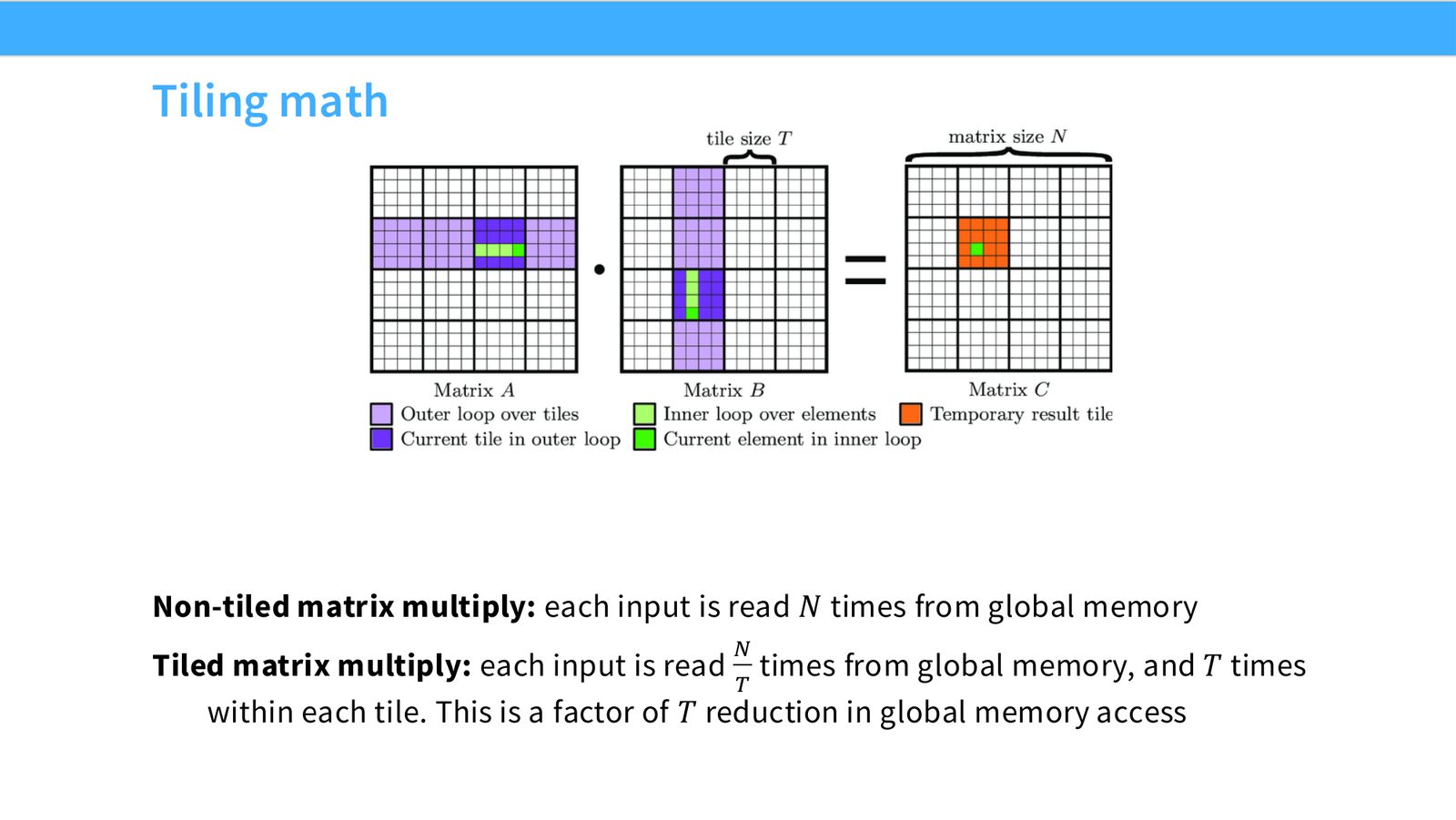
展开说明:Non-tiled matrix multiply: each input is read \(N\) times from global memory
读图:Slide 42 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
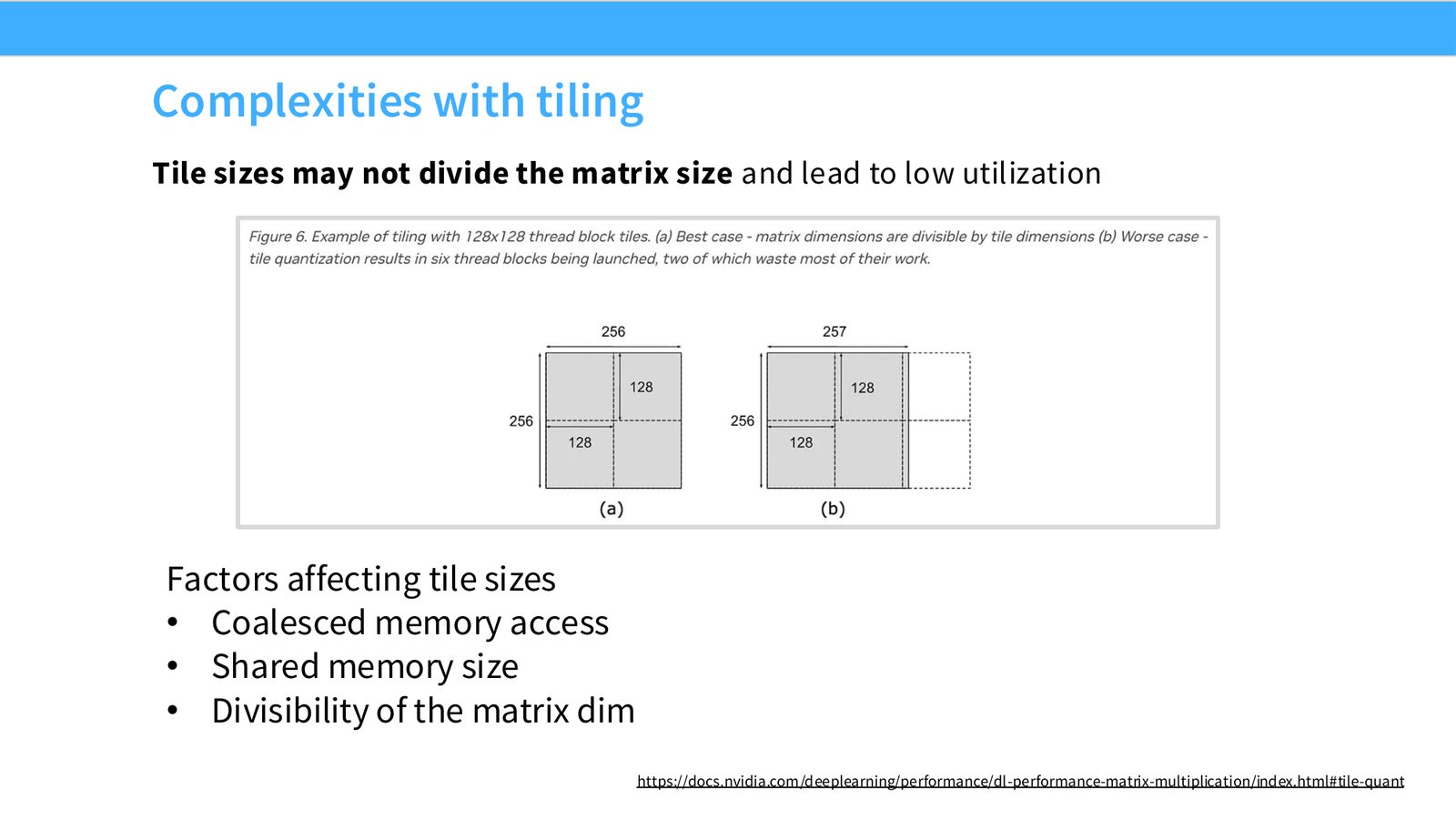
