MIT 6.S191: Convolutional Neural Networks
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Alexander Amini 授课内容整理 |
| 来源 | Alexander Amini (MIT) |
| 日期 | 2025年春季 |

引言:什么是计算机视觉
视觉是人类最重要的感官之一。它使我们能够检测和解读情感与面部表情、在世界中导航、操纵物体以及与周围环境互动。Alexander Amini 在这节课的开篇提出了一个简洁的定义:计算机视觉(Computer Vision)就是赋予计算机"通过观察来了解什么在哪里"(to know what is where by looking)的能力。

来源:Slides 第2页。
视觉不仅仅是静态地识别物体,还包括理解场景的动态变化。例如,当我们看到一张城市街道照片时,我们不仅能识别出汽车、行人和交通信号灯,还能推断出哪些汽车在行驶、哪些停在路边,以及行人的运动方向。这种从单幅图像中推断动态信息的能力,正是计算机视觉希望实现的目标。

来源:Slides 第3页。
为什么计算机视觉如此困难?
人类视觉系统经过数百万年的进化,能够毫不费力地完成物体识别、场景理解等任务。但对计算机而言,即使是同一物体,由于视角变化(viewpoint variation)、尺度变化(scale variation)、形变(deformation)、遮挡(occlusion)、光照变化(illumination conditions)、背景杂乱(background clutter)和类内变化(intra-class variation)等因素,在像素层面的表现可能截然不同。这些都使得计算机视觉成为一个极具挑战性的问题。
计算机视觉的应用与影响
深度学习正在推动计算机视觉领域的巨大革命,其应用无处不在:

来源:Slides 第4页。
- 面部检测与识别:不仅检测人脸的存在,还能分析面部关键点和微表情。这是最早获得广泛应用的计算机视觉任务之一。
- 自动驾驶:MIT 的 Amini 实验室曾构建端到端自动驾驶系统,仅凭视觉输入即可在从未见过的道路上自主驾驶。与大多数自动驾驶汽车使用模块化流水线(多个模型加预定义地图)不同,端到端方法使用单一模型直接从图像到方向盘转角。
- 医学影像:CNN 在乳腺癌筛查中已超越专业放射科医生的准确率,能够检测到人类医生遗漏的病灶。此外还广泛应用于皮肤癌检测、COVID-19 影像诊断等领域。
- 无障碍辅助:例如 Google Project Guideline 项目,帮助视障人士独立跑步。
- 移动计算:每个人的手机中都运行着大量计算机视觉模型。
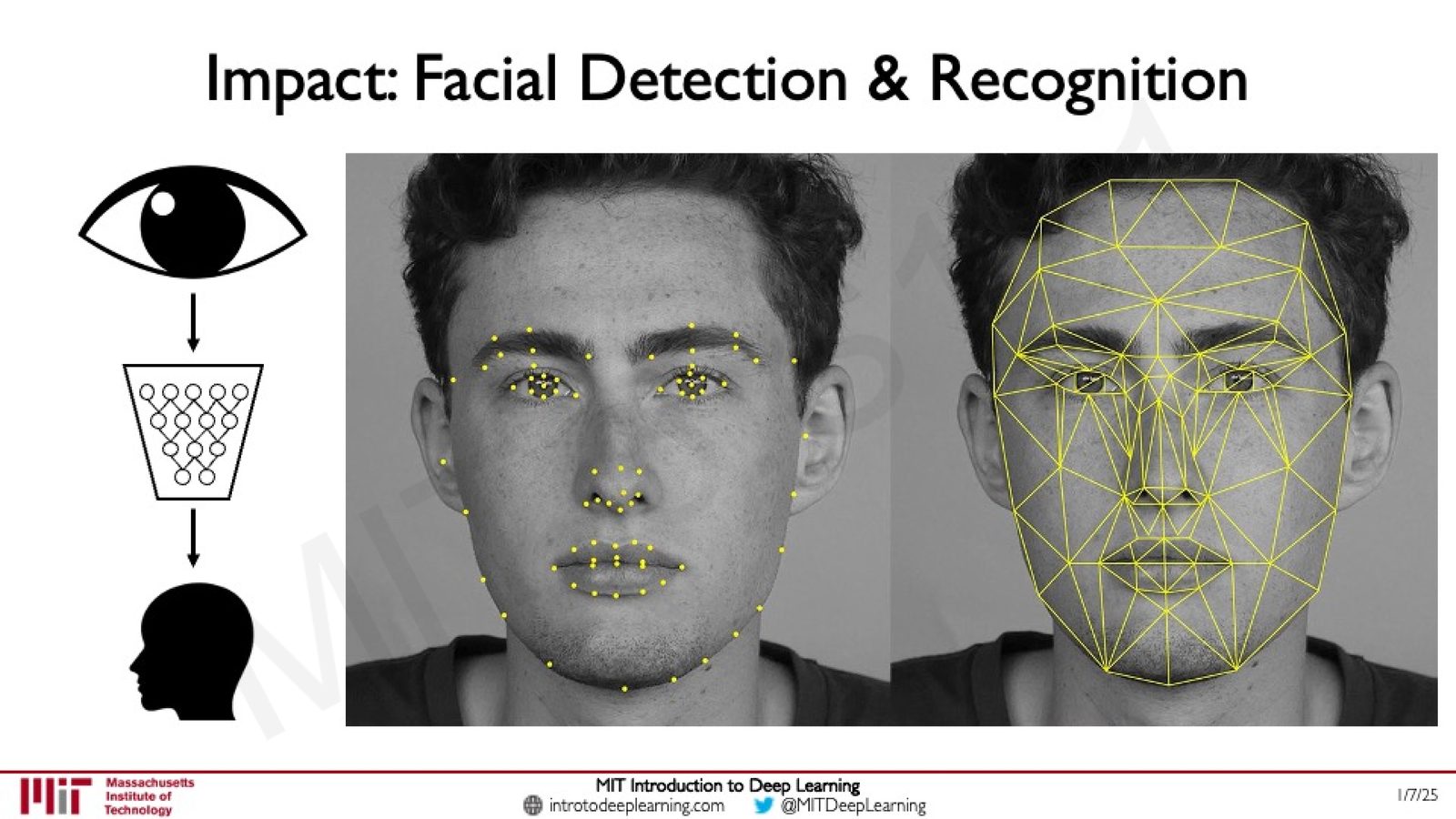
来源:Slides 第5页和第7页。
本章小结
计算机视觉是赋予计算机理解视觉世界的能力。虽然人类做起来轻而易举,但由于物体外观的巨大变异性,这对计算机来说极具挑战。深度学习的兴起正在从根本上改变这一领域,使得计算机在许多视觉任务上达到甚至超越人类水平。
计算机如何"看"图像
图像的数字表示
对于计算机而言,图像仅仅是数字。一幅灰度图像是一个二维数组,其中每个元素(像素)是 \([0, 255]\) 范围内的一个整数,表示该像素的亮度。一幅彩色图像则是一个三维数组,尺寸为 \(H \times W \times 3\),其中第三个维度对应 RGB 三个颜色通道。

来源:Slides 第12页。
图像的数学表示
- 灰度图像:\(\mathbf{I} \in \mathbb{R}^{H \times W}\),每个像素值 \(I_{i,j} \in [0, 255]\)
- 彩色图像:\(\mathbf{I} \in \mathbb{R}^{H \times W \times 3}\),三个通道分别对应红(R)、绿(G)、蓝(B)
- 例如,一张 \(1080 \times 1080\) 的 RGB 图像包含 \(1080 \times 1080 \times 3 = 3,499,200\) 个数字
Amini 指出,从表示的角度看,图像实际上比语言更容易处理,因为图像天然就是数字数组,而语言则需要先进行词嵌入(embedding)等转换。
计算机视觉的两类基本任务
计算机视觉中最基本的两类任务是回归(Regression)和分类(Classification):
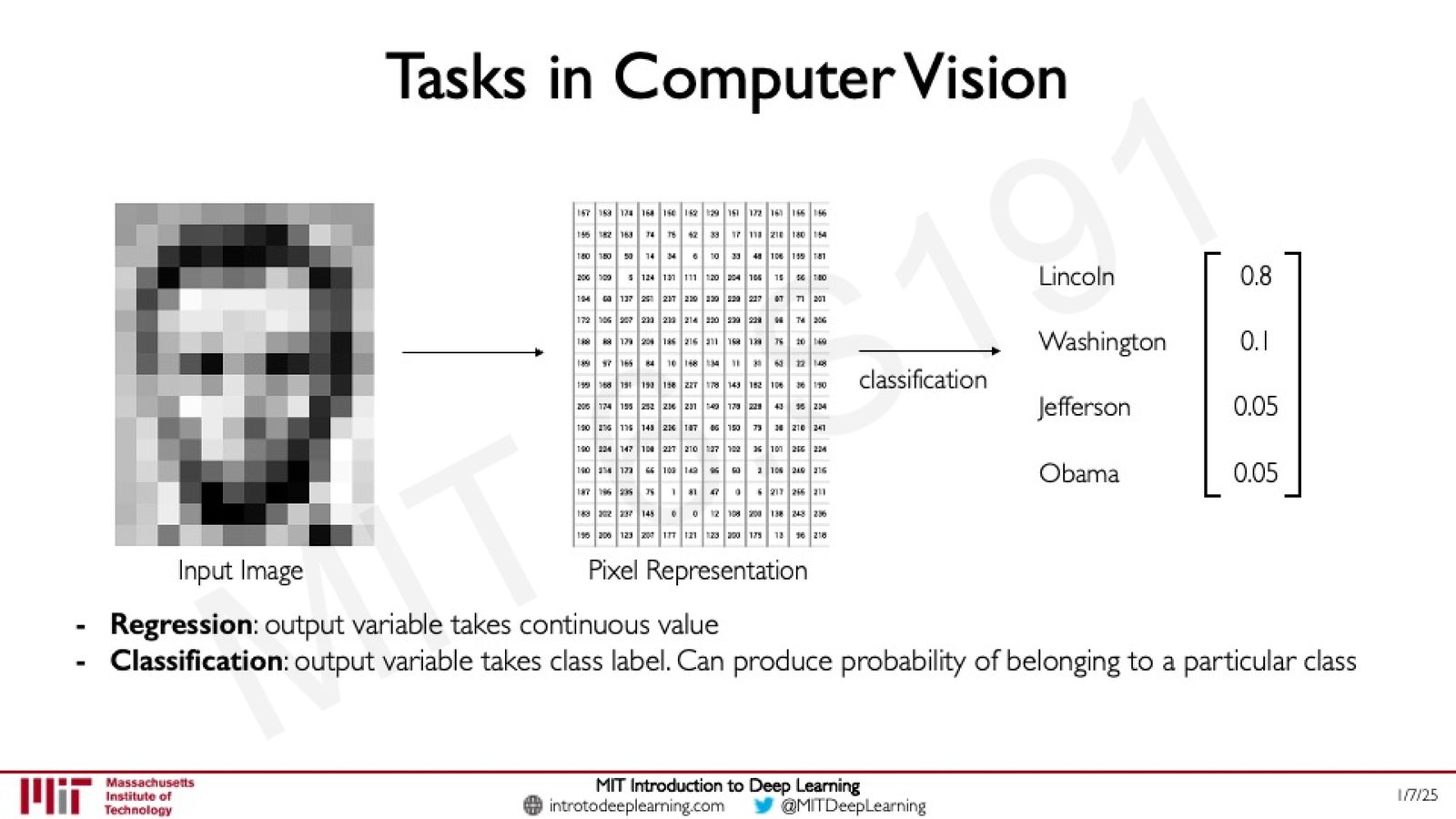
来源:Slides 第13页。
- 回归:输出变量取连续值,例如预测方向盘的转角。
- 分类:输出变量取离散类别标签,例如判断图片中的人物是哪位美国总统。分类任务可以输出属于每个类别的概率分布。
无论是哪种任务,核心问题都是特征检测(Feature Detection)——理解是什么特征使得不同类别之间存在区分。
本章小结
计算机通过像素值矩阵来表示图像。彩色图像是三维张量(高度 \(\times\) 宽度 \(\times\) 通道数)。计算机视觉的两类基本任务——分类和回归——都依赖于从图像中有效提取特征的能力。
特征提取:从手工设计到自动学习
手工特征提取的局限
为了正确分类图像,我们需要提取能区分不同类别的特征。传统方法依赖手工特征提取(Manual Feature Extraction),流程如下:
来源:Slides 第15页。
例如,要识别人脸,你可能定义特征为"鼻子、眼睛、嘴巴"。但这立即引出一个递归问题:如何检测"眼睛"?你又需要定义更底层的特征来描述眼睛的外观。
手工特征的核心困境
手工特征提取面临两个根本性挑战:
- 特征定义的递归性:定义高层特征需要定义低层特征,而低层特征的定义又需要更低层特征,形成无穷递归。
- 变异性:同一类物体在不同视角、光照、尺度、形变和遮挡条件下的外观差异巨大,手工规则无法穷举所有情况。
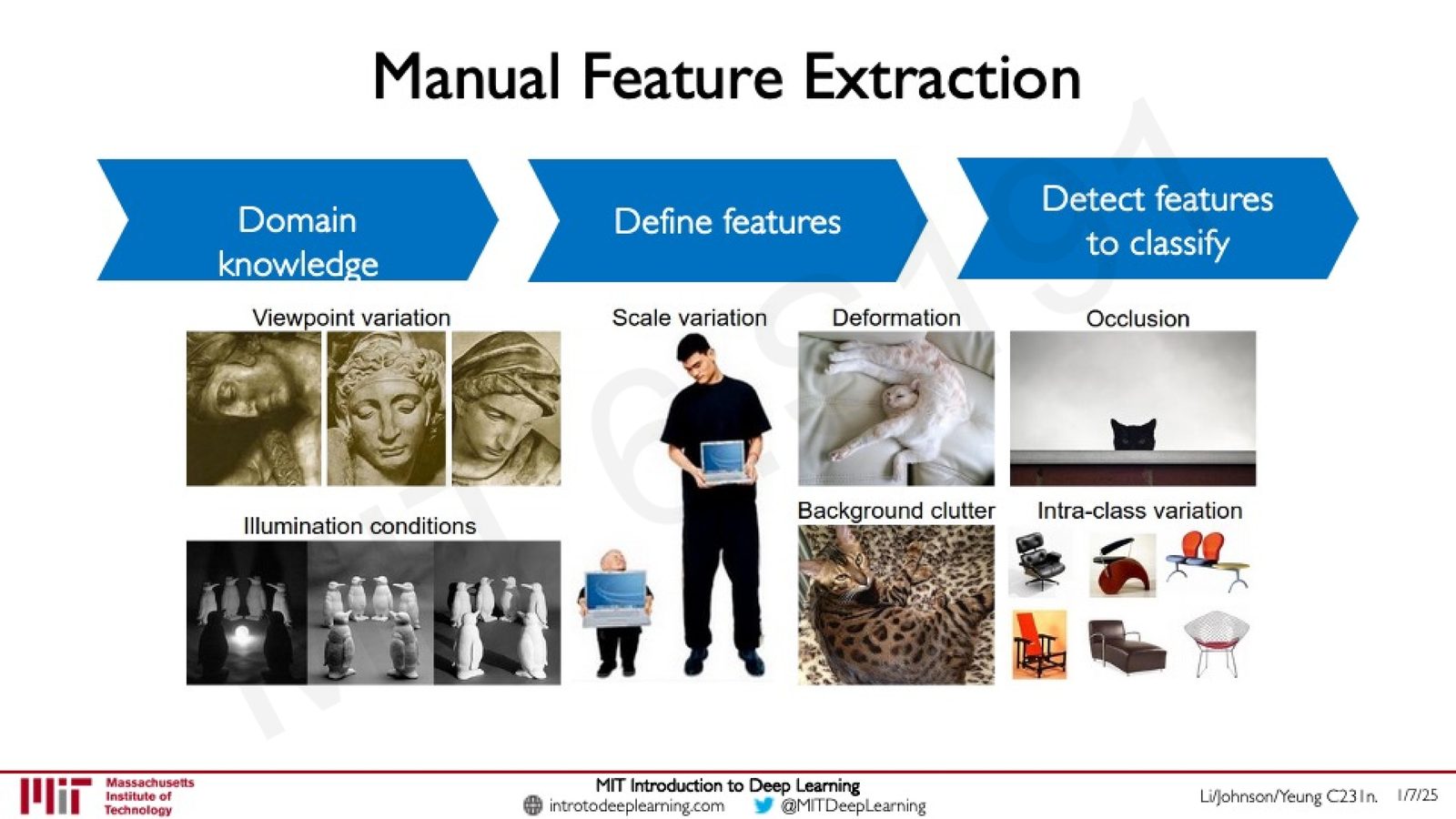
来源:Slides 第16页。
学习特征层次结构
深度学习的核心思想是:能否直接从数据中学习特征的层次结构(hierarchy of features),而不是手工设计?
