CS224N Lecture 3: Backpropagation and Neural Networks
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Chris Manning 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2024年4月9日 |

引言:课程概览
本节课是 Stanford CS224N(Natural Language Processing with Deep Learning)的第三讲,由 Chris Manning 教授讲授。课程的核心目标是让学生理解神经网络训练的数学原理——如何手动推导梯度(矩阵微积分)以及如何用算法自动计算梯度(反向传播算法)。

来源:Slides 第1页。
课程分为三个部分:

来源:Slides 第10页。
本讲核心学习目标
- 理解神经网络中梯度的数学推导——矩阵微积分(Matrix Calculus)
- 掌握反向传播算法(Backpropagation)——链式法则的高效实现
- 建立“前向传播计算函数值、反向传播计算梯度”的直觉
本章小结
本讲聚焦于神经网络训练的数学基础。Manning 教授强调,虽然现代深度学习框架(如 PyTorch)已经自动化了梯度计算,但理解底层原理对于调试、设计新模型和理解训练行为至关重要。
神经网络基础回顾
从逻辑回归到神经网络
上一讲介绍了神经网络的基本概念:每个神经元本质上是一个小型的逻辑回归单元。与传统机器学习中单个逻辑回归不同的是,神经网络将这些单元级联起来,形成多层结构。
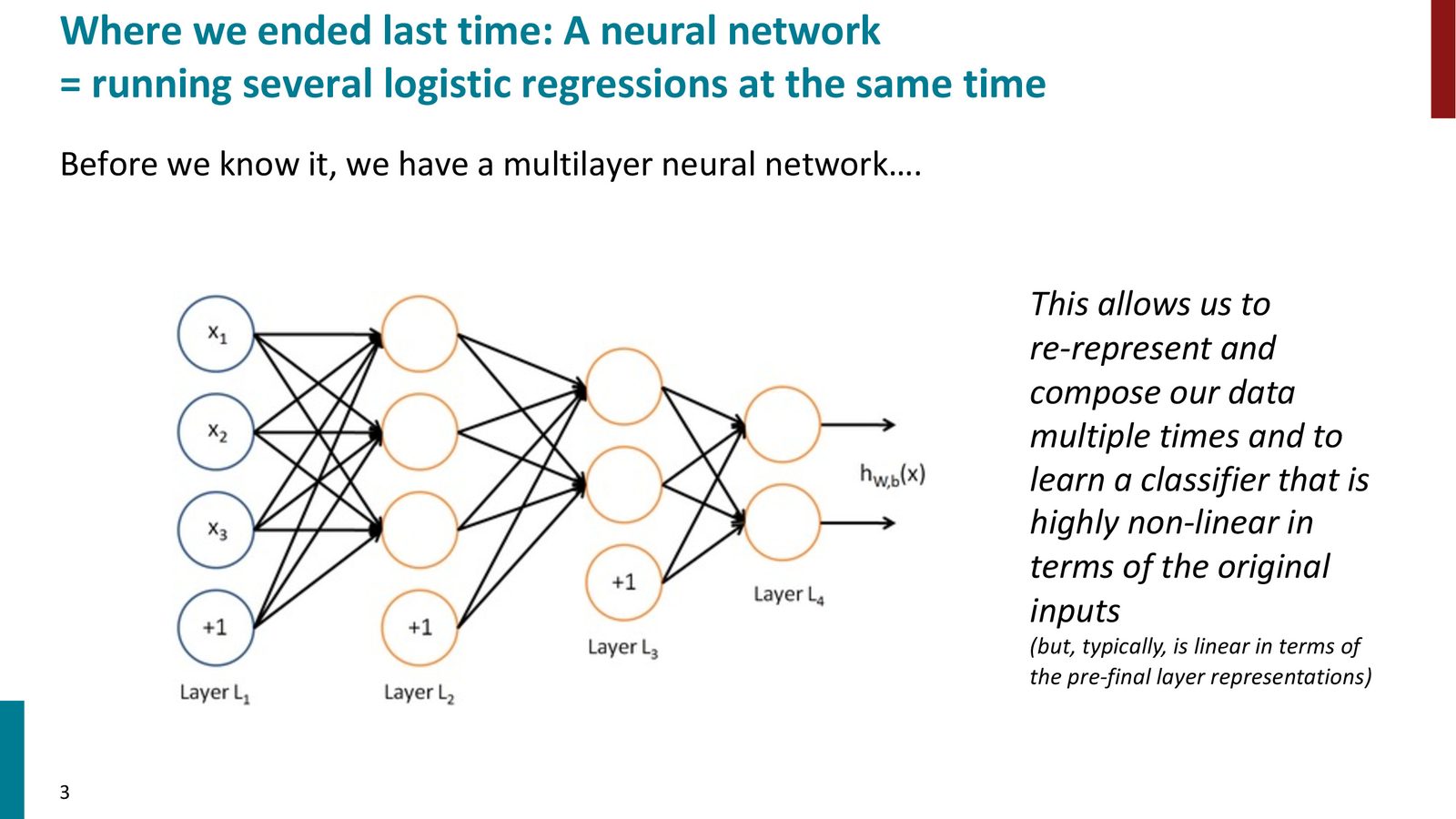
来源:Slides 第3页。
神经网络的核心优势——表示学习
神经网络最强大的特性在于中间层的自组织(self-organization of intermediate representations)。网络不需要人工设计特征,而是自动学习“什么样的中间表示对最终任务有用”。这正是神经网络在大多数场景下优于传统机器学习的根本原因。
层的矩阵表示
当神经网络采用规则的层状结构时,每一层的计算可以用矩阵运算表示:
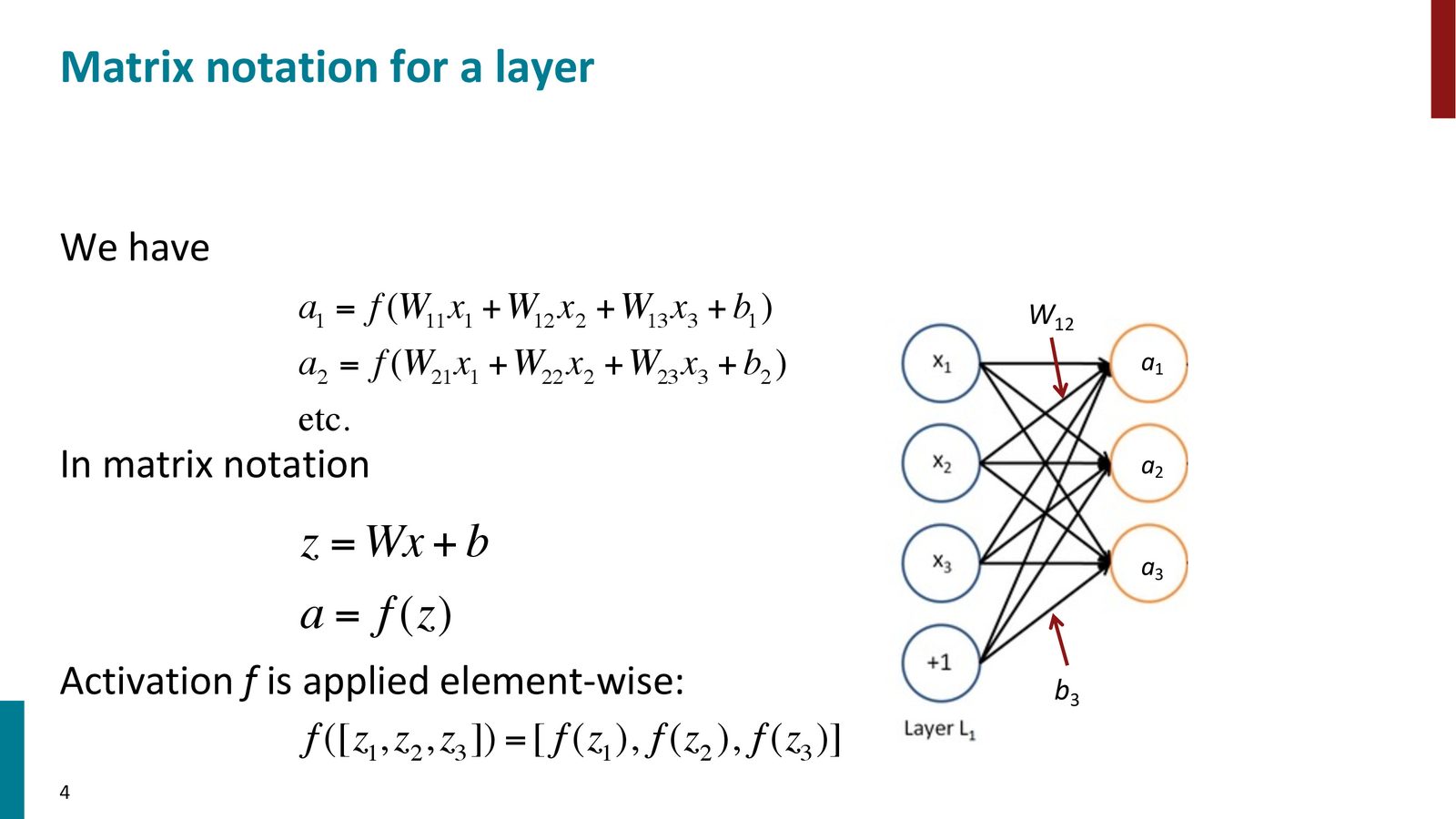
来源:Slides 第4页。
具体来说,一层神经网络的计算包含两步:
第一步:线性变换
其中:
- \(x \in \mathbb{R}^m\):输入向量
- \(W \in \mathbb{R}^{n \times m}\):权重矩阵
- \(b \in \mathbb{R}^n\):偏置向量
- \(z \in \mathbb{R}^n\):线性变换输出
第二步:非线性激活
激活函数 \(f\) 逐元素应用:\(f([z_1, z_2, z_3]) = [f(z_1), f(z_2), f(z_3)]\)。
NER 示例:命名实体识别
Manning 教授使用一个具体的 NER(命名实体识别)任务来贯穿整个讲解:判断一个上下文窗口中心的词是否为地点名称。