展开说明:Tile sizes may not divide the matrix size and lead to low utilization
读图:Slide 43 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
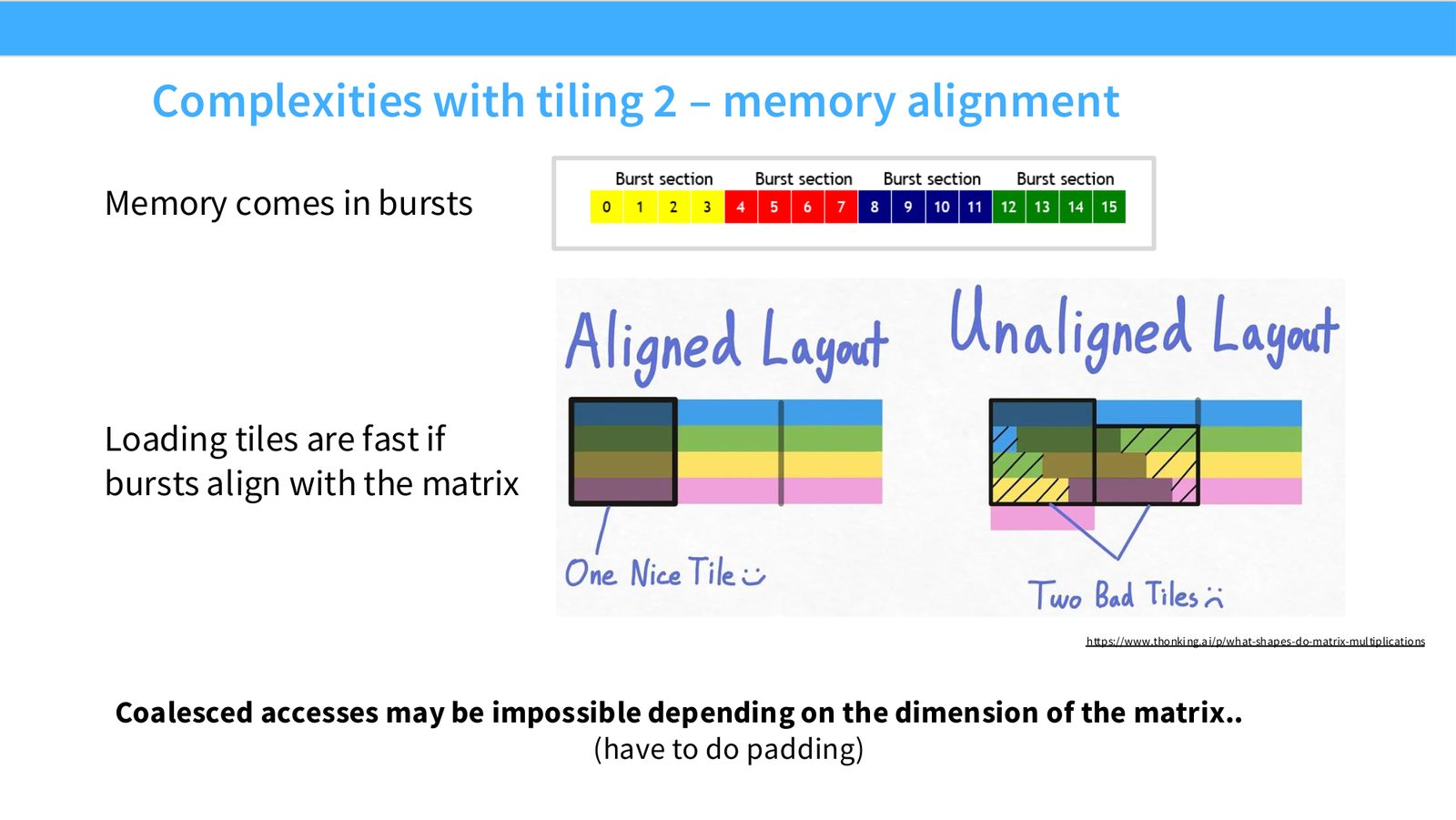
展开说明:Memory comes in bursts
读图:Slide 44 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