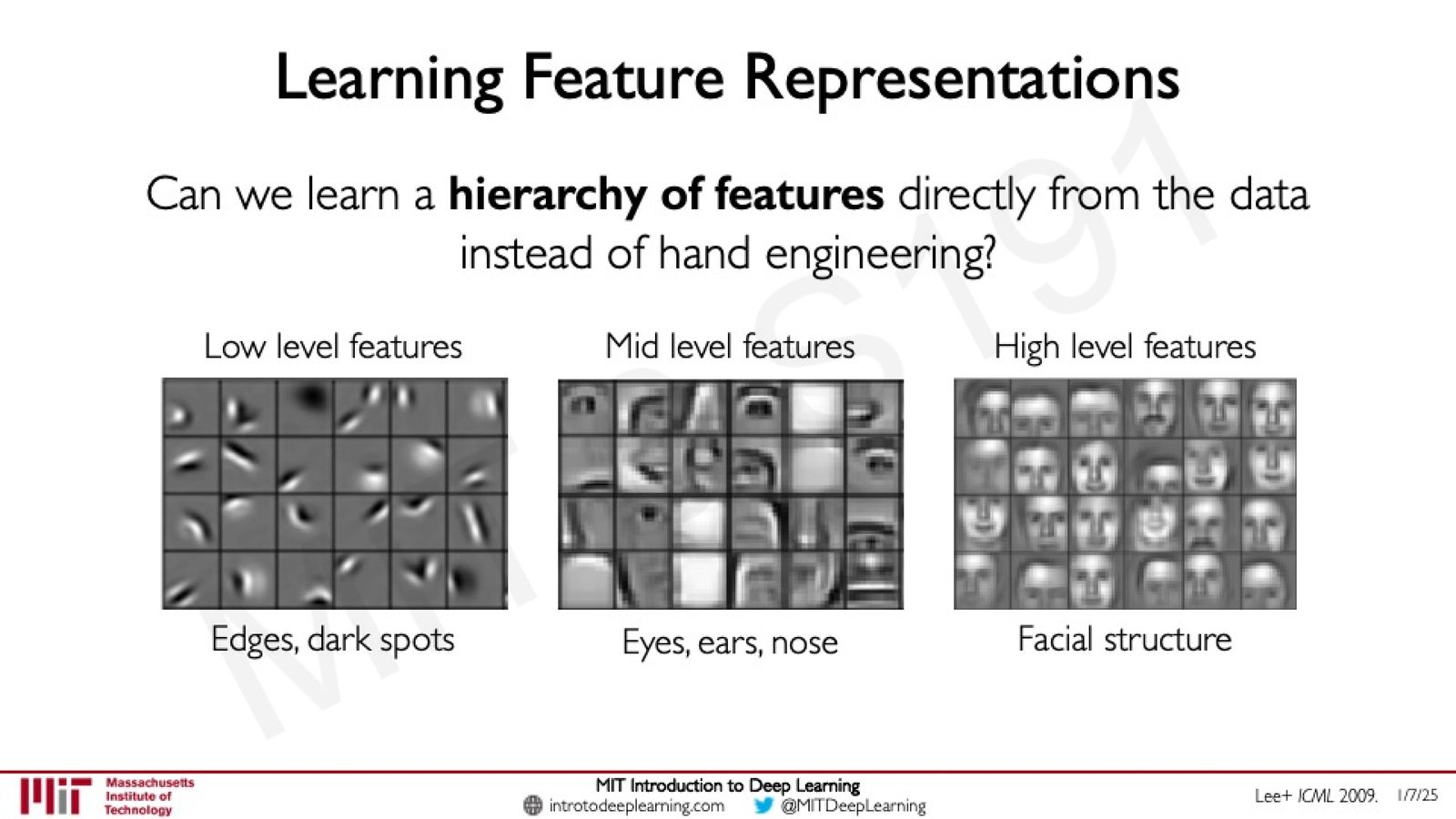
来源:Slides 第18页。参考 Lee+ ICML 2009。
特征层次结构的关键洞察
视觉特征是分层组织的:
- 低层特征(Low-level features):边缘、暗斑等最基本的视觉元素
- 中层特征(Mid-level features):由低层特征组合而成,如眼睛、耳朵
- 高层特征(High-level features):由中层特征组合而成,如完整的面部结构
深度学习的目标就是让网络自动学习这种层次化的特征表示。
本章小结
手工特征提取由于递归性和变异性问题而不可扩展。深度学习的核心贡献是让网络自动从数据中学习分层特征表示,从低层的边缘检测到高层的语义理解,全程无需人工干预。
从全连接网络到卷积:空间结构的利用
全连接网络处理图像的问题
在第一讲中,我们学习了全连接神经网络(Fully Connected Neural Network)。如果直接用全连接网络处理图像,必须先将二维图像展平(flatten)为一维向量:
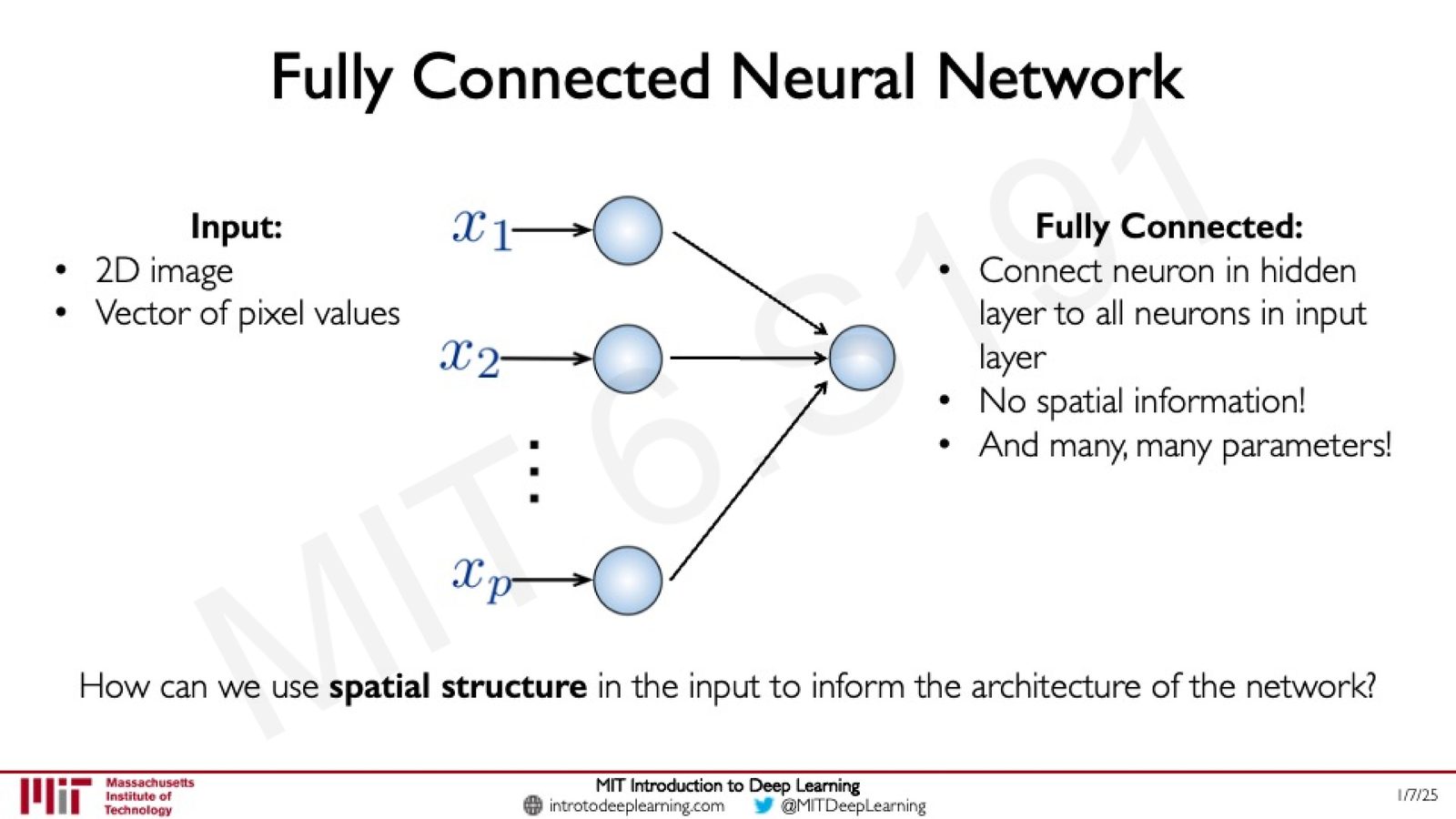
来源:Slides 第22页。
全连接网络用于图像的两大缺陷
- 空间信息完全丧失:将二维图像展平为一维向量后,像素之间的空间关系被完全破坏。相邻像素在展平后可能相距甚远。
- 参数量爆炸:每个像素都连接到隐藏层的每个神经元。例如,一张 \(256 \times 256\) 的灰度图像有 65,536 个像素,如果隐藏层有 1,024 个神经元,仅第一层就需要 \(65,536 \times 1,024 \approx 6700\) 万个参数。
关键问题是:如何利用输入的空间结构来指导网络架构设计?