来源:Slides 第5页。
该网络的完整计算过程:
- 将 5 个词的词向量拼接为输入 \(x \in \mathbb{R}^{5d}\)
- 经过隐藏层:\(h = f(Wx + b)\)
- 点积得到分数:\(s = u^T h\)
- 通过 sigmoid 得到概率:\(J_t(\theta) = \sigma(s) = \frac{1}{1 + e^{-s}}\)
为什么用词嵌入而不是 one-hot?
One-hot 向量维度极高(词表大小)且稀疏,无法表达词与词之间的语义关系。词嵌入(word embeddings)将每个词映射为一个低维稠密向量,使得语义相近的词在向量空间中距离也近。在深度学习中,\(\theta\) 不仅包含权重矩阵等传统参数,词向量本身也是需要学习的参数。
本章小结
神经网络通过将多个“小型逻辑回归”级联,自动学习中间表示。每一层的计算可以简洁地表示为矩阵乘法加偏置再加非线性激活:\(a = f(Wx + b)\)。接下来的问题是:如何训练这个网络?答案是梯度下降,而这需要我们计算梯度。
激活函数:为什么需要非线性
从阈值函数到可微激活函数
神经元模型的历史始于 McCulloch & Pitts(1943)的阈值单元:
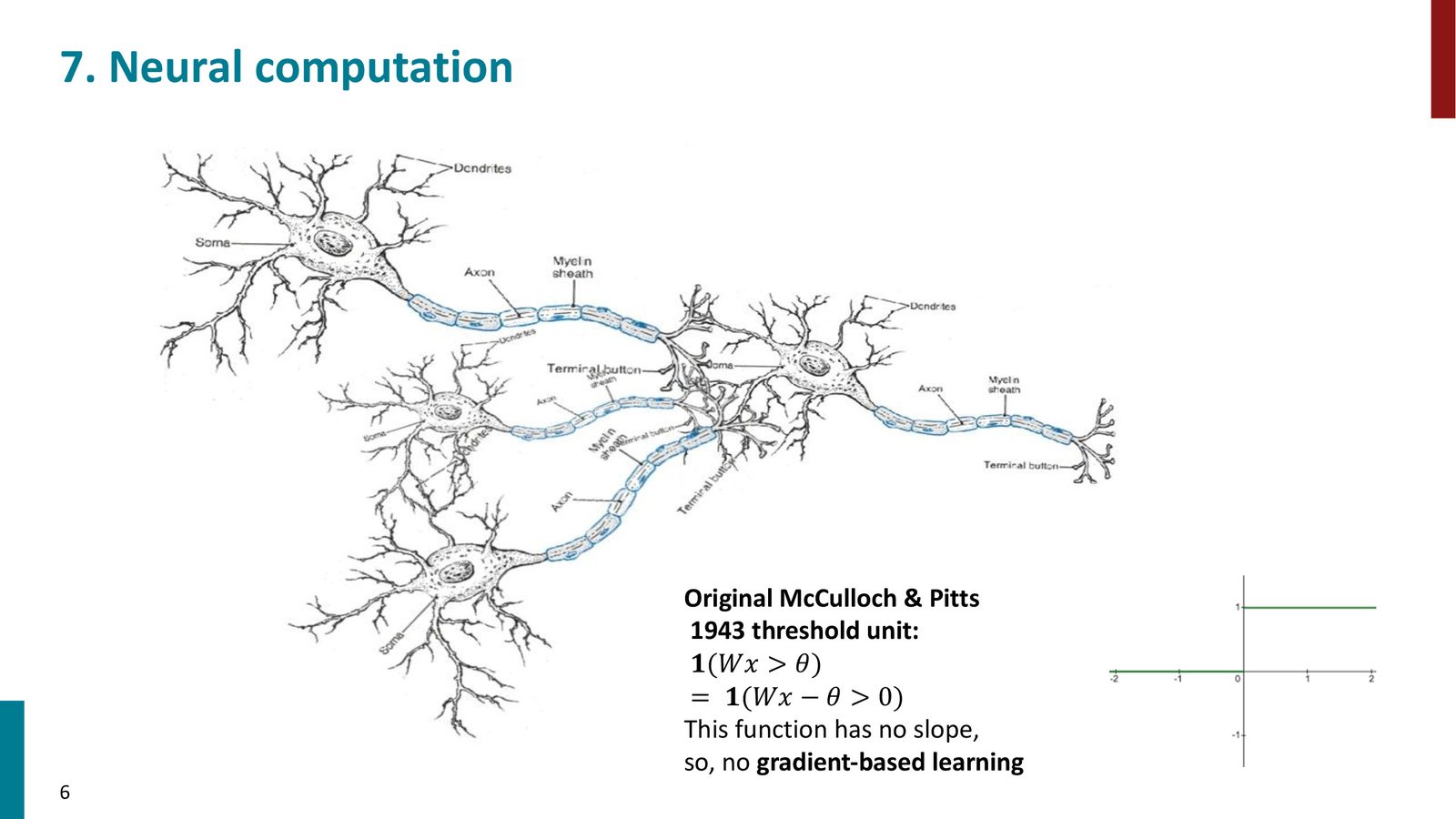
来源:Slides 第6页。
阈值函数的问题在于它是分段常数函数——斜率处处为零(除了不连续点),因此无法提供梯度信息来指导学习。梯度学习的核心思想是“找到哪里更陡峭,朝那个方向走”——如同滑雪,你需要坡度来决定方向。
常见激活函数一览

来源:Slides 第7页。
Logistic(Sigmoid)函数:
输出范围 \((0, 1)\),常用于输出层(映射到概率)。缺点:输出始终为正,且在两端梯度趋近于零(梯度消失)。
Tanh 函数:
输出范围 \((-1, 1)\),是 sigmoid 的缩放平移版本:\(\tanh(z) = 2\sigma(2z) - 1\)。
ReLU(Rectified Linear Unit):
正半轴斜率恒为 1,计算极快。虽然负半轴“死区”(梯度为零)看似矛盾,但实践中效果极好——它提供了一种自然的稀疏激活和特化机制。
ReLU 的“死区”问题
当 ReLU 神经元的输入持续为负时,梯度为零,该神经元“永久死亡”,无法再被激活。这就是所谓的 dying ReLU 问题。虽然在正常训练中这通常不是致命问题(网络中总有一部分神经元是活跃的),但在学习率过大或初始化不当时可能导致大量神经元死亡。
Leaky ReLU / Parametric ReLU:在负半轴给予一个小斜率(如 0.01),避免完全死亡。Parametric ReLU 将负半轴斜率作为可学习参数。
Swish 和 GELU:近年来在 Transformer 模型中广泛使用。
两者形状类似:正半轴近似 \(y = x\),负半轴有一小段“弯曲”区域提供梯度。
为什么非线性不可或缺
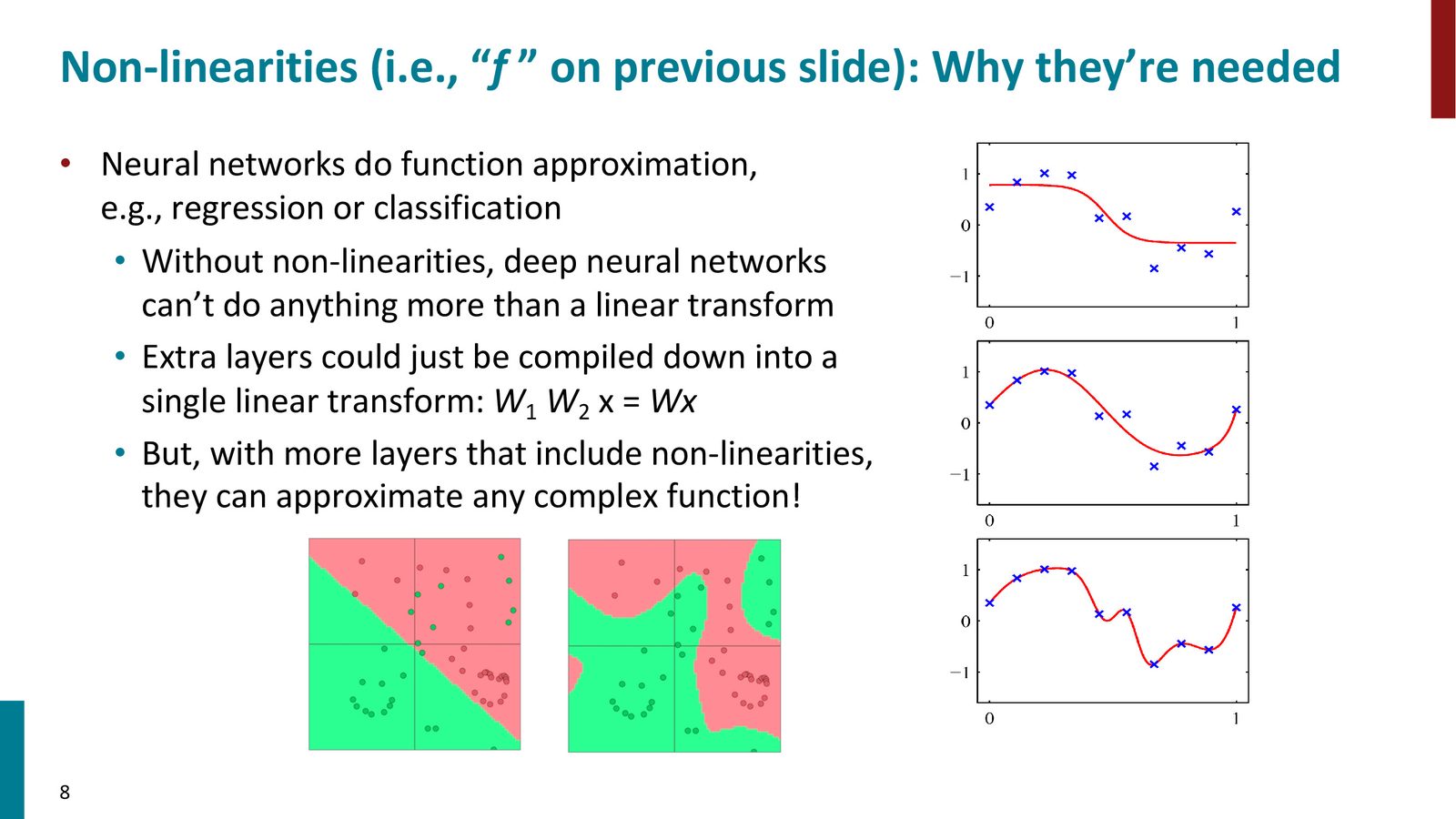
来源:Slides 第8页。
线性层的叠加 = 单层线性变换
如果只做矩阵乘法而没有非线性:
多层网络在表示能力上与单层完全等价!非线性激活函数是使神经网络成为万能函数逼近器(universal function approximator)的关键。
线性网络在学习理论中的价值
Manning 教授指出了一个有趣的现象:虽然线性神经网络在表示能力上没有优势(等价于单层线性变换),但在学习动力学上却有独特性质。理论界有相当多论文研究线性网络的学习行为,因为多层结构即使没有非线性也会影响优化路径。
本章小结
激活函数是神经网络能够学习复杂非线性映射的关键。从历史上的阈值函数到 sigmoid/tanh,再到 ReLU 及其变体,直到 Transformer 时代的 Swish/GELU,激活函数的演进反映了对“梯度流通性”和“计算效率”的不断追求。核心原则是:保留足够的梯度信号使学习成为可能。
梯度下降与梯度计算
随机梯度下降(SGD)回顾
神经网络的训练依赖于随机梯度下降(Stochastic Gradient Descent):