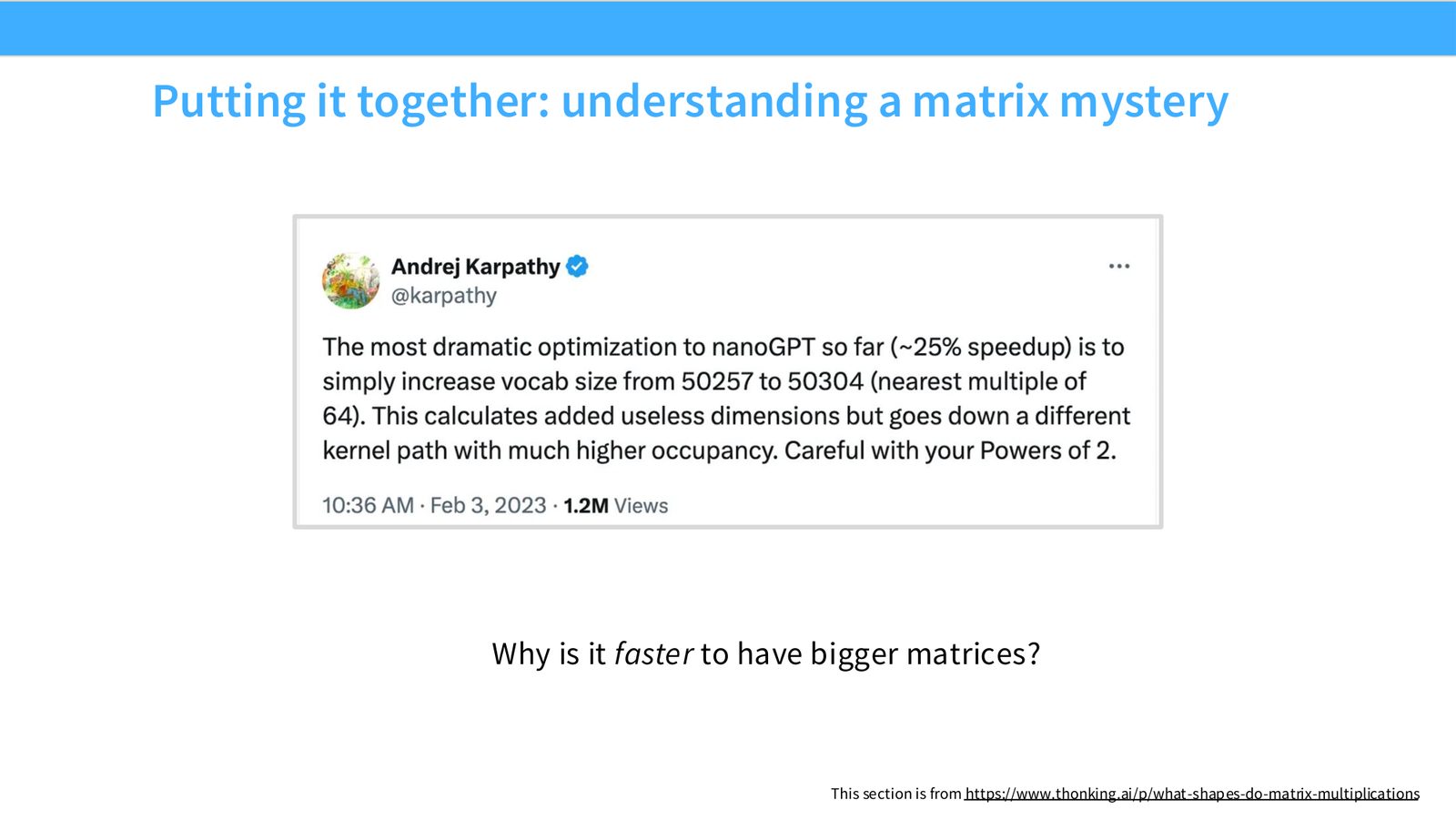
展开说明:Why is it faster to have bigger matrices?
读图:Slide 45 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
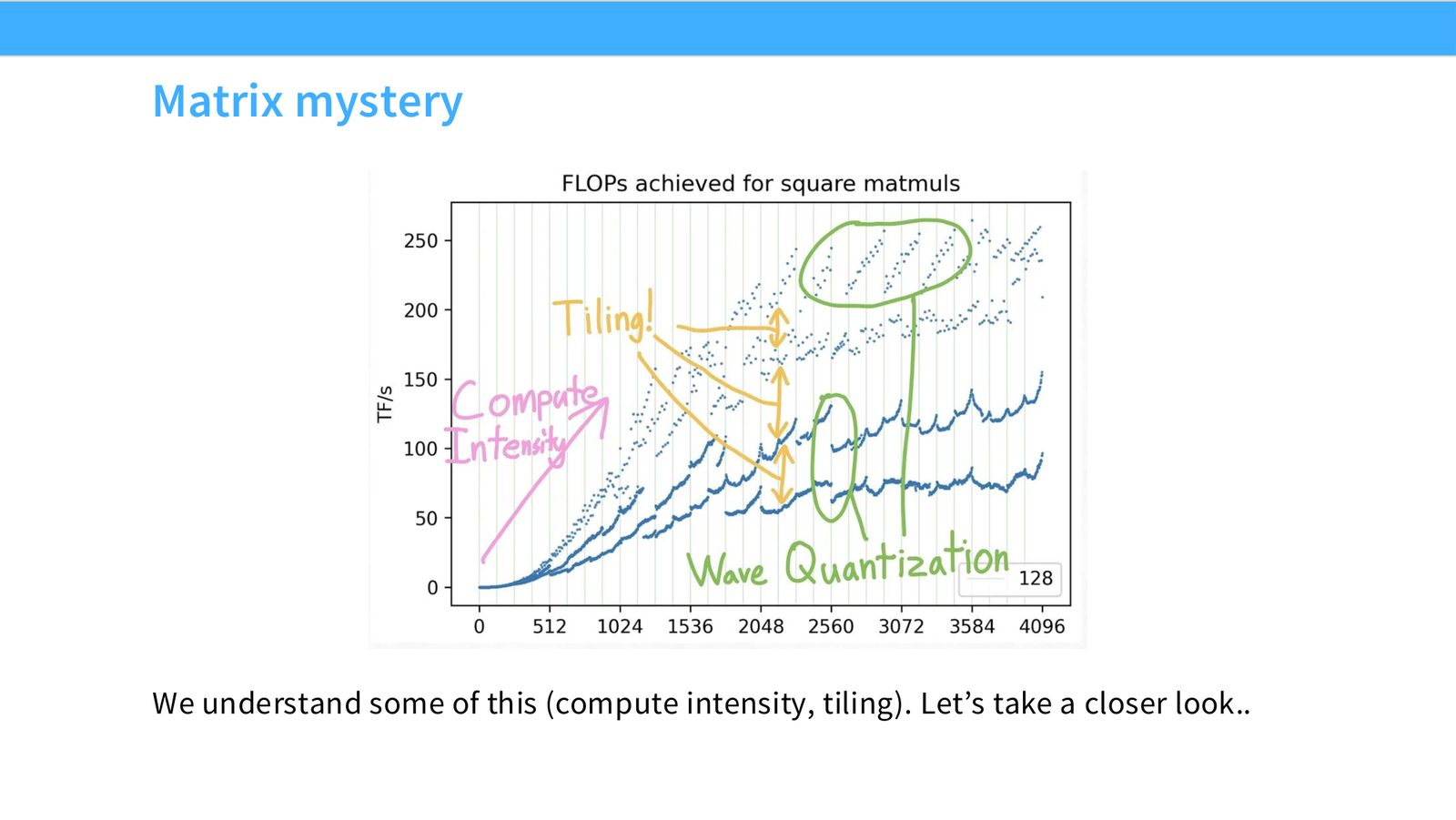
展开说明:We understand some of this (compute intensity, tiling). Let’s take a closer look..