局部连接的思想
解决方案的核心思想很简单:不再让每个神经元连接到整幅图像的所有像素,而是只连接到输入图像的一个局部区域(local patch)。
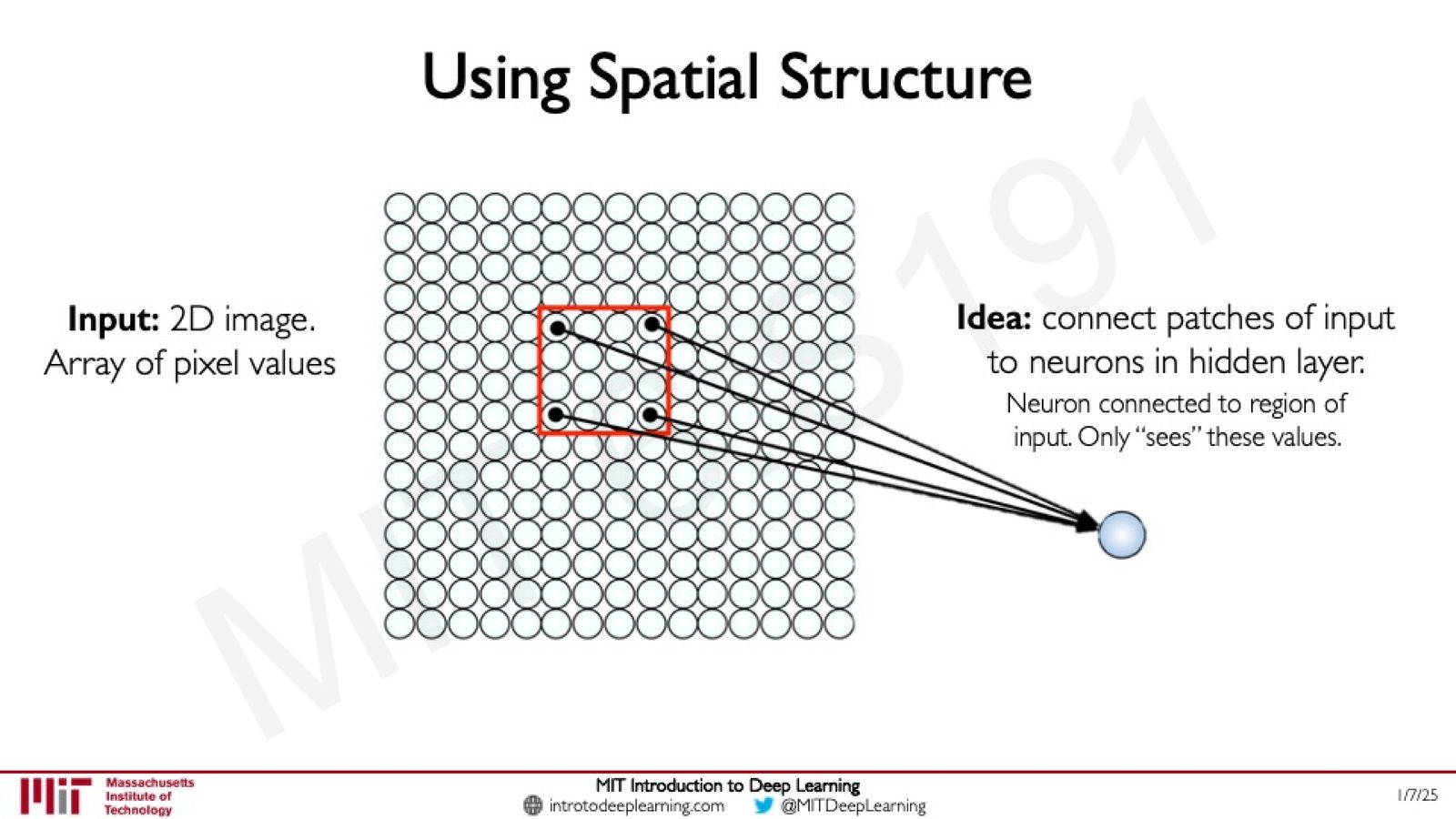
来源:Slides 第23页。
然后,使用滑动窗口(sliding window)的方式,让同一个权重矩阵在图像的不同位置上重复应用。这就是卷积(Convolution)操作的核心思想。
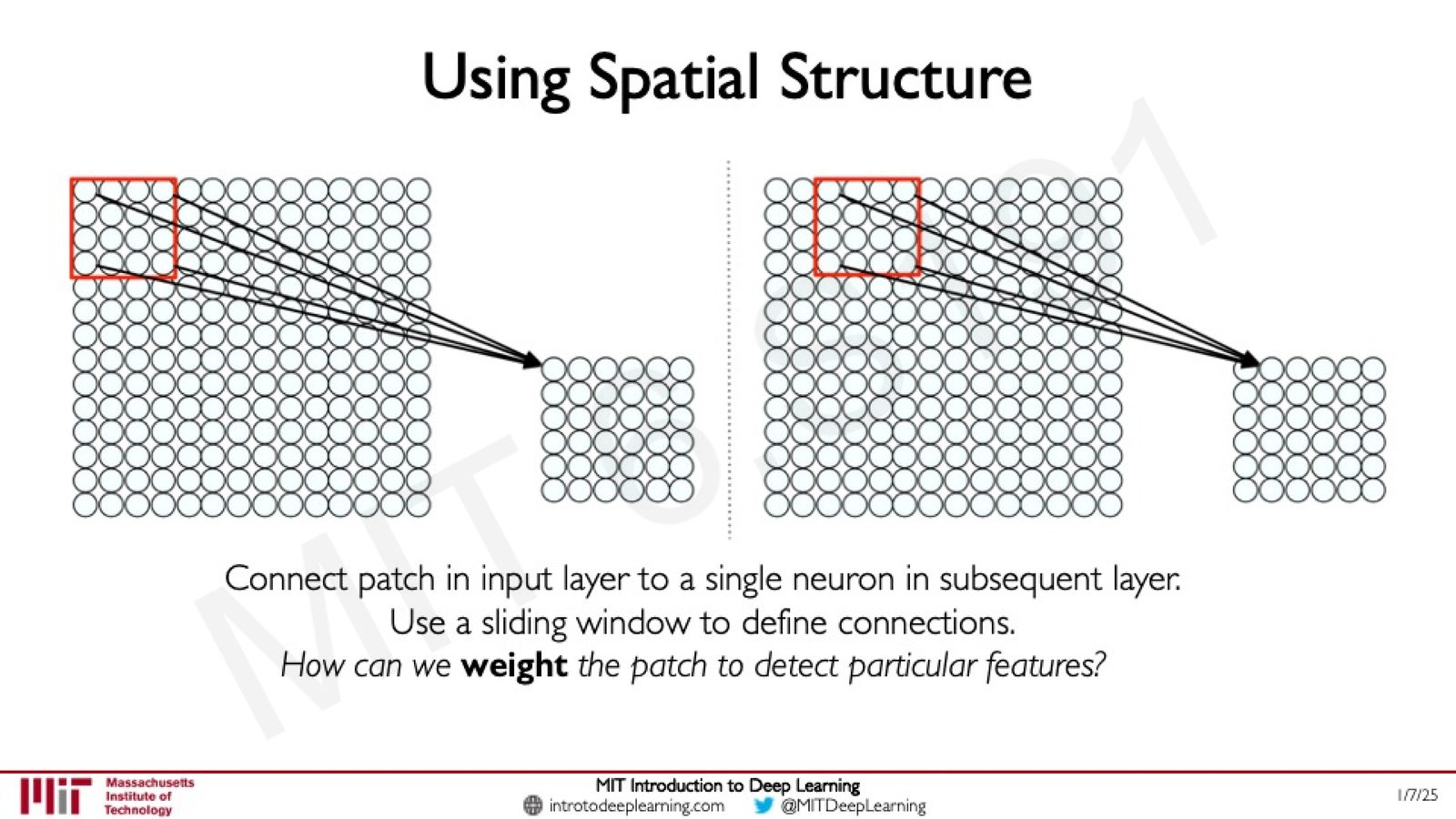
来源:Slides 第24页。
卷积操作的三个核心特性
- 局部特征提取:使用一组权重(滤波器/filter)提取局部特征
- 多滤波器:使用多个滤波器提取不同类型的特征
- 参数共享:每个滤波器的参数在空间上共享(spatial sharing),即同一个滤波器应用于图像的所有位置
本章小结
全连接网络将图像展平会丧失空间信息且参数量爆炸。卷积的核心思想是局部连接加参数共享,既保留了空间结构,又大幅减少了参数数量。
卷积操作详解
案例研究:检测字母 X
Amini 使用了一个经典的教学示例来直观解释卷积操作。假设我们要判断一幅图像是否包含字母"X"。即使两个"X"在位移、缩放或旋转后看起来不同,计算机也应该能将它们都识别为"X"。

来源:Slides 第27页。参考 Rohrer "How do CNNs work?"。
解决方案:不在全局层面比较,而是在局部特征层面比较。一个"X"由若干特征组成——对角线、交叉点等。只要在两幅图像中都能找到这些局部特征,就可以认为它们都是"X"。
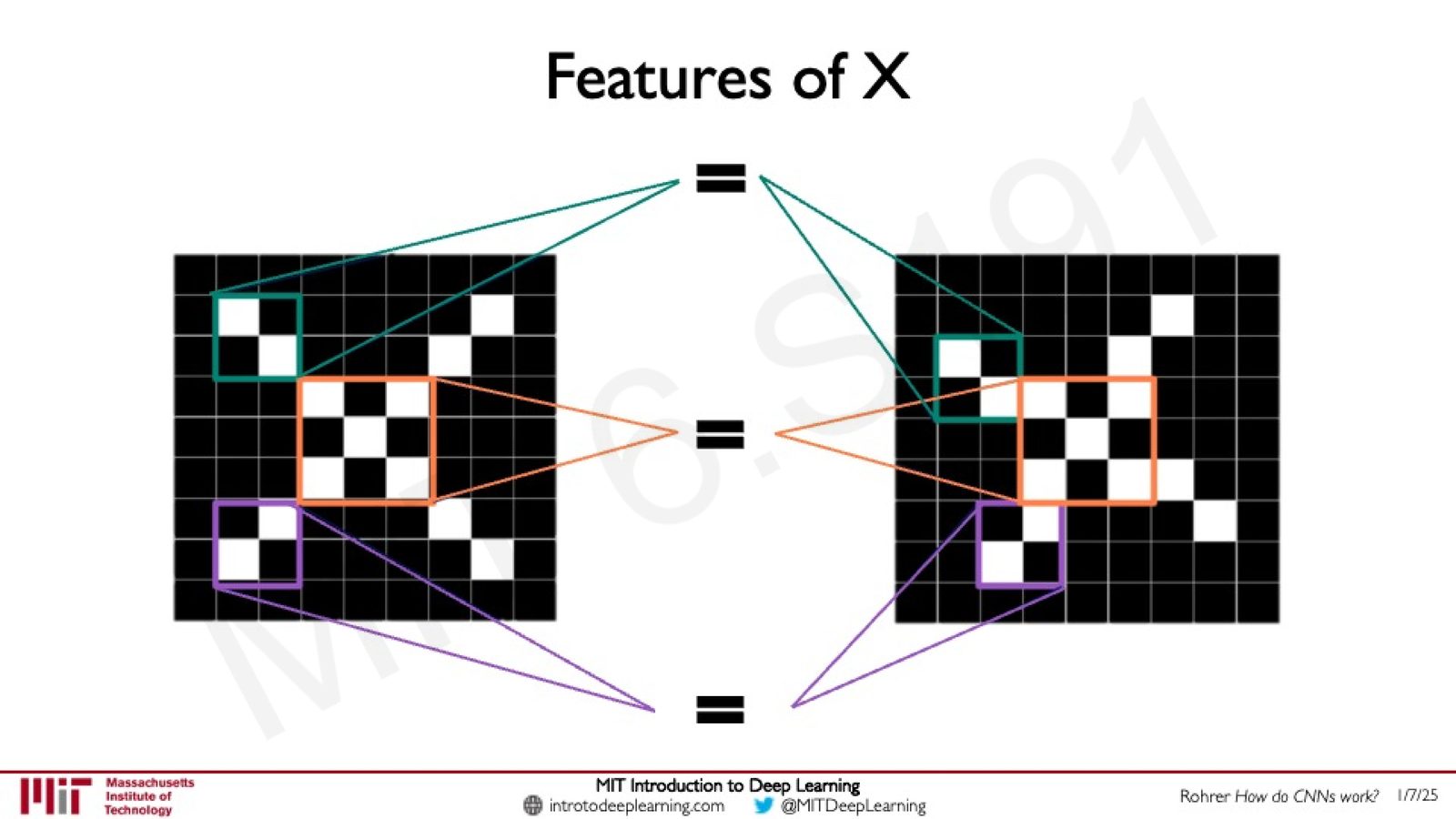
来源:Slides 第28页。
这些局部特征就是滤波器(filters)。每个滤波器是一个小的数字矩阵,代表我们想要检测的某种模式。

来源:Slides 第29页。
卷积运算的数学定义
卷积操作的步骤如下:
- 将滤波器放置在输入图像的某个位置上
- 对滤波器覆盖的区域,执行逐元素乘法(element-wise multiplication)
- 将所有乘积求和
- 将结果写入特征图(feature map)的对应位置
- 将滤波器滑动到下一个位置,重复上述过程
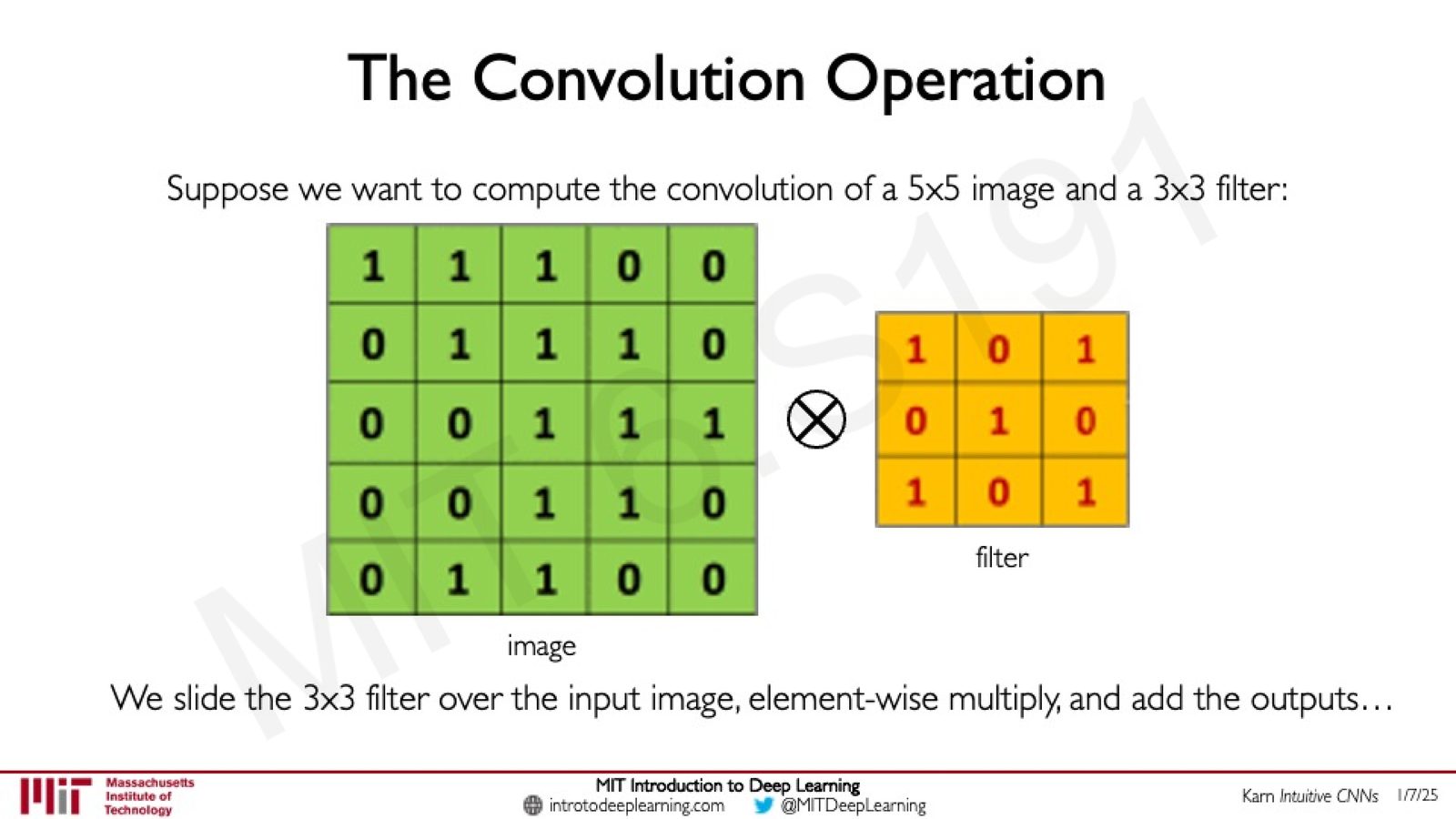
来源:Slides 第31页。参考 Karn "Intuitive CNNs"。
以 \(5 \times 5\) 的输入图像和 \(3 \times 3\) 的滤波器为例,卷积过程生成一个 \(3 \times 3\) 的特征图:
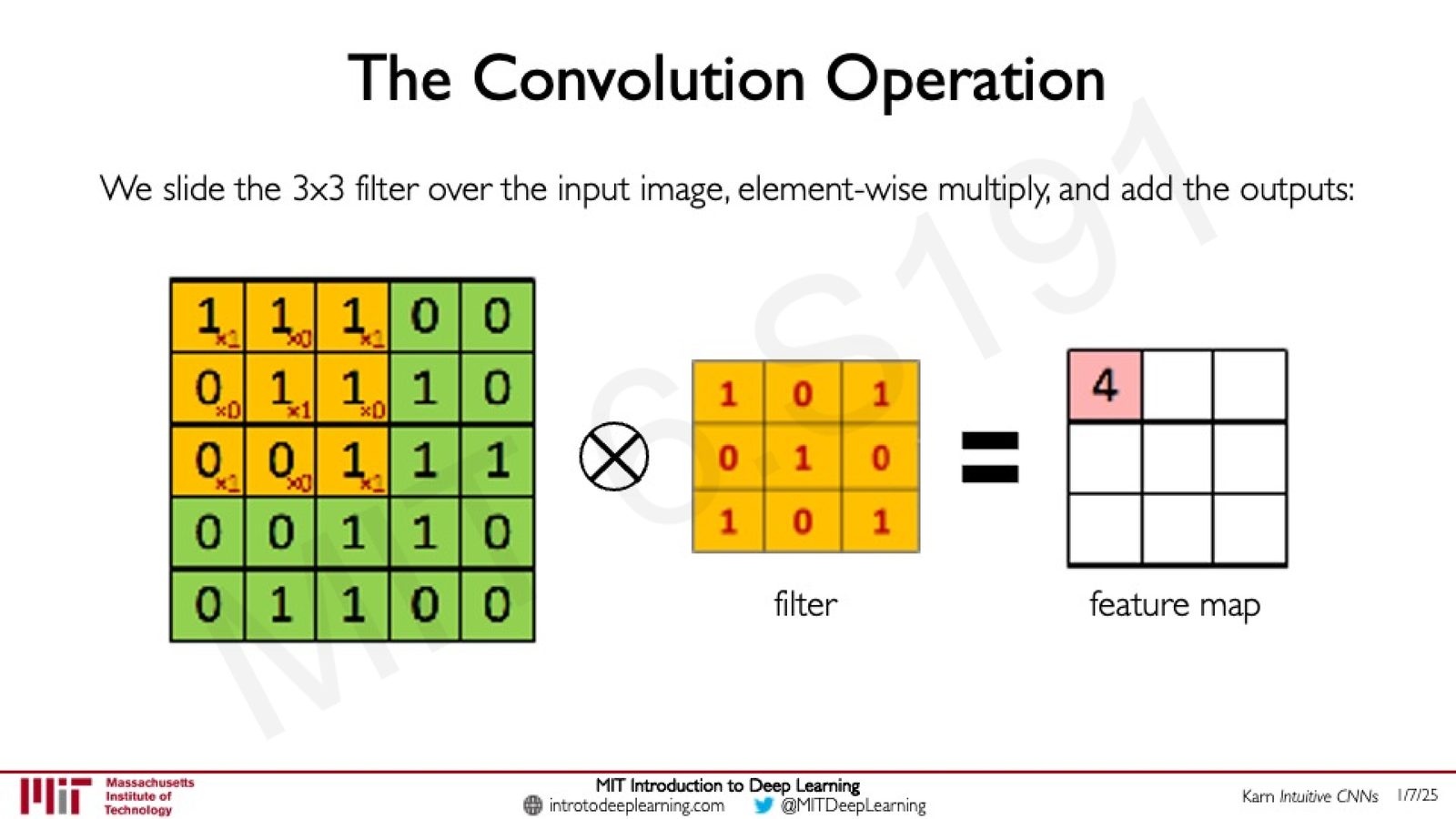
来源:Slides 第32页。
对于一般情况,卷积操作可以用如下公式表示:
其中:
- \(x\) 是输入图像
- \(w\) 是 \(k \times k\) 的滤波器权重矩阵
- \(b\) 是偏置项
- \(y_{p,q}\) 是特征图在位置 \((p,q)\) 的输出值
- \((p,q)\) 是隐藏层中神经元的位置

来源:Slides 第40页。
卷积的本质就是"加权求和"
如果你理解了 Lecture 1 中全连接层的前向传播——对输入进行加权求和再加偏置——那么卷积层做的事情在本质上完全一样。唯一的区别是:全连接层的每个神经元看到所有输入,而卷积层的每个神经元只看到一个局部窗口内的输入,且窗口的权重在空间上共享。
滤波器产生不同的特征图
不同的滤波器权重会产生完全不同的特征图。通过改变滤波器的值,可以实现:

来源:Slides 第41页。
- 锐化滤波器:放大中心像素、减小周围像素的权重,增强图像细节