来源:Slides 第9页。
其中:
- \(\theta\):模型的所有参数(包括权重矩阵 \(W\)、偏置 \(b\)、词向量等)
- \(\alpha\):学习率(step size)
- \(\nabla_\theta J(\theta)\):损失函数关于参数的梯度
核心问题:如何计算 \(\nabla_\theta J(\theta)\)? 有两种方法:
- 手动推导(By hand)——矩阵微积分
- 算法自动计算(Algorithmically)——反向传播算法
本讲两种方法都会讲解。
本章小结
SGD 是训练神经网络的核心算法,其关键步骤是计算损失函数关于所有参数的梯度。在深度学习中,参数 \(\theta\) 不仅包括传统的权重和偏置,还包括词嵌入等数据表示参数。
矩阵微积分:手动推导梯度
从单变量到多变量
Manning 教授给出了一个关键的思维口诀:
矩阵微积分的核心口诀
“Multivariable calculus is just like single-variable calculus if you use matrices.”(多变量微积分就是单变量微积分——只不过用矩阵代替标量。)

来源:Slides 第11页。
回顾单变量微积分的基本例子:\(f(x) = x^3\),导数 \(f'(x) = 3x^2\)。导数衡量的是斜率——输入的微小变化如何被放大到输出上。例如在 \(x = 4\) 处,\(f'(4) = 48\),意味着 \(x\) 从 4 变到 4.01 时,\(f(x)\) 大约增加 \(48 \times 0.01 = 0.48\)(即从 64 变为约 64.48)。
梯度与 Jacobian 矩阵
当函数有 \(n\) 个输入和 1 个输出时(\(f: \mathbb{R}^n \to \mathbb{R}\)),梯度是一个向量:
当函数有 \(n\) 个输入和 \(m\) 个输出时(\(f: \mathbb{R}^n \to \mathbb{R}^m\)),偏导数构成一个 \(m \times n\) 的矩阵,称为 Jacobian 矩阵:

来源:Slides 第15页。
Jacobian 在神经网络中的角色
神经网络的每一层都是一个多输入多输出的函数。例如一个隐藏层 \(h = f(Wx + b)\) 将 \(m\) 维输入映射到 \(n\) 维输出。该层的 Jacobian 就是一个 \(n \times m\) 的矩阵,描述了每个输出维度对每个输入维度的敏感度。
链式法则的矩阵形式
对于复合函数,链式法则变为 Jacobian 矩阵的乘法。如果 \(h = f(g(x))\),则:
这与单变量的链式法则 \(\frac{dz}{dx} = \frac{dz}{dy} \cdot \frac{dy}{dx}\) 形式完全一致——只是标量乘法变成了矩阵乘法。

来源:Slides 第18页。
逐元素激活函数的 Jacobian
对于逐元素激活函数 \(h = f(z)\)(其中 \(h_i = f(z_i)\)),其 Jacobian 是一个对角矩阵:

来源:Slides 第21页。
即:
对角结构的直觉
为什么是对角矩阵?因为激活函数是逐元素应用的:\(h_i\) 只依赖于 \(z_i\),不依赖于 \(z_j\)(\(j \neq i\))。因此非对角元素(\(i \neq j\))的偏导数为零。
线性层的 Jacobian
对于线性变换 \(z = Wx + b\):
类比单变量:\(y = wx + b\) 的导数关于 \(x\) 是 \(w\),关于 \(b\) 是 \(1\)。矩阵版本中,\(w\) 变为 \(W\),\(1\) 变为单位矩阵 \(I\)。
对于点积 \(s = u^T h\):

来源:Slides 第23页。
NER 网络的完整梯度推导
现在将所有 Jacobian 组合起来,对 NER 示例网络推导梯度。网络结构为:

来源:Slides 第31页。
计算 \(\frac{\partial s}{\partial b}\):
化简后:
其中 \(\circ\) 表示 Hadamard 乘积(逐元素乘法)。
Hadamard 乘积
Hadamard 乘积(记作 \(\circ\) 或 \(\odot\))是将两个相同维度的向量/矩阵逐元素相乘。不同于点积(结果是标量),Hadamard 乘积的结果维度与输入相同。在神经网络的梯度计算中,它出现在对角 Jacobian 乘以向量时——等价于两个向量的逐元素乘法。
上游梯度 \(\delta\) 的概念:
注意到计算 \(\frac{\partial s}{\partial b}\) 和 \(\frac{\partial s}{\partial W}\) 时,前两项是共享的:
\(\delta\) 称为上游梯度(upstream gradient)或误差信号(error signal)。它可以计算一次、复用多次,这是反向传播算法效率的关键。

来源:Slides 第36页。
于是:
- \(\frac{\partial s}{\partial b} = \delta\)(因为 \(\frac{\partial z}{\partial b} = I\))
- \(\frac{\partial s}{\partial W} = \delta^T x^T\)(外积形式)
计算 \(\frac{\partial s}{\partial W}\):