读图:Slide 46 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
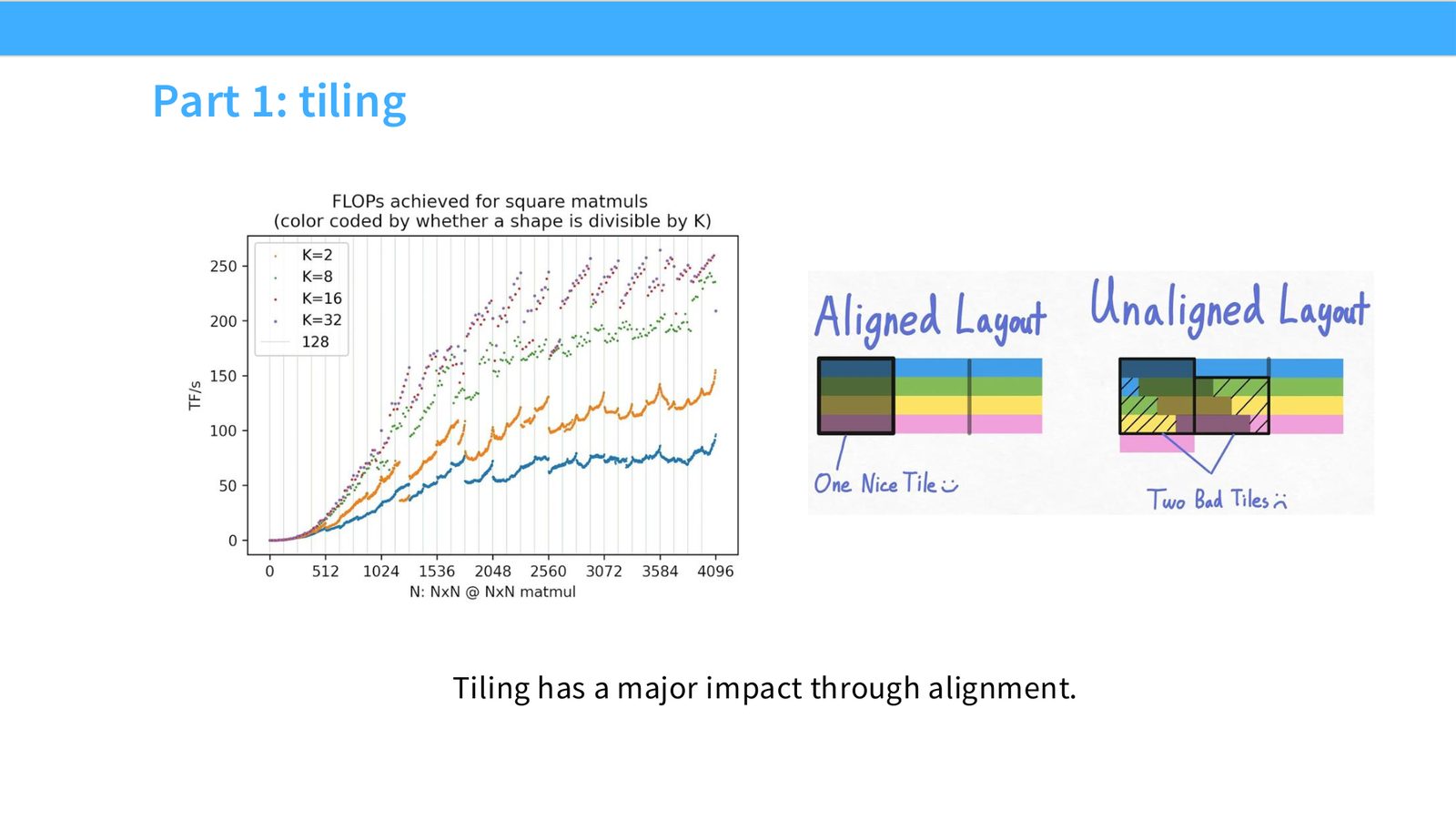
展开说明:Tiling has a major impact through alignment.