- 边缘检测滤波器:本质上是一种导数算子,检测亮度从高到低的突变
- 强边缘检测滤波器:更激进的导数算子,产生更明显的边缘
从手工设计到自动学习滤波器
在深度学习之前,人们长期使用手工设计的滤波器(如 Sobel 算子、Laplacian 算子等)来检测特定模式。深度学习的关键突破是:让滤波器的权重成为可学习的参数,通过反向传播和梯度下降从数据中自动优化。这样,网络能自动发现对当前任务最有用的特征,而无需人工设计。
输出尺寸的计算
卷积操作的输出尺寸取决于三个超参数:
| 超参数 | 说明 |
|---|---|
| 滤波器大小 (kernel size) | 滤波器的空间尺寸,如 \(3 × 3\), \(5 × 5\) |
| 步幅 (stride) | 滤波器每次滑动的像素数。stride=1 表示每次移动一个像素,stride=2 表示每次跳两个像素 |
| 填充 (padding) | 是否在输入边缘补零。如果不填充,输出尺寸会缩小 |
对于输入尺寸为 \(n\)、滤波器大小为 \(k\)、步幅为 \(s\) 的情况,输出尺寸为:
本章小结
卷积操作通过滑动滤波器在图像上进行逐元素乘法和求和,生成特征图。不同的滤波器检测不同的模式。在深度学习中,滤波器权重通过训练自动优化,而非手工设计。卷积的三个核心优势是:局部连接、参数共享和保留空间结构。
卷积神经网络(CNN)架构
CNN 的三个核心组件
了解了卷积操作后,我们可以构建完整的卷积神经网络。一个典型的 CNN 由三种层交替组成:
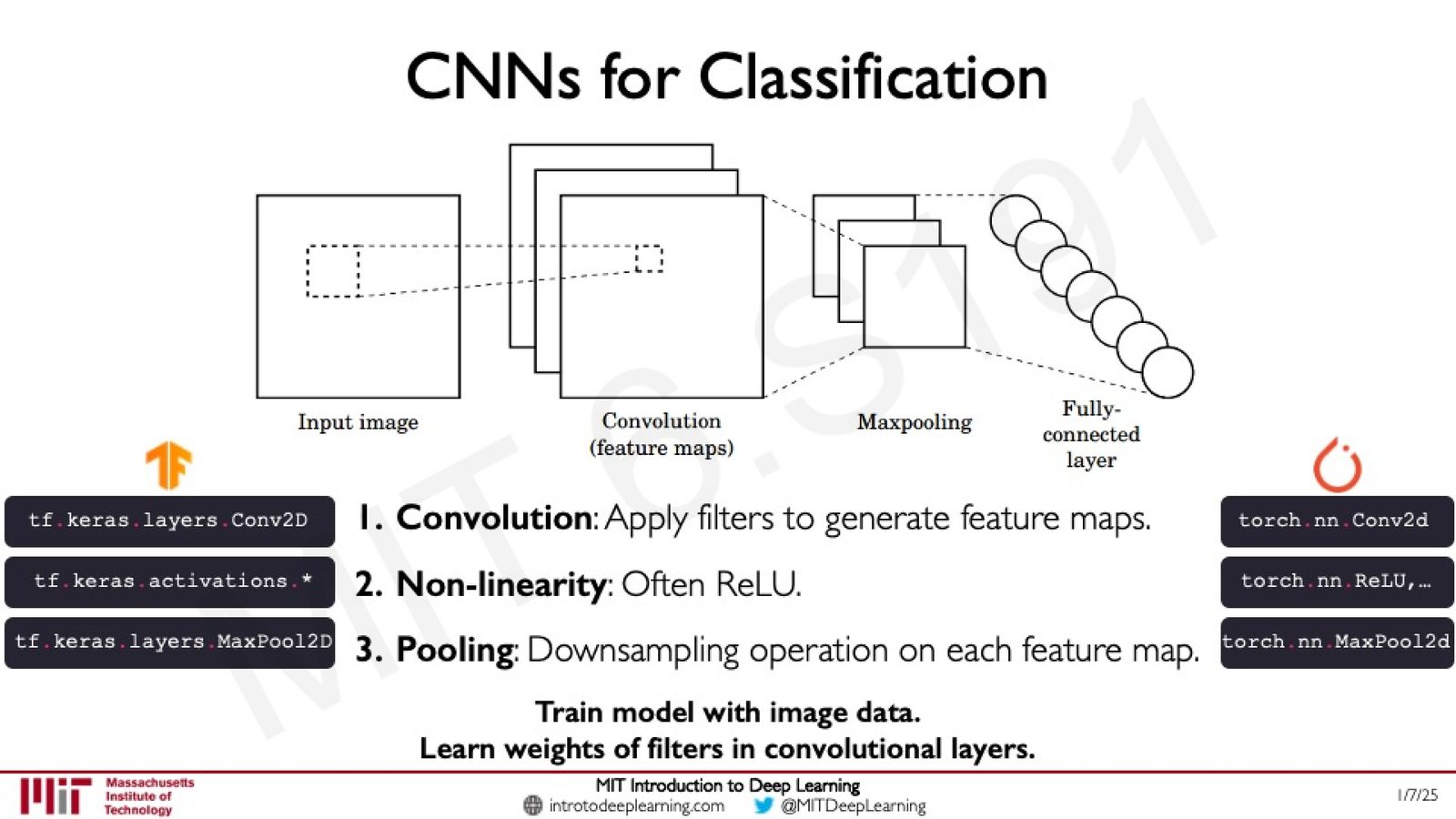
来源:Slides 第44页。
CNN 的三个核心操作
- 卷积(Convolution):应用滤波器生成特征图,提取局部特征
- 非线性激活(Non-linearity):通常使用 ReLU,引入非线性表达能力
- 池化(Pooling):对每个特征图进行下采样,降低维度并获得空间不变性
通过训练,CNN 自动学习卷积层中滤波器的权重。
卷积层:局部连接
卷积层中的每个神经元只与输入的一个局部区域相连。对于隐藏层中位置 \((p,q)\) 的神经元:
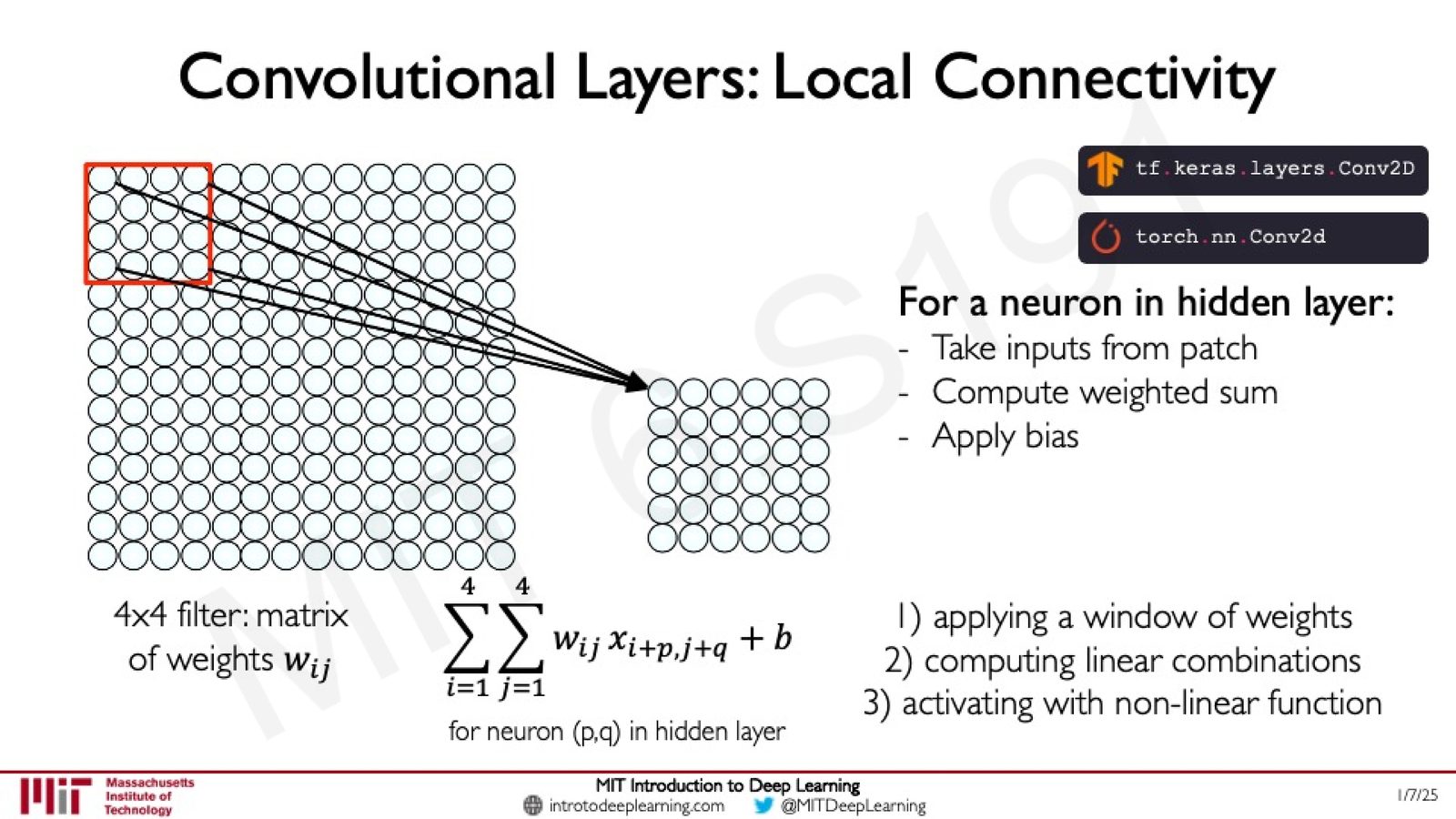
来源:Slides 第46页。
这个过程包括三步:(1) 应用权重窗口,(2) 计算线性组合,(3) 使用非线性函数激活。
输出体积的空间排列
每一层的输出不是一个二维平面,而是一个三维体积(volume),维度为 \(h \times w \times d\):
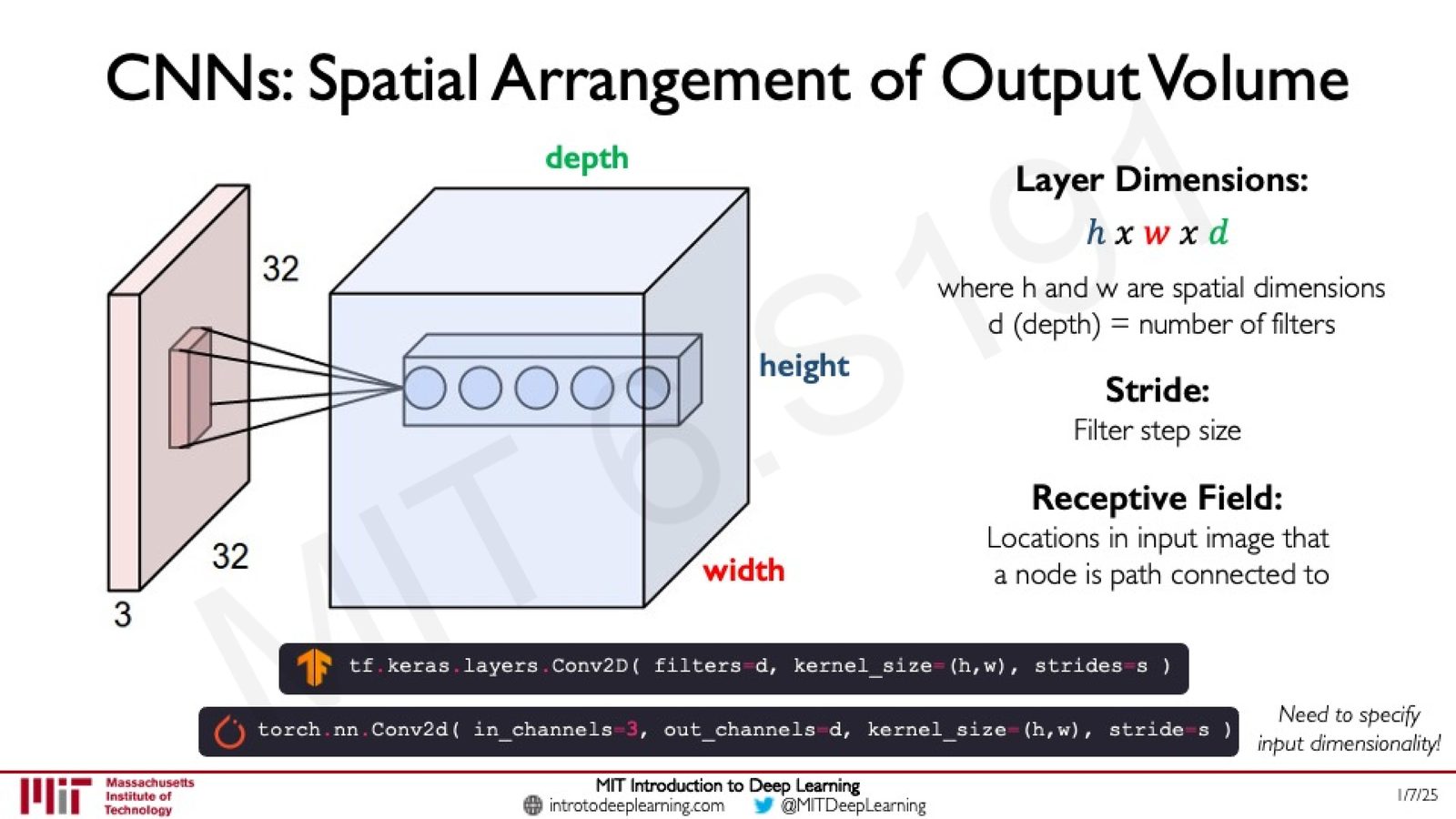
来源:Slides 第47页。
- \(h\) 和 \(w\):输出的空间维度(由输入尺寸、滤波器大小和步幅决定)
- \(d\):深度,等于该层使用的滤波器数量
- Stride(步幅):滤波器的滑动步长
- Receptive Field(感受野):输入图像中与某个输出节点相连的区域
在 TensorFlow 中:tf.keras.layers.Conv2D(filters=d, kernel_size=(h,w), strides=s)
在 PyTorch 中:torch.nn.Conv2d(in_channels, out_channels=d, kernel_size, stride=s)
PyTorch 需要指定输入通道数
TensorFlow/Keras 的 Conv2D 会自动推断输入维度,但 PyTorch 的 Conv2d 要求显式指定 in_channels。初学者经常忘记这一点导致报错。
非线性激活函数:ReLU