来源:Slides 第41页。
按照严格的 Jacobian 定义,\(\frac{\partial s}{\partial W}\) 应该是一个 \(1 \times nm\) 的行向量(因为 \(s\) 是标量,\(W\) 有 \(nm\) 个参数)。但在实际工程中,我们采用形状约定(shape convention),将梯度整形为与参数相同的形状,以便直接做 SGD 更新 \(W^{\text{new}} = W^{\text{old}} - \alpha \frac{\partial s}{\partial W}\)。
最终结果:
这是 \(\delta^T\)(\(n \times 1\))与 \(x^T\)(\(1 \times m\))的外积。
Jacobian 形式 vs 形状约定
数学上,Jacobian 矩阵有严格的定义和形状,链式法则在 Jacobian 形式下是矩阵乘法。但在工程实现中,为了方便 SGD 更新,我们通常将梯度“reshape”为与参数相同的形状。这两种约定混用可能导致困惑——Manning 教授建议:可以先用 Jacobian 做正确的数学推导,最后再 reshape 结果;或者始终按形状约定做,但要灵活使用转置。
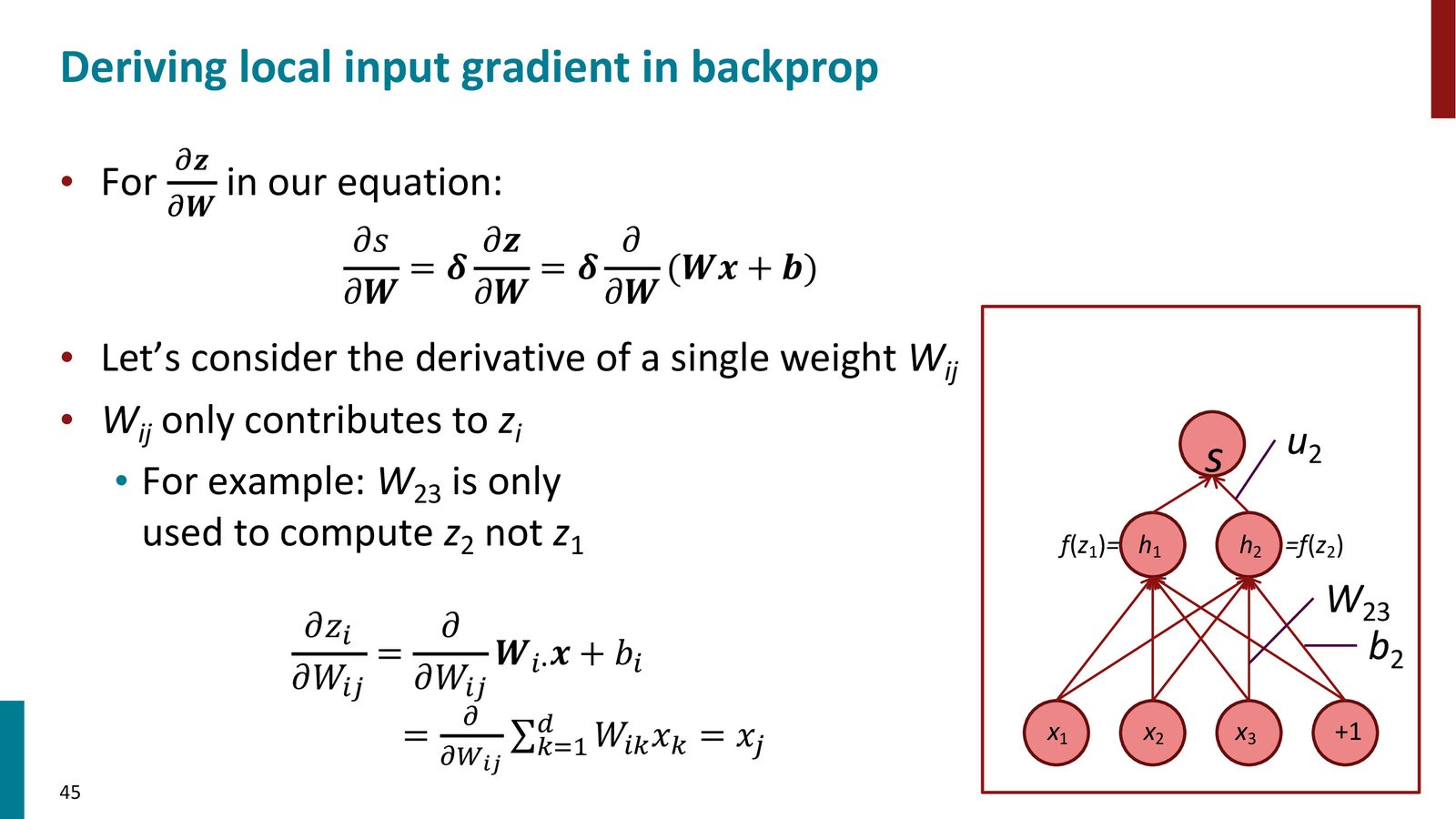
来源:Slides 第45页。
外积梯度的直觉
为什么 \(\frac{\partial s}{\partial W} = \delta^T x^T\) 是对的?考虑单个权重 \(W_{ij}\):它只参与计算 \(z_i = \sum_k W_{ik} x_k + b_i\),即只连接输入 \(x_j\) 到隐藏层 \(z_i\)。因此:
这恰好是外积 \(\delta^T x^T\) 的第 \((i,j)\) 个元素。
本章小结
矩阵微积分的核心是:用 Jacobian 矩阵表示多输入多输出函数的导数,用矩阵乘法表示链式法则。对于神经网络的常见操作(线性层、激活函数、点积),Jacobian 都有简洁的封闭形式。关键概念是上游梯度 \(\delta\)——它在不同参数的梯度计算中被复用,避免重复计算。
反向传播算法
反向传播的本质
反向传播算法 = 两件事
- 使用链式法则:将复合函数的梯度分解为局部梯度的乘积
- 存储中间结果:避免重复计算——同一个上游梯度被多个下游节点共享
这就是反向传播算法的全部。
计算图
为了系统化地实现反向传播,我们将计算过程表示为计算图(Computation Graph):