读图:Slide 47 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
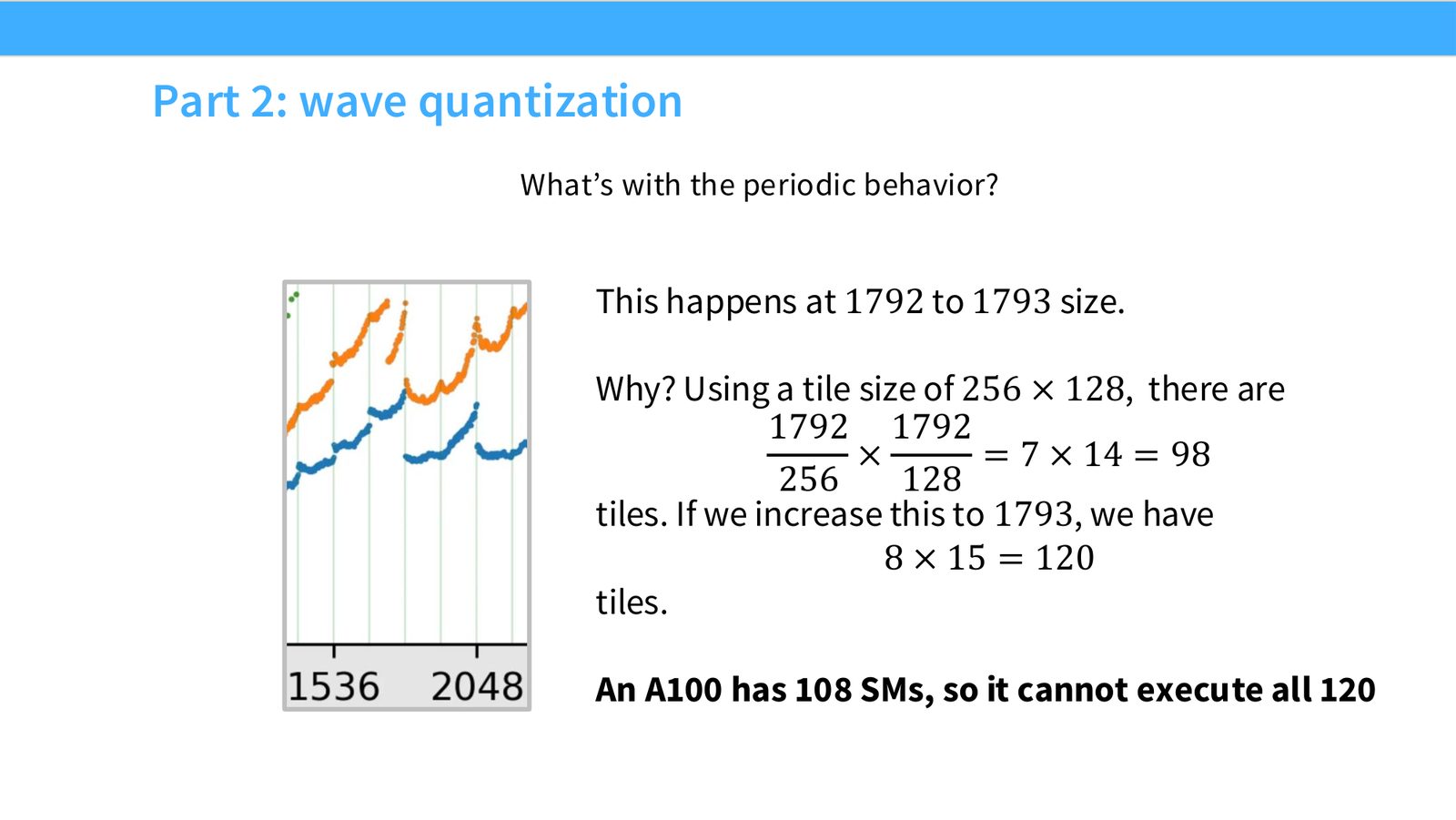
展开说明:What’s with the periodic behavior?
本章小结
本节的共同问题是如何减少昂贵的数据移动并提高硬件利用率。GPU 的速度来自海量并行和专用矩阵硬件,但只有当 memory access、shape、precision 和 kernel 组织匹配时,这些速度才会真正出现。
FlashAttention:把 attention 写成 IO-aware 算法
本节把前面所有硬件技巧汇总到 FlashAttention:KQV tiling、online softmax、forward pass 分块。
FlashAttention 的本质