在每次卷积操作之后,需要应用非线性激活函数。CNN 中最常用的是ReLU(Rectified Linear Unit):

来源:Slides 第48页。
ReLU 的作用是将特征图中的所有负值替换为零,只保留正值(即检测到特征的区域)。为什么在图像任务中特别适合使用 ReLU?因为当滤波器检测到某个模式时输出为正值(匹配),而未检测到时输出为负值或零(不匹配),ReLU 恰好保留了"有检测到"的信号。
池化:降维与空间不变性
池化(Pooling)是卷积层之后的下采样操作。最常用的是最大池化(Max Pooling):
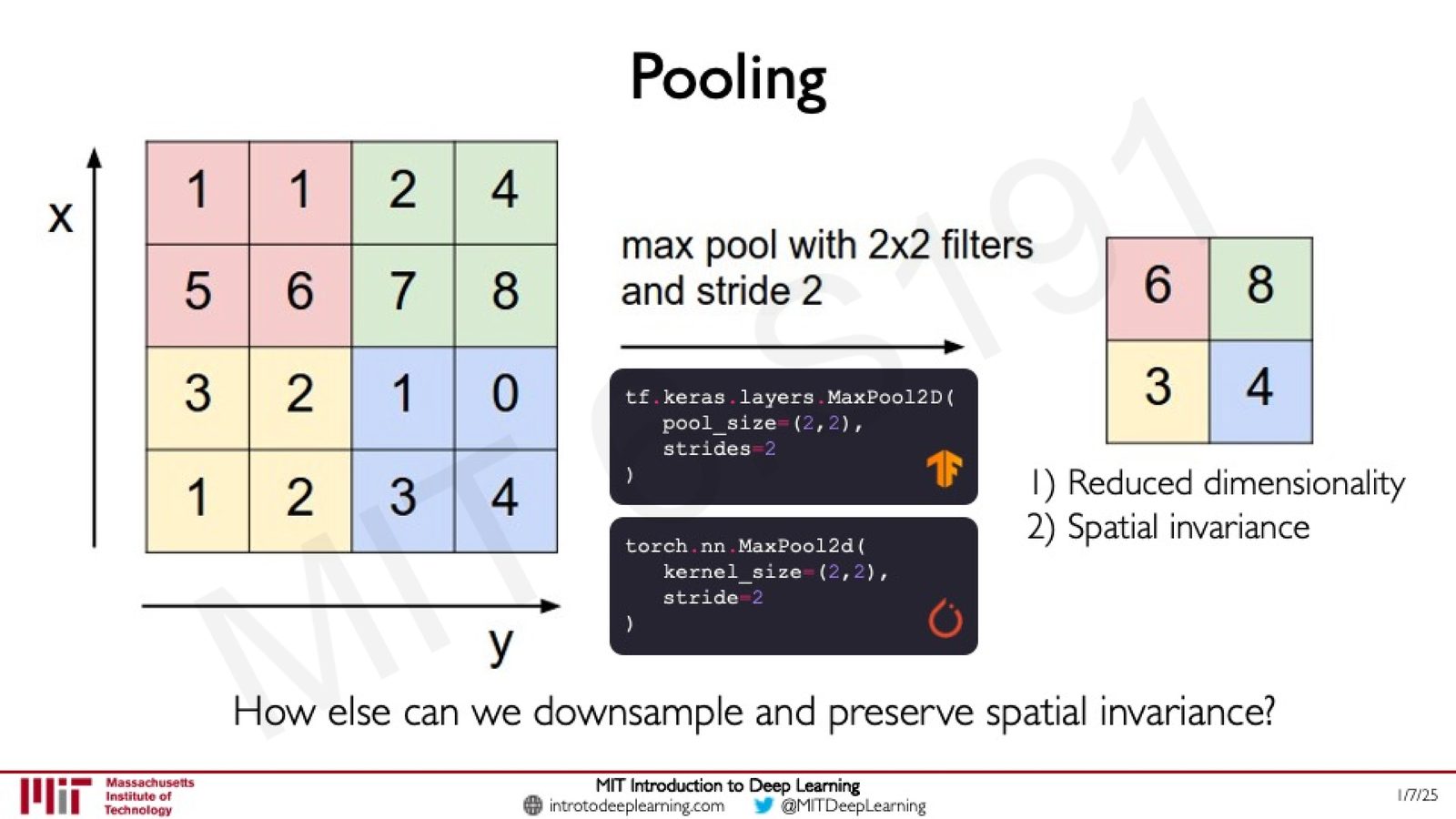
来源:Slides 第49页。
池化的两大作用
- 降低维度(Reduced dimensionality):减小特征图的空间尺寸,从而减少后续层的计算量和参数量
- 空间不变性(Spatial invariance):由于取最大值,特征的精确位置变得不那么重要,增强了对位移的鲁棒性
Amini 提到,除了 Max Pooling,还可以问一个更一般的问题:"还有什么其他方式可以实现下采样并保持空间不变性?"这暗示了后续课程可能介绍的其他技术,如带步幅的卷积(strided convolution)等。
深层 CNN 中的表示学习
通过堆叠多个"卷积 + ReLU + 池化"模块,CNN 能够学习越来越抽象的特征表示:
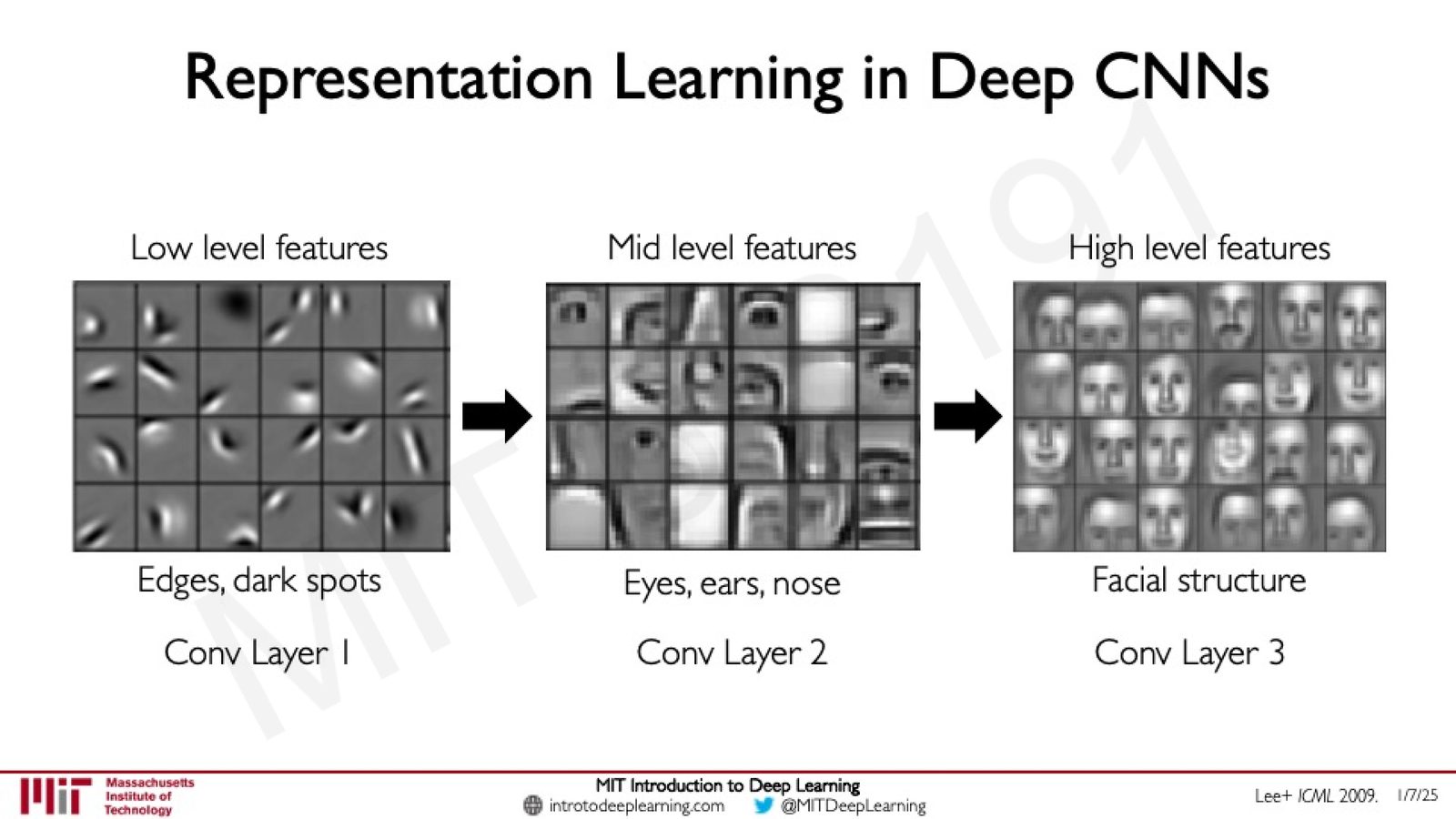
来源:Slides 第50页。参考 Lee+ ICML 2009。
特征的层级组合
深层 CNN 之所以强大,是因为每一层都在前一层检测到的特征基础上进行组合:
- 第一个卷积层检测原始特征(如各种方向的边缘)
- 池化后,特征图缩小,相当于在更大的空间尺度上观察
- 第二个卷积层在缩小后的特征图上检测,相当于组合多个低层特征形成中层特征
- 如此重复,特征越来越抽象、语义越来越丰富
这种从简单到复杂的层级特征学习,正是深度学习中"深度"一词的含义。
本章小结
一个完整的 CNN 分类网络由特征学习部分和分类部分组成。特征学习部分通过交替使用卷积层(提取局部特征)、非线性激活(引入表达力)和池化层(降维并增加不变性),逐层构建越来越抽象的特征表示。分类部分则将学习到的特征展平后通过全连接层输出类别概率。
CNN 的完整流程:从特征提取到分类
完整架构概览
一个完整的 CNN 分类网络可以分为两个阶段:
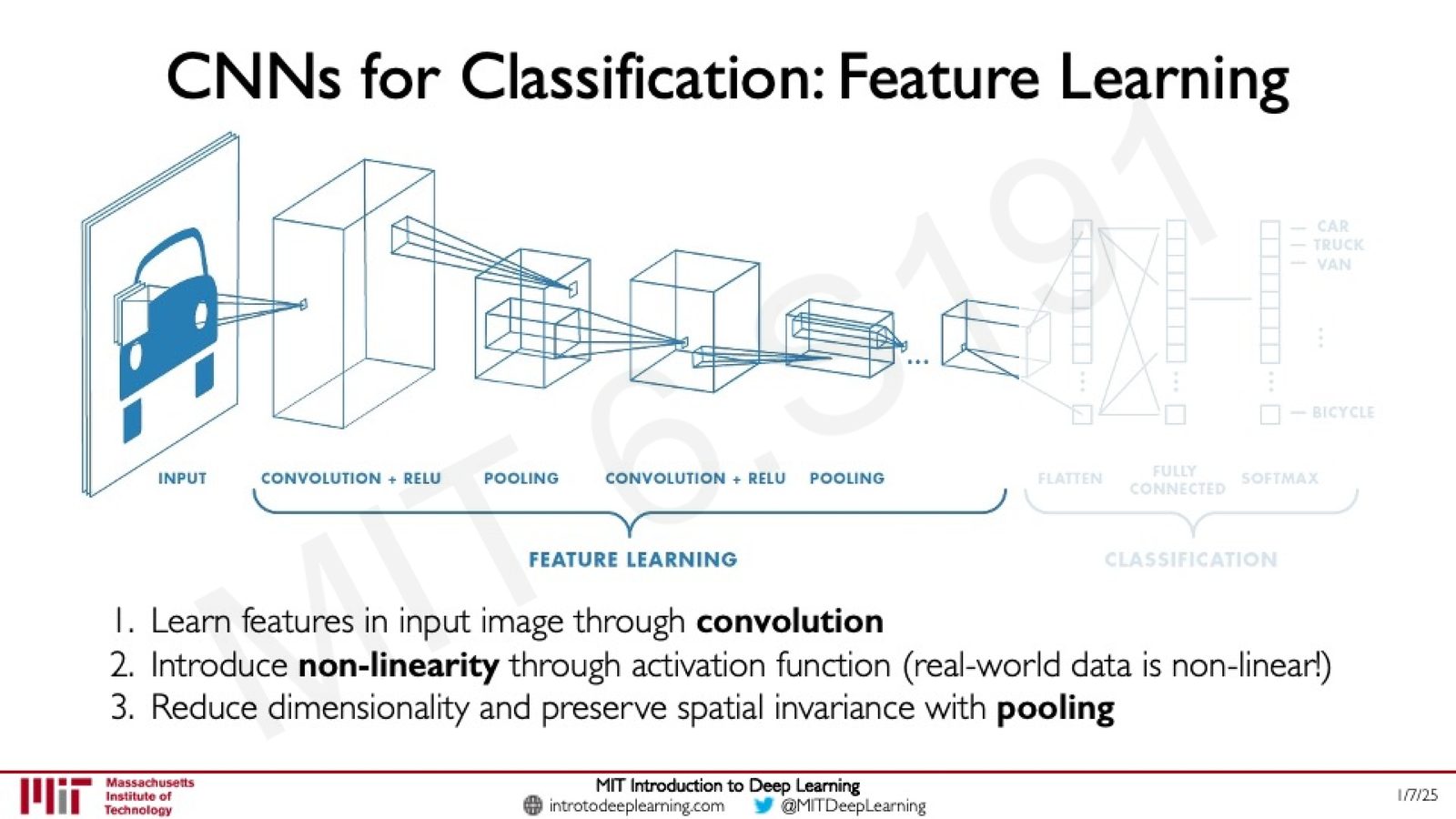
来源:Slides 第51页。
-
特征学习阶段:
-
通过卷积学习输入图像中的特征
- 通过非线性激活引入非线性(因为真实世界的数据是非线性的)
- 通过池化降低维度并保留空间不变性
- 重复上述过程若干次
-
分类阶段:
-
将最后的特征图展平(flatten)为一维向量
- 通过全连接层进行分类
- 使用 Softmax 输出各类别的概率
分类头:Softmax 输出
CNN 的卷积和池化层输出高层特征表示后,通过全连接层将其映射到各类别,最后使用 Softmax 函数输出概率分布:
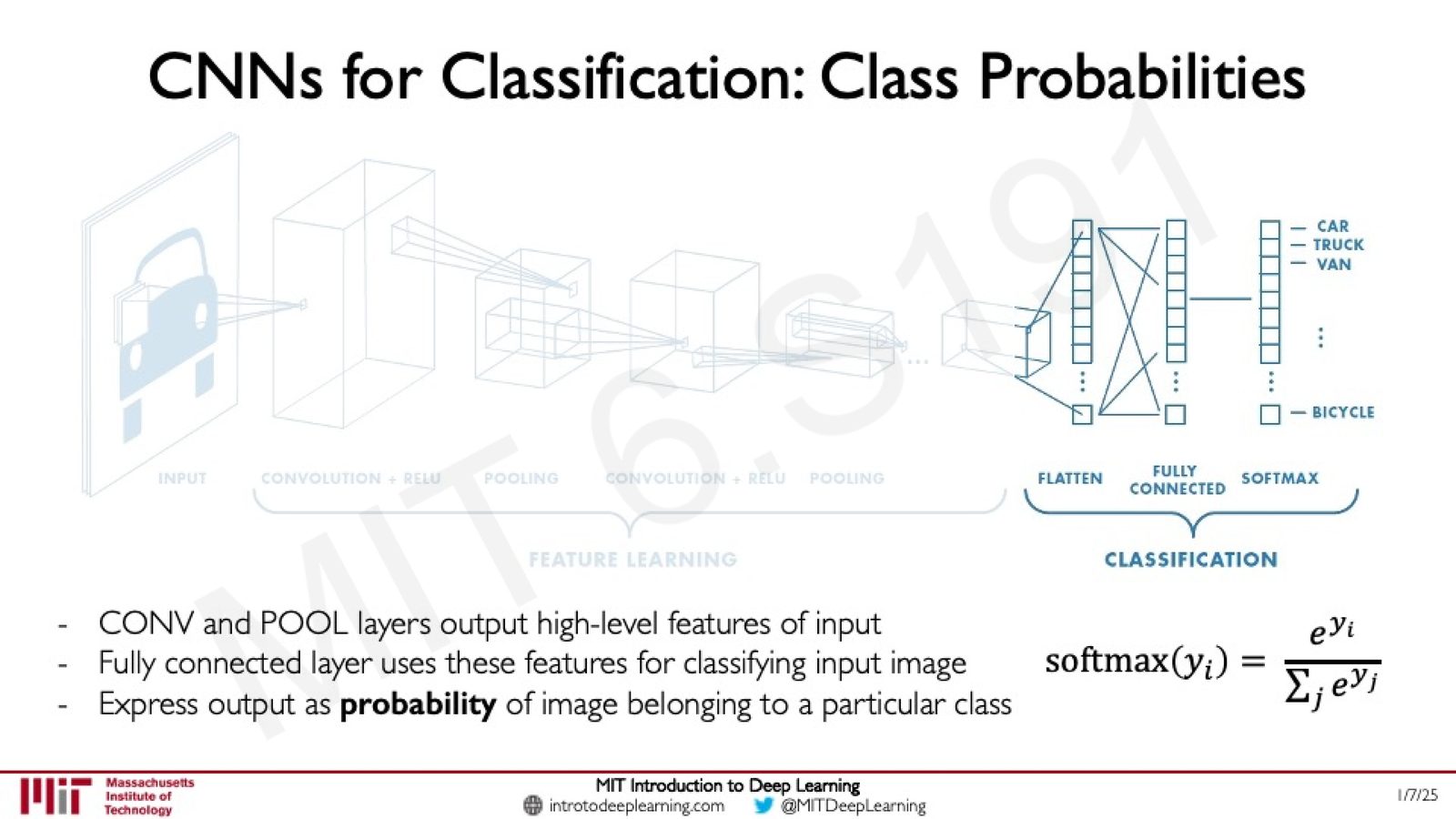
来源:Slides 第52页。
其中 \(y_i\) 是全连接层输出的第 \(i\) 个类别的原始分数(logit),Softmax 将其转换为概率值,所有类别的概率之和为 1。
代码实现:TensorFlow 与 PyTorch
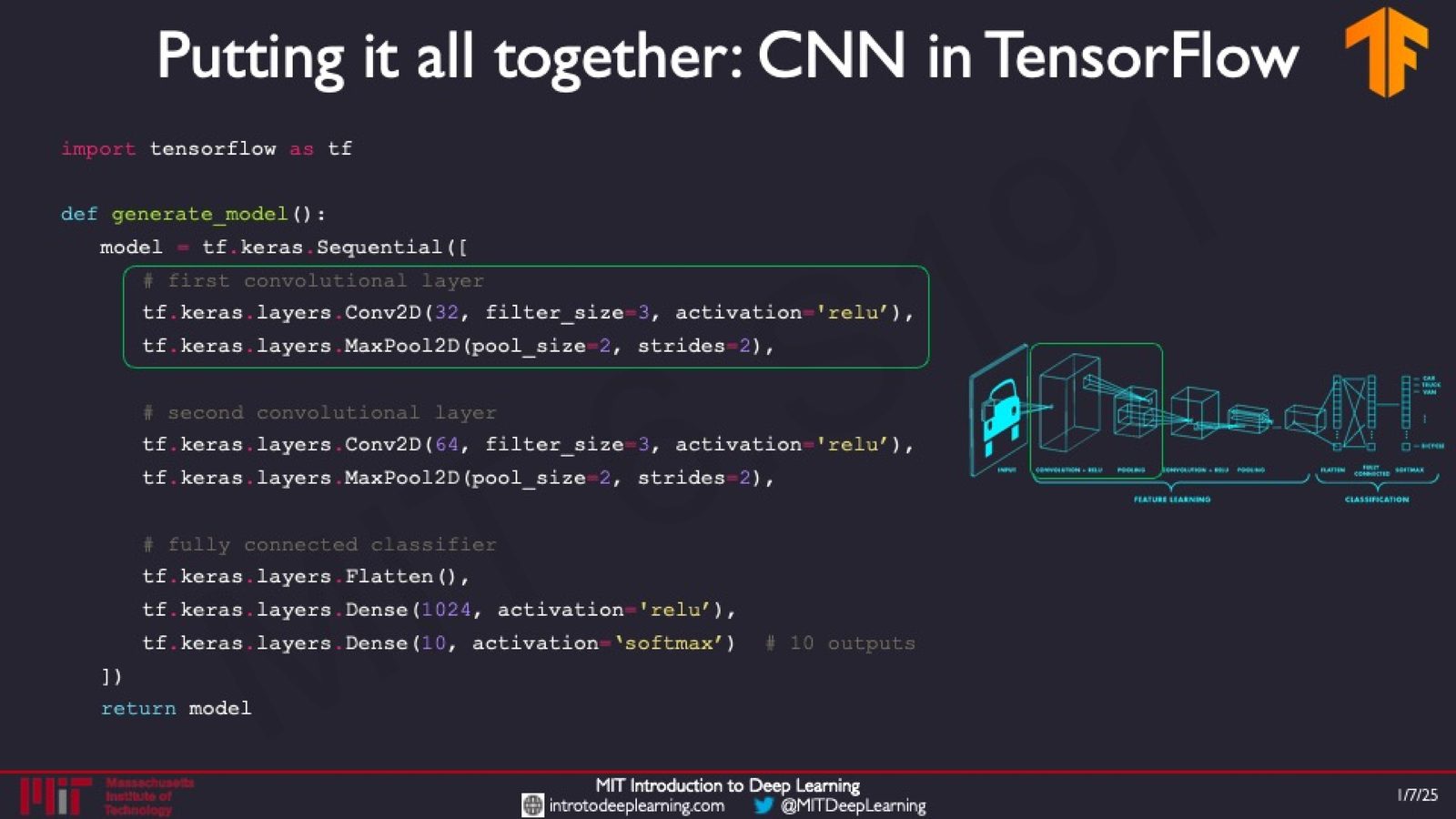
来源:Slides 第53页。