来源:Slides 第51页。
计算图中:
- 源节点:输入变量(\(x, W, b, u\))
- 内部节点:运算操作(矩阵乘法、加法、激活函数、点积)
- 边:传递操作的结果
前向传播(Forward Propagation):沿计算图从左到右,依次计算每个节点的值。
反向传播(Backward Propagation / Backpropagation):沿计算图从右到左,依次计算梯度。
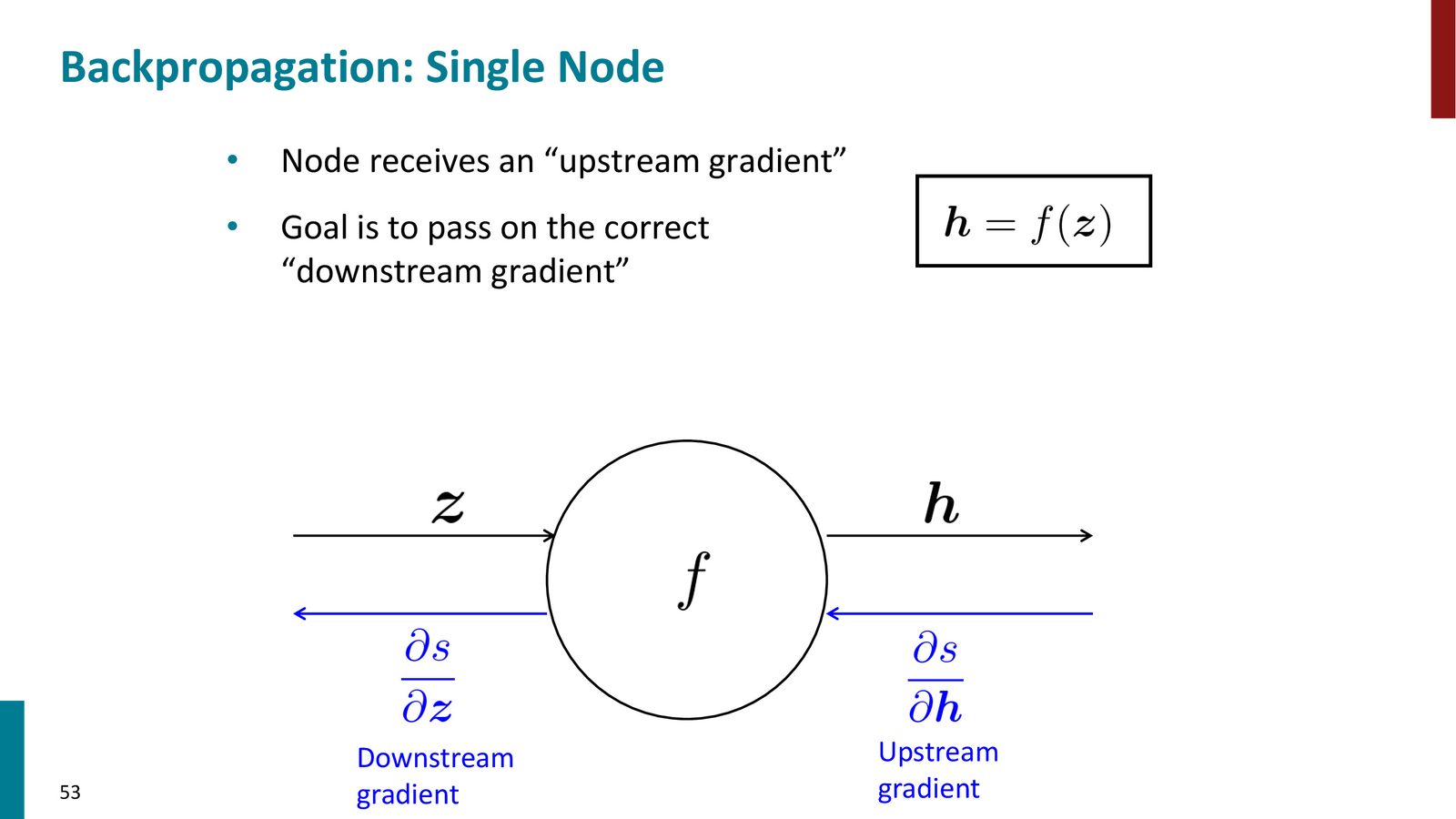
来源:Slides 第53页。
单节点的梯度传播规则
对于计算图中的任意一个节点,设其计算为 \(h = f(z)\):
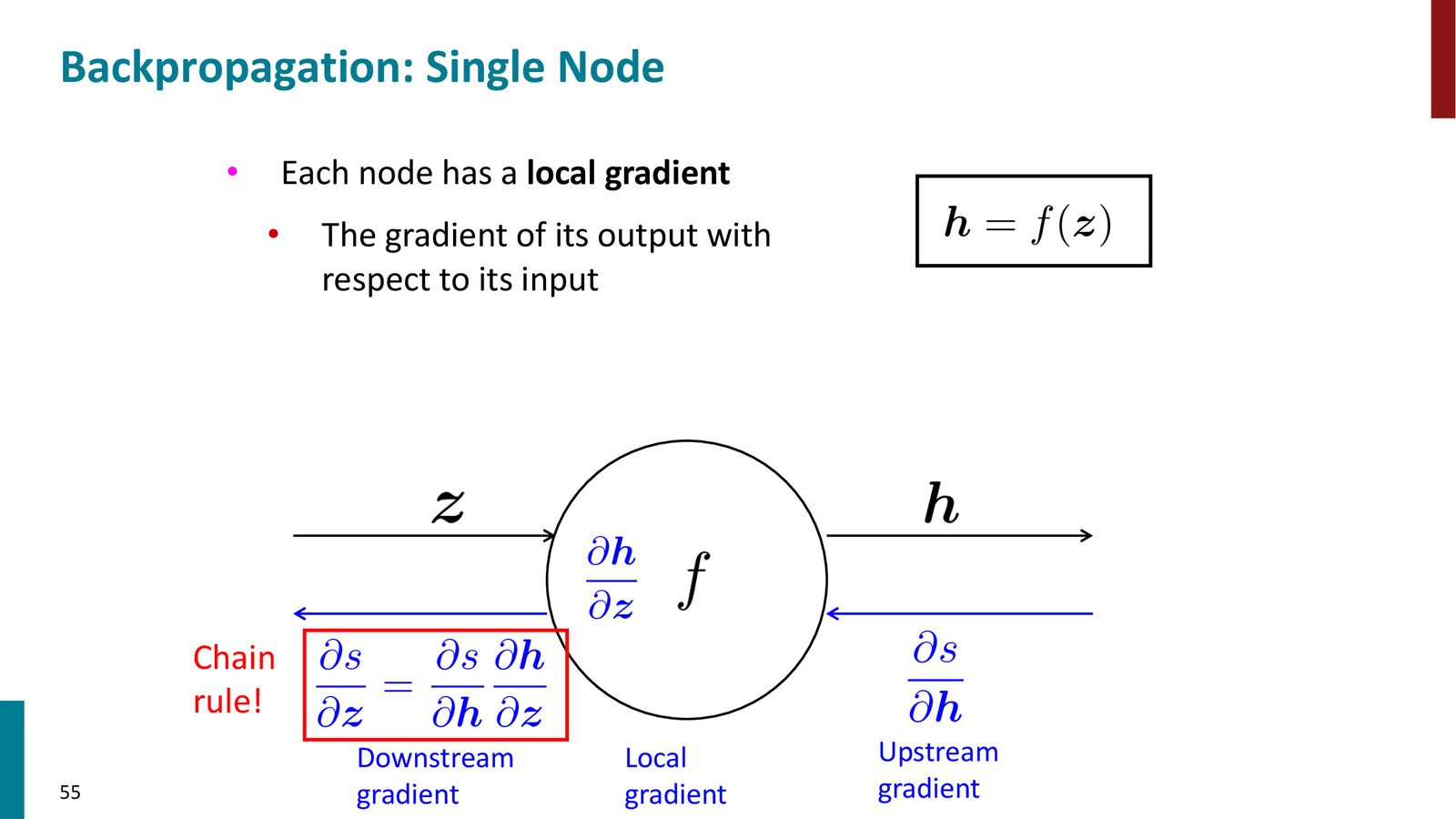
来源:Slides 第55页。
这就是链式法则在计算图中的体现。当节点有多个输入时,对每个输入分别计算局部梯度,然后分别与上游梯度相乘。
实例:\(f(x,y,z) = (x+y) · (y,z)\)
Manning 教授用一个具体的非神经网络的例子来演示反向传播的过程。
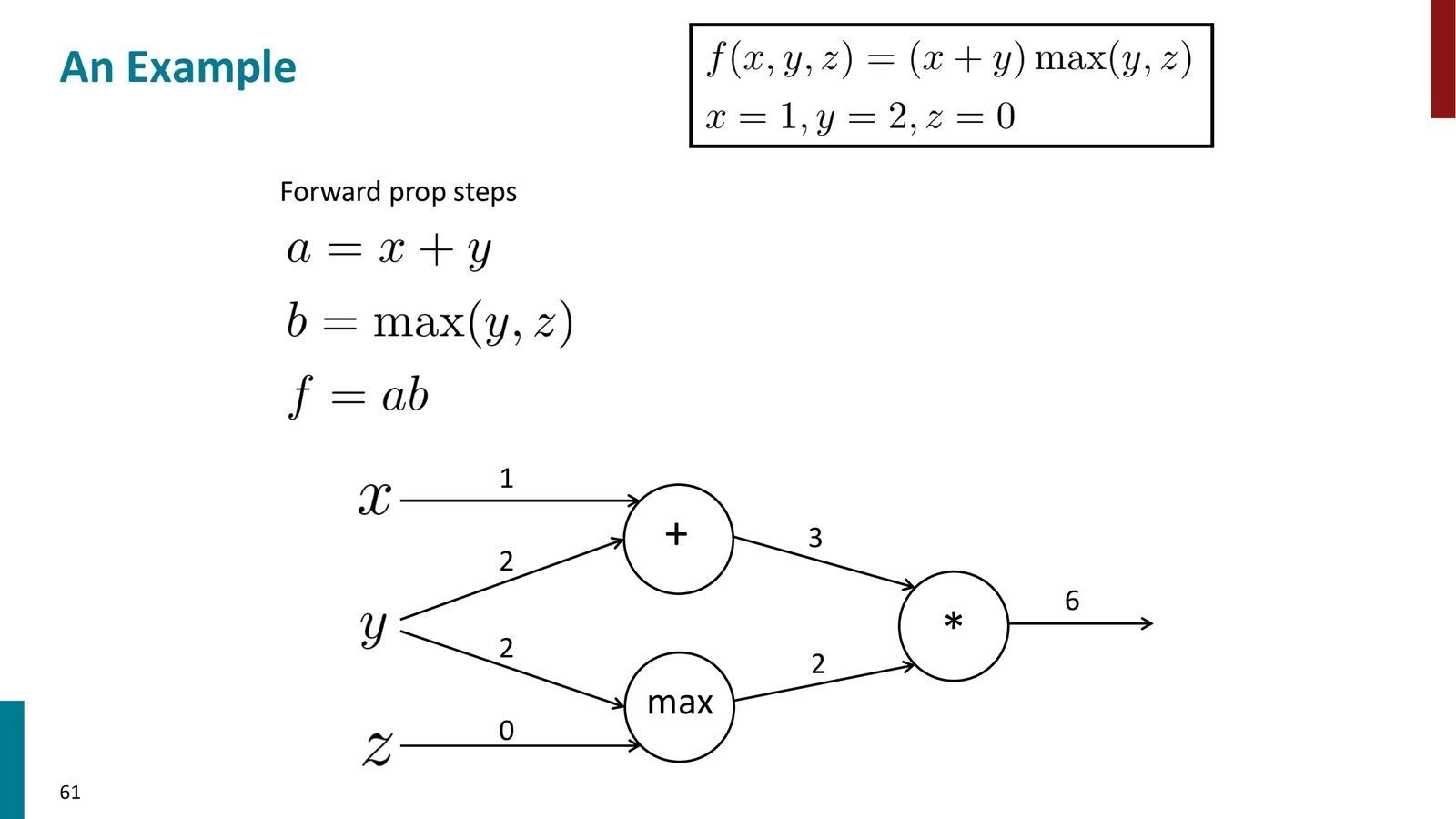
来源:Slides 第61页。
前向传播:
- \(a = x + y = 1 + 2 = 3\)
- \(b = \max(y, z) = \max(2, 0) = 2\)
- \(f = a \cdot b = 3 \times 2 = 6\)
局部梯度:
- 加法节点:\(\frac{\partial a}{\partial x} = 1\), \(\frac{\partial a}{\partial y} = 1\)
- max 节点:\(\frac{\partial b}{\partial y} = 1\)(\(y > z\)),\(\frac{\partial b}{\partial z} = 0\)
- 乘法节点:\(\frac{\partial f}{\partial a} = b = 2\),\(\frac{\partial f}{\partial b} = a = 3\)
反向传播(从右到左):
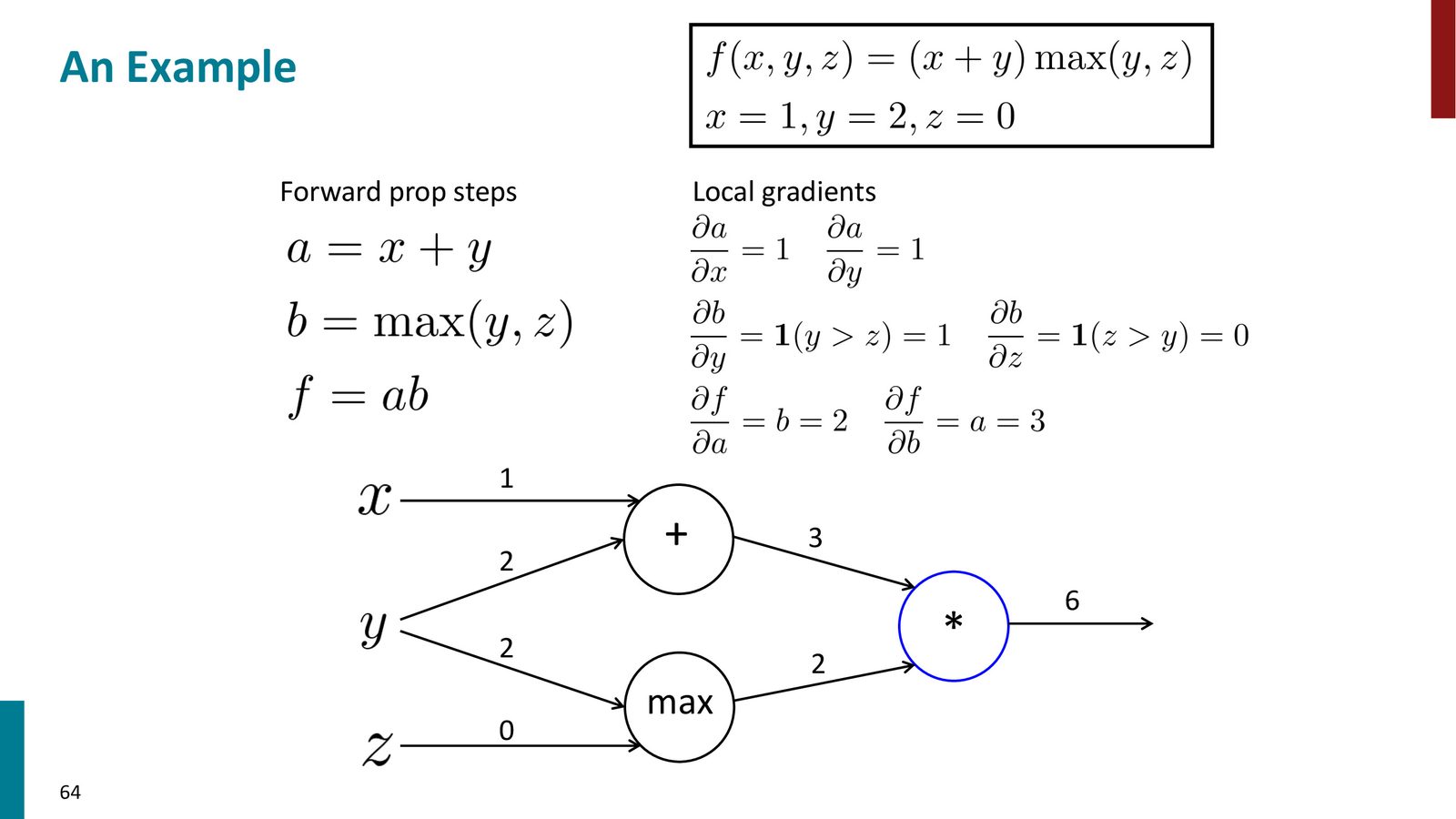
来源:Slides 第64页。
- \(\frac{\partial f}{\partial f} = 1\)
- 乘法节点:\(\frac{\partial f}{\partial a} = b = 2\),\(\frac{\partial f}{\partial b} = a = 3\)
- 加法节点:\(\frac{\partial f}{\partial x} = \frac{\partial f}{\partial a} \cdot 1 = 2\),从加法到 \(y\):\(\frac{\partial f}{\partial a} \cdot 1 = 2\)
- max 节点:到 \(y\):\(\frac{\partial f}{\partial b} \cdot 1 = 3\),到 \(z\):\(\frac{\partial f}{\partial b} \cdot 0 = 0\)
- \(y\) 有两条路径:\(\frac{\partial f}{\partial y} = 2 + 3 = 5\)
最终结果:\(\frac{\partial f}{\partial x} = 2\),\(\frac{\partial f}{\partial y} = 5\),\(\frac{\partial f}{\partial z} = 0\)。
验证:将 \(y\) 从 2 改为 2.1,则 \(a = 3.1\),\(b = 2.1\),\(f = 3.1 \times 2.1 = 6.51\),变化量 \(\approx 0.51 \approx 5 \times 0.1\),与梯度 5 吻合。
分支处的梯度求和
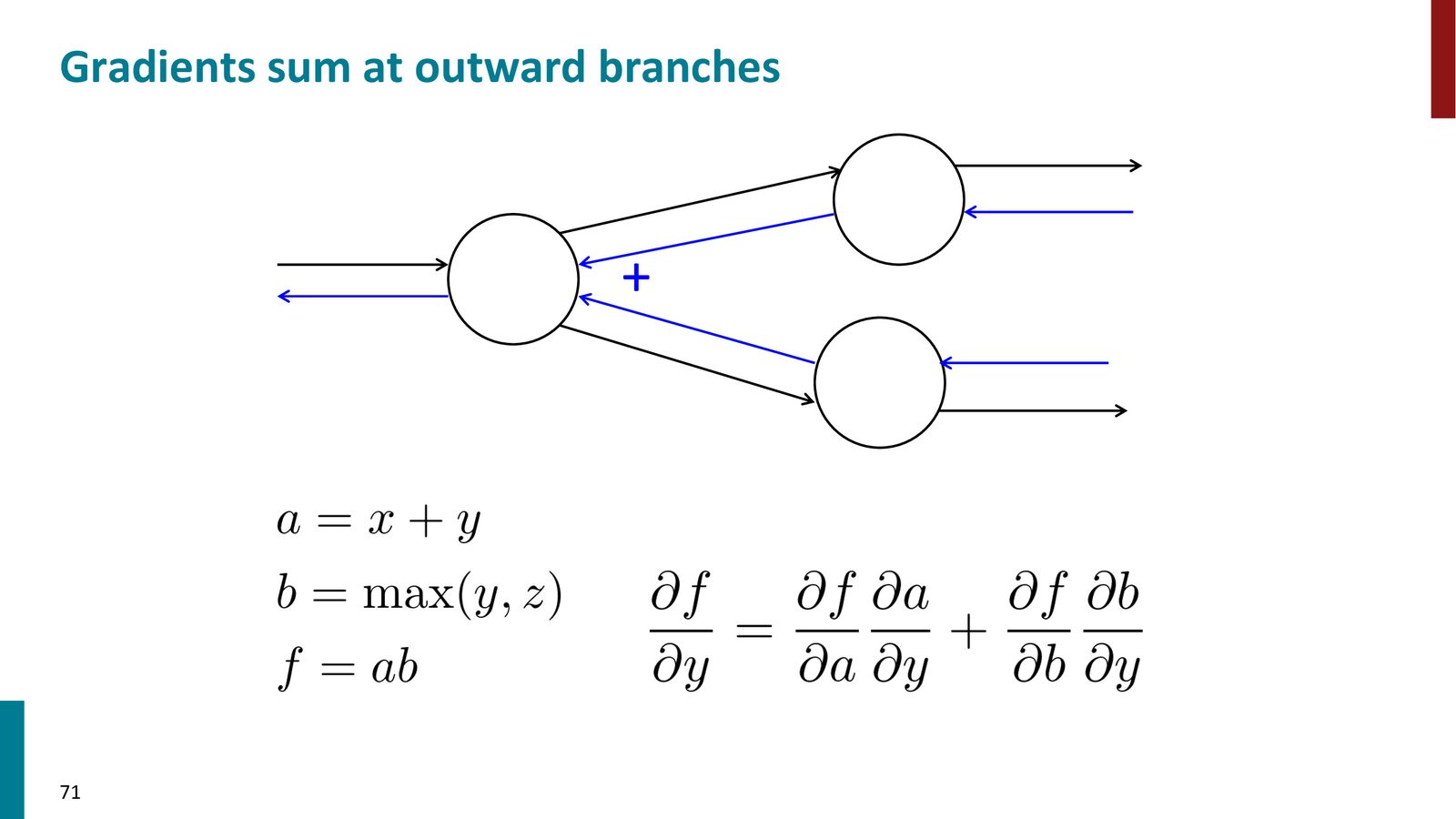
来源:Slides 第71页。
上例中 \(y\) 同时参与了加法和 max 两个计算,因此它的总梯度是两条路径上梯度的和:
这就是多元链式法则的体现。
三种基本操作的梯度直觉
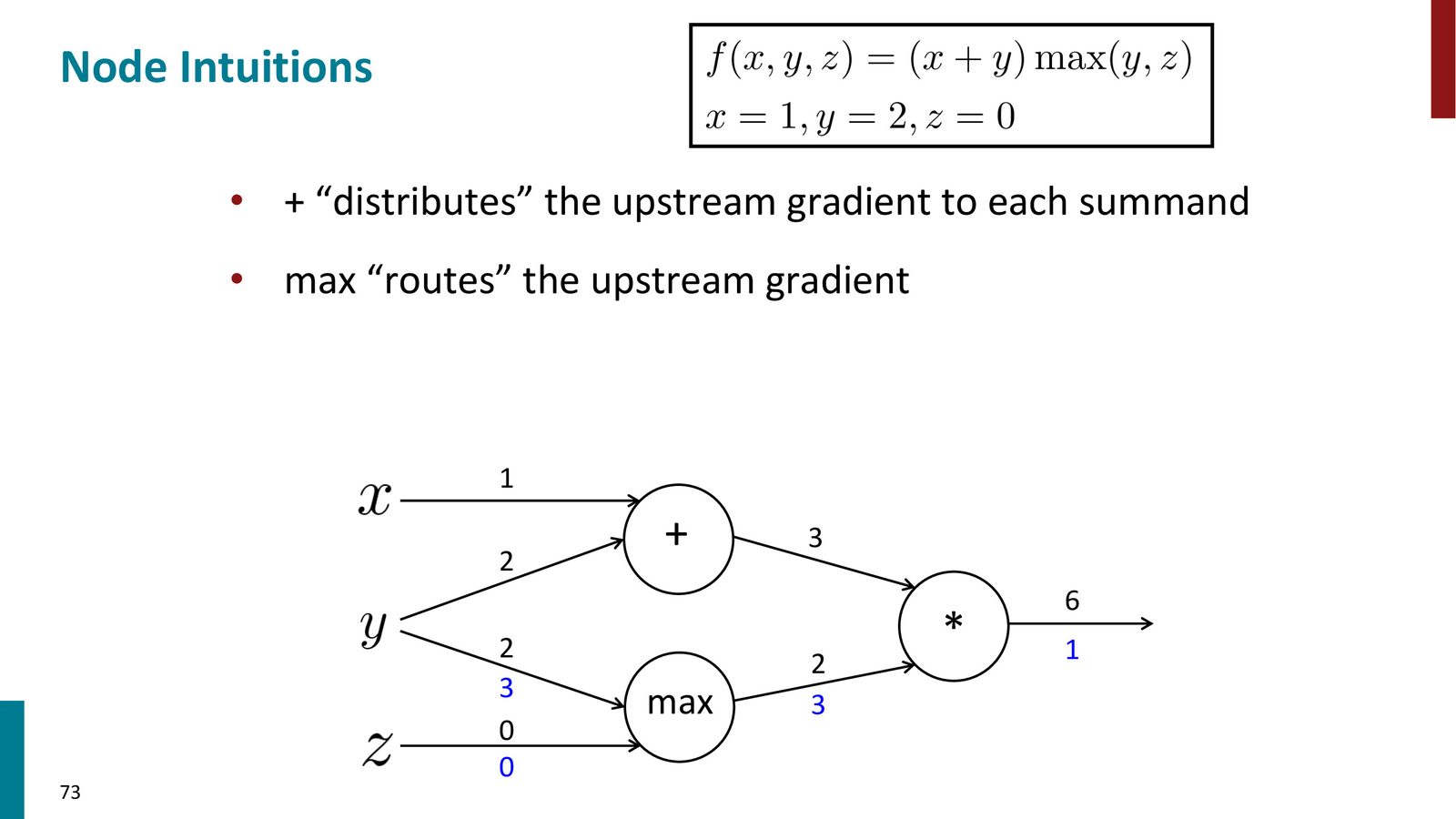
来源:Slides 第73页。
三种基本操作的梯度行为
- 加法(\(+\)):分发梯度——上游梯度原封不动地传给两个输入
- Max:路由梯度——上游梯度全部传给较大的那个输入,另一个输入得到零
- 乘法(\(\times\)):切换梯度——上游梯度乘以另一个输入的值传给当前输入