FlashAttention 不是改变 attention 数学,而是改变计算顺序:把 Q/K/V 分块载入 SRAM,分块计算 softmax 统计量并在线更新输出,避免把完整 \(n\times n\) attention matrix 写回 HBM。
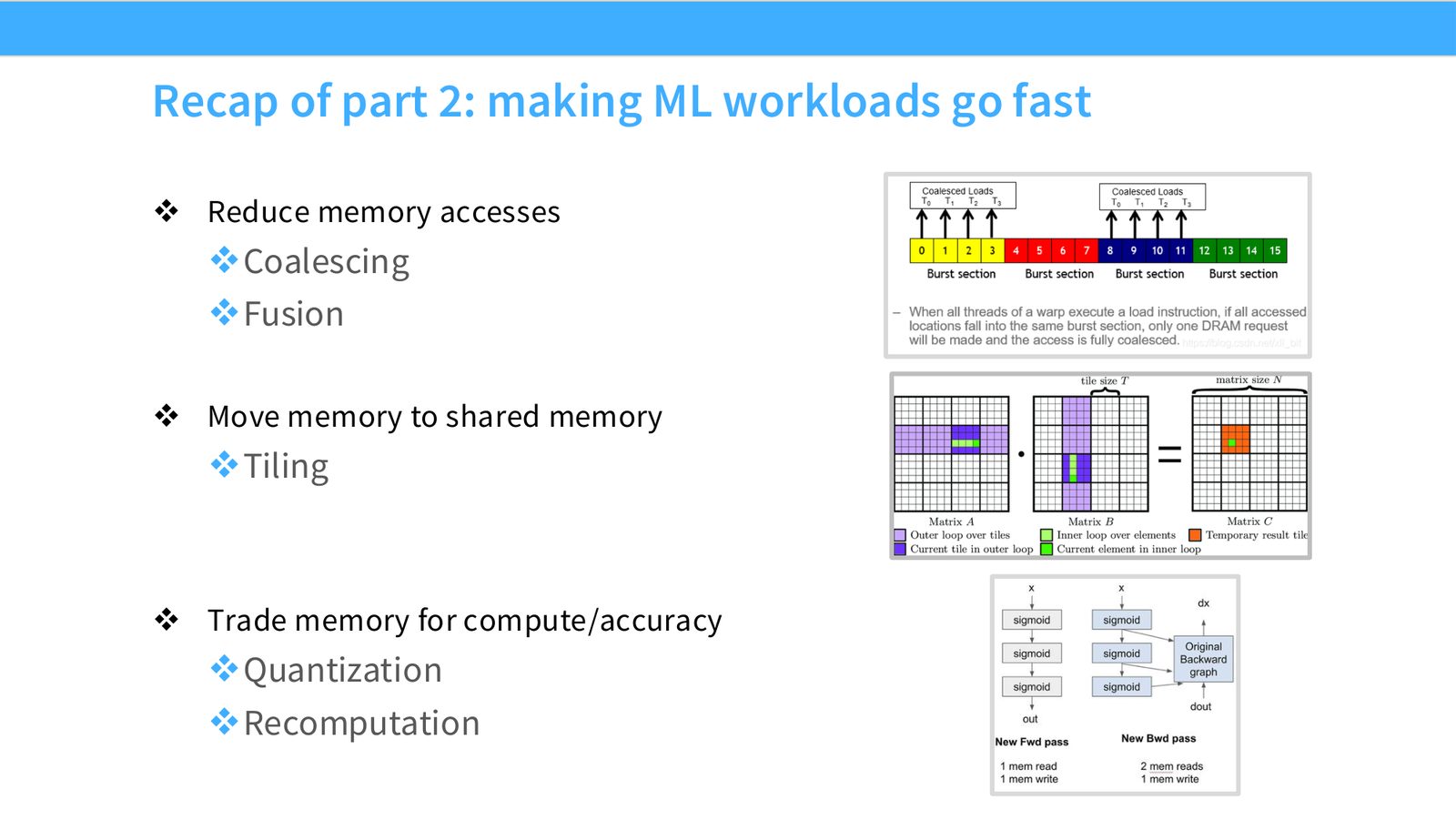
展开说明: Reduce memory accesses
读图:Slide 49 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
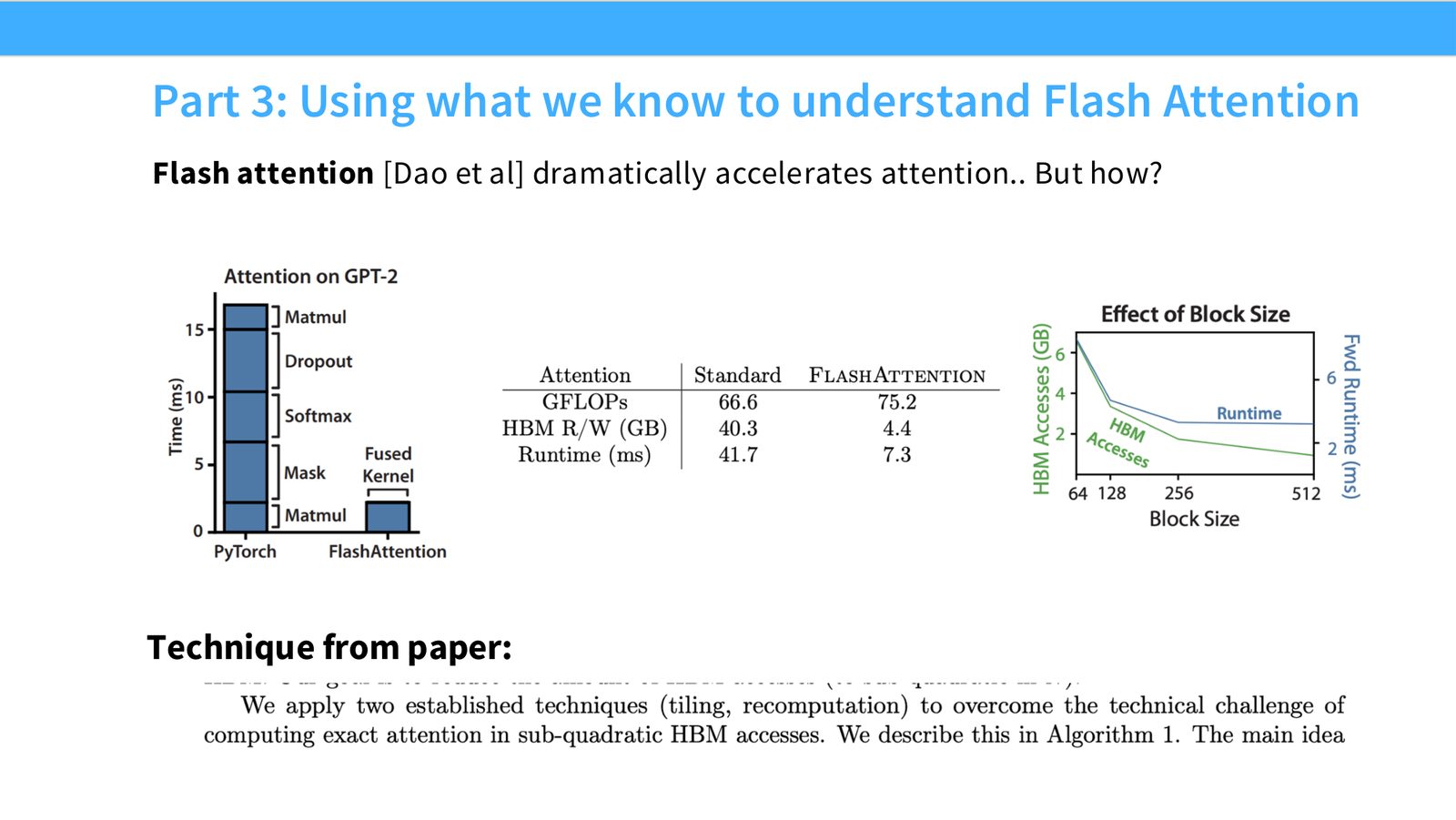
展开说明:Flash attention [Dao et al] dramatically accelerates attention.. But how?