import tensorflow as tf
def generate_model():
model = tf.keras.Sequential([
# First convolutional layer
tf.keras.layers.Conv2D(32, filter_size=3, activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
# Second convolutional layer
tf.keras.layers.Conv2D(64, filter_size=3, activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
# Fully connected classifier
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1024, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax') # 10 outputs
])
return model
import torch
import torch.nn as nn
def generate_model():
model = nn.Sequential(
# First and second convolutional layer
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
# Fully connected classifier
nn.Flatten(),
nn.Linear(64*6*6, 1024), # flattened dim after 2 conv layers
nn.ReLU(),
nn.Linear(1024, 10), # 10 outputs
)
return model
超参数选择的"艺术与科学"
Amini 坦言,CNN 超参数的选择(滤波器数量、大小、层数等)"更多是一种艺术而非科学"(more art than science),但也有一些经验法则:
- 滤波器大小通常较小(\(3 \times 3\) 或 \(5 \times 5\)),因为局部特征不需要很大的感受野
- 滤波器数量通常逐层递增(如 \(32 \rightarrow 64 \rightarrow 128\)),因为更高层需要表示更多种类的复合特征
- 空间尺寸通过池化逐层递减,与滤波器数量的递增形成互补
本章小结
完整的 CNN 分类网络分为特征学习和分类两个阶段。特征学习通过卷积+ReLU+池化的堆叠逐层提取抽象特征;分类阶段通过展平和全连接层将特征映射为类别概率。TensorFlow 和 PyTorch 都提供了简洁的 API 来构建 CNN。
CNN 的广泛应用
超越分类:一种通用架构
CNN 的特征学习部分是高度通用的——学到的特征表示可以用于多种不同的下游任务:
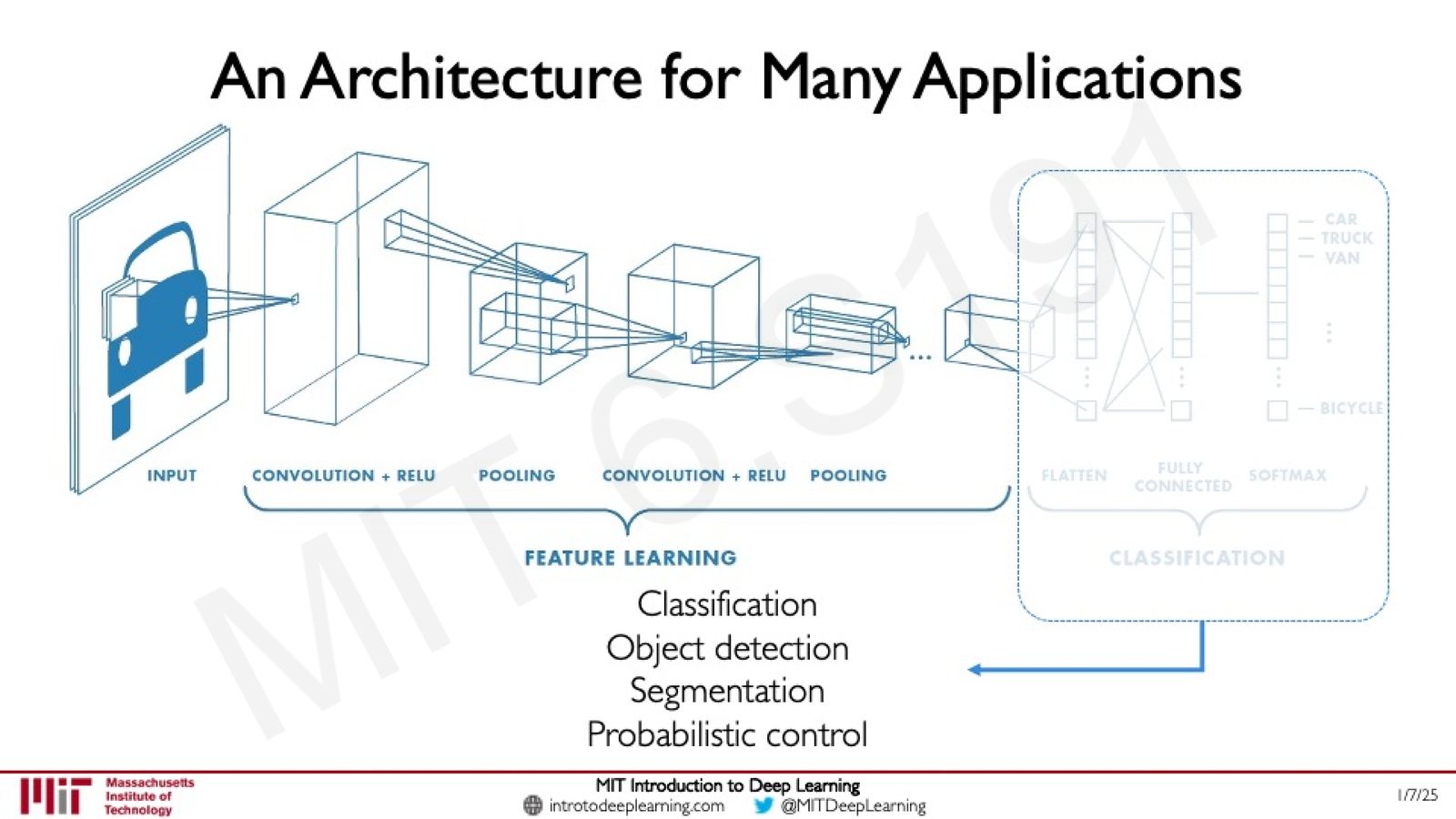
来源:Slides 第56页。
- 分类(Classification):判断整张图像属于哪个类别
- 目标检测(Object Detection):定位并分类图像中的所有物体
- 语义分割(Segmentation):对每个像素进行分类
- 概率控制(Probabilistic Control):如自动驾驶中从图像到方向盘转角
应用一:医学影像中的乳腺癌筛查
CNN 在医学影像分析中取得了突破性成果。Amini 展示了一项发表在 Nature 上的研究,证明基于 CNN 的 AI 系统在乳腺癌筛查中超越了专业放射科医生的表现:
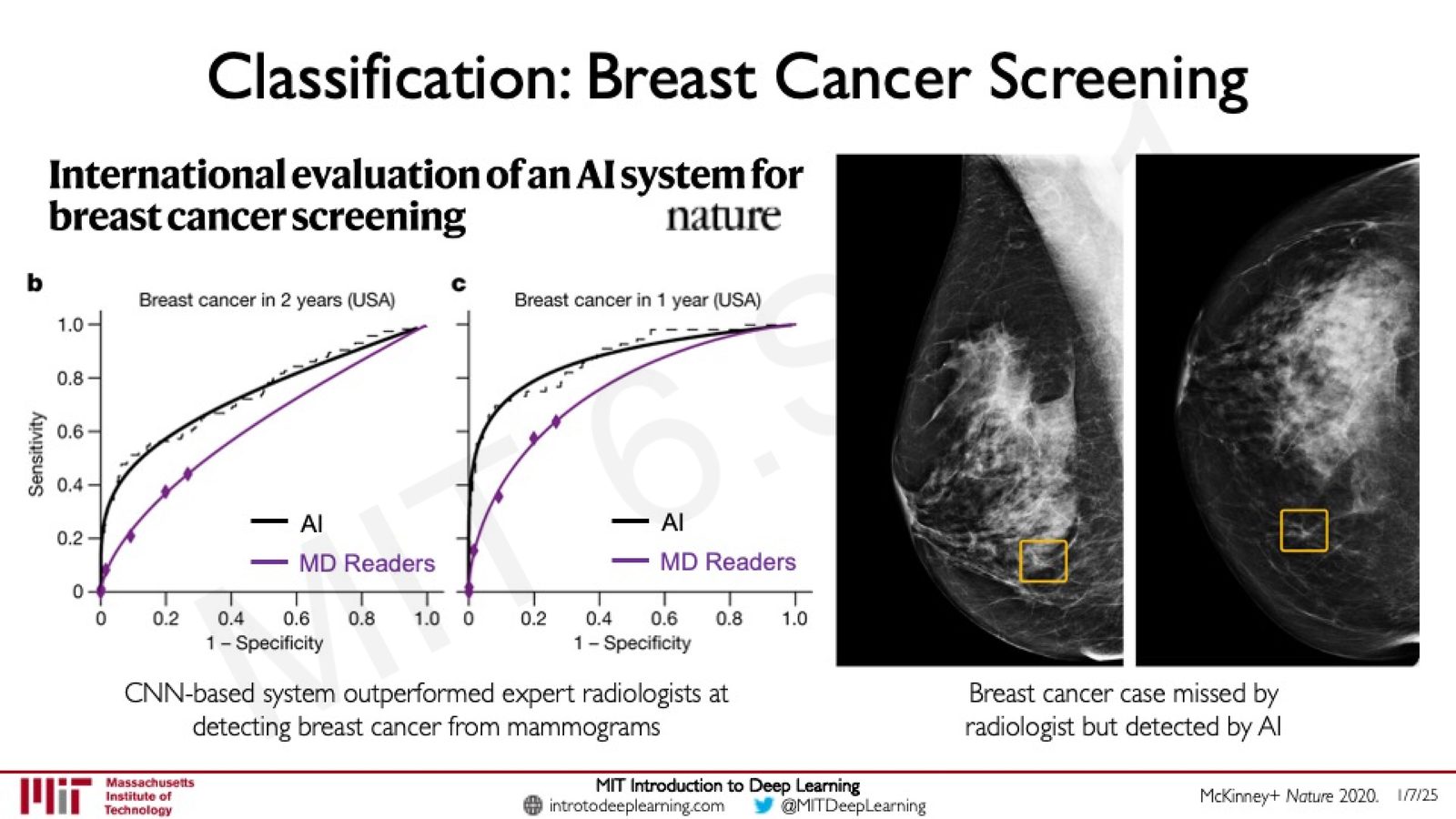
来源:Slides 第57页。参考 McKinney+ Nature 2020。
CNN 在医学影像中的价值
- 在美国乳腺癌 2 年筛查和 1 年筛查的评估中,AI 系统的 ROC 曲线均优于放射科医生群体
- AI 能检出人类医生遗漏的微小病灶,具有重要的临床辅助价值
- 类似的 CNN 方法已扩展到皮肤癌检测(Esteva+ Nature 2017)和 COVID-19 影像诊断
应用二:目标检测
目标检测(Object Detection)比分类更进一步——不仅要识别物体类别,还要给出物体的精确位置(bounding box)。
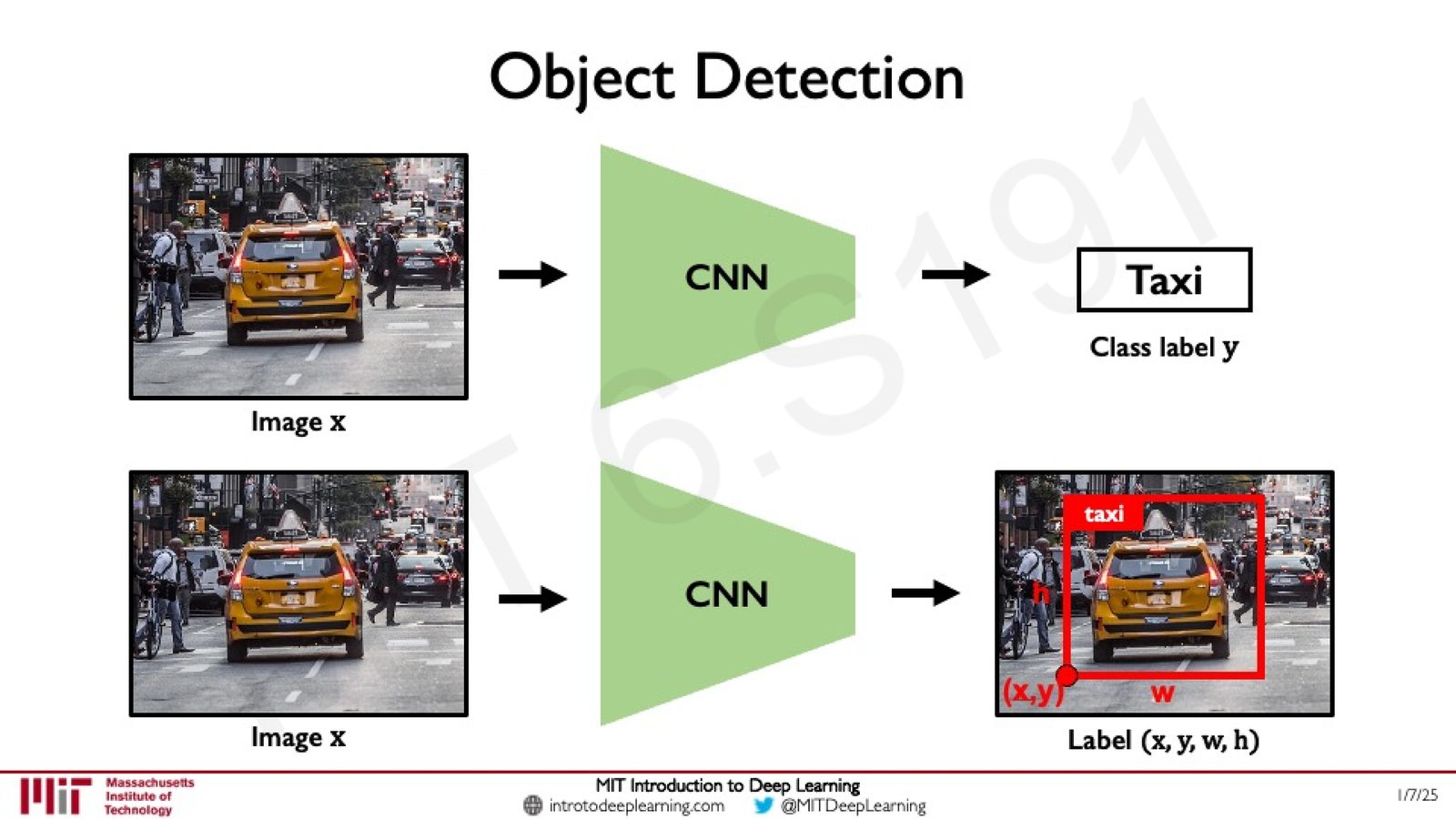
来源:Slides 第58页。
目标检测的输出格式为每个检测到的物体一组 \((class, x, y, w, h)\):
- \(class\):物体类别
- \((x, y)\):边界框左上角坐标
- \((w, h)\):边界框的宽度和高度
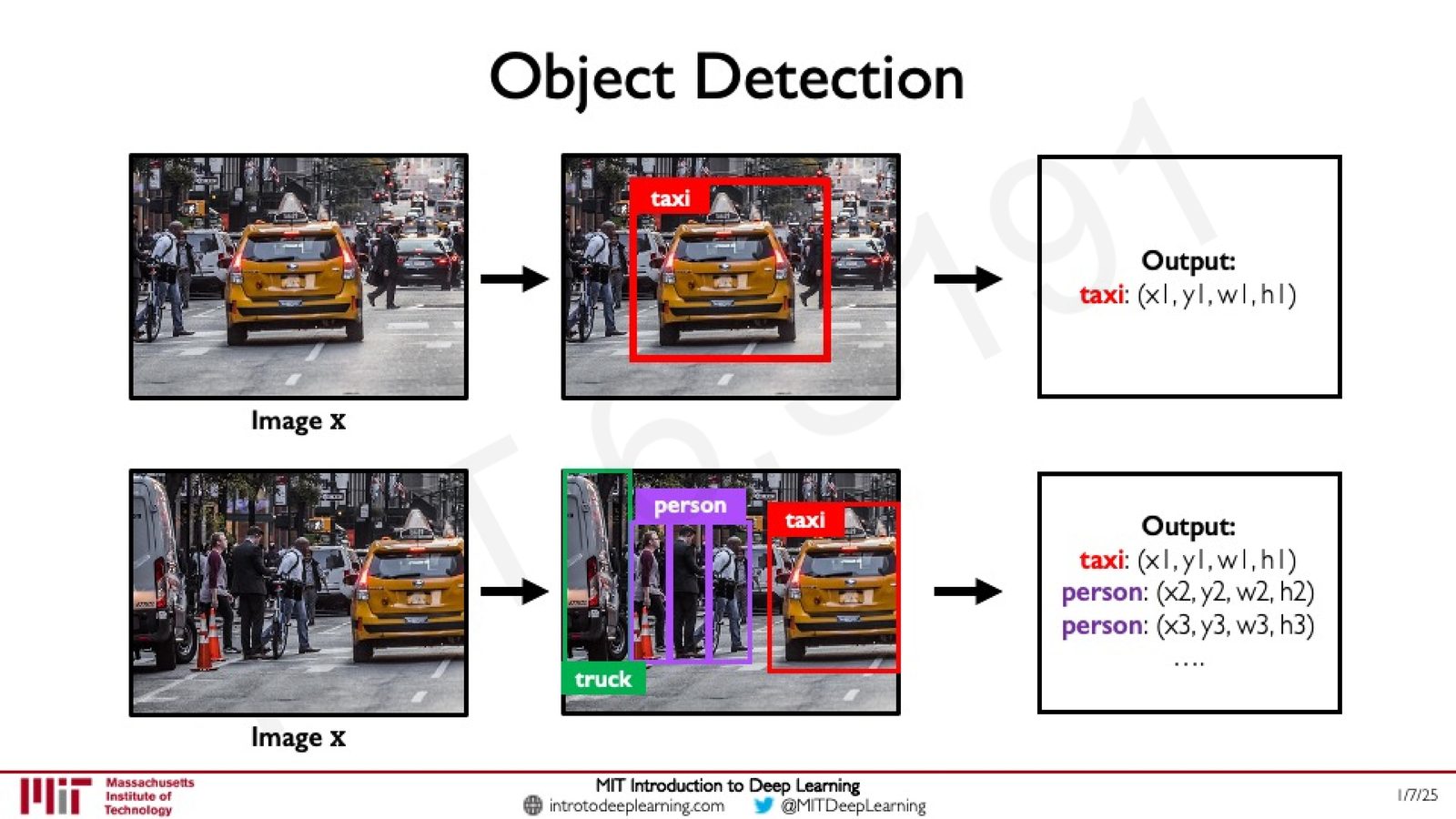
来源:Slides 第59页。
目标检测的难点
目标检测比分类困难得多,主要原因是:
- 边界框可以出现在图像的任何位置
- 边界框可以是任意大小
- 场景中物体的数量不固定——可以是零个、一个或多个
- 不同物体可能有不同的类别
这使得输出空间的维度不再固定,需要特殊的网络设计来处理。
朴素方法:滑动窗口
最直觉的方法是在图像上尝试所有可能的位置和大小的边界框,对每个框内的图像区域用 CNN 分类。但这种方法的计算量是灾难性的——可能的窗口数量随位置、大小和宽高比呈指数增长。

来源:Slides 第60页。
R-CNN 系列
为了解决效率问题,研究者提出了 R-CNN(Region-based CNN)系列方法。核心思想是先用选择性搜索(Selective Search)等方法生成少量候选区域(region proposals),然后只对这些候选区域进行 CNN 分类。后续发展包括 Fast R-CNN 和 Faster R-CNN,进一步将区域提议网络(Region Proposal Network, RPN)集成到 CNN 中,实现端到端训练。
R-CNN 到 Faster R-CNN 的演进
- R-CNN(2014):选择性搜索生成约 2000 个候选区域,每个独立通过 CNN 提取特征,再用 SVM 分类。速度很慢。
- Fast R-CNN(2015):先对整幅图像做一次 CNN 特征提取,再从特征图上裁剪候选区域。共享了特征计算,速度大幅提升。
- Faster R-CNN(2015):引入 Region Proposal Network (RPN) 直接在特征图上生成候选区域,完全端到端训练。
本章小结
CNN 的特征学习模块是通用的,可以支持分类、目标检测、分割等多种视觉任务。在医学影像中,CNN 已经达到甚至超越人类专家水平。目标检测需要同时预测类别和位置,朴素的滑动窗口方法效率低下,R-CNN 系列通过区域提议机制大幅提升了效率。
实验环节:面部检测 Lab
Amini 在课堂上介绍了本讲配套的实验(Lab 2)——面部检测任务。这个实验让学生亲手构建一个 CNN 来检测图像中的人脸,是将本讲理论付诸实践的绝佳机会。
实验的主要步骤包括:
- 构建卷积神经网络架构(包括卷积层、ReLU 激活、池化层和全连接分类头)
- 使用面部图像数据集训练模型
- 评估模型在新图像上的检测性能
- 分析模型学到的特征可视化
面部检测的历史意义