Max 操作导致梯度消失
Max 操作对“输的那一方”梯度为零——这与 ReLU 的行为一致(\(\text{ReLU}(x) = \max(0, x)\))。当 \(x < 0\) 时,ReLU 的梯度为零,意味着该方向的信息完全被阻断。这从计算图的角度解释了 dying ReLU 现象。
高效反向传播:避免重复计算
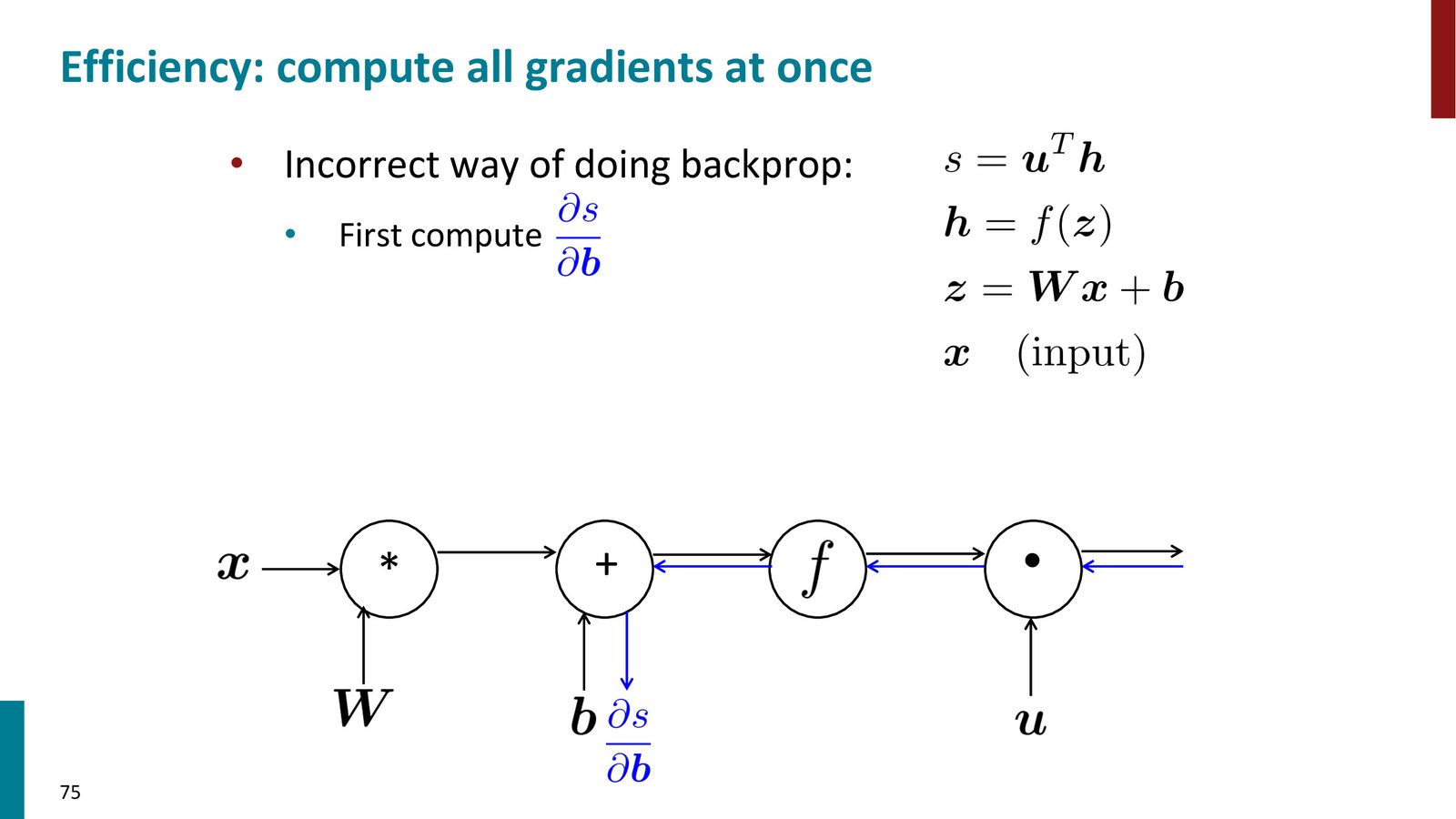
来源:Slides 第75页。
如果分别独立地计算 \(\frac{\partial s}{\partial b}\)、\(\frac{\partial s}{\partial W}\)、\(\frac{\partial s}{\partial x}\)、\(\frac{\partial s}{\partial u}\),会发现它们共享大量的中间计算(上游梯度 \(\delta\))。反向传播的核心效率在于:按照拓扑排序的逆序一次性遍历计算图,每个中间梯度只计算一次。
反向传播的计算复杂度
如果正确实现,反向传播的时间复杂度与前向传播的时间复杂度同阶(Big-O 相同)。如果你的反向传播比前向传播慢很多,说明你在某处做了重复计算。
通用反向传播算法
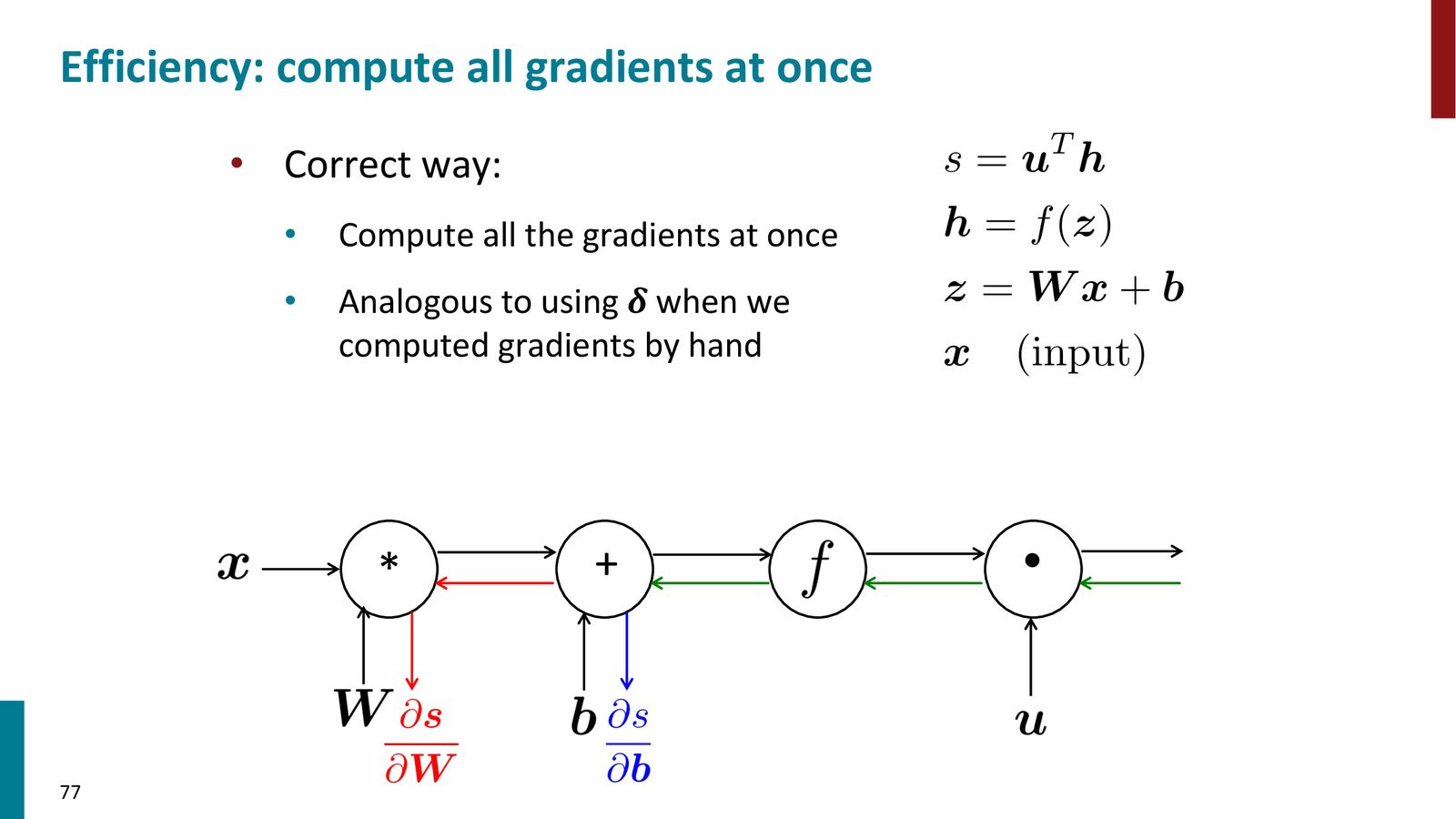
来源:Slides 第77页。
算法流程:
前向传播:
- 对计算图做拓扑排序,确保每个节点只依赖已计算的节点
- 按拓扑序遍历,对每个节点调用其
forward方法计算输出值
反向传播:
- 初始化输出梯度:\(\frac{\partial s}{\partial s} = 1\)
- 按逆拓扑序遍历节点
- 对每个节点:\(\text{下游梯度} = \text{上游梯度} \times \text{局部梯度}\)
- 对分支节点:将多条路径的梯度求和
该算法适用于任意有向无环图(DAG),不要求网络是规整的层状结构。
本章小结
反向传播算法是链式法则在计算图上的高效实现。其核心是“一次前向、一次反向”,利用中间结果共享避免重复计算。对于任意 DAG 结构的计算图,反向传播的复杂度与前向传播同阶。
自动微分与框架实现
自动微分
既然反向传播算法是如此系统化,能否让计算机完全自动完成?
自动微分的历史
早期的深度学习框架 Theano(蒙特利尔大学开发)尝试了完全符号化的自动微分:给定前向计算的符号表达式,自动推导出反向传播的符号表达式。但这种方式过于重量级,难以灵活处理各种情况。
现代深度学习框架(PyTorch、TensorFlow 等)采用了一种折中方案:
- 框架负责:管理计算图、执行拓扑排序、运行前向/反向遍历、传递上游梯度
- 用户负责:为每种操作实现
forward(前向计算)和backward(局部梯度计算)方法
Forward/Backward API
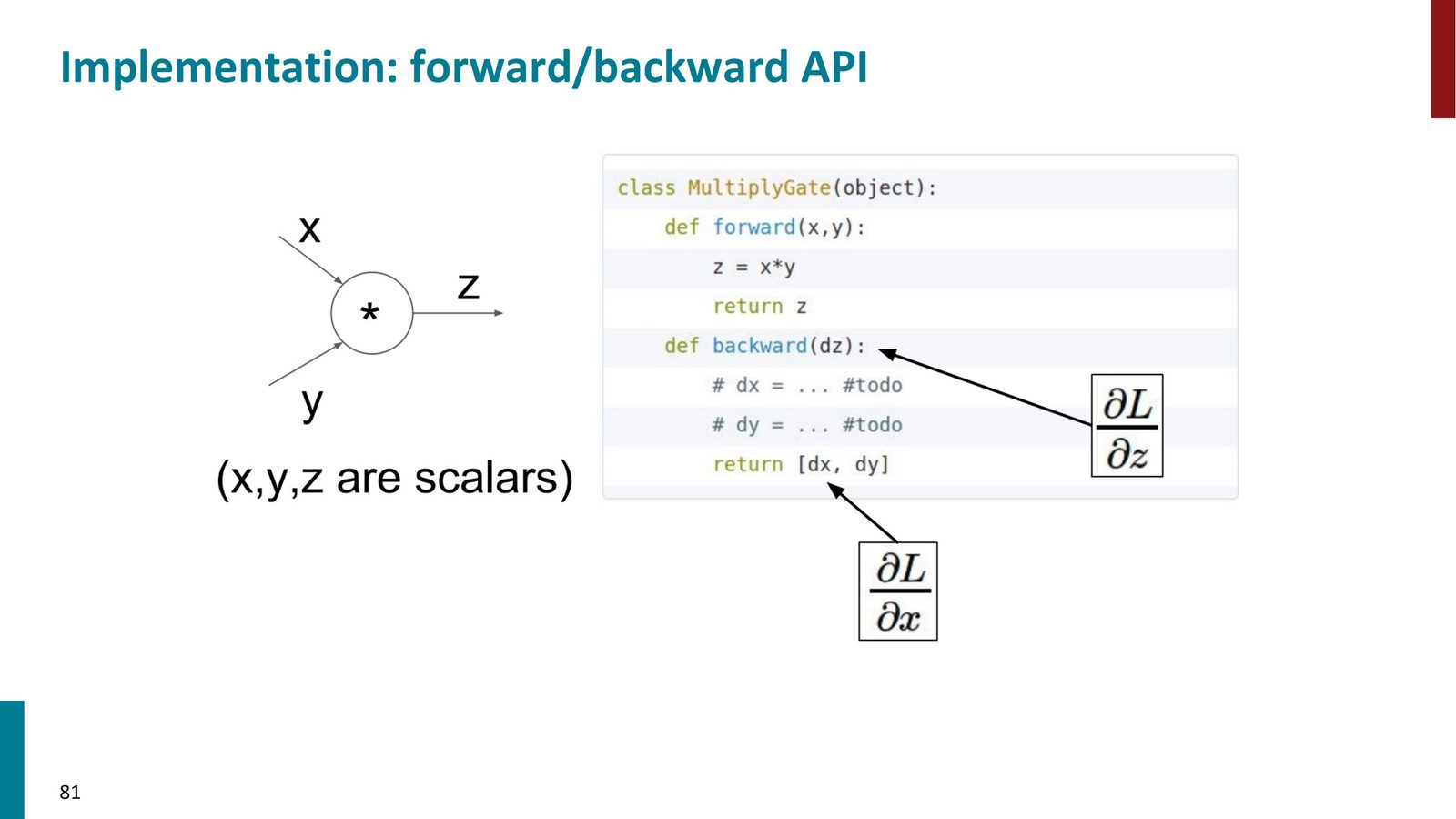
来源:Slides 第81页。
class MultiplyGate(object):
def forward(self, x, y):
z = x * y
self.x = x # 缓存输入,供 backward 使用
self.y = y
return z
def backward(self, dz):
dx = dz * self.y # 上游梯度 * 对方输入
dy = dz * self.x
return [dx, dy]
backward 依赖 forward 的缓存
注意一个关键细节:backward 方法需要用到前向传播时的输入值(如乘法门中的 \(x\) 和 \(y\))。因此 forward 方法必须将这些值缓存起来(存为类的属性)。这就是为什么在 PyTorch 的 autograd.Function 中,forward 需要用 ctx.save_for_backward() 保存张量。
实际上,PyTorch 已经预定义了大量常用操作的 forward 和 backward 实现。用户只需像搭积木一样组合这些操作,PyTorch 会自动管理计算图和梯度传播。这正是“高中生也能做深度学习项目”的原因。
本章小结
现代深度学习框架将反向传播的“基础设施”(计算图管理、梯度传播)自动化,用户只需为每个操作定义前向计算和局部梯度。常见操作(线性层、激活函数、损失函数等)都已预实现,使用者通常不需要手动编写 backward 方法。但理解底层原理对于调试和设计新操作至关重要。
梯度检验:数值验证
数值梯度
如何验证你手动推导或实现的梯度是否正确?可以用数值梯度(Numerical Gradient)进行检验:
其中 \(h\) 是一个很小的数(通常取 \(10^{-4}\))。