读图:Slide 50 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
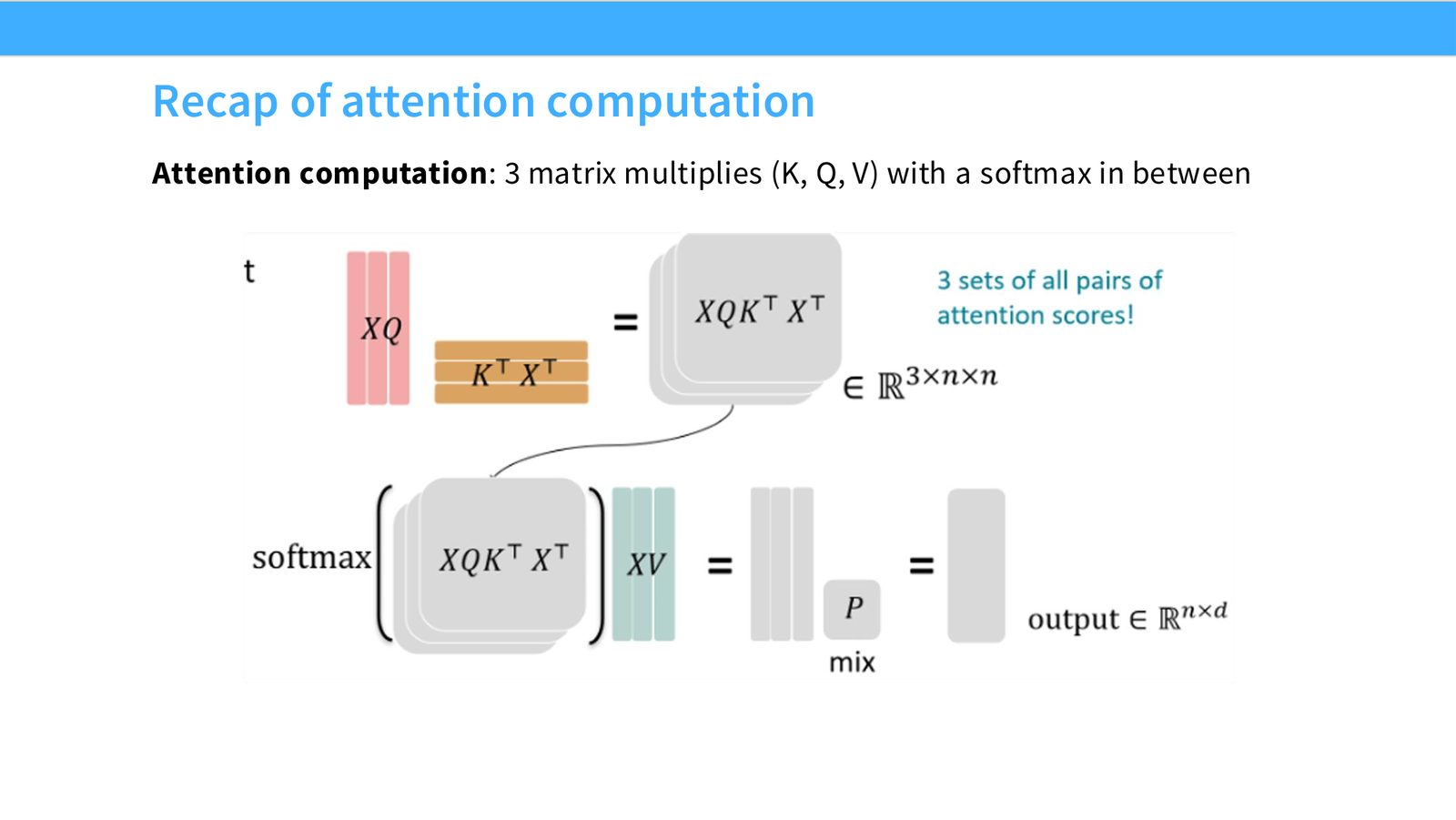
展开说明:Attention computation: 3 matrix multiplies (K, Q, V) with a softmax in between
读图:Slide 51 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
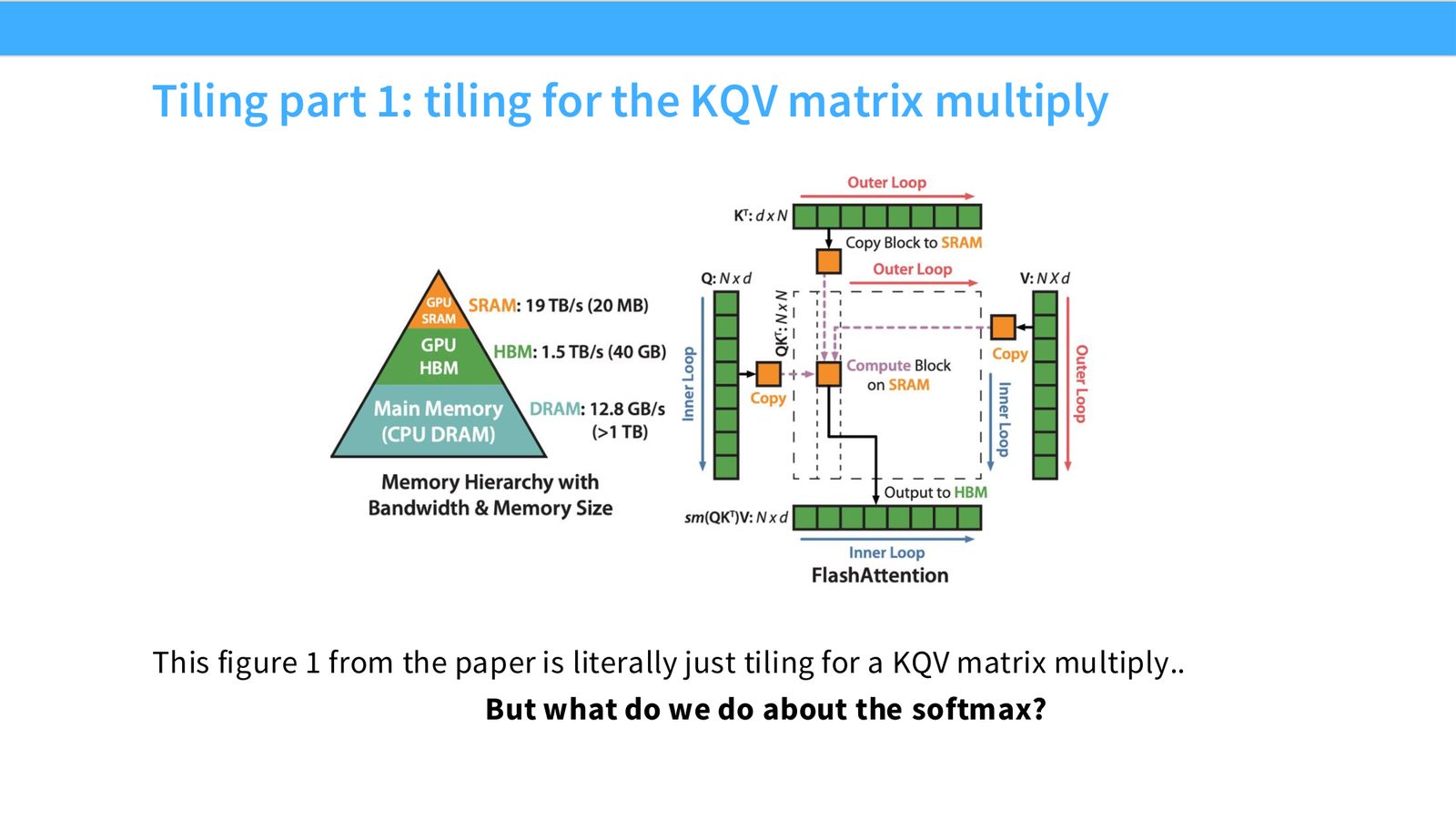
展开说明:This figure 1 from the paper is literally just tiling for a KQV matrix multiply..