面部检测是最早获得大规模商业应用的计算机视觉任务之一。从 Viola-Jones 人脸检测器(2001年,基于手工设计的 Haar 特征和 AdaBoost 分类器)到现代的深度学习方法,面部检测的精度和速度都有了质的飞跃。如今,面部检测技术已经深入到手机解锁、社交媒体滤镜、安防监控等日常应用中。
面部识别的伦理考量
虽然面部检测和识别技术非常强大,但也引发了严重的隐私和伦理问题。包括:种族和性别偏见(模型在某些群体上表现更差)、监控滥用、Deepfake 伪造等。在开发和部署这类技术时,必须认真考虑其社会影响。
总结与延伸
本讲核心要点
- 图像是数字:计算机通过 \(H \times W \times C\) 的数字矩阵来表示图像,其中 \(C\) 是通道数(灰度图 \(C=1\),彩色图 \(C=3\))。
- 特征提取是视觉识别的核心:要识别物体,需要提取能区分不同类别的特征。手工特征设计面临递归性和变异性的困境,深度学习通过从数据中自动学习特征层次结构来解决这一问题。
- 全连接网络不适合图像:展平操作丧失空间信息,且参数量过大。
-
卷积操作的三大优势:
-
局部连接——保留空间结构
- 参数共享——大幅减少参数量
- 平移等变——同一模式无论出现在图像哪个位置都能被检测到
- CNN 架构:卷积层 + ReLU + 池化层的堆叠构成特征学习模块,全连接层 + Softmax 构成分类模块。
- CNN 是通用视觉架构:同样的特征学习框架可以用于分类、目标检测、语义分割等多种任务。
与前两讲的联系
| 方面 | Lecture 1 (全连接网络) | Lecture 3 (CNN) |
|---|---|---|
| 输入形式 | 一维特征向量 | 二维/三维图像张量 |
| 连接方式 | 全连接(所有输入到所有神经元) | 局部连接(每个神经元只看局部区域) |
| 参数共享 | 无 | 滤波器在空间上共享 |
| 空间信息 | 不保留 | 保留并利用 |
| 核心操作 | 矩阵乘法 | 卷积操作 |
核心哲学:让数据结构指导架构设计
CNN 的设计哲学是利用数据的内在结构来设计网络架构。图像具有空间局部性——相邻像素之间的关系比远距像素更密切;图像具有平移不变性——同一模式可以出现在任何位置。卷积操作完美地利用了这两个先验知识。这一哲学在深度学习中反复出现:RNN 利用了序列的时间结构,Transformer 中的注意力机制利用了元素间的关系结构。
拓展阅读
- MIT 6.S191 课程官网:http://introtodeeplearning.com
- LeCun et al. (1998), "Gradient-Based Learning Applied to Document Recognition" — CNN 的奠基之作
- Krizhevsky et al. (2012), "ImageNet Classification with Deep Convolutional Neural Networks" (AlexNet) — 深度学习在计算机视觉领域的里程碑
- Lee et al. (2009), ICML — 本讲中特征层次结构可视化的原始论文
- McKinney et al. (2020), Nature — CNN 在乳腺癌筛查中超越人类医生的研究
- Esteva et al. (2017), Nature — CNN 用于皮肤癌诊断的研究
- Rohrer, "How do CNNs work?" — 本讲中 X 检测案例的参考
- Karn, "An Intuitive Explanation of CNNs" — 本讲中卷积操作动画的参考