来源:Slides 第83页。
双侧差分 vs 单侧差分
一定要用双侧差分(centered difference)\(\frac{f(x+h) - f(x-h)}{2h}\),而不是单侧差分 \(\frac{f(x+h) - f(x)}{h}\)。双侧差分的误差是 \(O(h^2)\),而单侧差分的误差是 \(O(h)\),精度差了一个数量级。
为什么不直接用数值梯度训练?
数值梯度计算简单,为什么不直接用它代替反向传播?因为它极其缓慢:需要对每一个参数单独做一次前向计算。如果模型有 \(N\) 个参数,就需要 \(2N\) 次前向传播(双侧差分)。而反向传播只需要一次前向 + 一次反向就能得到所有参数的梯度。
梯度检验的正确用法
数值梯度仅用于验证你的 backward 实现是否正确,绝不用于训练。检验方法:
- 用反向传播计算梯度 \(g_{\text{analytic}}\)
- 用数值差分估计梯度 \(g_{\text{numeric}}\)
- 检查 \(|g_{\text{analytic}} - g_{\text{numeric}}| < \epsilon\)(通常 \(\epsilon \sim 10^{-5}\))
在 PyTorch 已预实现大部分操作的今天,梯度检验的需求减少了,但在实现自定义操作时仍然是必不可少的验证手段。
本章小结
数值梯度提供了一种“暴力但可靠”的梯度估计方法,是验证解析梯度实现正确性的黄金标准。使用双侧差分可以获得更高的精度。但由于计算量与参数数量成正比,数值梯度只适合验证,不适合训练。
总结与延伸
讲者的核心总结