读图:Slide 52 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。

展开说明:From Mikailov and Gimelshein 2018,
读图:Slide 53 应该怎么看
这页是硬件机制或性能证据页。先看数据从哪里来、在哪里复用、是否写回 HBM;再判断瓶颈是 compute、memory bandwidth、thread scheduling 还是 alignment。GPU 优化不是让公式更漂亮,而是让数据在正确层级停留更久、让 tensor cores 少等数据。
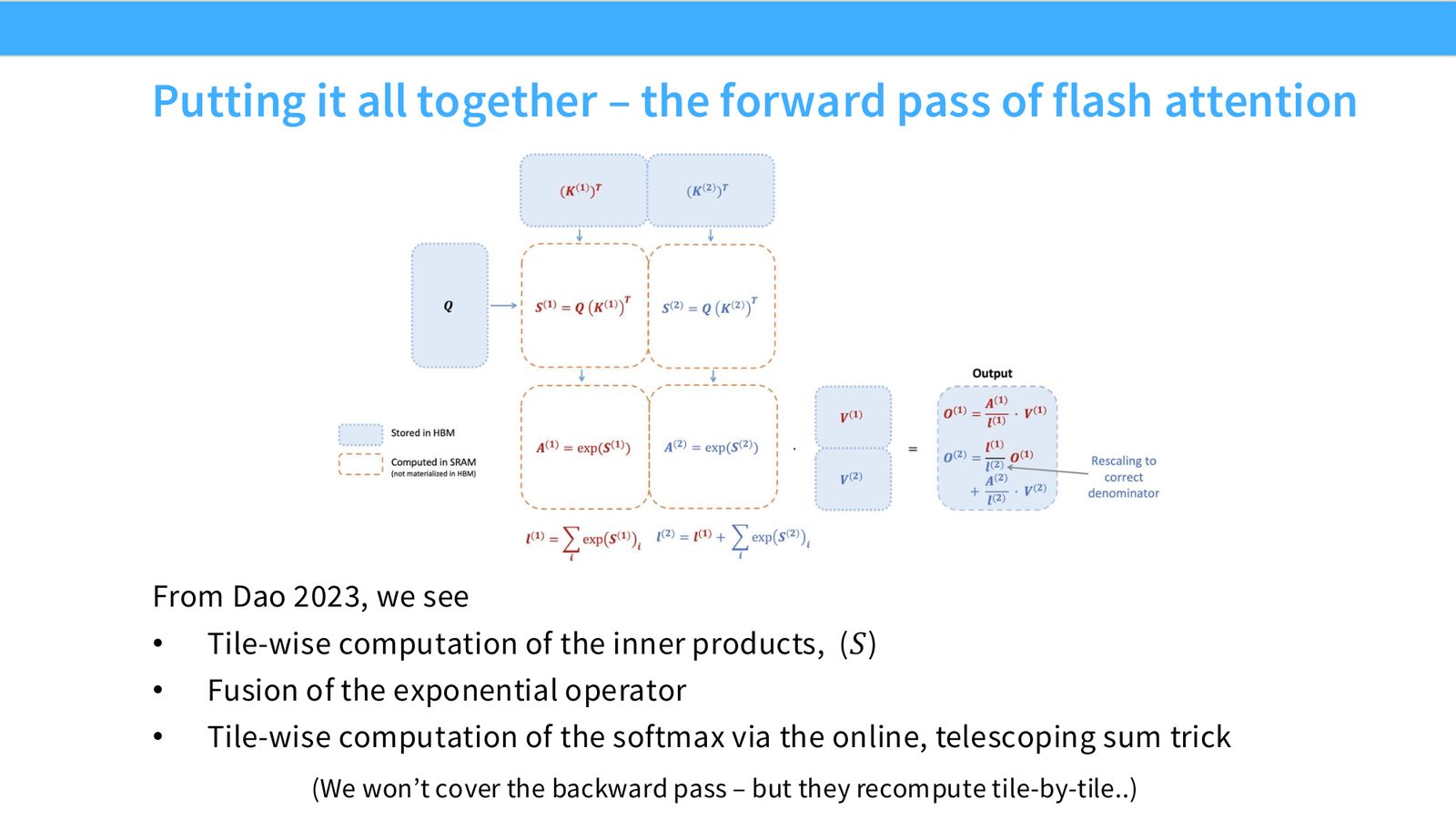
展开说明:From Dao 2023, we see
本章小结
本节的共同问题是如何减少昂贵的数据移动并提高硬件利用率。GPU 的速度来自海量并行和专用矩阵硬件,但只有当 memory access、shape、precision 和 kernel 组织匹配时,这些速度才会真正出现。
总结
最后综合 GPU 低层细节如何支撑模型 scaling。

展开说明: Hardware powers scale, and low-level details
本章小结
本节的共同问题是如何减少昂贵的数据移动并提高硬件利用率。GPU 的速度来自海量并行和专用矩阵硬件,但只有当 memory access、shape、precision 和 kernel 组织匹配时,这些速度才会真正出现。
总结与延伸
Lecture 5 把 GPU 性能拆成三个层级:硬件结构、算子组织、算法重排。硬件层给出 SM/warp/shared memory/HBM/tensor cores;算子层使用 low precision、fusion、coalescing、tiling;算法层用 FlashAttention 这类 IO-aware 设计避免不必要 HBM 写回。
最终 takeaway
大模型训练不是“把 PyTorch 放到 GPU 上”这么简单。真正的 GPU-aware thinking 是:每个 byte 从 HBM 进来后要被复用多少次?中间结果是否必须写回?thread/warp/block 是否对齐硬件?算法能否重排成更少 IO 的形式?
拓展阅读
- NVIDIA CUDA Programming Guide and H100/B200 architecture material.
- JAX Scaling Book roofline and inference chapters.
- Dao et al. FlashAttention papers.
- NVIDIA Transformer Engine low precision documentation.