来源:Slides 第85页(最后一页)。
Manning 教授在课程结尾总结了以下要点:
- 反向传播 = 链式法则的高效实现:前向传播计算函数值,反向传播计算梯度
- 理解底层原理很重要:虽然现代框架(PyTorch 等)自动化了一切,但理解反向传播的数学有助于调试和设计新架构
- 梯度消失/爆炸:后续讲解 RNN 时会看到,多层梯度连乘可能导致梯度指数级增长或衰减
- 实践中的平衡:框架预定义了常用操作的 forward/backward,用户像拼积木一样组合即可
全课知识图谱

关键 Takeaways
五条核心原则
- 非线性是必须的:没有激活函数,再多层也只是一个线性变换
- 矩阵微积分 = 单变量微积分 + 矩阵:Jacobian、链式法则在形式上与标量版完全类似
- \(\delta\)(上游梯度)是核心概念:它代表从损失函数回传到当前位置的“误差信号”,是多个参数梯度共享的部分
- 反向传播的效率来自复用:按逆拓扑序一次遍历,每个中间梯度只计算一次
- 形状约定简化工程实现:将梯度整形为与参数相同的形状,使 SGD 更新变为简单的减法
拓展阅读
- CS224N 官方讲义(Lecture Notes)与矩阵微积分教程:https://web.stanford.edu/class/cs224n/
- Stanford Math 51 在线教材(线性代数与多变量微积分):http://web.stanford.edu/class/math51/textbook.html
- Karpathy, “Yes you should understand backprop”:https://karpathy.medium.com/yes-you-should-understand-backprop-e2f06eab496b
- Goodfellow et al., Deep Learning Chapter 6: Deep Feedforward Networks
- Justin Johnson, “Backpropagation for a Linear Layer”: https://web.eecs.umich.edu/ justincj/teaching/eecs442/notes/linear-backprop.html
- PyTorch 官方教程 -- Autograd: https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html